#Hadoop Big Data Analytics Market Size
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
How to Start a Career in Big Data: A Comprehensive Guide

Big Data is reshaping industries worldwide, creating countless opportunities for individuals to build dynamic, data-driven careers. If you’re considering a career in Big Data, you’re not alone. The demand for data professionals is skyrocketing, and the need for individuals with analytical, technical, and managerial skills is higher than ever. This guide will walk you through the steps to kickstart your career in this exciting and rapidly evolving field.
What Is Big Data?
Big Data refers to the vast amounts of structured and unstructured data that organizations collect daily. This data is so massive that traditional data processing methods fall short, necessitating advanced tools and technologies. Big Data includes everything from customer interactions and social media activities to sensor data from IoT devices.https://internshipgate.com
Why Big Data Matters
In today's world, data is considered the new oil. Companies use Big Data analytics to gain insights, improve decision-making, and optimize performance. Whether it’s personalized marketing, predicting trends, or enhancing customer experiences, Big Data is at the heart of innovation.
Key Skills Required for a Career in Big Data
Starting a career in Big Data requires a unique set of skills that span both technical and analytical domains. Below are the essential competencies you’ll need:
1. Programming Skills
Knowing programming languages such as Python, R, or Java is crucial in Big Data roles. These languages help in data manipulation, automation, and building algorithms for data analysis.
2. Data Analysis and Statistics
A solid understanding of statistics and data analysis is fundamental for working with Big Data. You'll need to interpret large datasets and derive meaningful insights from them.
3. Knowledge of Big Data Tools
Familiarity with tools like Hadoop, Spark, and NoSQL databases (e.g., MongoDB, Cassandra) is essential for handling large-scale data efficiently. These tools allow you to store, process, and analyze massive datasets in real-time.
4. Data Visualization
Data visualization tools like Tableau or Power BI enable Big Data professionals to present complex data in a comprehensible and visually appealing manner.
5. Cloud Computing
With the shift towards cloud-based data storage, knowing how to work with cloud platforms such as AWS, Google Cloud, or Microsoft Azure is becoming increasingly important.
6. Soft Skills
Problem-solving, critical thinking, and communication skills are as vital as technical abilities. Big Data professionals need to collaborate with different departments and explain data findings to non-technical stakeholders.
Educational Pathways to Big Data Careers
There is no one-size-fits-all approach to breaking into Big Data. However, certain academic qualifications can give you an edge.
1. Bachelor's Degree in Computer Science, Data Science, or Related Fields
A solid foundation in computer science, statistics, or data science is essential. Universities offer a wide range of courses tailored to Big Data and data analysis.
2. Master's Degree or Specialized Certification
Pursuing a master’s degree in data science, business analytics, or a related field can significantly boost your job prospects. Additionally, online certifications such as Google's Professional Data Engineer or AWS Certified Big Data – Specialty are great options for career advancement.
Top Big Data Job Roles
Once equipped with the necessary skills and education, you can explore various job roles in the Big Data field:
1. Data Scientist
Data scientists analyze complex datasets to discover patterns and trends that can help businesses make informed decisions. This role requires a mix of technical and analytical skills.
2. Data Analyst
Data analysts focus on interpreting data, providing actionable insights, and making recommendations to drive business decisions.
3. Big Data Engineer
Big Data engineers design, develop, and manage scalable systems for storing, processing, and analyzing data.
4. Machine Learning Engineer
In this role, you’ll develop algorithms that allow computers to learn from and make predictions based on data, enabling businesses to automate processes and improve accuracy.
5. Business Intelligence Analyst
Business Intelligence (BI) analysts focus on converting data into actionable business insights. They use data visualization tools and techniques to present their findings.
Industries That Rely on Big Data
Big Data is transforming multiple industries. Below are some of the sectors where Big Data plays a significant role:
1. Healthcare
In healthcare, Big Data is used for predictive analytics, patient management, and optimizing treatment plans based on data from electronic health records.
2. Finance
Financial institutions leverage Big Data for fraud detection, risk management, and improving customer experiences through personalized services.
3. Retail
Retailers use Big Data for trend forecasting, inventory management, and personalizing marketing strategies to enhance customer satisfaction.
4. Telecommunications
Telecom companies rely on Big Data to optimize networks, predict customer churn, and improve service delivery.
How to Gain Practical Experience in Big Data
While education is essential, hands-on experience is equally crucial for success in Big Data.
1. Internships
Many companies offer internships for aspiring Big Data professionals. Internships provide real-world experience and help you apply what you’ve learned in a practical setting.
2. Projects
Working on data projects, either through academic programs or self-initiated efforts, can help you gain a deeper understanding of Big Data tools and methodologies.
3. Hackathons and Competitions
Participating in data science competitions like Kaggle can enhance your skills and expose you to real-world Big Data challenges.
4. Open Source Contributions
Contributing to open-source Big Data projects is another way to gain practical experience and network with professionals in the field.
Building a Portfolio
A strong portfolio is crucial when applying for Big Data roles. Here's how to build one:
1. Showcase Projects
Highlight your most significant projects, including any data analytics or visualization work you’ve done.
2. Document Tools and Technologies Used
Clearly specify the Big Data tools and technologies you’ve used in each project. This demonstrates your technical proficiency.
3. Include Certifications
List any certifications or courses you’ve completed. Employers value candidates who continuously improve their skills.
Networking in the Big Data Field
Networking is key to advancing in any career, including Big Data. Here are some ways to build professional connections:
1. Attend Conferences and Meetups
Big Data conferences and local meetups are great places to meet industry professionals and learn about the latest trends.
2. Join Online Communities
Platforms like LinkedIn, Reddit, and specialized Big Data forums offer a space to connect with others in the field.
3. Participate in Webinars
Many organizations offer webinars on Big Data topics. These events provide valuable knowledge and networking opportunities.
Common Challenges in Starting a Big Data Career
Starting a career in Big Data can be daunting. Here are some common challenges and how to overcome them:
1. Rapidly Changing Technologies
The field of Big Data is constantly evolving, making it essential to stay up-to-date with new tools and technologies.
2. Data Privacy and Security
As a Big Data professional, you’ll need to navigate complex issues around data privacy and security.
3. Finding the Right Job Role
Given the wide range of Big Data roles, finding the one that fits your skills and interests can be challenging. Take time to explore different areas of specialization.
FAQs: How to Start a Career in Big Data
1. Do I need a degree to start a career in Big Data?
While a degree is helpful, many professionals enter the field through certifications and practical experience.
2. What programming languages should I learn for Big Data?
Python, R, and Java are widely used in Big Data for data analysis, automation, and building algorithms.
3. Can I transition into Big Data from a non-technical background?
Yes, many people transition from business, finance, and other non-technical fields by acquiring relevant skills and certifications.
4. What is the salary range for Big Data professionals?
Salaries vary by role and location, but Big Data professionals can expect competitive pay, often exceeding six figures.
5. How do I gain practical experience in Big Data?
Internships, data projects, hackathons, and open-source contributions are excellent ways to gain hands-on experience.
6. What industries hire Big Data professionals?
Big Data professionals are in demand across industries such as healthcare, finance, retail, telecommunications, and more.
Conclusion
Starting a career in Big Data can be highly rewarding, offering a dynamic work environment and countless opportunities for growth. By building a solid foundation in programming, data analysis, and Big Data tools, you’ll be well on your way to success in this exciting field. Don’t forget to continuously learn, stay up-to-date with industry trends, and expand your network.https://internshipgate.com
#career#internship#internshipgate#virtualinternship#internship in india#job opportunities#big data#analytics#education
1 note
·
View note
Text
Hadoop Market Outlook: Global Trends and Forecast Analysis (2023-2032)

The global demand for hadoop was valued at USD 36518.5 Million in 2022 and is expected to reach USD 485934 Million in 2030, growing at a CAGR of 38.2% between 2023 and 2030.
The Hadoop market has witnessed significant growth, driven by the increasing need for big data analytics across various industries. As organizations accumulate vast amounts of unstructured data, Hadoop has emerged as a powerful, cost-effective solution for managing and analyzing large data sets. Key industries, including retail, banking, healthcare, and telecommunications, are leveraging Hadoop to gain insights, improve decision-making, and enhance customer experiences. The open-source nature of Hadoop, combined with its scalability and flexibility, has made it an attractive option for businesses of all sizes. However, challenges such as complex implementation, a shortage of skilled professionals, and security concerns persist. The market is expected to grow as companies continue to adopt data-driven strategies and invest in advanced analytics. With ongoing developments in cloud computing and integration with other data-processing platforms, the Hadoop market is poised for continued expansion, driven by the increasing demand for real-time analytics and business intelligence solutions.
The key drivers fueling growth in the Hadoop market include:
Explosion of Big Data: The rapid increase in the volume of structured and unstructured data from various sources, such as social media, IoT devices, and enterprise applications, has created a demand for powerful data processing and storage solutions like Hadoop.
Cost-Effective Data Storage: Hadoop provides a highly cost-efficient way to store and manage large datasets, making it an attractive option for organizations looking to reduce data storage costs.
Scalability and Flexibility: Hadoop's distributed computing model allows businesses to scale their data storage and processing capabilities easily, adapting to growing data needs over time.
Increasing Demand for Data Analytics: Companies are increasingly leveraging data analytics to gain insights, improve decision-making, and enhance customer experiences, driving adoption of platforms like Hadoop for big data analysis.
Cloud Integration: With the rise of cloud computing, Hadoop has become more accessible and easier to deploy on cloud platforms, enabling businesses to process big data without significant infrastructure investment.
Real-Time Analytics: The need for real-time insights and business intelligence is growing, and Hadoop, in combination with other tools, enables organizations to perform near real-time data analysis.
IoT and Machine Learning Applications: The proliferation of IoT and the growing adoption of machine learning have increased demand for data processing platforms like Hadoop, which can handle and analyze vast amounts of sensor and machine-generated data.
Open-Source Nature: As an open-source platform, Hadoop provides flexibility and a lower total cost of ownership, allowing organizations to modify and optimize the software based on specific business requirements.
Access Complete Report - https://www.credenceresearch.com/report/hadoop-market
Key Players
Amazon Web Services
Cisco Systems Inc
Cloudera Inc
Datameer Inc
Hitachi Data Systems
Fair Isaac Corporation
MapR Technologies
MarkLogic
Microsoft Corporation
Teradata Corporation
The Hadoop market demonstrates varying growth patterns and adoption levels across different regions:
North America: This region holds the largest share of the Hadoop market, driven by early adoption of big data technologies and strong demand from sectors such as retail, finance, and healthcare. The presence of major technology companies and advanced IT infrastructure facilitates the deployment of Hadoop. Additionally, growing demand for advanced analytics and business intelligence tools is pushing organizations to invest in big data solutions like Hadoop.
Europe: Europe is a significant market for Hadoop, particularly in industries such as banking, manufacturing, and telecommunications. Increasing regulatory requirements, such as GDPR, are compelling organizations to implement robust data management and analytics systems. Countries like the UK, Germany, and France are at the forefront, with businesses focusing on data-driven strategies to enhance competitiveness and customer experiences.
Asia-Pacific: The Asia-Pacific region is witnessing rapid growth in Hadoop adoption, fueled by expanding IT infrastructure, increasing digital transformation efforts, and a growing e-commerce sector. Countries like China, India, and Japan are driving the demand due to rising awareness of big data analytics and increased investments in cloud-based Hadoop solutions. Additionally, the proliferation of IoT and smart city projects in the region is generating massive data volumes, further driving the need for Hadoop solutions.
Latin America: In Latin America, the Hadoop market is growing steadily, with adoption primarily concentrated in Brazil, Mexico, and Argentina. The rise of digital initiatives, along with increased investment in big data and cloud technologies, is supporting market expansion. However, limited technical expertise and infrastructural challenges still pose obstacles to widespread adoption in this region.
Middle East and Africa: The Hadoop market in the Middle East and Africa is emerging, as governments and enterprises invest in digital transformation and big data technologies. Key industries driving adoption include telecommunications, banking, and public sector organizations. While there is significant potential for growth, challenges such as limited infrastructure and the need for skilled professionals remain barriers. Nonetheless, increasing investments in smart city projects and IoT are expected to drive Hadoop adoption in this region over the coming years.
Overall, North America and Asia-Pacific lead the Hadoop market, while Europe follows closely behind. Emerging regions such as Latin America and the Middle East & Africa hold promising growth potential as digital transformation and data-centric strategies become more widespread.
Segmentation
By Hadoop Components
Hadoop Distributed File System (HDFS)
MapReduce
Hadoop Common
Hadoop YARN (Yet Another Resource Negotiator)
Hadoop Ecosystem Projects
By Deployment Types
On-Premises Hadoop
Cloud-Based Hadoop
Hybrid Deployments
By Applications and Use Cases
Data Warehousing
Log and Event Data Analysis
Data Lakes
Machine Learning and AI
IoT Data Analysis
Genomic Data Analysis
Financial Data Analysis
By Industry Verticals
Financial Services
Healthcare
Retail and E-commerce
Telecommunications
Government and Public Sector
Energy and Utilities
By Hadoop Service Providers
Hadoop Distribution Providers
Cloud Service Providers
Consulting and Support Services
By Company Size
Small and Medium-Sized Enterprises (SMEs)
Large Enterprises
By Security and Compliance
Hadoop Security Solutions
Regulatory Compliance
Browse the full report – https://www.credenceresearch.com/report/hadoop-market
Contact Us:
Phone: +91 6232 49 3207
Email: [email protected]
Website: https://www.credenceresearch.com
0 notes
Text
Data Wrangling For Success: Streamlining Processes In Small And Large Enterprises
In the age of big data, organizations are continuously seeking ways to streamline their processes and seek knowledgeable insights from the vast amounts of data they collect. The need for efficiency and precision has never been higher, making data-wrangling tools an essential resource for businesses of all sizes. Data wrangling, or the process of cleaning and transforming raw data into a structured format, is the key to unlocking the potential of your data for business intelligence and analytics.
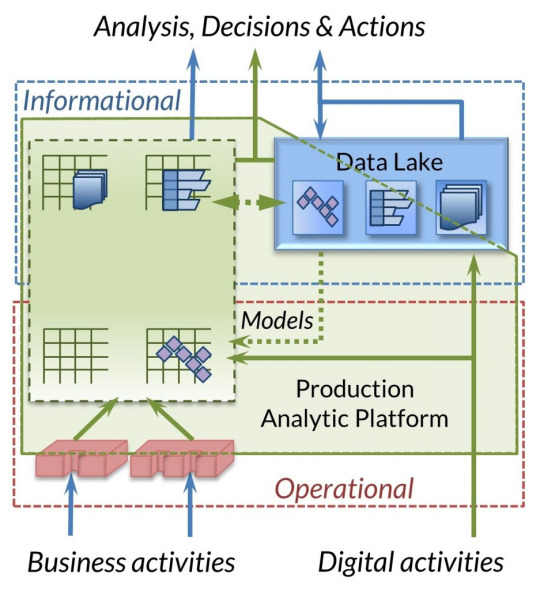
The Role of Data Wrangling in Today's Enterprises
Data wrangling plays a crucial role in helping businesses prepare their data for analysis. It involves gathering, filtering, and reformatting data from various sources so it can be effectively used by business intelligence (BI) tools. With the right data-wrangling software, enterprises can accelerate decision-making processes by providing clean and actionable data. Whether you are a small startup or a large multinational corporation, having organized data is the utmost step to gaining a competitive edge in your market.
Streamlining Small Enterprise Operations through Data Wrangling
Small businesses, with their limited resources, can benefit immensely from data-wrangling techniques. By using data wrangling tools, they can filter and aggregate data in a way that simplifies their operations. Instead of relying on manual processes, small enterprises can automate data preparation, ensuring that only the most relevant data is used for decision-making. This streamlined approach not only saves time but also helps small businesses stay agile in a competitive market, allowing them to respond to changes and opportunities more quickly.
How Large Enterprises Benefit from Advanced-Data Wrangling Techniques
For large enterprises, the volume of data collected can be overwhelming. Advanced data wrangling techniques allow large companies to manage big data more effectively. Using a platform like IRI Voracity, large enterprises can filter, scrub, and aggregate their data in a single job, reducing the time and effort required to prepare data for BI tools. This approach helps companies build data subsets that are easier to analyze, leading to faster insights and more informed business decisions.
Choosing the Right Provider for Data Wrangling
When selecting a provider for data wrangling, it's essential to choose one that offers robust and scalable solutions. Innovative Routines International (IRI), Inc. is a top provider in this space, known for its powerful data preparation tools like Voracity and CoSort. IRI's Voracity platform allows businesses to rapidly prepare big data for BI and analytics by filtering, transforming, and aggregating data in a single process. Built on the Eclipse framework and powered by CoSort or Hadoop engines, Voracity ensures that businesses can prepare data efficiently for multiple targets, whether it's for dashboards, scorecards, or scatter plots.
With the right provider, businesses can simplify the complexities of data wrangling and unlock the full potential of their data.
Conclusion
In today's data-driven world, businesses must embrace data wrangling to stay competitive. Whether you are a small enterprise looking to streamline operations or a large corporation managing vast amounts of data, the right data-wrangling tool can transform how you handle data. By choosing trusted providers like IRI, businesses can ensure their data is ready for insightful analysis, leading to better decision-making and overall success.
0 notes
Text
The global demand forhadoop market was valued at USD 36518.5 Million in 2022 and is expected to reach USD 485934 Million in 2030, growing at a CAGR of 38.2% between 2023 and 2030. The explosion of big data has revolutionized industries across the globe, driving the need for robust data management solutions. One technology that has significantly shaped this landscape is Hadoop. Since its inception, Hadoop has become synonymous with big data analytics, offering scalable, cost-effective, and flexible solutions for managing vast amounts of data. This article explores the growth, key drivers, and future prospects of the Hadoop market.Hadoop, an open-source framework developed by the Apache Software Foundation, emerged from the need to handle large datasets that traditional databases struggled to manage. Inspired by Google's MapReduce and Google File System papers, Hadoop was designed to process and store massive data efficiently across distributed systems. It comprises two main components: the Hadoop Distributed File System (HDFS) for data storage and MapReduce for data processing.
Browse the full report at https://www.credenceresearch.com/report/hadoop-market
Market Growth
The Hadoop market has witnessed exponential growth over the past decade. According to various industry reports, the global Hadoop market was valued at approximately USD 35 billion in 2020 and is projected to reach USD 87 billion by 2025, growing at a compound annual growth rate (CAGR) of around 20%. This remarkable growth is driven by several factors, including the increasing volume of structured and unstructured data, advancements in technology, and the rising adoption of cloud-based solutions.
Key Drivers
1. Data Explosion: The rapid proliferation of data from various sources such as social media, IoT devices, and enterprise applications has created an urgent need for effective data management solutions. Hadoop's ability to handle petabytes of data cost-effectively makes it a preferred choice for organizations.
2. Scalability and Flexibility: Hadoop’s architecture allows for horizontal scaling, meaning that organizations can easily add more nodes to handle increasing data volumes without significant changes to the existing infrastructure. Its flexibility to process both structured and unstructured data is also a significant advantage.
3. Cost Efficiency: Traditional data warehouses and databases can be expensive to scale. Hadoop, being open-source, offers a cost-effective alternative, reducing the total cost of ownership. Its ability to run on commodity hardware further lowers expenses.
4. Cloud Integration: The integration of Hadoop with cloud platforms has been a game-changer. Cloud providers like AWS, Microsoft Azure, and Google Cloud offer Hadoop as a service, making it more accessible to businesses of all sizes. This has simplified the deployment and management of Hadoop clusters, driving its adoption.
Challenges
Despite its advantages, Hadoop faces several challenges that could impact its market growth. These include:
1. Complexity: Implementing and managing Hadoop clusters can be complex, requiring specialized skills and expertise. This complexity can be a barrier for smaller organizations.
2. Security Concerns: As with any data management system, security is a critical concern. Ensuring data privacy and protection in Hadoop environments requires robust security measures, which can be challenging to implement.
3. Competition: The big data analytics market is highly competitive, with numerous alternatives to Hadoop emerging. Technologies like Apache Spark, which offers faster processing for certain workloads, and various commercial big data platforms present significant competition.
Future Prospects
The future of the Hadoop market looks promising, driven by continuous advancements and evolving business needs. Several trends are likely to shape its trajectory:
1. AI and Machine Learning: The integration of Hadoop with AI and machine learning frameworks is expected to open new avenues for advanced analytics. This will enhance its capabilities in predictive analytics, real-time processing, and data-driven decision-making.
2. Edge Computing: As edge computing gains traction, Hadoop is likely to play a pivotal role in managing and processing data at the edge. This will be particularly relevant for industries like IoT, where real-time data processing is crucial.
3. Enhanced Security: Ongoing developments in cybersecurity are expected to address the security concerns associated with Hadoop, making it a more secure choice for enterprises.
4. Hybrid Deployments: The trend towards hybrid cloud deployments is expected to benefit Hadoop, as organizations seek to leverage the best of both on-premises and cloud environments.
Key Players
Amazon Web Services
Cisco Systems Inc
Cloudera Inc
Datameer Inc
Hitachi Data Systems
Fair Isaac Corporation
MapR Technologies
MarkLogic
Microsoft Corporation
Teradata Corporation
Others
Segmentation
By Hadoop Components
Hadoop Distributed File System (HDFS)
MapReduce
Hadoop Common
Hadoop YARN (Yet Another Resource Negotiator)
Hadoop Ecosystem Projects
By Deployment Types
On-Premises Hadoop
Cloud-Based Hadoop
Hybrid Deployments
By Applications and Use Cases
Data Warehousing
Log and Event Data Analysis
Data Lakes
Machine Learning and AI
IoT Data Analysis
Genomic Data Analysis
Financial Data Analysis
By Industry Verticals
Financial Services
Healthcare
Retail and E-commerce
Telecommunications
Government and Public Sector
Energy and Utilities
By Hadoop Service Providers
Hadoop Distribution Providers
Cloud Service Providers
Consulting and Support Services
By Company Size
Small and Medium-Sized Enterprises (SMEs)
Large Enterprises
By Security and Compliance
Hadoop Security Solutions
Regulatory Compliance
By Region
North America
The U.S.
Canada
Mexico
Europe
Germany
France
The U.K.
Italy
Spain
Rest of Europe
Asia Pacific
China
Japan
India
South Korea
South-east Asia
Rest of Asia Pacific
Latin America
Brazil
Argentina
Rest of Latin America
Middle East & Africa
GCC Countries
South Africa
Rest of the Middle East and Africa
Browse the full report at https://www.credenceresearch.com/report/hadoop-market
About Us:
Credence Research is committed to employee well-being and productivity. Following the COVID-19 pandemic, we have implemented a permanent work-from-home policy for all employees.
Contact:
Credence Research
Please contact us at +91 6232 49 3207
Email: [email protected]
Website: www.credenceresearch.com
0 notes
Text
0 notes
Text
Discovering R7i Instances for Big Data, AI, and Memory
Big Data and R7i instances
The Amazon Elastic Compute Cloud (Amazon EC2) R7i instance is now generally available, thanks to an announcement from Intel and Amazon Web Services (AWS). With Xeon you can trust and AWS’s vast global footprint, this compute-optimized EC2 custom instance is powered by 4th Gen Intel Xeon processors and Intel Accelerator Engines.
Over the course of the projection period, the in-memory database market alone is anticipated to grow at a CAGR of 19%. At this critical juncture, machine learning and artificial intelligence (AI) are growing rapidly, requiring more processing power to analyze vast volumes of data faster. As enterprises continue to migrate more and more to the cloud, security is becoming increasingly important. Furthermore, data lakes are a sort of architecture that is becoming more and more popular and are completely changing how businesses store and use data.
Global enterprises’ adoption of memory-intensive workloads and big data trends call for the strength of specialized cloud computing instances like R7i, which may provide superior, automated decision-making that aids in the successful achievement of business decision-making goals.
An Excellent Option for Tasks Requiring a Lot of Memory and SAP Certified
All memory-intensive workloads, including SAP, SQL, and NoSQL databases, distributed web scale in-memory caches, in-memory databases like SAP HANA, and real-time big data analytics like Hadoop and Spark, are well suited for these SAP-certified instances. An early analysis for SAP indicates very good ~30% Better SAPS/$ over R6i that businesses can use right now.
Utilize Built-in Accelerators to Boost AI and Big Data
Four inbuilt accelerators are present in the R7i instances, and they each offer the following acceleration features:
The Intel AMX extensions, also known as the Intel Advanced Matrix Extensions, are intended to speed up workloads involving matrix operations and machine learning. By offering specific hardware instructions and registers designed for matrix computations, it increases the efficiency of these operations. Multiplication and convolution are two basic matrix operations that are used in many different computer tasks, particularly in machine learning methods.
The Intel Data Streaming Accelerator (IntelDSA) allows developers to fully use their data-driven workloads by improving data processing and analytics capabilities for a variety of applications. DSA gives you access to hardware acceleration that is optimized and provides outstanding performance for operations involving a lot of data.
The Intel In-Memory Analytics Accelerator (Intel IAA) is a prospective higher power efficiency accelerator that runs analytic and database applications. In-memory databases, open-source databases, and data stores like RocksDB and ClickHouse are supported by in-memory compression, decompression, encryption at very high throughput, and a set of analytics primitives.
By offloading encryption, decryption, and compression, Intel QuickAssist Technology (Intel QAT) accelerators free up CPU cores and lower power consumption. Additionally, it allows encryption and compression to be combined into a single data flow.
All R7i instance sizes have access to Advanced Matrix Extensions. The instances r7i.metal-24xl and r7i.metal-48xl will support the Intel QAT, Intel IAA, and Intel DSA accelerators.
Reduced Total Cost/Adaptability/Optimal Solution Selection
Compared to R6i instances, R7i instances offer price performance that is up to 15% better. With up to 192 vCPUs and 1,536 GiB of memory, R7i instances can provide up to 1.5x more virtual CPUs and memory than R6i instances, allowing you to consolidate workloads on fewer instances.
R7i instances come with the newest DDR5 RAM and larger instance sizes up to 48xlarge. Additionally, clients using R7i instances can now attach up to 128 EBS volumes (compared to 28 EBS volume attachments on R6i).
The variety and depth of EC2 instances available on AWS are enhanced by R7i instances. R7i offers 11 sizes with different capacities for vCPU, memory, networking, and storage, including two bare-metal sizes (r7i.metal-24xl and r7i.metal-48xl) that are coming shortly.
Accessibility
The following AWS Regions are home to R7i instances:
Europe (Stockholm, Spain), US West (Oregon), and US East (North Virginia, Ohio).
Businesses and partners in the big data and in-memory database analytics computing community may now meet their future demands for high performance, efficiency, TCO, and transformation thanks to the announcement of Intel and AWS’s new R7i instance.
Read more on Govindhtech.com
#govindhtech#technology#technews#news#ai#bigdata#r7iInstances#R6iInstances#EC2Instances#DDR5RAM#machinelearning
0 notes
Text
TRENDING TECHNOLOGIES
What is Big Data?
Big data is a term used to describe a collection of unstructured, organized, and semi-structured large amounts of data that have been gathered by many organizations and contain a wide range of information. The Fresh York Stock Exchange (NYSE), for instance, produces around one terabyte of new trade data each year as an example of big data.
Big Data can also be described by the following categories:
Volume: - As it relates to the volume of data a firm or organization has, it is the most significant big data attribute. Terabytes, gigabytes, zettabytes, and yottabytes are units of measurement for data volume. The volume of the data is a very important factor in assessing its value.
Variety: - Another feature of big data informs us of the various data types obtained by various sources. As it affects performance, it is the biggest problem the data industry is currently facing.
Velocity: - It speaks about how quickly data is generated and processed. Any big data process must have high velocity. It establishes the true potential of the data.
Importance of Big Data
Organizations may harness their data and use big data analytics to find new opportunities. This results in wiser company decisions, more effective operations, greater profitability, and happier clients. Businesses that employ big data and advanced analytics benefit in a variety of ways, including cost reduction, quicker and better decision-making, the development and marketing of new goods and services, etc.
Latest technologies used in big data industry
Artificial Intelligence: - It is one of the trending technologies. Big Data is playing a key role in the advancement of AI through its two subgroups: Machine Learning and Deep Learning.
Machine Learning: - It refers to the ability of computers to learn without being monotonously programmed. Applying this to Big Data analytics enables systems to analyse historical data, recognize patterns, build models, and predict future outcomes. Deep learning is a type of machine learning that mimics the working of human brain by creating artificial neural networks that use multiple layers of the algorithm to analyse data.
Predictive analysis is a subpart of big data analytics, and primarily works towards predicting future behaviour by using prior data. It works by leveraging Data mining, Machine Learning technologies, and statistical modelling along with some mathematical models to forecast future events. With the help of predictive analytics models, organizations can organize historical as well as the latest data to strain out trends and behaviours that could occur at a particular time.
HADOOP: - It is currently one of the evolving big data tools. It is an open-source software framework developed for storing and processing Big Data by Apache Software Foundation. Hadoop processes and stores data in a distributed computing environment across the cluster of commodity hardware Hadoop is a profitable, fault-tolerant, and highly available framework that can process data of any size and format and is a very unfailing storage tool, also enables you to cluster several computers to analyze large datasets in parallel and more quickly.
MongoDB: - Released in February2009, Mongo is an open-source software to store large scale data and allow to work with the data efficiently is a document-oriented, NoSQL database written in C, C++, and JavaScript and easy to set up. MongoDB is a profitable and highly reliable Big Data technology. It has a powerful query language that supports geo-based search, aggregation, text search, graph search, and more.
R: - It denotes to an open-source project and programming language. A free software that is mainly used for statistical computing, visualization, and integrated developing environments like Eclipse and Visual Studio assistance communication. It has been increasing popularly over the past few years in universities and colleges. According to specialists, the R programming language has the most prominent language across the world. Data miners and statisticians widely use it to design statistical software, primarily in data analytics.
Blockchain: - It is a distributed database system that stores and manages the transaction. This technology plays a crucial role in working towards reducing fraudulent transactions and helps increase financial security.
Conclusion
In applying the analytical power of Big Data Technologies to their supreme potential, businesses can guarantee that their success in every aspect of operations will reach new altitudes, and they can continue to become more competitive in the marketplace. About Rang Technologies: Headquartered in New Jersey, Rang Technologies has dedicated over a decade delivering innovative solutions and best talent to help businesses get the most out of the latest technologies in their digital transformation journey. Read More...
0 notes
Text
Hadoop Distribution Market Detailed Strategies, Competitive Landscaping and Developments for next 5 years
Global Hadoop Distribution Market Report from AMA Research highlights deep analysis on market characteristics, sizing, estimates and growth by segmentation, regional breakdowns & country along with competitive landscape, players market shares, and strategies that are key in the market. The exploration provides a 360° view and insights, highlighting major outcomes of the industry. These insights help the business decision-makers to formulate better business plans and make informed decisions to improved profitability. In addition, the study helps venture or private players in understanding the companies in more detail to make better informed decisions. Major Players in This Report Include:
Amazon Web Services (AWS) (United States)
Cloudera (United States)
Cray (United States)
Google Cloud Platform (United States)
Hortonworks (United States)
Huawei (China)
IBM (United States)
MapR Technologies (United States)
Microsoft (United States)
Oracle (United States)
Hadoop distribution service is an open-source distributed processing framework that manages data processing and storage for big data applications in scalable forms of computer servers. Market Drivers Rising Demand for Big Data Technologies for Analytics and Business Decision
Increasing Presence of a Large Amount of Unstructured Data
Market Trend Growing Adoption from North America Region
Opportunities Growing Demand across Various Business Vertical And Along With Rising Made By Leading Market Player
The Propagation of Several Real-Time Information from Sources
Challenges Rising Concern towards the Data PrivacyThe Hadoop Distribution market study is being classified by Application (Manufacturing, Retail, Financial, Government, Telecommunication, Healthcare, Others), Deployment Mode (Cloud-Based, On-Premises), Services (Consulting Services, Hadoop Training and Outsourcing Services, Integration and Deployment Services, Middleware and Support Services), Software (Application Software, Packaged Software, Performance Monitoring Software, Management Software) Presented By
AMA Research & Media LLP
0 notes
Text
Visual Analytics Market Analysis: Unveiling Growth and Development (2019-2027)
Visual Analytics Market report whichdelivers detailed overview of the visual analytics marketin terms of market segmentation by component, by deployment, by end use industry, by intended audience and by region.
Further, for the in-depth analysis, the report encompasses the industry growth drivers, restraints, supply and demand risk, market attractiveness, BPS analysis and Porter’s five force model.
Visual Analytics Market Statistics –
The Visual Analytics Market is slated to observe 22% growth rate through 2019-2027
Get Free Sample Copy of this Report @:https://www.researchnester.com/sample-request-688
The global visual analytics market is segmented on the basis of component, deployment, end use industry and region. On the basis of end use industry, the market is further bifurcated into IT, retail, BFSI, manufacturing, military & defense, and transportation. The market is further segmented by component into software and services; by deployment into on-demand, on-premise and finally, on the basis of intended audience, the market is divided into OEMs, system integrators, research, government, private equity groups and others.
The visual analytics market is anticipated to record a CAGR of around 22% during the forecast period i.e. 2019-2027 owing to worldwide attempt by various government agencies to standardize the data security protocols. The field of logistics and supply chain is anticipated to invest highly in information technology to improve data quality and availability on the back of the fact that the supply chain intelligence provide demand patterns, quality and customer requirements from numerous sources for demand driven planning. Additionally, growing necessity for real-time data management coming from various logistics operations and rising adoption of cloud technology for visual analytics is positively impacting the growth of the market.
According to recent study by Research Nester, the Visual Analytics Market size is projected to expand at CAGR of over 22% from 2019 to 2027.
Major players include in the global Visual Analytics Market:
Tableau Software
SAP SE
Qlik Technologies
TIBCO Software
ADVIZOR Solutions Pvt. Ltd.
SAS Institute
Oracle Corporation
MicroStrategy
IBM Corporation
Alteryx, Inc.
Get Your Free Sample Copy of this Report @https://www.researchnester.com/sample-request-688
Regionally, the market in North America is anticipated to hold the largest market share owing to rising technological developments and applications of visual analytics in various industries coupled with merging of IoT, big data and cloud technology. The Europe market for visual analytics is anticipated to witness high growth rate on the back of growing demand for business intelligence technology in order to enhance the business productivity. The presence of diverse manufacturing industries coupled with huge investments by developing countries like Japan, Singapore, China and India in technology is estimated to boost the growth of the market in Asia Pacific region.
Growing Technological Advancements
Recent technological advancements leading to the adoption of Apache open source technologies and SQL-on-Hadoop, in-memory computing, and in-database processing coupled with continuous updating analytics facilities are anticipated to hone the market growth. Additionally, rising demand for visual analytics tools among various enterprises to access, interpret, and analyze information is estimated to boost the market revenue in upcoming years.
However, lack of trained professionals who are efficient in working with business intelligence tools is expected to operate as a key restraint to the growth of visual analytics market over the forecast period.
This report also provides the existing competitive scenario of some of the key players of the visual analytics market which includes company profiling of Tableau Software,SAP SE, Qlik Technologies, TIBCO Software, ADVIZOR Solutions Pvt. Ltd., SAS Institute, Oracle Corporation, MicroStrategy, IBM Corporation, Alteryx, Inc.
The profiling enfolds key information of the companies which encompasses business overview, products and services, key financials and recent news and developments. On the whole, the report depicts detailed overview of the visual analytics market that will help industry consultants, equipment manufacturers, existing players searching for expansion opportunities, new players searching possibilities and other stakeholders to align their market centric strategies according to the ongoing and expected trends in the future.
Buy a Copy of this Strategic Report to drive your Business Growth @https://www.researchnester.com/purchage/purchase_product.php?token=688
0 notes
Link
The Hadoop big data analytics market refers to the market for technologies and services related to the processing and analysis of large datasets using the Apache Hadoop framework. Hadoop is an open-source software framework that enables distributed storage and processing of large datasets across clusters of commodity hardware. The market for Hadoop big data analytics includes various solutions such as Hadoop software distributions, data management tools, analytics tools, and consulting services. The growing demand for big data analytics in various industries such as banking, healthcare, retail, and government is driving the growth of the Hadoop big data analytics market. The market is also being fueled by the increasing adoption of cloud computing and the Internet of Things (IoT), which generate large amounts of data that need to be processed and analyzed.
0 notes
Text
0 notes
Text
https://www.marketwatch.com/press-release/hadoop-big-data-analytics-solution-market-share-size-industry-growth-covid-19-impact-analysis-and-forecast-2030-2023-03-08
0 notes
Text
Hadoop and Big Data Analytics Market Statistics, Trends, Analysis Size and Growth Factors by 2028
In the domain of data management and analysis, Hadoop and Big Data Analytics are two interrelated ideas. Hadoop is an open-source software architecture that enables the shared storage and processing of large datasets on commodity hardware clusters. The act of evaluating and understanding vast and complicated datasets to reveal hidden information, connections, and other insights that may be utilised to inform business choices is referred to as big data analytics.
The Hadoop and Big Data Analytics industry has grown significantly in recent years and is likely to develop even faster in the coming years. According to MarketsandMarkets, the global Hadoop market is predicted to expand from USD 8.2 billion in 2020 to USD 18.9 billion by 2025. During the projection period, the compound annual growth rate (CAGR) will be 18.2%.
According to another analysis, the global Big Data Analytics market is predicted to rise from USD 138.9 billion in 2020 to USD 229.4 billion by 2025, at a CAGR of 10.6% during the forecast period.
The increasing demand for data-driven decision-making, the growing volume of structured and unstructured data generated by various sources, the availability of low-cost storage solutions, and the development of advanced analytics tools and technologies are all factors driving the growth of the Hadoop and Big Data Analytics market.
Healthcare, banking and finance, retail, and telecommunications are among the key industries that use Hadoop and Big Data Analytics solutions. These industries are progressively embracing these technologies in order to acquire insights on customer behaviour, streamline operations, cut costs, and improve the entire customer experience.
Finally, the Hadoop and Big Data Analytics market is likely to continue growing in the future years as organisations across industries recognise the value of data-driven decision-making and invest in sophisticated analytics technology.
Read more@ https://techinforite.blogspot.com/2023/02/hadoop-and-big-data-analytics-market.html
#Hadoop and Big Data Analytics Trend#Hadoop and Big Data Analytics size#Hadoop and Big Data Analytics growth#Hadoop and Big Data Analytics#Hadoop and Big Data Analytics Industry#Hadoop and Big Data Analytics Price#Hadoop and Big Data Analytics Size#Hadoop and Big Data Analytics Share#Hadoop and Big Data Analytics Analysis#Hadoop and Big Data Analytics Forecast#Hadoop and Big Data Analytics Consumption#Hadoop and Big Data Analytics Sales#Hadoop and Big Data Analytics Segmentation#Hadoop and Big Data Analytics Manufacturers#Hadoop and Big Data Analytics Prospectus#Hadoop and Big Data Analytics Industry Trends#Hadoop and Big Data Analytics Growth#Hadoop and Big Data Analytics Trends#Global Hadoop and Big Data Analytics Industry#Global Hadoop and Big Data Analytics Trends#Global Hadoop and Big Data Analytics Share#Global Hadoop and Big Data Analytics Size
0 notes
Text
BIG DATA-The Big Question?
Examining huge data sets with a variety of data kinds, or "big data," is the process of looking for hidden patterns, unidentified relationships, market trends, client preferences, and other valuable business information. The results of the analysis may result in greater customer service, more operational effectiveness, more effective marketing, new revenue prospects, and other business advantages.

By enabling data scientists, predictive modellers, and other analytics experts to analyse large volumes of transaction data as well as other types of data that may be underutilised by traditional business intelligence (BI) programmes, big data analytics' main objective is to assist businesses in making more informed business decisions. This could include web server logs and clickstream data, social media posts and activity reports, text from customer emails and survey responses, call detail records from mobile phones, and machine data gathered by Internet of Things-connected sensors.
However, consulting companies like Gartner Inc. and Forrester Research Inc. also view transactions and other structured data as viable components of big data analytics applications. Some people only connect big data with that type of semi-structured and unstructured data. The software tools that are frequently used in advanced analytics disciplines including predictive analytics, data mining, text analytics, and statistical analysis can be utilised to examine big data.
Tools for data visualisation and mainstream BI software can both contribute to the analytical process. However, traditional data warehouses built on relational databases might not be able to accommodate semi-structured and unstructured data efficiently. Furthermore, data warehouses might not be able to meet the processing requirements posed by collections of large data that must be updated regularly, if not continuously, such as real-time data on the performance of oil and gas pipelines or mobile applications.
In order to gather, process, and analyse large data, many businesses have resorted to a more recent class of technologies, including Hadoop and associated tools like YARN, MapReduce, Spark, Hive, and Pig as well as NoSQL databases. A framework of open-source software built around these technologies enables the analysis of sizable and varied data volumes across clustered platforms.
The Challenges of Big Data Analytics:
The majority of businesses find big data analysis difficult. Consider the enormous amount of data that is gathered throughout the entire organisation in a variety of formats (both structured and unstructured data), as well as the numerous ways that different types of data can be combined, contrasted, and analysed to discover trends and other useful business information.
To access all of the data that an organisation holds in various locations, often in several systems, the first task is to break down data silos. Making platforms that can import unstructured data as easily as structured data is a second big data challenge. The size of this enormous amount of data makes it challenging to process it using conventional database and software techniques. The majority of businesses find big data analysis difficult. Consider the enormous amount of data that is gathered across the entire organisation in a variety of formats (both structured and unstructured data), as well as the numerous ways that different types of data can be combined, contrasted, and analysed to discover trends and other useful business information.
To access all of the data that an organisation holds in various locations, often in several systems, the first task is to break down data silos. Making platforms that can import unstructured data as easily as structured data is a second big data challenge. The size of this enormous amount of data makes it challenging to process it using conventional database and software techniques. Before data is imported into a data warehouse for analysis, Hadoop clusters and NoSQL systems are sometimes used as landing pads and staging places for data. Often, the data is summarised in a way that is more suited to relational structures.
However, big data suppliers are increasingly promoting the idea of a Hadoop data lake that acts as the main storage facility for incoming streams of raw data into an enterprise. Subsets of the data in these structures can then be filtered for analysis in data warehouses and analytical databases, or they can be studied directly in Hadoop utilising batch query tools, stream processing programmes, and SQL on Hadoop technologies that execute interactive, ad hoc SQL queries. Lack of internal analytics expertise and the high cost of acquiring seasoned analytics personnel are two potential stumbling blocks that might trip up firms working on big data analytics initiatives.
The normal volume and variety of information involved can also lead to problems with data management, such as problems with data consistency and quality. Although many manufacturers now offer software connectors between Hadoop and relational databases as well as other data integration tools with big data capabilities, combining Hadoop systems and data warehouses can still be difficult.
0 notes
Text
0 notes