#ETL automation testing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
ETL Automation for Cloud Data Migration

Migrating data to the cloud is one of the most significant shifts in today’s digital landscape. However, transferring large amounts of data while ensuring accuracy and consistency is no small feat. ETL automation is the solution. BuzzyBrains specializes in automating ETL processes for smooth and efficient cloud data migration.
Challenges of Manual ETL in Cloud Migrations Manually migrating data to the cloud is time-consuming and prone to errors. With large datasets, the risk of data corruption increases, as does the likelihood of incomplete data transfers. This is where automation becomes crucial.

How Automation Simplifies Cloud Data Migration Automated ETL systems ensure data is moved seamlessly between on-premise systems and the cloud. Automation reduces the risk of errors and ensures that all data is validated before being loaded into the cloud environment.
Top Tools for Cloud-Based ETL Automation Tools like Talend Cloud, AWS Glue, and Informatica Cloud are popular for automating cloud ETL processes. At BuzzyBrains, we assess client requirements and recommend tools based on scalability, integration, and cost-efficiency.
Best Practices for Automated Cloud Migration
Data Auditing: Before migrating, conduct a thorough audit of the data.
Incremental Migration: Migrate data in stages to avoid overwhelming the system.
Automated Testing: Implement automated testing for data accuracy during the migration.
Automating ETL processes for cloud migration ensures efficient and error-free data transfer. BuzzyBrains provides businesses with the tools and expertise they need for a successful cloud migration.
0 notes
Text
What is ETL Test Automation? Discover a comprehensive guide to ETL automation testing. Learn about the tools, processes, and best practices for automating ETL testing to ensure data accuracy and efficiency.
0 notes
Text
Comprehending the Process of ETL Automation and Its Testing

As industries grapple with the ever-growing volume and complexity of data, the automation of ETL processes has become a cornerstone for operational efficiency. Read more: https://medium.com/@appzlogic519/comprehending-the-process-of-etl-automation-and-its-testing-a1f74091cc3a
0 notes
Text
Leading The Way in ETL Testing: Proven Strategies with ETL Validator
In data management, maintaining the accuracy and reliability of information is paramount for informed decision-making. ETL (Extract, Transform, Load) testing plays a pivotal role in safeguarding data integrity throughout its lifecycle. Datagaps' ETL Validator emerges as a game-changer in this domain, boasting remarkable efficiency and cost-saving benefits. For instance, a leading French personal care company witnessing significant reductions in migration testing time and overall Total Cost of Ownership (TCO) through its adoption.
This blog delves into the core practices of ETL testing, delineating its importance in ensuring data fidelity from extraction to loading. While ETL focuses on data processing, ETL testing verifies this data's accuracy and completeness. It encompasses numerous techniques such as data completeness, correctness, performance, metadata, anomaly testing, and validation, each playing a crucial role in guaranteeing data reliability.
The ETL testing process comprises phases like test planning, design, execution, and closure, all aimed at meticulously assessing data integrity and system performance. A comprehensive ETL testing checklist ensures thorough validation, covering data transformation, integrity, volume verification, error logging, and validation.
The business impact of effective ETL testing cannot be overstated, as it mitigates risks, boosts productivity, and ensures data-driven decisions are based on clean, reliable data. Datagaps' ETL Validator emerges as a key player in this landscape, offering automated data validation, comprehensive test coverage, pre-built test cases, metadata comparison, performance testing, seamless integration with CI/CD pipelines, enhanced reporting, and regulatory compliance.
In conclusion, ETL testing serves as a linchpin in a successful data management strategy, enabling organizations to harness the full potential of their data assets. By embracing advanced ETL testing tools and methodologies, enterprises can enhance operational efficiency, mitigate risks, and confidently drive business growth.��
1 note
·
View note
Text

Quality Engineering Services | Nitor Infotech
Nitor Infotech’s agile approach towards quality engineering and test automation services can help organizations achieve a flawless performance of applications and prolonged product sustenance, thus improving scalability as well as boosting revenues. Owing to an increase in demand for better, more flexible software systems, their complexity is increasing day by day. To ensure that these systems comply with quality engineering (QE) standards, a drastic evolution is seen in testing methods as well. Testing frameworks are now more complex than ever and deploying them adequately is often challenging.
#nitorinfotech#etl testing#software engineering#software development#nitor#blog#software services#qa testing#quality assurance#software testing#performance testing#manual testing#software automation#it services#it engineering services#quality tester#ascendion
0 notes
Text
ETL Testing: How to Validate Your Python ETL Pipelines
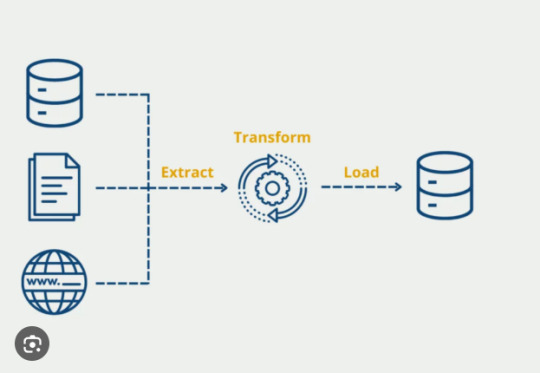
In the world of data engineering, building a strong Extract Transform Load (ETL) process is only half the battle. Ensuring that your ETL pipelines are reliable, accurate, and efficient is just as crucial. When working with Extract Transform Load Python workflows, proper ETL testing is essential to maintain data quality, catch errors early, and guarantee trustworthy outputs for downstream applications. In this article, we'll explore why ETL testing matters and how to effectively validate your Python ETL pipelines.
Why ETL Testing Is Critical
ETL processes move and transform data between systems — often at massive scales. A small mistake during extraction, transformation, or loading can result in significant business consequences, from incorrect analytics to failed reporting. Especially when using Extract Transform Load Python pipelines, where flexibility is high and custom scripts are common, thorough testing helps to:
Detect data loss or corruption
Ensure transformations are applied correctly
Validate that data is loaded into the target system accurately
Confirm that performance meets expectations
Maintain data consistency across different stages
Without systematic ETL testing, you risk pushing flawed data into production, which could impact decision-making and operations.
Key Types of ETL Testing
When validating Extract Transform Load Python pipelines, several types of testing should be performed:
1. Data Completeness Testing
This ensures that all the expected data from the source system is extracted and made available for transformation and loading. You might use row counts, checksum comparisons, or aggregate validations to detect missing or incomplete data.
2. Data Transformation Testing
In this step, you verify that transformation rules (like calculations, data type changes, or standardizations) have been correctly applied. Writing unit tests for transformation functions is a best practice when coding ETL logic in Python.
3. Data Accuracy Testing
Data must be correctly inserted into the target system without errors. Validation includes checking field mappings, constraints (like foreign keys), and ensuring values match expectations after loading.
4. Performance Testing
An efficient Extract Transform Load Python pipeline should process data within acceptable timeframes. Performance testing identifies slow stages and bottlenecks in your ETL workflow.
5. Regression Testing
Whenever changes are made to the ETL code, regression testing ensures that new updates don't break existing functionality.
How to Perform ETL Testing in Python
Python provides a wide range of tools and libraries that make ETL testing approachable and powerful. Here’s a practical roadmap:
1. Write Unit Tests for Each Stage
Use Python’s built-in unittest framework or popular libraries like pytest to create test cases for extraction, transformation, and loading functions individually. This modular approach ensures early detection of bugs.
2. Validate Data with Pandas
Pandas is excellent for comparing datasets. For example, after extracting data, you can create Pandas DataFrames and use assertions like:
python
CopyEdit
import pandas as pd
3. Create Test Data Sets
Set up controlled test databases or files containing predictable datasets. Using mock data ensures that your Extract Transform Load Python process can be tested repeatedly under consistent conditions.
4. Automate ETL Test Workflows
Incorporate your ETL testing into automated CI/CD pipelines. Tools like GitHub Actions, Jenkins, or GitLab CI can trigger tests automatically whenever new code is pushed.
5. Use Data Validation Libraries
Libraries like great_expectations can make ETL testing even more robust. They allow you to define "expectations" for your data — such as field types, allowed ranges, and value uniqueness — and automatically validate your data against them.
Common ETL Testing Best Practices
Always test with real-world data samples when possible.
Track and log all test results to maintain visibility into pipeline health.
Isolate failures to specific ETL stages to debug faster.
Version-control both your ETL code and your test cases.
Keep test cases updated as your data models evolve.
Final Thoughts
Validating your Extract Transform Load Python pipelines with thorough ETL testing is vital for delivering trustworthy data solutions. From unit tests to full-scale validation workflows, investing time in testing ensures your ETL processes are accurate, reliable, and scalable. In the fast-paced world of data-driven decision-making, solid ETL testing isn't optional — it’s essential.
0 notes
Text
Consultant - Java, Selenium, API Automation, ETL, SQL, Java/Python
strategies across both Android and iOS platforms. Collaborate with developers, business analysts, and stakeholders to ensure… WebDriver for automated testing. Hands-on experience with Appium for mobile automation testing (Android and iOS). Solid… Apply Now
0 notes
Text
Eye Tracking Market Growth Opportunities and Segment Report 2032
The Eye Tracking Market size was USD 1.01 Billion in 2023 and is expected to Reach USD 11.4 Billion by 2032 and grow at a CAGR of 30.6% over the forecast period of 2024-2032.
The Eye Tracking Market is evolving as a crucial technology across multiple sectors, driven by the increasing demand for real-time human-computer interaction and enhanced user experience. Eye tracking systems measure the point of gaze or the motion of an eye relative to the head and are being integrated into a wide range of applications from healthcare and automotive to marketing, research, gaming, and virtual reality. The need to understand consumer behavior, cognitive load, and attention patterns is pushing the boundaries of how this technology is used in both research and practical applications.
The Eye Tracking Market is gaining attention not just for its ability to revolutionize accessibility and UX, but also as a powerful tool in data-driven decision-making. Whether for improving driver safety through monitoring fatigue and distraction, or enhancing immersive experiences in AR/VR environments, the versatility of eye tracking is paving the way for innovation across domains. As organizations look to understand user attention in increasingly digital ecosystems, eye tracking is positioned as a core component of next-generation analytics.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/2984
Market Keyplayers:
Tobii AB (Tobii Pro Glasses 3, Tobii Eye Tracker 5)
SR Research Ltd. (EyeLink 1000 Plus, EyeLink Portable Duo)
Smart Eye AB (AIS DMS, Smart Eye Aurora)
Seeing Machines (FOVIO Driver Monitoring System, Guardian)
Ergoneers GmbH (Dikablis Professional Glasses, D-Lab Software)
Pupil Labs GmbH (Pupil Core, Invisible Eye Tracking Glasses)
Gazepoint Research Inc. (GP3 HD Eye Tracker, Gazepoint Control)
EyeTech Digital Systems (AEye VT3, EyeTech TM5 Mini)
iMotions (iMotions Lab, iMotions API)
EyeSee (EyeSee Glasses, EyeSee Online Eye Tracking)
The Eye Tribe (Eye Tribe Tracker, Eye Tribe SDK)
SensoMotoric Instruments (SMI) (SMI Eye Tracking Glasses 2.0, RED250mobile)
ISCAN, Inc. (ETL-500 Remote Eye Tracking Lab, RK-826PCI-Eye Tracking System)
PRIMA Research & Production (FaceLAB, OptiLAB)
RightEye LLC (RightEye Vision System, RightEye Reading Test)
Converus, Inc. (EyeDetect, EyeDetect Plus)
Visage Technologies AB (Visage SDK, Visage Core)
Mirametrix Inc. (S2 Eye Tracker, Glance by Mirametrix)
Market Analysis
The Eye Tracking Market is witnessing significant momentum as industries across the globe prioritize personalization, automation, and neuro-analytics. The technology has transitioned from a niche academic tool to a commercially viable solution, widely adopted in sectors like psychology research, gaming, advertising, assistive technology, and security. Increasing R&D efforts and rising awareness of human behavior analytics have helped push adoption, especially in UX design, retail analytics, and healthcare diagnostics.
Technology advancements, particularly in AI, machine learning, and miniaturization of sensors, are making eye tracking more accessible and accurate. Eye tracking is no longer limited to bulky lab equipment but is being integrated into wearables, glasses, and even mobile devices. Collaborations between tech giants and startups are accelerating development in consumer-friendly and enterprise-level applications.
Scope
The scope of the eye tracking market spans across both hardware and software solutions. Hardware components include remote and wearable trackers, while software platforms process and analyze gaze data for insights. Applications include:
Healthcare & Assistive Technology: Used for diagnosing neurological conditions and enabling hands-free communication for individuals with disabilities.
Automotive: Enhances driver safety through driver monitoring systems (DMS) that detect fatigue or inattention.
Marketing & Advertising: Allows brands to optimize visual content by analyzing viewer attention and engagement.
Gaming & VR/AR: Elevates immersive experiences by adapting environments based on where the user is looking.
Academic Research: Utilized in psychology, neuroscience, and education to assess attention span, cognitive load, and learning behavior.
This broad scope makes the technology highly adaptable and essential for companies seeking insight-driven growth and innovation.
Enquiry of This Report: https://www.snsinsider.com/enquiry/2984
Market Segmentation:
By Type
Eye Attached Tracking
Optical Tracking
Electrooculography
By Location
Remote
Mobile
By Component
Hardware
Software
By Application
Healthcare
Retail
Research
Automotive
Consumer Electronics
Forecast
The eye tracking industry is projected to grow steadily over the next few years, backed by increased investments in smart technology and user experience solutions. Expansion in emerging economies, coupled with growing interest in AI-integrated analytics, will play a major role in the market's acceleration. Key developments in augmented and virtual reality ecosystems—especially with headsets from leading brands—will be a strong catalyst for growth.
Eye tracking technology is also expected to expand in use for biometric authentication, lie detection, and educational performance tracking. The scalability of solutions and the decline in hardware costs will make adoption easier for small- and mid-sized organizations as well.
Trends
Several trends are shaping the future of the eye tracking market:
Integration with AR/VR: Eye tracking is becoming a key input mechanism in immersive environments, used to create more realistic and adaptive experiences.
AI-Enhanced Gaze Analysis: Artificial intelligence is enabling deeper, more predictive insights into human behavior based on gaze patterns.
Hands-Free Interfaces: Eye tracking is being used to create accessible digital interfaces for people with mobility challenges, revolutionizing communication tools.
Advertising and UX Analytics: Brands are employing eye tracking to understand exactly what captures user attention in campaigns and interfaces.
Automotive Safety Systems: As autonomous driving evolves, eye tracking will play a critical role in ensuring that drivers are alert and responsive when needed.
Future Prospects
The future of the eye tracking market lies in its convergence with other advanced technologies. The synergy between eye tracking, voice recognition, gesture control, and emotion analysis will open new frontiers in intuitive computing. Its role in healthcare, especially in mental health assessment and neurorehabilitation, is also expected to grow.
As digital environments become more immersive and user-centric, eye tracking will be instrumental in optimizing interaction and feedback mechanisms. Eye tracking data may also become a valuable input for personalizing content in e-learning, e-commerce, and social media platforms.
Access Complete Report: https://www.snsinsider.com/reports/eye-tracking-market-2984
Conclusion
In conclusion, the Eye Tracking Market is emerging as a foundational technology for a future driven by personalized, intuitive, and intelligent interaction. Its applications are wide-ranging and impactful, touching industries from healthcare to entertainment. As innovation continues and costs decrease, eye tracking will become more mainstream, influencing how we engage with technology and how technology understands us in return.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Eye Tracking Market#Eye Tracking Market Scope#Eye Tracking Market Growth#Eye Tracking Market Trends
0 notes
Text
h
Technical Skills (Java, Spring, Python)
Q1: Can you walk us through a recent project where you built a scalable application using Java and Spring Boot? A: Absolutely. In my previous role, I led the development of a microservices-based system using Java with Spring Boot and Spring Cloud. The app handled real-time financial transactions and was deployed on AWS ECS. I focused on building stateless services, applied best practices like API versioning, and used Eureka for service discovery. The result was a 40% improvement in performance and easier scalability under load.
Q2: What has been your experience with Python in data processing? A: I’ve used Python for ETL pipelines, specifically for ingesting large volumes of compliance data into cloud storage. I utilized Pandas and NumPy for processing, and scheduled tasks with Apache Airflow. The flexibility of Python was key in automating data validation and transformation before feeding it into analytics dashboards.
Cloud & DevOps
Q3: Describe your experience deploying applications on AWS or Azure. A: Most of my cloud experience has been with AWS. I’ve deployed containerized Java applications to AWS ECS and used RDS for relational storage. I also integrated S3 for static content and Lambda for lightweight compute tasks. In one project, I implemented CI/CD pipelines with Jenkins and CodePipeline to automate deployments and rollbacks.
Q4: How have you used Docker or Kubernetes in past projects? A: I've containerized all backend services using Docker and deployed them on Kubernetes clusters (EKS). I wrote Helm charts for managing deployments and set up autoscaling rules. This improved uptime and made releases smoother, especially during traffic spikes.
Collaboration & Agile Practices
Q5: How do you typically work with product owners and cross-functional teams? A: I follow Agile practices, attending sprint planning and daily stand-ups. I work closely with product owners to break down features into stories, clarify acceptance criteria, and provide early feedback. My goal is to ensure technical feasibility while keeping business impact in focus.
Q6: Have you had to define technical design or architecture? A: Yes, I’ve been responsible for defining the technical design for multiple features. For instance, I designed an event-driven architecture for a compliance alerting system using Kafka, Java, and Spring Cloud Streams. I created UML diagrams and API contracts to guide other developers.
Testing & Quality
Q7: What’s your approach to testing (unit, integration, automation)? A: I use JUnit and Mockito for unit testing, and Spring’s Test framework for integration tests. For end-to-end automation, I’ve worked with Selenium and REST Assured. I integrate these tests into Jenkins pipelines to ensure code quality with every push.
Behavioral / Cultural Fit
Q8: How do you stay updated with emerging technologies? A: I subscribe to newsletters like InfoQ and follow GitHub trending repositories. I also take part in hackathons and complete Udemy/Coursera courses. Recently, I explored Quarkus and Micronaut to compare their performance with Spring Boot in cloud-native environments.
Q9: Tell us about a time you challenged the status quo or proposed a modern tech solution. A: At my last job, I noticed performance issues due to a legacy monolith. I advocated for a microservices transition. I led a proof-of-concept using Spring Boot and Docker, which gained leadership buy-in. We eventually reduced deployment time by 70% and improved maintainability.
Bonus: Domain Experience
Q10: Do you have experience supporting back-office teams like Compliance or Finance? A: Yes, I’ve built reporting tools for Compliance and data reconciliation systems for Finance. I understand the importance of data accuracy and audit trails, and have used role-based access and logging mechanisms to meet regulatory requirements.
0 notes
Text
How to Ace a Data Engineering Interview: Tips & Common Questions
The demand for data engineers is growing rapidly, and landing a job in this field requires thorough preparation. If you're aspiring to become a data engineer, knowing what to expect in an interview can help you stand out. Whether you're preparing for your first data engineering role or aiming for a more advanced position, this guide will provide essential tips and common interview questions to help you succeed. If you're in Bangalore, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can significantly boost your chances of success by providing structured learning and hands-on experience.
Understanding the Data Engineering Interview Process
Data engineering interviews typically consist of multiple rounds, including:
Screening Round – A recruiter assesses your background and experience.
Technical Round – Tests your knowledge of SQL, databases, data pipelines, and cloud computing.
Coding Challenge – A take-home or live coding test to evaluate your problem-solving abilities.
System Design Interview – Focuses on designing scalable data architectures.
Behavioral Round – Assesses your teamwork, problem-solving approach, and communication skills.
Essential Tips to Ace Your Data Engineering Interview
1. Master SQL and Database Concepts
SQL is the backbone of data engineering. Be prepared to write complex queries and optimize database performance. Some important topics include:
Joins, CTEs, and Window Functions
Indexing and Query Optimization
Data Partitioning and Sharding
Normalization and Denormalization
Practice using platforms like LeetCode, HackerRank, and Mode Analytics to refine your SQL skills. If you need structured training, consider a Data Engineering Course in Indira Nagar for in-depth SQL and database learning.
2. Strengthen Your Python and Coding Skills
Most data engineering roles require Python expertise. Be comfortable with:
Pandas and NumPy for data manipulation
Writing efficient ETL scripts
Automating workflows with Python
Additionally, learning Scala and Java can be beneficial, especially for working with Apache Spark.
3. Gain Proficiency in Big Data Technologies
Many companies deal with large-scale data processing. Be prepared to discuss and work with:
Hadoop and Spark for distributed computing
Apache Airflow for workflow orchestration
Kafka for real-time data streaming
Enrolling in a Data Engineering Course in Jayanagar can provide hands-on experience with these technologies.
4. Understand Data Pipeline Architecture and ETL Processes
Expect questions on designing scalable and efficient ETL pipelines. Key topics include:
Extracting data from multiple sources
Transforming and cleaning data efficiently
Loading data into warehouses like Redshift, Snowflake, or BigQuery
5. Familiarize Yourself with Cloud Platforms
Most data engineering roles require cloud computing expertise. Gain hands-on experience with:
AWS (S3, Glue, Redshift, Lambda)
Google Cloud Platform (BigQuery, Dataflow)
Azure (Data Factory, Synapse Analytics)
A Data Engineering Course in Hebbal can help you get hands-on experience with cloud-based tools.
6. Practice System Design and Scalability
Data engineering interviews often include system design questions. Be prepared to:
Design a scalable data warehouse architecture
Optimize data processing pipelines
Choose between batch and real-time data processing
7. Prepare for Behavioral Questions
Companies assess your ability to work in a team, handle challenges, and solve problems. Practice answering:
Describe a challenging data engineering project you worked on.
How do you handle conflicts in a team?
How do you ensure data quality in a large dataset?
Common Data Engineering Interview Questions
Here are some frequently asked questions:
SQL Questions:
Write a SQL query to find duplicate records in a table.
How would you optimize a slow-running query?
Explain the difference between partitioning and indexing.
Coding Questions: 4. Write a Python script to process a large CSV file efficiently. 5. How would you implement a data deduplication algorithm? 6. Explain how you would design an ETL pipeline for a streaming dataset.
Big Data & Cloud Questions: 7. How does Apache Kafka handle message durability? 8. Compare Hadoop and Spark for large-scale data processing. 9. How would you choose between AWS Redshift and Google BigQuery?
System Design Questions: 10. Design a data pipeline for an e-commerce company that processes user activity logs. 11. How would you architect a real-time recommendation system? 12. What are the best practices for data governance in a data lake?
Final Thoughts
Acing a data engineering interview requires a mix of technical expertise, problem-solving skills, and practical experience. By focusing on SQL, coding, big data tools, and cloud computing, you can confidently approach your interview. If you’re looking for structured learning and practical exposure, enrolling in a Data Engineering Course in Hebbal, Data Engineering Course in Indira Nagar, or Data Engineering Course in Jayanagar can provide the necessary training to excel in your interviews and secure a high-paying data engineering job.
0 notes
Text
ETL Testing in Agile and DevOps: What You Need to Know

Introduction
ETL (Extract, Transform, Load) testing is the lifeline of management, as it tests the datamovement from source to destination for accuracy, completeness, and reliability. The conventional way of ETL testing in effect was treated in the form of a waterfall model, testing after the whole of ETL built. With the emergence of AGILE and DevOps themes, however, ETL testing is also made to be automated inline with fast development cycles and continuous integration/continuous deployment (CI/CD) methods.
If ETL testing interests you, consider better taking ETL testing course in Chennai to indulge in practical aspect and awareness about industry.
The Role of ETL Testing under Agile
Agile is iterative development, faster feedbacks and collaborates between teams. ETL Testing because of this means:
Incremental Development: In smaller iterations data pipelines are built, where every iteration has to undergo continuous validation and incremental executions.
Early Testing: This is integrated into every sprint, which is always tested after the final set of activities.
Automated Testing: Since the pace in Agile is generally so quick, it befits automation for the working of repetitive tests efficaciously.
Collaboration: They are working closely because of the quality of test against the requirements put forward by the business in synch with developers, business analysts, or stakeholders.
Agile ETL testing challenges
Transforming the ETL testing from the waterfall to the Agile paradigm brings along unique challenges like the following:
Changes in Schema Mercilessly Frequent: In short, timescales make it such testing such that a change in one schema one day would require continuous validation of all stages of development.
Volume and Complexity of Data: And this means more often than not that it will not possible to perform full-scale testing for short sprints.
Automation Complex: Automating ETL tests requires specialized tools and true understanding of most of the data structure and unlike most of UI based testing doesn't support automated ETL tests.
Data Dependence: Multiple teams will be simultaneously working on different pieces of the data pipeline in Agile, thus giving rise to dependency issues.
ETL Testing in DevOps
While it has developed continuous integration and continuous deployment, ETL has now been converted into an ongoing process instead of being treated as a separate phase. In accordance with these considerations, the following parts define ETL testing in the context of DevOps:
CI and CD Integration: Each ETL test case added into the CI/CD pipeline plays an integral role in its involvement at all levels of deployment.
Automation in ETL Testing: Using test tools like Informatica, Talend, and of course Selenium test automation (for UI basis validation) indeed increases some repetitive tests in their execution.
Real-Time Data Validation: Continuous monitoring of the pipelines of the data helps in identifying discrepancies or errors earlier.
Associated Teamwork: Such a culture within DevOps would have improved relations between development, operation, and testing teams regarding overall data integrity.
Best Practices for ETL Testing in Agile and DevOps
This is the way by and large an ETL testing program can be successfully adopted in Agile, DevOps, and general practice:
Incidentally early and continuous testing which has incorporated all of the tests from the start of a development cycle.
Automation Complexity: Beginning with all that knowledge about conventional UI-based testing, the automated ETL testing becomes highly valuable with the incorporation into specialized tools and highly in-depth understanding of the data structures involved.
Agile Dependence: With multiple teams running in parallel to other parts of the data pipeline, Agile dependency issues arise.
ETL Testing in DevOps
DevOps is a continuous integration and continuous deployment practice where ETL testing is not a phase but an ongoing process. The main aspects of ETL testing in DevOps include:
Integration into CI/CD: In CI/CD, the ETL test case is integrated to ensure data validation at all levels of deployment.
Automated ETL Testing: With Informatica, Talend, and Selenium, automated test execution is achieved through UI-based validations.
Real-Time Data Validation: Pipelines will be continuously monitored for any significant inconsistencies and errors.
Teams Workmen: Together in DevOps, development, operations, and testing teams are enabled to work towards data integrity.
Future of ETL Testing
With the increasing shift into cloud data warehouses, AI-driven analytics, and big data design, ETL testing transforms as these grow. ETL testing is emerging along various trends, including the following:
Cloud-based ETL Testing: Most organizations will simultaneously move to the cloud, whether it's AWS, Microsoft's Azure, or Google's Google Cloud. It means that even the test done to certify an ETL pipeline will have to conform to being cloud-based.
AI & Machinery Learning in ETL Testing: AI-driven testing tools will add value to the technology for data validation and anomaly detection.
Self Healing Test Automation: Intelligent frameworks for test automation will detect test failures and self-correct the scripts of the test to make them more efficient.
Conclusion
ETL testing in traditional Agile and DevOps should be less concentrated on the respective techniques of testing but should be highly integrated, collaborative, and automated. It means successive transformations for organizations to ensure proper and high-quality data delivery along with fast provision time. For instance, those aspiring to enter ETL testing careers might consider taking ETL testing courses in Chennai to get quality training and learning opportunities for a successful career in ETL testing.
0 notes
Text
Harnessing Automated Data Scheduling and REST API Data Automation with Match Data Pro LLC
In today's data-driven world, organizations handle vast amounts of information that require streamlined processing, efficient management, and real-time accessibility. Manual data handling is no longer feasible for businesses aiming to scale operations and maintain accuracy. Enter Match Data Pro LLC, a leader in automated data scheduling and REST API data automation. These cutting-edge solutions empower businesses to manage data workflows seamlessly, ensuring efficiency, security, and precision.
Understanding Automated Data Scheduling
Automated data scheduling is an important feature of contemporary data management that allows companies to run, track, and optimize their data processes automatically. This technology makes sure that data processing operations are run at scheduled times or initiated under certain conditions, greatly improving efficiency.
Advantages of Automated Data Scheduling:
Efficiency – Eliminates manual labor, enabling employees to concentrate on strategic activities.
Accuracy – Reduces errors due to human involvement.
Scalability – Efficiently handles huge amounts of data as companies expand.
Cost Savings – Saves on operational expenses involved in manual data processing.
Timely Execution – Facilitates timely completion of data tasks, enabling real-time decision-making.
Match Data Pro LLC offers robust automated data scheduling solutions that equip businesses with effortless execution and monitoring of data pipelines.
How Automated Data Scheduling Works
Automated data scheduling functions by using sophisticated data pipeline schedulers that run workflows in accordance with specified triggers, time windows, or external events. Such workflows may comprise data extraction, transformation, and loading (ETL), report creation, and system refresh.
In Match Data Pro LLC, the process of automated data scheduling is governed through a formal procedure:
Task Identification – Identifying critical business processes to be automated.
Workflow Design – Designing formal workflows that combine disparate data sources.
Scheduling Execution – Automating tools to run tasks at scheduled intervals.
Monitoring & Optimization – Continuous tracking of performance and error handling.
REST API Data Automation – Automating Data Operations
REST API data automation allows for smooth communication between various systems, applications, and databases through automated API calls. APIs (Application Programming Interfaces) serve as connectors between software components, enabling them to pass data back and forth with ease.
With Match Data Pro LLC, companies can automate their REST API data automation to:
Automate updates and retrieval of data on various platforms.
Connect third-party applications without any human intervention.
Ensure data consistency and synchronization across systems.
Optimize operational efficiency by removing redundant manual processes.
REST API Data Automation Key Features
Seamless Integration – Integrate various software applications for streamlined data management.
Real-Time Data Processing – Updates data on multiple platforms in real time.
Scalability – Manages growing volumes of data without performance decline.
Improved Security – Provides safe data transfer with authentication and encryption mechanisms.
Error Handling & Logging – Detects and fixes data discrepancies effectively.
Putting REST API Data Automation to Work with Match Data Pro LLC
Implementation of REST API data automation is a multi-step process for a smooth shift from manual to automatic processes. Match Data Pro LLC adopts a systematic approach:
Assessment of Business Requirements – Determining precise automation needs.
API Planning for Integration – Creating API endpoints for effective data exchange.
Development of Automation – Executing scripts and tools for automating API interactions.
Testing & Validation – Facilitating seamless data transfer with thorough testing.
Deployment & Monitoring – Deploying automation processes with real-time monitoring.
Real-World Applications of Automated Data Scheduling and REST API Data Automation
Companies in different sectors use automated data scheduling and REST API data automation to automate operations, enhance efficiency, and increase data accuracy. Some of the main uses are:
1. E-commerce Sites
Automated order processing and inventory refresh.
Synchronization of product listings in real-time across multiple channels.
Data-driven marketing campaigns using user behavior analytics.
2. Financial Institutions
Automated transaction processing and fraud detection.
Secure banking API integration for effortless data sharing.
Compliance reporting efficiently through scheduled data extraction.
3. Healthcare & Life Sciences
EHR system integration.
Data exchange between healthcare organizations and insurers automatically.
Patient monitoring and reporting in real-time via networked devices.
4. Medical Resource Planning (ERP)
Auto-synchronization of HR records, financial data, and procurement.
Third-party software integration without gaps for greater workflow automation.
Automated generation of performance reports and data analytics on schedule.
Why Automate with Match Data Pro LLC?
With robust expertise in automated data scheduling and REST API data automation, Match Data Pro LLC is a reliable partner for companies intending to streamline their data management solutions. Here's why companies trust Match Data Pro LLC:
Integrated Data Automation Solutions – Providing full-cycle solutions aligned with business requirements.
State-of-the-Art Technology – Employs the newest automation tools and frameworks.
Scalability & Flexibility – Suitable for businesses of any size and type.
Secure & Reliable – Enforcing industry standards for data security and compliance.
Expert Support & Consultation – Offering live help for smooth implementation of automation.
Conclusion
In the digital age, data scheduling automation and REST API data automation are no longer a choice but a necessity for companies to improve efficiency and data precision. Match Data Pro LLC provides innovative solutions that streamline complicated data processes so that companies can invest in growth and innovation. By leveraging automation, businesses are able to realize streamlined operations, cost savings, and better decision-making, setting themselves up for long-term success.
0 notes
Text
Automated ETL Testing
The Rise of Automated ETL Testing:
Traditionally, ETL testing has been a manual and resource-intensive process. However, with the increasing demands for agility, speed, and accuracy, automated ETL testing has emerged as a strategic solution. Automated testing involves the use of specialized tools and scripts to execute tests, validate results, and identify potential issues in the ETL process.
Challenges in Automated ETL Testing:
Tool Selection: Choosing the right automation tool is crucial. Consider factors such as compatibility with ETL platforms, ease of use, and the ability to support a variety of test scenarios.
Script Maintenance: As ETL processes evolve, test scripts must be updated accordingly. Maintenance can become challenging without proper version control and documentation.
Data Quality: Automated testing is only as effective as the quality of the test data. Ensuring realistic and representative test data is crucial for meaningful results.
Complex Transformations: Some ETL processes involve intricate business rules and complex transformations. Creating accurate and maintainable automated tests for such scenarios requires careful consideration.
Conclusion:
Automated ETL testing is a transformative approach that empowers organizations to enhance the reliability and efficiency of their data pipelines. By adopting best practices, addressing challenges proactively, and leveraging the right tools, businesses can streamline their ETL testing processes, ensuring that data remains a trustworthy asset in the era of data-driven decision-making
0 notes
Text
What Are the Key Steps in the Data Conversion Process?
In the digital era, seamless data conversion is crucial for businesses transitioning between systems, formats, or platforms. Whether migrating legacy databases to modern infrastructures or transforming raw data into usable insights, an effective data conversion strategy ensures accuracy, integrity, and consistency. Below are the essential steps in the data conversion process.
1. Requirement Analysis
A comprehensive assessment of source and target formats is vital before initiating data conversion. This stage involves evaluating data structures, compatibility constraints, and potential transformation challenges. A detailed roadmap minimizes errors and ensures a structured migration.
2. Data Extraction
Data must be retrieved from its original repository, whether a relational database, flat file, or cloud storage. This step demands meticulous extraction techniques to preserve data fidelity and prevent corruption. In large-scale data conversion projects, automation tools help streamline extraction while maintaining efficiency.
3. Data Cleansing and Validation
Raw data often contains inconsistencies, redundancies, or inaccuracies. Cleansing involves deduplication, formatting corrections, and anomaly detection to enhance quality. Validation ensures data meets predefined integrity rules, eliminating discrepancies that could lead to processing errors post-conversion.
4. Data Mapping and Transformation
Source data must align with the target system’s structure, necessitating meticulous mapping. This step involves schema alignment, datatype standardization, and structural modifications. Advanced transformation techniques such as ETL (Extract, Transform, Load) pipelines facilitate seamless data conversion by automating complex modifications.
5. Data Loading
Once transformed, the data is loaded into the destination system. This phase may involve bulk insertion or incremental loading, depending on the project’s scale. Performance optimization techniques, such as indexing and parallel processing, enhance speed and efficiency while minimizing system downtime.
6. Data Verification and Testing
A thorough validation process is crucial to confirm the integrity and accuracy of the converted data. Cross-checking against the source dataset, conducting sample audits, and running test scenarios help identify anomalies before final deployment. This step ensures that data conversion outcomes meet operational and compliance standards.
7. Post-Conversion Optimization
After successful deployment, performance monitoring and fine-tuning are essential. Index optimization, query performance analysis, and periodic audits help maintain long-term data integrity. Additionally, continuous monitoring allows early detection of emerging inconsistencies or system bottlenecks.
A meticulously executed data conversion process minimizes risks associated with data loss, corruption, or incompatibility. By adhering to structured methodologies and leveraging automation, businesses can seamlessly transition between systems while safeguarding data reliability. Whether for cloud migrations, software upgrades, or enterprise integrations, a well-planned data conversion strategy is indispensable in modern data management.
0 notes
Text
Automation Tester with ETL/UI/Big Data Testing - C11 - PUNE
The Applications Development Intermediate Programmer Analyst is an intermediate level position responsible for participation in the establishment and implementation of new or revised application systems and programs in coordination with the Technology team. The overall objective of this role is to contribute to applications systems analysis and programming activities.Responsibilities:Hands on…
0 notes
Text
Understanding Data Testing and Its Importance

In today’s data-driven world, businesses rely heavily on accurate and high-quality data to make critical decisions. Data testing is a crucial process that ensures the accuracy, consistency, and reliability of data within databases, data warehouses, and software applications. By implementing robust data testing services, organizations can avoid costly errors, improve decision-making, and enhance operational efficiency.
What is Data Testing?
Data testing is the process of validating data for accuracy, integrity, consistency, and completeness. It involves checking whether the data being used in an application or system meets predefined quality standards. Organizations use data testing to detect discrepancies, missing values, duplicate records, or incorrect formats that can compromise data integrity.
Key Aspects of Data Testing
Data Validation – Ensures that data conforms to predefined rules and constraints.
Data Integrity Testing – Checks for consistency and correctness of data across different databases and systems.
Data Migration Testing – Validates data movement from one system to another without loss or corruption.
ETL Testing – Tests the Extract, Transform, Load (ETL) process to ensure accurate data extraction, transformation, and loading into the target system.
Regression Testing – Ensures that changes in data do not negatively impact the system’s functionality.
Performance Testing – Assesses the speed and reliability of data processes under varying conditions.
Why Are Data Testing Services Essential?
With the exponential growth of data, organizations cannot afford to overlook data quality. Investing in professional data testing services provides several benefits:
Prevention of Data Errors: Identifying and fixing data issues before they impact business processes.
Regulatory Compliance: Ensuring data adheres to industry regulations such as GDPR, HIPAA, and SOX.
Optimized Performance: Ensuring that databases and applications run efficiently with high-quality data.
Enhanced Decision-Making: Reliable data enables better business insights and informed decision-making.
Seamless Data Integration: Ensuring smooth data migration and integration between different platforms.
How to Implement Effective Data Testing?
Define Clear Data Quality Standards: Establish rules and benchmarks for data accuracy, consistency, and completeness.
Automate Testing Where Possible: Leverage automation tools for efficient and accurate data validation.
Conduct Regular Data Audits: Periodic testing helps identify and rectify data anomalies.
Use Robust Data Testing Tools: Tools like Informatica, Talend, and Apache Nifi help streamline the process.
Engage Professional Data Testing Services: Partnering with expert service providers ensures thorough testing and high-quality data.
Conclusion
In an era where data fuels business success, ensuring its accuracy and reliability is paramount. Data testing services play a crucial role in maintaining data integrity and enhancing operational efficiency. Organizations that invest in proper data testing can mitigate risks, improve compliance, and make data-driven decisions with confidence. Prioritizing data testing today means securing a smarter and more efficient business future.
0 notes