#Databricks SQL Data Warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Data Lakehouse

Data Lakehouse: революция в мире данных, о которой вы не знали. Представьте себе мир, где вам больше не нужно выбирать между хранилищем структурированных данных и озером неструктурированной информации.
Data Lakehouse — это как швейцарский нож в мире данных, объединяющий лучшее из двух подходов. Давайте разберёмся, почему 75% компаний уже перешли на эту архитектуру и как она может изменить ваш бизнес.
Что такое Data Lakehouse на самом деле?
Data Lakehouse — это не просто модное словечко. Это принципиально новый подход к работе с данными, который ломает традиционные барьеры. В отличие от старых систем, где данные приходилось постоянно перемещать между разными хранилищами, здесь всё живёт в одной экосистеме. Почему это прорыв? - Больше никакой головной боли с ETL — данные доступны сразу после поступления. - Один источник правды — все отделы работают с одинаковыми данными. - Масштабируемость без ограничений — растёт бизнес, растёт и ваше хранилище.
Как работает эта магия?
Секрет Data Lakehouse в трёх китах. Единый слой хранения Вместо разделения на data lakes и warehouses — общее хранилище для всех типов данных. Apache Iceberg (тот самый, за который Databricks выложили $1 млрд) — это лишь один из примеров технологий, делающих это возможным.
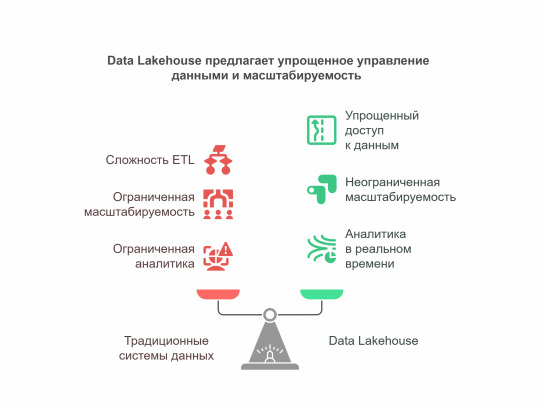
Революция в мире данных, о которой вы не знали Реальное время — не просто слова 56% IT-директоров подтверждают: аналитика в реальном времени сокращает их расходы вдвое. Финансовые операции, маркетинговые кампании, обнаружение мошенничества — всё это теперь можно делать мгновенно. SQL и не только Старые добрые запросы работают бок о бок с машинным обучением и сложной аналитикой. Никаких "или-или" — только "и то, и другое".
Кто двигает этот рынок?
Три компании, за которыми стоит следить: - SingleStore — анализирует петабайты данных за миллисекунды ($464 млн инвестиций). - dbt Labs — превращает сырые данные в готовые для анализа без перемещения (60 тыс. клиентов). - Tinybird — создание приложений для работы с данными в реальном времени ($70 млн финансирования).
Почему вам стоит задуматься об этом уже сегодня?
70% технологических лидеров называют доступность данных для реальной аналитики критически важной. Data Lakehouse — это не будущее, это настоящее. Компании, которые внедряют эти решения сейчас, получают: - Конкурентное преимущество — быстрее принимают решения. - Экономию — до 50% на инфраструктуре. - Гибкость — работа с любыми данными в любом формате.
Динамика тренда С чего начать? Попробуйте облачные решения от Databricks или Amazon Redshift. Начните с малого — одного проекта или отдела. Убедитесь сами, как это работает, прежде чем масштабировать на всю компанию. Data Lakehouse — это не просто технология. Это новый образ мышления о данных. Как вы планируете использовать этот подход в своем бизнесе?
Часто задаваемые вопросы (ЧаВо)
Что такое Data Lakehouse и чем он отличается от традиционных хранилищ данных? Data Lakehouse — это современная архитектура данных, объединяющая преимущества Data Lakes (хранение неструктурированных данных) и Data Warehouses (структурированная аналитика). В отличие от традиционных систем, он обеспечивает единое хранилище для всех типов данных с поддержкой SQL-запросов, машинного обучения и аналитики в реальном времени без необходимости перемещения данных между системами. Какие ключевые преимущества Data Lakehouse для бизнеса? Основные преимущества включают: 1) Снижение затрат на инфраструктуру до 50% 2) Возможность аналитики в реальном времени 3) Устранение необходимости сложных ETL-процессов 4) Поддержка всех типов данных (структурированных, полуструктурированных и неструктурированных) 5) Единый источник данных для всей организации. Какие технологии лежат в основе Data Lakehouse? Ключевые технологии включают: 1) Apache Iceberg, Delta Lake и Apache Hudi для управления таблицами 2) Облачные хранилища (S3, ADLS) 3) Вычислительные движки (Spark, Presto) 4) SQL-интерфейсы 5) Инструменты машинного обучения. Эти технологии обеспечивают ACID-транзакции, версионность данных и высокую производительность. Как начать внедрение Data Lakehouse в моей компании? Рекомендуется начинать с пилотного проекта: 1) Выберите одну бизнес-задачу или отдел 2) Оцените облачные решения (Databricks, Snowflake, Amazon Redshift) 3) Начните с миграции части данных 4) Обучите команду 5) Измерьте результаты перед масштабированием. Многие провайдеры предлагают бесплатные пробные версии. Какие компании являются лидерами в области Data Lakehouse? Ключевые игроки рынка: 1) Databricks (Delta Lake) 2) Snowflake 3) AWS (Redshift, Athena) 4) Google (BigQuery) 5) Microsoft (Fabric). Также стоит обратить внимание на инновационные стартапы: SingleStore для аналитики в реальном времени, dbt Labs для трансформации данных и Tinybird для приложений реального времени. Какие проблемы решает Data Lakehouse? Data Lakehouse решает ключевые проблемы: 1) Фрагментация данных между разными системами 2) Задержки в аналитике из-за ETL 3) Высокая стоимость содержания отдельных хранилищ и озер данных 4) Сложность работы с неструктурированными данными 5) Ограничения масштабируемости традиционных решений. Каковы основные варианты использования Data Lakehouse? Типичные сценарии: 1) Аналитика в реальном времени (финансы, маркетинг) 2) Обнаружение мошенничества 3) Персонализация клиентского опыта 4) IoT и обработка потоковых данных 5) Машинное обучение и AI 6) Консолидация корпоративных данных 7) Управление клиентскими данными (CDP). Read the full article
0 notes
Text
10 Must-Have Skills for Data Engineering Jobs

In the digital economy of 2025, data isn't just valuable – it's the lifeblood of every successful organization. But raw data is messy, disorganized, and often unusable. This is where the Data Engineer steps in, transforming chaotic floods of information into clean, accessible, and reliable data streams. They are the architects, builders, and maintainers of the crucial pipelines that empower data scientists, analysts, and business leaders to extract meaningful insights.
The field of data engineering is dynamic, constantly evolving with new technologies and demands. For anyone aspiring to enter this vital domain or looking to advance their career, a specific set of skills is non-negotiable. Here are 10 must-have skills that will position you for success in today's data-driven landscape:
1. Proficiency in SQL (Structured Query Language)
Still the absolute bedrock. While data stacks become increasingly complex, SQL remains the universal language for interacting with relational databases and data warehouses. A data engineer must master SQL far beyond basic SELECT statements. This includes:
Advanced Querying: JOIN operations, subqueries, window functions, CTEs (Common Table Expressions).
Performance Optimization: Writing efficient queries for large datasets, understanding indexing, and query execution plans.
Data Definition and Manipulation: CREATE, ALTER, DROP tables, and INSERT, UPDATE, DELETE operations.
2. Strong Programming Skills (Python & Java/Scala)
Python is the reigning champion in data engineering due to its versatility, rich ecosystem of libraries (Pandas, NumPy, PySpark), and readability. It's essential for scripting, data manipulation, API interactions, and building custom ETL processes.
While Python dominates, knowledge of Java or Scala remains highly valuable, especially for working with traditional big data frameworks like Apache Spark, where these languages offer performance advantages and deeper integration.
3. Expertise in ETL/ELT Tools & Concepts
Data engineers live and breathe ETL (Extract, Transform, Load) and its modern counterpart, ELT (Extract, Load, Transform). Understanding the methodologies for getting data from various sources, cleaning and transforming it, and loading it into a destination is core.
Familiarity with dedicated ETL/ELT tools (e.g., Apache Nifi, Talend, Fivetran, Stitch) and modern data transformation tools like dbt (data build tool), which emphasizes SQL-based transformations within the data warehouse, is crucial.
4. Big Data Frameworks (Apache Spark & Hadoop Ecosystem)
When dealing with petabytes of data, traditional processing methods fall short. Apache Spark is the industry standard for distributed computing, enabling fast, large-scale data processing and analytics. Mastery of Spark (PySpark, Scala Spark) is vital for batch and stream processing.
While less prominent for direct computation, understanding the Hadoop Ecosystem (especially HDFS for distributed storage and YARN for resource management) still provides a foundational context for many big data architectures.
5. Cloud Platform Proficiency (AWS, Azure, GCP)
The cloud is the default environment for modern data infrastructures. Data engineers must be proficient in at least one, if not multiple, major cloud platforms:
AWS: S3 (storage), Redshift (data warehouse), Glue (ETL), EMR (Spark/Hadoop), Lambda (serverless functions), Kinesis (streaming).
Azure: Azure Data Lake Storage, Azure Synapse Analytics (data warehouse), Azure Data Factory (ETL), Azure Databricks.
GCP: Google Cloud Storage, BigQuery (data warehouse), Dataflow (stream/batch processing), Dataproc (Spark/Hadoop).
Understanding cloud-native services for storage, compute, networking, and security is paramount.
6. Data Warehousing & Data Lake Concepts
A deep understanding of how to structure and manage data for analytical purposes is critical. This includes:
Data Warehousing: Dimensional modeling (star and snowflake schemas), Kimball vs. Inmon approaches, fact and dimension tables.
Data Lakes: Storing raw, unstructured, and semi-structured data at scale, understanding formats like Parquet and ORC, and managing data lifecycle.
Data Lakehouses: The emerging architecture combining the flexibility of data lakes with the structure of data warehouses.
7. NoSQL Databases
While SQL handles structured data efficiently, many modern applications generate unstructured or semi-structured data. Data engineers need to understand NoSQL databases and when to use them.
Familiarity with different NoSQL types (Key-Value, Document, Column-Family, Graph) and examples like MongoDB, Cassandra, Redis, DynamoDB, or Neo4j is increasingly important.
8. Orchestration & Workflow Management (Apache Airflow)
Data pipelines are often complex sequences of tasks. Tools like Apache Airflow are indispensable for scheduling, monitoring, and managing these workflows programmatically using Directed Acyclic Graphs (DAGs). This ensures pipelines run reliably, efficiently, and alert you to failures.
9. Data Governance, Quality & Security
Building pipelines isn't enough; the data flowing through them must be trustworthy and secure. Data engineers are increasingly responsible for:
Data Quality: Implementing checks, validations, and monitoring to ensure data accuracy, completeness, and consistency. Tools like Great Expectations are gaining traction.
Data Governance: Understanding metadata management, data lineage, and data cataloging.
Data Security: Implementing access controls (IAM), encryption, and ensuring compliance with regulations (e.g., GDPR, local data protection laws).
10. Version Control (Git)
Just like software developers, data engineers write code. Proficiency with Git (and platforms like GitHub, GitLab, Bitbucket) is fundamental for collaborative development, tracking changes, managing different versions of pipelines, and enabling CI/CD practices for data infrastructure.
Beyond the Technical: Essential Soft Skills
While technical prowess is crucial, the most effective data engineers also possess strong soft skills:
Problem-Solving: Identifying and resolving complex data issues.
Communication: Clearly explaining complex technical concepts to non-technical stakeholders and collaborating effectively with data scientists and analysts.
Attention to Detail: Ensuring data integrity and pipeline reliability.
Continuous Learning: The data landscape evolves rapidly, demanding a commitment to staying updated with new tools and technologies.
The demand for skilled data engineers continues to soar as organizations increasingly rely on data for competitive advantage. By mastering these 10 essential skills, you won't just build data pipelines; you'll build the backbone of tomorrow's intelligent enterprises.
0 notes
Text
The Difference Between Business Intelligence and Data Analytics

Introduction
In today’s hyper-digital business world, data flows through every corner of an organization. But the value of that data is only realized when it’s converted into intelligence and ultimately, action.
That’s where Business Intelligence (BI) and Data Analytics come in. These two often-interchanged terms form the backbone of data-driven decision-making, but they serve very different purposes.
This guide unpacks the nuances between the two, helping you understand where they intersect, how they differ, and why both are critical to a future-ready enterprise.
What is Business Intelligence?
Business Intelligence is the systematic collection, integration, analysis, and presentation of business information. It focuses primarily on descriptive analytics — what happened, when, and how.
BI is built for reporting and monitoring, not for experimentation. It’s your corporate dashboard, a rearview mirror that helps you understand performance trends and operational health.
Key Characteristics of BI:
Historical focus
Dashboards and reports
Aggregated KPIs
Data visualization tools
Low-level predictive power
Examples:
A sales dashboard showing last quarter’s revenue
A report comparing warehouse efficiency across regions
A chart showing customer churn rate over time
What is Data Analytics?
Data Analytics goes a step further. It’s a broader umbrella that includes descriptive, diagnostic, predictive, and prescriptive approaches.
While BI focuses on “what happened,” analytics explores “why it happened,” “what might happen next,” and “what we should do about it.”
Key Characteristics of Data Analytics:
Exploratory in nature
Uses statistical models and algorithms
Enables forecasts and optimization
Can be used in real-time or batch processing
Often leverages machine learning and AI
Examples:
Predicting next quarter’s demand using historical sales and weather data
Analyzing clickstream data to understand customer drop-off in a sales funnel
Identifying fraud patterns in financial transactions
BI vs Analytics: Use Cases in the Real World
Let’s bring the distinction to life with practical scenarios.
Retail Example:
BI: Shows sales per store in Q4 across regions
Analytics: Predicts which product category will grow fastest next season based on external factors
Banking Example:
BI: Tracks number of new accounts opened weekly
Analytics: Detects anomalies in transactions suggesting fraud risk
Healthcare Example:
BI: Reports on patient visits by department
Analytics: Forecasts ER admission rates during flu season using historical and external data
Both serve a purpose, but together, they offer a comprehensive view of the business landscape.
Tools That Power BI and Data Analytics
Popular BI Tools:
Microsoft Power BI — Accessible and widely adopted
Tableau — Great for data visualization
Qlik Sense — Interactive dashboards
Looker — Modern BI for data teams
Zoho Analytics — Cloud-based and SME-friendly
Popular Analytics Tools:
Python — Ideal for modeling, machine learning, and automation
R — Statistical computing powerhouse
Google Cloud BigQuery — Great for large-scale data
SAS — Trusted in finance and healthcare
Apache Hadoop & Spark — For massive unstructured data sets
The Convergence of BI and Analytics
Modern platforms are increasingly blurring the lines between BI and analytics.
Tools like Power BI with Python integration or Tableau with R scripts allow businesses to blend static reporting with advanced statistical insights.
Cloud-based data warehouses like Snowflake and Databricks allow real-time querying for both purposes, from one central hub.
This convergence empowers teams to:
Monitor performance AND
Experiment with data-driven improvements
Skills and Teams: Who Does What?
Business Intelligence Professionals:
Data analysts, reporting specialists, BI developers
Strong in SQL, dashboard tools, storytelling
Data Analytics Professionals:
Data scientists, machine learning engineers, data engineers
Proficient in Python, R, statistics, modeling, and cloud tools
While BI empowers business leaders to act on known metrics, analytics helps technical teams discover unknowns.
Both functions require collaboration for maximum strategic impact.
Strategic Value for Business Leaders
BI = Operational Intelligence
Track sales, customer support tickets, cash flow, delivery timelines.
Analytics = Competitive Advantage
Predict market trends, customer behaviour, churn, or supply chain risk.
The magic happens when you use BI to steer, and analytics to innovate.
C-level insight:
CMOs use BI to measure campaign ROI, and analytics to refine audience segmentation
CFOs use BI for financial health tracking, and analytics for forecasting
CEOs rely on both to align performance with vision
How to Choose What Your Business Needs
Choose BI if:
You need faster, cleaner reporting
Business users need self-service dashboards
Your organization is report-heavy and reaction-focused
Choose Data Analytics if:
You want forward-looking insights
You need to optimize and innovate
You operate in a data-rich, competitive environment
Final Thoughts: Intelligence vs Insight
In the grand scheme, Business Intelligence tells you what’s going on, and Data Analytics tells you what to do next.
One is a dashboard; the other is a crystal ball.
As the pace of business accelerates, organizations can no longer afford to operate on gut instinct or lagging reports. They need the clarity of BI and the power of analytics together.
Because in a world ruled by data, those who turn information into insight, and insight into action, are the ones who win.
0 notes
Text
Unlocking Data Excellence with Kadel Labs: Leveraging the Databricks Lakehouse Platform and Unity Catalog
In today’s data-driven world, organizations are constantly seeking innovative ways to harness the power of their data. The ability to unify disparate data sources, streamline data governance, and accelerate analytics is more critical than ever. Enter Kadel Labs, a forward-thinking technology partner that empowers businesses to transform their data strategies using cutting-edge tools like the Databricks Lakehouse Platform and Databricks Unity Catalog.
The Data Challenge in Modern Enterprises
Modern enterprises generate enormous volumes of data daily, coming from various sources such as customer interactions, IoT devices, transactional systems, and third-party applications. Managing this complex data ecosystem involves overcoming several challenges:
Data Silos: Data often resides in disconnected systems, creating fragmented views.
Governance and Compliance: Ensuring data security, privacy, and regulatory compliance is difficult without centralized controls.
Data Quality and Consistency: Maintaining clean, reliable data across platforms is essential for accurate insights.
Speed and Agility: Traditional data architectures often fail to support rapid analytics and machine learning workflows.
To meet these challenges, companies need a unified approach that blends the best of data lakes and data warehouses, alongside robust governance mechanisms. This is where the Databricks Lakehouse Platform and Databricks Unity Catalog come into play, with Kadel Labs expertly guiding clients through adoption and implementation.
What is the Databricks Lakehouse Platform?
The Databricks Lakehouse Platform is a revolutionary data architecture that combines the scalability and flexibility of data lakes with the reliability and performance of data warehouses. Unlike traditional architectures that separate raw data storage and analytics, the lakehouse unifies these functions on a single platform.
Key Features and Benefits
Unified Data Storage: Stores structured, semi-structured, and unstructured data in an open format, allowing for seamless integration.
High Performance: Utilizes advanced optimizations to support interactive SQL analytics and machine learning workloads at scale.
Collaboration-Driven: Enables data engineers, scientists, and analysts to work in the same environment, reducing friction.
Open Ecosystem: Compatible with a variety of data tools and programming languages, promoting flexibility and innovation.
By leveraging the Databricks Lakehouse Platform, enterprises can break down data silos and accelerate time-to-insight.
How Kadel Labs Drives Value with the Databricks Lakehouse Platform
As a leader in data engineering and analytics consulting, Kadel Labs specializes in architecting and deploying scalable lakehouse solutions tailored to each organization’s unique needs. Their expertise spans:
Data Architecture Design: Crafting lakehouse frameworks that optimize performance and cost-efficiency.
Data Engineering: Building robust ETL pipelines that ingest and prepare data for analysis.
Machine Learning Integration: Enabling organizations to operationalize AI models directly within the lakehouse.
Performance Optimization: Fine-tuning workloads to ensure responsiveness even at massive scale.
Kadel Labs partners with clients throughout the journey—from initial strategy workshops to ongoing platform management—ensuring successful outcomes with the Databricks Lakehouse Platform.
Introducing Databricks Unity Catalog: Governance Made Simple
While unifying data storage and analytics is vital, enterprises must also prioritize governance to maintain trust and comply with regulations. Managing data access, lineage, and auditing across diverse datasets can be daunting. This is where Databricks Unity Catalog offers a game-changing solution.
What is Databricks Unity Catalog?
The Databricks Unity Catalog is a unified governance solution designed to provide centralized, fine-grained access control and comprehensive metadata management across all data assets within the lakehouse environment.
Core Capabilities
Centralized Metadata Management: Tracks data assets, schemas, and lineage in a single pane of glass.
Fine-Grained Access Controls: Enables role-based and attribute-based permissions down to the column level.
Data Lineage and Auditing: Provides visibility into data usage, transformations, and access patterns.
Cross-Platform Governance: Supports consistent policies across multiple workspaces and clouds.
By implementing the Unity Catalog, organizations gain peace of mind knowing their data is secure, compliant, and auditable.
Kadel Labs and Databricks Unity Catalog: Securing Data for the Future
Kadel Labs understands that governance is not just about technology—it’s about aligning data policies with business objectives and regulatory demands. Their consultants work closely with clients to:
Define Governance Policies: Tailoring controls that balance security with ease of access.
Implement Unity Catalog: Configuring catalog structures, roles, and permissions for optimal protection.
Ensure Regulatory Compliance: Supporting frameworks such as GDPR, HIPAA, and CCPA.
Train Teams: Empowering users to understand and respect governance boundaries.
With Kadel Labs’ guidance, organizations can confidently leverage the full power of the Databricks Lakehouse Platform while maintaining strict governance through the Unity Catalog.
Real-World Impact: Transforming Businesses with Kadel Labs
Several organizations across industries have partnered with Kadel Labs to modernize their data ecosystems. These clients report significant improvements:
Faster Data Access: Reduction in time to access trusted data from days to minutes.
Improved Data Security: Centralized governance reduces the risk of data breaches and unauthorized use.
Scalable Analytics: Support for high-volume AI and BI workloads without sacrificing performance.
Cost Efficiency: Optimized use of cloud storage and compute resources.
These outcomes not only enhance operational efficiency but also enable data-driven innovation that fuels growth.
Why Choose Kadel Labs for Your Databricks Journey?
The technology alone is powerful, but success requires deep expertise and a strategic approach. Here’s why Kadel Labs stands out:
Certified Databricks Experts: Proven experience in implementing and optimizing Databricks solutions.
End-to-End Services: From strategy and architecture to training and support.
Custom Solutions: Tailored to meet specific industry, regulatory, and business needs.
Strong Partnership Approach: Collaborative engagement focused on long-term success.
Kadel Labs ensures that your investment in the Databricks Lakehouse Platform and Unity Catalog delivers measurable business value.
Getting Started with Kadel Labs and Databricks
For organizations ready to elevate their data capabilities, Kadel Labs offers an initial consultation to assess readiness, identify pain points, and outline a roadmap. Whether starting fresh or migrating existing data infrastructure, Kadel Labs can accelerate your journey to a modern lakehouse architecture with comprehensive governance.
Conclusion
In a world where data is the lifeblood of business, leveraging the right platforms and governance frameworks is crucial. The Databricks Lakehouse Platform breaks down traditional data barriers, while the Databricks Unity Catalog ensures secure and compliant access. Together, they form the foundation for a future-proof data strategy.
With Kadel Labs as your trusted partner, you gain not only access to these groundbreaking technologies but also the expertise to implement, govern, and optimize them for maximum impact. Unlock the true potential of your data today with Kadel Labs and transform your enterprise into a data-driven powerhouse.
0 notes
Text
Datametica achieved significant runtime reduction by migrating Oracle Exadata workloads to Databricks through a strategic cloud migration and data warehouse migration approach. Leveraging Oracle data migration tools and automated SQL conversion, they replatformed efficiently, optimizing performance with Delta Iceberg and phased deployment. Powered by Pelican, their AI-powered automated data validation tool, the process ensured data integrity. This seamless shift was part of a broader Google Cloud migration strategy to modernize analytics at scale.
#cloud migration#oracle data migration tools#google cloud migration#AI-powered automated data validation tool – Pelican
0 notes
Text
Only Data Engineering Roadmap You Need 2025
6 Course Combo Pack (Python, SQL, Data Warehouse (Snowflake), Apache Spark (Databricks), Airflow and Kafka with 16 … source
0 notes
Text
Snowflake vs Redshift vs BigQuery vs Databricks: A Detailed Comparison
In the world of cloud-based data warehousing and analytics, organizations are increasingly relying on advanced platforms to manage their massive datasets. Four of the most popular options available today are Snowflake, Amazon Redshift, Google BigQuery, and Databricks. Each offers unique features, benefits, and challenges for different types of organizations, depending on their size, industry, and data needs. In this article, we will explore these platforms in detail, comparing their performance, scalability, ease of use, and specific use cases to help you make an informed decision.
What Are Snowflake, Redshift, BigQuery, and Databricks?
Snowflake: A cloud-based data warehousing platform known for its unique architecture that separates storage from compute. It’s designed for high performance and ease of use, offering scalability without complex infrastructure management.
Amazon Redshift: Amazon’s managed data warehouse service that allows users to run complex queries on massive datasets. Redshift integrates tightly with AWS services and is optimized for speed and efficiency in the AWS ecosystem.
Google BigQuery: A fully managed and serverless data warehouse provided by Google Cloud. BigQuery is known for its scalable performance and cost-effectiveness, especially for large, analytic workloads that require SQL-based queries.
Databricks: More than just a data warehouse, Databricks is a unified data analytics platform built on Apache Spark. It focuses on big data processing and machine learning workflows, providing an environment for collaborative data science and engineering teams.
Snowflake Overview
Snowflake is built for cloud environments and uses a hybrid architecture that separates compute, storage, and services. This unique architecture allows for efficient scaling and the ability to run independent workloads simultaneously, making it an excellent choice for enterprises that need flexibility and high performance without managing infrastructure.
Key Features:
Data Sharing: Snowflake’s data sharing capabilities allow users to share data across different organizations without the need for data movement or transformation.
Zero Management: Snowflake handles most administrative tasks, such as scaling, optimization, and tuning, so teams can focus on analyzing data.
Multi-Cloud Support: Snowflake runs on AWS, Google Cloud, and Azure, giving users flexibility in choosing their cloud provider.
Real-World Use Case:
A global retail company uses Snowflake to aggregate sales data from various regions, optimizing its supply chain and inventory management processes. By leveraging Snowflake’s data sharing capabilities, the company shares real-time sales data with external partners, improving forecasting accuracy.
Amazon Redshift Overview
Amazon Redshift is a fully managed, petabyte-scale data warehouse solution in the cloud. It is optimized for high-performance querying and is closely integrated with other AWS services, such as S3, making it a top choice for organizations that already use the AWS ecosystem.
Key Features:
Columnar Storage: Redshift stores data in a columnar format, which makes querying large datasets more efficient by minimizing disk I/O.
Integration with AWS: Redshift works seamlessly with other AWS services, such as Amazon S3, Amazon EMR, and AWS Glue, to provide a comprehensive solution for data management.
Concurrency Scaling: Redshift automatically adds additional resources when needed to handle large numbers of concurrent queries.
Real-World Use Case:
A financial services company leverages Redshift for data analysis and reporting, analyzing millions of transactions daily. By integrating Redshift with AWS Glue, the company has built an automated ETL pipeline that loads new transaction data from Amazon S3 for analysis in near-real-time.
Google BigQuery Overview
BigQuery is a fully managed, serverless data warehouse that excels in handling large-scale, complex data analysis workloads. It allows users to run SQL queries on massive datasets without worrying about the underlying infrastructure. BigQuery is particularly known for its cost efficiency, as it charges based on the amount of data processed rather than the resources used.
Key Features:
Serverless Architecture: BigQuery automatically handles all infrastructure management, allowing users to focus purely on querying and analyzing data.
Real-Time Analytics: It supports real-time analytics, enabling businesses to make data-driven decisions quickly.
Cost Efficiency: With its pay-per-query model, BigQuery is highly cost-effective, especially for organizations with varying data processing needs.
Real-World Use Case:
A digital marketing agency uses BigQuery to analyze massive amounts of user behavior data from its advertising campaigns. By integrating BigQuery with Google Analytics and Google Ads, the agency is able to optimize its ad spend and refine targeting strategies.
Databricks Overview
Databricks is a unified analytics platform built on Apache Spark, making it ideal for data engineering, data science, and machine learning workflows. Unlike traditional data warehouses, Databricks combines data lakes, warehouses, and machine learning into a single platform, making it suitable for advanced analytics.
Key Features:
Unified Analytics Platform: Databricks combines data engineering, data science, and machine learning workflows into a single platform.
Built on Apache Spark: Databricks provides a fast, scalable environment for big data processing using Spark’s distributed computing capabilities.
Collaboration: Databricks provides collaborative notebooks that allow data scientists, analysts, and engineers to work together on the same project.
Real-World Use Case:
A healthcare provider uses Databricks to process patient data in real-time and apply machine learning models to predict patient outcomes. The platform enables collaboration between data scientists and engineers, allowing the team to deploy predictive models that improve patient care.

People Also Ask
1. Which is better for data warehousing: Snowflake or Redshift?
Both Snowflake and Redshift are excellent for data warehousing, but the best option depends on your existing ecosystem. Snowflake’s multi-cloud support and unique architecture make it a better choice for enterprises that need flexibility and easy scaling. Redshift, however, is ideal for organizations already using AWS, as it integrates seamlessly with AWS services.
2. Can BigQuery handle real-time data?
Yes, BigQuery is capable of handling real-time data through its streaming API. This makes it an excellent choice for organizations that need to analyze data as it’s generated, such as in IoT or e-commerce environments where real-time decision-making is critical.
3. What is the primary difference between Databricks and Snowflake?
Databricks is a unified platform for data engineering, data science, and machine learning, focusing on big data processing using Apache Spark. Snowflake, on the other hand, is a cloud data warehouse optimized for SQL-based analytics. If your organization requires machine learning workflows and big data processing, Databricks may be the better option.
Conclusion
When choosing between Snowflake, Redshift, BigQuery, and Databricks, it's essential to consider the specific needs of your organization. Snowflake is a flexible, high-performance cloud data warehouse, making it ideal for enterprises that need a multi-cloud solution. Redshift, best suited for those already invested in the AWS ecosystem, offers strong performance for large datasets. BigQuery excels in cost-effective, serverless analytics, particularly in the Google Cloud environment. Databricks shines for companies focused on big data processing, machine learning, and collaborative data science workflows.
The future of data analytics and warehousing will likely see further integration of AI and machine learning capabilities, with platforms like Databricks leading the way in this area. However, the best choice for your organization depends on your existing infrastructure, budget, and long-term data strategy.
1 note
·
View note
Text
Best Azure Data Engineer Course In Ameerpet | Azure Data
Understanding Delta Lake in Databricks
Introduction
Delta Lake, an open-source storage layer developed by Databricks, is designed to address these challenges. It enhances Apache Spark's capabilities by providing ACID transactions, schema enforcement, and time travel, making data lakes more reliable and efficient. In modern data engineering, managing large volumes of data efficiently while ensuring reliability and performance is a key challenge.

What is Delta Lake?
Delta Lake is an optimized storage layer built on Apache Parquet that brings the reliability of a data warehouse to big data processing. It eliminates the limitations of traditional data lakes by adding ACID transactions, scalable metadata handling, and schema evolution. Delta Lake integrates seamlessly with Azure Databricks, Apache Spark, and other cloud-based data solutions, making it a preferred choice for modern data engineering pipelines. Microsoft Azure Data Engineer
Key Features of Delta Lake
1. ACID Transactions
One of the biggest challenges in traditional data lakes is data inconsistency due to concurrent read/write operations. Delta Lake supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable data updates without corruption. It uses Optimistic Concurrency Control (OCC) to handle multiple transactions simultaneously.
2. Schema Evolution and Enforcement
Delta Lake enforces schema validation to prevent accidental data corruption. If a schema mismatch occurs, Delta Lake will reject the data, ensuring consistency. Additionally, it supports schema evolution, allowing modifications without affecting existing data.
3. Time Travel and Data Versioning
Delta Lake maintains historical versions of data using log-based versioning. This allows users to perform time travel queries, enabling them to revert to previous states of data. This is particularly useful for auditing, rollback, and debugging purposes. Azure Data Engineer Course
4. Scalable Metadata Handling
Traditional data lakes struggle with metadata scalability, especially when handling billions of files. Delta Lake optimizes metadata storage and retrieval, making queries faster and more efficient.
5. Performance Optimizations (Data Skipping and Caching)
Delta Lake improves query performance through data skipping and caching mechanisms. Data skipping allows queries to read only relevant data instead of scanning the entire dataset, reducing processing time. Caching improves speed by storing frequently accessed data in memory.
6. Unified Batch and Streaming Processing
Delta Lake enables seamless integration of batch and real-time streaming workloads. Structured Streaming in Spark can write and read from Delta tables in real-time, ensuring low-latency updates and enabling use cases such as fraud detection and log analytics.
How Delta Lake Works in Databricks?
Delta Lake is tightly integrated with Azure Databricks and Apache Spark, making it easy to use within data pipelines. Below is a basic workflow of how Delta Lake operates: Azure Data Engineering Certification
Data Ingestion: Data is ingested into Delta tables from multiple sources (Kafka, Event Hubs, Blob Storage, etc.).
Data Processing: Spark SQL and PySpark process the data, applying transformations and aggregations.
Data Storage: Processed data is stored in Delta format with ACID compliance.
Query and Analysis: Users can query Delta tables using SQL or Spark.
Version Control & Time Travel: Previous data versions are accessible for rollback and auditing.
Use Cases of Delta Lake
ETL Pipelines: Ensures data reliability with schema validation and ACID transactions.
Machine Learning: Maintains clean and structured historical data for training ML models. Azure Data Engineer Training
Real-time Analytics: Supports streaming data processing for real-time insights.
Data Governance & Compliance: Enables auditing and rollback for regulatory requirements.
Conclusion
Delta Lake in Databricks bridges the gap between traditional data lakes and modern data warehousing solutions by providing reliability, scalability, and performance improvements. With ACID transactions, schema enforcement, time travel, and optimized query performance, Delta Lake is a powerful tool for building efficient and resilient data pipelines. Its seamless integration with Azure Databricks and Apache Spark makes it a preferred choice for data engineers aiming to create high-performance and scalable data architectures.
Trending Courses: Artificial Intelligence, Azure AI Engineer, Informatica Cloud IICS/IDMC (CAI, CDI),
Visualpath stands out as the best online software training institute in Hyderabad.
For More Information about the Azure Data Engineer Online Training
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text

🚀 Azure AI-102 Course in Hyderabad – Get Certified with VisualPath! 🚀
Advance your career with VisualPath’s Azure AI Engineer Training in Chennai and earn your AI-102 Certification. Gained hands-on expertise in AI technologies, including Matillion, Snowflake, ETL, Informatica, SQL, Data Warehouses, Power BI, Databricks, Oracle, SAP, and Amazon Redshift.
🎯 Our Azure AI Engineer Training offers: ✅ Flexible schedules for working professionals ⏳ 24/7 access to recorded sessions 🌍 Global self-paced learning 🎓 Training from industry experts
📢 Take the next step in your AI & Data journey! 📞 Call +91-7032290546 for a FREE demo today! 💬 WhatsApp: https://wa.me/c/917032290546 📖 Visit Blog: https://visualpathblogs.com/category/azure-ai-102/ 🌐 Learn More: https://www.visualpath.in/azure-ai-online-training.html
#visualpathedu#AzureAI102#AzureAIEngineer#MicrosoftAzureAI#AIEngineerTraining#AzureMachineLearning#ArtificialIntelligence#AI102Certification#AzureAITraining#CloudAI#AIinCloudComputing#AzureCognitiveServices#MachineLearningAzure#AI102ExamPrep#AzureAIExperts#DeepLearningAzure#AITrainingOnline#AzureAI102Course#MicrosoftCertifiedAIEngineer#CloudComputing#AIForBusiness
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
Exploring the Role of Azure Data Factory in Hybrid Cloud Data Integration

Introduction
In today’s digital landscape, organizations increasingly rely on hybrid cloud environments to manage their data. A hybrid cloud setup combines on-premises data sources, private clouds, and public cloud platforms like Azure, AWS, or Google Cloud. Managing and integrating data across these diverse environments can be complex.
This is where Azure Data Factory (ADF) plays a crucial role. ADF is a cloud-based data integration service that enables seamless movement, transformation, and orchestration of data across hybrid cloud environments.
In this blog, we’ll explore how Azure Data Factory simplifies hybrid cloud data integration, key use cases, and best practices for implementation.
1. What is Hybrid Cloud Data Integration?
Hybrid cloud data integration is the process of connecting, transforming, and synchronizing data between: ✅ On-premises data sources (e.g., SQL Server, Oracle, SAP) ✅ Cloud storage (e.g., Azure Blob Storage, Amazon S3) ✅ Databases and data warehouses (e.g., Azure SQL Database, Snowflake, BigQuery) ✅ Software-as-a-Service (SaaS) applications (e.g., Salesforce, Dynamics 365)
The goal is to create a unified data pipeline that enables real-time analytics, reporting, and AI-driven insights while ensuring data security and compliance.
2. Why Use Azure Data Factory for Hybrid Cloud Integration?
Azure Data Factory (ADF) provides a scalable, serverless solution for integrating data across hybrid environments. Some key benefits include:
✅ 1. Seamless Hybrid Connectivity
ADF supports over 90+ data connectors, including on-prem, cloud, and SaaS sources.
It enables secure data movement using Self-Hosted Integration Runtime to access on-premises data sources.
✅ 2. ETL & ELT Capabilities
ADF allows you to design Extract, Transform, and Load (ETL) or Extract, Load, and Transform (ELT) pipelines.
Supports Azure Data Lake, Synapse Analytics, and Power BI for analytics.
✅ 3. Scalability & Performance
Being serverless, ADF automatically scales resources based on data workload.
It supports parallel data processing for better performance.
✅ 4. Low-Code & Code-Based Options
ADF provides a visual pipeline designer for easy drag-and-drop development.
It also supports custom transformations using Azure Functions, Databricks, and SQL scripts.
✅ 5. Security & Compliance
Uses Azure Key Vault for secure credential management.
Supports private endpoints, network security, and role-based access control (RBAC).
Complies with GDPR, HIPAA, and ISO security standards.
3. Key Components of Azure Data Factory for Hybrid Cloud Integration
1️⃣ Linked Services
Acts as a connection between ADF and data sources (e.g., SQL Server, Blob Storage, SFTP).
2️⃣ Integration Runtimes (IR)
Azure-Hosted IR: For cloud data movement.
Self-Hosted IR: For on-premises to cloud integration.
SSIS-IR: To run SQL Server Integration Services (SSIS) packages in ADF.
3️⃣ Data Flows
Mapping Data Flow: No-code transformation engine.
Wrangling Data Flow: Excel-like Power Query transformation.
4️⃣ Pipelines
Orchestrate complex workflows using different activities like copy, transformation, and execution.
5️⃣ Triggers
Automate pipeline execution using schedule-based, event-based, or tumbling window triggers.
4. Common Use Cases of Azure Data Factory in Hybrid Cloud
🔹 1. Migrating On-Premises Data to Azure
Extracts data from SQL Server, Oracle, SAP, and moves it to Azure SQL, Synapse Analytics.
🔹 2. Real-Time Data Synchronization
Syncs on-prem ERP, CRM, or legacy databases with cloud applications.
🔹 3. ETL for Cloud Data Warehousing
Moves structured and unstructured data to Azure Synapse, Snowflake for analytics.
🔹 4. IoT and Big Data Integration
Collects IoT sensor data, processes it in Azure Data Lake, and visualizes it in Power BI.
🔹 5. Multi-Cloud Data Movement
Transfers data between AWS S3, Google BigQuery, and Azure Blob Storage.
5. Best Practices for Hybrid Cloud Integration Using ADF
✅ Use Self-Hosted IR for Secure On-Premises Data Access ✅ Optimize Pipeline Performance using partitioning and parallel execution ✅ Monitor Pipelines using Azure Monitor and Log Analytics ✅ Secure Data Transfers with Private Endpoints & Key Vault ✅ Automate Data Workflows with Triggers & Parameterized Pipelines
6. Conclusion
Azure Data Factory plays a critical role in hybrid cloud data integration by providing secure, scalable, and automated data pipelines. Whether you are migrating on-premises data, synchronizing real-time data, or integrating multi-cloud environments, ADF simplifies complex ETL processes with low-code and serverless capabilities.
By leveraging ADF’s integration runtimes, automation, and security features, organizations can build a resilient, high-performance hybrid cloud data ecosystem.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Unlocking the Power of Delta Live Tables in Data bricks with Kadel Labs
Introduction
In the rapidly evolving landscape of big data and analytics, businesses are constantly seeking ways to streamline data processing, ensure data reliability, and improve real-time analytics. One of the most powerful solutions available today is Delta Live Tables (DLT) in Databricks. This cutting-edge feature simplifies data engineering and ensures efficiency in data pipelines.
Kadel Labs, a leader in digital transformation and data engineering solutions, leverages Delta Live Tables to optimize data workflows, ensuring businesses can harness the full potential of their data. In this article, we will explore what Delta Live Tables are, how they function in Databricks, and how Kadel Labs integrates this technology to drive innovation.
Understanding Delta Live Tables
What Are Delta Live Tables?
Delta Live Tables (DLT) is an advanced framework within Databricks that simplifies the process of building and maintaining reliable ETL (Extract, Transform, Load) pipelines. With DLT, data engineers can define incremental data processing pipelines using SQL or Python, ensuring efficient data ingestion, transformation, and management.
Key Features of Delta Live Tables
Automated Pipeline Management
DLT automatically tracks changes in source data, eliminating the need for manual intervention.
Data Reliability and Quality
Built-in data quality enforcement ensures data consistency and correctness.
Incremental Processing
Instead of processing entire datasets, DLT processes only new data, improving efficiency.
Integration with Delta Lake
DLT is built on Delta Lake, ensuring ACID transactions and versioned data storage.
Monitoring and Observability
With automatic lineage tracking, businesses gain better insights into data transformations.
How Delta Live Tables Work in Databricks
Databricks, a unified data analytics platform, integrates Delta Live Tables to streamline data lake house architectures. Using DLT, businesses can create declarative ETL pipelines that are easy to maintain and highly scalable.
The DLT Workflow
Define a Table and Pipeline
Data engineers specify data sources, transformation logic, and the target Delta table.
Data Ingestion and Transformation
DLT automatically ingests raw data and applies transformation logic in real-time.
Validation and Quality Checks
DLT enforces data quality rules, ensuring only clean and accurate data is processed.
Automatic Processing and Scaling
Databricks dynamically scales resources to handle varying data loads efficiently.
Continuous or Triggered Execution
DLT pipelines can run continuously or be triggered on-demand based on business needs.
Kadel Labs: Enhancing Data Pipelines with Delta Live Tables
As a digital transformation company, Kadel Labs specializes in deploying cutting-edge data engineering solutions that drive business intelligence and operational efficiency. The integration of Delta Live Tables in Databricks is a game-changer for organizations looking to automate, optimize, and scale their data operations.
How Kadel Labs Uses Delta Live Tables
Real-Time Data Streaming
Kadel Labs implements DLT-powered streaming pipelines for real-time analytics and decision-making.
Data Governance and Compliance
By leveraging DLT’s built-in monitoring and validation, Kadel Labs ensures regulatory compliance.
Optimized Data Warehousing
DLT enables businesses to build cost-effective data warehouses with improved data integrity.
Seamless Cloud Integration
Kadel Labs integrates DLT with cloud environments (AWS, Azure, GCP) to enhance scalability.
Business Intelligence and AI Readiness
DLT transforms raw data into structured datasets, fueling AI and ML models for predictive analytics.
Benefits of Using Delta Live Tables in Databricks
1. Simplified ETL Development
With DLT, data engineers spend less time managing complex ETL processes and more time focusing on insights.
2. Improved Data Accuracy and Consistency
DLT automatically enforces quality checks, reducing errors and ensuring data accuracy.
3. Increased Operational Efficiency
DLT pipelines self-optimize, reducing manual workload and infrastructure costs.
4. Scalability for Big Data
DLT seamlessly scales based on workload demands, making it ideal for high-volume data processing.
5. Better Insights with Lineage Tracking
Data lineage tracking in DLT provides full visibility into data transformations and dependencies.
Real-World Use Cases of Delta Live Tables with Kadel Labs
1. Retail Analytics and Customer Insights
Kadel Labs helps retailers use Delta Live Tables to analyze customer behavior, sales trends, and inventory forecasting.
2. Financial Fraud Detection
By implementing DLT-powered machine learning models, Kadel Labs helps financial institutions detect fraudulent transactions.
3. Healthcare Data Management
Kadel Labs leverages DLT in Databricks to improve patient data analysis, claims processing, and medical research.
4. IoT Data Processing
For smart devices and IoT applications, DLT enables real-time sensor data processing and predictive maintenance.
Conclusion
Delta Live Tables in Databricks is transforming the way businesses handle data ingestion, transformation, and analytics. By partnering with Kadel Labs, companies can leverage DLT to automate pipelines, improve data quality, and gain actionable insights.
With its expertise in data engineering, Kadel Labs empowers businesses to unlock the full potential of Databricks and Delta Live Tables, ensuring scalable, efficient, and reliable data solutions for the future.
For businesses looking to modernize their data architecture, now is the time to explore Delta Live Tables with Kadel Labs!
0 notes
Text
Best DBT Course in Hyderabad | Data Build Tool Training
What is DBT, and Why is it Used in Data Engineering?
DBT, short for Data Build Tool, is an open-source command-line tool that allows data analysts and engineers to transform data in their warehouses using SQL. Unlike traditional ETL (Extract, Transform, Load) processes, which manage data transformations separately, DBT focuses solely on the Transform step and operates directly within the data warehouse.
DBT enables users to define models (SQL queries) that describe how raw data should be cleaned, joined, or transformed into analytics-ready datasets. It executes these models efficiently, tracks dependencies between them, and manages the transformation process within the data warehouse. DBT Training

Key Features of DBT
SQL-Centric: DBT is built around SQL, making it accessible to data professionals who already have SQL expertise. No need for learning complex programming languages.
Version Control: DBT integrates seamlessly with version control systems like Git, allowing teams to collaborate effectively while maintaining an organized history of changes.
Testing and Validation: DBT provides built-in testing capabilities, enabling users to validate their data models with ease. Custom tests can also be defined to ensure data accuracy.
Documentation: With dbt, users can automatically generate documentation for their data models, providing transparency and fostering collaboration across teams.
Modularity: DBT encourages the use of modular SQL code, allowing users to break down complex transformations into manageable components that can be reused. DBT Classes Online
Why is DBT Used in Data Engineering?
DBT has become a critical tool in data engineering for several reasons:
1. Simplifies Data Transformation
Traditionally, the Transform step in ETL processes required specialized tools or complex scripts. DBT simplifies this by empowering data teams to write SQL-based transformations that run directly within their data warehouses. This eliminates the need for external tools and reduces complexity.
2. Works with Modern Data Warehouses
DBT is designed to integrate seamlessly with modern cloud-based data warehouses such as Snowflake, BigQuery, Redshift, and Databricks. By operating directly in the warehouse, it leverages the power and scalability of these platforms, ensuring fast and efficient transformations. DBT Certification Training Online
3. Encourages Collaboration and Transparency
With its integration with Git, dbt promotes collaboration among teams. Multiple team members can work on the same project, track changes, and ensure version control. The autogenerated documentation further enhances transparency by providing a clear view of the data pipeline.
4. Supports CI/CD Pipelines
DBT enables teams to adopt Continuous Integration/Continuous Deployment (CI/CD) workflows for data transformations. This ensures that changes to models are tested and validated before being deployed, reducing the risk of errors in production.
5. Focus on Analytics Engineering
DBT shifts the focus from traditional ETL to ELT (Extract, Load, Transform). With raw data already loaded into the warehouse, dbt allows teams to spend more time analyzing data rather than managing complex pipelines.
Real-World Use Cases
Data Cleaning and Enrichment: DBT is used to clean raw data, apply business logic, and create enriched datasets for analysis.
Building Data Models: Companies rely on dbt to create reusable, analytics-ready models that power dashboards and reports. DBT Online Training
Tracking Data Lineage: With its ability to visualize dependencies, dbt helps track the flow of data, ensuring transparency and accountability.
Conclusion
DBT has revolutionized the way data teams approach data transformations. By empowering analysts and engineers to use SQL for transformations, promoting collaboration, and leveraging the scalability of modern data warehouses, dbt has become a cornerstone of modern data engineering. Whether you are cleaning data, building data models, or ensuring data quality, dbt offers a robust and efficient solution that aligns with the needs of today’s data-driven organizations.
Visualpath is the Best Software Online Training Institute in Hyderabad. Avail complete Data Build Tool worldwide. You will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/online-data-build-tool-training.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit Blog: https://databuildtool1.blogspot.com/
#DBT Training#DBT Online Training#DBT Classes Online#DBT Training Courses#Best Online DBT Courses#DBT Certification Training Online#Data Build Tool Training in Hyderabad#Best DBT Course in Hyderabad#Data Build Tool Training in Ameerpet
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] Leverage the power of Microsoft Azure Data Factory v2 to build hybrid data solutions Key Features Combine the power of Azure Data Factory v2 and SQL Server Integration Services Design and enhance performance and scalability of a modern ETL hybrid solution Interact with the loaded data in data warehouse and data lake using Power BI Book Description ETL is one of the essential techniques in data processing. Given data is everywhere, ETL will always be the vital process to handle data from different sources. Hands-On Data Warehousing with Azure Data Factory starts with the basic concepts of data warehousing and ETL process. You will learn how Azure Data Factory and SSIS can be used to understand the key components of an ETL solution. You will go through different services offered by Azure that can be used by ADF and SSIS, such as Azure Data Lake Analytics, Machine Learning and Databrick’s Spark with the help of practical examples. You will explore how to design and implement ETL hybrid solutions using different integration services with a step-by-step approach. Once you get to grips with all this, you will use Power BI to interact with data coming from different sources in order to reveal valuable insights. By the end of this book, you will not only learn how to build your own ETL solutions but also address the key challenges that are faced while building them. What you will learn Understand the key components of an ETL solution using Azure Data Factory and Integration Services Design the architecture of a modern ETL hybrid solution Implement ETL solutions for both on-premises and Azure data Improve the performance and scalability of your ETL solution Gain thorough knowledge of new capabilities and features added to Azure Data Factory and Integration Services Who this book is for This book is for you if you are a software professional who develops and implements ETL solutions using Microsoft SQL Server or Azure cloud. It will be an added advantage if you are a software engineer, DW/ETL architect, or ETL developer, and know how to create a new ETL implementation or enhance an existing one with ADF or SSIS. Table of Contents Azure Data Factory Getting Started with Our First Data Factory ADF and SSIS in PaaS Azure Data Lake Machine Learning on the Cloud Sparks with Databrick Power BI reports ASIN : B07DGJSPYK Publisher : Packt Publishing; 1st edition (31 May 2018) Language : English File size : 32536 KB Text-to-Speech : Enabled Screen Reader : Supported Enhanced typesetting : Enabled X-Ray : Not Enabled Word Wise : Not Enabled Print length : 371 pages [ad_2]
0 notes
Text

🚀 Azure AI Engineer Online Training – Get Certified with VisualPath! 🚀
Advance your career with VisualPath’s Azure AI-102 Course in Hyderabad and achieve your AI-102 Certification. Master AI technologies with hands-on expertise in Matillion, Snowflake, ETL, Informatica, SQL, Data Warehouses, Power BI, Databricks, Oracle, SAP, and Amazon Redshift.
🎯 Our Azure AI Engineer Certification Training offers: ✅ Flexible schedules for working professionals ⏳ 24/7 access to recorded sessions 🌍 Global self-paced learning 🎓 Training from industry experts
📢 Take the next step in your AI & Data journey! 📞 Call +91-7032290546 for a FREE demo today! 💬 WhatsApp: https://wa.me/c/917032290546 📖 Visit Blog: https://visualpathblogs.com/category/azure-ai-102/ 🌐 Learn More: https://www.visualpath.in/azure-ai-online-training.html
#visualpathedu#AzureAI102#AzureAIEngineer#MicrosoftAzureAI#AIEngineerTraining#AzureMachineLearning#ArtificialIntelligence#AI102Certification#AzureAITraining#CloudAI#AIinCloudComputing#AzureCognitiveServices#MachineLearningAzure#AI102ExamPrep#AzureAIExperts#DeepLearningAzure#AITrainingOnline#AzureAI102Course#MicrosoftCertifiedAIEngineer#CloudComputing#AIForBusiness
0 notes