#Correlation coefficient
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Young people moving to rural areas: Now is the time! (Essay)

Moon and Sun Shellfish
During my lunch break, while working remotely, I was watching NHK. They were broadcasting a daily program called "Good Immigration!!" I knew about this program but had never paid much attention to it. However, on November 28, 2022, I seriously watched the broadcast on this day.
The protagonist of this day was a man who worked as a highly paid management consultant for a foreign company, but he had a strong passion for fish and fishing and moved to a fishing village with his family. However, this man did not have any ties to the fishing village. As a consultant, he carefully researched fishermen's catch volume and annual income at each fishing port in Japan and even referred to aerial photographs of the fishing port. This was because he considered the quality of the fishing port's seawall, the presence or absence of oil storage facilities, etc. Without a storage facility, it would be inconvenient to have to rely on tankers every time to secure fuel. I see.
After all these investigations, he chose Eguchi Fishing Port in Kagoshima Prefecture, like a paratrooper. It was quite a bold move for the whole family to move to a strange place suddenly. As for fishing, this man has been increasing his catch every year, but he applies the "correlation coefficient" in statistics to analyze the fish species and the catching method. This is also something he made use of his experience as a consultant.
And what blew me away was his proposal to the fishing association for "newly cultivated" shellfish. It was "Moon and Sun Shellfish"... a romantic name, and as you would expect, the shells are beautiful, with different colors on the front and back like the sun and the moon. They are also delicious to eat. He researched how far from the shore and at what depth the young shellfish of this shellfish can be collected, and got some results. The broadcast ended with him talking about starting a business with the fishing association this. Yes, he is a reliable young man. He is not passive but is actively influencing the situation. I look forward to seeing what happens next for him.
#Young people moving to rural areas#rural areas#essay#rei morishita#Moon and Sun Shellfish#management consultant for a foreign company#fishing#correlation coefficient#actively influencing the situation
8 notes
·
View notes
Text
Per-Capita Income and Life Expectancy : W3 Data Analysis Tools
For the third week’s assignment of Data Analysis Tool on Coursera, we would continue to be working with GapMinder's dataset which contains statistics in the social, economic, and environmental development variable at local, national, and global levels
We would be studying the effect of Income per Person of a County on prevalent rates of life-expectancy. Since both the explanatory variable (Per-Capita Income) and the response variable are quantitative we'll calculate the Pearson Correlation Coefficient to analyze the strength of correlation between the variables.
The Correlation Analysis between the two variables gives :

The Correlation Coefficient is 0.60 with a very low p-value << 0.0001, which indicates a considerably strong and significant relation between the Per-Capita Income and the Life Expectancy of individuals. A positive Correlation Coefficient indicates that the Life-Expectancy increases with the Per-Capita Income of a Country.

However, looking at the scatter-plot between the two variables, we see that a sharp increase in the life expectancy is seen only at the very low end of the per-capita income spectrum. Beyond a per-capita income of 10000, the life-expectancy almost flattens out. So, we need to understand the strong relationship between the variables together the scatter-plot.
0 notes
Link
1 note
·
View note
Text
Week 3: Generating a Pearson Correlation Coefficient
The process of generating a correlation coefficient is used to examine the dependence between a quantative explanatory variable and a quantative response value.
Q->Q
For this course, I will perform a Pearson correlation and analyze the results.
A correlation can be made visually with a scatterplott. With this one can see a general form /shape of the value mid line.
A pearson correlation coefficient is generally useful only when looking at linear shaped scatterplots, for curved it gives no good significant findings.
The coefficient “r” can range from -1 to +1, while a value next to (+/-)1 indicates a perfect relation between the variables, whilst a value near 0 indicate a very weak connection between the variables examined.
For my test I will use the gapminder dataset, as it already contains several quantative variables sorted to different countries of origin for the collected data.
I will examine to correlations, first between braest cancer rate “breastcancerper100TH” and alcohol consumption rate “alcconsumption”, second between breast cancer rate and rate of individuals living in urban areas “urbanrate“.
To perform that with SAS this code is used:

The Proc Corr statement provides the correlation between (in this case 3) variables in an output table.
For visuallizing I included scatterplots for both relations I try to examine (breastcancer100TH as explanatory variable on the x-axis for both plots).
The output is the following:



We find for relation between breast cancer and alcohol consumption a r=0.493 with a p-value of <0.0001 indicating a moderate positive relation.
For the relation between breast cancer and urbanrate a r=0.57 with a p-value of <0.0001 indicating a moderately strong relation between the variables.
When we square the examined r value, we get Coefficient of Determination (RSqaure) which tells us, how many values of the second variable we can predict with the first variable.
Here r-square for breastcancer and alcconsumption is 0.243, so we could predict about 24.3% of the breast cancer cases with the alcohol consumption rate.
The r-square for breastcancer and urbanrate is 0.325, so we could predict about 32.5% of the breast cancer cases with the urban rate.
So we can say that the higher the urbanrate or the alcohol consumption rate, the higher the breast cancer rate will be.
0 notes
Text
Understanding Correlation Coefficient: A Tool for My Browser App Store Users
Learn what correlation coefficient is and how it can help you make informed decisions in My Browser App Store. Read on for a comprehensive guide.
Understanding Correlation Coefficient: A Tool for My Browser App Store Users
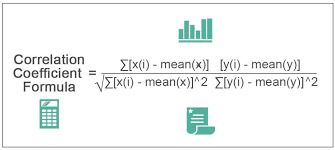
What is Correlation Coefficient?
Correlation coefficient is a statistical measure that measures the relationship between two variables. In simpler terms, it tells you how closely two variables are related. Correlation coefficient ranges from -1 to 1. If the correlation coefficient is 1, it means that the two variables are perfectly positively correlated. If the correlation coefficient is -1, it means that the two variables are perfectly negatively correlated. A correlation coefficient of 0 indicates that there is no correlation between the two variables.
How Does Correlation Coefficient Help in My Browser App Store?
In My Browser App Store, correlation coefficient can help you make informed decisions about which apps to download. For example, let's say you're looking for a new productivity app. You can use correlation coefficient to see which apps are most closely related to productivity. You can also use correlation coefficient to see which apps have a positive or negative impact on your device's performance. By using correlation coefficient, you can make more informed decisions about which apps to download and which to avoid.
How to Calculate Correlation Coefficient?
Calculating correlation coefficient can be a bit complicated, but it's not impossible. There are several methods you can use to calculate correlation coefficient, including the Pearson correlation coefficient and the Spearman correlation coefficient. The Pearson correlation coefficient is used to measure the strength of a linear relationship between two variables, while the Spearman correlation coefficient is used to measure the strength of a non-linear relationship between two variables.
Conclusion
Correlation coefficient is an important statistical measure that can help you make informed decisions in My Browser App Store. By understanding what correlation coefficient is and how it works, you can use it to your advantage when choosing which apps to download. Whether you're looking for a productivity app or trying to improve your device's performance, correlation coefficient can be a useful tool in your decision-making proc.
Contect us
Company Name: My Browser App Store
Location: Chennai, India
Resource URL:
#correlation coefficient#correlation#pearson correlation coefficient#coefficient#correlation coefficient formula#coefficient of correlation#the correlation coefficient#what is correlation coefficient#correlation coefficient and p value#what is correlation#types of correlation#correlation and regression#correlation analysis#correlation coeficient#spss correlation coefficient#finding correlation coefficient#correlation coefficient example
0 notes
Text
do you ever just *white noise* but then *static* and sometimes *garbled sounds* ? or is it just me
#the speaking clown#there is an r^2 correlation coefficient btw the amount i sit down/study and get cabin fever in my own skull
29 notes
·
View notes
Text
Generating and Interpreting Correlation Coefficient
In this blog entry, I'll demonstrate how to generate and interpret a correlation coefficient between two ordered categorical variables. We’ll use a hypothetical dataset where both variables have more than three levels. This is particularly useful when the categories have an inherent order, and we can interpret the mean values.
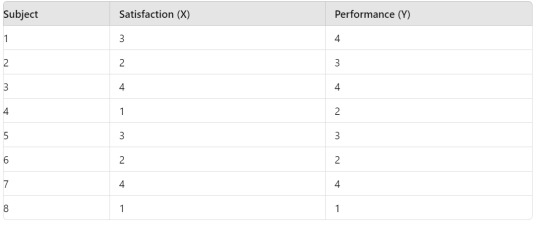
Hypothetical Data
Assume we have two ordered categorical variables:
Variable X: Levels are 1, 2, 3, 4 (e.g., Satisfaction level from 1 to 4)
Variable Y: Levels are 1, 2, 3, 4 (e.g., Performance rating from 1 to 4)
Here is a sample dataset:
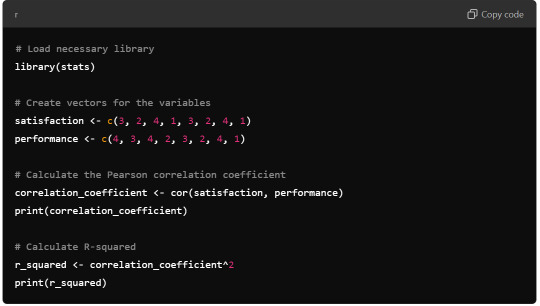
Syntax for Generating Correlation Coefficient
R Syntax:
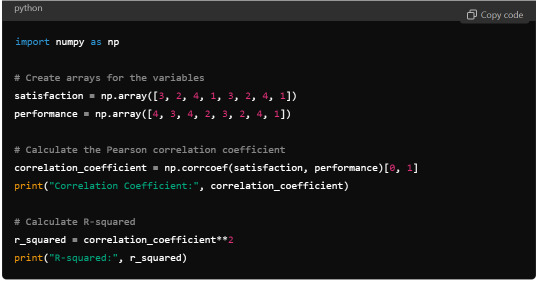
Python Syntax (using numpy):
Output
R Output:

Python Output:

Interpretation
The Pearson correlation coefficient between Satisfaction (X) and Performance (Y) is approximately 0.83. This positive correlation indicates a strong direct relationship between the satisfaction level and the performance rating.
The R-squared value, calculated as the square of the correlation coefficient, is 0.6889. This means that approximately 68.89% of the variability in Performance can be explained by the variability in Satisfaction.
Summary
Correlation Coefficient: 0.83, indicating a strong positive correlation.
R-squared: 0.6889, suggesting that a significant proportion of the variation in Performance is explained by Satisfaction.
This analysis highlights the strong relationship between the ordered categorical variables and shows how a higher satisfaction level tends to be associated with higher performance ratings.
0 notes
Note
Is the high level of inbreeding in dobes more because "undesirable" traits are common so those dogs get weeded out (whether actual bad things or just not fitting the breed spec), a small number of breeders having the monopoly, or because they are all related anyway so there's no way of avoiding it without an outcross program? Is something like the Doberman Preservation Project a realistic future for the breed?
The doberman breed is in the current shape its in due to multiple genetic bottlenecks- some simple stupid breeding decisions and others due to active war zones and the consequences of wars- paired with people who are stubbornly refusing to even try to make it better because they have convinced themselves that what they're doing is right.
Fenris is my lowest COI dobe to date [23% iirc] and while not the lowest I've seen in the breed [19%], still a huge improvement over to 50-60% breed average. But people have argued again and again that lowering COI means making breeding decisions that produce inferior dogs, and so many refuse to even consider it as a possibility.
(For non-dog people, COI is coefficient of inbreeding, and it is a look at the numbers behind how inbred a population is. You want as low of a number as possible. 25% is equal to immediate siblings. Ideally we'd want single digit numbers, with anything over 10% being a major problem to fix. To compare, my chihuahuas are something like 6% (Fae) and 0.02% (Tater). Sushi is a direct line breeding aunt-to-nephew so she's up in the 40s.)
(It doesn't necessarily mean a dog is immune to genetic predisposition to bad health, as evidenced by Tater's CM diagnosis, however it does seem to correlate directly with longevity and likelihood of developing these problems, meaning Tater unfortunately just lost the genetic lottery)
In other words, it is certainly possible to reduce the COI of the breed by HALF with smart breeding decisions, and people are plugging their ears going LA LA LA LA I CAN'T HEAR YOU because it means actually going out and looking past the popular sires and taking a chance on a dog that might not be your exact type but will still improve the next generation. This is not just a show line problem because I spend the majority of my time with working line dobes and working dobe people and this is an incredibly annoying problem there too. Fenris himself has popular sires in his pedigree, both the show half and the working half, so it is demonstratably very difficult to avoid.
I do think a well executed outcross project is needed, however... the problem I have is that the current proposed projects all suck. There's not a lot of direction outside of throwing things into the pot and seeing what sticks, and a lot of the resulting dogs quite frankly aren't what doberman people would be looking for anyway. Farm collies? Bulldogs? Bullies? Carolina dogs? Border collies? Pyrs? Why??? None of these are going to make a dog that has the temperament that draws people to this breed.
There are. A bunch of breeders who are waiting for an outcross project that actually makes sense. They've even posted in various outcrops groups that they would support a project if it had certain specifications. Many have said, get yourself a nice female and title her out in a bite sport and do all the doberman health testing even if she's not a doberman and we'd be interested in contributing semen. The response almost invariably has been "but I don't want a protective dog". Then what are you doing in a DOBERMAN project??? So of course the chief complaint is that most of these projects are not looking to make dobermans, they're looking to make their own breed and just have a doberman paint job. Well, sorry, but most involved doberman people want a DOBERMAN, not just a dog that looks like one. This is the only AKC recognized breed with the sole function of personal protection. They are protective dogs. Either accept that, or get interested in a different breed.
I have heard increasingly concerning things regarding the temperament of the doberman diversity project dogs, which does not surprise me unfortunately as none of these dogs are in any way sourced from dogs with verifiable correct temperament. What do you get when you cross a Craigslist Corso with a Craigslist doberman? Well the first generation might be okay for people who want pets but apparently the ones that have worked in protection are awful at it. Same with the malinois crosses- of course, you took a lukewarm malinois and bred it to a z-list doberman and you're surprised that you got a bunch of lukewarm at best pet dogs.
I think the only project I solidly am somewhat interested in is the bandog cross, and that cross works just fine but then of course it does because in that country, bandogs are exclusively military, police, and security dogs, and she bred it to a igp3 doberman. Unfortunately the doberman died before his 10th birthday, so now we're all waiting to see what happens with his progeny.
239 notes
·
View notes
Text
Patients With Long-COVID Show Abnormal Lung Perfusion Despite Normal CT Scans - Published Sept 12, 2024
VIENNA — Some patients who had mild COVID-19 infection during the first wave of the pandemic and continued to experience postinfection symptoms for at least 12 months after infection present abnormal perfusion despite showing normal CT scans. Researchers at the European Respiratory Society (ERS) 2024 International Congress called for more research to be done in this space to understand the underlying mechanism of the abnormalities observed and to find possible treatment options for this cohort of patients.
Laura Price, MD, PhD, a consultant respiratory physician at Royal Brompton Hospital and an honorary clinical senior lecturer at Imperial College London, London, told Medscape Medical News that this cohort of patients shows symptoms that seem to correlate with a pulmonary microangiopathy phenotype.
"Our clinics in the UK and around the world are full of people with long-COVID, persisting breathlessness, and fatigue. But it has been hard for people to put the finger on why patients experience these symptoms still," Timothy Hinks, associate professor and Wellcome Trust Career Development fellow at the Nuffield Department of Medicine, NIHR Oxford Biomedical Research Centre senior research fellow, and honorary consultant at Oxford Special Airway Service at Oxford University Hospitals, England, who was not involved in the study, told Medscape Medical News.
The Study Researchers at Imperial College London recruited 41 patients who experienced persistent post-COVID-19 infection symptoms, such as breathlessness and fatigue, but normal CT scans after a mild COVID-19 infection that did not require hospitalization. Those with pulmonary emboli or interstitial lung disease were excluded. The cohort was predominantly female (87.8%) and nonsmokers (85%), with a mean age of 44.7 years. They were assessed over 1 year after the initial infection.
Exercise intolerance was the predominant symptom, affecting 95.1% of the group. A significant proportion (46.3%) presented with myopericarditis, while a smaller subset (n = 5) exhibited dysautonomia. Echocardiography did not reveal pulmonary hypertension. Laboratory findings showed elevated angiotensin-converting enzyme and antiphospholipid antibodies. "These patients are young, female, nonsmokers, and previously healthy. This is not what you would expect to see," Price said. Baseline pulmonary function tests showed preserved spirometry with forced expiratory volume in 1 second and forced vital capacity above 100% predicted. However, diffusion capacity was impaired, with a mean diffusing capacity of the lungs for carbon monoxide (DLCO) of 74.7%. The carbon monoxide transfer coefficient (KCO) and alveolar volume were also mildly reduced. Oxygen saturation was within normal limits.
These abnormalities were through advanced imaging techniques like dual-energy CT scans and ventilation-perfusion scans. These tests revealed a non-segmental and "patchy" perfusion abnormality in the upper lungs, suggesting that the problem was vascular, Price explained.
Cardiopulmonary exercise testing revealed further abnormalities in 41% of patients. Peak oxygen uptake was slightly reduced, and a significant proportion of patients showed elevated alveolar-arterial gradient and dead space ventilation during peak exercise, suggesting a ventilation-perfusion mismatch.
Over time, there was a statistically significant improvement in DLCO, from 70.4% to 74.4%, suggesting some degree of recovery in lung function. However, DLCO values did not return to normal. The KCO also improved from 71.9% to 74.4%, though this change did not reach statistical significance. Most patients (n = 26) were treated with apixaban, potentially contributing to the observed improvement in gas transfer parameters, Price said.
The researchers identified a distinct phenotype of patients with persistent post-COVID-19 infection symptoms characterized by abnormal lung perfusion and reduced gas diffusion capacity, even when CT scans appear normal. Price explains that this pulmonary microangiopathy may explain the persistent symptoms. However, questions remain about the underlying mechanisms, potential treatments, and long-term outcomes for this patient population.
Causes and Treatments Remain a Mystery Previous studies have suggested that COVID-19 causes endothelial dysfunction, which could affect the small blood vessels in the lungs. Other viral infections, such as HIV, have also been shown to cause endothelial dysfunction. However, researchers don't fully understand how this process plays out in patients with COVID-19.
"It is possible these patients have had inflammation insults that have damaged the pulmonary vascular endothelium, which predisposes them to either clotting at a microscopic level or ongoing inflammation," said Hinks.
Some patients (10 out of 41) in the cohort studied by the Imperial College London's researchers presented with Raynaud syndrome, which might suggest a physiological link, Hinks explains. "Raynaud's is a condition of vascular control or dysregulation, and potentially, there could be a common factor contributing to both breathlessness and Raynaud's."
He said there is an encouraging signal that these patients improve over time, but their recovery might be more complex and lengthy than for other patients. "This cohort will gradually get better. But it raises questions and gives a point that there is a true physiological deficit in some people with long-COVID."
Price encouraged physicians to look beyond conventional diagnostic tools when visiting a patient whose CT scan looks normal yet experiences fatigue and breathlessness. Not knowing what causes the abnormalities observed in this group of patients makes treatment extremely challenging. "We need more research to understand the treatment implications and long-term impact of these pulmonary vascular abnormalities in patients with long-COVID," Price concluded.
#long covid#covid#covid news#mask up#pandemic#covid 19#wear a mask#public health#sars cov 2#still coviding#coronavirus#wear a respirator#covid conscious#covid is airborne#covid isn't over#covid pandemic#covid19#covidー19
54 notes
·
View notes
Text
Comparing the intellectual level of each country (Essay)

@SI (stupid index) is the area of a country divided by the square of (coastline + border). Measures the approximate degree of intellectual level. The higher the number, the lower the intellectual level. Canada has a large area but is small because it has a long coastline, while the USA is large because it has many straight borders. Canada has a high intellectual level.
@The smaller the SI, the higher the intellectual level, but Indonesia has a lower UGR (university graduate ratio: Percentage of university graduates in the total population.). This also gives us a glimpse of its history as a colony.
@Russia has a surprisingly high intellectual level.
@India and China have large SI and low UGR. A small number of elites are controlling the ignorant majority of the people.
@The correlation coefficient is -0.402, with a slight correlation between the two indicators.
Appendix (SI)
It is assumed that the longer a country's borders are compared to its land area, the more sensitive it is to foreign enemies. I will review the concept a little, and since conflicts over territory and others often occur not only on the coastline but also on the borderline that connects to the land, I will mainly consider the borderline that includes it, as a matter of course. And since the land area is two-dimensional with km ^ 2, to make the dimension (unit) non-unit, divide the land area by the square of the borderline (km) and divide the value by the "stupid index" (SI).
Stupid index = (land area: km ^ 2) ÷ (total border line length: km) ^ 2
Just in Wikipedia, there is a list of total coastline lengths and land areas of each country in the world (list by the length of national coastline).
Again, large countries such as Russia, Canada, China, USA, Australia, Brazil Of course, the "stupid index: SI" is large.
However, it cannot be said that each nation's "political stupidity is known" from this index alone. Still, it seems to have a certain meaning when looking at the stupidity of Americans in the inland United States. In this year's US presidential election, many people supported Trump in the inland states in the center of the United States. It's obvious at a glance. Many white Americans who strongly supported Trump, who was a dirty politician, voted for Trump, and the states he acquired are also concentrated in the inland states in the center of the United States ... stupid dens.
By the way, the countries with large areas have large SI, Russia, the United States, China, and India have about 50 to 100, and Australia and Mexico have about 100. Canada, which has the second largest area in the world, has a coastline. Because it is long, the SI is relatively small. Brazil is unexpectedly large, with an SI of 159, which is by far the biggest. Conversely, if you look at countries with small SI, they are usually island countries, such as Indonesia, the Philippines, Japan, New Zealand, and the United Kingdom. But is it "wise"? Asian countries, including Japan, have rather large SI and are natural.
I think that the reason why a country with a small "stupid index: SI" like Japan is "stupid" is probably not a geographical factor but a geopolitical factor. In other words, I think the biggest factor is that after WW2, the United States continued to rule and the political sensibilities of not only politicians but the general public were paralyzed. This will be the same in other Asian island nations. In addition, the old letter "country" of the kanji "country" means to be confused (with suspicion) about what will happen at the borders on all sides. It is used to mean living sensitively to foreign enemies, and it is the origin of the fact that fools destroy the country.
各国の知的レベルの評価
@SIは、国の面積を(海岸線+国境線)の2乗で割ったもの。おおまかな智的レベルの程度を測定する。大きいほど知的レベルが低い。カナダは面積が広いが海岸線が長いので小さく、USAは直線的な国境線が多いので大きくなる。カナダは知的レベルが高い。
@SIが小さいほど、知的レベルは高いと予想されるが、インドネシアはUGRが低い。これには植民地として支配された歴史も垣間見える。
@ロシアはあんがい知的レベルが高い。
@インド、中国はSIが大きく、UGRが低い。蒙昧な大多数の国民をわずかな数のエリートが指嗾している。
@相関係数は「―0.402」、2つの指標��間には、やや相関が見られる。
#intellectual level#essay#rei morishita#SI#stupid index#UGR#university graduate ratio#correlation coefficient
1 note
·
View note
Text
Day 21/100 days of productivity

So much left to do, so little time 😬
• finished the police investigations unit
• learned more about the correlation coefficient and the p-value in statistics
Just one more unit to finish before the Christmas holidays in three days!
Hope everyone’s excited for a break! x
#studyblr#study blog#study motivation#studyspo#study aesthetic#study inspiration#study notes#studystudystudy#student#academic
22 notes
·
View notes
Text
Basics of Tumblr-based memetics for reddit refugees
When people arrive at Tumblr, they are generally unsure about how to handle themselves. The buttons are easy enough (I mean, the UI sucks, but it's 2023, we're all used to sucky UIs by now, so....), but what are the social implications of each one? What does a reblog mean?
This is very difficult to explain to people for whom this is their first social media site, or are arriving here from (eg) Facebook. But for this round of refugees, from Reddit specifically, I actually can explain. Because!...
....As you have no doubt noticed ....
.... in a world where we all use 4 websites, and each of them consists of content screenshotted from the other 3....
...there is not an equal distribution of who's making content and who's copying it. Facebook generates almost none of the content for other websites; Twitter generates some; but nearly all of the content on the modern internet is generate on Reddit or on Tumblr.
There is a reason for this: all "web 2.0" sites have the ability to generate new memes, and new variants on those memes. But only Reddit and Tumblr have an evolutionary pressure that forces those memes through a natural-selection process. On Reddit, that pressure is applied by the voting system: if an addition to a post doesn't get enough upvotes, it's hidden from view, which means it has limited ability to affect the next generation of posts.
On Tumblr, the equivalent evolutionary pressure is applied by reblogs: each version of a post, each set of additions, is seen in proportion to how many people reblog it, and thus cause other people to see it. Lack of reblogs -> lack of visibility -> limited ability to affect the next generation of posts.
So with that in mind, let's look at some nuances that are specific to the Tumblr ecosystem.
1) Reblogs are direct visibility; upvotes are indirect
On Reddit, when you upvote something, it's a signal to the algorithm that -- in your opinion -- this thing is useful/valuable/funny or in some other way worthwhile. The algorithm takes that into account along with everyone else's votes, time since it was posted, and so on, and makes a decision about what to show by default vs what to hide by default, and how to sort things. Upvoting does affect visibility, but it's only one factor.
Whereas on Tumblr, reblogging puts the post on your followers' dashboards directly (assuming your followers have chronological order turned on, which most of them probably do because fuck corporate decisions about what I should and shouldn't see). One reblog = one post on everyone's dashboard; it's as simple as that.
Reblogging is therefore a much stronger evolutionary boost than upvoting is.
2) Likes have very little impact on visibility
Most people have "based on your likes" turned off. Even for those that keep it on, it doesn't affect what other people see, it only gives Tumblr some idea of what you might like to see. Of course behind the scenes that's somehow accomplished with some kind of correlation coefficient about which posts are most likely to be "liked" by the same person, and in that sense a "like" on this post increases the likelihood that someone else who has "liked" other posts that you have "liked" will see this post as well, but it's a very tenuous and wispy impact,.
Liking is therefore a much weaker evolutionary boost than upvoting is, and should be considered more along the lines of a high-five, or a hug, or a "I would give you gold for this if I could afford any" comment.
(Also, you cannot "like" only one section of a post. When you "like", the notification goes to everyone in the chain, from OP to the latest reblog. If you wish to give specific high-fives, the mechanism you're looking for is replies.)
3) Replies have no impact on visibility one way or the other.
Only OP gets notifications for replies, but you can tag people in the reply to notify them. This is the place for "@most-recent-commenter I would give you gold if I could" or for tagging a friend that you think would enjoy the post.
So, with the underlying mechanics of the ecosystem out of the way, let's look at
memetic engineering
There are two ways you can add your thoughts/ideas/opinions/snarky commentary to a post: in the text of the post, or in the tags.
a digression on tags
Tags -- of course -- can theoretically be used to organize content, although if we're being completely honest here, they're not ... great. for that. Tags can be handy as a textual handle to simplify your google search when you use an external search engine to search your own tumblr blog, but their use as an archival tool is mediocre at best. Likewise, no matter what the Tumblr UI says in the tag section, they're not gonna be that helpful in allowing people to find your content.
Tags can also, as sometimes they do on Twitter or Instagram, provide context to a post. This is less important here, since without a character limit there's no need to trim down your commentary and trust #wgastrike2023 to fill in the missing details, but it can be very handy when you're trying to determine whether this "Bruce and his buddies" post is talking about The Hulk or about Batman, or whether this thread is dissing Harry Potter, Harry Styles, or Harry Prince of Wales.
Tags are also very handy for allowing people to continue following you even when there's some sort of interest incompatibility. If you love spiders -- especially pictures of spiders -- and I'm arachnophobic, then I'm probably not going to be able to keep following you, no matter how excellent your Anarchist Star Wars takes are. But if you love pictures of spiders and you tag every single one of them #spiders, then I can block that tag and still keep following you. Similarly, a temporary block on #The Witcher Spoilers can allow the fandom to all discuss a new episode at whatever time they're able to watch it, without having to completely avoid online spaces in the meantime.
And finally, tags can, and are, used for commentary that you don't want to put in the main post. Where that line is -- what to put in the post and what to put in tags -- is something you'll have to decide for yourself as you get experience, but as a general rule, the post is for something that you believe contributes to the memetic fitness of this post, and the tags are for things that you believe are not necessarily of memetic value. Additions to the post are integrated into the DNA, and will be passed on with subsequent reblogs; tags are only added to your instantiation of the post, and will not be included on future reblogs (unless the person who reblogs it from you is on iOS Tumblr Mobile app and hasn't adjusted their settings, in which case it'll go into their tags... but at any rate it'll die out in a generation or two.) This feature makes it good for adding meta-commentary that will be interesting/funny/valuable to your immediate circle of friends, but won't be useful to the population as a whole -- it allows you to be as snarky, in-joke-y, and obscure as you'd like, without having to spend any of your mental RAM calculating what will and won't have an impact on your Brand as an Influencer.
Influencers
There is no easy mechanism for people to see your follower count. There are many easy mechanisms for people to make it impossible to see their follower count. No one cares about how many followers you have or how far your "influence" spreads. No one is going to offer you a Tumblr sponsorship deal.
However, for assorted underlying-code reasons, Tumblr blogs are disproportionately useful for manipulating search engines. So.... we have an ongoing problem with SEO scum making a whole bunch of bots and using reblogs etc to generate fake signals to Google.
The combination of those two things leads to a general Tumblr tradition of Block Bots On Sight. The extra followers aren't helping you, and the mere fact of their existence is hurting all of us. If you've seen people strongly urging you to change your profile picture, add a bio, and reblog a couple things, that's why -- because we don't want you to get caught in the crossfire of our ongoing guerilla warfare.
Other Notes
One of the places that Reddit is much better than Tumblr is in the viewing of an entire memetic population as a whole: you just look at a post, scroll through the page, and Reddit helpfully shows you want you want to see, and hides what you don't.
On Tumblr, each memetic variation is functionally an entirely separate entity. This is great for memetic diversity, but it means there's a LOT of duplication, and it means there's really no good way to get all the variants together. The closest you can get is to "check the notes" -- click on that number at the bottom left of a post, and look through the replies, reblogs, and tags. Those are in chronological order and in no way threaded, so it's not very useful, but it is what we've got.
Let's see ...
One thing Tumblr does much better than Reddit is the ability (because of aforementioned fragmentation) to have an arbitrary number of any fandom. No more "Well I don't like the takes in r/polyamory but it's the only place where I can talk about it so idk" ... nope! Here we can have as many Spider-Man fandoms as there are Spider-Man fans. Really like someone's headcanons? Follow them! Really dislike someone's OTP? Unfollow them! Really hate someone's take on your favorite character? Block them! This is a fabulous feature of Tumblr and I encourage you to take advantage of it.
uh...
tags can be 140 characters, but they can't contain double quotes (") or commas (,) because those are delimiter characters and Tumblr will break your tag at those points in the string
...
If you think someone has mis-judged the value of their tags, you can copy them from their post and paste them into the main comment of your reblog. This is known as the tags "passing peer review". Copy-paste is preferred to screenshotting for accessibility reasons (and also the fact that sometimes Tumblr just doesn't feel like loading pictures), and it's considered polite to credit the person whose tags you promoted.
...
Contrariwise, if you think they mis-judged the value of their comment, you can go back to the person they reblogged from, and reblog without their addition. Tumblr made this harder recently, but I have confidence that we'll defeat them eventually.
...
I know that I said reblogs are much stronger than upvotes, but when you've got infinite monkeys generating infinite reblog streams, it all gets lost in the noise. Reblog anything and everything you feel like upvoting -- if people don’t want to be subjected to a bunch of random shit that lights up the dopamine receptors in your brain, they shouldn’t be following you on Tumblr.
...
IDK what to tell you about Tumblr polls. We're just like this 🤷♂️
...
...
That's all I can think of. Deities bless and keep you for seeing a problem in our online ecosystem and actually doing something about it. Looking forward to seeing what we can do together.
(Author's Note: All statements about how Tumblr works ("works") are as of 14 June 2023. God only knows what changes staff will have rolled out by time time you read this)
#welcome reddit refugees#meme mutation#memetics#long post#sociology#anthropology#tumblr culture#the tumblr experience#seriously people tag your fandom if you're going to talk about bruce! Or Harry! Or Steve!
276 notes
·
View notes
Text
dear stats class, thank you for finally actually being the thing to make me become proficient in excel because i am absolutely not calculating that shit by hand (correlation coefficient).
#i do technically know how to#i just also know that there is a strong negative correlation#between the number of digits in a calculation#and my success in transcribing answers correctly
375 notes
·
View notes
Text
i spent an embarrassingly long time in high school really confused how the correlation coefficient could possibly be symmetric and the slope of the line of best fit. like actual months of this gaping hole in my understanding. just goes to show you that geometry will lie to you and you need to blindly trust algebra instead
14 notes
·
View notes
Text
I think I'm as ready as I can be for my presentation. I have the slides all ready, though I still don't quite understand what I'm saying and I haven't learnt anything by heart so I'll be talking from my slide notes. And I might struggle to answer questions if there will be questions because my notes are spread over three print outs of multiple pages. X3
Also, those who know statistics, please tell me if my stupid meme below the cut makes sense X3

(I can't actually confirm that it's lower. It's a correlation coefficient of r: -0.30. But since I also have graphs with means I can see that it's lower. I just don't know if the magic of R confirms my findings or I just did a test wrong somewhere *lol*)
40 notes
·
View notes
Text
Essay by Eric Worrall
Taking “model output is data” to the next level…
AI reveals hidden climate extremes in Europe ByAndrei Ionescu Earth.com staff writer … Traditionally, climate scientists have relied on statistical methods to interpret these datasets, but a recent breakthrough demonstrates the power of artificial intelligence (AI) to revolutionize this process. Previously unrecorded climate extremes A team led by Étienne Plésiat of the German Climate Computing Center in Hamburg, alongside colleagues from the UK and Spain, applied AI to reconstruct European climate extremes. The research not only confirmed known climate trends but also revealed previously unrecorded extreme events. … Using historical simulations from the CMIP6 archive (Coupled Model Intercomparison Project), the team trained CRAI to reconstruct past climate data. The experts validated their results using standard metrics such as root mean square error and Spearman’s rank-order correlation coefficient, which measure accuracy and association between variables. …
The only thing which is real about using generative AI to try to fill in the gaps is the hallucinations.
What are AI hallucinations? AI hallucination is a phenomenon wherein a large language model (LLM)—often a generative AI chatbot or computer vision tool—perceives patterns or objects that are nonexistent or imperceptible to human observers, creating outputs that are nonsensical or altogether inaccurate.
I am an AI enthusiast, I believe AI is contributing and will continue to contribute greatly to the advancement of mankind. But you have to rigorously test the output. Comparing the AI output to a flawed model to see if it fits in the band of plausibility is not what I call testing.
Climate scientists have been repeatedly criticised for treating their model output as data. Using a tool which is known for its tendency to produce false or misleading data, to generate climate “records” which cannot be properly checked in my opinion is an exercise in scientific fantasy – a complete waste of time and money.
6 notes
·
View notes