#BigQuery analytics
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
ColdFusion with Google BigQuery: Running Analytics on Large Datasets
#ColdFusion with Google BigQuery: Running Analytics on Large Datasets#ColdFusion with Google BigQuery
0 notes
Text
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
New Post has been published on https://thedigitalinsider.com/anais-dotis-georgiou-developer-advocate-at-influxdata-interview-series/
Anais Dotis-Georgiou, Developer Advocate at InfluxData – Interview Series
Anais Dotis-Georgiou is a Developer Advocate for InfluxData with a passion for making data beautiful with the use of Data Analytics, AI, and Machine Learning. She takes the data that she collects, does a mix of research, exploration, and engineering to translate the data into something of function, value, and beauty. When she is not behind a screen, you can find her outside drawing, stretching, boarding, or chasing after a soccer ball.
InfluxData is the company building InfluxDB, the open source time series database used by more than a million developers around the world. Their mission is to help developers build intelligent, real-time systems with their time series data.
Can you share a bit about your journey from being a Research Assistant to becoming a Lead Developer Advocate at InfluxData? How has your background in data analytics and machine learning shaped your current role?
I earned my undergraduate degree in chemical engineering with a focus on biomedical engineering and eventually worked in labs performing vaccine development and prenatal autism detection. From there, I began programming liquid-handling robots and helping data scientists understand the parameters for anomaly detection, which made me more interested in programming.
I then became a sales development representative at Oracle and realized that I really needed to focus on coding. I took a coding boot camp at the University of Texas in data analytics and was able to break into tech, specifically developer relations.
I came from a technical background, so that helped shape my current role. Even though I didn’t have development experience, I could relate to and empathize with people who had an engineering background and mind but were also trying to learn software. So, when I created content or technical tutorials, I was able to help new users overcome technical challenges while placing the conversation in a context that was relevant and interesting to them.
Your work seems to blend creativity with technical expertise. How do you incorporate your passion for making data ‘beautiful’ into your daily work at InfluxData?
Lately, I’ve been more focused on data engineering than data analytics. While I don’t focus on data analytics as much as I used to, I still really enjoy math—I think math is beautiful, and will jump at an opportunity to explain the math behind an algorithm.
InfluxDB has been a cornerstone in the time series data space. How do you see the open source community influencing the development and evolution of InfluxDB?
InfluxData is very committed to the open data architecture and Apache ecosystem. Last year we announced InfluxDB 3.0, the new core for InfluxDB written in Rust and built with Apache Flight, DataFusion, Arrow, and Parquet–what we call the FDAP stack. As the engineers at InfluxData continue to contribute to those upstream projects, the community continues to grow and the Apache Arrow set of projects gets easier to use with more features and functionality, and wider interoperability.
What are some of the most exciting open-source projects or contributions you’ve seen recently in the context of time series data and AI?
It’s been cool to see the addition of LLMs being repurposed or applied to time series for zero-shot forecasting. Autolab has a collection of open time series language models, and TimeGPT is another great example.
Additionally, various open source stream processing libraries, including Bytewax and Mage.ai, that allow users to leverage and incorporate models from Hugging Face are pretty exciting.
How does InfluxData ensure its open source initiatives stay relevant and beneficial to the developer community, particularly with the rapid advancements in AI and machine learning?
InfluxData initiatives remain relevant and beneficial by focusing on contributing to open source projects that AI-specific companies also leverage. For example, every time InfluxDB contributes to Apache Arrow, Parquet, or DataFusion, it benefits every other AI tech and company that leverages it, including Apache Spark, DataBricks, Rapids.ai, Snowflake, BigQuery, HuggingFace, and more.
Time series language models are becoming increasingly vital in predictive analytics. Can you elaborate on how these models are transforming time series forecasting and anomaly detection?
Time series LMs outperform linear and statistical models while also providing zero-shot forecasting. This means you don’t need to train the model on your data before using it. There’s also no need to tune a statistical model, which requires deep expertise in time series statistics.
However, unlike natural language processing, the time series field lacks publicly accessible large-scale datasets. Most existing pre-trained models for time series are trained on small sample sizes, which contain only a few thousand—or maybe even hundreds—of samples. Although these benchmark datasets have been instrumental in the time series community’s progress, their limited sample sizes and lack of generality pose challenges for pre-training deep learning models.
That said, this is what I believe makes open source time series LMs hard to come by. Google’s TimesFM and IBM’s Tiny Time Mixers have been trained on massive datasets with hundreds of billions of data points. With TimesFM, for example, the pre-training process is done using Google Cloud TPU v3–256, which consists of 256 TPU cores with a total of 2 terabytes of memory. The pre-training process takes roughly ten days and results in a model with 1.2 billion parameters. The pre-trained model is then fine-tuned on specific downstream tasks and datasets using a lower learning rate and fewer epochs.
Hopefully, this transformation implies that more people can make accurate predictions without deep domain knowledge. However, it takes a lot of work to weigh the pros and cons of leveraging computationally expensive models like time series LMs from both a financial and environmental cost perspective.
This Hugging Face Blog post details another great example of time series forecasting.
What are the key advantages of using time series LMs over traditional methods, especially in terms of handling complex patterns and zero-shot performance?
The critical advantage is not having to train and retrain a model on your time series data. This hopefully eliminates the online machine learning problem of monitoring your model’s drift and triggering retraining, ideally eliminating the complexity of your forecasting pipeline.
You also don’t need to struggle to estimate the cross-series correlations or relationships for multivariate statistical models. Additional variance added by estimates often harms the resulting forecasts and can cause the model to learn spurious correlations.
Could you provide some practical examples of how models like Google’s TimesFM, IBM’s TinyTimeMixer, and AutoLab’s MOMENT have been implemented in real-world scenarios?
This is difficult to answer; since these models are in their relative infancy, little is known about how companies use them in real-world scenarios.
In your experience, what challenges do organizations typically face when integrating time series LMs into their existing data infrastructure, and how can they overcome them?
Time series LMs are so new that I don’t know the specific challenges organizations face. However, I imagine they’ll confront the same challenges faced when incorporating any GenAI model into your data pipeline. These challenges include:
Data compatibility and integration issues: Time series LMs often require specific data formats, consistent timestamping, and regular intervals, but existing data infrastructure might include unstructured or inconsistent time series data spread across different systems, such as legacy databases, cloud storage, or real-time streams. To address this, teams should implement robust ETL (extract, transform, load) pipelines to preprocess, clean, and align time series data.
Model scalability and performance: Time series LMs, especially deep learning models like transformers, can be resource-intensive, requiring significant compute and memory resources to process large volumes of time series data in real-time or near-real-time. This would require teams to deploy models on scalable platforms like Kubernetes or cloud-managed ML services, leverage GPU acceleration when needed, and utilize distributed processing frameworks like Dask or Ray to parallelize model inference.
Interpretability and trustworthiness: Time series models, particularly complex LMs, can be seen as “black boxes,” making it hard to interpret predictions. This can be particularly problematic in regulated industries like finance or healthcare.
Data privacy and security: Handling time series data often involves sensitive information, such as IoT sensor data or financial transaction data, so ensuring data security and compliance is critical when integrating LMs. Organizations must ensure data pipelines and models comply with best security practices, including encryption and access control, and deploy models within secure, isolated environments.
Looking forward, how do you envision the role of time series LMs evolving in the field of predictive analytics and AI? Are there any emerging trends or technologies that particularly excite you?
A possible next step in the evolution of time series LMs could be introducing tools that enable users to deploy, access, and use them more easily. Many of the time series LMs I’ve used require very specific environments and lack a breadth of tutorials and documentation. Ultimately, these projects are in their early stages, but it will be exciting to see how they evolve in the coming months and years.
Thank you for the great interview, readers who wish to learn more should visit InfluxData.
#access control#ai#algorithm#Analytics#anomaly detection#Apache#Apache Spark#architecture#autism#background#Beauty#benchmark#best security#bigquery#billion#Biomedical engineering#Blog#Building#chemical#Chemical engineering#Cloud#cloud storage#coding#Community#Companies#complexity#compliance#content#creativity#data
0 notes
Text
Why You Should Integrate Google Analytics 4 With BigQuery

With the introduction of Google Analytics 4, an improved data collection and reporting tool, the future of digital marketing is now AI and privacy-focused. Along with new capabilities, GA4 enables users to access BigQuery for free. Initially only available to Google Analytics 360 (paid) users, BigQuery allows you to store massive datasets.
In this blog post, we look at how BigQuery integration with GA4 helps you simplify complex data and derive actionable insights for marketing campaigns.
#ga4 big query#link google analytics 4 to bigquery#ga4 big query schema#ga4 big query linking#google analytics 4
0 notes
Text
Why Tableau is Essential in Data Science: Transforming Raw Data into Insights

Data science is all about turning raw data into valuable insights. But numbers and statistics alone don’t tell the full story—they need to be visualized to make sense. That’s where Tableau comes in.
Tableau is a powerful tool that helps data scientists, analysts, and businesses see and understand data better. It simplifies complex datasets, making them interactive and easy to interpret. But with so many tools available, why is Tableau a must-have for data science? Let’s explore.
1. The Importance of Data Visualization in Data Science
Imagine you’re working with millions of data points from customer purchases, social media interactions, or financial transactions. Analyzing raw numbers manually would be overwhelming.
That’s why visualization is crucial in data science:
Identifies trends and patterns – Instead of sifting through spreadsheets, you can quickly spot trends in a visual format.
Makes complex data understandable – Graphs, heatmaps, and dashboards simplify the interpretation of large datasets.
Enhances decision-making – Stakeholders can easily grasp insights and make data-driven decisions faster.
Saves time and effort – Instead of writing lengthy reports, an interactive dashboard tells the story in seconds.
Without tools like Tableau, data science would be limited to experts who can code and run statistical models. With Tableau, insights become accessible to everyone—from data scientists to business executives.
2. Why Tableau Stands Out in Data Science
A. User-Friendly and Requires No Coding
One of the biggest advantages of Tableau is its drag-and-drop interface. Unlike Python or R, which require programming skills, Tableau allows users to create visualizations without writing a single line of code.
Even if you’re a beginner, you can:
✅ Upload data from multiple sources
✅ Create interactive dashboards in minutes
✅ Share insights with teams easily
This no-code approach makes Tableau ideal for both technical and non-technical professionals in data science.
B. Handles Large Datasets Efficiently
Data scientists often work with massive datasets—whether it’s financial transactions, customer behavior, or healthcare records. Traditional tools like Excel struggle with large volumes of data.
Tableau, on the other hand:
Can process millions of rows without slowing down
Optimizes performance using advanced data engine technology
Supports real-time data streaming for up-to-date analysis
This makes it a go-to tool for businesses that need fast, data-driven insights.
C. Connects with Multiple Data Sources
A major challenge in data science is bringing together data from different platforms. Tableau seamlessly integrates with a variety of sources, including:
Databases: MySQL, PostgreSQL, Microsoft SQL Server
Cloud platforms: AWS, Google BigQuery, Snowflake
Spreadsheets and APIs: Excel, Google Sheets, web-based data sources
This flexibility allows data scientists to combine datasets from multiple sources without needing complex SQL queries or scripts.
D. Real-Time Data Analysis
Industries like finance, healthcare, and e-commerce rely on real-time data to make quick decisions. Tableau’s live data connection allows users to:
Track stock market trends as they happen
Monitor website traffic and customer interactions in real time
Detect fraudulent transactions instantly
Instead of waiting for reports to be generated manually, Tableau delivers insights as events unfold.
E. Advanced Analytics Without Complexity
While Tableau is known for its visualizations, it also supports advanced analytics. You can:
Forecast trends based on historical data
Perform clustering and segmentation to identify patterns
Integrate with Python and R for machine learning and predictive modeling
This means data scientists can combine deep analytics with intuitive visualization, making Tableau a versatile tool.
3. How Tableau Helps Data Scientists in Real Life
Tableau has been adopted by the majority of industries to make data science more impactful and accessible. This is applied in the following real-life scenarios:
A. Analytics for Health Care
Tableau is deployed by hospitals and research institutions for the following purposes:
Monitor patient recovery rates and predict outbreaks of diseases
Analyze hospital occupancy and resource allocation
Identify trends in patient demographics and treatment results
B. Finance and Banking
Banks and investment firms rely on Tableau for the following purposes:
✅ Detect fraud by analyzing transaction patterns
✅ Track stock market fluctuations and make informed investment decisions
✅ Assess credit risk and loan performance
C. Marketing and Customer Insights
Companies use Tableau to:
✅ Track customer buying behavior and personalize recommendations
✅ Analyze social media engagement and campaign effectiveness
✅ Optimize ad spend by identifying high-performing channels
D. Retail and Supply Chain Management
Retailers leverage Tableau to:
✅ Forecast product demand and adjust inventory levels
✅ Identify regional sales trends and adjust marketing strategies
✅ Optimize supply chain logistics and reduce delivery delays
These applications show why Tableau is a must-have for data-driven decision-making.
4. Tableau vs. Other Data Visualization Tools
There are many visualization tools available, but Tableau consistently ranks as one of the best. Here’s why:
Tableau vs. Excel – Excel struggles with big data and lacks interactivity; Tableau handles large datasets effortlessly.
Tableau vs. Power BI – Power BI is great for Microsoft users, but Tableau offers more flexibility across different data sources.
Tableau vs. Python (Matplotlib, Seaborn) – Python libraries require coding skills, while Tableau simplifies visualization for all users.
This makes Tableau the go-to tool for both beginners and experienced professionals in data science.
5. Conclusion
Tableau has become an essential tool in data science because it simplifies data visualization, handles large datasets, and integrates seamlessly with various data sources. It enables professionals to analyze, interpret, and present data interactively, making insights accessible to everyone—from data scientists to business leaders.
If you’re looking to build a strong foundation in data science, learning Tableau is a smart career move. Many data science courses now include Tableau as a key skill, as companies increasingly demand professionals who can transform raw data into meaningful insights.
In a world where data is the driving force behind decision-making, Tableau ensures that the insights you uncover are not just accurate—but also clear, impactful, and easy to act upon.
#data science course#top data science course online#top data science institute online#artificial intelligence course#deepseek#tableau
3 notes
·
View notes
Text
Aible And Google Cloud: Gen AI Models Sets Business Security
Enterprise controls and generative AI for business users in real time.
Aible
With solutions for customer acquisition, churn avoidance, demand prediction, preventive maintenance, and more, Aible is a pioneer in producing business impact from AI in less than 30 days. Teams can use AI to extract company value from raw enterprise data. Previously using BigQuery’s serverless architecture to save analytics costs, Aible is now working with Google Cloud to provide users the confidence and security to create, train, and implement generative AI models on their own data.
The following important factors have surfaced as market awareness of generative AI’s potential grows:
Enabling enterprise-grade control
Businesses want to utilize their corporate data to allow new AI experiences, but they also want to make sure they have control over their data to prevent unintentional usage of it to train AI models.
Reducing and preventing hallucinations
The possibility that models may produce illogical or non-factual information is another particular danger associated with general artificial intelligence.
Empowering business users
Enabling and empowering business people to utilize gen AI models with the least amount of hassle is one of the most beneficial use cases, even if gen AI supports many enterprise use cases.
Scaling use cases for gen AI
Businesses need a method for gathering and implementing their most promising use cases at scale, as well as for establishing standardized best practices and controls.
Regarding data privacy, policy, and regulatory compliance, the majority of enterprises have a low risk tolerance. However, given its potential to drive change, they do not see postponing the deployment of Gen AI as a feasible solution to market and competitive challenges. As a consequence, Aible sought an AI strategy that would protect client data while enabling a broad range of corporate users to swiftly adapt to a fast changing environment.
In order to provide clients complete control over how their data is used and accessed while creating, training, or optimizing AI models, Aible chose to utilize Vertex AI, Google Cloud’s AI platform.
Enabling enterprise-grade controls
Because of Google Cloud’s design methodology, users don’t need to take any more steps to ensure that their data is safe from day one. Google Cloud tenant projects immediately benefit from security and privacy thanks to Google AI products and services. For example, protected customer data in Cloud Storage may be accessed and used by Vertex AI Agent Builder, Enterprise Search, and Conversation AI. Customer-managed encryption keys (CMEK) can be used to further safeguard this data.
With Aible‘s Infrastructure as Code methodology, you can quickly incorporate all of Google Cloud’s advantages into your own applications. Whether you choose open models like LLama or Gemma, third-party models like Anthropic and Cohere, or Google gen AI models like Gemini, the whole experience is fully protected in the Vertex AI Model Garden.
In order to create a system that may activate third-party gen AI models without disclosing private data outside of Google Cloud, Aible additionally collaborated with its client advisory council, which consists of Fortune 100 organizations. Aible merely transmits high-level statistics on clusters which may be hidden if necessary instead of raw data to an external model. For instance, rather of transmitting raw sales data, it may communicate counts and averages depending on product or area.
This makes use of k-anonymity, a privacy approach that protects data privacy by never disclosing information about groups of people smaller than k. You may alter the default value of k; the more private the information transmission, the higher the k value. Aible makes the data transmission even more secure by changing the names of variables like “Country” to “Variable A” and values like “Italy” to “Value X” when masking is used.
Mitigating hallucination risk
It’s crucial to use grounding, retrieval augmented generation (RAG), and other strategies to lessen and lower the likelihood of hallucinations while employing gen AI. Aible, a partner of Built with Google Cloud AI, offers automated analysis to support human-in-the-loop review procedures, giving human specialists the right tools that can outperform manual labor.
Using its auto-generated Information Model (IM), an explainable AI that verifies facts based on the context contained in your structured corporate data at scale and double checks gen AI replies to avoid making incorrect conclusions, is one of the main ways Aible helps eliminate hallucinations.
Hallucinations are addressed in two ways by Aible’s Information Model:
It has been shown that the IM helps lessen hallucinations by grounding gen AI models on a relevant subset of data.
To verify each fact, Aible parses through the outputs of Gen AI and compares them to millions of responses that the Information Model already knows.
This is comparable to Google Cloud’s Vertex AI grounding features, which let you link models to dependable information sources, like as your company’s papers or the Internet, to base replies in certain data sources. A fact that has been automatically verified is shown in blue with the words “If it’s blue, it’s true.” Additionally, you may examine a matching chart created only by the Information Model and verify a certain pattern or variable.
The graphic below illustrates how Aible and Google Cloud collaborate to provide an end-to-end serverless environment that prioritizes artificial intelligence. Aible can analyze datasets of any size since it leverages BigQuery to efficiently analyze and conduct serverless queries across millions of variable combinations. One Fortune 500 client of Aible and Google Cloud, for instance, was able to automatically analyze over 75 datasets, which included 150 million questions and answers with 100 million rows of data. That assessment only cost $80 in total.
Aible may also access Model Garden, which contains Gemini and other top open-source and third-party models, by using Vertex AI. This implies that Aible may use AI models that are not Google-generated while yet enjoying the advantages of extra security measures like masking and k-anonymity.
All of your feedback, reinforcement learning, and Low-Rank Adaptation (LoRA) data are safely stored in your Google Cloud project and are never accessed by Aible.
Read more on Govindhtech.com
#Aible#GenAI#GenAIModels#BusinessSecurity#AI#BigQuery#AImodels#VertexAI#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
A Comprehensive Analysis of AWS, Azure, and Google Cloud for Linux Environments
In the dynamic landscape of cloud computing, selecting the right platform is a critical decision, especially for a Linux-based, data-driven business. Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) stand as the giants in the cloud industry, each offering unique strengths. With AWS Training in Hyderabad, professionals can gain the skills and knowledge needed to harness the capabilities of AWS for diverse applications and industries. Let’s delve into a simplified comparison to help you make an informed choice tailored to your business needs.

Amazon Web Services (AWS):
Strengths:
AWS boasts an extensive array of services and a global infrastructure, making it a go-to choice for businesses seeking maturity and reliability. Its suite of tools caters to diverse needs, including robust options for data analytics, storage, and processing.
Considerations:
Pricing in AWS can be intricate, but the platform provides a free tier for newcomers to explore and experiment. The complexity of pricing is offset by the vast resources and services available, offering flexibility for businesses of all sizes.
Microsoft Azure:
Strengths:
Azure stands out for its seamless integration with Microsoft products. If your business relies heavily on tools like Windows Server, Active Directory, or Microsoft SQL Server, Azure is a natural fit. It also provides robust data analytics services and is expanding its global presence with an increasing number of data centers.
Considerations:
Azure’s user-friendly interface, especially for those familiar with Microsoft technologies, sets it apart. Competitive pricing, along with a free tier, makes it accessible for businesses looking to leverage Microsoft’s extensive ecosystem.
Google Cloud Platform (GCP):
Strengths:
Renowned for innovation and a developer-friendly approach, GCP excels in data analytics and machine learning. If your business is data-driven, Google’s BigQuery and other analytics tools offer a compelling proposition. Google Cloud is known for its reliability and cutting-edge technologies.
Considerations:
While GCP may have a slightly smaller market share, it compensates with a focus on innovation. Its competitive pricing and a free tier make it an attractive option, especially for businesses looking to leverage advanced analytics and machine learning capabilities. To master the intricacies of AWS and unlock its full potential, individuals can benefit from enrolling in the Top AWS Training Institute.

Considerations for Your Linux-based, Data-Driven Business:
1. Data Processing and Analytics:
All three cloud providers offer robust solutions for data processing and analytics. If your business revolves around extensive data analytics, Google Cloud’s specialization in this area might be a deciding factor.
2. Integration with Linux:
All three providers support Linux, with AWS and Azure having extensive documentation and community support. Google Cloud is also Linux-friendly, ensuring compatibility with your Linux-based infrastructure.
3. Global Reach:
Consider the geographic distribution of data centers. AWS has a broad global presence, followed by Azure. Google Cloud, while growing, may have fewer data centers in certain regions. Choose a provider with data centers strategically located for your business needs.
4. Cost Considerations:
Evaluate the pricing models for your specific use cases. AWS and Azure offer diverse pricing options, and GCP’s transparent and competitive pricing can be advantageous. Understand the cost implications based on your anticipated data processing volumes.
5. Support and Ecosystem:
Assess the support and ecosystem offered by each provider. AWS has a mature and vast ecosystem, Azure integrates seamlessly with Microsoft tools, and Google Cloud is known for its developer-centric approach. Consider the level of support, documentation, and community engagement each platform provides.
In conclusion, the choice between AWS, Azure, and GCP depends on your unique business requirements, preferences, and the expertise of your team. Many businesses adopt a multi-cloud strategy, leveraging the strengths of each provider for different aspects of their operations. Starting with the free tiers and conducting a small-scale pilot can help you gauge which platform aligns best with your specific needs. Remember, the cloud is not a one-size-fits-all solution, and the right choice depends on your business’s distinctive characteristics and goals.
2 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier. 3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards. 4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning. 6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it. 7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query. 8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable. 9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science. 10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
2 notes
·
View notes
Text
Unlock Business Insights with Google Cloud Data Analytics Services
Google Cloud Data Analytics Services provide powerful tools for collecting, processing, and analyzing large datasets in real time. With services like BigQuery, Dataflow, and Dataproc, businesses can gain valuable insights to improve decision-making. Whether you need predictive analytics, machine learning integration, or scalable data processing, Google Cloud ensures high performance and security. Leverage AI-driven analytics to transform raw data into actionable insights, helping your business stay competitive in a data-driven world.
0 notes
Text
Navigating the Data World: A Deep Dive into Architecture of Big Data Tools

In today’s digital world, where data has become an integral part of our daily lives. May it be our phone’s microphone, websites, mobile applications, social media, customer feedback, or terms & conditions – we consistently provide “yes” consents, so there is no denying that each individual's data is collected and further pushed to play a bigger role into the decision-making pipeline of the organizations.
This collected data is extracted from different sources, transformed to be used for analytical purposes, and loaded in another location for storage. There are several tools present in the market that could be used for data manipulation. In the next sections, we will delve into some of the top tools used in the market and dissect the information to understand the dynamics of this subject.
Architecture Overview
While researching for top tools, here are a few names that made it to the top of my list – Snowflake, Apache Kafka, Apache Airflow, Tableau, Databricks, Redshift, Bigquery, etc. Let’s dive into their architecture in the following sections:
Snowflake
There are several big data tools in the market serving warehousing purposes for storing structured data and acting as a central repository of preprocessed data for analytics and business intelligence. Snowflake is one of the warehouse solutions. What makes Snowflake different from other solutions is that it is a truly self-managed service, with no hardware requirements and it runs completely on cloud infrastructure making it a go-to for the new Cloud era. Snowflake uses virtual computing instances and a storage service for its computing needs. Understanding the tools' architecture will help us utilize it more efficiently so let’s have a detailed look at the following pointers:

Image credits: Snowflake
Now let’s understand what each layer is responsible for. The Cloud service layer deals with authentication and access control, security, infrastructure management, metadata, and optimizer manager. It is responsible for managing all these features throughout the tool. Query processing is the compute layer where the actual query computation happens and where the cloud compute resources are utilized. Database storage acts as a storage layer for storing the data.
Considering the fact that there are a plethora of big data tools, we don’t shed significant light on the Apache toolkit, this won’t be justice done to their contribution. We all are familiar with Apache tools being widely used in the Data world, so moving on to our next tool Apache Kafka.
Apache Kafka
Apache Kafka deserves an article in itself due to its prominent usage in the industry. It is a distributed data streaming platform that is based on a publish-subscribe messaging system. Let’s check out Kafka components – Producer and Consumer. Producer is any system that produces messages or events in the form of data for further processing for example web-click data, producing orders in e-commerce, System Logs, etc. Next comes the consumer, consumer is any system that consumes data for example Real-time analytics dashboard, consuming orders in an inventory service, etc.
A broker is an intermediate entity that helps in message exchange between consumer and producer, further brokers have divisions as topic and partition. A topic is a common heading given to represent a similar type of data. There can be multiple topics in a cluster. Partition is part of a topic. Partition is data divided into small sub-parts inside the broker and every partition has an offset.
Another important element in Kafka is the ZooKeeper. A ZooKeeper acts as a cluster management system in Kafka. It is used to store information about the Kafka cluster and details of the consumers. It manages brokers by maintaining a list of consumers. Also, a ZooKeeper is responsible for choosing a leader for the partitions. If any changes like a broker die, new topics, etc., occur, the ZooKeeper sends notifications to Apache Kafka. Zookeeper has a master-slave that handles all the writes, and the rest of the servers are the followers who handle all the reads.
In recent versions of Kafka, it can be used and implemented without Zookeeper too. Furthermore, Apache introduced Kraft which allows Kafka to manage metadata internally without the need for Zookeeper using raft protocol.

Image credits: Emre Akin
Moving on to the next tool on our list, this is another very popular tool from the Apache toolkit, which we will discuss in the next section.
Apache Airflow
Airflow is a workflow management system that is used to author, schedule, orchestrate, and manage data pipelines and workflows. Airflow organizes your workflows as Directed Acyclic Graph (DAG) which contains individual pieces called tasks. The DAG specifies dependencies between task execution and task describing the actual action that needs to be performed in the task for example fetching data from source, transformations, etc.
Airflow has four main components scheduler, DAG file structure, metadata database, and web server. A scheduler is responsible for triggering the task and also submitting the tasks to the executor to run. A web server is a friendly user interface designed to monitor the workflows that let you trigger and debug the behavior of DAGs and tasks, then we have a DAG file structure that is read by the scheduler for extracting information about what task to execute and when to execute them. A metadata database is used to store the state of workflow and tasks. In summary, A workflow is an entire sequence of tasks and DAG with dependencies defined within airflow, a DAG is the actual data structure used to represent tasks. A task represents a single unit of DAG.

As we received brief insights into the top three prominent tools used by the data world, now let’s try to connect the dots and explore the Data story.
Connecting the dots
To understand the data story, we will be taking the example of a use case implemented at Cubera. Cubera is a big data company based in the USA, India, and UAE. The company is creating a Datalake for data repository to be used for analytical purposes from zero-party data sources as directly from data owners. On an average 100 MB of data per day is sourced from various data sources such as mobile phones, browser extensions, host routers, location data both structured and unstructured, etc. Below is the architecture view of the use case.

Image credits: Cubera
A node js server is built to collect data streams and pass them to the s3 bucket for storage purposes hourly. While the airflow job is to collect data from the s3 bucket and load it further into Snowflake. However, the above architecture was not cost-efficient due to the following reasons:
AWS S3 storage cost (for each hour, typically 1 million files are stored).
Usage costs for ETL running in MWAA (AWS environment).
The managed instance of Apache Airflow (MWAA).
Snowflake warehouse cost.
The data is not real-time, being a drawback.
The risk of back-filling from a sync-point or a failure point in the Apache airflow job functioning.
The idea is to replace this expensive approach with the most suitable one, here we are replacing s3 as a storage option by constructing a data pipeline using Airflow through Kafka to directly dump data to Snowflake. The following is a newfound approach, as Kafka works on the consumer-producer model, snowflake works as a consumer here. The message gets queued on the Kafka topic from the sourcing server. The Kafka for Snowflake connector subscribes to one or more Kafka topics based on the configuration information provided via the Kafka configuration file.

Image credits: Cubera
With around 400 million profile data directly sourced from individual data owners from their personal to household devices as Zero-party data, 2nd Party data from various app partnerships, Cubera Data Lake is continually being refined.
Conclusion
With so many tools available in the market, choosing the right tool is a task. A lot of factors should be taken into consideration before making the right decision, these are some of the factors that will help you in the decision-making – Understanding the data characteristics like what is the volume of data, what type of data we are dealing with - such as structured, unstructured, etc. Anticipating the performance and scalability needs, budget, integration requirements, security, etc.
This is a tedious process and no single tool can fulfill all your data requirements but their desired functionalities can make you lean towards them. As noted earlier, in the above use case budget was a constraint so we moved from the s3 bucket to creating a data pipeline in Airflow. There is no wrong or right answer to which tool is best suited. If we ask the right questions, the tool should give you all the answers.
Join the conversation on IMPAAKT! Share your insights on big data tools and their impact on businesses. Your perspective matters—get involved today!
0 notes
Text
A comparison of Snowflake with legacy systems and other cloud platforms.
Here’s a structured comparison of Snowflake vs. Legacy Systems vs. Other Cloud Platforms to highlight their differences in terms of architecture, performance, scalability, cost, and use cases.
1. Architecture
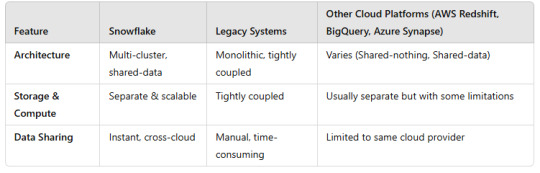
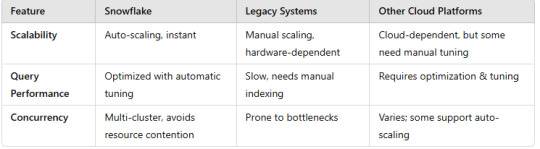
2. Performance & Scalability
3. Cost & Pricing
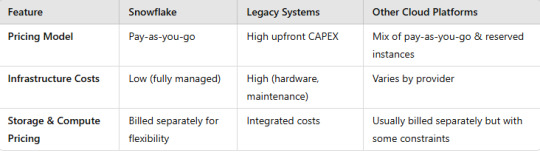
4. Security & Compliance
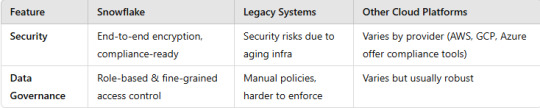
5. Use Cases

Key Takeaways
Snowflake offers seamless scalability, pay-as-you-go pricing, and cross-cloud flexibility, making it ideal for modern analytics workloads.
Legacy Systems struggle with scalability, maintenance, and cost efficiency.
Other Cloud Platforms like AWS Redshift, BigQuery, and Azure Synapse provide similar capabilities but with vendor lock-in and varying scalability options.
WEBSITE: https://www.ficusoft.in/snowflake-training-in-chennai/
0 notes
Text
How Does CAI Differ from CDI in Informatica Cloud?
Informatica Cloud is a powerful platform that offers various integration services to help businesses manage and process data efficiently. Two of its core components—Cloud Application Integration (CAI) and Cloud Data Integration (CDI)—serve distinct but complementary purposes. While both are essential for a seamless data ecosystem, they address different integration needs. This article explores the key differences between CAI and CDI, their use cases, and how they contribute to a robust data management strategy. Informatica Training Online

What is Cloud Application Integration (CAI)?
Cloud Application Integration (CAI) is designed to enable real-time, event-driven integration between applications. It facilitates communication between different enterprise applications, APIs, and services, ensuring seamless workflow automation and business process orchestration. CAI primarily focuses on low-latency and API-driven integration to connect diverse applications across cloud and on-premises environments.
Key Features of CAI: Informatica IICS Training
Real-Time Data Processing: Enables instant data exchange between systems without batch processing delays.
API Management: Supports REST and SOAP-based web services to facilitate API-based interactions.
Event-Driven Architecture: Triggers workflows based on system events, such as new data entries or user actions.
Process Automation: Helps in automating business processes through orchestration of multiple applications.
Low-Code Development: Provides a drag-and-drop interface to design and deploy integrations without extensive coding.
Common Use Cases of CAI:
Synchronizing customer data between CRM (Salesforce) and ERP (SAP).
Automating order processing between e-commerce platforms and inventory management systems.
Enabling chatbots and digital assistants to interact with backend databases in real time.
Creating API gateways for seamless communication between cloud and on-premises applications.
What is Cloud Data Integration (CDI)?
Cloud Data Integration (CDI), on the other hand, is focused on batch-oriented and ETL-based data integration. It enables organizations to extract, transform, and load (ETL) large volumes of data from various sources into a centralized system such as a data warehouse, data lake, or business intelligence platform.
Key Features of CDI: Informatica Cloud Training
Batch Data Processing: Handles large datasets and processes them in scheduled batches.
ETL & ELT Capabilities: Transforms and loads data efficiently using Extract-Transform-Load (ETL) or Extract-Load-Transform (ELT) approaches.
Data Quality and Governance: Ensures data integrity, cleansing, and validation before loading into the target system.
Connectivity with Multiple Data Sources: Integrates with relational databases, cloud storage, big data platforms, and enterprise applications.
Scalability and Performance Optimization: Designed to handle large-scale data operations efficiently.
Common Use Cases of CDI:
Migrating legacy data from on-premises databases to cloud-based data warehouses (e.g., Snowflake, AWS Redshift, Google BigQuery).
Consolidating customer records from multiple sources for analytics and reporting.
Performing scheduled data synchronization between transactional databases and data lakes.
Extracting insights by integrating data from IoT devices into a centralized repository.
CAI vs. CDI: Key Differences
CAI is primarily designed for real-time application connectivity and event-driven workflows, making it suitable for businesses that require instant data exchange. It focuses on API-driven interactions and process automation, ensuring seamless communication between enterprise applications. On the other hand, CDI is focused on batch-oriented data movement and transformation, enabling organizations to manage large-scale data processing efficiently.
While CAI is ideal for integrating cloud applications, automating workflows, and enabling real-time decision-making, CDI is better suited for ETL/ELT operations, data warehousing, and analytics. The choice between CAI and CDI depends on whether a business needs instant data transactions or structured data transformations for reporting and analysis. IICS Online Training
Which One Should You Use?
Use CAI when your primary need is real-time application connectivity, process automation, and API-based data exchange.
Use CDI when you require batch processing, large-scale data movement, and structured data transformation for analytics.
Use both if your organization needs a hybrid approach, where real-time data interactions (CAI) are combined with large-scale data transformations (CDI).
Conclusion
Both CAI and CDI play crucial roles in modern cloud-based integration strategies. While CAI enables seamless real-time application interactions, CDI ensures efficient data transformation and movement for analytics and reporting. Understanding their differences and choosing the right tool based on business needs can significantly improve data agility, process automation, and decision-making capabilities within an organization.
For More Information about Informatica Cloud Online Training
Contact Call/WhatsApp: +91-9989971070
Visit: https://www.visualpath.in/informatica-cloud-training-in-hyderabad.html
Visit Blog: https://visualpathblogs.com/category/informatica-cloud/
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
#Informatica Training in Hyderabad#IICS Training in Hyderabad#IICS Online Training#Informatica Cloud Training#Informatica Cloud Online Training#Informatica IICS Training#Informatica Training Online#Informatica Cloud Training in Chennai#Informatica Cloud Training In Bangalore#Best Informatica Cloud Training in India#Informatica Cloud Training Institute#Informatica Cloud Training in Ameerpet
0 notes
Text
Echobase AI Review: Query, Create & Analyze Files with AI
New Post has been published on https://thedigitalinsider.com/echobase-ai-review-query-create-analyze-files-with-ai/
Echobase AI Review: Query, Create & Analyze Files with AI
There’s no question businesses have a lot of data to manage. From customer interactions to operational metrics, every click, purchase, and decision leaves a trail of valuable information. Yet, extracting actionable insights can feel like searching for a needle in a haystack amidst this sea of data.
I recently came across Echobase AI, a platform designed to simplify and supercharge how your business analyzes data. It’s an incredibly user-friendly platform that empowers teams to harness their information assets’ full potential easily.
I’ll show you how to use Echobase later in this article, but in a nutshell, all you have to do is upload your business files onto the platform. Echobase uses advanced AI models to analyze and derive insights from your data, saving you time and enabling you to focus on growing your business. These AI models can also answer questions and generate content for you.
In this Echobase AI review, I’ll discuss what it is, what it’s used for, and its key features. From there, I’ll show you how to use Echobase so you can start uploading your business files and quickly accessing your data with AI.
I’ll finish the article with my top three Echobase AI alternatives. By the end, I hope you’ll understand what Echobase AI is and find the best software for you and your business!
Whether you’re a small startup or a seasoned enterprise, Echobase AI promises to manage and analyze data more effectively, making complex analysis as simple as a conversation. Let’s take a look!
Verdict
Echobase is a versatile AI platform empowering teams to efficiently analyze and access company data with top AI models like Google Gemini, Anthropic Claude, and OpenAI ChatGPT. Its user-friendly interface, collaborative features, and robust security measures make it an accessible and reliable choice for businesses looking to integrate AI seamlessly into their operations.
Pros and Cons
Echobase helps teams find, ask questions about, and analyze their company’s data efficiently.
Access top AI models like Google Gemini, Anthropic Claude, and OpenAI ChatGPT.
Train AI Agents specifically on your business data for tailored insights and actions.
A wide array of AI-powered tools to enhance productivity and creativity when creating content.
Query, create, and analyze real-time data for instant actionable insights from your knowledge base.
Easy uploading and syncing of files from various sources like Google Drive and SharePoint.
No coding or technical expertise is required, making it accessible for all team members.
Enables team members to collaborate and share prompts and outputs in real time.
Precise control over access and permissions, enhancing security and management.
Complies with GDPR, DSS, and PCI standards, with robust encryption and privacy measures.
Valuable resources, including a Quick Start guide with use cases, a blog, and other articles.
It offers a free trial without requiring a credit card, so there’s no upfront financial commitment.
Depending on the subscription plan, the number of queries and other features may be limited.
While no coding is required, new users may need to learn to use all features fully.
What is Echobase AI?
Echobase is a versatile AI-powered platform designed to help teams seamlessly integrate artificial intelligence into business operations. It allows businesses to upload files and synchronize cloud storage services, empowering teams to query, create, and analyze data from their knowledge base in real time. In a nut-shell, Echobase AI is a tool that uses artificial intelligence to make working with business data easier.
To start using Echobase, upload your business files in PDF, DOCX, CSV, and TXT formats. Uploading these files will give the AI the context to understand your data and generate insights.
Once uploaded, you can train AI Agents on these files to answer questions, create content, and analyze data. Echobase ensures that your data is secure with robust encryption and compliance with industry standards, allowing you to leverage AI to enhance your business operations confidently.
The platform supports advanced AI models (Google Gemini, Anthropic Claude, and OpenAI ChatGPT) tailored to your business. You can even create custom AI agents for consulting, marketing, finance, and operations!
Using this technology, Echobase lets businesses automate a wide range of tasks, meaning less time spent on monotonous obligations and more time making important decisions based on solid data. Plus, since it’s built on cloud infrastructure, any business, no matter its size, can jump right in and start scaling up without hassle. Echobase continuously improves and adds new features, so you won’t want to miss out!
What is Echobase Used For?
Echobase AI is handy for many different jobs tailored to your business. All you have to do is upload relevant files to the Knowledge Base, give one of the AI models a prompt, and receive an output immediately!
I’ve listed the most popular ways people use Echobase and provided a brief description to give you an idea of how to use it. You can create These AI Agents with Echobase to streamline various tasks and improve efficiency.
For more detailed information with example knowledge bases, prompts, and use case scenarios, click the links below:
Proposal Writing: The AI Proposal Agent uses your past proposals, RFPs, and company information to create and enhance upcoming proposals.
Report Writing: The AI Report Writing Agent uses your previous reports, relevant research, and company data to produce, improve, and evaluate upcoming and current reports.
Grant Writing: A Grant Writing Agent uses previous grants, instructions, and organizational information to create, improve, and develop upcoming grant proposals.
Policy & Procedures: An AI Agent for Policy and Procedure evaluates current policies, regulatory guidelines, and company information to create, enhance, and revise procedures.
Learning Support: An AI Agent for Education and Learning personalizes lesson plans, assesses progress, offers customized learning materials, and enables interactive online tutoring sessions.
IT Helpdesk Agent: An AI Helpdesk Agent addresses technical questions, resolves issues, and aids users with difficulties. It acts as a bridge connecting stakeholders and technical assistance.
Stakeholder Interviews: Use an AI Stakeholder Interview Agent to pinpoint main themes and observations effortlessly and corroborate details from interviews with both internal and external stakeholders.
Teaching Agent: Use the Teaching Agent to create customized educational materials, enhance lesson plans, and effectively deliver content to students.
Recruitment: A recruitment agent reviews CVs and resumes, evaluates candidate suitability, coordinates interview arrangements, and assists in making hiring decisions based on data.
Desktop Research: The AI Desktop Research Agent reviews reports, papers, journals, emails, data files, and websites to generate summaries on particular research subjects.
Key Features of Echobase AI
Echobase offers a range of key features designed to integrate AI seamlessly into your business operations:
File Management and Upload: Easily upload or sync files from your cloud storage services to give AI Agents the context needed to become experts in your specific business knowledge.
3 Advanced AI Models: Access the latest AI models like Google Gemini, Anthropic Claude, and OpenAI ChatGPT to query, create, and analyze information from your files.
AI Agent Training: Train AI Agents on your business-specific data to complete tasks ranging from basic Q&A to complex data analysis and content creation.
Collaboration: Invite team members to collaborate in real-time, sharing prompts, outputs, agents, and chat histories.
Role Management: Assign roles and permissions to team members, allowing for controlled access and management of datasets and AI agents.
Comprehensive AI Tools: Access diverse AI-powered tools to enhance creativity, streamline workflows, and achieve business goals more effectively.
Visual Data Insights: Echobase AI provides intuitive visualizations and data insights to empower users to make informed decisions and confidently drive strategic initiatives.
How to Use Echobase
Login to Echobase
Upload Business Files
Go to Agents
Chat with an AI Agent
Create a New AI Agent
Select an Agent Type
Step 1: Login to Echobase
I started by opening my browser, going to the Echobase website, and selecting “Try Free.” No credit card is required, but you’ll want to create an account for Echobase to retain your files.
Step 2: Upload Business Files
The Dashboard gives you an overview of your analytics, but the File Management tab is where you’ll want to start. This section allowed me to upload files about my business to Echobase AI. Some file examples include policies, budget information, pitch decks, service agreements, and more, but feel free to upload whatever files are essential to your business you want to utilize through Echobase!
Echobase supports various file types, including PDF, DOCX, CSV, and TXT. I could easily upload my files onto the platform by dragging and dropping them or uploading them from Google Drive or SharePoint.
With Echobase, you don’t need to worry about exposing your business files. The platform complies with GDPR, DSS, and PCI standards, ensuring strong data protection and privacy through encryption, API utilization, and data control!
Step 3: Go to Agents
Once I uploaded my files, I went to my Agents tab. Here, I had access to the most popular AI models, including Google Gemini, Anthropic Claude, and OpenAI Chat GPT, to perform different tasks, from answering questions to complex data analysis and content creation.
These chatbots use your uploaded files to provide tailored responses based on their content. Rather than searching through business files, you can instantly access the specific information you need, allowing you to focus on strategic initiatives and drive your business forward.
Step 4: Chat with an AI Agent
Selecting one of these AI models is what you would expect: A chatbot-like interface where you can type in a text prompt and send it to receive an immediate response from the AI model. The AI models use natural language processing (NLP) to answer questions like humans do!
Depending on your subscription plan, you’ll get a certain number of queries. Echobase will keep a Chat History log of your discussion you can refer to at any time.
Step 5: Create a New AI Agent
Returning to the Agents page, select “New AI Agent” to train the AI on specific business files!
Step 6: Select an Agent Type
Selecting “New AI Agent” took me to a new page where I could name my custom AI agent and select an Agent Type to give the agent a role. Each type has fundamental behaviors and skills designed for a particular purpose.
Clicking “Select an Agent Type” took me to a new page to explore pre-built agent types based on the tasks I wanted to complete. The categories included consulting, marketing, finance, and operations.
That’s a quick behind-the-scenes look at Echobase and how easy it is to integrate AI into your business! Echobase keeps things simple and efficient, making it a valuable tool for any organization leveraging AI technology. By integrating Echobase into your daily business operations routine, you’ll notice a significant boost in productivity and efficiency.
How Echobase AI Enhances Business Operations
Here are the main ways Echobase Ai enhances business operations:
Businesses see a significant improvement in their day-to-day tasks.
Companies can work smarter and not harder.
Echobase ensures businesses stay ahead of the curve.
Streamlining Workflow Processes
Echobase AI makes work easier and saves companies time and resources. Here’s a look at how it does that:
Echobase AI lets businesses pay more attention to essential tasks by automating routine jobs.
Echobase AI helps improve workflow by boosting productivity with tools that make things run smoother.
Through its collaborative features, teams can collaborate easily, enhancing how they communicate and cooperate on projects.
Echobase AI offers insights into data analytics that help refine workflows for even better results.
Improving Team Collaboration
Echobase AI makes it easier for teams to work together by offering tools designed for collaboration. Here’s a look at how Echobase AI boosts teamwork:
Echobase AI creates a centralized workspace where team members can collaborate in real time. Team members can share chat histories, prompts, and outputs.
With role management features, businesses can assign specific roles and permissions to their team members. Role management ensures secure and well-managed access to essential data and resources.
Through its collaborative tools, Echobase AI improves communication among team members. It helps solve problems faster so teams can achieve more together.
By streamlining collaboration and bringing everyone into one shared workspace, Echobase AI significantly increases team productivity.
Enhancing Data Analysis and Insights
Echobase AI steps up the game in data analysis, offering businesses some beneficial insights. Here’s a breakdown of what Echobase AI brings to the table:
Echobase’s data means companies can extract more meaningful information from their numbers.
Echobase’s data analysis tools help companies make choices based on solid facts.
Echobase saves businesses significant amounts of time and effort by automating the boring stuff like processing data.
Echobase turns complex data into easy-to-understand visuals so companies can see what’s happening at a glance.
Top 3 Echobase AI Alternatives
Here are the best Echobase alternatives you’ll want to consider.
Julius AI
Echobase and Julius AI are both AI-powered platforms designed to enhance business operations. However, they each have unique features and serve different purposes.
Julius AI specializes in transforming complex data analysis into automated processes. It generates sleek data visualizations, charts, graphs, and polished reports, making data insights easily accessible.
With advanced analysis tools and a user-friendly interface, Julius AI simplifies data querying, cleaning, and visualization for those without technical expertise. It also allows for instant export and data sharing to streamline collaboration.
On the other hand, Echobase allows businesses to upload files and synchronize cloud storage, enabling real-time data querying, creation, and analysis. It supports advanced AI models like Google Gemini, Anthropic Claude, and OpenAI ChatGPT and allows for the creation of custom AI agents for various business tasks.
Echobase is ideal for integrating AI across multiple business functions, while Julius AI excels in efficient and user-friendly data analysis and visualization. Choose Julius if you need more simplified, interactive data analysis and visualization. Otherwise, Echobase AI is great for businesses wanting secure AI integration in various operations.
Read Review →
Visit Julius AI →
DataLab
Echobase and DataLab offer distinct approaches for leveraging AI for data analysis and business operations.
DataLab focuses on easy-to-understand data analysis using an AI assistant. This assistant links to data sources like CSV files, Google Sheets, Snowflake, and BigQuery. From there, it uses generative AI to analyze data structures and runs code to provide insights.
DataLab strongly emphasizes enterprise-grade security with ISO 27001:2017 certification, encrypted data transmission, and robust access controls like SSO and MFA. It’s great for organizations requiring rigorous security measures and detailed data access over user control.
Echobase simplifies AI integration into business operations through easy file upload and real-time synchronization for querying, content creation, and data analysis. It supports advanced AI models such as Google Gemini, Anthropic Claude, and OpenAI ChatGPT for creating custom AI agents suited to various sectors like consulting, marketing, finance, and operations. Echobase is perfect for businesses aiming to automate tasks and enhance decision-making with a user-friendly cloud-based infrastructure.
Echobase is perfect for small to medium-sized businesses looking for a simple AI integration solution that enhances operational efficiency and decision-making without advanced technical skills. DataLab, on the other hand, is ideal for enterprises prioritizing data security, accuracy, and detailed control over data access and insights, especially those with complex data structures and compliance requirements.
If you can’t decide, these platforms offer free plans so you can try both!
Visit DataLab →
Microsoft Power BI
The final Echobase AI alternative I’d recommend is Microsoft Power BI. Microsoft’s comprehensive business intelligence tool by Microsoft that allows you to connect to various data sources, visualize data, and create interactive reports and dashboards. It emphasizes creating a data-driven culture with advanced analytics tools, AI capabilities, and integration with Microsoft 365 services.
Power BI supports enterprise-grade ingestion and scaling capabilities and offers robust governance, security, and compliance features. It’s geared towards establishing a single source of truth for data, fostering self-service BI, and embedding reports into everyday Microsoft applications.
Meanwhile, Echobase is an AI-powered platform that integrates artificial intelligence into business operations. It offers easy file uploads and synchronization, empowering teams to query, create, and analyze data in real-time.
Echobase supports advanced AI models and enables customization for specific business needs, such as consulting, marketing, finance, and operations. It automates tasks and enhances decision-making with solid data insights.
Choose Echobase if you’re a small to medium-sized business looking to integrate AI efficiently into your operations without extensive technical knowledge. It’s also great when creating customizable AI models for specific business tasks like data analysis, content creation, and basic automation.
Alternatively, choose Power BI if your enterprise requires robust, enterprise-grade BI solutions with extensive scalability, governance, and security needs. It’ll also be helpful for organizations that are deeply integrated into the Microsoft ecosystem and need seamless integration with Microsoft 365 apps for widespread data access and collaboration.
Visit Microsoft →
Echobase AI Review: The Right Tool For You?
Echobase AI is a user-friendly, versatile tool for seamlessly integrating AI into business operations. I was impressed by how simple the interface was and how quickly I could leverage AI models to enhance workflows. Uploading files was effortless, and the real-time collaboration features make it easy for teams to use Echobase effectively from day one.
For anyone looking for a straightforward AI integration solution that doesn’t require extensive technical expertise, Echobase is an excellent choice. It’s well-suited for small to medium-sized businesses looking to automate tasks, enhance productivity, and make informed decisions based on reliable data insights. Plus, its user-friendly interface and file management versatility make it accessible to teams without compromising on data security or compliance.
On the other hand, DataLab caters to enterprises needing more serious security measures and detailed control over data access and insights. This robust security makes DataLab more suitable for complex data structures and compliance requirements.
Meanwhile, Microsoft Power BI excels in enterprise-grade BI solutions. It offers extensive scalability, governance, and seamless integration with Microsoft 365 for widespread access to data and collaboration. If your company is heavily integrated with the Microsoft ecosystem, Power BI will be the most suitable option.
Echobase is the best AI tool for businesses looking to integrate AI quickly and efficiently. It’s especially great for businesses that want operational efficiency with the least technical complexity.
Thanks for reading my Echobase AI review! I hope you found it helpful. Echobase has a free plan, so I’d encourage you to try it yourself!
Visit Echobase →
Frequently Asked Questions
Is Echobase free?
Echobase offers a free plan with limited features. For more features, such as more queries and access to the most recent ChatGPT version, Echobase offers different paid subscriptions. For all the details on these pricing tiers, head to the Echobase pricing page.
#agent#agents#ai#ai agent#AI AGENTS#ai assistant#AI integration#ai model#AI models#ai platform#ai tools#AI Tools 101#AI-powered#amp#Analysis#Analytics#anthropic#API#applications#apps#Article#Articles#artificial#Artificial Intelligence#assets#attention#automation#bases#bi#bigquery
0 notes
Text
Does Google Analytics for Your Website Cost to Set It up?
Google Analytics is the most popular tool for tracking and analyzing website traffic. Decrypting it whether you are a small business owner, a blogger, a marketing professional or anyone — Google Analytics is a boon, as it gives you insightful information on how users are interacting with your website. However, there is a most common question that comes in mind is “Is there any cost for Google Analytics setup for a website?
So let’s explain the costs and how to set up Google Analytics and if there are other potential expenses you should keep in mind.
Google Analytics is Easily Accessible for Most Users. The good part is, Google Analytics is free for most users as small businesses, bloggers, personal websites, etc. There’s a free variant of Google Analytics that gives you the ability to see how much traffic your site is getting, how your audience behaves, how much you’re converting, and much more!
The latest version, Google Analytics 4 (GA4), is also entirely free, but it has advanced features compared to previous versions (including better event tracking, cross-platform integration, and machine learning-powered insights).
When Would You Have to Pay for Google Analytics?
Google Analytics has two versions: the base version, which is free, and Google Analytics 360, a paid version. However, the paid version of GA4 has a few extra features mainly designed for large enterprises or websites with very high traffic volumes, and this version is part of the Google Marketing Platform.
Google Analytics 360 Key Features:
Increased data limits: Google Analytics 360 allows you to process larger volumes of data, which can be crucial for high-traffic websites or e-commerce sites that have millions of visitors per month.
More, customizable options: 360 users gain advanced customization and support options.
This article is for users who are on aggregate data (360) and need premium support from Google.
This allows for advanced integrations and access: Google Analytics 360 is better linked to other Google products (such as BigQuery), and it enables higher levels of data sampling (which means it ensures better accuracy in reports).
The license for Google Analytics 360 is expensive — roughly $150,000 per year. Generally this is only available for big companies or sites with huge amounts of traffic.
Get started with Google Analytics Setup costs
Although the tool is free, there are other costs involved in implementing Google Analytics on your site:
Development Costs
However, if you are not familiar with the tool or don’t have experience working with tracking codes, then implementing Google Analytics can be a challenge.
Here are some examples of when you may incurdevelopment costs:
Adding the tracking code: You may need to hire a developer to insert the Google Analytics tracking code into the pages of your website if you are not familiar with how to install this code. Installation itself is usually a quick copy-and-paste into your site’s header or footer, but with complicated platforms or content management systems (WordPress, anyone?), a developer may be able to assist with ensuring it’s installed successfully.
Even e-commerce setup: If you're an e-commerce and want to track transactions, product views and other metrics, enhanced e-commerce tracking with Google Analytics requires some additional setup. Depending on your platform, a developer might be required to configure this tracking.
Limited customization: Some aspects of Google Analytics, such as goals or events, may limit your ability to customize your reports to meet your specific needs. You need a specialist who can configure everything to align with what you want to achieve if you want custom reports or established goals.
Time and Learning Costs
Google Analytics is free to use, but it takes time to learn the tool. Web analytics involves knowing how to use it — this can take some time if you or your team aren’t familiar with it. You might decide to spend resources on classes to help you experience upskill.
There are a lot of free resources that include:
Google’s Analytics Academy: Free online courses covering everything from basic setup to advanced features.
Online Youtube tutorials: There are many free tutorials available online guiding you through setting up of Google Analytics features.
Or, you can have a consultant or agency come in to set up Google Analytics and train you on how to use it. Consultant fees range from $50-$200/hr depending on their expertise and complexity of your setup.
Should You Hire a Professional?
If you have a very simple website and want to monitor some basic stats (such as page views, bounce rates, and traffic sources), it is usually enough to just set up Google Analytics yourself. Excellent Google Docs documentation is available, and there are many free guides online to help you get started.
"But if your website is complex, you have an e-commerce store or you need specific custom tracking, such as event tracking, user behaviour tracking or enhanced e-commerce setup, you might want to hire a pro to help make sure everything’s set up properly.” This will help you not to miss anything but also avoid making mistakes during the configuration, which would reduce the quality of your reports.
Ongoing Maintenance Costs
After initial set-up, there will be little maintenance cost, unless you need advanced features or custom reports that require regular updating. However, if your website receives a major overhaul (such as a redesign or migration to a new platform), you might want to revisit the setup to ensure the tracking is properly functioning.
Conclusion: Is Google Analytics Paid or Free?
Simply put, the basic version of Google Analytics is free for most users, and there are no costs involved with the setup process itself. Both free and paid versions offer all the tools to track your website performance and optimize your marketing efforts.
However, the paid version -- Google Analytics 360 -- offers extra features and greater levels of support, making sense for large enterprises with huge websites and specific requirements. While signing up for Google Analytics is free, and initial setup won't cost anything yet, you may need to budget for developer costs or consultation fees if you want advanced setup or custom configurations.
For most businesses, particularly small to medium-sized ones, the free Google Analytics version is adequate and offers incredible value for zero cost.
Would you like assistance with implementing Google Analytics to your website? Contact us what you’re wondering, and we’ll walk you through the process!

#GoogleAnalytics#WebsiteAnalytics#AnalyticsSetup#GoogleAnalyticsForBusiness#DigitalMarketingTools#WebsiteTracking#SEOTracking#ConversionTracking#MarketingTools#WebAnalytics#BusinessGrowth#DataDrivenMarketing#OnlineMarketingTips
1 note
·
View note
Text
How Data Engineering Services Drive Business Growth
Data is the new oil, and businesses must manage, analyze, and process data efficiently to stay competitive. Data engineering services enable organizations to transform raw data into actionable insights.
What Are Data Engineering Services?
The role of data engineers in ETL (Extract, Transform, Load) processes
Importance of data pipelines, cloud storage, and data integration
How businesses use data engineering for AI, ML, and analytics
Key Benefits of Data Engineering Services
Scalability: Handling large datasets efficiently
Data Security & Compliance: Ensuring privacy regulations are met
Real-Time Analytics: Faster decision-making with structured data
Technologies We Use
Big Data Platforms: Apache Hadoop, Spark
Cloud Data Warehouses: AWS Redshift, Google BigQuery
Database Management: PostgreSQL, MongoDB, Snowflake
Conclusion: AcmeMinds provides customized data engineering solutions to help businesses gain actionable insights. Contact us to leverage the power of data for your business success.
📩 Optimize Your Data with Experts! | 🌐 www.acmeminds.com
0 notes
Text
Gemini Code Assist Enterprise: AI App Development Tool

Introducing Gemini Code Assist Enterprise’s AI-powered app development tool that allows for code customisation.
The modern economy is driven by software development. Unfortunately, due to a lack of skilled developers, a growing number of integrations, vendors, and abstraction levels, developing effective apps across the tech stack is difficult.
To expedite application delivery and stay competitive, IT leaders must provide their teams with AI-powered solutions that assist developers in navigating complexity.
Google Cloud thinks that offering an AI-powered application development solution that works across the tech stack, along with enterprise-grade security guarantees, better contextual suggestions, and cloud integrations that let developers work more quickly and versatile with a wider range of services, is the best way to address development challenges.
Google Cloud is presenting Gemini Code Assist Enterprise, the next generation of application development capabilities.
Beyond AI-powered coding aid in the IDE, Gemini Code Assist Enterprise goes. This is application development support at the corporate level. Gemini’s huge token context window supports deep local codebase awareness. You can use a wide context window to consider the details of your local codebase and ongoing development session, allowing you to generate or transform code that is better appropriate for your application.
With code customization, Code Assist Enterprise not only comprehends your local codebase but also provides code recommendations based on internal libraries and best practices within your company. As a result, Code Assist can produce personalized code recommendations that are more precise and pertinent to your company. In addition to finishing difficult activities like updating the Java version across a whole repository, developers can remain in the flow state for longer and provide more insights directly to their IDEs. Because of this, developers can concentrate on coming up with original solutions to problems, which increases job satisfaction and gives them a competitive advantage. You can also come to market more quickly.
GitLab.com and GitHub.com repos can be indexed by Gemini Code Assist Enterprise code customisation; support for self-hosted, on-premise repos and other source control systems will be added in early 2025.
Yet IDEs are not the only tool used to construct apps. It integrates coding support into all of Google Cloud’s services to help specialist coders become more adaptable builders. The time required to transition to new technologies is significantly decreased by a code assistant, which also integrates the subtleties of an organization’s coding standards into its recommendations. Therefore, the faster your builders can create and deliver applications, the more services it impacts. To meet developers where they are, Code Assist Enterprise provides coding assistance in Firebase, Databases, BigQuery, Colab Enterprise, Apigee, and Application Integration. Furthermore, each Gemini Code Assist Enterprise user can access these products’ features; they are not separate purchases.
Gemini Code Support BigQuery enterprise users can benefit from SQL and Python code support. With the creation of pre-validated, ready-to-run queries (data insights) and a natural language-based interface for data exploration, curation, wrangling, analysis, and visualization (data canvas), they can enhance their data journeys beyond editor-based code assistance and speed up their analytics workflows.
Furthermore, Code Assist Enterprise does not use the proprietary data from your firm to train the Gemini model, since security and privacy are of utmost importance to any business. Source code that is kept separate from each customer’s organization and kept for usage in code customization is kept in a Google Cloud-managed project. Clients are in complete control of which source repositories to utilize for customization, and they can delete all data at any moment.
Your company and data are safeguarded by Google Cloud’s dedication to enterprise preparedness, data governance, and security. This is demonstrated by projects like software supply chain security, Mandiant research, and purpose-built infrastructure, as well as by generative AI indemnification.
Google Cloud provides you with the greatest tools for AI coding support so that your engineers may work happily and effectively. The market is also paying attention. Because of its ability to execute and completeness of vision, Google Cloud has been ranked as a Leader in the Gartner Magic Quadrant for AI Code Assistants for 2024.
Gemini Code Assist Enterprise Costs
In general, Gemini Code Assist Enterprise costs $45 per month per user; however, a one-year membership that ends on March 31, 2025, will only cost $19 per month per user.
Read more on Govindhtech.com
#Gemini#GeminiCodeAssist#AIApp#AI#AICodeAssistants#CodeAssistEnterprise#BigQuery#Geminimodel#News#Technews#TechnologyNews#Technologytrends#Govindhtech#technology
2 notes
·
View notes
Text
A diverse landscape unfolds in the realm of major Cloud Data Warehouse vendors—Amazon Redshift, Google BigQuery, Microsoft Synapse, Snowflake, and Databricks. Amazon Redshift offers robust scalability; Google BigQuery excels in real-time analytics; Microsoft Synapse integrates seamlessly with the Microsoft ecosystem; Snowflake boasts elasticity and ease of use, while Databricks specializes in data science and machine learning integration.
0 notes