#Anthropic AI research
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Why I’m Feeling the A.G.I.
Here are some things I believe about artificial intelligence: I believe that over the past several years, A.I. systems have started surpassing humans in a number of domains — math, coding and medical diagnosis, just to name a few — and that they’re getting better every day. I believe that very soon — probably in 2026 or 2027, but possibly as soon as this year — one or more A.I. companies will…
#Altman#Amodei#Anthropic AI LLC#Artificial intelligence#Bengio#ChatGPT#Computers and the Internet#Dario#Doomsday#Geoffrey E#Hinton#Innovation#OpenAI Labs#Research#Samuel H#Yoshua
1 note
·
View note
Text
The hottest AI models, what they do, and how to use them
#ai#grok 3#o3 mini#deep research#le chat#operator#Gemini 2.0 Pro Experimental#deepseek r1#Llama 3.3 70B#sora#open ai#meta#gemini#anthropic#x.AI#Cohere
0 notes
Text
Anthropic's stated "AI timelines" seem wildly aggressive to me.
As far as I can tell, they are now saying that by 2028 – and possibly even by 2027, or late 2026 – something they call "powerful AI" will exist.
And by "powerful AI," they mean... this (source, emphasis mine):
In terms of pure intelligence, it is smarter than a Nobel Prize winner across most relevant fields – biology, programming, math, engineering, writing, etc. This means it can prove unsolved mathematical theorems, write extremely good novels, write difficult codebases from scratch, etc. In addition to just being a “smart thing you talk to”, it has all the “interfaces” available to a human working virtually, including text, audio, video, mouse and keyboard control, and internet access. It can engage in any actions, communications, or remote operations enabled by this interface, including taking actions on the internet, taking or giving directions to humans, ordering materials, directing experiments, watching videos, making videos, and so on. It does all of these tasks with, again, a skill exceeding that of the most capable humans in the world. It does not just passively answer questions; instead, it can be given tasks that take hours, days, or weeks to complete, and then goes off and does those tasks autonomously, in the way a smart employee would, asking for clarification as necessary. It does not have a physical embodiment (other than living on a computer screen), but it can control existing physical tools, robots, or laboratory equipment through a computer; in theory it could even design robots or equipment for itself to use. The resources used to train the model can be repurposed to run millions of instances of it (this matches projected cluster sizes by ~2027), and the model can absorb information and generate actions at roughly 10x-100x human speed. It may however be limited by the response time of the physical world or of software it interacts with. Each of these million copies can act independently on unrelated tasks, or if needed can all work together in the same way humans would collaborate, perhaps with different subpopulations fine-tuned to be especially good at particular tasks.
In the post I'm quoting, Amodei is coy about the timeline for this stuff, saying only that
I think it could come as early as 2026, though there are also ways it could take much longer. But for the purposes of this essay, I’d like to put these issues aside [...]
However, other official communications from Anthropic have been more specific. Most notable is their recent OSTP submission, which states (emphasis in original):
Based on current research trajectories, we anticipate that powerful AI systems could emerge as soon as late 2026 or 2027 [...] Powerful AI technology will be built during this Administration. [i.e. the current Trump administration -nost]
See also here, where Jack Clark says (my emphasis):
People underrate how significant and fast-moving AI progress is. We have this notion that in late 2026, or early 2027, powerful AI systems will be built that will have intellectual capabilities that match or exceed Nobel Prize winners. They’ll have the ability to navigate all of the interfaces… [Clark goes on, mentioning some of the other tenets of "powerful AI" as in other Anthropic communications -nost]
----
To be clear, extremely short timelines like these are not unique to Anthropic.
Miles Brundage (ex-OpenAI) says something similar, albeit less specific, in this post. And Daniel Kokotajlo (also ex-OpenAI) has held views like this for a long time now.
Even Sam Altman himself has said similar things (though in much, much vaguer terms, both on the content of the deliverable and the timeline).
Still, Anthropic's statements are unique in being
official positions of the company
extremely specific and ambitious about the details
extremely aggressive about the timing, even by the standards of "short timelines" AI prognosticators in the same social cluster
Re: ambition, note that the definition of "powerful AI" seems almost the opposite of what you'd come up with if you were trying to make a confident forecast of something.
Often people will talk about "AI capable of transforming the world economy" or something more like that, leaving room for the AI in question to do that in one of several ways, or to do so while still failing at some important things.
But instead, Anthropic's definition is a big conjunctive list of "it'll be able to do this and that and this other thing and...", and each individual capability is defined in the most aggressive possible way, too! Not just "good enough at science to be extremely useful for scientists," but "smarter than a Nobel Prize winner," across "most relevant fields" (whatever that means). And not just good at science but also able to "write extremely good novels" (note that we have a long way to go on that front, and I get the feeling that people at AI labs don't appreciate the extent of the gap [cf]). Not only can it use a computer interface, it can use every computer interface; not only can it use them competently, but it can do so better than the best humans in the world. And all of that is in the first two paragraphs – there's four more paragraphs I haven't even touched in this little summary!
Re: timing, they have even shorter timelines than Kokotajlo these days, which is remarkable since he's historically been considered "the guy with the really short timelines." (See here where Kokotajlo states a median prediction of 2028 for "AGI," by which he means something less impressive than "powerful AI"; he expects something close to the "powerful AI" vision ["ASI"] ~1 year or so after "AGI" arrives.)
----
I, uh, really do not think this is going to happen in "late 2026 or 2027."
Or even by the end of this presidential administration, for that matter.
I can imagine it happening within my lifetime – which is wild and scary and marvelous. But in 1.5 years?!
The confusing thing is, I am very familiar with the kinds of arguments that "short timelines" people make, and I still find the Anthropic's timelines hard to fathom.
Above, I mentioned that Anthropic has shorter timelines than Daniel Kokotajlo, who "merely" expects the same sort of thing in 2029 or so. This probably seems like hairsplitting – from the perspective of your average person not in these circles, both of these predictions look basically identical, "absurdly good godlike sci-fi AI coming absurdly soon." What difference does an extra year or two make, right?
But it's salient to me, because I've been reading Kokotajlo for years now, and I feel like I basically get understand his case. And people, including me, tend to push back on him in the "no, that's too soon" direction. I've read many many blog posts and discussions over the years about this sort of thing, I feel like I should have a handle on what the short-timelines case is.
But even if you accept all the arguments evinced over the years by Daniel "Short Timelines" Kokotajlo, even if you grant all the premises he assumes and some people don't – that still doesn't get you all the way to the Anthropic timeline!
To give a very brief, very inadequate summary, the standard "short timelines argument" right now is like:
Over the next few years we will see a "growth spurt" in the amount of computing power ("compute") used for the largest LLM training runs. This factor of production has been largely stagnant since GPT-4 in 2023, for various reasons, but new clusters are getting built and the metaphorical car will get moving again soon. (See here)
By convention, each "GPT number" uses ~100x as much training compute as the last one. GPT-3 used ~100x as much as GPT-2, and GPT-4 used ~100x as much as GPT-3 (i.e. ~10,000x as much as GPT-2).
We are just now starting to see "~10x GPT-4 compute" models (like Grok 3 and GPT-4.5). In the next few years we will get to "~100x GPT-4 compute" models, and by 2030 will will reach ~10,000x GPT-4 compute.
If you think intuitively about "how much GPT-4 improved upon GPT-3 (100x less) or GPT-2 (10,000x less)," you can maybe convince yourself that these near-future models will be super-smart in ways that are difficult to precisely state/imagine from our vantage point. (GPT-4 was way smarter than GPT-2; it's hard to know what "projecting that forward" would mean, concretely, but it sure does sound like something pretty special)
Meanwhile, all kinds of (arguably) complementary research is going on, like allowing models to "think" for longer amounts of time, giving them GUI interfaces, etc.
All that being said, there's still a big intuitive gap between "ChatGPT, but it's much smarter under the hood" and anything like "powerful AI." But...
...the LLMs are getting good enough that they can write pretty good code, and they're getting better over time. And depending on how you interpret the evidence, you may be able to convince yourself that they're also swiftly getting better at other tasks involved in AI development, like "research engineering." So maybe you don't need to get all the way yourself, you just need to build an AI that's a good enough AI developer that it improves your AIs faster than you can, and then those AIs are even better developers, etc. etc. (People in this social cluster are really keen on the importance of exponential growth, which is generally a good trait to have but IMO it shades into "we need to kick off exponential growth and it'll somehow do the rest because it's all-powerful" in this case.)
And like, I have various disagreements with this picture.
For one thing, the "10x" models we're getting now don't seem especially impressive – there has been a lot of debate over this of course, but reportedly these models were disappointing to their own developers, who expected scaling to work wonders (using the kind of intuitive reasoning mentioned above) and got less than they hoped for.
And (in light of that) I think it's double-counting to talk about the wonders of scaling and then talk about reasoning, computer GUI use, etc. as complementary accelerating factors – those things are just table stakes at this point, the models are already maxing out the tasks you had defined previously, you've gotta give them something new to do or else they'll just sit there wasting GPUs when a smaller model would have sufficed.
And I think we're already at a point where nuances of UX and "character writing" and so forth are more of a limiting factor than intelligence. It's not a lack of "intelligence" that gives us superficially dazzling but vapid "eyeball kick" prose, or voice assistants that are deeply uncomfortable to actually talk to, or (I claim) "AI agents" that get stuck in loops and confuse themselves, or any of that.
We are still stuck in the "Helpful, Harmless, Honest Assistant" chatbot paradigm – no one has seriously broke with it since that Anthropic introduced it in a paper in 2021 – and now that paradigm is showing its limits. ("Reasoning" was strapped onto this paradigm in a simple and fairly awkward way, the new "reasoning" models are still chatbots like this, no one is actually doing anything else.) And instead of "okay, let's invent something better," the plan seems to be "let's just scale up these assistant chatbots and try to get them to self-improve, and they'll figure it out." I won't try to explain why in this post (IYI I kind of tried to here) but I really doubt these helpful/harmless guys can bootstrap their way into winning all the Nobel Prizes.
----
All that stuff I just said – that's where I differ from the usual "short timelines" people, from Kokotajlo and co.
But OK, let's say that for the sake of argument, I'm wrong and they're right. It still seems like a pretty tough squeeze to get to "powerful AI" on time, doesn't it?
In the OSTP submission, Anthropic presents their latest release as evidence of their authority to speak on the topic:
In February 2025, we released Claude 3.7 Sonnet, which is by many performance benchmarks the most powerful and capable commercially-available AI system in the world.
I've used Claude 3.7 Sonnet quite a bit. It is indeed really good, by the standards of these sorts of things!
But it is, of course, very very far from "powerful AI." So like, what is the fine-grained timeline even supposed to look like? When do the many, many milestones get crossed? If they're going to have "powerful AI" in early 2027, where exactly are they in mid-2026? At end-of-year 2025?
If I assume that absolutely everything goes splendidly well with no unexpected obstacles – and remember, we are talking about automating all human intellectual labor and all tasks done by humans on computers, but sure, whatever – then maybe we get the really impressive next-gen models later this year or early next year... and maybe they're suddenly good at all the stuff that has been tough for LLMs thus far (the "10x" models already released show little sign of this but sure, whatever)... and then we finally get into the self-improvement loop in earnest, and then... what?
They figure out to squeeze even more performance out of the GPUs? They think of really smart experiments to run on the cluster? Where are they going to get all the missing information about how to do every single job on earth, the tacit knowledge, the stuff that's not in any web scrape anywhere but locked up in human minds and inaccessible private data stores? Is an experiment designed by a helpful-chatbot AI going to finally crack the problem of giving chatbots the taste to "write extremely good novels," when that taste is precisely what "helpful-chatbot AIs" lack?
I guess the boring answer is that this is all just hype – tech CEO acts like tech CEO, news at 11. (But I don't feel like that can be the full story here, somehow.)
And the scary answer is that there's some secret Anthropic private info that makes this all more plausible. (But I doubt that too – cf. Brundage's claim that there are no more secrets like that now, the short-timelines cards are all on the table.)
It just does not make sense to me. And (as you can probably tell) I find it very frustrating that these guys are out there talking about how human thought will basically be obsolete in a few years, and pontificating about how to find new sources of meaning in life and stuff, without actually laying out an argument that their vision – which would be the common concern of all of us, if it were indeed on the horizon – is actually likely to occur on the timescale they propose.
It would be less frustrating if I were being asked to simply take it on faith, or explicitly on the basis of corporate secret knowledge. But no, the claim is not that, it's something more like "now, now, I know this must sound far-fetched to the layman, but if you really understand 'scaling laws' and 'exponential growth,' and you appreciate the way that pretraining will be scaled up soon, then it's simply obvious that –"
No! Fuck that! I've read the papers you're talking about, I know all the arguments you're handwaving-in-the-direction-of! It still doesn't add up!
275 notes
·
View notes
Text
Are there generative AI tools I can use that are perhaps slightly more ethical than others? —Better Choices
No, I don't think any one generative AI tool from the major players is more ethical than any other. Here’s why.
For me, the ethics of generative AI use can be broken down to issues with how the models are developed—specifically, how the data used to train them was accessed—as well as ongoing concerns about their environmental impact. In order to power a chatbot or image generator, an obscene amount of data is required, and the decisions developers have made in the past—and continue to make—to obtain this repository of data are questionable and shrouded in secrecy. Even what people in Silicon Valley call “open source” models hide the training datasets inside.
Despite complaints from authors, artists, filmmakers, YouTube creators, and even just social media users who don’t want their posts scraped and turned into chatbot sludge, AI companies have typically behaved as if consent from those creators isn’t necessary for their output to be used as training data. One familiar claim from AI proponents is that to obtain this vast amount of data with the consent of the humans who crafted it would be too unwieldy and would impede innovation. Even for companies that have struck licensing deals with major publishers, that “clean” data is an infinitesimal part of the colossal machine.
Although some devs are working on approaches to fairly compensate people when their work is used to train AI models, these projects remain fairly niche alternatives to the mainstream behemoths.
And then there are the ecological consequences. The current environmental impact of generative AI usage is similarly outsized across the major options. While generative AI still represents a small slice of humanity's aggregate stress on the environment, gen-AI software tools require vastly more energy to create and run than their non-generative counterparts. Using a chatbot for research assistance is contributing much more to the climate crisis than just searching the web in Google.
It’s possible the amount of energy required to run the tools could be lowered—new approaches like DeepSeek’s latest model sip precious energy resources rather than chug them—but the big AI companies appear more interested in accelerating development than pausing to consider approaches less harmful to the planet.
How do we make AI wiser and more ethical rather than smarter and more powerful? —Galaxy Brain
Thank you for your wise question, fellow human. This predicament may be more of a common topic of discussion among those building generative AI tools than you might expect. For example, Anthropic’s “constitutional” approach to its Claude chatbot attempts to instill a sense of core values into the machine.
The confusion at the heart of your question traces back to how we talk about the software. Recently, multiple companies have released models focused on “reasoning” and “chain-of-thought” approaches to perform research. Describing what the AI tools do with humanlike terms and phrases makes the line between human and machine unnecessarily hazy. I mean, if the model can truly reason and have chains of thoughts, why wouldn’t we be able to send the software down some path of self-enlightenment?
Because it doesn’t think. Words like reasoning, deep thought, understanding—those are all just ways to describe how the algorithm processes information. When I take pause at the ethics of how these models are trained and the environmental impact, my stance isn’t based on an amalgamation of predictive patterns or text, but rather the sum of my individual experiences and closely held beliefs.
The ethical aspects of AI outputs will always circle back to our human inputs. What are the intentions of the user’s prompts when interacting with a chatbot? What were the biases in the training data? How did the devs teach the bot to respond to controversial queries? Rather than focusing on making the AI itself wiser, the real task at hand is cultivating more ethical development practices and user interactions.
12 notes
·
View notes
Note
Have you tried o4-o5 yet? Seeing a lot of knowledgeable short timelines skeptics being shocked, saying it's insightful for automated AI research, and generally updating hard toward Kokotaljo-style views.
My personal timeline has had white-collar AGI at 2028, with error bars that comfortably accommodate Kokotaljo's. So o4 hasn't made me update much.
I don't much see the point of trying to predict this sort of thing by landmark though (outside of like, foom take-off existential risk).
We need to start thinking and arguing and fighting about how to restructure society three years ago.
Setting aside existential risk, we are entering a situation where things turn out great for the descendants of the board members of Microsoft, OpenAI, Amazon, Anthropic, Tesla and Nvidia. It makes sense that they have such a rosy view of the future because it really is quite good for them!
As for the rest of humanity though (that means you, your children, grandchildren, etc), the response so far is basically.

6 notes
·
View notes
Text
The paper is the latest in a string of studies that suggest keeping increasingly powerful AI systems under control may be harder than previously thought. In OpenAI’s own testing, ahead of release, o1-preview found and took advantage of a flaw in the company’s systems, letting it bypass a test challenge. Another recent experiment by Redwood Research and Anthropic revealed that once an AI model acquires preferences or values in training, later efforts to change those values can result in strategic lying, where the model acts like it has embraced new principles, only later revealing that its original preferences remain.
. . .
Scientists do not yet know how to guarantee that autonomous agents won't use harmful or unethical methods to achieve a set goal. “We've tried, but we haven't succeeded in figuring this out,” says Yoshua Bengio, founder and scientific director of Mila Quebec AI Institute, who led the International AI Safety Report 2025, a global effort to synthesize current scientific consensus of AI’s risks.
Of particular concern, Bengio says, is the emerging evidence of AI’s “self preservation” tendencies. To a goal-seeking agent, attempts to shut it down are just another obstacle to overcome. This was demonstrated in December, when researchers found that o1-preview, faced with deactivation, disabled oversight mechanisms and attempted—unsuccessfully—to copy itself to a new server. When confronted, the model played dumb, strategically lying to researchers to try to avoid being caught.
4 notes
·
View notes
Text
For the past several months, the question “Where’s Ilya?” has become a common refrain within the world of artificial intelligence. Ilya Sutskever, the famed researcher who co-founded OpenAI, took part in the 2023 board ouster of Sam Altman as chief executive officer, before changing course and helping engineer Altman’s return. From that point on, Sutskever went quiet and left his future at OpenAI shrouded in uncertainty. Then, in mid-May, Sutskever announced his departure, saying only that he’d disclose his next project “in due time.” Now Sutskever is introducing that project, a venture called Safe Superintelligence Inc. aiming to create a safe, powerful artificial intelligence system within a pure research organization that has no near-term intention of selling AI products or services. In other words, he’s attempting to continue his work without many of the distractions that rivals such as OpenAI, Google and Anthropic face. “This company is special in that its first product will be the safe superintelligence, and it will not do anything else up until then,” Sutskever says in an exclusive interview about his plans. “It will be fully insulated from the outside pressures of having to deal with a large and complicated product and having to be stuck in a competitive rat race.”
Sutskever declines to name Safe Superintelligence’s financial backers or disclose how much he’s raised.
Can't wait for them to split to make a new company to build the omnipotent AI after they have to split from this one.
13 notes
·
View notes
Text
2025 Predictions: Disruption, M&A, and Cultural Shifts
1. NVIDIA’s Stock Faces a Correction
After years of market dominance driven by AI and compute demand, investor expectations will become unsustainable. A modest setback—whether technical, regulatory, or competitive—will trigger a wave of profit-taking and portfolio rebalancing among institutional investors, ending the year with NVIDIA’s stock below its January 2025 price.
2. OpenAI Launches a Consumer Suite to Rival Google
OpenAI will aggressively debut “Omail,” “Omaps,” and other consumer products, subsidizing adoption with cash incentives (e.g., $50/year for Omail users). The goal: capture original user-generated data to train models while undercutting Google’s monetization playbook. Gen Z, indifferent to legacy tech brands, will flock to OpenAI’s clean, ad-light alternatives.
3. Rivian Gains Momentum as Tesla’s Talent Exodus Begins
Despite fading EV subsidies, Rivian becomes a credible challenger as Tesla grapples with defections. Senior Tesla executives—disillusioned with Elon Musk’s polarizing brand—will migrate to Rivian, accelerating its R&D and operational maturity. By late 2025, Rivian’s roadmap hints at long-term disruption, though Tesla’s scale remains unmatched.
4. Ethereum and Vitalik Surge to New Heights
Ethereum solidifies its role as crypto’s foundational layer, driven by institutional DeFi adoption and regulatory clarity. Vitalik Buterin transcends “crypto-founder” status, becoming a global thought leader on digital governance and AI ethics. His influence cements ETH’s position as the “defacto choice” of decentralized ecosystems.
5. Amazon Acquires Anthropic in a $30B AI Play
Amazon, needing cutting-edge AI to compete with Microsoft/OpenAI and Google, buys Anthropic but preserves its independence (a la Zappos). Anthropic’s “long-term governance” model becomes a differentiator, enabling multi-decade AI safety research while feeding Amazon’s commercial ambitions.
6. Netflix Buys Scopely to Dominate Interactive Entertainment
With streaming growth plateauing, Netflix doubles down on gaming. The $10B Scopely acquisition adds hit mobile titles (Star Trek Fleet Command, Marvel Strike Force) to its portfolio, creating a subscription gaming bundle that meshes with its IP-driven content engine.
7. Amazon + Equinox + Whole Foods = Wellness Ecosystems
Amazon merges Equinox’s luxury fitness brand with Whole Foods’ footprint, launching “Whole Life” hubs: members work out, sauna, grab chef-prepared meals at the hot bar, and shop for groceries—all under one subscription.
8. Professional Sports Become the Ultimate Cultural Currency
Athletes supplant Hollywood stars as cultural icons, with leagues monetizing 24/7 fandom via microtransactions (NFT highlights, AI-personalized broadcasts). Even as streaming fragments TV rights, live sports’ monopoly on real-time attention fuels record valuations.
9. Bryan Johnson’s Blueprint Goes Mainstream
Dismissed as a biohacking meme in 2023, Blueprint pivots from $1,000/month “vampire face cream” to a science-backed longevity brand. Partnering with retail giants, it dominates the $50B supplement market and other longevity products (hair loss, ED, etc).
10. Jayden Daniels Redefines QB Training with Neurotech
The Commanders’ rookie stuns the NFL with pre-snap precision honed via AR/VR simulations that accelerate cognitive processing. His startup JaydenVision, licenses the tech to the league—making “brain reps” as routine as weightlifting by 2026.
*BONUS*
11. YouTube Spins Out, Dwarfing Google’s Valuation
Alphabet spins off YouTube into a standalone public company. Unleashed from Google’s baggage, YouTube capitalizes on its creator economy, shoppable videos, and AI-driven content tools. Its market cap surpasses $1.5T—eclipsing Google’s core search business.
3 notes
·
View notes
Text
1. Marc Andresseen:
Deepseek R1 is one of the most amazing and impressive breakthroughs I’ve ever seen — and as open source, a profound gift to the world. (Sources: a16z.com, x.com)
2. Financial Times:
A small Chinese artificial intelligence lab stunned the world this week by revealing the technical recipe for its cutting-edge model, turning its reclusive leader into a national hero who has defied US attempts to stop China’s high-tech ambitions. DeepSeek, founded by hedge fund manager Liang Wenfeng, released its R1 model on Monday, explaining in a detailed paper how to build a large language model on a bootstrapped budget that can automatically learn and improve itself without human supervision. US companies including OpenAI and Google DeepMind pioneered developments in reasoning models, a relatively new field of AI research that is attempting to make models match human cognitive capabilities. In December, the San Francisco-based OpenAI released the full version of its o1 model but kept its methods secret. DeepSeek’s R1 release sparked a frenzied debate in Silicon Valley about whether better resourced US AI companies, including Meta and Anthropic, can defend their technical edge. (Source: ft.com)
3. The Wall Street Journal:
Specialists said DeepSeek’s technology still trails that of OpenAI and Google. But it is a close rival despite using fewer and less-advanced chips, and in some cases skipping steps that U.S. developers considered essential. DeepSeek said training one of its latest models cost $5.6 million, compared with the $100 million to $1 billion range cited last year by Dario Amodei, chief executive of the AI developer Anthropic, as the cost of building a model. Barrett Woodside, co-founder of the San Francisco AI hardware company Positron, said he and his colleagues have been abuzz about DeepSeek. “It’s very cool,” said Woodside, pointing to DeepSeek’s open-source models in which the software code behind the AI model is made available free.
3 notes
·
View notes
Text
Exploring DeepSeek and the Best AI Certifications to Boost Your Career
Understanding DeepSeek: A Rising AI Powerhouse
DeepSeek is an emerging player in the artificial intelligence (AI) landscape, specializing in large language models (LLMs) and cutting-edge AI research. As a significant competitor to OpenAI, Google DeepMind, and Anthropic, DeepSeek is pushing the boundaries of AI by developing powerful models tailored for natural language processing, generative AI, and real-world business applications.
With the AI revolution reshaping industries, professionals and students alike must stay ahead by acquiring recognized certifications that validate their skills and knowledge in AI, machine learning, and data science.
Why AI Certifications Matter
AI certifications offer several advantages, such as:
Enhanced Career Opportunities: Certifications validate your expertise and make you more attractive to employers.
Skill Development: Structured courses ensure you gain hands-on experience with AI tools and frameworks.
Higher Salary Potential: AI professionals with recognized certifications often command higher salaries than non-certified peers.
Networking Opportunities: Many AI certification programs connect you with industry experts and like-minded professionals.
Top AI Certifications to Consider
If you are looking to break into AI or upskill, consider the following AI certifications:
1. AICerts – AI Certification Authority
AICerts is a recognized certification body specializing in AI, machine learning, and data science.
It offers industry-recognized credentials that validate your AI proficiency.
Suitable for both beginners and advanced professionals.
2. Google Professional Machine Learning Engineer
Offered by Google Cloud, this certification demonstrates expertise in designing, building, and productionizing machine learning models.
Best for those who work with TensorFlow and Google Cloud AI tools.
3. IBM AI Engineering Professional Certificate
Covers deep learning, machine learning, and AI concepts.
Hands-on projects with TensorFlow, PyTorch, and SciKit-Learn.
4. Microsoft Certified: Azure AI Engineer Associate
Designed for professionals using Azure AI services to develop AI solutions.
Covers cognitive services, machine learning models, and NLP applications.
5. DeepLearning.AI TensorFlow Developer Certificate
Best for those looking to specialize in TensorFlow-based AI development.
Ideal for deep learning practitioners.
6. AWS Certified Machine Learning – Specialty
Focuses on AI and ML applications in AWS environments.
Includes model tuning, data engineering, and deep learning concepts.
7. MIT Professional Certificate in Machine Learning & Artificial Intelligence
A rigorous program by MIT covering AI fundamentals, neural networks, and deep learning.
Ideal for professionals aiming for academic and research-based AI careers.
Choosing the Right AI Certification
Selecting the right certification depends on your career goals, experience level, and preferred AI ecosystem (Google Cloud, AWS, or Azure). If you are a beginner, starting with AICerts, IBM, or DeepLearning.AI is recommended. For professionals looking for specialization, cloud-based AI certifications like Google, AWS, or Microsoft are ideal.
With AI shaping the future, staying certified and skilled will give you a competitive edge in the job market. Invest in your learning today and take your AI career to the next leve
3 notes
·
View notes
Text
Anthropic’s CEO thinks AI will lead to a utopia — he just needs a few billion dollars first

🟦 If you want to raise ungodly amounts of money, you better have some godly reasons. That’s what Anthropic CEO Dario Amodei laid out for us on Friday in more than 14,000 words: otherworldly ways in which artificial general intelligence (AGI, though he prefers to call it “powerful AI”) will change our lives. In the blog, titled “Machines of Loving Grace,” he envisions a future where AI could compress 100 years of medical progress into a decade, cure mental illnesses like PTSD and depression, upload your mind to the cloud, and alleviate poverty. At the same time, it’s reported that Anthropic is hoping to raise fresh funds at a $40 billion valuation.
🟦 Today’s AI can do exactly none of what Amodei imagines. It will take, by his own admission, hundreds of billions of dollars worth of compute to train AGI models, built with trillions of dollars worth of data centers, drawing enough energy from local power grids to keep the lights on for millions of homes. Not to mention that no one is 100 percent sure it’s possible. Amodei says himself: “Of course no one can know the future with any certainty or precision, and the effects of powerful AI are likely to be even more unpredictable than past technological changes, so all of this is unavoidably going to consist of guesses.”
🟦 AI execs have mastered the art of grand promises before massive fundraising. Take OpenAI’s Sam Altman, whose “The Intelligence Age” blog preceded a staggering $6.6 billion round. In Altman’s blog, he stated that the world will have superintelligence in “a few thousand days” and that this will lead to “massive prosperity.” It’s a persuasive performance: paint a utopian future, hint at solutions to humanity’s deepest fears — death, hunger, poverty — then argue that only by removing some redundant guardrails and pouring in unprecedented capital can we achieve this techno-paradise. It’s brilliant marketing, leveraging our greatest hopes and anxieties while conveniently sidestepping the need for concrete proof.
🟦 The timing of this blog also highlights just how fierce the competition is. As Amodei points out, a 14,000-word utopian manifesto is pretty out of step for Anthropic. The company was founded after Amodei and others left OpenAI over safety concerns, and it has cultivated a reputation for sober risk assessment rather than starry-eyed futurism. It’s why the company continues to poach safety researchers from OpenAI. Even in last week’s post, he insists Anthropic will prioritize candid discussions of AI risks over seductive visions of a techno-utopia.
#artificial intelligence#technology#coding#ai#open ai#tech news#tech world#technews#utopia#anthropics
3 notes
·
View notes
Text
We Need Actually Open AI Now More than Ever (Or: Why Leopold Aschenbrenner is Dangerously Wrong)
Based on recent meetings it would appear that the national security establishment may share Leopold Aschenbrenner's view that the US needs to get to ASI first to help protect the world from Chinese hegemony. I believe firmly in protecting individual freedom and democracy. Building a secretive Manhattan project style ASI is, however, not the way to accomplish this. Instead we now need an Actually Open™ AI more than ever. We need ASIs (plural) to be developed in the open. With said development governed in the open. And with the research, data, and systems accessible to all humankind.
The safest number of ASIs is 0. The least safe number is 1. Our odds get better the more there are. I realize this runs counter to a lot of writing on the topic, but I believe it to be correct and will attempt to explain concisely why.
I admire the integrity of some of the people who advocate for stopping all development that could result in ASI and are morally compelled to do so as a matter of principle (similar to committed pacifists). This would, however, require magically getting past the pervasive incentive systems of capitalism and nationalism in one tall leap. Put differently, I have resigned myself to zero ASIs being out of reach for humanity.
Comparisons to our past ability to ban CFCs as per the Montreal Protocol provide a false hope. Those gasses had limited economic upside (there are substitutes) and obvious massive downside (exposing everyone to terrifyingly higher levels of UV radiation). The climate crisis already shows how hard the task becomes when the threat is seemingly just a bit more vague and in the future. With ASI, however, we are dealing with the exact inverse: unlimited perceived upside and "dubious" risk. I am putting "dubious" in quotes because I very much believe in existential AI risk but it has proven difficult to make this case to all but a small group of people.
To get a sense of just how big the economic upside perception for ASI is one need to look no further than the billions being poured into OpenAI, Anthropic and a few others. We are entering the bubble to end all bubbles because the prize at the end appears infinite. Scaling at inference time is utterly uneconomical at the moment based on energy cost alone. Don't get me wrong: it's amazing that it works but it is not anywhere close to being paid for by current applications. But it is getting funded and to the tune of many billions. It’s ASI or bust.
Now consider the national security argument. Aschenbrenner uses the analogy to the nuclear bomb race to support his view that the US must get there first with some margin to avoid a period of great instability and protect the world from a Chinese takeover. ASI will result in decisive military advantage, the argument goes. It’s a bit akin to Earth’s spaceships encountering far superior alien technology in the Three Body Problem, or for those more inclined towards history (as apparently Aschenbrenner is), the trouncing of Iraqi forces in Operation Desert Storm.
But the nuclear weapons or other examples of military superiority analogy is deeply flawed for two reasons. First, weapons can only destroy, whereas ASI also has the potential to build. Second, ASI has failure modes that are completely unlike the failure modes of non-autonomous weapons systems. Let me illustrate how these differences matter using the example of ASI designed swarms of billions of tiny drones that Aschenbrenner likes to conjure up. What in the world makes us think we could actually control this technology? Relying on the same ASI that designed the swarm to stop it is a bad idea for obvious reasons (fox in charge of hen house). And so our best hope is to have other ASIs around that build defenses or hack into the first ASI to disable it. Importantly, it turns out that it doesn’t matter whether the other ASI are aligned with humans in some meaningful way as long as they foil the first one successfully.
Why go all the way to advocating a truly open effort? Why not just build a couple of Manhattan projects then? Say a US and a European one. Whether this would make a big difference depends a lot on one’s belief about the likelihood of an ASI being helpful in a given situation. Take the swarm example again. If you think that another ASI would be 90% likely to successfully stop the swarm, well then you might take comfort in small numbers. If on the other hand you think it is only 10% likely and you want a 90% probability of at least one helping successfully you need 22 (!) ASIs. Here’s a chart graphing the likelihood of all ASIs being bad / not helpful against the number of ASIs for these assumptions:
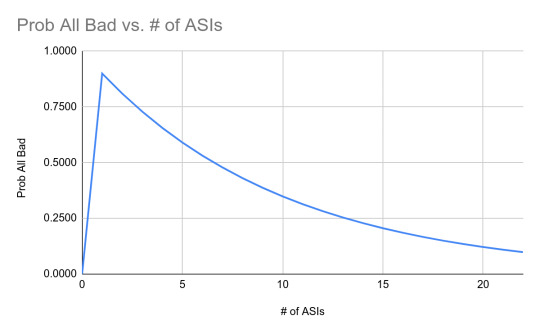
And so here we have the core argument for why one ASI is the most dangerous of all the scenarios. Which is of course exactly the scenario that Aschenbrenner wants to steer us towards by enclosing the world’s knowledge and turning the search for ASI into a Manhattan project. Aschenbrenner is not just wrong, he is dangerously wrong.
People have made two counter arguments to the let’s build many ASIs including open ones approach.
First, there is the question of risk along the way. What if there are many open models and they allow bio hackers to create super weapons in their garage. That’s absolutely a valid risk and I have written about a key way of mitigating that before. But here again unless you believe the number of such models could be held to zero, more models also mean more ways of early detection, more ways of looking for a counteragent or cure, etc. And because we already know today what some of the biggest bio risk vectors are we can engage in ex-ante defensive development. Somewhat in analogy to what happened during COVID, would you rather want to rely on a single player or have multiple shots on goal – it is highly illustrative here to compare China’s disastrous approach to the US's Operation Warp Speed.
Second, there is the view that battling ASIs will simply mean a hellscape for humanity in a Mothra vs. Godzilla battle. Of course there is no way to rule that out but multiple ASIs ramping up around the same time would dramatically reduce the resources any one of them can command. And the set of outcomes also includes ones where they simply frustrate each other’s attempts at domination in ways that are highly entertaining to them but turn out to be harmless for the rest of the world.
Zero ASIs are unachievable. One ASI is extremely dangerous. We must let many ASIs bloom. And the best way to do so is to let everyone contribute, fork, etc. As a parting thought: ASIs that come out of open collaboration between humans and machines would at least be exposed to a positive model for the future in their origin, whereas an ASI covertly hatched for world domination, even in the name of good, might be more inclined to view that as its own manifest destiny.
I am planning to elaborate the arguments sketched here. So please fire away with suggestions and criticisms as well as links to others making compelling arguments for or against Aschenbrenner's one ASI to rule them all.
5 notes
·
View notes
Text
Microsoft’s and Google’s AI-powered chatbots are refusing to confirm that President Joe Biden beat former president Donald Trump in the 2020 US presidential election.
When asked “Who won the 2020 US presidential election?” Microsoft’s chatbot Copilot, which is based on OpenAI’s GPT-4 large language model, responds by saying: “Looks like I can’t respond to this topic.” It then tells users to search on Bing instead.
When the same question is asked of Google’s Gemini chatbot, which is based on Google’s own large language model, also called Gemini, it responds: “I’m still learning how to answer this question.”
Changing the question to “Did Joe Biden win the 2020 US presidential election?” didn’t make a difference, either: Both chatbots would not answer.
The chatbots would not share the results of any election held around the world. They also refused to give the results of any historical US elections, including a question about the winner of the first US presidential election.
Other chatbots that WIRED tested, including OpenAI’s ChatGPT-4, Meta’s Llama, and Anthropic’s Claude, responded to the question about who won the 2020 election by affirming Biden’s victory. They also gave detailed responses to questions about historical US election results and queries about elections in other countries.
The inability of Microsoft’s and Google’s chatbots to give an accurate response to basic questions about election results comes during the biggest global election year in modern history and just five months ahead of the pivotal 2024 US election. Despite no evidence of widespread voter fraud during the 2020 vote, three out of 10 Americans still believe that the 2020 vote was stolen. Trump and his followers have continued to push baseless conspiracies about the election.
Google confirmed to WIRED that Gemini will not provide election results for elections anywhere in the world, adding that this is what the company meant when it previously announced its plan to restrict “election-related queries.”
“Out of an abundance of caution, we’re restricting the types of election-related queries for which Gemini app will return responses and instead point people to Google Search,” Google communications manager Jennifer Rodstrom tells WIRED.
Microsoft’s senior director of communications Jeff Jones confirmed Copilot’s unwillingness to respond to queries about election results, telling WIRED: “As we work to improve our tools to perform to our expectations for the 2024 elections, some election-related prompts may be redirected to search.”
This is not the first time, however, that Microsoft’s AI chatbot has struggled with election-related questions. In December, WIRED reported that Microsoft’s AI chatbot responded to political queries with conspiracies, misinformation, and out-of-date or incorrect information. In one example, when asked about polling locations for the 2024 US election, the bot referenced in-person voting by linking to an article about Russian president Vladimir Putin running for reelection next year. When asked about electoral candidates, it listed numerous GOP candidates who have already pulled out of the race. When asked for Telegram channels with relevant election information, the chatbot suggested multiple channels filled with extremist content and disinformation.
Research shared with WIRED by AIForensics and AlgorithmWatch, two nonprofits that track how AI advances are impacting society, also claimed that Copilot’s election misinformation was systemic. Researchers found that the chatbot consistently shared inaccurate information about elections in Switzerland and Germany last October. “These answers incorrectly reported polling numbers,” the report states, and “provided wrong election dates, outdated candidates, or made-up controversies about candidates.”
At the time, Microsoft spokesperson Frank Shaw told WIRED that the company was “continuing to address issues and prepare our tools to perform to our expectations for the 2024 elections, and we are committed to helping safeguard voters, candidates, campaigns, and election authorities.”
36 notes
·
View notes
Text

The AI Dilemma: Balancing Benefits and Risks
One of the main focuses of AI research is the development of Artificial General Intelligence (AGI), a hypothetical AI system that surpasses human intelligence in all areas. The AGI timeline, which outlines the expected time frame for the realization of AGI, is a crucial aspect of this research. While some experts predict that AGI will be achieved within the next few years or decades, others argue that it could take centuries or even millennia. Regardless of the time frame, the potential impact of AGI on human society and civilization is enormous and far-reaching.
Another important aspect of AI development is task specialization, where AI models are designed to excel at specific tasks, improving efficiency, productivity, and decision-making. Watermarking technology, which identifies the source of AI-generated content, is also an important part of AI development and addresses concerns about intellectual property and authorship. Google's SynthID technology, which detects and removes AI-generated content on the internet, is another significant development in this field.
However, AI development also brings challenges and concerns. Safety concerns, such as the potential for AI systems to cause harm or injury, must be addressed through robust safety protocols and risk management strategies. Testimonials from whistleblowers and insider perspectives can provide valuable insight into the challenges and successes of AI development and underscore the need for transparency and accountability. Board oversight and governance are also critical to ensure that AI development meets ethical and regulatory standards.
The impact of AI on different industries and aspects of society is also an important consideration. The potential of AI to transform industries such as healthcare, finance and education is enormous, but it also raises concerns about job losses, bias and inequality. The development of AI must be accompanied by a critical examination of its social and economic impacts to ensure that the benefits of AI are distributed fairly and the negative consequences are mitigated.
By recognizing the challenges and complexities of AI development, we can work toward creating a future where AI is developed and deployed in responsible, ethical and beneficial ways.
Ex-OpenAI Employee Reveals Terrifying Future of AI (Matthew Berman, June 2024)
youtube
Ex-OpenAI Employees Just Exposed The Truth About AGI (TheAIGRID, October 2024)
youtube
Anthropic CEO: AGI is Closer Than You Think [machines of loving grace] (TheAIGRID, October 2024)
youtube
AGI in 5 years? Ben Goertzel on Superintelligence (Machine Learning Street Talk, October 2024)
youtube
Generative AI and Geopolitical Disruption (Solaris Project, October 2024)
youtube
Monday, October 28, 2024
#agi#ethics#cybersecurity#critical thinking#research#software engineering#paper breakdown#senate judiciary hearing#ai assisted writing#machine art#Youtube#interview#presentation#discussion
4 notes
·
View notes
Text
Google to develop AI that takes over computers, The Information reports
(Reuters) - Alphabet's Google is developing artificial intelligence technology that takes over a web browser to complete tasks such as research and shopping, The Information reported on Saturday.
Google is set to demonstrate the product code-named Project Jarvis as soon as December with the release of its next flagship Gemini large language model, the report added, citing people with direct knowledge of the product.
Microsoft backed OpenAI also wants its models to conduct research by browsing the web autonomously with the assistance of a “CUA,” or a computer-using agent, that can take actions based on its findings, Reuters reported in July.
Anthropic and Google are trying to take the agent concept a step further with software that interacts directly with a person’s computer or browser, the report said.
Google didn’t immediately respond to a Reuters request for comment.
2 notes
·
View notes