
SavageGardens is an attempt to develop a truly next generation programming language.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by savagegardensprogramming and here's what we found interesting.
Average Info
Notes Per Post
6
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
4
Time Between Posts
1 day
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
App Building and Portability
I was raised around the C language and regarding portability I was told C is fairly portable. Write your code in C and it will compile on several platforms. Hence, I made the decision to rest SavageGardens on top of C.

On the figure above, I stated I would be using GNU-C because it has some extensions not found in ANSI C. The decision isn't necessarily bad. GNU-C would open me to several platforms but not WASM. I have to change my decision to use ANSI C in order to be able to target web-assembly.
🤔 Now lets consider what the other guys have done.
In early 2000s, to achieve platform independence engineers started to develop byte code languages. There is JAVA bytecode. There is Microsoft MSIL and there is WASM. If I target ANSI C I am still in the game with WASM.
🤔 If portability is achieved then what is the deal with Gradle and Maven?
Well it turns out that those technologies are not part of the ladder of abstraction in the figure above. They are to manage dev-ops and politics. Say I only care about Linux. Well, there are multiple distros that have different packaging requirements. For very large projects there are multiple builds for beta testing. And then there is the politics. Google decided to enforce some specs to protect our privacy and security. Personally, I think its more of an excuse for them to force us into getting new phones. Never-the-less politics. There are reasons for making different versions of the same program on the same platform.
Anyways I have decided not to worry about deployment technologies for the following reasons:
1 - Its not part of the ladder of abstraction
2- It can be dealt with separately. I don't see a reason for tight integration.
🤔 I do have to integrate a pre-processor and pragma directives which I haven't taken into consideration. Pragma directives do make the code very ugly which affects code-comprehension. They do deserve some attention.
0 notes
Text
Smart Documentation
I’ve made the decision to tightly integrate documentation into SavageGardens. I hesitated to talk about this aspect of SavageGardens because programmers don’t think of documentation as a language. Still, the goal for SavageGardens is to extend our ability to manage massively complex projects. Documentation is important for large projects, therefore I am including it.

It is a somewhat controversial decision to include documentation as part of the source code. It makes SavageGardens a rather complex application in itself. I am actually asking to integrate a wiki data and discussion forum data inside the source code. It changes the face of SavageGardens but, so be it. I see it as the future. A future which I first saw in StarTrek the Next Generation. That TV Show has several scenes where Geordi La Forge documents his work and accesses documentation. That is the goal. That is the dream.

In SavageGardens, Sub-Layer 0 or the ground level is designated for this purpose. Everything on this layer is strictly for human consumption. Human-to-Human communication. None of its constructs will translate to actual code that the machine will see. Never the less documentation will be tightly integrated into the source code, because part of my design goals is to facilitate in code comprehension and code navigation.
How is documentation related to code comprehension is pretty straight forward. Most of use make use of tutorials before we start using a new library or platform. Why not allow the designer of those libraries to include a tutorial as part of his source code. Let the senior developer include a couple of diagrams as to how the data structures or APIs are structured.
Using documentation for code navigation is new and revolutionary. Most of us navigate code by opening a file manager, going thru the directories, opening and closing source files trying to find a lead or a clue that will help us. Some of us are bit more clever and use grep to do the searching. I find that approach archaic. The future I want to live in is one where you open the source code and you find diagrams that visually outline how the source code is organized. Then you click on parts of these diagrams to navigate different aspects of the source code until you find what you want. Hollywood style.
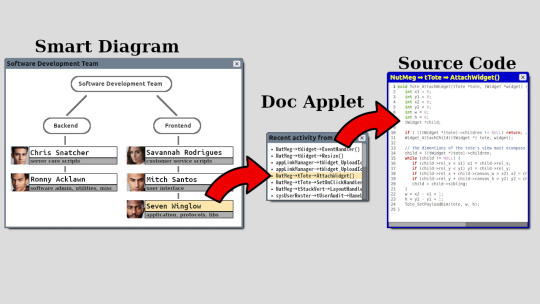
In the diagram above, its a case use for a team manager. Lets say you are a team manager and you want to audit someone's work. You pull up the smart-diagram of your team. You click on the person you want to audit. It runs a script that pulls up everything he worked on recently. Then you click on what you want to audit. That is code navigation like few of us have seen before.
The following are a set of constructs I am considering. I am borrowing some ideas from the web. I am not importing technologies from the web thou. I see it done all around me and I don’t like it. Apps these days are pretty much integrated web-browsers.
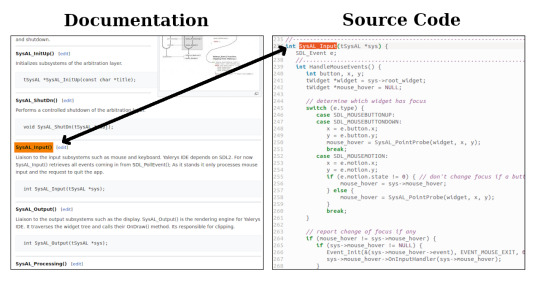
1) Hyper text: The idea to click on text and it brings up source code. Or vice versa. Clicking on a function call and it brings up related documentation. Rather then HTML, I will probably adopt a simpler format like markdown.
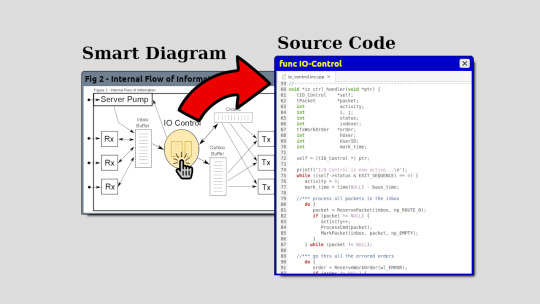
2) Smart Diagrams: This idea is the same as image maps in HTML. You have a picture or diagram and certain areas are clickable. This is how you would navigate source code.
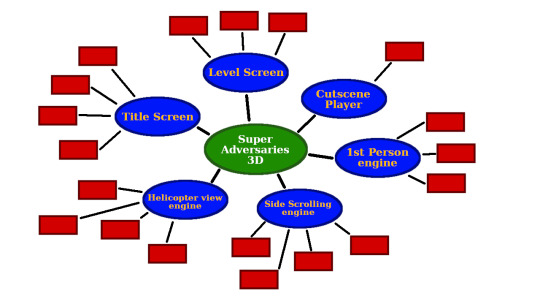
3) Mind-Maps: This is to allow developers to brain storm and keep track of themselves and they proceed with their project. Also used to navigate code.
4) Document side scripting: serves a purpose similar to PHP, it allows for dynamic documentation. Documentation that updates itself as changes are made.
NOTE: constructs from lower layers will cooperate in creating self updating documentation. For example every time you create a variable or function, an entry is made in an internal database that keeps track of them. Depending on the changes certain documents will be automatically created and updated. Quick examples of this is a table of contents, an index table and a quick reference guide.
0 notes
Text
Note on building applications
Soo I am getting back into Android, its been a long, long, long time. While trying to get re-acquainted with F-Droid app submitting procedures some dude told me to start using Gradle. The old process of building Android apps is deprecated.
I started to get acquainted with Gradle. So I learn, its a programing language itself. And get this. It considers a project as a construct.
The point. Here I am claiming things like executables and even documentation should be thought of as constructs. All this time, I am thinking I am alone in this. Well, not really. Gradle did something similar.
The difference is that they came up with this via a necessity point of view. I come from a theoretical point of view.
🤔 I didn't consider the build process, I guess I should.
The main take away: When you think of things as constructs, you can then make use of them in programming languages AND you might be able to represent them graphically. The reason I needed to think of executables as constructs was to be able to represent them in GUI form. I needed to think of documentation as constructs to be able to tightly integrate it to source code. I should also look into the build process and integrate that into SavageGardens. Gradle sees projects as constructs to be able to use programming languages to manage the build process.
🤔 Representing code in GUI form. <- that's furture right there.
0 notes
Text

Executive Widgets
On SavageGardens, Executive Widgets are sub-level 1 constructs. This is the highest possible level that translates into code. This level represents executive level decisions.
The idea is to think about GUI objects as code constructs. The other way around is to represent code as GUI objects.
Lets look at the picture and consider the saying: "give something a name and you gain power over it". Here instead of a name, we assign an icon to it. You see the little icon of the space shuttle launch. That icon represents an executable file. From a architect's point of view. We have encapsulated a whole program into a small image. This image represents thousands if not millions of lines of code. Now we can make executive decisions over it. We can delete it, copy it, move it somewhere else and we can run the program.
Lets say this executable is empty. In the C language is the same as saying its an empty main() function. We are associating an icon to actual code. Those of you who understand the C language you understand that essentially C source code is a bunch of dot C files and dot H files. Hence that is what this little icon represents.
In SavageGardens we want aspects of the source code represented graphically. After all we are at the executive level. Hence we can open this executable as a GUI window and inside this window we see all the components of the executable in GUI form. These GUI is directly tied to code. By making changes at this level you would be changing code.
We can do things like add and remove global variables. Import libraries. Define or modify major memory structures. Modules exist at this level. We could play around with modules here. This level is the architect's chair. The goal for this level is to navigate and modify code at the highest level possible.

0 notes
Text
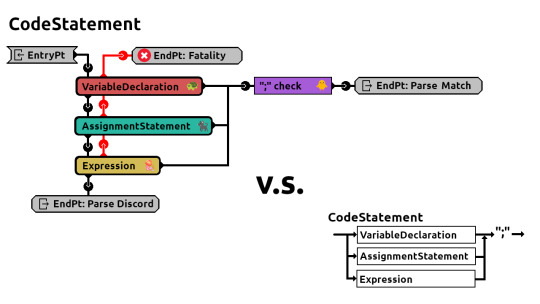
CB-Cells vs Modules
CB-Cells and Modules look similar visually but they are different.
This is a compare and contrast.
Within SavageGardens you will not see them side by side. Modules are a sub-level 1 construct where as CB-Cells are a sub-level 2 construct.
Modules are designed to be reusable and interchangeable. Modules are considered loosely coupled. Where as CB-Cells are not. On the contrary CB-Cells are thought to be unique and inter-dependent. CB-Cells are considered tightly coupled.
Both CB-Cells and Modules have end-points but they work differently. They would not be compatible with each other. CB-Cells represent flow of logic. Work flow comes in from one end-point and comes out thru another. The end-points within Modules work in request respond form. Like a function call. The work flow echoes back to the caller.
The mesh of CB-Cells working together represent an algorithm. Not quite so with Modules. Modules are inter-linked to work in an event driven fashion.
Both CB-Cells and Modules encapsulate code but they do abstraction differently. A module represents a series of related services. A CB-Cell represents a single consolidated objective.
CB-Maps can be nested. CB-Maps inside CB-Maps inside CB-Maps and so on. This is possible because a CB-Cell can represent a CB-Map. A mesh of CB-Cells represent an algorithm and the nesting represents breaking down a task into smaller tasks. Modules do not work this way and hence are not nested in this fashion.
🤔 as a note: The idea of having nested modules is intriguing and possible. Never seen it done. It does deserve to be looked into. Its something that may happen in the future when systems become highly complex. Not something that is practical right now.
0 notes
Text
Looking for a tech-writer that will help me put all these articles together into a book.
0 notes
Text
youtube
I expect great things from CB-Maps. I believe it is the one. The one to break us away from the 1st dimension and guide us into the 2nd dimension.

1 note
·
View note
Text
youtube
CodeBlock Maps in relation how the brain works.
CB-Maps was conceived because I went out and tried to bring in concepts from fields related in organizing information. Code constructs basically organize code. And code is basically information. Anyways, two techniques I found interesting: MindMaps and Memory Palaces. My Objective was to try to make graphical code constructs out of them. What I came up with was CB-Maps.
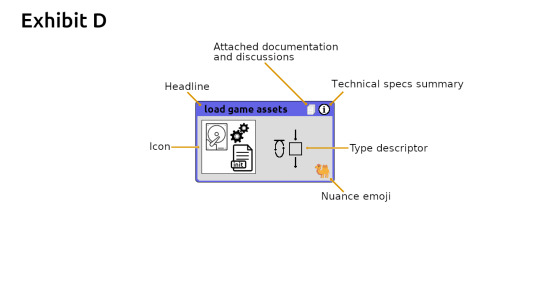
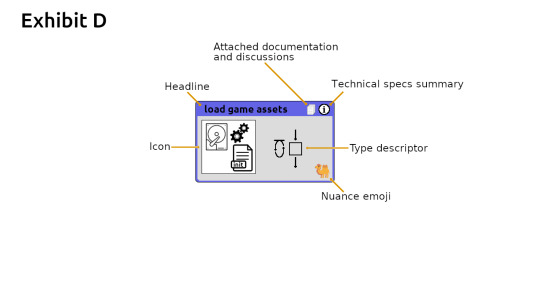
The MindMap guys emphasized to color code and draw objects that helped you remember a specific topic. A technique used by memory champions. They attach some sort of story or object to the item they want to remember. Hence I find it necessary for CB-Cells to have an icon. Having a headline is obvious because of how important identifiers and comments are in traditional text based programming languages. I also added a couple support secondary icons such as the type descriptor and nuance emoji. Those are automatically handled by the IDE.
The memory palace guys say that its easy to remember one thing associated with another. In their minds they place objects in relation to one another. In their head they make a sort of museum of objects. Each object representing a concept or memory. This technique is backed up by the science on the video above. The video states what our brain has memory cells dedicated for storing information in relation to space. Its how we find our way around a city or building.
In a sense we have brain machinery dedicated for storing and navigating a map. What this comes down to is, that there is brain machinery for storing and navigating CB-Maps. Machinery that is not available to us with traditional text based source code.
The bottom line. CB-Maps enhance code comprehension and code navigation.
As far as communications. Let me state that good communication is achieved by bridging the gap between us and machines. Human to machine communication is a translation process from the way we do things to the way machines do things. CB-Maps is a high level construct that takes advantages of our brain machinery (the way we do things) and brings it a step closer to the machine.
0 notes
Text
I do love CB-Maps, I conceived it several years back but I never took it seriously until about a year ago next month. Fell in love with it because it has science behind it. Good strong science.
0 notes
Text

CodeBlock Maps - Introduction
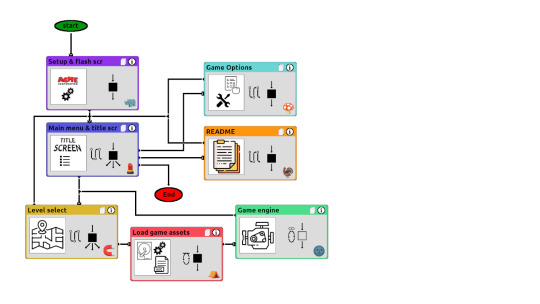
Take a look at Exhibit A – Its what I call a Code Block-Map. This is my crown jewel. A graphical code construct suitable for management level programming. Sub-Level 2 of SavageGardens.
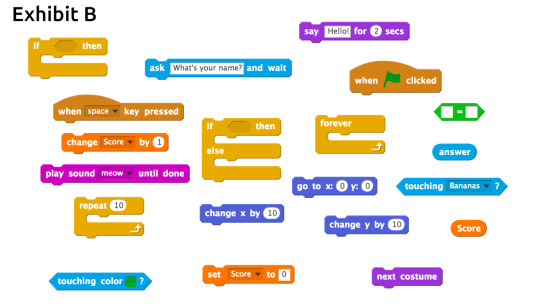
Exhibit B is the sketch programming language. Its what the bright minds at MIT are working on. Its a toy. Its impractical for professional use. I am well aware as to why. I conceived something similar almost 30 years ago. I bet I wasn’t the only one.
Exhibit C is the book I was first taught programming. This book takes the flow chart approach. It does not want you take write a single line of code until you’ve drawn a full flowchart of your program. Its a painstaking approach because it takes a long time to draw a flowchart compared to the functionality you get from it. Very good for learning flow of logic but impractical for professional uses. This is the reason why the sketch programming language is what it is. It sits on the same situation. It takes too long to draw. It also takes too long to drag and drop. Mind you in the future we will have eye tracking and dragging & dropping will be done at a fraction of a second. Still, this kind of language will remain impractical.
I been sitting on this situation for literally decades. My break thru was to break out of the box. Stop using graphics to represent details. Graphical code constructs are not suitable for representing details. Lets look at sketch again Exhibit B. You see how they mapped a graphical representation to individual code constructs. One graphical representation for the if statement. Another one for a repeat loop. Another one for an individual function call such as play, stop, set volume, etc. Those are details.
Stepping out of the box for me was when I realized that graphical code constructs are good for representing big pictures. Managing the big pictures. Metaphorically speaking. Step away from the forest and look at the landscape. At a higher level you can move a whole mountain from the right to the left, Put the lake right next to it. Have the river move down from the lake and curb to the left. Put a small town situated at the curb of river. And finally mark an X on the mountain where Smaug the dragon hangs out. The point is managing the big picture items as opposed little details.
If mind-maps and flowcharts got together. CodeBlock Maps would be their child. CodeBlock maps is basically a map of blocks of code. What it maps out is flow of logic. Let rectangles represent a block of code. The code can be it as simple as adding two numbers together. Or as complex an AI algorithm with millions of lines of code. Then interlink these rectangles indicating flow of logic. That is it. LISP is just commas and parenthesis. CodeBlock maps is just rectangles and lines.
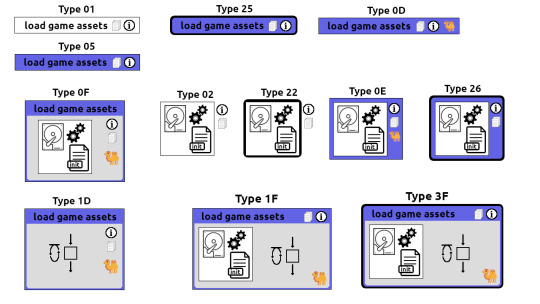
Exhibit D CodeBlock Maps are made up of individual CodeBlock Cells. A rectangle is referred to as a cell. Anyways here are the individual parts of a code block cell. Most of it is verbiage. I would say the only thing that translates into code is the fact that its a cell, the interlinks and the type descriptor.
Exhibit E. There are different verbiage requirements depending on the situation. Here I have enumerated them all. But at the core they are all the same fundamental construct. A rectangle interlinked with lines.
Exhibit F is syntax diagrams represented as a code block map. Good for representing recursive descent graphically. Note that CodeBlock Maps are about making code look pretty. It turns out that beauty has a practical use in code comprehension. I suspect women will enjoy programming in SavageGardens.
In SavageGardens I have designated code block maps as a sub-language for code management but mind you its quite capable on its own. It is touring complete. As simple and powerful as LISP. Its good for encapsulation. Good for divide-n-conquer. Good for abstraction. It fullfills the goals I have set out for SavageGardens. It exploits the brain functions of memory recall. It is 2 dimensional. It is graphical in nature. Good for code comprehension. Good for code navigation. Does not hinder code efficiency. Not so good for code articulation but three out of four is not bad. It does work well with other languages. Hence good for management.
0 notes
Text
youtube
Comedy relief. Referring to the idea that the human brain hasn't changed in over a hundred thousand years. It begs the question what enabled civilization to jump skyhigh only these last couple thousand years? My answer is language. In the early days we had crude language. Crude language makes for crude thoughts. Where as sophisticated language allows for sophisticated thoughts. That is the only difference between us back then and us today.
0 notes
Text



Modular Oriented Programming and Communications
I would describe Modular Oriented Programming as programming with the intent on having reusable and interchangeable compiled code. The term used to describe their design is “Loose Coupling”. Modules interacting with other modules is a communications problem. Its Machine-to-Machine communication.
Language allows us to communicate with complete strangers or people we’ve never met. The same situation exists with modules. Modules are meant to be designed by different developers. Hence, when working with modules, there will be a lot of foreign code. The term “foreign code” is a term I use to describe code that is completely outside of your control. Code that was given to you but you had no part in its design. This means that there needs to be a set of agreements that you can rely on, that allows you to use foreign code safely and efficiently. Such set of agreements is a language. People might use the term protocol or standard but I like to use the term language. This is code interacting with other code. The term language implies flexibility and interoperability. The terms protocol and standard imply rigidity, restrain or limitation.
Modules can be represented graphically. Exhibit A is a graphical representation of two modules. The tentacles and spikes coming out of them are called end-points. These are the inputs and outputs of a module. End-points used for input are receivers (abbreviated RX). End-points used for output are transmitters (abbreviated TX). Modules work with each other by connecting these end-points. Hence no programming is necessary. All an application developer needs to do is connect these end-points together.
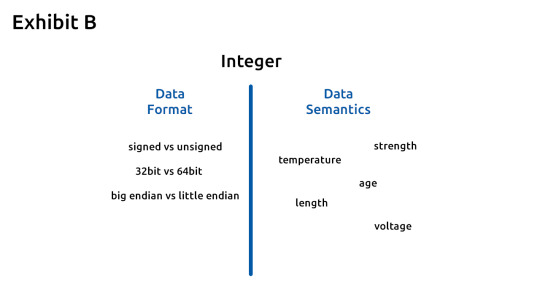
To enable modules to work together we have to agree on the data that comes out of the transmitters. Lets look at exhibit B. We have two aspects of data that we have to look into. Data format and data semantics. Lets look at an integer. Data format would be the integer is 32bits or 64bits. Big endian or little endian. Data semantics is basically what does this integer represent. It could be temperature, length, age, strength, voltage, etc. Modules can be blindly connected together by matching data formats but matching data semantics is also necessary. Because this is where hacks and bugs come into play. Say that a receiver accepts an integer and expects it to represent temperature. There has to be an upper and lower limit. Its theoretically impossible to have temperatures lower then -273 degrees Celsius. But hackers will attempt to hack and try to send temperatures lower then -273 to the receiving module.
When you are in control of both the transmitters and receivers you don’t have to formally define data semantics because you know how your code will behave. If its behaviour is to your satisfaction then everything is fine. BUT when you are dealing with foreign code you will have to worry about data semantics. You will want a set of agreements and expectations about the nature of the data you are getting from foreign code.
Exhibit C. I propose that we start standardizing machine-to-machine vocabulary. Basically we need to develop a worldwide dictionary of data semantics. Hence when you publish your modules you can declare that they conform to specs such and such. And everyone who understands that spec can work with your modules. As a note: SavageGardens will concern itself with machine vocabulary.
Exhibit D just illustrates how modules easily allow for interception or a man-in-the-middle. Sure middlemen could be hackers but they could also be security. They can have a useful purpose such as auditing, filtering or sanitation of data. Useful for debugging or making sure data you are getting is safe. A blast door or firewall if you will. These blast doors can be opened or closed at run time depending on threat level. Call it adjustments between safety and performance.
1 note
·
View note
Text

Modular Oriented Programming and DevOps
The idea is as follows.
If you were an application developer, you would go into a market place and shop for parts. For example (see figure above). You would get some buttons, an LCD display, a back panel and a control circuit. Then you would wire the components together to create an application. Even thou you would be a software developer you would not need to do any programming what so ever. For example the calculator can be put together with a simple bash script or even simpler. An XML file.
This is possible with Modular Oriented Programming. It would change DevOps for software developers to operate similar to the automobile industry. The engine is made in one country. The tires in another. The dashboards and bumpers in another and so on. All the automobile manufacturers really focus on is the outter body. The chassis that glues all the parts together.
Software DevOps would have three distinct industries:
1. - Module developer focused on a specific situation or problem.
2. - Application developer who brings together different modules and creates an application
3. - The technician who is akin to the auto mechanic. This guy would maintain and tweak the application by adding and removing modules. Rewiring the app in a sense.
4 notes
·
View notes
Text
youtube
Anjana Vakil, another colleague. This woman comes from other sciences into computer science to see what she can contribute in computer science. Its interesting because I do the opposite. What I do is try to go into other sciences and try to grab ideas to contribute back into computer science.
Anyways, here she talks about OOP and mixes it up with biology. Which is kinda near my interest in modules.
0 notes
Text

Just a little propaganda poster.
0 notes
Text

Verbage vs Information
Information in programming languages is anything that is useful the the assembler or compiler that would eventually turn into code.
Verbage is stuff that is useful only to the programmer. The assembler or compiler would throw it away because its useless to the machine.
🤔 I would say the most obvious form of verbage would be comments. Identifier names are more subtle but crucial form of verbage. People need the words. Machines only care about numbers.
In the figure above. On the left with have a set of example identifiers. We label our variables and functions because that is the only way we can identify information. On the right would be a representation of what the machine finds useful. It has no need for names. In reality it only cares about memory addresses.
Verbage hasn't been a topic of concern in computer science. But its something I had to pay attention when trying to design graphical code constructs. A graphical representation of an identifier is an icon. Unfortunately an icon takes a long time to draw relative to typing a word. In spite of that I found icons necessary. I am thinking as we get into creating higher level constructs we might need to look more closely at the science of verbage. (note: in the future AI will come in handy in drawing icons for us. 🙂)
Good language design aims to minimize verbage. For example in Pascal, it uses keywords for operators such as AND, NOT, OR, XOR, BEGIN, END, etc. The C language uses symbols, &&, !, ||, ^, {, }, etc. The C language approach seems to be preferred even thou keywords have clearer meaning. The Cobol language used a lot of verbage and it just didn't take off.
Although a minimal amount of verbage is preferred there is no way to get rid of verbage in identifier names because that is just the way we think. Some programmers promote long wordy identifiers because its a kind of self documenting code. Other programmers promote short mnemonic identifiers because their code is more compact and they take less time to type.
The work of Judy Fan studies minimizing verbage in drawings. I don't yet see any practical use in programming languages but it is interesting. https://www.youtube.com/watch?v=AF3XJT9YKpM
0 notes
Text
youtube
Comedy relief for this blog. It funny clip about interesting communication. and below is the Groot language. The most compact language in all the universe.

0 notes