
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by neuraxio and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
2
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
25 days
Number of Posts By Type
Text
5
Photo
1
Link
3
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
Clean Machine Learning Training
Applying clean code and SOLID principles to your ML projects is crucial, and is so often overlooked. Successful artificial intelligence projects require good programmers to work in pair with the mathematicians.
Ugly research code simply won’t do it. You need to do Clean Machine Learning at the moment you begin your project.
Despite all the hype being about the deep learning algorithms, we decided at Neuraxio to do a training about Clean Machine Learning, because it is was we feel the industry really needs.
Clean code is excessively hard to achieve in a codebase that is already dirty, action truly must be taken at the beginning of the project. It must not be postponed.
youtube
We’re glad to have organized this event at Le Camp in March just before the COVID-19 outbreak. It was a fantastic event.
Thanks to participants from Thales, Shutterstock, Novatize, Artifici, Spress.ai, La Cité, LP, IA groupe financier, LGS - An IBM Company, Ville de Québec, STICKÔBOT INC., and Levio.
And also big thanks to the other event organizers including William Simetin Grenon, Francis B. Lemay, Maxime Bouchard Roy and Alexandre Brillant, as well as the other speakers outside of Neuraxio: Jérôme Bédard from Umaneo, and Vincent Bergeron from ROBIC.
It was fun, thank you all!
Guillaume Chevalier, Founder & Machine Learning Expert @ Neuraxio
You can interact with the present post on social media:
LinkedIn
Facebook
YouTube
Twitter
You can also check out our Machine Learning trainings.
source https://store.neuraxio.com/blogs/news/clean-machine-learning-training
0 notes
Text
Clean Machine Learning Training

Applying clean code and SOLID principles to your ML projects is crucial, and is so often overlooked. Successful artificial intelligence projects require good programmers to work in pair with the mathematicians.
Ugly research code simply won’t do it. You need to do Clean Machine Learning at the moment you begin your project.
Despite all the hype being about the deep learning algorithms, we decided at Neuraxio to do a training about Clean Machine Learning, because it is was we feel the industry really needs.
Clean code is excessively hard to achieve in a codebase that is already dirty, action truly must be taken at the beginning of the project. It must not be postponed.
youtube
We’re glad to have organized this event at Le Camp in March just before the COVID-19 outbreak. It was a fantastic event.
Thanks to participants from Thales, Shutterstock, Novatize, Artifici, Spress.ai, La Cité, LP, IA groupe financier, LGS - An IBM Company, Ville de Québec, STICKÔBOT INC., and Levio.
And also big thanks to the other event organizers including William Simetin Grenon, Francis B. Lemay, Maxime Bouchard Roy and Alexandre Brillant, as well as the other speakers outside of Neuraxio: Jérôme Bédard from Umaneo, and Vincent Bergeron from ROBIC.
It was fun, thank you all!
Guillaume Chevalier, Founder & Machine Learning Expert @ Neuraxio
You can interact with the present post on social media:
LinkedIn
Facebook
YouTube
Twitter
You can also check out our Machine Learning trainings.
source https://www.neuraxio.com/en/blog/clean-code/2020/06/21/clean-machine-learning-training.html
0 notes
Text
Your Data Scientist is a Mom

Daily, what does a data scientist do? And how can Automated Machine Learning avoid you to babysit your AI, practically?
The data scientist creates a nice artificial neural network and trains it on data. Then he’s going to supervise the learning. The data scientist will make sure that the learning converges in the right way so that the artificial neural network can give good predictions and then flourish.
Seriously, that’s all well and good, but it costs time, and it costs money.
Is there anything we can do to automate the process of being a mom - actually being a data scientist? Actually, we can use Automated Machine Learning.
youtube
Automated Machine Learning allows us to automate the process of being a mom.
Doing Automated Machine Learning (AutoML)
Firstly, when we define a model, an artificial neural network for example, we have to define the hyperparameters: The number of neurons, the number of layers of neurons on top of each other.
So we’re going to define things like the learning rate, and then the way the data is formatted to send it to the Artificial Neural Network (ANN).
Those are hyperparameters and they are all very well, but above that, to do Automated Machine Learning, we can actually define a space of hyperparameters. E.g.: the number of neurons varies between this and that.
The data can be formatted to send a certain amount of data of a certain length or a certain shape. You can disable or enable certain pre-processing steps in the data.
We can have a space in which, if we pick a point in that space, we find a special case like finally sampling a gene - a hyperparameter - a hyperparameter sample for our artificial neural network.
In other words, every point (sample) in the space is a different setting (or gene) to try.
With Automated Machine Learning, we can finally iterate in this space to pick up new points, try them out, in a somewhat random way, but still intelligent, so that after having made several attempts, converge towards a result.
The True Added Benefits of Automated Machine Learning
It avoids the data scientist to constantly have to supervise the model and to wait for the learning to finish.
It will also allow the model to finally run during the night.
The whole process will be repeatable later whenever the dataset (or project) changes.
There’s no need for the data scientist to be around all the time. AutoML can run for weeks, even months, for larger models if you want, and so on. With all this, eventually, then we can get the best results.
Moreover, it makes easier reusing the code of your last project into your next one. Which provides even more speed in the long run.
Hyperparameter Tuning is an Important of Every Machine Learning Project
We can also analyze the effect of hyperparameters on neural network’s performance. That’s a problem in data science: the neural networks or the model that’s going to perform best on a set of data, isn’t the model with the most neurons, nor the model with the most everything.
In fact, it’s not the one with the least neither. It has to be somewhere in between. You have to find what’s best - there’s a trade-off between bias and then variance.
A biased model is going to take some stupid rules of thumb eventually. Maybe it lacks complexity, it lacks neurons, and something’s going on, that’s not good enough in all of this.
Then a model, on the contrary, that has a lot of variance, has so much learning abilities that, yes, it will pass every exercise during training, but when it comes to the test, it won’t be able to generalize the substance of it correctly. He’s going to end up rote in the end. He’s going to memorize the questions and answers and then, because he was too smart, there was like too much memory or something like that, and then by the time he gets to the test, he’s not going to be able to generalize what he should have. He’s going to be lazy, and then he’s going to get bad results.
In the end, that’s one of the things we’re going to automate with Automated Machine Learning: finding the best model with a good bias/variance tradeoff.
That’s why we need a data scientist or Automated Machine Learning to supervise the artificial neural network, and then try and retry different hyperparameters, as there are no free lunches (NFL theorem).
Conclusion
There are different algorithms that allow you to choose the next point - not by chance - you can analyze what you’ve tried, and what the results were, and then pick the next point in space, and try it all out in an intelligent way.
Machine Learning software has more value if it has the ability to be automatically adapted to new data or a new dataset later on when things will change. The ability to adapt quickly to new data and changes in requirements is important. Those two factors that are often ignored are important in explaining why 87% of data science projects never make it into production.
In our projects, we use the free tool Neuraxle to optimize our Machine Learning algorithms’ hyperparameters. The trick is to define an hyperparameter space for our models and even for our data preprocessing functions using the good software abstraction for ML.
source https://www.neuraxio.com/en/blog/automated-machine-learning-automl/2020/02/22/your-data-scientisti-is-a-mom-(seriously).html
0 notes

Text
What's wrong with Scikit-Learn.

Scikit-Learn’s “pipe and filter” design pattern is simply beautiful. But how to use it for Deep Learning, AutoML, and complex production-level pipelines?
Scikit-Learn had its first release in 2007, which was a pre deep learning era. However, it’s one of the most known and adopted machine learning library, and is still growing. On top of all, it uses the Pipe and Filter design pattern as a software architectural style - it’s what makes scikit-learn so fabulous, added to the fact it provides algorithms ready for use. However, it has massive issues when it comes to do the following, which we should be able to do in 2020 already:
Automatic Machine Learning (AutoML),
Deep Learning Pipelines,
More complex Machine Learning pipelines.
Let’s first clarify what’s missing exactly, and then let’s see how we solved each of those problems with building new design patterns based on the ones scikit-learn already uses.
TL;DR: How could things work to allow to do what’s in the above list with the Pipe and Filter design pattern / architectural style that is particular of Scikit-Learn?
Don’t get me wrong, I used to love Scikit-Learn, and I still love to use it. It is a nice status quo: it offers useful features such as the ability to define pipelines with a panoply of premade machine learning algorithms. However, there are serious problems that they just couldn’t see upfront back in 2007.
The Problems
Some of the problems are highlighted by the creator of scikit-learn himself in one of his conference and he suggests himself that new libraries should solve those problems instead of doing that within scikit-learn:
youtube
Source: the creator of scikit-learn himself - Andreas Mueller @ SciPy Conference
Inability to Reasonably do Automatic Machine Learning (AutoML)
In scikit-learn, the hyperparameters and the search space of the models are awkwardly defined.
Think of builtin hyperparameter spaces and AutoML algorithms. With scikit-learn, a pipeline step can only have some hyperparameters, but they don’t each have an hyperparameter distribution.
It’d be really good to have get_hyperparams_space as well as get_params in scikit-learn, for instance.
This lack of parameter distributions definition is the root of much of the limitations of scikit-learn, and there are more technical limitations out there regarding constructor arguments of pipeline steps and nested pipelines.
Inability to Reasonably do Deep Learning Pipelines
Think about mini-batching, repeating epochs during train, train/test mode of steps, pipelines that mutates in shape to change data sources and data structures amidst the training (e.g.: unsupervised pre-training before supervised learning), and having evaluation strategies that works with the mini-batching and all of the aforementioned things. Mini-batching also involves that the steps of a pipeline should be able to have “fit” called many times in a row on subsets of the data, which isn’t the standard in scikit-learn. None of that is available within a Scikit-Learn Pipeline, yet all of those things are required for Deep Learning algorithms to be trained and deployed.
Plus, Scikit-Learn lacks a compatibility with Deep Learning frameworks (i.e.: TensorFlow, Keras, PyTorch, Poutyne). Scikit-learn lacks to provide lifecycle methods to manage resources and GPU memory allocation, for instance.
You’d also want some pipelines steps to be able to manipulate labels, for instance in the case of an autoregressive autoencoder where some “X” data is extracted to “y” data during the fitting phase only, or in the case of applying a one-hot encoder to the labels to be able to feed them as integers.
Not ready for Production nor for Complex Pipelines
Parallelism and serialization are convoluted in scikit-learn: it’s hard, for not saying broken. When some steps of your pipeline imports libraries coded in C++ which objects aren’t serializable, it doesn’t work with the usual way of saving in Scikit-Learn.
Also, when you build pipelines meant for being deployed in production, there are more things you’ll want to add on top of the previous ones. Think about nested pipelines, funky multimodal data, parallelism and scaling, cloud computing.
Shortly put: with Scikit-Learn, it’s hard to code Metaestimators. Metaestimators are algorithms that wrap other algorithms in a pipeline so as to change the function of the wrapped algorithm (decorator design pattern).
Metaestimators are crucial for advanced features. For instance, a ParallelTransform step could wrap a step to dispatch computations across different threads. A ClusteringWrapper could dispatch computations of the step it wraps to different worker computers within a pipeline by first sending the step to the workers and then the data as it comes. A pipeline is itself a metaestimator, as it contains many different steps. There are many metaestimators out there. Here, we name those “meta steps” for simplicity.
Solutions that we’ve Found to Those Scikit-Learn’s Problems
For sure, Scikit-Learn is very convenient and well-built. However, it needs a refresh. Here are our solutions to make scikit-learn fresh and useable within modern computing projects!
Inability to Reasonably do Automatic Machine Learning (AutoML)
Problem: Defining the Search Space (Hyperparameter Distributions)
Problem: Defining Hyperparameters in the Constructor is Limiting
Problem: Different Train and Test Behavior
Problem: You trained a Pipeline and You Want Feedback on its Learning.
Inability to Reasonably do Deep Learning Pipelines
Problem: Scikit-Learn Hardly Allows for Mini-Batch Gradient Descent (Incremental Fit)
Problem: Initializing the Pipeline and Deallocating Resources
Problem: It is Difficult to Use Other Deep Learning (DL) Libraries in Scikit-Learn
Problem: The Ability to Transform Output Labels
Not ready for Production nor for Complex Pipelines
Problem: Processing 3D, 4D, or ND Data in your Pipeline with Steps Made for Lower-Dimensionnal Data
Problem: Modify a Pipeline Along the Way, such as for Pre-Training or Fine-Tuning
Problem: Getting Model Attributes from Scikit-Learn Pipeline
Problem: You can’t Parallelize nor Save Pipelines Using Steps that Can’t be Serialized “as-is” by Joblib
Conclusion
Unfortunately, most Machine Learning pipelines and frameworks, such as for instance scikit-learn, fail at combining Deep Learning algorithms within neat pipeline abstractions allowing for clean code, automatic machine learning, parallelism & cluster computing, and deployment in production. Scikit-learn has those nice pipeline abstractions already, but they are lacking some necessary stuff to do AutoML, deep learning pipelines, and more complex pipelines such as for deploying to production.
Fortunately, we found some design patterns and solutions that combines the best of all, making it easy for coders, bringing concepts from most recent frontend frameworks (e.g.: component lifecycle) into machine learning pipelines with the right abstractions, allowing for more possibilities. We also break past scikit-learn and Python’s parallelism limitations with a neat trick, allowing easier parallelization and serialization of pipelines for deployment in production, as well as enabling complex mutating pipelines of unsupervised pre-training and fine-tuning.
We’re glad we’ve found a clean way to solve the most spread problems out there, and we hope for you that the results of our findings will be prolific to many machine learning projects, as well as projects that can actually be deployed to production.
If you liked this reading, subscribe to Neuraxio’s updates to be kept in the loop!
source https://www.neuraxio.com/en/blog/scikit-learn/2020/01/03/what-is-wrong-with-scikit-learn.html
0 notes
Text
Why Deep Learning has a Bright Future

Would you like to see the future? This post aims at predicting what will happen to the field of Deep Learning. Scroll on.
Microprocessor Trends
Who doesn’t like to see the real cause of trends?
“Get Twice the Power at a Constant Price Every 18 months”
Some people have said that Moore’s Law was coming to an end. A version of this law is that every 18 months, computers have 2x the computing power than before, at a constant price. However, as seen on the chart, it seems like improvements in computing got to a halt between 2000 and 2010.
See the Moore’s Law Graph
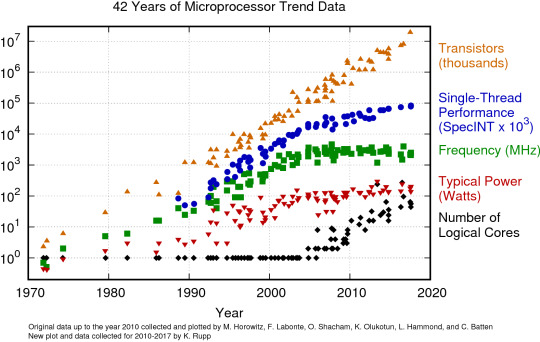
But the Growth Stalled…
This halt is in fact that we’re reaching the limit size of the transistors, an essential part in CPUs. Making them smaller than this limit size will introduce computing errors, because of quantic behavior. Quantum computing will be a good thing, however it won’t replace the function of classical computers as we know them today.
Faith isn’t lost: invest in parallel computing
Moore’s Law isn’t broken yet on another aspect: the number of transistors we can stack in parallel. This means that we can still have a speedup of computing when doing parallel processing. In simpler words: having more cores. GPUs are growing towards this direction: it’s fairly common to see GPUs with 2000 cores in the computing world, already.
That means Deep Learning is a good bet
Luckily for Deep Learning, it comprise matrix multiplications. This means that deep learning algorithms can be massively parallelized, and will profit from future improvements from what remains of Moore’s Law.
See also: Awesome Deep Learning Resources
The AI Singularity in 2029
A prediction by Ray Kurtzweil
Ray Kurtzweil predicts that the singularity will happen in 2029. That is, as he defines it, the moment when a 1000$ computer will contain as much computing power as the brain. He is confident that this will happen, and he insists that what needs to be worked on to reach true singularity is better algorithms.

“We’re limited by the algorithms we use”
So we’d be mostly limited by not having found the best mathematical formulas yet. Until then, for learning to properly take place using deep learning, one needs to feed a lot of data to deep learning algorithms.
We, at Neuraxio, predict that Deep Learning algorithms built for time series processing will be something very good to build upon to get closer to where the future of deep learning is headed.
Big Data and AI
Yes, this keyword is so 2014. It still holds relevant.
“90% of existing data was created in the last 2 years”
It is reported by IBM New Vantage that 90% of the financial data was accumulated in the past 2 years. That’s a lot. At this rate of growth, we’ll be able to feed deep learning algorithms abundantly, more and more.
“By 2020, 37% of the information will have a potential for analysis”
That is what The Guardian reports, according to big data statistics from IDC. In contrast, only 0.5% of all data was analyzed in 2012, according to the same source. Information is more and more structured, and organization are now more conscious of tools to analyze their data. This means that deep learning algorithms will soon have access to the data more easily, wheter the data is stored locally or in the cloud.

It’s about intelligence.
It is about what defines us humans compared to all previous species: our intelligence.
The key of intelligence and cognition is a very interesting subject to explore and is not yet well understood. Technologies related to this field are are promising, and simply, interesting. Many are driven by passion.
On top of that, deep learning algorithms may use Quantum Computing and will apply to machine-brain interfaces in the future. Trend stacking at its finest: a recipe for success is to align as many stars as possible while working on practical matters.

Conclusion
First, Moore’s Law and computing trends indicate that more and more things will be parallelized. Deep Learning will exploit that.
Second, the AI singularity is predicted to happen in 2029 according to Ray Kurtzweil. Advancing Deep Learning research is a way to get there to reap the rewards and do good.
Third, data doesn’t sleep. More and more data is accumulated every day. Deep Learning will exploit that.
Finally, deep learning is about intelligence. It is about technology, it is about the brain, it is about learning, it is about what defines humans compared to all previous species: their intelligence. Curious people will know their way around deep learning.
If you liked this article, consider following us for more!
source https://www.neuraxio.com/en/blog/deep-learning/2019/12/29/why-deep-learning-has-a-bright-future.html
0 notes

Link

Have you ever coded an ML pipeline which was taking a lot of time to run? Or worse: have you ever got to the point where you needed to save on disk intermediate parts of the pipeline to be able to focus on one step at a time by using checkpoints? Or even worse: have you ever tried to refactor such poorly-written machine learning code to put it to production, and it took you months? Well, we’ve all been there working on machine learning pipelines for long enough. So how should we build a good pipeline that will give us flexibility and the ability to easily refactor the code to put it in production later?
2 notes
·
View notes
Link
Have you ever coded an ML pipeline which was taking a lot of time to run? Or worse: have you ever got to the point where you needed to save on disk intermediate parts of the pipeline to be able to focus on one step at a time by using checkpoints? Or even worse: have you ever tried to refactor such poorly-written machine learning code to put it to production, and it took you months? Well, we��ve all been there working on machine learning pipelines for long enough. So how should we build a good pipeline that will give us flexibility and the ability to easily refactor the code to put it in production later?
2 notes
·
View notes