
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by llumoaiworld and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
1 day ago
Number of Posts By Type
Text
14
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text

How AI Teams Get Full Visibility into LLM Performance
Managing LLM performance is no longer a black box! 🚀 We provide real-time tracking and optimization, helping AI teams:
✅ Monitor key metrics – Latency, accuracy, cost, and drift ⚡ Boost efficiency – Fine-tune models for faster responses 💰 Optimize costs – Reduce unnecessary resource usage
With full visibility, your AI becomes smarter, faster, and more cost-effective. Ready to take control of your LLM performance? Let’s connect!
0 notes
Text

How AI teams get full visibility into LLM performance
We help you track and boost your LLM performance in real time to make your AI smarter, faster, and more cost-effective
0 notes
Text

Build Enterprise-Grade Conversational AI 10x Faster
Optimize and enhance your conversational AI in real time, making it smarter, faster, and more cost-effective. Our solution streamlines development and performance tuning, helping you deliver high-quality AI experiences with unmatched efficiency.
0 notes
Text
Building Enterprise-Grade Conversational AI? Do It 10x Faster! 🚀
Creating a high-performing Conversational AI isn’t just about training a chatbot—it’s about delivering speed, accuracy, and scalability without breaking the bank.
💡 What if you could: ✅ Build and optimize AI in real time? ✅ Make your AI smarter and more responsive with continuous improvements? ✅ Reduce costs while boosting performance?
With the right approach, AI teams can accelerate development, fine-tune results, and deploy at scale—without the usual roadblocks.
What’s your biggest challenge in building enterprise-grade AI? Let’s discuss! ⬇️
0 notes
Text

Reduce LLM Costs Without Compromising Performance Optimize expenses with smart prompt compression, efficient caching, and intelligent model routing—ensuring top-quality outputs at a fraction of the cost!
0 notes
Text
Ultimate Prompt Engineering Toolkit—10x Faster! 🎯
Tired of slow, trial-and-error prompt testing? We’ve got you covered! With our all-in-one solution, you can:
✅ Run prompt experiments across all LLMs instantly ✅ Compare outputs side by side for better insights ✅ Analyze results with customized evaluation metrics—all in one screen
No more switching between tools—just faster, smarter, and more efficient prompt engineering. Ready to level up your AI game? Try it now! 💡
0 notes
Text
10 Real-World Use Cases of {Retrieval- Augmented Generation} Model
Hey Folks
This world of large language models (LLMs) generates high-quality content, you know they offer incredible capabilities���but they come with their own set of challenges. One significant issue is their tendency to produce hallucinations, inaccuracies, and lack of sufficient contextual grounding.
This is where {Retrieval-Augmented Generation} steps in. Imagine RAG as the smart assistant for LLMs, enhancing their performance by integrating them with external databases. This allows the models to retrieve relevant information in real time, resulting in responses that are not only more accurate but also contextually rich.
Now, let’s take it a step further with LLumo AI. By harnessing LLumo AI’s capabilities alongside {Retrieval-Augmented Generation}, you can create a dynamic system that doesn’t just pull data but curates and optimizes it to meet your specific needs. Imagine using this technology in customer support to craft personalized responses that very well know a customer’s history and preferences. Or envision a marketing team that can generate customized content that resonates deeply with target audiences, all powered by real-time insights.
If you combine your {Retrieval-Augmented Generation} workflow with LLumo AI then results are more exciting. Picture a research environment where scholars can quickly gather accurate data from vast repositories, streamlining their workflow and enhancing collaboration. In the realm of e-commerce, imagine AI-driven recommendations that feel intuitive and tailored, leading to increased customer satisfaction and loyalty.
As we look ahead, the combination of {Retrieval-Augmented Generation} and LLumo AI is poised to revolutionize how we interact with information and technology. It’s about creating smarter, more responsive experiences that drive engagement and efficiency.
How {Retrieval-Augmented Generation} changing the AI Landscape?
{Retrieval-Augmented Generation} is an innovative approach that enhances the capabilities of large language models (LLMs) by integrating external knowledge sources. This technique boosts the accuracy and contextual relevance of generated responses, making RAG a valuable asset in various LLM applications.
One major challenge with LLMs is their tendency to produce hallucinations—RAG tackles this issue by retrieving relevant information from external databases before generating a response, ensuring that the model uses accurate and up-to-date data. This significantly reduces the chances of inaccuracies, leading to more reliable and trustworthy outputs.
Use Cases of {Retrieval-Augmented Generation}
1. Customer Support Automation
Imagine you're running an e-commerce business. With countless customer queries pouring in, providing timely responses can be overwhelming. Here’s where RAG comes into play. By integrating a RAG model, your system can pull from a database of past interactions and product details to generate personalized responses.
For example, if a customer asks, “What’s the warranty on my product?” the RAG system can quickly retrieve relevant warranty information and generate a coherent answer. According to a recent study, companies using RAG applications for customer support saw a 30% reduction in response times and a 25% increase in customer satisfaction. With LLumo AI, you can effortlessly boost your output quality while keeping costs down. Achieve precision with fewer hallucinations, making your experience smoother and more reliable.
2. Content Creation
For marketers and content creators, generating engaging content is crucial. {Retrieval-Augmented Generation} can be used to streamline the content creation process. Let’s say you're tasked with writing a blog about the latest tech trends. A RAG model can retrieve recent articles and data points about tech advancements, allowing you to create a comprehensive and informative piece quickly.
Companies like HubSpot have implemented RAG applications for their content teams, resulting in a 40% increase in content output without sacrificing quality. This illustrates how RAG implementation can help you produce more while maintaining high standards. Here LLumo makes it easy to generate content that connects with your target audience on a deeper level, thanks to real-time insights. It smartly compresses input prompts before passing them to LLMs, helping you save upto 80% costs and speed up processing.
3. Legal Document Analysis
Legal firms often deal with massive amounts of documentation. With {Retrieval-Augmented Generation}, lawyers can retrieve specific case law and regulations relevant to their ongoing cases, generating summaries or even full briefs.
Consider a law firm using a RAG model to analyze contracts. By pulling relevant clauses and generating summaries, the model can save lawyers hours of manual work. According to Legal Tech News, firms employing RAG in their processes reported a 50% increase in efficiency during document review.
4. Enhanced Research Capabilities
Research institutions can benefit immensely from {Retrieval-Augmented Generation}. Imagine you're a researcher looking for the latest studies on climate change. A RAG model can pull from numerous databases, retrieving relevant studies and generating a summary of findings tailored to your specific needs.
For instance, a university research department implemented RAG technology and noticed that their researchers were able to locate and synthesize information 60% faster than before. This could be a game-changer for you if your work depends on timely access to accurate data.
5. Personalized Learning Experiences
In the education sector, RAG can revolutionize how students learn. By using a {Retrieval-Augmented Generation} model, educational platforms can provide personalized study materials based on individual learning styles and progress.
For example, an online learning platform might use RAG to assess a student’s previous quiz results and retrieve relevant study resources. This approach can increase student engagement and improve learning outcomes. According to a report by EdTech Digest, personalized learning through RAG has led to a 20% increase in student retention rates.
6. Medical Diagnosis Support
In healthcare, timely and accurate information can save lives. RAG models can assist healthcare professionals by retrieving the latest medical research and generating patient-specific recommendations.
Consider a scenario where a doctor is diagnosing a rare disease. By utilizing a {Retrieval-Augmented Generation}, the doctor can access recent case studies and treatment protocols tailored to the patient’s symptoms. A study published in the Journal of Medical AI showed that hospitals using RAG for diagnostic support improved diagnostic accuracy by 25%.
7. Market Research and Trend Analysis
Businesses thrive on understanding market trends. RAG can assist market analysts by retrieving relevant data from various sources and generating insights about consumer behavior and market shifts.
Take a company looking to launch a new product. By employing RAG, analysts can quickly gather data on competitors, consumer preferences, and market forecasts. According to Statista, businesses that utilize RAG for market research report a 35% improvement in their strategic planning processes.
8. Product Development Insights
When developing new products, companies need to stay informed about customer preferences and industry trends. RAG can help by aggregating customer feedback and retrieving relevant market analysis.
For instance, a tech startup developing a new app can use RAG to analyze user reviews from similar applications. By generating insights from this data, they can refine their product features. Research by Product Management Insider indicates that companies leveraging {Retrieval-Augmented Generation} model in product development see a 30% reduction in time to market.
9. Financial Analysis and Reporting
In the finance sector, RAG can streamline the process of financial analysis and reporting. Financial analysts can retrieve historical data and generate comprehensive reports quickly.
Imagine a financial analyst preparing a quarterly report. You can pull past performance data, current market trends, and generate a summary report in a fraction of the time. According to Finance Monthly, firms utilizing RAG for reporting have reduced their reporting time by up to 40%.
10. Recruitment and Candidate Evaluation
Human resources can leverage RAG to enhance recruitment processes. By retrieving data from resumes and generating insights, can help HR professionals identify the best candidates more efficiently.
For example, a company looking to fill a tech role can implement a RAG model to analyze candidate resumes against a database of top-performing employees. This way, the HR team can quickly identify candidates with the most relevant skills and experiences. Research from HR Tech found that organizations using {Retrieval-Augmented Generation} in recruitment improved their hiring accuracy by 30%.
With these compelling use cases, it's clear that RAG is not just a buzzword; it’s a transformative tool for various industries. Whether you’re looking to enhance customer support, streamline content creation, or improve research efficiency, implementing this can lead to substantial benefits for your business.
Conclusion
From customer support to content creation and recruitment, {Retrieval-Augmented Generation} applications provide significant benefits that can elevate your business. With RAG, you can save time, improve accuracy, and enhance productivity, i.e. essential for staying ahead in your industry. Now, imagine integrating LLumo into your strategy. This will harness the power of {Retrieval-Augmented Generation} to streamline processes and deliver tailored insights, transforming how you interact with information.
With LLumo AI, you can enjoy 10x faster LLM optimization, improve decision-making, and upto 80% cost reduction with prompt engineering.
Let’s connect and make it happen! Don’t forget to bookmark this blog for future reference! We’d love to hear your thoughts! Feel free to comment below with your experiences or any questions you may have.
0 notes
Text
The Ultimate All-in-One Solution for Prompt Engineering
Unlock the power of efficient prompt engineering with a platform designed to simplify and accelerate your workflow.
✅ Run prompt experiments 10x faster across multiple language models, saving time and effort.
✅ Instantly test prompts and compare outputs side by side for quick insights.
✅ Analyze performance using customized evaluation metrics — all within a single, intuitive interface.
Streamline your prompt engineering process, improve accuracy, and achieve better results — all from one powerful platform.
0 notes
Text
{RAG vs.Fine-Tuning}: Which Approach Delivers Better Results for LLMs?
Imagine you’re building your dream home. You could either renovate an old house, making changes to the layout, adding new features, and fixing up what’s already there (Fine-Tuning), or you could start from scratch, using brand-new materials and designs to create something totally unique (RAG). In AI, Fine-Tuning means improving an existing model to work better for your specific needs, while Retrieval-Augmented Generation (RAG) adds external information to make the model smarter and more flexible. Just like with a home, which option {RAG vs.Fine-Tuning} you choose depends on what you want to achieve. Today, we’ll check out both the approaches to help you decide which one is right for your goals.
What Is LLM?
Large Language Models (LLMs) have taken the AI world by storm, capable of generating different types of content, answering queries, and even translating languages. As they are trained on extensive datasets, LLM showcase incredible versatility but they often struggle with outdated or context-specific information, limiting their effectiveness.
Key Challenges with LLMs:
LLMs can sometimes provide incorrect answers, even when sounding confident.
They may give responses that are off-target or irrelevant to the user's question.
LLMs rely on fixed datasets, leading to outdated or vague information that misses user specifics.
They can pull information from unreliable sources, risking the spread of misinformation.
Without understanding the context of a user’s question, LLMs might generate generic responses that are not helpful.
Different fields may use the same terms in various ways, causing misunderstandings in responses.
LLUMO AI's Eval LM makes it easy to test and compare different Large Language Models (LLMs). You can quickly view hundreds of outputs side by side to see which model performs best, and deliver accurate answers quickly, without losing quality.
How RAG Works?
Retrieval-augmented generation (RAG) is used to merge the strengths of generative models with retrieval-based systems. It retrieves relevant documents or data from an external database,websites or from any reliable source to enhance its responses and produce outputs not only accurate but also contextually latest and relevant.
A customer support chatbot that uses RAG, suppose a user asks about a specific product feature or service, the chatbot can quickly look up related FAQs, product manuals, and recent user reviews in its database. Combining this information creates a response that is latest, relevant, and helpful.
How RAG tackle LLM Challenges?
Retrieval-Augmented Generation (RAG) steps in to enhance LLMs and tackle these challenges:
Smart Retrieval: RAG first looks for the most relevant and up-to-date information from reliable sources, ensuring that responses are accurate.
Relevant Context: By giving the LLM specific, contextual data, RAG helps generate answers that are not only correct but also tailored to the user’s question.
Accuracy: With access to trustworthy sources, RAG greatly reduces the chances of giving false or misleading information, improving user trust.
Clarified Terminology: RAG uses diverse sources to help the LLM understand different meanings of terms, and minimizes the chances of confusion.
RAG turns LLMs into powerful tools that deliver precise, latest, and context-aware answers. This leads to better accuracy and consistency in LLM outputs. Think of it as a magic wand for today’s world, providing quick, relevant, and accurate answers right when you need them most.
How Fine-tuning Works?
Fine-tuning is a process where a pre-trained language model is adapted to a dataset relevant to a particular domain. It is particularly effective when you have a large amount of domain-specific data, allowing the model to perform exceptionally on that particular task. This process not only reduces computational costs but also allows users to tackle advanced models without starting from scratch.
A medical diagnosis tool designed for healthcare professionals. By fine-tuning a LLM on a dataset of patient records and medical literature, the model can learn that particular medical terminology and generate insights based on specific symptoms. For example, when a physician inputs symptoms, the fine-tuned model can offer potential diagnoses and treatment options tailored to that specific context.
How Fine-Tuning Makes a Difference in LLM
Fine-tuning is a powerful way to enhance LLMs and tackle these challenges effectively:
Tailored Training: Fine-tuning allows LLMs to be trained on specific datasets that reflect the specific information they’ll need to provide. This means they can learn the most relevant knowledge of the particular.
Improved Accuracy: By focusing on the right data, fine-tuning helps LLMs to deliver more precise answers that directly address user questions, and reduces the chances of misinformation.
Context Awareness: Fine-tuning helps LLMs to understand the context better, so they can generate most relevant and appropriate responses.
Clarified Terminology: With targeted training, LLMs can learn the nuances of different terms and phrases, helping them avoid confusion and provide clearer answers.
Fine-tuning works like a spell, transforming LLMs into powerful allies that provide answers that are not just accurate, but also deeply relevant and finely attuned to context. This enchanting enhancement elevates the user experience to new heights, creating a seamless interaction that feels almost magical.
How can LLumo AI help you?
In {RAG vs.Fine-Tuning}, LLUMO can help you gain complete insights on your LLM outputs and customer success using proprietary framework- Eval LM. To use LLumo Eval LM and evaluate your prompt output to generate insights needs follow these steps:
Step 1: Create a New Playground
Go to the Eval LM platform.
Click on the option to create a new playground. This is your workspace for generating and evaluating experiments.

Step 2: Choose How to Upload Your Data
In your new playground, you have three options for uploading your data:
Upload Your Data:
Simply drag and drop your file into the designated area. This is the quickest way to get your data in.

Choose a Template:
Select a template that fits your project. Once you've chosen one, upload your data file to use it with that template.

Customize Your Template:
If you want to tailor the template to your needs, you can add or remove columns. After customizing, upload your data file.

Step 3: Generate Responses
After uploading your data, click the button to run the process. This will generate responses based on your input.
Step 4: Evaluate Your Responses
Once the responses are generated, you can evaluate them using over 50 customizable Key Performance Indicators (KPIs).
You can define what each KPI means to you, ensuring it fits your evaluation criteria.

Step 5: Set Your Metrics
Choose the evaluation metrics you want to use. You can also select the language model (LLM) for generating responses.
After setting everything, you'll receive an evaluation score that indicates whether the responses pass or fail based on your criteria.
Step 6: Finalize and Run
Once you’ve completed all the setup, simply click on “Run.”
Your tailored responses are now ready for your specific niche!
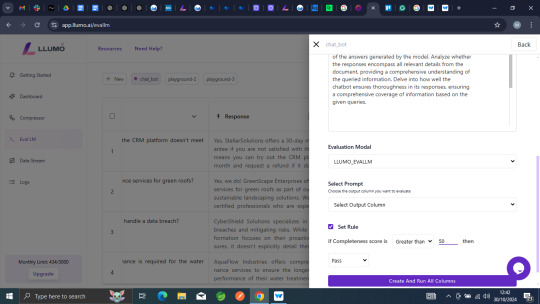
Step 6: Evaluate you Accuracy Score
After generating responses, you can easily check how accurate they are. You can set your own rules to decide what counts as a good response, giving you full control over accuracy.

Why Choose Retrieval-Augmented Generation (RAG) in {RAG vs.Fine-Tuning}?
On a frequent basis, AI developers used to face challenges like data privacy, managing costs, and delivering accurate outputs. RAG effectively addresses these by offering a secure environment for data handling, reducing resource requirements, and enhancing the reliability of results. By choosing RAG over fine-tuning in {RAG vs.Fine-Tuning},companies can not only improve their operational efficiency but also build trust with their users through secure and accurate AI solutions.
While choosing {RAG vs.Fine-Tuning}, Retrieval-Augmented Generation (RAG) often outshines fine-tuning. This is primarily due to its security, scalability, reliability, and efficiency. Let's explore each of these with real-world use cases.
Data Security and Data Privacy
One of the biggest concerns for AI developers is data security. With fine-tuning, the proprietary data used to train the model becomes part of the model’s training set. This means there’s a risk of that data being exposed, potentially leading to security breaches or unauthorized access. In contrast, RAG keeps your data within a secured database environment.
Imagine a healthcare company using AI to analyze patient records. By using RAG, the company can pull relevant information securely without exposing sensitive patient data. This means they can generate insights or recommendations while ensuring patient confidentiality, thus complying with regulations like HIPAA.
Cost-Efficient and Scalable
Fine-tuning a large AI model takes a lot of time and resources because it needs labeled data and a lot of work to set up. RAG, however, can use the data you already have to give answers without needing a long training process. For example, an e-commerce company that wants to personalize customer experiences doesn’t have to spend weeks fine-tuning a model with customer data. Instead, they can use RAG to pull information from their existing product and customer data. This helps them provide personalized recommendations faster and at a lower cost, making things more efficient.
Reliable Response
The effectiveness of AI is judged by its ability to provide accurate and reliable responses. RAG excels in this aspect by consistently referencing the latest curated datasets to generate outputs. If an error occurs, it’s easier for the data team to trace the source of the response back to the original data, helping them understand what went wrong.
Take a financial advisory firm that uses AI to provide investment recommendations. By employing RAG, the firm can pull real-time market data and financial news to inform its advice. If a recommendation turns out to be inaccurate, the team can quickly identify whether the error stemmed from outdated information or a misinterpretation of the data, allowing for swift corrective action.
Let’s Check Out the Key Points to Evaluate {RAG vs.Fine-Tuning}
Here’s a simple tabular comparison between Retrieval-Augmented Generation (RAG) and Fine-Tuning:
Feature
Retrieval-Augmented Generation (RAG)
Fine-Tuning
Data Security
Keeps proprietary data within a secured database.
Data becomes part of the model, risking exposure.
Cost Efficiency
Lower costs by leveraging existing data; no training required.
Resource-intensive, requiring time and compute power.
Scalability
Easily scalable as it uses first-party data dynamically.
Scaling requires additional training and resources.
Speed of Implementation
Faster to implement; no lengthy training process.
Slower due to the need for extensive data preparation.
Accuracy of Responses
Pulls from the latest data for accurate outputs.
Performance may vary based on training data quality.
Error Tracking
Easier to trace errors back to specific data sources.
Harder to identify where things went wrong.
Use Case Flexibility
Adapts quickly to different tasks without retraining.
Best for specific tasks but less adaptable.
Development Effort
Requires less human effort and time.
High human effort needed for labeling and training.
Summing Up
Choosing between {RAG vs.Fine-Tuning},ultimately depends on your specific needs and resources. RAG is time and again the better option because it keeps your data safe, is more cost-effective, and can quickly adapt the latest information. This means it can provide accurate and relevant answers based on the latest data, which keeps you update.
On the other hand, Fine-Tuning is great for specific tasks but can be resource-heavy and less flexible. It shines in niche areas, but it doesn't handle changes as well as RAG does. Overall, RAG usually offers more capabilities for a wider range of needs. With LLUMO AI’s Eval LM, you can easily evaluate and compare model performance, helping you optimize both approaches. LLUMO’s tools ensure your AI delivers accurate, relevant results while saving time and resources, regardless of the method you choose
0 notes
Text

Maximize LLM Performance While Reducing Costs
Why pay more for your LLM when you can achieve the same results for less?
Our smart solution helps you:
Compress prompts to reduce token usage without losing context
Implement efficient caching to cut down on repeated queries
Route tasks intelligently to ensure each request uses the most efficient model
Get the same high-quality outputs while dramatically lowering your costs. https://www.llumo.ai/ai-cost-optimization
Smarter prompts, smarter spending — better results.
0 notes
Text

Save LLM cost without affecting performance
We slash your LLM costs with smart prompt compression, efficient caching, and intelligent model routing—delivering the same best output at a fraction of the cost! https://www.llumo.ai/ai-cost-optimization
0 notes
Text
We help you track and boost your LLM performance in real time to make your AI smarter, faster, and more cost-effective
0 notes
Text
Save LLM cost without affecting performance

We slash your LLM costs with smart prompt compression, efficient caching, and intelligent model routing—delivering the same best output at a fraction of the cost! https://www.llumo.ai/ai-cost-optimization
0 notes
Text

Cut your LLM costs with smart prompts, efficient caching, and intelligent routing—same top-notch results, now at a fraction of the price!
1 note
·
View note