
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by lawrencehenfner and here's what we found interesting.
Average Info
Notes Per Post
2
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
6 days
Number of Posts By Type
Text
8
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Change Data Capture in Real Time in Postgres
PostgreSQL, also known as Postgres, is a highly optimized database management system that functions in a wide range of industries. Typically, Postgres takes care of the transactional data of applications and integrates third-party data systems for a wide range of functionalities such as a data warehouse for analytics or a BI tool for reporting.
This open-source database is now much preferred by organizations for accessing real-time data for critical tasks. Further, Postgres even though an RDMS database also doubles up as a data warehouse, and thus, it makes sense to migrate data to Postgres to reduce costs.
Postgres and CDC
Postgres traditional approach is batch-based when it comes to connecting with other data stores. Periodically, data is extracted by data pipelines from Postgres and sent downstream to data stores which are not only prone to errors but also an inefficient process. Postgres CDC on the other hand is a high-performing solution for extracting record-level change events (Insert, Update, And Delete) from Postgres in real-time.
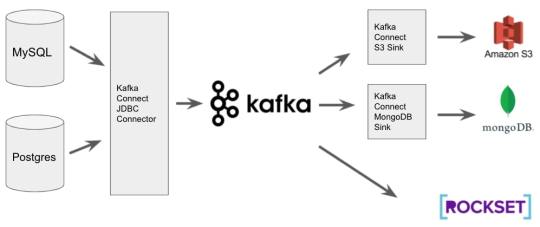
Here are the cutting-edge benefits of Postgres CDC.
Postgres CDC helps to capture changes in real-time, making sure that data warehouses are always in sync with PostgreSQL, thereby enabling fully event-driven data architectures.
By using CDC, the load on Postgres is reduced as only the changes are processed.
Postgres CDC efficiently implements use cases requiring access to change events of Postgres. These include audits or changelogs without modifying the application code.
Types of Change Data Capture in Postgres
There are several types of Postgres CDC and these will be detailed here.
Postgres CDC with Triggers
The Postgres CDC trigger feature records all changes taking place in the table of interest and for each event inserts one row into a second table thereby building a changelog. The generic trigger function or Code which supports PostgreSQL version 9.1 and after stores all change events in the table audit. logged actions.
In the trigger function of CDC Postgres
All changes are instantly captured ensuring real-time processing of change events
All event types such as Insert, Update, or Delete, can be captured by the triggers.
Trigger-based Postgres CDC includes helpful metadata such as the statement that caused the change, the transaction ID, or the session user name.
Postgres CDC with Queries
If the schema of the monitored database table features a timestamp column indicating when a row has been changed the last time, Postgres can be recurringly queried using that column and all records that were modified since the last Postgres query. Such Postgres CDC with queries would be implemented as follows:
Query-based Postgres CDC cannot capture Delete records unless soft deletions are used and are only restricted to Insert and Update changes.
If the schema holds a timestamp column indicating the modification time of rows, query-based CDC can be implemented without introducing any changes to PostgreSQL.
These are the main types of Postgres CDC.
0 notes
Text
Migrating Databases From Oracle to Snowflake
Since it was first released commercially in 1979, the Oracle Database Management System has been the mainstay of most data-driven organizations around the world. It can quickly and effortlessly store and retrieve high volumes of data and can be run on a wide range of hardware and software. The point then is why businesses all over the world are now migrating their databases from Oracle to Snowflake. The answer lies in the several benefits of Snowflake.

Benefits of Snowflake
Snowflake is a cloud-based data warehousing solution that is offered as a SaaS (Software-as-a-service) product. The reason why businesses are migrating databases to Snowflake is because of the many advantages it brings to the table. Given here are some of them.
Since Snowflake is based in the cloud it offers unlimited data storage capabilities. Users can scale up or down in data usage whenever required by paying only for the quantum availed.
Snowflake is very powerful with high computing facilities. There is no lag or drop in performance even when multiple users execute multiple intricate queries simultaneously.
A critical advantage of migrating databases from Oracle to Snowflake is that there is zero downtime or loss of data in the event of an outage or crash of the primary server. At such times, secondary servers where the data has been migrated are automatically triggered and there is no disruption in work. When the issue is resolved, the primary server is auto-updated with all records and changes that occurred in the break period.
These are some of the reasons why it makes sense to migrate databases from Oracle to Snowflake
Migrating Databases from Oracle to Snowflake
The process of migrating databases to Snowflake from Oracle takes place in four steps.
The data to be migrated is first extracted from the Oracle database with the SQL Plus Query tool of the Oracle Database Server. The “Spool” command is used and it keeps on running till switched off. The data extracted is now placed in a CSV file.
The extracted data is now processed and formatted so that it matches one of the data structures supported by Snowflake. Presently, the data types supported by Snowflake are EUC-KR, UTF-8, ISO-8859-1 to 9, Big5, and UTF-16. In case of a data structure mismatch, the “File Format Option” is used to create a customized format marked with the date and time on the file.
The formatted data cannot yet be loaded into Snowflake but has to be kept in a temporary internal or external staging area. In the first instance, users have to create appropriate tables to which a name and date are automatically applied. For external staging areas, Snowflake supports Amazon S3 (Simple Storage Service) and Microsoft Azure.
The final step is loading data from the staging area to Snowflake.
This is the Oracle to Snowflake database migration process.
0 notes
Text
Migrating your business data to the cloud? Here’s what you need to know
For data driven businesses, an ERP system is mission critical to the success of an organisation. An ERP tool can give managers, executives and decision makers access and insights into what’s happening and how the core business functions are performing on a day-to-day basis. However, in today’s hyper-competitive, always-connected world, organisations require more than an ERP system to stay ahead, agile and make real-time decisions at the speed of action. Since the last few decades, better technology and infrastructure have enabled businesses to leverage the power of robust, feature-rich and scalable data platforms and tools in conjunction with an ERP system. In this post, you will learn about the benefits of combining an ERP system with a data platform for complete database management and application across different use-cases and industries.
When it comes to ERP systems, SAP HANA is one of the leading and trusted names with built-in technologies such as AI, Machine Learning, and Real-Time Analytics. All of this results in faster data processing with real-time analytics, whether on-premise or in the cloud. With the release of SAP HANA, SAP introduced a code-to-data approach that decreases data runtime due to decreased distance between the application server and the database. SAP CDS view enables the use of logic replication from SAP applications to the database, enabling the use of enriching features such as - associations (ability to create joins); entities (ability to make custom-defined structured tables); expressions (for calculating fields) and annotations (used for adding component specific metadata).
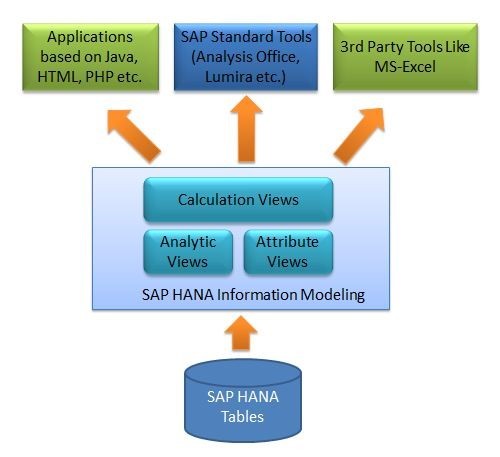
A SAP CDS view is basically used for the purpose of defining an existing database, and it can also be used to project onto one or several database tables. Therefore, CDS views are used for data selection in the ABAP CDS view or for creating data models from scratch in the HANA CDS view.
So what exactly are the benefits of using SAP HANA for businesses? Well, firstly SAP HANA is known for its wide suite of database management solutions which can provide a range of useful and simplify the entire IT environment. Secondly, SAP HANA offers infinite scalability for businesses that are constantly evolving and growing with a need for increased data storage and processing capabilities. This means all your data models can scale as you grow, without worrying about slowdowns. Moreover, SAP HANA provides unique flexibility to be deployed on-premise, or in the cloud, this means your organization can get access to massive data computing capability from anywhere.
SAP CDS views are highly useful for providing a singular, unified data model which can further be utilized for multiple applications. With more functionality, data analysts and managers can use it outside the ABAP domain as well. CDS views also support automatic client handling.
0 notes
Text
Migrating Databases from Oracle to Snowflake
One of the main reasons why organizations want to migrate their databases from Oracle to Snowflake is because of the many benefits that this cloud-based data warehousing solution brings to the table.
On Snowflake, users can sync and replicate databases with various accounts that already exist in different cloud providers and regions, thereby ensuring business continuity. In case of an outage in the primary server, the remote servers in secondary locations are automatically triggered and work is not disrupted. After resolving the issue, the primary server is updated with the data generated in the break period. This is one of the key reasons for migrating databases from Oracle to Snowflake even though Oracle has been the foundation for database management for many decades now.

Additionally, seamless data portability is assured as Snowflake is based in the cloud. Users can move databases to another cloud or region such as Oracle to Snowflake within a fully secured and safe ecosystem.
The process to Migrate Databases from Oracle to Snowflake
There are four steps to migrate databases from Oracle to Snowflake.
Extracting Data from the Oracle Database
The data to be migrated from Oracle to Snowflakeisfirst extracted from the source database with the in-built SQL Plus Query tool of the Oracle Database Server and the “Spool” command which extracts data till it is switched off. The extracted data is then placed in a CSV file.
Formatting the Extracted Data
The extracted data cannot be loaded directly into Snowflake since its structure has to match one that is supported by Snowflake. Hence, the data has to be formatted and processed accordingly. Currently, Snowflake supports EUC-KR, UTF-8, ISO-8859-1 to 9, Big5, and UTF-16 data types. If there is a mismatch between the structure of the extracted data and one of the Snowflake-supported types, the “File Format Option” is used to create a customized format marked with the date and time on the file.
Using a staging area for keeping data
This processed and formatted data cannot be directly migrated from Oracle to Snowflake and has to be kept in a temporary cloud staging area that can either be an internal or external one. In the case of an internal staging area, users have to create appropriate tables to which a name and date are automatically applied. On the other hand, an external staging area can either be Amazon S3 (Simple Storage Service) or Microsoft Azure, both of which are supported by Snowflake.
Loading database Oracle to Snowflake
The final step in the process of migrating the database from Oracle to Snowflake is loading data from the temporary internal or external staging area to Snowflake. The Data Loading Overview tool is used for loading small databaseswhile the COPY INTO command is for loading large databases.
This completes the migration procedure of the databaseOracle to Snowflake.
0 notes
Text
Snowflake Data Lake – Overview and Best Practices
A cloud-based data warehousing solution, the Snowflake Data Lake provides unlimited storage and computing facilities. Users can seamlessly scale up or down in data usage, paying only for the resources used, unlike traditional systems where flat fees are charged. It is cost-effective for businesses facing a sudden spike in demand for data storage as they do not have to invest heavily in additional hardware or software to meet this excess demand.
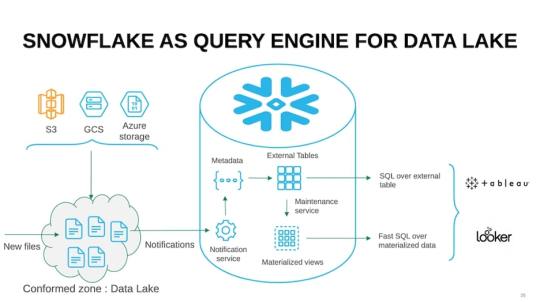
The Snowflake Data Lake is a high-performing platform that allows multiple users to simultaneously execute intricate queries without facing any slowdown in speeds and performance.This is a very critical requirement in the modern data-driven business environment. Further, the extendable structure of the Snowflake Data Lake makes sure that databases are seamlessly loaded within the same cloud ecosystem so that businesses do not have to choose a specific data warehouse or a data lake to operate on.
An example will explain this aspect better. For instance, data generated through Kafka can be transferred to a cloud bucket from where the data is converted to a columnar format with Apache Spark. This can then be loaded to the conformed data zone, doing away with the need for organizations to choose between a data lake or a data warehouse.
The Snowflake Data Lake can also load data in its native format – unstructured, semi-structured, or structured – thereby allowing cutting-edge business analytics in mixed data formats. This increases the efficiency of the Data Lake many times over and since it is highly scalable, it reacts immediately to any decrease or increase in data volumes.
Features of the Snowflake Data Lake
Because of its several optimized features, the Snowflake Data Lake is a powerful data-driven solution for organizations. Here are some of them.
Scalability: Snowflake has very dynamic and scalable computing resources that vary according to the volume of data requirements and the number of users at a particular point in time. The quantum of resources provided changes automatically without affecting running queries whenever there is a rise or fall in computing needs. To cope with a sudden spike in demand, the compute engine auto-adjusts to the increased flows without a drop in speed or performance. Single-point data storage: The Snowflake Data Lake can directly ingest large volumes of structured and semi-structured data such as JSON, CSV, tables, Parquet, ORC, and more without the use of separate silos for data storage. Cost-effective data storage: Snowflake provides flexible and very cost-effective data storage solutions as users have to pay only for the base cost charged by its cloud providers such as Microsoft Azure, Amazon S3, and Google Cloud. Guaranteed data consistency: This is possible as the Snowflake Data Lake can easily manipulate cross-database links and multi-statement transactions.
Summing up, Snowflake Data Lake users, therefore, have the benefits of affordable computing and storage facilities along with maximized scaling capabilities.
0 notes
Text
The SAP Extractor Defined – Functions and Types
One of the primary functions of SAP Data Services, a software application, is to integrate and transform data. It is widely used for developing and executing workflows for extracting SAP data from various sources such as web services, data stores, applications, and databases. After extraction, the data is transformed and processed so that it is optimized for business analytics. Users can also query Data Services and carry out batch processing, the older model of data transformation.
The SAP Extractor also called the BW Extractor previously, is used for extracting SAP data from source databases to be stored in downstream data warehouses or business intelligence systems. The primary objective of the SAP Extractor is extracting SAP data for feeding various SAP BW applications.

The Role of the SAP Extractor
The SAP Extractor is a program in SAP ERP that can be set off for SAP data extraction for transferring to BW. The Extractor can be a traditional DataSource or a customized one that provides full load details of various delta processes. The data transfer part of the SAP Extractor is remotely controlled by the SAP BW.
However, before users can extract SAP datafor transferringto the input layer of the SAP Business Warehouse it is necessary to define the load process with an InfoPackage in the scheduler. A request IDoc to the source system starts the data load process necessary for SAP data extraction when the InfoPackage is to be implemented with process chains used for executions.
Extracting SAP Data with the SAP Extractor
SAP data can be extracted in three ways with the SAP Extractor. In the first instance, Application Specific Content Extractors extract BW content, FI, HR, CO, SAP CRM, and LO cockpit. Next, Application Specific Customer-Generated Extractors are used when data related to LIS, FI-SL, and CO-PA need to be extracted. Finally, Cross Application Generic Extractors are used for DB View, Infoset, and Function Modules. The type of Extractor used by organizations depends on their specific purpose.
The Working of the SAP Extractor
The SAP Extractor used is specific to the application it is meant for. Only after the extractors are hard-coded for the Data Source will the BI Content of the Business Warehouse be delivered. It is necessary though that the structure of the Data Source match the Extractor used. An advantage of the SAP Extractor is that after the Data Source is identified by the generic extractor, it can recognize which data needs to be extracted and the tables where data is in read-only form as the tool is automated and can work without human intervention at any stage.
Further, SAP Extractor can extract SAP data regardless of the application. However, the pre-condition is that it must contain related database views, master data attributes or texts, SAP query functional areas, or transaction data from all transparent tables.
1 note
·
View note
Text
The Function of the Change Data Capture Feature in SQL Server
This post examines the various intricacies of how the CDC (Change Data Capture) feature applies to SQL Server tables.
The basic functioning is as follows. All changes like Insert, Update, and Delete that are applied to SQL Server tables are tracked by SQL Server CDC. These changes are then recorded and transformed into relational change tables that are easy to understand. Moreover, these change tables show the structure of the columns of the source table that is being tracked. Users can understand the changes that have been made by SQL Server CDC through metadata that is available to them.

Evolution of SQL Server CDC
It is a critical requirement of businesses that the value of data in a database should be recorded before the specifications of an application are changed. That means that the history of the changes made to the data must be saved, specifically for safety and security purposes. In the past, timestamps, triggers, and complex queries to audit data were widely used for this purpose.
In 2005, Microsoft launched SQL Server CDC with ���after update’, ‘after insert’, and ‘after delete’ triggers that solved the problem of tracking changes to the data. However, a more optimized version was released in 2008 that rectified a few glitches of the 2005 release. This Change Data Capture (CDC) model helped developers to provide SQL Server data archiving and capturing without going through additional programming to do so.
The main point of difference between the 2005 and the 2008 versions is that in the latter case, SQL Server CDC tracks changes only in user-created tables. These can be later assessed and retrieved quickly through the standard T-SQL as the data captured is stored in relational tables.
The Functioning of the SQL Server CDC
When the SQL Server CDC feature is applied to a database table, a mirror is created of the tracked table with the same column structure as the original table. However, the additional columns that have the metadata in the original tables are retained as they are used to track the changes in the database table row. Users monitoring the SQL Server CDC can track the activity of the logged tables by using the new audit tables.
All changes are recorded in mirrored tables by SQL Server CDC but the other columns are recorded in different formats. They are as follows.
For every Insert statement, one record is written by the SQL Server showing the inserted values.
For every Delete statement, one record is written by the SQL Server showing the deleted values.
For every Update statement, two records are written by the SQL Server showing the updated values.
SQL Server CDC first fills the database change tables with the changed data and then cleans the change tables by deleting those records that are older than the configurable retention.
0 notes
Text
Creating CDS Views in SAP HANA – A Study
Core Data Services (CDS) created and designed by SAP is a semantically robust definition language. With CDS Views in SAP HANA, users can define and consume models on the database outside the application server. CDS Views is a very optimized and specialized platform for designing data models that can be moved outside the applications with OData services.
Apart from these attributes, CDS Views in SAP HANAalso leverage the high-performing database of SAP HANA to ensure real-time activities by achieving operations at the database level. This in turn leads to quick retrieval of databases and lowers application execution time. The data models that are created by SAP CDS are provided to clients as UI and CDS Views in SAP HANA by application servers.
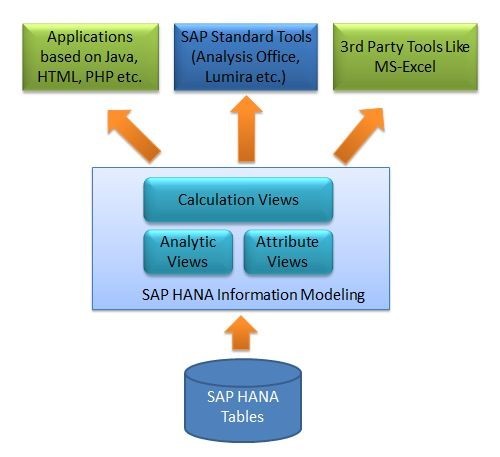
CDS Views in SAP HANA, introduced by SAP as a programming model, permit direct and quick access to the underlying tables of the HANA database. The objective is to ensure a smooth transition of logic from the application server to the client-side database named ‘Code-to-Data’ or ‘Code Pushdown’ by SAP. CDS Views in SAP HANAextract this logic from the ABAP applications and executes it on the database.
Functioning of CDS Views in SAP HANA
With CDS Views in SAP HANA, you can define a view in an SAP CDS Viewdocument which can be stored as a design-time file in the repository. Specially designed and developed applications can read these repository files. Moreover, it is also possible to move these files to other SAP HANA systems like a delivery unit.
Further, any changes made to the repository version of the file are visible once they are committed to the repository provided an application refers to the design-time version of a view from the repository. The benefit here is that you do not have to wait for the activation of a runtime version of the view by the repository.
A corresponding catalog object for each object defined in the document is generated whenever a CDS document is activated. However, the specific type of object generated determines its location in the catalog. For example, the corresponding catalog object in SAP HANA XS classic forCDS Views in SAP HANAdefinition is generated in the location <SID> Catalog <MYSCHEMA> Views.
Benefits of CDS Views in SAP HANA
There are several benefits of CDS Views in SAP HANA.
The first is that it is a code-to-data technology in ABAP where all computing and calculations are done on the database layer instead of the application server and every feature can be accessed outside the SAP native applications as they are less conventional in SE11 views. Next, client operations are supported automatically by CDS as it can publish ODATA service annotations directly fromCDS Views in SAP HANA.Finally, this model optimally supports automatic client handling and servicing.
1 note
·
View note