
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by kavindius and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
10 days ago
Number of Posts By Type
Text
10
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
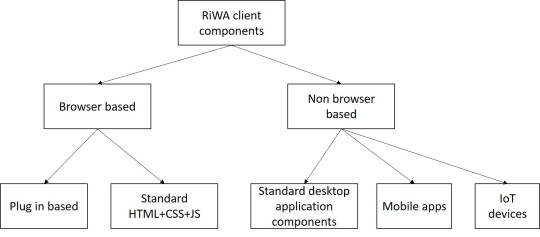
Rich Web Based Applications
Introduction to Rich web Based Applications
There is a wide range of web-based applications, which use a rich communication model such as Rich Internet Applications, mobile apps, cloud-based systems, Internet of Things based systems, etc.
Rich web - based applications
Use advanced GUIs
Use delta communication
Provide rich user experience
Delta communication,
Happens behind the GUI and it eliminates page refreshes.
Can process asynchronously and it eliminates page freezing.
Works faster and it eliminates the work wait pattern.
Delta Communication Technologies
Delta-Communication can be seen as the power of Rich Internet Applications, and there are different Techniques and Technologies available for the development of Delta-Communication, which should be selected carefully into the Rich Internet Application development.
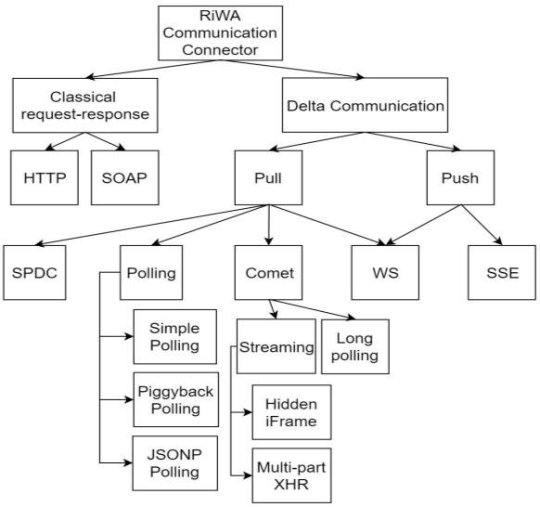
Simple-Pull-Delta-Communication (SPDC) can be seen as the simplest form of DC
o Used in AJAX
o Single XHR request to the server
o Client-side: Native JS support
o Server-side: special technology is not needed
Polling
Polling is used to simulate the data push.
Client side – Native JS support
Server side – Special technology is not needed
Comet
Comet is used to simulate the data push.
Long – lived XHR requests
Client side – Native JS support
Server side – Need a streaming server
Blank responses are limited
Reduce network traffic than polling
Server Sent Events (SSE)
Server Sent Events is used (only) for true data-push
Client side - HTML5 provides native JS support
Server side – Need a streaming server
Reduce network traffic than polling/comet
Blank responses and requests are totally eliminated
Web Socket (WS)
Web socket is bi-directional
Client side - HTML5 provides native JS support
Server side – Need a WS server
Reduce network traffic than polling/comet/SSE
Architecture

The client-side controller contains the event handlers for the GUI.
The events are triggered at the GUIs of the Views
Views are in the client-side, thus the events are triggered at the client-side
Therefore, placing the controller in the client side can be seen as an optimal solution
Client-side controller and model reduce the roundtrips to the server.
Thus, improve the performance and increase the scalability.
SPDC/AJAX
JQuery API
1. jQuery.ajax() - Perform an asynchronous HTTP (Ajax) request.
2. jQuery.get() - Load data from the server using a HTTP GET request.
3. jQuery.getJSON() - Load JSON-encoded data from the server using a GET HTTP request.
4. jQuery.getScript() - Load a JavaScript file from the server using a GET HTTP request, then execute it.
5. jQuery.post() - Load data from the server using a HTTP POST request.
6. .serialize() - Encode a set of form elements as a string for submission.
7. .load() - Load data from the server and place the returned HTML into the matched elements.
References
https://www.researchgate.net/publication/326395849_Rich_Web-based_Applications_An_Umbrella_Term_with_a_Definition_and_Taxonomies_for_Development_Techniques_and_Technologies
http://ir.kdu.ac.lk/handle/345/1704
http://api.jquery.com/category/ajax/
0 notes
Text
Client - Side Development – Jquery
Introduction to Jquery
Jquery is a framework/library which can hide the complexity of pure JS.
- Cross – browser compatible
- Backward compatible
Jquery offers many advanced features
Change content
Change CSS
Reveal GUI element
Delta communication
o find – elements in an HTML document
o change – HTML content
o listen – to what a user does and react accordingly
o animate – content on the page
o talk – over the network to fetch new content
How to use JQuery?
1. Using the downloaded source
I. Download
II. Link - <script src>”jQuery.min.js”</script>
III. Use it in your code <script src>myCode.js</script>
2. Using CDN
I. Link - <script src>”CDNPath”</script>
II. Use it in your code <script src>myCode.js</script>
Ways to use JQuery
jQuery(<selector>); -> jQuery(document);
$(<selector>); -> $(document);
document provides access to the current page
JS may execute before the page loads
- We have to make sure the page is completely loaded, before using JS/jQuery
JQuery Selectors
JQuery can use CSS selectors
Additionally, provides advanced selectors to access elements faster and efficiently
Basic Selectors

Advanced Selectors
Descendent selector
Child selector
Pseudo classes
DOM, DOM Navigation and DOM Objects
DOM
The Document Object Model(DOM) is a cross-platform and language-independent application programming interface that treats an XML document as a tree structure wherein each node is an object representing a part of the document.
The DOM represents a document with a logical tree. Each branch of the tree ends in a node, and each node contains objects.
DOM methods allow programmatic access to the tree; with them one can change the structure, style or content of a document. Nodes can have event handlers attached to them. Once an event is triggered, the event handlers get executed

o Jquery provides API to traverse through the DOM
o These DOM navigating APIs are faster
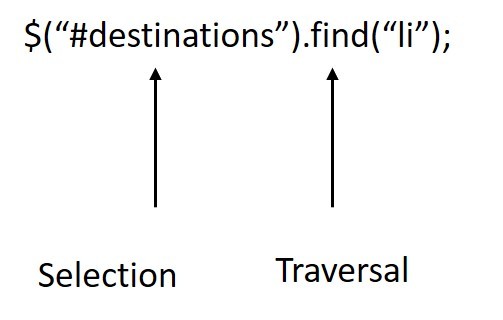
o Can navigate through the DOM, element by element
$(“li”).first();
$(“li”).first().next();
o Can use DOM element objects
var price = $(‘<p>From $399.99</p>’);
Event Handling
Event handlers can be set on elements, to be triggered by different events.
.on(<event>, <event handler>)
Advanced features
“(this)” object refers to the current object within the scope
Inside event handlers, “(this)” refers to the element, the event has triggered on
o Data Attributes
$('.vacation’).first().data(‘price’);
o Refactoring with DOM objects
var vacation = $(this).closest(‘.vacation’);
var amount = vacation.data(‘price’);
vacation.append(price);
o Target on specific element with generic names
$(‘.vacation’).on(‘click’, ‘button’, function() {});
o Filters
Filter(‘.onsale’)
o CSS manipulation
$(‘.vacation’).filter(‘.onsale’).addClass(‘highlighted’);
o Animation
.slideDown()
.slideUp()
.slideToggle()
0 notes
Text
Introduction to Client-Side Development
Introduction to client-side elements
Distributed systems use client-side elements, so that users can interact with.
The client-side elements include,
Views – what user see
Controller – contain event handlers for the views
Client-model – business logic and data
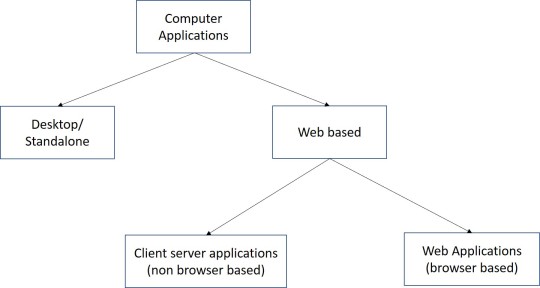
View Development
Browser-based clients’ Views comprises two main elements
Content – HTML
Formatting – CSS
HTML
HTML Elements
o Structural elements – header, footer, nav, aside
o Text elements – headings, paragraphs, line breaks
o Images
o Hyperlinks
o Data representational elements – Lists, Tables
o Form elements – Input, Radio buttons, Check boxes, Buttons
CSS (Cascading Style Sheets)
Used to decorate or format content.
Advantages:
Reduce HTML formatting tags
Easy modification
Faster loading
Save lot of work and time
Three main selectors of CSS
Element Selector
- Selects elements based on the name
ID Selector
- Uses the id attribute of HTML element to select a specific element
Class Selector
- Selects elements with a specific class attribute

Advanced selectors
Pseudo Classes Pseudo Elements
:link first-letter
:visited first-line
:hover first-child
Specificity:
Specificity is, which browser decide which css property values are the most relevant to an element and, therefore, will be applied.
Specificity is a weight that is applied to a given css declaration determined by the number of each selector type in the matching selector.
The following list of selector types increases by specificity
1. Type selector and pseudo elements
2. Class selectors, attribute selectors and pseudo classes
3. ID selectors
CSS Advanced features
Web fonts - Allow you to use custom fonts other than device fonts
Colors, gradients, backgrounds
Transformations and animations
Media
Media queries
Media queries can be used to check many things.
- Width and height of the viewport
- Width and height of the device
- Orientation
- Resolution
Can be used as
o Inline CSS
o Internal CSS sheets
o External CSS sheets
Inline CSS
Advantages:
Inline CSS can be used for many purposes, some of which include:
Testing: Many web designers use Inline CSS when they begin working on new projects, this is because its easier to scroll up in the source, rather than change the source file. Some also using it to debug their pages, if they encounter a problem which is not so easily fixed. This can be done in combination with the Important rule of CSS.
Quick-fixes: There are times where you would just apply a direct fix in your HTML source, using the style attribute, but you would usually move the fix to the relevant files when you are either able, or got the time.
Smaller Websites: The website such as Blogs where there are only limited number of pages, using of Inline CSS helps users and service provider.
Lower the HTTP Requests: The major benefit of using Inline CSS is lower HTTP Requests which means the website loads faster than External CSS.
Disadvantages
Inline CSS some of the disadvantages of which includes:
Overriding: Because they are the most specific in the cascade, they can over-ride things you didn’t intend them to.
Every Element: Inline styles must be applied to every element you want them on. So if you want all your paragraphs to have the font family “Arial” you have to add an inline style to each <p> tag in your document. This adds both maintenance work for the designer and download time for the reader.
Pseudo-elements: It’s impossible to style pseudo-elements and classes with inline styles. For example, with external and internal style sheets, you can style the visited, hover, active, and link color of an anchor tag. But with an inline style all you can style is the link itself, because that’s what the style attribute is attached to.
Internal CSS
Advantages
Since the Internal CSS have more preference over Inline CSS. There are numerous advantages of which some of important are an under:
Cache Problem: Internal styles will be read by all browsers unless they are hacked to hide from certain ones. This removes the ability to use media=all or @import to hide styles from old, crotchety browsers like IE4 and NN4.
Pseudo-elements: It’s impossible to style pseudo-elements and classes with inline styles. With Internal style sheets, you can style the visited, hover, active, and link color of an anchor tag.
One style of same element: Internal styles need not be applied to every element. So if you want all your paragraphs to have the font family “Arial” you have to add an Inline style <p> tag in Internal Style document.
No additional downloads: No additional downloads necessary to receive style information or we have less HTTP Request
Disadvantages
Multiple Documents: This method can’t be used, if you want to use it on multiple web pages.
Slow Page Loading: As there are less HTTP Request but by using the Internal CSS the page load slow as compared to Inline and External CSS.
Large File Size: While using the Internal CSS the page size increases but it helps only to Designers while working offline but when the website goes online it consumers much time as compared to offline.
External CSS
Advantages
There are many advantages for using external CSS and some of are:
Full Control of page structure: CSS allows you to display your web page according to W3C HTML standards without making any compromise with the actual look of the page.
Reduced file-size: By including the styling of the text in a separate file, you can dramatically decrease the file-size of your pages. Also, the content-to-code ratio is far greater than with simple HTML pages, thus making the page structure easier to read for both the programmer and the spiders.
Less load time: Today, when Google has included the Loading time in his algorithm, its become more important to look into the page loading time and another benefit of having low file-size pages translates into reduced bandwidth costs.
Higher page ranking: In the SEO, it is very important to use external CSS. In SEO, the content is the King and not the amount of code on a page. Search engines spider will be able to index your pages much faster, as the important information can be placed higher in the HTML document. Also, the amount of relevant content will be greater than the amount of code on a page. The search engine will not have to look too far in your code to find the real content. You will be actually serving it to the spiders “on a platter”.
There are many frameworks/libraries/plugins to support view development
o They dynamically generate HTML+CSS code
o In server and/or client side
o May have JS-based advanced interactive features
Other tools
jQuery - A JS library, but can be seen a framework too
jQuery UI - Focus on GUI development
Bootstrap - To rapidly design and develop responsive web pages and templates
Angular - A JS framework/platform to build frontend applications
React – A JavaScript library for building user interfaces
Templates are used to maintain consistency across pages in the web site/application.
Template engines are available for both server and client sides
Client-side (JS-based) template engines - NUNJUCKS, PUG, MUSTACHE.JS, HANDLEBARS
Server-side template engines - Twig, jTwig, Thymeleaf, Apache Velocity
Plug-ins
Plug-ins are mainly to add widgets to the Views
Component Development
Browser-based clients’ components comprises two main aspects
Controllers
Client-model
The components of browser-based clients are developed using JS/JS-based frameworks, libraries, and plugins.
Main features of client-side development tools
o DOM processing (dynamic content generation, change, removal)
o Data processing
o Data persistence
o Session management
o Communication
JS6 (JavaScript6)
Also called ECMAScript6
New features
JavaScript let
- The let statement allows you to declare a variable with block scope.
JavaScript const
- The const statement allows you to declare a constant
Exponentiation (**)
- The exponentiation operator (**) raises the first operand to the power of the second operand.
Default parameter values
- Default parameter values allows function parameters to have default values.
Array.find()
- The find() method returns the value of the first array element that passes a test function.
- function takes 3 arguments:
The item value
The item index
The array itself
Array.findIndex()
- The findIndex() method returns the index of the first array element that passes a test function.
- function takes 3 arguments:
The item value
The item index
The array itself
Web workers
This API is meant to be invoked by web application to spawn background workers to execute scripts which run in parallel to UI page
Web storage / Session storage
This is for persistent data storage of key-value pair data in Web clients.
GeoLocation
Identify the device location
File API
Handle the local files
Image capturing
Use local hardware
Top JS frameworks/ libraries
jQuery - Basic and simple. Cover the complexity of JS and provides cross-browser compatibility.
React - powers Facebook, Ease of Learning, DOM Binding, Reusable Components, Backward Compatibility
Angular - Support for Progressive Web Applications, Build Optimizer, Universal State Transfer API and DOM, Data Binding and MVVM
Vue – light weight, with a much-needed speed and accuracy
Generic client-side features
Form/ data validation
Dynamic content generating/updating
Some business logic
Delta communication
References
https://www.w3schools.com/css/css_syntax.asp
https://developer.mozilla.org/en-US/docs/Web/CSS/Specificity
https://www.w3schools.com/cssref/css3_pr_mediaquery.asp
https://vineetgupta22.wordpress.com/2011/07/09/inline-vs-internal-vs-external-css/
https://www.w3schools.com/js/js_es6.asp
0 notes
Text
Data Persistence
Introduction to Data Persistence
Information systems process data and convert them into information.
The data should persist for later use;
To maintain the status
For logging purposes
To further process and derive knowledge
Data can be stored, read, updated/modified, and deleted.
At run time of software systems, data is stored in main memory, which is volatile.
Data should be stored in non-volatile storage for persistence.
Two main ways of storing data
- Files
- Databases
Data, Files, Databases and DBMSs
Data : Data are raw facts and can be processed and convert into meaningful information.
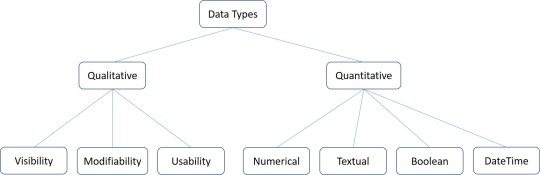
Data Arrangements
Un Structured : Often include text and multimedia content.
Ex: email messages, word processing documents, videos, photos, audio files, presentations, web pages and many other kinds of business documents.
Semi Structured : Information that does not reside in a relational database but that does have some organizational properties that make it easier to analyze.
Ex: CSV but XML and JSON, NoSQL databases
Structured : This concerns all data which can be stored in database SQL in table with rows and columns
Databases : Databases are created and managed in database servers
SQL is used to process databases
- DDL - CRUD Databases
- DML - CRUD data in databases
Database Types
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database model, data is organized into a tree like structure.
The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children
Ex: The IBM Information Management System (IMS) and Windows Registry
Advantages : Hierarchical database can be accessed and updated rapidly
Disadvantages : This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers.
A network database looks more like a cobweb or interconnected network of records.
Ex: Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Ex: Oracle, SQL Server, MySQL, SQLite, and IBM DB2
Object Oriented model
Object DBMS's increase the semantics of the C++ and Java. It provides full-featured database programming capability, while containing native language compatibility.
It adds the database functionality to object programming languages.
Ex: Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Ex: The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic
ER Model Databases
An ER model is typically implemented as a database.
In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents.
Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Ex: Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB
DBMSs : DBMSs are used to connect to the DB servers and manage the DBs and data in them
Data Arrangements
Data warehouse
Big data
- Volume
- Variety
- Velocity
Applications to Files/DB
Files and DBs are external components
Software can connect to the files/DBs to perform CRUD operations on data
- File – File path, URL
- Databases – Connection string
To process data in DB
- SQL statements
- Prepared statements
- Callable statements
Useful Objects
o Connection
o Statement
o Reader
o Result set
SQL Statements - Execute standard SQL statements from the application
Prepared Statements - The query only needs to be parsed once, but can be executed multiple times with the same or different parameters.
Callable Statements - Execute stored procedures
ORM
Stands for Object Relational Mapping
Different structures for holding data at runtime;
- Application holds data in objects
- Database uses tables
Mismatches between relational and object models
o Granularity – Object model has more granularity than relational model.
o Subtypes – Subtypes are not supported by all types of relational databases.
o Identity – Relational model does not expose identity while writing equality.
o Associations – Relational models cannot determine multiple relationships while looking into an object domain model.
o Data navigations – Data navigation between objects in an object network is different in both models.
ORM implementations in JAVA
JavaBeans
JPA (JAVA Persistence API)
Beans use POJO
POJO stands for Plain Old Java Object.
It is an ordinary Java object, not bound by any special restriction
POJOs are used for increasing the readability and re-usability of a program
POJOs have gained most acceptance because they are easy to write and understand
A POJO should not;·
Extend pre-specified classes
Implement pre-specified interfaces
Contain pre-specified annotations
Beans
Beans are special type of POJOs
All JavaBeans are POJOs but not all POJOs are JavaBeans
Serializable
Fields should be private
Fields should have getters or setters or both
A no-arg constructor should be there in a bean
Fields are accessed only by constructor or getters setters
POJO/Bean to DB
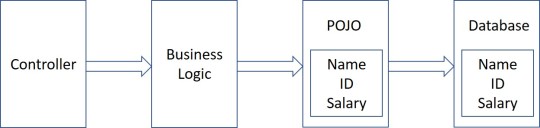
Java Persistence API
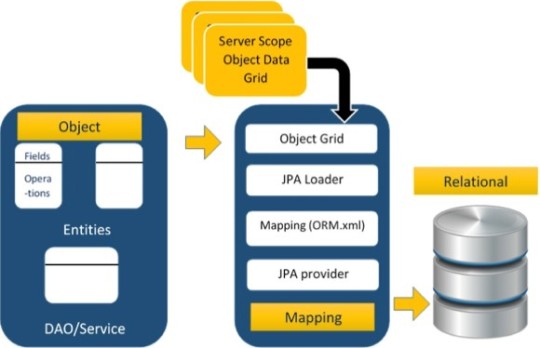
The above architecture explains how object data is stored into relational database in three phases.
Phase 1
The first phase, named as the Object data phase contains POJO classes, service interfaces and classes. It is the main business component layer, which has business logic operations and attributes.
Phase 2
The second phase named as mapping or persistence phase which contains JPA provider, mapping file (ORM.xml), JPA Loader, and Object Grid
Phase 3
The third phase is the Relational data phase. It contains the relational data which is logically connected to the business component.
JPA Implementations
Hybernate
EclipseLink
JDO
ObjectDB
Caster
Spring DAO
NoSQL and HADOOP
Relational DBs are good for structured data and for semi-structured and un-structured data, some other types of DBs can be used.
- Key value stores
- Document databases
- Wide column stores
- Graph stores
Benefits of NoSQL
Compared to relational databases, NoSQL databases are more scalable and provide superior performance
Their data model addresses several issues that the relational model is not designed to address
NoSQL DB Servers
o MongoDB
o Cassandra
o Redis
o Hbase
o Amazon DynamoDB
HADOOP
It is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
HADOOP Core Concepts
HADOOP Distributed File System
- A distributed file system that provides high-throughput access to application data
HADOOP YARN
- A framework for job scheduling and cluster resource management
HADOOP Map Reduce
- A YARN-based system for parallel processing of large data sets
Information Retrieval
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
1. Keyword Search
2. Full-text search
The output can be
1. Text
2. Multimedia
The information retrieval process should be;
Fast/performance
Scalable
Efficient
Reliable/Correct
Major implementations
Elasticsearch
Solr
Mainly used in search engines and recommendation systems
Additionally may use
Natural Language Processing
AI/Machine Learning
Ranking
References
https://www.tutorialspoint.com/jpa/jpa_orm_components.htm
https://www.c-sharpcorner.com/UploadFile/65fc13/types-of-database-management-systems/
0 notes
Text
Server side development 2 – REST
Introduction to REST
REST stands for Representational State Transfer.
REST is an architectural style for the service of web.
REST is
Resource based
Focus on representations
Derived using six constraints
Resource based
Things vs. Actions
Nouns vs. Verbs
Identified by URIs
Multiple URIs may refer to same resource
Separate from their representations
Representation
How resources get manipulated and presented
Part of the resource state is transferred between client and server.
Constraints
1) Client-Server
The REST is explicitly for networked distributed systems, which are based on the client-server style.
2) Layered systems
A client doesn’t need to know whether it is connected directly to the end server, or to an intermediary along the way.
3) Stateless
One client can send multiple requests to the server
Each request is independent
The server must not hold any information about the client state
4) Cacheable
As many clients access the same server, often they may request the same resources
It is necessary that these responses might be cached, avoiding unnecessary processing, which may affect performance
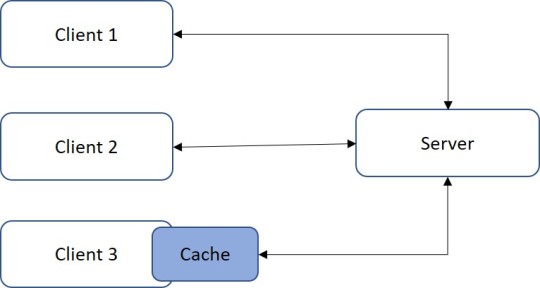
5) Code-on-demand (optional)
This allows the customer to run some code on demand, that is, extend part of server logic to the client, either through an applet or scripts
6) Uniform Interface
Defines the interface between clients and servers
REST is defined by four interface constraints:
Identification of resources
Based on web’s request response model
Request = URL + HTTP Verb (GET, POST, PUT, DELETE)
Response = HTML, XML, JSON
Manipulation of resources through representations
Self- descriptive messages
Hypermedia as the engine of application state
Elements of REST style
Components
Software that interacts with one another
Communicate by transferring representations of resources through a standard interface
Connectors
Represent activities involved in accessing resources and transferring representations
Connectors are abstract interfaces for component communication
Key aspect of REST is the state of the data elements, its components communicate by transferring representations of the current or desired state of data elements
REST manages data in following ways.
Render the data where it is located and send a fixed format image to the recipient.
Encapsulate the data with a rendering engine and send both to the recipient.
Send raw data to the recipient along with the meta data.
RESTful URLs
URL is the key technique in RESTful communication
The API of the RESTful service is a set of URLs
Operation = Read, Verb = GET
Collection
SLIIT.com/students/
Single item
SLIIT.com/students/IT123456
Multiple items
SLIIT.com/students/IT123456;IT456456;IT998877
Operation = Create, Verb = POST
Single item
SLIIT.com/students/
Multiple items
Same URL, items will be in the payload
Operation = Update, Verb = PUT
Collection
SLIIT.com/students/
Single item
SLIIT.com/students/IT123456
Multiple items
SLIIT.com/students/IT123456;IT456456;IT998877
Operation = Delete, Verb = DELETE
Collection
SLIIT.com/students/
Single item
SLIIT.com/students/IT123456
Multiple items
SLIIT.com/students/IT123456;IT456456;IT998877
Use MVC with REST and RESTful web services
Basic structure
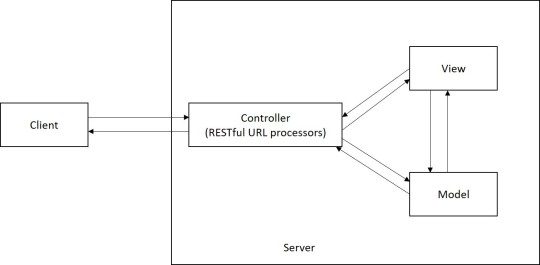
RESTful web services JAX-RS


Ref : https://docs.oracle.com/javaee/6/tutorial/doc/gilik.html
0 notes
Text
Server side development 1 – SOAP
Introduction to the web services
Web services are server-side application components, which provides a set of services.
The services of the web service are exposed via API.
An API is a set of functions and procedures allowing the creation of applications that access the features or data of an operating system, application or other service.
Multiple types of clients can communicate with the web service via the API.
Web services vs. Web Applications
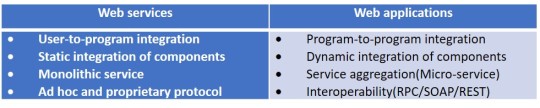
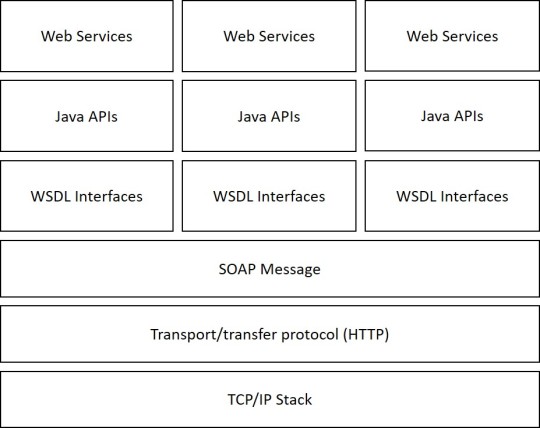
WSDL
WSDL stands for Web Services Description Language. It is the standard format for describing a web service. WSDL was developed jointly by Microsoft and IBM.
Features of WSDL
WSDL is an XML based protocol for information exchange in decentralized and distributed environments.
WSDL definitions describe how to access a web service and what operations it will perform.
WSDL is a language for describing how to interface with XML based services.
WSDL is and integral part of Universal Description, Discovery and Integration (UDDI), an XML based worldwide business registry.
WSDL is the language that UDDI uses
WSDL Usage
WSDL is often used in combination with SOAP and XML schema to provide web services over the internet. A client program connecting to a web service can read the WSDL to determine what functions are available on the server. Any special data types used are embedded in the WSDL file in the form of XML schema. The client can then use SOAP to actually call one of the functions listed in the WSDL.
Ref: https://www.tutorialspoint.com/wsdl/wsdl_introduction.htm
Specifies three fundamental properties:
1. What a service does – Operations (methods) provided by the service.
2. How a service is accessed – Data format and protocol details.
3. Where a service is located – Address (URL) details.
The document written in WSDL is also simply called a WSDL (or WSDL document).
The service provides the WSDL document and the web service client uses the WSDL document to create the stub (or to dynamically decode the message).
Stub
A stub is a small program routine that substitutes for a longer program, possibly to be loaded later or that is located remotely. For example, a program that uses Remote Procedure Calls (RPC ) is compiled with stubs that substitute for the program that provides a requested procedure.
The stub accepts the request and then forwards it (through another program) to the remote procedure. When that procedure has completed its service, it returns the results or other status to the stub which passes it back to the program that made the request.
Ref: https://whatis.techtarget.com/definition/stub
WSDL Elements – Type
Use the XML schema language to declare complex data types and elements that are used elsewhere in the WSDL document.
Serve as a container for defining any data types that are not described by the XML schema built-in types.
WSDL Elements – Message
Any WSDL interface is a set of messages that the service behind the interface expects to send and receive.
Messages are abstraction of request and response messages that client and web services exchange.
Messages are constructed from a number of XML schema typed part elements.
Ex:
<message name="getQuoteResponse">
<part name="Result" type="xsd:float"/>
</message>
WSDL Elements – Port type
Define web service functionality at abstract level, grouping sets of message exchanges into operations.
Contain a set of operations that incorporates input, output and fault messages and parameter order.
portType element may have one or more operation elements, each of which defines an RPC style or document style web service method.
WSDL Elements – Binding
Map a portType to a specific protocol, typically SOAP over HTTP, using a specific data encoding style.
One portType can be bound to several different protocols by using more that one port.
Binding style may be either RPC or Document (SOAP)
WSDL Elements – Service
It binds the web service to a specific network addressable location
Contain one or more port elements.
Access point for each port
- portType – The operations performed by the web service.
- message – The message used by the web service.
- types – The data types used by the web service.
- binding – The communication protocols used by the web service.
SOAP
SOAP stands for Simple Object Access Protocol.
SOAP supports both functional oriented and message oriented communication.
SOAP messages are carried as the payloads of some other network protocols.
(EX: HTTP or SMTP or FTP or TCP/IP)
Web services use SOAP as the logical transport mechanism for moving messages between services described by WSDL interfaces.
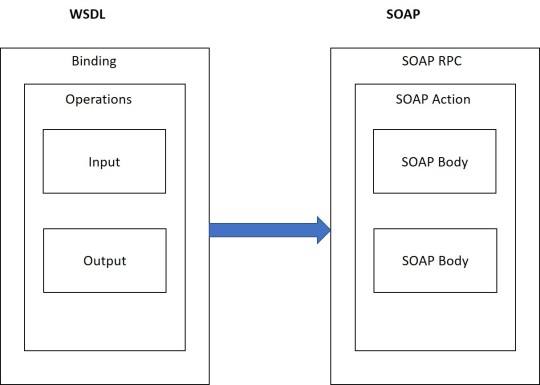
SOAP combines the data capabilities of XML with the transport capability of HTTP.
SOAP Messaging Modes
RPC/ Literal Document/ Literal
RPC/ Encoded Document/ Encoded
SOAP Messaging
Consistent envelope – Header and body
Consistent data encoding – Based on XML schema type system
Protocol binding framework
SOAP messages have encoding rules:
Defines a serialization mechanism that can be used to exchange instance of application- defined objects.
SOAP Elements – Envelope
Wraps entire message and contain header and body.
Defines an overall framework for expressing what is in a message, who should deal with it and whether it is optional or mandatory.
Envelope is a root XML element.
This tag indicates the start and end of the message to the receiver.
SOAP Elements – Header
An optional element with additional information.
If the header is presented in the message, it must be the immediate child of envelope element.
Header adds meta-data about the content of a SOAP message and extends it with extra information.
Headers may be processed independently of the body.
SOAP Elements – Body
Application- specific message content being communicated as arbitrary XML payloads in the request and response messages.
Fault elements provides information about errors.
This is the only mandatory part of the envelope. Contains the actual message sent for the final recipient
SOAP Elements – Fault
SOAP message that contains a fault element in the body is called a fault message.
SOAP faults are returned to the receiver’s immediate sender.
SOAP Elements – AttachmentPart
SOAP messages may have one or more attachments.
Each AttachmentPart object has a MIME header to indicate the type of data it contains.
MIME (Multipurpose Internet Main Extension) is an internet standard that extends the format of email to support
- Text in character sets other that ASCII.
- Non text attachments: audio, video, images, application programs
- Message bodies with multiple parts
- Header information is non-ASCII character sets
Ref: https://en.m.wikipedia.org/wiki/MIME
Frameworks for SOAP web service development environments
Apache CXF – Java
CodeIgniter – PHP
gSOAP – C and C++
Apache Axis – Java
Jello Framework – GAE/Java
.NET Framework – C#, VB.NET
Implement SOAP services
JAX-WS (Java API for XML Web Services) is a java package/ library for developing web services.
It supports both functional oriented and message-oriented communication via SOAP.
JAX-WS uses the javax.jws package and it uses annotations.
(Ex: @WebService, @WebMethod, @Oneway etc…)
0 notes
Text
Distributed Systems
Introduction to Distributed Systems
There are two types of computer based systems, according to the distribution of the components.
Standalone systems (Desktop applications)
Distributed systems
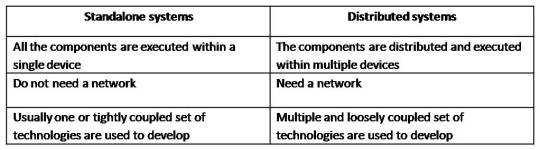
Distributed Computing :
Distributed computing is where multiple computing units are connected to achieve a common task.
Distributed systems :
Distributed system consists of a collection of autonomous computers, connected through a network and distribution middleware.
Elements of distributed system
Processing components
Data networks
Data stores and data
Configuration of above elements
Advantages of Distributed Systems
All the nodes in the distributed system are connected to each other. So nodes can easily share data with other nodes
More nodes can easily be added to the distributed system
Failure of one node does not lead to the failure of the entire distributed system. Other nodes can still communicate with each other
Disadvantages of Distributed Systems
It is difficult to provide adequate security in distributed systems because the nodes as well as the connections need to be secured
Some messages and data can be lost in the network while moving from one node to another
The database connected to the distributed systems is quite complicated and difficult to handle as compared to a single user system
Overloading may occur in the network if all the nodes of the distributed system try to send data at once
Types of services in distributed systems
Mail service (SMTP, POP)
File transferring and sharing (FTP)
Remote logging (telnet)
Games and multimedia (RTP,SIP)
Web(HTTP)
Types of systems
Web sites
Web applications
Web services and client apps
Rich Internet Applications(RIAs)/ Rich Web based Applications (RiWAs)
Architecture of Distributed Systems
The basic architecture is client-server architecture (two-tier architecture)
The client sends a request asking the server for some service and the server responses with the resources.
The application is modeled as a set of services that are provided by servers and a set of clients that use these services
Clients know of servers but servers need not know of clients
Clients and servers are logical processes
Three-tier architecture is used, when data is needed and also to separate application logic of data
In a three-tier architecture, each of the application architecture layers may execute on a separate processor
When further separation and distribution of components is needed, more layers can be added and extend the 2-tier or 3-tier architecture into a n-tier architecture
Service oriented architecture
Distributed systems use Service Oriented Architecture (SOA) to communicate and share their services forming enterprise level services.
These different systems may
provide different services
are developed using different technologies
communicate via the Enterprise Service Bus (ESB)
Enterprise Service Bus (ESB)
An Enterprise Service Bus (ESB) is fundamentally an architecture. It is a set of rules and principles for integrating numerous applications together over a bus-like infrastructure. ESB products enable users to build this type of architecture, but vary in the way that they do it and the capabilities that they offer. The core concept of the ESB architecture is that you integrate different applications by putting a communication bus between them and then enable each application to talk to the bus. This decouples systems from each other, allowing them to communicate without dependency on or knowledge of other systems on the bus. The concept of ESB was born out of the need to move away from point-to-point integration, which becomes brittle and hard to manage over time.
https://www.mulesoft.com/resources/esb/what-esb
Modularizing styles
Monolithic vs. Microservices
Monolithic architecture
A monolithic architecture is the traditional unified model for the design of a software program.Monolithic, in this context, means composed all in one piece. Monolithic software is designed to be self-contained; components of the program are interconnected and interdependent rather than loosely coupled as is the case with modular software programs
Micro service architecture
Micro service architecture, or simply micro services, is a distinctive method of developing software systems that tries to focus on building single-function modules with well-defined interfaces and operations.
The trend has grown popular in recent years as Enterprises look to become more Agile and move towards a DevOps and continuous testing. Micro services can help create scalable, testable software that can be delivered weekly, not yearly.
https://smartbear.com/learn/api-design/what-are-microservices/
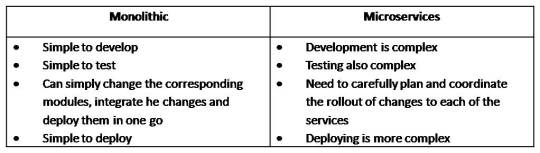
Communication in Distributed Systems
Communication techniques/technologies
Functional oriented communication
RPC/RMI
CORBA
Message oriented communication
SOAP
Resource oriented communication
REST
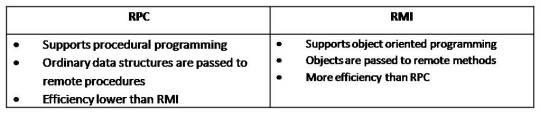
Data formatting/structuring
Plain text
Files (text, images)
Query String
XML
JSON
XML
XML is designed to store and transport data and both human and machine readable.
The main and the only component of the XML is an Element.
An element has 3 components
Start tag
Body
End tag
An element has a name.
Elements name are case sensitive and must start with a letter or underscore
Element names can contain letters, digits, hyphens, underscores and periods
Element names cannot contain names
Etc.
XML vs. JSON

0 notes
Text
Industry Practices and Tools 2
Code quality
Importance of code quality
The long-term usefulness and long-term maintainability of the code
Minimize errors and easily debugged
Improve understandability
Decrease risks
Impact of code quality
Clarity
Maintainable
Documented
Re-factored
Well-tested
Efficiency
Extensible
The quality of the code can be measured by different aspects
Weighted Micro Function Points (WMFP)
Weighted Micro Function Points is a modern software sizing algorithm invented by Logical Solutionsin 2009 which is a successor to solid ancestor scientific methods as COCOMO, COSYSMO, maintainability index, cyclomatic complexity, function points, and Halstead complexity.
It produces more accurate results than traditional software sizing methodologies while requiring less configuration and knowledge from the end user, as most of the estimation is based on automatic measurements of an existing source code.
As many ancestor measurement methods use source lines of code (SLOC) to measure software size, WMFP uses a parser to understand the source code breaking it down into micro functions and derive several code complexity and volume metrics, which are then dynamically interpolated into a final effort score.
Halstead complexity measures
Halstead complexity measures are software metrics introduced by Maurice Howard Halstead in 1977 as part of his treatise on establishing an empirical science of software development.
Halstead made the observation that metrics of the software should reflect the implementation or expression of algorithms in different languages, but be independent of their execution on a specific platform. These metrics are therefore computed statically from the code.
Halstead's goal was to identify measurable properties of software, and the relations between them.
Cyclomatic complexity
Cyclomatic complexity is a software metric used to indicate the complexity of a program. It is a quantitative measure of the number of linearly independent paths through a program's source code.
Cyclomatic complexity is computed using the control flow graph of the program: the nodes of the graph correspond to indivisible groups of commands of a program, and a directed edge connects two nodes if the second command might be executed immediately after the first command. Cyclomatic complexity may also be applied to individual functions, modules, methods or classes within a program.
Dependency/Package management
Software project may have a backbone framework and many external artefacts linked.
These external artefacts may introduce many integration issues.
There are tools to manage these external artefacts towards minimizing these issues.
Composer (PHP)
Maven (Java)
NPM(Node Package Manager)(JS)
Manage packages with Maven
Maven is a multi-purpose tool
~ It makes the build process easy and provide a uniform build system
~ It provides quality project information
~ It allows transparent migration to new features
Maven is not only a dependency or package management tool, but also it is a build tool.
Role of package manager
A package manager deals with packages, distributions of software and data in archive files. Packages contain metadata, such as the software's name, description of its purpose, version number, vendor, checksum, and a list of dependencies necessary for the software to run properly. Upon installation, metadata is stored in a local package database. Package managers typically maintain a database of software dependencies and version information to prevent software mismatches and missing prerequisites. They work closely with software repositories, binary repository managers, and app stores.
Use of the repositories
A repository in Maven holds build artifacts and dependencies of varying types.
There are exactly two types of repositories:
Local
Remote.
- Internal – Within the company
- External – via the internet, from the original repo.
The local repository is a directory on the computer where Maven runs. It caches remote downloads and contains temporary build artifacts that you have not yet released.
When using Maven, particularly in a corporate environment, connecting to the internet to download dependencies is not acceptable for security, speed or bandwidth reasons. For that reason, it is desirable to set up an internal repository to house a copy of artifacts, and to publish private artifacts to.
Repository manager purpose
Act as dedicated proxy server for public Maven repositories
Provide repositories as a deployment destination for your Maven project outputs
Benefits and features
Significantly reduced number of downloads off remote repositories, saving time and bandwidth resulting in increased build performance
Improved build stability due to reduced reliance on external repositories
Increased performance for interaction with remote SNAPSHOT repositories
Potential for control of consumed and provided artifacts
Creates a central storage and access to artifacts and meta data about them exposing build outputs to consumer such as other projects and developers, but also QA or operations teams or even customers
Provides an effective platform for exchanging binary artifacts within your organization and beyond without the need for building artifact from source
Use the POM
Project Object Model (POM) is an XML representation of a Maven project held in a file named pom.xml
Contains the configurations of the project
Developers involved and the roles they play
The defect tracking system
The organization and licenses
The URL of where the project lives
The project's dependencies
Build tools
Build tools are programs that automate the creation of executable applications from source code.
(Ant/Ivy, Maven, Gradle, Sbt, MSBuild)
Build automation
On-demand automation
A user running a script in the command line
Scheduled automation
A continuous integration server running a nightly build.
Triggered automation
A continuous integration server running a build on every commit to version control system
Role of build automation
Automating the creation of a software build and the associated processes including, compiling computer source code into binary code, packaging binary code and running automated tests.
Maven uses Convention over Configuration,
which means developers are not required to create build process themselves.Developers do not have to mention each and every configuration detail.
Maven build life cycle
A Build Lifecycle is a well-defined sequence of phases, which define the order in which the goals are to be executed
The default life cycle of Maven uses 23 phases to build the application.
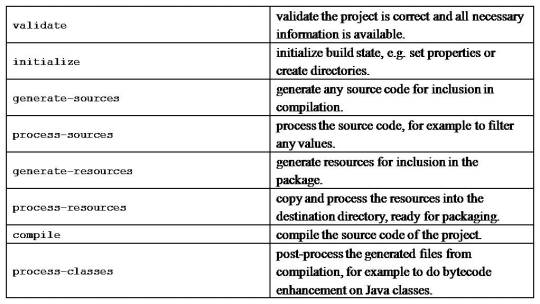
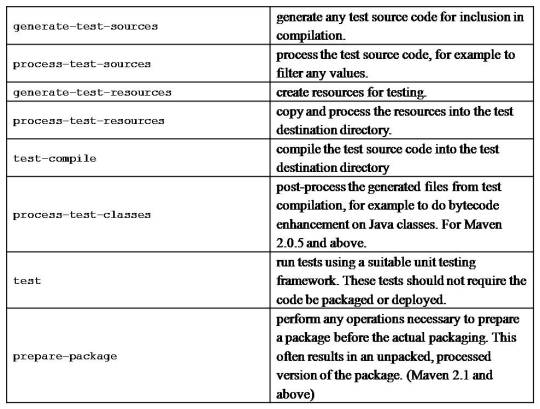
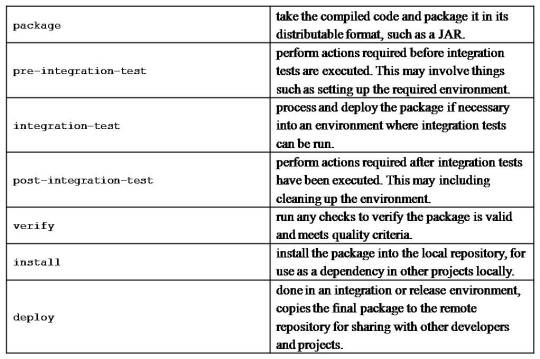
Maven build profile
A Build profile is a set of configuration values, which can be used to set or override default values of Maven build.
Additional tools and practices
Continuous integration
Continuous Integration (CI) is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
By integrating regularly, you can detect errors quickly, and locate them more easily.
Configuration management
Configuration management (CM) is a systems engineering process for establishing and maintaining consistency of a product's performance, functional, and physical attributes with its requirements, design, and operational information throughout its life.
Test automation
Automation testing is an Automatic technique where the tester writes scripts by own and uses suitable software to test the software. It is basically an automation process of a manual process.
The main goal of Automation testing is to increase the test efficiency and develop software value.
0 notes
Text
Industry Practices and Tools 1
Version Controlling
Version control systems are a category of software tools that help a software team to manage changes to source code over time.
Version control software keeps track of every modification to the source in a special kind of database.
If a mistake is made
~ developers can turn back the clock
~ compare earlier versions of the code to help fix the mistake
~ minimizing disruption to all team members
Why VCS?
Collaboration
~ With a VCS, everybody on the team is able to work absolutely freely - on any file at any time.
Storing versions properly
~ A version control system acknowledges that there is only one project
Restoring previous versions
Understanding what happened
Back up
Models of VCS

GIT
GIT is the most commonly used version control system today and has quickly become the standard for version control.
Popular implementations:
GitHub, GitLab, GitBucket, CloudForge
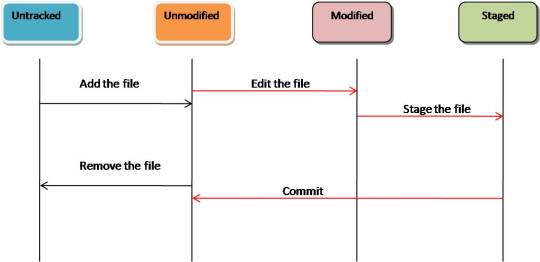
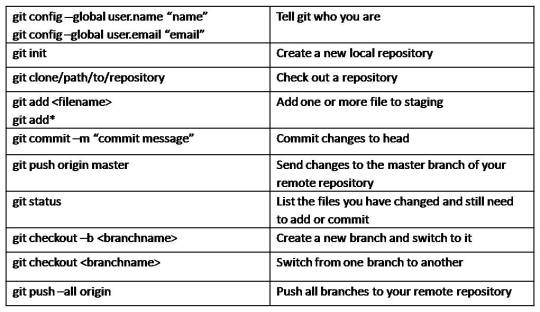
GIT Terminology

GIT File Status Life Cycle
GIT Commands
Content Delivery/Distributed Networks(CDN)
CDN is a geographically distributed network of proxy servers and their data centers.
The goal is to provide high availability and high performance by distributing the service spatially relative to end-users
Today, content delivery networks or CDNs have gained prominence. These are simply networked systems that are in cooperative mode and peak with neural networks.
Benefits
Improving web site load times
Reducing bandwidth costs
Increasing content availability and redundancy
Improving web site security
Difference between web hosting servers and CDNs
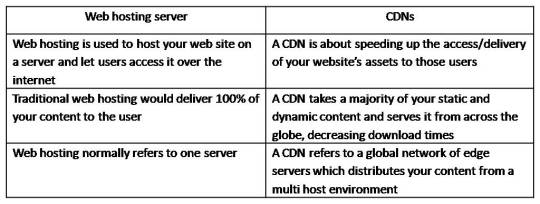
Virtualization
Virtualization refers to the creation of a virtual resource such as a server, desktop, operating system, file, storage or network.
The main goal of virtualization is to manage workloads by radically transforming traditional computing to make it more scalable. Virtualization has been a part of the IT landscape for decades now, and today it can be applied to a wide range of system layers, including operating system-level virtualization, hardware-level virtualization and server virtualization.
Hardware virtualization - VMs, emulators
OS level virtualization (Desktop virtualization )
- Remote desktop terminals
Application level virtualization
- Runtimes (JRE/JVM, .NET), engines (games engines)
Containerization (also OS/application level )
- Dockers
Other virtualization types - Database, network, storage
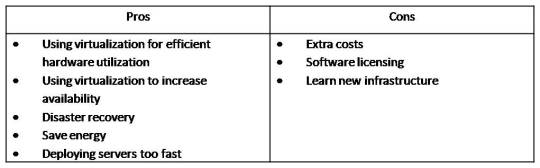
Pros and Cons of Virtualization
What is a Hypervisor in virtual machines?
A hypervisor is a process that separates a computer’s operating system and applications from the underlying physical hardware. Usually done as software although embedded hypervisors can be created for things like mobile devices.
The hypervisor drives the concept of virtualization by allowing the physical host machine to operate multiple virtual machines as guests to help maximize the effective use of computing resources such as memory, network bandwidth and CPU cycles.
0 notes
Text
Programming Frameworks
Programming Paradigms
Programming paradigms classify programming languages based on their features and characteristics.
Ex: Functional programming, Object oriented programming
Some computer languages support multiple paradigms.
Ex: C++ support both functional OOP.
Non- structured programming
Earliest paradigm
A series of code
Becomes complex as the number of lines increases
Structured programming
Handle the issues of non structured programming by introducing the ways to structure the code using blocks.
- Control structures
- Functions/Procedures/Methods
- Classes/Blocks
Types of structured programming
- Block structured (functional) programming
- Object oriented programming
Event driven programming
Focus on the events launched outside the system.
- User events (Click, drag/drop)
- Schedulers/compilers
- Sensors, messages , hardware interrupts
Mostly related to the systems with GUIs.
Functional programming
Origins from Lambda Calculus.
Lambda Calculus : This is a formal system in mathematical logic for expressing computation based on function abstraction and application using variable binding and substitution.
No side – effects = Referential transparency
Execution of a function does not effect on the global state of the system.
Use a declarative approach
Declarative approach : is a programming paradigm that expresses the logic of computation without describing its control flow.
This helps to minimize the side – effects.
Procedural programming
This paradigm helps to structure the code using blocks (procedures, routines, sub-routines, functions, methods).
A procedure can implement a single algorithm using the control structures.
Has side – effects.
Use imperative approach.
Imperative approach : is a programming paradigm that uses statements to change program’s state.
Software Runtime Architecture
Languages can be categorized to the way they are processed and executed.
The general software runtime architecture
The communication between the application and the OS
needs additional components.
Compiled languages
Some executables can directly run on the OS.
Some uses virtual runtime machines.
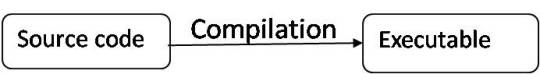
Scripting languages
Source code is not compiled, it is directly executed and at the execution time the code is interpreted by a runtime machine.
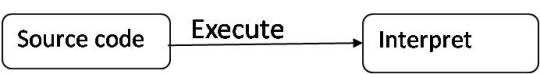
Markup languages
No execution process for the markup languages.
The tools who have the knowledge to understand the markup languages can generate the output.
Development tools
Computer Aided Software Engineering (CASE) tools are used throughout the engineering life cycle of the software systems.
CASE software types
Individual tools – for specific task
Workbenches – multiple tools are combined focusing on a specific part of SDLC.
Environments – Combines many tools to support many activities throughout the SDLC.
Frameworks vs Plugins vs Libraries
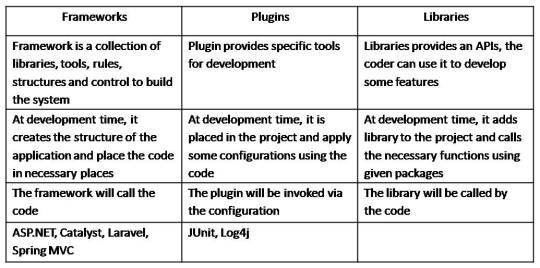
Frameworks are concrete
A framework is incomplete
Framework helps solving recurring problems
The difference between JDK and JRE
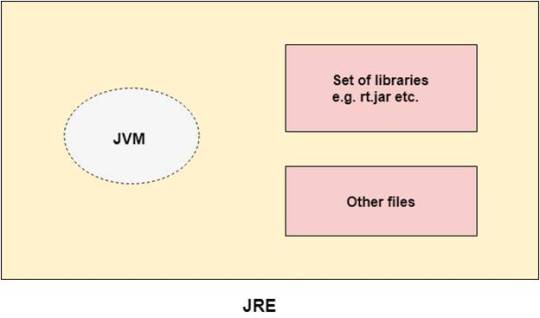
JRE
JRE is an acronym for Java Runtime Environment. It is also written as Java RTE. The Java Runtime Environment is a set of software tools which are used for developing Java applications. It is used to provide the runtime environment. It is the implementation of JVM (Java Virtual Machine). It physically exists. It contains a set of libraries + other files that JVM uses at runtime.
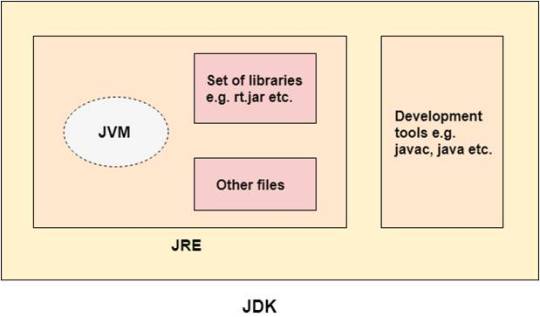
JDK
JDK is an acronym for Java Development Kit. The Java Development Kit (JDK) is a software development environment which is used to develop Java applications and HYPERLINK applets. It physically exists. It contains JRE + development tools.
JDK is an implementation of any one of the below given Java Platforms released by Oracle Corporation:
Standard Edition Java Platform
Enterprise Edition Java Platform
Micro Edition Java Platform
The JDK contains a private Java Virtual Machine (JVM) and a few other resources such as an interpreter/loader (java), a compiler (javac), an archiver (jar), a documentation generator (Javadoc), etc. to complete the development of a Java Application.
JVM
JVM (Java Virtual Machine) is an abstract machine. It is called a virtual machine because it doesn't physically exist. It is a specification that provides a runtime environment in which Java bytecode can be executed. It can also run those programs which are written in other languages and compiled to Java bytecode.
The JVM performs the following main tasks:
Loads code
Verifies code
Executes code
Provides runtime environment
JDK = JRE + Development tools
JRE = JVM + Library classes
Why we have to edit the path after installing the JDK?
When you type any thing in Command prompt , except the standard keywords like ( cd , dir) , the command prompt searches them in the folder where you are and tries to execute it , also as the cmd ( Command Prompt ) is from C:\WINDOWS\SYSTEM32 , so all the programs from here are accessible form anywhere in windows , also this is necessary , here , this is a necessity for windows to keep them in hand , whenever needed , where ever needed .
The path points to the location of the jre i.e. the java binary files such as the jvm and necessary libraries. The classpath points to the classes you developed so that the jvm can find them and load them when you run your product.
So essentially you need the path to find java so it can then find your classes and run them from the classpath.
Why you should need to set JAVA_HOME?
When you run a Java program you need to first start the JVM, typically this is done by running an executable, on Windows this is java.exe. You can get that in lots of ways for example just giving a full path:
C:\somedir\bin\java.exe
or may having it on your PATH.
You specify as command line arguments some class files or Jar files containing class files which are your program. But that's not enough, the java.exe itself needs various other resources, not least all the Java libraries. By setting the environment variable JAVA_HOME you specify where the JRE, and hence all those runtime resources, are to be found. You should ensure that the particular Java you execute matches the setting of JAVA_HOME.
Difference between PATH and JAVA HOME

Java IDE’s and comparisons
Eclipse
Eclips is an open source platform. This is used in both open source and commercial projects. Starting in a humble manner, this has now emerged as a major platform, which is also used in several other languages.
The greatest advantage of Eclipse is that it features a whole plethora of plugins, which makes it versatile and highly customizable. This platform works for you in the background, compiling code, and showing up errors as they occur. The entire IDE is organized in Perspectives, which are essentially sort of visual containers, which offer a set of views and editors.
Eclipse’s multitasking, filtering and debugging are yet other pluses. Designed to fit the needs of large development projects, it can handle various tasks such as analysis and design, product management, implementation, content development, testing, and documentation as well.
NetBeans
NetBeans was independently developed and it emerged as an open source platform after it was acquired by Sun in 1999. This IDE can be used to develop software for all versions of Java ranging from Java ME up to the Enterprise Edition.
NetBeans offers you various different bundles – 2 C/C++ and PHP editions, a Java SE edition, the Java EE edition, and 1 kitchen sink edition that offers everything you will ever need for your project. This IDE also offers tools and editors which can be used for HTML, PHP, XML, JavaScript and more. You can now find support for HTML5 and other Web technologies as well.
NetBeans scores over Eclipse in that it features database support, with drivers for Java DB, MySQL, PostgreSQL, and Oracle. Its Database Explorer enables you to easily create, modify and delete tables and databases within the IDE.
IntelliJ Idea
IntelliJ offers support for a variety of languages, including Java, Scala, Groovy, Clojure and more. This IDE comes with features such as smart code completion, code analysis, and advanced refactoring. The commercial “Ultimate” version, which mainly targets the enterprise sector, additionally supports SQL, ActionScript, Ruby, Python, and PHP. Version 12 of this platform also comes with a new Android UI designer for Android app development.
IntelliJ too features several user-written plugins. It currently offers over 900 plugins, plus an additional 50+ in its enterprise version.
Conclusion
All of the above IDEs come with their own advantages. While Eclipse is still the widest used IDE, NetBeans is now gaining popularity with independent developers. While the enterprise edition of IntelliJ works like a marvel, some developers may consider it an unnecessary expense.
1 note
·
View note