
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by blogdegustavop-blog and here's what we found interesting.
Average Info
Notes Per Post
7
Likes Per Post
1
Reblog Per Post
6
Reply Per Post
0
Time Between Posts
14 days
Number of Posts By Type
Text
7
Photo
1
Last Seen Tumblr Blogs




Fun Fact
12.7% of mobile users access Tumblr.
Text
Week 3 Homework
This is my program:
# -*- coding: utf-8 -*- """ Spyder Editor @author: Gustavo """ #import libraries import pandas import numpy #Starts Week 1 # Data charge of the dataset dataraw = pandas.read_csv('gapminderV4.csv', low_memory=False) #remove unnecessary columns and make a copy of the subdata data1 = dataraw[["country","continent","reselectricity", "energyused","co2emissions"]] data = data1.copy() print(data) #remove missing values(in my case '0' values) data= data.replace(0, numpy.NaN) # Now I want to drop all rows where both the variables are NA data=data.dropna(subset=['reselectricity','energyused','co2emissions'], how='all') print(len(data)) print(len(data.columns)) #Ends Week 1 #Starts Week 2 # Change the data type for chosen variables data['reselectricity'] = pandas.to_numeric(data['reselectricity']) data['energyused'] = pandas.to_numeric(data['energyused']) data['co2emissions'] = pandas.to_numeric(data['co2emissions']) ##calculate frequencies for variables that you decided to work with (as requested) #Residential electricity consumption print('Counts for relectricperperson - Residential Electricity Consumption, per person in kWh') #Count c1 = data["reselectricity"].value_counts(sort=False) print (c1) #Percent p1 = data["reselectricity"].value_counts(sort=False, normalize=True) #Percent print (p1) #Frequency print("first values for reselectricity:") reselectricity_freq = pandas.concat(dict(counts = data["reselectricity"].value_counts(sort=False, dropna=False), percentages = data["reselectricity"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print(reselectricity_freq.head(5)) #Print the first 5 items #Energy used print('Counts for energyused - Energy used ') #Count c1 = data["energyused"].value_counts(sort=False) print (c1) #Percent p1 = data["energyused"].value_counts(sort=False, normalize=True) #Percent print (p1) #Frequency print("first values for energyused:") energyused_freq = pandas.concat(dict(counts = data["energyused"].value_counts(sort=False, dropna=False), percentages = data["energyused"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print(energyused_freq.head(5)) #Print the first 5 items #Energy used print('Counts for co2emissions - CO2 Emissions ') #Count c1 = data["co2emissions"].value_counts(sort=False) print (c1) #Percent p1 = data["co2emissions"].value_counts(sort=False, normalize=True) #Percent print (p1) #Frequency print("first values for co2emissions:") energyused_freq = pandas.concat(dict(counts = data["co2emissions"].value_counts(sort=False, dropna=False), percentages = data["co2emissions"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print(energyused_freq.head(5)) #Print the first 5 items #Ends Week 2 # Show only the information for analysis #subdata= data[['country','reselectricity','energyused','co2emissions']] subdata= data[['continent','reselectricity','energyused','co2emissions']] #Starts Week 3 ##Create variable quartiles and calculate frequency in bins #calculate frequency in bins #Recidential Electricity Consumption data['reselectricitypercent'] =pandas.cut(data.reselectricity,4,labels=['0-25%','26-50%','51-74%','75-100%']) reselectricity_freq = pandas.concat(dict(counts = data["reselectricitypercent"].value_counts(sort=False, dropna=False), percentages = data["reselectricitypercent"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print("Frequency distribution - Residential Electricity Consumption:\n", reselectricity_freq) #What are the countries with high and very high Recidential Electricity Consumption print('Countries with high and very high Recidential Electricity Consumption') highreselectricity = data[(data['reselectricitypercent'] == '51-74%') | (data['reselectricitypercent'] == '75-100%') ] print(highreselectricity.loc[:, ['country', 'reselectricity', 'reselectricitypercent']].sort_values(by='reselectricitypercent', ascending=False)) #Energy Used data['energyusedpercent'] =pandas.cut(data.energyused,4,labels=['0-25%','26-50%','51-74%','75-100%']) energyused_freq = pandas.concat(dict(counts = data["energyusedpercent"].value_counts(sort=False, dropna=False), percentages = data["energyusedpercent"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print("Frequency distribution - Energy used:\n", energyused_freq) #What are the countries with high and very high Recidential Electricity Consumption print('Countries with high and very high Energy used') highenergyused = data[(data['energyusedpercent'] == '51-74%') | (data['energyusedpercent'] == '75-100%') ] print(highenergyused.loc[:, ['country', 'energyused', 'energyusedpercent']].sort_values(by='energyusedpercent', ascending=False)) #Energy Used data['co2emissionspercent'] =pandas.cut(data.co2emissions,4,labels=['0-25%','26-50%','51-74%','75-100%']) co2emissions_freq = pandas.concat(dict(counts = data["co2emissionspercent"].value_counts(sort=False, dropna=False), percentages = data["co2emissionspercent"].value_counts(sort=False, dropna=False, normalize=True)), axis=1) print("Frequency distribution - CO2 Emissions:\n", co2emissions_freq) #What are the countries with high and very high Recidential Electricity Consumption print('Countries with high and very high CO2 Emissions') highco2emissions = data[(data['co2emissionspercent'] == '51-74%') | (data['co2emissionspercent'] == '75-100%') ] print(highco2emissions.loc[:, ['country', 'co2emissions', 'co2emissionspercent']].sort_values(by='co2emissionspercent', ascending=False)) The main outputs are:
Name: co2emissions, Length: 128, dtype: float64 first values for co2emissions: counts percentages 24.00 1 0.007692 3.29 1 0.007692 14.50 1 0.007692 9.25 1 0.007692 22.50 1 0.007692 Frequency distribution - Residential Electricity Consumption: counts percentages 0-25% 127 0.976923 26-50% 1 0.007692 51-74% 0 0.000000 75-100% 1 0.007692 NaN 1 0.007692 Countries with high and very high Recidential Electricity Consumption country reselectricity reselectricitypercent 122 United States 1.380000e+12 75-100% Frequency distribution - Energy used: counts percentages 0-25% 106 0.815385 26-50% 16 0.123077 51-74% 5 0.038462 75-100% 3 0.023077 Countries with high and very high Energy used country energyused energyusedpercent 115 Trinidad and Tobago 14100 75-100% 94 Qatar 16400 75-100% 52 Iceland 16400 75-100% 120 United Arab Emirates 8600 51-74% 71 Luxembourg 8610 51-74% 65 Kuwait 10800 51-74% 17 Brunei 9340 51-74% 8 Bahrain 11300 51-74% Frequency distribution - CO2 Emissions: counts percentages 0-25% 114 0.876923 26-50% 11 0.084615 51-74% 4 0.030769 75-100% 1 0.007692 Countries with high and very high CO2 Emissions country co2emissions co2emissionspercent 94 Qatar 46.7 75-100% 115 Trinidad and Tobago 33.7 51-74% 65 Kuwait 31.2 51-74% 17 Brunei 24.0 51-74% 8 Bahrain 26.7 51-74%
I only have a NaN value in all my DataSet, it is the Residencial Electricity Consumption for Iraq. I couldn´t make and aproximation because the last information registered is in 1987, it is more than 20 years ago. For that reason I deside do not include this country in my analysis.
I created 3 second varibles to help my visualization:
highreselectricity
highenergyused
highco2emissions
I going to investigate how to find out if there is a correlation between the primary variables.
0 notes
Photo
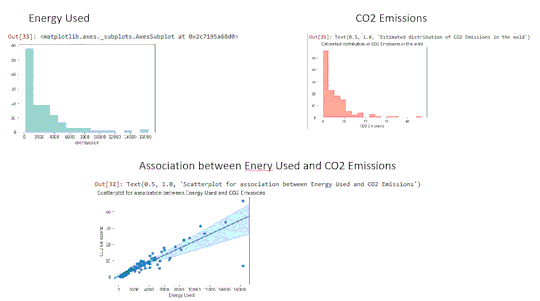
Here you can see the Association between Enery Used and CO2 Emissions. It as a possitive slope whish mean they are related so close.
So my conclusion is as much energy is used in our countries we produce mos CO2 that can increase the global warming.
0 notes
Text
WEEK 4
# -*- coding: utf-8 -*- """ Spyder Editor @author: Gustavo """ #import libraries import pandas import numpy import seaborn import matplotlib.pyplot as plt #Starts Week 4 # Data charge of the dataset dataraw = pandas.read_csv('D:\Personal\Cursos\Coursera\Data Management and Visualization\Python Docs\gapminderV4.csv', low_memory=False) #remove unnecessary columns and make a copy of the subdata data1 = dataraw[["country","continent","reselectricity", "energyused","co2emissions"]] data = data1.copy() print(data) #remove missing values(in my case '0' values) data= data.replace(0, numpy.NaN) # Now I want to drop all rows where both the variables are NA data=data.dropna(subset=['reselectricity','energyused','co2emissions'], how='all') print(len(data)) print(len(data.columns)) # Change the data type for chosen variables data['reselectricity'] = pandas.to_numeric(data['reselectricity']) data['energyused'] = pandas.to_numeric(data['energyused']) data['co2emissions'] = pandas.to_numeric(data['co2emissions']) #First evaluation of the information is not clear reselectricity_description = data['reselectricity'].describe() print(reselectricity_description) energyused_description = data['energyused'].describe() print(energyused_description) co2emissions_description = data['co2emissions'].describe() print(co2emissions_description) #Plotting distribution of each variable #'Energy Used' seaborn.distplot(data['energyused'].dropna(), kde=False) plt.xlabel('Energy Used') plt.title('Estimated distribution of Energy Used in the wold') #'Energy Used' seaborn.distplot(data['co2emissions'].dropna(), color='red', kde=False) plt.xlabel('CO2 Emissions') plt.title('Estimated distribution of CO2 Emissions in the wold') #Scatter analysis of variables energyused and co2emissions #scat1 = seaborn.regplot(x="energyused", y="co2emissions", fit_reg=False, data=data) scat1 = seaborn.regplot(x="energyused", y="co2emissions", data=data) plt.xlabel('Energy Used') plt.ylabel('CO2 Emissions') plt.title('Scatterplot for association between Energy Used and CO2 Emissions')
0 notes
Text
Week 2 Homework
Following is my Python program.
# -*- coding: utf-8 -*- """ Spyder Editor
@author: Gustavo """
#import libraries import pandas import numpy
# Data charge of the dataset dataraw = pandas.read_csv('gapminderV3.csv', low_memory=False)
#remove unnecessary columns and make a copy of the subdata data1 = dataraw[["country","continent","residential_electricity_use_tot", "energy_use_per_person","co2_emissions_tonnes_per_person"]] data = data1.copy()
# Make all the Columns as Numeric Except Country Column as it is categorical data colnames=data.columns.values.tolist() #Get all the column names colnames2=colnames[1:len(data.columns)] for i in colnames2: data[i]=pandas.to_numeric(data[i], errors='coerce')
# Now try to find no of NA values in my varible of interest data[colnames[0]]=data[colnames[0]].astype('category')
# Now I want to drop all rows where both the variables are NA data=data.dropna(subset=['residential_electricity_use_tot','energy_use_per_person','co2_emissions_tonnes_per_person'], how='all')
print('Total of Country in Report') print(len(data))
print('Total of Countries without Residential electricity consumption information') print(data['residential_electricity_use_tot'].isnull().sum()) #No of NA
print('Total of Countries without CO2 Emissions information') print(data['co2_emissions_tonnes_per_person'].isnull().sum()) #No of NA
print(data.isnull().sum())
# Title of the report print('Report of Residential electricity consumption and CO2 Emissions by Country')
# Show only the information for analysis subdata= data[['country','residential_electricity_use_tot','co2_emissions_tonnes_per_person']] print(subdata)
Output:
Total of Country in Report 130 Total of Countries without Residential electricity consumption information 0 Total of Countries without CO2 Emissions information 0 country 0 continent 130 residential_electricity_use_tot 0 energy_use_per_person 0 co2_emissions_tonnes_per_person 0 dtype: int64 Report of Residential electricity consumption and CO2 Emissions by Country country ... co2_emissions_tonnes_per_person 0 Albania ... 1.460000 1 Algeria ... 3.160000 2 Angola ... 1.180000 3 Argentina ... 4.680000 4 Armenia ... 1.910000 5 Australia ... 18.100000 6 Austria ... 8.280000 7 Azerbaijan ... 4.020000 8 Bahrain ... 26.700000 9 Bangladesh ... 0.333000 10 Belarus ... 6.640000 11 Belgium ... 9.690000 12 Benin ... 0.507000 13 Bolivia ... 1.380000 14 Bosnia and Herzegovina ... 5.350000 15 Botswana ... 2.320000 16 Brazil ... 2.010000 17 Brunei ... 24.000000 18 Bulgaria ... 6.760000 19 Cambodia ... 0.281000 20 Cameroon ... 0.293000 21 Canada ... 16.800000 22 Chile ... 4.310000 23 China ... 5.620000 24 Colombia ... 1.520000 25 Congo, Dem. Rep. ... 0.030800 26 Congo, Rep. ... 0.318000 27 Costa Rica ... 1.840000 28 Cote d'Ivoire ... 0.348000 29 Croatia ... 5.190000 .. ... ... ... 100 Singapore ... 7.450000 101 Slovak Republic ... 6.990000 102 Slovenia ... 8.570000 103 South Africa ... 9.850000 104 South Korea ... 10.300000 105 Spain ... 7.160000 106 Sri Lanka ... 0.612000 107 Sudan ... 0.453000 108 Sweden ... 5.320000 109 Switzerland ... 5.280000 110 Syria ... 3.330000 111 Tajikistan ... 0.397000 112 Tanzania ... 0.142000 113 Thailand ... 3.790000 114 Togo ... 0.273000 115 Trinidad and Tobago ... 33.700000 116 Tunisia ... 2.390000 117 Turkey ... 4.030000 118 Turkmenistan ... 11.500000 119 Ukraine ... 6.730000 120 United Arab Emirates ... 22.800000 121 United Kingdom ... 8.390000 122 United States ... 18.500000 123 Uruguay ... 2.470000 124 Uzbekistan ... 4.470000 125 Venezuela ... 6.360000 126 Vietnam ... 1.360000 127 Yemen ... 0.999000 128 Zambia ... 0.166000 129 Zimbabwe ... 0.573000
[130 rows x 3 columns]
Because my Hipothesis the frequency distribution analysis doesn’t apply. I going to investigate how to do a Correlation Analysis. This is because I trying to find is there is a relationship between two quantitative variables.
0 notes
Text
My First Hipothesis is that depends of the region, the electricity consumption increase because the increment of electronic devices but CO2 emissions wil not increase if the country produce this electrical energy by no fossil fuel.
My secondary hipothesis is the CO2 emissions doesn’t have any connection with the electrical consumption because in my region (Central America) the CO2 production is for the increment of the number of vehicules on the roads.
Research Question for Electrical Consumption.
I want to know if the consumption of electricity in homes affects the amount of CO2 in the environment.
My questions are:
1. There is more electricity consumption in homes because there are now more people doing Home Office. If so, then CO2 emissions go down because at least one vehicle is used a day less a week.
2. We need to generate more electricity to meet the demand through fossil fuel generators and therefore increases CO2 emissions.
3. If we use electric vehicles, CO2 emissions would fall in a proportion of the increment in electricity generation by fossil fuel generators.
4. In countries with more residential electricity consumption, what is the amount of CO2 that they produce and how the CO2 generated.
In order to develop my research I plan to use the Codebook and Data Set from Gapminder. Until how I have no a clear definition of the variables for my personal Codebook.
After a quick view, I think I will select variables such as co2emissions and relectricperperson.
I will to read some documents and do some Internet searching in order get a best understanding of this topic.
2 notes
·
View notes
Text
I am checking some information from internet such as:
-Impact of household consumption on CO2 emissionsAuthor links open overlay panel by JesperMunksgaarda
-El suministro y consumo de energía produce el 79% de las emisiones de gases de efecto invernadero de la UE. www.factorco2.com
Research Question for Electrical Consumption.
I want to know if the consumption of electricity in homes affects the amount of CO2 in the environment.
My questions are:
1. There is more electricity consumption in homes because there are now more people doing Home Office. If so, then CO2 emissions go down because at least one vehicle is used a day less a week.
2. We need to generate more electricity to meet the demand through fossil fuel generators and therefore increases CO2 emissions.
3. If we use electric vehicles, CO2 emissions would fall in a proportion of the increment in electricity generation by fossil fuel generators.
4. In countries with more residential electricity consumption, what is the amount of CO2 that they produce and how the CO2 generated.
In order to develop my research I plan to use the Codebook and Data Set from Gapminder. Until how I have no a clear definition of the variables for my personal Codebook.
After a quick view, I think I will select variables such as co2emissions and relectricperperson.
I will to read some documents and do some Internet searching in order get a best understanding of this topic.
2 notes
·
View notes
Text
Research Question for Electrical Consumption.
I want to know if the consumption of electricity in homes affects the amount of CO2 in the environment.
My questions are:
1. There is more electricity consumption in homes because there are now more people doing Home Office. If so, then CO2 emissions go down because at least one vehicle is used a day less a week.
2. We need to generate more electricity to meet the demand through fossil fuel generators and therefore increases CO2 emissions.
3. If we use electric vehicles, CO2 emissions would fall in a proportion of the increment in electricity generation by fossil fuel generators.
4. In countries with more residential electricity consumption, what is the amount of CO2 that they produce and how the CO2 generated.
In order to develop my research I plan to use the Codebook and Data Set from Gapminder. Until how I have no a clear definition of the variables for my personal Codebook.
After a quick view, I think I will select variables such as co2emissions and relectricperperson.
I will to read some documents and do some Internet searching in order get a best understanding of this topic.
2 notes
·
View notes
Text
Mi primer Blog
Esta es mi primera experiencia con la actividad de Blogs.
1 note
·
View note