
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by 9treeblog-blog and here's what we found interesting.
Average Info
Notes Per Post
20
Likes Per Post
7
Reblog Per Post
13
Reply Per Post
0
Time Between Posts
4 months ago
Number of Posts By Type
Text
13
Video
1
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
MockJS - Mockito syntax for JavaScript Unit Testing
A couple of weeks ago I've learnt about Mockito. (yes, I've been hiding under a rock all this time)
Like most developers, I instantly found that Mockito's API syntax makes it really easy to learn and use mock objects.
I've looked around for an equivalent in JavaScript but found nothing suitable... Most solutions rely on unfriendly syntaxes or strange dependencies and, in my view, none was able to implement JavaScript mock objects in a simple and reliable way.
So, as a part-time project, I developed an alternative Mock object library in JavaScript. I ported the raw concepts of Mockito, thrown in the JavaScript specifics, added a fresh perspective and some ECMA5 magic, mixed everything up in a repo and came up with something new.
The resulting project is MockJS and can be followed at https://github.com/badoo/MockJS
More and more I start developing APIs by developing the use case first, and only later the API core itself - a kind of API Driven Development if you will. I found it to generate the best usability for the end developer and very clear achievements while developing the API.
So for MockJS I started with a very simple goal - use Mockito syntax to mock the following object:
var myObject = { foo:function(str){ alert(str); return str; } }
I started with the Mockito original stubbing syntax:
var mock = Mock(myObject); when( mock.foo() ).thenReturn(true); mock.foo(); //returns true
The next step was to match arguments. I took advantage of how easy it is using callbacks in JavaScript and took care of wrapping the default callbacks in a nice Match object to avoid possible conflicts in the global scope.
So I hooked a few default argument matchers:
var mock = Mock(myObject); when( mock.foo(Match.anyString) ).thenReturn(true); mock.foo("yay!"); //returns true
As an added bonus, because matchers are just simple callbacks, it allows the developer to easily create their own custom argument matchers:
var mock = Mock(myObject); var positive = function(arg){ return arg>0; } when( mock.foo(positive) ).thenReturn(true); mock.foo(6); //returns true
OK, now we need to be able to return a result based on the matched arguments, or even an argument itself - stubbing with callbacks is very simple in JavaScript:
var mock = Mock(myObject); when( mock.foo(Match.anyString) ).thenReturn(function(str){ return str; }); mock.foo("yay!") //returns "yay!"
To wrap up the Mockito basics, we need to verify behaviours:
var mock = Mock(myObject); mock.foo(); //returns undefined (default) verify( Acts.once, mock.foo() );
Great! We actually improved the original Mockito syntax a bit by making it even simpler! Nice.
...
Wait, what about functions? In javascript a function does not have to be a method of a class instance... it can be just a variable in the current scope.. Oh Crap!
Let's try to mock functions too:
function answer(question){ return someAnswer; } var mockAnswer = Mock(answer); when( mockAnswer(Match.everything) ).thenReturn(42); // :) mockAnswer("what?"); //returns 42 verify( Acts.once, mockAnswer(Match.everything) );
Nice! What other JavaScript specifics do we need? - right... context calls for our functions and methods.
when( mockAnswer.apply(Match.anyContext, [Match.everything]) ).thenReturn(42); when( mock.foo.call(myContext) ).thenReturn(true); var myContext = {} var myContext.foo = mock.foo; myContext.foo(); //works!
Awesome! Now we can mock anything!!
Well, not anything.. what about jQuery? The $ wrapper itself we can easily mock, but how can we mock the returned DOM wrapper object without actually being able to access the generating class?
So, the final piece of the puzzle was the ability to mock inaccessible objects. Initially it looked like a big problem, but looking at it from a simplistic point of view we only need to mock the object with the methods that will be used in our test case...
So, we only really needed a simple syntax to create a custom mock object with a few methods of our choice:
var kennyMock = Mock.new(['addClass', 'removeClass', 'remove']); $ = Mock($); when( $('#kenny') ).thenReturn(kennyMock); when( kennyMock.remove() ).thenThrow("OMG! They killed Kenny!"); var kenny = $('#kenny'); kenny.addClass('headshot'); kenny.remove(); //throws exception
Great! Now we have something really cool!!
All this and more is available at https://github.com/badoo/MockJS
This project has been released by Badoo Trading Limited under MIT License.
Thank you to Will for introducing me to Mockito and Diego for helping with releasing it open source.
And thank you to the original Mockito's bartenders for creating such an inspiring drink ;)
2 notes
·
View notes
Text
Proper continuous integration using Github
Hours of dealing with painful merges, rollbacks and fixing commits have driven me to write this post.
Be it open source or enterprise, it is very common seing developers using GiT as a single central repository. And common errors like copy/pasting code across branches or moving files around in the filesystem are, unfortunately, very common.
No, no, no! Oh no, no, no!
One can argue that GiT and Github may be used in a number of different setups, but never with the practices above.
Allow me to explain.
The Evil practices
Don't copy/paste code across branches! Ever! Ever! Ever!
First of all you should know copy/pasting stuff across branches is the root of all evil and it will have your virtual head cut off and set on a stake at the London Bridge of developers. It completely takes out the purpose of a repository by leading you to lose the entire commit history.
This will break the entire "merge" functionality of the repo, leading you to have to manual merge any future commits on other branches. It will remove all accountability and developer credit for the developed functionalities.
Like I said - the root of all evil.
Don't take me wrong - almost everyone has, at some point when using GiT, done it. I have done it in the past, thinking of it as a simple and quick solution to an immediate problem, and I was oh so wrong.
It is technically possible to correct the mistake later on - but it takes a much deeper knowledge of GiT to rollback, cherry-pick, remerge, rebase, etc to make it proper again.. It can become a real pain.
Ok, but what if you want to copy a single feature across to another branch?
Always use the cherry-pick commands, then manual merge the necessary code to make it work. Whatever you do, never copy-paste across branches.
Don't move files around in the filesystem!
The issue with it is that moving a file in the filesystem without notifying git can often result in git tracking the change as 2 different actions, a deleted file and new file created.
This means you won't be able to see a diff of the changes to the file in the commit, you will see it as a whole new file. Also, if someone else is working on the same file git won't be able to merge the changes across as it won't know the 2 files are effectively the same.
So, if you want to move a file within your repo always use the git command for it:
$git mv folderA/file.a folderB/file.a #move a file within a git repo
I can't stress the "always" enough - developers who have come across this issue will know what I mean.
Best Practices
Commit often
Committing often will keep your history very organised, simpler to understand and to merge, and much simpler to correct if a rollback or picking out features is required.
There is no exact measure, but ideally it will be a few lines of code or a relevant change per commit - whichever comes first.
Eg. Commit 'Changed search backend to support receiving search queries from querystring' - a few lines of code.
Commit 'Changed search form to GET instead of POST' - probably small code change, but relevant.
Merge often
The more often you merge, the simpler it is to merge, and less prone you are to manual merging errors.
If the code is still "warm" in your head it will be very easy to merge. 5mins a day if you merge everyday.
People who have had to merge branches that have diverged for several weeks or even months will understand the pain it can be to merge it. It can take up to several days and a lot of regression tests to make it work properly.
Use and abuse branches
Branches are not evil, quite the other way around.
A branch a day will blow you away.
Using a lot of branches will make it easier for each merge operation, it will allow to continue working on new features while others are being reviewed or tested, it will allow you to have different stable and unstable versions of your application.
The different use cases for branches are explained further below.
Continuous Integration and Distributed Revision Control
For the sake of simplicity - I'll explain this setup using GitHub as the example frontend.
Have one central repository as a "main" repository - let's call it origin - fork this one to each of the developers in github, let's call each of these fork the developers hub. These two repos are "stored" remotely in github itself. Have everyone participating in developing the project with read+write access to origin. This way, everyone will be able to participate in the pull-request review process later on.
The next step is for the developers to $git clone the origin repository into their local development environment - this will be the developers local repo. Now, on the local repo, add a reference for the developers hub, the upstream repository the developer will be pushing to.
$git remote add upstream https://github.com/carlosouro/MyProject.git
The model for a small team will look something like this:

Notes:
Downstream is where the merged code comes from;
Upstream is where your new code goes to in order to be merged;
To Live/Test is the mainstream where the common merged code travels to test/live environments.
Special Note: In case of a really big project, our mainstream would probably be just another upstream into a more centralised repo - this chain can continue indefinitely with several filtering steps where merge and regression tests are made. This is why GiT is the perfect tool for open source projects.
Main branches per sprint, individual branches per feature
Starting the sprint - Lead Developer
Ok, let's build a new set of features.
Let's start by creating a branch for our sprint in the origin (main) repository - this branch will serve as baseline for our sprints work and as a regression test branch if necessary.
$git checkout master #go into your master code $git pull origin master #get the updated master code from origin $git checkout -b sprint_12 #create a new branch for the sprint $git push origin sprint_12 #push the sprint branch into github's origin repo
Developing a feature - Developer
$git pull origin sprint_12 #get the sprint branch
Downstream code can be pulled directly from the origin (main repo) into your local repo.
$git checkout -b myFeature #create a branch for the new feature
Before starting to work, create a branch for what you are about to do - this will make it so that you don't have to wait for your code to be merged in to continue your work and you don't have to rollback everything and rebase if one of your features is not accepted or requires some changes.
$git push upstream myFeature #push feature into your developer hub
Upstream code will work it's way up the chain from the developer's local repo to his developer hub, and then pull requested into the main repository origin into the sprint_12 branch. Another developer can now review your pull request, know a little bit more about your code and maybe advise some changes. Naturally the more complex or deep the change, usually a more senior developer will review it, just in case. This way the code is reviewed in a fairly distributed way without wasting anyone too much time.
$git checkout sprint_12 #get back to the sprint branch $git pull origin sprint_12 #update the sprint branch
And you're ready to start working on your next feature! No waiting time or having to wait your feature to be approved first.
Code Freeze, Regression and closing the sprint
After a certain date you all agree the sprint is finished and no more features will be included. Ok, It's regression time, let's test the sprint_12 branch and make sure everything works well together. When finished and happy with the result, let's merge it into master and make a release.
The sprint is now closed and we can move on to the next one, in fact, testers can fallback a day or two in regression testing while the developers already started working on the next sprint*.
Note: *for this you should create the sprint_13 branch from sprint_12 (as it is not yet merged into master) and you can have everyone working in parallel to it's fullest without waiting times.
A note on bigger projects:
On bigger projects there are usually authoritative repos along the way to the actual origin in order for senior "lieutenants" to filter out what really matters. See more info on these models at http://git-scm.com/book/en/Distributed-Git-Distributed-Workflows
Hope you put it to good use!
9 notes
·
View notes
Video
youtube
Great video on HTML5 browser rendering and JavaScript performance.
Reflows, Hardware Acceleration, requestAnimationFrame(), Web Workers.
1 note
·
View note
Text
Javascript code performance review
Within the scope of my latest projects, I had to review a lot of performance details on JavaScript to determine best possible solutions for core functionalities and architecture.
If you follow the classic "by the book" rules, you should avoid, when possible:
loops
closures
object spawning
DOM access, specially DOM writes
DOM queries (find DOM objects)
Ok, but how bad is it? How do they compare to each other? What options do I have? Which are the best ways to get the same result?
This study focuses on answering these questions as best as possible in order to achieve an approximate scale on comparative performance results in JavaScript.
1. Loops
It's easy to intuitively understand unrolled loops are faster than having the loop itself. However for ease of development, we sometimes tend to use unnecessary loops for common tasks;
Take a look at http://jsperf.com/unrolling-loops
You can see the difference between running direct code vs doing the same in a loop is massive, really massive. Of course the unrolling above is way too much work unless you have a system where performance is hugely more important than anything else - including a huge file size...
But the overall point is, if it takes you only 3 or 4 more lines to do it and it doesn't involve extra functions call, etc, it's probably better just to unroll the loop.
2. Closures
Look at this example: http://jsperf.com/closure-vs-no-closure
Free code is, as expected, faster, followed by the function call and finally the closure. However the gap between each use case performance varies between implementations, we can see Chrome running free code much, much faster than having a closure, while other browsers can have a very close match between all use cases.
So what does it mean?
in average : - closure - slowest! - function call - 2x faster than closure; - free code - 4x faster faster than closure;
Finally I've confirmed this performance test in a practical case testing loops against "forEach" callbacks in http://jsperf.com/loops-vs-each-callbacks
You can see regular loops perform twice as fast, as expected. To put it in perspective this means running the function call alone, takes about the same time to run as this example's entire loop.
3. Object Spawning
Take a look at http://jsperf.com/instance-vs-object-create/4
We can see the new ECMA5 Object.create is, in average, as fast as instancing a new object from a function, with the exception of Chrome where instancing a function is clearly very, very optimised, along with creating direct object and arrays - actually, this is one of the reasons why JavaScript "is" so fast in Chrome.
As you can see, instancing is still faster than using a closure, about 2x faster more or less the same as a function call (by our previous example; But it will probably be much slower if you have a big prototype.
However be aware that creating an object or array directly actually takes longer than instancing, even if you use an interim functional call to get rid of the "new" keyword (eg. jQuery's $()).
To conclude I would say it is ok to use instances and objects altogether, however if there is something which can be easily done through simple function calls instead, use them.
4. DOM Access - read and write
Ok, this is a big one.
Let us start with an overview of the most common tasks: http://jsperf.com/dom-read-vs-dom-write/2
You can immediately identify that using single style reads and writes is much slower than using CSS classes, and, as one would expect, using computedStyle is always slower than regular reads and style writes are the absolute slowest - in fact, changing the same property via class is about 4x faster then a style.property write.
But wait a second! setAttribute and getAttribute are incredibly fast! Let's play around with them a little bit more and check out what is better/worse
4.1 Data API : attribute vs .dataset
You can see by the previous test results that using attributes is way faster. Clearly dataset.data hasn't been optimised yet.
However it is very likely as its use becomes more and more common, .dataset will very likely be optimised too.
4.2 attribute class vs .className :
http://jsperf.com/classname-vs-setattriubute-getattribute
Fairly close, but .className is still a faster solution, attributes loose in this case;
4.2.1 Extra: classList vs .className:
http://jsperf.com/classname-vs-classlist-showdown/2
Serves to show if your browser supports ECMA5 standards, classList is highly optimised; Use it.
4.3 style.property vs setAttribute style :
http://jsperf.com/style-property-vs-setattribute-style
Ok, style is clearly optimised vs setAttribute use as expected, except... Wait... What?! What the hell is up with firefox?? Why is it so fast?
I double checked and it actually changes the style as expected, it really works! And it appears to be 4x faster than using style.property on all other browsers... A setAttribute("style") + computedStyle read in Firefox is still faster than a style.property read in chrome! There is something really strange going on here... - if anyone can explain why this is happening please let me know in the comments.
So overall writes are indeed slower than DOM reads, but not that slower. Actually getting the computedStyle takes much longer that a write.
So: avoid computedStyle reads, and if you do it, try doing it only once until you actually change it again.
DOM queries and selectors
Lastly, the DOM query selectors, here are the results: http://jsperf.com/dom-queries
When can clearly see the advantage of always using document.getElementById as it is twice as fast as any other option.
If you cannot rely on a specific id but are still just looking for one item, use querySelector as it is, for the most part, the second fastest option.
If you really require more than one items returned, consider first if you can use document.getElementsByClassName, and only use querySelectorAll as a last resource.
Remember that having up to 5 or 6 getElementById calls is still faster than a single querySelectorAll call. Use it wisely.
Comparing them all together
For the sake of fully grasping the concept, I have combined a jsperf with a mix of a few results above and put them all against each other.
Here it is: http://jsperf.com/mother-of-comparisons
The results table:
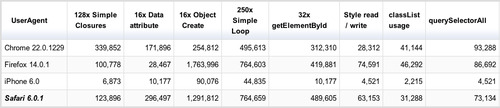
So, as you can see, messing with CSS things always cost you the most, no matter what. All code you can do is fairly insignificant comparing to it, but if you want to go into performance details, here you have it:
Results: (best to worst)
Simple code & functions
Closures
getElementById
instance new Object
messing with DOM objects without reflows* - most attributes, etc
querySelectorAll
messing with DOM objects that triggers reflows* - CSS, classes, etc
1-5 everything is pretty fast
6-7 avoid when possible (at least 20x slower than 1-4)
* Note: reflows is, in a simplistic view, when the browser has to redraw all or part of the page - more on this later ;)
2 notes
·
View notes
Text
Working on jqMobi 1.1 update
Recently I have been deeply involved in the 1.1 development of jqMobi (core) and jqMobi UI, and here I will try to point out some technical details of what was done, how, and why.
For those of you unaware, jqMobi is a jQuery-like framework - a DOM element(s) wrapper with common functionalities which jQuery's success as made a standard in the industry. The main difference is jqMobi focuses exclusively on webkit-based mobile touch devices - iOS, Android 2+ and Blackberry OS6+; So, although not nearly as featured as jQuery itself, it's performance is highly optimised for these devices.
On top of the core framework it has a neat UI plugin similar to many other "new age" mobile UIs ( Sencha, Enyo, jQuery Mobile, Kendo UI, etc).
When our team first tested jqMobi 1.0 in Jan 2012, it's UI demonstrated to be the top performant UI core in a webkit touch device at the time. In our project's pilot it rendered better than all others, the scroll was good, the animations were smooth and It supported most of the core input elements (instead of using javascript based replacements). So, the decision was made to choose it as the core and UI framework for our project.
But we soon realised we would need more. Much more.
We needed perfect smooth scrolling for heavy media content and a better and broader compatibility across devices, specially on native input elements. We needed improved animations and responsiveness, events, usability.
We needed to put jqMobi on steroids.
I joined the team in March and I was tasked with designing and implementing these improvements. I immediately turned my attention to the core UI scrolling engine - it needed an urgent upgrade.
I had been reading about the latest native touch scrolling shipped with iOS5 and how some developers at the time had deemed impossible to implement into a UI due to event handling issues. I decided to give it a try. In a few days we built a proof of concept it could work and a couple of days later we started implementing it into jqMobi's core. This is how we started working with the jqMobi guys.
Here is what we've done:
Native scroll support
Native scroll involved changing quite of the core UI and scroller plugin. The scroller plugin was split into two child classes, one managing JS scroll for older devices, and another managing the new native scroll features. While Native scroll can be achieved only with HTML and CSS, maintaining consistency with the UI, touch events, pull to refresh and "no click delay" was a big challenge, but not impossible. Scrollstart and scrollend events were added cross-device, pull to refresh feature implemented and panning the page prevented.
Note: For those of you unaware, "no click delay" is a block layer on touch events, allowing the page to stay in place and click event to be delivered immediately thus working around the default 300ms delay on iOS click events - it does, however, also block some native input controls and native scrolling altogether.
TouchLayer
Eventually "no click delay" was redesigned from the ground up to accomodate these and other changes, and became the touchLayer plugin, managing native events flow and translating them to the rest of the application as necessary - but not necessarily blocking. This way we were able to keep the immediate click feature on iOS but still allow native scroll and native events on input controls.
Now, the touchLayer deals with a great number of compatibility issues, including delivering proper resize/orientation events in a clear way to the application and managing to keep the address bar hidden across different devices. In a way, it became the UI police officer, keeping everything consistent and abstracting most of the cross-browser / cross-device stuff.
Native input Controls
Along the way, a great deal of work was done in keeping as much native interaction with input controls as possible. This allowed for native text input features to regain most native features of the OS such as copy/paste and autocomplete.
Improved JavaScript Scroller
The next step was to improve the non-native scrolling plugin to its possible best on older iOS, Android and Blackberry devices.
The current implementation relied on changing the CSS transform on every touchmove and a CCS transition for the momentum scroll. This lead to considerable performance problems when having a large amount of content and images on the scrolled panel. The problem was the browser was being forced to render every couple of milliseconds (every touchmove) and it "choked" on so many redraws in such a short amount of time leading the whole UI to feel sluggish and uncomfortable.
The solution was achieved by separating the read stack from the write stack and having a kind of "frame rate" on the write process. Movement information is now cached and recalculated on every touchmove but a separate interval takes care of updating the CSS, still fast enough for the human eye to render it as smooth, but spaced enough so the browser wouldn't choke.
CSS 3 animations
The issue we encountered with CSS3 animations set on having multiple elements animating simultaneously, sometimes with different timeframes and not necessarily starting in the same exact JS stack (imagine a transition of element X starts on click, and element Y only starts on setTimeout(c,0)). Thus the CSS3 animation plugin was improved to allow binding element animations. In practice this means the transition callbacks only fire when the last of the (aggregated) transitions finishes, enabling the developer to chain multiple sets of transitions without worrying of time lapses on browser render delays. We have also added support for setting the transition instance by CSS classes and added the ability to cancel an animation chain - resulting in a failure callback.
Behind the scenes there were also a number of small improvements to core functionalities and APIs.
Javascript Object events
Methods for binding and unbinding events to Javascript (non-DOM) objects were also added. This allows the developer to bind custom events to objects such as the Touchlayer, Scroller or the UI manager as you would on a regular DOM element.
Note: The way it works internally it is probably not a best standard and can certainly be improved with the use of internal caching or ECMA5 properties in the future, but, for our use cases, it solved a great number of issues.
$.asap
$.asap(callback [, scope, arguments]) is a setTimeout(callback,0) replacement relying on window.postMessage to deliver a near-instant response. The classic setTimeout has an internal default delay (around 40ms in most cases), while postMessage events act in 1 to 5ms delay, allowing for a much quicker reaction than setTimeout, while still retaining all the same advantages.
Bugfixes and other stuff
The UI plugin was refactored to be compatible with the new features and a number of small improvements were added to the core, selectBox and carousel plugins. Bugfixes were also mostly focused on device compatibility and fixing memory leaks and stability in some core functionality and plugin objects.
And this was just our part, other developers built a lot of new stuff for the 1.1. You can check out the awesome result at jqMobi's github.
On a personal note its been quite an experience and I hope to be able to keep improving and creating stuff like this in the future. There is still so much more to be done.
Special thanks to Ian Maffet, Diego Perez, Kenneth Lam, Anton Laurens, William Lewis and Jessica Reid who have all, in one way or another, also contributed their work for the features mentioned above.
Cheers, Carlos Ouro
2 notes
·
View notes
Text
HTML5 vs Native apps - It's pointless
Since the big Facebook Hybrid app failure there has been a lot of talk resurfaced about HTML5 vs Native.
Curiously in 2012 Native is winning the discussion, whereas in 2011 HTML5 ruled all.
So, what happened?
Well, let me tell you, this entire discussion is rubbish.
The point of whether HTML5 will "replace" Native or not in the future may be debatable, but currently they are still 2 different technologies, with 2 different purposes.
Deal with it.
What are the differences?
HTML5 is evolving very quickly, yes.
Coded by the right developers, it can do a lot of cool stuff, and, for simpler things it can completely "replace" Native apps, yes.
But that doesn't make it do everything Native is capable of!
Native apps code and UI rendering are still run much, much faster!
V8 may be really cool and all, but the fact remains that Javascript is still a step by step stack VM attached to the browser.
In Native apps you have real threads, you have access to many more APIs, you control what renders, how and when, you have Native controls and content that render way, way faster.
So please stop tricking users with your crappy hybrid apps, if you are "selling" the Native experience, give it to them. Otherwise be realistic about it and have it clearly accessed via the browser and an URL like a real web app!
HTML5 should be used if you focus on accessibility and ease of deployment, not if you have a million-user iPhone app downloaded from the app store.
And if you want a close-to-native experience you'll have to get really top-class JavaScript developers, and these are really hard to come by, and very expensive.
Saying a HTML5 app is as simple as a regular website is the same as saying a native app is just a view with some controls on it. Right, my 7 years old nephew can do that.. on both platforms.
Actually, coordinating the performance and the browser rendering engines of complex content along with cross-browser compatibility, multiple versions, mobile devices, etc - makes it a much taller order than you would probably expect - thus much more expensive.
Open source projects are coming up that make easier dealing with all this, I have worked on a few of these myself, but it is a huge task, and it is going to take time.
To conclude:
If you want a truly flawless experience, go native.
If you want it more accessible and cross-device - go HTML5 and JavaScript - but be realistic about the resulting experience and don't try to "sell it" as a real native app.
In the end there is no winner - HTML5 is really cool, so is Native - you just have to know what you are doing.
That's where Facebook failed the first time around.
4 notes
·
View notes
Text
Webkit: Entity 'nbsp' not defined - Convert HTML entities to XML
This is a very common XHTML mistake, now growing in visibility much due to the Google Chrome boom. Google Chrome is based on Webkit, an open source browser engine also used in Apple's Safari; Webkit is very restrict on XHTML rules;
This particular error is caused due to common HTML entities usage on XHTML outputs, which follows XML entities rules. Basically means you are using a -like entity, when in XHTML you should use a -like entity; The only named entities for XML are &, > and <. For all others you need to use the Unicode character code (eg. ).
0 notes
Text
How to check Linux version from command line
To check your linux version from command line:
$cat /proc/version
0 notes
Text
how to check linux distro on a command line
For what i know, there is no standard way to know for sure... but each Distro have their own version file you can cat somewhere. Try these:
- "$cat /etc/redhat-release" will show you information for red hat based distros.
- "$cat /etc/SuSE-release" for SUSE based distros.
- "$cat /etc/mandrake-release" for mandrake distros.
- "$cat /etc/debian_version" for debian based distros.
- "$cat /etc/UnitedLinux-release" might also return some more information.
I also found this useful tip at linuxhelp.net: You *might* get some clues by running "uname -r" which will show you kernel version - Some ditributors will rename the kernel to make it specific to their distro (eg, RHEL kernels have RHEL in their name)
Note: "$cat /etc/debian_version" won't return the distro itself, but the version of the distro.
0 notes
Text
how to install yum on Red Hat Enterprise Linux 4
This case applies to most Red Hat Enterprise Linux 4, from i386 to i686 machines, i've successfully used it on our Red Hat Enterprise Linux ES release 4 (Nahant Update 6): To use it for other systems / architectures, check the packages given at (check).
1. Get the main packages
(check) http://dag.wieers.com/rpm/packages/yum/
$wget http://dag.wieers.com/rpm/packages/yum/yum-2.4.2-0.4.el4.rf.noarch.rpm
(check) http://rpmfind.net/linux/rpm2html/ search.php?query=libsqlite.so.0&submit=Search+...&system=&arch=
$wget ftp://fr2.rpmfind.net/linux/PLD/dists/ac/ready/i386/libsqlite-2.8.15-1.i386.rpm
(check) http://rpmfind.net/linux/rpm2html/ search.php?query=python-elementtree&submit=Search+...&system=&arch=
$wget ftp://rpmfind.net/linux/dag/redhat/el4/en/i386/dag/RPMS/python-elementtree-1.2.6-7.el4.rf.i386.rpm
(check) http://rpmfind.net/linux/rpm2html/ search.php?query=python-sqlite&submit=Search+...&system=&arch=
$wget ftp://rpmfind.net/linux/dag/redhat/el4/en/i386/dag/RPMS/python-sqlite-0.5.0-1.2.el4.rf.i386.rpm
(check) http://rpmfind.net/linux/rpm2html/ search.php?query=urlgrabber&submit=Search+...&system=&arch=
$wget ftp://rpmfind.net/linux/dag/redhat/el4/en/x86_64/dag/RPMS/python-urlgrabber-2.9.7-1.2.el4.rf.noarch.rpm
2. Install Rpm's
$rpm -ivh libsqlite-2.8.15-1.i386.rpm $rpm -ivh python-elementtree-1.2.6-7.el4.rf.i386.rpm $rpm -ivh python-sqlite-0.5.0-1.2.el4.rf.i386.rpm $rpm -ivh python-urlgrabber-2.9.7-1.2.el4.rf.noarch.rpm $rpm -ivh yum-2.4.2-0.4.el4.rf.noarch.rpm
3. Setup the Repository (check) http://dag.wieers.com/rpm/packages/rpmforge-release/
$wget http://dag.wieers.com/rpm/packages/rpmforge-release/rpmforge-release-0.3.6-1.el4.rf.i386.rpm $rpm -ivh rpmforge-release-0.3.6-1.el4.rf.i386.rpm
4. Yum update all packages
$yum update
0 notes
Text
Using MySQL Stored Procedures in PHP ( MySQL error #1312 )
in order to use Stored Procedures in MySQL through PHP you usually either use pdo or mysqli connections. However if do not wish to redo your application connections and you don't require any out parameters you can use "mysql_connect($host, $user, $password, true, 65536);" on connection, using the 65536 ( CLIENT_MULTI_STATEMENTS ) internal magic constant. But you can make only one stored procedure call per connection, and there is no support for OUT parameters. It is not currently documented, but can be found in the php header file.
If you do not use this connection method, you'll get a "#1312 - PROCEDURE database.procedure can't return a result set in the given context" error whenever you CALL a procedure that returns a result set.
0 notes
Text
MySQL 5 Storage Engines: MyISAM, MRG_MyISAM and InnoDB
I've been around choosing the appropriate Storage Engine for a new project, and so i'm posting some tips on Storage Engines for MySQL 5.
Storage engines differ essencially in how they organize the data, indexes, caching, etc. The pratical results are different possibilities in data organization and restrictions (foreign keys, constraints, triggers (on delete, on update), etc) as well as different performance capabilities.
Technical Differences:
MyISAM is designed to be a simple and effective storage engine, ideal for small websites, blogs, etc. Doesn't require much technical knowledge and get's the work done. It also features full-text index, allowing you to take advantage of the very useful "MATCH col AGAINT('needle')" text search clause.
MRG_MyISAM is treated as MyISAM but can be "shared" among different databases - very useful for main tables in multiple-database applications, as long as your working on the same MySQL server.
InnoDB is designed to be more of a storage engine for applications. It features foreign keys, triggers, etc - essential for multi-million rows and organizational data.
Performance:
A few years back MyISAM would kick ass on SELECT clauses, whereas InnoDB was usually better for heavy INSERT / UPDATE and DELETE clauses. These days InnoDB can be even faster than MyISAM for SELECT clauses.
Though MyISAM can be much faster for a simple "SELECT count(*) from table" query as it caches the amount of rows on a table, they work more or less the same when you use the "where some_col='some_val'" clause. On the other hand text searching on full-text index kicks ass over any "LIKE '%needle%' " clause.
MRG_MyISAM is pretty much like MyISAM, though it can usually get a little bit slower due to multiple database usage and locking.
All in all InnoDB has come a long way these past few years, and has become my first choice for applications, though i still use separate MyISAM tables for full-text searching on text fields.
0 notes
Text
Mac - mysql does not connect on localhost but connect's on 127.0.0.1
this issue came to me after i got "Can't connect to local MySQL server through socket '/var/mysql/mysql.sock'" on a mysql connection on php on a fresh installed mac - php connect's correctly to 127.0.0.1 , but does not connect to localhost .
On a mac the default mysql socket is '/private/tmp/mysql.sock' and not '/var/mysql/mysql.sock', you can confirm it by using $ locate mysql.sock on a Terminal.
So basically you have to change the php default connection socket to mysql to '/private/tmp/mysql.sock' . To do this you have to edit your php.ini - probably located at '/private/etc/php.ini' - via:
$ sudo nano /private/etc/php.ini
ctrl+w (where is) "mysql.default_socket"
alter to "mysql.default_socket = /private/tmp/mysql.sock"
crtl+x followed by y and enter to save php.ini
$ sudo httpd -k restart to restart Apache 2
Retry connecting to mysql localhost on php - should be working :)
Update: if you use mysqli you also must set "mysqli.default_socket = /private/tmp/mysql.sock" on php.ini;
0 notes
Text
Is there a limit to the css z-index property?
Theorically the z-index property should be unlimited, or at least within an int type range, depending on OS and browser. However, to avoid browser bugs you should limit your z-index values to +/- 32767 .
It should be enough to handle just about anything.
0 notes