
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by yuqi-y-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Number of Posts By Type
Text
1
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Assessing Tea Quality with Electronic Nose and Electronic Tongue
Are you a tea drinker? If so, do you have your favorite leaf, or prefer some types of tea to others? There are many teas, from the high-end ones packed in delicate gift boxes to those sold in bulk at their origins, which may be unfamiliar for tea drinkers in the more developed regions. But is that the more expensive, the better? Who decides the grades of teas, and how do they judge the quality?
The Traditional Method
Traditionally, “tea masters” assign the grade by tea-tasting, but this method is realized to be increasingly unreliable. Masters are still human, just with more expertise and experience, and human is inevitably subjective. Different masters may give different results; even the same person may give a different result on a different day depending on their physical or mental state. Leaving alone the subjectivity, human testing is also not efficient enough. With millions of, if not more, different types of teas sold through various channels in the market today, it is impractical for each of them to be examined by experts.
A New Approach
Is there a more accurate and more efficient way to grade the teas? The answer is “yes,” by artificial intelligence. Zhi et al. have presented a framework for Electronic Nose (E-Nose) and Electronic Tongue (E-Tongue) to assess tea quality (2017).
E-Nose and E-Tongue are not hard to understand literally, but exactly how do they function, and how is the information integrated to grade a tea?

Despite the huge difference in their appearances, E-Nose and E-Tongue collect information under a similar logic as human’s organs. They comprise of an array of sensors that detect the chemicals in the test samples and generate diverse signatures. The difference comes about in the perception of those signatures. Human’s interpretation turns out to be rather rough: bitter, sweet, fragrant, etc., since the signals are forced to go through multiple built-in filters in our brains, while E-Nose and E-Tongue provide raw signals, which are quantified and ready for more scientific analysis.
Feature Extraction and Dimension Reduction
Raw signals are hard to work with directly. In Zhi’s experiment, the E-Nose has 18 sensors and the E-Tongue has 7, so there are 25 distinct signal curves, with each curve consisting of 241 data points collected in 120 seconds for each test sample. It is impossible to tell anything by just looking at 25*241 plain numbers, so feature extraction is essential.
Zhi et al. extract the features in two different domains: time and frequency. The time-domain features are easy to acquire and easy to understand. The maximum value and the average value are calculated among the 241 points for each sensor. The frequency-domain features, on the other hand, is less straight forward. In brief, you can imagine the discrete points are connected to form a curve that bounces up and down, and the frequency-domain features describe how vividly the curve bounces. The importance to include the frequency domain is illustrated in the graph below. As we can see, data sets A and B have the same maximum and average value, yet their dynamic “energy” is different. It is probably not a good idea to conclude that these two signals are the same as if we are only looking at the time-domain features.
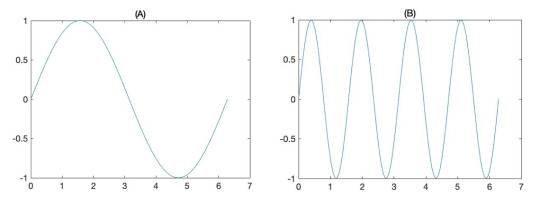
Now, we have successfully reduced the data size to 25*4 for each sample, but what’s next? Although decreased in size, the data is still numbers. How can we assign different grades to the teas according to those sets of numbers?
Let the machine learn!
Of course, we can manually observe the data and try to summarize some kind of regularities, but that would be tedious and thus running counter to our objective of improving efficiency. Luckily, we have assistants who are good at dealing with data of large sizes and doing repetitive jobs: computers.
Just like tea masters taste a lot of teas to form their experience, computers need to first form their knowledge bases and then apply the knowledge to solve the problem. In machine learning, the process of forming knowledge bases is called training. There’s one thing that is easy to get wrong: computers never learn on their own. It is human who programs the algorithms, and all computers do is executing the algorithms that take in the data and turn it into a knowledge base.
In the case of tea testing, the computer is trained with a number of samples given their grades so that it can get a sense of which characteristics correspond to which grades. Well, to “get a sense” is the human way; the computer way is to match the data points with the grades and construct reference maps for applications. For the matching, Zhi et al. adopt Kernel Linear Discriminant Analysis (KLDA). The purpose of this high-level mathematical trick is to maximize between-class separation and minimize in-class variance. In other words, we want the teas to be as similar to each other as possible if they belong to the same grade, and elsewise as different from each other as possible. We can’t manipulate the data, but what we can do is weighting it to highlight particular data. KLDA is a nonlinear transformation that maps the original data points to a more classified distribution. With this optimized matching, which is impossible without machine learning due to the huge amount of computation, the accuracy of grading is significantly improved.
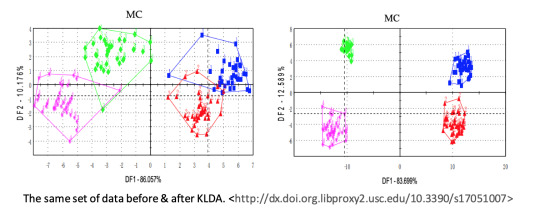
Assign a grade to an unknown tea
After training, the computer is ready to assess the quality of unknown teas. Given a new tea sample, we let the E-Nose smell it and let the E-Tongue taste it, obtain the raw signals, extract the features, and transform the data through the same KLDA filter used in training. Then we get a new data point to be compared to the ones in the computer’s knowledge base, namely the reference map constructed with the training set. How can we make the comparison, or, to be precise, which algorithm do we tell the computer to execute to make the comparison?
Zhi et al. use the K-nearest neighbor (KNN) classifier, which is, unlike the previous algorithms, one of the simplest among the classification algorithms. It assigns a class to the unclassified point by looking at a number (k) of its nearest neighbors and taking the majority vote from them.
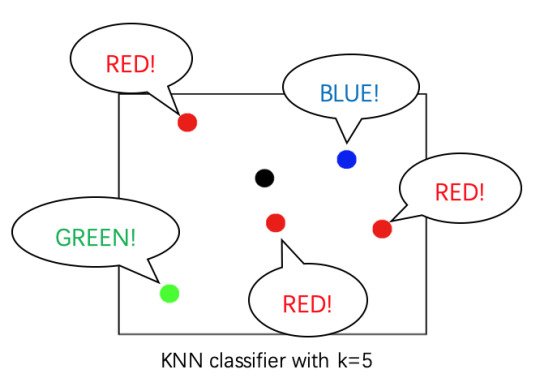
There is only one problem left. I have been counting the data for the E-Nose and E-Tongue together so far in order to demonstrate the size of data, yet in fact, they are quite different data since one describes the smell and one describes the taste, and so cannot be calculated as one. Hence at this point, we actually have two separate results from the E-Nose and the E-Tongue. The problem is how to combine the two results to give a final assignment.
Here comes the last mathematical tool in the assessment: D-S evidence, which is perfect for solving this problem. It generates one probability function by combining two bodies of evidence, which, in our case, are the E-Nose and the E-Tongue. The method is rather simple: taking the product of the probabilities suggested by the two bodies of evidence and calculating the proportion of each shared outcome. For instance, consider the following case:

Since D-S evidence only accounts for shared outcomes, the probabilities of the sample being grade 1 and grade 4 are omitted. The probability of grade 2 is 80%*90%=72%, and that of grade 3 is 10%*5%=0.5%. So the final probability of grade 2 is 72%/(72%+0.5%)=99.31%, a quite determinate probability for the computer to conclude that the sample belongs to grade 2. Noticeably, there’s one big assumption made by D-S evidence: the conflict between the two bodies of evidence is small. Consider this case:

Because there are no shared outcomes, the result would be completely inconclusive. Fortunately, big conflicts are not expected to happen since a tea sample naturally should not show such huge different characteristics in smell and taste, and that is why D-S evidence is suitable for this scenario.
Conclusion and outlook for artificial intelligence
Compared to tea masters, E-Nose and E-Tongue guarantee to be fully objective and statistically more accurate with the implementation of KDLA. Moreover, both time efficiency and cost efficiency can be largely improved. E-Nose and E-Tongue can work non-stop with each sample only taking 120 seconds, and the computer can then process the data 1,000 times faster than a human does. The main cost would be the fixed cost, including setting up the machines and training the model. Once the setup is done, the operation cost is expected to be fairly low. Therefore, tea quality assessment with E-Nose and E-Tongue can definitely be promoted to the market for practical use.
As we go through the full process, I also hope you get a better sense of how AI works. To many people’s disappointment, AIs are not like creatures and never generate ideas on their own. The fundamental of all AIs is humble mathematics and computer science, very unromantically. Yet isn’t that exciting, that human is able to do things unimaginable decades ago today with the power of computers, which is neither magic nor miracle, but still the product of our own intelligence?
More on KLDA: https://youtu.be/mICWQEUpgEQ
Reference: Zhi, Ruicong, Lei Zhao, and Dezheng Zhang. "A Framework for the Multi-Level Fusion of Electronic Nose and Electronic Tongue for Tea Quality Assessment." Sensors, vol. 17, no. 5, 2017, pp. 1007. doi: http://dx.doi.org.libproxy2.usc.edu/10.3390/s17051007.
1 note
·
View note