
Statistics
We looked inside some of the posts by xinchaocode and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
4
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 months ago
Number of Posts By Type
Text
8
Note
2
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Hướng dẫn sử dụng Search Engine Apache Solr

1. Apache Solr là gì?
Apache Solr (viết tắt của Searching On Lucene w / Replication) là một công cụ tìm kiếm mã nguồn mở, miễn phí dựa trên thư viện Apache Lucene. Một tiểu dự án Apache Lucene, đã có từ năm 2004 và là một trong những công cụ tìm kiếm phổ biến nhất hiện nay trên toàn thế giới.
Được viết bằng ngôn ngữ lập trình Java, Solr có các API RESTful XML / HTTP và JSON và các thư viện ứng dụng client cho nhiều ngôn ngữ lập trình như Java, Phyton, Ruby, C #, PHP và nhiều ngôn ngữ khác đang được sử dụng để xây dựng các ứng dụng phân tích dữ liệu lớn và dựa trên tìm kiếm cho các trang web, cơ sở dữ liệu, tệp.
Solr nhận dữ liệu có cấu trúc, bán cấu trúc và phi cấu trúc từ nhiều nguồn khác nhau, lưu trữ và lập chỉ mục, đồng thời cung cấp dữ liệu có sẵn để tìm kiếm trong thời gian thực. Solr cũng được sử dụng cho khả năng phân tích, cho phép thực hiện tìm kiếm sản phẩm theo từng khía cạnh, tổng hợp nhật ký / sự kiện bảo mật, phân tích phương tiện truyền thông xã hội.
2. Tính năng của Apache Solr
Solr hỗ trợ kiến trúc nhiều đối tượng cho phép bạn mở rộng quy mô, phân phối và quản lý chỉ mục cho các ứng dụng quy mô lớn.
Solr là một nền tảng tìm kiếm ổn định, đáng tin cậy và có khả năng chịu lỗi với bộ chức năng cốt lõi phong phú cho phép cải thiện cả trải nghiệm người dùng và mô hình dữ liệu cơ bản. Ví dụ: trong số các chức năng giúp mang lại trải nghiệm người dùng tốt, Solr có thể kiểm tra lỗi chính tả, tìm kiếm không gian địa lý, phân loại hoặc tự động đề xuất.
Các tính năng cốt lõi của Solr:
+ Khả năng tìm kiếm toàn văn mạnh mẽ: Solr cung cấp các khả năng tìm kiếm nâng cao gần thời gian thực như tìm kiếm theo trường, truy vấn Boolean, truy vấn cụm từ, truy vấn mờ, kiểm tra chính tả, ký tự đại diện, nối, nhóm, tự động hoàn thành và nhiều hơn nữa trên các loại dữ liệu khác nhau.
+ Giao diện quản trị toàn diện: Solr cung cấp giao diện người dùng đáp ứng được tích hợp sẵn cho phép bạn thực hiện các tác vụ quản trị như quản lý ghi nhật ký, thêm, xóa, cập nhật hoặc tìm kiếm tài liệu.
+ Khả năng mở rộng và tính linh hoạt cao: Solr có thể được triển khai cho bất kỳ loại hệ thống nào như độc lập, phân tán, đám mây, tất cả trong khi đơn giản hóa cấu hình.
+ Kiến trúc plugin có thể mở rộng: Solr xuất bản các điểm mở rộng giúp dễ dàng bổ sung các plugin thời gian truy vấn và lập chỉ mục.
+ Bảo mật tích hợp: Solr đi kèm với các tính năng giải quyết một số khía cạnh của bảo mật:
o SSL để mã hóa lưu lượng HTTP giữa các máy khách Solr và Solr, cũng như giữa các nút.
o Xác thực cơ bản và dựa trên Kerberos.
o API ủy quyền để xác định người dùng, vai trò và quyền.
+ Dễ dàng giám sát: Solr hiển thị các chỉ số thông qua JMX MBeans, vì vậy có thể thực hiện một số giám sát đặc biệt (như kiểm tra tại chỗ) bằng cách sử dụng các công cụ như JConsole hoặc JMXC. Kể từ Solr 6.4, Solr cũng bắt đầu hiển thị các chỉ số của mình thông qua API HTTP.
+ Khả năng phân tích mạnh mẽ: Solr có hai cách phân tích dữ liệu:
o Các khía cạnh: Đây là những thứ tốt cho phân tích thời gian thực. Ví dụ: trong tìm kiếm sản phẩm, chúng ta sẽ chia nhỏ kết quả theo thương hiệu. Trong phân tích nhật ký, chúng ta sẽ xem xét khối lượng lỗi mỗi giờ.
o Tổng hợp phát trực tuyến: Solr cho phép thực hiện các quá trình xử lý phức tạp hơn, dù thường chậm hơn các khía cạnh. Các ví dụ bao gồm kết hợp kết quả với một tập dữ liệu khác (có thể nằm ngoài Solr) và các tác vụ học máy như phân cụm hoặc hồi quy.
3. Thuật ngữ và các khái niệm cơ bản trong Solr.
- Document: Là một đơn vị thông tin cơ bản trong Solr có thể được lưu trữ và lập chỉ mục. Document được lưu trữ trong các collection. Document có thể được thêm, xóa và cập nhật, thường thông qua trình xử lý chỉ mục.
- Field: Field lưu trữ dữ liệu trong document, chứa một cặp key-value, trong đó key chỉ ra tên field và value dữ liệu field thực tế. Solr hỗ trợ các loại field khác nhau như: float, long, double, date, date, text, integer, boolean,...
- Collection: Là một nhóm các phân đoạn / lõi tạo thành một chỉ mục logic duy nhất. Mỗi collection có bộ cấu hình và định nghĩa lược đồ riêng, có thể khác với các collection khác.
- Shard: Shard cho phép chia nhỏ và lưu trữ chỉ mục của mình thành một hoặc nhiều phần, do đó phân đoạn là một phần của tập hợp. Mỗi phân đoạn sống trên một nút và được lưu trữ trong một lõi.
- Node: Một node là một phiên bản Máy ảo Java duy nhất chạy Solr, còn được gọi là máy chủ Solr. Một node có thể lưu trữ nhiều phân đoạn.
- Replica: Replica là một bản sao vật lý của một phân đoạn chạy như một core trong một node. Một trong những bản sao này là một Leader. Các bản sao khác của cùng một phân đoạn sẽ sao chép dữ liệu từ trình dẫn đầu.
- Leaders: Leader là bản sao của phân đoạn gửi yêu cầu của SolrCloud đến phần còn lại của các bản sao trong phân đoạn bất cứ khi nào có cập nhật chỉ mục, chẳng hạn như bổ sung hoặc xóa tài liệu. Nếu leader đi xuống, một trong những bản sao khác sẽ tự động được bầu làm leader.
- Cluster: Riêng đối với SolrCloud, một cluster được tạo thành từ một hoặc nhiều node lưu trữ tất cả dữ liệu, cung cấp khả năng lập chỉ mục và tìm kiếm phân tán trên tất cả các node.
4. Cách hoạt động của Solr.
Solr hoạt động bằng cách thu thập, lưu trữ và lập chỉ mục tài liệu từ các nguồn khác nhau và làm cho có thể tìm kiếm được trong thời gian thực. Solr tuân theo một quy trình 3 bước bao gồm lập chỉ mục, truy vấn và cuối cùng là xếp hạng kết quả - tất cả đều trong thời gian gần thực, mặc dù nó có thể hoạt động với khối lượng dữ liệu khổng lồ.
Các bước để Solr thực hiện tìm kiếm như sau:
Bước 1: L���p chỉ mục
Có 3 cách để lập chỉ mục:
· Nếu dữ liệu đang ở định dạng JSON, XML/XSLT hoặc CSV thì có thể tải lên trực tiếp.
· Nếu dữ liệu đang ở định dạng PDF hoặc tài liệu Office được Apache hỗ trợ thì có thể sử dụng ExtractionRequestHandler, còn được gọi là Solr Cell. Trình xử lý yêu cầu này phân tích cú pháp các tệp đến bằng Tika và trích xuất các trường cần lập chỉ mục.
· Nhập dữ liệu từ cơ sở dữ liệu, email, nguồn cấp RSS, dữ liệu XML, tệp văn bản thuần túy, v.v. Solr có một plugin gọi là DataImportHandler, có thể tìm nạp dữ liệu từ cơ sở dữ liệu và lập chỉ mục nó, sử dụng tên cột làm tên trường tài liệu.
Solr sử dụng Lucene để tạo chỉ mục ngược vì nó đảo cấu trúc dữ liệu tập trung vào trang (tài liệu ⇒ từ) sang cấu trúc tập trung vào từ khóa (từ ⇒ tài liệu). Giống như chỉ mục ta thấy ở cuối bất kỳ cuốn sách nào mà ta có thể tìm thấy vị trí các từ nhất định xuất hiện trong sách. Tương tự, chỉ mục Solr là một danh sách chứa ánh xạ các từ, thuật ngữ hoặc cụm từ và vị trí tương ứng của chúng trong các tài liệu được lưu trữ.
Do đó, Solr đạt được phản hồi nhanh hơn vì nó tìm kiếm các từ khóa trong chỉ mục thay vì quét văn bản trực tiếp.
Solr sử dụng các trường để lập chỉ mục một tài liệu. Tuy nhiên, trước khi được thêm vào chỉ mục, dữ liệu sẽ đi qua bộ phân tích trường, nơi Solr sử dụng bộ lọc char, bộ lọc mã thông báo và bộ lọc mã thông báo để làm cho dữ liệu có thể tìm kiếm được. Bộ lọc biểu đồ có thể thực hiện các thay đổi đối với toàn bộ chuỗi. Sau đó, các bộ mã hóa chia nhỏ dữ liệu trường thành các đơn vị từ vựng hoặc mã thông báo sau đó chuyển qua các bộ lọc quyết định giữ lại, chuyển đổi (ví dụ: đặt tất cả dữ liệu thành chữ thường, loại bỏ các gốc từ) hoặc loại bỏ chúng hoặc tạo các bộ lọc mới. Các mã thông báo cuối cùng này được thêm vào chỉ mục hoặc được tìm kiếm tại thời điểm truy vấn.
Tuy nhiên, cần thiết lập các quy tắc để xử lý nội dung được tìm thấy trong các field khi tài liệu được lập chỉ mục. Các quy tắc này chỉ định các loại field, field nào là bắt buộc và field nào nên được sử dụng làm khóa chính / duy nhất cũng như cách lập chỉ mục và tìm kiếm từng field.
Các field và quy tắc được xác định trong tệp lược đồ được quản lý (trước đây là schema.xml), thường được lưu trữ trong confDir cho core hoặc collection.
Bước 2: Truy vấn
Ví dụ, có thể tìm kiếm các thuật ngữ khác nhau như từ khóa, hình ảnh hoặc dữ liệu vị trí địa lý. Khi gửi một truy vấn, Solr sẽ xử lý nó với một trình xử lý yêu cầu truy vấn (hoặc đơn giản là trình xử lý truy vấn) hoạt động tương tự như trình xử lý chỉ mục, chỉ điều đó được sử dụng để trả về tài liệu từ chỉ mục Solr thay vì tải chúng lên.
Bước 3: Xếp hạng kết quả
Vì so khớp các tài liệu được lập chỉ mục với một truy vấn, Solr xếp hạng các kết quả theo điểm mức độ liên quan của chúng - các lần truy cập có liên quan nhất xuất hiện ở đầu các tài liệu phù hợp.
5. Cài đặt Solr.
Tải xuống bản phát hành Solr theo liên kết: https://solr.apache.org/downloads.html
Yêu cầu cài đặt Java 7 trở lên để khởi chạy Solr.
Sau khi giải nén tệp đã tải xuống sẽ nhận được một thư mục có tên solr-*, với cấu trúc sau:
· Thư mục bin các tập lệnh sử dụng để khởi động và dừng Solr.
· Thư mục example, docs chứa các tài liệu muốn lập chỉ mục, cũng như tập lệnh sẽ sử dụng để giao tiếp với Solr.
Để khởi chạy Solr, mở chương trình cmd, di chuyển đến thư mục bin và chạy dòng lệnh sau:
solr start
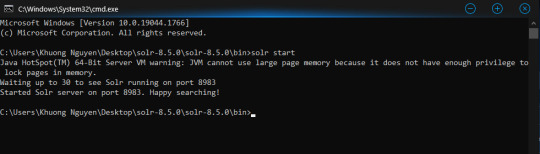
Truy cập vào giao diện người dùng quản trị Solr thông qua liên kết sau:
http://localhost:8983/solr
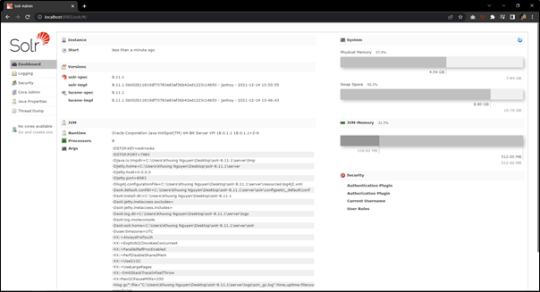
6. Tìm kiếm toàn văn với Solr
Tạo document collection với tên là “cars” bằng câu lệnh sau:
solr create –c cars
Trong từ vựng, solr gọi bộ sưu tập tài liệu này là “core”.
Sau khi tạo core thành công, giao diện người dùng sẽ hiển thị như sau:

Cấu hình Solr
Có thể được thực hiện thông qua giao diện người dùng quản trị hoặc trực tiếp thông qua các tệp. Các tệp quan trọng nhất cần biết là tệp lược đồ lập chỉ mục (Managed-schema) và tệp cấu hình Solr (solrconfig.xml). Cả hai đều được đặt dưới server/solr/cars/conf/
Tệp giản đồ có thể truy cập được trong phần giản đồ trong giao diện người dùng quản trị. Trong phần Tệp, ta có thể truy cập vào tệp cấu hình Solr, cũng như các tệp có liên quan khác cho cấu hình.
Lược đồ lập chỉ mục Solr
Tệp này được sử dụng để cho Solr biết cách lập chỉ mục các tài liệu muốn cung cấp để tìm kiếm. Đó là một cách hiệu quả để đảm bảo rằng Solr đang lập chỉ mục nội dung theo đúng cách. Tệp này chứa định nghĩa trường tài liệu và kiểu của những trường này.
Lược đồ cũng chứa field “id”, là khóa duy nhất cho mỗi document. Field “id” đã được xác định trước trong mọi lược đồ (<uniqueKey> id </uniqueKey>).
Dynamic Fields
Solr hỗ trợ hai loại field: dynamic field và static field.
Có một số tùy chọn để xác định các field mới:
· Chỉnh sửa tệp lược đồ để xác định các field. Điều này có thể được thực hiện thông qua giao diện người dùng quản trị hoặc bằng cách chỉnh sửa tệp trực tiếp.
· Sử dụng API lược đồ để xác định các field mới.
· Sử dụng dynamic field, một dạng cấu hình quy ước ánh xạ tên trường thành các kiểu trường dựa trên các mẫu trong tên field.
· Sử dụng chế độ "schemaless", trong đó các loại field được tự động phát hiện (đoán) dựa trên giá trị đầu tiên được nhìn thấy cho field đó.
Các dynamic field bao gồm những lợi ích thiết yếu của schemaless - cụ thể là khả năng thêm các field mới một cách nhanh chóng mà không cần phải xác định trước chúng.
Các loại Field
Chỉ định rõ ràng các loại phân tích và phân tích cú pháp sẽ được áp dụng trên nội dung. Có hai giai đoạn trong quá trình tìm kiếm. Đối với mỗi giai đoạn, có thể xác định các loại cụ thể:
· Giai đoạn lập chỉ mục: chỉ định cách chúng ta muốn tài liệu của mình được phân tích và lập chỉ mục.
· Giai đoạn truy vấn: chỉ định cách chúng ta muốn truy vấn người dùng được phân tích cú pháp và phân tích
Các loại Type
Có 3 loại Type:
· Xác định trước: int, float, string, date, boolean,...
· Được định nghĩa bởi Solr: text, phonetic, location,...
· Tùy chỉnh: Tự định nghĩa để đáp ứng các nhu cầu cụ thể
Các loại máy phân tích
Có 2 loại máy phân tích:
· Tokenizers: Xác định cách tách văn bản. ví dụ: sử dụng dấu câu, dấu cách,...
· Bộ lọc: Xác định cách muốn xử lý văn bản. ví dụ: loại bỏ các từ dừng, xuất phát từ, lemmatization, các từ khóa exampand bằng c��c từ đồng nghĩa, bảo vệ một số từ khóa cụ thể,...
Đây là một ví dụ về loại được xác định trước “text_general”. Trong ví dụ này, chúng ta có hai bộ phân tích:
· Bộ phân tích lập chỉ mục (<analyzer type = ”index”>): được áp dụng trên các trường tài liệu tại thời điểm lập chỉ mục. Nó có một tokenizer tiêu chuẩn, một bộ lọc từ khóa và một bộ lọc chữ thường.
· Truy vấn phân tích (<analyzer type = ”query”>): được áp dụng tại thời điểm truy vấn. Nó có một tokenizer tiêu chuẩn, một bộ lọc từ khóa, một bộ lọc từ đồng nghĩa và một bộ lọc viết thường.
stopwords.txt và synyms.txt là hai tệp văn bản chứa các từ dừng tương ứng (ví dụ: a, the, an, v.v.) cần được xóa khỏi văn bản và các mối quan hệ từ đồng nghĩa (ví dụ: automobile, auto, car) nên được áp dụng để mở rộng văn bản. Hai tệp này được vận chuyển cùng với Solr và có thể được sửa đổi dựa trên nhu cầu.
Trong ví dụ này, sẽ chỉ sử dụng các từ đồng nghĩa tại thời điểm truy vấn. Không cần đồng thời áp dụng mở rộng từ đồng nghĩa ở giai đoạn lập chỉ mục.
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Hình minh họa sau đây mô tả cách Solr sử dụng các kiểu để xử lý tài liệu và truy vấn.
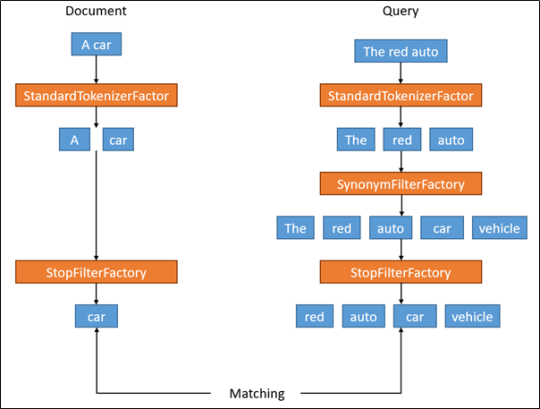
Fields
Khi chúng ta đã xác định các Field, chúng ta có thể sử dụng chúng để tạo các Field của tài liệu sẽ được lập chỉ mục. Trường xác định đặc điểm kỹ thuật về cách nó phải được Solr lập chỉ mục và tìm kiếm.
Cú pháp với các thuộc tính cơ bản như sau:
<field name="…" type="…" indexed="true|false" stored="true|false" required="true|false" … />
Chú thích:
· name: tên của field trong chỉ mục. Tên này phải là duy nhất trong một giản đồ.
· type: một trong các loại được xác định như mô tả trong phần trên.
· indexed (true | false): chỉ định trường có thể tìm kiếm được hay không. Trong một số trường hợp, có thể có các phần tài liệu không muốn đưa vào trong quá trình tìm kiếm. Trong trường hợp đó, lập chỉ mục là false.
· stored (true | false): chỉ định liệu một field có nên được lưu trữ để có thể trả về trong tập kết quả hay không.
· required (true | false): chỉ định một field phải tồn tại trong tài liệu để được lập chỉ mục hay không.
Hãy lấy một ví dụ cơ bản mô tả car. Một chiếc xe có kiểu dáng, mô hình, mô tả, màu sắc và giá cả. Để lập chỉ mục các tài liệu mô tả ô tô, có thể xác định các trường sau trong lược đồ:
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="make" type="string" indexed="true" stored="true" required="true" />
<field name="model" type="string" indexed="true" stored="true"/>
<field name="description" type="text_general" indexed="true" stored="true" />
<field name="colour" type="string" indexed="true" stored="true"/>
<field name="price" type="pint" indexed="true" stored="true"/>
Như đã mô tả ở trên, ta có thể sử dụng các trường động. Thay vì xác định rõ ràng tên trường trong lược đồ, ta có thể sử dụng hậu tố trường trong tài liệu muốn lập chỉ mục. Ví dụ: ta không tạo trường “make” trong lược đồ, thay vào đó, bạn sử dụng “make_s” trong tài liệu.
Phần xml ở trên nên được thêm vào tệp lược đồ (Managed-schema). Có thể thực hiện thông qua giao diện người dùng quản trị hoặc bằng cách chỉnh sửa tệp theo cách thủ công. Tệp lược đồ được quản lý nằm trong solr-*/server/solr/cars/conf.
Lược đồ hiện tại đã có một số trường và kiểu. Phải luôn đảm bảo rằng các trường và loại tạo mới không xung đột với các trường và loại hiện có.
Nếu chỉnh sửa tệp theo cách thủ công, thì khởi động lại máy chủ solr để thay đổi có hiệu lực bằng lệnh sau:
solr restart –p 8983
Sau khi thêm các field thành công thì giao diện sẽ hiển thị như sau, truy cập liên kết:
http://localhost:8983/solr/#/cars/schema

Các documents
Bây giờ các field và type đã được xác định, đã có thể bắt đầu chuẩn bị các document muốn lập chỉ mục. Có ba tiêu chí cần được lưu ý trong khi chuẩn bị document để lập chỉ mục:
· Document phải chứa các tên field giống như được mô tả trong lược đồ. Đối với các dynamic field, nên tuân thủ hậu tố field.
· Value của các document field phải tuân thủ các loại field này.
· Các field được xác định là "required" trong lược đồ phải có trong document, nếu không document đó sẽ không được lập chỉ mục.
Có thể đặt nhiều document trong cùng một tệp và lập chỉ mục tất cả cùng một lúc. Cú pháp của tệp mà Solr có thể lập chỉ mục:
<add>
<doc>
<field name="field 1">value 1</field>
<field name="field 2">value 2</field>
...
<field name="field n">value n</field>
</doc>
<doc>
...
</doc>
...
</add>
Đây là một ví dụ cơ bản của các tài liệu mô tả car.
<add>
<doc>
<field name="id">1</field>
<field name="make">BMW</field>
<field name="model">X5</field>
<field name="description">Brand new car</field>
<field name="colour">Grey</field>
<field name="price">45000</field>
</doc>
<doc>
<field name="id">2</field>
<field name="make">Audi</field>
<field name="model">A4</field>
<field name="description">Not afraid of the snow</field>
<field name="colour">Grey</field>
<field name="price">40000</field>
</doc>
</add>
Giai đoạn lập chỉ mục
Hiện tại core cars vẫn chưa được lập chỉ mục bất kỳ document nào nên Solr sẽ hiển thị như sau:
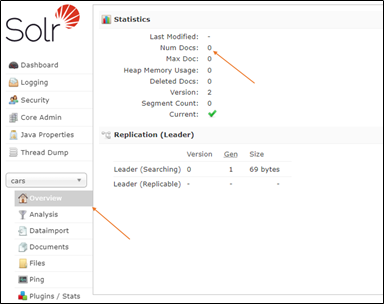
Có thể lập chỉ mục tài liệu của mình bằng dòng lệnh thông qua yêu cầu http hoặc thông qua giao diện người dùng. Trong ví dụ này sẽ sử dụng curl để giao tiếp với máy chủ Solr thông qua http.
Để giao tiếp với Solr, cần chỉ định máy chủ lưu trữ Solr, hành động muốn thực hiện (thêm, cập nhật, xóa,...) và nội dung đến document muốn lập chỉ mục.
Câu lệnh curl sẽ là:
Request URL: http://localhost:8983/solr/cars/update?commit=true&overwrite=true" --data-binary
Method: POST
Header name: content-type: application/xml;charset=utf-8
Body: application/xml
<add>
<doc>
<field name="id">1</field>
<field name="make">BMW</field>
<field name="model">X5</field>
<field name="description">Brand new car</field>
<field name="colour">Grey</field>
<field name="price">45000</field>
</doc>
<doc>
<field name="id">2</field>
<field name="make">Audi</field>
<field name="model">A4</field>
<field name="description">Not afraid of the snow</field>
<field name="colour">Grey</field>
<field name="price">40000</field>
</doc>
</add>
Sử dụng công cụ Advanced REST Client để gửi câu lệnh trên:
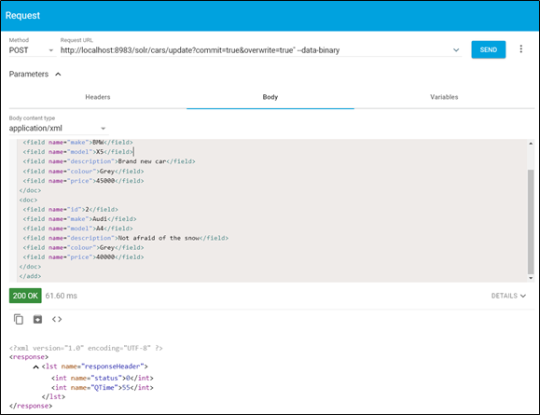
Sau khi thực hiện thành công với status code 200 OK giao diện Solr sẽ hiển thị như sau:

Nếu muốn xóa document gọi lệnh CURL sau:
Request URL: http://localhost:8983/solr/cars/update?commit=true
Method: POST
Header name: content-type: application/xml
Body: application/xml
<delete><id>1</id></delete>
*Nếu muốn xóa tất cả document ta sử dụng:
<delete><id>*:*</id></delete>

Câu lệnh trên sẽ xóa document có id là 1
Sau khi thực hiện gọi thành công với status code 200 OK giao diện Solr sẽ hiển thị như sau:
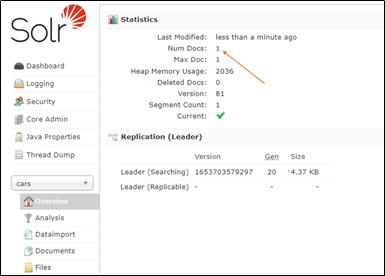
Giai đoạn truy vấn
Bây giờ đã có các tài liệu trong chỉ mục, đã có thể bắt đầu tìm kiếm. Trong quá trình tìm kiếm, có hai bước:
Bước 1: Xây dựng và thực thi truy vấn
Khái niệm này rất giống với lập chỉ mục. Ta gọi máy chủ Solr và chỉ định rằng hành động là một “lựa chọn”. Ta cũng chỉ định truy vấn người dùng và một tập hợp các tham số tìm kiếm. Solr sẽ chọn, từ chỉ mục, những document phù hợp với truy vấn của người dùng theo tập hợp các tham số. Đây là cú pháp của yêu cầu http được gửi đến Solr:
http://solr_server_name/solr/core_name/select?q=query&search_parameters
Trong q, có thể chỉ định tập hợp các từ khóa được tìm kiếm.
Ngoài truy vấn (q), có một số tham số mà bạn có thể sử dụng để xây dựng trải nghiệm tìm kiếm mạnh mẽ. Sau đây là một vài ví dụ:
· sort (asc | desc): Sắp xếp các document trả về theo một thứ tự cụ thể. Có thể kết hợp nhiều loại trong một truy vấn duy nhất. ví dụ: sort = inStock, desc, price asc.
· rows: Chỉ định số lượng document muốn Solr trả về trong tập kết quả. Điều này rất hữu ích cho việc phân trang. Theo mặc định, giá trị được đặt là 10.
· start: Được sử dụng để phân trang để chỉ định số docuemtn mà Solr sẽ bắt đầu hiển thị kết quả. Theo mặc định, giá trị này được đặt là 0.
· fq: Đó là một tham số rất mạnh mẽ giúp lọc các docuemtn được trả về. Ví dụ: để tìm kiếm những chiếc BMW rẻ hơn $ 15000, có thể chỉ định các thông số sau: fq = price: [* TO 15000] & fq = make: BMW.
· fl: Được sử dụng để chỉ định tập hợp các trường muốn trả về trong tập kết quả. Ví dụ, nếu chỉ muốn trả lại make, price và color, có thể làm như sau: fl = make, price, color. Nếu không chỉ định tham số này, Solr sẽ trả về tất cả các trường có sẵn trong chỉ mục.
Bước 2: Kết quả tìm kiếm
Trong bước này, sẽ nhận được bộ kết quả từ Solr theo định dạng và thứ tự mà đã chỉ định trong truy vấn. Có thể chỉ định để nhận định dạng XML, JSON, Python, Ruby, PHP, CSV.
Truy vấn cơ bản nhất có thể thực hiện là q: *: *. Điều này trả về tất cả các tài liệu có sẵn trong chỉ mục.

Một số ví dụ khác sử dụng các tham số tìm kiếm:
· Truy vấn yêu cầu tất cả các xe do BMW sản xuất (q = make: BMW).
· Tập hợp kết quả tìm kiếm phải bắt đầu từ tài liệu phản hồi đầu tiên (start = 0).
· Số lượng tài liệu cần được trả lại trong tập kết quả là 10 (rows = 10).
· Giới hạn các field được trả là make, model và price (fl = make, model, price).
· Định dạng của phản hồi phải là PHP
Câu lệnh truy vấn sẽ là:
http://localhost:8983/solr/cars/select?q=make:BMW&start=0&rows=10&fl=make,model,price
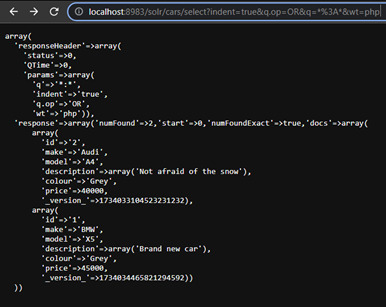
Trong phần responseHeader, Solr trả về truy vấn và các tham số tìm kiếm. numFound chứa số lượng tài liệu mà Solr tìm thấy phù hợp với truy vấn của người dùng. Phần docs chứa các tài liệu phản hồi. Chính xác hơn, nó chứa các field đã được chỉ định trong tham số fl.
0 notes
Note
Bạn là ai
Chào bạn, mình tên là Nguyễn Lập An Khương, tác giả của blog Xin chào code.
Mình là sinh viên năm 3 ngành Kỹ Thuật Phầm Mềm trường Kỹ Thuật - Công Nghệ Cần Thơ.
Blog này được tạo ra nhằm chia sẻ những kiến thức, mẹo hay về lập trình và nhiều thứ khác mà mình đã học tập được từ những thầy cô quý mến trong suốt quá trình học tập ở trường.
Đây là một số thông tin liên hệ mình:
Email: [email protected]
FB: https://www.facebook.com/ankhuong.nguyenlap
Điện thoại: 0907892198
0 notes
Note
Sự khác nhau giữa override và overload là gì? Mong ad trả lời ạ :3
cảm ơn câu hỏi của bạn.
Câu hỏi này rất phổ biến trên internet nên mình gợi ý cho bạn trang web để bạn có thể tìm hiểu sự khác nhau về Override và Overload:
https://beginnersbook.com/2014/01/difference-between-method-overloading-and-overriding-in-java/#:~:text=The%20most%20basic%20difference%20is,inherited%20method%20of%20parent%20class.
0 notes
Text
Xây dựng Hệ Thống Trợ Giúp cho riêng bạn trong vòng 5 phút với Python

Ứng dụng thành công và rộng rãi nhất của công nghệ học máy trong kinh doanh là Hệ trợ giúp quyết định.
Bạn đang duyệt qua Spotify để nghe một bài hát nhưng không thể quyết định bài hát nào. Bạn đang lướt qua YouTube để xem một số video nhưng không thể quyết định xem video nào. Có rất nhiều trường hợp khác như thế này, nơi chúng tôi có nhiều dữ liệu nhưng chúng tôi không thể quyết định mình muốn gì. Đây là nơi mà các hệ thống giới thiệu sẽ hỗ trợ chúng tôi.
Hệ thống giới thiệu phổ biến trên thị trường ngày nay và có tầm quan trọng thương mại lớn, bằng chứng là số lượng lớn các công ty bán giải pháp hệ thống giới thiệu. Hệ thống đề xuất đã thay đổi cách các trang web vô tri giao tiếp với người dùng của họ. Thay vì cung cấp trải nghiệm tĩnh trong đó người dùng tìm kiếm và có khả năng mua sản phẩm, các hệ thống giới thiệu tăng cường tương tác để cung cấp trải nghiệm phong phú hơn. Hệ thống đề xuất xác định các đề xuất một cách độc lập cho từng người dùng dựa trên các giao dịch mua và tìm kiếm trước đây cũng như hành vi của những người dùng khác.
Hôm nay, chúng ta sẽ tập trung vào việc cung cấp một hệ thống đề xuất cơ bản bằng cách đề xuất các mục giống nhất với một mục cụ thể, trong trường hợp này là phim. Hãy nhớ rằng đây không phải là một hệ thống đề xuất mạnh mẽ thực sự, để mô tả chính xác hơn, nó chỉ cho bạn biết những phim / mục nào giống nhất với lựa chọn phim của bạn.
Import vào thư viện
import numpy as np import pandas as pd
Bạn có thể lấy tập dữ liệu bằng cách nhấp vào đây. Các cột trong tập dữ liệu có tên là ‘u.data’ đại diện cho ID người dùng, ID mặt hàng, Xếp hạng và dấu thời gian như chúng tôi đã xác định trong mã bên dưới.
Nhận dữ liệu
column_names = ['user_id', 'item_id', 'rating', 'timestamp'] df = pd.read_csv('u.data', sep='\t', names=column_names) print(df.head())

Bây giờ chúng ta hãy lấy tên phim:
movie_titles = pd.read_csv("Movie_Id_Titles") print(movie_titles.head())

Chúng ta có thể hợp nhất chúng lại với nhau:
df = pd.merge(df,movie_titles,on='item_id') print(df.head())
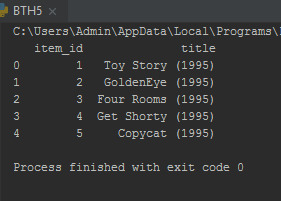
EDA
Hãy cùng khám phá dữ liệu một chút và xem một số bộ phim được xếp hạng hay nhất.
Visualization Imports
import matplotlib.pyplot as plt import seaborn as sns sns.set_style('white') %matplotlib inline
Hãy tạo khung dữ liệu xếp hạng với xếp hạng trung bình và số lượng xếp hạng:
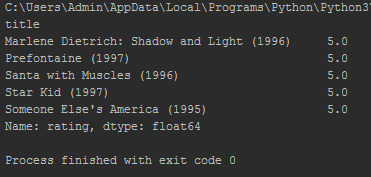
print(df.groupby('title')['rating'].mean().sort_values(ascending=False).head())
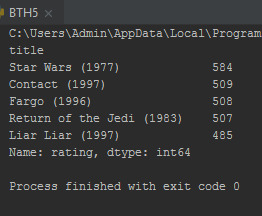
print(df.groupby('title')['rating'].count().sort_values(ascending=False).head())
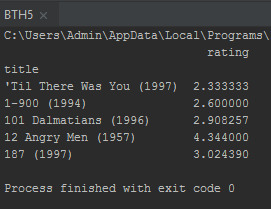
ratings = pd.DataFrame(df.groupby('title')['rating'].mean()) print(ratings.head())
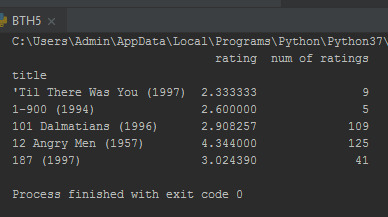
Bây giờ đặt số lượng cột xếp hạng:
ratings['num of ratings'] = pd.DataFrame(df.groupby('title')['rating'].count()) print(ratings.head())
sns.jointplot(x='rating',y='num of ratings',data=ratings,alpha=0.5)
plt.show()
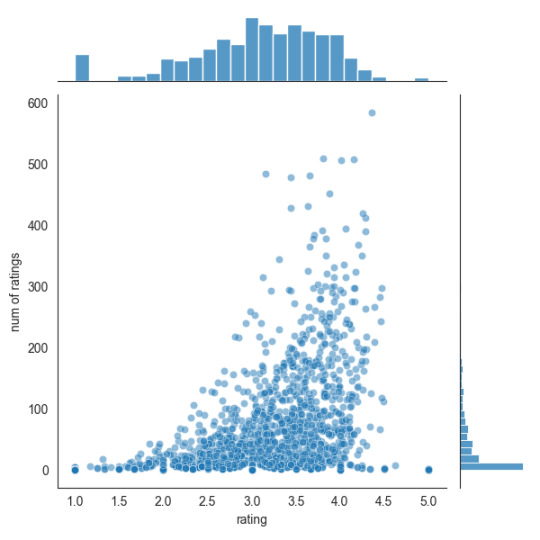
Được chứ! Bây giờ chúng ta đã có ý tưởng chung về dữ liệu trông như thế nào, hãy chuyển sang tạo một hệ thống đề xuất đơn giản:
Đề xuất phim tương tự
Bây giờ, hãy tạo một ma trận có id người dùng trên một quyền truy cập và tiêu đề phim trên một trục khác. Sau đó, mỗi ô sẽ bao gồm xếp hạng mà người dùng đã cho phim đó. Lưu ý sẽ có rất nhiều giá trị NaN, vì hầu hết mọi người chưa xem hầu hết các bộ phim.
moviemat = df.pivot_table(index='user_id',columns='title',values='rating') display(tabulate(moviemat.head(5), moviemat.head(), tablefmt="grid"))

print(ratings.sort_values('num of ratings',ascending=False).head(10))

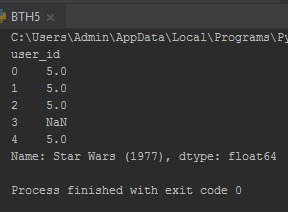
Hãy chọn hai bộ phim: starwars, một bộ phim khoa học viễn tưởng. Và Liar Liar, một bộ phim hài. Bây giờ, hãy lấy xếp hạng của người dùng cho hai bộ phim đó:
starwars_user_ratings = moviemat['Star Wars (1977)'] liarliar_user_ratings = moviemat['Liar Liar (1997)'] print(starwars_user_ratings.head())
Sau đó, chúng ta có thể sử dụng phương thức corrwith () để nhận các mối tương quan giữa hai chuỗi gấu trúc:
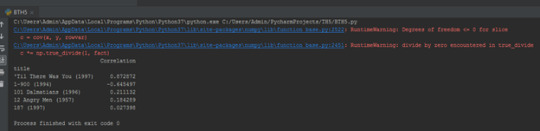
similar_to_starwars = moviemat.corrwith(starwars_user_ratings) similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings)
Khi thực hiện lệnh này, một cảnh báo sẽ được đưa ra trông giống như thế này.

Hãy làm sạch điều này bằng cách xóa các giá trị NaN và sử dụng DataFrame thay vì một chuỗi:
corr_starwars = pd.DataFrame(similar_to_starwars,columns=['Correlation']) corr_starwars.dropna(inplace=True) print(corr_starwars.head())
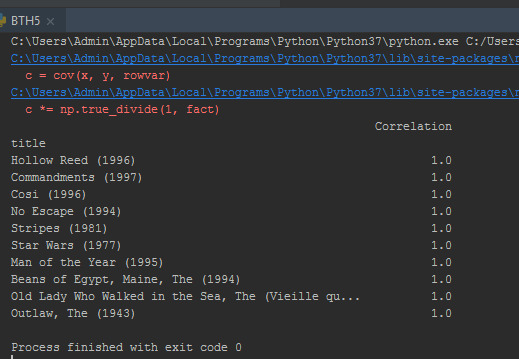
Bây giờ, nếu chúng tôi sắp xếp khung dữ liệu theo mối tương quan, chúng tôi s�� nhận được những bộ phim tương tự nhất, tuy nhiên lưu ý rằng chúng tôi nhận được một số kết quả không thực sự có ý nghĩa. Điều này là do có rất nhiều bộ phim chỉ được xem một lần bởi những người dùng cũng đã xem chiến tranh giữa các vì sao (đó là bộ phim nổi tiếng nhất).
print(corr_starwars.sort_values('Correlation',ascending=False).head(10))
Hãy khắc phục điều này bằng cách lọc ra các phim có ít hơn 100 bài đánh giá (giá trị này được chọn dựa trên biểu đồ trước đó).
corr_starwars = corr_starwars.join(ratings['num of ratings']) print(corr_starwars.head().sort_values('num of ratings',ascending=True))

Bây giờ hãy sắp xếp các giá trị và lưu ý cách tiêu đề có ý nghĩa hơn:
print(corr_starwars[corr_starwars['num of ratings']>100].sort_values('Correlation',ascending=False).head())

Giờ đây, bộ phim hài Liar Liar cũng vậy:
corr_liarliar = pd.DataFrame(similar_to_liarliar,columns=['Correlation']) corr_liarliar.dropna(inplace=True) corr_liarliar = corr_liarliar.join(ratings['num of ratings']) print(corr_liarliar[corr_liarliar['num of ratings']>100].sort_values('Correlation',ascending=False).head())

Bài viết được dịch lại từ bài viết: https://towardsdatascience.com/build-your-own-recommender-system-within-5-minutes-30dd40388fbf
0 notes
Text
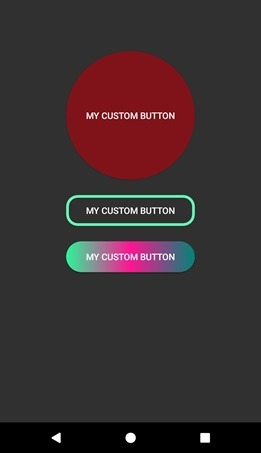
Tùy chỉnh button sử dụng XML Styles trong Android
Bước 1 - Tạo một dự án mới trong Android Studio, đi tới Tệp ⇒ Dự án Mới và điền tất cả các chi tiết cần thiết để tạo một dự án mới.
Bước 2 - Thêm code sau vào res / layout / activity_main.xml.
<?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <Button android:id="@+id/customButton" android:layout_width="200dp" android:layout_height="wrap_content" android:layout_centerInParent="true" android:background="@drawable/custom_button" android:text="My Custom button"/> <Button android:id="@+id/customButton2" android:layout_width="200dp" android:layout_height="wrap_content" android:layout_centerInParent="true" android:layout_below="@id/customButton" android:layout_marginTop="24sp" android:background="@drawable/custom_button2" android:text="My Custom button"/> <Button android:id="@+id/customButton3" android:layout_width="200dp" android:layout_height="200dp" android:layout_centerInParent="true" android:layout_above="@id/customButton" android:layout_marginBottom="24sp" android:layout_marginTop="24sp" android:background="@drawable/custom_button3" android:text="My Custom button"/> </RelativeLayout>
Bước 3 - Nhấp chuột phải vào res / drawable, Chọn mới → tệp tài nguyên có thể vẽ và thêm code sau vào custom_dialog.xml
<?xml version="1.0" encoding="utf-8"?> <shape xmlns:android="http://schemas.android.com/apk/res/android" android:shape="rectangle"> <stroke android:color="#66F9B9" android:width="4dp"/> <corners android:radius="16sp"/> </shape>
Bước 4 - Nhấp chuột phải vào res / drawable, Chọn tệp tài nguyên mới → Drawable và thêm code vào custom_dialog2.xml
<?xml version="1.0" encoding="utf-8"?> <shape xmlns:android="http://schemas.android.com/apk/res/android" android:shape="rectangle"> <gradient android:startColor="#2AF598" android:centerColor="#ff1493" android:endColor="@color/colorPrimary"/> <corners android:radius="50dp"/> </shape>
Bước 5 - Nhấp chuột phải vào res / drawable, Chọn tệp tài nguyên mới → Drawable và thêm code sau vào custom_dialog3.xml
<?xml version="1.0" encoding="utf-8"?> <shape xmlns:android="http://schemas.android.com/apk/res/android" android:shape="rectangle"> <solid android:color="#80121a" /> <corners android:radius="999dp"/> </shape>
Bước 6 - Thêm code sau vào src / MainActivity.java
package app.com.sample; import android.support.v7.app.AppCompatActivity; import android.os.Bundle; public class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); } }
Bước 7 - Thêm code sau vào androidManifest.xml
<?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="app.com.sample"> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:roundIcon="@mipmap/ic_launcher_round" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest>
Hãy thử chạy ứng dụng của bạn.
0 notes
Text
Hướng dẫn INSERT hình ảnh vào SQL Server
BaĐể chèn vào và truy xuất hình ảnh từ cơ sở dữ liệu máy chủ SQL mà không cần sử dụng các thủ tục được lưu trữ và cũng để thực hiện các thao tác chèn, tìm kiếm, cập nhật và xóa và điều hướng các bản ghi.
Khi chúng ta muốn chèn hình ảnh vào cơ sở dữ liệu, trước tiên chúng ta phải tạo một bảng trong cơ sở dữ liệu, chúng ta có thể sử dụng kiểu dữ liệu 'image' hoặc 'binary' để lưu trữ hình ảnh.
create table student(sno int primary key,sname varchar(50),course varchar(50),fee money,photo image)
Truy vấn để tạo bảng trong ứng dụng của chúng ta
Thiết kế giao diện
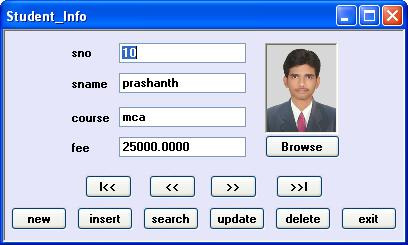
Thiết kế biểu mẫu như trên với 1 control PictureBox, 1 control OpenFileDialog, 4 Labels, 4 control TextBox và 11 control Buttons.
Thuộc tính PictureBox1
BorderStyle = Cố định3D; SizeMode = StrechImage
Lưu ý rằng control OpenFileDialog xuất hiện bên dưới biểu mẫu (không phải trên biểu mẫu), có thể được sử dụng để duyệt hình ảnh.
Bắt đầu lập trình
using thư viện
using System.Data.SqlClient
Trong ứng dụng này, chúng ta sẽ tìm kiếm một bản ghi bằng cách lấy đầu vào từ InputBox. Đối với điều này, chúng tôi phải thêm tham chiếu đến Microsoft.VisualBasic.
Thêm tham chiếu vào 'Microsoft.VisualBasic'
Goto Project Menu -> Add Reference -> chọn 'Microsoft.VisualBasic' từ tab .NET.
Để sử dụng tham chiếu này, chúng tôi phải bao gồm không gian tên:
using Microsoft.VisualBasic
Chuyển đổi hình ảnh thành dữ liệu nhị phân
Chúng ta không thể lưu trữ hình ảnh trực tiếp vào cơ sở dữ liệu. Đối với điều này, chúng tôi có hai giải pháp: Để lưu trữ vị trí của hình ảnh trong cơ sở dữ liệu
Chuyển đổi hình ảnh thành dữ liệu nhị phân và chèn dữ liệu nhị phân đó vào cơ sở dữ liệu và chuyển đổi dữ liệu đó trở lại hình ảnh trong khi truy xuất các bản ghi. Nếu chúng ta lưu trữ vị trí của một hình ảnh trong cơ sở dữ liệu và giả sử nếu hình ảnh đó bị xóa hoặc di chuyển khỏi vị trí đó, chúng tôi sẽ gặp phải vấn đề khi truy xuất các bản ghi. Vì vậy, tốt hơn là chuyển đổi hình ảnh thành dữ liệu nhị phân và chèn dữ liệu nhị phân đó vào cơ sở dữ liệu và chuyển đổi lại thành hình ảnh trong khi truy xuất bản ghi.
Chúng ta có thể chuyển đổi một hình ảnh thành dữ liệu nhị phân bằng cách sử dụng
FileStream
MemoryStream
1. FileStream sử dụng vị trí tệp để chuyển đổi hình ảnh thành dữ liệu nhị phân mà chúng ta có thể / không cung cấp trong khi cập nhật bản ghi.
FileStream fs = new FileStream(openFileDialog1.FileName, FileMode.Open, FileAccess.Read); byte[] photo_aray = new byte[fs.Length]; fs.Read(photo_aray, 0, photo_aray.Length);
2. Vì vậy, tốt hơn là sử dụng MemoryStream sử dụng hình ảnh trong PictureBox để chuyển đổi hình ảnh thành dữ liệu nhị phân.
MemoryStream ms = new MemoryStream(); pictureBox1.Image.Save(ms, ImageFormat.Jpeg); byte[] photo_aray = new byte[ms.Length]; ms.Position = 0; ms.Read(photo_aray, 0, photo_aray.Length);
Để sử dụng FileStream hoặc MemoryStream, chúng ta phải using thư viên:
using System.IO
OpenFileDialog Control Chúng ta sử dụng điều khiển OpenFileDialog để duyệt các hình ảnh (ảnh) để chèn vào bản ghi
Tải chi tiết ràng buộc vào dataTable
Trong ứng dụng này. chúng ta sử dụng phương thức Find () để tìm kiếm một bản ghi, yêu cầu chi tiết về cột khóa chính, có thể được cung cấp bằng câu lệnh:
adapter.MissingSchemaAction = MissingSchemaAction.AddWithKey;
Trỏ tới bản ghi hiện tại trong dataTable
Sau khi tìm kiếm một bản ghi, chúng ta phải lấy chỉ mục của bản ghi đó để có thể điều hướng các bản ghi tiếp theo và trước đó.
rno= ds.Tables[0].Rows.IndexOf(drow);
code tham khảo
using System; using System.Windows.Forms; using System.Data; using System.Data.SqlClient; using System.Drawing; using System.Drawing.Imaging; using System.IO; using Microsoft.VisualBasic; namespace inserting_imgs { public partial class Form1 : Form { public Form1() { InitializeComponent(); } SqlConnection con; SqlCommand cmd; SqlDataAdapter adapter; DataSet ds; int rno = 0; MemoryStream ms; byte[] photo_aray; private void Form1_Load(object sender, EventArgs e) { con = new SqlConnection("user id=sa;password=123;database=prash"); loaddata(); showdata(); } void loaddata() { adapter = new SqlDataAdapter("select sno,sname,course,fee,photo from student", con); adapter.MissingSchemaAction = MissingSchemaAction.AddWithKey; ds = new DataSet(); adapter.Fill(ds, "student"); } void showdata() { if (ds.Tables[0].Rows.Count > 0) { textBox1.Text = ds.Tables[0].Rows[rno][0].ToString(); textBox2.Text = ds.Tables[0].Rows[rno][1].ToString(); textBox3.Text = ds.Tables[0].Rows[rno][2].ToString(); textBox4.Text = ds.Tables[0].Rows[rno][3].ToString(); pictureBox1.Image = null; if (ds.Tables[0].Rows[rno][4] != System.DBNull.Value) { photo_aray = (byte[])ds.Tables[0].Rows[rno][4]; MemoryStream ms = new MemoryStream(photo_aray); pictureBox1.Image = Image.FromStream(ms); } } else MessageBox.Show("No Records"); } private void browse_Click(object sender, EventArgs e) { openFileDialog1.Filter = "jpeg|*.jpg|bmp|*.bmp|all files|*.*"; DialogResult res = openFileDialog1.ShowDialog(); if (res == DialogResult.OK) { pictureBox1.Image = Image.FromFile(openFileDialog1.FileName); } } private void newbtn_Click(object sender, EventArgs e) { cmd = new SqlCommand("select max(sno)+10 from student", con); con.Open(); textBox1.Text = cmd.ExecuteScalar().ToString(); con.Close(); textBox2.Text = textBox3.Text = textBox4.Text = ""; pictureBox1.Image = null; } private void insert_Click(object sender, EventArgs e) { cmd = new SqlCommand("insert into student(sno,sname,course,fee,photo) values(" + textBox1.Text + ",'" + textBox2.TabIndex + "','" + textBox3.Text + "'," + textBox4.Text + ",@photo)", con); conv_photo(); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("record inserted"); loaddata(); } else MessageBox.Show("insertion failed"); } void conv_photo() { //converting photo to binary data if (pictureBox1.Image != null) { //using FileStream:(will not work while updating, if image is not changed) //FileStream fs = new FileStream(openFileDialog1.FileName, FileMode.Open, FileAccess.Read); //byte[] photo_aray = new byte[fs.Length]; //fs.Read(photo_aray, 0, photo_aray.Length); //using MemoryStream: ms = new MemoryStream(); pictureBox1.Image.Save(ms, ImageFormat.Jpeg); byte[] photo_aray = new byte[ms.Length]; ms.Position = 0; ms.Read(photo_aray, 0, photo_aray.Length); cmd.Parameters.AddWithValue("@photo", photo_aray); } } private void search_Click(object sender, EventArgs e) { try { int n = Convert.ToInt32(Interaction.InputBox("Enter sno:", "Search", "20", 100, 100)); DataRow drow; drow = ds.Tables[0].Rows.Find(n); if (drow != null) { rno = ds.Tables[0].Rows.IndexOf(drow); textBox1.Text = drow[0].ToString(); textBox2.Text = drow[1].ToString(); textBox3.Text = drow[2].ToString(); textBox4.Text = drow[3].ToString(); pictureBox1.Image = null; if (drow[4] != System.DBNull.Value) { photo_aray = (byte[])drow[4]; MemoryStream ms = new MemoryStream(photo_aray); pictureBox1.Image = Image.FromStream(ms); } } else MessageBox.Show("Record Not Found"); } catch { MessageBox.Show("Invalid Input"); } } private void update_Click(object sender, EventArgs e) { cmd = new SqlCommand("update student set sname='" + textBox2.Text + "', course='" + textBox3.Text + "', fee='" + textBox4.Text + "', photo=@photo where sno=" + textBox1.Text, con); conv_photo(); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("Record Updated"); loaddata(); } else MessageBox.Show("Updation Failed"); } private void delete_Click(object sender, EventArgs e) { cmd = new SqlCommand("delete from student where sno=" + textBox1.Text, con); con.Open(); int n = cmd.ExecuteNonQuery(); con.Close(); if (n > 0) { MessageBox.Show("Record Deleted"); loaddata(); rno = 0; showdata(); } else MessageBox.Show("Deletion Failed"); } private void first_Click(object sender, EventArgs e) { rno = 0; showdata(); MessageBox.Show("First record"); } private void previous_Click(object sender, EventArgs e) { if (rno > 0) { rno--; showdata(); } else MessageBox.Show("First record"); } private void next_Click(object sender, EventArgs e) { if (rno < ds.Tables[0].Rows.Count - 1) { rno++; showdata(); } else MessageBox.Show("Last record"); } private void last_Click(object sender, EventArgs e) { rno = ds.Tables[0].Rows.Count - 1; showdata(); MessageBox.Show("Last record"); } private void exit_Click(object sender, EventArgs e) { this.Close(); } } }
Bài viết gốc: https://www.c-sharpcorner.com/UploadFile/e628d9/inserting-retrieving-images-from-sql-server-database-without-using-stored-procedures/
0 notes
Text
Chọn SQLite hay Firebase?

Firebase miễn phí trừ khi ứng dụng của bạn phát triển và bạn có nhiều người dùng thực hiện cuộc gọi đến API của họ.
Firebase không chỉ dành cho thông báo đẩy.

SQLite là tuyệt vời. TUY NHIÊN, nếu bạn làm rơi và làm hỏng điện thoại của mình, thông tin được lưu trữ trong cơ sở dữ liệu SQLite sẽ mất cùng với điện thoại của bạn.
Nếu bạn sư dụng Firebase. Bạn không phải lo lắng về việc viết mã cho SELECT và các câu truy vấn. Firebase thực hiện tất cả. Nếu bạn cập nhật bất cứ thứ gì thông qua trang tổng quan, ứng dụng cũng sẽ cập nhật theo thời gian thực. Nó khá tuyệt.
1 note
·
View note
Text
Một số giải thuật TRÍ TUỆ NHÂN TẠO
Đây là bài tập mà mình đã hoàn thành trong môn học Trí Tuệ Nhân Tạo

Các bạn có thể tham khảo tại đây!
1 note
·
View note
Text
Firebase là gì?
Đó là một nền tảng ứng dụng hoàn toàn nổi bật
Firebase là một Backend-as-a-Service - BaaS - khởi đầu là một công ty khởi nghiệp YC11 và lớn lên thành một nền tảng phát triển ứng dụng thế hệ tiếp theo trên Google Cloud Platform.
Firebase giúp các nhà phát triển tập trung vào việc tạo ra trải nghiệm người dùng tuyệt vời. Bạn không cần quản lý máy chủ. Bạn không cần phải viết API. Firebase là máy chủ của bạn, API và kho dữ liệu của bạn, tất cả đều được viết chung đến mức bạn có thể sửa đổi nó cho phù hợp với hầu hết các nhu cầu.
Đó là Cơ sở dữ liệu thời gian thực
Khi bạn kết nối ứng dụng của mình với Firebase, bạn sẽ không kết nối qua HTTP thông thường. Bạn đang kết nối qua WebSocket. WebSockets nhanh hơn rất nhiều so với HTTP. Bạn không phải thực hiện các cuộc gọi WebSocket riêng lẻ. Tất cả dữ liệu của bạn sẽ tự động đồng bộ hóa thông qua WebSocket duy nhất đó nhanh như mạng của khách hàng của bạn có thể mang nó.
Firebase gửi cho bạn dữ liệu mới ngay sau khi được cập nhật. Khi máy khách của bạn lưu thay đổi đối với dữ liệu, tất cả các máy khách được kết nối sẽ nhận được dữ liệu cập nhật gần như ngay lập tức.
Đó là File Storage
Firebase Storage cung cấp một cách đơn giản để lưu các tệp nhị phân - thường là hình ảnh, nhưng nó có thể là bất kỳ thứ gì - vào Google Cloud Storage trực tiếp từ máy khách !!!
Firebase Storage có hệ thống quy tắc bảo mật riêng để bảo vệ nhóm GCloud của bạn khỏi nhiều người, đồng thời cấp đặc quyền ghi chi tiết cho các khách hàng đã xác thực của bạn.
Đó là Authentication
Firebase auth có một hệ thống xác thực email / mật khẩu được tích hợp sẵn. Nó cũng hỗ trợ OAuth2 cho Google, Facebook, Twitter và GitHub. Phần lớn chúng tôi sẽ tập trung vào xác thực email / mật khẩu. Hệ thống OAuth2 của Firebase được ghi chép đ��y đủ và chủ yếu là sao chép / dán. Nếu bạn đã từng viết một hệ thống xác thực, hãy vui mừng trong giây lát. Xác thực tùy chỉnh là khủng khiếp. Tôi sẽ không bao giờ viết lại hệ thống xác thực trong thời gian còn sống. Tôi đã yêu Firebase Auth ngay từ cái nhìn đầu tiên và ngọn lửa chưa bao giờ lay chuyển. Đôi khi tôi thấy nản lòng. Đôi khi chúng tôi đánh nhau. Nhưng tôi không bao giờ quên vực thẳm tối tăm lạnh lẽo của hệ thống xác thực tùy chỉnh. Tôi đếm phước lành của tôi. Ồ, Firebase Auth tích hợp trực tiếp vào Cơ sở dữ liệu Firebase, vì vậy bạn có thể sử dụng nó để kiểm soát quyền truy cập vào dữ liệu của mình. Tôi đang viết điều này như thể đó là một suy nghĩ muộn màng. Nó không thể. Đó là lý do thứ hai khiến bạn yêu thích Firebase Auth.
Đó là Hosting
Firebase bao gồm một dịch vụ lưu trữ dễ sử dụng cho tất cả các tệp tĩnh của bạn. Nó phục vụ chúng từ một CDN toàn cầu với HTTP / 2. Và để làm cho việc phát triển của bạn trở nên đặc biệt dễ dàng, lưu trữ Firebase sử dụng Superstatic, bạn có thể chạy cục bộ cho tất cả các thử nghiệm của mình. Tôi chạy Superstatic làm phần mềm trung gian BrowserSync. Việc triển khai sau sử dụng Gulp, nhưng Gulp hoàn toàn là tùy chọn.
var gulp = require('gulp'); var superstatic = require('superstatic'); var browserSync = require('browser-sync').create(); gulp.task('serve', function() { browserSync.init({ server: { middleware: [superstatic({stack: 'strict'})] } }); gulp.watch('public/*.html').on('change', browserSync.reload); });
Môi trường phát triển BrowserSync + Superstatic rất mượt mà. BrowserSync xử lý việc tải lại ứng dụng phát triển của bạn trên tất cả các thiết bị được kết nối và Superstatic sao chép cục bộ lưu trữ Firebase theo cách mà bạn có thể triển khai thẳng tới Firebase để sử dụng trong sản xuất.
Đó là một nền tảng ứng dụng hoàn toàn nổi bật
Nhóm Firebase đã tích hợp một loạt các sản phẩm mới và hiện có của Google với Firebase. Tôi chưa có kế hoạch trình bày chi tiết các tính năng này…
Một loạt các tính năng này áp dụng cho iOS và Android nhưng không áp dụng cho web.
Remote Config
Test Lab
Crash
Notifications
Dynamic Links
AdMob
youtube
0 notes
Text
Cách mã hóa dữ liệu 2 chiều trong SQL Server

Hàm mã hóa 2 chiều EncryptByPassPhrase
Mình sẽ demo mã hóa chuôi "nguyenlapankhuong"
Vậy câu lệnh sql sẽ là:
select EncryptedData = EncryptByPassPhrase('abc', 'nguyenlapankhuong' )
Với 'abc' là key, khi giải mã cần điền vào đúng với key này để giải mã
Kết quả:
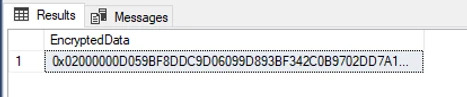
Vậy là mình được kết quả của đoạn mã hóa trên là:
0x02000000D059BF8DDC9D06099D893BF342C0B9702DD7A18750D12CCD1AE4CC826485F87E984F6611CB0A886FBC90F8638008A7A5
Hàm giải mã 2 chiều DecryptByPassPhrase trong SQL server:
Bây giờ mình sẽ giải mã chuỗi mình vừa mã hóa phía trên:
select convert(varchar(100),DecryptByPassPhrase('abc', 0x02000000D059BF8DDC9D06099D893BF342C0B9702DD7A18750D12CCD1AE4CC826485F87E984F6611CB0A886FBC90F8638008A7A5))
Kết quả thu được:
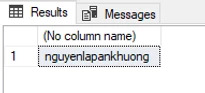
Vậy là m��nh hướng dẫn các bạn xong về mã hóa 2 chiều trong SQL Server sử dụng hàm hỗ trợ sẵn EncryptByPassPhrase và DecryptByPassPhrase
Nếu có vấn đề gì thắc mắc xin bạn vui lòng bình luận bên dưới.
2 notes
·
View notes