#there’s a screenshot in that thread of the broadcast so it’s probably real
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
I can’t fucking take it anymore
#the genocide that occurs alongside the quirky study of fucking harry potter and the methods of rationality#it feels like a bad joke#there’s a screenshot in that thread of the broadcast so it’s probably real#I can’t take this
8 notes
·
View notes
Text
Version 364
youtube
windows
zip
exe
os x
app
linux
tar.gz
source
tar.gz
I had a difficult week, but I got some nice work done. There is a new way to add complicated tag seaches, and repository processing is now a lot easier to work with.
complicated tag searching
Users in help->advanced mode will now see a new 'OR' button on their search pages' autocomplete dropdowns. Click this, and you will be able to paste a logically complicated pure-text query such as "( blue eyes and blonde hair ) or ( green eyes and red hair )", and it will automatically convert it to a tag query hydrus can understand! (It converts it to conjunctive normal form, or ANDs of ORs)
This code is thanks to user prkc, who wrote a really neat parser to do the conversion. The system even supports XOR! Complicated searches will produce similarly crazy hydrus search predicates--which may in some cases run a little slow--so give it a go and see how you like it. This is mostly a first prototype to see how it goes in the real world, and I am happy to revisit it based on feedback.
thoughts on current big tag work
I spent a bit of time thinking about tag management and inefficiencies this week, planning what I want to do in this big tag overhaul job. I also did some statistical analysis of the public tag repository to see how different tags are distributed.
not sure how well this will embed, I’ll post it in follow-up if it stays small
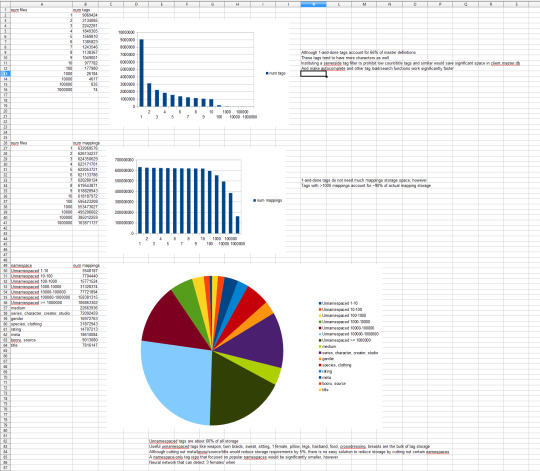
Of the nine million unique tags in the PTR, six million only apply to one file. These are mostly 'title:' tags and some misparsed garbage. These tags have long been a concern for me, and I feared they consumed a huge amount of space, but in truth (and of course, when you think about it), one-and-done tags are less than one percent of the actual file-tag mapping storage. They eat up a bunch of 'definition' space, but barely any 'content' space. About two thirds of total storage is taken up by good unnamespaced tags like 'hairband' or 'sitting' or 'twin braids'. Namespaced tags like 'series:' and 'character:' and newer sorts I have been tentatively approving siblings for, like 'clothing:', generally distribute a few percent each, perhaps 20 million each (out of a total 630 million or so). There are some non-descriptive tags I don't like much, like 'booru:' and 'filename:' tags, but there are no gigantic wastes of space in the PTR.
This is a pleasant surprise, but also its own problem: in the back of my mind, I had hoped I might be able to cut the PTR neatly in half by eliminating wasteful/useless tags, but it turns out the vast majority of tags, in terms of sheer storage, are good. I had considered adding a complicated serverside Tag List approved-tag filter as many boorus have, but I do not think it is worth the trouble at this time.
Therefore, I will focus my upcoming work on improving clientside control of what you see, where you see it, and how you see it. If you do not want to see 'booru:' tags, I want to make it easy to hide them. If you want all the new 'bodypart:' tags to display as unnamespaced, I want it to be one quick rule to set that. I want it to be simple to move a hundred million tags from one place to another, and to share them with other users.
The separate question of dealing with running the PTR and my current bandwidth throttle is a different problem that I have yet to plan out. I may add an IPFS plugin for the hydrus server, or server mirroring tech, or there may be another solution. I am a developer most of all, not a natural server administrator, so my dream scenario here is probably to freeze the current PTR and make its snapshot easy to modify and migrate about so users can run their own tag repositories and it is out of my hands. This would also neatly remove my single point of failure. My preference is to focus my time on improving how the servers work and improve administration functionality, but I am still thinking about it.
better repo processing
After thinking about tags and workflows, I decided to just go nuts and rework tag repository processing to no longer be a big application-blocking job! Somehow, it seems to work!
So, rather than making the 'dialog' popup that blocks the program, repo processing now works in a normal bottom-right popup. It streams work to the database in packets and no longer locks anything for long. You can still browse your files and do everything else in the program, with the only significant caveat being some operations like autocomplete tag results fetching may be a bit juddery. The program will no longer lock up for long periods while doing this work, and the cancel button will always be available.
As a result, the 'process now' button under services->review services is now available for all users, not just advanced ones, and loses its big warning. Please feel free to try it out.
The basic workflow and feedback is the same. It will still work through update files and report current rows/s. For this initial version, in most situations it will be slower than before, but in others it will actually be faster. As before, it runs best if left to work in idle/shutdown mode, where it will be greedier and work harder. I still recommend users leave it to work in normal maintenance cycles, but manual catch-up, if desired, is now much more pleasant and easily cancelled.
This is a first version of a big change. The pre-process disk cache run is no longer called, and work and break and transactions timings have been altered. Users on fast SSDs with good CPUs should not notice any big differences, but those who PTR-sync on HDDs may have trouble (or at least be better able to see the ~300 rows/s trouble they have been having all along). Please let me know how you get on and what sort of rows/s you see. Does it accelerate over time? Does it make your browsing or video rendering juddery? I will write a more intelligent throttle in the coming weeks that will speed this processing up when there is CPU available.
This is an important step forward on the tag work and my new unified global maintenance pipeline. I'd love to have the similarly chunky 'analyze' and 'vacuum' commands work a bit more like this as well.
I have been chasing an ui-lockup bug recently that may have been tied to long-running tag repository processing while the client was idle and/or minimised. If you got this (on restoring your client, you'd see black except perhaps a bit of a garbled screenshot in one corner), please let me know if this week happens to fix it.
the rest
The 'this video has an audio track, but it is silent' code from last week had a flaw (such files were detected as having audio) that slipped through testing. I have fixed this and extended the test to recognise more types of silent file. Thank you for submitting test files here. If you discover any more video files that detect as having audio--or not--incorrectly with this new code, please submit them.
Also, an odd issue where thumbnails of files that underwent a file metadata regeneration would not display archive/tag/rating updates until they were reloaded is now fixed. This bug had been in for a long time, but the rush of new files into the file maintenance system from last week exposed it.
I extended and improved some of the recent 'don't do work while page is not shown or gui is minimised' stuff this week. Duplicate processing pages should be more careful about when they fetch new duplicate counts (speeding up session load for users with several dupe processing pages), and the animation issue from last week that froze media viewers' videos while the main gui was minimised should all be fixed.
I also gave the autocomplete fast-typing logic another pass. Some users were reporting that typing 'blue eyes' might instead add 'blue ey' and similar. I cleaned up the 'should I broadcast the current typed text or the currently selected result?' test and I think I have it working better now. If you are a very fast typer, please continue to let me know how this works for you.
Query texts for some booru downloaders that contain '&', such as 'panty_&_stocking', should now be fixed!
The pixiv login script no longer works and has been removed from the defaults. They added some sort of captcha. If you wish to log in to pixiv with hydrus, please use the Client API and Hydrus Companion to copy your web browser's cookies to hydrus:
https://gitgud.io/prkc/hydrus-companion
Logging in this way seems to work well for many situations, and will be the go-to recommendation for any site that has a login system more complicated than hydrus can currently deal with. I believe the Deviant Art login system may have gone/be going that way as well, so if you have had DA trouble, give Hydrus Companion a go.
full list
repo processing makeover:
repository processing is now no longer a monolithic atomic database job! it now loads update files at a 'higher' level and streams packets of work to the database without occupying it continuously! hence, repository processing no longer creates a 'modal' popup that blocks the client--you can keep browsing while it works, and it won't hang up the client!
this new system runs on some different timings. in this first version, it will have lower rows/s in some situations and higher in others. please send me feedback if your processing is running significantly slower than before and I will tweak how this new routine decides to work and take breaks
multiple repos can now sync at once, ha ha
shutdown repository processing now states the name of the service being processed and x/y update process in the exit splash screen
the process that runs after repository processing that re-syncs all the open thumbnails' tags now works regardless of the number of thumbnails open and works asynchronously, streaming new tag managers in a way that will not block the main thread
'process now' button on review services is now available to all users and has a reworded warning text
the 1 hour limit on a repo processing job is now gone
pre-processing disk cache population is tentatively gone--let's see how it goes
the 10s db transaction time is raised to 30s. this speed some things up, including the new repo processing, but if a crash occurs, hydrus may now lose up to 30s of changes before the crash
.
the rest:
users in advanced mode now have a 'OR' button on their serch autocomplete input dropdown panels. this button opens a new panel that plugs into prkc's neat raw-text -> CNF parser, which allows you to enter raw-text searches such as '( blue eyes and blonde hair ) or ( green eyes and red hair )' into hydrus
fixed the silent audio track detection code, which was handling a data type incorrectly
improved the silent audio track detection code to handle another type of silence, thank you to the users who submitted examples--please send more false positives if you find them
fixed an issue where thumbnails that underwent a file metadata regeneration were not appearing to receive content updates (such as archive, or new tags/ratings) until a subsequent reload showed they had happened silently. this is a long-time bug, but the big whack of files added to the files maintenance system last week revealed it
the 'pause ui update cycles while main gui is minimised' change from last week now works on a per-frame basis. if the main gui is minimised, media viewers that are up will still run videos and so on, and vice versa
a few more ui events (e.g. statusbar & menubar updates) no longer occur while the client is minimised
duplicate processing pages will now only initialise and refresh their maintenance and dupe count numbers while they are the current page. this should speed up session load for heavy users and those with multiple duplicate pages open
gave the new autocomplete 'should broadcast the current text' tests another pass--it should be more reliable now broadcasting 'blue eyes' in the up-to-200ms window where the stub/full results for, say, 'blue ey' are still in
fixed an accidental logical error that meant 'character:'-style autocomplete queries could do a search and give some odd results, rather than just 'character:*anything*'. a similar check is added to the 'write' autocomplete
fixed an issue with autocomplete not clearing its list properly, defaulting back to the last cached results, when it wants to fetch system preds but cannot due to a busy db
fixed GET-argument gallery searches for search texts that include '&', '=', '/', or '?' (think 'panty_&_stocking_with_garterbelt')
removed the pixiv login script from the defaults--apparently they have added a captcha, so using Hydrus Companion with the Client API is now your best bet
the client's petition processing page will now prefer to fetch the same petition type as the last completed job, rather than always going for the top type with non-zero count
the client's petition processing page now has options to sort parent or sibling petitions by the left side or right--and it preserves check status!
the client's petition processing page now sorts tags by namespace first, then subtag
the client now starts, restarts, and stops port-hosted services using the same new technique as the server, increasing reliability and waiting more correctly for previous services to stop and so on
the client now explicitly commands its services to shut down on application close. a rare issue could sometimes leave the process alive because of a client api still hanging on to an old connection and having trouble with the shut-down db
the file maintenance manager will no longer spam to log during shutdown maintenance
sketched out first skeleton of the new unified global maintenance manager
improved some post-boot-error shutdown handling that was also doing tiny late errors on server 'stop' command
added endchan bunker links to contact pages and github readme
updated to ffmpeg 4.2 on windows
next week
Next week is a 'small jobs' week, and I have a ton to catch up on. I want to do some more Client API stuff and just hammer out a whole bunch of small things. I'll also tweak the new repository processing as needed and start work on better local tag management, maybe exploring how best to add multiple local tag services.
1 note
·
View note