#so i linked the github which has the steps and everything and they were like 'but it's not on [homebrew app]'
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr office adopted Tommy, an 11-year-old Pomeranian.
Text
I know a lot of people have been saying that tech literacy is falling bc a lot of younger people aren't properly taught how to use computers anymore and they only interact with their devices through applications. and like that made sense to me given how much tech education had already been cut when I was in school, but I didn't have much contact with younger genZers to have noticed the change myself. but god now that I'm on reddit (mistake) there are so many of these people in homebrew/console hacking communities. like it boggles my mind that an intersection of people exists that 1) are tech savvy enough to be interested in console hacking 2) completely fall to pieces whenever something requires doing something on a PC and not the console itself. like it's frustrating for the people trying to help them AND for them, I'd imagine. they don't have the tools they need
#your pc and the console are friends. they like working together let them work together#for reference I'm mostly talking about vita hacking communities here#you don't need a pc to hack the thing and there's a homebrew app to uh. acquire most games without needing to transfer data#so you can do a lot without using a pc! which is convenient#but some custom stuff and some games require a pc and you see people asking for help with with basic related stuff all the time#someone was looking for a english patch of a specific game and i happened to have used a patcher for it before#so i linked the github which has the steps and everything and they were like 'but it's not on [homebrew app]'#well ok i can't help with that sorry#also i don't understand people that download pirated games directly to their vita in front of god and everyone sans vpn#maybe I'm paranoid though idk#reilly.txt
1 note
·
View note
Note
Glances at your post about Gerry's name in the ARG files... Speaking as someone who totally missed the Magnus Protocol ARG...do you mind explaining it? Or point me in the direction of other posts/summaries/videos *etc* that break it down? Or is it very much 'you had to be there' thing?
Cuz I keep seeing references to it and am very confused...
Hi!
I wasn't able to follow and keep on top of the TMAGP ARG when it was happening last year in September/October (it was a super busy time for me in my offline life), so I am definitely missing a lot of information.
There is a sort of "ARG explained" video on YouTube here which people tend to recommend, but um. I think it's very poorly structured and the speaker backtracks a lot as they remember things that they forgot to mention or adds in their own speculation. I didn't find it very cohesive and didn't watch the whole thing because I felt like it was just confusing me (but I appreciate their enthusiasm).
I just wanted a step-by-step chronological breakdown of everything from the ARG and what was found (in-universe or not), which I have not seen anyone post. You might get more out of it than me.
Rusty Quill's website has a summary of the ARG here, but it's a bit more focused on the overall structure of the ARG and doesn't really show how some solutions were found (at least not in ways that made sense to me), and doesn't always include images of what is being said?
At the end of the summary, Rusty Quill linked to a GitHub repository for various parts of the ARG. Most of it is code which isn't very helpful to me, but you can access the text used for some of the ARG websites (which no longer work) as well as some images, and the excel document that Gerry appears on. You sort of have to hunt around a bunch for files that aren't just code tho.
Based on RQ's summary and what I've heard, the ARG also gave players access to a forum with in-universe conversations. I don't know if there's anything interesting in there in terms of lore hints or if it was just a place for ARG clue hunting. I don't know how to access these forums or if anyone saved the text anywhere, but I sure would love to have a look :c
That's about all I know. I seriously doubt knowing anything about the ARG will actually matter in terms of following the story in TMAGP, but it's fun and interesting to see.
#ramblings of a bystander#tmagp arg#the magnus protocol#tmagp#tmagp spoilers#magpod#ask#answer#just-prime
11 notes
·
View notes
Text
@romancedeldiablo just reminded me the entire cybersecurity/information security industry is having the greatest field days ever since this whole Covid-19 triggered a mass work from home exodus.
I have so much to say about it and all the security issues that are occurring. This mostly pertains to the US. This isn’t meant to scare anyone, they’re just food for thought and a bit of explanation about my industry.
PSA: Not all hackers are bad, just a reminder. There are very legitimate reasons for hacking such as compliance and research. When I talk about hackers here, I’m talking about the bad ones who are exploiting without permission and for malicious reasons.
The main thing about this whole working from home thing is that most organizations don’t have the infrastructure to support their entire workforce. Not every company uses Google Drive or OneDrive or DropBox.
This means that companies with on-premise servers, isolated servers or networks are screwed. Imagine trying to connect to your friend’s computer who lives on the other side of the world and controlling their mouse. Can’t do it. Gotta download something on both ends to do it. Now imagine that for 500 people at home who are trying to connect to a single server. You’d need to open that server/network up to the internet. That has its own risks because without controlling WHO can access the server, you’re basically allowing anyone (hackers especially) to go in and take all your data.
But then you ask, “Isn’t that what passwords are for?” BITCH look at your own passwords. Do you really think 500 people will have passwords strong enough to withstand a rainbow table attack or that the server won’t shit itself when receiving 500 connections from unknown locations by means of a not-often used method? Hackers only need to exploit one password (for the most part) while the company needs to ensure ALL 500 are protected. That’s difficult as all hell and if it were that easy, I wouldn’t have a job.
Then there’s shit like Virtual Private Networks (VPNs) and RADIUS servers that’ll secure the network connection so it can’t be hijacked and do authentication respectively. Here’s the problem. VPN solutions need to be downloaded on the client system (your computer). When your organization has very technically illiterate people, that becomes a nightmare. ‘Cause you have to set up their accounts on the VPN system and set the permissions for each of them so they can only access what they’re allowed to access otherwise Bob from sales now has access to the HR system with everyone’s social security numbers. It’s very time consuming and can get very complicated. Even worse is that VPNs often require licenses. When you only have 50 licenses and suddenly 500 people want access, you’re screwed. But you can always purchase more licenses, no problem. Here’s the rub. Suddenly, this VPN tunnel needs to accept connections from 500 people. This tunnel is only strong enough to accept 50 concurrent sessions. When 10x that amount get on, guess what? The tunnel shits itself and basically the company has DoS’d itself. Now no one can get any work done until IT figures out how to get 500 people on a system that’s only capable of supporting 50.
Fuck, almost forgot about RADIUS. There’s DIAMETER, too, but shut up about it. It’s an authentication system but depending on how it’s set up, you’ll have to also set up the users. That’s an extra step and it’s a pain in the ass if RADIUS somehow isn’t connected to AD and the user has different passwords and shit.
Not to mention hackers suddenly gaining access to all this information because they’ve already infected people’s home computers and routers prior to the work from home stuff. There’s very limited way for IT to control what happens on a personal computer, so these personal computers can have no anti-virus or security software. This means all data is in danger because someone decided Windows Defender is annoying. (Windows Defender is pretty great, btw.)
Physical robberies are occurring a little more because there’s no one to protect the stores and such. Physical security is taking a hell of a beating.
There’s been an increase in phishing scams around COVID-19. Unemployment sites are probably being (and probably already have been) hacked and the data is being stolen. I think there were some people who were creating fake unemployment sites to steal PII. There are e-mails going out to people saying stuff like, “Your computer has been infected with the CORONAVIRUS. Click here to clean it up.” And you’re wondering, “What sort of morons…?” Don’t. It’s very easy to give in to your panic. Hackers don’t hack computers solely. They hack into human emotion, into the psyche. Anyone can fall for their shit.
The thing with Zoom? Basically they’re so insecure, people are hacking them without issue. How? Because people are silly and put out links, chat logs are saved onto insecure machines that have already been hacked, there are a bunch of exploits available for Zoom, etc.
Healthcare organizations. Oh boy. So, we all know healthcare organizations are working their damnedest to save people suffering from COVID-19. Every second counts and any delay in that process could mean life or death. They work hard. Here’s the thing. There has always been a delicate balance between security and usability. Too secure and it’ll make it difficult for the end user to do their job. Usable without security just makes it easier for an attacker to do their job. Why am I talking about this?
Healthcare organizations usually hold sensitive information. Health information. Social security numbers. Birth dates. Addresses. Insurance information. Family member information. So much stuff. They are a beautiful target for hackers because all that shit is right there and it’s accessible. Healthcare organizations, by and large, do not put a lot of emphasis on security. That’s changing a bit, but for the most part, the don’t care about security. They do the bare minimum because guess what? Every additional control can add time to a doctor or healthcare worker’s routine. Computer lockscreen every 5 minutes? Now the doctor has to re-logon every 5 minutes. This adds about 15 seconds to their rountine. Multiply that several times over for every patient that comes in assuming a doctor will need to log in at least 3 times during a single visit. That can clock in at at least an hour throughout the day. A hour that they could’ve spent doing something else. So imagine more controls. Password needs to be reset. Need to badge in. Log into this extra program to access this file. Call IT because this thing locked them out. Each one of these normal controls now feel insanely restrictive. The ease of use isn’t there and so organizations might look at reversing these security controls, potentially making things even less secure than before in the name of efficiency.
Don’t @ me about HIPAA. I will start rants about how non-prescriptive and ineffective it is to actually get proper security implemented.
LOL @ internet service providers. Internet speeds are dropping due to the amount of traffic they’re getting. Commercial internet really wasn’t prepared for this. Those poor bastards.
Some organizations outsource their IT teams. Those people (Managed Service Providers aka MSPs) are not prepared for this nonsense. It’s popular now to go after these guys for hacking. An MSP usually works for multiple organizations. So, why try going after 50 organizations individually when you have just one organization with poor security controls managing everything from one place? You’d logically go after the one rather than 50. It’s easier.
MSPs are now overworked because they also have to work from home to connect to systems that can’t support so many people connecting to it on personal computers that the MSP can’t log into like they normally would to fix any issues. This makes them tired. What happens when you’re tired? You make more mistakes. And that’s exactly what hackers go after. Once they’re in the MSP’s system, the hacker can now potentially gain access to the 50 clients’ systems. Easy win.
Shadow IT and alternate solutions. This is another doozy. Imagine all your files and shit are on your company’s network. No one is able to access it because there isn’t any VPN or remote sharing system or FTP server set up for this stuff, but you still need to do your job. So, what do you do? Obviously, you start making stuff on your own computer using whatever you’re comfortable with. Google Drive. Dropbox. Box. Slack. That shitty PDF reader you downloaded three years ago and didn’t update.
Now imagine sharing it through things like your personal e-mail which may or may not have been hacked without your knowledge. Or maybe the recipient’s been hacked without anyone’s knowledge. Maybe your files are normally encrypted if they’re on the company network. Now you’re off of it and nothing’s encrypted. Maybe you forget it delete a file or 80 off of your system which has been infected. Or maybe you pasted shit on pastebin or github and it’s available to the public because that’s just easier. Now anyone searching can find it. This is how database dumps are found sometimes and they’re really entertaining.
Shadow IT putting in alternate solutions without the company’s knowledge is always a fucking nightmare. I get that people need to do their jobs and want to do things a certain way, but can you not be selfish and put everyone at risk because you decided your way or the high way?
That sounds awfully familiar…it feels like a situation that we’re going through right now…hey, wait a minute…
Long story short, this whole working from home thing opens up a lot of security issues. Most companies are ill-equipped to handle IT issues, let alone cybersecurity/information security/IT security issues, but because of that, we’re seeing a lot of interesting things happening. Such as finding out New Jersey’s unemployment system runs on a 60+ year old programming language.
Holy shit I can talk about this all day. I’ve definitely glossed over a lot of stuff and oversimplified it. If anyone wants me to talk about any specific topic related to this or cybersecurity or information security in general, drop an ask. I’m always, always more than happy to talk about it.
26 notes
·
View notes
Text
Version 330
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week. There are some more login scripts and a bit of cleanup and speed-up.
The poll for what big thing I will work on next is up! Here are the poll + discussion thread:
https://www.poll-maker.com/poll2148452x73e94E02-60
https://8ch.net/hydrus/res/10654.html
login stuff
The new 'manage logins' dialog is easier to work with. It now shows when it thinks a login will expire, permits you to enter 'empty' credentials if you want to reset/clear a domain, and has a 'scrub invalid' button to reset a login that fails due to server error or similar.
After tweaking for the problem I discovered last week, I was able to write a login script for hentai foundry that uses username and pass. It should inherit the filter settings in your user profile, so you can now easily exclude the things you don't like! (the click-through login, which hydrus has been doing for ages, sets the filters to allow everything every time it works) Just go into manage logins, change the login script for www.hentai-foundry.com to the new login script, and put in some (throwaway) credentials, and you should be good to go.
I am also rolling out login scripts for shimmie, sankaku, and e-hentai, thanks to Cuddlebear (and possibly other users) on the github (which, reminder, is here: https://github.com/CuddleBear92/Hydrus-Presets-and-Scripts/tree/master/Download%20System ).
Pixiv seem to be changing some of their login rules, as many NSFW images now work for a logged-out hydrus client. The pixiv parser handles 'you need to be logged in' failures more gracefully, but I am not sure if that even happens any more! In any case, if you discover some class of pixiv URLs are giving you 'ignored' results because you are not logged in, please let me know the details.
Also, the Deviant Art parser can now fetch a sometimes-there larger version of images and only pulls from the download button (which is the 'true' best, when it is available) if it looks like an image. It should no longer download 140MB zips of brushes!
other stuff
Some kinds of tag searches (usually those on clients with large inboxes) should now be much faster!
Repository processing should also be faster, although I am interested in how it goes for different users. If you are on an HDD or have otherwise seen slow tag rows/s, please let me know if you notice a difference this week, for better or worse. The new system essentially opens the 'new tags m8' firehose pretty wide, but if that pressure is a problem for some people, I'll give it a more adaptable nozzle.
Many of the various 'select from a list of texts' dialogs across the program will now size themselves bigger if they can. This means, for example, that the gallery selector should now show everything in one go! The manage import/export folder dialogs are also moved to the new panel system, so if you have had trouble with these and a small screen, let me know how it looks for you now.
The duplicate filter page now has a button to edit your various duplicate merge options. The small button on the viewer was too-easily missed, so this should make it a bit easier!
full list
login:
added a proper username/password login script for hentai foundry--double-check your hf filters are set how you want in your profile, and your hydrus should inherit the same rules
fixed the gelbooru login script from last week, which typoed safebooru.com instead of .org
fixed the pixiv login 'link' to correctly say nsfw rather than everything, which wasn't going through last week right
improved the pixiv file page api parser to veto on 'could not access nsfw due to not logged in' status, although in further testing, this state seems to be rarer than previously/completely gone
added login scripts from the github for shimmie, sankaku, and e-hentai--thanks to Cuddlebear and any other users who helped put these together
added safebooru.donmai.us to danbooru login
improved the deviant art file page parser to get the 'full' embedded image link at higher preference than the standard embed, and only get the 'download' button if it looks like an image (hence, deviant art should stop getting 140MB brush zips!)
the manage logins panel now says when a login is expected to expire
the manage logins dialog now has a 'scrub invalidity' button to 'try again' a login that broke due to server error or similar
entering blank/invalid credentials is now permitted in the manage logins panel, and if entered on an 'active' domain, it will additionally deactivate it automatically
the manage logins panel is better at figuring out and updating validity after changes
the 'required cookies' in login scripts and steps now use string match names! hence, dynamically named cookies can now be checked! all existing checks are updated to fixed-string string matches
improved some cookie lookup code
improved some login manager script-updating code
deleted all the old legacy login code
misc login ui cleanup and fixes
.
other:
sped up tag searches in certain situations (usually huge inbox) by using a different optimisation
increased the repository mappings processing chunk size from 1k to 50k, which greatly increases processing in certain situations. let's see how it goes for different users--I may revisit the pipeline here to make it more flexible for faster and slower hard drives
many of the 'select from a list of texts' dialogs--such as when you select a gallery to download from--are now on the new panel system. the list will grow and shrink depending on its length and available screen real estate
.
misc:
extended my new dialog panel code so it can ask a question before an OK happens
fixed an issue with scanning through videos that have non-integer frame-counts due to previous misparsing
fixed a issue where file import objects that have been removed from the list but were still lingering on the list ui were not rendering their (invalid) index correctly
when export folders fail to do their work, the error is now presented in a better way and all export folders are paused
fixed an issue where the export files dialog could not boot if the most previous export phrase was invalid
the duplicate filter page now has a button to more easily edit the default merge options
increased the sibling/parent refresh delay for 1s to 8s
hydrus repository sync fails due to network login issues or manual network user cancel will now be caught properly and a reasonable delay added
additional errors on repository sync will cause a reasonable delay on future work but still elevate the error
converted import folder management ui to the new panel system
refactored import folder ui code to ClientGUIImport.py
converted export folder management ui to the new panel system
refactored export folder ui code to the new ClientGUIExport.py
refactored manual file export ui code to ClientGUIExport.py
deleted some very old imageboard dumping management code
deleted some very old contact management code
did a little prep work for some 'show background image behind thumbs', including the start of a bitmap manager. I'll give it another go later
next week
I have about eight jobs left on the login manager, which is mostly a manual 'do login now' button on manage logins and some help on how to use and make in the system. I feel good about it overall and am thankful it didn't explode completely. Beyond finishing this off, I plan to continue doing small work like ui improvement and cleanup until the 12th December, when I will take about four weeks off over the holiday to update to python 3. In the new year, I will begin work on what gets voted on in the poll.
2 notes
·
View notes
Text
The beginning of the major project story
In October 2020 I began putting ideas together for a project. Something that I wanted to last, become part of my life on a longterm basis; something I cared about. At the time of writing this (January 2021), I cannot for the life of me remember what those initial ideas were. I had spent the summer reading and reflecting on my creative practice. The pandemic was going on way longer than I thought it would have and it had started to expose a lot of things for me that were just hiding from plain sight. I had many conversations with friends (Squad) over Zoom and ‘the group chat’ about internet cultures and the impact URL life is having on IRL life. Generally speaking we were finding the divide between the internet that we love, and the internet that was pissing us off, and trying to find out why we were getting so miffed about certain things. We had been talking a lot about Spotify, about how we didn’t like the network effect it had over musicians to release music on there despite the remuneration system seeming so unfair. I use Spotify to listen to a lot of music, so there’s definitely some cognitive dissonance going on there. I get that it’s convenient for listeners. And I also get that getting your track in a popular playlist can get you loads of streams (and so maybe earn a bit of money). But as a group we reflected on the namelessness of this system. How easy it was to leave playlist running and not know who or what you are listening to even if asked. "Ah its on this playlist" was a phrase we discussed a fair bit. You might argue that this system allows for greater music exploration, finding things you’ve never heard before. And you’d be right. But radio does this and I have no gripes with radio. What’s all that about? Artist and Computer Person, Elliott Cost wrote a short paper on the vastness of a website. In it he talks about how over the last few years… "platforms have stripped away any hint of how vast they actually are. As a result, users only get to see a tiny sliver of an entire platform. There’s been an overwhelming push to build tools specifically designed for engagement (like buttons, emoji responses, comment threading) instead of building tools that help users actually explore. This has replaced any sense of play with a bleak struggle for users attention. The marketing line for these new tools could easily be, "engage more, explore less."" He tries to combat this in the websites he designs by adding explore buttons that randomise content, for example. You can see this in action in a website he contributed to called the The Creative Independent. "One thing we did implement was a random button that served up a random interview from over 600 articles across the site. I ended up moving this button into the main navigation so that readers could continue to click the button until they found an interview that interested them. It’s fairly easy to implement a “randomized items/articles” section on a website. In the case of The Creative Independent, this simple addition revealed how expansive the site really was.”
https://elliott.computer/pages/exploring-the-vastness-of-a-website.html Sticking with the website theme, another thing we discussed as a Squad was the increase of Web 3.0 models in comparison to out current 2.0 models. We’d all done some listening to and reading of Jaron Lanier, who after writing a few books about the future of big data and the potential to monetise your own, eventually just wrote a really on those nose book about getting off social media. It’s called ‘Ten Arguments for Deleting Your Social Media Accounts Right Now’. To the point right? After feeling the negative effects of social media throughout 2018 and 2019, I’d reached breaking point, and this book tipped me over the edge to try going cold turkey. It was surprisingly easy and I loved being away from it all, especially Instagram. That app can do things to you. For quite some time I was obsessed over crafting the perfect post for my music and creative practice that I stopped making my core content to focus on keeping up appearances on Instagram. I don’t think it works like this for everyone. Perhaps some people are more susceptible to the allure of its powers. Maybe it rooted in some insecurities. Either way, the network of people I was following and that were following me back were certainly not social. Our relationships were built on tokenistic and obligatory likes and comments. The FOMO was hitting hard and I wasn’t getting anywhere with my art and music. I’m still off Instagram, all Facebook platforms in fact. I got rid of WhatsApp and forced my friends to use Signal. Cos that’s what you do to people you love, shine a light down on anything toxic in their life while sitting on that high horse. I have returned to Twitter, months and months after being away from everything, because I’m trying to start a record label during a pandemic. You can’t meet up with anyone or go anywhere, how am I supposed to do guerrilla marketing if everyone is staring at their computer at home everyday? I could’ve come up with something online perhaps, and perhaps I might still. But for know I’ve jumped on Twitter and am just following everyone in Cardiff involved with music. I’m playing the spam game until we can go outside again. Then I’ll delete that little blue bird from my computer again. I appreciate that these networks are useful and convenient. And there aren’t any good alternative with the same network effect. But the thing that Lanier said that really struck me was this idea that there needs to be enough people on the outside of it all to show others that it can be done. So until something better comes along, I am happy to sit outside of it all. Jenny Odell is helping me through this with her book “How to Do Nothing.” As we discussed this as a Squad we noticed that much of what we were talking about was about aligning your actions with your values. It’s something seemingly impossible to maintain in all aspects of your life, but I genuinely think the more you can do this the happier you’ll be. We do it in so many other aspects of our lives, I wondered why it was so difficult to musicians who hate Spotify to not use, or for those riddled with anxiety to not use Instagram. I think a huge factor of this is down to that word convenience again. Now, convenience is king. But, “At what cost?” I will ask. For every few seconds shaved off, kj of energy saved, or steps reduced in completing a task or getting something, there are hidden costs elsewhere that the consumer doesn’t have to worry about. And I think this is worrying. Not that I think things should be deliberately inconvenient for people. But on reflecting on this, I am happy for things to be a little ‘anti-convenient’. For processes of consumption and creation, to have that extra step I do myself perhaps, or for it to take that little bit longer for a package to get to me. Or even that I spend some time learning how to do whole processes myself. Anyway, back to those Web3 chats���. the Squad noticed that the new Web seems to include glimmers of Web 1.0 and the return of personal websites, as well as newer ideas like decentralised systems of exchange. Artists that can do a bit of coding and seasoned web designers alike are creating an online culture that focuses on liberating the website and our online presence from platform capitalism. Instructions for how to set up your own social network (https://runyourown.social) are readily available with a quick search, and calls for a community focused web are common place from those dying to get off Twitter and live in their own corner of the internet with their Squad, interconnected with other Squads. What’s this got to do with Third Nature? Well it means I decided to build our website from scratch using simple HTML and CSS. I intend to maintain this and eventually try to move the hosting from GitHub Pages over to a personal server ran on a Raspberry Pi. There is a link between the anti-Spotify movement and the pro-DIY-website culture, which is that ‘aligning your actions with your values’ thing. Before Third Nature had a website though - before it was called Third Nature for that matter - I had this idea… What if there were an alternative to Spotify that was as fair as the #BrokenRecord campaign wanted it to be? I could so have a go at making that. Maybe on a small scale. Like for Cardiff, and then expand. After sharing the idea with the Squad though we did some research and actually came across a few music platforms that were doing these types of things. More on this in the next post…
0 notes
Text
How to Build a Blog with Gatsby and Netlify CMS – A Complete Guide
In this article, we are going to build a blog with Gatsby and Netlify CMS. You will learn how to install Gatsby on your computer and use it to quickly develop a super fast blog site.
You are also going to learn how to add Netlify CMS to your site by creating and configuring files, then connecting the CMS to your site through user authentication.
And finally, you'll learn how to access the CMS admin so that you can write your first blog post.
The complete code for this project can be found here.
Here's a brief introduction to these tools.
What is Gatsby?
Gatsby is a free and open-source framework based on React that helps you build fast websites and web apps. It is also a static site generator like Next.js, Hugo, and Jekyll.
It includes SEO (Search Engine Optimization), accessibility, and performance optimization from the get-go. This means that it will take you less time to build production-ready web apps than if you were building with React alone.
What is Netlify CMS?
Netlify CMS is a CMS (Content Management System) for static site generators. It is built by the same people who made Netlify. It allows you to create and edit content as if it was WordPress, but it's a much simpler and user-friendly interface.
The main benefit of Netlify CMS is you don't have to create markdown files every time you want to write a post. This is useful for content writers who don't want to deal with code, text editors, repositories, and anything to do with tech - they can just focus on writing articles.
Alright, without any further ado, let's start building the blog!
But before we get going, a quick heads up: This guide requires prior knowledge of JavaScript and React. If you are not comfortable with these tools yet, I've linked the resources at the end of the article to help you brush up on those skills.
Even if you're new to those technologies, I tried to make this guide as simple as I was able so you can follow along.
How to set up the environment
Before we can build Gatsby sites, we have to make sure that we have installed all the right software required for the blog.
Install Node.js
Node.js is an environment that can run JavaScript code outside of a web browser.
It is a tool that allows you to write backend server code instead of using other programming languages such as Python, Java, or PHP. Gatsby is built with Node.js and that's why we need to install it on our computer.
To install Node.js, go to the download page and download it based on your operating system.
When you are done following the installation prompts, open the terminal and run node -v to check if it was installed correctly. Currently, the version should be 12.18.4 and above.
Install Git
Git is a free and open-source distributed version control system that helps you manage your coding projects efficiently.
Gatsby starter uses Git to download and install its required files and that's why you need to have Git on your computer.
To install Git, follow the instructions based on your operating system:
Install Gatsby CLI
Gatsby CLI (Command Line Interface) is the tool that lets you build Gatsby-powered sites. By running this command, we can install any Gatsby sites and the plugins we want.
To install Gatsby CLI, open the terminal and run this command:
npm install -g gatsby-cli
Once everything is set up successfully then we are ready to build our first Gatsby site.
How to build a Gatsby site
In this guide, we're going to use the default Gatsby starter theme, but you're free to choose any themes on the Gatsby starter library. I personally use the Lekoart theme because the design is minimalist and beautiful, and it has a dark mode.
In the terminal, run this command to install the new Gatsby blog:
gatsby new foodblog https://github.com/gatsbyjs/gatsby-starter-blog
Note for Windows users: If you encounter "Error: Command failed with exit code 1: yarnpkg" while creating Gatsby site, see this page to troubleshoot it. You may have to clean up dependencies of old yarn installations or follow the Gatsby on Windows instructions.
What's does this command line mean exactly? Let me explain.
new - This is the command line that creates a new Gatsby project
foodblog - This is the name of the project. You can name it whatever you want here. I named this project foodblog as an example only.
The URL (https://github.com/gatsbyjs/gatsby-starter-blog) - This URL specified points to a code repository that holds the starter code you want to use. In other words, I picked the theme for the project.
Once the installation is complete, we'll run the cd foodblog command which will take us to the location of our project file.
cd foodblog
Then we'll run gatsby develop that will start running on the local machine. Depending on the specs of your computer, it will take a little while before it is fully started.
gatsby develop
Open a new tab in your browser and go to http://localhost:8000/. You should now see your new Gatsby site!

How a Gatsby starter blog homepage looks
Now that we've created the blog, the next step is to add Netlify CMS to make writing blog posts easier.
How to add Netlify CMS to your site
Adding Netlify CMS to your Gatsby site involves 4 major steps:
app file structure,
configuration,
authentication, and
accessing the CMS.
Let's tackle each of these stages one at a time.
How to set up the app's file structure
This section deals with the file structure of your project. We are going to create files that will contain all Netlify CMS codes.
When you open your text editor, you will see a lot of files. You can read this article if you are curious about what each of these files does.
├── node_modules ├── src ├── static ├── .gitignore ├── .prettierrc ├── gatsby-browser.js ├── gatsby-config.js ├── gatsby-node.js ├── gatsby-ssr.js ├── LICENSE ├── package-lock.json ├── package.json └── README.md
Do not worry about all these files — we are going to use very few of them here.
What we are looking for is the static folder. This is the folder where it will form the main structure of the Netlify CMS.
If your project does not have Static folder, then create the folder at the root directory of your project.
Inside the static folder, create an admin folder. Inside this folder, create two files index.html and config.yml:
admin ├ index.html └ config.yml
The first file, index.html, is the entry point to your CMS admin. This is where Netlify CMS lives. You don't need to do styling or anything as it is already done for you with the script tag in the example below:
<!doctype html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Content Manager</title> </head> <body> <script src="https://unpkg.com/netlify-cms@^2.0.0/dist/netlify-cms.js"></script> </body> </html>
The second file, config.yml, is the main core of the Netlify CMS. It's going to be a bit complicated as we are going to write backend code. We'll talk more about it in the configuration section.
How to configure the back end
In this guide, we are using Netlify for hosting and authentication and so the backend configuration process should be relatively straightforward. Add all the code snippets in this section to your admin/config.yml file.
We'll begin by adding the following codes:
backend: name: git-gateway branch: master
Heads up: This code above works for GitHub and GitLab repositories. If you're using Bitbucket to host your repository, follow these instructions instead.
The code we just wrote specifies your backend protocol and your publication branch (which is branch: master). Git Gateway is an open-source API that acts as a proxy between authenticated users of your site and your site repository. I'll explain more what this does in the authentication section.
Next up, we will write media_folder: "images/uploads". This will allow you to add media files like photos directly to your CMS. Then you won't need to use a text editor to manually add media and all that.
media_folder: "images/uploads"
Make sure you created a folder called images in the admin folder. Inside the images folder, create an uploads folder as this is the place where you'll host your images.
Configure Collections
The collections will define the structure for the different content types on your static site. As every site can be different, how you configure the collection's settings will differ from one site to another.
Let's just say your site has a blog, with the posts stored in content/blog, and files saved in a date-title format, like 2020-09-26-how-to-make-sandwiches-like-a-pro.md. Each post begins with settings in the YAML-formatted front matter in this way:
--- layout: blog title: "How to make sandwiches like a pro" date: 2020-09-26 11:59:59 thumbnail: "/images/sandwich.jpg" --- This is the post body where I write about how to make a sandwich so good that will impress Gordon Ramsay.
With this example above, this is how you will add collections settings to your Netlify CMS config.yml file:
collections: - name: "blog" label: "Blog" folder: "content/blog" create: true slug: "---" fields: - {label: "Layout", name: "layout", widget: "hidden", default: "blog"} - {label: "Title", name: "title", widget: "string"} - {label: "Publish Date", name: "date", widget: "datetime"} - {label: "Body", name: "body", widget: "markdown"}
Let's examine what each of these fields does:
name: This one is used in routes like /admin/collections/blog
label: This one is used in the UI (User Interface). When you are in the admin page, you will see a big word "Blog" on the top of the screen. That big word "Blog" is the label.
folder: This one points to the file path where your blog posts are stored.
create: This one lets the user (you or whoever has admin access) create new documents (blog posts in this case) in these collections.
slug: This one is the template for filenames. , , and which are pulled from the post's date field or save date. is a URL-safe version of the post's title. By default it is .
The fields are where you can customize the content editor (the page where you write the blog post). You can add stuff like ratings (1-5), featured images, meta descriptions, and so on.
For instance, in this particular code, we add curly braces {}. Inside them we write label with the value "Publish Date" which will be the label in the editor UI.
The name field is the name of the field in the front matter and we name it "date" since the purpose of this field is to enter the date input.
And lastly, the widget determines how the UI style will look and the type of data we can enter. In this case, we wrote "datetime" which means we can only enter the date and time.
- {label: "Publish Date", name: "date", widget: "datetime"}
You can check the list right here to see what exactly you can add. If you want, you can even create your own widgets, too. For the sake of brevity, we'll try to keep things simple here.
Enable Authentication
At this point, we are nearly done with the installation and configuration of Netlify CMS. Now it's time to connect your Gatsby site to the CMS by enabling authentication.
We'll add some HTML code and then activate some features from Netlify. After that, you are on the way to creating your first blog post.
We are going to need a way to connect a front end interface to the backend so that we can handle authentication. To do that, add this HTML script tag to two files:
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script>
The first file to add this script tag is the admin/index.html file. Place it between the <head> tags. And the second file to add the tag is the public/index.html file. This one also goes in between the <head> tags.
When a user logs in with the Netlify Identity widget, an access token directs them to the site homepage. In order to complete the login and get back to the CMS, redirect the user back to the /admin/ path.
To do this, add the following code before the closing body tag of the public/index.html file:
<script> if (window.netlifyIdentity) { window.netlifyIdentity.on("init", user => { if (!user) { window.netlifyIdentity.on("login", () => { document.location.href = "/admin/"; }); } }); } </script>
With this, we are now done writing the code and it's time to visit Netlify to activate authentication.
Before we move on, you should Git commit your changes and push them to the repository. Plus, you will have to deploy your site live so you can access the features in the Enable Identity and Git Gateway section.
Deploy your site live with Netlify
We are going to use Netlify to deploy our Gatsby site live. The deployment process is pretty straightforward, quick, and most importantly, it comes with a free SSL (Secure Sockets Layer). This means your site is protected (you can tell by looking at the green lock on the browser search).
If you haven't signed up for the platform, you can do it right here. When you've finished signing up, you can begin the deployment process by following these 3 steps.
Click the "New site from Git" button to create a new site to be deployed. Choose the Git provider where your site is hosted. My site is hosted on GitHub so that's what I will choose.
Choose the repository you want to connect to Netlify. The name of my Gatsby site is "foodblog" but you have to pick your own project name.
The last one asks how you would like Netlify to adjust your builds and deploy your site. We are going to leave everything as it is and we will click the "Deploy site" button. This will begin deploying your site to live.
Once the deployment is complete, you can visit your live site by clicking the green link that has been generated for you on the top left of the screen. Example: https://random_characters.netlify.app.
With this, the world can now view your site. You can replace the weird URL with your custom domain by reading this documentation.
How to enable Identity and Git Gateway
Netlify's Identity and Git Gateway services help you manage CMS admin users for your site without needing them to have an account with your Git host (Like GitHub) or commit access on your repository.
To activate these services, head to your site dashboard on Netlify and follow these steps:
Go to Settings > Identity, and select Enable Identity service.

In the Overview page of your site, click the "Settings" link.

After clicking "Settings", scroll down the left sidebar and click the "Identity" link.

Click the "Enable Identity" button to activate the Identity feature.
2. Under Registration preferences, select Open or Invite only. Most of the time, you want only invited users to access your CMS. But if you are just experimenting, you can leave it open for convenience.

Under the Identity submenu, click the "Registration" link and you'll be taken to the registration preferences.
3. Scroll down to Services > Git Gateway, and click Enable Git Gateway. This authenticates with your Git host and generates an API access token.
In this case, we're leaving the Roles field blank, which means any logged-in user may access the CMS.

Under the Identity submenu, click the "Services" link.

Click the "Enable Git Gateway" button to activate the Git Gateway feature.
With this, your Gatsby site has been connected with Netlify CMS. All that is left is to access the CMS admin and write blog posts.
How to access the CMS
All right, you are now ready to write your first blog post!
There are two ways to access your CMS admin, depending on what accessing options you chose from the Identity.
If you selected Invite only, you can invite yourself and other users by clicking the Invite user button. Then an email message will be sent with an invitation link to login to your CMS admin. Click the confirmation link and you'll be taken to the login page.
Alternatively, if you selected Open, you can access your site's CMS directly at yoursite.com/admin/. You will be prompted to create a new account. When you submit it, a confirmation link will be sent to your email. Click the confirmation link to complete the signup process and you'll be taken to the CMS page.
Note: If you cannot access your CMS admin after clicking the link from the email, the solution is to copy the link in the browser starting with #confirmation_token=random_characters and paste the link after the hashtag "#", like this: https://yoursite.com/admin/#confirmation_token=random_characters. This should fix the problem.
If everything goes well, you should see your site's admin dashboard:

Netlify CMS admin.
You can create your new post by clicking the "New post" button.
When you're ready to publish your post, you can click the "Publish Now" button to publish it immediately.
When you hit the publish button, the post file is automatically created. Then it will add to the changes with the commit message based on the name of the post along with the date and time of publishing. Finally, it will be pushed to the host repository, and from there your post will be seen live.
You can view the changes by looking at the commit message in your host repository.
After waiting for a few minutes, your new post should be live.
One more thing
The last thing to do is clean up the sample articles. To delete these posts, go to the blog files in your text editor and delete them one by one. Make sure you check your terminal when deleting them so that there will be no issues on your site.
Once all the sample posts are cleared out, commit these changes and push them to the repository.
And now, you are all done! You can now create your new posts from the comfortable CMS dashboard and share your stories to the world.
Summary
In this guide you have learned how to:
Create a Gatsby blog site
Added the Netlify CMS to your Gatsby site by creating and configuring files
Enable user authentication by activating Identity and Git Gateway
Access your site's CMS admin
Publish your first post powered by Gatsby and Netlify CMS
By the end of this guide, you should now be able to enjoy writing blog posts with a fast website and simple content editor. And you probably don't have to touch the code unless it needs further customization.
There is still more to cover about Gatsby and Netlify CMS. One of the best ways to learn about them is to go through their documentation.
I hope you found this guide beneficial, and happy posting!
Check out my blog to learn more tips, tricks, and tutorials about web development.
Cover photo by NeONBRAND on Unsplash.
Resources for JavaScript and React
Here are some resources that may help you to learn JavaScript and React:
JavaScript
React
0 notes
Photo

JS1024 winners, TypeScript gets a new site, and the future of Angular
#500 — August 7, 2020
Unsubscribe | Read on the Web
It's issue 500! Thanks for your support over the years, we're not too far away from our 10th anniversary which we'll cover separately. But do I think issue 512 will be even cooler to celebrate? Yes.. 🤓
JavaScript Weekly
1Keys: How I Made a Piano in Only 1KB of JavaScript — A month ago we promoted JS1024, a contest to build the coolest thing possible in just 1024 bytes of JavaScript. It’s well worth looking at all the winners/results, but one winner has put together a fantastic writeup of how he went about the task. If this genius seems familiar, he also did a writeup about implementing a 3D racing game in 2KB of JavaScript recently, and more besides.
Killed By A Pixel
Announcing the New TypeScript Website — The official TypeScript site at typescriptlang.org is looking fresh. Learn about the updates here or just go and enjoy it for yourself.
Orta Therox (Microsoft)
Get a Free T-Shirt. It Doesn’t Cost Anything to Get Started — FusionAuth provides authentication, authorization, and user management for any app: deploy anywhere, integrate with anything, in minutes. Download and install today and we'll send you a free t-shirt.
FusionAuth sponsor
A Roadmap for the Future of Angular — The Angular project now has an official roadmap outlining what they’re looking to bring to future versions of the popular framework.
Jules Kremer (Google)
You May Finally Use JSHint for 'Evil'(!) — JSHint is a long standing tool for detecting errors and problems in JavaScript code (it inspired ESLint). A curious feature of JSHint’s license is that the tool couldn’t be used for “evil” – this has now changed with a switch to the MIT license(!)
Mike Pennisi
⚡️ Quick bytes:
Apparently Twitter's web app now runs ES6+ in modern browsers, reducing the polyfill bundle size by 83%.
Salesforce has donated $10K to ESLint – worth recognizing, if only to encourage similar donations to JavaScript projects by big companies 😄
A nifty slide-rule implemented with JavaScript. I used to own one of these!
💻 Jobs
Backend Engineering Position in Beautiful Norway — Passion for building fast and globally scalable eCommerce APIs with GraphQL using Node.js? 😎 Join our engineering team - remote friendly.
Crystallize
JavaScript Developer at X-Team (Remote) — Join the most energizing community for developers and work on projects for Riot Games, FOX, Sony, Coinbase, and more.
X-Team
One Application, Hundreds of Hiring Managers — Use Vettery to connect with hiring managers at startups and Fortune 500 companies. It's free for job-seekers.
Vettery
📚 Tutorials, Opinions and Stories
How Different Versions of Your Site Can Be 'Running' At The Same Time — You might think that the version of your site or app that’s ‘live’ and in production is the version everyone’s using.. but it’s not necessarily the case and you need to be prepared.
Jake Archibald
Let's Debug a Node Application — A brief, high level look at some ways to step beyond the console.log approach, by using Node Inspect, ndb, llnode, or other modules.
Julián Duque (Heroku)
3 Common Mistakes When Using Promises — Spoiler: Wrapping everything in a Promise constructor, consecutive vs parallel thens, and executing promises immediately after creation.
Mateusz Podlasin
Stream Chat API & JavaScript SDK for Custom Chat Apps — Build real-time chat in less time. Rapidly ship in-app messaging with our highly reliable chat infrastructure.
Stream sponsor

Matching Accented Letters in Regular Expressions — A quick tip for when a range like A-z doesn’t quite work..
David Walsh
Setting Up Redux For Use in a Real-World Application — For state management there’s Redux in theory and then there is Redux in practice. This is the tutorial you need to get over the hump from one to the other.
Jerry Navi
Reviewing The 'Worst Piece of Code Ever' — I don’t think it really is but it’s not great and it’s allegedly in production. Hopefully you will read this for entertainment purposes only.
Michele Riva
Get an Instant GraphQL API with Hasura to Build Fullstack Apps, Fast
Hasura sponsor
The 10 Best Angular Tips Selected by The Community — Well, the Angular tips by one person that were liked the most on Twitter, at least :-)
Roman Sedov
Node Modules at 'War': Why CommonJS and ES Modules Can’t Get Along — No, it’s not really a ‘war’, but it’s a worthwhile reflection on the differences between the two module types from the Node perspective.
Dan Fabulich
Four Ways to Combine Strings in JavaScript
Samantha Ming
🔧 Code & Tools

GPU.js: GPU Accelerated JavaScript — It’s been a while since we linked to this project but it continues to get frequent updates. It’s compiles JavaScript functions into shader language so they can run on GPUs (via WebGL or HeadlessGL). This has a lot of use cases (and there are plenty of demos here) but if you need to do lots of math in parallel.. you need to check this out.
gpu.js Team
Moveable: A Library to Make Elements Easier to Manipulate — Add moving, dragging, resizing, and rotation functionality to elements with this. GitHub repo.
Daybrush (Younkue Choi)
A Much Faster Way to Debug Code Than with Breakpoints or console.log — Wallaby catches errors in your tests and code and displays them right in your editor as you type, making your development feedback loop more productive.
Wallaby.js sponsor
react-digraph 7.0: A Library for Creating Directed Graph Editors — Create a directed graph editor without implementing SVG drawing or event handling logic yourself.
Uber Open Source
JSchallenger: Learn JavaScript by Solving Coding Exercises — I like that the home page shows the “most failed” challenges, which can give you an idea of the kind of thing other developers are having trouble with.
Erik Kückelheim
JSON Schema Store: Schemas for All Commonly Known JSON File Formats
SchemaStore
WordSafety: Check a Name for Unwanted Meanings in Other Languages — A neat idea. Rather than name your next project something that offends half of a continent, run it through this to pick up any glaring issues.
Pauli Olavi Ojala
🆕 Quick releases:
Handsontable 8.0 — A data grid meets spreadsheet control.
Fabric.js 4.0 — Canvas library and SVG to Canvas parser.
Fastify 3.2.0 — Low overhead Node.js web framework.
Escodegen 2.0 — ECMAScript code generator.
Acorn 7.4.0 — Small pure JS JavaScript parser.
Material Design for Angular ��� v1.2.0
by via JavaScript Weekly https://ift.tt/33B9YQQ
0 notes
Text
Version 320
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week. The downloader overhaul is in its last act, and I've fixed and added some other neat stuff. There's also a neat hydrus-related project for advanced users to try out.
Late breaking edit: Looks like I have broken e621 queries that include the '/' character this week, like 'male/female'! Hold off on updating if you have these, or pause them and wait a week for me to fix it!
misc
I fixed an issue introduced in last week's new pipeline with new subs sometimes not parsing the first page of results properly. If you missed files you wanted in the first sync, please reset the affected subs' caches.
Due to an oversight, a mappings cache that I now take advantage of to speed up tag searches was missing an index that would speed it up even further. I've now added these indices--and your clients will spend a minute generating them on update--and most tag searches are now superfast! My IRL client was taking 1.6s to do the first step of finding 5000-file tag results, and now it does it in under 5ms! Indices!
The hyperlinks on the media viewer now use any custom browser launch path in options->files and trash.
downloader overhaul (easy)
I have now added gallery parsers for all the default sites hydrus supports out the box. Any regular download now entirely parses in the new system. With luck, you won't notice any difference, but let me know if you get any searches that terminate early or any other problems.
I have also written the new Gallery URL Generator (GUG) objects for everything, but I have not yet plugged these in. I am now on the precipice of switching this final legacy step over to the new system. This will be a big shift that will finally allow us to have new gallery 'seachers' for all kinds of new sites. I expect to do this next week.
When I do the GUG switch, anything that is supported by default in the client should switch over silently and automatically, but if you have added any new custom boorus, a small amount of additional work will be required on your end to get them working again. I will work with the other parser-creators in the community to make this as painless as possible, and there will be instructions in next week's release post. In any case, I expect to roll out nicer downloaders for the popular desired boorus (derpibooru, FA, etc...) as part of the normal upcoming update process, along with some other new additions like artstation and hopefully twitter username lookup.
In any case, watch this space! It's almost happening!
downloader overhaul (advanced)
So, all the GUGs are in place, and the dialog now saves. If you are interested in making some of your own, check what I've done. I'm going to swap out the legacy 'gallery identifier' object with GUGs this coming week, and fingers-crossed, it will mostly all just swap out no prob. I can update existing gallery identifiers to my new GUGs, which will automatically inherit the url classes and parsers I've already got in place, but custom boorus are too complicated for me to update completely automatically. I will try to auto-generate gallery and post url parsers, but users will need GUGs and url classes to get working again. I think the best solution is if we direct medium-level users to the parser github and have them link things together manually, and then follow-up with whatever 'easy import' object I come up with to bundle downloader-capability into a single object. And as I say above, I'll also fold in the more popular downloaders into some regular updates. I am open to discuss this more if you have ideas!
Furthermore, I've extended url classes this week to allow 'default' values for path components and query parameters. If that component or parameter is missing from a given URL, it will still be recognised as the URL class, but it will gain the default value during import normalisation. e.g. The kind of URL safebooru gives your browser when you type in a query:
https://safebooru.org/index.php?page=post&s=list&tags=contrapposto
Will be automatically populated with an initialising pid=0 parameter:
https://safebooru.org/index.php?page=post&pid=0&s=list&tags=contrapposto
This helps us with several "the site gives a blank page/index value for the first page, which I can't match to a paged URL that will then increment via the url class"-kind of problems. It will particularly help when I add drag-and-drop search--we want it so a user can type in a query in their browser, check it is good, and then DnD the URL the site gave them straight into hydrus and the page stuff will all get sorted behind the scenes without them having to think about it.
I've updated a bunch of the gallery url classes this week with these new defaults, so again, if you are interested, please check them out. The Hentai Foundry ones are interesting.
I've also improved some of the logic behind download sites' 'source url' pre-import file status checking. Now, if URL X at Site A provides a Source URL Y to Site B, and the file Y is mapped to also has a URL Z that fits the same url class as X, Y is now distrusted as a source (wew). This stops false positive source url recognition when the booru gives the same 'original' source url for multiple files (including alternate/edited files). e621 has particularly had several of these issues, and I am sure several others do as well. I've been tracking this issue with several people, so if you have been hit by this, please let me if and know this change fixes anything, particularly for new files going forward, which have yet to be 'tainted' by multiple incorrect known url mappings. I'll also be adding some 'just download the damned file' checkboxes to file import options as I have previously discussed.
A user on the discord helpfully submitted some code that adds an 'import cookies.txt' button to the review session cookies panels. This could be a real neat way to effect fake logins, where you just copy your browser's cookies, so please play with this and let me know how you get on. I had mixed success getting different styles of cookies.txt to import, so I would be interested in more information, and to know which sites work great at logging in this way, and which are bad, and which cookies.txt browser add-ons are best!
a web interface to the server
I have been talking for a bit with a user who has written a web interface to the hydrus server. He is a clever dude who has done some neat work, and his project is now ready for people to try out. If you are fairly experienced in hydrus and would like to experiment with a nice-looking computer- and phone-compatible web interface to the general file/tag mapping system hydrus uses, please check this out:
https://github.com/mserajnik/hydrusrvue
https://github.com/mserajnik/hydrusrv
https://github.com/mserajnik/hydrusrv-docker
In particular, check out the live demo and screenshots here:
https://github.com/mserajnik/hydrusrvue/#demo
Let him know how you like it! I expect to write proper, easier APIs in the coming years, which will allow projects like this to do all sorts of new and neat things.
full list
clients should now have objects for all default downloaders. everything should be prepped for the big switchover:
wrote gallery url generators for all the default downloaders and a couple more as well
wrote a gallery parser for deviant art--it also comes with an update to the DA url class because the meta 'next page' link on DA gallery pages is invalid wew!
wrote a gallery parser for hentai foundry, inkbunny, rule34hentai, moebooru (konachan, sakugabooru, yande.re), artstation, newgrounds, and pixiv artist galleries (static html)
added a gallery parser for sankaku
the artstation post url parser no longer fetches cover images
url classes can now support 'default' values for path components and query parameters! so, if your url might be missing a page=1 initialsation value due to user drag-and-drop, you can auto-add it in the normalisation step!
if the entered default does not match the rules of the component or parameter, it will be cleared back to none!
all appropriate default gallery url classes (which is most) now have these default values. all default gallery url classes will be overwritten on db update
three test 'search initialisation' url classes that attempted to fix this problem a different way will be deleted on update, if present
updated some other url classes
when checking source urls during the pre-download import status check, the client will now distrust parsed source urls if the files they seem to refer to also have other urls of the same url class as the file import object being actioned (basically, this is some logic that tries to detect bad source url attribution, where multiple files on a booru (typically including alternate edits) are all source-url'd back to a single original)
gallery page parsing now discounts parsed 'next page' urls that are the same as the page that fetched them (some gallery end-points link themselves as the next page, wew)
json parsing formulae that are set to parse all 'list' items will now also parse all dictionary entries if faced with a dict instead!
added new stop-gap 'stop checking' logic in subscription syncing for certain low-gallery-count edge-cases
fixed an issue where (typically new) subscriptions were bugging out trying to figure a default stop_reason on certain page results
fixed an unusual listctrl delete item index-tracking error that would sometimes cause exceptions on the 'try to link url stuff together' button press and maybe some other places
thanks to a submission from user prkc on the discord, we now have 'import cookies.txt' buttons on the review sessions panels! if you are interested in 'manual' logins through browser-cookie-copying, please give this a go and let me know which kinds of cookies.txt do and do not work, and how your different site cookie-copy-login tests work in hydrus.
the mappings cache tables now have some new indices that speed up certain kinds of tag search significantly. db update will spend a minute or two generating these indices for existing users
advanced mode users will discover a fun new entry on the help menu
the hyperlinks on the media viewer hover window and a couple of other places are now a custom control that uses any custom browser launch path in options->files and trash
fixed an issue where certain canvas edge-case media clearing events could be caught incorrectly by the manage tags dialog and its subsidiary panels
think I fixed an issue where a client left with a dialog open could sometimes run into trouble later trying to show an idle time maintenance modal popup and give a 'C++ assertion IsRunning()' exception and end up locking the client's ui
manage parsers dialog will now autosort after an add event
the gug panels now normalise example urls
improved some misc service error handling
rewrote some url parsing to stop forcing '+'->' ' in our urls' query texts
fixed some bad error handling for matplotlib import
misc fixes
next week
The big GUG overhaul is the main thing. The button where you select which site to download from will seem only to get some slightly different labels, but in truth a whole big pipeline behind that button needs to be shifted over to the new system. GUGs are actually pretty simple, so I hope this will only take one week, but we'll see!
1 note
·
View note
Text
Weekly Digest
Dec 16, 2017, 3rd issue.
A roundup of stuff I consumed this week. Published weekly(ish).
Read
Whoever your graphic design portfolio site is aimed at, you have to remember that people’s time and attention is limited. Employers, to take one example, may look at dozens of portfolios in the space of 10 minutes. So you only have a few seconds to really grab their attention and enthuse them.
—8 great graphic design portfolio sites for 2018
Paying for more than 3,500 daily drinks for six years, it turns out, is expensive. The NIH would need more funding—and soon, a team stepped up to the plate. The Foundation of the NIH, a little-known 20-year-old non-profit that calls on donors to support NIH science, was talking to alcohol corporations. By the fall of 2014, the study was relying on the industry for “separate contributions to the Foundation of the NIH beyond what the NIAAA could afford,” as Mukamal put it in an e-mail to a prospective collaborator. Later that year, Congress encouraged the NIH to sponsor the study, but lawmakers didn’t provide any money. Five corporations—Anheuser-Busch InBev, Diageo, Pernod Ricard, Heineken, and Carlsberg—have since provided a total of $67 million. The foundation is seeking another $23 million, according to its director of development, Julie Wolf-Rodda.
—A MASSIVE HEALTH STUDY ON BOOZE, BROUGHT TO YOU BY BIG ALCOHOL
When Starbucks (SBUX) announced that it was closing its Teavana tea line and wanted to shutter all of its stores, mall operator Simon Property Group (SPG) countered with a lawsuit. Simon cited in part the effect the store closures might have on other mall tenants.
Earlier this month, a judge upheld Simons' suit, ordering Teavana to keep 77 of its stores open.
—America's malls are rotting away
The Dots claims to have a quarter of a million members and current clients include Google, Burberry, Sony Pictures, Viacom, M&C Saatchi, Warner Music, Tate, Discovery Networks and VICE amongst others.
—Aiming to be the LinkedIn for creatives, The Dots raises £4m
The Cboe's bitcoin futures fell 10 percent Wednesday, triggering a two-minute trading halt early Wednesday afternoon.
—Bitcoin futures briefly halted after plunging 10%
Through a very clever scheme, the people behind Tether can continue to send Bitcoin into the stratosphere until it reaches a not-yet-known breaking point.
—Bitcoin Only Has One Way To Go If This Is True
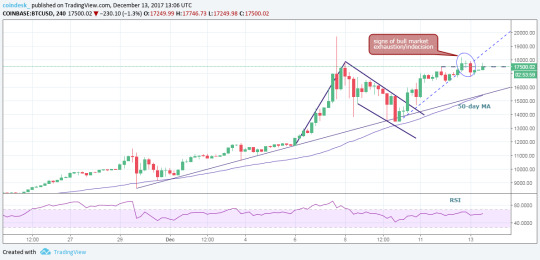
—Bitcoin Price Dilemma: Bull and Bear Paths in Play

—Botera – Free Font
"He is being a huge assh*le and avoiding you so it literally forces you to be the one to break up with him because he's too much of a coward to do it himself. GOD, I HATE GUYS."
—"Breakup Ghosting" Is the Most Cowardly Way to End a Relationship
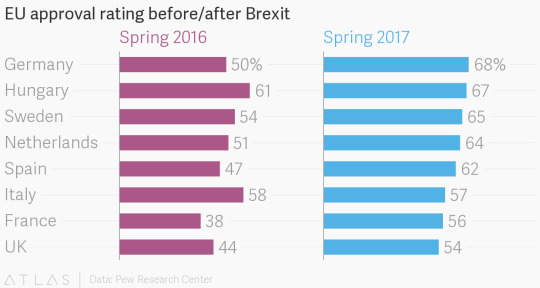
—Britain rejected the EU, and the EU is loving its new life
“Although the science is still evolving, there are concerns among some public health professionals and members of the public regarding long-term, high use exposure to the energy emitted by cellphones,” Dr. Karen Smith, CDPH Director and State Public Health Officer, said in a statement.
—California Warns People to Limit Exposure to Cellphones
There is a way CSS can get its hands on data in HTML, so long as that data is within an attribute on that HTML element.
—The CSS attr() function got nothin’ on custom properties
“The recent coverage of AI as a single, unified power is a predictable upshot of a self-aggrandizing Silicon Valley culture that believes it can summon a Godhead,” says Thomas Arnold
—Former Google and Uber engineer is developing an AI 'god'
Here are two facts: 1) Throughout the tail end of Matt Lauer’s tenure at NBC’s Today, ABC’s Good Morning America beat it in the ratings, and 2) In the two weeks since Lauer was kicked to the curb for sexual misconduct and replaced by Hoda Kotb, Today’s viewership has surpassed GMA’s by a considerable margin.
Here are two opinions: 1) No one ever really liked Matt Lauer, but tolerated him as you would a friend you’ve known for 20 years but have nothing in common with anymore, 2) Hota Kotb makes everything better.
—A Funny Thing Is Happening to Today Now That Matt Lauer Is Gone: Its Ratings Are Going Up
The game challenges you to build an empire that stands the test of time, taking your civilization from the Stone Age to the Information Age as you wage war, conduct diplomacy, advance your culture, and go head-to-head with history’s greatest leaders.
—Get the newest game in 'Sid Meier’s Civilization' series for 50% off
Amazingly, despite the mind control and hypnosis, the girl resisted being totally drawn into her father’s “cult of three.” But she suffered from self-loathing and took to self-harm as a coping mechanism.
—Girl’s father tortured her for a decade to make her ‘superhuman’
The most searched for dog breed was the golden retriever.
—Google's top searches for 2017: Matt Lauer, Hurricane Irma and more

"A few months ago, I started collecting stories from people about their real experiences with loneliness. I started small, asking my immediate network to share with their friends/family, and was flooded with submissions from people of all ages and walks of life.
"The Loneliness Project is an interactive web archive I created to present and give these stories a home online. I believe in design as a tool to elevate others' voices. Stories have tremendous power to spark empathy, and I believe that the relationship between design and emotion only strengthens this power.
—Graphic designer tackles issue of wide-spread loneliness in moving campaign
While the Windows 10 OpenSSH software is currently in Beta, it still works really well. Especially the client as you no longer need to use a 3rd party SSH client such as Putty when you wish to connect to a SSH server.
—Here's How to Enable the Built-In Windows 10 OpenSSH Client
In America we have settled on patterns of land use that might as well have been designed to prevent spontaneous encounters, the kind out of which rich social ties are built.
—How our housing choices make adult friendships more difficult
Today was "Break the Internet" day, in which many websites altered their appearance and urged visitors to contact members of Congress about the pending repeal (see the gallery above for examples from Reddit, Kickstarter, GitHub, Mozilla, and others).
—How Reddit and others “broke the Internet” to support net neutrality today
“He’s the Usain Bolt of business for Jamaica,” Richards said. “For each Jamaican immigrant, Lowell Hawthorne is me, he’s you. He was the soul of Jamaica, the son of our soil, and all of our struggles were identified with him.”
—How the Jamaican patty king made it to the top — before ending it all

—How to break a CAPTCHA system in 15 minutes with Machine Learning
After the trap has snapped shut, the plant turns it into an external stomach, sealing the trap so no air gets in or out. Glands produce enzymes that digest the insect, first the exoskeleton made of chitin, then the nitrogen-rich blood, which is called hemolyph.
The digestion takes several days depending on the size of the insect, and then the leaf re-opens. By that time, the insect is a "shadow skeleton" that is easily blown away by the wind.
—How the Venus Flytrap Kills and Digests Its Prey
Back at The Shed, Phoebe has arrived. She's an intuitive waitress who can really get across the nuances of our menu, like how – by serving pudding in mugs – we're aiming to replicate the experience of what it's like to eat pudding out of a mug.
—I Made My Shed the Top Rated Restaurant On TripAdvisor
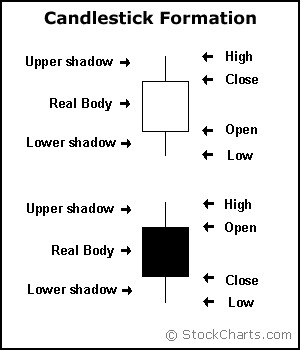
In order to create a candlestick chart, you must have a data set that contains open, high, low and closevalues for each time period you want to display. The hollow or filled portion of the candlestick is called “the body” (also referred to as “the real body”). The long thin lines above and below the body represent the high/low range and are called “shadows” (also referred to as “wicks” and “tails”). The high is marked by the top of the upper shadow and the low by the bottom of the lower shadow.
—Introduction to Candlesticks
The object in question is ‘Oumuamua, an asteroid from another star system currently zipping past Jupiter at about 196,000 miles per hour, too fast to be trapped by the sun’s gravitational pull. First discovered in mid-October by astronomers at the Pan-STARRS project at the University of Hawaii, the 800-meter-long, 80-meter-wide, cigar-shaped rock is, technically speaking, weird as hell—and that’s precisely why some scientists think it’s not a natural object.
—Is This Cigar-Shaped Asteroid Watching Us?
I tried out LinkedIn Career Advice and Bumble Bizz over the course of a work week and compared them in terms of how easy they are to use and the kind of people they introduce you to.
—I tried LinkedIn's career advice app vs. dating app Bumble's version and discovered major flaws with both
“The Bitcoin dream is all but dead,” I wrote.
—I Was Wrong About Bitcoin. Here’s Why.

—Jessen's Orthogonal Icosahedron
In the study, depressed patients who got an infusion of ketamine reported rapid relief from suicidal thoughts—many as soon as a few hours after receiving the drug.
—Ketamine Relieved Suicidal Thoughts Within Hours in Hospital Study
We are trying to create an Open Source Website that searches through an open database of Interactive Maps focused on learning in a linear way. It leverages all of world’s knowledge in a unique way. It takes the Wikipedia model of curating knowledge but applies it to curating links in a meaningful and visual way.
—Learn Anything White Paper
"It was a very new word [in 1841]," Sokolowski said. "[Noah Webster’s] definition is not the definition that you and I would understand today. His definition was, 'The qualities of females,' so basically feminism to Noah Webster meant femaleness. We do see evidence that the word was used in the 19th century in a medical sense, for the physical characteristics of a developing teenager, before it was used as a political term, if you will."
—Merriam-Webster's word of the year for 2017: 'Feminism'
The Wall Street Journal issued a new note on its style blog earlier this week, suggesting the publication not write about millennials with such disdain.
"What we usually mean is young people, so we probably should just say that," the new WSJ note reads. "Many of the habits and attributes of millennials are common for people in their 20s, with or without a snotty term."
—'Millennials': Be Careful How We Use This Label
As of writing, the CoinDesk's Bitcoin Price Index (BPI) is at $16,743 levels. The world's largest cryptocurrency by market capitalization has appreciated 0.72 percent in the last 24 hours, going by CoinMarketCap data.
—No Stopping? After New High, Bitcoin Price Eyes $20k
People who tested as being more conscientious but less open were more sensitive to typos, while those with less agreeable personalities got more upset by grammatical errors.
"Perhaps because less agreeable people are less tolerant of deviations from convention," the researchers wrote.
Interestingly, how neurotic someone was didn't affect how they interpreted mistakes.
—People Who Constantly Point Out Grammar Mistakes Are Pretty Much Jerks, Scientists Find
Hydrogen particles are made up of an electron and a proton. Exciton particles, then, are made up of an electron that’s escaped and the negative space it left behind when it did so. The hole actually acts like a particle, attracting the escaped electron and bonding with it; they orbit each other the same way an electron and a proton would.
—PHYSICS BREAKTHROUGH: NEW FORM OF MATTER, EXCITONIUM, FINALLY PROVED TO EXIST AFTER 50-YEAR SEARCH
For reasons that people are now trying to determine, this weekend the internet turned its collective gaze to a short story called “Cat Person.”
Response to the story has varied from praise for its relatability to flat dismissal to jokes about how everyone is talking about a—Who’da thunk it?—short story of all things.
—The reaction to “Cat Person” shows how the internet can even ruin fiction

—Regular Icosahedron

—Repeal Day Poster – Summit Brewing Co.
[Dr. Simon Bramhall of the UK] pleaded guilty to charges that he etched his initials, “SB,” onto the livers of two transplant patients with an argon beam in 2013. Bramhall admitted the assaults in a hearing in Birmingham crown court on Wednesday, according to several news outlets.
—SB WUZ HERE: Surgeon pleads guilty to burning initials into patients’ organs
I get what you’re doing. Really, I do. You’re trying to shit on people’s musical tastes to either appear more well-versed in music than them or you just want to see the shocked look on people’s faces as you besmirch their favorite band. And listen, I don’t blame you for either. They’re both fun activities that I partake in on the reg. If you name me a band you like, I will find a hundred different ways to judge you on your taste. If the band happens to feature a white guy with dreads, make it three hundred. But The Beatles, dude? The fucking Beatles? You are really scraping the barrel if you are knocking people for liking The Beatles, you moron.
—Shut Your Dumb, Stupid Mouth about the Beatles Being Overrated
—Sonakinatography I Movement #III for Multi-Media
The font the menu is written in can convey similar messages; for instance an italic typeface conveys a perception of quality. But using elaborate fonts that are hard to read could also have another effect – it could alter how the food itself tastes.
A study conducted by researchers in Switzerland found that a wine labelled with a difficult-to-read script was liked more by drinkers than the same wine carrying a simpler typeface. Spence’s own research has also found that consumers often associate rounder typefaces with sweeter tastes, while angular fonts tend to convey a salty, sour or bitter experience.
—The secret tricks hidden inside restaurant menus
On Allison Benedikt, Lorin Stein, and the perils of extracting universal principles from fairytale endings...
“My career, at the time, was in his hands,” Allison Benedikt wrote at Slate this week, about the beginning of her relationship with John Cook, her husband of 14 years. They were colleagues at a magazine when they first kissed, and he was her senior. That kiss took place “on the steps of the West 4th subway station,” Benedikt writes, and Cook did it “without first getting [her] consent.” The piece is an intervention into the conversation on office sexual harassment, with Benedikt fearing “the consequences of overcorrection” on this issue.
—So You Married Your Flirty Boss
“We encourage the use of Teslas for commercial purposes and we’ll work proactively with these customers to find charging solutions that work best for them,” the statement said.
—Tesla Tells New Taxi, Uber Drivers Not to Use Its Superchargers
The deep web refers to anything you can’t access in a search engine, either because it’s protected behind a password or because it’s buried deep within a regular website. The dark web is a subsection of the deep web that you can only access with a special browser like Tor to mask your IP address.
—Things You Can Do on the Dark Web That Aren't Illegal
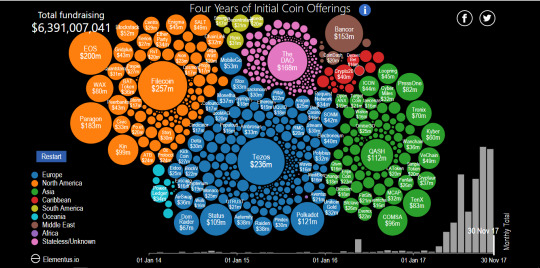
—This Graphic Explains Just How Crazy The Cryptocurrency Bubble Is
One such study published in the journal Neuroimage and highlighted on PsyBlog actually found that some forms of daydreaming cause measurable changes in the brain. This suggests that, done right, daydreaming actually requires attention and control.
—This Is the Correct Way to Daydream, According to a Harvard Psychiatrist
"VR can be stored in the brain's memory center in ways that are strikingly similar to real-world physical experiences," said Stanford's Bailenson, author of the forthcoming book "Experience on Demand," about his two decades of research on the psychological effects of virtual reality. "When VR is done well, the brain believes it is real."
—The very real health dangers of virtual reality
Respect for children means respect for the adults that they will one day become; it means helping them to the knowledge, skills, and social graces that they will need if they are to be respected in that wider world where they will be on their own and no longer protected. For the teacher, respect for children means giving them whatever one has by way of knowledge, teaching them to distinguish real knowledge from mere opinion, and introducing them to the subjects that make the mind adaptable to the unforeseen.
—The Virtue of Irrelevance

—You Will Lose Your Job to a Robot—and Sooner Than You Think
Watched
youtube
—Jessen's Orthogonal Icosahedron
3 notes
·
View notes
Text
The W3C At Twenty-Five
The W3C At Twenty-Five
Rachel Andrew
2019-10-11T12:30:00+02:002019-10-11T10:54:40+00:00
Last week, the World Wide Web Consortium (W3C) celebrated its 25th anniversary and invited folks to share why the open web platform matters to them via the hashtag #WebStories. As I’m both a member of the CSS Working Group at W3C and the representative for Fronteers, I think it’s a good time to explain a bit more about the role of the W3C in the work that we all do.
What Exactly Is The W3C?
On the W3C website, the About page describes the W3C as:
"... an international community where Member organizations, a full-time staff, and the public work together to develop Web standards. Led by Web inventor and Director Tim Berners-Lee and CEO Jeffrey Jaffe, W3C’s mission is to lead the Web to its full potential."
There are links on that page to details of the mission and vision of the W3C, however, the key motivation of the organization is to ensure that the web is for everybody — and on everything.
Access to the web should not be limited by who you are, where you are, or the device you are using.
“
Who Are The Member Organizations?
A W3C Member is an organization who pays a membership fee to be part of the W3C. At the time of writing, there are 449 members, and you can see the full list here. If you read through this list, you will find that the majority of members are very large companies. Some are names that we as web developers readily recognize: browser vendors such as Google and Mozilla, large internet companies such as Airbnb and Facebook. However, there are members from many different industries. The web touches pretty much every area of life and business, and there are companies doing interesting things in the space that we might not think of as web companies. For example, people working in traditional publishing (a lot of books are formatted using web technologies) and the automotive industry.
What all the members have in common is that the web impacts the work that they do, and they are keen to have a say in the direction things move, and even to play a part in creating and specifying web technologies.
I represent Fronteers (the Dutch organization of web developers) in the W3C. This year, Fronteers took the unusual* step of becoming a W3C Member Organization.
* “Unusual” because they are a voluntary organization representing web developers, rather than a big company representing the interests of a big company.
The Advisory Committee (AC)
Member organizations take part in the business of the W3C by having a vote on various matters. This is organized by the organization’s AC representative whose job it is to ferry information from the W3C to the organization, and also bring the point of view of the organization to relevant topics being discussed at the W3C.
I’m the rep for Fronteers and so I attend two AC meetings a year — and get a lot of emails! On voting matters, I have to find out from Fronteers how they want to vote and then cast the Fronteers vote. In the last year, one important voting matter was the election of Advisory Board (AB) members; Fronteers held an internal vote, and I took the results back to make the official vote at the W3C.
W3C Groups
Most web developers are probably more aware of the W3C working groups than the rest of the organization, as it is through these groups that most of the work we care about goes on. Any member organization can opt people from their organization onto a working group. In addition, the groups may invite certain people (known as Invited Experts) to participate in that group. I was an Invited Expert on the CSS Working Group, and now am part of the group as the representative for Fronteers. In practical terms, my interaction with the CSS Working Group remains the same, however, I now have a role to play in the W3C as a whole as the W3C rep for Fronteers.
There are a large number of working groups, covering a whole range of technologies. These groups typically work on some kind of deliverable, such as the specifications produced by the CSS Working Group. There are also a number of Interest Groups, which allow for the exchange of ideas around particular topics which may also fall partly into the remit of some of the working groups.
The above groups require a significant time commitment and either a W3C membership or Invited Expert status, however, there are a number of Community and Business Groups that are open to any interested person and do not impose a particular time commitment. The Web Platform Incubator Community Group is one such group and has a Discourse forum for the discussion of new web features, and also various proposals on GitHub. Many of these features ultimately become CSS or other language specifications and therefore part of the platform.
Getting Involved And Following Along
In addition to joining a community group, it is worth noting that anyone can become involved in the work of the W3C, i.e. you don’t need to be an Invited Expert, part of a member organization, or have any special qualifications. For example, if you want to know what is happening at the CSS Working Group, you can take a look at our Issues on GitHub. Anyone can comment on these issues to offer new use cases for a feature and can even raise an issue for a feature they feel should be part of a CSS specification.
As with most W3C groups, the CSS WG uses IRC to minute meetings; any discussion on an issue will be posted back to the issue afterward so anyone who is interested can follow along.
An example of a message that was auto-generated regarding an issue that had been discussed in a meeting.
If you are keen to know what the wider W3C is doing, then the strategic highlights document is a good place to look. The latest document was produced in September, and exposes some of the key work recently achieved by W3C groups. Scrolling through that document demonstrates the wide range of activities that the W3C is involved with. It is so important for the web community to engage with standards, as we’ve already seen examples in the past of what happens when vendors control the direction of the web.
This history is explained beautifully by Amy Dickens in her post, “Web Standards: The What, The Why, And The How”:
"Without the Web Standards community, browser makers would be the ones making decisions on what should and shouldn’t be features of the world wide web. This could lead to the web becoming a monopolized commodity, where only the largest players would have a say in what the future holds."
My #WebStory
Why does all of this matter to me? One of the reasons I care so much about the web platform remaining open and accessible to new people who want to publish on and build things for the web is because of the route I took to get here.
As mentioned earlier, the W3C is celebrating their anniversary by inviting people to share stories of how they became involved in the web.* In that spirit (and perhaps to encourage Smashing readers to share their stories), here is mine.
* So many folks have already shared their journey on the W3C Blog of how they were first amazed by the web and continue to be in awe of its potential. Join in and share your story!
I had never intended to work with computers. I intended to become a dancer and singer, and I left school at 16 to go to dance college. My father is a programmer, however, so we were fairly unusual at the time as we had a computer in the house by 1985 when I was 10.
As a child, I liked typing in the code of “choose your own adventure” games, which appeared in books and magazines. I liked spotting the strings of text which would then show up in the game I would later play (usually, once my dad had fixed it up) on our Amstrad CPC464. I liked to visit the computer lab at Newcastle University, see the huge computers, and talk to the women who worked on them. Perhaps most importantly (and despite my arty interests), I never grew up thinking I couldn’t use computers. I just wasn’t especially interested.

The books I copied games out of as a child.
At school, I learned to type on an electronic typewriter, and the only computer in evidence was in the art room that was used for basic drawing applications. As we did have computers at home, I had used them for schoolwork, despite some teachers not being happy about printed essays.
I ultimately left dance and went backstage, working in the West-End of London. Moving lights, automated sets, and show control systems were about to make huge changes to an industry that had seen little change in years. We were seeing the beginnings of that change when I was in the West End; I remember laughing with the crew as we heard news about some show with a “fancy computer system” which had lots of problems that our traditional production didn’t have. None of us could have imagined the changes that were coming.
Then I became pregnant with my daughter and had to leave the theatre. I was good at crewing and loved the theatre, but it was heavy and sometimes dangerous work with unsociable hours — not really a job for someone with a baby. I didn’t know what I would do, but I could type so I thought that perhaps I could type up essays for people. I was upsold to a computer — having gone into PC World looking for a wordprocessor. It was a Packard Bell 486 with a built-in 640×480 screen — a terrible machine that would allow me to either get the sound card working or the modem, but not both at once. I chose the modem and this is where my web story really begins. Even getting this modem working and getting the computer onto the Internet was something of a challenge and, once I did, I went looking for information about… babies.
I didn’t know anything about babies. All my friends were men who worked backstage in theatre. I had no support network, no family around me to help, and so I logged onto ParentsPlace and found people who didn’t mind my questions and were happy to help. At the time, there obviously was no Facebook. This meant that if you wanted to share photos and stories, you built a website. So among the forums about childbirth and toddler tantrums, there were people teaching each other HTML and sharing sets of graphics along with the code to place them. It was like typing out those “choose your own adventure” books again. I was amazed that I didn’t need anyone to fix my code — it just worked!

Pulled out from the Internet Archive, this was a website named ‘ParentsPlace’ that existed around the time I was pregnant with my daughter. archive.org link
Before long, people would pay me to build them a website, and I felt that I should repay at least in some way for all of the questions I had asked. So, I started to answer questions in the forums. That was how it seemed to work. People would learn and move one step up the ladder, the new people would come in with the same questions and the people a step ahead would answer — all the while asking their own questions of those further along. I loved this. I could never have afforded lessons, but I had time. I could help others, and in return, people helped me. I discovered through this that I was quite good at explaining technical things in a straightforward way — an ability I have always accredited to the fact that I struggled to learn these new things myself. It was never easy. I was willing to spend the time, however, and found it interesting.
With my daughter on my knee, I started to teach myself Perl because I didn’t like any of the off-the-shelf guestbooks and wanted to write my own. I installed Linux on a second-hand Compaq, and learned the basics of systems administration, how to compile Apache, wrapped my head round file permissions, and so by the time my daughter was three years old, I got a job heading up a technical team in a property “dot com” company.
I became interested in web standards essentially because it made no sense to me that we would have to build the same website twice — in order that it would work in both browsers. At the time, Dreamweaver was the tool of choice for many web developers, as it made dealing with the mess of nested tables we had to battle with much easier. So, influenced by the work of The Web Standards Project, I (along with my then-boyfriend, now-husband Drew McLellan) began sharing tips and Dreamweaver extensions with the Dreamweaver Usenet group, while all along explaining why web standards were important and showing how to make Dreamweaver support standards.

My bio on the WaSP site in 2002 — there wasn’t much to say! (archive.org link)
Ultimately, we both ended up on the Macromedia Beta, helping to make Dreamweaver itself more standards-compliant. We were also invited to join the Web Standards Project — specifically to be part of the Dreamweaver Task Force. I couldn’t believe that Jeffrey Zeldman emailed me, asking me to join WaSP! These were the people I looked up to and had learned so much from. The fact that they wanted me to be part of the organization was amazing and gave me so much confidence to continue with the work I was already doing.
That involvement became the bedrock of my career; I realized that my ability to explain technical things could help other web developers learn these new technologies and understand the need for standards. I also discovered that being able to explain things clearly was useful in raising bug reports, and writing up use cases for new software features (in browsers or tools such as Dreamweaver). Two decades after discovering web standards, I am still doing this work. It continues to interest me, and I think it is more important than ever.
The open nature of the web, the relative simplicity of the technologies, and the helpful, sharing attitude of the community is why I am here at all. One of the biggest reasons why I have stayed after all these years is because of Web standards and the continued fight for the open web. That’s why I think that the W3C and the standards process is vitally important, and why I think it so important that web developers get involved in the process, too.
I want to help ensure that the voice of the web developer working on small projects is heard, and that the direction of the web isn’t dictated by a few giant companies. The web is where we have made our careers, and often even our social lives; it is the way that we communicate with each other. I want it to stay a place where I want to be. I want it to remain open enough that the next person without a technical background can pitch up and start publishing and creating, and find it a place they want to establish a career, too.
What’s Your Web Story?
Whether you have been working on the web for over 20 years or only one, please share your stories on the W3C blog, on your own site, or perhaps write up something in the comments section here below. I’d love to hear your journey!

(il)
0 notes
Text
Something Awesome! Week 6
“The world today abounds in open information to an extent unimaginable to intelligence officers of the Cold War.” - CIA
Welcome back for another week of stalking... Last week I managed to find some social profiles, evidence of exchange, usernames and Andrew’s Full Name! (surprisingly hard to find). This week I’m hoping to be able to find more email addresses and social profiles like github/bitbucket, tumblr, twitter, etc. Google Dorking + Social Media Searching I started with trying to target the social profiles first via google. Literally, nothing came up. I tried each site’s own search engine with the emails I found earlier, the two user IDs from Facebook and LinkedIn and sensible variations of his name as a username but I couldn’t find a profile that matched Andrew’s.
At this point, I was getting a little worried, because I’m sure Andrew has a github profile, twitter and he has to have tumblr otherwise I’m not sure how he will mark our work, but I couldn’t find any such profiles. It is entirely possible that he has made his profiles unable to be found via search, but I had no way of confirming this. I tried to get creative, I know he is the wellbeing head at UNSW SecSoc, so I tried checking the twitter followers of UNSW SecSoc, Lachlan Jones (caff), Adam Smallhorn, Richard Buckland and some others. I wasn’t just looking for an @andrewcarmichaelTwitter account, I had a feeling he would use a username that was obscure so I even checked out most of the accounts with obscure usernames to see if it was even remotely possible for them to be Andrew’s Account. Nothing. In a similar fashion, I tried on github. I checked the followers of unswsecsoc’s github account, Lachlan Jone’s account, etc. I was hoping he had made a commit in some repo and that information would pop up but still nothing. It’s quite possible that he doesn’t actually use github/bitbucket but rather something like gitlab where everything is already private. If that is the case, then there's no way to find his account. What makes it even harder is that he doesn’t have a personal website, usually people who have a personal website will have the code on github somewhere and you can find their account via the commits for that repo. :(
I still had hope. There’s one thing left to check. Google Docs. Andrew made the initial doc for the first chapter of the course textbook, maybe there’s a way, perhaps through comments or version history, of checking his profile and getting his gmail address. Sadly, the OSINT Gods are looking favorably upon Andrew - not me. Google Docs doesn’t expose the email address of the person making changes, only the full name. Maltego (pls...help meh)
Since last week I have watched a couple of videos on how to use Maltego so this was the perfect time to give it a go. As I’ve explained in some previous blog, Maltego is a data mining and visualising software, you basically add information as nodes in a graph and Maltego runs little programs on each node trying to find out more information! I decided to start with Andrew’s full name.

This gave me a set of companies (mainly based in the UK), some really arbitrary documents and some names of people (again mainly based in the UK) who could be associates of Andrew. The documents were very random and definitely not related to Andrew. Since most of the people were registered in the UK, I felt that they weren’t relevant. They could have been some cousins/extended family but I didn’t have a way of confirming this. I tried to look up his name without the second middle name.

While the connections with people were the same, this search yielded the same kind of results as the previous one. A bunch of random documents/records from the UK ranging from 1600s-1800s. Upon reflection, I realised that this is most likely because Maltego doesn’t have access to Australian records since our current records aren’t public. Interestingly, I ran all transforms available on both names and neither one revealed a useful email/social media profile/phone number. Some of this could also be because I’m using the community (free) edition of the software, thus I expect that the search results are limited. I tried to run direct searches on the LinkedIn and Facebook profiles, but the main transform required API keys for a paid service. My search resulted in no new information.

Lastly, I tried to use the known emails so far to generate new information. This was finally getting interesting!

As expected, I found links to UNSW and UNSW SecSoc. I also found links to ANZNN (Australia New Zealand Neonatal Network), a research organisation that seems to be managed by UNSW. I cross-checked the phone number and email addresses found to the contact us page on the ANZNN website. Is Andrew involved in international neonatal research? Since he is a mechatronics/compsci student with a strong interest in security, it seems unlikely. I tried to check for Andrew’s name media or papers released from the organisation but as expected I found nothing. I think the only useful information I got from running all this was finding out that his emails haven’t been breached according to haveibeenpwned.com. Namechk
I hit up bellingcat’s online investiagation toolkit again to see what resources it had for social media information and found Namechk. It’s a site that lets you test usernames to see how many different social media profiles already have that username taken. I think it’s good for people who only want one username on all platforms, for me however, I can use it to see if any of Andrew’s known user Ids are used anywhere else. andrew-rc-carmichael: Apparently invalid on all sites since its too long? andrew.carmichael.395: Apparently besides facebook, this username is invalid on all other services?? (is this site broken or is there actually a 12-15 char limit?) arc: There are a few sites I found which could have accounts that likely belong to Andrew:
Twitter: Account seems like a bot, only follows Japanese content, no likes, no security-related content. Not Andrew
Flickr: 1 Follower who I can’t check, but joined in 2004 (Andrew’s approx age at the time would’ve been 7-8 - who has an email at age 7/8?). Not Andrew
Steam: From Profile: Szymon Herman (Slaskie, Poland). Not Andrew
Soundcloud: Profile photo doesn’t match at all. Not Andrew
CoderWall: Account belongs to an Aaron Crane. Not Andrew
Disqus: Old account (2008 - seriously, Disqus has been around since then??), only 1 comment about getting some bank ID? Not Andrew
Codecademy: Of course, I’ve left the best to last. This account belongs to a ‘Michael’. This is significant because there’s no or names or identifiable information on the profile. There's only ‘Michael‘ with the username ‘arc’. Given Andrew’s last name and experience with code, it’s possible that this account could be his!!! This could be Andrew!
What’s the impact of having this data? None?? Given what we already know about him from his LinkedIn profile and University degree, having an account on Codecademy hardly adds anything new to his profile. What would be interesting, however, is if Codecademy had a known data leak/hack. If a hacker exposed user accounts/emails and/or passwords then by getting a hold of that dataset and checking for user ‘arc’, we might be able to find his password or email. Thankfully Codecademy hasn’t had any such data breach. Reflection From a pure data gathering point of view, this week feels like a waste. I barely secured new information, and I think it’s better to move on to set a different goal of finding information such as where he might live or places he visits. I know this is harder to find, but I think I’ve reached a dead end here. From a learnings point of view, this week has been fruitful! And that is more important to me. I came up with creative ideas for getting information (even though they failed) and that strengthened my skills of thinking like a security engineer and problem solving. I also learned how to use Maltego which is sooo common and widespread in the industry. Even though I didn’t get much information on Andrew from Maltego, I understand why, for American targets and under a professional Maltego license, investigators love this software. It allows you to step through the OSINT Methodology and takes a lot of the manual searching out of your hands so you can focus on organising and creating links in your data. To put things in perspective for myself: My target is a professionally certified hacker and security tutor, it was never going to be easy.
0 notes
Text
An interview with Cory Doctorow on beating death, post-scarcity, and everything

So, this is a sort of prequel to Down and Out. Is it also a sort of sequel to Makers, at least on the theme of the end of scarcity?
You know, that's an interesting question. I just finished reading a whole ton of essays that a group of academics wrote about Walkaway for the Perfect Timber blog, which is doing a symposium. A lot of them were like, "Well, this is a novel that's about 3D printing producing abundance." I was like, "Well actually I wrote that novel [Makers] 10 years ago." This novel is about coordination changing what abundance is—our ability to, in that kind of GitHub-ian way, make some stuff, and then have someone else make some stuff, and then someone else, and for all three of those things to be captured and combined.
If you think of abundance being a triangle, one side is what we want, one is what we can make, and one is how efficiently we can coordinate and use it. Makers was definitely about what we can make. But this is about using the things we already have—fully automated leisure communism, the ZipCar edition. We have high-quality physical objects, and we don't have to have a personal one because they're all circling in a probabilistic cloud that we can collapse down into "the car will always be there when we need it." That's a form of even better abundance than everyone having their own lawnmower in their garage because, if everyone had a lawnmower, they would also have to have some place to store it.
The question of what we want is the third piece of abundance that I addressed a little in Walkaway. But it's something that's come up a lot in our wider debate, because everyone keeps bringing up the old Keynes essay where everyone will have a three-day week by 2015 and that his grandchildren would lack for work because productivity has increased to the point where we can just fill all of our needs.
We kind of got there, but then we had this advertising innovation to produce more goods than we ever wanted. Even though we can produce enough goods for John Keynes to be happy, we can't produce enough for everyone to be happy in 2017—because we want so much more. And, of course, that's the other way to adjust what our view of abundance is—how much we want. And those three levers—three dials that we can turn—are what determine whether we feel like we're moving into an era of scarcity or abundance.
I think that's why Marie Kondo is so hot. A lot of people are coming to realize that there's a luxury in getting rid of all of your stuff. There's a real class dimension there, too, because one of the reasons to hold onto a bunch of things is because the opportunity cost of getting rid of it means you might not be able to afford to replace it later; whereas, the richer you are, the more you can afford to buy things as you go. Buying your clothes as you travel as the cheap way to not have to carry luggage with you is great unless you don't have enough money to buy more clothes.
The model you use for the walkaway community in your novel and the social behaviors that are exhibited remind me a lot of some of what we see in open-source software communities. You've clearly drawn from a lot of experience there.
Yeah, totally. I mean—I've been in the middle of these fights about things like free and open source software, and whether they're a meaningful category, whether open source is incompatible with free. I've been around people who fork and unfork and refork and merge, and I've kind of lived through multiple versions of that. And I've lived through watching people who open things up and then wished they could close them again, that felt like they made the wrong choice. So having a front-row seat to all that stuff was hugely influential in how I wrote the book.
There are also reflections of other cultures, or countercultures, in Walkaway—aspects that reflect Depression-era "hobo" culture. Walking away with almost nothing, the walkaways seemed like a futuristic version of what hobos were.
Well, in a sense that hobos were a response to vapor lock in the economy. There was stuff that needed doing and people who wanted to do it, and the economy couldn't figure out how to marry those two phenomena. Job one for an economy is to marry stuff with people who can do it. And certainly in the high-tech world, hobo culture has had an interesting overlap. Warchalking, for example, exists because Matt Jones wanted to adapt hobo-glyphs for people who wanted Wi-Fi. Then there was John Hodgeman and his hobo names. Hobo-ness seems to have been in the air through the era of tech.
Wi-Fi is a little parable about abundance. To go from networks as planned, explicitly connected things where literally someone has to go to a patch panel and connect a switch to light up a jack near the place where you're standing, and sometimes you even have to let somebody know what your TCP settings are, to like, "Oh, I'm in a place and there's radio energy, let me see if that radio energy will give me Internet"—that's sort of a death-of-scarcity parable.
How close do you think we are technologically to being able to sustain the kind of world where the sort of post-scarcity in Walkaway exists?
I think that out of the triangle of technology making, coordinating things, and changing what things we want, that the one that is really most advanced and most reliable is coordinating things. Changing what people want is hard. We treat marketing like it's super good at what it does, but the reality is that there's a massive survivor bias in marketing. Everything gets marketed [and] most things fail. We only notice the tiny number of things that succeed and the fact that a lot of them are materially like garbage. That leads us to conclude that marketing can sell anything, but marketing really sells nothing—it's a statistical rounding error.
Coordinating things, though, we're good at. McDonald's was successful because it's a supply chain management system with hamburgers in it. Wal-Mart, al-Qaeda, open-source and free software—all these are things where people are doing collaboration and coordination. Sometimes we do it in a very improvisational way. Compare what it was like, growing up, going out 30 years ago to hang out on a Friday night, versus now. Thirty years ago, you would have to find those people on Thursday, and look at what movies were playing, and figure out where you were going to meet on Friday night. Now, you just go to the center of town and send out a text to all your friends or put up a beacon on your social network and say, "Who's up for the movies?" And they all find you or you find them.
That's the sort of fluid improvisational thing that happens all the time now. And then there's collaboration across time and space without any intention—for example, when you need to do code a thing, and you find a library, and you integrate that into your thing, and that person doesn't know that you've done that and you don't know that they've done it.
Every person who ever did hypertext wanted to do back links, and they'd all given up on them as being too hard for version 1.0 and swore they would come back and do them later. And every time, they failed to do them later. You know, Google was started to create Backrub, which was just back links. And it turned out to be transcendentally hard. Xanadu... every one who wanted to make these explicit collaborative mechanisms found it to be transcendentally hard, and they dramatically underestimated how much we can do with inexplicit hooks for collaboration, without explicit semantic tagging, and without explicit APIs.
You think about all the sets of APIs, and how much has been done successfully just with REST—with all those sites that don't have APIs, but Google can figure out how to search them because they can tell they have something RESTful in their URL. Like in WordPress, you just add a question mark to the base URL and then "s=" and what you're looking for, and you get back search query results.
That phenomenon of unintentional inexplicit... "coordinated" is the wrong word, but a coordination without the two parties ever having to communicate or even knowing that they're coordinating... it's an amazing story. And it's amazing because it works so well that when it occasionally falls apart it's huge news and it makes us all step back and say, "Wait a second—how does the whole Internet work now?" You remember when Leftpad got yanked?
Yes.
And it was like, "Wait a second, what the F is Leftpad, and, like, how did it get embedded in all of these websites? And how much more of this stuff is there?" But you think about 10 seconds and you realize, of course! Because code reuse is good coding, because the way to improve code is to iterate it, and so anything you write as a first iteration will not be as good as something someone has re-factored four or five times. So rolling your own is often the worst possible option, and you know the whole Web is built on small pieces loosely joined in this way that we only discover when it stops working—because it works so well most of the time that we don't even noticed that we're doing it. We're just soaking in it.
Read the rest:
https://arstechnica.com/the-multiverse/2017/04/an-interview-with-cory-doctorow-on-beating-death-post-scarcity-and-everything/
17 notes
·
View notes
Text
Build an OpenStack/Ceph cluster with Cumulus Networks in GNS3: part 2
Adding virtual machine images to GNS3
I’m going to assume that at this stage, you’ve got a fully working (and tested) GNS3 install on a suitably powerful Linux host. Once that is complete, the next step is to download the two virtual machine images we discussed in part 1 of this blog, and integrate them into GNS3.
In my setup, I downloaded the Cumulus VX 4.0 QCOW2 image (though you are welcome to try newer releases which should work), which you can obtain by visiting this link: https://cumulusnetworks.com/accounts/login/?next=/products/cumulus-vx/download/
I also downloaded the Ubuntu Server 18.04.4 QCOW2 image from here: https://cloud-images.ubuntu.com/bionic/current/bionic-server-cloudimg-amd64.img
Once you have downloaded these two images, the next task is to integrate them into GNS3. To do this:
Select Edit > Preferences in the GNS3 interface.
When the Preferences dialog pops up, from the left pane select QEMU VMs, then click New.
Enter a name for the Image (e.g. Cumulus VM 4.0)
Select the Qemu binary, and specify default RAM size for each instance (I used 1024MB). You can override this for each VM you create on the GNS3 canvas, so don’t worry too much about it.
Select the Console type – I used telnet for both images.
Finally browse to the image file you downloaded earlier. When asked if you want to copy the image to the default images directory, I prefer to say Yes.
Make the following additional changes once the images have been copied over:
Edit each VM and set an appropriate symbol for it – this makes the canvas easier to interpret, but has no effect on the operation of GNS3. I used: a. :/symbols/classic/ethernet_switch.svg for Cumulus VX b. :/symbols/classic/server.svg for Ubuntu Server
Change the On close setting from “Power off the VM” to “Send the shutdown signal (ACPI)” for the Ubuntu server VM’s – this ensures they cleanly shutdown when you close your GNS3 infrastructure.
With this stage complete, you can proceed to building your infrastructure on the canvas.
Build virtual infrastructure on the canvas
Once we’ve defined our QEMU VM’s, the real fun starts! We can now simply click and drag our infrastructure onto the canvas. GNS3 doesn’t support orthogonal lines for the connections, so it can be a little crowded by the time you’ve completed as complex an architecture as we are building here – however the effort is well worth it, especially when you consider that you can right click on any connection and sniff the traffic running over it! This is a great learning and investigative tool.
One important learning is this – GNS3 does not have the capability to edit the number of network connections on a device on the canvas once you’ve connected it up – you have to delete all your connections if you want to edit this property. Thus it’s worth taking some time to plan out the design or simply add more ports than you need.
You’ll also need to edit the amount of RAM some of the VM’s are allocated, and the disk sizes too. Also for our static DHCP allocations for the Cumulus VX switches you will need to set the MAC addresses recorded in the table below. Note that the sizes and values recorded in this table are the ones I have tested with -\ they should however be viewed as minimum viable values, and may need to be increased depending on how you want to test your virtualized infrastructure:
Note that all disks are created as sparse disks, and so will not occupy the amount of storage specified above. When I had fully built my demo environment, it occupied a total of around 112GB.
In general, the network topology is laid out as follows:
Mgmt01 connects to both a Cloud and a NAT device in GNS3 – the NAT device provides fast connectivity, outbound, for all VM’s on the canvas. The Cloud device is very slow, but allows you to SSH directly into your management VM if you wish. You can leave this out if you prefer.
On all other nodes, eth0 is connected to swmgmt, and is used for out-of-band management.
All OpenStack VM’s have 5 Ethernet ports. After eth0 (management), the other 4 are used in bonded pairs for the two physical networks suggested in the openstack-ansible example document. They are wired up alternatively to leaf01 and leaf02 in pairs, starting at eth3 on these switches (eth1 and eth2 were used for testing purposes in the early stages of the design and are not assigned in the current version).
The high numbered ports on the switches are used for the interconnects between the switches that enable MLAG to operate.
Your resulting canvas should look something like this:
Creating cloud-init configurations
Once you have built your infrastructure on the canvas, the next task on our list is to build a set of cloud-init ISO images. Although the Cumulus VX images have a well known default username and password that we can make use of, the Ubuntu images do not – in fact they have no default password set at all, as they expect to get this from the cloud orchestration system (e.g. OpenStack, Amazon EC2, etc.). Fortunately for us, cloud-init is built into the Ubuntu cloud images we downloaded, and can perform any of a number of tasks, from setting a default password, to configuring the network interfaces (even bonding can be set up!), and running arbitrary commands. On the first boot of every VM, cloud-init searches a well known set of locations for its configuration data, and one of these happens to be an ISO image attached to the VM. Thus we can create a small, unique ISO image for each VM that does the following:
Sets the hostname for each VM
Sets the password for the default user account (ubuntu)
Adds an SSH public key to this user account for passwordless management
Changes the boot parameters of the VM to use the old eth0, eth1,… style of network interface naming
Installs Python (to enable further automation with Ansible later on).
In addition, for our “management” VM, our cloud-init scripts go even further, both installing Ansible and even cloning the GitHub repository that accompanies this article to the home ubuntu user’s directory.
Rather than go through the code in detail here, we’ll leave you to explore it yourself, as it is all available here: https://github.com/jamesfreeman959/gns3-cumulus-openstack-ansible
Makefile’s have been placed at appropriate places in the directory structure to help you get started easily. The process for building the ISO files is as simple as:
Clone the Git repository to the machine running Ansible: a. git clone https://github.com/jamesfreeman959/gns3-cumulus-openstack-ansible
Change into the clone directory, and run “make” to generate an SSH keypair for the out-of-band management network.
Change into the “2-cloud-init” directory – in here you will find one directory named after each node you created on the canvas in the previous section. Within each subdirectory, simply run the “make” command to generate the ISO file.
On the GNS3 canvas, right click on each VM in turn and select Configure. Change to the CD/DVD tab and select the ISO image you generated in the previous step.
Once this is completed, you will find that all your VM images will have all essential configuration performed on their first boot. However don’t boot all your nodes just yet! For everything to come up cleanly, we need to configure the network in a logical sequence, the next step in which is to complete the configuration of the management node.
Configuring the management node
Right click on the mgmt01 VM and click Start. Leave all other VM’s powered off at this stage. Now when you double-click on it, a console should open and you should see the VM boot up. You will also see it reboot – this is part of the cloud-init configuration which disables persistent network port naming.
Once the reboot completes, you should be presented with a normal login prompt. If you are using the cloud-init examples that accompany this blog, log in with ubuntu/ubuntu. If all has gone well, you will have a clone of the accompanying git repository in your home directory.
In our infrastructure, our management VM is going to perform a number of important functions (as well as running the Ansible playbooks to configure the rest of the infrastructure). It will act as a DNS server for our infrastructure, and also a DHCP server with static leases defined for the Cumulus VX images. It even acts as a simple NAT router so that our infrastructure can download files from the internet, via the NAT1 cloud we placed onto the canvas.
Assuming you’ve created the infrastructure as described (including the MAC addresses), you can simply change into the 3-mgmt01 subdirectory on the git clone, and run the Ansible playbook as follows:
ansible-playbook -i inventory site.yml
When the playbook completes, all the functionality of the management VM will be configured, and we can power the out-of-band management switch.
Configuring the out-of-band management network
The out-of-band management switch is a simple, layer 2 switch – however it still needs to be told that this is its configuration. Fortunately, Cumulus Networks’ switches are easy to configure using Ansible, and a playbook is provided in the accompanying git repository. Simply change into the 4-swmgmt subdirectory, and run the playbook as follows:
ansible-playbook -i inventory site.yml
Once it completes successfully, swmgmt will be configured as a layer-2 switch for managing all the other devices on our virtual infrastructure. From here, you can power the other 4 switches.
Configuring the spine-leaf switch topology
Once the 4 switches which comprise the spine-leaf topology boot up, you can proceed to configure them. Once again, Ansible playbooks are provided for exactly this purpose. The switch configuration for these switches is a simple layer-2 MLAG configuration – more advanced configurations are possible and I’ll leave it to you to explore more advanced options – however the code provided in the accompanying repository will set up a spine and leaf topology, with the switch ports configured to support resilient bonding on all the OpenStack nodes. Note that the port configuration assumes you have wired up the virtual machines as discussed earlier in this blog, and you will need to edit the configuration if you wish to change the port assignments.
Once you are ready to configure the switches, simply run the playbook in the 5-swcore subdirectory, as follows:
ansible-playbook -i inventory site.yml
When that playbook completes successfully, you will have a fully configured infrastructure with a resilient switching architecture and bonded network configurations on all nodes. The final stage is to power up all remaining nodes, and to install OpenStack.
Deploying OpenStack
With the switching infrastructure set up, you should now be able to power on all remaining virtual machines. They will obtain all their initial configuration (including networking) from the cloud-init ISO’s we attached earlier, and will present themselves as a blank canvas on which OpenStack can be installed. It is worth noting that although I have created this as a worked example for OpenStack, you could use this to simulate just about any distributed architecture.
Installing OpenStack, even from the openstack-ansible project, is a fairly lengthy and involved process. All details are given in the README.md file of the 6-osansible subdirectory of the GitHub repository accompanying this article, so we won’t repeat them again here.
In short the process involves cloning the openstack-ansible code onto the management node, preparing the node for OpenStack deployment (a special bootstrap script is provided for this), setting appropriate variables to configure the installation, and then running the playbooks in the correct sequence. If you’ve never done this before, this can be quite a daunting task, especially when you come across issues such as the incompatibility between ceilometer and the ujson Python module that exists in the openstack-ansible 19 release.
A great deal of credit goes to the team that manage the official openstack-ansible IRC channel, without whom the creation of this demo environment would not have been possible.
Wrapping up
Although the nested virtualization that this setup takes advantage of can at times be slow, and the hardware requirements, especially in terms of memory and I/O performance are significant, the techniques we have covered here offer great potential for both training, and development purposes.
For example, you could build a real production OpenStack configuration on physical servers, using real physical Cumulus Networks powered switches using most of the same playbooks and cloud-init configuration data that we have used here. Similarly, you could simulate your production environment in GNS3 on a suitably powerful host, thus performing penetration testing, or testing new configurations, or even failure modes, to see how the environment responds. For example, you can easily power down entire sections of the GNS3 virtual infrastructure, or delete connections, in full confidence that you are not going to (accidentally or otherwise) impact any other vital services. The environment is a complete sandbox, and so is ideal for security testing, especially if you are investigating the impact of certain kinds of attacks or malware.
The opportunities provided by this kind of setup are endless, and the kindness of Cumulus Networks in making Cumulus VX available for free means you can easily simulate your real network infrastructure in a contained, virtual environment.
Build an OpenStack/Ceph cluster with Cumulus Networks in GNS3: part 2 published first on https://wdmsh.tumblr.com/
0 notes
Text
Advice for Writing a Technical Resume
Marco Rogers asked a very good question on Twitter:
I talk to a lot of people new to tech from non-traditional backgrounds, e.g. bootcamps or self-taught. I'm looking for good information for those people on how to build out a strong resume when they don't have work experience yet. Advice is fine, links to resources is better.
— Marco Rogers (@polotek) April 10, 2020
https://platform.twitter.com/widgets.js
I’ve been on both sides of the interview table for many years now, both searching for jobs and as a hiring manager. My resume skills and most salient advice for writing one is likely from my experiences looking though thousands of applications.
When it comes to writing a resume, It’s helpful to think about the human aspect first and foremost. Imagining a hiring manager’s perspective will give you an edge because it helps speak to them directly. Remember, a coveted position or reputable company commonly sifts through anywhere between tens and thousands of applications. It takes a staff that is materially impacted in the time and energy it takes to review every candidate and evaluate those who make it in to the interview stage. Even attention to minor details will help your odds of standing out.
Here are my general suggestions to make the best possible resume.
Formatting is important
Spelling, grammar and formatting are all crucial to a well-written resume. Typos, errors, and poor use of things like bold and italic styles (especially when used together) are clear red flags, so pay extra attention to what you write and how it is written. These types of mistakes give the impressions that you either lack attention to detail or are unwilling to go the extra step. As trivial as this might seem, use your spell check and get a second set of eyes on your resume before submitting it.
A few formatting tips to keep in mind:
Use headings to separate sections
Use lists to help summarize highlights and things scannable
Use a good font and font size that makes the content legible
Use line spacing that lets content breath rather than packing it close together
Avoid using all caps, or combining bold, italic, and underlines on the same content.
I don’t have a strong opinion on charts that show off your skills or lists of hobbies. But I will say that I’ve noticed them more frequently on the applications of junior developers, so you might unintentionally communicate you have less experience by including it.
If you don’t have a lot of work history, it’s totally OK to throw in open source projects!
Or side projects! Or working on your own site! A few folks mentioned the same thing in the Twitter thread and it’s solid advice. A good hiring manager should know that senior-level candidates don’t grow on trees — they just want to see some work that shows you have promise.
This is problematic advice in some ways, as not everyone has time on the side to devote to projects. I wouldn’t so far as to say including those things is a hard requirement for a good resume. But if you’re otherwise lacking relevant work experience, including personal projects can show the kind of work you’re capable of doing as well as the kind of work that excites you. I’ve taken chances on folks with slim-to-no work experience but with a solid combination of a portfolio site, GitHub contributions, or even a few CodePen demos that show potential.
Call out your contributions to your work experience
Each time you list a work example, answer this: what did you accomplish? This is a good way to provide valuable information without or any unnecessary fluff. Everyone is going to tout their work experience. Adding the outcomes of your work will make you stand out.
Here’s an example that would catch my attention:
Due to my team’s work refactoring the product page, we were able to meet the demands of our customers, which resulted in a 25% growth in sales. We also took the opportunity to upgrade the codebase from React.createClass to React Hooks for all of our components, ensuring a more flexible and maintainable system.
This tells me you can work on a team to deliver goals. It also tells me that you understand technical debt and how to solve it. That’s the sort of person I want to hire.
If so far your experience is limited to a code bootcamp, it’s great to talk through that.
Every job applicant is coming from a different background and from varying degrees of experience. It’s safe to assume you are not the most experienced person in the pool.
And that’s OK!
For example, let’s say your development experience is limited to online or in-person coding bootcamps rather than commercial projects. What did you learn there? What were you excited by? What was your final project? Is there a link to that work? When I’m hiring someone who’s coming in early in their career, I’m mostly looking for curiosity and enthusiasm. I’m probably not alone there.
Don’t be too long… or too short
We mentioned earlier that hiring is a time-consuming job. It’s good to keep this in mind as you’re writing by making your resume as brief as possible — ideally on a single standard page. And, yes, two pages is OK if you really need it.
Keeping everything short is a balancing act when you’re also attempting to include as much useful information as possible. Treat that constraint as a challenge to focus on the most important details. It’s a good problem if you have more to say than what fits!
At best, padding a resume into multiple pages conveys you’re unable to communicate in a succinct manner. At worst, it shows a lack of respect for a hiring manager’s time.
Make sure there’s a way to reach you
I cannot tell you how many resumes that lack the following essentials: name, email, and phone number. Seriously, it happens even on resumes that are otherwise very impressive.
Your name and contact information are hard requirements. I don’t want to search around for your email if you’re applying. To be honest, I probably won’t search at all because I’m busy and there are many other candidates to choose from.
Preparation is your friend
Make sure your accompanying cover letter (yes, you should include one) communicates you’ve done at least a little research on the company, conveys you understand what they need in a candidate, and how you fit into that need.
I will personally adjust my the descriptions in my own resume so there is a direct connection between my skills and the position.
Your work and education details should be reverse-chronological
Your most recent work is more important than your oldest work. It’s a better reflection of what you’re capable of doing today and how fresh your skills are in a particular area. The same goes for your education: lead with your most recent experience.
The person reviewing your resume can decide to continue reading further if they’re compelled by the most recent information.
Wrapping up
If you want to stand out in the crowd, make sure your resume is one that represents you well. Ask someone to help you proof and use spellcheck, and make sure you’ve put your best foot forward.
And don’t be discouraged by rejections or unreturned messages. It’s less likely to be about you personally and more likely due to the number of people applying. So keep trying!
The post Advice for Writing a Technical Resume appeared first on CSS-Tricks.
source https://css-tricks.com/advice-for-writing-a-technical-resume/
from WordPress https://ift.tt/2KF4CJK via IFTTT
0 notes
Photo

Create an Automated Scoreboard that Senses Your Score with a Raspberry Pi
On an impulse just before Christmas, I bought myself an NBA "over-the-door" mini basketball hoop. I wasn't sure what I'd do with it, but having a basketball hoop for my office seemed like a good move. In the end I decided to experiment and bring some connectivity to it by hooking it up to a Raspberry Pi to give it a scoreboard display. Here's how that went, with step-by-step instructions if you'd like to try to adapt and improve upon it!
This tutorial isn't intended to be used as a step-by-step "do exactly as I did" style guide — my hope is that you'll take this concept and use it for all sorts of other ideas. Add a virtual scoreboard that counts how often people come into your office. Or go with a different sport (maybe a mini soccer goal tracker?). Or use an entirely different sensor but track hits on it visually with a Raspberry Pi! There are so many potential applications of this technique. Try stuff and let me know how you go!
What You'll Need
In order to be able to follow along and make something similar, here's a list of the parts I used (or their equivalent for the things I had around my lab already):
Raspberry Pi 3 B+ — I used an older version of this from 2015, if you're going to buy one, get a newer version like this!
A MicroSD card with NOOBS — if you are looking to install this yourself and have an SD card ready to go Raspberry Pi foundation have a guide on how to do so here.
Spalding NBA Slam Jam Over-The-Door Mini Basketball Hoop — This is the mini basketball hoop I used. You could use a different one — especially if its net works better!
Raspberry Pi 3.3190G 7" Touchscreen Display — This is my favourite display for the Raspberry Pi, it is a touchscreen, so you can interact with the UI without needing to connect up a mouse.
RS Raspberry Pi 7-Inch LCD Touch Screen Case, Black — To make the display look a bit nicer when all together with the Pi, I have my Pi in this black case.
HC-SR04 Ultrasonic Distance Measuring Sensor Module — I had a spare cheap clone HC-SR04 sensor around, but I'd recommend buying a good quality one. My one has occasional odd readings and is a bit temperamental.
One thing to note — if you don't have a 7 inch display for your Pi, you could display the score on a nearby computer monitor too. Any device on your local network with a web browser and a screen would work!
The Code
Want to skip to downloading the code? It's available on GitHub here.
What I put together
I hung my new basketball hoop up on a door with an ultrasonic sensor attached to the hoop to track when a ball goes into the hoop. Underneath is a Raspberry Pi powered scoreboard — I'd actually recommend finding longer cables so you can connect it outside of basketball falling range.
[caption id="attachment_171361" align="aligncenter" width="1024"] Me testing out my connected scoreboard — with a customised Suns themed interface![/caption]
I'll go over why everything is as it is below — along with some suggestions for those who might want to improve upon this base!
Languages we'll be using
JavaScript - In order to follow along, you'll need a knowledge of the basics, but we won't have lines upon lines of code, things are actually pretty simple in the JS side of things.
Node.js - A basic knowledge of how to run npm and Node is needed to run our scoreboard server.
Setting up our Raspberry Pi
If you are completely new to the Raspberry Pi and haven't set anything up yet, never fear! There are many guides out there for setting things up and it's nice and straightforward. The Raspberry Pi foundation have a step by step guide for installing the Raspbian operating system using the NOOBS operating system manager. You'll want to make sure the operating system is running before you get onto any of the other steps.
Touchscreen setup
I put together my connected scoreboard using a Raspberry Pi 3 with touchscreen. My touchscreen and case were already put together and screwed down tight as I've used this Pi 3 before for other projects, however if you are starting from scratch — it isn't too hard to connect up. Newer shipments (like mine) actually have a bunch of it already assembled, with the adapter board already screwed onto the LCD screen, if that's the case, half the steps are already complete! Instructions on how to assemble the screen are available online:
Official instructions — these are the instructions which come with the screen in case you lose them!
The Pi Hut have their own tutorial — they explain the details of the process too.
ZDNet's look at the touch display with case — they've got a good amount of detail and tips for setting up the screen and case to use in various situations.
Case setup
When it comes to putting the case around the LCD screen and Raspberry Pi, that process is also quite easy with the case I have. I already had mine together, however the general steps for this are:
Make sure you've already got your microUSB card inside the Raspberry Pi and are happy with how it's running! Annoyingly with a lot of cases, you can't get the card out once the case is in place. My case linked above is one of those... so make sure the card is all good before you lose access to it!
Place the Pi with screen into place inside the case
Arrange the ribbon cables and cables coming from the GPIO so they aren't in the way
Make sure the holes for your USB ports and such are on the correct side of the bulkier part of the case and line up nicely.
Once everything is lined up nicely, screw in the four screws to put it all together!
Turn it on! If you find that the screen comes up upside down, don't worry, it's a side effect of the case manufacturers lining up the power to come out of the top. When I mounted my scoreboard though, I mounted it with the power coming out of the bottom, so this wasn't an issue for me. If it is an issue for you:
Run sudo nano /boot/config.txt to open the config for the Pi
Then add lcd_rotate=2 to the end, this will rotate the screen around.
Press Ctrl X and the Ctrl Y to save your changes.
Restart your Pi and when it loads back up it should be the right way around!
Running Node.js on our Raspberry Pi
Conveniently, Raspbian has Node installed by default! However, it is a rather old version of Node. You can check which version is installed on your Pi by opening up the Terminal and typing in:
node -v
I've got version 8.15.0 installed on my Pi. You can upgrade by running the following commands:
sudo su - apt-get remove nodered -y apt-get remove nodejs nodejs-legacy -y apt-get remove npm -y curl -sL https://deb.nodesource.com/setup_5.x | sudo bash - apt-get install nodejs -y
After running all of those, if you type in that version command again, you should see a better version:
node -v
You can also check npm is installed correctly by running:
npm -v
With node running on our device, we're ready to get a scoreboard Node server running!
The post Create an Automated Scoreboard that Senses Your Score with a Raspberry Pi appeared first on SitePoint.
by Patrick Catanzariti via SitePoint https://ift.tt/2TR8BJy
0 notes
Text
Version 445
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a great week mostly working on optimisations and cleanup. A big busy client running a lot of importers should be a little snappier today.
optimisations
Several users have had bad UI hangs recently, sometimes for several seconds. It is correlated with running many downloaders at once, so with their help I gathered some profiles of what was going on and trimmed and rearranged some of the ways downloaders and file imports work this week. There is now less stress on the database when lots of things are going on at once, and all the code here is a little more sensible for future improvements. I do not think I have fixed the hangs, but they may be less bad overall, or the hang may have been pushed to a specific trigger like file loads or similar.
So there is still more to do. The main problem I believe is that I designed the latest version of the downloader engine before we even had multiple downloaders per page. An assumed max of about twenty download queues is baked into the system, whereas many users may have a hundred or more sitting around, sometimes finished/paused, but in the current system each still taking up a little overhead CPU on certain update calls. A complete overhaul of this system is long overdue but will be a large job, so I'm going to focus on chipping away at the worst offenders in the meantime.
As a result, I have improved some of the profiling code. The 'callto' profile mode now records the UI-side of background jobs (when they publish their results, usually), and the 'review threads' debug dialog now shows detailed information on the newer job scheduler system, which I believe is being overwhelmed by micro downloader jobs in heavy clients. I hope these will help as I continue working with the users who have had trouble, so please let me know how you get on this week and we'll give it another round.
the rest
I fixed some crazy add/delete logic bugs in the filename tagging dialog and its 'tags just for selected files' list. Tag removes will stick better and work more precisely on the current selection.
If you upload tags to the PTR and notice some lag after it finishes, this should be fixed now. A safety routine that verifies everything is uploaded and counted correct was not working efficiently.
I fixed viewing extremely small images (like 1x1) in the media viewer. The new tiled renderer had a problem with zooms greater than 76800%, ha ha ha.
A bunch of sites with weird encodings (mostly old or japanese) should now work in the downloader system.
Added a link, https://github.com/GoAwayNow/Iwara-Hydrus, to Iwara-Hydrus, a userscript to simplify sending Iwara videos to Hydrus Network, to the Client API help.
If you are a Windows user, you should be able to run the client if it is installed on a network location again. This broke around v439, when we moved to the new github build. It was a build issue with some new libraries.
full list
misc:
fixed some weird bugs on the pathname tagging dialog related to removal and re-adding of tags with its 'tags just for selected files' list. previously, in some circumstances, all selected paths could accidentally share the same list of tags, so further edits on a subset selection could affect the entire former selection
furthermore, removing a tag from that list when the current path selection has differing tags should now successfully just remove that tag and not accidentally add anything
if your client has a pending menu with 'sticky' small tag count that does not seem to clear, the client now tries to recognise a specific miscount cause for this situation and gives you a little popup with instructions on the correct maintenance routine to fix it
when pending upload ends, it is now more careful about when it clears the pending count. this is a safety routine, but it not always needed
when pending count is recalculated from source, it now uses the older method of counting table rows again. the new 'optimised' count, which works great for current mappings, was working relatively very slow for pending count for large services like the PTR
fixed rendering images at >76800% zoom (usually 1x1 pixels in the media viewer), which had broke with the tile renderer
improved the serialised png load fix from last week--it now covers more situations
added a link, https://github.com/GoAwayNow/Iwara-Hydrus, to Iwara-Hydrus, a userscript to simplify sending Iwara videos to Hydrus Network, to the client api help
it should now again be possible to run the client on Windows when the exe is in a network location. it was a build issue related to modern versions of pyinstaller and shiboken2
thanks to a user's help, the UPnPc executable discoverer now searches your PATH, and also searches for 'upnpc' executable name as a possible alternative on linux and macOS
also thanks to a user, the test script process now exits with code 1 if the test is not OK
.
optimisations:
when a db job is reading data, if that db job happens to fall on a transaction boundary, the result is now returned before the transaction is committed. this should reduce random job lag when the client is busy
greatly reduced the amount of database time it takes to check if a file is 'already in db'. the db lookup here is pretty much always less than a millisecond, but the program double-checks against your actual file store (so it can neatly and silently fill in missing files with regular imports), however on an HDD with a couple million files, this could often be a 20ms request! (some user profiles I saw were 200ms!!! I presume this was high latency drives, and/or NAS storage, that was also very busy at the time). since many download queues will have bursts of a page or more of 'already in db' results (from url or hash lookups), this is why they typically only run 30-50 import items a second these days, and until this week, why this situation was blatting the db so hard. the path existence disk request is pulled out of precious db time, allowing other jobs to do other db work while the importer can wait for disk I/O on its thread. I suspect the key to getting the 20ms down to 8ms will be future granulation of the file store (more than 256 folders when you have more than x files per folder, etc...), which I have plans for. I know this change will de-clunk db access when a lot of importers are working, but we'll see this week if the queues actually process a little faster since they can now do file presence checks in parallel and with luck the OS/disk will order their I/O requests cleverly. it may or may not relieve the UI hangs some people have seen, but if these checks are causing trouble it should expose the next bottleneck
optimised a small test that checks if a single tag is in the parent/sibling system, typically before adding tags to a file (and hence sometimes spammed when downloaders were working). there was a now-unneeded safety check in here that I believe was throwing off the query planner in some situations
the 'review threads' debug UI now has two new tabs for the job schedulers. I will be working with UI-lag-experiencing users in future to see where the biggest problems are here. I suspect part of it will overhead from downloader thread spam, which I have more plans for
all jobs that threads schedule on main UI time are now profiled in 'callto' profile mode
.
site encoding fixes:
fixed a problem with webpages that report an encoding for which there is no available decoder. This error is now caught properly, and if 'chardet' is available to provide a supported encoding, it now steps in fixes things automatically. for most users, this fixes japanese sites that report their encoding as "Windows-31J", which seems to be a synonym for Shift-JIS. the 'non-failing unicode decode' function here is also now better at not failing, ha ha, and it delivers richer error descriptions when all attempts to decode are non-successful
fixed a problem detecting and decoding webpages with no specified encoding (which defaults to windows-1252 and/or ISO-8859-1 in some weird internet standards thing) using chardet
if chardet is not available and all else fails, windows-1252 is now attempted as a last resort
added chardet presence to help->about. requests needs it atm so you likely definitely have it, but I'll make it specific in requirements.txt and expand info about it in future
.
boring code cleanup:
refactored the base file import job to its own file
client import options are moved to a new submodule, and file, tag, and the future note import options are refactored to their own files
wrote a new object to handle current import file status in a better way than the old 'toss a tuple around' method
implemented this file import status across most of the import pipeline and cleaned up a heap of import status, hash, mime, and note handling. rarely do downloaders now inspect raw file import status directly--they just ask the import and status object what they think should happen next based on current file import options etc...
a url file import's pre-import status urls are now tested main url first, file url second, then associable urls (previously it was pseudorandom)
a file import's pre-import status hashes are now tested sha256 first if that is available (previously it was pseudorandom). this probably doesn't matter 99.998% of the time, but maybe hitting 'try again' on a watcher import that failed on a previous boot and also had a dodgy hash parser, it might
misc pre-import status prediction logic cleanup, particularly when multiple urls disagree on status and 'exclude previously deleted' is _unchecked_
when a hash gives a file pre-import status, the import note now records which hash type it was
pulled the 'already in db but doesn't actually exist on disk' pre-import status check out of the db, fixing a long-time ugly file manager call and reducing db lock load significantly
updated a host of hacky file import unit tests to less hacky versions with the new status object
all scheduled jobs now print better information about themselves in debug code
next week
Next week is a 'medium size job' week. I would like to do some server work, particularly writing the 'null account' that will inherit all content ownership after a certain period, completely anonymising history and improving long-term privacy, and then see if I can whack away at some janitor workflow improvements.
0 notes