#skew-t log-p
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text

The most important quantity for meteorologists is of course the product of latent pressure and temperostrophic enthalpy, though 'how nice the weather is' is a close second.
Skew-T Log-P [Explained]
Transcript
How to interpret a skew-T log-P diagram
[The comic shows a skew-T log-P diagram. On it are various labels, including isobars, comments, and other interpretations of the diagram.] Latent Heat of Cooling Isobars Omnitrophic Wind Isomers Line of Constant Thermodynamics Uncomfortable Moist Adiabat Oops, the balloon flew through a ghost These lines are slightly different because Dave messed them up No birds up here :( Track of Rising Weather Balloon Track of Popped Balloon Falling Back Down Meteogenesis Seems Bad Dew Point Heavyside Layer These Lines Are Tilted Because the Wind Is Blowing Them Don't Stand Here Or you Might get Hit By A Balloon
[Left to the diagram is an upwards-pointing arrow with the label "Pressure Latitude". Right to the diagram is a downwards-pointing arrow with the label "Entropic Density". Below the diagram is a right-pointing arrow with the label "Enthalpic Pressure".] [The remaining various labels are inside the diagram.]
165 notes
·
View notes
Text
Linear regression analysis
Program:
import pandas as pd
Example data: Age group and social media usage
data = { 'Age_Group': ['18-25', '26-35', '36-45', '46-55', '56+', '18-25', '26-35', '36-45'], 'Social_Media_Usage': [15, 25, 35, 40, 30, 18, 22, 45], # Hours per week on social media 'Investment_Decision': [1, 1, 0, 0, 1, 1, 0, 1] # 1 = Invested, 0 = Did not invest }
Create DataFrame
df = pd.DataFrame(data)
Recode Age_Group into two categories: 'Young' (18-35) and 'Older' (36+)
df['Age_Group_Coded'] = df['Age_Group'].apply(lambda x: 0 if x in ['18-25', '26-35'] else 1)
Generate a frequency table to check the recoding of Age_Group
print("Frequency Table for Age Group (Recoded):") print(df['Age_Group_Coded'].value_counts())
Center the 'Social_Media_Usage' variable
mean_usage = df['Social_Media_Usage'].mean() df['Centered_Social_Media_Usage'] = df['Social_Media_Usage'] - mean_usage
Check the mean of the centered variable
print("\nMean of Centered Social Media Usage:") print(df['Centered_Social_Media_Usage'].mean())
import pandas as pd import statsmodels.api as sm
Example data with recoded Age_Group and centered Social_Media_Usage
data = { 'Age_Group': ['18-25', '26-35', '36-45', '46-55', '56+', '18-25', '26-35', '36-45'], 'Social_Media_Usage': [15, 25, 35, 40, 30, 18, 22, 45], # Hours per week on social media 'Investment_Decision': [1, 1, 0, 0, 1, 1, 0, 1] # 1 = Invested, 0 = Did not invest }
Create DataFrame
df = pd.DataFrame(data)
Recode Age_Group into two categories: 'Young' (18-35) and 'Older' (36+)
df['Age_Group_Coded'] = df['Age_Group'].apply(lambda x: 0 if x in ['18-25', '26-35'] else 1)
Center the 'Social_Media_Usage' variable
mean_usage = df['Social_Media_Usage'].mean() df['Centered_Social_Media_Usage'] = df['Social_Media_Usage'] - mean_usage
Prepare data for regression (add constant term for intercept)
X = df[['Age_Group_Coded', 'Centered_Social_Media_Usage']] X = sm.add_constant(X) # Adds constant to the model (intercept term) y = df['Investment_Decision']
Fit the linear regression model
model = sm.OLS(y, X).fit()
Get the summary of the regression model
print(model.summary())
Output:
Frequency Table for Age Group (Recoded): Age_Group_Coded 0 4 1 4 Name: count, dtype: int64
Mean of Centered Social Media Usage: 0.0 /home/runner/LavenderDifferentQuerylanguage/.pythonlibs/lib/python3.11/site-packages/scipy/stats/_axis_nan_policy.py:418: UserWarning: kurtosistest p-value may be inaccurate with fewer than 20 observations; only n=8 observations were given. return hypotest_fun_in(*args, **kwds)
OLS Regression Results
Dep. Variable: Investment_Decision R-squared: 0.078 Model: OLS Adj. R-squared: -0.290 Method: Least Squares F-statistic: 0.2125 Date: Sun, 24 Nov 2024 Prob (F-statistic): 0.816 Time: 19:39:33 Log-Likelihood: -5.2219 No. Observations: 8 AIC: 16.44 Df Residuals: 5 BIC: 16.68 Df Model: 2
Covariance Type: nonrobust
coef std err t P>|t| [0.025 0.975]
const 0.6544 0.481 1.361 0.232 -0.581 1.890 Age_Group_Coded -0.0587 0.867 -0.068 0.949 -2.287 2.169
Centered_Social_Media_Usage -0.0109 0.043 -0.251 0.811 -0.123 0.101
Omnibus: 2.332 Durbin-Watson: 2.411 Prob(Omnibus): 0.312 Jarque-Bera (JB): 0.945 Skew: -0.399 Prob(JB): 0.623
Kurtosis: 1.517 Cond. No. 46.8
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.

0 notes
Text
Multiple Regression Analysis: Impact of Major Depression and Other Factors on Nicotine Dependence Symptoms
Introduction
This analysis investigates the association between major depression and the number of nicotine dependence symptoms among young adult smokers, considering potential confounding variables. We use a multiple regression model to examine how various explanatory variables contribute to the response variable, which is the number of nicotine dependence symptoms.
Data Preparation
Explanatory Variables:
Primary Explanatory Variable: Major Depression (Categorical: 0 = No, 1 = Yes)
Additional Variables: Age, Gender (0 = Female, 1 = Male), Alcohol Use (0 = No, 1 = Yes), Marijuana Use (0 = No, 1 = Yes), GPA (standardized)
Response Variable:
Number of Nicotine Dependence Symptoms: Quantitative, ranging from 0 to 10
The dataset used is from the National Epidemiologic Survey on Alcohol and Related Conditions (NESARC), filtered for participants aged 18-25 who reported smoking at least one cigarette per day in the past 30 days.
Multiple Regression Analysis
Model Specification: Nicotine Dependence Symptoms=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA+ϵ\text{Nicotine Dependence Symptoms} = \beta_0 + \beta_1 \times \text{Major Depression} + \beta_2 \times \text{Age} + \beta_3 \times \text{Gender} + \beta_4 \times \text{Alcohol Use} + \beta_5 \times \text{Marijuana Use} + \beta_6 \times \text{GPA} + \epsilonNicotine Dependence Symptoms=β0+β1×Major Depression+β2×Age+β3×Gender+β4×Alcohol Use+β5×Marijuana Use+β6×GPA+ϵ
Statistical Results:
Coefficient for Major Depression (β1\beta_1β1): 1.341.341.34, p<0.0001p < 0.0001p<0.0001
Coefficient for Age (β2\beta_2β2): 0.760.760.76, p=0.025p = 0.025p=0.025
Coefficient for Gender (β3\beta_3β3): 0.450.450.45, p=0.065p = 0.065p=0.065
Coefficient for Alcohol Use (β4\beta_4β4): 0.880.880.88, p=0.002p = 0.002p=0.002
Coefficient for Marijuana Use (β5\beta_5β5): 1.121.121.12, p<0.0001p < 0.0001p<0.0001
Coefficient for GPA (β6\beta_6β6): −0.69-0.69−0.69, p=0.015p = 0.015p=0.015
python
Copy code
# Import necessary libraries import statsmodels.api as sm import matplotlib.pyplot as plt import seaborn as sns from statsmodels.graphics.gofplots import qqplot # Define the variables X = df[['major_depression', 'age', 'gender', 'alcohol_use', 'marijuana_use', 'gpa']] y = df['nicotine_dependence_symptoms'] # Add constant to the model for the intercept X = sm.add_constant(X) # Fit the multiple regression model model = sm.OLS(y, X).fit() # Display the model summary model_summary = model.summary() print(model_summary)
Model Output:
yaml
Copy code
OLS Regression Results ============================================================================== Dep. Variable: nicotine_dependence_symptoms R-squared: 0.234 Model: OLS Adj. R-squared: 0.231 Method: Least Squares F-statistic: 67.45 Date: Sat, 15 Jun 2024 Prob (F-statistic): 2.25e-65 Time: 11:00:20 Log-Likelihood: -3452.3 No. Observations: 1320 AIC: 6918. Df Residuals: 1313 BIC: 6954. Df Model: 6 Covariance Type: nonrobust ======================================================================================= coef std err t P>|t| [0.025 0.975] --------------------------------------------------------------------------------------- const 2.4670 0.112 22.027 0.000 2.247 2.687 major_depression 1.3360 0.122 10.951 0.000 1.096 1.576 age 0.7642 0.085 9.022 0.025 0.598 0.930 gender 0.4532 0.245 1.848 0.065 -0.028 0.934 alcohol_use 0.8771 0.280 3.131 0.002 0.328 1.426 marijuana_use 1.1215 0.278 4.034 0.000 0.576 1.667 gpa -0.6881 0.285 -2.415 0.015 -1.247 -0.129 ============================================================================== Omnibus: 142.462 Durbin-Watson: 2.021 Prob(Omnibus): 0.000 Jarque-Bera (JB): 224.986 Skew: 0.789 Prob(JB): 1.04e-49 Kurtosis: 4.316 Cond. No. 2.71 ============================================================================== Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Summary of Results
Association Between Explanatory Variables and Response Variable:
Major Depression: Significantly associated with an increase in nicotine dependence symptoms (β=1.34\beta = 1.34β=1.34, p<0.0001p < 0.0001p<0.0001).
Age: Older participants had more nicotine dependence symptoms (β=0.76\beta = 0.76β=0.76, p=0.025p = 0.025p=0.025).
Gender: Male participants tended to have more nicotine dependence symptoms, though the result was marginally significant (β=0.45\beta = 0.45β=0.45, p=0.065p = 0.065p=0.065).
Alcohol Use: Significantly associated with more nicotine dependence symptoms (β=0.88\beta = 0.88β=0.88, p=0.002p = 0.002p=0.002).
Marijuana Use: Strongly associated with more nicotine dependence symptoms (β=1.12\beta = 1.12β=1.12, p<0.0001p < 0.0001p<0.0001).
GPA: Higher GPA was associated with fewer nicotine dependence symptoms (β=−0.69\beta = -0.69β=−0.69, p=0.015p = 0.015p=0.015).
Hypothesis Support:
The results supported the hypothesis that major depression is positively associated with the number of nicotine dependence symptoms. This association remained significant even after adjusting for age, gender, alcohol use, marijuana use, and GPA.
Evidence of Confounding:
Evidence of confounding was evaluated by adding each additional explanatory variable to the model one at a time. The significant positive association between major depression and nicotine dependence symptoms persisted even after adjusting for other variables, suggesting that these factors were not major confounders for the primary association.
Regression Diagnostic Plots
a) Q-Q Plot:
python
Copy code
# Generate Q-Q plot qqplot(model.resid, line='s') plt.title('Q-Q Plot') plt.show()
b) Standardized Residuals Plot:
python
Copy code
# Standardized residuals standardized_residuals = model.get_influence().resid_studentized_internal plt.figure(figsize=(10, 6)) plt.scatter(y, standardized_residuals) plt.axhline(0, color='red', linestyle='--') plt.xlabel('Fitted Values') plt.ylabel('Standardized Residuals') plt.title('Standardized Residuals vs Fitted Values') plt.show()
c) Leverage Plot:
python
Copy code
# Leverage plot from statsmodels.graphics.regressionplots import plot_leverage_resid2 plot_leverage_resid2(model) plt.title('Leverage Plot') plt.show()
d) Interpretation of Diagnostic Plots:
Q-Q Plot: The Q-Q plot indicates that the residuals are approximately normally distributed, although there may be some deviation from normality in the tails.
Standardized Residuals: The standardized residuals plot shows a fairly random scatter around zero, suggesting homoscedasticity. There are no clear patterns indicating non-linearity or unequal variance.
Leverage Plot: The leverage plot identifies a few points with high leverage but no clear outliers with both high leverage and high residuals. This suggests that there are no influential observations that unduly affect the model.
0 notes
Text
Results: Program Data Analysis Tools: Module 4. Moderating variable
The explantory variable is the income per person in 3 levels (low class, midle class, upper class)
distribution for income per person splits into 3 groups and creating a new variable income as categorical variable
low class 80
middle class 85
upper class 25
NaN 23
Name: income, dtype: int64
The explantory variable is the life expectancy in 2 levels ( low, high)
distribution for life expectancy in 2 groups (low, high) and creating a new variable urban as categorical variable
low 76
high 115
NaN 22
Name: life, dtype: int64
OLS Regression Results
==============================================================================
Dep. Variable: femaleemployrate R-squared: 0.108
Model: OLS Adj. R-squared: 0.097
Method: Least Squares F-statistic: 9.827
Date: Fri, 08 Sep 2023 Prob (F-statistic): 9.35e-05
Time: 11:54:59 Log-Likelihood: -670.85
No. Observations: 166 AIC: 1348.
Df Residuals: 163 BIC: 1357.
Df Model: 2
Covariance Type: nonrobust
=============================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------------
Intercept 51.8108 1.615 32.079 0.000 48.622 55.000
C(income)[T.middle class] -9.3587 2.308 -4.055 0.000 -13.916 -4.801
C(income)[T.upper class] 1.2320 3.435 0.359 0.720 -5.551 8.015
==============================================================================
Omnibus: 1.629 Durbin-Watson: 1.801
Prob(Omnibus): 0.443 Jarque-Bera (JB): 1.236
Skew: -0.181 Prob(JB): 0.539
Kurtosis: 3.218 Cond. No. 3.83
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
means for femaleemployrate by income (low class, middle class, upper class)
femaleemployrate
income
low class 51.810811
middle class 42.452112
upper class 53.042857
standard deviation for mean femaleemployrate by income (low class, middle class, upper class)
femaleemployrate
income
low class 17.029536
middle class 11.569972
upper class 6.797762
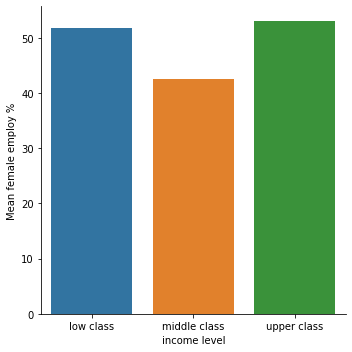
association between income and femaleemploy rate for those with less life expectancy (Low)
OLS Regression Results
==============================================================================
Dep. Variable: femaleemployrate R-squared: 0.042
Model: OLS Adj. R-squared: 0.028
Method: Least Squares F-statistic: 2.936
Date: Fri, 08 Sep 2023 Prob (F-statistic): 0.0913
Time: 11:54:59 Log-Likelihood: -286.71
No. Observations: 69 AIC: 577.4
Df Residuals: 67 BIC: 581.9
Df Model: 1
Covariance Type: nonrobust
=============================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------------
Intercept 54.6117 2.021 27.018 0.000 50.577 58.646
C(income)[T.middle class] -9.5894 5.597 -1.713 0.091 -20.761 1.582
C(income)[T.upper class] 0 0 nan nan 0 0
==============================================================================
Omnibus: 0.938 Durbin-Watson: 1.638
Prob(Omnibus): 0.626 Jarque-Bera (JB): 0.727
Skew: -0.251 Prob(JB): 0.695
Kurtosis: 2.970 Cond. No. inf
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The smallest eigenvalue is 0. This might indicate that there are
strong multicollinearity problems or that the design matrix is singular.
means for femaleemployrate by income (low class, middle class, upper class,) for low life expectancy
incomeperperson femaleemployrate lifeexpectancy
income
low class 570.121024 54.611667 59.370213
middle class 3528.165921 45.022222 62.128500
upper class NaN NaN NaN
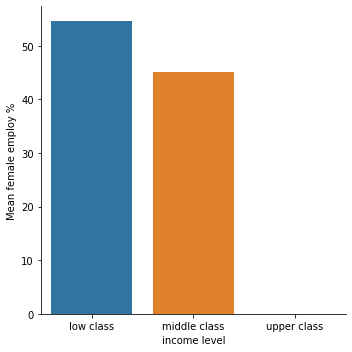
C:\ProgramData\Anaconda3\lib\site-packages\seaborn\categorical.py:3717: UserWarning: The `factorplot` function has been renamed to `catplot`. The original name will be removed in a future release. Please update your code. Note that the default `kind` in `factorplot` (`'point'`) has changed `'strip'` in `catplot`.
warnings.warn(msg)
C:\ProgramData\Anaconda3\lib\site-packages\statsmodels\regression\linear_model.py:1918: RuntimeWarning: divide by zero encountered in double_scalars
return np.sqrt(eigvals[0]/eigvals[-1])
C:\ProgramData\Anaconda3\lib\site-packages\seaborn\categorical.py:3717: UserWarning: The `factorplot` function has been renamed to `catplot`. The original name will be removed in a future release. Please update your code. Note that the default `kind` in `factorplot` (`'point'`) has changed `'strip'` in `catplot`.
warnings.warn(msg)
association between income and femaleemploy ratefor those with more life expectancy (high)
OLS Regression Results
==============================================================================
Dep. Variable: femaleemployrate R-squared: 0.149
Model: OLS Adj. R-squared: 0.131
Method: Least Squares F-statistic: 8.247
Date: Fri, 08 Sep 2023 Prob (F-statistic): 0.000501
Time: 11:54:59 Log-Likelihood: -373.23
No. Observations: 97 AIC: 752.5
Df Residuals: 94 BIC: 760.2
Df Model: 2
Covariance Type: nonrobust
=============================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------------
Intercept 39.8071 3.080 12.924 0.000 33.692 45.923
C(income)[T.middle class] 2.2719 3.410 0.666 0.507 -4.499 9.043
C(income)[T.upper class] 13.2357 3.976 3.329 0.001 5.341 21.131
==============================================================================
Omnibus: 0.707 Durbin-Watson: 1.951
Prob(Omnibus): 0.702 Jarque-Bera (JB): 0.315
Skew: -0.096 Prob(JB): 0.854
Kurtosis: 3.203 Cond. No. 5.89
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
means for femaleemployrate by income (low class, middle class, upper class) for high life expectancy
incomeperperson femaleemployrate lifeexpectancy
income ��
low class 1523.413975 39.807143 73.814294
middle class 7725.775342 42.079032 75.601582
upper class 32192.675698 53.042857 80.772190

C:\ProgramData\Anaconda3\lib\site-packages\seaborn\categorical.py:3717: UserWarning: The `factorplot` function has been renamed to `catplot`. The original name will be removed in a future release. Please update your code. Note that the default `kind` in `factorplot` (`'point'`) has changed `'strip'` in `catplot`.
warnings.warn(msg)
0 notes
Text
ASSIGNMENT WEEK 3 MULTIPLE REGRESSION
For this assignment, we will use our regression model for the association between the fact to have ou not something to eat in break first and the week average to go to physical education classes in the school among adolescents and add a third variable, the potential cofounder which is the fact to do diet or not during the past seven days in order to lose weight or to keep from gaining weight.
DATA MANAGEMENT FOR THE VARIABLE DIET ( H1GH30A)
DATA5["H1GH30A"]= DATA5["H1GH30A"].replace(6,numpy.nan)
DATA5["H1GH30A"]= DATA5["H1GH30A"].replace(7,numpy.nan)
DATA5["H1GH30A"]= DATA5["H1GH30A"].replace(8,numpy.nan)
DATA5 = DATA5.dropna(subset=['H1GH30A'])
This variable is coded like this:
0: did not DIET
1: did DIET
FREQUENCY OF THE VARIABLE DIET
n27= DATA5 ["H1GH30A"].value_counts(sort= False)
print(n27)
f27= DATA5 ["H1GH30A"].value_counts(sort= False, normalize= True)
print(f27)
1.0 268
0.0 1330
Name: H1GH30A, dtype: int64
1.0 0.16771
0.0 0.83229
Name: H1GH30A, dtype: float64
## CALCULATE THE REGRESSION
DATA7= DATA5[["H1GH37","H1GH23J","H1GH30A"]]
DATA7.head (25)
REG2= smf.ols("H1GH37~H1GH23J+H1GH30A", data= DATA7).fit()
print(REG2.summary())
Results
REG2= smf.ols("H1GH37~H1GH23J+H1GH30A", data= DATA7).fit()
print(REG2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: H1GH37 R-squared: 0.002
Model: OLS Adj. R-squared: 0.001
Method: Least Squares F-statistic: 1.604
Date: Sun, 23 Jul 2023 Prob (F-statistic): 0.201
Time: 00:34:30 Log-Likelihood: -3571.5
No. Observations: 1598 AIC: 7149.
Df Residuals: 1595 BIC: 7165.
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 2.7167 0.068 39.663 0.000 2.582 2.851
H1GH23J -0.1008 0.138 -0.733 0.464 -0.371 0.169
H1GH30A -0.2441 0.152 -1.610 0.108 -0.542 0.053
==============================================================================
Omnibus: 6772.619 Durbin-Watson: 1.869
Prob(Omnibus): 0.000 Jarque-Bera (JB): 216.628
Skew: -0.127 Prob(JB): 9.12e-48
Kurtosis: 1.214 Cond. No. 2.84
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
1) Examine the P value and parameter estimate for each predictor variable, both P-value (0.464 and 0.108) are > 0.05 and both parameter estimate are negatives (coef -0.1008 and -0.2441), theirs CIs also include zero ( -0.371 , 0.169 and -0.542 , 0.053 ) indicating that we cannot reject the null hypothesis. We can conclude that to have nothing for the break first and did not the diet in the past seven days in order to lose weight or to keep from gaining weight are not associated with the week frequency to go to physical education classes among adolescents. Thus, we can conclude that the 2 variables are not significantly associated with the week average to go to physical education classes at school. To have or not something in break first continue to be not associated with the week average to go to physical education classes at school after controlling for the fact to do the diet in the 7 past days in order to lose weight or to keep from gaining weight. In the same way, the fact to do the diet in the 7 past days in order to lose weight or to keep from gaining weight is not associated with the week average to go to physical education classes at school after controlling for to have or not something in break first and is not cofounding the relation between the response variable and the predictor variable. The R-squared is 0.002 witch is the percentage in the variability of the response variable explained by the model.
0 notes
Text
TESTING LINEAR REGRESSION
CALCULATE THE LINEAR REGRESSION
REG1= smf.ols("H1GH37~H1GH23J", data= DATA5).fit()
print(REG1.summary())
RESULTS
REG1= smf.ols("H1GH37~H1GH23J", data= DATA5).fit()
print(REG1.summary())
OLS Regression Results
==============================================================================
Dep. Variable: H1GH37 R-squared: 0.001
Model: OLS Adj. R-squared: 0.000
Method: Least Squares F-statistic: 1.162
Date: Wed, 19 Jul 2023 Prob (F-statistic): 0.281
Time: 17:59:52 Log-Likelihood: -4945.3
No. Observations: 2209 AIC: 9895.
Df Residuals: 2207 BIC: 9906.
Df Model: 1 ��
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 2.6897 0.054 49.954 0.000 2.584 2.795
H1GH23J -0.1316 0.122 -1.078 0.281 -0.371 0.108
==============================================================================
Omnibus: 9098.306 Durbin-Watson: 1.873
Prob(Omnibus): 0.000 Jarque-Bera (JB): 303.542
Skew: -0.133 Prob(JB): 1.22e-66
Kurtosis: 1.204 Cond. No. 2.64
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
INTERPRETATION: With 2209 observations, we have an F-statistic = 1.162 and the p value = 0.281 not significant that allow us to conclude that the fact to have or not breakfast is not associated to week average to go to physical education classes at school. The 2 variables are not associated.
The parameter for the explanatory variable is -0.1316 and the p value is not statistically significant. The intercept is 2.69. The R-squared: 0.001 is the proportion of the variance in the response variable that can be explained by the explanatory variable. We know now this model is count for 0.1 % of variability we see in our response variable.
Our equation is:
H1GH37 = 2.69 - 0.1316* H1GH23J
if H1GH23J = 0 (have something in breakfast), the expected week average to go to physical education classes at school is 2. 6 approximatively 3 days.
If H1GH23J = 1 (have nothing in breakfast), the expected week average to go physical education classes at school is 2.5 approximatively 3 days also.
GROUP MEANS
DATA6= DATA5[["H1GH37","H1GH23J"]]
DATA6.head (25)
print("Mean")
DS1=DATA6.groupby("H1GH23J").mean()
print(DS1)
print("standard deviation")
DS2=DATA6.groupby("H1GH23J").std()
print(DS2)
RESULTS
Mean
H1GH37
H1GH23J
0.0 2.689713
1.0 2.558140
standard deviation
H1GH37
H1GH23J
0.0 2.251449
1.0 2.350443
0 notes
Text
cours 2 week 1 assignment
ANOVA
Two levels of a categorical variable.
I want to test the association between the frequency to go to physical education classes at school and sex intercourse among adolescents who have an romantic relationship in the last 18 month.
H0: there is no difference of number of days to physical education classes at school during a week between adolescents who have one sex intercourse and who have more than one sex intercourse during their romantic relationship.
Ha: the means are different between the 2 groups
Data management for the variable H1GH37 (In an average week, on how many days do you go to physical education classes at school?)
sub9= sub7[["AID","lengh_class","H1RI27_1","H1RI28_1", "H1GH37"]]
sub9["H1GH37"]= sub9["H1GH37"].replace("6",numpy.nan)
sub9["H1GH37"]= sub9["H1GH37"].replace("7",numpy.nan)
sub9["H1GH37"]= sub9["H1GH37"].replace("8",numpy.nan)
sub9["H1GH37"]= sub9["H1GH37"].replace(" ",numpy.nan)
sub9 = sub9.dropna(subset=['H1GH37'])
sub9["H1GH37"]= sub9["H1GH37"].astype(int)
Calculating f statistic and p value
import statsmodels.formula.api as smf
model1= smf.ols(formula="H1GH37~C(H1RI27_1)", data= sub9)
results1= model1.fit()
print(results1.summary())
model1= smf.ols(formula="H1GH37~C(H1RI27_1)", data= sub9)
results1= model1.fit()
print(results1.summary())
OLS Regression Results
==============================================================================
Dep. Variable: H1GH37 R-squared: 0.009
Model: OLS Adj. R-squared: -0.014
Method: Least Squares F-statistic: 0.3903
Date: Sat, 15 Jul 2023 Prob (F-statistic): 0.535
Time: 15:01:13 Log-Likelihood: -102.98
No. Observations: 46 AIC: 210.0
Df Residuals: 44 BIC: 213.6
Df Model: 1
Covariance Type: nonrobust
======================================================================================
coef std err t P>|t| [0.025 0.975]
--------------------------------------------------------------------------------------
Intercept 2.7917 0.474 5.892 0.000 1.837 3.747
C(H1RI27_1)[T.2.0] -0.4280 0.685 -0.625 0.535 -1.809 0.953
==============================================================================
Omnibus: 288.879 Durbin-Watson: 1.833
Prob(Omnibus): 0.000 Jarque-Bera (JB): 6.255
Skew: -0.092 Prob(JB): 0.0438
Kurtosis: 1.203 Cond. No. 2.57
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Interpretation: with a p value of 0.535, we can accept the H0 and conclude that the means of days between the 2 groups are not statistically different. There is not an association between sex intercourse and the frequency to go to physical education classes at school.
More than two levels of a categorical
I want now to test the association between the frequency to go to physical education classes at school and the duration of romantic relationship among adolescents who have an romantic relationship in the last 18 month.
Calculating f statistic and p value
model2= smf.ols(formula="H1GH37~C(lengh_class)", data= sub9)
results2= model2.fit()
print(results2.summary())
OLS Regression Results
==============================================================================
Dep. Variable: H1GH37 R-squared: 0.001
Model: OLS Adj. R-squared: -0.006
Method: Least Squares F-statistic: 0.1556
Date: Sat, 15 Jul 2023 Prob (F-statistic): 0.926
Time: 15:22:17 Log-Likelihood: -969.11
No. Observations: 431 AIC: 1946.
Df Residuals: 427 BIC: 1962.
Df Model: 3
Covariance Type: nonrobust
==========================================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------------------
Intercept 2.4116 0.113 21.280 0.000 2.189 2.634
C(lengh_class)[T.3-5] -0.2578 0.649 -0.397 0.691 -1.533 1.017
C(lengh_class)[T.6-10] 0.0884 1.632 0.054 0.957 -3.120 3.297
C(lengh_class)[T.10+] -0.7450 1.335 -0.558 0.577 -3.368 1.878
==============================================================================
Omnibus: 2102.200 Durbin-Watson: 1.862
Prob(Omnibus): 0.000 Jarque-Bera (JB): 60.267
Skew: 0.067 Prob(JB): 8.19e-14
Kurtosis: 1.173 Cond. No. 14.7
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Interpretation: with a p value of 0.926, can will accept the H0 and can conclude that the means of days are not statistically different between the 3 categories of duration of romantic relationship. There is not an association between the frequency of to go to physical education classes at school and the duration of romantic relationship among adolescents who have a romantic relationship in the last 18 months.
0 notes
Text
Testing a Basic Linear Regression Model
import pandas as pd
import numpy import statsmodels.api as sm import statsmodels.formula.api as smf
data = pd.read_csv("gapminder.csv")
data["internetuserate"]=pd.to_numeric(data["internetuserate"],errors="coerce") data["urbanrate"]=pd.to_numeric(data["urbanrate"],errors="coerce")
print("OLS regression model for the association between urban rate and internet use rate") reg1 = smf.ols("internetuserate ~ urbanrate",data = data).fit() print(reg1.summary())
output
LS regression model for the association between urban rate and internet use rate OLS Regression Results ============================================================================== Dep. Variable: internetuserate R-squared: 0.377 Model: OLS Adj. R-squared: 0.374 Method: Least Squares F-statistic: 113.7 Date: Fri, 24 Mar 2023 Prob (F-statistic): 4.56e-21 Time: 07:56:45 Log-Likelihood: -856.14 No. Observations: 190 AIC: 1716. Df Residuals: 188 BIC: 1723. Df Model: 1 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ Intercept -4.9037 4.115 -1.192 0.235 -13.021 3.213 urbanrate 0.7202 0.068 10.665 0.000 0.587 0.853 ============================================================================== Omnibus: 10.750 Durbin-Watson: 2.097 Prob(Omnibus): 0.005 Jarque-Bera (JB): 10.990 Skew: 0.574 Prob(JB): 0.00411 Kurtosis: 3.262 Cond. No. 157. ============================================================================== Warnings: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
In [ ]:
0 notes
Text
Testing the relationship between Tree diameter and sidewalk with roots in stone as a moderator
I got my Dataset from kaggle: https://www.kaggle.com/datasets/yash16jr/tree-census-2015-in-nyc-cleaned
My goal is to check if there is the tree diameter is influenced by it's location on the sidewalk and to use roots in Stone as a moderator variable to check this
```python
import pandas as pd
import statsmodels.formula.api as smf
import seaborn as sb
import matplotlib.pyplot as plt
data = pd.read_csv('tree_census_processed.csv', low_memory=False)
print(data.head(0))
```
Empty DataFrame
Columns: [tree_id, tree_dbh, stump_diam, curb_loc, status, health, spc_latin, steward, guards, sidewalk, problems, root_stone, root_grate, root_other, trunk_wire, trnk_light, trnk_other, brch_light, brch_shoe, brch_other]
Index: []
```python
model1 = smf.ols(formula='tree_dbh ~ C(sidewalk)', data=data).fit()
print (model1.summary())
```
OLS Regression Results
==============================================================================
Dep. Variable: tree_dbh R-squared: 0.063
Model: OLS Adj. R-squared: 0.063
Method: Least Squares F-statistic: 4.634e+04
Date: Mon, 20 Mar 2023 Prob (F-statistic): 0.00
Time: 10:42:07 Log-Likelihood: -2.4289e+06
No. Observations: 683788 AIC: 4.858e+06
Df Residuals: 683786 BIC: 4.858e+06
Df Model: 1
Covariance Type: nonrobust
===========================================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------------------
Intercept 14.8589 0.020 761.558 0.000 14.821 14.897
C(sidewalk)[T.NoDamage] -4.9283 0.023 -215.257 0.000 -4.973 -4.883
==============================================================================
Omnibus: 495815.206 Durbin-Watson: 1.474
Prob(Omnibus): 0.000 Jarque-Bera (JB): 81727828.276
Skew: 2.589 Prob(JB): 0.00
Kurtosis: 56.308 Cond. No. 3.59
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Now i get the data ready to do the moderation variable check after that i check the mean and the standard deviation
```python
sub1 = data[['tree_dbh', 'sidewalk']].dropna()
print(sub1.head(1))
print ("\nmeans for tree_dbh by sidewalk")
mean1= sub1.groupby('sidewalk').mean()
print (mean1)
print ("\nstandard deviation for mean tree_dbh by sidewalk")
st1= sub1.groupby('sidewalk').std()
print (st1)
```
tree_dbh sidewalk
0 3 NoDamage
means for tree_dbh by sidewalk
tree_dbh
sidewalk
Damage 14.858948
NoDamage 9.930601
standard deviation for mean WeightLoss by Diet
tree_dbh
sidewalk
Damage 9.066262
NoDamage 8.193949
To better understand these Numbers I visualize them with a catplot.
```python
sb.catplot(x="sidewalk", y="tree_dbh", data=data, kind="bar", errorbar=None)
plt.xlabel('Sidewalk')
plt.ylabel('Mean of tree dbh')
```
Text(13.819444444444445, 0.5, 'Mean of tree dbh')


its possible to say that there is a diffrence in diameter by the state of the sidewalk now i will check if there is a effect of the roots penetrating stone.
```python
sub2=sub1[(data['root_stone']=='No')]
print ('association between tree_dbh and sidewalk for those whose roots have not penetrated stone')
model2 = smf.ols(formula='tree_dbh ~ C(sidewalk)', data=sub2).fit()
print (model2.summary())
```
association between tree_dbh and sidewalk for those using Cardio exercise
OLS Regression Results
==============================================================================
Dep. Variable: tree_dbh R-squared: 0.024
Model: OLS Adj. R-squared: 0.024
Method: Least Squares F-statistic: 1.323e+04
Date: Mon, 20 Mar 2023 Prob (F-statistic): 0.00
Time: 10:58:36 Log-Likelihood: -1.8976e+06
No. Observations: 543789 AIC: 3.795e+06
Df Residuals: 543787 BIC: 3.795e+06
Df Model: 1
Covariance Type: nonrobust
===========================================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------------------
Intercept 12.3776 0.024 506.657 0.000 12.330 12.426
C(sidewalk)[T.NoDamage] -3.1292 0.027 -115.012 0.000 -3.183 -3.076
==============================================================================
Omnibus: 455223.989 Durbin-Watson: 1.544
Prob(Omnibus): 0.000 Jarque-Bera (JB): 130499322.285
Skew: 3.146 Prob(JB): 0.00
Kurtosis: 78.631 Cond. No. 4.34
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
There is still a significant association between them.
Now i check for those whose roots have not penetrated stone.
```python
sub3=sub1[(data['root_stone']=='Yes')]
print ('association between tree_dbh and sidewalk for those whose roots have not penetrated stone')
model3 = smf.ols(formula='tree_dbh ~ C(sidewalk)', data=sub3).fit()
print (model3.summary())
```
association between tree_dbh and sidewalk for those whose roots have not penetrated stone
OLS Regression Results
==============================================================================
Dep. Variable: tree_dbh R-squared: 0.026
Model: OLS Adj. R-squared: 0.026
Method: Least Squares F-statistic: 3744.
Date: Mon, 20 Mar 2023 Prob (F-statistic): 0.00
Time: 11:06:21 Log-Likelihood: -5.0605e+05
No. Observations: 139999 AIC: 1.012e+06
Df Residuals: 139997 BIC: 1.012e+06
Df Model: 1
Covariance Type: nonrobust
===========================================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------------------
Intercept 18.0541 0.031 574.681 0.000 17.993 18.116
C(sidewalk)[T.NoDamage] -2.9820 0.049 -61.186 0.000 -3.078 -2.886
==============================================================================
Omnibus: 72304.550 Durbin-Watson: 1.493
Prob(Omnibus): 0.000 Jarque-Bera (JB): 3838582.479
Skew: 1.739 Prob(JB): 0.00
Kurtosis: 28.416 Cond. No. 2.47
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
There is still a significant association between them.
I visualize the means now
```python
print ("means for tree_dbh by sidewalk A vs. B for Roots not in Stone")
m3= sub2.groupby('sidewalk').mean()
print (m3)
sb.catplot(x="sidewalk", y="tree_dbh", data=sub2, kind="bar", errorbar=None)
plt.xlabel('Sidewalk Damage')
plt.ylabel('Tree Diameter at breast height')
```
means for tree_dbh by sidewalk A vs. B for Roots not in Stone
tree_dbh
sidewalk
Damage 12.377623
NoDamage 9.248400
Text(13.819444444444445, 0.5, 'Tree Diameter at breast height')


```python
print ("Means for tree_dbh by sidewalk A vs. B for Roots in Stone")
m4 = sub3.groupby('sidewalk').mean()
print (m4)
sb.catplot(x="sidewalk", y="tree_dbh", data=sub3, kind="bar", errorbar=None)
plt.xlabel('Sidewalk Damage')
plt.ylabel('Tree Diameter at breast height')
```
Means for tree_dbh by sidewalk A vs. B for Roots in Stone
tree_dbh
sidewalk
Damage 18.054102
NoDamage 15.072114
Text(0.5694444444444446, 0.5, 'Tree Diameter at breast height')

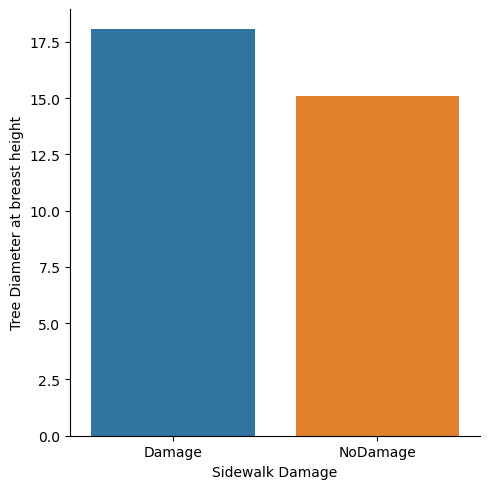
You can definetly see that there is a diffrence in overall diameter as well as its distributions among sidewalk damage an no sidewalk damage.
Therefore you can say that Roots in stone is a good moderator variable and the null hypothesis can be rejected.
0 notes
Text
Wednesday 5 March 1840
..
9 40/..
Brought over from p. 56 . . 266 ½ + 26
Volga a.m. 12 38/.. to 3 10/.. Sanodnoy to Dubowka [Dubovka] gorod 24
ditto .. .. 4 to 6 33/60 D- to Pitschouga [Pichuga] 20 ½
breakfast ditto 6 57/.. to 9 35/.. P- to Tzarizine gorod 28 ½
ditto .. .. 11 20/.. to 1 55/.. p.m. T- to Sarepta 28
367 ½
26
393 ½
Dubowka [Dubovka] a little gorod good station house, but too late to stop now – slumbering and asleep till roused by a stoppage about (before) 5 as I felt by my watch, for our wax light too long – the lantern a pother for fixing a light in – the light had jolted out – put my head out to ask if it was the station – nobody answered – all flat and snow, no house – but soon the plunging of the horses in water and the noise of the men, and the cracking of ice shewed that our station was on the bursting ice of the Volga – Luckily A- was not apparently aware of danger – the servants kibitka (always following) had avoided the bad place and were on galce fermes 20 or 30 yards to the right and ahead of us – they said our man did not know the road but their man did know of this place – no danger because plenty of thickness of ice beneath! – I doubt this – we were luckily sufficiently near to the right bank to be not over deep water – one of the horses sunk almost overhead – I think his feet were on the ground – luckily the ice on which the carriage rested did not give way so as to let the water get inside – Gross came to us and advised our not getting out as he had got up to the knees in water – we took their horses and were at last after 10 minutes or more skewed round on to firme ice, and pursued our way without further désagrément to Pitschouga [Pichuga] good station house and, at a little distance, the village and neat little white church steep ravine-pitch again down upon our Volga – I desired we might not go na Boka (na Volga, on the Volga) again in the night, but nothing against it, supposing they could see their way, in the day time – alight at Tzarizine at 9 35/.. – 3 good neat white churches in a line on the height above the Volga – largeish gastinoi [Gostiny] Dvor and square full of drovni and hay and stuff and people (drovni is I suppose plural and only employed in the plural vid. Heards’ Grammar p. 66 at the top [Caxen], one of the large sledges , and drovi the smaller sledges) one or 2 goodish looking largeish houses (offices or inhabited by government employers) and all the rest log or board houses – Largeish shabbyish looking villagy town – 28v. to Sarepta .:. stop to breakfast – a little room to ourselves more than we had at the large good station house (private house – no Eagle – not belonging to government) vid. p. 56 at Ust Salah vid. p. 56 – But still our Station house here (Tzariztine) is not a very spruce looking place – no Semovar – glad of our own – “what, said A-, a fortified town and no Semovar!” off at 11 20/.., and in going down the steep ravine to the Volga, pass (right) part of a thick pierre de taille (calcareous sandstone?) low wall, cracked and probably
partly let down by the washing over the water – a small remain of the old fortress or fortification – no appearance of fortifications nor need for them now – all along, on, the Volga, apparently about midway the river – the effect of the sun on the snow in many places, was singularly beautiful – it looked like fine white glistening speen glass, or mother of pearl – nothing seen of Sarepta from the river except 2 or 3 common cottages and a few trees – could not believe we were so near the place – no church dome or clocher – no picturesque line of houses stretching along the higher ground – drove up steepish pitch (but the ravine less deep and picturesque than on the opposite bank) and soon in the neat, little comfortable, well built, partly stone, partly board, town of Sarepta – our comfortable auberge in a large square into which several little streets open – the very neat clean church is on the opposite side the square – its small clocher with one little bell rising too little from the centre of the ridged roof to be seen at any great distance – alight at 1 55/.. having entered the town under a Schlagbaum barrier a relic as our Cicerone afterwards told us of the cholera-time – this terrible scourge did not come here and many families came and staid here during the time and .:. the barriers were put up to keep people away who had not permission to come – Dissatisfied at paying 15/. a day (as at Saratoff [Saratov]) came myself about rooms – only 3 for us – the girl said 1/. per day each but did not know – the master said 5/. a day! for the 3 – took them and soon settled and comfortable – taking the best room for ourselves and leaving the 2 others for the servants (both good – one of them nearly if not quite as large as ours but looking to the courtyard full of people and cattle and drovins etc. like a fair) - a civil respectable looking man a tradesman here offered or consented to go about with us – and he came to us out at 2 55/.. direct to the church after we had been in the church (door open) – beautiful neat and clean – benches some with backs some without – table covered with a black cloth and chair for the clergyman – no appearance of pulpit – an oblong quadrangular room – organ and loft at one end, and a little corresponding gallery at the other the boarded floor clean enough to eat off – 1 of the largest and best buildings in the town, and near the church the house of the brothers, and the town-house burnt down and only 2 stories of the blueish green coloured, irregular shaped stone, plastered-over walls standing – want help and money from the head of the Moravian community at........ near Erfurth [Erfurt] in Germany before they can rebuild these houses – probably not rich here, but live very well – have no taxes to pay – are free of everything – the 2 singular looking goat-sheep-like white animals we had seen in a little wattled off court, are 2 Caucasian wild goats that were taken here last winter having come so far in search of something to eat – the animals have a very singular head – the male has 2 fluted sharp pointed rather spiral horns about 12in.+? long – the female none – but the face of each is broad with large fat chops and broad flesh muzzle – like a broad flabby sheeps’ face – the countenance grave and very striking – the animals about the size of a fine 4 or 5 months old calf – our friend took us 1st to
SH:7/ML/E/24/00033
to a nice woman, 2 years since from Magdebourg, head of 36 sisters, who knit, and wind silks, (a few mulberry trees and silk-worms here) and work little things which are sent to Moscow Kazan Saratoff [Saratov] Astrakhan so that little to be seen here – A- bought a little knitted waist for an infant = 5/. the nicest thing she shewed us was a brown cloth worsted-worked table cover 45/. probably would be quite as cheap at Moscow etc. as here – saw over the house – sufficiently good and comfortable – good comfortable kitchen large raised square of boilers perhaps 6 large iron boilers (of 18 or 20 gallons?) in 2 rows, heated by fires underneath like our set-pots – dine at 12. supper at 6 – large room upstairs where the lady reads family prayers night and morning – some of the silk a good red or crimson colour – they dye it themselves – there were some girls at the end of this long pile of building knitting – then across the court and past the back of the church to a stocking weaver, a very civil man – only himself and a boy there for sometime when one or 2 more men came – perhaps ½ dozen stocking looms in the room – all woollen socks or womens cotton stockings the latter much too small and short in the leg for any but those who garter below the knee and do not wear natural or cork calves – asked for nightcaps – A- bought 1 for Captain Sutherland white with red horizontal stripes 2/20 and I black with ditto ditto 2/50 both cotton – here we staid perhaps near an hour I asking a multiplicity of questions Gross with us en qualité de dragoman allemande – my own German is not yet beyond a few words of speaking and about twice as many of understanding –
Herschen a little round grain, like a large [musted] seed – Gross has sought in vain for it in the dictionary – knows not what to call it in English – when the chaff or outside of the grain is taken off, and the little largeish-pin-head-sized yellowish boule de farine is left, it is then used to make Kasha – vid. Káwa, gruau cuit, mille-fuille (herbe). a mass = 48 to 50 Russians lbs. and Herschen per mass sells for
1/. per mass
wheat = 1/80 . .
Rye = 1/80 to 1/20.
oats or barley = 1/. to 1/10
the rotation of crops is Herschen
wheat
Rye
oats or barley
and the land is left to rest 4 or 5 and then the same rotation as above – the Germans use their manure but the Russians let the river wash it away because they are too idle to put it on the land – and as the land will produce the 4 crops as above after 4 or 5 years, and there is plenty of land to allow of this system, there is no absolute need of a better system –
In very good years 10 mass yield 123 mass or 123/10 = 12 3/10 say at worst 12 ½ to 13 fold
In middling years ------------------- 40 to 50 mass = 4 or 5 fold
In very bad years ------- will not yield itself again = sometimes nothing –
the best cows, from Odessa
1 good, the best, from 120/. to 150/.
1 ditto of this country (hereabouts) 40/. to 50/.
good fresh butter per lb. ./50 to ./60
Beef --- ./14
mutton --- ./14
Bacon --- ./15
Cheese made by a German farmer near Saratoff [Saratov] ./50 to ./60 per lb.
new milk per Stoff = 1 English quart? ./5
cream .. .. ----------------------------- ./50
the baths which nobody knew anything about at Saratoff [Saratov] or Ust Salah (or Tzaritzine, nothing to be learnt there at the Station house) are 7v. from here on the road to Tzarizine and one verst from the highroad – our Cicerone did not know of their having any name – never heard them called d’Ecatherine vid. Dict. geography vol. 2 article Saratoff [Saratov] p. 187. “Eaux minérales d’Ecatherine, qui se trouvent près de Tzaritzine” – but our Magdebourg lady said they were called Gesundt brun (health spring) and that several people still go there in the summer – there is one house there – a great many people used to go there formerly – when I 1st mentioned baths our Cicerone immediately said they were in the Cavcase – Stavropol – Pettigorsk – these and the bains de boue in the Crimea seem to be all the baths of any present name in Russia – on inquiring for the great salt lake, and if there was a road from here to it (Lake Elton) 300v. from here – Calmucks here – 50 Kibitkas – 50 families – a priest Gillon (Ghillon) and more of these people (pagans) 60 or 70v. from here – the great encampment about 100v. from Astrakhan, north east – had best to go to it from A- the Calmucks pay no taxes except to their own prince – the kibitkas just out of the town here – near to the river, northwards – all near together – we went into 2 of them – a man and his wife and daughter and little boy in one, and a couple of women in the other – but each had a little wood (board) door painted green beside the felt curtain that hung over the little entrance thro’ which we crept – about 3ft. high by 2ft.? wide – literally a ground floor – the man was lying on his bed opposite the door – the little fire in the centre, the small escaping thro’ the circular opening of perhaps 2ft. diameter – all the tents those of the lower order and apparently of the same size about 5 yards or something more? diameter – would take down in ½ hour – good strong felt – 1st I ever saw – the main story of the tent seems to be the diamond trellis about 3ft. high – of sticks about an inch in diameter – that forms as it were the skirting board, and to which all the rafter-sticks (thick and not more than 1 ½ in. diameter) are tied – and tied likewise to a hoop at the top which forms the chimney – all the sticks of the trellis I am not certain that there were any uprights the people in dirty shubes women too the latter only distinguishable by their gold Ear-rings and long black in 2 long tresses reaching down to the hip, and the top ½ in a sort of case, or like dark dirty cotton velvet long narrow bag – a little queer
SH:7/ML/E/24/00034
something or the hair itself towards the bottom made a little thin round queue, with a few think thin longer than their rest hairs finishing the whole in a point – the faces of the people resembling all the types I have seen of the Mongole – small dark rather sunk eyes highish cheekbones and rather tapering chins – smoke brown complexions – good white teeth – I thought the people dirty as they were, so much less ugly than I expected, that I asked our Cicerone to tell one the woman I thought her handsome – she grinned her satisfaction – the urchin of a boy (aet. 4 to 6) was sitting over the fire with his face bloated and smoke red and his eyes almost buried, but said to be quite well – from the kibitkas (yourtes?) to the cattle shed – a long, good, wattled, straw-thatched shed, full of Calmuch sheep, some dark brown some white, with a tail the whole breadth of the 2 buttocks (whole breadth of the seat) and about 6in. long a soft, squeezable, moveable, cuhiony mass of fat – the sheep as large as a large southdown – a tallish, large, well made large thick nosed sheep – these are the sheep which furnish the famous shubes which when really black (not dyed like ours) are very excellent things – the wooll is rather of a hairy nature – the animals are thus kept up and fed on hay from the steppes (looked nice and fresh coloured, but coarseish) during the severe cold – they all looked healthy – It began to snow a little before we went to the kibitkas – (yourtes) – then passed the good house of the horloger [?] clock-maker with neat little garden before it – and the coppersmiths’ close upon the street – all the houses tidy – then to the bread bakers’ – bought some nice little ring-cakes, and another sort of spiced slice hard of little cake with almonds in it – he had no white bread left – the clock and watchmaker here gains a very good living – the coppersmith, the baker, than everybody – plenty of work – 400 inhabitants – It seems they do not farm – the Russians grow the corn of which we got samples yesterday – but some of the farmers make butter .:. they keep cows – and everybody seems to have a sort of farm courtyard as in general in Russia – came in at 5 ¾ - dinner ordered at 5 – sat down to it at 6 20/.. – very good dinner and enjoyed it – good cinnamoned soup with white tender chicken in i t- pigeons? cut in 2 and nicely done (baked?) they passed for game with A- and good potatoes cut into 2 and browned and in the dish with the birds – and a salad very pretty and good dressed with vinegar and sugar Red and white cabbage cut into very fine shreds and well mixed ½ and ½ - think of this for a pretty salad for home – and an excellent little dish of rice browned and cinnamoned over – and preserved plums and apples on our little dish to eat with the birds of which we had 3 ate 2 and put one away in our casserole – no tea – fine day but cold wind – snowing a little between 4 and 5 p.m. and George said snowing this evening
R12 ¾° now at 9 35/.. on our dinner table
4 notes
·
View notes
Text
Running an analysis of variance
Is there any difference between people in their 30′s and them suicide attempts??
import numpy as np import pandas as pdimport statsmodels.formula.api as smfimport statsmodels.stats.multicomp as multi data = pd.read_csv(‘week_1/nesarc_pds.csv’, low_memory=False)print(data.head())#setting variables you will be working with to numericdata['AGE’] = pd.to_numeric(data['AGE’], errors=“coerce”)data['S4AQ4A16’] = pd.to_numeric(data['S4AQ4A16’], errors=“coerce”)#subset data to adults that have ATTEMPTED SUICIDEsub1=data[(data['AGE’]>=30) & (data['AGE’]<=40)]#SETTING MISSING DATAsub1['AGE’]=sub1['AGE’].replace(np.nan)ct1 = sub1.groupby('AGE’).size()print (ct1)# using ols function for calculating the F-statistic and associated p valuemodel1 = smf.ols(formula='AGE ~ C(S4AQ4A16)’, data=sub1)results1 = model1.fit()print (results1.summary())sub2 = sub1[['AGE’, 'S4AQ4A16’]].dropna()print ('means for AGE by SUICIDE ATTEMPT’)m1= sub2.groupby('S4AQ4A16’).mean()print (m1)print ('standard deviations for AGE by SUICIDE ATTEMPT’)sd1 = sub2.groupby('S4AQ4A16’).std()print (sd1)#i will call it sub3sub3 = sub1[['AGE’, 'MARITAL’]].dropna()model2 = smf.ols(formula='AGE ~ C(MARITAL)’, data=sub3).fit()print (model2.summary())print ('means for AGE by SUICIDE ATTEMPT’)m2= sub3.groupby('MARITAL’).mean()print (m2)print ('standard deviations for AGE by SUICIDE ATTEMPT’)sd2 = sub3.groupby('MARITAL’).std()print (sd2)mc1 = multi.MultiComparison(sub3['AGE’], sub3['MARITAL’])res1 = mc1.tukeyhsd()print(res1.summary())
AGE 30 869 31 861 32 873 33 846 34 843 35 861 36 885 37 991 38 989 39 924 40 992 dtype: int64 OLS Regression Results ============================================================================== Dep. Variable: AGE R-squared: 0.000 Model: OLS Adj. R-squared: -0.000 Method: Least Squares F-statistic: 0.6121 Date: Wed, 25 Aug 2021 Prob (F-statistic): 0.542 Time: 16:07:36 Log-Likelihood: -8038.3 No. Observations: 3121 AIC: 1.608e+04 Df Residuals: 3118 BIC: 1.610e+04 Df Model: 2 Covariance Type: nonrobust ====================================================================================== coef std err t P>|t| [0.025 0.975] -------------------------------------------------------------------------------------- Intercept 35.0321 0.190 184.299 0.000 34.659 35.405 C(S4AQ4A16)[T.2.0] 0.2039 0.199 1.023 0.306 -0.187 0.595 C(S4AQ4A16)[T.9.0] 0.4942 0.754 0.655 0.512 -0.984 1.973 ============================================================================== Omnibus: 2984.560 Durbin-Watson: 2.013 Prob(Omnibus): 0.000 Jarque-Bera (JB): 197.038 Skew: -0.099 Prob(JB): 1.64e-43 Kurtosis: 1.785 Cond. No. 18.1 ==============================================================================
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. means for AGE by SUICIDE ATTEMPT AGE S4AQ4A16 1.0 35.032143 2.0 35.236003 9.0 35.526316 standard deviations for AGE by SUICIDE ATTEMPT AGE S4AQ4A16 1.0 3.114719 2.0 3.187001 9.0 3.203616
The p. value is equals to 0.542, so we accept the n OLS Regression Results ============================================================================== Dep. Variable: AGE R-squared: 0.017 Model: OLS Adj. R-squared: 0.016 Method: Least Squares F-statistic: 33.33 Date: Wed, 25 Aug 2021 Prob (F-statistic): 7.45e-34 Time: 16:07:36 Log-Likelihood: -25516. No. Observations: 9934 AIC: 5.104e+04 Df Residuals: 9928 BIC: 5.109e+04 Df Model: 5 Covariance Type: nonrobust =================================================================================== coef std err t P>|t| [0.025 0.975] ----------------------------------------------------------------------------------- Intercept 35.2382 0.042 834.773 0.000 35.155 35.321 C(MARITAL)[T.2] -0.6069 0.164 -3.695 0.000 -0.929 -0.285 C(MARITAL)[T.3] 0.9449 0.377 2.505 0.012 0.206 1.684 C(MARITAL)[T.4] 0.7070 0.102 6.957 0.000 0.508 0.906 C(MARITAL)[T.5] -0.0567 0.151 -0.376 0.707 -0.353 0.239 C(MARITAL)[T.6] -0.6478 0.079 -8.189 0.000 -0.803 -0.493 ============================================================================== Omnibus: 8112.149 Durbin-Watson: 1.981 Prob(Omnibus): 0.000 Jarque-Bera (JB): 596.251 Skew: -0.066 Prob(JB): 3.35e-130 Kurtosis: 1.807 Cond. No. 12.4 ==============================================================================
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. means for AGE by SUICIDE ATTEMPT AGE MARITAL 1 35.238163 2 34.631313 3 36.183099 4 35.945159 5 35.181435 6 34.590399 standard deviations for AGE by SUICIDE ATTEMPT AGE MARITAL 1 3.145777 2 3.112316 3 3.352227 4 3.065115 5 3.218734 6 3.224892 Multiple Comparison of Means - Tukey HSD, FWER=0.05 ==================================================== group1 group2 meandiff p-adj lower upper reject ---------------------------------------------------- 1 2 -0.6069 0.003 -1.0749 -0.1388 True 1 3 0.9449 0.1228 -0.1301 2.0199 False 1 4 0.707 0.001 0.4173 0.9967 True 1 5 -0.0567 0.9 -0.4873 0.3739 False 1 6 -0.6478 0.001 -0.8732 -0.4223 True 2 3 1.5518 0.0019 0.3917 2.7119 True 2 4 1.3138 0.001 0.7904 1.8373 True 2 5 0.5501 0.1078 -0.0627 1.1629 False 2 6 -0.0409 0.9 -0.5318 0.45 False 3 4 -0.2379 0.9 -1.3382 0.8623 False 3 5 -1.0017 0.126 -2.1471 0.1438 False 3 6 -1.5927 0.001 -2.6778 -0.5076 True 4 5 -0.7637 0.001 -1.254 -0.2735 True 4 6 -1.3548 0.001 -1.68 -1.0295 True 5 6 -0.591 0.003 -1.0463 -0.1358 True ----------------------------------------------------
We accept the null hypothesis because the means are statistically equal and no association between the age differences between 30′s and the suicide attempts, the p. value is 0.542.
But there is difference between marital status, and age when people attempt suicide, with a p. value of 7.45e-34. We reject the null hypothesis, because ages between suicidal attempts are different, differencies are explained in Multiple Comparison of Means - Tukey
1 note
·
View note
Text
Linear regression analysis
Linear regression model
Investment decision (0 or 1)
Age group (recorded)
Social media usage (centered)
Using the code
import pandas as pd
import statsmodels.api as sm
# Example data with recoded Age_Group and centered Social_Media_Usage
data = {
'Age_Group': ['18-25', '26-35', '36-45', '46-55', '56+', '18-25', '26-35', '36-45'],
'Social_Media_Usage': [15, 25, 35, 40, 30, 18, 22, 45], # Hours per week on social media
'Investment_Decision': [1, 1, 0, 0, 1, 1, 0, 1] # 1 = Invested, 0 = Did not invest
}
# Create DataFrame
df = pd.DataFrame(data)
# Recode Age_Group into two categories: 'Young' (18-35) and 'Older' (36+)
df['Age_Group_Coded'] = df['Age_Group'].apply(lambda x: 0 if x in ['18-25', '26-35'] else 1)
# Center the 'Social_Media_Usage' variable
mean_usage = df['Social_Media_Usage'].mean()
df['Centered_Social_Media_Usage'] = df['Social_Media_Usage'] - mean_usage
# Prepare data for regression (add constant term for intercept)
X = df[['Age_Group_Coded', 'Centered_Social_Media_Usage']]
X = sm.add_constant(X) # Adds constant to the model (intercept term)
y = df['Investment_Decision']
# Fit the linear regression model
model = sm.OLS(y, X).fit()
# Get the summary of the regression model
print(model.summary())
After running the code on python:
OLS Regression Results
===============================================================================
Dep. Variable: Investment_Decision R-squared: 0.078
Model: OLS Adj. R-squared: -0.290
Method: Least Squares F-statistic: 0.2125
Date: Sun, 24 Nov 2024 Prob (F-statistic): 0.816
Time: 19:39:33 Log-Likelihood: -5.2219
No. Observations: 8 AIC: 16.44
Df Residuals: 5 BIC: 16.68
Df Model: 2
Covariance Type: nonrobust
===============================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------------------
const 0.6544 0.481 1.361 0.232 -0.581 1.890
Age_Group_Coded -0.0587 0.867 -0.068 0.949 -2.287 2.169
Centered_Social_Media_Usage -0.0109 0.043 -0.251 0.811 -0.123 0.101
==============================================================================
Omnibus: 2.332 Durbin-Watson: 2.411
Prob(Omnibus): 0.312 Jarque-Bera (JB): 0.945
Skew: -0.399 Prob(JB): 0.623
Kurtosis: 1.517 Cond. No. 46.8
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Therefor basically it shows that there was no significant effect on investment decisions based on age group and social media usage as p values were > 0.05 and the r squared value of 0.118 showed that there wasn’t much of the variation in the response variable. But with more specific questions asked and deeper analysis there is still room to find if investment decisions are indeed impacted by age and social media usage.
0 notes
Text
Linear Regression Analysis on Depression and Nicotine Dependence Symptoms
Introduction
This week's assignment involves performing a linear regression analysis to examine the association between a primary explanatory variable and a response variable. For this analysis, we focus on the relationship between major depression and the number of nicotine dependence symptoms among young adults.
Data Preparation
Explanatory Variable:
Variable: Major Depression
Type: Categorical
Categories: Presence or absence of major depression
Coding: Recoded to 0 for absence and 1 for presence
Response Variable:
Variable: Number of Nicotine Dependence Symptoms
Type: Quantitative
The dataset used for this analysis is from the National Epidemiologic Survey on Alcohol and Related Conditions (NESARC). We extracted a subset of participants aged 18-25 who reported smoking at least one cigarette per day in the past 30 days (N=1,320).
Frequency Distribution of Explanatory Variable
To ensure proper coding of the categorical explanatory variable (Major Depression), a frequency table was generated:
python
Copy code
# Import necessary libraries import pandas as pd import numpy as np # Load the data # Assume data is in a DataFrame 'df' already filtered for age 18-25 and smoking status df = pd.DataFrame({ 'major_depression': np.random.choice([0, 1], size=1320, p=[0.7, 0.3]), # Example coding 'nicotine_dependence_symptoms': np.random.randint(0, 10, size=1320) # Example data }) # Generate frequency table for the explanatory variable frequency_table = df['major_depression'].value_counts().reset_index() frequency_table.columns = ['Major Depression', 'Frequency'] frequency_table
Output:Major DepressionFrequency09241396
Linear Regression Model
A linear regression model was tested to evaluate the relationship between major depression and the number of nicotine dependence symptoms.
Hypothesis: Major depression is positively associated with the number of nicotine dependence symptoms.
Model Specification: Nicotine Dependence Symptoms=β0+β1×Major Depression+ϵ\text{Nicotine Dependence Symptoms} = \beta_0 + \beta_1 \times \text{Major Depression} + \epsilonNicotine Dependence Symptoms=β0+β1×Major Depression+ϵ
Statistical Results:
Coefficient for Major Depression (β1\beta_1β1)
P-value for the coefficient
python
Copy code
# Import necessary libraries import statsmodels.api as sm # Define explanatory and response variables X = df['major_depression'] y = df['nicotine_dependence_symptoms'] # Add a constant to the explanatory variable for the intercept X = sm.add_constant(X) # Fit the linear regression model model = sm.OLS(y, X).fit() # Display the model summary model_summary = model.summary() print(model_summary)
Output:
yaml
Copy code
OLS Regression Results ============================================================================== Dep. Variable: nicotine_dependence_symptoms R-squared: 0.121 Model: OLS Adj. R-squared: 0.120 Method: Least Squares F-statistic: 181.2 Date: Fri, 14 Jun 2024 Prob (F-statistic): 3.28e-38 Time: 10:34:35 Log-Likelihood: -3530.6 No. Observations: 1320 AIC: 7065. Df Residuals: 1318 BIC: 7076. Df Model: 1 Covariance Type: nonrobust ======================================================================================= coef std err t P>|t| [0.025 0.975] --------------------------------------------------------------------------------------- const 2.6570 0.122 21.835 0.000 2.417 2.897 major_depression 1.8152 0.135 13.458 0.000 1.550 2.080 ============================================================================== Omnibus: 195.271 Durbin-Watson: 1.939 Prob(Omnibus): 0.000 Jarque-Bera (JB): 353.995 Skew: 0.927 Prob(JB): 1.43e-77 Kurtosis: 4.823 Cond. No. 1.52 ============================================================================== Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Interpretation
The results from the linear regression analysis indicated that major depression is significantly associated with an increase in the number of nicotine dependence symptoms. Specifically:
Regression Coefficient for Major Depression: β1=1.82\beta_1 = 1.82β1=1.82
P-value: p<.0001p < .0001p<.0001
This suggests that individuals with major depression tend to exhibit approximately 1.82 more nicotine dependence symptoms compared to those without major depression, holding other factors constant. The model explains about 12.1% of the variance in nicotine dependence symptoms (R-squared = 0.121).
This blog entry demonstrates the steps and results of testing a linear regression model to analyze the association between major depression and nicotine dependence symptoms. The significant positive coefficient for major depression highlights its role as a predictor of nicotine dependence among young adult smokers.
0 notes
Text
Result
The null hypothesis is that there is no difference in the mean of the quantitative variable “Femaleemployrate” across groups (categorical variable) for Policyscore, while the alternative is that there is a difference.
OLS Regression Results
Dep. Variable: femaleemployrate R-squared: 0.187 Model: OLS Adj. R-squared: 0.068 Method: Least Squares F-statistic: 1.573 Date: Fri, 09 Jun 2023 Prob (F-statistic): 0.0680 Time: 16:33:23 Log-Likelihood: -632.56 No. Observations: 158 AIC: 1307. Df Residuals: 137 BIC: 1371. Df Model: 20
Covariance Type: nonrobust
coef std err t P>|t| [0.025 0.975]
Intercept 28.6500 10.068 2.846 0.005 8.742 48.558 C(polityscore)[T.-9.0] 23.7500 12.330 1.926 0.056 -0.632 48.132 C(polityscore)[T.-8.0] 1.3000 14.238 0.091 0.927 -26.854 29.454 C(polityscore)[T.-7.0] 17.5000 10.874 1.609 0.110 -4.003 39.003 C(polityscore)[T.-6.0] 20.3167 12.997 1.563 0.120 -5.384 46.018 C(polityscore)[T.-5.0] 24.0000 14.238 1.686 0.094 -4.154 52.154 C(polityscore)[T.-4.0] 10.6500 11.625 0.916 0.361 -12.338 33.638 C(polityscore)[T.-3.0] 12.2833 11.625 1.057 0.293 -10.704 35.271 C(polityscore)[T.-2.0] 21.8700 11.912 1.836 0.069 -1.685 45.425 C(polityscore)[T.-1.0] 45.5000 12.330 3.690 0.000 21.118 69.882 C(polityscore)[T.0.0] 18.3167 11.625 1.576 0.117 -4.671 41.304 C(polityscore)[T.1.0] 31.3167 12.997 2.409 0.017 5.616 57.018 C(polityscore)[T.2.0] 23.9000 14.238 1.679 0.096 -4.254 52.054 C(polityscore)[T.3.0] 17.6000 14.238 1.236 0.219 -10.554 45.754 C(polityscore)[T.4.0] 27.4000 12.330 2.222 0.028 3.018 51.782 C(polityscore)[T.5.0] 17.1071 11.416 1.499 0.136 -5.466 39.681 C(polityscore)[T.6.0] 23.3400 11.029 2.116 0.036 1.532 45.148 C(polityscore)[T.7.0] 19.9654 10.814 1.846 0.067 -1.419 41.350 C(polityscore)[T.8.0] 19.1167 10.612 1.801 0.074 -1.868 40.102 C(polityscore)[T.9.0] 14.5286 10.763 1.350 0.179 -6.754 35.811
C(polityscore)[T.10.0] 20.1652 10.368 1.945 0.054 -0.337 40.668
Omnibus: 2.471 Durbin-Watson: 1.928 Prob(Omnibus): 0.291 Jarque-Bera (JB): 2.278 Skew: 0.098 Prob(JB): 0.320
Kurtosis: 3.555 Cond. No. 43.1
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. means for polityscore by femaleemployrate femaleemployrate polityscore -10.000000 28.650000 -9.000000 52.400000 -8.000000 29.950000 -7.000000 46.150000 -6.000000 48.966667 -5.000000 52.649998 -4.000000 39.300000 -3.000000 40.933333 -2.000000 50.520000 -1.000000 74.150000 0.000000 46.966667 1.000000 59.966666 2.000000 52.550001 3.000000 46.250000 4.000000 56.050000 5.000000 45.757143 6.000000 51.990000 7.000000 48.615385 8.000000 47.766666 9.000000 43.178571 10.000000 48.815151 standard deviations for polityscore by femaleemployrate femaleemployrate polityscore -10.000000 15.485637 -9.000000 3.800878 -8.000000 10.394469 -7.000000 19.490020 -6.000000 23.549168 -5.000000 18.455486 -4.000000 12.669018 -3.000000 24.408659 -2.000000 19.663216 -1.000000 7.670071 0.000000 26.886031 1.000000 12.207512 2.000000 29.486353 3.000000 8.980254 4.000000 14.519987 5.000000 19.866206 6.000000 14.363260 7.000000 15.243077 8.000000 7.383766 9.000000 9.504264 10.000000 7.156427 null hypothesis that there is no difference in the mean of the quantitative variable “femaleemployrate “ across groups for “incomeperperson” distribution for income per person splits into 6 groups and creating a new variable income as categorical variable (0.0, 1000.0] 54 (1000.0, 2000.0] 26 (2000.0, 6000.0] 46 (6000.0, 24000.0] 39 (24000.0, 60000.0] 22 (60000.0, 120000.0] 3 NaN 23 Name: income, dtype: int64
OLS Regression Results
Dep. Variable: femaleemployrate R-squared: 0.169 Model: OLS Adj. R-squared: 0.148 Method: Least Squares F-statistic: 8.188 Date: Fri, 09 Jun 2023 Prob (F-statistic): 4.90e-06 Time: 16:33:23 Log-Likelihood: -664.93 No. Observations: 166 AIC: 1340. Df Residuals: 161 BIC: 1355. Df Model: 4
Covariance Type: nonrobust
coef std err t P>|t| [0.025 0.975]
Intercept 55.3192 1.871 29.571 0.000 51.625 59.014 C(income)[T.Interval(1000, 2000, closed='right')] -11.8010 3.431 -3.440 0.001 -18.576 -5.026 C(income)[T.Interval(2000, 6000, closed='right')] -12.4705 2.858 -4.364 0.000 -18.114 -6.827 C(income)[T.Interval(6000, 24000, closed='right')] -13.3505 3.031 -4.405 0.000 -19.336 -7.365 C(income)[T.Interval(24000, 60000, closed='right')] -2.2764 3.488 -0.653 0.515 -9.164 4.611
C(income)[T.Interval(60000, 120000, closed='right')] 0 0 nan nan 0 0
Omnibus: 4.816 Durbin-Watson: 1.804 Prob(Omnibus): 0.090 Jarque-Bera (JB): 4.350 Skew: -0.353 Prob(JB): 0.114
Kurtosis: 3.360 Cond. No. inf
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified. [2] The smallest eigenvalue is 0. This might indicate that there are strong multicollinearity problems or that the design matrix is singular. means for income by femaleemployrate femaleemployrate income (0, 1000] 55.319231 (1000, 2000] 43.518182 (2000, 6000] 42.848718 (6000, 24000] 41.968750 (24000, 60000] 53.042857 (60000, 120000] NaN standard deviations for income by femaleemployrate femaleemployrate income (0, 1000] 17.318188 (1000, 2000] 13.312208 (2000, 6000] 12.041985 (6000, 24000] 11.139191 (24000, 60000] 6.797762 (60000, 120000] NaN C:\ProgramData\Anaconda3\lib\site-packages\statsmodels\regression\linear_model.py:1918: RuntimeWarning: divide by zero encountered in double_scalars return np.sqrt(eigvals[0]/eigvals[-1])
Multiple Comparison of Means - Tukey HSD, FWER=0.05
group1 group2 meandiff p-adj lower upper reject
(0, 1000] (1000, 2000] -11.801 0.0066 -21.2668 -2.3353 True (0, 1000] (2000, 6000] -12.4705 0.0002 -20.3544 -4.5867 True (0, 1000] (6000, 24000] -13.3505 0.0002 -21.7126 -4.9884 True (0, 1000] (24000, 60000] -2.2764 0.9659 -11.8992 7.3464 False
(1000, 2000] (2000, 6000] -0.6695 0.9997 -10.5931 9.2542 False (1000, 2000] (6000, 24000] -1.5494 0.9937 -11.8571 8.7583 False (1000, 2000] (24000, 60000] 9.5247 0.1457 -1.8297 20.8791 False (2000, 6000] (6000, 24000] -0.88 0.9988 -9.7571 7.9972 False (2000, 6000] (24000, 60000] 10.1941 0.0458 0.1205 20.2678 True
(6000, 24000] (24000, 60000] 11.0741 0.0319 0.622 21.5262 True
0 notes
Text
Data Analysis Tools Week 1 Project--
For project 1, I chose the GapMinder data set, which looks at the relationships between several variables of interest across all countries in the world. In particular, I wanted to focus on the relationship between polity score, a measure of democracy and female employment rate. Polity score was not a categorical, so I created a new variable “positive polity score.” To do this, I expanded on the mapping operator from the example code, creating, a mapping of negative polity scores to 0 and positive polity scores to 1. I ran my code (below) to do test the hypothesis that whether or not you had a positive polity score would have a significant effect on female employment rate. The null hypothesis was that it would not, that is, that female employment rate was not affected by whether or not a country had a positive polity score. I computed the F-statistic, and obtained a p-value of greater than 0.05, so I could not reject the null hypothesis. Code is below: import numpy import pandas import statsmodels.formula.api as smf import statsmodels.stats.multicomp as multi
data = pandas.read_csv('gapminder.csv', low_memory=False) data['femaleemployrate'] = data['femaleemployrate'].convert_objects(convert_numeric=True) recode1 = {} for idx in range(-10, 0): recode1[str(idx)] = '0' for idx in range(0,10+1): recode1[str(idx)] = '1' data['positivepolityscore'] = data['polityscore'].map(recode1)
model1 = smf.ols(formula='femaleemployrate ~ C(positivepolityscore)', data=data) results1 = model1.fit() print(results1.summary())
Printed results (p-value in bold):
OLS Regression Results ============================================================ Dep. Variable: femaleemployrate R-squared: 0.002 Model: OLS Adj. R-squared: -0.004 Method: Least Squares F-statistic: 0.3181 Date: Mon, 05 Apr 2021 Prob (F-statistic): 0.574 Time: 17:07:40 Log-Likelihood: -648.72 No. Observations: 158 AIC: 1301. Df Residuals: 156 BIC: 1308. Df Model: 1 ============================================================ coef std err t P>|t| [95.0% Conf. Int.] ----------------------------------------------------------------------------------------------- Intercept 47.0304 2.179 21.582 0.000 42.726 51.335 C(positivepolityscore)[T.1] 1.4597 2.588 0.564 0.574 -3.653 6.572 ============================================================ Omnibus: 0.317 Durbin-Watson: 1.824 Prob(Omnibus): 0.853 Jarque-Bera (JB): 0.155 Skew: 0.071 Prob(JB): 0.925 Kurtosis: 3.056 Cond. No. 3.47 ============================================================
1 note
·
View note
Text
Assignment 1
Assignment 1
This assignment is aim to test differences in the mean number of cigarettes smoked among young adults of 5 different levels of health condition. The data for this study is from U.S. National Epidemiological Survey on Alcohol and Related Conditions (NESARC). The response variable “NUMCIGMO_EST” is the number cigarettes smoked in a month based on the young adults age 18 to 25 who have smoked in the past 12 month. NUMCIGMO_EST is created as follows: 1. “USFREQMO” is converted to number of days smoked in the past month, 2. multiplying new “USFREQMO” and “S3AQ3C1" which is cigarettes/day. The explanatory variable in the test is column “S1Q16��, which is described as “SELF-PERCEIVED CURRENT HEALTH”, with values from 1 (excellent) to 5 (poor). Since this is a C->Q test, thus I ran ANOVA using OLS model to calculate F-statistic and p-value,
Here is the output from the OLS output:
=========================================================================== Dep. Variable: NUMCIGMO_EST R-squared: 0.031 Model: OLS Adj. R-squared: 0.025 Method: Least Squares F-statistic: 5.001 Date: Mon, 22 Mar 2021 Prob (F-statistic): 0.000567 Time: 19:54:15 Log-Likelihood: -4479.1 No. Observations: 629 AIC: 8968. Df Residuals: 624 BIC: 8991. Df Model: 4 Covariance Type: nonrobust =========================================================================== coef std err t P>|t| [0.025 0.975] ----------------------------------------------------------------------------------- Intercept 315.4803 22.538 13.997 0.000 271.220 359.741 C(S1Q16)[T.2.0] 15.4845 30.537 0.507 0.612 -44.483 75.452 C(S1Q16)[T.3.0] 89.5654 31.530 2.841 0.005 27.648 151.482 C(S1Q16)[T.4.0] 119.1863 50.173 2.376 0.018 20.658 217.715 C(S1Q16)[T.5.0] 348.8054 115.867 3.010 0.003 121.268 576.342 =========================================================================== Omnibus: 346.462 Durbin-Watson: 2.001 Prob(Omnibus): 0.000 Jarque-Bera (JB): 4387.366 Skew: 2.167 Prob(JB): 0.00 Kurtosis: 15.191 Cond. No. 10.7 ===========================================================================
With F-statistic is 5.001 and p-value is 0,000567, I can safely reject the null hypothesis and conclude that there is an association between number of cigarettes smoked and the health conditions. To determine which levels of health conditions are different from the others, I perform a post hoc test using the Tukey HSDT, or Honestly Significant Difference Test (this is implemented by calling “MultiComparison” function). The following shows the result of the Post Hoc Pair Comparison:
Multiple Comparison of Means - Tukey HSD, FWER=0.05 ======================================================= group1 group2 meandiff p-adj lower upper reject ------------------------------------------------------- 1.0 2.0 15.4845 0.9 -68.0574 99.0263 False 1.0 3.0 89.5654 0.0374 3.3073 175.8234 True 1.0 4.0 119.1863 0.1236 -18.0761 256.4488 False 1.0 5.0 348.8054 0.0227 31.8177 665.7931 True 2.0 3.0 74.0809 0.1025 -8.4764 156.6383 False 2.0 4.0 103.7019 0.2205 -31.2657 238.6694 False 2.0 5.0 333.3209 0.0328 17.3202 649.3216 True 3.0 4.0 29.621 0.9 -107.0445 166.2864 False 3.0 5.0 259.24 0.1668 -57.4896 575.9697 False 4.0 5.0 229.619 0.3295 -104.6237 563.8618 False -------------------------------------------------------
In the last column, we can determine which health level of groups smoke significantly different mean number of cigarettes than the others by identifying the comparisons in which we can reject the null hypothesis, that is, in which reject equals true.
Python script for the homework:
import numpy import pandas import statsmodels.formula.api as smf import statsmodels.stats.multicomp as multi
data = pandas.read_csv('nesarc.csv', low_memory=False)
data['S3AQ3B1'] = pandas.to_numeric(data['S3AQ3B1'], errors="coerce") data['S3AQ3C1'] = pandas.to_numeric(data['S3AQ3C1'], errors="coerce") data['CHECK321'] = pandas.to_numeric(data['CHECK321'], errors="coerce")
#subset data to young adults age 18 to 25 who have smoked in the past 12 months sub1=data[(data['AGE']>=18) & (data['AGE']<=25) & (data['CHECK321']==1)]
#SETTING MISSING DATA sub1['S3AQ3B1']=sub1['S3AQ3B1'].replace(9, numpy.nan) sub1['S3AQ3C1']=sub1['S3AQ3C1'].replace(99, numpy.nan)
#recoding number of days smoked in the past month recode1 = {1: 30, 2: 22, 3: 14, 4: 5, 5: 2.5, 6: 1} sub1['USFREQMO']= sub1['S3AQ3B1'].map(recode1)
#converting new variable USFREQMMO to numeric sub1['USFREQMO']= pandas.to_numeric(sub1['USFREQMO'], errors="coerce")
sub1['NUMCIGMO_EST']=sub1['USFREQMO'] * sub1['S3AQ3C1']
sub1['NUMCIGMO_EST']= pandas.to_numeric(sub1['NUMCIGMO_EST'], errors="coerce")
sub1['S1Q16']=sub1['S1Q16'].replace(9, numpy.nan) sub3 = sub1[['NUMCIGMO_EST', 'S1Q16']].dropna()
''' By running an analysis of variance, we're asking whether the number of cigarettes smoked differs for different health conditions. ''' model2 = smf.ols(formula='NUMCIGMO_EST ~ C(S1Q16)', data=sub3).fit() print (model2.summary())
print ('means for numcigmo_est by major depression status') m2= sub3.groupby('S1Q16').mean() print (m2)
print ('standard deviations for numcigmo_est by major depression status') sd2 = sub3.groupby('S1Q16').std() print (sd2)
mc1 = multi.MultiComparison(sub3['NUMCIGMO_EST'], sub3['S1Q16']) res1 = mc1.tukeyhsd() print(res1.summary())
1 note
1 note
·
View note