#scrapestrom
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Great tool to get news from AOL
As a news service under America Online, AOL News has a wide influence and a stable user base in the field of Internet news with its diverse news content, customized services, multimedia presentation and in-depth news reports.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.


4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data

0 notes
Text
Extracting hotel information from Booking.com
Booking.com is an online travel company affiliated with the Booking Holdings group. As one of the world’s largest travel e-commerce companies, Booking.com is committed to providing consumers with high-quality and convenient booking and travel experiences. By investing in technology, it has provided hundreds of Million users offer a seamless and memorable travel experience, a range of transportation options and a variety of amazing accommodations.
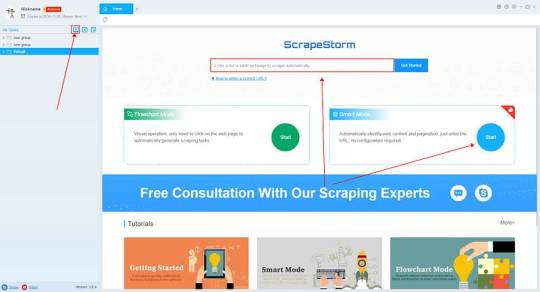
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
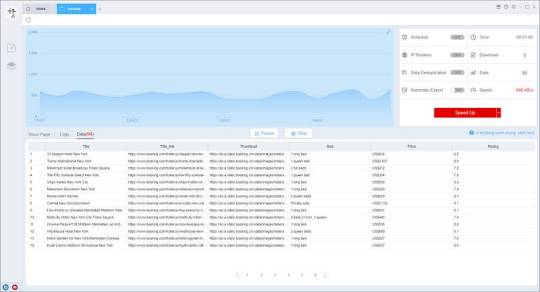
Preview of the scraped result
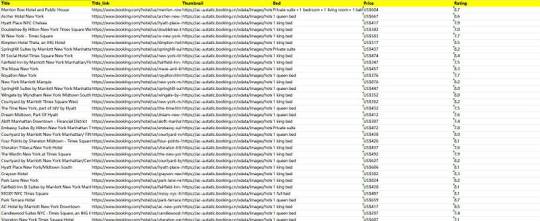
This is the demo task:
Google Drive:
OneDrive:
1. Create a task
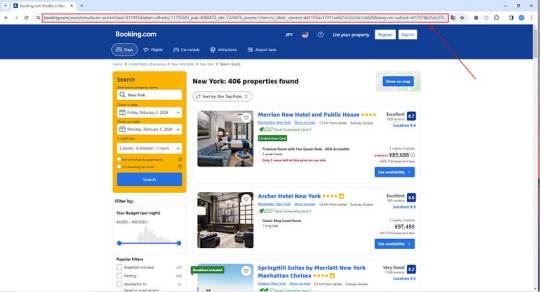
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
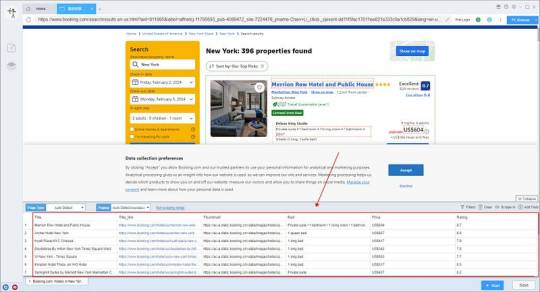
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
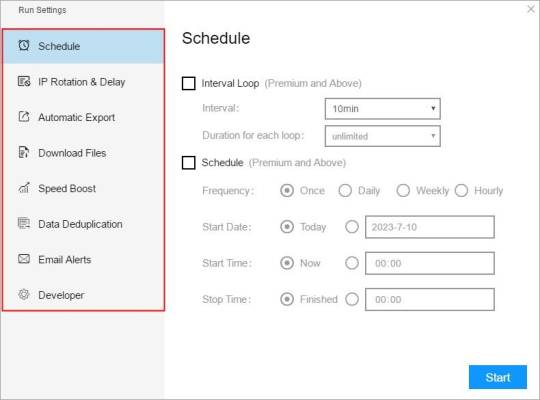
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
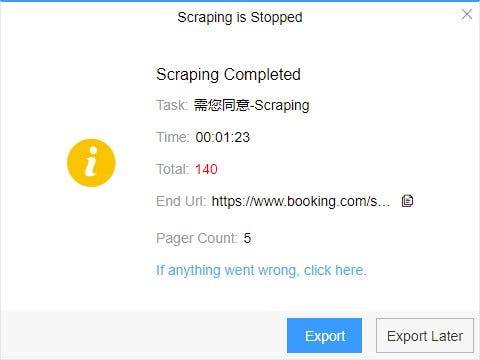
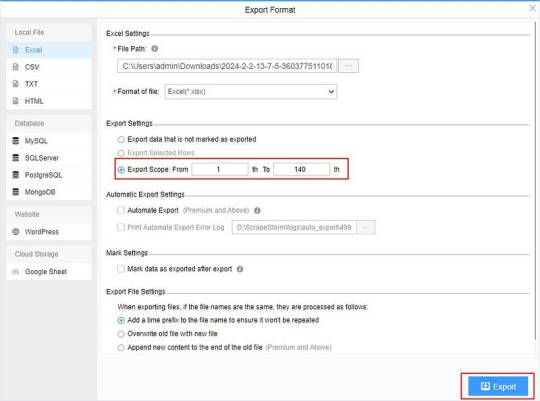
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
0 notes
Text
How to scrape feedback from eBay
eBay’s Feedback is a rating system on the eBay platform that is used to evaluate the performance of sellers and buyers during the transaction process. The purpose of Feedback is to promote integrity and transparency in the eBay community and help buyers and sellers build trusting relationships to ensure smooth transactions.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
Google Drive:
OneDrive:
1. Create a task
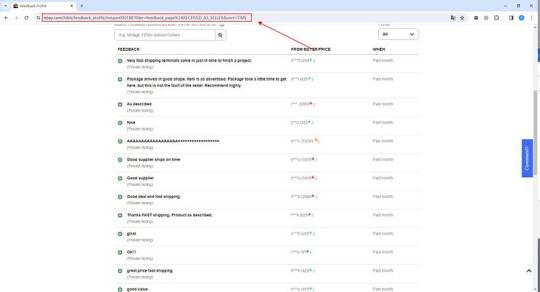
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
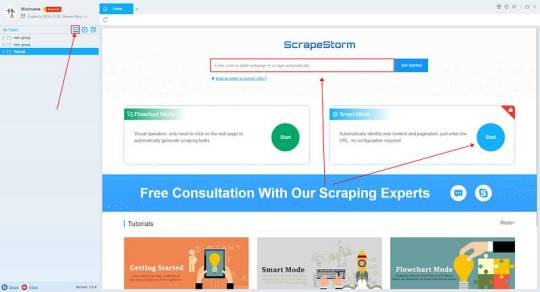
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
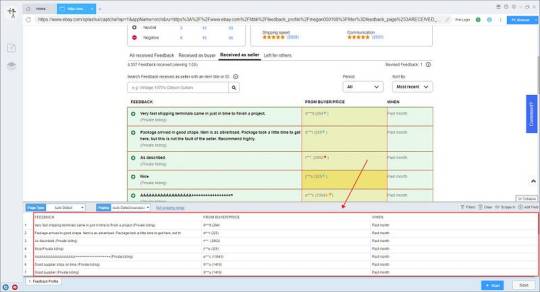
3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
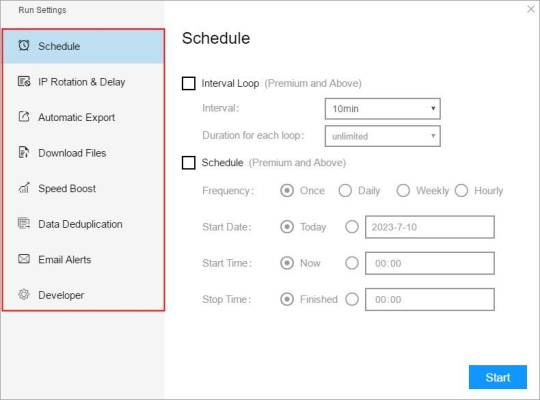
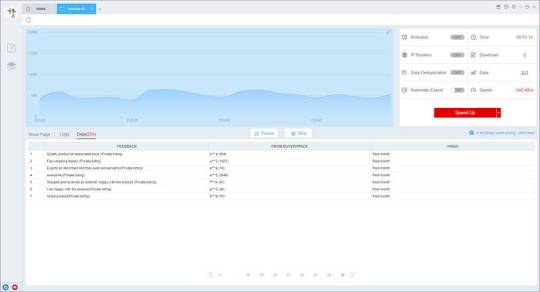
4. Export and view data
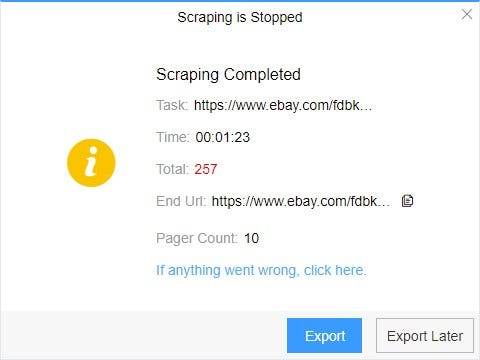
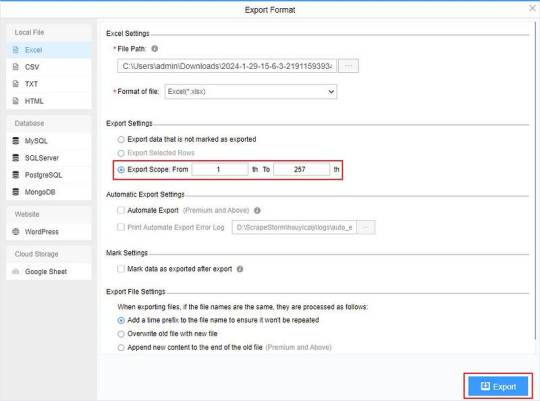
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
1 note
·
View note