#que es parsehub
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Cómo conseguir generación de leads con web scraping
La tecnología está cambiando el rostro del mundo empresarial y haciendo que las tácticas de marketing críticas y la información empresarial sean de fácil acceso. Una de esas tácticas que ha estado circulando por la generación de leads de calidad es el web scraping.
El web scraping no es más que recopilar información valiosa de páginas web y reunirlas todas para el uso futuro. Si alguna vez has copiado contenido de palabras de un sitio web y luego lo has utilizado para tu propósito, tú, también has utilizado el proceso de raspado web, aunque a un nivel minúsculo. Este artículo habla en detalle sobre el proceso de web scraping y su impacto en la generación de leads de calidad de alto-valor.
Tabla de contenido
1. Introducción al web scraping
Conceptos básicos del web scraping
Procesos de web scraping
Industrias beneficiadas por el web scraping
2. Cómo generar leads con Web Scraping
3. Otros beneficios de Web Scraping
4. Conclusiones
Introducción al web scraping
Conceptos básicos del web scraping
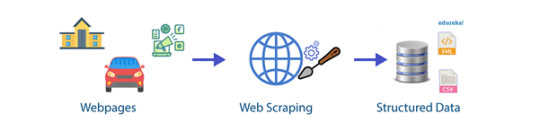
El flujo básico de los procesos de web scraping
¿Qué es?
Web scraping, también conocido como Recolección en la Web y Extracción de datos web, es el proceso de extraer o copiar datos específicos o información valiosa de sitios web y depositarlos en una base de datos central u hoja de cálculo para investigación, análisis o generación de prospectos más adelante. Si bien el web scraping también se puede realizar manualmente, las empresas utilizan cada vez más bots o rastreadores web para implementar un proceso automatizado.
#Tip: Yellow Pages es uno de los directorios de empresas más grandes de la web, especialmente en los EE. UU. Es la mejor vía para scrapear contactos como nombres, direcciones, números de teléfono y correos electrónicos para la generación de clientes potenciales.
Procesos de web scraping
Web Scraping es un proceso extremadamente simple e involucra solo dos componentes- un web crawler(rastreador web) y un web scraper(raspador web). Y gracias a la tecnología ninja, estos los realizan por bots de IA con una intervención manual mínima o nula. Mientras que el crawler, generalmente llamado un "spider(araña)", explora varias páginas web para indexar y buscar contenido siguiendo los enlaces, el scraper extrae rápidamente la información exacta.
El proceso comienza cuando el crawler accede a la World Wide Web directamente a través de un navegador y recupera las páginas descargándolas. El segundo proceso incluye la extracción en la que el web scraper copia los datos en una hoja de cálculo y los formatea en segmentos que no se pueden procesar para su posterior procesamiento.
El diseño y el uso de los raspadores web varían ampliamente, depende del proyecto y su propósito.
Industrias beneficiadas por el web scraping
Reclutamiento
Comercio electrónico
Industria minorista
Entretenimiento
Belleza y estilo de vida
Bienes raíces
Ciencia de los datos
Finanzas
Los minoristas de moda informan a los diseñadores sobre las próximas tendencias basándose en información extraída, los inversores cronometran sus posiciones en acciones y los equipos de marketing abruman a la competencia con información detallada. Un ejemplo generalizado de web scraping es extraer nombres, números de teléfono, ubicaciones e ID de correo electrónico de los sitios de publicación de trabajos por parte de los reclutadores de recursos humanos.
#Tip: Después de COVID 19, la generación de datos en el sector de la salud se ha multiplicado exponencialmente, debido a que el web scraping en la industria de la salud y farmacéutica relacionada ha aumentado en un 57%. Las empresas están analizando datos para diseñar nuevas políticas, desarrollar vacunas, ofrecer mejores soluciones de salud pública, etc. para transformar las oportunidades comerciales.
Web Scraping y Generación de Leads
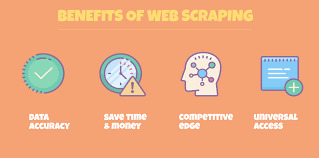
Beneficios de Web Scraping para la generación de leads
#Realidad: 79% de los especialistas en marketing ven el web scraping como una fuente muy beneficiosa de generación de leads.
Los analistas de datos y los expertos en negocios coinciden unánimemente en el hecho de que utilizar Web Scraping mediante la aplicación de proxies residenciales (los proxies residenciales le permiten elegir una ubicación específica y navegar por la web como un usuario real en esa área) es una de las formas más beneficiosas de generar clientes potenciales calificados de ventas para tu negocio. Diseñar un raspador de clientes potenciales único para generar clientes potenciales puede ser mucho más rentable y rentable para generar rápidamente clientes potenciales de calidad.
El web scraping juega un papel importante en la generación de leads mediante dos pasos:
Identificar fuentes
El primer paso para todas las empresas en la generación de leads es agilizar el proceso. ¿Qué fuentes vas a utilizar? ¿Quién es tu público objetivo? ¿A qué ubicación geográfica vas a apuntar? ¿Cuál es tu presupuesto de marketing? ¿Cuáles son los objetivos de tu marca? ¿Qué imagen quieres establecer a través de tu marca? ¿Qué tipo de marketing quieres seguir? ¿Quiénes son tus competidores?
Decodificar la respuesta a estas preguntas fundamentales y diseñar un bot raspador específicamente para cumplir con tus requisitos te llevará a extraer y acceder a información relativa de alta-calidad.
Tip: Si la información de los clientes de tus competidores está disponible públicamente, puedes raspar sus sitios web para su demografía. Esto te daría una buena visualización de quiénes son tus clientes potenciales y qué ofrecen actualmente.
Extraer datos
Después de descubrir las preguntas fundamentales para administrar un negocio exitoso, el siguiente paso es extraer los datos más relevantes, en tiempo real, procesables y de alto rendimiento para diseñar campañas de estratégicas de marketing para obtener el máximo beneficio. Sin embargo, hay dos formas posibles de hacerlo-
A) Optar por una herramienta de generación de leads
Uno de los proveedores de datos B2B más comunes, DataCaptive, ofrece un servicio de generación de lead y otras soluciones de marketing para brindar un soporte incomparable a tu negocio y aumentar el ROI por 4.
B) Usar herramientas de scraping
Octoparse es uno de los proveedores de herramientas de scraping más destacados que te proporciona información valiosa para maximizar el proceso de generación de clientes potenciales. Nuestra flexibilidad y escalabilidad de web scraping aseguran cumplir con los parámetros de tu proyecto con facilidad.
Nuestro proceso de raspado web de tres pasos incluye-
En el primer paso, personalizamos los raspadores que son únicos y complementan los requisitos de tu proyecto para identificar y extraer datos exactos que darán los resultados más beneficiosos. También puedes registrar el sitio web o las páginas web que deseas raspar específicamente.
Los raspadores recuperan los datos en formato HTML. A continuación, eliminamos lo que rodea a los datos y los analizamos para extraer los datos que desees. Los datos pueden ser simples o complejos, según el proyecto y su demanda.
En el tercer y último proceso, los datos se formatean según la demanda exacta del proyecto y se almacenan en consecuencia.
Otros beneficios de Web Scraping
Comparación de precios
Tener acceso al precio actual y en tiempo real de los servicios relacionados ofrecidos por tus competidores puede revolucionar tus procedimientos comerciales diarios y aumentar la visibilidad de tu marca. El web scraping es la solución de un solo paso para determinar soluciones de precios automáticas y analizar perspectivas rentables.
Analizar sentimiento / psicología del comprador
El análisis de sentimientos o persona del comprador ayuda a las marcas a comprender a su clientela mediante el análisis de su comportamiento de compra, historial de navegación y participación en línea. Los datos extraídos de la Web desempeñan un papel clave en la erradicación de interpretaciones sesgadas mediante la recopilación y el análisis de datos de compradores relevantes y perspicaces.
Marketing- contenido, redes sociales y otros medios digitales
El raspado web es la solución definitiva para monitorear, agregar y analizar las historias más críticas de tu industria y generar contenido a tu alrededor para obtener respuestas más impactantes.
Inversión de las empresas
Datos web diseñados explícitamente para que los inversores estimen los fundamentos de la empresa y el gobierno y analicen las perspectivas de las presentaciones ante la SEC y comprendan los escenarios del mercado para tomar decisiones de inversión sólidas.
Investigación de mercado
El web scraping está haciendo que el proceso de investigación de mercado e inteligencia empresarial sea aún más crítico en todo el mundo al proporcionar datos de alta calidad, gran volumen y muy perspicaz de todas las formas y tamaños.
Conclusiones
Web scraping es el proceso de seleccionar páginas web en busca de contenido relevante y descargarlas en una hoja de cálculo para el uso posterior con un rastreador web y un raspador web.
Las industrias más destacadas para practicar el web scraping para generar lead e impulsar las ventas son la ciencia de datos, bienes raíces, el marketing digital, el entretenimiento, la educación, el comercio minorista, reclutamiento y la belleza y estilo de vida, entre muchas otras.
Después de la pandemia de COVD 19, la industria farmacéutica y de la salud ha sido testigo de un aumento significativo en su porcentaje de raspado web debido a su aumento continuo y exponencial en la generación de datos.
Además de la generación de leads, el web scraping también es beneficioso para la investigación de mercado, la creación de contenido, la planificación de inversiones, el análisis de la competencia, etc.
Algunas de las mejores y más utilizadas herramientas de raspado web o proveedores de herramientas son Octoparse, ScraperAPI, ScrapeSimple, Parsehub, Scrappy, Diffbot y Cheerio.
1 note
·
View note
Link
#scraping y crawling#web scraping extracción de datos#que es parsehub#web scraping import io#web scraper chrome#scraper parsers#Copiar datos de web a excel#excel importar datos web contraseña#table capture#macro para obtener datos externos de una web#extraer datos de una página web a excel macro#Descargar datos página web python
0 notes
Text
9 herramientas de Web Scraping Gratuitas que No Te Puedes Perder en 2021
¿Cuánto sabes sobre web scraping? No te preocupe, este artículo te informará sobre los conceptos básicos del web scraping, cómo acceder a una herramienta de web scraping para obtener una herramienta que se adapte perfectamente a tus necesidades y por último, pero no por ello menos importante, te presentará una lista de herramientas de web scraping para tu referencia.
Web Scraping Y Como Se Usa
El web scraping es una forma de recopilar datos de páginas web con un bot de scraping, por lo que todo el proceso se realiza de forma automatizada. La técnica permite a las personas obtener datos web a gran escala rápidamente. Mientras tanto, instrumentos como Regex (Expresión Regular) permiten la limpieza de datos durante el proceso de raspado, lo que significa que las personas pueden obtener datos limpios bien estructurados en un solo lugar.
¿Cómo funciona el web scraping?
En primer lugar, un robot de raspado web simula el acto de navegación humana por el sitio web. Con la URL de destino ingresada, envía una solicitud al servidor y obtiene información en el archivo HTML.
A continuación, con el código fuente HTML a mano, el bot puede llegar al nodo donde se encuentran los datos de destino y analizar los datos como se ordena en el código de raspado.
Por último, (según cómo esté configurado el bot de raspado) el grupo de datos raspados se limpiará, se colocará en una estructura y estará listo para descargar o transferir a tu base de datos.
Cómo Elegir Una Herramienta De Web Scraping
Hay formas de acceder a los datos web. A pesar de que lo has reducido a una herramienta de raspado web, las herramientas que aparecieron en los resultados de búsqueda con todas las características confusas aún pueden hacer que una decisión sea difícil de alcanzar.
Hay algunas dimensiones que puedes tener en cuenta antes de elegir una herramienta de raspado web:
Dispositivo: si eres un usuario de Mac o Linux, debes asegurarte de que la herramienta sea compatible con tu sistema.
Servicio en la nube: el servicio en la nube es importante si deseas acceder a tus datos en todos los dispositivos en cualquier momento.
Integración: ¿cómo utilizarías los datos más adelante? Las opciones de integración permiten una mejor automatización de todo el proceso de manejo de datos.
Formación: si no sobresales en la programación, es mejor asegurarte de que haya guías y soporte para ayudarte a lo largo del viaje de recolección de datos.
Precio: sí, el costo de una herramienta siempre se debe tener en cuenta y varía mucho entre los diferentes proveedores.
Ahora es posible que desees saber qué herramientas de raspado web puedes elegir:
Tres Tipos De Herramientas De Raspado Web
Cliente Web Scraper
Complementos / Extensión de Web Scraping
Aplicación de raspado basada en web
Hay muchas herramientas gratuitas de raspado web. Sin embargo, no todo el software de web scraping es para no programadores. Las siguientes listas son las mejores herramientas de raspado web sin habilidades de codificación a un bajo costo. El software gratuito que se enumera a continuación es fácil de adquirir y satisfaría la mayoría de las necesidades de raspado con una cantidad razonable de requisitos de datos.
Software de Web Scraping de Cliente
1. Octoparse
Octoparse es una herramienta robusta de web scraping que también proporciona un servicio de web scraping para empresarios y empresas.
Dispositivo: como se puede instalar tanto en Windows como en Mac OS, los usuarios pueden extraer datos con dispositivos Apple.
Datos: extracción de datos web para redes sociales, comercio electrónico, marketing, listados de bienes raíces, etc.
Función:
- manejar sitios web estáticos y dinámicos con AJAX, JavaScript, cookies, etc.
- extraer datos de un sitio web complejo que requiere inicio de sesión y paginación.
- tratar la información que no se muestra en los sitios web analizando el código fuente.
Casos de uso: como resultado, puedes lograr un seguimiento automático de inventarios, monitoreo de precios y generación de leads al alcance de tu mano.
Octoparse ofrece diferentes opciones para usuarios con diferentes niveles de habilidades de codificación.
El Modo de Plantilla de Tareas Un usuario con habilidades básicas de datos scraping puede usar esta nueva característica que convirte páginas web en algunos datos estructurados al instante. El modo de plantilla de tareas solo toma alrededor de 6.5 segundos para desplegar los datos detrás de una página y te permite descargar los datos a Excel.
El modo avanzado tiene más flexibilidad comparando los otros dos modos. Esto permite a los usuarios configurar y editar el flujo de trabajo con más opciones. El modo avanzado se usa para scrape sitios web más complejos con una gran cantidad de datos.
La nueva función de detección automática te permite crear un rastreador con un solo clic. Si no estás satisfecho con los campos de datos generados automáticamente, siempre puedes personalizar la tarea de raspado para permitirte raspar los datos por ti.
Los servicios en la nube permiten una gran extracción de datos en un corto período de tiempo, ya que varios servidores en la nube se ejecutan simultáneamente para una tarea. Además de eso, el servicio en la nube te permitirá almacenar y recuperar los datos en cualquier momento.
2.
ParseHub
Parsehub es un raspador web que recopila datos de sitios web que utilizan tecnologías AJAX, JavaScript, cookies, etc. Parsehub aprovecha la tecnología de aprendizaje automático que puede leer, analizar y transformar documentos web en datos relevantes.
Dispositivo: la aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux, o puedes usar la extensión del navegador para lograr un raspado instantáneo.
Precio: no es completamente gratuito, pero aún puedes configurar hasta cinco tareas de raspado de forma gratuita. El plan de suscripción paga te permite configurar al menos 20 proyectos privados.
Tutorial: hay muchos tutoriales en Parsehub y puedes obtener más información en la página de inicio.
3.
Import.io
Import.io es un software de integración de datos web SaaS. Proporciona un entorno visual para que los usuarios finales diseñen y personalicen los flujos de trabajo para recopilar datos. Cubre todo el ciclo de vida de la extracción web, desde la extracción de datos hasta el análisis dentro de una plataforma. Y también puedes integrarte fácilmente en otros sistemas.
Función: raspado de datos a gran escala, captura de fotos y archivos PDF en un formato factible
Integración: integración con herramientas de análisis de datos
Precios: el precio del servicio solo se presenta mediante consulta caso por caso
Complementos / Extensión de Web Scraping1.
Data Scraper (Chrome)
Data Scraper puede extraer datos de tablas y datos de tipo de listado de una sola página web. Su plan gratuito debería satisfacer el scraping más simple con una pequeña cantidad de datos. El plan pagado tiene más funciones, como API y muchos servidores proxy IP anónimos. Puede recuperar un gran volumen de datos en tiempo real más rápido. Puede scrapear hasta 500 páginas por mes, si necesitas scrapear más páginas, necesitas actualizar a un plan pago.
2.
Web scraper
El raspador web tiene una extensión de Chrome y una extensión de nube.
Para la versión de extensión de Chrome, puedes crear un mapa del sitio (plan) sobre cómo se debe navegar por un sitio web y qué datos deben rasparse.
La extensión de la nube puede raspar un gran volumen de datos y ejecutar múltiples tareas de raspado al mismo tiempo. Puedes exportar los datos en CSV o almacenarlos en Couch DB.
3.
Scraper (Chrome)
El Scraper es otro raspador web de pantalla fácil de usar que puede extraer fácilmente datos de una tabla en línea y subir el resultado a Google Docs.
Simplemente selecciona un texto en una tabla o lista, haz clic con el botón derecho en el texto seleccionado y elige "Scrape similar" en el menú del navegador. Luego obtendrás los datos y extraerás otro contenido agregando nuevas columnas usando XPath o JQuery. Esta herramienta está destinada a usuarios de nivel intermedio a avanzado que saben cómo escribir XPath.
4.
Outwit hub(Firefox)
Outwit hub es una extensión de Firefox y se puede descargar fácilmente desde la tienda de complementos de Firefox. Una vez instalado y activado, puedes extraer el contenido de los sitios web al instante.
Función: tiene características sobresalientes de "Raspado rápido", que rápidamente extrae datos de una lista de URL que ingresas. La extracción de datos de sitios que usan Outwit Hub no requiere habilidades de programación.
Formación: El proceso de raspado es bastante fácil de aprender. Los usuarios pueden consultar sus guías para comenzar con el web scraping con la herramienta.
Outwit Hub also offers services of tailor-making scrapers.Outwit Hub también ofrece servicios de raspadores a medida.
Aplicación de raspado basada en web1.
Dexi.io (anteriormente conocido como raspado de nubes)
Dexi.io está destinado a usuarios avanzados que tienen habilidades de programación competentes. Tiene tres tipos de robots para que puedas crear una tarea de raspado - Extractor, Crawler, y Pipes. Proporciona varias herramientas que te permiten extraer los datos con mayor precisión. Con su característica moderna, podrás abordar los detalles en cualquier sitio web. Sin conocimientos de programación, es posible que debas tomarte un tiempo para acostumbrarte antes de crear un robot de raspado web. Consulta su página de inicio para obtener más información sobre la base de conocimientos.
El software gratuito proporciona servidores proxy web anónimos para raspar la web. Los datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de ser archivados, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios de pago para satisfacer tus necesidades de obtención de datos en tiempo real.
2.
Webhose.io
Webhose.io te permite obtener datos en tiempo real de raspar fuentes en línea de todo el mundo en varios formatos limpios. Incluso puedes recopilar información en sitios web que no aparecen en los motores de búsqueda. Este raspador web te permite raspar datos en muchos idiomas diferentes utilizando múltiples filtros y exportar datos raspados en formatos XML, JSON y RSS.
El software gratuito ofrece un plan de suscripción gratuito para que puedas realizar 1000 solicitudes HTTP por mes y planes de suscripción pagados para realizar más solicitudes HTTP por mes para satisfacer tus necesidades de raspado web.
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
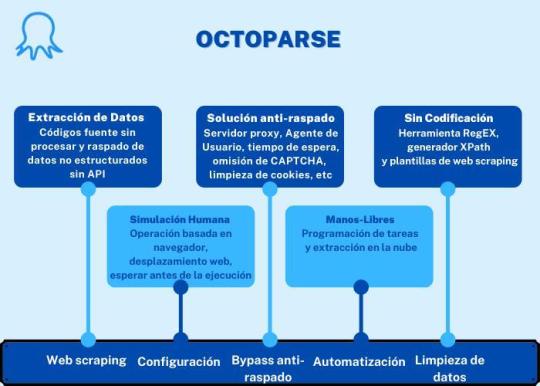
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Text
Las 20 Mejores Herramientas de Web Scraping para 2021
Herramienta Web Scraping (también conocido como extracción de datos de la web, web crawling) se ha aplicado ampliamente en muchos campos hoy en día. Antes de que una herramienta de scraping llegue al público, es la palabra mágica para personas normales sin habilidades de programación. Su alto umbral sigue bloqueando a las personas fuera de Big Data. Una herramienta de web scraping es la tecnología de captura automatizada y cierra la brecha entre Big Data y cada persona.
Enumeré 20 MEJORES web scrapers incluyen sus caracterísiticas y público objetivo para que tomes como referencia. ¡Bienvenido a aprovecharlo al máximo!
Tabla de Contenidos
¿Cuáles son los beneficios de usar técnicas de web scraping?
20 MEJORES web scrapers
Octoparse
Cyotek WebCopy
HTTrack
Getleft
Scraper
OutWit Hub
ParseHub
Visual Scraper
Scrapinghub
Dexi.io
Webhose.io
Import. io
80legs
Spinn3r
Content Grabber
Helium Scraper
UiPath
Scrape.it
WebHarvy
ProWebScraper
Conclusión
¿Cuáles son los beneficios de usar técnicas de web scraping?
Liberar tus manos de hacer trabajos repetitivos de copiar y pegar.
Colocar los datos extraídos en un formato bien estructurado que incluye, entre otros, Excel, HTML y CSV.
Ahorrarte tiempo y dinero al obtener un analista de datos profesional.
Es la cura para comercializador, vendedores, periodistas, YouTubers, investigadores y muchos otros que carecen de habilidades técnicas.
1. Octoparse
Octoparse es un web scraper para extraer casi todo tipo de datos que necesitas en los sitios web. Puedes usar Octoparse para extraer datos de la web con sus amplias funcionalidades y capacidades. Tiene dos tipos de modo de operación: Modo Plantilla de tarea y Modo Avanzado, para que los que no son programadores puedan aprender rápidamente. La interfaz fácil de apuntar y hacer clic puede guiarte a través de todo el proceso de extracción. Como resultado, puedes extraer fácilmente el contenido del sitio web y guardarlo en formatos estructurados como EXCEL, TXT, HTML o sus bases de datos en un corto período de tiempo.
Además, proporciona una Programada Cloud Extracción que tle permite extraer datos dinámicos en tiempo real y mantener un registro de seguimiento de las actualizaciones del sitio web.
También puedes extraer la web complejos con estructuras difíciles mediante el uso de su configuración incorporada de Regex y XPath para localizar elementos con precisión. Ya no tienes que preocuparte por el bloqueo de IP. Octoparse ofrece Servidores Proxy IP que automatizarán las IP y se irán sin ser detectados por sitios web agresivos.
Octoparse debería poder satisfacer las necesidades de rastreo de los usuarios, tanto básicas como avanzadas, sin ninguna habilidad de codificación.
2. Cyotek WebCopy
WebCopy es un web crawler gratuito que te permite copiar sitios parciales o completos localmente web en tu disco duro para referencia sin conexión.
Puedes cambiar su configuración para decirle al bot cómo deseas capturar. Además de eso, también puedes configurar alias de dominio, cadenas de agente de usuario, documentos predeterminados y más.
Sin embargo, WebCopy no incluye un DOM virtual ni ninguna forma de análisis de JavaScript. Si un sitio web hace un uso intensivo de JavaScript para operar, es más probable que WebCopy no pueda hacer una copia verdadera. Es probable que no maneje correctamente los diseños dinámicos del sitio web debido al uso intensivo de JavaScript
3. HTTrack
Como programa gratuito de rastreo de sitios web, HTTrack proporciona funciones muy adecuadas para descargar un sitio web completo a su PC. Tiene versiones disponibles para Windows, Linux, Sun Solaris y otros sistemas Unix, que cubren a la mayoría de los usuarios. Es interesante que HTTrack pueda reflejar un sitio, o más de un sitio juntos (con enlaces compartidos). Puedes decidir la cantidad de conexiones que se abrirán simultáneamente mientras descarga las páginas web en "establecer opciones". Puedes obtener las fotos, los archivos, el código HTML de su sitio web duplicado y reanudar las descargas interrumpidas.
Además, el soporte de proxy está disponible dentro de HTTrack para maximizar la velocidad.
HTTrack funciona como un programa de línea de comandos, o para uso privado (captura) o profesional (espejo web en línea). Dicho esto, HTTrack debería ser preferido por personas con habilidades avanzadas de programación.
4. Getleft
Getleft es un web spider gratuito y fácil de usar. Te permite descargar un sitio web completo o cualquier página web individual. Después de iniciar Getleft, puedes ingresar una URL y elegir los archivos que deseas descargar antes de que comience. Mientras avanza, cambia todos los enlaces para la navegación local. Además, ofrece soporte multilingüe. ¡Ahora Getleft admite 14 idiomas! Sin embargo, solo proporciona compatibilidad limitada con Ftp, descargará los archivos pero no de forma recursiva.
En general, Getleft debería poder satisfacer las necesidades básicas de scraping de los usuarios sin requerir habilidades más sofisticadas.
5. Scraper
Scraper es una extensión de Chrome con funciones de extracción de datos limitadas, pero es útil para realizar investigaciones en línea. También permite exportar los datos a las hojas de cálculo de Google. Puedes copiar fácilmente los datos al portapapeles o almacenarlos en las hojas de cálculo con OAuth. Scraper puede generar XPaths automáticamente para definir URL para scraping.
No ofrece servicios de scraping todo incluido, pero puede satisfacer las necesidades de extracción de datos de la mayoría de las personas.
6. OutWit Hub
OutWit Hub es un complemento de Firefox con docenas de funciones de extracción de datos para simplificar sus búsquedas en la web. Esta herramienta de web scraping puede navegar por las páginas y almacenar la información extraída en un formato adecuado.
OutWit Hub ofrece una interfaz única para extraer pequeñas o grandes cantidades de datos por necesidad. OutWit Hub te permite eliminar cualquier página web del navegador. Incluso puedes crear agentes automáticos para extraer datos.
Es una de las herramientas de web scraping más simples, de uso gratuito y te ofrece la comodidad de extraer datos web sin escribir código.
7. ParseHub
Parsehub es un excelente web scraper que admite la recopilación de datos de la web que utilizan tecnología AJAX, JavaScript, cookies, etc. Sutecnología de aprendizaje automático puede leer, analizar y luego transformar documentos web en datos relevantes.
La aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux. Incluso puedes usar la aplicación web que está incorporado en el navegador.
Como programa gratuito, no puedes configurar más de cinco proyectos públicos en Parsehub. Los planes de suscripción pagados te permiten crear al menos 20 proyectos privados para scrape sitios web.
ParseHub está dirigido a prácticamente cualquier persona que desee jugar con los datos. Puede ser cualquier persona, desde analistas y científicos de datos hasta periodistas.
8. Visual Scraper
Visual Scraper es otro gran web scraper gratuito y sin codificación con una interfaz simple de apuntar y hacer clic. Puedes obtener datos en tiempo real de varias páginas web y exportar los datos extraídos como archivos CSV, XML, JSON o SQL. Además de SaaS, VisualScraper ofrece un servicio de web scraping como servicios de entrega de datos y creación de servicios de extracción de software.
Visual Scraper permite a los usuarios programar un proyecto para que se ejecute a una hora específica o repetir la secuencia cada minuto, día, semana, mes o año. Los usuarios pueden usarlo para extraer noticias, foros con frecuencia.
9. Scrapinghub
Scrapinghub es una Herramienta de Extracción de Datos basada Cloud que ayuda a miles de desarrolladores a obtener datos valiosos. Su herramienta de scraping visual de código abierto permite a los usuarios raspar sitios web sin ningún conocimiento de programación.
Scrapinghub utiliza Crawlera, un rotador de proxy inteligente que admite eludir las contramedidas de robots para rastrear fácilmente sitios enormes o protegidos por robot. Permite a los usuarios rastrear desde múltiples direcciones IP y ubicaciones sin la molestia de la administración de proxy a través de una simple API HTTP.
Scrapinghub convierte toda la página web en contenido organizado. Su equipo de expertos está disponible para obtener ayuda en caso de que su generador de rastreo no pueda cumplir con sus requisitos
10. Dexi.io
Como web scraping basado en navegador, Dexi.io te permite scrapear datos basados en su navegador desde cualquier sitio web y proporcionar tres tipos de robots para que puedas crear una tarea de scraping: extractor, rastreador y tuberías.
El software gratuito proporciona servidores proxy web anónimos para tu web scraping y tus datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de que se archiven los datos, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios pagos para satisfacer tus necesidades de obtener datos en tiempo real.
11. Webhose.io
Webhose.io permite a los usuarios obtener recursos en línea en un formato ordenado de todo el mundo y obtener datos en tiempo real de ellos. Este web crawler te permite rastrear datos y extraer palabras clave en muchos idiomas diferentes utilizando múltiples filtros que cubren una amplia gama de fuentes
Y puedes guardar los datos raspados en formatos XML, JSON y RSS. Y los usuarios pueden acceder a los datos del historial desde su Archivo. Además, webhose.io admite como máximo 80 idiomas con sus resultados de crawling de datos. Y los usuarios pueden indexar y buscar fácilmente los datos estructurados rastreados por Webhose.io.
En general, Webhose.io podría satisfacer los requisitos elementales de web scraping de los usuarios.
12. Import. io
Los usuarios pueden formar sus propios conjuntos de datos simplemente importando los datos de una página web en particular y exportando los datos a CSV.
Puede scrapear fácilmente miles de páginas web en minutos sin escribir una sola línea de código y crear más de 1000 API en función de sus requisitos. Las API públicas han proporcionado capacidades potentes y flexibles, controla mediante programación Import.io para acceder automáticamente a los datos, Import.io ha facilitado el rastreo integrando datos web en su propia aplicación o sitio web con solo unos pocos clics.
Para satisfacer mejor los requisitos de rastreo de los usuarios, también ofrece una aplicación gratuita para Windows, Mac OS X y Linux para construir extractores y rastreadores de datos, descargar datos y sincronizarlos con la cuenta en línea. Además, los usuarios pueden programar tareas de rastreo semanalmente, diariamente o por hora.
13. 80legs
80legs es una poderosa herramienta de web crawling que se puede configurar según los requisitos personalizados. Admite la obtención de grandes cantidades de datos junto con la opción de descargar los datos extraídos al instante. 80legs proporciona un rastreo web de alto rendimiento que funciona rápidamente y obtiene los datos requeridos en solo segundos.
80legs es utilizado por una amplia variedad de empresas. Cualquier empresa que necesite datos extraídos de la web puede usar 80legs para sus necesidades.
14. Spinn3r
Spinn3r te permite obtener datos completos de blogs, noticias y sitios de redes sociales y RSS y ATOM. Spinn3r se distribuye con un firehouse API que gestiona el 95% del trabajo de indexación. Ofrece protección avanzada contra spam, que elimina spam y los usos inapropiados del lenguaje, mejorando así la seguridad de los datos.
Spinn3r indexa contenido similar a Google y guarda los datos extraídos en archivos JSON. El web scraper escanea constantemente la web y encuentra actualizaciones de múltiples fuentes para obtener publicaciones en tiempo real. Su consola de administración te permite controlar los scraping y la búsqueda de texto completo permite realizar consultas complejas sobre datos sin procesar.
15. Content Grabber
Content Grabber es un software de web crawler dirigido a empresas. Te permite crear agentes de rastreo web independientes. Puedes extraer contenido de casi cualquier sitio web y guardarlo como datos estructurados en el formato que elijes, incluidos los informes de Excel, XML, CSV y la mayoría de las bases de datos.
Es más adecuado para personas con habilidades avanzadas de programación, ya que proporciona muchas potentes de edición de guiones y depuración de interfaz para aquellos que lo necesitan. Los usuarios pueden usar C # o VB.NET para depurar o escribir scripts para controlar la programación del proceso de scraping. Por ejemplo, Content Grabber puede integrarse con Visual Studio 2013 para la edición de secuencias de comandos, la depuración y la prueba de unidad más potentes para un rastreador personalizado avanzado y discreto basado en las necesidades particulares de los usuarios.
16. Helium Scraper
Helium Scraper es un software visual de datos web scraping que funciona bastante bien cuando la asociación entre elementos es pequeña. No es codificación, no es configuración. Y los usuarios pueden obtener acceso a plantillas en línea basadas en diversas necesidades de web scraping.
Básicamente, podría satisfacer las necesidades de web scraping de los usuarios dentro de un nivel elemental.
17. UiPath
UiPath es un software robótico de automatización de procesos para capturar automáticamente una web. Puede capturar automáticamente datos web y de escritorio de la mayoría de las aplicaciones de terceros. Si lo ejecutas en Windows, puedes instalar el software de automatización de proceso. Uipath puede extraer tablas y datos basados en patrones en múltiples páginas web.
Uipath proporciona herramientas incorporados para un mayor web scraping. Este método es muy efectivo cuando se trata de interfaces de usuario complejas. Screen Scraping Tool puede manejar elementos de texto individuales, grupos de texto y bloques de texto, como la extracción de datos en formato de tabla.
Además, no se necesita programación para crear agentes web inteligentes, pero el .NET hacker dentro de ti tendrá un control completo sobre los datos.
18. Scrape.it
Scrape.it es un software node.js de web scraping. Es una herramienta de extracción de datos web basada en la nube. Está diseñado para aquellos con habilidades avanzadas de programación, ya que ofrece paquetes públicos y privados para descubrir, reutilizar, actualizar y compartir código con millones de desarrolladores en todo el mundo. Su potente integración te ayudará a crear un rastreador personalizado según tus necesidades.
19. WebHarvy
WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. WebHarvy puede scrapear automáticamente Texto, Imágenes, URL y Correos Electrónicos de sitios web, y guardar el contenido raspado en varios formatos. También proporciona un programador incorporado y soporte proxy que permite el rastreo anónimo y evita que el software de web crawler sea bloqueado por servidores web, tiene la opción de acceder a sitios web objetivo a través de servidores proxy o VPN.
Los usuarios pueden guardar los datos extraídos de las páginas web en una variedad de formatos. La versión actual de WebHarvy Web Scraper te permite exportar los datos raspados como un archivo XML, CSV, JSON o TSV. Los usuarios también pueden exportar los datos raspados a una base de datos SQL.
20. ProWebScraper
ProWebScraper es un web scraper automatizado diseñado para la extracción de contenido web a escala empresarial que necesita una solución a escala empresarial. Los usuarios comerciales pueden crear fácilmente agentes de extracción en tan solo unos minutos, sin ninguna programación. La API REST de Prowebscraper puede extraer datos de páginas web para ofrecer respuestas instantáneas en segundos.
Los usuarios pueden crear fácilmente agentes de extracción simplemente apuntando y haciendo clic.
Conclusión
Este artículo primero dio una idea sobre Web Scraping en general. Luego enumeró 20 de las mejores herramientas de raspado web del mercado, considerando una serie de factores. La principal conclusión de este artículo, por lo tanto, es que al final, un usuario debe elegir las herramientas de raspado web que se adapten a sus necesidades.
Deseo que este artículo te ayude a tomar una decisión informada con respecto a la mejor herramienta de raspado web para tu negocio o trabajo.
0 notes
Text
Los 30 Mejores Software de Web Scraping Gratis en 2020
El Web scraping (también denominado extracción de datos web, web crawler, captura de pantalla o recolección web) es una técnica web para extraer datos de los sitios web. Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en una base de datos.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
1. Beautiful Soup
¿Para quién es esto?: desarrolladores que dominan la programación para crear un web scraping/web crawler para rastrear los sitios web.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tiene habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
2. Octoparse
¿Cómo hacer web scraping?: Las empresas o las personas tienen la necesidad de extraer datos de la web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué debería usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puede usar para raspar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates para usar, como eBay, Twitter, BestBuy y muchas otras. Octoparse también proporciona servicio de datos web. Puede personalizar el tarea scraper según sus necesidades de raspado.
3. Import.io
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite raspar datos de sitios web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
4. Mozenda
Para quién es esto: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué debería usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
5. Parsehub
Para quién es esto: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-raspado.
6. Crawlmonster
Para quién es esto: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software gratuito de web scraping. Le permite escanear sitios web y analizar el contenido de su sitio web, el código fuente, el estado de la página y muchos otros.
7. Connotate
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Connotate ha estado trabajando junto con Import.IO, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a raspar, recopilar y manejar los datos.
8. Common Crawl
Para quién es esto: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
9. Crawly
Para quién es esto: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué debería usarlo: Crawly proporciona un servicio automático que raspa un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
10. Content Grabber
Para quién es esto: Desarrolladores de Python que son expertos en programación.
Por qué debería usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
11. Diffbot
Para quién es esto: Desarrolladores y empresas.
Por qué debería usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
12. Dexi.io
Para quién es esto: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un rastreador web basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
13. DataScraping.co
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Data Scraping Studio es un software gratuito de raspado web para recolectar datos de páginas web, HTML, XML y pdf. Actualmente, el cliente de escritorio solo está disponible para Windows.
14. Easy Web Extract
Para quién es esto: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Easy Web Extract es un software visual de raspado web para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
15. FMiner
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite raspar desde sitios web dinámicos usando Ajax y Javascript.
16. Scrapy
Para quién es esto: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
17. Helium Scrape
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
18. Scrape.it
Para quién es esto: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
19. ScraperWiki
Para quién es esto: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: Tiene dos partes dentro de la empresa. Uno es QuickCode, que está diseñado para economistas, estadísticos y administradores de datos con conocimiento del lenguaje Python y R. La segunda parte es The Sensible Code Company, que proporciona un servicio de datos web para convertir información desordenada en datos estructurados.
20. Scrapinghub
¿Para quién es esto?: Python/Desarrolladores de web scraping
Por qué debería usarlo: Scraping Hub es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Scrapinghub ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
21. Screen-Scraper
Para quién es esto: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué debería usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
22. Salestools.io
Para quién es esto: Comercializador y ventas.
Por qué debería usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
23. ScrapeHero
¿Quién es este: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué debería usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
24. UniPath
Para quién es esto: Negocios con todos los tamaños
Por qué debería usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
25. Web Content Extractor
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días
26. Webharvy
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
27. Web Scraper.io
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos de sitios web. Es un software gratuito de web scraping para raspar páginas web dinámicas.
28. Web Sundew
Para quién es esto: Empresas, comercializadores e investigadores.
Por qué debería usarlo: WebSundew es una herramienta de raspado visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
29. Winautomation
Para quién es esto: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué debería usarlo: Winautomation es una herramienta de web scraping de Windows que le permite automatizar tareas de escritorio y basadas en la web.
30. Web Robots
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Robots es una plataforma de web scraping basada en la nube para raspar sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
#web scraping precios#cómo hhacer web scraping python#scraping mensaje#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#scrab in linkedin
0 notes
Text
Crear un Simple Web Crawler en PHP
Antes de comenzar, daré un resumen rápido del web scraping. El web scraping es extraer información del HTML de una página web. El web scraping con PHP no hace ninguna diferencia que cualquier otro tipo de lenguajes informáticos o herramientas de web scraping, como Octoparse.
Este artículo es para ilustrar cómo un principiante podría construir un rastreador web (web crawler) simple en PHP. Si planea aprender PHP y usarlo para el web scraping, siga los pasos a continuación.
Paso 1.
Agregue un cuadro de entrada y un botón de envío a la página web. Podemos ingresar la dirección de la página web en el cuadro de entrada. Se necesitan expresiones regulares al extraer datos.
Paso 2.
Se necesitan expresiones regulares al extraer datos.
function preg_substr($start, $end, $str) // Regular expression
{
$temp = preg_split($start, $str);
$content = preg_split($end, $temp[1]);
return $content[0];
}
Paso 3.
La división de cadenas es necesaria al extraer datos.
function str_substr($start, $end, $str) // string split
{
$temp = explode($start, $str, 2);
$content = explode($end, $temp[1], 2);
return $content[0];
}
Paso 4.
Agregue una función para guardar el contenido de la extracción:
function writelog($str)
{
@unlink("log.txt");
$open=fopen("log.txt","a" );
fwrite($open,$str);
fclose($open);
}
Cuando el contenido que extraemos es inconsistente con lo que se muestra en el navegador, no pudimos encontrar las expresiones regulares correctas. Aquí podemos abrir el archivo .txt guardado para encontrar la cadena correcta.
function writelog($str)
{
@unlink("log.txt");
$open=fopen("log.txt","a" );
fwrite($open,$str);
fclose($open);
}
Paso 5
También sería necesaria una función si necesita capturar imágenes.
function getImage($url, $filename='', $dirName, $fileType, $type=0)
{
if($url == ''){return false;}
//get the default file name
$defaultFileName = basename($url);
//file type
$suffix = substr(strrchr($url,'.'), 1);
if(!in_array($suffix, $fileType)){
return false;
}
//set the file name
$filename = $filename == '' ? time().rand(0,9).'.'.$suffix : $defaultFileName;
//get remote file resource
if($type){
$ch = curl_init();
$timeout = 5;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file = curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$file = ob_get_contents();
ob_end_clean();
}
//set file path
$dirName = $dirName.'/'.date('Y', time()).'/'.date('m', time()).'/'.date('d',time()).'/';
if(!file_exists($dirName)){
mkdir($dirName, 0777, true);
}
//save file
$res = fopen($dirName.$filename,'a');
fwrite($res,$file);
fclose($res);
return $dirName.$filename;
}
Paso 6
Escribiremos el código para la extracción. Tomemos una página web de Amazon como ejemplo. Ingrese un enlace de producto.
if($_POST[‘URL’]){
//---------------------example-------------------
$str = file_get_contents($_POST[‘URL’]);
$str = mb_convert_encoding($str, ‘utf-8’,’iso-8859-1’);
writelog($str);
//echo $str;
echo(‘Title:’ . Preg_substr(‘/<span id= “btAsinTitle”[^>}*>/’,’/<Vspan>/$str));
echo(‘<br/>’);
$imgurl=str_substr(‘var imageSrc = “’,’”’,$str);
echo ‘<img src=”’.getImage($imgurl,”,’img’ array(‘jpg’));
Entonces podemos ver lo que extraemos. A continuación se muestra la captura de pantalla.
No necesita codificar un rastreador web (web crawler) si tiene un rastreador web automático.
Como se mencionó anteriormente, PHP es solo una herramienta que se utiliza para crear un rastreador web. Los lenguajes de computadora, como Python y JavaScript, también son buenas herramientas para quienes están familiarizados con ellos. Hoy en día, con el desarrollo de la tecnología de web scraping, cada vez surgen más herramientas de web scraping, como Octoparse, Beautiful Soup, Import.io y Parsehub. Simplifican el proceso de creación de un rastreador web (web crawler).
Tome las plantillas de tareas de Octoparse como ejemplo, permite a todos raspar datos usando plantillas preconstruidas, no más configuraciones de rastreadores, simplemente ingrese las palabras clave para buscar y obtener datos al instante.
0 notes