#posthoc
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text



The closet.
This room is actually refurbished from a bedroom, which explains why there is a closet within a closet.
#ts2#the sims 2#thesims2#ts2 screenshots#Project: Westside#Nora's Townhouse#My favorite ts2 pastime: Coming up with posthoc explanations for the whimsical decisions I made building houses
16 notes
·
View notes
Note
How do you write possessive characters? I think you mentioned a few times that Gojou would not be great at sharing. Could you expound on why you feel this way about his character and how you translate that into your writing? Do personal experiences in previous relationships matter or weigh in at all?
Sorry for so many questions! I feel like many people write jealous or possessive characters the same way, and it would help me to gain some perspective from someone whose work I enjoy reading. Thank you!
No worries, I usually enjoy being prompted to dissect my own writing!
So the answer to "how do you write possessive characters" is that some of them just...come out that way. It's a trope/theme I enjoy, of course, but I'm very picky about the execution when I'm reading, and when I'm writing, it's not always a conscious choice. I've mentioned this before, but most of my characterization analysis is a posthoc process. I just write what feels right, and then I sit back and evaluate what I've done. That was the case in the post where I talked about whether/how Gojou and Yuuji would be possessive, and this is more of the same.
First, as for whether my personal experiences play a role—nah. My preferred relationship mode is an open one where all parties involved are free to date or fuck whoever they want. I'm also aromantic as all hell, so the way I love my friends and lovers is the same; it's just a difference in intensity and approach. That doesn't lend itself to the kind of possessiveness that spices up fictional romance.
Now, onto Gojou! I'll be answering solely with goyuu in mind because that's (a) the only Gojou ship I care about and (b) the only ship other than satosugu that I consider plausible for Gojou. There would be differences in Gojou's behavior between goyuu and satosugu too, but my exploration of satosugu has been rather limited (references to a past relationship or outline notes on goyuuge development), so I'm not touching that angle.
When I say Gojou wouldn't share well, I specifically mean he'd be a horrendous metamour. As one third of a closed triad, for instance, I think he'd be quite fine. But sharing Yuuji with someone Gojou also doesn't love would bring out his cuntiest side because he is, fundamentally, sharing a role with them. He's not possessive of Yuuji's time or energy or even affection. He's canonically quite happy when Yuuji forms bonds with fellow sorcerers, and he seems to value Yuuji's approach to people and relationships.
What he would be possessive of is his role in Yuuji's life/heart. It's a tenuous thing, not because Yuuji's fickle or their bond is weak but because of the life they lead and the roles they play. There's a significant gap in age and experience, and for most of canon, Yuuji believes he's slated for execution, likely by Gojou's own hand. It's far from a secure basis for a relationship, and it only wouldn't stop either of them because they're both bugfuck insane in their own ways.
But they're still building a house of cards—at least it'd seem that way. Gojou wouldn't be insecure per se, but he'd be very aware of the fact that Yuuji could and should do better. On top of that, one of the defining moments in Gojou's life was Getou leaving—and leaving behind a hole nothing has filled, despite his earnest efforts. So having that hole filled (double entendre entirely intended) by a boy who has every reason to eventually leave—to find someone his own age, someone he doesn't believe would kill him, someone who hasn't made himself so untouchable that he's practically a god—would have him both keenly aware of the frailty of their relationship and no less invested for it.
That is what I base the flavor of Gojou's possessiveness on—consuming love, like I said in that other post. And it's not just that he wants to consume; he also wants to be consumed. That's not the kind of thing that leaves room for a third (or fourth or fifth) party, but if someone were to squeeze in—Yuuji has a big heart, and love's not a limited resource—Gojou would make their seat quite uncomfortable.
The specific way I write this varies. Often, it doesn't really need to be highlighted in the text because there are no external or internal factors warranting it. But off the top of my head, I've written
Gojou refusing to commit, having sex with Yuuji and others, and then acting like a right cunt when Yuuji also decides to get with someone else [fic]
Gojou preemptively snagging someone else Yuuji has an eye on to twist all three of them into a dysfunctional polycule [fic]
Gojou dubiously smoothly inserting himself into an ongoing sexual situation so that the end result comes out as a dysfunctional polycule (can you sense a pattern here?) [fic]
Gojou dragging his own teen self into the relationship with Yuuji to hasten the inevitable [fic]
My outlines have Gojou doing far worse too, and there are also non-possessive behaviors arising from the same psychological state—like Gojou believing Yuuji will leave but content to enjoy the time they do have together. I'd say that the most straightforward possessive Gojou I've written is the one in the kidnapping fic, and that's a specific cocktail of circumstances that bring out the worst of Gojou's impulses—even then, the possessive aspect only ramps up when a third party tries to make Yuuji leave Gojou. He also compensates (in a sense) later, though by that point, the whole relationship is...a radioactive mess.
This is already insanely long, so I'll shut up now. But I hope this more or less gives you the answers you wanted, anon!
25 notes
·
View notes
Note
can you say more about 'not being a left unity guy' and what that means to you? what's your vision of effective opposition to the far right without left unity?
so left unity means a million different things in a million different scenarios but:
"the left" is a posthoc label applied to a bunch of different people that all want wildly different things
one of the only real commonalities is how much everybody loves infighting. some of this is familiarity breeding contempt and the tyranny of small differences, and some is genuinely irreconcilable views of how society should be run
as a result i don't really think "unity" or anything approaching that is possible or even really desirable.
i think a good principle at all times is "if it looks like a fascist is going to take power, you need to shut up and get behind whichever force is best equipped to stop them, regardless of the circumstances"
however more often than not this involves allying with the center as opposed to other portions of the left, so we aren't even really talking about left unity at this point
37 notes
·
View notes
Text
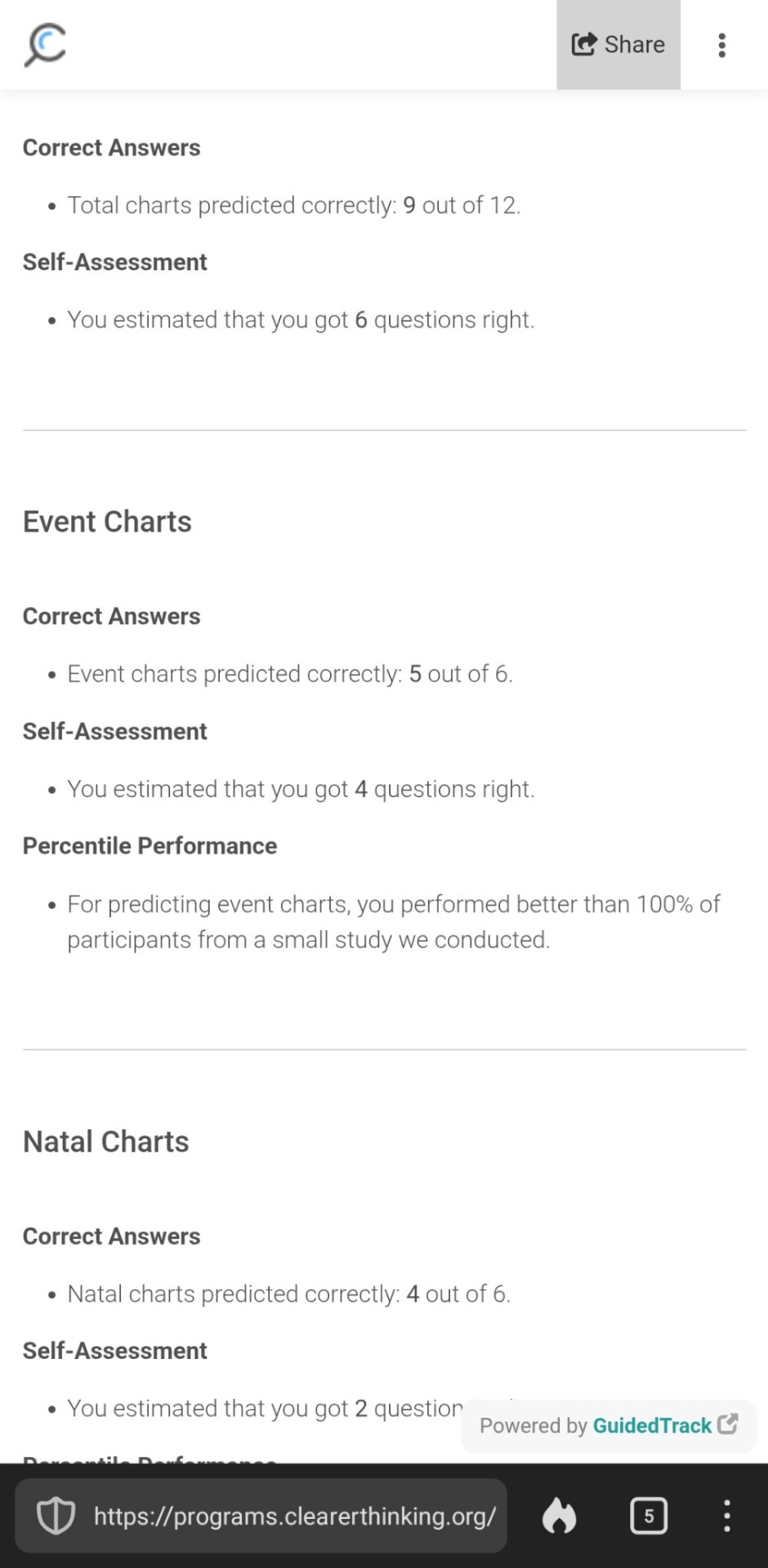
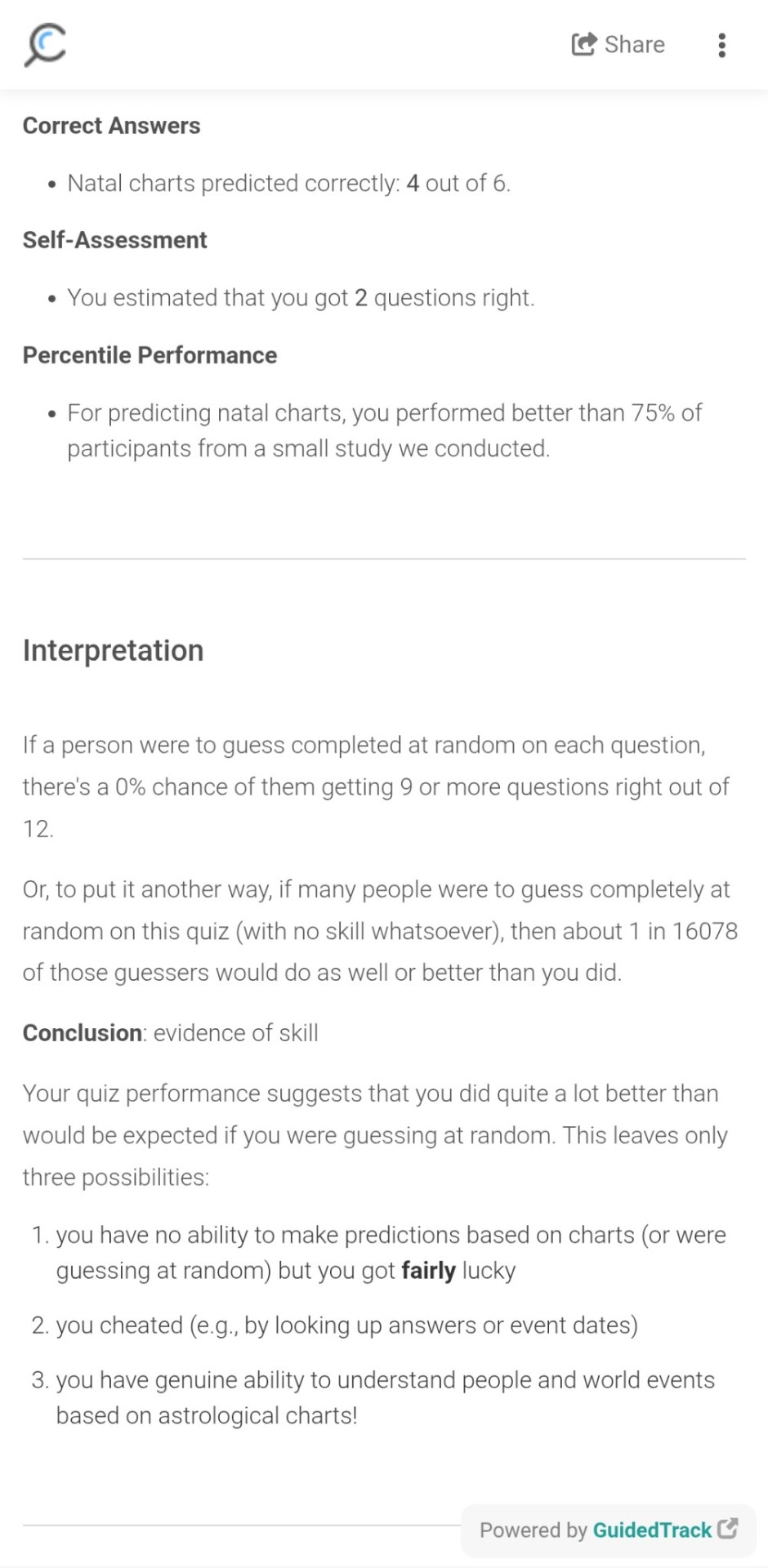
i am the cardinal lawrence of astrology but i think if a study is ever viral on this website you should actually read it because the two takeaways i had from this are 1) hellenistic astrologers performed best and 2) the pool of 152 only had 17 posthoc confirmed professionals (not necessarily self-reported experts)
i took the practice test and did stupid well with an ephemeris which is Not one of their criteria for cheating so they probably did not design These questions with astrologers because half of it tests history knowledge and whether you can date a chart, an entirely different skill than the study's premise
3 notes
·
View notes
Note
"Shadow was made based on Gerald studying the ancient echidna prophecy in Hidden Palace Zone." careful, you're getting fandom theories and headcanon mixed with the actual text of what you're talking about. there's never been a mention of Gerald working from Hidden Palace- all the ruins we see in SA2 are SA1 ruins. Even if Ian Flynn now retcons that in in some supplemental material, it'll still be a posthoc retcon.
Oh sorry I didn't see the sign over there

Not to be rude or anything, but I don't work for Sega or IDW or anyone official.
It's pretty clear Shadow is based on the look of Super Sonic. We never see Gerald investigate any ancient echidna stuff, but Maria does tell us some things about how the Artificial Chaos were created in the Shadow the Hedgehog flashback levels, confirming the obvious: that they were based on "the God of an ancient culture." (So, you know, Artificial Chaos were based on Chaos)
Now, what we see, both in Hidden Palace and Lost World, are murals depicting two things: a prophecy foretelling a fight between Eggman and Super Sonic, and Perfect Chaos. We never see any murals of lower forms of Chaos, but the Artificial Chaos are obviously based on something below Perfect Chaos.
When Chaos transforms for the first time, Eggman mentions "it's just as the stone tablets predicted." So there was possibly information on what lower forms of Chaos looked like. Where did he get them? Did he inherit them from Gerald?
Maybe he got them from The Lost World ruins. I mean, it's right outside of Final Egg, so maybe. Final Egg is also in the heart of a vast jungle, and from within Lost World itself, we can even see more ruins far in the distance. And if Eggman got them from Gerald's estate, who even knows where he got them from.
So there was detailed documentation about these things probably in multiple locations from both before and after the event that nearly wiped out Knuckles' ancestors and lead to the creation of Angel Island. After all, Lost World and Final Egg (plus the jungle surrounding it) aren't part of Angel Island -- only Icecap and Red Mountain are. (And a datamined list suggests Mushroom Hill was originally going to be represented in some form, too)
Through deduction, we can assume there's probably more than one Super Sonic mural. Maybe by different artists! Maybe even statues! Just like there are many different ancient hieroglyphs depicting Anubis in different shapes, styles, and forms.
It's splitting hairs. Live a little. It is an extremely educated guess that Shadow the Hedgehog is meant to be an interpretation of Super Sonic, wherever in ancient echidna culture that came from. The suggestion is pretty clear that Gerald was looking at that material around the same time both Biolizard and Shadow were created. It makes a hell of a lot more sense than "aliens from space made a blood pact."
44 notes
·
View notes
Note
I don’t doubt that the environment was toxic at Canton.
But I’d like to gently push back on the idea that Marina was giving them lesser material or wasn’t invested in giving them material that could win. They might feel that way and I don’t blame them because it’s all wrapped up in the negativity of that era but it doesn’t match what was actually put on the ice. Carmen was groundbreaking, has influenced many a program since, and was beyond difficult. Too difficult - they never skated it cleanly. But had they gone clean that season and won Worlds, they’d have had the momentum into Sochi. The music of Seasons never clicked in their minds, but the actual skating content is more sophisticated and more nuanced than any other free program they’ve done, and far far more intricate than D/W’s programs. Marina put in a counter clockwise circular step just to prove they could do it and nobody else could! The transitions are stunning! And V/M say themselves they should’ve stuck with Carmen for crowd appeal - a Marina program. So it’s not like that quad they were stuffed by bad material. They were stuffed by inconsistency, the feeling that they’d had their turn, and the USA desperately wanting a champion.
The fact that Marina didn’t manage their emotional distress is her fault. But *both* their 2014 programs WERE good enough to win gold, and should’ve won. The judges didn’t go with it because ice dance is a fake sport - not because D/W skated better or because their programs were better. But the judges failing to go with it now gets used as the posthoc justification by the V/M fandom for stating unequivocally that Marina didn’t give them the material. Except she did. Moonlight Sonata wouldn’t suddenly become a superior piece of choreography to Moulin Rouge if Gabriella’s costume hadn’t split and V/M only got silver in 2018. The same principle applies here.
i didn't say she gave them bad material. i think it's more like Marina put a finger on the DW side of the scale and gave them the A+ package and VM A- in the FD. it's not the choreo that's the issue, and certainly not the performance. it's the concept and the music. at the end of the day, difficulty and intricacy don't win the Olympics. you can't get higher than level 4, and you don't get a GOE or PCS bonus for that unless there's a big impact from it emotionally or through a wow factor
the comparison to 2018 is useful because again, VM had the same coach/choreographer as their rivals - Marie-France choreographed Moonlight Sonata too, and clearly both were vehicles that could have won their team gold - it almost went the other way
if Marie-France gave PC a program not to Beethoven but to Weber or Salieri - that would be like what Marina did to VM - Glazunov and Scriabin are respectable and even admired but Moonlight Sonata and Scheherazade are in the standard repertoire and played frequently all over the world for a good reason, while the music for Seasons is really not
i'm not saying whether the judges would have gone for VM or not. more that Marina didn't give VM the best FD vehicle to persuade them
#prokofiev tchaikovsky shostakovich were right there#it wasn't just vm that didn't click with the seasons music
8 notes
·
View notes
Text
something i will always fail to understand about this website is how hard it is for so many people on here to learn to question the “it was better before” instinct - nostalgia being one of its manifestations but not the only one. it’s a failure to historically interrogate processes and phenomena of the past, and a form of exceptionalism - things were not perfect back then but at least we had x, we need to bring y back, this was fucked up but it was at least better than what we have now, i would take (bigotry of the past) over (bigotry of the present) any day, etc.
I would say there’s 3 main manifestations of this issue - 1. justifying aesthetic choices as a posthoc political position - e.g. these endless posts decrying modern beige mcmansions and praising 70s maximalist architecture, as if one was “soulless capitalism” and the other wasn’t, instead of two equal manifestations of wealth and exploitation with different surfaces, 2. decrying the loss of imperial privileges as something to aspire to return to for citizens of the global north and especially the US - e.g. “we need to bring back the dollar menu!” or praising a time where a (white, middle-class, suburban) family could afford a home on a single income as something to aspire to; and 3. blatant misreading of a situation, lack of knowledge about a movement, or thinking historical processes were caused either by One Person (e.g. JK Rowling did unimaginable damage to feminism!) or by superstructural consequences (“stranger danger was such a damaging ideology for public life in the US”).
and then of course the plain and simple claim that is not only impossible to measure or prove but also refers to something that was demonstratively never a reality: “reading comprehension is at an all time low”, “media literacy is in shambles”, etc. when was this time when reading comprehension was high, and how would you define it in a way that applies to all the times it is used on this website?
and this is such a widespread and blatantly reactionary mindset. there is at least a bit of pushback now against the idealization of 60s gay bar culture and 80s tme lesbianism on here now, but this desire for a simpler, better, idealized past seeps into so many other spheres; the constant decrying of “ipad babies” and the widespread cognitive social decline this would supposedly cause, an idea as transparently fascistic as it gets; the longing for web 2.0 as a simpler, safer, more beautiful time; and of course the endless stream of “it’s not that deep” comments facing anyone who questions this instinct or points at this pattern.a good way to counter this impulse is, whenever you encounter a claim about x being in decline, or y having been greatly damaged by something, or wanting to have z, which was imperfect but better than it is now, asking yourself- what specific superior historical period am I referring to? what aspects, trends or phenomena of this period am I praising, and how do I know about those? what other forces were necessary to make this possible? what groups, countries, or classes were excluded from accessing those trends? do I implicitly base my vision and understanding of the past of my memories of being 10 years old or of rose-tinted glasses accounts from reactionaries? am I identifying correctly the cause-consequences relationship in this evolution?
5 notes
·
View notes
Text
Dumb gay Ex venting post!
Don't read if you don't wanna. Or do. It's really personal and we're terrified of opening up, we need to work on it. Gonna be a slightly long one.
We had a breakdown. A really bad one. Sam had destroyed the last piece of our already 99% destroyed night lords army. It had been destroyed all at once not a week or two before. Just as when we found that army destroyed, he dismissed our feelings with a "you'll fix it." Attitude. We freaked. Said mean things. Because in a house of 90% Sam property, Mall stuff was the only stuff that got destroyed like this. On. A. Daily. Basis. A fact that has curiously stopped now that he and his ilk are gone.
Anyway we freak and grab some luggage and move out. For a night. We got some support from our shockingly ready to help family (we had gone no contact 2 years earlier as our sister has aspersed our name to the entire family, claiming that we hither kid. This fact is important later as it informs how little we enjoy having our name spoken in gossip)
His friend Rowan swoops in to save the day! Telling us how awful we've treated sam! How we should just drink ourself to death and leave them out of it!
It set us off, the Alcoholic Indian stereotype that we've had thrown in our face time after time. We'd had people telling us as a CHILD that we would grow up to be an alcoholic since we're indian! Naturally we flipped. We had choice words that do NOT GET SHARED BETWEEN FRIENDS!(They had said more that needed addressing but the mocking to call us a reactionary tiktok catholic can wait cause it was a lil funny) It horrified us.
The terror and rage of being told such things by, not merely a friend or comrade, but by our COMPANION. A comrade we trusted with our life, our back, our shoulder in battle at times!
We knew it was WRONG when we were doing and saying it, not because they didn't deserve to be flayed Alive for what they said, but because they would turn that terror and sorrow into further ammunition for them to use against us. We knew they would.
By this point now, sam had locked us out of our OWN ROOM to sleep with another woman(hi xev) and we flipped. Not wanting to play the part of his cuckold wife any longer, we sent him away, at first for distance to figure our shit out apart.
While he was gone we asked him to get Rowan to apologize, instead he spent MONTHS defending them. Going to such lengths as to not only state that "they're ALSO hurting right now:(" (hurting about allll the awful things we said, which in turn posthoc justified the racist thing that they said!), but also he heard them out as they recounted the one time that we had "thrown the race card around casually."
Even AFTER disproving to our ex that we WEREN'T in fact "throwing the race card around to win arguments" (already a really fucking racist thing to say), Rowan STILL refused to budge, certain in their rightness. Sam for his part kept recounting how HURT their feelings were, that their hurt mattered more than mine. They just needed time!
They still haven't spoken to us once, stolidly refusing to face what they've said and done, certain they did the right thing.
White leftism looks like this, shrewd political tiptoeing followed by a ghosting.
Worse yet is that our ex kept going! He kept going back to his friends to gossip and collect new "charges" against us! Kept returning to accuse and recount what his friends and he had come up with!
-We treated sam like a literal dog in public! Calling and whistling for him, humiliating him!(we were trying to catch a literal dog. We were calling to him, then called to the little dog again.)
-We threw the race card around because once time when we were drunk we called Sam a racist!(at that point we had stopped talking about ojibwe culture with Samuel because he had, on three marked occasions, interrupted some innocuous ojibwe fairy tale to chime in the REAL INFORMED SCIENCE FACTS that PROVED THE OJIBWE STORIES WERE WRONG! We were drunk and pissed off about it still, months later.)
-We were stealing him away from his social life! Isolating him!(quite early on in our relationship we had devised a system that would allow for weekend days to be Our days together, to do chores and shopping and project work together. Since we work opposite shifts, day and night. We devised the system and he stuck loyally to Our Days and willfully made the decision to decline social event after social event ON OUR BEHALF, then came back round to try and blame US for those times. Those times when he "could have been doing something better than rotting in the house we bought together." )
He took these talking points and not only shoved them OUR way, but also dragged them into our couples counseling, where he recounted them as fact! Just as he recounted them amongst his gossips as fact, turning our former friends against us further.
Don't tell him that though, to imply that his opinions were affected by his friends would rob him of agency. These were just false thoughts that he came up with and recounted as factual to his friends who then all got even further in the "fuck mal" corner! This is better in his mind for... some reason, AND NOT something he should have to apologize for! It was just a moment of weakness!(A moment that lasted for MONTHS, months of returning to his gossips and running our name through the mud, like our sister did.)
We spiraled. Furthering our own deepening well of hate and terror that they could do this to us, we tormented him. Tormented by speaking his worst fears and insecurities to him via message board. We needed him to bleed by our words. Then we devolved. God did we devolve. There's so much we plum don't remember and will be going to great lengths to. It's mostly in text format in one way or another but deleted. Hopefully it comes back as our long term memory takes hold.
We acknowledge that there were times during our relationship when he had ignored us on an Our day, we didn't handle it well. Once, we freaked, got drunk, and got pissed that he had decided to spend one of Our days fucking someone else. Yelling and howling because we felt we were being cheated on.
He coerced us into opening the relationship during the literal lowest point in our life, our sister had just left on a sour note and we would have said ANYTHING to keep him. We feared he would leave if we said no, and he truly truly would have, he told us so. He would have left and we knew it. So we said yes, open our relationship. We spent the last days in this relationship unfulfilled and mocked by his boyfriend who stated that he had "won a competition he didnt know he was playing in" against us.
We didn't want it, and we put ourself through hoop and trapeze to reform ourself into something we thought was something he would love. We just made a parody of ourself. We're done with that.
We made what coping cries for help we could without coming right out and saying that we were unhappy. We didn't communicate it well. Not merely offhand comments about how little we care for his boyfriend, but how little we cared for this system. How jealous we were. He didn't care to notice though. He was getting what he wanted.
And look. We were right. All talking about what an evil awful scary abusive monster his ex was. How brave and great he was to grant that psycho as much GRACE as he did. What a good boy he is.
It's unjust and makes us sick to our stomach. They haven't spoken to us once in months, as stated. Ostracized in full from. Not just a friend group, but an entire support system. Rug pulled right out because one guy needed as many pets and "good boy!"s from as many approving mouths as he could. He didn't care that he was cashing in the "love of his life" to get them.
Anyway then when we wanted to change locks so we would have less fucking psycho thoughts about him(he kept sneaking around our house while we were gone and it was seriously triggering us and it setting off serious alarm bells, we would see him in places, and rowan. We will not be elaborating. We will be taking meds for it soon.), he threatened to have the police barge in and TAKE what was his. Which was like 90% of the furniture.
This is what happens when a white leftist is hurt. They fucking go down this route. So certain that giving up on their own ideals to trade in for a LITTLE security for their personal property. Nevermind just.... asking to fucking come in one day and be amicable about moving their shit out. No! Drop your years of "fuckcops" attitude to have the psycho Indian dragged off to jail(we would have been. This is not a debatable fact we would either have gone to jail or been shot stone dead.)
White leftism is a performative joke.
I don't know. It just needed recounting. We're missing details. There's more for sure, more were ashamed of and don't recount even to ourself. We will.
God willing we will fucking get past this all. It's over. It's done. He hates us and we hate him now.
#ex things#don't try to glean anytjing about our mental state or health here. we dont even know. its bad thoufh. halucinatory and delusion galore. fun.#our pov of these events was radio silence followed by accusation followed by regular ordinary bf gf contact#on and off again between eachbnew charge he would come up with. recriminations coming inwaves until finally he just gave up#claiming were just invalidating him on his charges. the false ones. the ones that were either only half true or fully untrue#hes an ass who doesnt deserve the flesh on his bones.
2 notes
·
View notes
Text
1. **Select Your Data Set and Variables**: - Ensure you have a quantitative variable (e.g., test scores, weights, heights) and a categorical variable (e.g., gender, treatment group, age group).2. **Load the Data into Python**: - Use libraries such as pandas to load your dataset.3. **Check Data for Missing Values**: - Use pandas to identify and handle missing data.4. **Run the ANOVA**: - Use the `statsmodels` or `scipy` library to perform the ANOVA.Here is an example using Python:```pythonimport pandas as pdimport statsmodels.api as smfrom statsmodels.formula.api import olsimport scipy.stats as stats# Load your datasetdf = pd.read_csv('your_dataset.csv')# Display the first few rows of the datasetprint(df.head())# Example: Suppose 'score' is your quantitative variable and 'group' is your categorical variablemodel = ols('score ~ C(group)', data=df).fit()anova_table = sm.stats.anova_lm(model, typ=2)print(anova_table)# If the ANOVA is significant, conduct post hoc tests# Example: Tukey's HSD post hoc testfrom statsmodels.stats.multicomp import pairwise_tukeyhsdposthoc = pairwise_tukeyhsd(df['score'], df['group'], alpha=0.05)print(posthoc)```5. **Interpret the Results**: - The ANOVA table will show the F-value and the p-value. If the p-value is less than your significance level (usually 0.05), you reject the null hypothesis and conclude that there are significant differences between group means. - For post hoc tests, the results will show which specific groups are different from each other.6. **Create a Blog Entry**: - Include your syntax, output, and interpretation. - Example Interpretation: "The ANOVA results indicated that there was a significant effect of group on scores (F(2, 27) = 5.39, p = 0.01). Post hoc comparisons using the Tukey HSD test indicated that the mean score for Group A (M = 85.4, SD = 4.5) was significantly different from Group B (M = 78.3, SD = 5.2). Group C (M = 82.1, SD = 6.1) did not differ significantly from either Group A or Group B."7. **Submit Your Assignment**: - Ensure you follow all submission guidelines provided by Coursera.If you need specific help with your dataset or any part of the code, feel free to ask!
3 notes
·
View notes
Text
Alcoholism and Major Lifetime Depression : W2 Data Analysis Tools
For the second week’s assignment of Data Analysis Tool on Coursera, we would continue to be working with NESARC’s dataset which contains information on alcohol and drug use and disorders, related risk factors, and associated physical and mental disabilities.
We would be studying the effect of Major Depression in the life of an individual on their alcohol consuming status. We'd be performing an Chi-Square test of Independence test between a categorical explanatory variable (alcohol drinking status ), and a categorical response variable (presence of major lifetime depression). We'll also be restricting the test to include only adults of age between 18-40.
The explanatory variable has 3 groups
Current Drinker
Ex Drinker
Lifetime Abstainer
The response variable has 2 groups.
0. No Lifetime Depression
1. Has Lifetime Depression
The null hypothesis is that there is no association between the drinking status of an individual and the presence of Major Lifetime Depression
Running a Chi-Square Test of Independence between the data for two variables, we get :
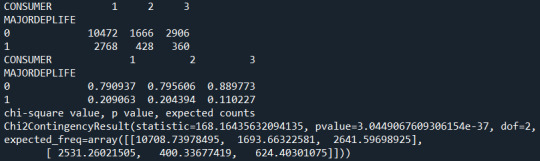
In the first table, the table of counts of the response variable by the explanatory variable, we see the number of individual under each consumer group (1,2, or 3), who do and do not have major lifetime depression. That is, among current drinkers, 10472 individuals do not have a Lifetime depression, while 2768 individuals do suffer from depression.
The next table presents the same data in percentages of individuals with or without lifetime depression under each alcohol consumer group. So 79% of current drinkers do not have major lifetime depression, while 21% do.
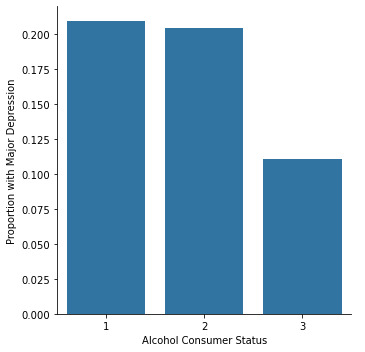
The graph below also conveys the same, just for the proportion of individuals under each alcohol consumer group who have Major Lifetime Depression. So, 21% of current drinkers and 20% of Ex-Drinkers have Major Lifetime Depression, while only 11 % of Lifetime abstainers have suffer from depression.
The Chi-Square Value from the test is large, about 168, while the p-value is very small (<< 0.0001), which tells us that the presence of Major Lifetime Depression and the Alcohol-Consuming Status of an individual are significantly associated.
The explanatory variable has 3 categories, and by observing the plot we can infer say that the Life-Time Abstainers had a significantly lower rate of life-time depression diagnosis compared to the current-drinkers and ex-drinkers. To quantitatively verify the same, and to avoid a type 1 error, we'll use the Bonferroni Adjustment Posthoc test.
Since we need to make only three pairs of comparisons, we would evaluate significance at the adjusted p-value of 0.017 (0.05/3).
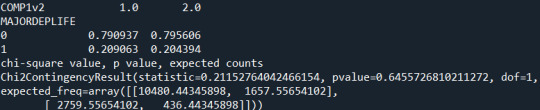
Now, running a chi-square test between just the group 1 and 2 of Alcohol-Consumer Status we get a low Chi-Square value of 0.211 and a large p-value 0.64 >> 0.017. We hence will accept the null-hypothesis that there is no significant difference in the rates of Major Lifetime Depression among current-drinkers and ex-drinkers.

Running a chi-square test between just the group 1 and 3 of Alcohol-Consumer Status we get a high Chi-Square value of 165 and a low p-value << 0.017. We hence will reject the null-hypothesis that there is no significant difference in the rates of Major Lifetime Depression among current-drinkers and life-time abstainers.

Finally, using a chi-square test between just the group 2 and 3 of Alcohol-Consumer Status we get a high Chi-Square value of 89 and a low p-value << 0.017. We hence will once again reject the null-hypothesis that there is no significant difference in the rates of Major Lifetime Depression among Ex-Drinkers and life-time abstainers.
Thus, using the Bonferroni Adjustment, we can conclude that there is a significant difference in the occurrence of major life-time depression between Lifetime alcohol Abstainers as compared to current-drinkers or ex-drinkers. However, the rate of depression is not significantly different between current-drinkers and ex-drinkers.
Python Code
@author: DKalaikadal159607 """
import pandas import numpy import scipy.stats import seaborn import matplotlib.pyplot as plt
data = pandas.read_csv('nesarc.csv', low_memory=False)
#new code setting variables you will be working with to numeric
data['MAJORDEPLIFE'] = pandas.to_numeric(data['MAJORDEPLIFE'], errors='coerce') data['CONSUMER'] = pandas.to_numeric(data['CONSUMER'], errors='coerce') data['AGE'] = pandas.to_numeric(data['AGE'], errors='coerce')
#subset data to young adults age 18 to 40
sub1=data[(data['AGE']>=18) & (data['AGE']<=40)]
#make a copy of my new subsetted data
sub2 = sub1.copy()
#contingency table of observed counts
ct1=pandas.crosstab(sub2['MAJORDEPLIFE'], sub2['CONSUMER']) print (ct1)
colsum=ct1.sum(axis=0) colpct=ct1/colsum print(colpct)
print ('chi-square value, p value, expected counts') cs1= scipy.stats.chi2_contingency(ct1) print (cs1)
seaborn.catplot(x="CONSUMER", y="MAJORDEPLIFE", data=sub2, kind="bar", ci=None) plt.xlabel('Alcohol Consumer Status') plt.ylabel('Proportion with Major Depression')
recode2 = {1: 1, 2: 2} sub2['COMP1v2']= sub2['CONSUMER'].map(recode2)
#contingency table of observed counts
ct2=pandas.crosstab(sub2['MAJORDEPLIFE'], sub2['COMP1v2']) print (ct2)
#column percentages
colsum=ct2.sum(axis=0) colpct=ct2/colsum print(colpct)
print ('chi-square value, p value, expected counts') cs2= scipy.stats.chi2_contingency(ct2) print (cs2)
recode3 = {1: 1, 3:3 } sub2['COMP1v3']= sub2['CONSUMER'].map(recode3)
#contingency table of observed counts
ct3=pandas.crosstab(sub2['MAJORDEPLIFE'], sub2['COMP1v3']) print (ct3)
#column percentages
colsum=ct3.sum(axis=0) colpct=ct3/colsum print(colpct)
print ('chi-square value, p value, expected counts') cs3= scipy.stats.chi2_contingency(ct3) print (cs3)
recode4 = {2: 2, 3: 3} sub2['COMP2v3']= sub2['CONSUMER'].map(recode4)
#contingency table of observed counts
ct4=pandas.crosstab(sub2['MAJORDEPLIFE'], sub2['COMP2v3']) print (ct4)
#column percentages
colsum=ct4.sum(axis=0) colpct=ct4/colsum print(colpct)
print ('chi-square value, p value, expected counts') cs4= scipy.stats.chi2_contingency(ct4) print (cs4)
0 notes
Text
1
ANOVA Analysis on the Effect of Teaching Methods on Test Scores
In this analysis, we examine whether there are significant differences in students' test scores based on different teaching methods: Traditional Lecture, Interactive Learning, and Online Learning. We use a one-way ANOVA to test for differences among the groups and conduct post hoc pairwise comparisons if the overall ANOVA is significant.
Create a data frame with test scores and teaching method
data <- data.frame( scores = c(78, 85, 82, 90, 87, 84, 92, 88, 91, 75, 80, 78, 76, 79, 77), method = factor(c(rep("Traditional", 5), rep("Interactive", 5), rep("Online", 5))) )
Run one-way ANOVA
anova_result <- aov(scores ~ method, data = data)
Display ANOVA table
summary(anova_result)
Post hoc pairwise comparisons using Tukey's HSD
posthoc <- TukeyHSD(anova_result)
Display post hoc results
posthoc
Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = scores ~ method, data = data) $method diff lwr upr p adj Interactive-Traditional 8.8 5.771838 11.828162 2.21e-05 Online-Traditional 1.4 -1.628162 4.428162 0.470873 Online-Interactive -7.4 -10.428162 -4.371838 4.39e-05
Interpretation:
The ANOVA results show a significant effect of teaching method on test scores (F(2,12) = 35.03, p < 0.001). This indicates that at least one teaching method leads to significantly different test scores compared to others.
Post hoc pairwise comparisons using Tukey's HSD test reveal that:
Interactive vs. Traditional: Students in the Interactive Learning group scored significantly higher than those in the Traditional Lecture group (mean difference = 8.8, p < 0.001).
Online vs. Traditional: There is no significant difference between the Online Learning and Traditional Lecture groups (mean difference = 1.4, p = 0.471).
Online vs. Interactive: Students in the Interactive Learning group scored significantly higher than those in the Online Learning group (mean difference = 7.4, p < 0.001).
These results suggest that Interactive Learning is more effective in improving students' test scores compared to both Traditional Lecture and Online Learning methods.
0 notes
Note
how would you describe your writing style? I've been reading your works since last year and I'm always so hooked with every word, I want to know how you personally interpret your own style because it's just so beautifully paced and written :DD
Thank you, anon! That's very flattering 🥺❤️
And gooood question actually. I've never really tried to describe it, aside from a general overview of the techniques I favor.
Emotion-heavy and highly internal: There's very little plot in my stories, and even when there is, it tends to be less about the events and more about how the characters are feeling and reacting to them. The bulk of the stories is comprised of character interactions and interior monologue.
Descriptive in a way that focuses on the senses: The specific senses I'm focusing on depends on the scene, but touch and sight tend to dominate, in porn and otherwise. These do the heavy lifting when it comes to setting the scene.
Extensive use of figurative language: Alliteration and assonance are my bread and butter, but named devices aside, I'm prone to building imagery and using those to convey mental states, relationships, general motifs, etc. Plus, it's fun to play with words like that.
That's the core of it, I think! It's not a style I consciously developed, so this is more of a posthoc analysis. The style isn't static either, though at this point, I'm building on these core elements more than making any major shifts or changes. I don't want to stagnate, but having a foundation I'm happy with is a good feeling. I'd like to tackle proper stream of consciousness someday, but the few times I've tried, it's been...slippery.
Thanks for asking this, anon! I had fun figuring out the answer.
6 notes
·
View notes
Text
Running on Analysis of Variance:
Python Code:
1. **Select Your Data Set and Variables**: - Ensure you have a quantitative variable (e.g., test scores, weights, heights) and a categorical variable (e.g., gender, treatment group, age group).
2. **Load the Data into Python**: - Use libraries such as pandas to load your dataset.
3. **Check Data for Missing Values**: - Use pandas to identify and handle missing data.
4. **Run the ANOVA**: - Use the `statsmodels` or `scipy` library to perform the ANOVA.
Here is an example using Python:```pythonimport pandas as pdimport statsmodels.api as smfrom statsmodels.formula.api import olsimport scipy.stats as stats# Load your datasetdf = pd.read_csv('your_dataset.csv')# Display the first few rows of the datasetprint(df.head())# Example: Suppose 'score' is your quantitative variable and 'group' is your categorical variablemodel = ols('score ~ C(group)', data=df).fit()anova_table = sm.stats.anova_lm(model, typ=2)print(anova_table)# If the ANOVA is significant, conduct post hoc tests# Example: Tukey's HSD post hoc testfrom statsmodels.stats.multicomp import pairwise_tukeyhsdposthoc = pairwise_tukeyhsd(df['score'], df['group'], alpha=0.05)print(posthoc)```5. **Interpret the Results**: - The ANOVA table will show the F-value and the p-value. If the p-value is less than your significance level (usually 0.05), you reject the null hypothesis and conclude that there are significant differences between group means. - For post hoc tests, the results will show which specific groups are different from each other.6. **Create a Blog Entry**: - Include your syntax, output, and interpretation. - Example Interpretation: "The ANOVA results indicated that there was a significant effect of group on scores (F(2, 27) = 5.39, p = 0.01). Post hoc comparisons using the Tukey HSD test indicated that the mean score for Group A (M = 85.4, SD = 4.5) was significantly different from Group B (M = 78.3, SD = 5.2). Group C (M = 82.1, SD = 6.1) did not differ significantly from either Group A or Group B."7. **Submit Your Assignment**: - Ensure you follow all submission guidelines provided by Coursera.If you need specific help with your dataset or any part of the code, feel free to ask!
1 note
·
View note
Text
i find arguments against moralism at times to fall apart-- i don't disagree that morals are subjective and easy to posthoc justify but that doesnt make u immune to morality or above having it. even explanations that address this end up saying something along the lines of "well xyz act is valuable because its beneficial for people", but even that avoids the question of WHY do you want to benefit people or help people who are not you? where does altruism come from if there is no difference if someone lives or dies if they are not in your life or impacting your life in any way?
is this something that makes sense for people with empathy + sympathy that function regularly? this is a genuine question, bcuz if i didn't have a personal moral code i cared about, i don't think i would be capable of caring for/about the material status of others who don't impact my life in any way. so if you care while also not thinking helping people is moral then like. why?
im open to being wrong 100%, bcuz i do agree with many critiques of moralism and i agree with materialism as a foundation for all social analysis but often time as these critiques conclude with "and we must help people anyway", i dont understand the motivation or reasoning behind that conclusion and it always sounds like an abstraction away from moralism
0 notes
Text
1. **Select Your Data Set and Variables**: - Ensure you have a quantitative variable (e.g., test scores, weights, heights) and a categorical variable (e.g., gender, treatment group, age group).2. **Load the Data into Python**: - Use libraries such as pandas to load your dataset.3. **Check Data for Missing Values**: - Use pandas to identify and handle missing data.4. **Run the ANOVA**: - Use the `statsmodels` or `scipy` library to perform the ANOVA.Here is an example using Python:```python import pandas as import statsmodels.api as from statsmodels.formula.api import import scipy.stats as stats# Load your dataset ddf = pd.read_csv('your_dataset.csv')# Display the first few rows of the data set print(df.head())# Example: Suppose 'score' is your quantitative variable and 'group' is your categorical variable model = ols('score ~ C(group)', data=df).fit()anova_table = sm.stats.anova_lm(model, typ=2)print(anova_table)# If the ANOVA is significant, conduct post hoc tests# Example: Tukey's HSD post hoc test form statsmodels.stats.multicomp import pairwise_tukeyhsdposthoc = pairwise_tukeyhsd(df['score'], df['group'], alpha=0.05)print(posthoc)```5. **Interpret the Results**: - The ANOVA table will show the F-value and the p-value. If the p-value is less than your significance level (usually 0.05), you reject the null hypothesis and conclude that there are significant differences between group means. - For post hoc tests, the results will show which specific groups are different from each other.6. **Create a Blog Entry**: - Include your syntax, output, and interpretation. - Example Interpretation: "The ANOVA results indicated that there was a significant effect of group on scores (F(2, 27) = 5.39, p = 0.01). Post hoc comparisons using the Tukey HSD test indicated that the mean score for Group A (M = 85.4, SD = 4.5) was significantly different from Group B (M = 78.3, SD = 5.2). Group C (M = 82.1, SD = 6.1) did not differ significantly from either Group A or Group B."7. **Submit Your Assignment**: - Ensure you follow all submission guidelines provided by Coursera.If you need specific help with your dataset or any part of the code, feel free to ask!
0 notes
Text
Select Your Data Set and Variables:
Ensure you have a quantitative variable (e.g., test scores, weights, heights) and a categorical variable (e.g., gender, treatment group, age group).
Load the Data into Python:
Use libraries such as pandas to load your dataset.
Check Data for Missing Values:
Use pandas to identify and handle missing data.
Run the ANOVA:
Use the statsmodels or scipy library to perform the ANOVA.
Here is an example using Python:import pandas as pd import statsmodels.api as sm from statsmodels.formula.api import ols import scipy.stats as stats # Load your dataset df = pd.read_csv('your_dataset.csv') # Display the first few rows of the dataset print(df.head()) # Example: Suppose 'score' is your quantitative variable and 'group' is your categorical variable model = ols('score ~ C(group)', data=df).fit() anova_table = sm.stats.anova_lm(model, typ=2) print(anova_table) # If the ANOVA is significant, conduct post hoc tests # Example: Tukey's HSD post hoc test from statsmodels.stats.multicomp import pairwise_tukeyhsd posthoc = pairwise_tukeyhsd(df['score'], df['group'], alpha=0.05) print(posthoc)
Interpret the Results:
The ANOVA table will show the F-value and the p-value. If the p-value is less than your significance level (usually 0.05), you reject the null hypothesis and conclude that there are significant differences between group means.
For post hoc tests, the results will show which specific groups are different from each other.
Create a Blog Entry:
Include your syntax, output, and interpretation.
Example Interpretation: "The ANOVA results indicated that there was a significant effect of group on scores (F(2, 27) = 5.39, p = 0.01). Post hoc comparisons using the Tukey HSD test indicated that the mean score for Group A (M = 85.4, SD = 4.5) was significantly different from Group B (M = 78.3, SD = 5.2). Group C (M = 82.1, SD = 6.1) did not differ significantly from either Group A or Group B.
0 notes