#polinomi
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text

“Inferocita, la Bestia contorceva i suoi integrali doppi e tripli per rintuzzare i polinomi con cui il re cercava di colpirla, scivolava in una serie infinita di termini indeterminati, poi si risollevava elevandosi a potenza, ma il re la attaccava con una serie di derivazioni parziali e totali da azzerare tutti i suoi coefficienti (si veda il Lemma di Riemann), e nella confusione che ne seguì i costruttori persero completamente di vista il re e la bestia.”
-Stanislav Lem
10 notes
·
View notes
Text
i have a cramp in my hand and i still suck at using taylor's polinomials
1 note
·
View note
Text
le persone che dicono che il latino non serve a niente, che non hanno mai usato la chimica o la trigonometria imparate al liceo nella vita VERA hanno in un certo senso inequivocabilmente ragione ma anche allo stesso tempo non hanno capito il motivo per cui sono andati a scuola.
Immagina avere la saggezza dei 50 anni e dire eh ma alla fine i polinomi mica ti servono per fare il 730
7 notes
·
View notes
Text
if nobody got me i know Tecnica Di Scomposizione Di Polinomi: Metodo Di Ruffini got me
#sunflower rambles#maths is a nightmare and this is one of the most painful techniques but also the most fun
6 notes
·
View notes
Note
based on the asks you sent to lyn, I think you might be interested in hearing about the weird number system me & my friend designed a year or two back.
it was based around the prime factorization of a number, so 124 would be written something like this: [2(2) 31]. This makes it really easy to multiply numbers, however addition is much harder, even counting is hard.
It's completely impractical for most usages, but it was interesting to think about & try to add two numbers
so I had a whole essay as an answer for this and then Tumblr crashed and it's gone :')
anyways ← smiling through the pain
yes I am interested about this! please come talk to me about math. I'm wondering now why you came up with this tho, because you are totally right. multiplication is almost trivial like this, but the rest of things??? at least you practice factorization
and how did you go about adding? im mostly curious about that
also!!!
fun fact, but we don't know if there exists an algorithm that computes the factorization of big numbers in a polinomial amount of time (a time that doesn't last centuries)
this is actually the base for RSA, an encryption method
basically you get two enormous primes p and q (like, hundreds of digits), and compute the following:
n=pq and ¶(n)=(p-1)(q-1)
then you want e such that e and ¶(n) are coprimes (their mcd is 1). you chose the e that strikes your fancy
then you want the opposite d of e mod ¶(n)
d = e(-1) mod (¶(n))
the equal should have three lines and not two. mods are a weird thing. very annoying and also very cool. basically what you are saying here is that ¶(n) divided by d has a residue of e(-1)
this is an easy computation because we know p, q and d
e and n are public numbers. everyone has access to them
now, i want to send a message using this encryption. because I made it, I know p,q and e. and say I'm sending the message to you, you also have p,q and e
i encrypt my message m using the following method:
c = m(e) mod (n)
and then you can easily get m using d
(the proof uses other concepts of mods that I'm too tired to explain but yeah)
the method is secured because to decrypt c you need to know the factorization of n, which computers can't compute quickly
#maths my beloveds#just sometimes tho#i will nerd over this#thanks for the ask btw!#i know i went very math student on you with this
12 notes
·
View notes
Text
O New FX COG Master System é uma reinter... https://forexlucro.com/introducao-ao-sistema-de-trading-new-fx-cog-master?feed_id=23917&_unique_id=67625a84d5c4b
0 notes
Text
Descripción del curso Cada minuto, las computadoras de todo el mundo recopilan millones de gigabytes de datos. ¿Qué puedes hacer para darle sentido a esta montaña de datos? ¿Cómo utilizan los científicos de datos estos datos para las aplicaciones que impulsan nuestro mundo moderno? La ciencia de datos es un campo en constante evolución que utiliza algoritmos y métodos científicos para analizar conjuntos de datos complejos. Los científicos de datos utilizan una variedad de lenguajes de programación, como Python y R, para aprovechar y analizar datos. Este curso se centra en el uso de Python en la ciencia de datos. Al final del curso, tendrá una comprensión fundamental de los modelos de aprendizaje automático y los conceptos básicos sobre el aprendizaje automático (ML) y la inteligencia artificial (IA). Usando Python, los estudiantes estudiarán modelos de regresión (lineal, multilineal y polinomial) y modelos de clasificación (kNN, logístico), utilizando bibliotecas populares como sklearn, Pandas, matplotlib y numPy. El curso cubrirá conceptos clave del aprendizaje automático, como: elegir la complejidad correcta, prevenir el sobreajuste, regularización, evaluar la incertidumbre, sopesar las compensaciones y evaluar modelos. La participación en este curso aumentará su confianza en el uso de Python, preparándolo para estudios más avanzados en aprendizaje automático (ML) e inteligencia artificial (IA), y avances en su carrera. Los estudiantes deben tener una base mínima de conocimientos de programación (preferiblemente en Python) y estadísticas para tener éxito en este curso. Los requisitos previos de Python se pueden cumplir con un curso introductorio de Python ofrecido a través de Introducción a la programación con Python de CS50, y los requisitos previos de estadística se pueden cumplir a través de Fat Chance o con Stat110 ofrecido a través de HarvardX. Lo que aprenderás Obtenga experiencia práctica y practique el uso de Python para resolver desafíos reales de ciencia de datos. Practique la programación y codificación de Python para modelado, estadística y narración de historias. Utilice bibliotecas populares como Pandas, numPy, matplotlib y SKLearn. Ejecute modelos básicos de aprendizaje automático utilizando Python, evalúe el rendimiento de esos modelos y aplíquelos a problemas del mundo real. Construya una base para el uso de Python en el aprendizaje automático y la inteligencia artificial, preparándolo para futuros estudios de Python. Si es un entusiasta de los datos, un profesional de la informática experimentado o está interesado en ingresar a la industria de más rápido crecimiento, este programa de certificación profesional desentraña las complejidades del panorama de datos actual y lo equipa con las habilidades necesarias para crear datos eficientes, precisos y procesables. perspectivas. Este programa de certificación profesional beneficiará a cualquier persona que posea o aspire a los siguientes puestos de trabajo: científico de datos, analista de datos, ingeniero de software, analista de inteligencia empresarial, ingeniero de aprendizaje automático, consultor de análisis de datos. La demanda de especialistas en IA y ML crecerá un 40% entre 2023 y 2027. La programación R tiene una gran demanda entre los científicos de datos. La encuesta salarial de Dice Technology realizada en diciembre de 2022 mostró que el salario promedio de los programadores de R aumentó un 3,8% con respecto a 2019. Contáctanos para más información y comienza a transformar tu futuro ahora mismo! Previatura: para obtener el certificado profesional completo hay que realizar tambien el curso introductorio CS50: Introducción a la informática A partir de CS50: Introducción a la informática, los estudiantes completarán una inmersión intensiva y completa en los conceptos básicos de la informática desarrollados por el renombrado profesor de la Universidad de Harvard, David J. Malan. El curso cubrirá conceptos como abstracción, algoritmos y estructuras y gestión ...
0 notes
Text

#tb al prof del liceo che mi insegna a trovare l'asintoto obliquo facendo la divisione tra polinomi (scrivendo sul mio quaderno, che non butterò mai)
non c'entra nulla, ma da lui mi sono sempre sentita capita
0 notes
Video
youtube
Penjumlahan Pengurangan Perkalian Polinomial
0 notes

Text
Os computadores quânticos, utilizando qubits versáteis, estão na vanguarda da solução de problemas complexos de otimização, como o dilema do caixeiro viajante, tradicionalmente atormentado pela ineficiência computacional. Através de análises matemáticas rigorosas, os investigadores demonstraram que a computação quântica pode transformar fundamentalmente a resolução de problemas, oferecendo um aumento polinomial mais eficiente no tempo de computação em comparação com os métodos clássicos e produzindo soluções superiores. O problema do caixeiro viajante é considerado um excelente exemplo de problema de otimização combinatória. Agora, uma equipe de Berlim liderada pelo físico teórico Prof. Jens Eisert da Freie Universität Berlin e HZB mostrou que uma certa classe de tais problemas pode realmente ser resolvida melhor e muito mais rápido com computadores quânticos do que com métodos convencionais. Os computadores quânticos usam os chamados qubits, que não são zero nem um como nos circuitos lógicos convencionais, mas podem assumir qualquer valor intermediário. Esses qubits são realizados por átomos altamente resfriados, íons ou circuitos supercondutores, e ainda é fisicamente muito complexo construir um computador quântico com muitos qubits. No entanto, métodos matemáticos já podem ser usados para explorar o que os computadores quânticos tolerantes a falhas poderão alcançar no futuro. “Existem muitos mitos sobre isso e, às vezes, uma certa quantidade de ar quente e exagero. Mas abordamos o assunto com rigor, utilizando métodos matemáticos, e entregamos resultados sólidos sobre o assunto. Acima de tudo, esclarecemos em que sentido pode haver alguma vantagem”, diz o Prof. Jens Eisert, que dirige um grupo de pesquisa conjunto na Freie Universität Berlin e no Helmholtz-Zentrum Berlin. O problema do caixeiro viajante é um clássico da matemática. Um viajante deve visitar N cidades pelo caminho mais curto e retornar ao ponto de partida. À medida que o número N aumenta, o número de rotas possíveis explode. Este problema pode então ser resolvido usando métodos de aproximação. Os computadores quânticos poderiam fornecer soluções significativamente melhores e mais rapidamente. Crédito: HZB Resolvendo Problemas Complexos O conhecido problema do caixeiro-viajante serve como um excelente exemplo: um viajante tem que visitar várias cidades e depois retornar à sua cidade natal. Qual é o caminho mais curto? Embora este problema seja fácil de entender, torna-se cada vez mais complexo à medida que o número de cidades aumenta e o tempo de cálculo explode. O problema do caixeiro viajante representa um conjunto de problemas de otimização de enorme importância económica, quer envolvam redes ferroviárias, logística ou otimização de recursos. Soluções suficientemente boas podem ser encontradas usando métodos de aproximação. O presente trabalho (seta) mostra que uma certa parte dos problemas combinatórios pode ser resolvida muito melhor com computadores quânticos, possivelmente até com exatidão. Crédito: HZB/Eisert Soluções e avanços quânticos A equipe liderada por Jens Eisert e seu colega Jean-Pierre Seifert usou agora métodos puramente analíticos para avaliar como um computador quântico com qubits poderia resolver esta classe de problemas. Um experimento mental clássico com caneta e papel e muita experiência. “Simplesmente assumimos, independentemente da realização física, que existem qubits suficientes e analisamos as possibilidades de realizar operações computacionais com eles”, explica Vincent Ulitzsch, estudante de doutoramento na Universidade Técnica de Berlim. Ao fazê-lo, revelaram semelhanças com um problema bem conhecido na criptografia, ou seja, a encriptação de dados. “Percebemos que poderíamos usar o algoritmo Shor para resolver uma subclasse desses problemas de otimização”, diz Ulitzsch. Isto significa que o tempo de computação não “explode” mais com o número de cidades (exponencial, 2N), mas só aumenta polinomialmente, ou seja, com Nx, onde x é uma constante.
A solução obtida desta forma também é qualitativamente muito melhor que a solução aproximada usando o algoritmo convencional. “Mostramos que para uma classe específica, mas muito importante e praticamente relevante de problemas de otimização combinatória, os computadores quânticos têm uma vantagem fundamental sobre os computadores clássicos para certas instâncias do problema”, diz Eisert. Referência: “Uma vantagem quântica superpolinomial em princípio para aproximar problemas de otimização combinatória por meio da teoria de aprendizagem computacional” por Niklas Pirnay, Vincent Ulitzsch, Frederik Wilde, Jens Eisert e Jean-Pierre Seifert, 15 de março de 2024, Avanços da Ciência. DOI: 10.1126/sciadv.adj5170 https://w3b.com.br/salto-quantico-redefinindo-a-solucao-de-problemas-complexos/?feed_id=9025&_unique_id=6695c0c1b2e84
0 notes
Text

“Inferocita, la Bestia contorceva i suoi integrali doppi e tripli per rintuzzare i polinomi con cui il re cercava di colpirla, scivolava in una serie infinita di termini indeterminati, poi si risollevava elevandosi a potenza, ma il re la attaccava con una serie di derivazioni parziali e totali da azzerare tutti i suoi coefficienti (si veda il Lemma di Riemann), e nella confusione che ne seguì i costruttori persero completamente di vista il re e la bestia.”
-Stanislaw Lem
3 notes
·
View notes
Text
MML - Minimal Math Library - release 1.0
Konačno gotovo 😎. Vektori, matrice, tenzori, polinomi, pravci, krivulje, ravnine, površine, funkcije realne, skalarne, vektorske s pripadnim derivacijama, interpolirane funkcije, integratori realnih, 2D i 3D skalarnih funkcija, line(path) i general surface integratori, solveri za linearne i ODE sisteme, root finding algoritmi te ugrađeni skup koordinatnih transformacija s mogućnošću…
View On WordPress
0 notes
Text
I geni sono tutti rinchiusi nei manicomi, non siamo più persone ma polinomi.
0 notes
Text
regression-modeling-practice Course Week_3
Test a Multiple Regression Model
(Testen Sie ein multiples Regressionsmodell)
My Research:
My research question was to establish the relationship and possible causality between global pollution (co2 emissions levels) and breastcancer per 100.000 female among countries. The relationship was later extended to include internet use and female employe rate among all countries.
Sample and measure
The aim of this assignment is to analysis the association and model fit among the following variables from the Gapminder dataset.
Explanatory variables – internet use rate, female employe rate, , co2 emissions
Response - Breastcancer per 100th Women
Code
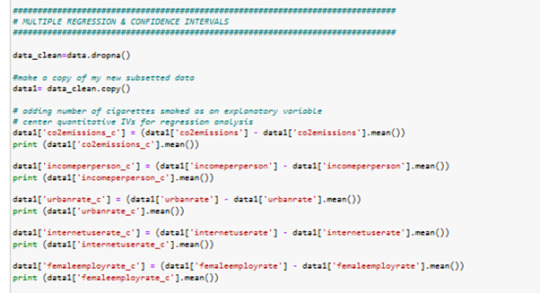
all columns of interest centered...
liniar regression anaylsis between values breastcancer100th and CO2emissions centered value:
R sguared is 8%
Pvalue is 0.001
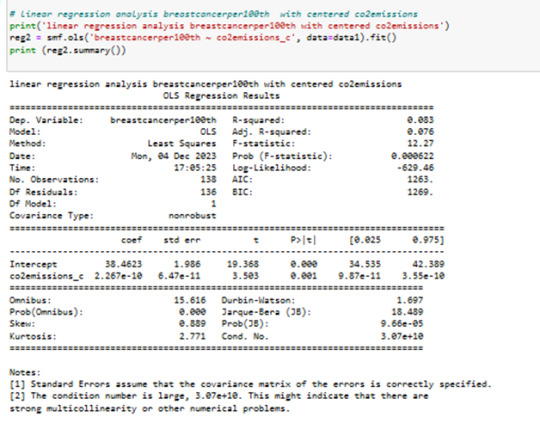
R sguared is 8%;
In fact, Co2 emissions explain only about 8% of the variability in breastcanserper100th.
So, there's clearly some error in estimating the response value with this model.
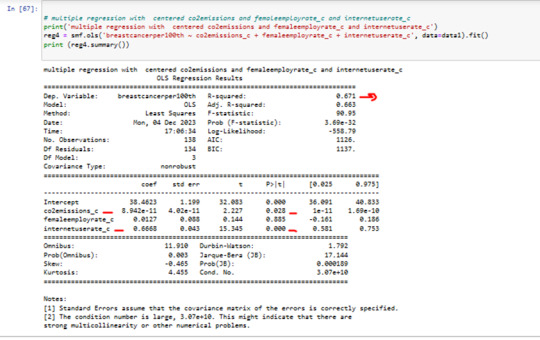
I added some other Values to my Modell
femaleemployrate and internetuserate are my new Values in my Modell
femaleemployrate has a P value0.88 >0.05
p value for femaleemployrate is not significant in this Modell
we can see that the R squared in 0.67
it means Co2 emissions + internetuserate together explain 67% of the variability in breastcanserper100th.
P value of internetuserrate is 0.001 and < 0.05
p value for internetuserate is significant in this Modell
as next I have added internetuserate^2 in my Modell
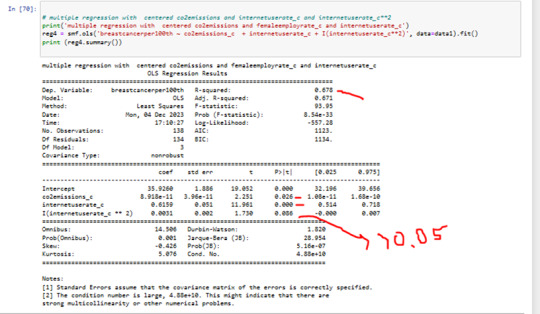
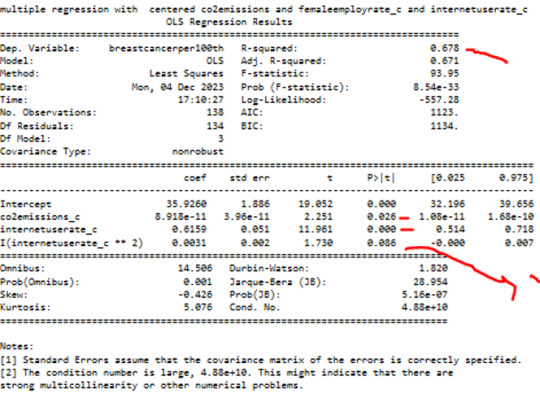
P value of quadratic term of internetuserate 0.08
.The quadratic term of internetuserate in our modell is not significant.
Plots
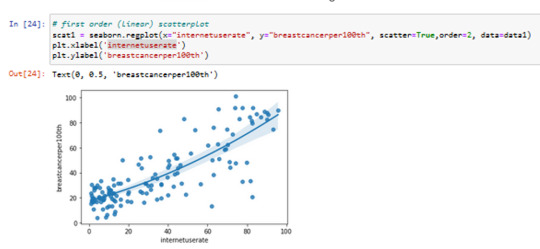
First Order scatter plot
x=internetuserate
y=breastcancerper100th

2 order scatterplot
x=internetuserate
y=breastcancerper100th
2 different modells to compare and Calculation Results

---------
Actually it was better to use linear model with internetuserate with R Value
But I have decided to use polinomial model for my further investigations to see the problems with this Modell
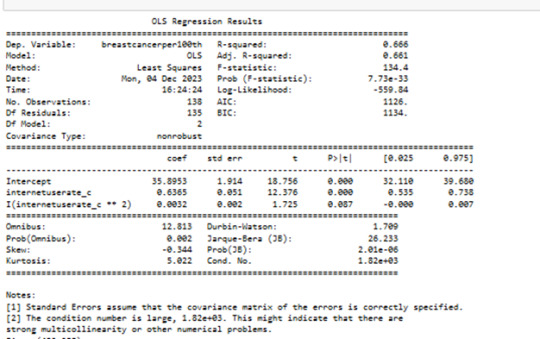
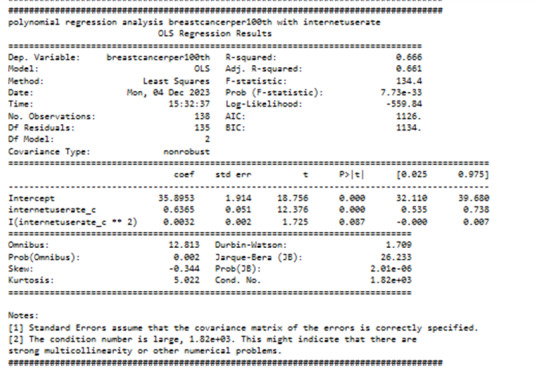
The governing beta equation is breastcancerperr100th = 33,89 + 0.5363 internateusarate_c + 0.0032 internateusarate_c**2.
Results 8: Residual analysis
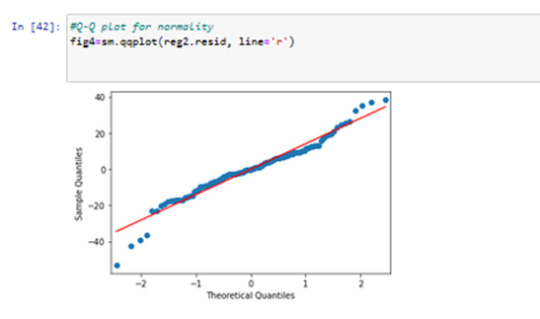
in QQ plot I can see the modell is not perfect fitting in first and last quartiles..
qq plot is not perfect normally distributed.
Results 9: Standardized Residual analysis
in residuals plot we can see some outliers by -3.5 standardized Reziduals..
I used standardized plot residuals, this is transformed to have a mean of 0 and standard deviation (Std) of 1. Most residuals fall within 2 Std of the mean (-2to 2). A few have more than 2 Stds (below 3 ), and below -3. For a normal distribution, I expect that 95% of the values falls within 2 stds of the mean. About 8 values fall aside this range indicating the possibility of outliers. There is only 1 extreme outlier outside 3 Stds of the mean.
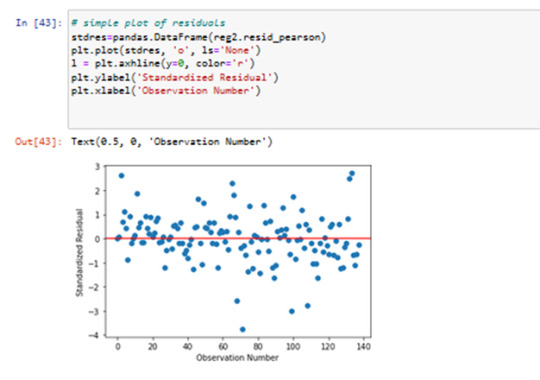
----Results 10: contribution of specific explanatory values to the model fit
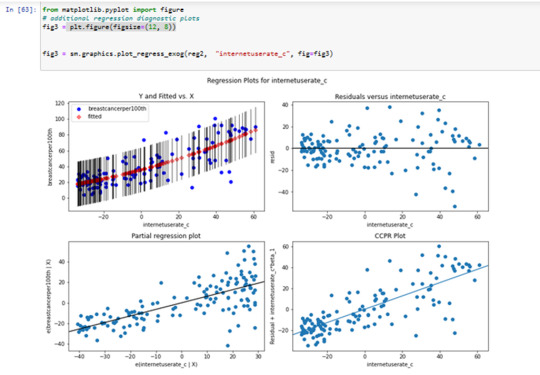
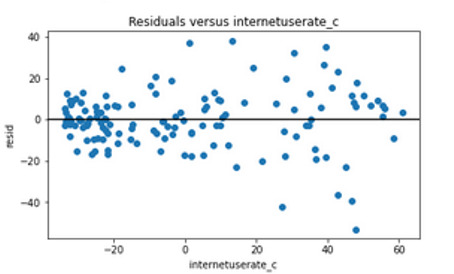
The plot in the upper right hand corner shows the residuals for
each observation at different values of Internet use rate.
There , we can see that the absolute values of the residuals
are significantly larger at higher values of Internet use rate.
But get smaller, closer to zero, as Internet use rate decreases.
I think, it' s better to use in this case only the linear modell with internetuserate.
Results 11: leverage plot analysis
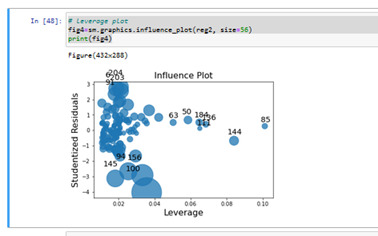
We've already identified some of these outliers in some of the other plots we've looked at, but this plot also tells us that these outliers have small or close to
zero leverage values, meaning that although they are outlying observations,
they don't have an undue influence on the estimation of the regression model.
On the other hand, we see that there are a few cases with higher average leverage.
This observation has a high leverage but is not an outlier.
(The leverage always takes on values between zero and one.)
Summary:
Conclusion
The hypothesis test shows that there is association between some of the explanatory variables CO2emissions, internet use and the response variable Breastcancer100th. The model fit better for linear regression than quadratic polynomial regression. As of now there is not enough evidence to prove causality.
0 notes