#partiql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
SNOWFLAKE REDSHIFT

Snowflake vs. Redshift: Choosing the Right Cloud Data Warehouse for Your Needs
Cloud-based data warehousing is the latest trend for modern businesses. These platforms offer immense scalability, elasticity, and simplified management compared to traditional on-premises solutions. Two titans in this space are Snowflake and Amazon Redshift. Choosing between them can have major implications for your budget, performance, and data strategy.
Let’s explore the key factors to consider when making this decision:
Architecture
Snowflake: Snowflake employs a unique multi-cluster, shared data architecture. It decouples storage and compute resources, allowing you to scale them independently. This results in greater flexibility and potential cost savings.
Redshift: Redshift uses a cluster-based architecture where computing and storage are more tightly coupled. While Redshift Spectrum allows you to query data directly in S3, scaling storage or computing usually requires resizing or adding nodes to your cluster.
Pricing
Snowflake: Snowflake’s pricing is based on separate storage and compute usage charges. You pay for storage per terabyte and compute resources based on per-second usage of virtual warehouses.
Redshift: Redshift pricing bundles compute and storage. You can choose on-demand pricing or save costs by committing to Reserved Instances for predictable workloads.
Performance
Both Snowflake and Redshift deliver excellent performance but exhibit strengths in different areas:
Snowflake: This type generally excels at handling highly concurrent workloads and scaling seamlessly due to its separation of computing and storage.
Redshift: May outperform Snowflake in specific scenarios with predictable workloads or where data locality optimizations can be carefully crafted.
Data Types and Support
Snowflake: Traditionally held an advantage in its native support for semi-structured data formats like JSON. It offers powerful features for easily manipulating and querying this data.
Redshift: Redshift has significantly closed the gap with its SUPER data type and PartiQL query language extensions, providing robust support for semi-structured data.
Management and Maintenance
Snowflake: Snowflake boasts a high degree of automation. It handles tasks like performance tuning, indexing, and vacuuming mainly behind the scenes, minimizing administrative overhead.
Redshift: While offering powerful tools, Redshift often demands more hands-on management and optimization efforts for peak performance.
The Verdict
There’s no single “best” choice; the right solution hinges on your specific needs and priorities:
Choose Snowflake if:
It would help if you had seamless scaling to handle highly variable workloads.
You prioritize low administrative overhead.
Your data strategy heavily involves semi-structured data.
Choose Redshift if:
You want more profound integration with other AWS services.
You can leverage Reserved Instances for cost optimization with predictable workloads.
You desire high customization and control over your data warehouse environment.
Beyond the Basics
This comparison merely scratches the surface. Other factors, such as security, compliance, ease of use, and specific features in each platform, should influence your decision. Thorough research and testing are vital before committing to either solution.
youtube
You can find more information about Snowflake in this Snowflake
Conclusion:
Unogeeks is the No.1 IT Training Institute for SAP Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Snowflake here – Snowflake Blogs
You can check out our Best In Class Snowflake Details here – Snowflake Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Photo

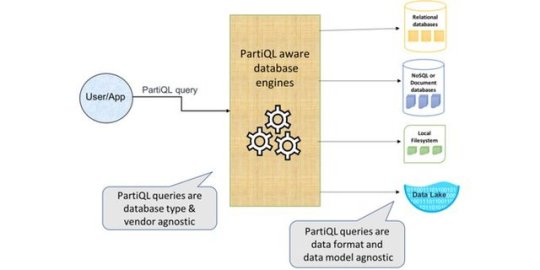
PartiQL: PartiQL’s extensions to SQL are easy to understand, treat nested data as first class citizens and compose seamlessly with each other and SQL. This enables intuitive filtering, joining and aggregation on the combination of structured, semistructured and nested datasets. via Pocket https://partiql.org/
0 notes
Text
Setting up Dev Endpoint using Apache Zeppelin with AWS Glue
AWS Glue is a powerful tool that is managed, relieving you of the hassle associated with maintaining the infrastructure. It is hosted by AWS and offers Glue as Serverless ETL, which converts the code into Python/Scala and execute it in Spark environment.

AWS Glue provisions all the required resources (Spark cluster) at runtime to execute the Spark Job which it takes ~7-10 mins and then starts executing your actual ETL code. To reduce this time AWS Glues provides Development endpoint, which can be configured in Apache Zeppelin (provisioned with the spark environment) to interactively, run, debug and test ETL code before deploying as Glue job or scheduling the ETL process.
In order to successfully set up the Dev Endpoint on AWS Glue, first let us understand some of its prerequisites:
An IAM Role for the Glue Dev Endpoint with the necessary policies. E.g.: AWSGlueServiceRole
Table in Glue Data Catalog and the necessary connection
I am assuming that you know your way around VPC networking, security groups, etc., E.g.: The Dev Endpoint requires a security group that allows the port 22, since we need that for the SSH tunneling.
Further, we can move on to the process involved in setting up the Dev Endpoint on AWS Glue. Here’s how it goes:
Create an SSL Key Pair
You can create it using PuTTyGen tool or you can create it under AWS EC2 -> Network & Security -> Key Pairs
You need the Public Key which should look like:
You will need the Private Key in .ppk format. If you’re using PuTTYgen, you will get it in the .ppk format whereas in case of EC2 you will get the file in .pem format and you will have to convert it into .ppk using the PuTTygen conversion tool.
Make sure that the file has permissions of 400 or 600 – in case of Linux whereas in case of windows follow the below steps:
Right click on PEM file > Properties > Security > Advanced.
Make sure that you are the owner of the file and have disabled the inheritance (once you have disabled it, it will look like below screenshot)
Spin up the AWS Glue Dev Endpoints:
Create it by going to AWS Glue -> Dev endpoints -> Add endpoint and you should see this:
In Development endpoint name: Give it any name; IAM Role: Select the role which you’ve created; and Click Next.
Choose “Skip Networking Information” if you have S3 data stores, otherwise you can select the rest two as per your instances or security groups. Click Next.
Now from your key pair values, paste the Public Key here as shown below and click Next:
Review the details and click on Finish:
Now let the process run and wait until the Provisioning status shows a “READY” State.
SSH tunnel for Glue Dev Endpoint: When your dev endpoint is provisioned, check that its network interface has a public address attached to it and make note of it (e.g., ec2-xx-xxx-xxx-xx.us-west-2.compute.amazonaws.com).
a. Create SSH tunnel using PuTTY:
b. Using SSH:
Zeppelin Notebook:
Write your first Glue program:
Download the Zeppelin Notebook 0.7.3 version.
Unzip the file and copy the folder under C: Drive.
Go to localhost:8080
On the top-right corner, click anonymous > interpreter > Search for spark > edit
Have Connect to existing process checked
Set host to localhost and port to 9007
Under properties, set master to yarn-client
Remove executor.memory and spark.driver.memory properties if they exist.
Save, Ok.
Under Notebook, create Notebook > select Spark Interpreter
Try your program and execute it.
And with that, your AWS Glue is up and running. Obviously this was just scratching the surface. There is a lot more to learn but I’ll cover those in another blog.
Reach out to us at Nitor Infotech to learn more about how you can deploy AWS Glue to simplify your ETL work, and if you’re in the mood for some light reading, you can take a look at a blog that I had penned down about AWS Redshift PartiQL.
1 note
·
View note
Text
Announcing PartiQL: One query language for all your data
https://aws.amazon.com/blogs/opensource/announcing-partiql-one-query-language-for-all-your-data/ Comments
1 note
·
View note
Text
A QLDB Cheat Sheet for MySQL Users
The AWS ledger database (QLDB) is an auditors best friend and lives up to the stated description of “Amazon QLDB can be used to track each and every application data change and maintains a complete and verifiable history of changes over time.” This presentation will go over what was done to take a MySQL application that provided auditing activity changes for key data, and how it is being migrated to QLDB. While QLDB does use a SQL-format for DML (PartiQL), and you can perform the traditional INSERT/UPDATE/DELETE/SELECT, the ability to extend these statements to manipulate Amazon Ion data (a superset of JSON) gives you improved capabilities and statements. Get a comparison of how to map a MySQL structure multiple tables and lots of columns into a single QLDB table and then benefit with an immutable and cryptographically verifiable transaction log. No more triggers, duplicated tables, extra auditing for abuse of binary log activity. We also cover the simplicity of using X Protocol and JSON output for data migration, and the complexity of AWS RDS not supporting X Protocol. Presented at Percona Live Online 2021 Slides http://ronaldbradford.com/blog/a-qldb-cheat-sheet-for-mysql-users-2021-05-13/
0 notes
Photo
RT @AWSOpen: Announcing PartiQL, one query language for your relational and non-relational data: https://t.co/ykrFrrOFEO https://t.co/VN2FLJkvqN (via Twitter http://twitter.com/awscloud/status/1158441700332724224)
0 notes
Text
AWS lanceert query-taal PartiQL
Onderzoekers van Amazon Web Services (AWS) hebben de nieuwe SQL-compatibele query-taal PartiQL gelanceerd. Hiermee is het mogelijk om data efficiënt te ‘queryen’, ongeacht de locatie of het format. De query-taal moet het mogelijk maken om gestructureerde data vanuit relationele databases te verwerken, schrijft Analytics India Magazine. PartiSQL belooft meer functies te hebben dan SQL, één van […] http://dlvr.it/RBC6hl
0 notes
Photo

Amazon's PartiQL query language eyes all data sources: Enterprises have another option for data management tasks with PartiQL, an open-source query language that AWS says can tap into data spread across multiple types of information stores in a unified fashion. The move comes after a proliferation of AWS data management service options. via Pocket https://ift.tt/2KuhQZg
0 notes
Text
2019/08/05-12
*AWS、SQL互換の新問い合わせ言語「PartiQL」をオープンソースで公開。RDB、KVS、JSON、CSVなどをまとめて検索可能 https://www.publickey1.jp/blog/19/awssqlpartiqlrdbkvsjsoncsv.html
*グーグルが出した「最終解」 理想のリーダーとチーム https://style.nikkei.com/article/DGXMZO48146440S9A800C1000000/ >習慣1 よいコーチであれ。 >習慣2 部下に権限を委譲せよ。��イクロマネジメントはするな。 >習慣3 部下の成功と幸せに関心を持て。 >習慣4 くよくよするな。生産的で結果志向であれ。 >習慣5 よいコミュニケーターであれ。そしてチームの声を聞け。 >習慣6 部下のキャリアについてサポートせよ。 >習慣7 明確なチームのビジョンと戦略を持て。 >習慣8 チームにアドバイスができるように技術的なスキルを磨け。
*サンワサプライ、窓やドアから引き込める0.25mm厚の隙間用LANケーブル https://pc.watch.impress.co.jp/docs/news/1201080.html
CPUの脆弱性「Spectre」に新たな亜種、これまでの対策は通用せず https://www.itmedia.co.jp/enterprise/articles/1908/08/news092.html
*「RHEL 7.7」公開、今後7系はメンテナンスフェイズへ https://mag.osdn.jp/19/08/07/160000
*【Amazon Elasticsearch Service】設計や運用をする前に読むべきドキュメントの要点まとめ http://blog.serverworks.co.jp/tech/2019/08/05/todo-aes-production/ > 1.ストレージ要件の確認 > 2.シャード数の検討 > 3.インスタンスタイプ、インスタンス数の検討 > 4.構築後、テスト、アラート設定
>ドキュメントの記載にもあるとおり、レプリカシャード数を増やすことで >検索パフォーマンスを改善することができますが、インデックス全体と >同量のディスク容量が必要とされます。
>レプリカシャード数の上限は[データノード数 -1]となり、越えている場合 >は書き込みできずにクラスターステータスが黄色となるので注意しましょう。
>ソースデータ x (1+ レプリカの数) x (1 + インデックス作成オーバー >ヘッド) ÷ (1 ? Linux 予約スペース) ÷ (1 ? Amazon ES のオーバー >ヘッド) = 最小ストレージ要件
>プライマリシャード数についてはシャードのサイズが10-50GiBにすると >良いと記載があります。 > >デフォルトはプライマリシャード数:5、レプリカシャード数:1
>インスタンスタイプによりEBSサイズの制限が異なるので、注意しましょう。
>データノード数については、専用マスターノードを使う場合は2以上、 >使わない場合は3以上が推奨です。
>また��よりパフォーマンスとクラスターの信頼性を向上させたい場合は >専用マスターノードを利用しましょう。
>ローリングインデックス(継続的にデータを投入し、保存期間などを >決めてローテーションする)の場合、インデックスのローテーションが >必要となります。
*Trusted Advisorて゛最低限のセキュリティチェックを行う https://dev.classmethod.jp/etc/trustedadvisor-security-check/
*EC2 Eメール送信制限解除はなぜ必要なのか https://dev.classmethod.jp/beginners/ec2-port-25-throttle/ >初期状態の EC2 インスタンスでは Eメールを送信する際に利用する >SMTP ポート 25番の通信に制限が設けられています。
>逆引き設定がなされていないサーバーから Eメールを送信した場合には >スパムメールと認識され、送信した Eメールの受信を拒否されてしまう >ことがあります。
>AWS では Amazon SES(Simple Email Service) という Eメール送信の >仕組みを提供しています。
0 notes
Quote
こんな情報を見つけたよ AWS、SQL互換の新問い合わせ言語「PartiQL」をオープンソースで公開。RDB、KVS、JSON、CSVなどをまとめて検索可能 - Publickey https://t.co/EbVV2egwuD— 壊れbot 2号 (@broken_bot_2) August 7, 2019 August 07, 2019 at 01:21PM
http://twitter.com/broken_bot_2/status/1158956296881745921
0 notes
Link
0 notes
Text
2020: The year in review for Amazon DynamoDB
2020 has been another busy year for Amazon DynamoDB. We released new and updated features that focus on making your experience with the service better than ever in terms of reliability, encryption, speed, scale, and flexibility. The following 2020 releases are organized alphabetically by category and then by dated releases, with the most recent release at the top of each category. It can be challenging to keep track of a service’s changes over the course of a year, so use this handy, one-page post to catch up or remind yourself about what happened with DynamoDB in 2020. Let us know @DynamoDB if you have questions. Amazon CloudWatch Application Insights June 8 – Amazon CloudWatch Application Insights now supports MySQL, DynamoDB, custom logs, and more. CloudWatch Application Insights launched several new features to enhance observability for applications. CloudWatch Application Insights has expanded monitoring support for two databases, in addition to Microsoft SQL Server: MySQL and DynamoDB. This enables you to easily configure monitors for these databases on Amazon CloudWatch and detect common errors such as slow queries, transaction conflicts, and replication latency. Amazon CloudWatch Contributor Insights for DynamoDB April 2 – Amazon CloudWatch Contributor Insights for DynamoDB is now available in the AWS GovCloud (US) Regions. CloudWatch Contributor Insights for DynamoDB is a diagnostic tool that provides an at-a-glance view of your DynamoDB tables’ traffic trends and helps you identify your tables’ most frequently accessed keys (also known as hot keys). You can monitor each table’s item access patterns continuously and use CloudWatch Contributor Insights to generate graphs and visualizations of the table’s activity. This information can help you better understand the top drivers of your application’s traffic and respond appropriately to unsuccessful requests. April 2 – CloudWatch Contributor Insights for DynamoDB is now generally available. Amazon Kinesis Data Streams for DynamoDB November 23 – Now you can use Amazon Kinesis Data Streams to capture item-level changes in your DynamoDB tables. Enable streaming to a Kinesis data stream on your table with a single click in the DynamoDB console, or via the AWS API or AWS CLI. You can use this new capability to build advanced streaming applications with Amazon Kinesis services. AWS Pricing Calculator November 23 – AWS Pricing Calculator now supports DynamoDB. Estimate the cost of DynamoDB workloads before you build them, including the cost of features such as on-demand capacity mode, backup and restore, DynamoDB Streams, and DynamoDB Accelerator (DAX). Backup and restore November 23 – You can now restore DynamoDB tables even faster when recovering from data loss or corruption. The increased efficiency of restores and their ability to better accommodate workloads with imbalanced write patterns reduce table restore times across base tables of all sizes and data distributions. To accelerate the speed of restores for tables with secondary indexes, you can exclude some or all secondary indexes from being created with the restored tables. September 23 – You can now restore DynamoDB table backups as new tables in the Africa (Cape Town), Asia Pacific (Hong Kong), Europe (Milan), and Middle East (Bahrain) Regions. You can use DynamoDB backup and restore to create on-demand and continuous backups of your DynamoDB tables, and then restore from those backups. February 18 – You can now restore DynamoDB table backups as new tables in other AWS Regions. Data export to Amazon S3 November 9 – You can now export your DynamoDB table data to your data lake in Amazon S3 to perform analytics at any scale. Export your DynamoDB table data to your data lake in Amazon Simple Storage Service (Amazon S3), and use other AWS services such as Amazon Athena, Amazon SageMaker, and AWS Lake Formation to analyze your data and extract actionable insights. No code-writing is required. DynamoDB Accelerator (DAX) August 11 – DAX now supports next-generation, memory-optimized Amazon EC2 R5 nodes for high-performance applications. R5 nodes are based on the AWS Nitro System and feature enhanced networking based on the Elastic Network Adapter. Memory-optimized R5 nodes offer memory size flexibility from 16–768 GiB. February 6 – Use the new CloudWatch metrics for DAX to gain more insights into your DAX clusters’ performance. Determine more easily whether you need to scale up your cluster because you are reaching peak utilization, or if you can scale down because your cache is underutilized. DynamoDB local May 21 – DynamoDB local adds support for empty values for non-key String and Binary attributes and 25-item transactions. DynamoDB local (the downloadable version of DynamoDB) has added support for empty values for non-key String and Binary attributes, up to 25 unique items in transactions, and 4 MB of data per transactional request. With DynamoDB local, you can develop and test applications in your local development environment without incurring any additional costs. Empty values for non-key String and Binary attributes June 1 – DynamoDB support for empty values for non-key String and Binary attributes in DynamoDB tables is now available in the AWS GovCloud (US) Regions. Empty value support gives you greater flexibility to use attributes for a broader set of use cases without having to transform such attributes before sending them to DynamoDB. List, Map, and Set data types also support empty String and Binary values. May 18 – DynamoDB now supports empty values for non-key String and Binary attributes in DynamoDB tables. Encryption November 6 – Encrypt your DynamoDB global tables by using your own encryption keys. Choosing a customer managed key for your global tables gives you full control over the key used for encrypting your DynamoDB data replicated using global tables. Customer managed keys also come with full AWS CloudTrail monitoring so that you can view every time the key was used or accessed. Global tables October 6 – DynamoDB global tables are now available in the Europe (Milan) and Europe (Stockholm) Regions. With global tables, you can give massively scaled, global applications local access to a DynamoDB table for fast read and write performance. You also can use global tables to replicate DynamoDB table data to additional AWS Regions for higher availability and disaster recovery. April 8 – DynamoDB global tables are now available in the China (Beijing) Region, operated by Sinnet, and the China (Ningxia) Region, operated by NWCD. With DynamoDB global tables, you can create fully replicated tables across Regions for disaster recovery and high availability of your DynamoDB tables. With this launch, you can now add a replica table in one AWS China Region to your existing DynamoDB table in the other AWS China Region. When you use DynamoDB global tables, you benefit from an enhanced 99.999% availability SLA at no additional cost. March 16 – You can now update your DynamoDB global tables from version 2017.11.29 to the latest version (2019.11.21) with a few clicks on the DynamoDB console. By upgrading the version of your global tables, you can easily increase the availability of your DynamoDB tables by extending your existing tables into additional AWS Regions, with no table rebuilds required. There is no additional cost for this update, and you benefit from improved replicated write efficiencies after you update to the latest version of global tables. February 6 – DynamoDB global tables are now available in the Asia Pacific (Mumbai), Canada (Central), Europe (Paris), and South America (São Paulo) Regions. NoSQL Workbench May 4 – NoSQL Workbench for DynamoDB adds support for Linux. NoSQL Workbench for DynamoDB is a client-side application that helps developers build scalable, high-performance data models, and simplifies query development and testing. NoSQL Workbench is available for Ubuntu 12.04, Fedora 21, Debian 8, and any newer versions of these Linux distributions, in addition to Windows and macOS. March 3 – NoSQL Workbench for DynamoDB is now generally available. On-demand capacity mode March 16 – DynamoDB on-demand capacity mode is now available in the Asia Pacific (Osaka-Local) Region. On-demand is a flexible capacity mode for DynamoDB that is capable of serving thousands of requests per second without requiring capacity planning. DynamoDB on-demand offers simple pay-per-request pricing for read and write requests, so you only pay for what you use, making it easy to balance cost and performance. PartiQL support November 23 – You can now use PartiQL, a SQL-compatible query language, to query, insert, update, and delete table data in DynamoDB. PartiQL makes it easier to interact with DynamoDB and run queries on the AWS Management Console. Training June 17 – Coursera offers a new digital course about building DynamoDB-friendly apps. AWS Training and Certification has launched “DynamoDB: Building NoSQL Database-Driven Applications,” a self-paced, digital course now available on Coursera. About the Author Craig Liebendorfer is a senior technical editor at Amazon Web Services. He also runs the @DynamoDB Twitter account. https://aws.amazon.com/blogs/database/2020-the-year-in-review-for-amazon-dynamodb/
0 notes
Link
Amazon Web Services(以下AWS)は、SQL互換の新しい問い合わせ言語およびそのリファレンス実装である「PartiQL」をオープンソースとして公開したことを発表しました。
0 notes
Text
AWS、SQL互換の新問い合わせ言語「PartiQL」をオープンソースで公開。RDB、KVS、JSON、CSVなどをまとめて検索可能 https://t.co/MSYfJA0OZNhttps://twitter.com/narinarita1980/status/1158038188650196992Sun Aug 04 15:33:14 +0000 2019
0 notes