#my image tag was “bitmap” and that's the only one i remember
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
how come we all used to tag file types when we reblogged posts. why'd we do that. i remember i did it too but that's just 'cause i saw everybody else doing it
#my image tag was “bitmap” and that's the only one i remember#and actually the only reason i bring this up is because i just saw someone doing it on ffp#so i guess it's less of a “used to” than i thought
2 notes
·
View notes
Photo
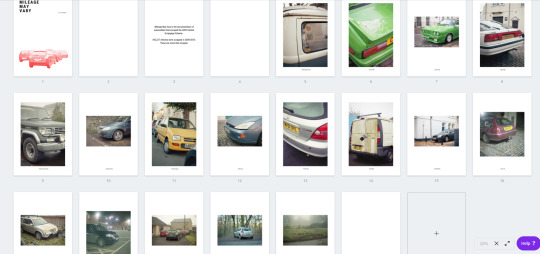
PHOT301 - Mileage May Vary - Work in Progress Zine & Experimental Journal Ideas
The zine is something that I had mentioned in the formative assessment for PHOT301. I wanted to make this because I was curious to see how this body of work came together in a book/zine/magazine format. One of the end results that I want to have for the FMP is a coffee table style book that can be viewed at Free Range, and contain a multitude of images from this project that clearly shows what my project is about. For this, I need to run a few tests to figure out what I should be creating, and how to make it.
For this, I decided to create a zine style of booklet, displaying images from this project that I particularly enjoy. The rationale for the selection process was selecting the cars that had an air of intrigue within them, whether that be with damage to the vehicle, or that the vehicle is particularly rare to see. I then decided to lay out the zine with the cars in chronological order, going from oldest to newest. However, it finishes with the aftermath of the crash that happened very close to where I was staying during Christmas, but sadly missing its departure only by an hour or so.
The front cover was also something that I was contemplating for a while, and was the most worrisome part of the whole experience. I knew how I wanted to display my images, and how which ones I wanted, but was very unsure on what would represent the front cover. I have always wanted to rejuvenate my graphic design style of work that I undertook during my Access Course and PHOT103.

This is my favourite example from Exploded Image, all the way back in first year. This project was mainly a spin on our very alienating, fast paced and transport centric world. It was heavily influenced by Stanley Donwood’s artwork for the ever inspiring 1997 OK Computer by Radiohead. This is a style I have wanted to revive and to place elements of it into my current work - I also find it interesting how a lot of the earlier aspects of my degree are surfacing up again, which is a welcome change to the fairly similar work that was undertaken during year two.
I had an idea of what I wanted to create, but unsure about how undertake it. The graphic elements had to be a part of it to make somewhat of a statement with the front cover. I don’t necessarily want it to be a straight photograph, as it only really tells you about the photograph, rather than the project. Subtle hints to what the project is about, seems like a good aim for me.

Before

After
Above, is what I had created. I chose to use the cluster of parked Fiats and Alfa Romeo as it featured a good amount of cars, rather than a singular vehicle in the image. I opened it up into GIMP and erased away the surroundings, only keeping the parked cars. The photograph was then desaturated and then coloured red in a gradient map style, with an added a bitmap style of manipulation. This was the emulate the newspaper print styling of new reports of the scheme, and the red colouring represents the Labour government that brought the scheme to fruition.

The plates were also covered up with a piece of paper that I found around a while ago. Its a form of tag which was most likely used to detail scrap parts in a yard, by K.J. Pike.

The back features a few options to fill in, mostly in a warehouse setting. K.J. Pike comes up as a company in Blandford Forum that repairs and refurbishes trolleys. Annoyingly I can’t remember where I found it, but I do remember that it was on a rather wet and drizzly day, and it was stuck to the road. I also knew that I had use it at some point for MMV.

Final Version
There is also a second version which has been edited differently and features no blacks and blends more into the white. For me, I prefer this version purely because it blends more into the whites and the aesthetic is likened to poster design, of which I enjoy. This was created by adjusting the contrast and the lightness of the colouring, with the addition of the ‘scrapped’ tag being merged into the car layer.

The front cover has been kept fairly clean and clinical. I wanted there to be a lot of white space like a gleaming shopping mall to juxtapose the featuring images, with the cover to represent the entire project in such a way that it doesn’t spell it out - almost having a level of ambiguity to it. I also used Roboto Condensed for all of the writing (albeit minimal) as I rather like the modern sans style font. It also manages to lend itself quite well to the graphic design style of the cover image.

This isn’t just an online zine, it is also a physical one. I wanted to have something physical, as it seemed a shame to not have anything physical apart from a selection of prints. The zine is more of a work in progress publication, rather than what the final thing will look like. I wanted to see how my images work in a physical space, culminated into a small A4 booklet. I decided to print this at The Artside, just so I could have it fastback bound. I didn’t want to have it stapled together, or have it ring bound as I am not a massive fan of both of those options for something that will be a photo book in the end. Stapling the book will make it look like a magazine, and ring binding will make it more of a document. Fastback binding, to me, looks far more professional and sleek, keeping everything clean and low profile. It was printed onto 200gsm satin card with a black card backing.

The print quality is pleasing, and perfectly fits the ‘zine’ aesthetic. An example of the front cover here shows the sharpness of the print, in addition to the colour reproduction. The photographs of the zine was taken with my Lumix G1 with a CCTV 25mm F1.4 lens. This lens gives a unique swirly bokeh and the fast aperture of F1.4.





In total, this zine cost me £15 including printing and binding, which I think is a decent price for the end result. Not to mention that it only took around 30 minutes to make, so it was nice to hand in my PDF file, grab a coffee and come back with it all finished and ready to take home. Another bonus to this, is supporting a local business. While it is sometimes nice to order a nice photo book online, I would rather help support local business who still get a good footfall of students come in for there printing - it keeps them in business and provides us with quality products. Whilst this is a good thing, I would also like to invest in a thermal binder somewhere down the line, so I would be able to make my own zines. However, for the time being I am happy to support local businesses and keeping them going. I am also happy with the zines outcome, and I am looking forward to seeing what I’ll be able to create next with the up and coming work flow.
Experimental Journal Plans
The experimental research journal takes on the same form of the zine, in terms of the cover at least. This is to keep a level of continuity within the project. However, I would like to make it more of a manual rather than a journal, and link in some MOT certificate aspects.

This shows the changes to the MOT certificate back in 2018, with the older version on the left and the new version on the right. I would like to utilise the older version, which would contain details about the shoot/research, with the opposite page showing contact sheets/images and practitioners work. Along with this will be an ‘advisories’ and a ‘reasons for failure’ section detailing things to change and things that didn’t work. These are to reflect the MOT test needed for cars to stay on the road.
The journal will include all shoots, containing the contact sheets and some highlighted images. Practitioners work will also be included with the same advisory and failure sections. These sections will be redacted and kept to a very minimal word count. This blog is very wordy, and I want the experimental/condensed journal to be a cut down version of my shoots and contextual information that advises my thinking. This shall also be created in Canva, following the same front cover and adding the MOT certificate base to form the journal.
0 notes
Text
Version 241
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a good week. I fixed things and moved the duplicate search stuff way forward.
fixes and a note on cv
I've fixed the stupid 'add' subscription bug I accidentally introduced last week. I apologise again--I have added a specific weekly test to make sure it doesn't happen again.
With the help of some users, I've also updated the clientside pixiv login for their new login system. It seems to work ok for now, but if they alter their system any more I'll have to go back to it. Ideally, I'd like to write a whole login engine for the client to allow login for any site and make pixiv and anything else work with less duct tape and more easily maintainable.
For Windows users, I've updated the client's main image library (OpenCV) this week, and this new version looks to be more stable (it loads some files that crashed the old version). If you are on Windows and have 'load images with PIL' checked under options->media, I recommend you now turn it off--if you have a decent graphics card, your images will load about twice as fast.
duplicate files are now findable
Dupe file display or filtering is not yet here. If you are interested in this stuff, then please check it out and let me how you get on, but if you are waiting for something more fun than some numbers slowly getting bigger, please hang in there for a little longer!
I have written code to auto-find duplicate pairs and activated the buttons on the new duplicates page (which is still at pages->new search page->duplicates for now).
The idea of this page is to:
Prepare the database to search for duplicate pairs.
Search for duplicate pairs at different confidence levels (and cache the results).
Show those pairs one at a time and judge what kind of dupe they are.
Parts 1 and 2 now work. I would appreciate, if you are interested, in you putting some time into them and giving me some numbers so I can design part 3 well.
Since originally introducing duplicate search, I have updated the 'phash' algorithm (which represents how an image 'looks' for easy comparison) several times. I improved it significantly more this week and am now pleased with it, so I do not expect to do any more on it. As all existing phashes are low quality, I have scheduled every single eligible file (jpgs and pngs) for phash regeneration. This is a big job--for me, this is about 250k files that need to be completely read again and have some CPU thrown at them. I'm getting about 1-2 thousand per minute, so I'm expecting to be at it for something like three hours. This only has to be done once, and only for your old files--new files will be introduced to the new system with correct phashes as they are imported.
To save redundant tree rebalancing, I recommend you set the time aside and regenerate them all in one go. The db will be locked while it runs. The maintenance code here is still ugly and may hang your gui. If it does hang, just leave it running--it'll get there in the end.
Then, once the 'preparation' panel is happy, run some searches at different distances--you don't have to search everything, but maybe do a few thousand and write down the rough number of files searched and duplicate pairs discovered.
I am very interested to know:
How inconvenient was it doing the regen in real time? Approximately how fast did it run?
At 'exact match' search distance, roughly how many potential duplicate pairs per thousand files does it find? What about 'very similar' and (if it isn't too slow) 'similar'?
How much of this heavy CPU/HDD work would you like to run in the background on the normal idle routines?
Did anything go wrong?
I'm still regenerating files as I write this, but I will update with my own numbers once I can. Thanks!
full list
fixed the 'setnondupename' problem that was affecting 'add' actions on manage subscriptions, scripts, and import/export folders
added some more tests to catch this problem automatically in future
cleaned up some similar files phash regeneration logic
cleaned up similar files maintenance code to deal with the new duplicates page
wrote a similar files duplicate pair search maintenance routine
activated file phash regen button on the new duplicates page
activated branch rebalancing button on the new duplicates page
activated duplicate search button on the new duplicates page
search distance on the new duplicates page is now remembered between sessions
improved the phash algorithm to use median instead of mean--it now gives fewer apparent false positives and negatives, but I think it may also be stricter in general
the duplicate system now discards phashes for blank, flat colour images (this will be more useful when I reintroduce dupe checking for animations, which often start with a black frame)
misc phash code cleanup
all local jpegs and pngs will be scheduled for phash regeneration on update as their current phashes are legacies of several older versions of the algorithm
debuted a cog menu button on the new duplicates page to refresh the page and reset found potential duplicate pairs--this cog should be making appearances elsewhere to add settings and reduce excess buttons
improved some search logic that was refreshing too much info on an 'include current/pending tags' button press
fixed pixiv login--for now!
system:dimensions now catches an enter key event and passes it to the correct ok button, rather than always num_pixels
fixed some bad http->https conversion when uploading files to file repo
folder deletion will try to deal better with read-only nested files
tag parent uploads will now go one at a time (rather than up to 100 as before) to reduce commit lag
updated to python 2.7.13 for windows
updated to OpenCV 3.2 for windows--this new version does not crash with the same files that 3.1 does, so I recommend windows users turn off 'load images with pil' under options->media if they have it set
I think I improved some unicode error handling
added LICENSE_PATH and harmonised various instances of default db dir creation to DEFAULT_DB_DIR, both in HydrusConstants
misc code cleanup and bitmap button cleanup
next week
I'm going to collect my different thoughts on how to filter duplicate pairs into a reasonable and pragmatic plan and finally get this show on the road. I do not think I will have a working workflow done in one week, but I'd like to have something to show off--maybe displaying pairs at the least, so we can see well how the whole system is working at different distances.
0 notes