#memorystore
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
Valkey 7.2 On Memorystore: Open-Source Key-Value Service

The 100% open-source key-value service Memorystore for Valkey is launched by Google Cloud.
In order to give users a high-performance, genuinely open-source key-value service, the Memorystore team is happy to announce the preview launch of Valkey 7.2 support for Memorystore.
Memorystore for Valkey
A completely managed Valkey Cluster service for Google Cloud is called Memorystore for Valkey. By utilizing the highly scalable, reliable, and secure Valkey service, Google Cloud applications may achieve exceptional performance without having to worry about handling intricate Valkey deployments.
In order to guarantee high availability, Memorystore for Valkey distributes (or “shards”) your data among the primary nodes and duplicates it among the optional replica nodes. Because Valkey performance is greater on many smaller nodes rather than fewer bigger nodes, the horizontally scalable architecture outperforms the vertically scalable architecture in terms of performance.
Memorystore for Valkey is a game-changer for enterprises looking for high-performance data management solutions reliant on 100% open source software. It was added to the Memorystore portfolio in response to customer demand, along with Memorystore for Redis Cluster and Memorystore for Redis. From the console or gcloud, users can now quickly and simply construct a fully-managed Valkey Cluster, which they can then scale up or down to suit the demands of their workloads.
Thanks to its outstanding performance, scalability, and flexibility, Valkey has quickly gained popularity as an open-source key-value datastore. Valkey 7.2 provides Google Cloud users with a genuinely open source solution via the Linux Foundation. It is fully compatible with Redis 7.2 and the most widely used Redis clients, including Jedis, redis-py, node-redis, and go-redis.
Valkey is already being used by customers to replace their key-value software, and it is being used for common use cases such as caching, session management, real-time analytics, and many more.
Customers may enjoy a nearly comparable (and code-compatible) Valkey Cluster experience with Memorystore for Valkey, which launches with all the GA capabilities of Memorystore for Redis Cluster. Similar to Memorystore for Redis Cluster, Memorystore for Valkey provides RDB and AOF persistence, zero-downtime scaling in and out, single- or multi-zone clusters, instantaneous integrations with Google Cloud, extremely low and dependable performance, and much more. Instances up to 14.5 TB are also available.
Memorystore for Valkey, Memorystore for Redis Cluster, and Memorystore for Redis have an exciting roadmap of features and capabilities.
The momentum of Valkey
Just days after Redis Inc. withdrew the Redis open-source license, the open-source community launched Valkey in collaboration with the Linux Foundation in March 2024 (1, 2, 3). Since then, they have had the pleasure of working with developers and businesses worldwide to propel Valkey into the forefront of key-value data stores and establish it as a premier open source software (OSS) project. Google Cloud is excited to participate in this community launch with partners and industry experts like Snap, Ericsson, AWS, Verizon, Alibaba Cloud, Aiven, Chainguard, Heroku, Huawei, Oracle, Percona, Ampere, AlmaLinux OS Foundation, DigitalOcean, Broadcom, Memurai, Instaclustr from NetApp, and numerous others. They fervently support open source software.
The Valkey community has grown into a thriving group committed to developing Valkey the greatest open source key-value service available thanks to the support of thousands of enthusiastic developers and the former core OSS Redis maintainers who were not hired by Redis Inc.
With more than 100 million unique active users each month, Mercado Libre is the biggest finance, logistics, and e-commerce company in Latin America. Diego Delgado discusses Valkey with Mercado Libre as a Software Senior Expert:
At Mercado Libre, Google Cloud need to handle billions of requests per minute with minimal latency, which makes caching solutions essential. Google Cloud especially thrilled about the cutting-edge possibilities that Valkey offers. They have excited to investigate its fresh features and add to this open-source endeavor.”
The finest is still to come
By releasing Memorystore for Valkey 7.2, Memorystore offers more than only Redis Cluster, Redis, and Memcached. And Google Cloud is even more eager about Valkey 8.0’s revolutionary features. Major improvements in five important areas performance, reliability, replication, observability, and efficiency were introduced by the community in the first release candidate of Valkey 8.0. With a single click or command, users will be able to accept Valkey 7.2 and later upgrade to Valkey 8.0. Additionally, Valkey 8.0 is compatible with Redis 7.2, exactly like Valkey 7.2 was, guaranteeing a seamless transition for users.
The performance improvements in Valkey 8.0 are possibly the most intriguing ones. Asynchronous I/O threading allows commands to be processed in parallel, which can lead to multi-core nodes working at a rate that is more than twice as fast as Redis 7.2. From a reliability perspective, a number of improvements provided by Google, such as replicating slot migration states, guaranteeing automatic failover for empty shards, and ensuring slot state recovery is handled, significantly increase the dependability of Cluster scaling operations. The anticipation for Valkey 8.0 is already fueling the demand for Valkey 7.2 on Memorystore, with a plethora of further advancements across several dimensions (release notes).
Similar to how Redis previously expanded capability through modules with restricted licensing, the community is also speeding up the development of Valkey’s capabilities through open-source additions that complement and extend Valkey’s functionality. The capabilities covered by recently published RFCs (“Request for Comments”) include vector search for extremely high performance vector similarly search, JSON for native JSON support, and BloomFilters for high performance and space-efficient probabilistic filters.
Former vice president of Gartner and principal analyst of SanjMo Sanjeev Mohan offers his viewpoint:
The advancement of community-led initiatives to offer feature-rich, open-source database substitutes depends on Valkey. Another illustration of Google’s commitment to offering really open and accessible solutions for customers is the introduction of Valkey support in Memorystore. In addition to helping developers looking for flexibility, their contributions to Valkey also support the larger open-source ecosystem.
It seems obvious that Valkey is going to be a game-changer in the high-performance data management area with all of the innovation in Valkey 8.0, as well as the open-source improvements like vector search and JSON, and for client libraries.
Valkey is the secret to an OSS future
Take a look at Memorystore for Valkey right now, and use the UI console or a straightforward gcloud command to establish your first cluster. Benefit from OSS Redis compatibility to simply port over your apps and scale in or out without any downtime.
Read more on govindhtech.com
#Valkey72#Memorystore#OpenSourceKey#stillcome#GoogleCloud#MemorystoreforRedisCluster#opensource#Valkey80#vectorsearch#OSSfuture#momentum#technology#technews#news#govindhtech
2 notes
·
View notes
Text
Google Cloud、Redisをフォークした「Valkey 7.2」のマネージドサービス「Memorystore for Valkey」プレビュー版を開始
Google Cloudは、Redisをフォークしたインメモリデータベース「Valkey」を��ネージドサービスで提供する「Memorystore for Valkey」プレビュー版の提供開始を発表しました。 Google Cloudは以前か... https://www.publickey1.jp/blog/24/google_cloudredisvalkey_72memorystore_for_valkey.html?utm_source=dlvr.it&utm_medium=tumblr Publickey
0 notes
Text

memoryStores
49 notes
·
View notes
Text
Cloud Memorystore for Redis
After we made a basic comparison of AWS vs Google Cloud for DevOps, we encountered a new interesting tool from Google introduced this May. It is called Google Cloud Memorystore and is fully managed Redis instances by Google. In other words, it is Cloud Memorystore for Redis. Let’s explore w...
#application caches#applications#browser#cache#Cloud Memorystore#Cloud Memorystore for Redis#Cloud storage#cloud storage for Redis#data#DevOps#GCP#google#Google Cloud#Google Grade Security#Google Platform for DevOps#IAM role-based access control#in-memory data store service#in-memory data structure store#Memorystore#message broker#Redis#Redis protocol#Redis protocol compatible#scaling#software development#used as a database
0 notes
Text
What is Google Cloud Platform Labs?
Google Cloud Platform Labs is a place where Google engineers explore new technologies and share them with the world. It is a place where they learn what customers want, and then turn those insights into new products and features for the entire Google Cloud Platform. The Lab is a hands-on environment where you can work on the latest technologies, experiment with and learn from each other, and get access to some of Google’s newest products and features before they are generally available. Some of the latest technologies launching in Google Cloud Platform Labs are as follows:
• Google Cloud Memorystore, a managed object store for large-scale in-memory data processing applications.
• Google Compute Engine Dedicated Hosts, offering lower latency and higher bandwidth for your cloud computing instances
• Google Cloud Storage Nearline, leveraging inexpensive and cost-effective storage options that are optimized for low latency access and retrieval of data written over long periods of time.
• Google Cloud Endpoints, a RESTful API management service for easily developing and deploying Internet of Things (IoT) smart home applications.
• GCP Billing, a new billing and metering service for cloud computing resources.
• Google Cloud Trace, a fully-managed time-series log data solution that provides performance insights and troubleshooting capabilities to businesses.
• Google Compute Engine Custom Instance Types, which enable you to build custom instances on Compute Engine that are not currently available in the standard product offerings.
and much more!
0 notes
Text
Artificial Intelligence in Data Analytics, Various Google Cloud Platform Services | E-Connect
AI in data analytics is the power to explore and learn about enormous amounts of data from numerous sources and observe patterns to make future predictions with the help of Artificial intelligence. Businesses and industries can benefit when people make production, marketing, and development decisions from predictive analytics.Analytics refers to the procedure of identifying, analyzing, and communicating significant patterns of data. Business analytics means applying this method to respond to business queries, make predictions, discover new connections and eventually make better decisions.
AI is a wide domain of computer science that refers to intelligence exhibited by machines. Usually, this term means machines imitating functions such as learning, problem-solving, reasoning, and representation. AI can be used for everything from understanding human language, driving cars, playing games, and analytics. Several other techniques for solving problems with the help of AI include statistical techniques, search optimization, and artificial neural networks. AI analytics means a set of business intelligence that utilizes machine learning techniques to find insights, and discover new patterns and relationships in the data.
AI analytics is the procedure of automating the work that a data analyst would usually do.
Google Cloud Platform Services offers a lot of IaaS, PaaS, and SaaS services.Compute
App Engine
Batch
Compute Engine
Google Cloud VMware Engine (GCVE)
Storage
Cloud Storage
Persistent Disk
Cloud Filestore
Cloud Storage for Firebase
Databases
Cloud Bigtable
Datastore
Firestore
Memorystore
Cloud Spanner
Cloud SQL
Networking
Cloud CDN
Cloud DNS
Cloud IDS (Cloud Intrusion Detection System)
Cloud Interconnect
Cloud Load Balancing
Cloud NAT (Network Address Translation)
Cloud Router
Cloud VPN
Google Cloud Armor
Google Cloud Armor Managed Protection Plus
Network Connectivity Center
Network Intelligence Center
Network Service Tiers
Service Directory
Spectrum Access System
Traffic Director
Virtual Private Cloud
Operations
Cloud Debugger
Cloud Logging
Cloud Monitoring
Cloud Profiler
Cloud Trace
Developer Tools
Artifact Registry
Container Registry
Cloud Build
Cloud Source Repositories
Firebase Test Lab
Google Cloud Deploy
Test Lab
Data Analytics
BigQuery
Cloud Composer
Cloud Data Fusion
Cloud Life Sciences (formerly Google Genomics)
Data Catalog
Data Studio
Dataplex
Dataflow
Datalab
Dataproc
Dataproc Metastore
Datastream
Google Earth Engine
Pub/Sub
AI and Machine LearningAI Building BlocksAutoML
AutoML Natural Language
AutoML Tables
AutoML Translation
AutoML Video
AutoML Vision
Cloud Natural Language APICloud Translation (including Cloud Translation v2 or any subsequent general availability version/release)Cloud VisionContact Center AI (CCAI).Contact Center AI InsightsDialogflow Essentials(ES)Dialogflow Customer Experience Edition (CX)
Document AI
Human-in-the-Loop AI
Media Translation APISpeaker IDSpeech-to-TextText-to-SpeechVideo Intelligence APIVertex AI, AI Platform, and Accelerators
AI Platform Data Labeling
AI Platform Deep Learning Container
AI Platform Neural Architecture Search (NAS)
AI Platform Training and Prediction
Notebooks
Vertex AI
Industry Solutions
Talent Solution
Discovery Solutions
API Management
Apigee
API Gateway
Cloud Endpoints
Payment Gateway
Hybrid and Multi-cloud
Authors: Anthos is an integrated platform incorporating cloud-based services and software components, including:
Anthos Config Management
Anthos Identity Service
Anthos Integration with Google Cloud Platform Services
Anthos Premium Software
Anthos Service Mesh
Google Kubernetes Engine
Connect
Hub
Cloud Run for AnthosGoogle-Managed Multi-Cloud ServicesBigQuery OmniBare MetalBare Metal SolutionMigration
BigQuery Data Transfer Service
BigQuery Migration Service
Database Migration Service
Migrate for Compute Engine V5.0 and up
Storage Transfer Service
Transfer Appliance
Security and IdentitySecurity
Access Transparency
Assured Workloads
Binary Authorization
Certificate Authority Service
Certificate Manager
Cloud Asset Inventory
Cloud Data Loss Prevention
Cloud External Key Manager (Cloud EKM)
Cloud HSM
Cloud Key Management Service
Event Threat Detection
Key Access Justifications (KAJ)
Risk Manager
Security Command Center
VPC Service Controls
Secret Manager
Web Security Scanner
Identity & Access
Access Approval
Access Context Manager
BeyondCorp EnterpriseBeyondCorp Enterprise is an integrated platform incorporating cloud-based services and software components, including:
On-premises Connector
BCE app connector
BCE client connector
Endpoint Verification
Threat and Data Protection ServicesBeyondCorp Enterprise Integration with Chrome Browser Cloud ManagementCloud Identity Services
Firebase Authentication
Google Cloud Identity-Aware Proxy
Identity & Access Management (IAM)
Identity Platform.
Resource Manager APIGoogle Distributed CloudGoogle Distributed Cloud - EdgeSovereign Controls by Sovereign PartnersUser Protection Services
reCAPTCHA Enterprise
Web Risk API
Serverless Computing
Cloud Run
Cloud Functions
Cloud Functions for Firebase
Cloud Scheduler
Cloud Tasks
Eventarc
Workflows
Internet of Things (IoT)IoT CoreManagement Tools
Google Cloud App
Cloud Deployment Manager
Cloud Shell
Recommenders
Service InfrastructureHealthcare and Life Sciences
Cloud Healthcare
Healthcare Data Engine (HDE)
Media and Gaming
Game Servers
Live Stream API
Transcoder API
Video Stitcher API
Google Cloud Platform Software
BigQuery Connector for SAP
Cloud Run for Anthos deployed on VMware e
Config Connector
Google Cloud SDK:
Kf
Migrate for Anthos
E-connect is the most-preferred Salesforce consulting company for many organizations across the industry. From Salesforce App Development, Salesforce Implementation, and Salesforce Integration to Salesforce Administration and Support, they provide end-to-end Salesforce consulting services to organizations and business enterprises all over the world.
Their Salesforce practices are reinforced by certified consultants with over 15 years of CRM experience in assessment, implementation, customization, and support. With the help of E-connect Salesforce consulting services, you will understand how to unlock the true potential of Salesforce and take decisions and improve your customer acquisition, transformation, and retention.
#Salesforce consulting company#Salesforce Administration and Support#Salesforce App Development#Salesforce Implementation#AI in data analytics#Google Cloud Platform Services
0 notes
Link
こんにちは。はてなで SRE をしている id:nabeop です。最近の趣味は、AWS CDK で TypeScript と戯れることです。 今回は、社内の開発合宿で AWS と GCP を VPN で接続して、実運用に載せた場合の課題や構成を検討したので、その内容について書いてみます。 VPN で AWS と GCP をつなげたい背景 どんな構成の VPN を開発合宿で試したか VPN の見え方が AWS と GCP で異なる構成 手軽に VGW で試してみたけど TGW でも大丈夫 VPN エンドポイントにおける IP アドレスの扱い GCP VPC を構成してみて浮上した課題 複数のサービスが VPN を共有する構成 VPC ピアリングで接続するサブネットが作成される おわりに VPN で AWS と GCP をつなげたい背景 はてなでは、クラウド環境として長らく AWS がデファクトスタンダードとなっています。ただし、最近は GCP で構築したシステムも少しずつ増えてきました。現時点では GCP で構築されているシステムが、はてなの内部ネットワークと通信する要件はありません。しかし将��的には、新しく GCP で構築されたシステムで内部ネットワークと通信する必要が出てくることも想像できます。 そのような事情があり、GCP でシステムを構築しているチームに所属している Web アプリケーションエンジニアの id:t_kyt や SRE の id:taketo957 と、共通基盤を管理するチームに所属している id:nabeop で、AWS と GCP を VPN で接続するときに発生する課題などを確認するため、開発合宿で検証してみることになりました。 どんな構成の VPN を開発合宿で試したか はてなの内部ネットワークは、以前紹介したように AWS Transit Gateway (TGW) を中心として、オンプレミス環境と AWS 環境を接続するような構成に変更している最中です。GCP 環境も、TGW に接続することを想定しています。 ただし、GCP からの VPN は1つで、VPN の先に複数のサービスが各自でシステムを構築し、VPN と Cloud Router で接続する構成を想定しています。 VPN の見え方が AWS と GCP で異なる構成 実際に開発合宿中に構築した環境は以下のようになりました。VPN 部分は AWS と GCP で見え方が異なるため、両方の視点で見たときの構成図を書いています。 構成図 AWS と GCP で VPN の構成が異なって見える原因は、それぞれの環境における VPN 終端の構成が、実際に構築しているリソースと1対1で対応できないためです。 つまり、VPN 終端としては以下のようになっています。 AWS ... 2つの VPN 終端を持つ AWS Site-to-Site VPN (AWS VPN) を2つ作成 つまり、AWS 側のリソースとしては、2つ作成している GCP ... VPN 終端として4つの GCP ピア VPN ゲートウェイを作成 つまり、GCP 側のリソースとしては、4つ作成している この構成の違いは、VPN 回線の冗長性を確保するときに重要な要素となってくるので、注意が必要です。 手軽に VGW で試してみたけど TGW でも大丈夫 当初、開発合宿では VPN の構築を主題に置いていたため、AWS 側では VPN を AWS 仮想プライベートゲートウェイ (VGW) でお手軽に収容する構成からスタートしました。TGW を構築・運用している経験から、VPN さえつながれば、AWS 側の収容は TGW でも VGW でもとくに大きな差異は出ないだろうと想定していました。 開発合宿の最終日に時間が余ったので、実際に VGW から TGW に構成を変更してみましたが、大きなハマりごともなく構成変更は完了しました。 ただし、GCP 側の Cloud Router では、BGP の経路再計算で40秒ほどのネットワーク断を確認しました。このあたりは GCP のドキュメントにあるとおり、避けられない問題のようでした。実際に本番環境で構築する場合は、最初から TGW で収容するような構成にしておく必要がありそうです。 VPN エンドポイントにおける IP アドレスの扱い VPN の構成は開発合宿初日の昼過ぎに完成しましたが、構築中に唯一ハマったのは、AWS と GCP の双方で VPN 関連のリソースを作るときでした。 今回は、Terraform や AWS CDK といった Infrastructure as Code (IaC) 的なアプローチは取らず、それぞれのコンソール画面でリソースを作っていました。VPN 関連のリソースを作るにあたり、双方で対向の VPN 終端の IP アドレスが決まっているという前提になっていました。このためリソース作成時にデッドロックが発生して���作業が進まないという事態になりました。 幸い、GCP 側では最初に VPN 終端である GCP クラウドゲートウェイを作成する手順になっていたので、GCP クラウドゲートウェイが作られたところで GCP 側の作業を止めて、GCP クラウドゲートウェイで使用されているグローバル IP アドレスを AWS CGW として、AWS 側のリソースを作成しました。 あるいは、VPN 接続を完了した後に、GCP であらかじめグローバル IP アドレスを確保してから、GCP クラウドゲートウェイを作成するという手段も取れることに気づきました。GCP 側で VPN 終端用の IP アドレスを確保してから、AWS 側の VPN リソースを構築するというアプローチでもできそうでした。 また、マルチクラウド環境の IaC 的アプローチを取るときには、このようなデッドロック状態を回避するため、リソースの依存関係などを考慮しつつリソース作成をする必要がありそうです。 GCP VPC を構成してみて浮上した課題 AWS と GCP の VPN 接続が開発合宿の初日にできてしまったので、残りの時間は、実際に本番環境で使う場合の懸念点や、運用ポリシーを議論しました。 まず最初に、VPN で通信させたい場合、GCP VPC はカスタムモードの VPC ネットワークとして作成しておく必要があります。初期状態で作成されている GCP VPC は、自動モードの VPC ネットワークが作成されているので注意が必要です。 複数のサービスが VPN を共有する構成 また本番環境では、AWS と GCP の VPN は1つとして、複数のサービスが VPN を共有する形態を想定しています。したがって、以下のような構成で検証環境を構築しました。 GCP VPCの構成図 つまり、ネットワーク全体を管理するチームが運用するホストプロジェクトに共有 VPC を作成して、GCP で構築するサービスやシステム単位で作られたサービスプロジェクトが共有 VPC に接続するイメージです。共有リソースであるネットワークとシステム固有のコンポーネントを分離することで、責任分界点とすることを検討しています。 このような構成で作成したサービスプロジェクト側で使いそうな GCP リソースを実際に構築して挙動を確かめたところ、運用上の課題が浮かび上がってきました。 VPC ピアリングで接続するサブネットが作成される まず、サービスプロジェクト側で MemoryStore を作成したところ、サービスを構築している VPC とは別の VPC とサブネットが作成されたことを確認しました。 ホストプロジェクト側のルートテーブルや AWS 側のルートテーブルを確認したところ、MemoryStore によって作成されたサブネットの経路は登録されていません。MemoryStore の作成で作られたサブネットは VPC ピアリングで接続しているため、GCP 外のネットワークには経路広報されないようでした。 ただし、共有 VPC で作成すると、接続しているサービスプロジェクトにも経路伝播していることが確認できたので、共有 VPC で作成する場合は十分に注意する必要がありそうです。これは、共有 VPC では外部環境と接続する VPN 関連のリソースのみを作る、ということで回避はできそうです。 MemoryStore によって作成されるサブネットは、既存の GCP リソースが使用しているサブネットとは異なるネットワークアドレスで構築されるようですが、GCP 外の環境で使用しているネットワークアドレスとバッティングすることは考えられます。全体での IP アドレスの管理方針など、運用ポリシーを定めておく必要がありそうです。 また、VPC ピアリングで接続する GCP リソースは他にもあるはずなので、どのようなリソースを作ると同じ挙動をするかということも把握しておく必要がありそうです。 おわりに 仕事から少し離れて、普段一緒に仕事をしていない同僚と、普段は触っていないサービスを検証して議論することはリフレッシュになるし、普段とは別の視点から気づきも得られて、充実した3日間でした。 GCP は普段触っている AWS とは勝手が違い、考え方を変えて向き合う必要があったりしますが、今回の開発合宿で得られた知見を���かしてプロダクション環境への実装についても進めていきたいですね。
0 notes
Photo

Google Cloud launches a managed Memcached service Google today announced the beta of Memorystore for Memcached, a new service that provides a fully managed in-memory datastore that is compatible with the open-source Memcached protocol. It will join Redis in the Memorystore family, which first launched in 201… Read More
0 notes
Text
Unity Ads Performs 10M Tasks Per Second With Memorystore

Memorystore powers up to 10 million operations per second in Unity Ads.
Unity Ads
Prior to using its own self-managed Redis infrastructure, Unity Ads, a mobile advertising company, was looking for a solution that would lower maintenance costs and scale better for a range of use cases. Memorystore for Redis Cluster, a fully managed service built for high-performance workloads, is where Unity moved their workloads. Currently, a single instance of their infrastructure can process up to 10 million Redis operations per second.The business now has a more dependable and expandable infrastructure, lower expenses, and more time to devote to high-value endeavors.
Managing one million actions per second is an impressive accomplishment for many consumers, but it’s just routine at Unity Ads. Unity’s mobile performance ads solution readily manages this daily volume of activities, which feeds ads to a wide network of mobile apps and games, showcasing the reliable capabilities of Redis clusters. Extremely high performance needs result from the numerous database operations required for real-time ad requests, bidding, and ad selection, as well as for updating session data and monitoring performance indicators.
Google Cloud knows that this extraordinary demand necessitates a highly scalable and resilient infrastructure. Here comes Memorystore for Redis Cluster, which is made to manage the taxing demands of sectors where speed and scale are essential, such as gaming, banking, and advertising. This fully managed solution combines heavier workloads into a single, high-performance cluster, providing noticeably higher throughput and data capacity while preserving microsecond latencies.
Providing Memorystore for Redis Cluster with success
Unity faced several issues with their prior Do-It-Yourself (DIY) setup before utilizing Memorystore. For starters, they employed several types of self-managed Redis clusters, from Kubernetes operators to static clusters based on Terraform modules. These took a lot of work to scale and maintain, and they demand specific understanding. They frequently overprovisioned these do-it-yourself clusters primarily to minimize possible downtime. However, in the high-performance ad industry, where every microsecond and fraction of a penny matters, this expense and the time required to manage this infrastructure are unsustainable.
Memorystore presented a convincing Unity Ads solution. Making the switch was easy because it blended in perfectly with their current configuration. Without the managerial overhead, it was just as expensive as their do-it-yourself solution. Since they were already Google Cloud users, they also thought it would be beneficial to further integrate with the platform.
The most crucial characteristic is scalability. The ability of Memorystore for Redis Cluster to scale with no downtime is one of its best qualities. With just a click or command, customers may expand their clusters to handle terabytes of keyspace, allowing them to easily adjust to changing demands. Additionally, Memorystore has clever features that improve use and dependability. The service manages replica nodes, putting them in zones other than their primary ones to guard against outages, and automatically distributes nodes among zones for high availability. What would otherwise be a difficult manual procedure is made simpler by this automated method.
All of this made Unity Ads decide to relocate their use cases, which included state management, distributed locks, central valuation cache, and session data. The relocation process proceeded more easily than expected. By using double-writing during the shift, they were able to successfully complete their most important session data migration, which handled up to 1 million Redis operations per second. Their valuation cache migration, which served up to half a million requests per second (equivalent to over 1 million Redis operations per second) with little impact on service, was even more astounding. It took only 15 minutes to complete. In order to prevent processing the same event twice, the Google team also successfully migrated Unity’s distributed locks system to Memorystore.
Memorystore in operation: the version of Unity Ads
Google Cloud has a life-changing experience using Memorystore for Redis Cluster. Its infrastructure’s greater stability was one of the most obvious advantages it observed. Because its prior DIY Redis cluster was operating on various tiers of virtualization services, such as Kubernetes and cloud computing, where it lacked direct observability and control, it frequently ran into erratic performance issues that were challenging to identify.
Consider this CPU utilization graph of specific nodes from its previous self-managed arrangement, for example:Image credit to Google Cloud
As you can see, the CPU consumption across many nodes fluctuated a lot and spiked frequently. It was challenging to sustain steady performance in these circumstances, particularly during times of high traffic.
During Kubernetes nodepool upgrades, which are frequently the result of automatic upgrades to a new version of Kubernetes, it also encountered issues with its do-it-yourself Redis clusters. The p99 latency is skyrocketing, as you can see!Image credit to Google Cloud
Another big benefit is that we can now grow production seamlessly because of Memorystore. This graph displays its client metrics as it increased the cluster’s size by 60%.
With very little variations, the operation rate was impressively constant throughout the procedure. For us, this degree of seamless scaling changed everything since it made it possible to adjust to shifting needs without compromising our offerings.
The tremendous performance and steady low latency it has been able to attain using Memorystore are described in the data presented above. For its ad-serving platform, where every microsecond matters, this performance level is essential.
Making a profit from innovation
Unity ads switch to Memorystore has resulted in notable operational enhancements in addition to performance gains. It no longer invests effort in preparing its Redis clusters for production by testing and fine-tuning them.
Business-wise, it anticipates that by properly scaling clusters and applying the relevant Committed Use Discounts, it should be able to get cost savings on par with its prior do-it-yourself solution, particularly with the addition of single zone clusters to cut down on networking expenses. For a comparable price to prior self-managed Redis deployment, it is now able to obtain a fully managed, scalable, and far more dependable (99.99% SLA) solution with Memorystore.
With an eye toward the future, Memorystore has created new opportunities for system architecture. For many of the use cases, it is currently thinking about taking a “Memorystore-first” strategy. For instance, engineers frequently choose persistent database solutions like Bigtable when creating crucial data systems because they don’t want to take chances, even whether the use case actually requires persistence and/or consistency.
Databases like Bigtable are better suited for data that will persist for months to years, but occasionally the use case just requires data durability for about an hour. It may save money and development time by avoiding such shortcuts and optimizing for its shorter persistent (such as hours-to-day) data use cases with a hardened, dependable Redis Cluster solution like Memorystore. Overall, it can confidently extend the use of Redis across more infrastructure to reduce costs and boost performance because of Memorystore’s scalability and dependability.
The ease with which persistence (AOF or RDB) can be enabled on Memorystore is another revolutionary advantage. Its use cases were restricted to caching scenarios with transitory data that it could afford to lose because its Kubernetes DIY Redis cluster did not allow permanence. It can expand use cases and even mix use cases within the same cluster with Memorystore’s one-click persistence, which boosts usage and reduces expenses.
Every second matters in business. Memorystore is helping them remain competitive and provide its publishers and advertisers with better outcomes by allowing the team to concentrate on core business innovation instead of infrastructure administration.
Read more on Govindhtech.com
#MemorystoreforRedisCluster#memorystore#rediscluster#Unity#unityads#Google#googlecloud#govindhtech#news#TechNews#Technology#technologynews#technologytrends
0 notes
Text
Google Cloud launches a managed Memcached service
Google today announced the beta of Memorystore for Memcached, a new service that provides a fully managed in-memory datastore that is compatible with the open-source Memcached protocol. It will join Redis in the Memorystore family, which first launched in 2018.
As Gopal Ashok, Google’s product manager for Memorystore notes in today’s announcement, Redis remains a popular choice for use cases like…
View On WordPress
#Caching#Cloud#cloud infrastructure#COMPUTING#data management#Developer#GKE#Google#Google App Engine#product manager#redis#TC
0 notes
Text
Google Cloud launches a managed Memcached service
Google today announced the beta of Memorystore for Memcached, a new service that provides a fully managed in-memory datastore that is compatible with the open-source Memcached protocol. It will join Redis in the Memorystore family, which first launched in 2018.
As Gopal Ashok, Google’s product manager for Memorystore notes in today’s announcement, Redis remains a popular choice for use cases like session stores, gaming leaderboard, stream analytics, threat detection and API rate limiting, while Memcached is typically used as a caching layer for databases. Developers also regularly use Memcached as a session store and with this new service, developers can scale their clusters up to 5TB of memory per instance.
Since the service is fully compatible with Memcached, developers should be able to take any of their applications that use the protocol and migrate them over to Google Cloud and its Memorystore platform. As a fully managed service, Google will handle all of the routine tasks like monitoring and patching. Figuring out the right size of a cache remains a bit of an art, though, but Google Cloud argues that its detailed metrics will allow developers to easily scale their instances up and down as needed to optimize the service for their specific use cases. Those metrics, the company notes, are exposed in Cloud Monitoring, Google Cloud’s centralized monitoring dashboard, and the Cloud Console.
Currently, Memorystore for Memcached can be used for applications that run on Compute Engine, Google Kubernetes Engine (GKE), App Engine Flex, App Engine Standard and Cloud Functions.
It’s worth noting that Amazon, with ElastiCache for Memcached, and specialized startups like MemCachier. And Redis Labs, too, is offering a fully managed Memcached service that can run on AWS, Azure and Google Cloud.
0 notes
Text
Cloud Memorystore for Redis
After we made a basic comparison of AWS vs Google Cloud for DevOps, we encountered a new interesting tool from Google introduced this May. It is called Google Cloud Memorystore and is fully managed Redis instances by Google. In other words, it is Cloud Memorystore for Redis. Let’s explore w...
#application caches#applications#browser#cache#Cloud Memorystore#Cloud Memorystore for Redis#Cloud storage#cloud storage for Redis#data#DevOps#GCP#google#Google Cloud#Google Grade Security#Google Platform for DevOps#IAM role-based access control#in-memory data store service#in-memory data structure store#Memorystore#message broker#Redis#Redis protocol#Redis protocol compatible#scaling#software development#used as a database
0 notes
Text
Google Cloud launches a managed Memcached service

Google today announced the beta of Memorystore for Memcached, a new service that provides a fully managed in-memory datastore that is compatible with the open-source Memcached protocol. It will join Redis in the Memorystore family, which first launched in 2018.
As Gopal Ashok, Google’s product manager for Memorystore notes in today’s announcement, Redis remains a popular choice for use cases…
View On WordPress
0 notes
Text
Best of Google Database
New Post has been published on https://is.gd/42EFDP
Best of Google Database

Google Cloud Database By
Google provides 2 different types of databases i.e google database
Relational
No-SQL/ Non-relational
Google Relational Database
In this google have 2 different products .
Cloud SQL
Cloud Spanner
Common uses of this relational database are like below
Compatibility
Transactions
Complex queries
Joins
Google No-SQL/ Non-relational Database
In this google provide 4 different types of product or databases
Cloud BigTable
Cloud Firestore
Firebase Realtime database
Cloud Memorystore
Common uses cases for this is like below
TimeSeries data
Streaming
Mobile
IoT
Offline sync
Caching
Low latency
Google relational Databases
Cloud SQL
It is Google fully managed service that makes easy to setup MySQL, PostgreSQL and SQL server databases in the cloud.
Cloud SQL is a fully-managed database service that makes easy to maintain, Manage and administer database servers on the cloud.
The Cloud SQL offers high performance, high availability, scalability, and convenience.
This Cloud SQL takes care of managing database tasks that means you only need to focus on developing an application.
Google manage your database so we can focus on our development task. Cloud SQL is perfect for a wide variety of applications like geo-hospital applications, CRM tasks, an eCommerce application, and WordPress sites also.
Features of Cloud SQL
Focus on our application: managing database is taken care of by google so we can focus on only application development.
Simple and fully managed: it is easy to use and it automates all backups, replication, and patches and updates are having 99.955 of availability anywhere in the world. The main feature of Cloud SQL is automatic fail-over provides isolation from many types of infrastructure hardware and software. It automatically increases our storage capacity if our database grows.
Performance and scalability: it provides high performance and scalability up to 30 TB of storage capacity and 60,000 IOPS and 416Gb of ram per instance. Having 0 downtimes.
Reliability and Security: As it is google so security issue is automatically resolved but the data is automatically encrypted and Cloud SQL is SSAE 16, ISO 27001 and PCI DSS v3.0 compliant and supports HIPAA compliance so you can store patient data also in Cloud SQL.
Cloud SQL Pricing:
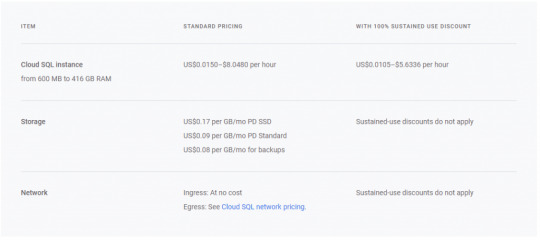
Google Cloud SQL Pricing -Image From Official Google Site
Cloud Spanner
It is a fully managed scalable relational database service for regional and global application data.
Cloud spanner is the first database who takes advantage of relational database and non-relational database.
It is enterprise-grade, globally distributed and strongly consistent database service which built for cloud and it combines benefits of relational and non-relational horizontal scale.
By using this combination you can deliver high-performance transactions and strong consistency across rows, regions and continent.
Cloud spanner have high availability of 99.999% it has no planned downtime and enterprise-grade security.
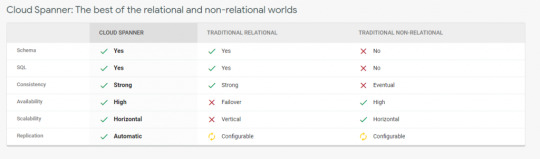
Google Cloud Spanner Features:- Image from official google site
Features of Cloud Spanner:
Scale+SQL:– in today’s world most database fail to deliver consistency and scale but at their, Cloud Spanner comes what it means? It means Cloud Spanner provides you advantage of relational database structure and not relational database scale and performance feature with external consistency across rows, regions and continents.
Cloud spanner scales it horizontally and serves data with low latency and along with that it maintains transactional consistency and industry-leading availability means 99.999%. It can scale up arbitrarily large database size means what It provides it avoids rewrites and migrations.
Less Task– it means google manage your database maintenance instead of you. If you want to replicate your database in a few clicks only you can do this.
Launch faster: it Is relational database with full relational semantics and handles schema changes it has no downtime. This database is fully tested by google itself for its mission-critical applications.
Security and Control:- encryption is by-default and audit logging, custom manufactured hardware and google owned and controlled global network.
Multi-language support means support c#, Go, Java, Php, Python and Ruby.
Pricing for Cloud Spanner:
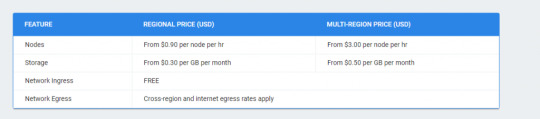
Google Cloud Spanner Pricing – Image from official google site
Non-relational Database by Google
BigTable
This Bigtable database is created by Google, it is compressed, high performance and proprietary data storage system which is created by Google and is built on top of google file system, LevelDB and other few google technologies.
This database development is starting in 2004 and now it is widely used by google like web indexing,google maps, google book search and google earth, blogger, google code, youtube.
The google is designed its own database because they need high scalability and better control over performance.
Bigtable is like wide column store. It maps 2 arbitrary string values which are row key and column key and timestamp for 3-dimensional mappings into an arbitrary byte array.
Remember it is not a relational database and it is more kind of sparse, distributed multi-dimensional sorted map.
BigTable is designed to scale in petabyte range across hundreds and thousands of machines and also to add additional commodity hardware machines is very easy in this and there is no need for reconfiguration.
Ex.
Suppose google copy of web can be stored in BigTable where row key is what is domain URL and Bigtable columns describe various properties of a web page and every column holds different versions of webpage.
He columns can have different timestamped versions of describing different copies of web page and it stores timestamp page when google retrieves that page or fetch that page.
Every cell in Bigtable has zero or timestamped versions of data.
In short, Bigtable is like a map-reduce worker pool.
A google cloud Bigtable is a petabyte-scale, fully managed and it is NoSQL database service provided by Google and it is mainly for large analytical and operational workloads.
Features Of Google Cloud BigTable:
It is having low latency and massively scalable NoSQL. It is mainly ideal for ad tech, fin-tech, and IoT. By using replication it provides high availability, higher durability, and resilience in the face of zonal failures. It is designed for storage for machine learning applications.
Fast and Performant
Seamless scaling and replication
Simple and integrated- it means it integrates easily with popular big data tools like Hadoop, cloud dataflow and Cloud Dataproc also support HBase API.
Fully Managed- means google manage the database and configuration related task and developer needs only focus on development.
Charges for BigTable- server: us-central
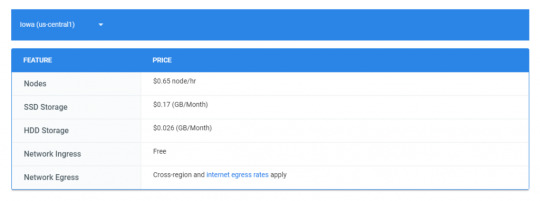
Google Bigtable Pricing- Image from official google site
Cloud Firestore
It is mainly serverless. Cloud Firestore is fast and serverless and fully managed and cloud-native NoSQL. It is document database which simplifies our storing data, syncing data and querying data from your IoT devices, mobile devices or web at global scale. It also provides offline support and its security features and integration with firebase and googles cloud platform.
Cloud Firestore features are below:
You can increase your development velocity with serverless: Is a cloud-native database and Cloud Firestore provides automatic scaling solution and it takes that advantage from googles powerful infrastructure. It provides live synchronization and offline support and also supports ACID properties for hundreds of documents and collections. From your mobile you can directly talk with cloud Firestore.
Synchronization of data on different devices: Suppose client use the different platform of your app means mobile, tab, desktop and when it do changes one device it will automatically reflected other devices with refresh or firing explicit query from user. Also if your user does offline changes and after while he comes back these changes sync when he is online and reflected across.
Simple and effortless: Is robust client libraries. By using this you can easily update and receive new data. You can scale easily as your app grows.
Enterprise-grade and scalable NoSQL: It is fast and managed NoSQL cloud database. It scales by using google infrastructure with horizontal scaling. It has built-in security access controls for data and simple data validations.
Pricing of Google Cloud Firestore:
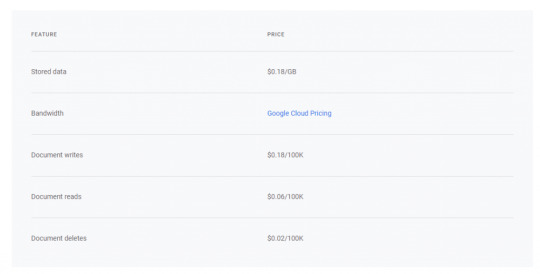
Google Cloud Firestore Pricing – Image from official googles site
FireBase
By tag line, it stores and sync data real-time. It stores data in JSON format. Different devices can access the same database.
It is also optimized for offline use and is having strong user-based security. This is also cloud-hosted database with a NoSQL database. It syncs In real-time across all clients and remains available if you go offline.
Capabilities of FireBase:
Realtime
Offline
Accessible from client devices
Scales across multiple databases: Means if you have blaze plan and your app go grow very fast and you need to scale your database so you can do in same firebase project with multiple database instances.
Firebase allows you to access the database from client-side code directly. Data is persisted locally and offline also in this realtime events are continuous fires by using this end-user experiences realtime responsiveness. When the client disconnected data is stored locally and when he comes online then it syncs with local data changes and merges automatically conflicts.
Firebase designed only to allow operations that can execute quickly.
Pricing of Firebase
Google Firebase pricing-image from official google site
Cloud MemoryStores
This is an in-memory data store service for Redis. It is fully managed in-memory data store service which is built for scalability, security and highly available infrastructure which is managed by Google.
It is very much compatible with Redis protocol so it allows easy migration with zero code changes. When you want to store your app data in sub-millisecond then you can use this.
Features of Cloud memory stores:
It has the power of open-source Redis database and googles provide high availability, failure and monitoring is done by google
Scale as per your need:- by using this sub-millisecond latency and throughput achieve. It supports instances up to 300 Gb and network throughput 12 Gbps.
It is highly available- 99.9% availability
Google grade security
This is fully compatible with Redis protocol so your open-source Redis move to cloud memory store without any code change by using simple import and export feature.
Price for Cloud MemoryStore:
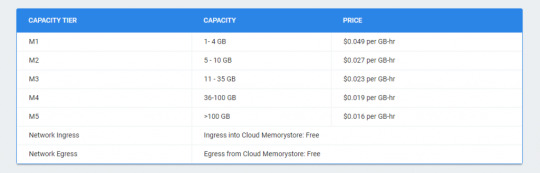
Google Cloud Memorystore price – image from official site of google
0 notes
Text
2019年のDevOps/MLOpsエンジニアの標準的スキルセット
from https://qiita.com/poly_soft/items/8dd105341869f93b129c?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items

以前「2018年の最先端DevOpsエンジニアになるためのロードマップ」という翻訳記事を投稿させて頂いたのですが、その記事は主に「オンプレ環境におけるDevOpsエンジニア」を想定した説明になっており、クラウドネイティブ時代の技術としては少々違和感があるかなということと、最近はDevOpsだけでなくMLOpsもかなり注目を集めているということで、今回は、私の考える「2019年のクラウド環境におけるDevOps/MLOpsエンジニアの標準的スキルセット」に関して述べ���みたいと思います。
ちなみに現時点の私のスキルセットはこんな感じになっておりまして、下記で説明する技術の大体90%以上は一通り実務で経験済みですが、未使用の技術も含まれますので、記述内容に誤りがありましたらコメント欄等でご指摘頂けますと幸いです)
前提
「DevOps」の範囲は非常に広く、また人によって解釈がかなり異なりますが、この記事ではDevOpsの定義として「サービスを安定稼働させたまま、ユーザからのフィードバックを取り入れた新機能や改善を、迅速にサービスに反映するためのあらゆる取り組みや文化のこと」という前提で話を進めさせて頂きます。(MLOpsはDevOpsの機械学習バージョンという理解で問題ないと思います)
また、上記の通り「DevOps」は非常に範囲の広い概念であり、非テクノロジー的な要素も含まれますので「DevOpsエンジニア」という呼称は本来おかしい(職種の範囲が曖昧すぎる&広すぎる)のですが、ここでは「DevOpsの目的を実現する上で必要なテクノロジー面のスキルセットを保持しているエンジニア」という風に考えて頂ければと思います。
また、開発工数および運用工数の削減がリードタイムの短縮には欠かせませんが、そのためには「可能な限りクラウドやSaaSのマネージドサービスだけで機能を実現する(巨人の肩に乗る)」ことがクラウドネイティブ時代のDevOpsエンジニアの必須条件というのが私の認識であり、そのためこちらの記事は「マネージドサービスを使いこなすこと」にかなり主眼を置いた内容となりますので、その点はあらかじめご認識頂ければと思います。
DevOps
まずはDevOpsエンジニアに必要なスキルセットを見ていきましょう。
AWSとGCPの各種マネージドサービスの知見
数年前であればクラウドに関してはAWSの知識だけで十分でしたが、ここ数年のGCPの進化により、サービスの新規開発の際に「IaaSとしてAWSとGCPのどちらを使うか」を検討するフェーズがほぼ必ずと言っていいほど入ってくるようになりました。
お客様の方では「GCPはより先進的(Kubernetesや機械学習系サービスに関してAWSよりも先行している)」というイメージがあるようで、(それ以外にもAWSに対する「技術者の飽き」もあると思いますが)「GCPを使ってみたい」という要望が増えており、2019年時点ではもう「AWSしか扱えないDevOpsエンジニアは時代遅れ」という状況になっていると考えて差し支えないでしょう。
���クラウドサービスの全てのマネージドサービスに関して詳しくなることは不可能ですが、一般的によく使用される下記のサービスの存在と用途とその対比に関してはある程度把握しておく必要があると思われます。
種類 AWS GCP
VM EC2 GCE
ストレージ S3 GCS
PaaS Beanstalk GAE(SE/FE)
FaaS Lambda Cloud Functions Cloud Run
コンテナ基盤 ECS EKS GKE
RDB RDS Cloud SQL
NoSQL DynamoDB Cloud Bigtable Cloud Spanner
KVS ElastiCache Cloud Memorystore
メッセージキュー SQS Cloud Tasks
Pub/Sub SNS Cloud Pub/Sub
バッチ/ジョブフロー制御 AWS Batch Step Functions Cloud Composer
ビッグデータ分散処理 EMR Cloud Dataflow Cloud Dataproc
認証 Cognito Firebase Authentication
ロギング/モニタリング CloudWatch Stackdriver
ちなみに、IT業界全体のシェアとしてはMicrosoftのAzureの方がGCPを上回っていますが、Web業界においてIaaSにAzureを採用している企業さんは2019年時点ではまだまだ少ないので、現状ではとりあえずAzureへのキャッチアップは後回しにしておいて問題ないと思われます。
クラウドアーキテクチャ設計
前述したAWSやGCPの各種マネージドサービスを適切に組み合わせてアーキテクチャ設計を行い、それを構成図に落とし込める能力は必須となります。
いわゆる「アーキテクト」という職種の担当領域でもありますが、「サービスを安定稼働させたまま、バリューをユーザに迅速に届ける」ためには、自動化のしづらい構成が採用されてしまったり、無駄な機能が開発されてしまったり、アンマネージドなツールやサービスが使用されて管理工数が肥大化したりしないように、アーキテクチャ設計の段階からDevOpsエンジニアが関与する必要があります。(小規模なサービスの場合はDevOpsエンジニアがアーキテクトを兼務する場合も多いと思います)
AWSやGCPの各種マネージドサービスに関しては、下記のような書籍でざっと学習して、どんどん実際に手を動かしてサービスを触ってみると良いでしょう。
Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂版 【ダウンロード版】AWSをはじめよう ~AWSによる環境構築を1から10まで~ GCPの教科書 プログラマのためのGoogle Cloud Platform入門
VPCのネットワーク設計やIPアドレス範囲の設計に関する知識も重要です。拡張性を考慮した上で、自分なりのパターンを確立しておいた方が良いでしょう。下記の記事が参考になると思います。
AWSのネットワーク設計をサボらないでちゃんとやる Amazon VPC IPアドレス設計レシピ 【AWSしかやったことない人向け】AWSとGCPのネットワークの違いを理解してみよう
Gitブランチモデルの適切な設計とタスク粒度の管理
ソースコードのバージョン管理を行うことは当然ですし、その場合大抵はGitを使うことになると思いますが、適切なブランチモデル(git-flow|github-flow|gitlab-flow|あるいはそれらのアレンジ版)を採用し、さらにタスクの粒度を小さく保っておかないと、コンフリクトやデグレードの可能性が高まり、「リードタイムを短縮する」というDevOpsの目的が達成できなくなってしまいます。
「これが絶対の正解」というブランチモデルやタスク管理の手法は存在しませんが、何らかの新機能を追加したりする際のコードサイズがどうしても肥大化してしまうようであれば、「フィーチャートグル」等を使用して、作業ブランチの生存期間を出来るだけ短くするように工夫する必要があるでしょう。
Git利用時のフローはどれを使うか Pete HodgsonさんのFeature-togglesが面白かったので翻訳してみた
ちなみにGitブランチモデルに関しては、私の場合はgilab-flowを基本にして、多少のアレンジを加えた方式で対応することが多いです。
GitLab flowから学ぶワークフローの実践
インフラのコード化
インフラをクラウドのWebコンソールから手動で作成したり、あるいはサーバにSSHでログインして直接ライブラリ等をインストールする方式は、「別環境を作る際にまた手動で同じ作業を行う必要がある」「現在のインフラやサーバの構成を把握することが難しい」「手順書管理になってしまう」「属人性が発生する(いわゆる「デプロイ職人」��必要になってしまう)」等の様々なデメリットがありますので、リードタイムを短縮するにはインフラの構成は基本的に全てコード化して管理する必要があります。
インフラのコード化���ールとしては
といった辺りが一般的ですが、最近は特にTerraformの人気が高いので、Terraformに関しては必須知識になっていると考えて良いでしょう。
【ダウンロード版】Pragmatic Terraform on AWS
ただし、tfstateファイルをクラウド上で管理するために、AWSの場合にはS3バケットを、GCPの場合にはGCSバケットを事前に作成する必要があり、このtfstateファイル管理用のバケットの作成や削除も自動化したい場合には必然的にCloudFormationかDeployment Managerを使うことになりますので、この両者に関しても一応押さえておいた方が良いと思われます。
また、最近は
といったツールも注目されており、まだメインストリームというほどには広まっていないという印象ではありますが、Terraformからトレンドが移行する可能性もゼロではないので、注視しておいた方が良いかもしれません。
Terraform と Pulumiを比較する AWS CDK が GA! さっそく TypeScript でサーバーレスアプリケーションを構築するぜ【 Cloud Development Kit 】
コンテナ基盤とマイクロサービス
Dockerを活用することにより「環境の差異によって生じる様々な問題を防止できる」「デプロイやロールバックやオートスケールが容易になる」等の明確なメリットがありますので、コンテナ基盤に関する知識もDevOpsエンジニアにとっては非常に重要です。
コンテナ基盤としては、AWSだとまだまだECSやBeanstalkがよく使われているようですが、現状のトレンドから考えてKubernetesへのキャッチアップはDevOpsエンジニアにとっては必須と考えて良いでしょう。
AWSだとEKS、GCPだとGKEを使うということになりますが、最低限どちらのプラットフォームにおいてもマネージドサービスによるKubernetesクラスタの構築およびPod/Service/Ingress等のデプロイを行えるようになっておく必要があると思われます。
サービスメッシュに関しては、使うメリットがある企業さんは限定的だとは思いますが、AWSの「App Mesh」およびGCP��「Istio」に関してはある程度押さえておいた方が良いでしょう。(App Meshはまだほとんど使い物にならないという印象ですが、GCPではIstioを使うことが恐らく今後一般的になっていくと思われます)
Service meshとは何か Kubernetes上でgRPCサービスを動かす
また、Kubernetesを使用したマイクロサービスの開発においては、言語は「Go」が採用されることが多く、そしてKubernetesクラスタ内でのマイクロサービス間の通信においては「gRPC」が使われることが多いため、GoとgRPCを使用した開発に関しても慣れておいた方が良いと思われます。
Goで始めるgRPC入門
認証基盤
クラウドのマネージドな認証基盤を活用することで、アプリケーション側で認証コードを実装したり自分達で認証基盤を構築したりする必要がなくなりますので、アプリケーションの安全性や保守性が向上し、開発工数も管理工数も大幅に削減することが可能になります。
AWSだとCognito、GCPだとFirebase Authenticationが認証基盤を提供していますので、これらのサービスの概要に関してはある程度把握しておいた方が良いでしょう。(Cognitoは相当学習コストが高いですが、API GatewayだけでなくALBと連携できるようになってから一気に利便性が向上したという印象です)
最近はAuth0というサードパーティのIDaaSも注目されているようです。
認証プラットフォーム Auth0 とは?
サーバーレス/FaaS
何らかのイベントをトリガーとして処理を実行したい場合、自前で常時起動のサーバーを用意してAPIをホストするのは手間とコストが必要になりますが、FaaS(Function as a Service)を使えばサーバーレスで処理を実行できるので工数もコストも大幅に削減できます。
AWSならLambda、GCPならCloud FunctionsもしくはCloud Run(on GKE)がFaaSに該当します。
各サービスの設定方法やデプロイ方法、「最大実行可能時間」や「同時起動可能数」「複数回リトライされる可能性があるため冪等性を持たせる必要がある」という点、および「何らかのイベントをトリガとして起動できるFaaSと、単にHTTPのエンドポイントとしてのみ使用可能なFaaSがある」「VPC内のリソースにアクセス可能なFaaSとそうでないFaaSがある」という点に関してはある程度把握しておいた方が良いでしょう。
Amazon VPC 内のリソースにアクセスできるように Lambda 関数を構成する VPC ネットワークの内部リソースへの接続 | Cloud Functions のドキュメント Google Cloud Next 2019 in SF , サーバーレス関連発表まとめ
RDBのスキーマのマイグレーション
RDBのスキーマ変更が行われないWebサービスはまず存在しませんし、スキーマのマイグレーションを手動で行ってしまうと「属人性」や「オペレーションミス」という問題が発生することになりますので、マイグレーションをコードで管理して自動化することもDevOpsエンジニアの重要なタスクとなります。
こちらに関しても「これが絶対に正解」という手法は存在しませんが、私がAWSでRDB(RDS)のマイグレーションを行う場合は、大抵は「VPC Lambda」を使用しています。(Lambdaはコンピュート用のサービスなのでマイグレーション用ツールを実行可能であること、VPC LambdaはPrivateのRDSインスタンスにアクセス可能であること、Systems Manager Run CommandのようにEC2を常時起動しておいたりする必要がないので低コストなこと等、要件を満たしているため。ただし冪等性に注意する必要がある)
マイグレーションツールに関しては、個人的にはRidgepoleのように「スキーマファイルの差分を検出してDDLを自動生成してくれる」というツールが好みなのですが、実行されるDDLがコードレビュー時に分からないことや、スキーマ定義がツール独自のDSLに依存してしまうことが許容されない場合も多かったり、あるいはDDLだけでなくDMLを実行したい場合もあったりするので、一般的にはflyway系の、生のDDLやDMLをそのまま記述できるタイプのツールを使用する方が無難と思われます。
winebarrel/ridgepole Flyway by Boxfuse
権限管理/アカウント管理
AWSもGCPも「IAM」という権限管理の仕組みがあります。システムを安定稼働させる上ではセキュリティは最重要要件の一つなので、権限管理に関しては十分に勉強しておく必要があるでしょう。
AWS IAM(ユーザーアクセスと暗号化キーの管理) Cloud IAM - Identity & Access Management
AWSのIAMに関しては「Assume Role」の概念が最初は非常に理解しづらいと思います(私もしばらくAWSの案件から離れるとすぐ忘れてしまいます)。下記の記事等で学習しておきましょう。
IAMロール徹底理解 〜 AssumeRoleの正体 Assume Roleの用途・メリット
また、GCPに関しては以前から「開発環境」「ステージング環境」「本番環境」など、サービスや環境ごとにプロジェクトを分けるという手法が一般的でしたが、AWSも「AWS Organizations」の登場によってアカウントを非常にカジュアルに作成/削除出来るようになったため、今後はサービスや環境ごとにアカウントを分けるという手法が一般化していくと思われますので、こちらに関しても理解しておく必要があるでしょう。
(例えば業務委託の方は開発用のAWSアカウントのみアクセス可能にして、本番用のAWSアカウントは一部の社員の方だけしかアクセス出来ないようにすれば、サービスの安全性は大幅に向上しますので、今後は一つのAWSアカウントで全ての環境をホストするようなリスクの高い構成は廃れていくと思われます)
AWS Organizationsによるマルチアカウント戦略とその実装 AWS Organizations を実際に初めてみる第一歩
ビッグデータ分散処理
ビッグデータの分散処理に関しても、クラウドのマネージドサービスを活用することで、低コストで効率よく処理を実行することが可能です。
AWSならEMR、GCPならCloud DataprocかCloud Dataflowがビッグデータの分散処理基盤となります。
あくまで私の主観になりますが、「クラスタの管理をしないでよい」という点で、GCPを使う場合はCloud DataprocよりもCloud Dataflowの方が圧倒的に楽だと思います。Cloud Dataprocはクラスタの構築管理を自分達で行う必要がありますが、Cloud Dataflowは実行時に自動的にクラスタの構築とスケールと削除を行ってくれるので便利です。(DataflowはApache Beamのマネージドサービスです)
Apache beamとdataflow紹介
AWSに関してはEMR以外の選択肢がありません(AWS Batchも一応���列分散処理は可能ではありますがMapReduce系の処理には対応していません)。またEMRを使う場合は大抵の場合Sparkを使うことになると思いますので、Sparkの知識が必要になります。(過去の経験による個人的見解ですが、Apache Beamと比較すると、Sparkの学習コストはかなり高めです)
Spark on EMRの基礎をおさらいする
バッチ処理とジョブフロー制御
バッチ処理もバッチジョブのフロー制御も、現在はクラウドのマネージドサービス(の組み合わせ)で実現できるようになっています。
AWSであればStep FunctionsとAWS Batchの組み合わせ、GCPの場合はCloud Composerを使うことが一般的だと思います。
Step FunctionsとAWS Batchはそれほど難しくはありませんが、Cloud Composer(Airflow)は学習コストがかなり高い(特にWeb UIの使い方が非常に分かりにくい)ツールのため、使いこなせるようになるまでにはある程度学習期間が必要になると思われます。
また、Cloud Composerは、現時点では起動する際に最低でも3台のGCEインスタンスが必要になります(ComposerはKubernetesクラスタ上に構築されています)ので、ジョブフローの数がそれほど多くないサービスの場合はコスト面でかなり割高感があると思われます。
単体のジョブを実行したいだけであれば、GCPなら「Cloud Scheduler + Cloud Pub/Sub + Cloud Functions」という組み合わせでも実現可能です。(ただしCloud Functionsの最大実行可能時間には540秒という制限があります)
Pub/Sub を使用して Cloud ファンクションをトリガーする
また、私はやったことはありませんが、GKE上でJobを実行するという方法もあります。「とにかく何もかもKubernetesに寄せたい」という方針のチームであればこの方式もありかもしれません。
Running a job | Kubernetes Engine Documentation
CI/CDパイプラインの構築
CI/CDパイプラインの構築は、DevOpsエンジニアの最重要タスクの一つとなります。
CI/CDツールは色々ありますが、現時点では、一般的なWebサービスの開発においては「CircleCI一択」と考えて良いのではないでしょうか。
例えばAWSにはCodeBuildやCodePipeline、GCPにはCloud BuildというCI/CD用のサービスが存在しますが、「クラウドサービスのアクセスキー等の秘匿情報をCIサービスで管理してよい」という条件がOKならば、ほぼ全ての機能はCircleCIだけで実現可能なのと、CircleCIのノウハウはAWSでもGCPでもどちらでも共通で使えるので、わざわざ一つのクラウドベンダー限定でしか使用できないサービスに学習コストを浪費する必要はないのでは、というのが私の個人的見解です。
CircleCI vs. CodePipeline
ただしCircleCIも安泰というわけではなく、GitHub Actionsが先日のバージョンアップでCI/CDをサポートしたことにより、将来的にはCircleCIからGitHub Actionsへの移行が進んでいく可能性がかなり高くなってきているという印象です。
現状のGitHub Actionsは「キャッシュ機能がない」「ブランチのフィル��リングが一括で行えない」等、CircleCIと比較した際に明らかに不便な部分が存在するようですが、ここら辺の問題が解決されれば、CircleCIを置換していくのは時間の問題かもしれません。(ちなみにGitHub ActionsのバックエンドではAzure Pipelinesのfork版が動作しているようです)
circleciのbuild/test/deployをgithub actions(beta)に移行した 新 GitHub Actions 入門
ロギング/モニタリング
サービスを安定稼働させる上でロギング/モニタリングは必須です。AWSならCloudWatch、GCPならStackdriverの使用方法にある程度詳しくなっておく必要があるでしょう。
サードパーティのモニタリングサービスとしては「Datadog」が比較的よく使われています。(はてなさんのMackerelも名前はよく目にしますが、私が今までに参画したプロジェクトでは使われていませんでした)
Datadogに関しては、ダッシュボードのUIコンポーネントが豊富だったり、Slackへの通知にグラフ画像を含めることが出来たり、外形監視を行えたり等、機能そのものが充実しているという点以外に、(完全ではないものの)唯一「Monitoring as Code」に対応しているツールであるというメリットもあります。(CloudWatchやStackdriverでもダッシュボードは作成可能ですが、環境ごとに全て手動で作っていく必要があります。監視する対象が多いとかなりしんどい作業になります)
TerraformとDataDogで始めるMonitoring as Code入門 クラウド時代の監視ツールDatadogをあらためて紹介します DatadogのSynthetics(外形監視)つかってみた
分析基盤
ユーザのフィードバックをサービスに反映していく上で、分析基盤の構築もDevOpsエンジニアの重要なタスクとなっています。
AWSならRedshift、GCPならBigQueryが基本的な分析基盤となりますが、私が今まで参画した現場ではRedshiftを使っているチームはほとんど見かけませんでしたし、構築の容易さや、使い方を間違えなければ比較的低コストで運用できるというメリットから考えると、分析基盤に関してはとりあえずBigQueryだけ学習しておけば十分だと思います。
サードパーティのTreasure Dataというサービスを使っている会社さん���ありますが、料金がかなり高めということもあって、こちらもBigQueryと比較すると使っている会社さんは少ないので、私も一応使用経験はありますが、あえて勉強しておく必要はないのではという印象です。
データ分析基盤について
BashスクリプトとCLIツール
Bashスクリプトは、主にCI/CDにまつわる各種作業を自動化する上で必須のスキルとなります。
シェルスクリプトに関する書籍等で基本をしっかり学習しておきましょう。下記のエムスリーさんの研修資料もとても参考になると思います。
新しいシェルプログラミングの教科書 bashスクリプティング研修の資料を公開します
さらに、AWSの場合はAWS CLI、GCPの場合はgcloud、この2つのツールも自動化作業において必須なので、使用方法に関しては十分に詳しくなっておく必要があります。
AWS コマンドラインインターフェイス(CLI: AWSサービスを管理する統合ツール) gcloud コマンドライン ツールの概要
基盤コードの開発
こちらも本来はアーキテクトの仕事になりますが、開発人数が少ない場合や、経験の浅いエンジニアの方が多い場合は、DevOpsエンジニアがアプリケーションの基盤コード部分も作成することになります。
私が基盤コードを実装する場合は、
Webフレームワークの選定
パッケージマネージャの導入
サンプルAPIの実装
単体テスト
統合テスト
Linterの設定
Formatterの設定
.gitignore等の設定
ここら辺までをざっと実装してから、アプリケーションエンジニアや機械学習エンジニアの方にお引渡しするというケースが多いです。
ちなみにAWSの各種サービスに依存する部分のテストに関しては、AWSのサービスをエミュレートしてくれるlocalstackというDockerイメージが便利です。
MLOps
次に、MLOpsエンジニアに必要なスキルセットを見ていきましょう。DevOpsエンジニアのスキルセットに加えて、下記のような知見が必要になります。
機械学習の基礎知識
機械学習の深い知見は必要ありませんが、実際にMLOpsエンジニアとして機械学習エンジニアの方たちと働いてきた経験上、とりあえず下記レベルの知識はあった方が良いかなと考えております。
微分と線形代数と確率統計の基礎知識
Courseraの機械学習コース修了レベルの知識
Jupyter Notebook(またはJupyterLab)の基礎知識
KaggleのTitanicを一回やっておく
数学に関しては、大学レベルの知識は不要だと思います。高校3年生程度のレベルで十分だと思いますし、一回復習して大部分を忘れてしまってもMLOpsエンジニアとしてそれほど支障はないと思います。(ちなみに私の場合は下記の記事のように一ヶ月ほど仕事を休んで小学校の算数から高校3年生の数学までを全て勉強し直しました)
文系エンジニアが機械学習に入門するために小学校の算数から高校数学までを一気に復習してみました。
Courseraの機械学習コースは非常に評価の高いコースですが、実際に取り組んだ経験として「MLOpsエンジニアであればこのコースのカリキュラムをやっておけば機械学習の基礎知識としては十分」と考えております。(こちらは仕事をやりながら約1ヶ月程度で修了しました)
文系エンジニアがCourseraの機械学習コースを1ヶ月で修了したので振り返ってみました。
Jupyter Notebookに関しては、私の場合はフリーライブラリで学ぶ機械学習入門という書籍に取り組む中で勉強しました。ただし今後はJupyterLabが主流になるようですので、そちらの使い方に慣れておいた方が良いかもしれません。(GCPのAI PlatformではJupyterLab用のマネージドサービスであるAI Platform Notebooksが提供されています。
JupyterLabのすゝめ
また、Kaggleの初心者向け課題であるTitanicに取り組むと、機械学習エンジニアの方たちの作業の流れが一応おおまかには把握できますので、こちらもやっておいた方が良いと思います。
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
機械学習基盤
AWSであればSageMaker、GCPであればAI Platformが機械学習基盤となります。(GCPの機械学習基盤は以前は「ML Engine」という名称でしたが、色々なサービスの追加や機能変更に伴って名称が変更されたようです)
どちらも
分析(Jupyter NotebookやJupyterLab環境)
学習
学習済みモデルのデプロイとAPIとしてのホスト
といった、機械学習基盤としての基本的な機能は共通です。
MLOpsエンジニアの場合、分析業務に関しては基本的に携わりませんので、それぞれのサービスを使用した学習の実行、およびモデルのデプロイとAPIのホストをどのように行うのか、という辺りが把握出来ていれば十分だと思います。
MLワークフロー制御
データの収集、前処理、学習、モデルのデプロイといった一連の機械学習のワークフローを制御する作業は、MLOpsエンジニアの最重要タスクとなります。
MLワークフロー制御に関して「これがスタンダード」というツールは存在しませんが、AWSであればStep Functions、GCPであればCloud Composer(Airflow)を用いることで、マネージドサービスだけを用いたMLワークフロー制御は一応可能です。
AWS StepFunctions を使った機械学習ワークフローの管理 Practical Guide: How to automatize your ML process with Airflow and Cloud Composer
AWSの公式ドキュメントに、Airflowを使ったMLワークフロー制御に関する記事が存在しますが、Airflowをアンマネージドな方式で使用することを許容できるならば、この方法もありかもしれません。
Amazon SageMaker と Apache Airflow
GCPの場合、GKE上でkubeflow pipelinesを使用してMLワークフローを制御するという方式が推されているので今後このツールの使用が広まっていく可能性もありますが、まだかなり発展途上のツールのため、今のところは静観しておいた方が良さそうです。
AutoML
データに対する前処理、学習アルゴリズムやハイパーパラメータの選定、学習と評価といった一連の作業(もしくはその一部)を自動で処理してくれるサービスを総称して「AutoML」と言います。(GCPの「Cloud AutoML」は単なるサービス名です)
AWSの場合、Amazon PersonalizeがAutoML系サービスの代表格だと思います。GCPの場合はAutoML Visionが有名です。
機械学習エンジニアの方やデータサイエンティストの方たちに色々お話を伺う限りでは、今まで機械学習エンジニアの方にお願いしないと不可能だった作業が、今後AutoMLによってどんどん自動化(いわゆる「AIの民主化」)されていく可能性が非常に高くなっているという情勢のようですが、AutoMLがうまくハマるタイプの作業であれば工数を大幅に削減することが可能になるため、「機械学習サービスのリードタイムを短縮する」ことが主要な役割のMLOpsエンジニアにとって、AutoML系の技術へのキャッチアップは必須になっていくと思われます。
まとめ
こちらの記事で紹介した全ての技術を短期間で経験するのは難しいと思いますが、「自動化」「巨人の肩に乗る」「モダンな技術を採用する」という方針の企業さんのご案件を複数渡り歩いていけば、クラウドのマネージドサービスを適切に活用する知見は自然と身に付いていくと思います。(少なくとも「手作業」や「オレオレコード」や「僕の考えた最強の社内ツール」的なものが蔓延している企業さんで働くことは、DevOps/MLOpsエンジニアのキャリアにとってはほとんどメリットがないと思います)
また、最初の方でも述べましたが、現在は「AWSとGCPのどちらをインフラとして使用するか」を検討するフェーズが新規開発案件の場合はほぼ必ず入ってくるという状況ですので、例えばAWSに関してある程度詳しくなったら次はGCPを使える案件を選択する等、プラットフォームにこだわり過ぎずに両クラウドのマネージドサービスを幅広く経験していく方が、より先進的で面白い案件に携われる可能性が高くなるのではないかと思います。(ちなみに私の場合はAWS案件とGCP案件を掛け持ちするみたいなこともやっております)
私もまだまだ「クラウドネイティブ時代のDevOps/MLOpsエンジニア」として発展途上ですので、今後も引き続き様々なマネージドサービスにキャッチアップして、サービス全体の安定性やリードタイムの向上にさらに大きく貢献できるように頑張っていきたいと思います。
おまけ
Youtubeの方で、Web系エンジニアやWeb系エンジニアに興味のある方たち向けの雑食系エンジニアTVというチャンネルをやっています。もしご興味ございましたらチャンネル登録してみて頂けると大変嬉しいです。
また、2019年から「雑食系エンジニアサロン」というオンラインサロンも始めました。(ご登録者様は2019年8月時点で1,200名様を超えました)
Twitterの方でも「Web系エンジニアのキャリア戦略」を中心に色々と情報を発信しておりますので、もし宜しければフォローしてみてください。@poly_soft
0 notes
Text
Cloud Memorystore: A fully managed in-memory data store service for Redis
https://cloudplatform.googleblog.com/2018/05/Introducing-Cloud-Memorystore-A-fully-managed-in-memory-data-store-service-for-Redis.html Comments
0 notes