#i know i could import all my stuff to firefox directly
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
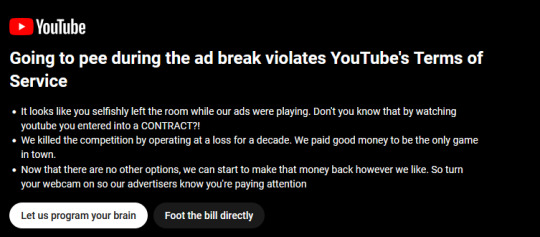
Wow, this blew up. This was a silly post i made before i'd had my coffee or meds but its a sentiment i've been thinking about a lot recently. ive been reading through the notes and theres way too many to reply to. but they mostly fall into these categories: apollo dodgeball / if you knock on enough doors asking for the devil: I think thats actually a big part of why i made this. Youtube (or any corporation) will do everything it can to make more money. they would implement this in a second if it were both technologically feasible and socially acceptable (or at least, acceptable enough to not cause too much of a backlash). a decade ago, this concept met neither criteria. now its dangerously close to meeting both.
The web was built on a model where the website sends you content and a suggestion of how to render it - to give users the freedom to interact with it however they choose. Since then, there's been a battle between corporations and this principle as they use every trick they can come up with to force you to render the content the way they want you to.
The most effective way that corporations have achieved this is with apps. Paraphrasing Cory Doctorow[1], an app is just a website that its illegal to mess with. So many of the notes are people saying "i wish i could block youtube ads on my phone/smart tv/game console". this is a problem, and a bad sign of what to come.
another thing that makes this concept technologically feasible and socially acceptable in my opinion is face id. Having a camera scan your face automatically before letting you progress has become normal. Its common to put tape over your webcam, but nobody puts tape over their phone camera. Somehow, we've been trained to view it differently. more broadly, I dont think the web is meant to be profitable. The old internet was full of small forums run at a loss fueled by the passion of their creators. When corporations moved in down the road with enough money to drive the forums away and take over, those corporations still didnt turn a profit. and they havent for a decade. Now they're getting desperate and they're going to extract as much as they can from their users to try and recoup those costs. Your outrage over the concept of this is important. Visible backlash to hostile practices works. its important that we all say Fuck That loudly and often. Youtube is adding a five second delay for firefox users: I read about this immediately after making the original post. this is such a brazen move by google. I hope they get in some serious shit for leveraging one monopoly to bolster another but im not familiar enough with international law to know if thats likely.
Regardless, google has been showing their hand lately with so many hostile decisions. Their only leverage is their user base. Don't help them. Switch to firefox. if you need to, you can make firefox pretend to be chrome for specific websites Ads are getting worse / loud ads in asmr videos / pragerU and other evil ads: Ad blocking still works! please use an ad block! install ublock origin! Youtube is working hard break ad blockers but the ublock devs are working harder to keep them working. you just need to update the filter lists every now and then. here's a guide I still want to support creators: Find a way to support them directly! youtube is a notoriously unreliable income source. Check how the creator you want to support would prefer you support them. Chucking them a few bucks once will go a lot further than watching ads.
Piss kink references: Thank you tumblr for being tumblr. A lot of the replies have been pretty heavy so these silly responses have been surprisingly refreshing.
----
I highly recommend Cory doctorow's defcon talk about the state of the web and how we can fix it. it put words to things i'd been feeling for a long time and introduced me to new ways of thinking about some of this stuff. Its linked at the bottom.
Its been wild having this post break containment like this. Tumblr is my place for shouting into the void and im used to most of my original posts not getting much traction (which is fine, or maybe even the point). the concept of over thirty thousand people reading something i wrote is hard to even conceptualize. I wasn't at all prepared for this but its touching that so many people resonated with my anger and frustration.
Okay, i'm going to go outside and remind myself that there is still so much good in the world. Fighting corporations is important but don't forget to also marvel at a cool bug or something to balance it out [1] - DEF CON 31 - An Audacious Plan to Halt the Internet's Enshittification - Cory Doctorow [Invidious link] [yt]
72K notes
·
View notes
Text
this is a daily reminder to stop the habit of opening chrome and getting more and more things to firefox
#i know i could import all my stuff to firefox directly#but the thing is i've been using firefox for business stuff for ages#so there are some accounts i'm leaving in chrome..... but i still wanna use firefox most of the time#i should also get gyazo here and install it on my phone mmm
0 notes
Note
Not to pry, but i saw your tags and i would love to hear any thoughts you have on what cornelia could have done w capricorn and basta instead of doing them like That, if you have any ideas/opinions?
really sorry for the late reply, but totally! ((and thank you for asking!!))
okay so, first off, Capricorn. I want to say that I’m not actually super upset by Capricorn’s death since the ending of Inkheart is great in my opinion, and narratively speaking it really ties everything up pretty neatly and cleanly in a satisfying way. it serves the story VERY well and is very gratifying since Capricorn is just nasty enough that we’re all very, very glad to see him get his just desserts.
I said that killing Capricorn off was a bad move, and what I mean is that, because of the way the other villains are written in Inkspell and Inkdeath, the stark contrast between them and Capricorn as a villain in Inkheart really grates on me, because I know Cornelia Funke can write really cool and intriguing yet blatantly evil and unsympathetic villains, but I don’t feel like the story delivers on that in the other books like Inkheart did, and it basically feels like we might as well have just kept Capricorn alive and let him do the cool scary stuff the rest of the story, lmao.
he’s such a good antagonist, but I don’t legitimately want his death undone or him to actually play a part post-Inkheart because I feel like Capricorn belongs squarely in Inkheart, in the real world, untouched by fantasy or magic or anything that delegitimizes how really, scarily, human Capricorn and his evils are. I feel like he really thrived in our world for a good reason, and I don’t rlly want to mess that up.
(also I think it’s interesting to note how the Inkworld trilogy is basically on a sliding scale of realness to pure story, and both of what I consider the strongest terrifyingly legit villains never make it to the last installment, where it directly crosses over into actual fantasy, instead of just nudging at it.)
what I’d have liked to see is actually maybe flashbacks of Capricorn. more mentions of him. some connections, more than just Mortola’s motivation in Inkspell or passing references to the former fire-raisers, you know? I stand by the fact that Capricorn is a villain fitted better to the irl world, but I also don’t like the feeling that Capricorn was just plucked out of thin air and never had a real impact on the Inkworld, which is what we get in Inkspell, to me. I want to know that the Capricorn that terrified us in Inkheart is the same Capricorn who used to have his own posse of men at his beck and call in the Inkworld.
also bit of a tangent but, this goes in general as well as a complaint I have for Inkspell. I want to feel like all of these supposed characters from the Inkheart book are real and their pasts matter, like Inkspell didn’t just drop us and the main characters into a world that doesn’t really exist and doesn’t really have any stakes, which is, unfortunately how it kinda feels to me. and I think Capricorn is a big part of that, given how huge a presence he has and how huge a part he plays in Inkheart. you can argue that it’s just foreshadowing in a way, that the Capricorn who made such a big impact in the very first story is only the tip of iceberg, he’s only a minor player in the real world of Inkheart, which is a very fair assessment, but I think it also has the unintended consequence of making the Inkworld feel less like a cohesive universe separate from ours and more like, well, a story, because of that.
my opinion about Capricorn’s past in the Inkworld also goes hand-in-hand with my opinions on Firefox–I would have loved to hear more about his past as a fire-raiser under Capricorn and what Capricorn was like then, what Firefox’s personal investment in that line of work was and how he was brought into it, his relationship with Capricorn and the others.
basically his stake in the story and his opinions of the old fire-raisers vs the new work under the Adderhead. I feel like Firefox would have been a really good way to connect the lore of Inkheart only mentioned in the first book and what we actually see stepping into the world itself in Inkspell. he has the right history to give us backstory and insight into the past we’ve heard of, while also bringing us into what the future of the Inkworld looks like right now and how it’s changed.
and Firefox is also an excellent way to fix my issues with Basta’s plot.
so my thoughts on Basta! I feel kinda the same about him as Capricorn, in a way, that his death is deserved and in it’s own way poetic (the fact that in the end, Basta is nothing more than an awful man whose death is only a footnote to the story at large) but his death is not very satisfying as a reader who’s been extremely invested in his role in the story up until that point. narratively I don’t think I actually have a huge problem with the decision to kill off Basta because it all checks out, but I also think it causes some other issues.
what I mean is, Basta is the most personal of the Inkworld trilogy villains, and I think serves an important role as sort of the bridge between the readers and more distant, high stakes of the story. AKA he is the very real, very intimate reminder of what exactly the heroes are fighting for and against, and what will happen if they lose–men like Basta will win. he also provides good interpersonal villainy that helps develop characters and move the story along in a way that a Bigger And Badder villain just can’t. and I think that taking him out of play while also not adding in anything else that serves the same role kinda takes away the tension in the story, I think.
I mean, the stakes are still there, it’s kinda hard to NOT feel the weight of the mass-murder of children but tension (as in narrative tension) is really important in a story and I don’t really feel that as much in Inkdeath as in the first two books? and I do think the villains are responsible for that (or also the lack of certain villains.)
I just honestly feel like the pros of Basta’s death in the story don’t outweigh the consequences.
what I would have liked to have seen, that I think fixes all my issues, is a Basta and Firefox team up in Inkdeath. Firefox always seemed awfully dissatisfied with his new job working for the Adderhead to me, and there are just SO MANY villains in Inkdeath working at once, all with their own agendas and own little teams, the idea of them all being at odds with each other while all also trying to capture the main characters is VERY cool.
like, you have, of course, the Piper, with his high-ranking station in the Adderhead’s court, being The Dragon to the Adderhead’s Big Bad. the very classic, very regal and threatening villains who make up the serious problem in the big story, the ones who are driving the actual plot going on. they’re the ones who have the resources and who actually have to be defeated by the characters and not just avoided.
and then imagine you have, pitted against them, Basta and Firefox, and Orpheus and Mortola, all working for their own ends and own reasons. Orpheus and Mortola who are pretending to be allied with the Piper and the Adderhead while working their own sneaky underhanded schemes in the shadows, and Basta and Firefox who have publicly defected from the Adderhead and are in hiding just as much as the heroes, while still trying to make their moves.
like Inkspell gives so much basis for a Piper/Firefox rivalry with no delivery and that’s a shame!!! I really feel like he was wasted as a character, and the question is not about him, but I REALLY feel like fixing Firefox’ arc in the books would automatically tie together a lot of other stuff.
and we all also know how lost Basta is without a master to devote himself to, and we know how displeased Firefox is as the Adderhead’s servant.
Mortola has absolutely no ties to Basta other than he’s convenient and loyal to her as an extension of his former loyalty to Capricorn–he’s an easy tool to use. Inkdeath already has Mortola growing steadily more unhinged and illogical as she accepts her own irrelevance after Capricorn’s death, so it’s totally plausible she might abandon Basta completely to go about her own goals when she decides to work with Orpheus, and of course Basta would flounder.
and so Basta, unsure and looking for any anchor to give him a purpose, would look for some sort of familiarity and companionship, and there’s two options there: the Piper or Firefox. the Piper is steadfast in his own loyalty to the Adderhead if for no other reason than greed, and Basta can’t stand him nowadays and never liked the Adderhead.
Firefox was someone Basta used to work with who is still someone Basta can at least tolerate. Firefox has his own issues with the Piper and the Adderhead and those two would be able to find common ground in that, and their other issues with how things are nowadays in the Inkworld
I can very easily see Basta persuading Firefox into a mutually beneficial partnership, speaking about his own experience with the Bluejay and his allies, and convincing Firefox to jump ship entirely. and I feel like Firefox might thrive under the ability to work with his own rules, unchallenged.
like seriously. Firefox who comes into himself and really becomes his own leader and own serious antagonist to be reckoned with, and gaining Basta’s respect and loyalty. them having a very good working relationship together as mostly equals, where Basta gives advice and information as a henchman, and Firefox actually calls the shots and plans the strategy. and they serve the same purpose in Inkdeath that Basta and Mortola did in Inkspell, that Basta and Flatnose and Cockerell served in Inkheart.
and that ties back into the post-Inkheart Capricorn disappearance, because with two of his former best men becoming allies later in the story, there’s plenty of room for mentions of him and backstory with the fire-raisers and how Basta and Firefox (and the Piper!!) all knew each other, and then how they used to interact with the rest of the Inkworld (Dustfinger, the Black Prince, Cosimo, etc) under Capricorn’s orders.
I just. h. feel like it would have been really cool to see Mo and Meggie and Dustfinger and everyone struggle against so many enemies from all sides, each with their own special ways of causing issues that have to be overcome. I would like to see that Piper and Firefox rivalry and confrontation and the consequences. I would really like to see Basta’s arc have him devoting himself to someone else and what that means for him, as a character.
I REALLY would like the antagonist situation in Inkdeath to be a lot more personal and interesting and complex.
anyway uh.
TL;DR:
my main issue with Capricorn isn’t his actual death, but how his time as an antagonist contrasts with how the villain situation ends up later, aka Not As Cool In My Personal Opinion (And These Guys Wish They Could Live Up To The Standard Capricorn Set). still would LOVE to see backstory of him regarding other villains that ties the whole universe together.
Basta’s death is valid but unsatisfying and I honestly really really miss him as a character in Inkdeath and because he was fun and delightfully horrible and twisted and I think he served an important purpose.
I think the way to fix both of these issues is UTILIZING FIREFOX.
I hope this sums up all my feelings and ideas about this subject well!
#TRIED TO DO A READMORE BUT TUMBLR WON'T LET ME FOR SOME REASON SO RIP TO EVERYONE WHO FOLLOWS ME AND SEES THIS LONG POST ON THEIR DASH#oh man this is so long#i'm rlly hope i've adequately expressed how cool i think the separate villain team-ups and rivalries would be bc#that would be so fucking neat and interesting#like i rlly think villains make a story and. idk if controversial opinion. but they're really not bringing it in inkspell and inkdeath#firefox is just woefully underused and the piper is frankly. kind of bland from everything i've seen of him#which is sad!!! they're full of such potential and i know cornelia funke can do really interesting and satisfying villains!!!#basta is rlly knifing his little heart out carrying the entire good villain characterization in inkspell on his shoulders#also again i really really cannot reasonably ask for capricorn to live past inkheart because its SUCH a good ending#but hes also s U CH A GOOD ANTAGONIST#HES SO AWFUL BUT SO ENTERTAINING TO READ#and i miss him especially when the rest of the villain situation isn't as fun#why can't yall be capricorn#anyway i've rambled enough on this fsdlifhgsidgsd#mine#inkheart#inkheart (book)#inkspell#inkdeath#capricorn#basta#firefox#uhh#aus#long post//
32 notes
·
View notes
Text
968
Finally got around to installing xkit, and it sure does make it easier to add posts to my queue on theEmberFlare. It mainly took this long because the official add-on isn’t available from, like Firefox directly, so you have to get it from GitHub. But just that extra step is, like, scary to me. I don’t know; I guess it’s just that I have very little experience with GitHub. I vaguely understand that it’s where software developers can make their stuff available, but I’m, like, ignorant of whether or not anything from there can be malicious. I’m sure I can look it up, but that’s even more steps—that I’m not exactly confident in taking either, because I’m not confident in doing research and looking things up. There’s the “unofficial” version available through Firefox, but the fact that it’s unofficial is also scary.
As an aside, I’ve been using the word “scary” instead of “anxiety-inducing” or “stressful”, because I’m using it to explore my suspected paranoia. I feel like I’ve been downplaying it this whole time—not just on this blog, but ever since being aware of my own mental health issues—by lumping it in with anxiety and stress. It’s possibly more accurate that I experience crippling, paralyzing fear of... things. I don’t know, maybe “paranoia” isn’t even quite the right word, but it’s what I happen to know.
Hmm, briefly looking it up, “delusions” seem to come up a lot. I’m not sure if I could accurately describe my experiences as delusions, at least not in ways that line up with these examples. Though, it’s possible that this sort of stuff is going on in my periconsciousness. Like, I could have certainly learned to suppress thoughts that would clearly be indicative of delusions such that I experience them as very vague anxieties. But maybe, if I interrogate those anxieties deeply enough, I might find that they are rooted in some sorts of delusions.
I mean, one that I have confidently identified before already is this, like, persistent fear of people in the neighborhood being aware of me: as if any of them might come after me [for being queer or any other reason]. I don’t have any particular justification for this: at most, I can say that I live in the southern US.
Hmm, I do also experience these intrusive thoughts of how I could potentially get into accidents whenever I drive. I’d categorized it under “catastrophizing” as a term I learned in regards to depression and anxiety. But it probably also applies to paranoia.
Oh! And there’s the big childhood delusion that led me to have suicidal thoughts as early as the fourth grade: the idea that I was just, like, fundamentally “wrong” somehow and deserved to have terrible things happen to me. For most of the past decade, I think I’ve had that logged as being due to dysphoria, but—while dysphoria can totally be an influence—there can quite possibly be other things going on.
And I’m confident that I’m not romanticizing extreme mental illness/disorder and wanting that for myself for, like, clout somehow. It’s more likely to me that I’ve been severely downplaying my symptoms due to internalized ableism. This whole time I’ve wanted to believe that I can get a handle on things with just a ltitle bit of effort: just some journaling, philosophizing, and self care is all. That most of my problems just come down to capitalism.
But if I’m truly, seriously honest about the symptoms I’ve lived with my whole life, I’d probably still be messed up in an anarchist/communist society. Of course, such a society would likely better accommodate my issues, but that’s the thing: if I’m being honest, I must admit that I’d likely still need accommodations even without capitalism.
And being honest about these sorts of things is important for me to be able to accurately identify my own needs, such that I can better form goals around them.
0 notes
Text
How to Think Like a Front-End Developer
This is an extended version of my essay “When front-end means full-stack” which was published in the wonderful Increment magazine put out by Stripe. It’s also something of an evolution of a couple other of my essays, “The Great Divide” and “Ooops, I guess we’re full-stack developers now.”
The moment I fell in love with front-end development was when I discovered the style.css file in WordPress themes. That’s where all the magic was (is!) to me. I could (can!) change a handful of lines in there and totally change the look and feel of a website. It’s an incredible game to play.
Back when I was cowboy-coding over FTP. Although I definitely wasn’t using CSS grid!
By fiddling with HTML and CSS, I can change the way you feel about a bit of writing. I can make you feel more comfortable about buying tickets to an event. I can increase the chances you share something with your friends.
That was well before anybody paid me money to be a front-end developer, but even then I felt the intoxicating mix of stimuli that the job offers. Front-end development is this expressive art form, but often constrained by things like the need to directly communicate messaging and accomplish business goals.
Front-end development is at the intersection of art and logic. A cross of business and expression. Both left and right brain. A cocktail of design and nerdery.
I love it.
Looking back at the courses I chose from middle school through college, I bounced back and forth between computer-focused classes and art-focused classes, so I suppose it’s no surprise I found a way to do both as a career.
The term “Front-End Developer” is fairly well-defined and understood. For one, it’s a job title. I’ll bet some of you literally have business cards that say it on there, or some variation like: “Front-End Designer,” “UX Developer,” or “UI Engineer.” The debate around what those mean isn’t particularly interesting to me. I find that the roles are so varied from job-to-job and company-to-company that job titles will never be enough to describe things. Getting this job is more about demonstrating you know what you’re doing more than anything else¹.
Chris Coyier Front-End Developer
The title variations are just nuance. The bigger picture is that as long as the job is building websites, front-enders are focused on the browser. Quite literally:
front-end = browsers
back-end = servers
Even as the job has changed over the decades, that distinction still largely holds.
As “browser people,” there are certain truths that come along for the ride. One is that there is a whole landscape of different browsers and, despite the best efforts of standards bodies, they still behave somewhat differently. Just today, as I write, I dealt with a bug where a date string I had from an API was in a format such that Firefox threw an error when I tried to use the .toISOString() JavaScript API on it, but was fine in Chrome. That’s just life as a front-end developer. That’s the job.
Even across that landscape of browsers, just on desktop computers, there is variance in how users use that browser. How big do they have the window open? Do they have dark mode activated on their operating system? How’s the color gamut on that monitor? What is the pixel density? How’s the bandwidth situation? Do they use a keyboard and mouse? One or the other? Neither? All those same questions apply to mobile devices too, where there is an equally if not more complicated browser landscape. And just wait until you take a hard look at HTML emails.
That’s a lot of unknowns, and the answers to developing for that unknown landscape is firmly in the hands of front-end developers.

Into the unknoooooowwwn. – Elsa
The most important aspect of the job? The people that use these browsers. That’s why we’re building things at all. These are the people I’m trying to impress with my mad CSS skills. These are the people I’m trying to get to buy my widget. Who all my business charts hinge upon. Who’s reaction can sway my emotions like yarn in the breeze. These users, who we put on a pedestal for good reason, have a much wider landscape than the browsers do. They speak different languages. They want different things. They are trying to solve different problems. They have different physical abilities. They have different levels of urgency. Again, helping them is firmly in the hands of front-end developers. There is very little in between the characters we type into our text editors and the users for whom we wish to serve.
Being a front-end developer puts us on the front lines between the thing we’re building and the people we’re building it for, and that’s a place some of us really enjoy being.
That’s some weighty stuff, isn’t it? I haven’t even mentioned React yet.
The “we care about the users” thing might feel a little precious. I’d think in a high functioning company, everyone would care about the users, from the CEO on down. It’s different, though. When we code a <button>, we’re quite literally putting a button into a browser window that users directly interact with. When we adjust a color, we’re adjusting exactly what our sighted users see when they see our work.

That’s not far off from a ceramic artist pulling a handle out of clay for a coffee cup. It’s applying craftsmanship to a digital experience. While a back-end developer might care deeply about the users of a site, they are, as Monica Dinculescu once told me in a conversation about this, “outsourcing that responsibility.”
We established that front-end developers are browser people. The job is making things work well in browsers. So we need to understand the languages browsers speak, namely: HTML, CSS, and JavaScript². And that’s not just me being some old school fundamentalist; it’s through a few decades of everyday front-end development work that knowing those base languages is vital to us doing a good job. Even when we don’t work directly with them (HTML might come from a template in another language, CSS might be produced from a preprocessor, JavaScript might be mostly written in the parlance of a framework), what goes the browser is ultimately HTML, CSS, and JavaScript, so that’s where debugging largely takes place and the ability of the browser is put to work.
CSS will always be my favorite and HTML feels like it needs the most love — but JavaScript is the one we really need to examine The last decade has seen JavaScript blossom from a language used for a handful of interactive effects to the predominant language used across the entire stack of web design and development. It’s possible to work on websites and writing nothing but JavaScript. A real sea change.
JavaScript is all-powerful in the browser. In a sense, it supersedes HTML and CSS, as there is nothing either of those languages can do that JavaScript cannot. HTML is parsed by the browser and turned into the DOM, which JavaScript can also entirely create and manipulate. CSS has its own model, the CSSOM, that applies styles to elements in the DOM, which JavaScript can also create and manipulate.
This isn’t quite fair though. HTML is the very first file that browsers parse before they do the rest of the work needed to build the site. That firstness is unique to HTML and a vital part of making websites fast.
In fact, if the HTML was the only file to come across the network, that should be enough to deliver the basic information and functionality of a site.
That philosophy is called Progressive Enhancement. I’m a fan, myself, but I don’t always adhere to it perfectly. For example, a <form> can be entirely functional in HTML, when it’s action attribute points to a URL where the form can be processed. Progressive Enhancement would have us build it that way. Then, when JavaScript executes, it takes over the submission and has the form submit via Ajax instead, which might be a nicer experience as the page won’t have to refresh. I like that. Taken further, any <button> outside a form is entirely useless without JavaScript, so in the spirit of Progressive Enhancement, I should wait until JavaScript executes to even put that button on the page at all (or at least reveal it). That’s the kind of thing where even those of us with the best intentions might not always toe the line perfectly. Just put the button in, Sam. Nobody is gonna die.
JavaScript’s all-powerfulness makes it an appealing target for those of us doing work on the web — particularly as JavaScript as a language has evolved to become even more powerful and ergonomic, and the frameworks that are built in JavaScript become even more-so. Back in 2015, it was already so clear that JavaScript was experiencing incredible growth in usage, Matt Mullenweg, co-founder of WordPress, gave the developer world homework: “Learn JavaScript Deeply”³. He couldn’t have been more right. Half a decade later, JavaScript has done a good job of taking over front-end development. Particularly if you look at front-end development jobs.
While the web almanac might show us that only 5% of the top-zillion sites use React compared to 85% including jQuery, those numbers are nearly flipped when looking around at front-end development job requirements.
I’m sure there are fancy economic reasons for all that, but jobs are as important and personal as it gets for people, so it very much matters.
So we’re browser people in a sea of JavaScript building things for people. If we take a look at the job at a practical day-to-day tasks level, it’s a bit like this:
Translate designs into code
Think in terms of responsive design, allowing us to design and build across the landscape of devices
Build systemically. Construct components and patterns, not one-offs.
Apply semantics to content
Consider accessibility
Worry about the performance of the site. Optimize everything. Reduce, reuse, recycle.
Just that first bullet point feels like a college degree to me. Taken together, all of those points certainly do.
This whole list is a bit abstract though, so let’s apply it to something we can look at. What if this website was our current project?

Our brains and fingers go wild!
Let’s build the layout with CSS grid.
What fonts are those? Do we need to load them in their entirety or can we subset them? What happens as they load in? This layout feels like it will really suffer from font-shifting jank.
There are some repeated patterns here. We should probably make a card design pattern. Every website needs a good card pattern.
That’s a gorgeous color scheme. Are the colors mathematically related? Should we make variables to represent them individually or can we just alter a single hue as needed? Are we going to use custom properties in our CSS? Colors are just colors though, we might not need the cascading power of them just for this. Should we just use Sass variables? Are we going to use a CSS preprocessor at all?
The source order is tricky here. We need to order things so that they make sense for a screen reader user. We should have a meeting about what the expected order of content should be, even if we’re visually moving things around a bit with CSS grid.
The photographs here are beautifully shot. But some of them match the background color of the site… can we get away with alpha-transparent PNGs here? Those are always so big. Can any next-gen formats help us? Or should we try to match the background of a JPG with the background of the site seamlessly. Who’s writing the alt text for these?
There are some icons in use here. Inline SVG, right? Certainly SVG of some kind, not icon fonts, right? Should we build a whole icon system? I guess it depends on how we’re gonna be building this thing more broadly. Do we have a build system at all?
What’s the whole front-end plan here? Can I code this thing in vanilla HTML, CSS, and JavaScript? Well, I know I can, but what are the team expectations? Client expectations? Does it need to be a React thing because it’s part of some ecosystem of stuff that is already React? Or Vue or Svelte or whatever? Is there a CMS involved?
I’m glad the designer thought of not just the “desktop” and “mobile” sizes but also tackled an in-between size. Those are always awkward. There is no interactivity information here though. What should we do when that search field is focused? What gets revealed when that hamburger is tapped? Are we doing page-level transitions here?
I could go on and on. That’s how front-end developers think, at least in my experience and in talking with my peers.
A lot of those things have been our jobs forever though. We’ve been asking and answering these questions on every website we’ve built for as long as we’ve been doing it. There are different challenges on each site, which is great and keeps this job fun, but there is a lot of repetition too.
Allow me to get around to the title of this article.
While we’ve been doing a lot of this stuff for ages, there is a whole pile of new stuff we’re starting to be expected to do, particularly if we’re talking about building the site with a modern JavaScript framework. All the modern frameworks, as much as they like to disagree about things, agree about one big thing: everything is a component. You nest and piece together components as needed. Even native JavaScript moves toward its own model of Web Components.

I like it, this idea of components. It allows you and your team to build the abstractions that make the most sense to you and what you are building.
Your Card component does all the stuff your card needs to do. Your Form component does forms how your website needs to do forms. But it’s a new concept to old developers like me. Components in JavaScript have taken hold in a way that components on the server-side never did. I’ve worked on many a WordPress website where the best I did was break templates into somewhat arbitrary include() statements. I’ve worked on Ruby on Rails sites with partials that take a handful of local variables. Those are useful for building re-usable parts, but they are a far cry from the robust component models that JavaScript frameworks offer us today.
All this custom component creation makes me a site-level architect in a way that I didn’t use to be. Here’s an example. Of course I have a Button component. Of course I have an Icon component. I’ll use them in my Card component. My Card component lives in a Grid component that lays them out and paginates them. The whole page is actually built from components. The Header component has a SearchBar component and a UserMenu component. The Sidebar component has a Navigation component and an Ad component. The whole page is just a special combination of components, which is probably based on the URL, assuming I’m all-in on building our front-end with JavaScript. So now I’m dealing with URLs myself, and I’m essentially the architect of the entire site. [Sweats profusely]
Like I told ya, a whole pile of new responsibility.
Components that are in charge of displaying content are almost certainly not hard-coded with data in them. They are built to be templates. They are built to accept data and construct themselves based on that data. In the olden days, when we were doing this kind of templating, the data has probably already arrived on the page we’re working on. In a JavaScript-powered app, it’s more likely that that data is fetched by JavaScript. Perhaps I’ll fetch it when the component renders. In a stack I’m working with right now, the front end is in React, the API is in GraphQL and we use Apollo Client to work with data. We use a special “hook” in the React components to run the queries to fetch the data we need, and another special hook when we need to change that data. Guess who does that work? Is it some other kind of developer that specializes in this data layer work? No, it’s become the domain of the front-end developer.
Speaking of data, there is all this other data that a website often has to deal with that doesn’t come from a database or API. It’s data that is really only relevant to the website at this moment in time.
Which tab is active right now?
Is this modal dialog open or closed?
Which bar of this accordion is expanded?
Is this message bar in an error state or warning state?
How many pages are you paginated in?
How far is the user scrolled down the page?
Front-end developers have been dealing with that kind of state for a long time, but it’s exactly this kind of state that has gotten us into trouble before. A modal dialog can be open with a simple modifier class like <div class="modal is-open"> and toggling that class is easy enough with .classList.toggle(".is-open"); But that’s a purely visual treatment. How does anything else on the page know if that modal is open or not? Does it ask the DOM? In a lot of jQuery-style apps of yore, yes, it would. In a sense, the DOM became the “source of truth” for our websites. There were all sorts of problems that stemmed from this architecture, ranging from a simple naming change destroying functionality in weirdly insidious ways, to hard-to-reason-about application logic making bug fixing a difficult proposition.
Front-end developers collectively thought: what if we dealt with state in a more considered way? State management, as a concept, became a thing. JavaScript frameworks themselves built the concept right in, and third-party libraries have paved and continue to pave the way. This is another example of expanding responsibility. Who architects state management? Who enforces it and implements it? It’s not some other role, it’s front-end developers.
There is expanding responsibility in the checklist of things to do, but there is also work to be done in piecing it all together. How much of this state can be handled at the individual component level and how much needs to be higher level? How much of this data can be gotten at the individual component level and how much should be percolated from above? Design itself comes into play. How much of the styling of this component should be scoped to itself, and how much should come from more global styles?
It’s no wonder that design systems have taken off in recent years. We’re building components anyway, so thinking of them systemically is a natural fit.
Let’s look at our design again:
A bunch of new thoughts can begin!
Assuming we’re using a JavaScript framework, which one? Why?
Can we statically render this site, even if we’re building with a JavaScript framework? Or server-side render it?
Where are those recipes coming from? Can we get a GraphQL API going so we can ask for whatever we need, whenever we need it?
Maybe we should pick a CMS that has an API that will facilitate the kind of front-end building we want to do. Perhaps a headless CMS?
What are we doing for routing? Is the framework we chose opinionated or unopinionated about stuff like this?
What are the components we need? A Card, Icon, SearchForm, SiteMenu, Img… can we scaffold these out? Should we start with some kind of design framework on top of the base framework?
What’s the client state we might need? Current search term, current tab, hamburger open or not, at least.
Is there a login system for this site or not? Are logged in users shown anything different?
Is there are third-party componentry we can leverage here?
Maybe we can find one of those fancy image components that does blur-up loading and lazy loading and all that.
Those are all things that are in the domain of front-end developers these days, on top of everything that we already need to do. Executing the design, semantics, accessibility, performance… that’s all still there. You still need to be proficient in HTML, CSS, JavaScript, and how the browser works. Being a front-end developer requires a haystack of skills that grows and grows. It’s the natural outcome of the web getting bigger. More people use the web and internet access grows. The economy around the web grows. The capability of browsers grows. The expectations of what is possible on the web grows. There isn’t a lot shrinking going on around here.
We’ve already reached the point where most front-end developers don’t know the whole haystack of responsibilities. There are lots of developers still doing well for themselves being rather design-focused and excelling at creative and well-implemented HTML and CSS, even as job posts looking for that dwindle.
There are systems-focused developers and even entire agencies that specialize in helping other companies build and implement design systems. There are data-focused developers that feel most at home making the data flow throughout a website and getting hot and heavy with business logic. While all of those people might have “front-end developer” on their business card, their responsibilities and even expectations of their work might be quite different. It’s all good, we’ll find ways to talk about all this in time.
In fact, how we talk about building websites has changed a lot in the last decade. Some of my early introduction to web development was through WordPress. WordPress needs a web server to run, is written in PHP, and stores it’s data in a MySQL database. As much as WordPress has evolved, all that is still exactly the same. We talk about that “stack” with an acronym: LAMP, or Linux, Apache, MySQL and PHP. Note that literally everything in the entire stack consists of back-end technologies. As a front-end developer, nothing about LAMP is relevant to me.
But other stacks have come along since then. A popular stack was MEAN (Mongo, Express, Angular and Node). Notice how we’re starting to inch our way toward more front-end technologies? Angular is a JavaScript framework, so as this stack gained popularity, so too did talking about the front-end as an important part of the stack. Node and Express are both JavaScript as well, albeit the server-side variant.
The existence of Node is a huge part of this story. Node isn’t JavaScript-like, it’s quite literally JavaScript. It makes a front-end developer already skilled in JavaScript able to do server-side work without too much of a stretch.
“Serverless” is a much more modern tech buzzword, and what it’s largely talking about is running small bits of code on cloud servers. Most often, those small bits of code are in Node, and written by JavaScript developers. These days, a JavaScript-focused front-end developer might be writing their own serverless functions and essentially being their own back-end developer. They’ll think of themselves as full-stack developers, and they’ll be right.
Shawn Wang coined a term for a new stack this year: STAR or Design System, TypeScript, Apollo, and React. This is incredible to me, not just because I kind of like that stack, but because it’s a way of talking about the stack powering a website that is entirely front-end technologies. Quite a shift.
I apologize if I’ve made you feel a little anxious reading this. If you feel like you’re behind in understanding all this stuff, you aren’t alone.
In fact, I don’t think I’ve talked to a single developer who told me they felt entirely comfortable with the entire world of building websites. Everybody has weak spots or entire areas where they just don’t know the first dang thing. You not only can specialize, but specializing is a pretty good idea, and I think you will end up specializing to some degree whether you plan to or not. If you have the good fortune to plan, pick things that you like. You’ll do just fine.
The only constant in life is change.
– Heraclitus – Motivational Poster – Chris Coyier
¹ I’m a white dude, so that helps a bunch, too. ↩️ ² Browsers speak a bunch more languages. HTTP, SVG, PNG… The more you know the more you can put to work! ↩️ ³ It’s an interesting bit of irony that WordPress websites generally aren’t built with client-side JavaScript components. ↩️
The post How to Think Like a Front-End Developer appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
How to Think Like a Front-End Developer published first on https://deskbysnafu.tumblr.com/
0 notes
Text
The Widening Responsibility for Front-End Developers
This is an extended version of my essay “When front-end means full-stack” which was published in the wonderful Increment magazine put out by Stripe. It’s also something of an evolution of a couple other of my essays, “The Great Divide” and “Ooops, I guess we’re full-stack developers now.”
The moment I fell in love with front-end development was when I discovered the style.css file in WordPress themes. That’s where all the magic was (is!) to me. I could (can!) change a handful of lines in there and totally change the look and feel of a website. It’s an incredible game to play.
Back when I was cowboy-coding over FTP. Although I definitely wasn’t using CSS grid!
By fiddling with HTML and CSS, I can change the way you feel about a bit of writing. I can make you feel more comfortable about buying tickets to an event. I can increase the chances you share something with your friends.
That was well before anybody paid me money to be a front-end developer, but even then I felt the intoxicating mix of stimuli that the job offers. Front-end development is this expressive art form, but often constrained by things like the need to directly communicate messaging and accomplish business goals.
Front-end development is at the intersection of art and logic. A cross of business and expression. Both left and right brain. A cocktail of design and nerdery.
I love it.
Looking back at the courses I chose from middle school through college, I bounced back and forth between computer-focused classes and art-focused classes, so I suppose it’s no surprise I found a way to do both as a career.
The term “Front-End Developer” is fairly well-defined and understood. For one, it’s a job title. I’ll bet some of you literally have business cards that say it on there, or some variation like: “Front-End Designer,” “UX Developer,” or “UI Engineer.” The debate around what those mean isn’t particularly interesting to me. I find that the roles are so varied from job-to-job and company-to-company that job titles will never be enough to describe things. Getting this job is more about demonstrating you know what you’re doing more than anything else¹.
Chris Coyier Front-End Developer
The title variations are just nuance. The bigger picture is that as long as the job is building websites, front-enders are focused on the browser. Quite literally:
front-end = browsers
back-end = servers
Even as the job has changed over the decades, that distinction still largely holds.
As “browser people,” there are certain truths that come along for the ride. One is that there is a whole landscape of different browsers and, despite the best efforts of standards bodies, they still behave somewhat differently. Just today, as I write, I dealt with a bug where a date string I had from an API was in a format such that Firefox threw an error when I tried to use the .toISOString() JavaScript API on it, but was fine in Chrome. That’s just life as a front-end developer. That’s the job.
Even across that landscape of browsers, just on desktop computers, there is variance in how users use that browser. How big do they have the window open? Do they have dark mode activated on their operating system? How’s the color gamut on that monitor? What is the pixel density? How’s the bandwidth situation? Do they use a keyboard and mouse? One or the other? Neither? All those same questions apply to mobile devices too, where there is an equally if not more complicated browser landscape. And just wait until you take a hard look at HTML emails.
That’s a lot of unknowns, and the answers to developing for that unknown landscape is firmly in the hands of front-end developers.

Into the unknoooooowwwn. – Elsa
The most important aspect of the job? The people that use these browsers. That’s why we’re building things at all. These are the people I’m trying to impress with my mad CSS skills. These are the people I’m trying to get to buy my widget. Who all my business charts hinge upon. Who’s reaction can sway my emotions like yarn in the breeze. These users, who we put on a pedestal for good reason, have a much wider landscape than the browsers do. They speak different languages. They want different things. They are trying to solve different problems. They have different physical abilities. They have different levels of urgency. Again, helping them is firmly in the hands of front-end developers. There is very little in between the characters we type into our text editors and the users for whom we wish to serve.
Being a front-end developer puts us on the front lines between the thing we’re building and the people we’re building it for, and that’s a place some of us really enjoy being.
That’s some weighty stuff, isn’t it? I haven’t even mentioned React yet.
The “we care about the users” thing might feel a little precious. I’d think in a high functioning company, everyone would care about the users, from the CEO on down. It’s different, though. When we code a <button>, we’re quite literally putting a button into a browser window that users directly interact with. When we adjust a color, we’re adjusting exactly what our sighted users see when they see our work.

That’s not far off from a ceramic artist pulling a handle out of clay for a coffee cup. It’s applying craftsmanship to a digital experience. While a back-end developer might care deeply about the users of a site, they are, as Monica Dinculescu once told me in a conversation about this, “outsourcing that responsibility.”
We established that front-end developers are browser people. The job is making things work well in browsers. So we need to understand the languages browsers speak, namely: HTML, CSS, and JavaScript². And that’s not just me being some old school fundamentalist; it’s through a few decades of everyday front-end development work that knowing those base languages is vital to us doing a good job. Even when we don’t work directly with them (HTML might come from a template in another language, CSS might be produced from a preprocessor, JavaScript might be mostly written in the parlance of a framework), what goes the browser is ultimately HTML, CSS, and JavaScript, so that’s where debugging largely takes place and the ability of the browser is put to work.
CSS will always be my favorite and HTML feels like it needs the most love — but JavaScript is the one we really need to examine The last decade has seen JavaScript blossom from a language used for a handful of interactive effects to the predominant language used across the entire stack of web design and development. It’s possible to work on websites and writing nothing but JavaScript. A real sea change.
JavaScript is all-powerful in the browser. In a sense, it supersedes HTML and CSS, as there is nothing either of those languages can do that JavaScript cannot. HTML is parsed by the browser and turned into the DOM, which JavaScript can also entirely create and manipulate. CSS has its own model, the CSSOM, that applies styles to elements in the DOM, which JavaScript can also create and manipulate.
This isn’t quite fair though. HTML is the very first file that browsers parse before they do the rest of the work needed to build the site. That firstness is unique to HTML and a vital part of making websites fast.
In fact, if the HTML was the only file to come across the network, that should be enough to deliver the basic information and functionality of a site.
That philosophy is called Progressive Enhancement. I’m a fan, myself, but I don’t always adhere to it perfectly. For example, a <form> can be entirely functional in HTML, when it’s action attribute points to a URL where the form can be processed. Progressive Enhancement would have us build it that way. Then, when JavaScript executes, it takes over the submission and has the form submit via Ajax instead, which might be a nicer experience as the page won’t have to refresh. I like that. Taken further, any <button> outside a form is entirely useless without JavaScript, so in the spirit of Progressive Enhancement, I should wait until JavaScript executes to even put that button on the page at all (or at least reveal it). That’s the kind of thing where even those of us with the best intentions might not always toe the line perfectly. Just put the button in, Sam. Nobody is gonna die.
JavaScript’s all-powerfulness makes it an appealing target for those of us doing work on the web — particularly as JavaScript as a language has evolved to become even more powerful and ergonomic, and the frameworks that are built in JavaScript become even more-so. Back in 2015, it was already so clear that JavaScript was experiencing incredible growth in usage, Matt Mullenweg, the founding developer of WordPress, gave the developer world homework: “Learn JavaScript Deeply”³. He couldn’t have been more right. Half a decade later, JavaScript has done a good job of taking over front-end development. Particularly if you look at front-end development jobs.
While the web almanac might show us that only 5% of the top-zillion sites use React compared to 85% including jQuery, those numbers are nearly flipped when looking around at front-end development job requirements.
I’m sure there are fancy economic reasons for all that, but jobs are as important and personal as it gets for people, so it very much matters.
So we’re browser people in a sea of JavaScript building things for people. If we take a look at the job at a practical day-to-day tasks level, it’s a bit like this:
Translate designs into code
Think in terms of responsive design, allowing us to design and build across the landscape of devices
Build systemically. Construct components and patterns, not one-offs.
Apply semantics to content
Consider accessibility
Worry about the performance of the site. Optimize everything. Reduce, reuse, recycle.
Just that first bullet point feels like a college degree to me. Taken together, all of those points certainly do.
This whole list is a bit abstract though, so let’s apply it to something we can look at. What if this website was our current project?

Our brains and fingers go wild!
Let’s build the layout with CSS grid.
What fonts are those? Do we need to load them in their entirety or can we subset them? What happens as they load in? This layout feels like it will really suffer from font-shifting jank.
There are some repeated patterns here. We should probably make a card design pattern. Every website needs a good card pattern.
That’s a gorgeous color scheme. Are the colors mathematically related? Should we make variables to represent them individually or can we just alter a single hue as needed? Are we going to use custom properties in our CSS? Colors are just colors though, we might not need the cascading power of them just for this. Should we just use Sass variables? Are we going to use a CSS preprocessor at all?
The source order is tricky here. We need to order things so that they make sense for a screen reader user. We should have a meeting about what the expected order of content should be, even if we’re visually moving things around a bit with CSS grid.
The photographs here are beautifully shot. But some of them match the background color of the site… can we get away with alpha-transparent PNGs here? Those are always so big. Can any next-gen formats help us? Or should we try to match the background of a JPG with the background of the site seamlessly. Who’s writing the alt text for these?
There are some icons in use here. Inline SVG, right? Certainly SVG of some kind, not icon fonts, right? Should we build a whole icon system? I guess it depends on how we’re gonna be building this thing more broadly. Do we have a build system at all?
What’s the whole front-end plan here? Can I code this thing in vanilla HTML, CSS, and JavaScript? Well, I know I can, but what are the team expectations? Client expectations? Does it need to be a React thing because it’s part of some ecosystem of stuff that is already React? Or Vue or Svelte or whatever? Is there a CMS involved?
I’m glad the designer thought of not just the “desktop” and “mobile” sizes but also tackled an in-between size. Those are always awkward. There is no interactivity information here though. What should we do when that search field is focused? What gets revealed when that hamburger is tapped? Are we doing page-level transitions here?
I could go on and on. That’s how front-end developers think, at least in my experience and in talking with my peers.
A lot of those things have been our jobs forever though. We’ve been asking and answering these questions on every website we’ve built for as long as we’ve been doing it. There are different challenges on each site, which is great and keeps this job fun, but there is a lot of repetition too.
Allow me to get around to the title of this article.
While we’ve been doing a lot of this stuff for ages, there is a whole pile of new stuff we’re starting to be expected to do, particularly if we’re talking about building the site with a modern JavaScript framework. All the modern frameworks, as much as they like to disagree about things, agree about one big thing: everything is a component. You nest and piece together components as needed. Even native JavaScript moves toward its own model of Web Components.

I like it, this idea of components. It allows you and your team to build the abstractions that make the most sense to you and what you are building.
Your Card component does all the stuff your card needs to do. Your Form component does forms how your website needs to do forms. But it’s a new concept to old developers like me. Components in JavaScript have taken hold in a way that components on the server-side never did. I’ve worked on many a WordPress website where the best I did was break templates into somewhat arbitrary include() statements. I’ve worked on Ruby on Rails sites with partials that take a handful of local variables. Those are useful for building re-usable parts, but they are a far cry from the robust component models that JavaScript frameworks offer us today.
All this custom component creation makes me a site-level architect in a way that I didn’t use to be. Here’s an example. Of course I have a Button component. Of course I have an Icon component. I’ll use them in my Card component. My Card component lives in a Grid component that lays them out and paginates them. The whole page is actually built from components. The Header component has a SearchBar component and a UserMenu component. The Sidebar component has a Navigation component and an Ad component. The whole page is just a special combination of components, which is probably based on the URL, assuming I’m all-in on building our front-end with JavaScript. So now I’m dealing with URLs myself, and I’m essentially the architect of the entire site. [Sweats profusely]
Like I told ya, a whole pile of new responsibility.
Components that are in charge of displaying content are almost certainly not hard-coded with data in them. They are built to be templates. They are built to accept data and construct themselves based on that data. In the olden days, when we were doing this kind of templating, the data has probably already arrived on the page we’re working on. In a JavaScript-powered app, it’s more likely that that data is fetched by JavaScript. Perhaps I’ll fetch it when the component renders. In a stack I’m working with right now, the front end is in React, the API is in GraphQL and we use Apollo Client to work with data. We use a special “hook” in the React components to run the queries to fetch the data we need, and another special hook when we need to change that data. Guess who does that work? Is it some other kind of developer that specializes in this data layer work? No, it’s become the domain of the front-end developer.
Speaking of data, there is all this other data that a website often has to deal with that doesn’t come from a database or API. It’s data that is really only relevant to the website at this moment in time.
Which tab is active right now?
Is this modal dialog open or closed?
Which bar of this accordion is expanded?
Is this message bar in an error state or warning state?
How many pages are you paginated in?
How far is the user scrolled down the page?
Front-end developers have been dealing with that kind of state for a long time, but it’s exactly this kind of state that has gotten us into trouble before. A modal dialog can be open with a simple modifier class like <div class="modal is-open"> and toggling that class is easy enough with .classList.toggle(".is-open"); But that’s a purely visual treatment. How does anything else on the page know if that modal is open or not? Does it ask the DOM? In a lot of jQuery-style apps of yore, yes, it would. In a sense, the DOM became the “source of truth” for our websites. There were all sorts of problems that stemmed from this architecture, ranging from a simple naming change destroying functionality in weirdly insidious ways, to hard-to-reason-about application logic making bug fixing a difficult proposition.
Front-end developers collectively thought: what if we dealt with state in a more considered way? State management, as a concept, became a thing. JavaScript frameworks themselves built the concept right in, and third-party libraries have paved and continue to pave the way. This is another example of expanding responsibility. Who architects state management? Who enforces it and implements it? It’s not some other role, it’s front-end developers.
There is expanding responsibility in the checklist of things to do, but there is also work to be done in piecing it all together. How much of this state can be handled at the individual component level and how much needs to be higher level? How much of this data can be gotten at the individual component level and how much should be percolated from above? Design itself comes into play. How much of the styling of this component should be scoped to itself, and how much should come from more global styles?
It’s no wonder that design systems have taken off in recent years. We’re building components anyway, so thinking of them systemically is a natural fit.
Let’s look at our design again:
A bunch of new thoughts can begin!
Assuming we’re using a JavaScript framework, which one? Why?
Can we statically render this site, even if we’re building with a JavaScript framework? Or server-side render it?
Where are those recipes coming from? Can we get a GraphQL API going so we can ask for whatever we need, whenever we need it?
Maybe we should pick a CMS that has an API that will facilitate the kind of front-end building we want to do. Perhaps a headless CMS?
What are we doing for routing? Is the framework we chose opinionated or unopinionated about stuff like this?
What are the components we need? A Card, Icon, SearchForm, SiteMenu, Img… can we scaffold these out? Should we start with some kind of design framework on top of the base framework?
What’s the client state we might need? Current search term, current tab, hamburger open or not, at least.
Is there a login system for this site or not? Are logged in users shown anything different?
Is there are third-party componentry we can leverage here?
Maybe we can find one of those fancy image components that does blur-up loading and lazy loading and all that.
Those are all things that are in the domain of front-end developers these days, on top of everything that we already need to do. Executing the design, semantics, accessibility, performance… that’s all still there. You still need to be proficient in HTML, CSS, JavaScript, and how the browser works. Being a front-end developer requires a haystack of skills that grows and grows. It’s the natural outcome of the web getting bigger. More people use the web and internet access grows. The economy around the web grows. The capability of browsers grows. The expectations of what is possible on the web grows. There isn’t a lot shrinking going on around here.
We’ve already reached the point where most front-end developers don’t know the whole haystack of responsibilities. There are lots of developers still doing well for themselves being rather design-focused and excelling at creative and well-implemented HTML and CSS, even as job posts looking for that dwindle.
There are systems-focused developers and even entire agencies that specialize in helping other companies build and implement design systems. There are data-focused developers that feel most at home making the data flow throughout a website and getting hot and heavy with business logic. While all of those people might have “front-end developer” on their business card, their responsibilities and even expectations of their work might be quite different. It’s all good, we’ll find ways to talk about all this in time.
In fact, how we talk about building websites has changed a lot in the last decade. Some of my early introduction to web development was through WordPress. WordPress needs a web server to run, is written in PHP, and stores it’s data in a MySQL database. As much as WordPress has evolved, all that is still exactly the same. We talk about that “stack” with an acronym: LAMP, or Linux, Apache, MySQL and PHP. Note that literally everything in the entire stack consists of back-end technologies. As a front-end developer, nothing about LAMP is relevant to me.
But other stacks have come along since then. A popular stack was MEAN (Mongo, Express, Angular and Node). Notice how we’re starting to inch our way toward more front-end technologies? Angular is a JavaScript framework, so as this stack gained popularity, so too did talking about the front-end as an important part of the stack. Node and Express are both JavaScript as well, albeit the server-side variant.
The existence of Node is a huge part of this story. Node isn’t JavaScript-like, it’s quite literally JavaScript. It makes a front-end developer already skilled in JavaScript able to do server-side work without too much of a stretch.
“Serverless” is a much more modern tech buzzword, and what it’s largely talking about is running small bits of code on cloud servers. Most often, those small bits of code are in Node, and written by JavaScript developers. These days, a JavaScript-focused front-end developer might be writing their own serverless functions and essentially being their own back-end developer. They’ll think of themselves as full-stack developers, and they’ll be right.
Shawn Wang coined a term for a new stack this year: STAR or Design System, TypeScript, Apollo, and React. This is incredible to me, not just because I kind of like that stack, but because it’s a way of talking about the stack powering a website that is entirely front-end technologies. Quite a shift.
I apologize if I’ve made you feel a little anxious reading this. If you feel like you’re behind in understanding all this stuff, you aren’t alone.
In fact, I don’t think I’ve talked to a single developer who told me they felt entirely comfortable with the entire world of building websites. Everybody has weak spots or entire areas where they just don’t know the first dang thing. You not only can specialize, but specializing is a pretty good idea, and I think you will end up specializing to some degree whether you plan to or not. If you have the good fortune to plan, pick things that you like. You’ll do just fine.
The only constant in life is change.
– Heraclitus – Motivational Poster – Chris Coyier
¹ I’m a white dude, so that helps a bunch, too. ↩️ ² Browsers speak a bunch more languages. HTTP, SVG, PNG… The more you know the more you can put to work! ↩️ ³ It’s an interesting bit of irony that WordPress websites generally aren’t built with client-side JavaScript components. ↩️
The post The Widening Responsibility for Front-End Developers appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
😉SiliconWebX | 🌐CSS-Tricks
0 notes
Text
Transcript of The Talk Show Episode 4
Title: James Duncan Davidson & Digital Photography
Hosts: John Gruber, Dan Benjamin
Special guest: James Duncan Davidson
Release date: 28 July 2007
Description: Special guest James Duncan Davidson joins us to talk about digital photography. JDD is a pro, and shares his experience as a professional photographer for WWDC and O’Reilly.
Dan Benjamin: So where are you right now, Duncan, what conference are you at this week?
James Duncan Davidson: I’m actually at two conferences simultaneously. Today, tomorrow, and the next day is the Ubuntu Live conference. And then, starting tomorrow and going for the rest of the week is the Open Source Convention.
Benjamin: And you’re covering these, you’re photographing them?
Davidson: Yeah, I’m shooting them both.
Benjamin: That’s what we’re here to talk about. Last week, John and I said we gotta get you on here.
Davidson: Oh, I know, and I heard that actually. I was listening to the podcast while I was riding the MAX, and I think I was going over the bridge right about that point, and it was a very freaky feeling to be volunteered to do something while you’re listening to yourself on public transit. But I’m down with it, it’s pretty cool.
John Gruber: For those of you who don’t know, we’re talking to James Duncan Davidson. James Duncan Davidson is right now primarily — is that your primary source of income, you’re a conference photographer? I mean, most of your time is spent on photography now.
Davidson: Yeah, this year will be the first year it’s crossed the 50 percent line.
Gruber: But your background is very, very varied, and you’ve done everything from Java to Ruby on Rails, a lot of programming stuff. You’ve written books on Cocoa programming.
Davidson: Yep.
Gruber: So you go to these tech conferences, but you could easily not just be attending them, you could be and in the past have actually spoken at them.
Davidson: Oh yeah, yeah.
Benjamin: You spoke at Rails conference last year, right?
Davidson: Yeah, and they actually wanted me to speak this year, but I didn’t think I could actually do the job of shooting, and the conference, and get the talk ready. And even more tricky, photographing myself speaking, I thought that might be a little hard.
Benjamin: With all those strobes flashing all over the place, that’s a full-time job just setting those up.
Davidson: The conferences really have turned into — I mean, when I’m at a conference, it’s more than a full-time job. Like today, you’re catching me, it all worked out where I can find a break, but it’s going to be a 14-hour day. But it’s precisely because I spoke at tech conferences for so long that O’Reilly first picked me up to do the photography. They had the theory, and I agreed with them at the time and still do, that since I knew most of the people in this environment and knew what was going on, I probably would have a decent enough eye for understanding what would be important to take pictures of and what wouldn’t be at a tech conference. And that’s how the professional photography career got started.
Benjamin: As far as actually learning to be a photographer, you don’t just show up at a conference and start taking pictures, and now all of a sudden O’Reilly is hiring you to shoot everything. It can’t work like that.
Davidson: No, no, I’ve been shooting pictures since I was six or seven years old. My grandmother taught me how, and I’ve been shooting ever since.
Benjamin: You don’t have any formal training or educational background in photography though?
Davidson: No. All my formal training was in architecture actually. So, lots of design work, but no specific classes in photography, just lots and lots of experience.
Benjamin: So you said you grandmother taught you, Duncan, what did you start — because when I was a little kid, maybe this is how you started, when I was a little kid, we took a little — I guess it was some construction paper, and we folded it up into a little box, we painted it black, and then you took a little pinhole, and you just poke a pinhole and this little piece of tinfoil — and I understand now it’s aluminum foil — which was taped to a cut-out piece in the front of a thing, and there was like a little flap, and you would open up the flap, and just on the back of this thing you had one of those — you remember the old style 35 mm or whatever, the little pocket cameras that you would give to kids that had the little plastic U-shaped film thing that would fit into the back of the camera.
Davidson: The 110 cassettes, yeah.
Benjamin: Exactly. And you would crank that with a quarter, and then you would open the front of the thing, count to three, and then close it, and your picture would come out. That’s actually still how I photograph today.
Davidson: For some people, that would be the purest expression of photography because you’re directly manipulating aperture and shutter and everything right there. But no, I didn’t learn with a pinhole camera. You actually have a better background than I do then.
Benjamin: Well, my whole experience pretty much ends there though.
Davidson: [laughs] My grandmother shot 35 mm film on Leicas and I quickly picked up a — I had my own little 110 camera, I had one of those disc cameras. You remember those?
Benjamin: Oh yeah, that was really — if you had one of those — wow.
Gruber: Yeah, they were crazy cool because they were such an odd form factor because they were, like, up vertical. They were so thin in terms of front to back.
Benjamin: Yeah. They had these teeny-tiny lenses on them because they had such a small negative.
Gruber: And they took such crap pictures.
Davidson: They did.
Benjamin: [laughs]
Gruber: I should —
Benjamin: What — oh, go ahead, John. That’s John Gruber, by the way.
Gruber: I was just going to mention, for everybody who doesn’t know, you’re listening to The Talk Show. I’m John Gruber. I’m here hosting the show with my friend Dan Benjamin. We have some sponsors to thank this week, I would like to thank them, that’s why this show is here. And first up, I’d like to mention 37signals.
Benjamin: Can you believe that? How did we get them?
Gruber: They’re sponsoring The Talk Show. They have a bunch of great web apps, they do great software. The one that I want to talk about is Ta-da Lists. You guys use Ta-da Lists? It’s sort of like the list feature from Basecamp, broken out into its own little app. It’s free, you just go there, you make like a to-do list. And the reason — I never used it, I checked it out, I used it, it’s pretty good. But all of a sudden now I use it every day because what they did — and it wouldn’t an episode of The Talk Show if we didn’t bring up iPhone. They have an iPhone-optimized version of Ta-da List. You go to tadalist.com, you sign up, you get your own username. So I have one, I share it with my wife, we do all of our shopping lists on Ta-da Lists now. You get the regular Ta-da List interface when you go to it in Safari or Firefox, your regular web browser on your computer, so we can share shopping lists. We just do one for each store we go to. Then I go to the store, take out my iPhone, go there, and I get an iPhone-optimized view of the website. It’s not a little thing I have to pinch down in Safari, it’s just perfect. Every time I buy something, you just tap it, click “done”, it’s off the list, and I never — I’m the most absent-minded person in the world. We live about two blocks from a Whole Foods here in Philadelphia. I will leave the house and my wife can say, “Don’t forget to buy soy milk.” And I will say, “Okay.” And I will go there and I will see, oh, look, a new kind of chips! And I’ll buy these chips, come home, and she’ll be like, “Where is the soy milk?” And I’ll be like, “Oh.” And she’s like, “That’s the whole reason you went.” Never happens anymore. So, Ta-da Lists from 37signals.
Benjamin: Saved the marriage, it sounds like.
Gruber: No, it just saved me extra trips back to the grocery store.
Davidson: So it saved you frustration.
Gruber: And it also makes me feel like my iPhone is useful.
Benjamin: That justifies the purchase, I think.
Gruber: Oh, absolutely.
Davidson: Of course.
Gruber: I think one of the big differences for me — I got started as a hobbyist photographer with an actual film 35 mm Rebel about eight years ago or so. And I think the bad habit that it drilled into my head is that every time I press the shutter button, it’s going to cost me 50–75 cents to get the film developed. So if you started with film, it costs some amount of money every time you press the shutter, and you get into habit of really pinching your shots, make every one count. Whereas with digital, it’s effectively free, I mean, you do have to go back afterwards and pick the ones that you want to keep and get rid of [the rest], but it’s really a little bit of your time to go through and get rid of the bad shots. And you get so much better results if you just shoot-shoot-shoot-shoot-shoot as opposed to wait-wait-wait-wait-wait-okay, there it is-shoot.
Davidson: Right. It’s cheap until you have to go buy a terabyte array because you’ve taken so many shots.
Benjamin: You had a whole post, probably about a year ago, where you were sort of — the dos and don’ts for conference speakers, and one of them was, get anti-reflective coating on your glasses if you wear glasses. If you don’t wear glasses, get some, because people who wear glasses are significantly more intelligent. A whole bunch of things. One of the things that you said, you were talking about — dress appropriately for your audience. If your audience is going to be in a suit, you probably need to wear a suit. If your audience is going to be in business casual or t-shirts or whatever, dress relative to them. But as a photographer of the event, working the event, do you have to adhere to that dress code as well?
Davidson: I do, I do.
Benjamin: So it’s possible we might see you in a three-piece suit with a bow tie?
Davidson: If I were photographing an event where everybody else is wearing a three-piece suit, yeah, I would have to do something about that.
Benjamin: Most of the time though you’re a t-shirt and jeans kind of a guy?
Davidson: Most of the time. Most of the conferences I shoot are geek conferences where most of the people are pretty relaxed in what they wear. I have been trending though towards neatening it up a little bit. Dark colors work well when you’re shooting in the dark because I don’t really want to pull a lot of attention to myself. The day I wore the bright screaming magenta shirt was not a good day. Just kidding, never did that.
Benjamin: [laughs]
Davidson: But, like, today I’m wearing black pants and a black short sleeve button-down shirt. It’s not a fancy shirt, it’s some Old Navy kind of shirt, but you know. It’s nice enough, right?
Benjamin: In a way though, don’t you want to wear some kind of a t-shirt or a shirt that’s going to grab attention?
Davidson: Actually, most of the time I just want to blend in and not have attention come my way. Nothing ruins a shot more than somebody seeing a camera and going, “Hey, there’s a camera!” and pointing right into it.
Benjamin: What do you think about — as far as speakers go — let’s say I’m speaking at Rails conference next year, which is a pretty casual conference. And we’ll see if Chad lets me come back, but it tends to be a casual conference, and some people are in polo style shirts, other people in t-shirts. Can I wear a t-shirt on stage, is that okay?
Davidson: You could, and it would really depend on what t-shirt. If you had a really nice cottony material t-shirt that was, you know, the American Eagle ones or the American Apparel ones — maybe. And you’re a skinny guy, you can get away with it.
Benjamin: Thank you. You know who’s doing some really cool t-shirts actually right now? And you know what, they’re a sponsor, insanelygreattees.com. If you’ve seen the Flickr photos of me with the old-school bomb on the shirt or the one with the binary tree, there’s a lot of cool things that they do. They came to us and said, “We want to —” I guess they see these pictures of me on Flickr, and John, don’t you have the bomb shirt?
Gruber: Of course I do. The system bomb.
Benjamin: Yeah, system bomb from old OS 7.
Gruber: That shirt is the bomb.
Davidson: I want that shirt.
Benjamin: We actually worked out a cool deal with them, since you want the shirt. There’s some kind of — I don’t know how this works, maybe you go to the site, John, or what do you do? There’s a coupon they have worked out for us. So if you buy two or more shirts, you get free domestic shipping. And if you happen to be stuck in some other country, then you get —
Gruber: And how do you apply this coupon? What’s the coupon code?
Benjamin: That’s a good question, but it expires at the end of July, so you better act now.
Gruber: So go to our website, thetalkshow.net, to see the coupon?
Benjamin: Yeah, we’ll have a link, we’ll put up a link.
Gruber: I like the way you worked that in, that was very smooth the way you segued. I’m going to have to practice that for next week’s show.
Benjamin: It will be less abrupt if you can work it in that way — but I was actually, the reason I was wondering is —
Gruber: I like the challenge of having to work in, before I say something about to thank a sponsor, to think of — no matter how obscure, some way to work it in. I’m going to do it, that’s a challenge.
Benjamin: There’s something I’ve been wanting to ask you, it’s a bit more technical photography type questions. Not really that technical because I’m still sort of starting out.
Davidson: You’ve still got the pinhole camera.
Benjamin: I finally moved up from the pinhole to the Canon Rebel Digital XTi. And it’s a great camera, I was definitely influenced by you and John and a few other people to go in the Canon direction, I’m happy I did it. So how come you wind up with these situations, very confusing to people who are just starting out, when they talk about a wide vs. a narrow aperture. You’ve actually got numbers going in the opposite direction that you would think, you think big and it’s actually small, and small is big. What is that and is there any kind of petition that I can be involved with or help support that would get them to straighten that out because it’s — I mean, I understand it philosophically but — we don’t need to keep that around anymore, do we?
Davidson: Oh hell yeah we do, it’s all about circles, it’s math. There’s a beautiful bit of math behind photography, and that number, f/1.4, f/2, f/2.8, f/4, f/5.6, f/8 — you can always tell when somebody’s been taking lots of pictures because they can rattle that scale off. It’s all ratios, it’s ratios, dealing with pi and circles, and each next step, going from 1 to 1.4, from 1.4 to 2, from 2.0 to 2.8 — that’s doubling the amount of light you’re getting in.
Gruber: But it does throw people off, it is an unfortunate circumstance that the numbers worked out like that because you end up with the thing where, for example, a lens that the fastest it gets is 2.8 is significantly slower than a lens that goes to f/1.8. But if you look at the total scale of numbers, and you show it to just some guy shopping at Best Buy, well, that looks like it’s almost the same. Because it also goes up to like f/16. Or f/7, you’re shooting in sunlight.
Benjamin: Your natural inclination is, well, this one goes all the way up to 16!
Davidson: [laughs] Or 32.
Gruber: 2.8, 1.8, what’s the difference. But the difference is actually huge. An f/1.8 lens, you can actually shoot indoors in relatively low light and get some really nice results. And then f/2.8, you really need a significant amount of light indoors to get a shot.
Benjamin: Duncan, when you’re shooting at these conferences, are you mainly shooting with a zoom lens? Do you use prime lenses at all in your conference shooting? Are you using prime lenses at all, period? I’ll tell you why I ask, when I first started out, John’s suggestion to me was, get one of a couple of these different prime lenses. I think one was 50 mm, and he also recommended a 28 mm, which makes sense if you take into consideration the crop factor on a digital SLR, which you can maybe hopefully explain in your answer. But I recall that when I was talking to you about it, you said, “Yeah, prime lenses are really great, you may also want to consider getting a lens that does zoom, but you’re going to zoom way less than you think you’re going to zoom.” So, to my original question, what are you shooting with most of the time? Does it vary? What’s the deal with the crop factor? And what do you think about the whole prime lens thing?
Davidson: Well, let’s take this one step at a time. What I shoot with right now in conference situations, there’s three lenses I lean on, it’s the 24–70, the 70–200, and then the 300 mm prime. So it’s two zooms and a prime. And they’re all f/2.8 lenses so they’re all pretty fast and pretty capable. I’ve got faster lenses in terms of aperture, I’ve got several 1.4 lenses and several 2.0 lenses, but I find when I’m shooting the events, I actually need to keep my aperture around f/4. So I’ve got enough depth of field to work with somebody’s head. So I don’t have, like, a totally focused nose and totally blurred out back of their hair. The 300 mm prime is an amazing lens, it’s also really expensive.
Benjamin: Is that the one with the white chassis?
Davidson: That’s the white long tube that looks like it’s going to suck your soul out when you see it.
Benjamin: [laughs]
Davidson: That one is my all-time favorite right now. It may be a little bit a new toy syndrome, but it’s just so damn sharp. I use the 70–200 as a zoom, and I prefer it as a zoom in that range because for the shooting I do I can’t necessarily jump right up on stage and get into somebody’s face, but a lot of times that’ll get me close enough to get the shot I want, or I can crank around and get a wider shot that encompasses most of the stage, at 70 mm, at the distances I’m usually work at. And the same is true about going sort of wide angle. Now, one thing I’ve considered doing is swapping out the 24–70 wide with just a prime, like a 24–35 mm prime for doing wide. But that’s for the professional shooting and that’s not really going to translate well into the kinds of pictures you want to take. So let’s take another example. When I go out, when I go out hiking or I go out on the town, or I just go running around, I’ll take a 50 mm 1.4 fixed lens, and sometimes I’ll take a 135 f/2 lens. Because when you have a little bit of time to work a shot, when somebody’s not paying you and you have to get the shot immediately, you can always zoom with your feet, or most of the time you can zoom with your feet. And you have time and usually ability to get closer to things. I liked John’s comment last episode where — one rule of thumb about photography is that you can always get closer, and that will usually make the picture better. And I agree with that a lot. So when I’m out doing more casual shooting, I tend more towards the primes than the zooms. So the zooms for me are convenience factor when I’m in the work situation. But I love the image quality you get with a good prime. And the reason that it’s really nice to recommend primes to learning photographers like you is that it forces you to think about composition more than a zoom. Zooms, you can get lazy and you can think, oh, I’ll just zoom and get closer. And really you should think about where you are in relation to your subject. And then the other thing that’s nice is that you can get extremely good quality at a lower price. Zooms have all these elements and to get a really good quality zoom you put out big bucks. Whereas you can get really good quality prime lenses for fairly cheap, in comparison. So it’s kind of the best of all worlds for people who are learning and people who are just doing photography for the love of photography.
Gruber: All the major SLR companies, Pentax, Canon, Nikon, they all have a 50 mm prime lens that costs about $100, maybe even less. You can get the Canon f/1.8 for like $85. I think the Nikon is similarly priced. And it is, in my mind, the single biggest bargain in all of photography. I mean, because for $85 you can get a lens that is very fast, f/1.8, and optically is better than just about any zoom that any consumer would ever consider buying.
Davidson: Right. To match one of those primes typically you’d have to spend at least $1000 on a zoom.
Gruber: And I think it just never occurs to people because they think, “well, I want a zoom”, or they think, “for $85 how good is it?” But it really is a fantastic lens, it just happens to be the easiest lens to manufacture so that’s why the price is so low.
Benjamin: So if I was a new photographer, and I asked you this question when I was going through it, but I think it’s a — I want to hear both of your answers — a new photographer, starting out, they’re done with the point-and-shoot, they’re ready to go to a digital SLR, maybe they’re going with the Nikon D40 perhaps, or they’re going with the Canon Digital Rebel XTi. What lens should they be getting? Should they get the kit lens that comes with it, should they say “forget that, I want to get a prime lens”, and if so, what should they be getting?
Davidson: I waffle on this a little bit. I mean, to some degree, I would say go ahead and get the kit lens that comes with it because it’s a zoom, it’s a typically okay zoom, it’s not a great zoom, but if you’re outside in the daytime, it’ll work fine. And it’ll give you a few different focal lengths that go with the camera, and it’s usually about $100 added onto the price or maybe a bit more. But then I would also go ahead and just immediately jump in and get a 50. It’s the best $100 you can ever do for your photography, as John said. And then start looking wide or start looking tall if that’s the kind of thoughts that you’re having for your pictures. That would be my starting point. What about you, John?
Gruber: I think the same thing. I waffle on whether to advise people to get the kit lens or not, because it’s the same thing where I don’t really like — I can tell — I know far, far less about photography than you, but I can see the results when I just look at the pictures people take with them, especially indoors.
Davidson: Oh yeah, you can always see the kit lens, yeah.
Gruber: But like you said, it’s only $100. But, see, my thought is if you get it, you’re going to be tempted to use it when you should be using a prime lens, learning to be a better photographer. So I would just say, especially if you’ve already got a point-and-shoot that almost always has some kind of zoom on it, if you really want to say, I want to become an avid amateur, I would say get the body without the lens and get the $85 50 mm lens. And just use that even for just a month where you got the camera, it’s brand new, of course you’re going to use it because it’s your new toy, but just have that 50, make it be the only lens you bought with the camera and you’ll have to use it, and it’ll give better muscles, better photographer muscles.
Davidson: I can’t argue with that, that’s totally solid advice too.
Gruber: I just think the one thing that I’ve gotten better at in five or six years of amateur photography, the one thing if anything that I’ve gotten better at is framing. And I look back at some of my older pictures, and I just see people with heads cut off or just weird stuff in the framing, and I think, boy, I wish I would’ve taken a couple more shots of that scene from a different angle. And having a fixed lens that doesn’t zoom at all, it just makes you think about moving the camera. If you can zoom, you just think, well, I can zoom, and it gives you two things to think about. So just removing the idea, just having a lens that only does one focal length, it makes you think about moving the camera because there’s no other way to change the framing.
Davidson: Right. So I totally agree, if you’re wanting to get good at photography, definitely stick to primes. I think the one case where the zoom might be handy is when you go to Disneyland, and your wife wants to use the camera or your husband wants to use the camera, your significant other who’s not necessarily wanting to join you in this endeavor, and you can slap that on there for them and say, here you go, knock yourself out. They might be happy with that. But then again, maybe not. Maybe zooms are just overrated at that level.
Benjamin: It was just such a weird experience for me when I did put the 50 mm lens on there. As far as I can remember, at least in my entire adult life, all of the cameras I’ve had have always been able to zoom. And it’s the weirdest thing, having a very expensive, relatively speaking, a very expensive camera with a somewhat expensive lens on it, the 50 or the 28, and all it does is focus. I mean, I certainly understand that photos are much, much better than anything else I’ve ever taken, but it’s sort of weird, you almost feel like the camera isn’t doing something that you’re used to cameras doing if that makes sense. My whole life — oh yeah, I’ll just zoom in.
Gruber: And it’s just an unfortunate fact that it’s a big selling point. People buy cameras based on the zoom. I can’t tell you — as a guy who, like, my friends know that I’m a hobbyist photographer, I get asked questions “what camera I should buy” and sometimes they’ll ask me a question like, “Look, these are the two cameras I’m looking at, I’m leaning towards this one, but it’s only got a 10× zoom and the other one has 12×, do you think that’s all right?” And that’s just how they think. You’re just so, so thinking about the wrong factors. I don’t even know where to start.
Davidson: It’s kind of like the Korean cell phone manufacturers looking at the iPhone saying, “well, we’ve got all those features and more” and yet not getting it.
Gruber: Right, right. “We’ve got a camera, we’ve got a web browser. What more do you want?”
Davidson: Right. “We’ve got the feature list.” Yeah, it’s a total mind-bender when you have to really think about framing without zooming, and it’s actually hitting me again with this new camera that I’ve got. Different cameras have a different amount of crop that you see through the viewfinder. This is getting a little esoteric, but my 5D only showed about 96 or something percent of what actually hit the sensor. So you get used to, when you’re framing through the viewfinder that the resulting image is going to have a little bit of extra stuff around the edge that you didn’t see through the viewfinder. And this new 1D, it’s 100 percent. What you see through the viewfinder is exactly where that crop line is going to be when you see the image resulting, and I’m already having to reprogram my head a little bit to make sure that I have enough space around people. But framing is everything. And having this little experience today, just the last few days, but especially today, as I watch the photos come through the camera, it’s a mind-bender, again, so I can totally understand how not putting a zoom on would bend somebody’s head too. It’s a good way to bend it.
Gruber: So one last quick question about the new camera, the — what is it, 3D?
Davidson: 1D Mark III, yeah. Super badass.
Gruber: So one of the big differences, your previous work camera was the full-frame Canon, what’s it, the 5D?
Davidson: Yeah.
Gruber: And now you’ve gone back to a camera which has the smaller digital sensor. It just makes up for it in a bunch of different ways. But do you find that that throws you off a little bit in terms of your lens selection because now you’re having to deal with the crop factor again whereas all that time you spent with the 5D you weren’t?
Davidson: It’s tossed me a little bit off but not too much, and that’s because the crop factor is different. It’s a 1.3× crop factor vs. the 1.6× crop factor. They call it APS-H for some reason. And it turns out that the 1D has the biggest sensor that you can image in one pass off of current chip technology machines, or the chip imaging machines. Whereas the 5D sensor, they actually have to stitch in multiple exposures so the yield goes way down. But I haven’t found it to be such a problem, because it doesn’t shift my lenses around as much as the 1.6 multiplier does. So when I stick on my 78–200 lens, it’s not really affected too much. I basically have a slight bit of cropping to the image and that’s about it from what I expected before. So it’s not too bad. The place where it hurts me a little bit is on the wides, and that’s why I keep the — I mean, the 5D I’m going to keep for landscapes, and I’m also going to keep as my back-up camera and for doing the wide angle stuff because if you really want 24 mm or you really want 17 mm, you’ve got to have the full frame.
Gruber: And that’s like the one thing in all of the brand name wars in photography, that is the one thing that Canon has, is Canon is the only company with a full-frame DSLR.
Davidson: Right. There’s two big differences: one is the full frame, and the second is the sensitivity of the sensors. Canon really rocks when you get up into the ISO 800, 1600, 3200 ranges. Both Nikons and Canons are great at ISO 100, which is when you’re out shooting landscapes and whatnot. But the high ISO characteristics of the Canon is really, really awesome.
Benjamin: What do you think of the camera on the iPhone?
Davidson: It’s great for snapshots. [laughs] As a camera, it sucks. It records images and if what you’re wanting is to make sure that you remember an event or remember somebody or a place for yourself, it’s perfectly serviceable.
Gruber: Do you find that it has a really weird white balance? I get the greenish-blue tint to almost every picture I take with it. Almost.
Davidson: It’s got a wonky white balance, yes.
Gruber: I’ll bet that that’s software. I mean, I’m hoping that that gets adjusted in a software update. Because I would think that the white balance is controlled by software, that it’s not part of the camera chip. Maybe it is, I don’t know. And I see pictures on Flickr from iPhones and it’s just rampant, this sort of sickly green fluorescent tone to pictures.
Davidson: Seems like they really optimized it for taking pictures under fluorescent lights. But yeah, it’s a little weird. It also has a lot of bloom, so if you have a bright area, you get all the lighting of the area around the bright areas. But I’ve found it pretty good if you’re out in daylight. I’ve had a lot of fun with it, just taking snaps and uploading them.
Gruber: What do you think of where the button is? I can’t stand where the shutter button is.
Benjamin: Horrible.
Davidson: The whole soft button thing, yeah, I hate it. I’m not sure I hate it because it’s a soft button, but I hate the location of it, for sure.
Gruber: And I think the worst thing about it — maybe they were thinking, because it’s right above the home button, which is the physical button, and maybe they were thinking, well, we’ll put it above the home button so you can feel it, it’s right above there. But what I found is that I keep hitting the home button by accident, and then I leave the camera app and go back to the iPhone home screen.
Davidson: I do that all the time. I wish you just tapped the screen to take the picture.
Benjamin: Anywhere on the screen.
Davidson: Because if you tap the screen, it does nothing. So might as well do something with that click.
Gruber: That’s the best solution, that’s the easiest solution, the best thing I’ve heard.
Benjamin: Who do we have to tell to implement that?
Gruber: I don’t know, we need someone with a popular Mac weblog, or something.
Davidson: [laughs]
Benjamin: So speaking of weblogs, Duncan has a weblog, he’s got a website, redoing it again. You almost redo it as much as I do.
Davidson: Well, that’s because both of us enjoy the challenge of it.
Benjamin: So it’s duncandavidson.com, right?
Davidson: Yep.
Benjamin: That’s the main one or is that the blog now?
Davidson: That’s everything. I had the blog separate because I was running over on Typepad and I nixed that, and it’s all collapsed down. So if you go to blog.duncandavidson.com, I do the Daring Fireball trick and just send you to duncandavidson.com and that’s it.
Benjamin: So if I want to hire you for a wedding or bar mitzvah to come out and take some pictures, you’re not doing it, you’re not available?
Davidson: [laughs] I’ve not actually done a wedding, I’ve done lots of events, but no weddings so far. So I would be a little hesitant unless that was somebody I really knew so that we could work through that and be a little bit less of a “oh my god, I’m dealing with a client I don’t know”.
Benjamin: Well, we’ve got to wrap it up. I don’t know how I’m going to edit this down, John.
Gruber: I don’t know, that’s your problem. I am so — I have never been happier that we worked it out that you do the editing and I just show up for the show and talk. Because I think we’ve been talking for about three hours here.
Benjamin: It’s been three and a half hours, 3 hours 38 minutes.
Gruber: It’s great, we’ll have lots of footage for our eventual director’s cut, complete, uncut The Talk Show DVD.
Benjamin: Right.
Davidson: There’s some edits you can make. Thinking back, there’s a few places I can think that you can cut down, but still.
Benjamin: Pretty much wherever John is talking.
Gruber: I was going to say the same thing but about yours.
Benjamin: Right. So the three things I think people need to remember today: James Duncan Davidson, 37signals, Insanely Great Tees. That’s it. If you leave nothing else, just remember those three things. And 50 mm.
Gruber: 50 mm fixed prime lens.
Davidson: 50 mm. 24, 35, any of those. Just fixed, fixed, fixed. [somebody talks into a megaphone in the background]
Benjamin: What is that in the background?
Gruber: I think James is getting arrested.
Davidson: Yeah, that would be security coming by.
Benjamin: It’s very sort of NPR of us to have that stuff in the background.
Gruber: I’ll call a lawyer.
Davidson: Yeah, and I have to say, it’s a bit embarrassing that I’m speaking on my laptop microphone after John took so much grief over his.
Benjamin: No, he was speaking into a high-quality microphone, he just had it in the closet.
Davidson: Ahh.
Gruber: The weird thing is that I actually sounded worse with a better microphone because I apparently wasn’t close enough to it.
Benjamin: Yeah, spend a few hundred bucks on a mic and you actually degrade the quality of his sound. We’ll end. We’re pretty much done.
Davidson: I think so, but it was a lot of fun doing this, guys. [somebody still talks into a megaphone in the background]
Gruber: Yeah, it was great, thanks.
Benjamin: I’m just so entertained by that sound in the background.
Davidson: [laughs]
Benjamin: Maybe there’s a filter I can put over what we’re saying right now that’ll make it sound like that.
Davidson: Maybe so, or maybe you can sample it out and have it running through the entire podcast.
Benjamin: I think it was anyway.
Davidson: Well, I’m running away from it, so it’s well in the background now.
Benjamin: All right, guys, we’re done.
Gruber: Thanks.
Davidson: Thanks, man.
Benjamin: See you later.
Davidson: Ciao.
Benjamin: We don’t have to even hang up if we don’t want.
Davidson: [laughs]
0 notes
Link
In the last few months, I have learned a lot about modern JavaScript and CSS development with a local toolchain powered by Node 8, Webpack 4, and Babel 7. As part of that, I am doing my second “re-introduction to JavaScript”. I first learned JS in 1998. Then relearned it from scratch in 2008, in the era of “The Good Parts”, Firebug, jQuery, IE6-compatibility, and eventually the then-fledgling Node ecosystem. In that era, I wrote one of the most widely deployed pieces of JavaScript on the web, and maintained a system powered by it. Now I am re-learning it in the era of ECMAScript (ES6 / ES2017), transpilation, formal support for libraries and modularization, and, mobile web performance with things like PWAs, code splitting, and WebWorkers / ServiceWorkers. I am also pleasantly surprised that JS, via the ECMAScript standard and Babel, has evolved into a pretty good programming language, all things considered. To solidify all this stuff, I am using webpack/babel to build all static assets for a simple Python/Flask web app, which ends up deployed as a multi-hundred-page static site. One weekend, I ported everything from Flask-Assets to webpack, and to play around with ES2017 features, as well as explore the Sass CSS preprocessor and some D3.js examples. And boy, did that send me down a yak shaving rabbit hole. Let’s start from the beginning! JavaScript in 1998 I first learned JavaScript in 1998. It’s hard to believe that this was 20 years — two decades! — ago. This post will chart the two decades since — covering JavaScript in 1998, 2008, and 2018. The focus of the article will be on “modern” JavaScript, as of my understanding in 2018/2019, and, in particular, what a non-JavaScript programmer should know about how the language — and its associated tooling and runtime — have dramatically evolved. If you’re the kind of programmer who thinks, “I code in Python/Java/Ruby/C/whatever, and thus I have no use for JavaScript and don’t need to know anything about it”, you’re wrong, and I’ll describe why. Incidentally, you were right in 1998, you could get by without it in 2008, and you are dead wrong in 2018. Further, if you are the kind of programmer who thinks, “JavaScript is a tire fire I’d rather avoid because it lacks basic infrastructure we take for granted in ‘real’ programming languages”, then you are also wrong. I’ll be able to show you how “not taking JavaScript seriously” is the 2018 equivalent of the skeptical 2008-era programmer not taking Python or Ruby seriously. JavaScript is a language that is not only here to stay, but has already — and will continue to — take over the world in several important areas. To be a serious programmer, you’ll have to know JavaScript’s Modern and Good Parts — as well as some other server-side language, like Python, Ruby, Go, Elixir, Clojure, Java, and so on. But, though you can swap one backend language for the other, you can’t avoid JavaScript: it’s pervasive in every kind of web deployment scenario. And, the developer tooling has fully caught up to your expectations. JavaScript during The Browser Wars Browsers were a harsh environment to target for development; not only was Internet adoption low and not only were internet connections slow, but the browser wars — mainly between Netscape and Microsoft — were creating a lot of confusion. Netscape Navigator 4 was released in 1997, and Internet Explorer 5 was released in 1998. The web was still trying to make sense of HTML and CSS; after all, CSS1 had only been released a year earlier. In this environment, the definitive web development book of the era was “JavaScript: The Definitive Guide”, which weighed in at over 500 pages. Note that, in 1998, the most widely used programming languages were C, C++, and Java, as well as Microsoft Visual Basic for Windows programmers. So expectations about “what programming was” were framed mostly around these languages. In this sense, JavaScript was quite, quite different. There was no compiler. There was no debugger (at least, not very good ones). There was no way to “run a JavaScript program”, except to write scripts in your browser, and see if they ran. Development tools for JavaScript were still primitive or inexistent. There was certainly not much of an open source community around JS; to figure out how to do things, you would typically “view source” on other people’s websites. Plus, much of the discussion in the programming community of web developers was how JavaScript represented a compatibility and security nightmare. Not only differing implementations across browsers, but also many ways for you to compromise the security of your web application by relying upon JavaScript too directly. A common security bug in that era was to validate forms with JavaScript, but still allow invalid (and insecure) values to be passed to the server. Or, to password-protect a system, but in a way that inspection of JavaScript code could itself crack access to that system. Combined with the lack of a proper development environment, the “real web programmers” used JavaScript as nothing more than a last resort — a way to inject a little bit of client-side code and logic into pages where doing it server-side made no sense. I remember one of the most common use cases for JavaScript at the time was nothing more than changing an image upon hover, as a stylistic effect, or implementing a basic on-hover menu on a complex multi-tab form. These days, these tasks can be achieved with vanilla CSS, but, at the time, JavaScript DOM manipulation was your only option. JavaScript in 2008 Fast forward 10 years. In 2008, Douglas Crockford released the book, “JavaScript: The Good Parts”. By using a language subsetting approach, Crockford pointed out that, not only was JavaScript not a bad language, it was actually a good language, well-designed, with certain key features that made it stand out vs competitors. Around this time, several JavaScript libraries were becoming popular, notably jQuery, Prototype, YUI, and Dojo. These libraries attempted to provide JavaScript with something it was missing: a cross-browser compatibility layer and programming model for doing dynamic manipulation of pages inside the browser, and especially for a new model of JavaScript programming that was emerging, with the moniker AJAX. This was the beginning of the trend of rich internet applications, “dynamic” web apps, single-page applications, and the like. JavaScript’s Tooling Leaps The developer tooling for JavaScript also took some important leaps. In 2006, the Firefox team released Firebug, a JavaScript and DOM debugger for Firefox, which was then one of the world’s most popular web browsers, and open source. Two years later, Google would make the first release of Google Chrome, which bundled some developer tooling. Around the same time that Chrome was released, Google also released V8, the JavaScript engine that was embedded inside of Chrome. That marked the first time that the world had seen a full-fledged, performant open source implementation of the JavaScript language that was not completely tied to a browser. Firefox’s JS engine, SpiderMonkey, was part of its source tree, but was not necessarily marketed to be modularized and used outside the context of the Firefox browser. I remember that aside from Crockford’s work on identifying the good parts of JavaScript, and aside from the new (and better) developer tooling, a specific essay on Mozilla’s website helped me re-appreciate the language, and throw away my 1998 conception. That article was called “A Reintroduction to JavaScript”. It showed how JavaScript was actually a real programming language, once you got past the tooling bumps. A little under-powered in its standard library, thus you had to rely upon frameworks (like jQuery) to give you some tools, and little micro-libraries beyond that. A year after reading that essay, I wrote my own about JavaScript, which was called “Real, Functional Programs with JavaScript” (archived PDF here). It described how JavaScript was, quite surprisingly, more of a functional language than Java 8 or Python 2.7. And that with a little focus on understanding the functional core, really good programs could be written. I recently converted this essay into a set of instructional slides with the name, “Lambda JavaScript” (archived notes here), which I now use to teach new designers/developers the language from first principles. But, let’s return to history. Only a year after the release of Chrome, in 2009, we saw the first release of NodeJS, which took the V8 JavaScript engine and embedded it into a server-side environment, which could be used to experiment with JavaScript on a REPL, to write scripts, and even to write HTTP servers on a performant event loop. People began to experiment with command-line tools written in JavaScript, and with web frameworks written in JavaScript. It was at this point that the pace of development in the JavaScript community accelerated. In 2010, npm — the Node Package Manager — was released, and it and its package registry quickly grew to represent the full JavaScript open source community. Over the next few years, the browser vendors of Mozilla, Google, Apple, and Microsoft engaged in the “JavaScript Engine Wars”, with each developing SpiderMonkey, V8, Nitro, and Chakra to new heights. Meanwhile, NodeJS and V8 became the “standard” JS engine running on developer’s machines from the command line. Though developers still had to target old “ECMAScript 3” browsers (such as IE6), and thus had to write restrained JavaScript code, the “evergreen” (auto-updating) browsers from Mozilla, Google, and Apple gained support for ECMAScript 5 and beyond, and mobile web browsing went into ascendancy, thus making Chrome and Safari dominant in market share especially on smartphones. I remember in 2012, I gave a presentation at a local tech conference entitled, “Writing Real Programs… with JavaScript!?”. The “!?” punctuation was intentional. That was the general zeitgeist I remember in a room full of developers: that is, “is writing real programs with JavaScript… actually possible!?” It’s funny to review those slides as a historical relic. I spent the first half of the talk convincing the audience that JavaScript’s functional core was actually pretty good. And then I spent the second half convincing them that NodeJS might… it just might… create a developer tooling ecosystem and standard library for JavaScript. There are also a few funny “detour” slides in there around things like Comet vs Ajax, a debate that didn’t really amount to much (but it’s good to remind one of fashion trends in tech). Zooming ahead a few years, in all of this noise of web 2.0, cloud, and mobile, we finally reached “mobilegeddon” in 2015, where mobile traffic surpassed desktop traffic, and we also saw several desktop operating systems move to a mostly-evergreen model, such as Windows 10, Mac OS X, and ChromeOS. As a result, as early as 2015 — but certainly by 2018 — JavaScript became the most widely deployed and performant programming language with “built-in support” on almost every desktop and mobile computer in the world. In other words, if you wanted your code to be “write once, run everywhere” in 2015 or so (but even as far back as 2009), your best option was JavaScript. Well, that’s even more true today. The solid choice for widespread distribution of your code continues to be JavaScript. As Crockford predicted in 2008: “It is better to be lucky than smart.” JavaScript in 2018-2019 In 2018-2019, several things have changed about the JavaScript community. Development tools are no longer fledgling, but are, instead, mature. There are built-in development tools in all of Safari, Firefox, and Chrome browsers (and the Firebug project is mostly deprecated). There are also ways to debug mobile web browsers using mobile development tools. NodeJS and npm are mature projects that are shared infrastructure for the whole JavaScript community. What’s more, JavaScript, as a language, has evolved. It’s no longer just the kernel language we knew in 1998, nor the “good parts” we knew in 2008, but instead the “modern parts” of JavaScript include several new language features that go by the name “ES6” (ECMAScript v6) or “ES2017” (ECMAScript 2017 Edition), and beyond. Some concepts in HTML have evolved, such as HTML5 video and audio elements. CSS, too, has evolved, with the CSS2 and CSS3 specifications being ratified and widely adopted. JSON has all but entirely replaced XML as an interchange format and is, of course, JavaScript-based. The V8 engine has also gotten a ton of performance-oriented development. It is now a JIT compiled language with speedy startup times and speedy near-native performance for CPU-bound blocks. Modern web performance techniques are almost entirely based on a speedy JavaScript engine and the ability to script different elements of a web application’s loading approach. The language itself has become comfortable with something akin to “compiler” and “command line” toolchains you might find in Python, Ruby, C, and Java communities. In lieu of a JavaScript “compiler”, we have node, JavaScript unit testing frameworks like Mocha/Jest, as well as eslint and babel for syntax checking. (More on this later.) In lieu of a “debugger”, we have the devtools built into our favorite browser, like Chrome or Firefox. This includes rich debuggers, REPLs/consoles, and visual inspection tools. Scriptable remote connections to a node environment or a browser process (via new tools like Puppeteer) further close the development loop. To use JavaScript in 2018/2019, therefore, is to adopt a system that has achieved 2008-era maturity that you would see in programming ecosystems like Python, Ruby, and Java. But, in many ways, JavaScript has surpassed those communities. For example, where Python 3’s reference implementation, CPython, is certainly fast as far as dynamic languages go, JavaScript’s reference implementation, V8, is optimized by JIT and hotspot optimization techniques that are only found in much more mature programming communities, such as Java’s (which received millions of dollars of commercial support in applied/advanced compiler techniques in the Sun era). That means that unmodified, hotspot JavaScript code can be optimized into native code automatically by the Node runtime and by browsers such as Chrome. Whereas Java and C users may still have debates about where, exactly, open source projects should publish their releases, that issue is settled in the JavaScript community: it’s npm, which operates similarly to PyPI and pip in the Python community. Some essential developer tooling issues were only recently settled. For example, because modern JavaScript (such as code written using ES2017 features) needs to target older browsers, a “transpilation” toolchain is necessary, to compile ES2017 code into ES3 or ES5 JavaScript code, suitable for older browsers. Because “old JavaScript” is a Turing complete, functional programming language, we know we can translate almost any new “syntactic sugar” to the old language, and, indeed, the designers of the new language features are being careful to only introduce syntax that can be safely transpiled. What this means, however, is that to do JavaScript development “The Modern Way”, while adopting its new features, you simply must use a local transpiler toolchain. The community standard for this at the moment is known as babel, and it’s likely to remain the community standard well into the future. Another issue that plagued 2008-era JavaScript was build tooling and modularization. In the 2008-2012 era, ad-hoc tools like make were used to concatenate JavaScript modules together, and often Java-based tools such as Google’s Closure Compiler or UglifyJS were used to assemble JavaScript projects into modules that could be included onto pages. In 2012, the Grunt tool was released as a JavaScript build tool, written atop NodeJS, runnable from the command-line, and configurable using a JavaScript “Gruntfile”. A whole slew of build tools similar to this were released in the period, creating a whole lot of code churn and confusion. Thankfully, today, Single Page Application frameworks like React have largely solved this problem, with the ascendancy of webpack and the reliance on npm run-script. Today, the webpack community has come up with a sane approach to JavaScript modularization that relies upon the modern JS support for modules, and then development-time tooling, provided mainly through the webpack CLI tool, allow for local development and production builds. This can all be scripted and wired together with simple npm run-script commands. And since webpack can be itself installed by npm, this keeps the entire development stack self-contained in a way that doesn’t feel too dissimilar from what you might enjoy with lein in Clojure or python/pip in Python. Yes, it has taken 20 years, but JavaScript is now just as viable a choice for your backend and CLI tooling projects as Python was in the past. And, for web frontends, it’s your only choice. So, if you are a programmer who cares, at all, about distribution of your code to users, it’s time to care about JavaScript! In a future post, I plan to go even deeper on JavaScript, covering: How to structure your first “modern” JavaScript project Using Modern JS with Python’s Flask web framework for simple static sites Understanding webpack, and why it’s important Modules, modules, modules. Why JS modules matter. Understanding babel, and why it’s important Transpilation, and how to think about evolving JS/ES features and “compilation” Using eslint for bonus points Using sourcemaps for debugging Using console.assert and console for debugging Production minification with uglify Building automated tests with jest Understanding the value of Chrome scripting and puppeteer Want me to keep going? Let me know via @amontalenti on Twitter.
0 notes
Text
New Post has been published on Atticusblog
New Post has been published on https://atticusblog.com/icloud-uploading-files-from-a-browser/
iCloud Uploading Files from a Browser
One of the iCloud functions that I don’t suppose could be very widely recognized is the “add” capability of iCloud.Com. So let’s say, as an instance, which you had been sitting at your paintings laptop (or a pal’s gadget, perhaps) and also you desired to throw a few files or images onto your Mac at domestic. Well, the use of this, you may! To achieve this, first, you’d log into iCloud.Com on the laptop you’d want to upload files from.When you’re in both vicinity, you’ll see a big ole’ “upload” button at the pinnacle of your browser window. Be conscious that how lengthy your upload will take is of route depending on the dimensions of the documents you pick out and the network speed you’ve were given. And if you signed in to your iCloud account on a chum’s gadget, make sure to sign off earlier than you stroll away!
How to Store Pictures Without Using Cloud or iCloud Storage
At instances, you have got a big collection of photos for your tool that you have a tendency to keep on the cloud.
However, with recent tendencies, it is already validated that the images saved on the cloud or your iCloud are also not safe. A scandal of movie star pics being leaked and hacked is everywhere in the media. For iOS users, it is a massive problem as because of restricted statistics storage potential they generally tend to rely on cloud service. But, there is nonetheless an approach to go cloud-loose for iOS, in addition to Android customers. Study on to discover how that is possible.
In preference to totally counting on online database or iCloud for your photos, an app by means of the call of Love Domestic does the trick. This app facilitates you manipulate your photos throughout all of the gadgets whilst managing all the available storage area. Despite the fact that, this app isn’t always best however the one component which you would admire about this app is the ability to integrate storage and manipulate matters correctly. This app will price you $299.
Google, Facebook, Flickr and Dropbox all store your images online unlike this app. This app even surpasses cloud storage. All you photographs gets copied to an important device whilst at the equal time making it be had on all your devices. You’ll be able to view any image the usage of the app as it routes photos or other documents from one device to another. that is how each picture saved gets easily accessible to every device owned by a person.
It undoubtedly offers users a choice to proportion their images at the cloud or lets in the app to manage it interested in them without any hassle.
On installing Live Domestic, it begins collecting copies of your images which might be present across all your gadgets and computer. This app gives you the 2TB capability that enables this functionality. A master index is created that shops all the date at the server of the organization. it’s miles stored in the form of particular codes which are assigned to every photo Rather than actual photos. it’s far like cataloging of all your pics that takes some time relying upon the number of pictures that you have.
While you launch the app, it communicates with the bigger database stored at the server and fetches you what you’re inquiring for.
How To Make Money On Instagram, Make Money Uploading Pictures!
Instagram has become the following big component
Customers of Fb are migrating in the direction of Instagram because the interface and usability are way higher. You may also engage along with your personal fans in place of simply pals, and this may potentially be VERY effective.
If you own a large Instagram account with numerous followers you’ll be visible as an expert. Something you submit may be liked and shared. Anybody will tag their buddies so their pals can see Anything you add. Instagram profiles can get viral, especially If you are into vines and funny pics, or fitness and motivational pictures.
In case you ever questioned whether or not it’s viable to make cash off of your fans, you aren’t on my own! With the notable response, there’s on Instagram, You could probably make loads of bucks weekly.
In case you combine advertisements along with your photographs you’ll get numerous site visitors, and probably sales. The most critical issue is to live away from spamming, and handiest provide useful associated advertisements subsequent to your pictures.
As maximum Instagram Users are on their cell, you may ought to goal cellular gives who’re viewable on a cellular telephone. Content material that doesn’t load on a cellular telephone won’t work in any respect. you may need to marketplace simple things, together with protein powder, health equipment etc. In case your page is related to fitness. You don’t need to have your personal business to sell stuff, as You could work as an affiliate for other business proprietors. They will provide you with commissions based totally on sales which you provide them. it’s in reality as smooth as that.
In case you’re already now thinking that this won’t paintings because the hyperlinks within the image description are not clickable, you’re very incorrect. The secret is to use a URL shortener for Something product or website you attempt to sell. You can use Bit.Ly which could be very famous, mainly on Twitter. Or You could use Google’s very own shortener: goo.Gl. Creating small hyperlinks will be smooth to keep in mind and to manually kind in a web browser.
You could additionally add your hyperlink for your BIO, which makes it clickable. Whilst importing your photograph You may virtually tell your fans to click the hyperlink on your bio and They may be redirected instantly to your site.
Web Browser Compatibility and Its Importance in Website Design
With the rapid growth of the internet, there may be a parallel growth inside the number of browsers. So, this text explains the importance of web browser compatibility and why you should get your website made compatible with all important internet browsers.
With the rapid boom of the net, there is a parallel increase in the range of current browsers with diverse capabilities. Browsers may be defined as software to view websites even though modern-day browsers offer a lot more capability than merely surfing websites.
With the number of browsers available inside the market, every having its very own merits and demerits, there may be a want for net website optimization in order that your internet site might be displayed and useful similarly nicely in all browsers.
Firefox, Google Chrome, net Explorer, Opera, and Safari are among the most famous browsers. They cover about 98% of marketplace share. Even within them, Firefox, Google Chrome, and internet Explorer cover almost ninety-two% of the browser market. So, it’s far very crucial that your website should be completely compatible and shows well at least in these net browsers. even though all of the browsers observe web standards set by means of W3C (International Wide internet Consortium), positive HTML (Hypertext Markup Language) tags, residences, and CSS (Cascading Style Sheets) residences might not be supported well with the aid of all of the web browsers. That is the case in which your net clothier ought to assume on browser compatibility before writing the code for the website.
It is evident that not all net users are using the equal browser and additionally there may be the possibility of them the use of one of a kind variations of different browsers. So, in case your clothier has not looked after browser compatibility, this can bring about the distinct interpretation of your website as all of the browsers and their one-of-a-kind versions might not support the HTML, Personal home page and CSS properties used on your internet website. And it can directly have an effect on your business as it would suggest customers might agree with your internet site less as they can not view it nicely. As an example, let us anticipate that you have the internet save and it isn’t always like-minded with Google Chrome but the client uses Google Chrome. In such a situation, he might either now not be capable of the shop at all if the buying cart isn’t operating properly or he might not trust your website properly enough to purchase the product from your website. This would mean a direct loss in the enterprise for you. This is why browser compatibility is a crucial thing to maintain in thoughts whilst you design your internet site or get it made for a person else.
A Very fundamental alternative to be had for a web developer is to go along with the residences supported by using all the most important browsers. on your layout code, it’s far clever to select the design residences common to all foremost browsers. this could ask for the compromise on an appearance of the site and it can not work out nicely at instances. So, in case it’s far not possible for the website online to be made completely compatible with all browsers due to coding obstacles, then the developer wishes to know the various sorts and versions of net browsers utilized by the majority of the website traffic. There are many techniques to get this information. You can use Javascript or Hypertext Preprocessor instructions to your code to recognize about browser name and model. Depending on the browser, your dressmaker can write special code snippets supported via various browsers.
0 notes
Text
The Widening Responsibility for Front-End Developers
This is an extended version of my essay “When front-end means full-stack” which was published in the wonderful Increment magazine put out by Stripe. It’s also something of an evolution of a couple other of my essays, “The Great Divide” and “Ooops, I guess we’re full-stack developers now.”
The moment I fell in love with front-end development was when I discovered the style.css file in WordPress themes. That’s where all the magic was (is!) to me. I could (can!) change a handful of lines in there and totally change the look and feel of a website. It’s an incredible game to play.

Back when I was cowboy-coding over FTP. Although I definitely wasn’t using CSS grid!
By fiddling with HTML and CSS, I can change the way you feel about a bit of writing. I can make you feel more comfortable about buying tickets to an event. I can increase the chances you share something with your friends.
That was well before anybody paid me money to be a front-end developer, but even then I felt the intoxicating mix of stimuli that the job offers. Front-end development is this expressive art form, but often constrained by things like the need to directly communicate messaging and accomplish business goals.
Front-end development is at the intersection of art and logic. A cross of business and expression. Both left and right brain. A cocktail of design and nerdery.
I love it.

Looking back at the courses I chose from middle school through college, I bounced back and forth between computer-focused classes and art-focused classes, so I suppose it’s no surprise I found a way to do both as a career.
The term “Front-End Developer” is fairly well-defined and understood. For one, it’s a job title. I’ll bet some of you literally have business cards that say it on there, or some variation like: “Front-End Designer,” “UX Developer,” or “UI Engineer.” The debate around what those mean isn’t particularly interesting to me. I find that the roles are so varied from job-to-job and company-to-company that job titles will never be enough to describe things. Getting this job is more about demonstrating you know what you’re doing more than anything else¹.
Chris Coyier Front-End Developer
The title variations are just nuance. The bigger picture is that as long as the job is building websites, front-enders are focused on the browser. Quite literally:
front-end = browsers
back-end = servers
Even as the job has changed over the decades, that distinction still largely holds.
As “browser people,” there are certain truths that come along for the ride. One is that there is a whole landscape of different browsers and, despite the best efforts of standards bodies, they still behave somewhat differently. Just today, as I write, I dealt with a bug where a date string I had from an API was in a format such that Firefox threw an error when I tried to use the .toISOString() JavaScript API on it, but was fine in Chrome. That’s just life as a front-end developer. That’s the job.
Even across that landscape of browsers, just on desktop computers, there is variance in how users use that browser. How big do they have the window open? Do they have dark mode activated on their operating system? How’s the color gamut on that monitor? What is the pixel density? How’s the bandwidth situation? Do they use a keyboard and mouse? One or the other? Neither? All those same questions apply to mobile devices too, where there is an equally if not more complicated browser landscape. And just wait until you take a hard look at HTML emails.
That’s a lot of unknowns, and the answers to developing for that unknown landscape is firmly in the hands of front-end developers.

Into the unknoooooowwwn. – Elsa
The most important aspect of the job? The people that use these browsers. That’s why we’re building things at all. These are the people I’m trying to impress with my mad CSS skills. These are the people I’m trying to get to buy my widget. Who all my business charts hinge upon. Who’s reaction can sway my emotions like yarn in the breeze. These users, who we put on a pedestal for good reason, have a much wider landscape than the browsers do. They speak different languages. They want different things. They are trying to solve different problems. They have different physical abilities. They have different levels of urgency. Again, helping them is firmly in the hands of front-end developers. There is very little in between the characters we type into our text editors and the users for whom we wish to serve.
Being a front-end developer puts us on the front lines between the thing we’re building and the people we’re building it for, and that’s a place some of us really enjoy being.
That’s some weighty stuff, isn’t it? I haven’t even mentioned React yet.
The “we care about the users” thing might feel a little precious. I’d think in a high functioning company, everyone would care about the users, from the CEO on down. It’s different, though. When we code a <button>, we’re quite literally putting a button into a browser window that users directly interact with. When we adjust a color, we’re adjusting exactly what our sighted users see when they see our work.

That’s not far off from a ceramic artist pulling a handle out of clay for a coffee cup. It’s applying craftsmanship to a digital experience. While a back-end developer might care deeply about the users of a site, they are, as Monica Dinculescu once told me in a conversation about this, “outsourcing that responsibility.”
We established that front-end developers are browser people. The job is making things work well in browsers. So we need to understand the languages browsers speak, namely: HTML, CSS, and JavaScript². And that’s not just me being some old school fundamentalist; it’s through a few decades of everyday front-end development work that knowing those base languages is vital to us doing a good job. Even when we don’t work directly with them (HTML might come from a template in another language, CSS might be produced from a preprocessor, JavaScript might be mostly written in the parlance of a framework), what goes the browser is ultimately HTML, CSS, and JavaScript, so that’s where debugging largely takes place and the ability of the browser is put to work.
CSS will always be my favorite and HTML feels like it needs the most love — but JavaScript is the one we really need to examine The last decade has seen JavaScript blossom from a language used for a handful of interactive effects to the predominant language used across the entire stack of web design and development. It’s possible to work on websites and writing nothing but JavaScript. A real sea change.
JavaScript is all-powerful in the browser. In a sense, it supersedes HTML and CSS, as there is nothing either of those languages can do that JavaScript cannot. HTML is parsed by the browser and turned into the DOM, which JavaScript can also entirely create and manipulate. CSS has its own model, the CSSOM, that applies styles to elements in the DOM, which JavaScript can also create and manipulate.
This isn’t quite fair though. HTML is the very first file that browsers parse before they do the rest of the work needed to build the site. That firstness is unique to HTML and a vital part of making websites fast.
In fact, if the HTML was the only file to come across the network, that should be enough to deliver the basic information and functionality of a site.
That philosophy is called Progressive Enhancement. I’m a fan, myself, but I don’t always adhere to it perfectly. For example, a <form> can be entirely functional in HTML, when it’s action attribute points to a URL where the form can be processed. Progressive Enhancement would have us build it that way. Then, when JavaScript executes, it takes over the submission and has the form submit via Ajax instead, which might be a nicer experience as the page won’t have to refresh. I like that. Taken further, any <button> outside a form is entirely useless without JavaScript, so in the spirit of Progressive Enhancement, I should wait until JavaScript executes to even put that button on the page at all (or at least reveal it). That’s the kind of thing where even those of us with the best intentions might not always toe the line perfectly. Just put the button in, Sam. Nobody is gonna die.
JavaScript’s all-powerfulness makes it an appealing target for those of us doing work on the web — particularly as JavaScript as a language has evolved to become even more powerful and ergonomic, and the frameworks that are built in JavaScript become even more-so. Back in 2015, it was already so clear that JavaScript was experiencing incredible growth in usage, Matt Mullenweg, co-founder of WordPress, gave the developer world homework: “Learn JavaScript Deeply”³. He couldn’t have been more right. Half a decade later, JavaScript has done a good job of taking over front-end development. Particularly if you look at front-end development jobs.
While the web almanac might show us that only 5% of the top-zillion sites use React compared to 85% including jQuery, those numbers are nearly flipped when looking around at front-end development job requirements.
I’m sure there are fancy economic reasons for all that, but jobs are as important and personal as it gets for people, so it very much matters.
So we’re browser people in a sea of JavaScript building things for people. If we take a look at the job at a practical day-to-day tasks level, it’s a bit like this:
Translate designs into code
Think in terms of responsive design, allowing us to design and build across the landscape of devices
Build systemically. Construct components and patterns, not one-offs.
Apply semantics to content
Consider accessibility
Worry about the performance of the site. Optimize everything. Reduce, reuse, recycle.
Just that first bullet point feels like a college degree to me. Taken together, all of those points certainly do.
This whole list is a bit abstract though, so let’s apply it to something we can look at. What if this website was our current project?

Our brains and fingers go wild!
Let’s build the layout with CSS grid.
What fonts are those? Do we need to load them in their entirety or can we subset them? What happens as they load in? This layout feels like it will really suffer from font-shifting jank.
There are some repeated patterns here. We should probably make a card design pattern. Every website needs a good card pattern.
That’s a gorgeous color scheme. Are the colors mathematically related? Should we make variables to represent them individually or can we just alter a single hue as needed? Are we going to use custom properties in our CSS? Colors are just colors though, we might not need the cascading power of them just for this. Should we just use Sass variables? Are we going to use a CSS preprocessor at all?
The source order is tricky here. We need to order things so that they make sense for a screen reader user. We should have a meeting about what the expected order of content should be, even if we’re visually moving things around a bit with CSS grid.
The photographs here are beautifully shot. But some of them match the background color of the site… can we get away with alpha-transparent PNGs here? Those are always so big. Can any next-gen formats help us? Or should we try to match the background of a JPG with the background of the site seamlessly. Who’s writing the alt text for these?
There are some icons in use here. Inline SVG, right? Certainly SVG of some kind, not icon fonts, right? Should we build a whole icon system? I guess it depends on how we’re gonna be building this thing more broadly. Do we have a build system at all?
What’s the whole front-end plan here? Can I code this thing in vanilla HTML, CSS, and JavaScript? Well, I know I can, but what are the team expectations? Client expectations? Does it need to be a React thing because it’s part of some ecosystem of stuff that is already React? Or Vue or Svelte or whatever? Is there a CMS involved?
I’m glad the designer thought of not just the “desktop” and “mobile” sizes but also tackled an in-between size. Those are always awkward. There is no interactivity information here though. What should we do when that search field is focused? What gets revealed when that hamburger is tapped? Are we doing page-level transitions here?
I could go on and on. That’s how front-end developers think, at least in my experience and in talking with my peers.
A lot of those things have been our jobs forever though. We’ve been asking and answering these questions on every website we’ve built for as long as we’ve been doing it. There are different challenges on each site, which is great and keeps this job fun, but there is a lot of repetition too.
Allow me to get around to the title of this article.
While we’ve been doing a lot of this stuff for ages, there is a whole pile of new stuff we’re starting to be expected to do, particularly if we’re talking about building the site with a modern JavaScript framework. All the modern frameworks, as much as they like to disagree about things, agree about one big thing: everything is a component. You nest and piece together components as needed. Even native JavaScript moves toward its own model of Web Components.

I like it, this idea of components. It allows you and your team to build the abstractions that make the most sense to you and what you are building.
Your Card component does all the stuff your card needs to do. Your Form component does forms how your website needs to do forms. But it’s a new concept to old developers like me. Components in JavaScript have taken hold in a way that components on the server-side never did. I’ve worked on many a WordPress website where the best I did was break templates into somewhat arbitrary include() statements. I’ve worked on Ruby on Rails sites with partials that take a handful of local variables. Those are useful for building re-usable parts, but they are a far cry from the robust component models that JavaScript frameworks offer us today.
All this custom component creation makes me a site-level architect in a way that I didn’t use to be. Here’s an example. Of course I have a Button component. Of course I have an Icon component. I’ll use them in my Card component. My Card component lives in a Grid component that lays them out and paginates them. The whole page is actually built from components. The Header component has a SearchBar component and a UserMenu component. The Sidebar component has a Navigation component and an Ad component. The whole page is just a special combination of components, which is probably based on the URL, assuming I’m all-in on building our front-end with JavaScript. So now I’m dealing with URLs myself, and I’m essentially the architect of the entire site. [Sweats profusely]
Like I told ya, a whole pile of new responsibility.
Components that are in charge of displaying content are almost certainly not hard-coded with data in them. They are built to be templates. They are built to accept data and construct themselves based on that data. In the olden days, when we were doing this kind of templating, the data has probably already arrived on the page we’re working on. In a JavaScript-powered app, it’s more likely that that data is fetched by JavaScript. Perhaps I’ll fetch it when the component renders. In a stack I’m working with right now, the front end is in React, the API is in GraphQL and we use Apollo Client to work with data. We use a special “hook” in the React components to run the queries to fetch the data we need, and another special hook when we need to change that data. Guess who does that work? Is it some other kind of developer that specializes in this data layer work? No, it’s become the domain of the front-end developer.
Speaking of data, there is all this other data that a website often has to deal with that doesn’t come from a database or API. It’s data that is really only relevant to the website at this moment in time.
Which tab is active right now?
Is this modal dialog open or closed?
Which bar of this accordion is expanded?
Is this message bar in an error state or warning state?
How many pages are you paginated in?
How far is the user scrolled down the page?
Front-end developers have been dealing with that kind of state for a long time, but it’s exactly this kind of state that has gotten us into trouble before. A modal dialog can be open with a simple modifier class like <div class="modal is-open"> and toggling that class is easy enough with .classList.toggle(".is-open"); But that’s a purely visual treatment. How does anything else on the page know if that modal is open or not? Does it ask the DOM? In a lot of jQuery-style apps of yore, yes, it would. In a sense, the DOM became the “source of truth” for our websites. There were all sorts of problems that stemmed from this architecture, ranging from a simple naming change destroying functionality in weirdly insidious ways, to hard-to-reason-about application logic making bug fixing a difficult proposition.
Front-end developers collectively thought: what if we dealt with state in a more considered way? State management, as a concept, became a thing. JavaScript frameworks themselves built the concept right in, and third-party libraries have paved and continue to pave the way. This is another example of expanding responsibility. Who architects state management? Who enforces it and implements it? It’s not some other role, it’s front-end developers.
There is expanding responsibility in the checklist of things to do, but there is also work to be done in piecing it all together. How much of this state can be handled at the individual component level and how much needs to be higher level? How much of this data can be gotten at the individual component level and how much should be percolated from above? Design itself comes into play. How much of the styling of this component should be scoped to itself, and how much should come from more global styles?
It’s no wonder that design systems have taken off in recent years. We’re building components anyway, so thinking of them systemically is a natural fit.
Let’s look at our design again:
A bunch of new thoughts can begin!
Assuming we’re using a JavaScript framework, which one? Why?
Can we statically render this site, even if we’re building with a JavaScript framework? Or server-side render it?
Where are those recipes coming from? Can we get a GraphQL API going so we can ask for whatever we need, whenever we need it?
Maybe we should pick a CMS that has an API that will facilitate the kind of front-end building we want to do. Perhaps a headless CMS?
What are we doing for routing? Is the framework we chose opinionated or unopinionated about stuff like this?
What are the components we need? A Card, Icon, SearchForm, SiteMenu, Img… can we scaffold these out? Should we start with some kind of design framework on top of the base framework?
What’s the client state we might need? Current search term, current tab, hamburger open or not, at least.
Is there a login system for this site or not? Are logged in users shown anything different?
Is there are third-party componentry we can leverage here?
Maybe we can find one of those fancy image components that does blur-up loading and lazy loading and all that.
Those are all things that are in the domain of front-end developers these days, on top of everything that we already need to do. Executing the design, semantics, accessibility, performance… that’s all still there. You still need to be proficient in HTML, CSS, JavaScript, and how the browser works. Being a front-end developer requires a haystack of skills that grows and grows. It’s the natural outcome of the web getting bigger. More people use the web and internet access grows. The economy around the web grows. The capability of browsers grows. The expectations of what is possible on the web grows. There isn’t a lot shrinking going on around here.
We’ve already reached the point where most front-end developers don’t know the whole haystack of responsibilities. There are lots of developers still doing well for themselves being rather design-focused and excelling at creative and well-implemented HTML and CSS, even as job posts looking for that dwindle.
There are systems-focused developers and even entire agencies that specialize in helping other companies build and implement design systems. There are data-focused developers that feel most at home making the data flow throughout a website and getting hot and heavy with business logic. While all of those people might have “front-end developer” on their business card, their responsibilities and even expectations of their work might be quite different. It’s all good, we’ll find ways to talk about all this in time.
In fact, how we talk about building websites has changed a lot in the last decade. Some of my early introduction to web development was through WordPress. WordPress needs a web server to run, is written in PHP, and stores it’s data in a MySQL database. As much as WordPress has evolved, all that is still exactly the same. We talk about that “stack” with an acronym: LAMP, or Linux, Apache, MySQL and PHP. Note that literally everything in the entire stack consists of back-end technologies. As a front-end developer, nothing about LAMP is relevant to me.
But other stacks have come along since then. A popular stack was MEAN (Mongo, Express, Angular and Node). Notice how we’re starting to inch our way toward more front-end technologies? Angular is a JavaScript framework, so as this stack gained popularity, so too did talking about the front-end as an important part of the stack. Node and Express are both JavaScript as well, albeit the server-side variant.
The existence of Node is a huge part of this story. Node isn’t JavaScript-like, it’s quite literally JavaScript. It makes a front-end developer already skilled in JavaScript able to do server-side work without too much of a stretch.
“Serverless” is a much more modern tech buzzword, and what it’s largely talking about is running small bits of code on cloud servers. Most often, those small bits of code are in Node, and written by JavaScript developers. These days, a JavaScript-focused front-end developer might be writing their own serverless functions and essentially being their own back-end developer. They’ll think of themselves as full-stack developers, and they’ll be right.
Shawn Wang coined a term for a new stack this year: STAR or Design System, TypeScript, Apollo, and React. This is incredible to me, not just because I kind of like that stack, but because it’s a way of talking about the stack powering a website that is entirely front-end technologies. Quite a shift.
I apologize if I’ve made you feel a little anxious reading this. If you feel like you’re behind in understanding all this stuff, you aren’t alone.
In fact, I don’t think I’ve talked to a single developer who told me they felt entirely comfortable with the entire world of building websites. Everybody has weak spots or entire areas where they just don’t know the first dang thing. You not only can specialize, but specializing is a pretty good idea, and I think you will end up specializing to some degree whether you plan to or not. If you have the good fortune to plan, pick things that you like. You’ll do just fine.
The only constant in life is change.
– Heraclitus – Motivational Poster – Chris Coyier
¹ I’m a white dude, so that helps a bunch, too. ↩️ ² Browsers speak a bunch more languages. HTTP, SVG, PNG… The more you know the more you can put to work! ↩️ ³ It’s an interesting bit of irony that WordPress websites generally aren’t built with client-side JavaScript components. ↩️
The post The Widening Responsibility for Front-End Developers appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
The Widening Responsibility for Front-End Developers published first on https://deskbysnafu.tumblr.com/
0 notes
Text
The Widening Responsibility for Front-End Developers
This is an extended version of my essay “When front-end means full-stack” which was published in the wonderful Increment magazine put out by Stripe. It’s also something of an evolution of a couple other of my essays, “The Great Divide” and “Ooops, I guess we’re full-stack developers now.”
The moment I fell in love with front-end development was when I discovered the style.css file in WordPress themes. That’s where all the magic was (is!) to me. I could (can!) change a handful of lines in there and totally change the look and feel of a website. It’s an incredible game to play.

Back when I was cowboy-coding over FTP. Although I definitely wasn’t using CSS grid!
By fiddling with HTML and CSS, I can change the way you feel about a bit of writing. I can make you feel more comfortable about buying tickets to an event. I can increase the chances you share something with your friends.
That was well before anybody paid me money to be a front-end developer, but even then I felt the intoxicating mix of stimuli that the job offers. Front-end development is this expressive art form, but often constrained by things like the need to directly communicate messaging and accomplish business goals.
Front-end development is at the intersection of art and logic. A cross of business and expression. Both left and right brain. A cocktail of design and nerdery.
I love it.

Looking back at the courses I chose from middle school through college, I bounced back and forth between computer-focused classes and art-focused classes, so I suppose it’s no surprise I found a way to do both as a career.
The term “Front-End Developer” is fairly well-defined and understood. For one, it’s a job title. I’ll bet some of you literally have business cards that say it on there, or some variation like: “Front-End Designer,” “UX Developer,” or “UI Engineer.” The debate around what those mean isn’t particularly interesting to me. I find that the roles are so varied from job-to-job and company-to-company that job titles will never be enough to describe things. Getting this job is more about demonstrating you know what you’re doing more than anything else¹.
Chris Coyier Front-End Developer
The title variations are just nuance. The bigger picture is that as long as the job is building websites, front-enders are focused on the browser. Quite literally:
front-end = browsers
back-end = servers
Even as the job has changed over the decades, that distinction still largely holds.
As “browser people,” there are certain truths that come along for the ride. One is that there is a whole landscape of different browsers and, despite the best efforts of standards bodies, they still behave somewhat differently. Just today, as I write, I dealt with a bug where a date string I had from an API was in a format such that Firefox threw an error when I tried to use the .toISOString() JavaScript API on it, but was fine in Chrome. That’s just life as a front-end developer. That’s the job.
Even across that landscape of browsers, just on desktop computers, there is variance in how users use that browser. How big do they have the window open? Do they have dark mode activated on their operating system? How’s the color gamut on that monitor? What is the pixel density? How’s the bandwidth situation? Do they use a keyboard and mouse? One or the other? Neither? All those same questions apply to mobile devices too, where there is an equally if not more complicated browser landscape. And just wait until you take a hard look at HTML emails.
That’s a lot of unknowns, and the answers to developing for that unknown landscape is firmly in the hands of front-end developers.

Into the unknoooooowwwn. – Elsa
The most important aspect of the job? The people that use these browsers. That’s why we’re building things at all. These are the people I’m trying to impress with my mad CSS skills. These are the people I’m trying to get to buy my widget. Who all my business charts hinge upon. Who’s reaction can sway my emotions like yarn in the breeze. These users, who we put on a pedestal for good reason, have a much wider landscape than the browsers do. They speak different languages. They want different things. They are trying to solve different problems. They have different physical abilities. They have different levels of urgency. Again, helping them is firmly in the hands of front-end developers. There is very little in between the characters we type into our text editors and the users for whom we wish to serve.
Being a front-end developer puts us on the front lines between the thing we’re building and the people we’re building it for, and that’s a place some of us really enjoy being.
That’s some weighty stuff, isn’t it? I haven’t even mentioned React yet.
The “we care about the users” thing might feel a little precious. I’d think in a high functioning company, everyone would care about the users, from the CEO on down. It’s different, though. When we code a <button>, we’re quite literally putting a button into a browser window that users directly interact with. When we adjust a color, we’re adjusting exactly what our sighted users see when they see our work.

That’s not far off from a ceramic artist pulling a handle out of clay for a coffee cup. It’s applying craftsmanship to a digital experience. While a back-end developer might care deeply about the users of a site, they are, as Monica Dinculescu once told me in a conversation about this, “outsourcing that responsibility.”
We established that front-end developers are browser people. The job is making things work well in browsers. So we need to understand the languages browsers speak, namely: HTML, CSS, and JavaScript². And that’s not just me being some old school fundamentalist; it’s through a few decades of everyday front-end development work that knowing those base languages is vital to us doing a good job. Even when we don’t work directly with them (HTML might come from a template in another language, CSS might be produced from a preprocessor, JavaScript might be mostly written in the parlance of a framework), what goes the browser is ultimately HTML, CSS, and JavaScript, so that’s where debugging largely takes place and the ability of the browser is put to work.
CSS will always be my favorite and HTML feels like it needs the most love — but JavaScript is the one we really need to examine The last decade has seen JavaScript blossom from a language used for a handful of interactive effects to the predominant language used across the entire stack of web design and development. It’s possible to work on websites and writing nothing but JavaScript. A real sea change.
JavaScript is all-powerful in the browser. In a sense, it supersedes HTML and CSS, as there is nothing either of those languages can do that JavaScript cannot. HTML is parsed by the browser and turned into the DOM, which JavaScript can also entirely create and manipulate. CSS has its own model, the CSSOM, that applies styles to elements in the DOM, which JavaScript can also create and manipulate.
This isn’t quite fair though. HTML is the very first file that browsers parse before they do the rest of the work needed to build the site. That firstness is unique to HTML and a vital part of making websites fast.
In fact, if the HTML was the only file to come across the network, that should be enough to deliver the basic information and functionality of a site.
That philosophy is called Progressive Enhancement. I’m a fan, myself, but I don’t always adhere to it perfectly. For example, a <form> can be entirely functional in HTML, when it’s action attribute points to a URL where the form can be processed. Progressive Enhancement would have us build it that way. Then, when JavaScript executes, it takes over the submission and has the form submit via Ajax instead, which might be a nicer experience as the page won’t have to refresh. I like that. Taken further, any <button> outside a form is entirely useless without JavaScript, so in the spirit of Progressive Enhancement, I should wait until JavaScript executes to even put that button on the page at all (or at least reveal it). That’s the kind of thing where even those of us with the best intentions might not always toe the line perfectly. Just put the button in, Sam. Nobody is gonna die.
JavaScript’s all-powerfulness makes it an appealing target for those of us doing work on the web — particularly as JavaScript as a language has evolved to become even more powerful and ergonomic, and the frameworks that are built in JavaScript become even more-so. Back in 2015, it was already so clear that JavaScript was experiencing incredible growth in usage, Matt Mullenweg, the founding developer of WordPress, gave the developer world homework: “Learn JavaScript Deeply”³. He couldn’t have been more right. Half a decade later, JavaScript has done a good job of taking over front-end development. Particularly if you look at front-end development jobs.
While the web almanac might show us that only 5% of the top-zillion sites use React compared to 85% including jQuery, those numbers are nearly flipped when looking around at front-end development job requirements.
I’m sure there are fancy economic reasons for all that, but jobs are as important and personal as it gets for people, so it very much matters.
So we’re browser people in a sea of JavaScript building things for people. If we take a look at the job at a practical day-to-day tasks level, it’s a bit like this:
Translate designs into code
Think in terms of responsive design, allowing us to design and build across the landscape of devices
Build systemically. Construct components and patterns, not one-offs.
Apply semantics to content
Consider accessibility
Worry about the performance of the site. Optimize everything. Reduce, reuse, recycle.
Just that first bullet point feels like a college degree to me. Taken together, all of those points certainly do.
This whole list is a bit abstract though, so let’s apply it to something we can look at. What if this website was our current project?

Our brains and fingers go wild!
Let’s build the layout with CSS grid.
What fonts are those? Do we need to load them in their entirety or can we subset them? What happens as they load in? This layout feels like it will really suffer from font-shifting jank.
There are some repeated patterns here. We should probably make a card design pattern. Every website needs a good card pattern.
That’s a gorgeous color scheme. Are the colors mathematically related? Should we make variables to represent them individually or can we just alter a single hue as needed? Are we going to use custom properties in our CSS? Colors are just colors though, we might not need the cascading power of them just for this. Should we just use Sass variables? Are we going to use a CSS preprocessor at all?
The source order is tricky here. We need to order things so that they make sense for a screen reader user. We should have a meeting about what the expected order of content should be, even if we’re visually moving things around a bit with CSS grid.
The photographs here are beautifully shot. But some of them match the background color of the site… can we get away with alpha-transparent PNGs here? Those are always so big. Can any next-gen formats help us? Or should we try to match the background of a JPG with the background of the site seamlessly. Who’s writing the alt text for these?
There are some icons in use here. Inline SVG, right? Certainly SVG of some kind, not icon fonts, right? Should we build a whole icon system? I guess it depends on how we’re gonna be building this thing more broadly. Do we have a build system at all?
What’s the whole front-end plan here? Can I code this thing in vanilla HTML, CSS, and JavaScript? Well, I know I can, but what are the team expectations? Client expectations? Does it need to be a React thing because it’s part of some ecosystem of stuff that is already React? Or Vue or Svelte or whatever? Is there a CMS involved?
I’m glad the designer thought of not just the “desktop” and “mobile” sizes but also tackled an in-between size. Those are always awkward. There is no interactivity information here though. What should we do when that search field is focused? What gets revealed when that hamburger is tapped? Are we doing page-level transitions here?
I could go on and on. That’s how front-end developers think, at least in my experience and in talking with my peers.
A lot of those things have been our jobs forever though. We’ve been asking and answering these questions on every website we’ve built for as long as we’ve been doing it. There are different challenges on each site, which is great and keeps this job fun, but there is a lot of repetition too.
Allow me to get around to the title of this article.
While we’ve been doing a lot of this stuff for ages, there is a whole pile of new stuff we’re starting to be expected to do, particularly if we’re talking about building the site with a modern JavaScript framework. All the modern frameworks, as much as they like to disagree about things, agree about one big thing: everything is a component. You nest and piece together components as needed. Even native JavaScript moves toward its own model of Web Components.

I like it, this idea of components. It allows you and your team to build the abstractions that make the most sense to you and what you are building.
Your Card component does all the stuff your card needs to do. Your Form component does forms how your website needs to do forms. But it’s a new concept to old developers like me. Components in JavaScript have taken hold in a way that components on the server-side never did. I’ve worked on many a WordPress website where the best I did was break templates into somewhat arbitrary include() statements. I’ve worked on Ruby on Rails sites with partials that take a handful of local variables. Those are useful for building re-usable parts, but they are a far cry from the robust component models that JavaScript frameworks offer us today.
All this custom component creation makes me a site-level architect in a way that I didn’t use to be. Here’s an example. Of course I have a Button component. Of course I have an Icon component. I’ll use them in my Card component. My Card component lives in a Grid component that lays them out and paginates them. The whole page is actually built from components. The Header component has a SearchBar component and a UserMenu component. The Sidebar component has a Navigation component and an Ad component. The whole page is just a special combination of components, which is probably based on the URL, assuming I’m all-in on building our front-end with JavaScript. So now I’m dealing with URLs myself, and I’m essentially the architect of the entire site. [Sweats profusely]
Like I told ya, a whole pile of new responsibility.
Components that are in charge of displaying content are almost certainly not hard-coded with data in them. They are built to be templates. They are built to accept data and construct themselves based on that data. In the olden days, when we were doing this kind of templating, the data has probably already arrived on the page we’re working on. In a JavaScript-powered app, it’s more likely that that data is fetched by JavaScript. Perhaps I’ll fetch it when the component renders. In a stack I’m working with right now, the front end is in React, the API is in GraphQL and we use Apollo Client to work with data. We use a special “hook” in the React components to run the queries to fetch the data we need, and another special hook when we need to change that data. Guess who does that work? Is it some other kind of developer that specializes in this data layer work? No, it’s become the domain of the front-end developer.
Speaking of data, there is all this other data that a website often has to deal with that doesn’t come from a database or API. It’s data that is really only relevant to the website at this moment in time.
Which tab is active right now?
Is this modal dialog open or closed?
Which bar of this accordion is expanded?
Is this message bar in an error state or warning state?
How many pages are you paginated in?
How far is the user scrolled down the page?
Front-end developers have been dealing with that kind of state for a long time, but it’s exactly this kind of state that has gotten us into trouble before. A modal dialog can be open with a simple modifier class like <div class="modal is-open"> and toggling that class is easy enough with .classList.toggle(".is-open"); But that’s a purely visual treatment. How does anything else on the page know if that modal is open or not? Does it ask the DOM? In a lot of jQuery-style apps of yore, yes, it would. In a sense, the DOM became the “source of truth” for our websites. There were all sorts of problems that stemmed from this architecture, ranging from a simple naming change destroying functionality in weirdly insidious ways, to hard-to-reason-about application logic making bug fixing a difficult proposition.
Front-end developers collectively thought: what if we dealt with state in a more considered way? State management, as a concept, became a thing. JavaScript frameworks themselves built the concept right in, and third-party libraries have paved and continue to pave the way. This is another example of expanding responsibility. Who architects state management? Who enforces it and implements it? It’s not some other role, it’s front-end developers.
There is expanding responsibility in the checklist of things to do, but there is also work to be done in piecing it all together. How much of this state can be handled at the individual component level and how much needs to be higher level? How much of this data can be gotten at the individual component level and how much should be percolated from above? Design itself comes into play. How much of the styling of this component should be scoped to itself, and how much should come from more global styles?
It’s no wonder that design systems have taken off in recent years. We’re building components anyway, so thinking of them systemically is a natural fit.
Let’s look at our design again:
A bunch of new thoughts can begin!
Assuming we’re using a JavaScript framework, which one? Why?
Can we statically render this site, even if we’re building with a JavaScript framework? Or server-side render it?
Where are those recipes coming from? Can we get a GraphQL API going so we can ask for whatever we need, whenever we need it?
Maybe we should pick a CMS that has an API that will facilitate the kind of front-end building we want to do. Perhaps a headless CMS?
What are we doing for routing? Is the framework we chose opinionated or unopinionated about stuff like this?
What are the components we need? A Card, Icon, SearchForm, SiteMenu, Img… can we scaffold these out? Should we start with some kind of design framework on top of the base framework?
What’s the client state we might need? Current search term, current tab, hamburger open or not, at least.
Is there a login system for this site or not? Are logged in users shown anything different?
Is there are third-party componentry we can leverage here?
Maybe we can find one of those fancy image components that does blur-up loading and lazy loading and all that.
Those are all things that are in the domain of front-end developers these days, on top of everything that we already need to do. Executing the design, semantics, accessibility, performance… that’s all still there. You still need to be proficient in HTML, CSS, JavaScript, and how the browser works. Being a front-end developer requires a haystack of skills that grows and grows. It’s the natural outcome of the web getting bigger. More people use the web and internet access grows. The economy around the web grows. The capability of browsers grows. The expectations of what is possible on the web grows. There isn’t a lot shrinking going on around here.
We’ve already reached the point where most front-end developers don’t know the whole haystack of responsibilities. There are lots of developers still doing well for themselves being rather design-focused and excelling at creative and well-implemented HTML and CSS, even as job posts looking for that dwindle.
There are systems-focused developers and even entire agencies that specialize in helping other companies build and implement design systems. There are data-focused developers that feel most at home making the data flow throughout a website and getting hot and heavy with business logic. While all of those people might have “front-end developer” on their business card, their responsibilities and even expectations of their work might be quite different. It’s all good, we’ll find ways to talk about all this in time.
In fact, how we talk about building websites has changed a lot in the last decade. Some of my early introduction to web development was through WordPress. WordPress needs a web server to run, is written in PHP, and stores it’s data in a MySQL database. As much as WordPress has evolved, all that is still exactly the same. We talk about that “stack” with an acronym: LAMP, or Linux, Apache, MySQL and PHP. Note that literally everything in the entire stack consists of back-end technologies. As a front-end developer, nothing about LAMP is relevant to me.
But other stacks have come along since then. A popular stack was MEAN (Mongo, Express, Angular and Node). Notice how we’re starting to inch our way toward more front-end technologies? Angular is a JavaScript framework, so as this stack gained popularity, so too did talking about the front-end as an important part of the stack. Node and Express are both JavaScript as well, albeit the server-side variant.
The existence of Node is a huge part of this story. Node isn’t JavaScript-like, it’s quite literally JavaScript. It makes a front-end developer already skilled in JavaScript able to do server-side work without too much of a stretch.
“Serverless” is a much more modern tech buzzword, and what it’s largely talking about is running small bits of code on cloud servers. Most often, those small bits of code are in Node, and written by JavaScript developers. These days, a JavaScript-focused front-end developer might be writing their own serverless functions and essentially being their own back-end developer. They’ll think of themselves as full-stack developers, and they’ll be right.
Shawn Wang coined a term for a new stack this year: STAR or Design System, TypeScript, Apollo, and React. This is incredible to me, not just because I kind of like that stack, but because it’s a way of talking about the stack powering a website that is entirely front-end technologies. Quite a shift.
I apologize if I’ve made you feel a little anxious reading this. If you feel like you’re behind in understanding all this stuff, you aren’t alone.
In fact, I don’t think I’ve talked to a single developer who told me they felt entirely comfortable with the entire world of building websites. Everybody has weak spots or entire areas where they just don’t know the first dang thing. You not only can specialize, but specializing is a pretty good idea, and I think you will end up specializing to some degree whether you plan to or not. If you have the good fortune to plan, pick things that you like. You’ll do just fine.
The only constant in life is change.
– Heraclitus – Motivational Poster – Chris Coyier
¹ I’m a white dude, so that helps a bunch, too. ↩️ ² Browsers speak a bunch more languages. HTTP, SVG, PNG… The more you know the more you can put to work! ↩️ ³ It’s an interesting bit of irony that WordPress websites generally aren’t built with client-side JavaScript components. ↩️
The post The Widening Responsibility for Front-End Developers appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
The Widening Responsibility for Front-End Developers published first on https://deskbysnafu.tumblr.com/
0 notes