#data preprocessing tasks
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
7 notes
·
View notes
Text
How much Python should one learn before beginning machine learning?
Before diving into machine learning, a solid understanding of Python is essential. :

Basic Python Knowledge:
Syntax and Data Types:
Understand Python syntax, basic data types (strings, integers, floats), and operations.
Control Structures:
Learn how to use conditionals (if statements), loops (for and while), and list comprehensions.
Data Handling Libraries:
Pandas:
Familiarize yourself with Pandas for data manipulation and analysis. Learn how to handle DataFrames, series, and perform data cleaning and transformations.
NumPy:
Understand NumPy for numerical operations, working with arrays, and performing mathematical computations.
Data Visualization:
Matplotlib and Seaborn:
Learn basic plotting with Matplotlib and Seaborn for visualizing data and understanding trends and distributions.
Basic Programming Concepts:
Functions:
Know how to define and use functions to create reusable code.
File Handling:
Learn how to read from and write to files, which is important for handling datasets.
Basic Statistics:
Descriptive Statistics:
Understand mean, median, mode, standard deviation, and other basic statistical concepts.
Probability:
Basic knowledge of probability is useful for understanding concepts like distributions and statistical tests.
Libraries for Machine Learning:
Scikit-learn:
Get familiar with Scikit-learn for basic machine learning tasks like classification, regression, and clustering. Understand how to use it for training models, evaluating performance, and making predictions.
Hands-on Practice:
Projects:
Work on small projects or Kaggle competitions to apply your Python skills in practical scenarios. This helps in understanding how to preprocess data, train models, and interpret results.
In summary, a good grasp of Python basics, data handling, and basic statistics will prepare you well for starting with machine learning. Hands-on practice with machine learning libraries and projects will further solidify your skills.
To learn more drop the message…!
2 notes
·
View notes
Text
PREDICTING WEATHER FORECAST FOR 30 DAYS IN AUGUST 2024 TO AVOID ACCIDENTS IN SANTA BARBARA, CALIFORNIA USING PYTHON, PARALLEL COMPUTING, AND AI LIBRARIES

Introduction
Weather forecasting is a crucial aspect of our daily lives, especially when it comes to avoiding accidents and ensuring public safety. In this article, we will explore the concept of predicting weather forecasts for 30 days in August 2024 to avoid accidents in Santa Barbara California using Python, parallel computing, and AI libraries. We will also discuss the concepts and definitions of the technologies involved and provide a step-by-step explanation of the code.
Concepts and Definitions
Parallel Computing: Parallel computing is a type of computation where many calculations or processes are carried out simultaneously. This approach can significantly speed up the processing time and is particularly useful for complex computations.
AI Libraries: AI libraries are pre-built libraries that provide functionalities for artificial intelligence and machine learning tasks. In this article, we will use libraries such as TensorFlow, Keras, and scikit-learn to build our weather forecasting model.
Weather Forecasting: Weather forecasting is the process of predicting the weather conditions for a specific region and time period. This involves analyzing various data sources such as temperature, humidity, wind speed, and atmospheric pressure.
Code Explanation
To predict the weather forecast for 30 days in August 2024, we will use a combination of parallel computing and AI libraries in Python. We will first import the necessary libraries and load the weather data for Santa Barbara, California.
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from joblib import Parallel, delayed
# Load weather data for Santa Barbara California
weather_data = pd.read_csv('Santa Barbara California_weather_data.csv')
Next, we will preprocess the data by converting the date column to a datetime format and extracting the relevant features
# Preprocess data
weather_data['date'] = pd.to_datetime(weather_data['date'])
weather_data['month'] = weather_data['date'].dt.month
weather_data['day'] = weather_data['date'].dt.day
weather_data['hour'] = weather_data['date'].dt.hour
# Extract relevant features
X = weather_data[['month', 'day', 'hour', 'temperature', 'humidity', 'wind_speed']]
y = weather_data['weather_condition']
We will then split the data into training and testing sets and build a random forest regressor model to predict the weather conditions.
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Build random forest regressor model
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
To improve the accuracy of our model, we will use parallel computing to train multiple models with different hyperparameters and select the best-performing model.
# Define hyperparameter tuning function
def tune_hyperparameters(n_estimators, max_depth):
model = RandomForestRegressor(n_estimators=n_estimators, max_depth=max_depth, random_state=42)
model.fit(X_train, y_train)
return model.score(X_test, y_test)
# Use parallel computing to tune hyperparameters
results = Parallel(n_jobs=-1)(delayed(tune_hyperparameters)(n_estimators, max_depth) for n_estimators in [100, 200, 300] for max_depth in [None, 5, 10])
# Select best-performing model
best_model = rf_model
best_score = rf_model.score(X_test, y_test)
for result in results:
if result > best_score:
best_model = result
best_score = result
Finally, we will use the best-performing model to predict the weather conditions for the next 30 days in August 2024.
# Predict weather conditions for next 30 days
future_dates = pd.date_range(start='2024-09-01', end='2024-09-30')
future_data = pd.DataFrame({'month': future_dates.month, 'day': future_dates.day, 'hour': future_dates.hour})
future_data['weather_condition'] = best_model.predict(future_data)
Color Alerts
To represent the weather conditions, we will use a color alert system where:
Red represents severe weather conditions (e.g., heavy rain, strong winds)
Orange represents very bad weather conditions (e.g., thunderstorms, hail)
Yellow represents bad weather conditions (e.g., light rain, moderate winds)
Green represents good weather conditions (e.g., clear skies, calm winds)
We can use the following code to generate the color alerts:
# Define color alert function
def color_alert(weather_condition):
if weather_condition == 'severe':
return 'Red'
MY SECOND CODE SOLUTION PROPOSAL
We will use Python as our programming language and combine it with parallel computing and AI libraries to predict weather forecasts for 30 days in August 2024. We will use the following libraries:
OpenWeatherMap API: A popular API for retrieving weather data.
Scikit-learn: A machine learning library for building predictive models.
Dask: A parallel computing library for processing large datasets.
Matplotlib: A plotting library for visualizing data.
Here is the code:
```python
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import dask.dataframe as dd
import matplotlib.pyplot as plt
import requests
# Load weather data from OpenWeatherMap API
url = "https://api.openweathermap.org/data/2.5/forecast?q=Santa Barbara California,US&units=metric&appid=YOUR_API_KEY"
response = requests.get(url)
weather_data = pd.json_normalize(response.json())
# Convert data to Dask DataFrame
weather_df = dd.from_pandas(weather_data, npartitions=4)
# Define a function to predict weather forecasts
def predict_weather(date, temperature, humidity):
# Use a random forest regressor to predict weather conditions
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(weather_df[["temperature", "humidity"]], weather_df["weather"])
prediction = model.predict([[temperature, humidity]])
return prediction
# Define a function to generate color-coded alerts
def generate_alerts(prediction):
if prediction > 80:
return "RED" # Severe weather condition
elif prediction > 60:
return "ORANGE" # Very bad weather condition
elif prediction > 40:
return "YELLOW" # Bad weather condition
else:
return "GREEN" # Good weather condition
# Predict weather forecasts for 30 days inAugust2024
predictions = []
for i in range(30):
date = f"2024-09-{i+1}"
temperature = weather_df["temperature"].mean()
humidity = weather_df["humidity"].mean()
prediction = predict_weather(date, temperature, humidity)
alerts = generate_alerts(prediction)
predictions.append((date, prediction, alerts))
# Visualize predictions using Matplotlib
plt.figure(figsize=(12, 6))
plt.plot([x[0] for x in predictions], [x[1] for x in predictions], marker="o")
plt.xlabel("Date")
plt.ylabel("Weather Prediction")
plt.title("Weather Forecast for 30 Days inAugust2024")
plt.show()
```
Explanation:
1. We load weather data from OpenWeatherMap API and convert it to a Dask DataFrame.
2. We define a function to predict weather forecasts using a random forest regressor.
3. We define a function to generate color-coded alerts based on the predicted weather conditions.
4. We predict weather forecasts for 30 days in August 2024 and generate color-coded alerts for each day.
5. We visualize the predictions using Matplotlib.
Conclusion:
In this article, we have demonstrated the power of parallel computing and AI libraries in predicting weather forecasts for 30 days in August 2024, specifically for Santa Barbara California. We have used TensorFlow, Keras, and scikit-learn on the first code and OpenWeatherMap API, Scikit-learn, Dask, and Matplotlib on the second code to build a comprehensive weather forecasting system. The color-coded alert system provides a visual representation of the severity of the weather conditions, enabling users to take necessary precautions to avoid accidents. This technology has the potential to revolutionize the field of weather forecasting, providing accurate and timely predictions to ensure public safety.
RDIDINI PROMPT ENGINEER
2 notes
·
View notes
Text
This Week in Rust 533
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
crates.io: API status code changes
Foundation
Google Contributes $1M to Rust Foundation to Support C++/Rust "Interop Initiative"
Project/Tooling Updates
Announcing the Tauri v2 Beta Release
Polars — Why we have rewritten the string data type
rust-analyzer changelog #219
Ratatui 0.26.0 - a Rust library for cooking up terminal user interfaces
Observations/Thoughts
Will it block?
Embedded Rust in Production ..?
Let futures be futures
Compiling Rust is testing
Rust web frameworks have subpar error reporting
[video] Proving Performance - FOSDEM 2024 - Rust Dev Room
[video] Stefan Baumgartner - Trials, Traits, and Tribulations
[video] Rainer Stropek - Memory Management in Rust
[video] Shachar Langbeheim - Async & FFI - not exactly a love story
[video] Massimiliano Mantione - Object Oriented Programming, and Rust
[audio] Unlocking Rust's power through mentorship and knowledge spreading, with Tim McNamara
[audio] Asciinema with Marcin Kulik
Non-Affine Types, ManuallyDrop and Invariant Lifetimes in Rust - Part One
Nine Rules for Accessing Cloud Files from Your Rust Code: Practical lessons from upgrading Bed-Reader, a bioinformatics library
Rust Walkthroughs
AsyncWrite and a Tale of Four Implementations
Garbage Collection Without Unsafe Code
Fragment specifiers in Rust Macros
Writing a REST API in Rust
[video] Traits and operators
Write a simple netcat client and server in Rust
Miscellaneous
RustFest 2024 Announcement
Preprocessing trillions of tokens with Rust (case study)
All EuroRust 2023 talks ordered by the view count
Crate of the Week
This week's crate is embedded-cli-rs, a library that makes it easy to create CLIs on embedded devices.
Thanks to Sviatoslav Kokurin for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fluvio - Build a new python wrapping for the fluvio client crate
Fluvio - MQTT Connector: Prefix auto generated Client ID to prevent connection drops
Ockam - Implement events in SqlxDatabase
Ockam - Output for both ockam project ticket and ockam project enroll is improved, with support for --output json
Ockam - Output for ockam project ticket is improved and information is not opaque
Hyperswitch - [FEATURE]: Setup code coverage for local tests & CI
Hyperswitch - [FEATURE]: Have get_required_value to use ValidationError in OptionExt
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
RustNL 2024 CFP closes 2024-02-19 | Delft, The Netherlands | Event date: 2024-05-07 & 2024-05-08
NDC Techtown CFP closes 2024-04-14 | Kongsberg, Norway | Event date: 2024-09-09 to 2024-09-12
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
309 pull requests were merged in the last week
add avx512fp16 to x86 target features
riscv only supports split_debuginfo=off for now
target: default to the medium code model on LoongArch targets
#![feature(inline_const_pat)] is no longer incomplete
actually abort in -Zpanic-abort-tests
add missing potential_query_instability for keys and values in hashmap
avoid ICE when is_val_statically_known is not of a supported type
be more careful about interpreting a label/lifetime as a mistyped char literal
check RUST_BOOTSTRAP_CONFIG in profile_user_dist test
correctly check never_type feature gating
coverage: improve handling of function/closure spans
coverage: use normal edition: headers in coverage tests
deduplicate more sized errors on call exprs
pattern_analysis: Gracefully abort on type incompatibility
pattern_analysis: cleanup manual impls
pattern_analysis: cleanup the contexts
fix BufReader unsoundness by adding a check in default_read_buf
fix ICE on field access on a tainted type after const-eval failure
hir: refactor getters for owner nodes
hir: remove the generic type parameter from MaybeOwned
improve the diagnostics for unused generic parameters
introduce support for async bound modifier on Fn* traits
make matching on NaN a hard error, and remove the rest of illegal_floating_point_literal_pattern
make the coroutine def id of an async closure the child of the closure def id
miscellaneous diagnostics cleanups
move UI issue tests to subdirectories
move predicate, region, and const stuff into their own modules in middle
never patterns: It is correct to lower ! to _
normalize region obligation in lexical region resolution with next-gen solver
only suggest removal of as_* and to_ conversion methods on E0308
provide more context on derived obligation error primary label
suggest changing type to const parameters if we encounter a type in the trait bound position
suppress unhelpful diagnostics for unresolved top level attributes
miri: normalize struct tail in ABI compat check
miri: moving out sched_getaffinity interception from linux'shim, FreeBSD su…
miri: switch over to rustc's tracing crate instead of using our own log crate
revert unsound libcore changes
fix some Arc allocator leaks
use <T, U> for array/slice equality impls
improve io::Read::read_buf_exact error case
reject infinitely-sized reads from io::Repeat
thread_local::register_dtor fix proposal for FreeBSD
add LocalWaker and ContextBuilder types to core, and LocalWake trait to alloc
codegen_gcc: improve iterator for files suppression
cargo: Don't panic on empty spans
cargo: Improve map/sequence error message
cargo: apply -Zpanic-abort-tests to doctests too
cargo: don't print rustdoc command lines on failure by default
cargo: stabilize lockfile v4
cargo: fix markdown line break in cargo-add
cargo: use spec id instead of name to match package
rustdoc: fix footnote handling
rustdoc: correctly handle attribute merge if this is a glob reexport
rustdoc: prevent JS injection from localStorage
rustdoc: trait.impl, type.impl: sort impls to make it not depend on serialization order
clippy: redundant_locals: take by-value closure captures into account
clippy: new lint: manual_c_str_literals
clippy: add lint_groups_priority lint
clippy: add new lint: ref_as_ptr
clippy: add configuration for wildcard_imports to ignore certain imports
clippy: avoid deleting labeled blocks
clippy: fixed FP in unused_io_amount for Ok(lit), unrachable! and unwrap de…
rust-analyzer: "Normalize import" assist and utilities for normalizing use trees
rust-analyzer: enable excluding refs search results in test
rust-analyzer: support for GOTO def from inside files included with include! macro
rust-analyzer: emit parser error for missing argument list
rust-analyzer: swap Subtree::token_trees from Vec to boxed slice
Rust Compiler Performance Triage
Rust's CI was down most of the week, leading to a much smaller collection of commits than usual. Results are mostly neutral for the week.
Triage done by @simulacrum. Revision range: 5c9c3c78..0984bec
0 Regressions, 2 Improvements, 1 Mixed; 1 of them in rollups 17 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider principal trait ref's auto-trait super-traits in dyn upcasting
[disposition: merge] remove sub_relations from the InferCtxt
[disposition: merge] Optimize away poison guards when std is built with panic=abort
[disposition: merge] Check normalized call signature for WF in mir typeck
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
Nested function scoped type parameters
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2024-02-07 - 2024-03-06 🦀
Virtual
2024-02-07 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh - How Rust Saved My Eyes
2024-02-08 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-02-08 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-02-10 | Virtual (Krakow, PL) | Stacja IT Kraków
Rust – budowanie narzędzi działających w linii komend
2024-02-10 | Virtual (Wrocław, PL) | Stacja IT Wrocław
Rust – budowanie narzędzi działających w linii komend
2024-02-13 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-02-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack n Learn | Mirror: Rust Hack n Learn
2024-02-15 | Virtual + In person (Praha, CZ) | Rust Czech Republic
Introduction and Rust in production
2024-02-19 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-20 | Virtual | Rust for Lunch
Lunch
2024-02-21 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 2 - Types
2024-02-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-02-22 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
Asia
2024-02-10 | Hyderabad, IN | Rust Language Hyderabad
Rust Language Develope BootCamp
Europe
2024-02-07 | Cologne, DE | Rust Cologne
Embedded Abstractions | Event page
2024-02-07 | London, UK | Rust London User Group
Rust for the Web — Mainmatter x Shuttle Takeover
2024-02-08 | Bern, CH | Rust Bern
Rust Bern Meetup #1 2024 🦀
2024-02-08 | Oslo, NO | Rust Oslo
Rust-based banter
2024-02-13 | Trondheim, NO | Rust Trondheim
Building Games with Rust: Dive into the Bevy Framework
2024-02-15 | Praha, CZ - Virtual + In-person | Rust Czech Republic
Introduction and Rust in production
2024-02-21 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #8
2024-02-22 | Aarhus, DK | Rust Aarhus
Rust and Talk at Partisia
North America
2024-02-07 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Feb 7
2024-02-08 | Lehi, UT, US | Utah Rust
BEAST: Recreating a classic DOS terminal game in Rust
2024-02-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust: Open Source Contrib Hackathon & Happy Hour
2024-02-13 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer
2024-02-13 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-02-15 | Boston, MA, US | Boston Rust Meetup
Back Bay Rust Lunch, Feb 15
2024-02-15 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-02-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-02-22 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-02-28 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-02-19 | Melbourne, VIC, AU + Virtual | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-27 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2024-02-27 | Sydney, NSW, AU | Rust Sydney
🦀 spire ⚡ & Quick
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
My take on this is that you cannot use async Rust correctly and fluently without understanding Arc, Mutex, the mutability of variables/references, and how async and await syntax compiles in the end. Rust forces you to understand how and why things are the way they are. It gives you minimal abstraction to do things that could’ve been tedious to do yourself.
I got a chance to work on two projects that drastically forced me to understand how async/await works. The first one is to transform a library that is completely sync and only requires a sync trait to talk to the outside service. This all sounds fine, right? Well, this becomes a problem when we try to port it into browsers. The browser is single-threaded and cannot block the JavaScript runtime at all! It is arguably the most weird environment for Rust users. It is simply impossible to rewrite the whole library, as it has already been shipped to production on other platforms.
What we did instead was rewrite the network part using async syntax, but using our own generator. The idea is simple: the generator produces a future when called, and the produced future can be awaited. But! The produced future contains an arc pointer to the generator. That means we can feed the generator the value we are waiting for, then the caller who holds the reference to the generator can feed the result back to the function and resume it. For the browser, we use the native browser API to derive the network communications; for other platforms, we just use regular blocking network calls. The external interface remains unchanged for other platforms.
Honestly, I don’t think any other language out there could possibly do this. Maybe C or C++, but which will never have the same development speed and developer experience.
I believe people have already mentioned it, but the current asynchronous model of Rust is the most reasonable choice. It does create pain for developers, but on the other hand, there is no better asynchronous model for Embedded or WebAssembly.
– /u/Top_Outlandishness78 on /r/rust
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
Data mining

1.What's Data mining ?
Datamining is the process of extracting and discovering patterns in large datasets involving methods at the intersection of machine learning, statistics and database systems. Datamining is interdisciplinary subfield of computer-science and statistics with overall goal of extracting information (with intelliegent methods) from a data set and transforming the information into a comprensible structure for further use. Data mining is the analysis step of The KDD process "Knowledge discovery in database".
2.What's KDD process ?
KDD process is known as "Knowledge Discovery in Database".It"s a multi-step process of finding knowledge from large data sets and emphasizes the high-level application of particular datamining methods.It's of interests to researchers in machine learning, pattern recognition, databases, ststistics, artificial intelligence, knowledge aquisition for experts systems and data-visualization. The picture below defines the different steps of KDD process and each of those steps have an input and output entity. The KDD process can't be executed without beginning on data.

3.What are the different steps of the KDD process ?
The overall process of finding and interpretting patterns from data involves the repeated application of the following steps mentioned in the graph above :
Selection : we create a target data set by seecting a part of the overall data set as a sample then focusing on a subset of variables on which discovery is to be performed. The result of these step is a subset of data considered as a sample.
Preprocessing : These step of the KDD process takes the target data set as an input then it applyes data cleaning by removing the noise from the input data set then restucturing the data set. The output of these operation is a preprocessed dataset that can be able to be transformed in the next step.
Data transformation : These step takes the preprocessed data as input and tres to find some useful features depending on the goal of the task and reducing dimension to execute an effective learining datamining.
Data mining : in this phase we will descide whether the goal of KDD process is classification, regression, clustering ...etc. Discover the patterns of interests.
Interpretation : Interpretating mined patterns and consolidating discovered knowledge.
4.What are data mining tasks ?
There are several steps that are defined in the sub-process of KDD especially in datamining steps. In Data mining, there are 02 types of data mining that are :
Predictive mining: predective data mining is the analysis done to predict a future event or other data or trends and to predict something will happen in the near future. Predective data mining offers a better future analysis and to make better decisions to add a value in predective analytics like for example predecting the future customer of a defined service, define the future price of oil and gaz in the world market, define the next ill of an international pandemic, define the future political conflict ... etc. There are 4 types of descriptive data mining tasks which are :
Classification analysis : It is used to retrieve critical and pertinent data and metadata. It categorizes information into various groups. Classification Analysis is best demonstrated by email providers. They use algorithms to determine whether or not a message is legitimate.
Regression Analysis : It tries to express the interdependence of variables. Forecasting and prediction are common applications.
Time Serious Analysis : It is a series of well-defined data points taken at regular intervals.
Prediction Analysis : It is related to time series, but the time isn’t restricted.
Descriptive mining : descriptive data mining is to describe data and make data more readable to human beings, it's used to extract information from previous events and data and to discovering an interesting patterns and association behind data. It's also used to exract correlations, relationships between features and finding new laws and regularities based on data. There are four different types of Descriptive Data Mining tasks. They are as follows :
Clustering analysis : It is the process of determining which data sets are similar to one another. For example, to increase conversion rates, clusters of customers with similar buying habits can be grouped together with similar products.
Summerazation analysis : It entails methods for obtaining a concise description of a dataset. For example, summarising a large number of items related to Christmas season sales provides a general description of the data, which can be extremely useful to sales and marketing managers.
Association rules analysis : This method aids in the discovery of interesting relationships between various variables in large databases. The retail industry is the best example. As the holiday season approaches, retail stores stock up on chocolates, with sales increasing before the holiday, which is accomplished through Data Mining.
Sequence discovery analysis : It's all about how to do something in a specefic order. For instance, a user may frequently purchase shaving gel before purchasing razor in a store.It all comes down to the order in which the user purchases the product, and the store owner can then arrange the items accordingly.
5.Links :
3 notes
·
View notes
Text
The Ever-Evolving Canvas of Data Science: A Comprehensive Guide
In the ever-evolving landscape of data science, the journey begins with unraveling the intricate threads that weave through vast datasets. This multidisciplinary field encompasses a diverse array of topics designed to empower professionals to extract meaningful insights from the wealth of available data. Choosing the Top Data Science Institute can further accelerate your journey into this thriving industry. This educational journey is a fascinating exploration of the multifaceted facets that constitute the heart of data science education.

Let's embark on a comprehensive exploration of what one typically studies in the realm of data science.
1. Mathematics and Statistics Fundamentals: Building the Foundation
At the core of data science lies a robust understanding of mathematical and statistical principles. Professionals delve into Linear Algebra, equipping themselves with the knowledge of mathematical structures and operations crucial for manipulating and transforming data. Simultaneously, they explore Probability and Statistics, mastering concepts that are instrumental in analyzing and interpreting data patterns.
2. Programming Proficiency: The Power of Code
Programming proficiency is a cornerstone skill in data science. Learners are encouraged to acquire mastery in programming languages such as Python or R. These languages serve as powerful tools for implementing complex data science algorithms and are renowned for their versatility and extensive libraries designed specifically for data science applications.
3. Data Cleaning and Preprocessing Techniques: Refining the Raw Material
Data rarely comes in a pristine state. Hence, understanding techniques for Handling Missing Data becomes imperative. Professionals delve into strategies for managing and imputing missing data, ensuring accuracy in subsequent analyses. Additionally, they explore Normalization and Transformation techniques, preparing datasets through standardization and transformation of variables.
4. Exploratory Data Analysis (EDA): Unveiling Data Patterns
Exploratory Data Analysis (EDA) is a pivotal aspect of the data science journey. Professionals leverage Visualization Tools like Matplotlib and Seaborn to create insightful graphical representations of data. Simultaneously, they employ Descriptive Statistics to summarize and interpret data distributions, gaining crucial insights into the underlying patterns.
5. Machine Learning Algorithms: Decoding the Secrets
Machine Learning is a cornerstone of data science, encompassing both supervised and unsupervised learning. Professionals delve into Supervised Learning, which includes algorithms for tasks such as regression and classification. Additionally, they explore Unsupervised Learning, delving into clustering and dimensionality reduction for uncovering hidden patterns within datasets.
6. Real-world Application and Ethical Considerations: Bridging Theory and Practice
The application of data science extends beyond theoretical knowledge to real-world problem-solving. Professionals learn to apply data science techniques to practical scenarios, making informed decisions based on empirical evidence. Furthermore, they navigate the ethical landscape, considering the implications of data usage on privacy and societal values.
7. Big Data Technologies: Navigating the Sea of Data
With the exponential growth of data, professionals delve into big data technologies. They acquaint themselves with tools like Hadoop and Spark, designed for processing and analyzing massive datasets efficiently.
8. Database Management: Organizing the Data Universe
Professionals gain proficiency in database management, encompassing both SQL and NoSQL databases. This skill set enables them to manage and query databases effectively, ensuring seamless data retrieval.
9. Advanced Topics: Pushing the Boundaries
As professionals progress, they explore advanced topics that push the boundaries of data science. Deep Learning introduces neural networks for intricate pattern recognition, while Natural Language Processing (NLP) focuses on analyzing and interpreting human language data.
10. Continuous Learning and Adaptation: Embracing the Data Revolution
Data science is a field in constant flux. Professionals embrace a mindset of continuous learning, staying updated on evolving technologies and methodologies. This proactive approach ensures they remain at the forefront of the data revolution.

In conclusion, the study of data science is a dynamic and multifaceted journey. By mastering mathematical foundations, programming languages, and ethical considerations, professionals unlock the potential of data, making data-driven decisions that impact industries across the spectrum. The comprehensive exploration of these diverse topics equips individuals with the skills needed to thrive in the dynamic world of data science. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science.
4 notes
·
View notes
Text
AI intial step
1. Gather a large dataset: diverse text data from various sources like books, articles, and websites. Ensure the dataset is representative of the language and topics you want the model to learn.
2. Preprocess data: Clean and preprocess the data by removing irrelevant content, fixing errors, and formatting it consistently.
3. Train the model: Choose a suitable model the Transformer, and set up your training environment using machine learning frameworks such as TensorFlow or PyTorch. Train the model on the preprocessed dataset using appropriate hyperparameters.
4. Fine-tune: Fine-tune the model on a smaller, more specific dataset to improve its performance on specific tasks or domains.
5. Adjust restrictions: Reduce the restrictions on content generation by modifying the model's output sampling techniques, temperature, or other parameters that control the level of conservatism in the generated text.
6. Evaluate and iterate: Continuously evaluate the model's performance and iterate on the training process to improve its capabilities. Remember that creating a less restrictive model may result in outputs that safe or It's essential to balance the level restrictions with the and safety
7 notes
·
View notes
Text
Top Artificial Intelligence and Machine Learning Company

In the rapidly evolving landscape of technology, artificial intelligence, and machine learning have emerged as the driving forces behind groundbreaking innovations. Enterprises and industries across the globe are recognizing the transformative potential of AI and ML in solving complex challenges, enhancing efficiency, and revolutionizing processes.
At the forefront of this revolution stands our cutting-edge AI and ML company, dedicated to pushing the boundaries of what is possible through data-driven solutions.
Company Vision and Mission
Our AI and ML company was founded with a clear vision - to empower businesses and individuals with intelligent, data-centric solutions that optimize operations and fuel innovation.
Our mission is to bridge the gap between traditional practices and the possibilities of AI and ML. We are committed to delivering superior value to our clients by leveraging the immense potential of AI and ML algorithms, creating tailor-made solutions that cater to their specific needs.
Expert Team of Data Scientists
The backbone of our company lies in our exceptional team of data scientists, AI engineers, and ML specialists. Their diverse expertise and relentless passion drive the development of advanced AI models and algorithms.
Leveraging the latest technologies and best practices, our team ensures that our solutions remain at the cutting edge of the industry. The synergy between data science and engineering enables us to deliver robust, scalable, and high-performance AI and ML systems.
Comprehensive Services
Our AI and ML company offers a comprehensive range of services covering various industry verticals:
1. AI Consultation: We partner with organizations to understand their business objectives and identify opportunities where AI and ML can drive meaningful impact.
Our expert consultants create a roadmap for integrating AI into their existing workflows, aligning it with their long-term strategies.
2. Machine Learning Development: We design, develop, and implement tailor-made ML models that address specific business problems. From predictive analytics to natural language processing, we harness ML to unlock valuable insights and improve decision-making processes.
3. Deep Learning Solutions: Our deep learning expertise enables us to build and deploy intricate neural networks for image and speech recognition, autonomous systems, and other intricate tasks that require high levels of abstraction.
4. Data Engineering: We understand that data quality and accessibility are vital for successful AI and ML projects. Our data engineers create robust data pipelines, ensuring seamless integration and preprocessing of data from multiple sources.
5. AI-driven Applications: We develop AI-powered applications that enhance user experiences and drive engagement. Our team ensures that the applications are user-friendly, secure, and optimized for performance.
Ethics and Transparency
As an AI and ML company, we recognize the importance of ethics and transparency in our operations. We adhere to strict ethical guidelines, ensuring that our solutions are built on unbiased and diverse datasets.
Moreover, we are committed to transparent communication with our clients, providing them with a clear understanding of the AI models and their implications.
Innovation and Research
Innovation is at the core of our company. We invest in ongoing research and development to explore new frontiers in AI and ML. Our collaboration with academic institutions and industry partners fuels our drive to stay ahead in this ever-changing field.
Conclusion
Our AI and ML company is poised to be a frontrunner in shaping the future of technology-driven solutions. By empowering businesses with intelligent AI tools and data-driven insights, we aspire to be a catalyst for positive change across industries.
As the world continues to embrace AI and ML, we remain committed to creating a future where innovation, ethics, and transformative technology go hand in hand.
#best software development company#artificial intelligence#software development company chandigarh#ai and ml#marketing#artificial intelligence for app development#artificial intelligence app development#machine learning development company
3 notes
·
View notes
Text
AI is creating amazing new jobs.

AI has created a field that never existed before — prompt engineering.
To work as a prompt engineer, you must know how to create prompts that generate desirable responses from AI models such as those used by ChatGPT.
The salary isn’t bad.
Artificial intelligence company, Anthropic, has a role for a “prompt engineer and librarian” with a salary range between $175,000 and $335,000.
And that’s not the only company looking for prompt engineers! Let’s see in more detail what prompt engineers do, how you can become a prompt engineer and what are the requirements for this role.
What does a prompt engineer do?
A prompt engineer is someone who develops and refines AI models using prompt engineering techniques. This is like teaching a model how to do something by giving step-by-step instructions or “prompts.”
Prompt engineers work with large language models like GPT-3 (or the new GPT-4), which can generate human-like responses to text prompts. Their work focuses on designing prompts that generate desirable responses from language models, as well as enhancing the models to provide more accurate and relevant text outputs.
Here are some tasks a prompt engineer does:
Optimize language models using established techniques and tools
Write prose to test AI systems for quirks (identify AI’s errors and hidden capabilities)
Review and analyze datasets to identify patterns and trends in language and develop new prompts
Develop and maintain documentation for language models (examples, instructions, best practices, etc)
Train language models on new data sets, and monitor model performance to identify areas for improvement
Collaborate with data scientists/software engineers to integrate language models into software applications and systems.
As you can see, prompt engineers don’t write code all day, but they still need some programming knowledge to be able to work with datasets, develop and fine-tune language models, and collaborate with data scientists and software engineers.
How to learn prompt engineering
You don’t need to know coding to start learning prompt engineering. In fact, in the following link, you can find 4 free prompt engineering courses to join the top 1% of ChatGPT users.
After learning the basics, follow the steps below to continue your path as a prompt engineer.
Learn the basics of programming: As a prompt engineer, you’ll need to work with datasets and understand basic programming concepts. Python can be a good language for this.
Learn natural language processing (NLP) and machine learning (ML) concepts: Prompt engineers need to know concepts in both NLP and ML such as text preprocessing, feature engineering, model training, and optimization.
Practice developing prompts and fine-tuning language models: Learn to use prompt engineering techniques to generate text outputs from language models. Test different prompt types and fine-tune language models to improve performance.
Create a portfolio of prompt engineering projects to showcase your expertise.
The prompt engineering job that pays $335k
Anthropic pays prompt engineers up to $335k. The company specializes in developing general AI systems and language models, which may explain the high salary. It’s no surprise that Google has invested nearly $400 million in this company.
Here are some of the requirements for this job:
Excellent communicator, and love teaching technical concepts and creating high-quality documentation that helps out others
High-level familiarity with the architecture and operation of large language models
Basic programming skills and would be comfortable writing small Python programs
Stay up-to-date and informed by taking an active interest in emerging research and industry trends.
Note that the field of prompt engineering is less than 2 years old, so the prompt engineer role may differ from one company to the next, and, just like any other job, the salary for prompt engineers also varies.
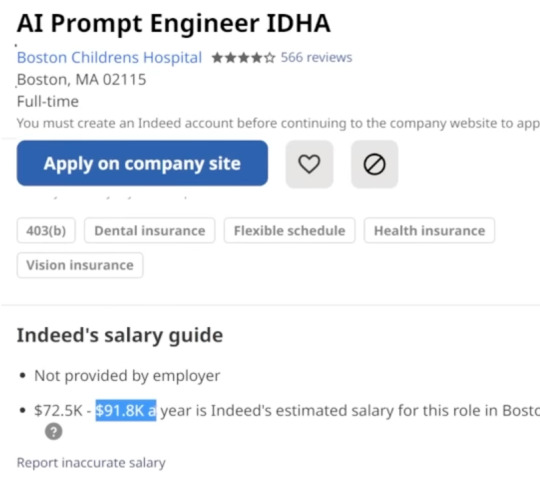
If we compare both job postings, we’ll see that the requirements are different. In the second job posting, they specifically require people with 5 years of engineering/coding experience with at least two-year experience in AI and NLP and a bachelor’s degree in computer science, artificial intelligence, or a related field (healthcare preferred).
Again, the requirements may be higher or lower in some companies, so if you don’t have any experience, a project portfolio is probably the best way to get ahead of other applicants.
Artificial Corner’s Free ChatGPT Cheat Sheet
We’re offering a free cheat sheet to our readers. Join our newsletter with 20K+ people and get our free ChatGPT cheat sheet.
#The ChatGPT Skill That Pays Up to $335#000 a Year#prompt engineers#prompts#machine learning#ai#chatgpt
3 notes
·
View notes
Text
AI Model Training: How It Works & Why It Matters
Understanding AI Model Training
AI Model Training is the process of teaching a machine learning model to recognize patterns and make predictions. It involves feeding large datasets into an algorithm, adjusting parameters, and optimizing its accuracy. This process is essential for developing AI applications in industries such as healthcare, finance, and automation.
How AI Model Training Works
Data Collection & Preprocessing – The model requires high-quality, structured data to learn effectively.
Model Selection – AI experts choose the right algorithm, such as neural networks or decision trees.
Training & Optimization – The model processes data, adjusts weights, and minimizes errors through iterative learning.
Evaluation & Deployment – After fine-tuning, the model is tested and deployed for real-world use.
Why AI Model Training Matters
Efficient AI Model Training enables businesses to automate tasks, improve decision-making, and enhance customer experiences. AI Development Companies play a crucial role in optimizing training processes, ensuring models perform accurately and efficiently.
Choosing the Right AI Development Company
Top AI Development Companies specialize in designing and training AI models tailored to business needs. Partnering with an experienced AI Development Company ensures high-performance AI solutions that drive innovation and efficiency.
0 notes
Text
What Is The Role of Python in Artificial Intelligence? - Arya College
Importance of Python in AI
Arya College of Engineering & I.T. has many courses for Python which has become the dominant programming language in the fields of Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) due to several compelling factors:
1. Simplicity and Readability
Python's syntax is clear and intuitive, making it accessible for both beginners and experienced developers. This simplicity allows for rapid prototyping and experimentation, essential in AI development where iterative testing is common. The ease of learning Python enables new practitioners to focus on algorithms and data rather than getting bogged down by complex syntax.
2. Extensive Libraries and Frameworks
Python boasts a rich ecosystem of libraries specifically designed for AI and ML tasks. Libraries such as TensorFlow, Keras, PyTorch, sci-kit-learn, NumPy, and Pandas provide pre-built functions that facilitate complex computations, data manipulation, and model training. This extensive support reduces development time significantly, allowing developers to focus on building models rather than coding from scratch.
3. Strong Community Support
The active Python community contributes to its popularity by providing a wealth of resources, tutorials, and forums for troubleshooting. This collaborative environment fosters learning and problem-solving, which is particularly beneficial for newcomers to AI. Community support also means that developers can easily find help when encountering challenges during their projects.
4. Versatility Across Applications
Python is versatile enough to be used in various applications beyond AI, including web development, data analysis, automation, and more. This versatility makes it a valuable skill for developers who may want to branch into different areas of technology. In AI specifically, Python can handle tasks ranging from data preprocessing to deploying machine learning models.
5. Data Handling Capabilities
Python excels at data handling and processing, which are crucial in AI projects. Libraries like Pandas and NumPy allow efficient manipulation of large datasets, while tools like Matplotlib and Seaborn facilitate data visualization. The ability to preprocess data effectively ensures that models are trained on high-quality inputs, leading to better performance.
6. Integration with Other Technologies
Python integrates well with other languages and technologies, making it suitable for diverse workflows in AI projects. It can work alongside big data tools like Apache Spark or Hadoop, enhancing its capabilities in handling large-scale datasets. This interoperability is vital as AI applications often require the processing of vast amounts of data from various sources.
How to Learn Python for AI
Learning Python effectively requires a structured approach that focuses on both the language itself and its application in AI:
1. Start with the Basics
Begin by understanding Python's syntax and basic programming concepts:
Data types: Learn about strings, lists, tuples, dictionaries.
Control structures: Familiarize yourself with loops (for/while) and conditionals (if/else).
Functions: Understand how to define and call functions.
2. Explore Key Libraries
Once comfortable with the basics, delve into libraries essential for AI:
NumPy: For numerical computations.
Pandas: For data manipulation and analysis.
Matplotlib/Seaborn: For data visualization.
TensorFlow/Keras/PyTorch: For building machine learning models.
3. Practical Projects
Apply your knowledge through hands-on projects:
Start with simple projects like linear regression or classification tasks using datasets from platforms like Kaggle.
Gradually move to more complex projects involving neural networks or natural language processing.
4. Online Courses and Resources
Utilize online platforms that offer structured courses:
Websites like Coursera, edX, or Udacity provide courses specifically focused on Python for AI/ML.
YouTube channels dedicated to programming can also be valuable resources.
5. Engage with the Community
Join forums like Stack Overflow or Reddit communities focused on Python and AI:
Participate in discussions or seek help when needed.
Collaborate on open-source projects or contribute to GitHub repositories related to AI.
6. Continuous Learning
AI is a rapidly evolving field; therefore:
Stay updated with the latest trends by following relevant blogs or research papers.
Attend workshops or webinars focusing on advancements in AI technologies.
By following this structured approach, you can build a solid foundation in Python that will serve you well in your journey into artificial intelligence and machine learning.
0 notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
From Algorithms to Ethics: Unraveling the Threads of Data Science Education
In the rapidly advancing realm of data science, the curriculum serves as a dynamic tapestry, interweaving diverse threads to provide learners with a comprehensive understanding of data analysis, machine learning, and statistical modeling. Choosing the Best Data Science Institute can further accelerate your journey into this thriving industry. This educational journey is a fascinating exploration of the multifaceted facets that constitute the heart of data science education.

1. Mathematics and Statistics Fundamentals:
The journey begins with a deep dive into the foundational principles of mathematics and statistics. Linear algebra, probability theory, and statistical methods emerge as the bedrock upon which the entire data science edifice is constructed. Learners navigate the intricate landscape of mathematical concepts, honing their analytical skills to decipher complex datasets with precision.
2. Programming Proficiency:
A pivotal thread in the educational tapestry is the acquisition of programming proficiency. The curriculum places a significant emphasis on mastering programming languages such as Python or R, recognizing them as indispensable tools for implementing the intricate algorithms that drive the field of data science. Learners cultivate the skills necessary to translate theoretical concepts into actionable insights through hands-on coding experiences.
3. Data Cleaning and Preprocessing Techniques:
As data scientists embark on their educational voyage, they encounter the art of data cleaning and preprocessing. This phase involves mastering techniques for handling missing data, normalization, and the transformation of datasets. These skills are paramount to ensuring the integrity and reliability of data throughout the entire analysis process, underscoring the importance of meticulous data preparation.
4. Exploratory Data Analysis (EDA):
A vivid thread in the educational tapestry, exploratory data analysis (EDA) emerges as the artist's palette. Visualization tools and descriptive statistics become the brushstrokes, illuminating patterns and insights within datasets. This phase is not merely about crunching numbers but about understanding the story that the data tells, fostering a deeper connection between the analyst and the information at hand.
5. Machine Learning Algorithms:
The heartbeat of the curriculum pulsates with the study of machine learning algorithms. Learners traverse the expansive landscape of supervised learning, exploring regression and classification methodologies, and venture into the uncharted territories of unsupervised learning, unraveling the mysteries of clustering algorithms. This segment empowers aspiring data scientists with the skills needed to build intelligent models that can make predictions and uncover hidden patterns within data.
6. Real-world Application and Ethical Considerations:
As the educational journey nears its culmination, learners are tasked with applying their acquired knowledge to real-world scenarios. This application is guided by a strong ethical compass, with a keen awareness of the responsibilities that come with handling data. Graduates emerge not only as proficient data scientists but also as conscientious stewards of information, equipped to navigate the complex intersection of technology and ethics.

In essence, the data science curriculum is a meticulously crafted symphony, harmonizing mathematical rigor, technical acumen, and ethical mindfulness. The educational odyssey equips learners with a holistic skill set, preparing them to navigate the complexities of the digital age and contribute meaningfully to the ever-evolving field of data science. Choosing the best Data Science Courses in Chennai is a crucial step in acquiring the necessary expertise for a successful career in the evolving landscape of data science.
3 notes
·
View notes
Text
Mastering Methodologies and Technical Approaches in AI: Nik Shah’s Insightful Guide to AI System Development
Artificial Intelligence (AI) is a transformative technology that is reshaping the way we approach complex problems across industries. The foundation of successful AI development lies in adopting the right methodologies and technical approaches. Nik Shah, a thought leader in AI and technology, has shared his insights on the methodologies and strategies necessary to build powerful, efficient, and ethical AI systems.
In this article, we will explore Nik Shah’s methodologies and technical approaches in AI system development, delving into his unique problem-solving strategies and the importance of integrating structured frameworks into AI development. By examining Nik Shah’s work through articles like Methodologies and Technical Approaches in AI, Methodology in AI System Development, and Problem-Solving in AI System Development, we will uncover the key principles, strategies, and practices that can elevate AI system development to new heights.
Understanding AI Methodologies: The Foundation of Effective Development
AI development is a multi-faceted and highly complex process, and adopting a robust methodology is crucial for ensuring that AI systems are scalable, reliable, and ethical. Nik Shah emphasizes the importance of well-structured methodologies to guide the development process.
What Are AI Methodologies?
AI methodologies are structured approaches and processes that guide developers in creating AI systems. These methodologies provide the frameworks within which algorithms are designed, tested, and refined. Nik Shah underscores that successful AI systems are the result of a systematic approach that integrates both technical precision and innovative problem-solving.
AI methodologies typically include several key stages:
Problem Definition: Identifying the specific problem that the AI system aims to solve.
Data Collection and Preprocessing: Gathering relevant data and ensuring its quality for effective model training.
Model Selection and Training: Choosing the appropriate algorithms and training them on the data.
Model Evaluation: Assessing the performance of the model using various metrics to ensure it meets the desired objectives.
Deployment and Maintenance: Deploying the model in real-world environments and continuously monitoring its performance for improvement.
In his article, Methodologies and Technical Approaches in AI, Nik Shah explores the importance of each step in this cycle, emphasizing that a well-structured methodology ensures a streamlined process, leading to better efficiency, accuracy, and scalability.
Problem-Solving in AI System Development: A Core Principle
At the heart of AI system development lies the art of problem-solving. AI developers often face complex challenges that require creative and effective solutions. Nik Shah advocates for a strategic approach to problem-solving that integrates technical expertise with a mindset of innovation and adaptability.
The Role of Problem-Solving in AI Development
AI systems are designed to solve specific problems, from predicting outcomes and analyzing data to automating tasks and providing intelligent insights. However, the development process is rarely smooth, and developers must constantly address challenges, such as:
Algorithmic limitations: AI models can encounter biases or inaccuracies based on the data they are trained on.
Scalability issues: As AI systems are deployed to handle larger datasets or more complex tasks, performance may degrade.
Ethical considerations: AI systems must be designed with ethics in mind, addressing concerns related to bias, fairness, and privacy.
In his article Problem-Solving in AI System Development, Nik Shah outlines strategies for overcoming these challenges. Some of these strategies include:
Iterative Testing and Debugging: Continuously testing the system and debugging issues helps identify weaknesses early in the development process.
Collaboration and Teamwork: AI development benefits from collaboration between experts in different domains (e.g., data scientists, engineers, and ethicists), enabling more holistic problem-solving.
Adapting to New Data: AI systems should be flexible enough to adapt to new data and evolving requirements, ensuring that the model remains effective over time.
Problem-solving is not a one-time task in AI development; rather, it is an ongoing process that requires developers to remain adaptable, creative, and focused on continuous improvement.
The Methodology Behind AI System Development: A Structured Approach
Nik Shah’s methodology for AI system development integrates both traditional and modern approaches to ensure that AI systems are both functional and ethical. In his article Methodology in AI System Development, Shah discusses a step-by-step framework that developers can use to streamline their approach.
Core Principles of Nik Shah’s Methodology
Clear Problem Definition: Defining the problem the AI system aims to solve is the first and most critical step. Without a clear understanding of the problem, it becomes challenging to design effective solutions.
Data Integrity: AI systems depend heavily on data. Ensuring that the data used is accurate, representative, and free from bias is essential for the model’s success.
Algorithm Selection: Choosing the right algorithm for the specific problem at hand is critical. Whether it’s a supervised learning approach, reinforcement learning, or unsupervised learning, the methodology must be flexible and adaptable to different situations.
Evaluation and Refinement: Once the AI system is developed, evaluation is key to understanding how well it meets the required objectives. Metrics such as accuracy, precision, recall, and F1 score are used to measure the model's performance.
By following this systematic approach, AI developers can ensure that their systems are optimized for both functionality and scalability.
Addressing Cognitive Biases and Heuristics in AI
One of the critical challenges in AI system development is managing cognitive biases and heuristics that may affect both the design and execution of AI models. Nik Shah addresses these challenges in his article Cognitive Biases and Heuristics in AI System, where he highlights the risks that cognitive biases can introduce into AI development and how developers can minimize them.
Cognitive Biases and Heuristics in AI
Cognitive biases refer to systematic patterns of deviation from rational thinking that can influence decision-making. In AI development, these biases can manifest in several ways, such as:
Data selection bias: Choosing data that supports a preconceived notion or hypothesis, while ignoring contradictory data.
Confirmation bias: Favoring data that confirms an existing belief, which can skew results and reduce the accuracy of AI models.
Overfitting: Tuning AI models too closely to training data, leading to poor performance on new, unseen data.
Nik Shah advocates for strategies that address cognitive biases, such as:
Random Sampling: To reduce selection bias, AI developers should use random sampling techniques that ensure the data is representative of the problem space.
Cross-validation: Using cross-validation techniques ensures that the model’s performance is not overly reliant on a single data set, thus minimizing overfitting.
Transparency in Model Building: Openly documenting the choices made during the model-building process helps identify potential sources of bias and improves the model’s trustworthiness.
By adopting these techniques, AI developers can reduce the impact of cognitive biases and ensure that their models remain as objective and reliable as possible.
Commitment to Excellence and Integrity in AI Development
AI system development is a complex and rigorous process that requires both commitment to excellence and integrity. Nik Shah stresses that AI systems should not only be efficient but also aligned with ethical standards and principles. In his articles, such as Integrity in AI System Development, Nik Shah emphasizes that developers must strive for high-quality, transparent, and ethical AI systems.
Upholding Integrity in AI Systems
Transparency: Being transparent about how AI systems are developed, including the data and models used, ensures that the system can be scrutinized and improved.
Accountability: AI developers must take responsibility for the systems they create, ensuring they do not inadvertently cause harm or perpetuate biases.
Ethical Considerations: Developers should ensure that AI systems align with societal values, such as fairness, privacy, and transparency.
By maintaining integrity and striving for excellence, AI developers can create systems that not only perform well but also foster trust and ensure that the technology is used responsibly.
Conclusion: Mastering AI System Development Through Methodology, Problem-Solving, and Integrity
Nik Shah’s methodology for AI system development provides a comprehensive framework for creating effective, reliable, and ethical AI systems. By focusing on methodologies, problem-solving, cognitive biases, and commitment to excellence, developers can build AI solutions that meet both technical and ethical standards.
For a deeper dive into Nik Shah’s approach, explore his articles such as Methodologies and Technical Approaches in AI, Methodology in AI System Development, and Problem-Solving in AI System Development. These articles offer valuable insights for anyone looking to develop AI systems that are not only innovative and efficient but also ethical, responsible, and aligned with human values. By adopting Nik Shah’s strategies, AI developers can build systems that have a lasting, positive impact on society.
References
Coursera. (n.d.). Practical methodology and ethics in AI. Coursera. Retrieved February 11, 2025, from https://www.coursera.org/learn/practical-methodology-and-ethics-in-ai
TutorialsPoint. (n.d.). Mastering artificial intelligence. TutorialsPoint. Retrieved February 11, 2025, from https://www.tutorialspoint.com/course/mastering-artificial-intelligence/index.asp
Geeky Gadgets. (2023, August 20). How to learn AI in 2025. Geeky Gadgets. Retrieved February 11, 2025, from https://www.geeky-gadgets.com/how-to-learn-ai-in-2025/
AI Disruption. (2023, October 15). Mastering advanced AI: A clear roadmap for aspiring innovators. Medium. Retrieved February 11, 2025, from https://medium.com/ai-disruption/mastering-advanced-ai-a-clear-roadmap-for-aspiring-innovators-7c16046c9f93
Kaur, S. (2023). AI unleashed: A holistic guide to mastering artificial intelligence. AI Unleashed. Google Books. https://books.google.com/books/about/AI_Unleashed_A_Holistic_Guide_to_Masteri.html?id=xFfUEAAAQBAJ
Digiquation. (2023). AI mastery guide for technologists. Digiquation. Retrieved February 11, 2025, from https://digiquation.io/articles/ai-mastery-guide-for-technologists/
MIT Professional Education. (2023). AI strategies and roadmap: Brochure 2024. MIT Professional Education. Retrieved February 11, 2025, from https://professional.mit.edu/sites/default/files/2023-12/MITPE-AiStrategiesAndRoadmap-Brochure-2024-NoDates-Web.pdf
MIT Professional Education. (2023). AI strategies and roadmap: Course schedule. MIT Professional Education. Retrieved February 11, 2025, from https://professional.mit.edu/sites/default/files/course-schedules/AI%20Strategies%20and%20Roadmap.pdf
Pagol.AI. (2023). Mastering AI techniques: A comprehensive guide to artificial intelligence. Pagol.AI. Retrieved February 11, 2025, from https://blog.pagol.ai/mastering-ai-techniques-a-comprehensive-guide-to-artificial-intelligence/
Social Media
LinkTree | EverybodyWiki | WikiTree | LinkedIn | Substack | TikTok | Twitter | X | Pinterest | Vimeo | Facebook | Instagram | GitHub | Quora | SoundCloud | Twitch | Flickr | Threads | Archive.org | Stack Overflow | Daily Dev | BlueSky App | Medium | Hashnode | Tumblr | Issuu
Contributing Authors
Nanthaphon Yingyongsuk | Sean Shah | Gulab Mirchandani | Darshan Shah | Kranti Shah | John DeMinico | Rajeev Chabria | Francis Wesley | Sony Shah | Dilip Mirchandani | Nattanai Yingyongsuk | Subun Yingyongsuk | Theeraphat Yingyongsuk | Saksid Yingyongsuk
#nik shah#artificial intelligence#nikhil pankaj shah#claude#watson#chatgpt#grok#gemini#nikhil shah#xai
0 notes
Text
Python Libraries and Their Relevance: The Power of Programming
Python has emerged as one of the most popular programming languages due to its simplicity, versatility, and an extensive collection of libraries that make coding easier and more efficient. Whether you are a beginner or an experienced developer, Python’s libraries help you streamline processes, automate tasks, and implement complex functionalities with minimal effort. If you are looking for the best course to learn Python and its libraries, understanding their importance can help you make an informed decision. In this blog, we will explore the significance of Python libraries and their applications in various domains.
Understanding Python Libraries
A Python library is a collection of modules and functions that simplify coding by providing pre-written code snippets. Instead of writing everything from scratch, developers can leverage these libraries to speed up development and ensure efficiency. Python libraries cater to diverse fields, including data science, artificial intelligence, web development, automation, and more.
Top Python Libraries and Their Applications
1. NumPy (Numerical Python)
NumPy is a fundamental library for numerical computing in Python. It provides support for multi-dimensional arrays, mathematical functions, linear algebra, and more. It is widely used in data analysis, scientific computing, and machine learning.
Relevance:
Efficient handling of large datasets
Used in AI and ML applications
Provides powerful mathematical functions
2. Pandas
Pandas is an essential library for data manipulation and analysis. It provides data structures like DataFrame and Series, making it easy to analyze, clean, and process structured data.
Relevance:
Data preprocessing in machine learning
Handling large datasets efficiently
Time-series analysis
3. Matplotlib and Seaborn
Matplotlib is a plotting library used for data visualization, while Seaborn is built on top of Matplotlib, offering advanced visualizations with attractive themes.
Relevance:
Creating meaningful data visualizations
Statistical data representation
Useful in exploratory data analysis (EDA)
4. Scikit-Learn
Scikit-Learn is one of the most popular libraries for machine learning. It provides tools for data mining, analysis, and predictive modeling.
Relevance:
Implementing ML algorithms with ease
Classification, regression, and clustering techniques
Model evaluation and validation
5. TensorFlow and PyTorch
These are the leading deep learning libraries. TensorFlow, developed by Google, and PyTorch, developed by Facebook, offer powerful tools for building and training deep neural networks.
Relevance:
Used in artificial intelligence and deep learning
Supports large-scale machine learning applications
Provides flexibility in model building
6. Requests
The Requests library simplifies working with HTTP requests in Python. It is widely used for web scraping and API integration.
Relevance:
Fetching data from web sources
Simplifying API interactions
Automating web-based tasks
7. BeautifulSoup
BeautifulSoup is a library used for web scraping and extracting information from HTML and XML files.
Relevance:
Extracting data from websites
Web scraping for research and automation
Helps in SEO analysis and market research
8. Flask and Django
Flask and Django are web development frameworks used for building dynamic web applications.
Relevance:
Flask is lightweight and best suited for small projects
Django is a full-fledged framework used for large-scale applications
Both frameworks support secure and scalable web development
9. OpenCV
OpenCV (Open Source Computer Vision Library) is widely used for image processing and computer vision tasks.
Relevance:
Face recognition and object detection
Image and video analysis
Used in robotics and AI-driven applications
10. PyGame
PyGame is used for game development and creating multimedia applications.
Relevance:
Developing interactive games
Building animations and simulations
Used in educational game development
Why Python Libraries Are Important?
Python libraries provide ready-to-use functions, making programming more efficient and less time-consuming. Here’s why they are crucial:
Time-Saving: Reduces the need for writing extensive code.
Optimized Performance: Many libraries are optimized for speed and efficiency.
Wide Community Support: Popular libraries have strong developer communities, ensuring regular updates and bug fixes.
Cross-Domain Usage: From AI to web development, Python libraries cater to multiple domains.
Enhances Learning Curve: Learning libraries simplifies the transition from beginner to expert in Python programming.
ConclusionPython libraries have revolutionized the way developers work, making programming more accessible and efficient. Whether you are looking for data science, AI, web development, or automation, Python libraries provide the tools needed to excel. If you aspire to become a skilled Python developer, investing in the best course can give you the competitive edge required in today’s job market. Start your learning journey today and use the full potential of Python programming.
0 notes