#data warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Highlighting the importance of finance and business analytics in corporate finance

How finance and business analytics revolutionize corporate finance
In the fast-paced business world, finance and business analytics have become essential tools for empowering corporate finance teams. These capabilities go beyond traditional financial management, offering actionable insights that shape strategic decisions, enhance efficiency, and fuel growth.
The Role of Business Analytics
Business analytics leverages data, statistical models, and technology to optimize financial processes. It transforms decision-making by enabling finance teams to rely on real-time insights rather than outdated reports. This data-driven approach improves forecasting accuracy, cost management, and risk mitigation. By analyzing patterns and trends, finance professionals can anticipate challenges and devise proactive strategies.
Transformative Impact on Corporate Finance
The integration of analytics into corporate finance processes elevates performance. For example, automation accelerates reporting, reduces stress, and enhances decision-making. Case studies demonstrate how companies can generate reports within minutes, streamline reconciliations, and improve cash flow management. Additionally, features like version control and audit trails ensure accuracy, accountability, and transparency in planning processes.
Driving Strategic Value
Finance and business analytics enable organizations to identify profitable investments, reduce inefficiencies, and align financial strategies with business goals. Tools like financial consolidation software simplify complex processes, allowing finance teams to focus on long-term growth and resilience.
By harnessing analytics, corporate finance evolves into a strategic powerhouse, equipping organizations to thrive in a competitive market.
To read the full article visit our website by clicking here
#business intelligence software#bi tool#bisolution#business intelligence#business solutions#businessintelligence#bicxo#data#businessefficiency#data warehouse#software#software services#epm software#gst software#analytics#services#mumbai#india
0 notes
Text
Uncover the differences between Data Warehouse and Data Mart through our in-depth comparison. Explore into their setups, data sources, focuses, and decision-making capabilities to optimize your data management strategy.
0 notes
Text
Maximize Your Business Intelligence with Big Data Warehousing
youtube
0 notes
Text
Best Practices for a Smooth Data Warehouse Migration to Amazon Redshift
In the era of big data, many organizations find themselves outgrowing traditional on-premise data warehouses. Moving to a scalable, cloud-based solution like Amazon Redshift is an attractive solution for companies looking to improve performance, cut costs, and gain flexibility in their data operations. However, data warehouse migration to AWS, particularly to Amazon Redshift, can be complex, involving careful planning and precise execution to ensure a smooth transition. In this article, we’ll explore best practices for a seamless Redshift migration, covering essential steps from planning to optimization.
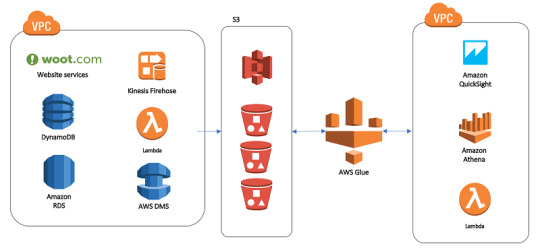
1. Establish Clear Objectives for Migration
Before diving into the technical process, it’s essential to define clear objectives for your data warehouse migration to AWS. Are you primarily looking to improve performance, reduce operational costs, or increase scalability? Understanding the ‘why’ behind your migration will help guide the entire process, from the tools you select to the migration approach.
For instance, if your main goal is to reduce costs, you’ll want to explore Amazon Redshift’s pay-as-you-go model or even Reserved Instances for predictable workloads. On the other hand, if performance is your focus, configuring the right nodes and optimizing queries will become a priority.
2. Assess and Prepare Your Data
Data assessment is a critical step in ensuring that your Redshift data warehouse can support your needs post-migration. Start by categorizing your data to determine what should be migrated and what can be archived or discarded. AWS provides tools like the AWS Schema Conversion Tool (SCT), which helps assess and convert your existing data schema for compatibility with Amazon Redshift.
For structured data that fits into Redshift’s SQL-based architecture, SCT can automatically convert schema from various sources, including Oracle and SQL Server, into a Redshift-compatible format. However, data with more complex structures might require custom ETL (Extract, Transform, Load) processes to maintain data integrity.
3. Choose the Right Migration Strategy
Amazon Redshift offers several migration strategies, each suited to different scenarios:
Lift and Shift: This approach involves migrating your data with minimal adjustments. It’s quick but may require optimization post-migration to achieve the best performance.
Re-architecting for Redshift: This strategy involves redesigning data models to leverage Redshift’s capabilities, such as columnar storage and distribution keys. Although more complex, it ensures optimal performance and scalability.
Hybrid Migration: In some cases, you may choose to keep certain workloads on-premises while migrating only specific data to Redshift. This strategy can help reduce risk and maintain critical workloads while testing Redshift’s performance.
Each strategy has its pros and cons, and selecting the best one depends on your unique business needs and resources. For a fast-tracked, low-cost migration, lift-and-shift works well, while those seeking high-performance gains should consider re-architecting.
4. Leverage Amazon’s Native Tools
Amazon Redshift provides a suite of tools that streamline and enhance the migration process:
AWS Database Migration Service (DMS): This service facilitates seamless data migration by enabling continuous data replication with minimal downtime. It’s particularly helpful for organizations that need to keep their data warehouse running during migration.
AWS Glue: Glue is a serverless data integration service that can help you prepare, transform, and load data into Redshift. It’s particularly valuable when dealing with unstructured or semi-structured data that needs to be transformed before migrating.
Using these tools allows for a smoother, more efficient migration while reducing the risk of data inconsistencies and downtime.
5. Optimize for Performance on Amazon Redshift
Once the migration is complete, it’s essential to take advantage of Redshift’s optimization features:
Use Sort and Distribution Keys: Redshift relies on distribution keys to define how data is stored across nodes. Selecting the right key can significantly improve query performance. Sort keys, on the other hand, help speed up query execution by reducing disk I/O.
Analyze and Tune Queries: Post-migration, analyze your queries to identify potential bottlenecks. Redshift’s query optimizer can help tune performance based on your specific workloads, reducing processing time for complex queries.
Compression and Encoding: Amazon Redshift offers automatic compression, reducing the size of your data and enhancing performance. Using columnar storage, Redshift efficiently compresses data, so be sure to implement optimal compression settings to save storage costs and boost query speed.
6. Plan for Security and Compliance
Data security and regulatory compliance are top priorities when migrating sensitive data to the cloud. Amazon Redshift includes various security features such as:
Data Encryption: Use encryption options, including encryption at rest using AWS Key Management Service (KMS) and encryption in transit with SSL, to protect your data during migration and beyond.
Access Control: Amazon Redshift supports AWS Identity and Access Management (IAM) roles, allowing you to define user permissions precisely, ensuring that only authorized personnel can access sensitive data.
Audit Logging: Redshift’s logging features provide transparency and traceability, allowing you to monitor all actions taken on your data warehouse. This helps meet compliance requirements and secures sensitive information.
7. Monitor and Adjust Post-Migration
Once the migration is complete, establish a monitoring routine to track the performance and health of your Redshift data warehouse. Amazon Redshift offers built-in monitoring features through Amazon CloudWatch, which can alert you to anomalies and allow for quick adjustments.
Additionally, be prepared to make adjustments as you observe user patterns and workloads. Regularly review your queries, data loads, and performance metrics, fine-tuning configurations as needed to maintain optimal performance.
Final Thoughts: Migrating to Amazon Redshift with Confidence
Migrating your data warehouse to Amazon Redshift can bring substantial advantages, but it requires careful planning, robust tools, and continuous optimization to unlock its full potential. By defining clear objectives, preparing your data, selecting the right migration strategy, and optimizing for performance, you can ensure a seamless transition to Redshift. Leveraging Amazon’s suite of tools and Redshift’s powerful features will empower your team to harness the full potential of a cloud-based data warehouse, boosting scalability, performance, and cost-efficiency.
Whether your goal is improved analytics or lower operating costs, following these best practices will help you make the most of your Amazon Redshift data warehouse, enabling your organization to thrive in a data-driven world.
#data warehouse migration to aws#redshift data warehouse#amazon redshift data warehouse#redshift migration#data warehouse to aws migration#data warehouse#aws migration
0 notes
Text
Role of AI in Building Data Warehouses

Discover how AI revolutionizes data warehousing by enhancing data integration, automation, quality control, security, and performance. Learn the key benefits of AI in transforming data storage and management.
0 notes
Text
Databricks vs. Snowflake: Key Differences Explained

What if businesses could overcome the challenges of data silos, slow query performance, and limited real-time analytics? Well, it's a reality now, as data cloud platforms like Databricks and Snowflake have transformed how organizations manage and analyze their data.
Founded in 2012, Snowflake emerged from the expertise of data warehousing professionals, establishing itself as a SQL-centric solution for modern data needs. In contrast, Databricks, launched shortly after in 2013, originated from the creators of Apache Spark, positioning itself as a managed service for big data processing and machine learning.

Scroll ahead to discover everything about these platforms and opt for the best option.
Benefits of Databricks and Snowflake
Here are the benefits that you can enjoy with Databricks:
It has been tailored for data science and machine learning workloads.
It supports complex data transformations and real-time analytics.
It adapts to the needs of data engineers and scientists.
It enables teams to work together on projects, enhancing innovation and efficiency.
It allows for immediate insights and data-driven decision-making.
In contrast, here are the benefits you can experience with Snowflake:
It is ideal for organizations focused on business intelligence and analytics.
It helps with storage and the compute resources can be scaled separately, ensuring optimal performance.
It efficiently handles large volumes of data without performance issues.
It is easy to use for both technical and non-technical users, promoting widespread adoption.
It offers a wide range of functionalities to support various industry needs.
Note: Visit their website to learn more about the pricing of Databricks and Snowflake.
Now, let’s compare each of the platforms based on various use cases/features.
Databricks vs. Snowflake: Comparison of Essential Features
When comparing essential features, several use cases highlight the differences between Databricks and Snowflake. Here are the top four factors that will provide clarity on each platform's strengths and capabilities:
1. Data Ingestion: Snowflake utilizes the ‘COPY INTO’ command for data loading, often relying on third-party tools for ingestion. In contrast, Databricks enables direct interaction with data in cloud storage, providing more flexibility in handling various data formats.
2. Data Transformation: Snowflake predominantly uses SQL for data transformations, while Databricks leverages Spark, allowing for more extensive customization and the ability to handle massive datasets effectively.
3. Machine Learning: Databricks boasts of a mature ecosystem for machine learning with features like MLflow and model serving. On the other hand, Snowflake is catching up with the introduction of Snowpark, allowing users to run machine learning models within its environment.
4. Data Governance: Snowflake provides extensive metadata and cost management features, while Databricks offers a robust data catalog through its Unity Catalog (it is still developing its cost management capabilities).
In a nutshell, both Databricks and Snowflake have carved their niches in the data cloud landscape, each with its unique capabilities. As both platforms continue to evolve and expand their feature sets, the above read will help businesses make informed decisions to optimize their data strategies and achieve greater insights.
Feel free to share this microblog with your network and connect with us at Nitor Infotech to elevate your business through cutting-edge technologies.
#data bricks#data warehouse#database warehousing#data lake#snowflake data#software development#snowflake pricing#snowflake#software engineering#blog#software services#artificial intelligence
0 notes
Text
Elevate your data management with top-tier Data Warehouse Solutions. Tailored tools to refine your data strategy and drive business growth
0 notes
Text
No! Your Most Used Data Isn't (Always) Your Most Valuable
Is your most used data set masking the real goldmine? This blog explores why familiar data may not be the most valuable, and how a data marketplace can empower users with a wider range of sources for deeper insights. #datademocratisation #datamarketplace
IntroductionThe Cost of ConvenienceThe Data Marketplace AdvantageBuilding a Data-Driven Oasis Introduction In the world of data warehouses and data catalogs, there’s a curious phenomenon. becomes the de facto “go-to” source, even if it’s not the perfect fit for every analysis. There’s a logic to this – data engineers have built pipelines, users are familiar with the format, and it offers a…
0 notes
Text

Data Warehouse Consulting: Achieve Maximum ROI Without Overspending
We ensure that businesses can effectively manage their vast amounts of data while extracting maximum value from it. Through our tailored solutions, we empower organizations to build flexible and secure data warehousing systems that cater to their unique needs and requirements.
0 notes
Text
Why business analysis in finance is crucial for today’s corporate success

Harnessing finance and business analytics for corporate growth
In today's dynamic business landscape, finance and business analytics are reshaping corporate finance into a strategic powerhouse. Beyond traditional functions like cash flow management and reporting, modern tools such as financial consolidation software are revolutionizing how companies approach decision-making and performance optimization.
Business analytics is pivotal in enabling finance teams to make data-driven decisions, enhancing accuracy and efficiency. With real-time data insights, teams can predict trends, manage risks, and optimize resources effectively. Advanced analytics also supports precise financial forecasting, aiding in cash flow predictions, resource allocation, and risk mitigation. Moreover, it empowers organizations to measure performance, track KPIs, and control costs all essential for maintaining financial health in a competitive market.
A prime example of this transformation is BiCXO’s financial consolidation software. By automating reporting and reconciliation processes, BiCXO has empowered companies to generate real-time financial insights, saving weeks of manual effort and delivering a significant return on investment. With a remarkable 340% ROI and enhanced decision-making agility, BiCXO demonstrates the power of analytics-driven finance. The integration of business analytics with financial consolidation software is no longer optional it is essential for achieving sustainable growth and navigating today’s complex financial landscape. Explore how these tools can transform your business.
To read the full article visit our website by clicking here
#business intelligence software#business intelligence#bi tool#business solutions#businessintelligence#bisolution#bicxo#data#businessefficiency#data warehouse#software#epm software#software services#analytics#services#mumbai#india
0 notes
Text
This blog is about how to implement a data warehouse , its components, benefits, best practices, resources required, and more.
0 notes
Text
0 notes
Text
Critical Differences: Between Database vs Data Warehouse
Summary: This blog explores the differences between databases and data warehouses, highlighting their unique features, uses, and benefits. By understanding these distinctions, you can select the optimal data management solution to support your organisation’s goals and leverage cloud-based options for enhanced scalability and efficiency.

Introduction
Effective data management is crucial for organisational success in today's data-driven world. Understanding the concepts of databases and data warehouses is essential for optimising data use. Databases store and manage transactional data efficiently, while data warehouses aggregate and analyse large volumes of data for strategic insights.
This blog aims to clarify the critical differences between databases and data warehouses, helping you decide which solution best fits your needs. By exploring "database vs. data warehouse," you'll gain valuable insights into their distinct roles, ensuring your data infrastructure effectively supports your business objectives.
What is a Database?
A database is a structured collection of data that allows for efficient storage, retrieval, and management of information. It is designed to handle large volumes of data and support multiple users simultaneously.
Databases provide a systematic way to organise, manage, and retrieve data, ensuring consistency and accuracy. Their primary purpose is to store data that can be easily accessed, manipulated, and updated, making them a cornerstone of modern data management.
Common Uses and Applications
Databases are integral to various applications across different industries. Businesses use databases to manage customer information, track sales and inventory, and support transactional processes.
In the healthcare sector, databases store patient records, medical histories, and treatment plans. Educational institutions use databases to manage student information, course registrations, and academic records.
E-commerce platforms use databases to handle product catalogues, customer orders, and payment information. Databases also play a crucial role in financial services, telecommunications, and government operations, providing the backbone for data-driven decision-making and efficient operations.
Types of Databases
Knowing about different types of databases is crucial for making informed decisions in data management. Each type offers unique features for specific tasks. There are several types of databases, each designed to meet particular needs and requirements.
Relational Databases
Relational databases organise data into tables with rows and columns, using structured query language (SQL) for data manipulation. They are highly effective for handling structured data and maintaining relationships between different data entities. Examples include MySQL, PostgreSQL, and Oracle.
NoSQL Databases
NoSQL databases are designed to handle unstructured and semi-structured data, providing flexibility in data modelling. They are ideal for high scalability and performance applications like social media and big data. Types of NoSQL databases include:
Document databases (e.g., MongoDB).
Key-value stores (e.g., Redis).
Column-family stores (e.g., Cassandra).
Graph databases (e.g., Neo4j).
In-Memory Databases
In-memory databases store data in the main memory (RAM) rather than on disk, enabling high-speed data access and processing. They are suitable for real-time applications that require low-latency data retrieval, such as caching and real-time analytics. Examples include Redis and Memcached.
NewSQL Databases
NewSQL databases aim to provide the scalability of NoSQL databases while maintaining the ACID (Atomicity, Consistency, Isolation, Durability) properties of traditional relational databases. They are used in applications that require high transaction throughput and firm consistency. Examples include Google Spanner and CockroachDB.
Examples of Database Management Systems (DBMS)
Understanding examples of Database Management Systems (DBMS) is essential for selecting the right tool for your data needs. DBMS solutions offer varied features and capabilities, ensuring better performance, security, and integrity across diverse applications. Some common examples of Database Management Systems (DBMS) are:
MySQL
MySQL is an open-source relational database management system known for its reliability, performance, and ease of use. It is widely used in web applications, including popular platforms like WordPress and Joomla.
PostgreSQL
PostgreSQL is an advanced open-source relational database system that supports SQL and NoSQL data models. It is known for its robustness, extensibility, and standards compliance, making it suitable for complex applications.
MongoDB
MongoDB is a leading NoSQL database that stores data in flexible, JSON-like documents. It is designed for scalability and performance, making it a popular choice for modern applications that handle large volumes of unstructured data.
Databases form the foundation of data management in various domains, offering diverse solutions to meet specific data storage and retrieval needs. By understanding the different types of databases and their applications, organisations can choose the proper database technology to support their operations.
Read More: What are Attributes in DBMS and Its Types?
What is a Data Warehouse?
A data warehouse is a centralised repository designed to store, manage, and analyse large volumes of data. It consolidates data from various sources, enabling organisations to make informed decisions through comprehensive data analysis and reporting.
A data warehouse is a specialised system optimised for query and analysis rather than transaction processing. It is structured to enable efficient data retrieval and analysis, supporting business intelligence activities. The primary purpose of a data warehouse is to provide a unified, consistent data source for analytical reporting and decision-making.
Common Uses and Applications
Data warehouses are commonly used in various industries to enhance decision-making processes. Businesses use them to analyse historical data, generate reports, and identify trends and patterns. Applications include sales forecasting, financial analysis, customer behaviour, and performance tracking.
Organisations leverage data warehouses to gain insights into operations, streamline processes, and drive strategic initiatives. By integrating data from different departments, data warehouses enable a holistic view of business performance, supporting comprehensive analytics and business intelligence.
Key Features of Data Warehouses
Data warehouses offer several key features that distinguish them from traditional databases. These features make data warehouses ideal for supporting complex queries and large-scale data analysis, providing organisations with the tools for in-depth insights and informed decision-making. These features include:
Data Integration: Data warehouses consolidate data from multiple sources, ensuring consistency and accuracy.
Scalability: They are designed to handle large volumes of data and scale efficiently as data grows.
Data Transformation: ETL (Extract, Transform, Load) processes clean and organise data, preparing it for analysis.
Performance Optimisation: Data warehouses enhance query performance using indexing, partitioning, and parallel processing.
Historical Data Storage: They store historical data, enabling trend analysis and long-term reporting.
Read Blog: Top ETL Tools: Unveiling the Best Solutions for Data Integration.
Examples of Data Warehousing Solutions
Several data warehousing solutions stand out in the industry, offering unique capabilities and advantages. These solutions help organisations manage and analyse data more effectively, driving better business outcomes through robust analytics and reporting capabilities. Prominent examples include:
Amazon Redshift
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It is designed to handle complex queries and large datasets, providing fast query performance and easy scalability.
Google BigQuery
Google BigQuery is a serverless, highly scalable, cost-effective multi-cloud data warehouse that enables super-fast SQL queries using the processing power of Google's infrastructure.
Snowflake
Snowflake is a cloud data platform that provides data warehousing, data lakes, and data sharing capabilities. It is known for its scalability, performance, and ability to handle diverse data workloads.
Key Differences Between Databases and Data Warehouses
Understanding the distinctions between databases and data warehouses is crucial for selecting the right data management solution. This comparison will help you grasp their unique features, use cases, and data-handling methods.

Databases and data warehouses serve distinct purposes in data management. While databases handle transactional data and support real-time operations, data warehouses are indispensable for advanced data analysis and business intelligence. Understanding these key differences will enable you to choose the right solution based on your specific data needs and goals.
Choosing Between a Database and a Data Warehouse

Several critical factors should guide your decision-making process when deciding between a database and a data warehouse. These factors revolve around the nature, intended use, volume, and complexity of data, as well as specific use case scenarios and cost implications.
Nature of the Data
First and foremost, consider the inherent nature of your data. Suppose you focus on managing transactional data with frequent updates and real-time access requirements. In that case, a traditional database excels in this operational environment.
On the other hand, a data warehouse is more suitable if your data consists of vast historical records and complex data models and is intended for analytical processing to derive insights.
Intended Use: Operational vs. Analytical
The intended use of the data plays a pivotal role in determining the appropriate solution. Operational databases are optimised for transactional processing, ensuring quick and efficient data manipulation and retrieval.
Conversely, data warehouses are designed for analytical purposes, facilitating complex queries and data aggregation across disparate sources for business intelligence and decision-making.
Volume and Complexity of Data
Consider the scale and intricacy of your data. Databases are adept at handling moderate to high volumes of structured data with straightforward relationships. In contrast, data warehouses excel in managing vast amounts of both structured and unstructured data, often denormalised for faster query performance and analysis.
Use Case Scenarios
Knowing when to employ each solution is crucial. Use a database when real-time data processing and transactional integrity are paramount, such as in e-commerce platforms or customer relationship management systems. Opt for a data warehouse when conducting historical trend analysis, business forecasting, or consolidating data from multiple sources for comprehensive reporting.
Cost Considerations
Finally, weigh the financial aspects of your decision. Databases typically involve lower initial setup costs and are easier to scale incrementally. In contrast, data warehouses may require more substantial upfront investments due to their complex infrastructure and storage requirements.
To accommodate your budgetary constraints, factor in long-term operational costs, including maintenance, storage, and data processing fees.
By carefully evaluating these factors, you can confidently select the database or data warehouse solution that best aligns with your organisation's specific needs and strategic objectives.
Cloud Databases and Data Warehouses
Cloud-based solutions have revolutionised data management by offering scalable, flexible, and cost-effective alternatives to traditional on-premises systems. Here's an overview of how cloud databases and data warehouses transform modern data architectures.
Overview of Cloud-Based Solutions
Cloud databases and data warehouses leverage the infrastructure and services provided by cloud providers like AWS, Google Cloud, and Microsoft Azure. They eliminate the need for physical hardware and offer pay-as-you-go pricing models, making them ideal for organisations seeking agility and scalability.
Advantages of Cloud Databases and Data Warehouses
The primary advantages include scalability to handle fluctuating workloads, reduced operational costs by outsourcing maintenance and updates to the cloud provider and enhanced accessibility for remote teams. Cloud solutions facilitate seamless integration with other cloud services and tools, promoting collaboration and innovation.
Popular Cloud Providers and Services
Leading providers such as AWS with Amazon RDS and Google Cloud's Cloud SQL offer managed database services supporting engines like MySQL, PostgreSQL, and SQL Server. For data warehouses, options like AWS Redshift, Google BigQuery, and Azure Synapse Analytics provide powerful analytical capabilities with elastic scaling and high performance.
Security and Compliance Considerations
Despite the advantages, security remains a critical consideration. Cloud providers implement robust security measures, including encryption, access controls, and compliance certifications (e.g., SOC 2, GDPR, HIPAA).
Organisations must assess data residency requirements and ensure adherence to industry-specific regulations when migrating sensitive data to the cloud.
By embracing cloud databases and data warehouses, organisations can optimise data management, drive innovation, and gain competitive advantages in today's data-driven landscape.
Frequently Asked Questions
What is the main difference between a database and a data warehouse?
A database manages transactional data for real-time operations, supporting sales and inventory management activities. In contrast, a data warehouse aggregates and analyses large volumes of historical data, enabling strategic insights, comprehensive reporting, and business intelligence activities critical for informed decision-making.
When should I use a data warehouse over a database?
Use a data warehouse when your primary goal is to conduct historical data analysis, generate complex queries, and create comprehensive reports. A data warehouse is ideal for business intelligence, trend analysis, and strategic planning, consolidating data from multiple sources for a unified, insightful view of your operations.
How do cloud databases and data warehouses benefit organisations?
Cloud databases and data warehouses provide significant advantages, including scalability to handle varying workloads, reduced operational costs due to outsourced maintenance, and enhanced accessibility for remote teams. They integrate seamlessly with other cloud services, promoting collaboration, innovation, and data management and analysis efficiency.
Conclusion
Understanding the critical differences between databases and data warehouses is essential for effective data management. Databases excel in handling transactional data, ensuring real-time updates and operational efficiency.
In contrast, data warehouses are designed for in-depth analysis, enabling strategic decision-making through comprehensive data aggregation. You can choose the solution that best aligns with your organisation's needs by carefully evaluating factors like data nature, intended use, volume, and cost.
Embracing cloud-based options further enhances scalability and flexibility, driving innovation and competitive advantage in today’s data-driven world. Choose wisely to optimise your data infrastructure and achieve your business objectives.
#Differences Between Database and Data Warehouse#Database vs Data Warehouse#Database#Data Warehouse#data management#data analytics#data storage#data science#pickl.ai#data analyst
0 notes
Text
Reasons to Leverage Data Warehouse Automation

Enhance productivity, boost data quality, and unlock data-driven insights with Data Warehouse Automation. Automate repetitive tasks and scale your data infrastructure effortlessly, helping your business thrive in today’s competitive landscape.
0 notes
Text
Data Lake vs Data Warehouse: 10 Key difference

Today, we are living in a time where we need to manage a vast amount of data. In today's data management world, the growing concepts of data warehouse and data lake have often been a major part of the discussions. We are mainly looking forward to finding the merits and demerits to find out the details. Undeniably, both serve as the repository for storing data, but there are fundamental differences in capabilities, purposes and architecture.
Hence, in this blog, we will completely pay attention to data lake vs data warehouse to help you understand and choose effectively.
We will mainly discuss the 10 major differences between data lakes and data warehouses to make the best choice.
Data variety: In terms of data variety, data lake can easily accommodate the diverse data types, which include semi-structured, structured, and unstructured data in the native format without any predefined schema. It can include data like videos, documents, media streams, data and a lot more. On the contrary, a data warehouse can store structured data which has been properly modelled and organized for specific use cases. Structured data can be referred to as the data that confirms the predefined schema and makes it suitable for traditional relational databases. The ability to accommodate diversified data types makes data lakes much more accessible and easier.
Processing approach: When it is about the data processing, data lakes follow a schema-on-read approach. Hence, it can ingest raw data on its lake without the need for structuring or modelling. It allows users to apply specific structures to the data while analyzing and, therefore, offers better agility and flexibility. However, for data warehouse, in terms of processing approach, data modelling is performed prior to ingestion, followed by a schema-on-write approach. Hence, it requires data to be formatted and structured as per the predefined schemes before being loaded into the warehouse.
Storage cost: When it comes to data cost, Data Lakes offers a cost-effective storage solution as it generally leverages open-source technology. The distributed nature and the use of unexpected storage infrastructure can reduce the overall storage cost even when organizations are required to deal with large data volumes. Compared to it, data warehouses include higher storage costs because of their proprietary technologies and structured nature. The rigid indexing and schema mechanism employed in the warehouse results in increased storage requirements along with other expenses.
Agility: Data lakes provide improved agility and flexibility because they do not have a rigid data warehouse structure. Data scientists and developers can seamlessly configure and configure queries, applications and models, which enables rapid experimentation. On the contrary, Data warehouses are known for their rigid structure, which is why adaptation and modification are time-consuming. Any changes in the data model or schema would require significant coordination, time and effort in different business processes.
Security: When it is about data lakes, security is continuously evolving as big data technologies are developing. However, you can remain assured that the enhanced data lake security can mitigate the risk of unauthorized access. Some enhanced security technology includes access control, compliance frameworks and encryption. On the other hand, the technologies used in data warehouses have been used for decades, which means that they have mature security features along with robust access control. However, the continuously evolving security protocols in data lakes make it even more robust in terms of security.
User accessibility: Data Lakes can cater to advanced analytical professionals and data scientists because of the unstructured and raw nature of data. While data lakes provide greater exploration capabilities and flexibility, it has specialized tools and skills for effective utilization. However, when it is about Data warehouses, these have been primarily targeted for analytic users and Business Intelligence with different levels of adoption throughout the organization.
Maturity: Data Lakes can be said to be a relatively new data warehouse that is continuously undergoing refinement and evolution. As organizations have started embracing big data technologies and exploring use cases, it can be expected that the maturity level has increased over time. In the coming years, it will be a prominent technology among organizations. However, even when data warehouses can be represented as a mature technology, the technology faces major issues with raw data processing.
Use cases: The data lake can be a good choice for processing different sorts of data from different sources, as well as for machine learning and analysis. It can help organizations analyze, store and ingest a huge volume of raw data from different sources. It also facilitates predictive models, real-time analytics and data discovery. Data warehouses, on the other hand, can be considered ideal for organizations with structured data analytics, predefined queries and reporting. It's a great choice for companies as it provides a centralized representative for historical data.
Integration: When it comes to data lake, it requires robust interoperability capability for processing, analyzing and ingesting data from different sources. Data pipelines and integration frameworks are commonly used for streamlining data, transformation, consumption and ingestion in the data lake environment. Data warehouse can be seamlessly integrated with the traditional reporting platforms, business intelligence, tools and data integration framework. These are being designed to support external applications and systems which enable data collaborations and sharing across the organization.
Complementarity: Data lakes complement data warehouse by properly and seamlessly accommodating different Data sources in their raw formats. It includes unstructured, semi-structured and structured data. It provides a cost-effective and scalable solution to analyze and store a huge volume of data with advanced capabilities like real-time analytics, predictive modelling and machine learning. The Data warehouse, on the other hand, is generally a complement transactional system as it provides a centralized representative for reporting and structured data analytics.
So, these are the basic differences between data warehouses and data lakes. Even when data warehouses and data lakes share a common goal, there are certain differences in terms of processing approach, security, agility, cost, architecture, integration, and so on. Organizations need to recognize the strengths and limitations before choosing the right repository to store their data assets. Organizations who are looking for a versatile centralized data repository which can be managed effectively without being heavy on your pocket, they can choose Data Lakes. The versatile nature of this technology makes it a great decision for organizations. If you need expertise and guidance on data management, experts in Hexaview Technologies will help you understand which one will suit your needs.
0 notes