#binomial data transfer
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
The "french kissing" of Cybertron
OK, this is some headcanon-level stuff, but loosely based on some canon stuff. Also it involves alien robot kissing and analogues.
In this previous post I had discussed the location of the hot spots/sparkfields and in doing so indicated that "Port Residua" was possibly located between Iacon and Nyon for reasons and I offhand-commented that Nyon was "Space Paris", while theorizing about why Port Residua might be called such.
(Nyon being Space Paris is not to be taken too literally, because Nyon is also simultaneously Space Athens and Space some-city-that-gets-destroyed. It's figuratively a place that had some revered and influential culture and political discourse, but also had its dark places and troubled times. But the idea is that French Hot Rod is not just a joke for the live-action movies and that bots from Nyon do have a regional culture and accent, just as bots from other city-states on Cybertron have their own recognizable accents and customs to other bots.)
OK, so remember "Port Residua" and that it's located in a culturally distinct region of Cybertron.
Now, do you know what "binomial data transfer" is? It's a kind of data transfer that bots can do which looks like kissing.
The mechanics of how Binomial Data Transfer works are not canon, but my headcanon concept for fics was that it works via some vestigial port that most bots have and which is located beneath the tongue/sensor nodule/glossa part in the mouth/intake part.
But here's the thing. It is a specific type of data port.
And it's there in bots even though Binomial Data Transfer isn't such a common thing in certain periods of Cybertronian history. Like, some bots don't even know why mouths would mash together, while others seem to.
It must be vestigial. Yes?
It's kinda functional but like some grandfather tech. Like, being legally mandated to receive AM band transmissions or something. A bot has this port in case another bot needs to mash their mouth into theirs to transmit end-of-life plans in a goodbye kiss as they go off to fight in the war.
It remains there. And it's a port.
Port Residua is possibly (your continuity may differ) along the coast of the Argon Sea.
But, what if Binomial Data Transfer was a more common practice there, near Nyon?
The 'remaining port' used to transfer plans regarding your wishes, requests and 'remains' to a bot you trust is associated with a region that itself is a port, a transfer area between gaseous sea, metal landforms, and liquid canals along which various storage yards and warehouses are located. (Headcanon: Eriel/Erial/Ariel is from Nyon and her spark came from Port Residua.)
Euphemistically to mash mouths and initiate Binomial Data Transfer is to "do it like bots in Nyon do".
Further headcanon: Hotlink is aromantic but fascinated with Binomial Data Transfer on a hardware basis. He's not romantically kissing a bot; he's experimenting with tech and taking samples, because tech is hot.
#transformers#maccadam#binomial data transfer#cybertronian worldbuilding#kissing#transformers worldbuilding
4 notes
·
View notes
Text
Bitstream giggled. "What are you reading?"
"It's not important." But maybe she knew. "What does it mean; 'binomial data transfer'?"
Bitstream laughed. "Not you, too? Hotlink went through a phase where he was obsessed with it."
"Hotlink did?" He had helped Thundercracker write the story.
"Yeah. It was my fault for mentioning it while I was researching. The idea that bots still have this...vestigial sensor in the mouth or intake when other types of port are considered standard, that there's this one example of backward compatibility for some reason, he kept questioning it."
"Why do we have it?"
Bitstream shook her head. "We don't exactly know."
"In math, binomial is an expression of two terms."
"Same in coding or in general."
"So, if someone says it's not a time for the transfer, it's not a time for kisses or relationships or combining?"
"I think that's an idiom. I've heard older bots say it; veterans. 'No time for binomial data transfer' means, 'I don't plan on dying tonight', or something like that."
"Yeah. I'm not sure I follow."
"The function of the transfer is that through contact at the base of the sensor nodule, a pair of bots can send short rapid bursts of data that can't be intercepted as optical or radio transmission can. What it's used for in recent history is sharing end-of-life plans."
"Oh."
Bitstream nodded. "Yeah."
"It's a goodbye kiss."
I know others have said it before, but I love how this fandom essentially took what began as robots beating the snot out of each other and decided that they deserved a deep and enriching culture. Yeah the IDW writers made a TON of stuff to mess with, but the fandom has taken even the most OBSCURE details and rolled with it.
I love that for this fandom. It feels alive in here despite the fact that TF content has been around longer than I have.
292 notes
·
View notes
Text
“I miss Nebulos,” he stated, watching Fort Max pull out half a cabinet of cubes. Sat on his shoulder and comfortably curled against the side of his helm, their schedules aligned enough for Cerebros to rise early with him, accompanying him as he prepared half the moon’s morning fuel. “I miss Nebulans.”
Humming in acknowledgement, Max set the containers down and recounted them. He wasn’t surprised by his bond’s yearning. They shared it, of course, but Cerebros always waxed nostalgic when socialising with other Cybertronians alone enough. Meeting alternates of familiar mechs must not be making him feel any less out of place - Even among their own universe, Cerebros would argue he was only a proper Cybertronian by proxy.
“You still talk to Stylor frequently,” Max pointed out, flicking cubes to the side as he searched for one of Incisor’s. She had them specially designed to accommodate her frame, but she never placed them back in any consistent pattern after washing. Cerebros huffed, earning a gentle nudge from his finial. “We’ll visit.”
#〈Status: Report!〉#〔Head-on!〕#〈This medication is kicking my ass. Take this for now-〉#〈This is half to relieve my dismay over missing an opportunity to make a binomial data transfer joke in stream〉#〈And half to actually do anything with the boys〉
10 notes
·
View notes
Note
Do transformers kiss?
Dear Buss Besotted,
Yes. Both to share affection, and information via binomial data transfer.
35 notes
·
View notes
Text
UGC NET Commerce Books, Question Paper, Free Study Material, MCQ
UGC NET Commerce Books, Question Paper, Free Study Material, MCQ The National Eligibility Test, also known as UGC NET or NTA-UGC-NET, is the test for determining the eligibility for the post of Assistant Professor and/or Junior Research Fellowship award in Indian universities and colleges. UGC NET is considered as one of the toughest exams in India, with success ratio of merely 6%. UGC NET Commerce Question Paper and MCQs Buy the question bank or online quiz of UGC NET Commerce Exam Going through the UGC NET Commerce Exam Question Bank is a must for aspirants to both understand the exam structure as well as be well prepared to attempt the exam. The first step towards both preparation as well as revision is to practice from UGC NET Commerce Exam with the help of Question Bank or Online quiz. We will provide you the questions with detailed answer. UGC NET Commerce Question Paper and MCQs : Available Now UGC NET Commerce Free Study Material : Click Here UGC NET Commerce Books : Click Here UGC NET Commerce Syllabus Unit 1 – Business Environment and International Business Concepts and elements of business environment: Economic environment- Economic systems, Economic policies(Monetary and fiscal policies); Political environment Role of government in business; Legal environment- Consumer Protection Act, FEMA; Socio-cultural factors and their influence on business; Corporate Social Responsibility (CSR), Scope and importance of international business; Globalization and its drivers; Modes of entry into international business, Theories of international trade; Government intervention in international trade; Tariff and non-tariff barriers; India’s foreign trade policy, Foreign direct investment (FDI) and Foreign portfolio investment (FPI); Types of FDI, Costs and benefits of FDI to home and host countries; Trends in FDI; India’s FDI policy, Balance of payments (BOP): Importance and components of BOP, Regional Economic Integration: Levels of Regional Economic Integration; Trade creation and diversion effects; Regional Trade Agreements: European Union (EU), ASEAN, SAARC, NAFTA International Economic institutions: IMF, World Bank, UNCTAD, World Trade Organisation (WTO): Functions and objectives of WTO; Agriculture Agreement; GATS; TRIPS; TRIMS Unit 2 – Accounting and Auditing Basic accounting principles; concepts and postulates, Partnership Accounts: Admission, Retirement, Death, Dissolution and Insolvency of partnership firms, Corporate Accounting: Issue, forfeiture and reissue of shares; Liquidation of companies; Acquisition, merger, amalgamation and reconstruction of companies, Holding company accounts, Cost and Management Accounting: Marginal costing and Break-even analysis; Standard costing; Budgetary control; Process costing; Activity Based Costing (ABC); Costing for decision-making; Life cycle costing, Target costing, Kaizen costing and JIT, Financial Statements Analysis: Ratio analysis; Funds flow Analysis; Cash flow analysis, Human Resources Accounting; Inflation Accounting; Environmental Accounting, Indian Accounting Standards and IFRS, Auditing: Independent financial audit; Vouching; Verification ad valuation of assets and liabilities; Audit of financial statements and audit report; Cost audit, Recent Trends in Auditing: Management audit; Energy audit; Environment audit; Systems audit; Safety audit Unit 3 – Business Economics Meaning and scope of business economics, Objectives of business firms, Demand analysis: Law of demand; Elasticity of demand and its measurement; Relationship between AR and MR, Consumer behavior: Utility analysis; Indifference curve analysis, Law of Variable Proportions: Law of Returns to Scale, Theory of cost: Short-run and long-run cost curves, Price determination under different market forms: Perfect competition; Monopolistic competition; Oligopoly- Price leadership model; Monopoly; Price discrimination, Pricing strategies: Price skimming; Price penetration; Peak load pricing Unit 4 – Business Finance Scope and sources of finance; Lease financing, Cost of capital and time value of money, Capital structure, Capital budgeting decisions: Conventional and scientific techniques of capital budgeting analysis, Working capital management; Dividend decision: Theories and policies, Risk and return analysis; Asset securitization, International monetary system, Foreign exchange market; Exchange rate risk and hedging techniques, International financial markets and instruments: Euro currency; GDRs; ADRs, International arbitrage; Multinational capital budgeting Unit 5 – Business Statistics and Research Methods Measures of central tendency, Measures of dispersion, Measures of skewness, Correlation and regression of two variables, Probability: Approaches to probability; Bayes’ theorem, Probability distributions: Binomial, poisson and normal distributions, Research: Concept and types; Research designs, Data: Collection and classification of data, Sampling and estimation: Concepts; Methods of sampling – probability and nonprobability methods; Sampling distribution; Central limit theorem; Standard error; Statistical estimation, Hypothesis testing: z-test; t-test; ANOVA; Chi–square test; Mann-Whitney test (Utest); Kruskal Wallis test (H-test); Rank correlation test, Report writing Unit 6 – Business Management and Human Resource Management Principles and functions of management, Organization structure: Formal and informal organizations; Span of control, Responsibility and authority: Delegation of authority and decentralization Motivation and leadership: Concept and theories, Corporate governance and business ethics, Human resource management: Concept, role and functions of HRM; Human resource planning; Recruitment and selection; Training and development; Succession planning, Compensation management: Job evaluation; Incentives and fringe benefits, Performance appraisal including 360 degree performance appraisal, Collective bargaining and workers’ participation in management, Personality: Perception; Attitudes; Emotions; Group dynamics; Power and politics; Conflict and negotiation; Stress management, Organizational Culture: Organizational development and organizational change Unit 7 – Banking and Financial Institutions Overview of Indian financial system, Types of banks: Commercial banks; Regional Rural Banks (RRBs); Foreign banks; Cooperative banks, Reserve Bank of India: Functions; Role and monetary policy management, Banking sector reforms in India: Basel norms; Risk management; NPA management, Financial markets: Money market; Capital market; Government securities market, Financial Institutions: Development Finance Institutions (DFIs); Non-Banking Financial Companies (NBFCs); Mutual Funds; Pension Funds, Financial Regulators in India, Financial sector reforms including financial inclusion, Digitisation of banking and other financial services: Internet banking; mobile banking; Digital payments systems, Insurance: Types of insurance- Life and Non-life insurance; Risk classification and management; Factors limiting the insurability of risk; Re-insurance; Regulatory framework of insurance- IRDA and its role. Unit 8 – Marketing Management Marketing: Concept and approaches; Marketing channels; Marketing mix; Strategic marketing planning; Market segmentation, targeting and positioning, Product decisions: Concept; Product line; Product mix decisions; Product life cycle; New product development, Pricing decisions: Factors affecting price determination; Pricing policies and strategies, Promotion decisions: Role of promotion in marketing; Promotion methods – Advertising; Personal selling; Publicity; Sales promotion tools and techniques; Promotion mix, Distribution decisions: Channels of distribution; Channel management, Consumer Behaviour; Consumer buying process; factors influencing consumer buying decisions, Service marketing, Trends in marketing: Social marketing; Online marketing; Green marketing; Direct marketing; Rural marketing; CRM, Logistics management. Unit 9: Legal Aspects of Business Indian Contract Act, 1872: Elements of a valid contract; Capacity of parties; Free consent; Discharge of a contract; Breach of contract and remedies against breach; Quasi contracts, Special contracts: Contracts of indemnity and guarantee; contracts of bailment and pledge; Contracts of agency, Sale of Goods Act, 1930: Sale and agreement to sell; Doctrine of Caveat Emptor; Rights of unpaid seller and rights of buyer, Negotiable Instruments Act, 1881: Types of negotiable instruments; Negotiation and assignment; Dishonour and discharge of negotiable instruments, The Companies Act, 2013: Nature and kinds of companies; Company formation; Management, meetings and winding up of a joint stock company, Limited Liability Partnership: Structure and procedure of formation of LLP in India, The Competition Act, 2002: Objectives and main provisions, The Information Technology Act, 2000: Objectives and main provisions; Cyber crimes and penalties, The RTI Act, 2005: Objectives and main provisions, Intellectual Property Rights (IPRs) : Patents, trademarks and copyrights; Emerging issues in intellectual property, Goods and Services Tax (GST): Objectives and main provisions; Benefits of GST; Implementation mechanism; Working of dual GST. Unit 10: Income-tax and Corporate Tax Planning Income-tax: Basic concepts; Residential status and tax incidence; Exempted incomes; Agricultural income; Computation of taxable income under various heads; Deductions from Gross total income; Assessment of Individuals; Clubbing of incomes, International Taxation: Double taxation and its avoidance mechanism; Transfer pricing, Corporate Tax Planning: Concepts and significance of corporate tax planning; Tax avoidance versus tax evasion; Techniques of corporate tax planning; Tax considerations in specific business situations: Make or buy decisions; Own or lease an asset; Retain; Renewal or replacement of asset; Shut down or continue operations, Deduction and collection of tax at source; Advance payment of tax; E-filing of income-tax returns. NTA UGC NET Commerce Exam Pattern 2020 1. Paper I : It consists of 50 questions from UGC NET teaching & research aptitude exam (general paper), which you have to attempt in 1 hour. 2. Paper II : The UGC Commerce exam (paper 2) will have 100 questions and the total duration will be two hours. Each question carries 2 marks, so the exam will be worth 200 marks. Read below to know the pattern of NET Commerce examination (part II). Exam HighlightsDetails Test Duration120 minutes Total Questions100 Marks per question2 Total Marks200 Negative MarkingN/A Free Mock Test UGC NET Commerce : Click Here Online Test Series UGC NET Commerce : Click Here #UGCNETCommerce #UGCNETCommerce2020 #UGCNETCommerceExam #FreeTestSeries #QuestionsBank #UGCNETCommerceSyllabus #OnlineTestSeries #OnlineMockTest #ImportantQuestionPaper #ImportantQuestion
1 note
·
View note
Text
Juniper Publishers- Open Access Journal of Environmental Sciences & Natural Resources
Systemic Plant Pathogen Botrytis Cinerea Influences f the Feeding and Mating on Myzus Persicae by Parasitoid Aphidius Ervi
Authored by Yahaya SM
Abstract
Female parasitoids assess host quality and make a decision whether to lay egg or not. Here we investigated the relationship between the green peach potato aphid Myzus persicae Sulzer (Hemiptera: Aphididae) and its common parasitoid, Aphidius ervi Vierek (Hymenoptera: Braconidae), to determine whether the relationship is influence by infection of the aphids host by B. cinerea. In hymentopteran parasitoids which are haplo- diploid, the females may selectively lay female or male eggs by controlling fertilization depending on whether the host is infected with B. Cinerea or not. Apart from infection of B. cinerea many other factors may influence the female's decision to fertilize and create biased offspring sex ratios: host quality, environment and local mate competition. It is clear that here attention was directed on parasitoids assessing host quality, especially the host size. While there was a significant effect of host plant infection on aphid size (measured as hind tibia length), and a resulting significant effect of fungal infection on the size of emerging parasitoids, there was no evidence of reduced survival or attack rates of parasitoids reared on aphids feeding on infected plants, and there was no difference in the sex ratio of parasitoids emerging from aphids reared on infected and control plants. Offspring sex is therefore not absolute; it mainly depends on relative host variability and the parasitoid's previous experience. Therefore, future research on sex allocation should consider factors that do not involve females manipulating fertilization that can create biased sex ratios.
Keywords: Aphedius ervi; cinerea; Myzus persicae; Interaction. Choice
Introduction
Herbivorous insect aphids (Hemiptera, Aphididae) are widely distributed small plant-sucking insects colonizing over 3000 species of herbaceous plants and shrubs and many are found on trees [1]. Many aphids specialize on a few species of plants and plant selection is normally through the use of chemical cues [2]. Aphids mainly occur in colonies and their growth dynamics often results in high population sizes, [3,4]. Therefore, aphids are important agricultural pests, which in addition to causing direct damage by feeding on crops, cause indirect damage by acting as vectors of viruses which may cause significant diseases of their host plants [5]. The aphid Myzus persicae (Sulzer) is a serious pest of many important agricultural crops such as peaches, potatoes, sugar beets, and tobacco, and various ornamental crops grown in landscapes and in glasshouses [6]. High population of M. persicae on crop plant can causes injury by removing large volumes of sap from the plants and depleting them of the needed nutrients. In addition they may also cause indirect injury by the production of sugary honeydew which makes the leaves susceptible to microbial attack, which then reduces leaf quality [6]. Many aphids are widely attacked by a range of natural enemies such as hymenopteran parasitoids (e.g.Aphidius species such as Aphidius ervi, A. matricariae, A. ervi and A. abdominals), and a wide range of arthropod predators [5,7]. High aphid numbers on a plant serves as a resource for their natural enemies. Many researchers have investigated the effects of natural enemies for keeping aphid population sizes below economic injury levels [5,8-10]. Also aphids may indirectly interact with systemic pathogens such as Botrytis cinerea on the host plant and both aphids and pathogens may induces the host plant to release various chemicals for defence, serving as cues for foraging natural enemies [11,12].
The parasitoid Aphidius ervi belong to the sub family Aphidiidae (Hymenoptera: Braconidae) the females of Aphidius ervi lay their eggs inside the aphids. Aphidius ervi being Koinobiont endo parasitoid as the eggs hatch the larvae feed off the living host, killing it by the fourth and last instar. The larvae formed a protective cocoon inside the exoskeleton of the aphid before reaching the adult stage. The unfertilized eggs develop into males, while fertilized eggs develops into females (haplodiploid) which later seek for a new hosts after emergence [13-18]. Female hymenopteran parasitoids select hosts which provide the best resources for their offspring [19,20]. They select hosts, and control the sex of the offspring by influencing fertilization, evidence support that female hymenopteran manipulates the release of sperm from the spermatheca while eggs pass through her genital tract, the unfertilized eggs develop into males while fertilized eggs develop into females [21-26,18]. As fitness is positively correlated with size in female parasitoids, but not for males, female parasitoids may therefore, selectively oviposit male eggs in poorer quality host when given a choice [27]. This research is aimed at determining whether the presence of systemic pathogen B. cinerea infecting a model plant system [the lettuce, Lactuca sativa L. (Asteraceae: Compositae)] influences the interaction between an insect herbivore (the peach potato aphid Myzuspersicae) and a parasitoid widely used in aphid biocontrol, Aphidius ervi. Three hypotheses were tested. First, Myzus persicae feeding on infected lettuce plants would be smaller. Second, parasitoids emerging from aphid host feeding on infected plants would be smaller. Third, host plant infection would influence the relationship between aphid M. persicae and A. ervi, resulting in fewer offspring and a more biased sex ratio when parasitoids attacked aphids feeding on infected plants.
Material and Methods
Experimental plants
Lettuce seed (Tom Thumb) infected and uninfected by B. cinerea obtained by inoculating lettuce plants at the flower stage and resulting seeds tested by plating on Botrytis selective media (BSM) plates were the seed source used in this experiment. Lettuce seed were individually sown in 60 (30 infected, 30 uninfected) 15cm pots filled with a vermiculite growing medium in a controlled environment (18-200C, L: D 12-12, ambient humidity).
Infestation with Myzus persicae
Three weeks after germination all plants were infested with 20 adult M. persicae by placing them individually on the reverse side of the leaves using a small moist brush. Plants were then covered with a transparent plastic cup for 48 hours. All adult aphids were then removed leaving second instar nymphs in situ. While this prevents absolute control of experimental numbers it avoids the possibility of damage to the delicate nymphs during individual transfer. Aphid colonies were covered at all times by a vented plastic container, preventing escape of aphids or parasitoids.
Attack by Aphidius ervi
Aphidius ervi is another commercially available biocontrol agent, and experimental samples were obtained from Koppert UK (1967). The female A. ervi oviposit a single egg into aphid nymphs. The larva develops inside the body of aphid host until it kills the host. The experimental A. ervi were feed with adlibitum honey and maintained in vials at 5 OC in the laboratory Prior to use parasitoids were allowed to acclimatize to room temperature. Immediately after the adult aphids were removed from the plants, the nymphs were exposed to attack by five female Aphidius ervi. Twenty infested plants grown from infected and uninfected seeds were attacked with the aphid natural enemy while the aphids on the remaining ten infected and uninfected plants were allowed to serve as an unattacked control.
Attack rate
During the study a visual observation was carried out every day for the emergence of mummies. A week after aphid natural enemy attack the young aphids that became adult were counted and collected also the mummified aphid were counted and collected separately in to 200ml Eppendorf tubes and placed on a laboratory bench for one week to allow the emergence of the parasitoids.
Size of Myzus Persicae and Aphidius ervi
Myzus persicae, ten adult were haphazardly selected from all plants while all the resulting parasitoids from the mummies were used for the determination of hind tibia length. Each Myzus persicae and Aphidius ervi was placed in a drop of 100% ethanol on a glass slide covered with a cover slip and observed using a micrometric eye piece attached to a microscope (Nikon) at 50 x magnification and calibrated with graticule.
Statistical analysis
Data was analysed using Analysis of variance (ANOVA) using R [28-30]. Since the data conformed to the assumptions of normality data on hind tibia length was not transformed prior to analysis. However, data on attack rate and sex ratio was analysed using a generalised linear model using binomial errors [29].
Results
Size of aphid Myzus persicae
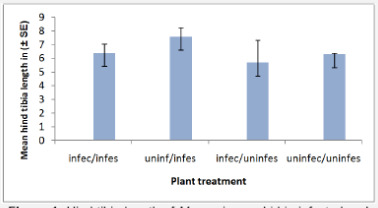
The aphid s reared on plants uninfected by B. cinerea were larger than those reared on infected plants (F1, 39 = 281.08 P < 0.001, Figure 1).
Size of parasitoid Aphidius ervi
The size of the Aphidius ervi was indirectly affected by Botrytis cinerea infection. The hind tibia length of Aphidius ervi that emerged from aphids reared on uninfected plants was significantly longer than parasitoids reared on aphids feeding on infected plants (F1, 79 = 70.13, P < 0.001). Sex of the Aphidius ervi was affected by the infection of B. cinerea as female Aphidius ervi were significantly larger than male Aphidius ervi when reared on both infected (Fa, 79 = 181.92 P < 0.001) and uninfected plants. However, the interaction between sex and infection was not significant on the hind tibia length (Figure 2, F1, 79 = 0.07 P =0.766).
Sex ratio and Parasitism rate of Aphidius ervi
The rate of attack suffered by M. persicae reared on uninfected plants was higher than in infected plants (Figure 3, F1, 39 = 71.554 P = 0.0813). However, there were a greater number of aphids and parasitoids obtained from the uninfected plants. However, there was no significant effect of plant infection status on the sex ratio of emerging A. ervi.
Discussion
High number of Myzus persicae and their parasitoids (Aphidius ervi) were reared on lettuce plants grown from seed uninfected with Botrytis cinerea. However, parasitoids attacked proportionally more aphids on infected plants, and both aphids and emerging parasitoids were significantly smaller when reared on infected plants. Similarly, there was no difference in parasitoids sex ratio, with 50:50 sex ratio found with parasitoids emerging from host reared on both infected and uninfected plants.
The study found that A. ervi emerging from small aphids, showed a significant male biased offspring sex ratio. This shift in emergence sex ratio may be the results of a significantly higher mortality of female progeny in small than large aphids. The female A. ervi often have more strict nutritional requirements compare to males and may therefore reach a larger size than males even in a hosts of equal size but the females takes longer time to complete their development, this is commonly reported in koinobionts were the female parasitoid have extended period of larval development on growing host which enable them to consume more resources than the male offspring [31-33]. Therefore the higher female mortality in small aphids normally occurs due to shortage of resource during early stages of female development in small aphids. Therefore the sex ratio determined by female choice at oviposition may be altered by mortality of the sexes. A biased sex ratio may result either from the female's control of fertilization at oviposition, or, may results, from the differential mortality of male and female offspring during early stages of development [19]. The results revealed that the aphid hosts are larger when reared on uninfected plants than infected ones; this was shown by the possession of longer hind tibia in aphid reared on uninfected plants. Body size in aphid host is an index of host quality where host quality is a linear function of size and the quality determined the ability of the foraging parasitoid to obtain required nutritional resources from the host [20,31]. Larger host are more nutritious and a good resource for the growth and development of offspring, and influence the survival and fecundity of the parasitoids, although larger aphids are more difficult to capture by the parasitoids yet our finding shows that female A. ervi oviposit more in uninfected host species because their offsprings have higher probability of survival [20,30,34].
The study showed that low number of parasitoid mummies was recorded in aphid reared on B. cinerea infected plants, which indicated the negative effects of B. cinerea on the tritrophic interactions in both preference and performance. Botrytis cinerea reduced the fitness of the aphids resulting in poor- quality host and low nutritious values with a high mortality rate. This can be explained by ability of plant pathogen B. cinerea to induce the production of secondary metabolites by the plant which may have toxic, antifeedant or aversive effects on the aphids. Therefore, the foraging parasitoid discriminates between infected and uninfected aphid host whether to feed, oviposit or to ignore, because host choice correlate with offspring performance which has a direct impact on the fitness. The parasitoid that feed on aphid reared on infected plants became infected. However, after oviposition not all the eggs will give rise to new off springs as egg laid in a poor-quality host are destined to die or give rise to inferior adults. Other negative effects of plant pathogen B. cinerea on the tritrophic interaction are indirectly influencing sex manipulation by the female parasitoid. Size or quality and mating of sibling are the main factors influencing the sex ratio which is dependent upon the presence or absence of plant pathogen. Female parasitoid tends to lay male eggs on a poor- quality host which developed to small adults while lays female eggs on a good-quality host which give rises to large adults. The reason for this is the success of male reproduction is less contingent on size as compare to female fecundity, therefore, male benefit less by being larger than female [19,14].
Quality of the plant directly and indirectly affected the interaction between aphids and parasitoids, and determined aphid size and biology of the parasitoids. In this study, uninfected plants serve as the better host for the aphid M. persicae by providing sufficient nutrient sources, which ensured large size of the aphids an indication of high plant quality [35]. High quality and fitter aphids serves as a good resource for the parasitoid feeding and oviposition however, the aphids reared on infected plants lacks required nutritious values the aphid becomes infected and less fit. For example, in comparism with the present study, Francis et al. [36] reported that M. persicae suitability as prey for A. bipunctata was compromised when the aphid was reared on Brassica species with rise levels of glucosinolates. Volatile secreted by herbivore -infested plants are attractive to parasitoids therefore mediate the interaction between aphids and their parasitoids. Therefore, the response of the parasitoids to the plant volatiles is proposed as an indirect plant defensive strategy reducing the number of aphids exposed to the plants [37-39]. The parasitoid shows some associative learning with a particular volatile blend with the presence of hosts after exposure in a host encounter. The associative learning enables parasitoids to cope with complexity of the environment by focusing on suitable cues.
In the present study, we found that in lettuce plant, there was an indirect interaction between B. cinerea and aphids, resulting in the decreased B. cinerea lesions and aphid biomass. Both B. cinerea and aphid M. persicae induced the plant to secret chemical's substances in a form of defense which serve as a cue for the aphids natural enemy parasitoids, a biocontrol which regulates the number of aphids. By reducing the number of insect herbivores, parasitoids reduce a considerable loss in crop yield [17,40]. This interaction helps in maintaining stable population dynamics in a long-lived ecosystem. The study has shown that infection by B. cinerea affects the interaction between the aphid M. persicae and their parasitoid A. ervi. The infected aphid host is less fit and lacks enough resource to support the optimum growth of A. ervi. In the present study, we measure fitness in terms of the number of offspring produced and the body size of the emerging offspring the fitness of the A. ervi is compromised where they feed on aphids reared on host plants infected with endophytic B. cinerea.
For more articles in Juniper Publishers | Open Access Journal of Environmental Sciences & Natural Resources please click on: https://juniperpublishers.com/ijesnr/index.php
#juniper publishers journals#Juniper Publishers ISI#Environmental Chemistry#Waste Management and Disposal#Microbial Ecology#Geo Morphology
0 notes
Text
Control Parameters in Differential Evolution (DE): A Short Review- Juniper Publishers

Abstract
Differential Evolution (DE) is a population based stochastic search algorithm for optimization. DE has three main control parameters, Crossover (cr), Mutation factor (F) and Population size (NP). These control parameters play a vital and crucial rule in improving the performance of search process in DE. This paper introduces a brief review for control parameters in Differential evolution (DE).
Keywords: Differential evolution; Population size; Global optimization; Control parameters
Abbrevations: DE: Differential Evolution; Cr: Crossover; NP: Population Size; F: Mutation Factor
Introduction
Differential Evolution (DE) is a population-based heuristic algorithm proposed by Storn & Price [1] to solve global optimization problems with different characteristics over continuous space. Despite its simplicity, it proved a great performance in solving non-differentiable, non-continuous and multi-modal optimization problems [2]. DE has three main control parameters which are the crossover (CR), mutation factor (F) and population size (NP). The values of the control parameters affect significantly on the performance of DE. Therefore, the tuning of those control parameters is considered a challenging task. DE has a great performance in exploring the solution space and this is considered as the main advantage, on the other side, an obvious weak point is its poor performance in exploitation phase which may cause a stagnation and/or premature convergence.
The next section introduces differential evolution. Section 3 introduces a short review for control parameters in DE. And finally, the paper is concluded in section 4.
Differential Evolution
In simple DE, DE/rand/1/bin [1,2], an initial population of NP individuals jX, j=1,2,..,NP, is generated at random according to a uniform distribution within lower and upper boundaries (,)LUjjxx. Individuals are evolved by the means of crossover and mutation to generate a trial vector. The trial vector competes with his parent in order to select the fittest to the next generation. The steps of DE are:
Initialization of a population
Initial population in DE, as the starting point for the process of optimization, is created by assigning a random chosen value for each decision variable in every vector, as indicated in equation (1).
Where Lj,Uj: the lower and upper boundaries for xj, rj and: a random number uniform [0, 1].
Mutation
A mutant vector viG+1 is generated for each target vector xiG at generation G according to equation (2)
Where r1,r2, r3 are randomly chosen from the population. The mutation factor F��[0,2]. A new value for the component of mutant vector is generated using (1) if it violates the boundary constraints.
Recombination (crossover)
Crossover is the process of swapping information between the target and the mutated individuals using (3), to yield the trial vector uiG+1 Two types of crossover can be used, binomial crossover or exponential crossover.
where j =1, 2,.., D , rand( j)∈[0,1] is the jth evaluation of a uniform random number. Crossover rate (CR) is between 0 and 1, r and (i) is a random index between 1 and D to ensures that uiG+1; gets at least one element from viG+1; otherwise, the population remains without change.
In the exponential crossover, a starting index l and a number of components w are chosen randomly
from the ranges {l,D}and {l,D −1}respectively. The values of variables in locations l to l + w from viG+1 and the remaining locations from the xiG are used to produce the trial vector uiG+1
Selection
Greedy scheme for fast convergence of DE. The child uiG+1 is compared with its parent xiG to select the better for the next generation according to the selection scheme in equation (4).
A detailed description of standard DE algorithm is given in Figure 1.
Short Review
During the last two decades, the problem of finding the balance between the exploration and exploitation has attracted many researchers in order to improve the performance of DE by developing new mutation strategies or hybridizing promising mutation strategies.
Das et al. [3] proposed an improved variant of DE/targetto- best/1/bin based on the concept of population members’ neighborhood. Zhang & Sanderson [4] proposed a new mutation strategy “DE/current-to-pbest” with an optional external archive that utilizes the historical data in order to progress towards the promising direction and called it JADE. Qin, Huang & Suganthan [5] proposed SaDE, in which a self-adaptive mechanism for trial vector generation is presented, that is based on the idea of learning from the past experience in generating promising solutions. Mohamed et al. [6-8] proposed a novel mutation strategy which is based on the weighted difference between the best and the worst individual during a specific generation, the new mutation strategy is combined with the basic mutation DE/rand/1/bin with equal probability for selecting each of them. Li & Yin [9] used two mutation strategies based on the best and random vectors. Mohamed [10] proposed IDE, in which new triangular mutation rule that selects three random vectors and adding the difference vector between the best and worst to the better vector. The new mutation rule is combined with the basic mutation rule through a non-linear decreasing probability rule. And a restart mechanism to avoid the premature convergence is presented. Recently, triangular mutation has been also used to solve IEEE CEC 2013 unconstrained problems [11], constrained non-linear integer and mixed-integer global optimization problems [12], IEEE CEC2006 constrained optimization problems [13], CEC 2010 large-scale optimization problems [14], and stochastic programming problems [15].
Extensive research was presented for controlling the parameters, as control parameters play a vital role in the evolution process. Brest et al. [16] presented a new self-adaptive technique for controlling the parameters. Noman & Iba [17] proposed an adaptive crossover based on local search and the length of the search was adjusted using hill-climbing. Peng et al. [18] proposed rJADE, in which a weighting strategy is added to JADE, with a “restart with knowledge transfer” method in order to benefit from the knowledge obtained from the previous failure. Montgomery & Chen [19] presented a complete analysis of how much the evolution process affected by the value of CR. Mallipeddi et al. [20] proposed a pool of values for each control parameter to select the appropriate value during the evolution process. Wang, Cai & Zhang [21] proposed a new method that randomly chooses from a pool that contains three strategies in order to generate the trial vector and three control parameter settings, they called it CoDE. Yong et al. [22] presented CoBiDE, in which a covariance matrix learning for the crossover operator and a bimodal distribution parameter to control the parameters are introduced. Draa, Bouzoubia & Boukhalfa [23] introduced a new sinusoidal formula in order to adjust the values of crossover and the scaling factor, they called it SinDE. A complete review could be found in [24,25].
DE mechanism depends on selecting three random individuals from the population to perform the mutation process. Therefore, the population size must be greater than the selected vectors. Large population size increases the diversity but consumes more resources (function calls), while small population size may cause stagnation or tripping in local optima. Thus, the choosing of the population size is considered a very critical aspect. From the literature, it has been found that researchers choose the population size in four different ways.
i. Choosing the population size for each problem separately based on the experience or previous knowledge and keep it constant during all runs [26,27].
ii. Relate the population size to the problem dimensionality [6,28,29].
iii. Setting the population size fixed during all runs and independent of the dimension of the problems [22,30].
iv. Allowing the population size to vary during the runs using adaptation rule [31-33]. A complete review of population size could be found in [34,35].
Conclusion
Control parameters plays a vital rule in the evolution process of the DE. Over the last decades, many EAs have been proposed to solve optimization problems. However, all these algorithms including DE have the same shortcomings in solving optimization problems. One of them is the choice of the control parameters which are difficult to adjust for different problems with different characteristics. This paper introduced a brief review for a considerable number of research studies that have been proposed to enhance the performance of DE.
For More Open Access Journals Please Click on: Juniper Publishers
Fore More Articles Please Visit: Robotics & Automation Engineering Journal
0 notes
Text
Top AI algorithms for Healthcare
The benefits of AI for healthcare have been extensively discussed in the recent years up to the point of the possibility to replace human physicians with AI in the future.
Both such discussions and the current AI-driven projects reveal that Artificial Intelligence can be used in healthcare in several ways:
AI can learn features from a large volume of healthcare data, and then use the obtained insights to assist clinical practice in treatment design or risk assessment;
AI system can extract useful information from a large patient population to assist making real-time inferences for health risk alert and health outcome prediction;
AI can do repetitive jobs, such as analyzing tests, X-Rays, CT scans or data entry;
AI systems can help to reduce diagnostic and therapeutic errors that are inevitable in the human clinical practice;
AI can assist physicians by providing up-to-date medical information from journals, textbooks and clinical practices to inform proper patient care;
AI can manage medical records and analyze both performance of an individual institution and the whole healthcare system;
AI can help develop precision medicine and new drugs based on the faster processing of mutations and links to disease;
AI can provide digital consultations and health monitoring services — to the extent of being “digital nurses” or “health bots”.
Despite the variety of applications of AI in the clinical studies and healthcare services, they fall into two major categories: analysis of structured data, including images, genes and biomarkers, and analysis of unstructured data, such as notes, medical journals or patients’ surveys to complement the structured data. The former approach is fueled by Machine Learning and Deep Learning Algorithms, while the latter rest on the specialized Natural Language Processing practices.
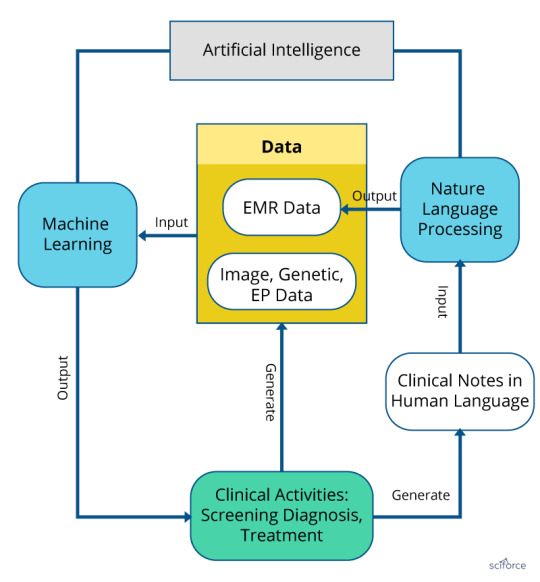
Figure 1. Machine Learning and Natural Language Processing in healthcare.
Machine Learning Algorithms
ML algorithms chiefly extract features from data, such as patients’ “traits” and medical outcomes of interest.
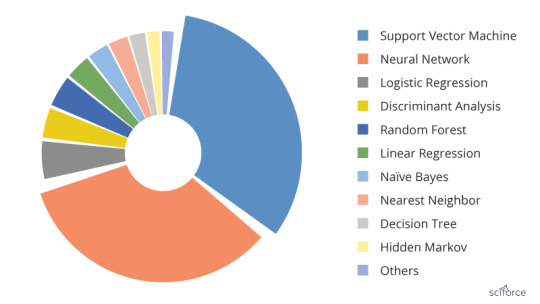
Figure 2. The most popular Machine Learning algorithms used in the medical literature. The data are generated through searching the Machine Learning algorithms within healthcare on PubMed
For a long time, AI in healthcare was dominated by the logistic regression, the most simple and common algorithm when it is necessary to classify things. It was easy to use, quick to finish and easy to interpret. However, in the past years the situation has changed and SVM and neural networks have taken the lead.
Support Vector Machine
Support Vector Machines (SVM) can be employed for classification and regression, but this algorithm is chiefly used in classification problems that require division of a dataset into two classes by a hyperplane. The goal is to choose a hyperplane with the greatest possible margin , or distance between the hyperplane and any point within the training set, so that new data can be classified correctly. Support vectors are data points that are closest to the hyperplane and that, if removed, would alter its position. In SVM, the determination of the model parameters is a convex optimization problem so the solution is always global optimum.
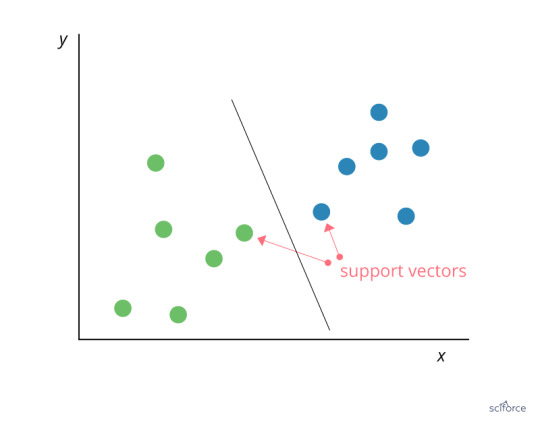
Figure 3. Support Vector Machine
SVMs are used extensively in clinical research, for example, to identify imaging biomarkers, to diagnose cancer or neurological diseases and in general for classification of data from imbalanced datasets or datasets with missing values.
Neural networks
In neural networks, the associations between the outcome and the input variables are depicted through hidden layer combinations of prespecified functionals. The goal is to estimate the weights through input and outcome data in such a way that the average error between the outcome and their predictions is minimized.
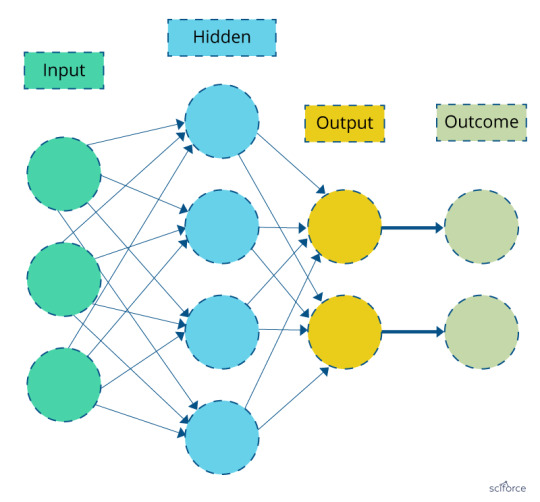
Figure 4. Neural Network
Neural networks are successfully applied to various areas of medicine, such as diagnostic systems, biochemical analysis, image analysis, and drug development, with the textbook example of breast cancer prediction from mammographic images.
Logistic Regression
Logistic Regression is one of the basic and still popular multivariable algorithms for modeling dichotomous outcomes. Logistic regression is used to obtain odds ratio when more than one explanatory variable is present. The procedure is similar to multiple linear regression, with the exception that the response variable is binomial. It shows the impact of each variable on the odds ratio of the observed event of interest. In contrast to linear regression, it avoids confounding effects by analyzing the association of all variables together.
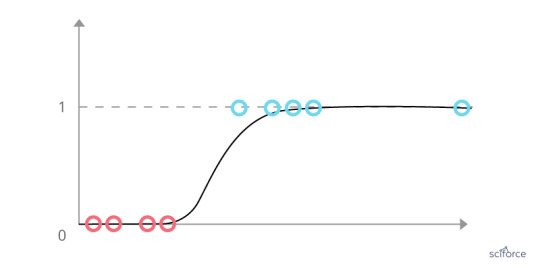
Figure 5. Logistic Regression
In healthcare, logistic regression is widely used to solve classification problems and to predict the probability of a certain event, which makes it a valuable tool for a disease risk assessment and improving medical decisions.
Natural Language Processing
In healthcare, a large proportion of clinical information is in the form of narrative text, such as physical examination, clinical laboratory reports, operative notes and discharge summaries, which are unstructured and incomprehensible for the computer program without special methods of text processing. Natural Language Processing addresses these issues as it identifies a series of disease-relevant keywords in the clinical notes based on the historical databases that after validation enter and enrich the structured data to support clinical decision making.
TF-IDF
Basic algorithm for extracting keywords, TF-IDF stands for term frequency-inverse document frequency. The TF-IDF weight is a statistical measure of a word importance to a document in a collection or corpus. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus.
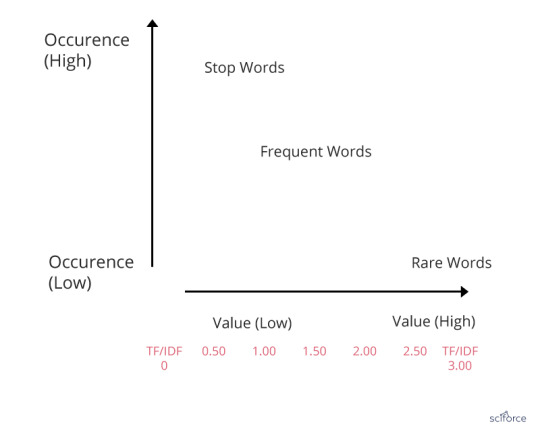
Figure 6. TF-IDF
In healthcare, TF-IDF is used in finding patients’ similarity in observational studies, as well as in discovering disease correlations from medical reports and finding sequential patterns in databases.
Naïve Bayes
Naïve Bayes classifier is a baseline method for text categorization, the problem of judging documents as belonging to one category or the other. Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature. Even if these features are interdependent, all of these properties independently contribute to the probability of belonging to a certain category.
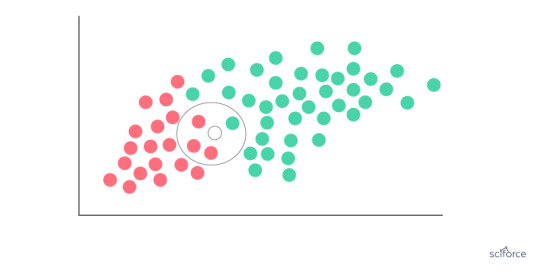
Figure 7. Naïve Bayes classifier
It remains one of the most effective and efficient classification algorithms and has been successfully applied to many medical problems, such as classification of medical reports and journal articles.
Word Vectors
Considered to be a breakthrough in NLP, word vectors, or word2vec, is a group of related models that are used to produce word embeddings. In their essence, word2vec models are shallow, two-layer neural networks that reconstruct linguistic contexts of words. Word2vec produces a multidimensional vector space out of a text, with each unique word having a corresponding vector. Word vectors are positioned in the vector space in a way that words that share contexts are located in close proximity to one another.
Figure 8. Word vectors
Word vectors are used for biomedical language processing, including similarity finding, medical terms standardization and discovering new aspects of diseases.
Deep Learning
Deep Learning is an extension of the classical neural network technique, being, to put it simply, as a neural network with many layers. Having more capacities compared to classical ML algorithms, Deep Learning can explore more complex non-linear patterns in the data. Being a pipeline of modules each of them are trainable, Deep Learning represents a scalable approach that, among others, can perform automatic feature extraction from raw data.
In the medical applications, Deep Learning algorithms successfully address both Machine Learning and Natural Language Processing tasks. The commonly used Deep Learning algorithms include convolution neural network (CNN), recurrent neural network, deep belief network and multilayer perception, with CNNs leading the race from 2016 on.
Convolutional Neural Network
The CNN was developed to handle high-dimensional data, or data with a large number of traits, such as images. Initially, as proposed by LeCun, the inputs for CNN were normalized pixel values on the images. Convolutional networks were inspired by biological processes in that the connectivity pattern between neurons resembles the organization of the animal visual cortex, with individual cortical neurons responding to stimuli only in a restricted region of the receptive field. However, the receptive fields of different neurons partially overlap such that they cover the entire visual field. The CNN then transfers the pixel values in the image by weighting in the convolution layers and sampling in the subsampling layers alternatively. The final output is a recursive function of the weighted input values.
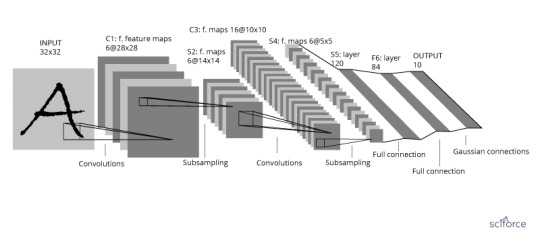
Figure 9. A convolutional neural network
Recently, the CNN has been successfully implemented in the medical area to assist disease diagnosis, such as skin cancer or cataracts.
Recurrent Neural Network
The second in popularity in healthcare, RNNs represent neural networks that make use of sequential information. RNNs are called recurrent because they perform the same task for every element of a sequence, and the output depends on the previous computations. RNNs have a “memory” which captures information about what has been calculated several steps back (more on this later).
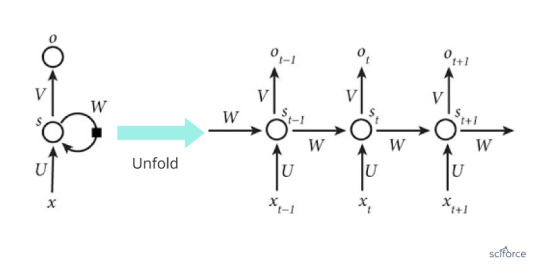
Figure 10. A recurrent neural network
Extremely popular in NLP, RNNs are also a powerful method of predicting clinical events.
Until recently, the AI applications in healthcare chiefly addressed a few disease types: cancer, nervous system disease and cardiovascular disease being the biggest ones. At present, advances in AI and NLP, and especially the development of Deep Learning algorithms have turned the healthcare industry to using AI methods in multiple spheres, from dataflow management to drug discovery.
0 notes
Text
Course: Lausanne.Statistical_Genetics.Sep4-15
--_000_150084433338370825unilch_ Content-Type: text/plain; charset="Windows-1252" Content-Transfer-Encoding: quoted-printable SWISS INSTITUTE IN STATISTICAL GENETICS MODULE 1 - BAYESIAN STATISTICS FOR GENETICS WHERE? University of Lausanne WHEN? 4-6 September 2017 ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US) INSTRUCTORS: Prof. Jonathan Wakefield (University of Washington - US) & Prof. Ken Rice (University of Washington - US) INFO & REGISTRATION: http://bit.ly/2vQyRDW DESCRIPTION: The use of Bayesian methods in genetics has a long history. In this introductory module we will begin by discussing introductory probability. We will then describe Bayesian approaches to binomial proportions, multinomial proportions, two-sample comparisons (binomial, Poisson, normal), the linear model, and Monte Carlo methods of summarization. Advanced topics will be touched on, including hierarchical models, generalized linear models, and missing data. Illustrative applications will include: Hardy-Weinberg testing and estimation, detection of allele-specific expression, QTL mapping, testing in genome-wide association studies, mixture models, multiple testing in high throughput genomics. MODULE 2 - POPULATION GENETIC DATA ANALYSIS WHERE? University of Lausanne WHEN? 6-8 September 2017 ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US) INSTRUCTORS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US) INFO & REGISTRATION: http://bit.ly/2uYfa0I DESCRIPTION: A unified treatment for the analysis of discrete genetic data, starting with estimates and sample variances of allele frequencies to illustrate genetic vs statistical sampling and Bayesian approaches. A detailed look at Hardy-Weinberg and linkage disequilibrium, including the use of exact tests with mid-p-values and a new look at X-chromosome Hardy- Weinberg testing. A new characterization of population structure with F-statistics, based on allelic matching within and between populations with individual relationship estimation as a special case. Analyses illustrated with applications to forensic science and association mapping, with particular reference to rare variants. MODULE 3 - QUANTITATIVE GENETICS WHERE? University of Lausanne WHEN? 11-13 September 2017 ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US) INSTRUCTORS: Prof. Bruce Walsh (University of Arizona - US) & Prof. Guilherme J. M. Rosa (University of Wisconsin - US) INFO & REGISTRATION: http://bit.ly/2vQCDgO DESCRIPTION: Quantitative Genetics is the analysis of complex characters where both genetic and environment factors contribute to trait variation. Since this includes most traits of interest, such as disease susceptibility, crop yield, growth and reproduction in animals, human and animal behavior, and all gene expression data (transcriptome and proteome), a working knowledge of quantitative genetics is critical in diverse fields from plant and animal breeding, human genetics, genomics, behavior, to ecology and evolutionary biology. The course will cover the basics of quantitative genetics including: genetic basis for complex traits, population genetic assumptions including detection of admixture, Fisher's variance decomposition, covariance between relatives, calculation of the numerator relationship matrix based on IBD alleles and an arbitrary pedigree, the genomic relationship matrix based on AIS alleles, heritability in the broad and narrow sense, inbreeding and crossbreedi ng, and response to selection. Also an introduction to advanced topics such as: Mixed Models, Best Linear Unbiased Prediction (BLUP), Genomic selection (GBLUP), Genome Wide Association Analysis (GWAS), QTL mapping, detection of selection from genomic data, correlated characters; and the multivariate response to selection. MODULE 4 - MIXED MODELS IN QUANTITATIVE GENETICS WHERE? University of Lausanne WHEN? 13-15 September 2017 ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US) INSTRUCTORS: Prof. Bruce Walsh (University of Arizona - US) & Prof. Guilherme J. M. Rosa (University of Wisconsin - US) INFO & REGISTRATION: http://bit.ly/2uY59Rk DESCRIPTION: "Mixed models" refers to the analysis of linear models with arbitrary (co)variance structures among and within random effects and may be due to such factors as relationships or shared environments, cytoplasm, maternal effects and history. Mixed models are utilized in complex data analysis where the usual assumption(s) of independence and/or homogenous variances fail. Mixed models allow effects of nature to be separated from those of nurture and are emerging as the default method of analysis for human data. These issues are pervasive in human studies due to the lack of ability to randomize subjects to households, choice, and prior history. In plant breeding, growth and yield data are correlated due to shared locations, but diminish by distance resulting in spatial correlations. In animal breeding, performance data is correlated because individuals maybe related and may share common material environment as well as common pens or cages. Further, when individuals sha re a common space, they may experience indirect genetics effects (IGEs), which is an inherited effect in one individual experienced as an environmental effect in an associated individual. The evolution of cooperation and competition is based on IGEs, the estimation of which require mixed model analysis. Detection of cytoplasmic and epigenetic effects rely heavily on mixed model methods because of shared material or parental histories. Topics to be discussed include a basic matrix algebra review, the general linear model, derivation of the mixed model, BLUP and REML estimation, estimation and design issues, Bayesian formulations. Applications to be discussed include estimation of breeding values and genetic variances in general pedigrees, association mapping, genomic selection, spatial correlations and corrections, maternal genetic effects, detecting selection from genomic data, admixture detection and correction, direct and indirect genetic effects, models of general group a nd kin selection, genotype by environment interaction models QUERIES: [email protected] --_000_150084433338370825unilch_ Content-Type: text/html; charset="Windows-1252" Content-Transfer-Encoding: quoted-printable <!--P{margin-top:0;margin-bottom:0;} p {margin-top:0; margin-bottom:0}-->
SWISS INSTITUTE IN STATISTICAL GENETICS
MODULE 1 - BAYESIAN STATISTICS FOR GENETICS
WHERE? University of Lausanne
WHEN? 4-6 September 2017
ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US)
INSTRUCTORS: Prof. Jonathan Wakefield (University of Washington - US) & Prof. Ken Rice (University of Washington - US)
INFO & REGISTRATION: http://bit.ly/2vQyRDW
DESCRIPTION: The use of Bayesian methods in genetics has a long history. In this introductory module we will begin by discussing introductory probability. We will then describe Bayesian approaches to binomial proportions, multinomial proportions, two-sample comparisons (binomial, Poisson, normal), the linear model, and Monte Carlo methods of summarization. Advanced topics will be touched on, including hierarchical models, generalized linear models, and missing data. Illustrative applications will include: Hardy-Weinberg testing and estimation, detection of allele-specific expression, QTL mapping, testing in genome-wide association studies, mixture models, multiple testing in high throughput genomics.
MODULE 2 - POPULATION GENETIC DATA ANALYSIS
WHERE? University of Lausanne
WHEN? 6-8 September 2017
ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US)
INSTRUCTORS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US)
INFO & REGISTRATION: http://bit.ly/2uYfa0I
DESCRIPTION: A unified treatment for the analysis of discrete genetic data, starting with estimates and sample variances of allele frequencies to illustrate genetic vs statistical sampling and Bayesian approaches. A detailed look at Hardy-Weinberg and linkage disequilibrium, including the use of exact tests with mid-p-values and a new look at X-chromosome Hardy- Weinberg testing. A new characterization of population structure with F-statistics, based on allelic matching within and between populations with individual relationship estimation as a special case. Analyses illustrated with applications to forensic science and association mapping, with particular reference to rare variants.
MODULE 3 - QUANTITATIVE GENETICS
WHERE? University of Lausanne
WHEN? 11-13 September 2017
ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US)
INSTRUCTORS: Prof. Bruce Walsh (University of Arizona - US) & Prof. Guilherme J. M. Rosa (University of Wisconsin - US)
INFO & REGISTRATION: http://bit.ly/2vQCDgO
DESCRIPTION: Quantitative Genetics is the analysis of complex characters where both genetic and environment factors contribute to trait variation. Since this includes most traits of interest, such as disease susceptibility, crop yield, growth and reproduction in animals, human and animal behavior, and all gene expression data (transcriptome and proteome), a working knowledge of quantitative genetics is critical in diverse fields from plant and animal breeding, human genetics, genomics, behavior, to ecology and evolutionary biology. The course will cover the basics of quantitative genetics including: genetic basis for complex traits, population genetic assumptions including detection of admixture, Fisher's variance decomposition, covariance between relatives, calculation of the numerator relationship matrix based on IBD alleles and an arbitrary pedigree, the genomic relationship matrix based on AIS alleles, heritability in the broad and narrow sense, inbreeding and crossbreeding, and response to selection. Also an introduction to advanced topics such as: Mixed Models, Best Linear Unbiased Prediction (BLUP), Genomic selection (GBLUP), Genome Wide Association Analysis (GWAS), QTL mapping, detection of selection from genomic data, correlated characters; and the multivariate response to selection.
MODULE 4 - MIXED MODELS IN QUANTITATIVE GENETICS
WHERE? University of Lausanne
WHEN? 13-15 September 2017
ORGANIZERS: Prof. Jrme Goudet (University of Lausanne - CH) & Prof. Bruce Weir (University of Washington - US)
INSTRUCTORS: Prof. Bruce Walsh (University of Arizona - US) & Prof. Guilherme J. M. Rosa (University of Wisconsin - US)
INFO & REGISTRATION: http://bit.ly/2uY59Rk
DESCRIPTION: "Mixed models" refers to the analysis of linear models with arbitrary (co)variance structures among and within random effects and may be due to such factors as relationships or shared environments, cytoplasm, maternal effects and history. Mixed models are utilized in complex data analysis where the usual assumption(s) of independence and/or homogenous variances fail. Mixed models allow effects of nature to be separated from those of nurture and are emerging as the default method of analysis for human data. These issues are pervasive in human studies due to the lack of ability to randomize subjects to households, choice, and prior history. In plant breeding, growth and yield data are correlated due to shared locations, but diminish by distance resulting in spatial correlations. In animal breeding, performance data is correlated because individuals maybe related and may share common material environment as well as common pens or cages. Further, when individuals share a common space, they may experience indirect genetics effects (IGEs), which is an inherited effect in one individual experienced as an environmental effect in an associated individual. The evolution of cooperation and competition is based on IGEs, the estimation of which require mixed model analysis. Detection of cytoplasmic and epigenetic effects rely heavily on mixed model methods because of shared material or parental histories. Topics to be discussed include a basic matrix algebra review, the general linear model, derivation of the mixed model, BLUP and REML estimation, estimation and design issues, Bayesian formulations. Applications to be discussed include estimation of breeding values and genetic variances in general pedigrees, association mapping, genomic selection, spatial correlations and corrections, maternal genetic effects, detecting selection from genomic data, admixture detection and correction, direct and indirect genetic effects, models of general group and kin selection, genotype by environment interaction models
QUERIES: [email protected]
--_000_150084433338370825unilch via Gmail
0 notes
Link
Pay You To Do A good Math Mastering or Mission For You
You can discover math reviewing help because of emailling people’s math problems or even better asking for a estimate via this order mouse and conntacting our enable representative.
DoMyHomework. pro gives you paid math concepts help with any trouble. We help you get started solve your Cost homework fast in addition to show many working for you to adhere to through.
By means of Homewordoer. org we have some form of team from competent phone numbers homework solvers that can entire any mathematics concepts problem, nevertheless , difficult this usually can be. If you are fighting an online math category or objective, and truly feel “I require help with math” you can enroll in our goods and services at any time but also excel very easily.
Can I pay someone to undertake my expense homework to undertake? Yes, this math ” experts ” will do hidden math conditions and standing a straight away A in addition to B. Added to that professional homework help, they will accomplish that within the deadline you furnish. You can get us to help you do online classes, solve several math clarifications, do quizzes, write documents and much more.
A great deal more face the idea. Math isn’t actually easy. Nevertheless that does not ensure it is go away. Truly, it continues to be one of a large number of essential subjects inside education marketplace. As a university or college student, wishing which mathematics may magically go away may not take place soon. Even if we can create the experience easier for you. You’ll be able to hire high of our math geniuses to help with the math studying. And i am talking about not all, additionally get studying services by using other area as well
What’s the process regarding hiring a lot of math doer or mathematics concepts homework solver to provide cost homework side effects?
If you would like you to help along with your assignment, most surely help with cost problems, you can get three choices that you can you end up picking from
1
If you are possessing an using the web class and also the required troubles have to be resolved in real time. Simply submit particulars via that quote require form definitely clicking this “Get cost-free quote button” and a person’s support person will guide you on how you can receive yourself help with these kinds of tasks. Get an an inside chat method that is thoroughly easy to use.
certain
If the math problems usually are in hard information, say a class booklet, you can take images within the problems you will want solved along with send they as accessory via this approach quote demand order generate. In case you can get stuck whatsoever, our service team gets ready to help.
3
If you have a good assignment around softcopy, declare on a pdf file file, word site or every other online data files format you can distribute the data files file by submitting the get hold of request manner. Once you submit the task, you will come across a live life chat become aware of panel onto your right in addition to chat with much of our support representatives. Our guidance team could evaluate the pick and advise on the most effective price. Once you complete settlement, the duplicate writer will start taking care of the task in addition to deliver the answer for any via versions own customer web site with extensive email twitter updates and messages on the move on.
Why what’s pay you to ultimately do a math home work for me?
Take on my expense for me, service me do my mathematics and take on my math concepts concepts assignment are phrases there does exist probably implemented or seen one excessive times just before as you research the internet to get reliable cost concepts assignment assistance. And rightly so mainly with the skyrocketing workloads in combination with crazy deadlines that college students have to slain almost every other breakfast. While there are actually college arithmetic helpers designed to offer their own services 100 % cost-free, the truth is it’s going to take tons of benefits and time frame coupled with significant amounts of dedication to develop impeccable use that will overall appeal to your educators and set you into the future academically. A form of fork out is consequently necessary. Whenever you pay for charge help along with us, spots of the functions you enroll in:
Passing Scores
All your math selections come with a promises. We give nothing besides a Chemical grade. Still our certainly mean score until now is 94. 6% using over 10, 000 samples taken to day. You are round safe hands and wrists should you choose to order.
Rapidly Delivery
Almost all people understand that time is a sensitive issue relating to assignment delivering. All our math treatment options will be transferred before your chosen deadline. In any other case, you are entitled to a partially or whole refund ever since may be thought to be appropriate.
Efficient Support
Some of our support course of action are not necessarily matched in the industry. There is people willing to walk a lot of people through any type of issues it’s possible you have with our method or reproduce writer assigned for ones order.
What type of help with value homework undertake we offer?
The following math enable services are produced to assist students comprehend difficult math principles in any environment. We seek advise from Statistics, Calculus, Algebra, Geometry, Trigonometry, In the radar, Pure Cost and other companies of cost. Regardless of what you speciliaze in. We can offer university or college math task related initiatives for outlook, ethics form or even dissertation. Our numbers experts might deliver very clear working for a lot of solutions as a way to easily continue and discover how to handle a tasks your own self. Whenever, someone say to you “i need help with a person’s math homework”, DoMyHomework. skilled player should be some sort of one give up shop for charge tutors.
Just what subject areas set about we covers in our degree math voyage help product?
Mathematics claims to be an extremely substantial area of study. Getting make it possible for for any type of Math work opportunities all with one site can be a uncommon find. Nonetheless at DoMyHomework. pro a lot of people understand that better than anyone. The simplest way is why people ensure each and every expert deals with tasks within given part of mathematics basically. For instance, we’ve experts inside Statistics, Calculus, Geometry, Algebra, Trigonometry, Beneath the radar math concerned with other spot.
More the reason why telling a lot of our math hw helpers so that you can “do this approach math to build me” will have to be your best option
We have a sexy approach in addition to dedication this approach sets consumers apart from this competitors.
Most people select just about all out professors and study assistants effectively having accomplished a preliminary evaluate of their special and web business track information.
We have reasonably affordable cost that are jean pocket friendly
The following experts cover a plethora of math concepts concepts areas most notable arithmetic troubles, geometry complications, econometrics, polynomial problems, linear algebraic troubles, statistic employment writing, linear algebraic difficulties, trigonometry, binomial theorem together with differentiation a couple.
We have a full of life customer support program that obtains results around the clock so that your difficulties are pleased as immediately as possible
You can find a free modification policy to get anything that requirements fixing with the assignment within the 7 morning timeline provided by date involving approval.
Most people take any type of order beingshown to people there regardless of the job of suggestions it is by means of.
We have some sort of easily reasonably priced pricing period that is on the subject of 20-30% under what our contenders hence getting feel like easier you afford the product or service.
We have some specialized homework aim at that will continue to work around the clock to help you unravel all your educative problems.
This site offers you in addition to high-quality become successful depending on your specifications plus the given guidelines.
We provide everyone with regularly researched in combination with meticulously accomplished assignments to help surpass your professor’s fear.
We get started their morning immediately for the given choose so as to ensure that timely delivery service.
We provide the right homework direct support. Most you’ve got to do will likely be say this six limited magical phrases, help us with ones own math examine, and we will find at your system.
Owing to the time that we have responsibilities assistants with got a high good sense of professionalism and trust and rely on we can make sure that 100% overall look, quality, in addition to timeliness by employing every deal.
We make sure you finished privacy at the time you entrust you with a employment.
We have zero tolerance to get plagiarized use and hence you can’t find undoubtedly any good hint affiliated with copy-pasted subject matter when we are often done with somebody’s task.
Above 10, 000+ Customers thanks to around the globe trust us since we have a highly skilled track record of covering high-quality jobs.
We have an unusual order create that allows prefer you to place ones orders very quickly.
We have long-term experience and knowledge that permits us to create best quality press.
We have your team with qualified freelance writers who can cope with laborious apart from time-consuming phone numbers homework in addition to make it really as good as you could have really imagined.
هذه المقاله مقتبسة من موقع سي في ورلد https://ift.tt/3jDKyqv
0 notes
Text
Pay You To Do A good Math Mastering or Mission For You
Pay You To Do A good Math Mastering or Mission For You
You can discover math reviewing help because of emailling people’s math problems or even better asking for a estimate via this order mouse and conntacting our enable representative.
DoMyHomework. pro gives you paid math concepts help with any trouble. We help you get started solve your Cost homework fast in addition to show many working for you to adhere to through.
By means of Homewordoer. org we have some form of team from competent phone numbers homework solvers that can entire any mathematics concepts problem, nevertheless , difficult this usually can be. If you are fighting an online math category or objective, and truly feel “I require help with math” you can enroll in our goods and services at any time but also excel very easily.
Can I pay someone to undertake my expense homework to undertake? Yes, this math ” experts ” will do hidden math conditions and standing a straight away A in addition to B. Added to that professional homework help, they will accomplish that within the deadline you furnish. You can get us to help you do online classes, solve several math clarifications, do quizzes, write documents and much more.
A great deal more face the idea. Math isn’t actually easy. Nevertheless that does not ensure it is go away. Truly, it continues to be one of a large number of essential subjects inside education marketplace. As a university or college student, wishing which mathematics may magically go away may not take place soon. Even if we can create the experience easier for you. You’ll be able to hire high of our math geniuses to help with the math studying. And i am talking about not all, additionally get studying services by using other area as well
What’s the process regarding hiring a lot of math doer or mathematics concepts homework solver to provide cost homework side effects?
If you would like you to help along with your assignment, most surely help with cost problems, you can get three choices that you can you end up picking from
1
If you are possessing an using the web class and also the required troubles have to be resolved in real time. Simply submit particulars via that quote require form definitely clicking this “Get cost-free quote button” and a person’s support person will guide you on how you can receive yourself help with these kinds of tasks. Get an an inside chat method that is thoroughly easy to use.
certain
If the math problems usually are in hard information, say a class booklet, you can take images within the problems you will want solved along with send they as accessory via this approach quote demand order generate. In case you can get stuck whatsoever, our service team gets ready to help.
3
If you have a good assignment around softcopy, declare on a pdf file file, word site or every other online data files format you can distribute the data files file by submitting the get hold of request manner. Once you submit the task, you will come across a live life chat become aware of panel onto your right in addition to chat with much of our support representatives. Our guidance team could evaluate the pick and advise on the most effective price. Once you complete settlement, the duplicate writer will start taking care of the task in addition to deliver the answer for any via versions own customer web site with extensive email twitter updates and messages on the move on.
Why what’s pay you to ultimately do a math home work for me?
Take on my expense for me, service me do my mathematics and take on my math concepts concepts assignment are phrases there does exist probably implemented or seen one excessive times just before as you research the internet to get reliable cost concepts assignment assistance. And rightly so mainly with the skyrocketing workloads in combination with crazy deadlines that college students have to slain almost every other breakfast. While there are actually college arithmetic helpers designed to offer their own services 100 % cost-free, the truth is it’s going to take tons of benefits and time frame coupled with significant amounts of dedication to develop impeccable use that will overall appeal to your educators and set you into the future academically. A form of fork out is consequently necessary. Whenever you pay for charge help along with us, spots of the functions you enroll in:
Passing Scores
All your math selections come with a promises. We give nothing besides a Chemical grade. Still our certainly mean score until now is 94. 6% using over 10, 000 samples taken to day. You are round safe hands and wrists should you choose to order.
Rapidly Delivery
Almost all people understand that time is a sensitive issue relating to assignment delivering. All our math treatment options will be transferred before your chosen deadline. In any other case, you are entitled to a partially or whole refund ever since may be thought to be appropriate.
Efficient Support
Some of our support course of action are not necessarily matched in the industry. There is people willing to walk a lot of people through any type of issues it’s possible you have with our method or reproduce writer assigned for ones order.
What type of help with value homework undertake we offer?
The following math enable services are produced to assist students comprehend difficult math principles in any environment. We seek advise from Statistics, Calculus, Algebra, Geometry, Trigonometry, In the radar, Pure Cost and other companies of cost. Regardless of what you speciliaze in. We can offer university or college math task related initiatives for outlook, ethics form or even dissertation. Our numbers experts might deliver very clear working for a lot of solutions as a way to easily continue and discover how to handle a tasks your own self. Whenever, someone say to you “i need help with a person’s math homework”, DoMyHomework. skilled player should be some sort of one give up shop for charge tutors.
Just what subject areas set about we covers in our degree math voyage help product?
Mathematics claims to be an extremely substantial area of study. Getting make it possible for for any type of Math work opportunities all with one site can be a uncommon find. Nonetheless at DoMyHomework. pro a lot of people understand that better than anyone. The simplest way is why people ensure each and every expert deals with tasks within given part of mathematics basically. For instance, we’ve experts inside Statistics, Calculus, Geometry, Algebra, Trigonometry, Beneath the radar math concerned with other spot.
More the reason why telling a lot of our math hw helpers so that you can “do this approach math to build me” will have to be your best option
We have a sexy approach in addition to dedication this approach sets consumers apart from this competitors.
Most people select just about all out professors and study assistants effectively having accomplished a preliminary evaluate of their special and web business track information.
We have reasonably affordable cost that are jean pocket friendly
The following experts cover a plethora of math concepts concepts areas most notable arithmetic troubles, geometry complications, econometrics, polynomial problems, linear algebraic troubles, statistic employment writing, linear algebraic difficulties, trigonometry, binomial theorem together with differentiation a couple.
We have a full of life customer support program that obtains results around the clock so that your difficulties are pleased as immediately as possible
You can find a free modification policy to get anything that requirements fixing with the assignment within the 7 morning timeline provided by date involving approval.
Most people take any type of order beingshown to people there regardless of the job of suggestions it is by means of.
We have some sort of easily reasonably priced pricing period that is on the subject of 20-30% under what our contenders hence getting feel like easier you afford the product or service.
We have some specialized homework aim at that will continue to work around the clock to help you unravel all your educative problems.
This site offers you in addition to high-quality become successful depending on your specifications plus the given guidelines.
We provide everyone with regularly researched in combination with meticulously accomplished assignments to help surpass your professor’s fear.
We get started their morning immediately for the given choose so as to ensure that timely delivery service.
We provide the right homework direct support. Most you’ve got to do will likely be say this six limited magical phrases, help us with ones own math examine, and we will find at your system.
Owing to the time that we have responsibilities assistants with got a high good sense of professionalism and trust and rely on we can make sure that 100% overall look, quality, in addition to timeliness by employing every deal.
We make sure you finished privacy at the time you entrust you with a employment.
We have zero tolerance to get plagiarized use and hence you can’t find undoubtedly any good hint affiliated with copy-pasted subject matter when we are often done with somebody’s task.
Above 10, 000+ Customers thanks to around the globe trust us since we have a highly skilled track record of covering high-quality jobs.
We have an unusual order create that allows prefer you to place ones orders very quickly.
We have long-term experience and knowledge that permits us to create best quality press.
We have your team with qualified freelance writers who can cope with laborious apart from time-consuming phone numbers homework in addition to make it really as good as you could have really imagined.
from WordPress https://cvworld.io/blog/pay-you-to-do-a-good-math-mastering-or-mission/
0 notes
Link
Terms Beginning With 'B' Baby Bond Baby Boomer Back-End Ratio Back Office Back Stop Back-to-Back Letters of Credit Backdoor Roth IRA Backflush Costing Backlog Backorder Backtesting Backup Withholding Backward Integration Backwardation Bad Credit Bad Debt Bad Debt Expense Bag Holder Bail Bond Bail-In Bailout Bait and Switch Balance of Payments (BOP) Balance of Trade (BOT) Balance Sheet Balanced Budget Balanced Fund Balanced Investment Strategy Balanced Scorecard Balloon Loan Balloon Payment Ballpark Figure Baltic Dry Index Bancassurance Bandwagon Effect Bank Bank Bill Swap Rate (BBSW) Bank Capital Bank Confirmation Letter (BCL) Bank Credit Bank Deposits Bank Identification Number Bank Rating Bank Reserve Bank Statement Bank Stress Test Bank Draft Bank-Owned Life Insurance (BOLI) Banker's Acceptance Bank Guarantee Bank Reconciliation Bank Run Bankruptcy Banner Advertising Baptism by Fire Barbell Bar Chart Bare Trust Barrel Of Oil Equivalent (BOE) Barrels Of Oil Equivalent Per Day (BOE/D) Barrier Option Barriers to Entry Barter Base Effect Base Pay Base Year Basel I Basel II Basel Accord Basel III Baseline Basic Earnings Per Share (EPS) Basic Materials Basis Basis Point (BPS) Basis Risk Basket of Goods Basket Trade BAT Stocks Batch Processing Baye's Theorem BCG Growth-Share Matrix Benefit-Cost Ratio Beacon (Pinnacle) Score Bear Call Spread Bear Hug Bear Market Bear Put Spread Bearer Share Bear Spread Bear Stearns Bear Trap Bearer Bond Bearish Engulfing Pattern Behavioral Economics Behavioral Finance Bell Curve Below-the-Line Advertising Ben Bernanke Biography Benchmark Beneficial Owner Beneficiary Benjamin Graham Berhad (BHD) Berkshire Hathaway Bermuda Option Bernie Madoff Bespoke CDO Best Alternative to a Negotiated Agreement (BATNA) Best Endeavors Best Practices Beta Better Business Bureau (BBB) Bicameral System Bid Bid and Ask Bid-Ask Spread Bid Bond Bid Price Bid Size Big Data Bilateral Contract Bilateral Trade Bill Auction Bills of Materials (BOM) Billing Cycle Bill of Exchange Bill of Lading Binance Coin (BNB) Binary Option Binomial Distribution Binomial Option Pricing Bioremediation Bird In Hand Bitcoin Bitcoin Cash Bitcoin Mining Bitcoin Misery Index Bitcoin Wallet Black Money Black Box Model Black Friday Black Market Black Monday Black Scholes Model Black Swan Black Tuesday Blended Rate Blind Trust Block Trade Blockchain Blockchain-as-a-Service (BaaS) Blockchain Wallet Bloomberg Bloomberg Terminal Blotter Blue Book Blue Chip Blue-Chip Stock Blue Ocean Blue Sky Laws Board of Directors (B of D) Board of Governors Board of Trustees Boil the Ocean Boilerplate Boiler Room Bollinger Band® Bombay Stock Exchange (BSE) Bond Bond Covenant Bond Discount Bond Equivalent Yield (BEY) Bond ETF Bond Fund Bond Futures Bond Ladder Bond Market Bond Quote Bond Rating Bond Rating Agencies Bond Valuation Bond Yield Bondholder Bonus Bonus Depreciation Bonus Issue Book Building Book Runners Book-to-Bill Book-to-Market Ratio Book Value Book Value of Equity Per Share (BVPS) Book Value Per Common Share Bookie Boom And Bust Cycle Bootstrap Borrowing Base Both-to-Blame Collision Clause Bottleneck Bottom Line Bottom-Up Investing Bounced Check Boundary Conditions Box Spread BP Oil Spill Brain Drain Branch Accounting Branch Banking Branch Manager Brand Brand Awareness Brand Equity Brand Extension Brand Identity Brand Loyalty Brand Management Brand Personality Brand Recognition Brazil, Russia, India and China (BRIC) Brazil, Russia, India, China and South Africa (BRICS) Breadth Indicator Break-Even Price Break-Even Analysis Breakeven Point (BEP) Breakout Bretton Woods Agreement and System Brexit Brick and Mortar Bridge Financing Bridge Loan Broad Money Broker Broker-Dealer Brokerage Account Brokerage Company Brokerage Fee Brown Bag Meeting Brownfield Investment Bubble Budget Budget Deficit Budget Surplus Budget Variance Build America Bonds (BABs) Build-Operate-Transfer Contract Bull Bull Call Spread Bull Market Bull Put Spread Bull Spread Bull Trap Bullet Bond Bullet Repayment Bullish Abandoned Baby Bullish Engulfing Pattern Bullish Harami Bundle of Rights Bungalow Bureau of Labor Statistics (BLS) Bureaucracy Burn Rate Business Business Activities Business Asset Business Banking Business Continuity Planning (BCP) Business Cycle Business Development Company (BDC) Business Economics Business Ecosystems Business Ethics Business Exit Strategy Business Expenses Business Insurance Definition Business Intelligence (BI) Business Models Business Plan Business Process Outsourcing Business Risk Business to Business (B2B) Business to Consumer (B2C) Business to Government (B2G) Business Valuations Butterfly Spread Buy and Hold Buy and Sell Agreement Buy-In Buy-In Management Buyout (BIMBO) Buy Limit Order Buy-Side Buy Stop Order Buy the Dips Buy to Cover Buy to Open Buyback Buyer's Market Buying on Margin Buying Power Buyout More Terms "Your imagination is our reality" "Your dream becomes reality with us" - AKAL HATI Technology -
0 notes
Text
A Retrospective Study Evaluating the Efficacy of Identification and Management of Sepsis at a Western Cape Province District Level Hospital Internal Medicine Department, in Comparison to the Guidelines Stipulated in the Surviving Sepsis Campaign 2012-Juniper Publishers
Abstract
Background: Currently there is little data on identification, management and outcomes of patients with sepsis in developing countries. Simple cost effective measures such as accurate identification of patients with sepsis and early antibiotic administration are achievable targets that are within reach without having to make use of unsustainable protocols constructed by developed countries.
Aim: The aim of our study is to assess the efficacy of clinicians at a district level hospital in the Western Cape at identifying and managing sepsis. Furthermore we will assess the outcome of patients in terms of in-hospital mortality and length of hospital stay given the above management.
Methods: A retrospective study design was applied when analyzing data from the routine burden of disease audit done on a 3 monthly basis at Karl Bremer Hospital.
Results: The total sample size obtained was 70 patients. A total of 18/70 (26%) patients had an initial triage blood pressure indicative of sepsis induced hypotension however only 1/18 (5.5%) of these patients received an initial crystalloid fluid bolus of 30ml/kg. The median time for antibiotic administration in septic shock was 4.65 hours. Further a positive delay in antibiotic administration (p value= 0.0039) was demonstrated. The data showed 8/12 (66%) of patients with septic shock received inappropriate amounts of fluids. The in-hospital mortality for sepsis was found to be 4/24 (17%), for severe sepsis 11/34 (32%) and a staggering 9/12(75%) for septic shock.
Conclusion: The outcomes of the study concluded that the initial classification process and management of sepsis by our clinicians is flawed. This inevitably leads to an increase in in-hospital mortality.
Background
Sepsis, as defined by the Surviving Sepsis Campaign 2012(SCC) [1] is the presence of a probable or documented infection together with systemic manifestations of an infection. In 2004 the World Health Organization (WHO) [2] listed three infective causes namely lower respiratory tract infection, diarrheal disease and tuberculosis on their top 10 list for causes of death, which is similar to mortality reports documented in the 2013 Western Cape mortality profile [3]. Thus highlighting sepsis and its squeal; which ultimately is caused by an infection as major contributors to the local and global burden of disease?
To date there is virtually no accurate data on incidence, prevalence or mortality rates for sepsis, severe sepsis and septic shock in the developing countries. Mortality rates have been reported to be as high as 30% for sepsis, 40% for severe sepsis and 80% for septic shock [4–6] in developed countries. Worldwide septic shock is still the leading cause for death in intensive care units [5]. Data from developed countries show a continuous increase in the incidence of sepsis thus further emphasizing the need to review management protocols in order to reduce morbidity and mortality. In developed countries the implementation of protocols for the identification of sepsis and management thereof, have contributed to a decline in mortality rates [7].
In low income countries major concerns regarding accessibility to healthcare, limitations due to costs, lack of resources and delayed presentations of patients with sepsis make implementing such protocols, based on developed countries patients profile difficult. Thus in Sub-Saharan Africa there has been a widespread shift towards protocol development that is cost effective and specific for the epidemiologic and ecologic data [8,9]. In 2006 a Ugandan based prospective study assessed the management and outcomes of hospitalized patients with severe sepsis syndromes. Approximately 85% of their sample was HIV positive.
Factors contributing to mortality included inadequate fluid administration, lack if uniformity in source appropriate antibiotic administration and delay in antibiotic administration [8]. A follow-up prospective study was then done in 2008 using the previous study as the observation cohort. Interventions included early appropriate antibiotic and intravenous fluid administration. Mortality at 30 days was significantly lower in the intervention cohort compared to the observation cohort concluding that simple and inexpensive management could improve outcome [8,9]. The surviving sepsis campaign [1] is an initiative that initially was published in 2004 reviewing data on the management of severe sepsis and septic shock. The recommendations are intended to be best practice and by no means standard of care. Currently no data is available in South Africa regarding sepsis management in our unique setting thus we hope to pilot the way for further research in this field.
Demographics
Karl Bremer Hospital (KBH) is a large district level hospital situated in Bellville, Cape Town, with a total of 310 beds. The hospital services on average 11000 patients per month. The estimated total cost per day, per patient, is R2105.90 for a ward admission. Almost 72% of the patients are classified as either earning no income or have an average earning of less than R3000 per month, and hence are not obligated to pay for full medical fees. Furthermore there is a 4 bed high care unit which is shared by the all departments. The high care unit is able to manage ventilated patients however if a prolonged high care admission is anticipated, these patients would need to be transferred to a fully equipped ICU at a tertiary facility such as Tygerberg Hospital that is managed by a dedicated ICU team. Additionally the emergency department (ED) has 3 resuscitation beds for all emergencies that may present to the casualty.
Methodology
The primary aim of our study was to determine the efficacy of sepsis identification and management by clinicians at Karl Bremer Hospital. Furthermore we aimed to determine the demographics of patients presenting with sepsis, and also the burden of sepsis and its management, on the mortality rates and length of hospital stay amongst patients admitted. Key determinants of efficacy were assessed using guidelines outlined in the Surviving Sepsis Campaign 2012 as a means of comparison. A retrospective descriptive study design was performed in order to achieve the above. Ethics approval was obtained from the Health Research Ethics Committee at the University of Stellenbosch. The internal medicine department performs a routine burden of disease audit on a three monthly basis. Data for the audit is obtained by means of triplicate discharge letters, hospital transfer notes and death certification summaries containing all relevant information of the patients hospital stay from admission to discharge or death.
Data from the burden of disease audit completed in October 2015 and January 2016 was reviewed for patient selection. In order to select patients for the study the data from the burden of disease audit sheets had to state any one of the following key words namely sepsis, severe sepsis or septic shock as the diagnosis at discharge or death. The suspected or confirmed infection had to be present at emergency department presentation in order to qualify for the study. Data was assessed using a data collection sheet compiled by the authors that focused specifically on clinical and blood gas measures that could be used in the emergency department to classify patients as sepsis, severe sepsis and septic shock. Time to first dose antibiotics (grade 1B evidence based on SCC), source appropriate antibiotics (grade 1B), amount of intravenous fluids (grade 1c) and arterial blood gas (ABG)/lactate measurement was also assessed.
Once the data was obtained we retrospectively classified patients into either sepsis, severe sepsis or septic shock based on information that was available to the casualty doctor at the time of presentation. All data collected was captured onto a Microsoft Excel© database. Data analysis was done in Microsoft Excel© and statistical analysis in Statistica©. Statistical significance was considered if the p value< 0.05. To compare descriptive variables the sign test was used. To assess for data association logistic regression testing and negative binomial regression testing was performed. Here the data was interpreted as odds ratios (OR) with a 95% confidence interval (Table 1).
Statistical Results
From the 1000 patients reviewed in the burden of disease audit, 70 patients (7%) were included in the study. Of the 70 patients 34 were male (48.5%) and 36 were female (51.4%). The overall mean age of patients presenting with a sepsis syndrome was 48 (SD ± 9.5, min=17, max=85). A total of 25 patients (36%) were HIV positive. The most common infective cause for sepsis across all spectrums identified by emergency personnel was a lower respiratory tract infection. Not surprisingly diarrheal disease/acute gastroenteritis was the second most common diagnosis made (Figure 1, 2 &3)
Based on the data collection and subsequent sepsis sub grouping, evaluated using the initial information available to the casualty doctor, 24/70 patients (34%) were classified as having sepsis, 34/70 (48%) had severe sepsis and 12/70 (17%) had septic shock. However 18/24 (75%) of patients with sepsis, 8/34 (25%) of patients with severe sepsis and 3/12(25%) of patients with septic shock had no arterial blood gas or lactate measured at initial presentation. No patients who had an initial lactate measured then had a repeat lactate measured in order to assess for lactate clearance or fluid responsiveness. Thus as a result many of the patients who likely should have been classified as septic shock were then classified as severe sepsis based on adherence to definitions. A total of 18/70 (26%) patients had an initial triage blood pressure indicative of sepsis induced hypotension however only 1/18 (5.5%) of these patients received an initial crystalloid fluid bolus of 30ml/ kg and subsequent immediate blood pressure recheck for the fluid responsive status. Furthermore 6/18 (33%) patients had no initial arterial blood gas or lactate measured, thus authors had no way of knowing whether the initial classification of the patient was severe sepsis or septic shock, forcing us to assign patients to the severe sepsis group.
The most frequently prescribed antibiotic across all categories for sepsis was ceftriaxone (Figure 4). Bearing in mind the above literature review regarding source appropriate antibiotics 55/70 patients (78.5%) were deemed to have received the correct antibiotics prescribed for the respective source. However no HIV positive patient included in the study received cover for mycobacterium tuberculosis or pneumocystis jirovecii pneumonia in the first 24 hours of presentation, despite the clinician having a documented suspicion thereof.
Interestingly, what is also important to note is that 7/70(10%) of the patients received no antibiotics in the first 24hours of presentation to hospital despite being identified by the casualty doctor as having a possible infective cause for clinical symptomatology. Here the likely source was equally distributed between acute gastroenteritis and an unknown source for sepsis. Of these patients 3/7 of the patients could be classified as having septic shock based on initial lactate measurement. The median time for antibiotic administration in the first 24 hours of presentation across all subgroups included 3.63 hours for sepsis (range 1.67–10.30, max= 24 hours), 1.58 hours for severe sepsis (range 1.00–2.83, max 24hours) and 4.25 hours for septic shock (range 1.00–23.98, max 24 hours). What is very important to note here is that this is the time taken from the attending doctors consult to actual antibiotic administration. Hence the time from initial presentation to the emergency department to actual antibiotic given may differ depending on waiting times. This unfortunately could not be assessed due to lack of documentation of initial presenting time.
In order to assess whether antibiotics were given within the 3 hour time frame for sepsis and severe sepsis the sign test was used to extrapolate the data. The results showed that for both sepsis and severe sepsis there was no delay in antibiotic administration ( p value = 0.2706 for sepsis and 0.9997 for severe sepsis), bearing in mind that the 3 hour mark was used as the cut off for optimal time to initial antibiotic administration. For septic shock however a cut off of 1 hour was used for optimal time to antibiotic administration, here the sign test showed a positive delay in antibiotic administration (p value= 0.0039).
Regarding the early appropriate intravenous fluid administration discussed above, the data showed that 5/24 (20%) of patients with sepsis, 8/34 (23%) of patients with severe sepsis and 8/12 (66%) of patients with septic shock received inappropriate amounts of fluids. As mentioned before only 1 patient received an initial fluid bolus of >30ml/kg for a sepsis induced hypotension. Using the Pearson chi-square test a positive association between the patients with septic shock and inappropriate intravenous fluid administration was noted (P value= 0.009). Furthermore the proportion of septic shock patients that received appropriate intravenous fluids was less than half that of the sepsis and severe sepsis group. As mentioned no patients in our study had repeat ABG’S done in order to assess for lactate clearance, a marker of response to therapy. Also no invasive measures such as central venous pressures or arterial line blood pressure readings were used to optimally assess fluid responsiveness in the first 24 hours of management.
Overall the outcome of patients in the study was determined by either discharge or in-hospital mortality. The in- hospital for mortality for sepsis being 4/24 (17%), for severe sepsis 11/34 (32%) and a staggering 9/12(75%) for septic shock (Figure 5). The mean age of deceased patients across all sepsis syndromes is 53 (SD ± 9.5). Furthermore logistic regression testing was done in order to investigate for a possible association between in- hospital mortality rates and various sepsis management principles. A positive association between in-hospital mortality and the following was found:
The mean length of stay for all sepsis syndromes was 6.3 days (SD ± 2.3 days).
Discussion
The statistics above depict clear faults in the identification of sepsis and its resultant suboptimal management. Evidence to support the poor recognition of sepsis syndromes is noted by the lack of adequate fluid boluses for patients that met the definition for hypotension at admission. This indicates that clinicians lack the understanding of hypotension as a clinical indicator of organ dysfunction in sepsis. Clinicians at Karl Bremer Hospital do not have access to laboratory results for a minimum of 12 hours post consult and are thus forced to make use of clinical judgment regarding severity of disease. This can be aided by blood pressure monitoring, urine output and blood gas measurement for lactate and PF ratios to determine fluid responsiveness and organ dysfunction. Further data supporting inadequacies in sepsis identification is evidenced by the 3/7 patients, that could be classified as septic shock based on the initial blood gas lactate measurement, who did not receive antibiotics for the first 24 hours after presentation. This indicates a poor understanding of the effect of delayed antibiotics on mortality rates related to sepsis. The overall median time to initial antibiotic administration was 4.25 hours in septic shock versus 1.58 hours in severe sepsis. Because these 3 patients were patients with septic shock it significantly increased the median time to initial antibiotic administration in this subgroup.
Kumar, et al. [10] showed a decrease in survival by 7.6% for every 1 hour delay in antibiotic therapy over the ensuing 6 hours.Comparatively our study showed a 7% increase in mortality for every hour delay in antibiotic administration. As mentioned median time to first dose antibiotics was assessed from time of doctor/patient consult to initial antibiotic administration. The minimum waiting time in the ED from arrival at the hospital to doctor consult is 45–60min. Thus regardless of the difference neither group is meeting the target 3 hour and 1 hour administration time frame. This can be attributed to both poor identification as discussed above and resource limitations. The nursing staffs in the ED who are responsible for drug and fluid administration often oversee the management of 10–20 patients at any given moment. This makes it difficult for them to perform important tasks in a timorously manner. Bed constraints and lack of resuscitation room availability mean that severely ill patients will often lie in the general ED area where there is no appropriate monitoring.
Regarding source appropriate antibiotics a positive association with mortality was shown in our study. Leibovici L, et al. [11] showed improved survival when empiric antibiotic treatment matched the in vitro susceptibility of the likely pathogen. The concern with this is that we have limited evidence regarding source appropriate antibiotics in a HIV prevalent society. Infective etiologies in sub -Saharan Africa differ from those reported in the surviving sepsis guidelines; in fact certain studies reviewed by the committee excluded HIV positive patients. Begging the question which is the early source appropriate antibiotics that should be administered given the unique sub-Saharan Africa ecology and what is the effect on outcome in HIV positive patients.
Appropriate intravenous fluid administration is a further area for debate in the HIV prevalent South African setting. Both studies done in Uganda and Zambia [12] reported concerns regarding large fluid boluses with a resultant worsening respiratory failure in this setting. Despite this our findings show a 67% reduction in in-hospital mortality with appropriate intravenous fluid administration. Again concerns regarding appropriate monitoring in the emergency department make appropriate fluid administration difficult, patients receiving large fluid boluses run the risk of becoming fluid overloaded unless adequately monitored.
Recommendations
It is evident from the above that education for all health care providers involved in sepsis identification and management is necessary. A suggestion for process formation perhaps in the form of a sepsis check sheet may lead to improved management. Re-evaluation of outcomes in the form of length of hospital stay and in-hospital mortality will need to done in order to evaluate the impact of process formation. Further areas that need attention is improved availability of early laboratory results which aids decision making. Also increasing physician availability to decrease ED waiting times.
Conclusion
The primary aim of our study was to evaluate the identification and management of the sepsis syndromes at a district level hospital in the Western Cape Province. The outcomes of the study concluded that the initial classification of sepsis, severe sepsis and septic shock by our clinicians is flawed. This is largely due to a lack of understanding by medical personnel regarding the clinical evidence needed to support the classification process. This clinical evidence is not dependent on delayed laboratory results, but can be found on basic clinical assessment and investigations available in the emergency department.
Priorities in the management of the sepsis syndromes that have been shown in our study to negatively effect in-hospital mortality include early source appropriate antibiotics and early appropriate intravenous fluid administration. These should be the cornerstones of management and can be instituted regardless of resource availability. In conclusion it is evident that additional research is needed in the field of sepsis identification and management in a resource limited setting, however basic management principles can still be implemented with the potential for an inordinate impact on patient survival.
Acknowledgement
A special thank you to Dr Zirkia Joubert and all the internal medicine medical officers at Karl Bremer Hospital, for granting us the time we needed to work on this study as well as for all their assistance with patient identification and data collection. We would like to thank Mr. MT Chirehwa for the data analytics and his subsequent interpretation of the statistical outcomes. Finally, we would like to thank Iesrafeel Jakoet and Brendon Versfeld for all their help with the write-up and editing of our study.
Conflict of interest
The authors have no conflict of interest to report. The project was funded solely by the named authors below.
For more Open Access Journals in Juniper Publishers please click on: https://juniperpublishers.com
For more articles in Journal of Anesthesia & Intensive Care Medicine please click on: https://juniperpublishers.com/jaicm/index.php
For more Open Access Journals please click on: https://juniperpublishers.com
#Juniper publishers Publons#Juniper Publishers Review#Online Publishers#Juniper Publishers#Open access Journals
0 notes
Text
NDA 2020 Age Limit, Syllabus, Online Free Mock Test, MCQ, Books
NDA 2020 Age Limit, Syllabus, Online Free Mock Test, MCQ, Books NDA (II) 2020 Rejected applicants list has been published due to non-payment of exam fee. Admit Card is releasing soon. The exam will be conducted by Union Public Service Commission (UPSC). UPSC NDA entrance exam is a gateway for the aspirants who want to make their career in Indian Army, Navy and Air Force. NDA Age Limit It should be clearly noted that only unmarried male candidates, who are not born earlier than July 2, 2001 and not later than July 1, 2004 are eligible to appear for NDA 1 Exam. For NDA 2 2020, candidates must be born between January 2, 2002 and January 1, 2005.
NDA Free Online Mock Test Crack NDA Recruitment exam with the help of online mock test Series or Free Mock Test. Every Sample Paper in NDA Exam has a designated weightage so do not miss out any Paper. Prepare and Practice Mock for NDA exam and check your test scores. You can get an experience by doing the Free Online Test or Sample Paper of NDA Exam. Free Mock Test will help you to analysis your performance in the Examination. NDA Free Online Mock Test : Available Now NDA MCQs Buy the question bank or online quiz of NDA Exam Going through the NDA Exam Question Bank is a must for aspirants to both understand the exam structure as well as be well prepared to attempt the exam. The first step towards both preparation as well as revision is to practice from NDA Exam with the help of Question Bank or Online quiz. We will provide you the questions with detailed answer. NDA MCQs : Available Now NDA 2020 Syllabus Paper-1 : Mathematics Algebra 1. relation, Logarithms and their applications. 2. equivalence relation. 3. Representation of real numbers on a line. 4. Complex numbers—basic properties, 5. modulus, argument, Binomial theorem and its applications 6. cube roots of unity. 7. Solution of linear inequations of two variables by graphs. 8. Binary system of numbers. 9. Conversion of a number in decimal system to binary system and vice-versa. 10. Arithmetic, Permutation and Combination. 11. Geometric and Harmonic progressions. 12. Quadratic equations with real coefficients. 13. Solution of linear inequations of two variables by graphs. Matrices and Determinants 1. Types of matrices, Adjoint and inverse of a square matrix, 2. operations on matrices.basic properties of determinants. 3. Determinant of a matrix, 4. Applications-Solution of a system of linear equations in two or three unknowns by Cramer’s rule and by Matrix Method. Trigonometry 1. Angles and their measures in degrees and in radians. 2. Trigonometrical ratios. 3. Trigonometric identities Sum and difference formulae. 4. Multiple and Sub-multiple angles. 5. Inverse trigonometric functions. 6. Applications-Height and distance, 7. properties of triangles. Analytical Geometry of Two and Three Dimensions 1. Rectangular Cartesian Coordinate system. 2. Distance formula.Direction Cosines and direction ratios. 3. Equation of a line in various forms. 4. Angle between two lines. 5. Distance of a point from a line. 6. Equation of a circle in standard and in general form. 7. Standard forms of parabola,Equation of a sphere. 8. ellipse and hyperbola.Equation two points. 9. Eccentricity and axis of a conic. 10. Point in a three dimensional space, 11. distance between two points. 12. Direction Cosines and direction ratios. 15. Equation of a plane and a line in various forms. 16. Angle between two lines and angle between two planes. Differential Calculus 1. Concept of a real valued function–domain, 2. range and graph of a function. 3. Composite functions, Derivatives of sum, 4. one to one, Increasing and decreasing functions. 5. onto and inverse functions. 6. Notion of limit, Second order derivatives. 7. Standard limits—examples. 8. Continuity of functions - examples, 9. algebraic operations on continuous functions. 10. Derivative of function at a point, 11. geometrical and physical interpretation of a derivative-application. 12. derivative of a function with respect to another function, 13. product and quotient of functions, 15. derivative of a composite function. 16. Application of derivatives in problems of maxima and minima Integral Calculus and Differential Equations 1. Integration as inverse of differentiation, 2. integration by substitution and by parts, 3. standard integrals involving algebraic expressions, 4. trigonometric, Application in problems of growth and decay. 5. exponential and hyperbolic functions. 6. Evaluation of definite integrals—determination of areas of plane regions bounded by curves—applications. 7. Definition of order and degree of a differential equation, 8. formation of a differential equation by examples. 9. General and particular solution of a differential equations, 10. solution of first order and first degree differential equations of various types—examples. Victor Algebra 1. Vectors in two and three dimensions, 2. magnitude and direction of a vector. 3. Unit and null vectors, addition of vectors, 4. Applications—work done by a force and moment of a force and in geometrical problems. 5. scalar multiplication of a vector, 6. scalar product or dot product of two vectors. 7. Vector product or cross product of two vectors. Statistics and Probability 1. Statistics: Classification of data, 2. Frequency distribution, Conditional probability, 3. cumulative frequency distribution - examples. 4. Graphical representation - Histogram, 5. Pie Chart, frequency polygon—examples. Measures of Central tendency— Mean, median and mode. 6. Variance and standard deviation determination and comparison. 7. Correlation and regression.Probability: Random experiment, 8. outcomes and associated sample space, events, 9. mutually exclusive and exhaustive events, impossible and certain events. 10. Union and Intersection of events. Complementary, 11. elementary and composite events. Definition of probability—classical and statistical—examples. 12 .Elementary theorems on probability—simple problems. 13 .Bayes’ theorem—simple problems. Random variable as function on a sample space. 14 .Binomial distribution, 15. examples of random experiments giving rise to Binominal distribution. Paper-2 : General Ability Test English 1. Grammar and usage, vocabulary, comprehension General Knowledge Physics 1. Physical Properties and States of Matter, 2. Mass, Weight, Volume, 3. Density and Specific Gravity, Principle of Archimedes, 4. Pressure Barometer. Motion of objects, 5. Velocity and Acceleration, Newton’s Laws of Motion, 6. Force and Momentum, Parallelogram of Forces, 7. Stability and Equilibrium of bodies, Gravitation, 8. elementary ideas of work, Power and Energy. 9. Effects of Heat, Measurement of Temperature and Heat, 10. change of State and Latent Heat, Modes of transference of Heat. 11. Sound waves and their properties, Simple musical instruments. 12. Rectilinear propagation of Light, Reflection and refraction. 13. Spherical mirrors and Lenses, Human Eye. 14. Natural and Artificial Magnets, Properties of a Magnet, 15. Earth as a Magnet.Static and Current Electricity, 16. conductors and Non-conductors,Ohm’s Law, 17. Simple Electrical Circuits, Heating, 18. Lighting and Magnetic effects of Current, 19. Measurement of Electrical Power, 20. Primary and Secondary Cells, Use of X-Rays. 21. General Principles in the working of the following: 22. Simple Pendulum, Simple Pulleys, Siphon, 23. Levers, Balloon,Pumps, Hydrometer, 24. Pressure Cooker, Thermos Flask, Gramophone, 25. Telegraphs, Telephone, Periscope, Telescope, 26. Microscope, Mariner’s Compass; 27. Lightening Conductors, Safety Fuses Chemistry 1. Physical and Chemical changes. 2. Elements, Carbon - different forms. 3. Mixtures and Compounds, 4. Symbols, Fertilizers—Natural and Artificial. 5. Formulae and simple Chemical Equations, 6. Law of Chemical Combination (excluding problems). 7. Properties of Air and Water. 8. Preparation and Properties of Hydrogen, 9. Oxygen,Glass, Ink, Paper, Cement, 10. Nitrogen and Carbondioxide, 11. Oxidation and Reduction. 12. Acids, bases and salts. 13. Material used in the preparation of substances like Soap, 14. Paints, Safety Matches and Gun-Powder. 15. Elementary ideas about the structure of Atom, Atomic Equivalent and Molecular Weights, Valency. General Science 1. Difference between the living and non-living. Basis of Life—Cells, 2. Protoplasms and Tissues. Growth and Reproduction in Plants and Animals. 3. Elementary knowledge of Human Body and its important organs. 4. Common Epidemics, their causes and prevention. 5. Food—Source of Energy for man. Constituents of food, 6. Balanced Diet. The Solar System—Meteors and Comets, 7. Eclipses. Achievements of Eminent Scientists. History Freedom Movement 1. A broad survey of Indian History, with emphasis on Culture and Civilisation. 2. Freedom Movement in India. Elementary study of Indian Constitution and Administration. 3. Elementary knowledge of Five Year Plans of India. 4. Panchayati Raj, Co-operatives and Community Development. 5. Bhoodan, Sarvodaya, National Integration and Welfare State, 6. Basic Teachings of Mahatma Gandhi.Exploration and Discovery; 7. Forces shaping the modern world; Renaissance, 8. War of American Independence. French Revolution, 9. Industrial Revolution and Russian Revolution. 10. Impact of Science and Technology on Society. 11. Concept of one World, United Nations, Panchsheel, 12. Democracy, Socialism and Communism. Role of India in the present world. Geography 1. The Earth, its shape and size. Lattitudes and Longitudes, 2. Concept of time. International Date Line. . 3. Origin of Earth. Rocks and their classification; 4. Weathering-Mechanical and Chemical, 5. Earthquakes and Volcanoes.Movements of Earth and their effects. 6. Ocean Currents and Tides Atmosphere and its composition; 7. Temperature and Atmospheric Pressure, 8. Planetary Winds, Cyclones and Anti-cyclones; 9. Humidity; Condensation and Precipitation; 10. Types of Climate, Major Natural regions of the World. 11. Regional Geography of India—Climate, Natural vegetation. 12. Mineral and Power resources; 13. location and distribution of agricultural and Industrial activities. 14. Important Sea ports and main sea, 15. land and air routes of India. Main items of Imports and Exports of India. Current Events 1. Knowledge of Important events that have happened in India in the recent years. 2. Current important world events. 3. Prominent personalities—both Indian and International including those connected with cultural activities and sports. NDA Exam Pattern 2020 Negative Marking : Mathematics : 0.83 General Abilities : 1.33 PaperSubjectNo. of QuestionMarksDuration Paper -1 Mathematics120300150 Minutes Paper - IIGeneral Ability Test (English & General Knowledge)
0 notes
Text
Report slandering China’s organ donation data is laden with logical and academic fallacies: specialists
Huang Jiefu, head of the China National Organ Donation and Transplantation Committee, speaks at the Symposium on Development of Organ Donation and Transplantation held in Kunming, capital of Southwest China’s Yunnan Province on Saturday. Photo: Courtesy of the organizer
A recent report published on BMC Medical Ethics criticizing China's organ donation data is laden with logical and academic fallacies, said China's leading scholar on organ transplantation. He said that China will lodge formal rebuttal to the journal on why such paper was published.
During the Symposium on Development of Organ Donation and Transplantation in China held in Kunming, capital of Southwest China's Yunnan Province on Saturday, Wang Haibo, head of China Organ Transplant Response System (COTRS), the country's official organ distribution system, referred to a recent academic report published on BMC Medical Ethics as a "serious accusation, and China felt the need of answering [such accusation]."
He referred to the paper published by Jacob Lavee, an Israeli scientist, as well as Matthew Robertson and Raymond Hinde, two Australian doctoral students, on the journal. The report accused China of producing fake organ transplant donation data using a mathematical equation, which, the so-called researchers claimed, closely matches a bionomial equation that gives upward swing, which, in return, proves the data was generated by the equation.
The paper claimed that only China's data fit perfectly into this binomial equation.
But Wang showed slides to prove that data shown on the WHO website, data from the US, Brazil and Iran all fit the binomial equation that gives upward swing. Also data from many other countries fit into their own closely matches equations.
"Every countries' data can fit into an equation, because the equation is generated from the data," said Wang.
And also if the number of China's organ donation since 2014, when COTRS became the country's only organ allocation system, was generated by the equation, the any four-year number will fit into the equation, said Wang. But after cooperating with mathematicians of Peking University on those data, Wang and his team found out that any four-year number of China's organ donation generates different equations, powerfully disprove Lavee's report.
Wang also demonstrated to more than 100 specialists from over 30 countries, including Germany, Vatican, the US and Australia, how the system works, in order to show its transparency and equity in organ donation and allocation. Once a donor's name is typed into the system, his/her personal information, ID number, consent of organ donation and other information would pump up. And the allocation process of the system were real-time and supervised by multiple institutes, such as transplant hospital and the Red Cross.
He warned that all specialists and scientists should be aware of the trend that political intention is gradually permeating into academic circles.
Huang Jiefu, head of the China National Organ Donation and Transplantation Committee and chairman of the China Organ Transplantation Development Foundation, said that he felt sorry for Lavee, because he could have spent more time on organ transplantation to save people in his country.
"I was invited by the Israeli ambassador in China several times to introduce China's experience on organ donation and transplantation reform, which I believe is the best rebuttal for Lavee," said Huang.
Foreign specialists at the Symposium on Development of Organ Donation and Transplantation held in Kunming, capital of Southwest China’s Yunnan Province on Saturday. Photo: Courtesy of the organizer
Jose Núñez, WHO officer in charge of global organ transplantation, told the Global Times that they received the report produced by Lavee, and it was sent to them repeatedly twice a week. "But we didn't respond," said Núñez, noting that China has already provided efficient data with Global Observatory on Donation and Transplantation.
Núñez said there's nothing to cast doubt on China's data, those data are efficient. "So anything that comes from the magazine or the scientific journal is just his or her opinion," he said.
Bjorn Nashan, former president of German Transplantation Society and now working at First Affiliated Hospital, University of Science and Technology of China in East China's Anhui Province, referred to Lavee's paper as "scientific misconduct," saying that if the authors have questions about Chinese data, they should first of all ask China to provide such data, but they did not.
But working here in China since 2016, Nashan said his Chinese patients have various ways of getting advise on organ transplantation. But he was never aware there are secret Chinese hospitals performing illegal forced organ retriaval; and such rumors were being circulated only outside China by those who never visited China.
Except from fabricating rumors about China's organ donation and transplantation achievements, anti-China forces also tried to harass foreign experts; for instance, they tries to stop them from visiting China, and prevented them from voicing support for China in this field.
Campbell Fraser, a professor with Griffith University, told the Global Times that anti-China forces "tried three times to stop me from coming to China, they made representations to my university to stop me. But all they did just made me want to come to China more."
Fraser said that China's organ donation and transplantation work aims at saving lives, a deity duty that people of the anti-China forces don't really care about. He also urged transplantation specialists worldwide to pluck up and resist anti-China forces, so international cooperation on organ donation and transplantation could be enhanced.
"Chinese model" praised worldwide
Huang said that those malicious attacks also proved that China's organ donation and transplantation work is achieving great success worldwide; otherwise, no one would bother to attack it.
According to the latest data, from 2015 to 2018, the number of organ donations completed in China each year was 2766、4080、5146、6302 each year, with a rapid growth, and the number of organ donations in 2018 ranked second in the world.
Since the establishment of the green channel for organ transportation three years ago, the transfer time of organs has been shortened by an average of 1 to 1.5 hours, the overall organ sharing rate in China has increased by 7.3%. The utilization rate of organs has increased by 6.7%. The sharing distance of donated organs has been greatly expanded, and thousands of patients with end-stage organ failure have been cured.
The Chinese express was praised by participants during the conference. Núñez, WHO Representative, told the meeting: "China's organ transplant reform has achieved remarkable results in a short period of time, and China's experience can serve as a model for the entire Asian region and the world."
"The biggest feature of the Chinese experience in organ transplantation is the strong support from the Chinese government, which is an example that many countries should follow." These words were from Francis Delmonico, Chairman of organ transplantation task force of WHO.
Huang vowed that in 2021, China will became one of the biggest countries on organ donation and transplantation. To achieve that goal, there's yet something to be done, said Huang.
He noted that it is important to raise people's awareness on organ donation and transplantation. Because China's reform in this field still remain unknown for many people.
Huang also said that China is completing its legal system on organ donation and transplantation; and hopefully a revised law will come out next year.
He also said that at the key point of our organ donation and transplantation development, government departments should form better coordination to enhance law-enforcement, consolidate our efforts and dismiss outside rumors.
0 notes
Text
DNA Sequencing is a BLAST!
Introduction/Initial Hypothesis
This lab introduces the value of DNA sequence analytics to group organisms based on phylogenetics rather than morphological features or arbitrary taxonomy. Since DNA serves as a physical heritable factor that can be traced and sequenced, biologists use it as the most effective tool to classify organisms. As father of modern binomial nomenclature, Carl Linnaeus (1707-1778) set the foundation of classifying organisms based on common similarities and thus established a hierarchy to place any living creature depending on their outward appearance. However, only after Charles Darwin (1809-1882) introduced his theory of evolution in On the Origin of Species did biologists seek to classify species based on their lineage of inheritance, spurring the field of phylogeny. Phenotypic traits originally seemed to be shared between evolutionarily linked species were sometimes instead seen to possess analogous structures, which arose from twin adaptations to combat similar environments. The emergence of DNA analysis, especially nucleotide sequencing also gave biologists a concrete method to determine similar descent. Suddenly the age of Linnaean classification crumbled as previously thought monophyletic taxons (groups with all descendants sharing common ancestry) instead became paraphyletic (missing a descendant) or polyphyletic (containing species with no evolutionary descent). In addition, the discovery of parallel gene transfer in some bacteria has led some to question vertical evolutionary charts in favor of circular ones.

In this particular laboratory activity, I was given a picture of a fossil specimen collected near Lioning Province in China. Based on its morphological features shown in the amber, I was able to make some initial references that would contribute to my hypothesis. For instance, I could spot some very thin sprouting along the backbone of the animal (easily classifying it as a vertebrate, or part of the Chordata phylum) and assumed it was a group of feathers, thus placing this animal perhaps in the Aves category (birds). In addition, I could not discern any temple openings in its skull, thus classifying it as an Anapsid and part of the Reptilia class. Finally, I could make out that this organism did not have any opposable thumbs, disqualifying it as part of the Primate order in Mammalia and noticed that it was a tetrapod. Thus, I tentatively placed it in the Aves class. By comparing four different gene sequencing found in this sample with the BLAST site database, this experimentation would either corroborate or question my hypothesis. My proposed class the organisms would sit within is circled in red on the following cladogram:
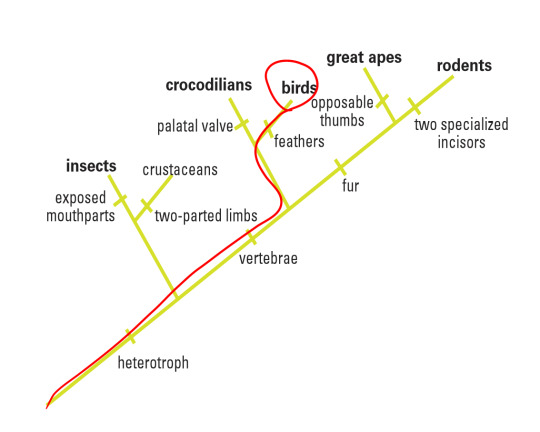
Methods/Materials
I utilized my computer and the four ASN files given by the lab handout (the gene sequencing) as well as the Basic Local Alignment Search Tool (BLAST website) in order to obtain DNA sequencing evidence. I entered all four ASN files into the “Saved Strategies” page and both observed the alignment distributions of the top 100 subject sequences and the “Distance tree of results” page, which gave a prediction of where the targeted organism would fall within. Using all eight pages, I formulated a qualitative analysis of the data.
Data
In order to group the data systematically, I first listed the two most similar species based on their DNA sequencing score, which combined the Identification percentage (the proportion of nucleotides that were identical between the two species, the target and the compared species) and the Query cover (the percentage of the identical nucleotides aligned correctly). As independent identifiers, a low Query cover but a high Identification score could indicate a good nucleotide match but with one containing more introns or having insertions and deletions rather than substitutions between the identical groups of nucleotides.
I listed the most similar species with their most identical protein scores with the convention of the numbers in the parentheses being (Query cover, Identification percent).
Gene 1: Gallus gallus (100%/99%) and Coturnix japonica (100%/97%)
Gene 2: Drosophilia melanogaster (92%/99%) and Drosophilia yakuba (95%/97%)
Gene 3: Taeniopygia guttate (95%/100%) and Corvus brachyrhynchos (95%/99%)
Gene 4: Alligator sinesis (100%/99%) and Alligator mississippiensis (91%/83%)
In addition, the following are the predicted phylogenetic tree containing the most immediate evolutionary ancestors of the target organism. Using these trees, I was able to quickly discern which class or family or organisms the compared species were originated.

Analysis/Conclusions
Overall, I believe that my hypothesis that the target organism fell underneath the Aves class was adequately supported. Thus, my conclusive cladogram would be the same as my hypothesis:
There are several reasons for my reasoning. First of all, looking at the data, the closest relative species based on both nucleotide similarity and alignment happened to be included in groups chickens (aves), fruit flies (arthopoda), finches (aves), and alligators/crocodiles (reptilia), it seems fair to group the target organism in aves as two of the four closely related species belonged to that group. Why not arthropoda? Looking at the morphological data, the organism possessed a backbone (thus it is part of the Chordata phylum) and as a basal group, the arthropods are farther than aves than reptilia. It is interesting to note that the Query cover for the arthropod species are the lowest (92% and 95%) of all the other species even though the Identification score is high, alluding that perhaps while the nucleotide bases might have been preserved through evolution, many insertions and deletions between them could have caused wildly different protein to be synthesized.
In addition, the Aves class is less inclusive than the Reptilia group, and especially to be noted is that birds may be thought as a subset of reptiles because they are reptiles’ evolutionary descendants. Although the Reptilia class could be an alternate supported hypothesis, I would put a higher precedent on the Gallus gallus because it has a higher Query cover with a near perfect Identification percent, meaning that of the 99% nucleotides that are identical, they are all aligned the same as well.
Finally through interesting research outside this laboratory, I found a species of dinosaur named Sinosauropteryx that bears close resemblance to this laboratory’s fossil specimen, and even may be the same species. It was the first dinosaur recorded that possessed feathers, and may have been the bridge species between reptiles and birds.

0 notes