#RemotePort
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
Find which program is using a Specific Port in Windows
Find which program is using a Specific Port in Windows
While installing a web server on a workstation, I kept getting an error that the port number was in use. This obviously caused some issues as it is an IT machine, who knows what was installed using the ports? There are two ways to figure out what software is using the ports required. The first is Command Prompt which is a Legacy way of doing it but still works fine.Secondly is with PowerShell…

View On WordPress
#FFS#ForFlukeSake#CMD#Get-NetTCPConnection#Get-process#LocalPort#NetStat#PowerShell#RemotePort#Tasklist
1 note
·
View note
Text
Do other guys crave drinking female squirt?
I'm dating a squirter and I love drinking all of her squirt. It's actually become my fetish and I can't wait for her to release into my mouth. I relish the smell of it even on the wet sheets afterwards.
After the first time I had to do some "is it pee?" research and found out that it *does* contain some urine and I'm totally fine with that.
Am I the only guy who enjoys this?
submitted by /u/remoteportal [link] [comments] from Sex https://ift.tt/A2QmbyE
0 notes
Text
BonFook Tello Drone Carrying Case Shockproof Waterproof Portable Shoulder Bag Compatible with DJI Tello/Tello EDU Quadcopter Drone and Remote Controller
BonFook Tello Drone Carrying Case Shockproof Waterproof Portable Shoulder Bag Compatible with DJI Tello/Tello EDU Quadcopter Drone and Remote Controller
Price: (as of – Details) Tello Carrying Case Portable Hand Bag Compatable with DJI Tello Drone and Fits Gamesir T1D Gamepad Remote Controller,3 Tello Batteries,Propellers and Charger cableCUSTOMIZED DESIGN – Specially designed for carrying DJI tello drone with remote controller, portable carrying case,Fits Tello drone with a Gamesir T1D RemotePORTABLE CARRYING CASE – Great Design makes easy to…

View On WordPress
0 notes
Text
How to Send Journald Logs From CoreOS to Remote Logging Server ?
https://cloudshift.co/gnu-linux/coreos/how-to-send-journald-logs-from-coreos-to-remote-logging-server/
How to Send Journald Logs From CoreOS to Remote Logging Server ?
CoreOS is an operating system that goes beyond the ordinary. When you need to send the journald logs to remote server, it will not be so simple but it is not too hard too.
First of all you can configure the rsyslogd but it will not send the journald logs. Journald daemon logs the events and outputs as binary file. Only solution is to be able to read that journald via journalctl command line utility. So this means we can not configure rsyslogd for sending journald logs to the remote logging server( Elasticsearch, Splunk, Graylog, etc… )
First of all we need to create a systemd configuration file for sending the logs to the remote.
# vi /etc/systemd/system/sentjournaldlogs.service Description=Sent Journald Logs to Remote Logging Service After=systemd-journald.service Requires=systemd-journald.service [Service] ExecStart=/bin/sh -c "journalctl -f | ncat -u RemoteServerIP RemotePort" TimeoutStartSec=0 Restart=on-failure RestartSec=5s [Install] WantedBy=multi-user.target
You need to change RemoteServerIP and RemotePort with your remote logging server’s IP address and service port.
If you are using or the remote logging server is listening on standard ports that will be 514. If you look closely to the ncat command there is -u argument which specifies that the connection will use UDP. If you want to use TCP then please delete -u argument.
# systemctl daemon-reload # systemctl enable sentjournaldlogs.service # systemctl start sentjournaldlogs.service # systemctl status sentjournaldlogs.service
We need to reload systemd daemon and start the service. That’s all.
#coreos#coreos journald#coreos logging#coreos service#coreos systemd#ncat logging#ncat service#nomad logging#remote logging#rsyslogd#service#syslog#syslog logging#systemd service
0 notes
Link

Price: 3997.95

2001 Autopilot – Magnetic Compass Sensor & Rotary Feedback Engineered for Performance, Reliability & Value Features: Fixed station autopilot, either flush or bracket mounted Reliable in any sea and weather conditions Suitable for larger vessels, in the range of 80 to 500+ feet Three "Turn" functions, Continuous, Emergency and "U" Turns Power steering feature for ease of maneuvering Port and Starboard dodge buttons for collision avoidance Compatible with most types of steering sysems "Hands Off" automatic trim Variable yaw and turn rates Optional full function Remotes, both fixed and hand held Two RemotePorts built in Easy course changes, from one degree to major changes Two Navigation ports for dual Nav input of NMEA 0183 Heading output provides N+1, NMEA 0183 or AD 10S heading information Output for optional analog Rudder Angle Indicator, up to 4 stations Backlit LCD display with an adjustable automatic dimmer for night viewing Visual and audible alarms Easy to install and fully compatible with your onboard instruments Ten selectable steering parameters Optional Gyro interface for stepper, syncro or NMEA gyro systems Optional Sail version with wind input and automatic Tack function Extended 3 year warranty Product : COMNAV 2001 AP W/ MAGNETIC COMPASS SENSOR & ROTARY Manufacturer : ComNav Marine Manufacturer Part No : 10030001 Product : COMNAV 2001 AP W/ MAGNETIC COMPASS SENSOR & ROTARY
#boating #boatingtips #boatingsupplies #boatingnews #boatingshop #wolfcreek
0 notes
Text
Uniform load distribution to anycast servers using BGP bandwidth community and unequal cost multipath forwarding
In the blog post, I provide an example solution to a complex problem using open standards-based Cumulus Linux switches.
The case in point is that the user has a large number of anycast services running in a multipod Clos network. The number of service endpoints can dynamically change and user expectation is that service endpoints get uniformly loaded.
This solution works well for both cases, one where Clos fabric is Layer-3 only network and another where we have Evpn vxlan overlay network. Care must be taken though to select switch hardware that can support overlay UCMP forwarding, I have validated this using Broadcom Trident 3 and Mellanox Spectrum 2 running CumulusLinux 4.1.0 but this should work on various other chips.
Layer3 only fabric
In the case of Layer3 only fabric hosts and firewalls all are on separate IP subnets and routing protocol ( ebgp in this case) provides connectivity.
Each service container (or VM) in addition to user applications also runs Frr bgpd. Bgp session is used to dynamically advertise service reachability to leaf switch. A Leaf switch is configured to advertise service addresses with bandwidth community towards spine switches. A Spine switch advertises service address with cumulative path bandwidth to Superspine switches. On both Superspines as well as at spines bgp path bandwidth is installed as weight in the kernel route table. This needs the following configuration on a leaf switch:
Configuration:
Leaf:
router bgp 65011 bgp router-id 6.0.0.8 bgp bestpath as-path multipath-relax neighbor fabric peer-group neighbor vrfpeers peer-group neighbor vrfpeers remote-as external neighbor 220.14.0.17 remote-as external neighbor 220.14.0.17 peer-group fabric bgp listen limit 5000 bgp listen range 0.0.0.0/0 peer-group vrfpeers
address-family ipv4 unicast redistribute connected neighbor fabric soft-reconfiguration inbound neighbor fabric maximum-prefix 120000 neighbor fabric allowas-in 1 maximum-paths 64 neighbor fabric route-map lbwnp out
address-family ipv6 unicast redistribute connected neighbor fabric activate neighbor fabric soft-reconfiguration inbound neighbor fabric maximum-prefix 120000 neighbor fabric allowas-in 1 neighbor vrfpeers activate maximum-paths 64 neighbor fabric route-map lbwnp out ! route-map lbwnp permit 10 set extcommunity bandwidth num-multipaths !
Service route on leaf12:
*= 188.188.188.1/32 21.2.0.4 0 0 1112 i * 220.14.0.17 0 65201 65011 1111 i *> 21.2.0.3 0 0 1111 i *= 190.1.1.190/32 21.2.0.4 0 0 1112 i * 220.14.0.17 0 65201 65011 1111 i *> 21.2.0.3 0 0 1111 i *= 190.1.2.190/32 21.2.0.4 0 0 1112 i
Default configuration on spine and superspine switches
Sample route on superspine:
BGP:
root@mlx-3700c-01:mgmt:~# net show bgp ipv4 uni 188.188.188.1/32 BGP routing table entry for 188.188.188.1/32 Paths: (3 available, best #3, table default) Advertised to non peer-group peers: spine11(220.17.0.2) spine21(220.17.0.18) spine31(220.17.0.34) 65202 65021 2111 220.17.0.18 from spine21(220.17.0.18) (6.0.0.15) Origin IGP, valid, external, multipath, bestpath-from-AS 65202 Extended Community: LB:65202:1179648 (9.000 Mbps) Last update: Wed Mar 25 17:07:07 2020
65203 65031 3111 220.17.0.34 from spine31(220.17.0.34) (6.0.0.16) Origin IGP, valid, external, multipath, bestpath-from-AS 65203 Extended Community: LB:65203:1703936 (13.000 Mbps) Last update: Wed Mar 25 17:09:10 2020
65201 65011 1111 220.17.0.2 from spine11(220.17.0.2) (6.0.0.14) Origin IGP, valid, external, multipath, bestpath-from-AS 65201, best (Older Path) Extended Community: LB:65201:655360 (5.000 Mbps) Last update: Wed Mar 25 17:05:28 2020 root@mlx-3700c-01:mgmt:~# Rib and Fib:
root@mlx-3700c-01:mgmt:~# net show route 188.188.188.1/32 RIB entry for 188.188.188.1/32 ============================== Routing entry for 188.188.188.1/32 Known via “bgp”, distance 20, metric 0, best Last update 2d01h00m ago * 220.17.0.34, via swp1s2, weight 48 * 220.17.0.18, via swp1s1, weight 33 * 220.17.0.2, via swp1s0, weight 18
FIB entry for 188.188.188.1/32 ============================== 188.188.188.1 proto bgp metric 20 nexthop via 220.17.0.34 dev swp1s2 weight 48 nexthop via 220.17.0.18 dev swp1s1 weight 33 nexthop via 220.17.0.2 dev swp1s0 weight 18 root@mlx-3700c-01:mgmt:~#
root@mlx-3700c-01:mgmt:~# net show lldp
LocalPort Speed Mode RemoteHost RemotePort ——— —– ———— ———- —————– eth0 1G Mgmt tor-swr-a1 swp8 swp1s0 10G Interface/L3 spine11 swp1 swp1s1 10G Interface/L3 spine21 swp1 swp1s2 10G Interface/L3 spine31 swp1 swp1s3 10G Interface/L3 fw1 00:02:00:00:00:01 root@mlx-3700c-01:mgmt:~#
With reference to the above diagram service blue’s address (188.188.188.1) should have a path pointing to 3 pods, but path via pod3 should have the highest weight.
Validation
Anycast validator o/p: {u’standard_deviation’: 5.323976835480161, u’Anycast_servers’: 27, u’transactions’: {u’cont3211′: 30, u’cont3212′: 40, u’cont3213′: 42, u’cont3214′: 32, u’cont3215′: 41, u’cont3216′: 30, u’cont3217′: 38, u’cont2114′: 36, u’cont2111′: 39, u’cont2112′: 44, u’cont2113′: 31, u’cont1111′: 36, u’cont1112′: 36, u’cont1212′: 30, u’cont1213′: 38, u’cont1211′: 43, u’cont3113′: 38, u’cont3112′: 37, u’cont3111′: 31, u’cont3116′: 40, u’cont3115′: 45, u’cont3114′: 28, u’cont2215′: 41, u’cont2214′: 33, u’cont2213′: 48, u’cont2212′: 41, u’cont2211′: 32}, u’Total_requests’: 1000, u’Avg_per_srv_load’: 37.03703703703704}
Note: due to the dynamic nature of setup numbers in o/p may not match the exact state shown in the diagram.
Evpn vxlan overlay network
In the case of Evpn vxlan overlay network, hosts and firewall share segments in common tenant vrf. Each service maintains bgp peer session to tenant vrf on connected leaf switches and advertises service address. The Leaf switch exports this address as Evpn prefix route (type-5 route) with bandwidth community set based on the number of services advertising reachability. On superspine this leads to UCMP programmed in the forwarding plane diverting the appropriate number of service requests to each pod leading to uniform load distribution to service endpoints. Notice in the example configuration on leaf32, route policy selectively sets bandwidth based on number paths for service address and then is applied at export attach-point (vrf advertise).
Configuration:
Leaf32:
router bgp 65032 vrf tenant1 bgp router-id 6.0.0.13 bgp bestpath as-path multipath-relax neighbor vrfpeers peer-group neighbor vrfpeers remote-as external bgp listen limit 5000 bgp listen range 0.0.0.0/0 peer-group vrfpeers
address-family ipv4 unicast redistribute connected maximum-paths 64
address-family ipv6 unicast redistribute connected neighbor vrfpeers activate maximum-paths 64
address-family l2vpn evpn advertise ipv4 unicast advertise ipv6 unicast advertise ipv4 unicast route-map lbwnp advertise ipv6 unicast route-map lbwnp6
ip prefix-list anyc188 seq 5 permit 188.188.188.1/32 ip prefix-list anyc188 seq 10 permit 190.1.0.0/16 le 32
ipv6 prefix-list anyc2188 seq 5 permit 2188:2188:2188::1/128 ipv6 prefix-list anyc2188 seq 10 permit 2190:1::/32 le 128 route-map lbwnp permit 10 match ip address prefix-list anyc188 set extcommunity bandwidth num-multipaths
route-map lbwnp6 permit 10 match ip address prefix-list anyc2188 set extcommunity bandwidth num-multipaths
Service peers under tenant vrf:
root@leaf32:mgmt:/home/cumulus# net show bgp vrf tenant1 sum show bgp vrf tenant1 ipv4 unicast summary ========================================= BGP router identifier 6.0.0.13, local AS number 65032 vrf-id 10 BGP table version 1569 RIB entries 484, using 87 KiB of memory Peers 7, using 145 KiB of memory Peer groups 1, using 64 bytes of memory
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd *cont3211(21.1.6.1) 4 3211 46 51 0 0 0 00:01:42 221 *cont3212(21.1.6.2) 4 3212 44 48 0 0 0 00:01:36 221 *cont3213(21.1.6.3) 4 3213 42 44 0 0 0 00:01:30 221 *cont3214(21.1.6.4) 4 3214 40 41 0 0 0 00:01:23 221 *cont3215(21.1.6.5) 4 3215 38 38 0 0 0 00:01:17 221 *cont3216(21.1.6.6) 4 3216 36 35 0 0 0 00:01:11 221 *cont3217(21.1.6.7) 4 3217 34 32 0 0 0 00:01:05 221
Total number of neighbors 7 * – dynamic neighbor
Routes on Leaf switches
ipdb> for node in self.topo.leafs: print(“%s –> %s\n” % (node.name, node.device.sudo(‘ip -4 ro show vrf tenant1 188.188.188.1/32’))) leaf11 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.1.1 dev vlan101 weight 1 nexthop via 21.1.1.2 dev vlan101 weight 1
leaf12 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.2.1 dev vlan101 weight 1 nexthop via 21.1.2.2 dev vlan101 weight 1 nexthop via 21.1.2.3 dev vlan101 weight 1
leaf21 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.3.1 dev vlan101 weight 1 nexthop via 21.1.3.2 dev vlan101 weight 1 nexthop via 21.1.3.3 dev vlan101 weight 1 nexthop via 21.1.3.4 dev vlan101 weight 1
leaf22 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.4.1 dev vlan101 weight 1 nexthop via 21.1.4.2 dev vlan101 weight 1 nexthop via 21.1.4.3 dev vlan101 weight 1 nexthop via 21.1.4.4 dev vlan101 weight 1 nexthop via 21.1.4.5 dev vlan101 weight 1
leaf31 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.5.1 dev vlan101 weight 1 nexthop via 21.1.5.2 dev vlan101 weight 1 nexthop via 21.1.5.3 dev vlan101 weight 1 nexthop via 21.1.5.4 dev vlan101 weight 1 nexthop via 21.1.5.5 dev vlan101 weight 1 nexthop via 21.1.5.6 dev vlan101 weight 1
leaf32 –> 188.188.188.1 proto bgp metric 20 nexthop via 21.1.6.1 dev vlan101 weight 1 nexthop via 21.1.6.2 dev vlan101 weight 1 nexthop via 21.1.6.3 dev vlan101 weight 1 nexthop via 21.1.6.4 dev vlan101 weight 1 nexthop via 21.1.6.5 dev vlan101 weight 1 nexthop via 21.1.6.6 dev vlan101 weight 1 nexthop via 21.1.6.7 dev vlan101 weight 1
Weighted Routes on Superspine
ipdb> for node in self.topo.superspines: print(node.device.sudo(‘ip -4 ro show vrf tenant1 188.188.188.1/32’)) 188.188.188.1 proto bgp metric 20 nexthop via 6.0.0.13 dev vlan11 weight 25 onlink nexthop via 6.0.0.12 dev vlan11 weight 22 onlink nexthop via 6.0.0.11 dev vlan11 weight 18 onlink nexthop via 6.0.0.10 dev vlan11 weight 14 onlink nexthop via 6.0.0.9 dev vlan11 weight 11 onlink nexthop via 6.0.0.8 dev vlan11 weight 7 onlink ipdb>
Validation for service load distribution
validate_anycast_load_distribution: {u’standard_deviation’: 4.484858984846694, u’Anycast_servers’: 27, u’transactions’: {u’cont3211′: 40, u’cont3212′: 36, u’cont3213′: 39, u’cont3214′: 35, u’cont3215′: 43, u’cont3216′: 41, u’cont3217′: 30, u’cont2114′: 32, u’cont2111′: 28, u’cont2112′: 41, u’cont2113′: 31, u’cont1111′: 38, u’cont1112′: 41, u’cont1212′: 35, u’cont1213′: 34, u’cont1211′: 36, u’cont3113′: 38, u’cont3112′: 41, u’cont3111′: 42, u’cont3116′: 36, u’cont3115′: 34, u’cont3114′: 45, u’cont2215′: 40, u’cont2214′: 29, u’cont2213′: 37, u’cont2212′: 42, u’cont2211′: 36}, u’Total_requests’: 1000, u’Avg_per_srv_load’: 37.03703703703704}[/fusion_text] Uniform load distribution to anycast servers using BGP bandwidth community and unequal cost multipath forwarding published first on https://wdmsh.tumblr.com/
0 notes
Text
“三次握手,四次挥手”你真的懂吗?
记得刚毕业找工作面试的时候,经常会被问到:你知道“3次握手,4次挥手”吗?这时候我会“胸有成竹”地“背诵”前期准备好的“答案”,第一次怎么怎么,第二次……答完就没有下文了,面试官貌似也没有深入下去的意思,深入下去我也不懂,皆大欢喜!
作为程序员,要有“刨根问底”的精神。知其然,更要知其所以然。这篇文章希望能抽丝剥茧,还原背后的原理。
什么是“3次握手,4次挥手”
TCP是一种面向连接的单播协议,在发送数据前,通信双方必须在彼此间建立一条连接。所谓的“连接”,其实是客户端和服务器的内存里保存的一份关于对方的信息,如ip地址、端口号等。
TCP可以看成是一种字节��,它会处理IP层或以下的层的丢包、重复以及错误问题。在连接的建立过程中,双方需要交换一些连接的参数。这些参数可以放在TCP头部。
TCP提供了一种可靠、面向连接、字节流、传输层的服务,采用三次握手建立一个连接。采用4次挥手来关闭一个连接。
TCP服务模型
在了解了建立连接、关闭连接的“三次握手和四次挥手”后,我们再来看下TCP相关的东西。
一个TCP连接由一个4元组构成,分别是两个IP地址和两个端口号。一个TCP连接通常分为三个阶段:启动、数据传输、退出(关闭)。
当TCP接收到另一端的数据时,它会发送一个确认,但这个确认不会立即发送,一般会延迟一会儿。ACK是累积的,一个确认字节号N的ACK表示所有直到N的字节(不包括N)已经成功被接收了。这样的好处是如果一个ACK丢失,很可能后续的ACK就足以确认前面的报文段了。
一个完整的TCP连接是双向和对称的,数据可以在两个方向上平等地流动。给上层应用程序提供一种双工服务。一旦建立了一个连接,这个连接的一个方向上的每个TCP报文段都包含了相反方向上的报文段的一个ACK。
序列号的作用是使得一个TCP接收端可丢弃重复的报文段,记录以杂乱次序到达的报文段。因为TCP使用IP来传输报文段,而IP不提供重复消除或者保证次序正确的功能。另一方面,TCP是一个字节流协议,绝不会以杂乱的次序给上层程序发送数据。因此TCP接收端会被迫先保持大序列号的数据不交给应用程序,直到缺失的小序列号的报文段被填满。
TCP头部
源端口和目的端口在TCP层确定双方进程,序列号表示的是报文段数据中的第一个字节号,ACK表示确认号,该确认号的发送方期待接收的下一个序列号,即最后被成功接收的数据字节序列号加1,这个字段只有在ACK位被启用的时候��有效。
当新建一个连接时,从客户端发送到服务端的第一个报文段的SYN位被启用,这称为SYN报文段,这时序列号字段包含了在本次连接的这个方向上要使用的第一个序列号,即初始序列号ISN,之后发送的数据是ISN加1,因此SYN位字段会消耗一个序列号,这意味着使用重传进行可靠传输。而不消耗序列号的ACK则不是。
头部长度(图中的数据偏移)以32位字为单位,也就是以4bytes为单位,它只有4位,最大为15,因此头部最大长度为60字节,而其最小为5,也就是头部最小为20字节(可变选��为空)。
ACK —— 确认,使得确认号有效。 RST —— 重置连接(经常看到的reset by peer)就是此字段搞的鬼。 SYN —— 用于初如化一个连接的序列号。 FIN —— 该报文段的发送方已经结束向对方发送数据。
当一个连接被建立或被终止时,交换的报文段只包含TCP头部,而没有数据。
状态转换
三次握手和四次挥手的状态转换如下图。
为什么要“三次握手,四次挥手”
三次握手
换个易于理解的视角来看为什么要3次握手。
客户端和服务端通信前要进行连接,“3次握手”的作用就是双方都能明确自己和对方的收、发能力是正常的。
第一次握手:客户端发送网络包,服务端收到了。这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
第二次握手:服务端发包,客户端收到了。这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。 从客户端的视角来看,我接到了服务端发送过来的响应数据包,说明服务端接收到了我在第一次握手时发送的网络包,并且成功发送了响应数据包,这就说明,服务端的接收、发送能力正常。而另一方面,我收到了服务端的响应数据包,说明我第一次发送的网络包成功到达服务端,这样,我自己的发送和接收能力也是正常的。
第三次握手:客户端发包,服务端收到了。这样服务端就能得出结论:客户端的接收、发送能力,服务端的发送、接收能力是正常的。 第一、二次握手后,服务端并不知道客户端的接收能力以及自己的发送能力是否正常。而在第三次握手时,服务端收到了客户端对第二次握手作的回应。从服务端的角度,我在第二次握手时的响应数据发送出去了,客户端接收到了。所以,我的发送能力是正常的。而客户端的接收能力也是正常的。
经历了上面的三次握手过程,客户端和服务端都确认了自己的接收、发送能力是正常的。之后就可以正常通信了。
每次都是接收到数据包的一方可以得到一些结论,发送的一方其实没有任何头绪。我虽然有发包的动作,但是我怎么知道我有没有发出去,而对方有没有接收到呢?
而从上面的过程可以看到,最少是需要三次握手过程的。两次达不到让双方都得出自己、对方的接收、发送能力都正常的结论。其实每次收到网络包的一方至少是可以得到:对方的发送、我方的接收是正常的。而每一步都是有关联的,下一次的“响应”是由于第一次的“请求”触发,因此每次握手其实是可以得到额外的结论的。比如第三次握手时,服务端收到数据包,表明看服务端只能得到客户端的发送能力、服务端的接收能力是正常的,但是结合第二次,说明服务端在第二次发送的响应包,客户端接收到了,并且作出了响应,从而得到额外的结论:客户端的接收、服务端的发送是正常的。
用表格总结一下:
视角 客收 客发 服收 服发 客视角 二 一 + 二 一 + 二 二 服视角 二 + 三 一 一 二 + 三
四次挥手
TCP连接是双向传输的对等的模式,就是说双方都可以同时向对方发送或接收数据。当有一方要关闭连接时,会发送指令告知对方,我要关闭连接了。这时对方会回一个ACK,此时一个方向的连接关闭。但是另一个方向仍然可以继续传输数据,等到发送完了所有的数据后,会发送一个FIN段来关闭此方向上的连接。接收方发送ACK确认关闭连接。注意,接收到FIN报文的一方只能回复一个ACK, 它是无法马上返回对方一个FIN报文段的,因为结束数据传输的“指令”是上层应用层给出的,我只是一个“搬运工”,我无法了解“上层的意志”。
“三次握手,四次挥手”怎么完成?
其实3次握手的目的并不只是让通信双方都了解到一个连接正在建立,还在于利用数据包的选项来传输特殊的信息,交换初始序列号ISN。
3次握手是指发送了3个报文段,4次挥手是指发送了4个报文段。注意,SYN和FIN段都是会利用重传进行可靠传输的。
三次握手
客户端发送一个SYN段,并指明客户端的初始序列号,即ISN(c).
服务端发送自己的SYN段作为应答,同样指明自己的ISN(s)。为了确认客户端的SYN,将ISN(c)+1作为ACK数值。这样,每发送一个SYN,序列号就会加1. 如果有丢失的情况,则会重传。
为了确认服务器端的SYN,客户端将ISN(s)+1作为返回的ACK数值。
四次挥手
客户端发送一个FIN段,并包含一个希望接收者看到的自己当前的序列号K. 同时还包含一个ACK表示确认对方最近一次发过来的数据。
服务端将K值加1作为ACK序号值,表明收到了上一个包。这时上层的应用程序会被告知另一端发起了关闭操作,通常这将引起应用程序发起自己的关闭操作。
服务端发起自己的FIN段,ACK=K+1, Seq=L
客户端确认。ACK=L+1
为什么建立连接是三次握手,而关闭连接却是四次挥手呢?
这是因为服务端在LISTEN状态下,收到建立连接请求的SYN报文后,把ACK和SYN放在一个报文里发送给客户端。而关闭连接时,当收到对方的FIN报文时,仅仅表示对方不再发送数据了但是还能接收数据,己方是否现在关闭发送数据通道,需要上层应用来决定,因此,己方ACK和FIN一般都会分开发送。
“三次握手,四次挥手”进阶
ISN
三次握手的一个重要功能是客户端和服务端交换ISN(Initial Sequence Number), 以便让对方知道接下来接收数据的时候如何按序列号组装数据。
如果ISN是固定的,攻击者很容易猜出后续的确认号。
ISN = M + F(localhost, localport, remotehost, remoteport)
M是一个计时器,每隔4毫秒加1。 F是一个Hash算法,根据源IP、目的IP、源端口、目的端口生成一个随机数值。要保证hash算法不能被外部轻易推算得出。
序列号回绕
因为ISN是随机的,所以序列号容易就会超过2^31-1. 而tcp对于丢包和乱序等问题的判断都是依赖于序列号大小比较的。此时就出现了所谓的tcp序列号回绕(sequence wraparound)问题。怎么解决?
/*
* The next routines deal with comparing 32 bit unsigned ints
* and worry about wraparound (automatic with unsigned arithmetic).
*/
static inline int before(__u32 seq1, __u32 seq2)
{
return (__s32)(seq1-seq2) < 0;
}
#define after(seq2, seq1) before(seq1, seq2)
上述代码是内核中的解决回绕问题代码。__s32是有符号整型的意思,而__u32则是无符号整型。序列号发生回绕后,序列号变小,相减之后,把结果变成有符号数了,因此结果成了负数。
假设seq1=255, seq2=1(发生了回绕)。
seq1 = 1111 1111 seq2 = 0000 0001
我们希望比较结果是
seq1 - seq2=
1111 1111
-0000 0001
-----------
1111 1110
由于我们将结果转化成了有符号数,由于最高位是1,因此结果是一个负数,负数的绝对值为
0000 0001 + 1 = 0000 0010 = 2
因此seq1 - seq2 < 0
syn flood攻击
最基本的DoS攻击就是利用合理的服务请求来占用过多的服务资源,从而使合法用户无法得到服务的响应。syn flood属于Dos攻击的一种。
如果恶意的向某个服务器端口发送大量的SYN包,则可以使服务器打开大量的半开连接,分配TCB(Transmission Control Block), 从而消耗大量的服务器资源,同时也使得正常的连接请求无法被相应。当开放了一个TCP端口后,该端口就处于Listening状态,不停地监视发到该端口的Syn报文,一 旦接收到Client发来的Syn报文,就需要为该请求分配一个TCB,通常一个TCB至少需要280个字节,在某些操作系统中TCB甚至需要1300个字节,并返回一个SYN ACK命令,立即转为SYN-RECEIVED即半开连接状态。系统会为此耗尽资源。
常见的防攻击方法有:
无效连接的监视释放
监视系统的半开连接和不活动连接,当达到一定阈值时拆除这些连接,从而释放系统资源。这种方法对于所有的连接一视同仁,而且由于SYN Flood造成的半开连接数量很大,正常连接请求也被淹没在其中被这种方式误释放掉,因此这种方法属于入门级的SYN Flood方法。
延缓TCB分配方法
消耗服务器资源主要是因为当SYN数据报文一到达,系统立即分配TCB,从而占用了资源。而SYN Flood由于很难建立起正常连接,因此,当正常连接建立起来后再分配TCB则可以有效地减轻服务器资源的消耗。常见的方法是使用Syn Cache和Syn Cookie技术。
Syn Cache技术
系统在收到一个SYN报文时,在一个专用HASH表中保存这种半连接信息,直到收到正确的回应ACK报文再分配TCB。这个开销远小于TCB的开销。当然还需要保存序列号。
Syn Cookie技术
Syn Cookie技术则完全不使用任何存储资源,这种方法比较巧��,它使用一种特殊的算法生成Sequence Number,这种算法考虑到了对方的IP、端口、己方IP、端口的固定信息,以及对方无法知道而己方比较固定的一些信息,如MSS(Maximum Segment Size,最大报文段大小,指的是TCP报文的最大数据报长度,其中不包括TCP首部长度。)、时间等,在收到对方 的ACK报文后,重新计算一遍,看其是否与对方回应报文中的(Sequence Number-1)相同,从而决定是否分配TCB资源。
使用SYN Proxy防火墙
一种方式是防止墙dqywb连接的有效性后,防火墙才会向内部服务器发起SYN请求。防火墙代服务器发出的SYN ACK包使用的序列号为c, 而真正的服务器回应的序列号为c’, 这样,在每个数据报文经过防火墙的时候进行序列号的修改。另一种方式是防火墙确定了连接的安全后,会发出一个safe reset命令,client会进行重新连接,这时出现的syn报文会直接放行。这样不需要修改序列号了。但是,client需要发起两次握手过程,因此建立连接的时间将会延长。
连接队列
在外部请求到达时,被服务程序最终感知到前,连接可能处于SYN_RCVD状态或是ESTABLISHED状态,但还未被应用程序接受。
对应地,服务器端也会维护两种队列,处于SYN_RCVD状态的半连接队列,而处于ESTABLISHED状态但仍未被应用程序accept的为全连接队列。如果这两个队列满了之后,就会出现各种丢包的情形。
查看是否有连接溢出
netstat -s | grep LISTEN
半连接队列满了
在三次握手协议中,服务器维护一个半连接队列,该队列为每个客户端的SYN包开设一个条目(服务端在接收到SYN包的时候,就已经创建了request_sock结构,存储在半连接队列中),该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包。这些条目所标识的连接在服务器处于Syn_RECV状态,当服务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。
目前,Linux下默认会进行5次重发SYN-ACK包,重试的间隔时间从1s开始,下次的重试间隔时间是前一次的双倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s, 总共31s, 称为指数退避,第5次发出后还要等32s才知道第5次也超时了,所以,总共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s, TCP才会把断开这个连接。由于,SYN超时需要63秒,那么就给攻击者一个攻击服务器的机会,攻击者在短时间内发送大量的SYN包给Server(俗称SYN flood攻击),用于耗尽Server的SYN队列。对于应对SYN 过多的问题,linux提供了几个TCP参数:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 来��整应对。
参数 作用 tcp_syncookies SYNcookie将连接信息编码在ISN(initialsequencenumber)中返回给客户端,这时server不需要将半连接保存在队列中,而是利用客户端随后发来的ACK带回的ISN还原连接信息,以完成连接的建立,避免了半连接队列被攻击SYN包填满。 tcp_syncookies 内核放弃建立连接之前发送SYN包的数量。 tcp_synack_retries 内核放弃连接之前发送SYN+ACK包的数量 tcp_max_syn_backlog 默认为1000. 这表示半连接队列的长度,如果超过则放弃当前连接。 tcp_abort_on_overflow 如果设置了此项,则直接reset. 否则,不做任何操作,这样当服务器半连接队列有空了之后,会重新接受连接。Linux坚持在能力许可范围内不忽略进入的连接。客户端在这期间会重复发送sys包,当重试次数到达上限之后,会得到connection time out响应。
全连接队列满了
当第三次握手时,当server接收到ACK包之后,会进入一个新的叫 accept 的队列。
当accept队列满了之后,即使client继续向server发送ACK的包,也会不被响应,此时ListenOverflows+1,同时server通过tcp_abort_on_overflow来决定如何返回,0表示直接丢弃该ACK,1表示发送RST通知client;相应的,client则会分别返回read timeout 或者 connection reset by peer。另外,tcp_abort_on_overflow是0的话,server过一段时间再次发送syn+ack给client(也就是重新走握手的第二步),如果client超时等待比较短,就很容易异常了。而客户端收到多个 SYN ACK 包,则会认为之前的 ACK 丢包了。于是促使客户端再次发送 ACK ,在 accept队列有空闲的时候最终完成连接。若 accept队列始终满员,则最终客户端收到 RST 包(此时服务端发送syn+ack的次数超出了tcp_synack_retries)。
服务端仅仅只是创建一个定时器,以固定间隔重传syn和ack到服务端
参数 作用 tcp_abort_on_overflow 如果设置了此项,则直接reset. 否则,不做任何操作,这样当服务器半连接队列有空了之后,会重新接受连接。Linux坚持在能力许可范围内不忽略进入的连接。客户端在这期间会重复发送sys包,当重试次数到达上限之后,会得到connection time out响应。 min(backlog, somaxconn) 全连接队列的长度。
命令
netstat -s命令
[root<a href="http://bit.ly/2TlNagb">@server</a> ~]# netstat -s | egrep "listen|LISTEN"
667399 times the listen queue of a socket overflowed
667399 SYNs to LISTEN sockets ignored
上面看到的 667399 times ,表示全连接队列溢出的次数,隔几秒钟执行下,如果这个数字一直在增加的话肯定全连接队列偶尔满了。
[root<a href="http://bit.ly/2TlNagb">@server</a> ~]# netstat -s | grep TCPBacklogDrop
查看 Accept queue 是否有溢出
ss命令
[root<a href="http://bit.ly/2TlNagb">@server</a> ~]# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:6379 *:*
LISTEN 0 128 *:22 *:*
如果State是listen状态,Send-Q 表示第三列的listen端口上的全连接队列最大为50,第一列Recv-Q为全连接队列当前使用了多少。 非 LISTEN 状态中 Recv-Q 表示 receive queue 中的 bytes 数量;Send-Q 表示 send queue 中的 bytes 数值。
小结
当外部连接请求到来时,TCP模块会首先查看max_syn_backlog,如果处于SYN_RCVD状态的连接数目超过这一阈值,进入的连接会被拒绝。根据tcp_abort_on_overflow字段来决定是直接丢弃,还是直接reset.
从服务端来说,三次握手中,第一步server接受到client的syn后,把相关信息放到半连接队列中,同时回复syn+ack给client. 第三步当收到客户端的ack, 将连接加入到全连接队列。
一般,全连接队列比较小,会先满,此时半连接队列还没满。如果这时收到syn报文,则会进入半连接队列,没有问题。但是如果收到了三次握手中的第3步(ACK),则会根据tcp_abort_on_overflow字段来决定是直接丢弃,还是直接reset.此时,客户端发送了ACK, 那么客户端认为三次握手完成,它认为服务端已经准备好了接收数据的准备。但此时服务端可能因为全连接队列满了而无法将连接放入,会重新发送第2步的syn+ack, 如果这时有数据到来,服务器TCP模块会将数据存入队列中。一段时间后,client端没收到回复,超时,连接异常,client会主动关闭连接。
“三次握手,四次挥手”redis实例分析
我在dev机器上部署redis服务,端口号为6379,
通过tcpdump工具获取数据包,使用如下命令
tcpdump -w /tmp/a.cap port 6379 -s0
-w把数据写入文件,-s0设置每个数据包的大小默认为68字节,如果用-S 0则会抓到完整数据包
在dev2机器上用redis-cli访问dev:6379, 发送一个ping, 得到回复pong
停止抓包,用tcpdump读取捕获到的数据包
tcpdump -r /tmp/a.cap -n -nn -A -x| vim -
(-x 以16进制形式展示,便于后面分析)
共收到了7个包。
抓到的是IP数据包,IP数据包分为IP头部和IP数据部分,IP数据部分是TCP头部加TCP数据部分。
IP的数据格式为: 它由固定长度20B+可变长度构成。
10:55:45.662077 IP dev2.39070 > dev.6379: Flags [S], seq 4133153791, win 29200, options [mss 1460,sackOK,TS val 2959270704 ecr 0,nop,wscale 7], length 0
0x0000: 4500 003c 08cf 4000 3606 14a5 0ab3 b561
0x0010: 0a60 5cd4 989e 18eb f65a ebff 0000 0000
0x0020: a002 7210 872f 0000 0204 05b4 0402 080a
0x0030: b062 e330 0000 0000 0103 0307
对着IP头部格式,来拆解数据包的具体含义。
字节值 字节含义 0x4 IP版本为ipv4 0x5 首部长度为5 * 4字节=20B 0x00 服务类型,现在基本都置为0 0x003c 总长度为3*16+12=60字节,上面所有的长度就是60字节 0x08cf 标识。同一个数据报的唯一标识。当IP数据报被拆分时,会复制到每一个数据中。 0x4000 3bit 标志 + 13bit 片偏移。3bit 标志对应 R、DF、MF。目前只有后两位有效,DF位:为1表示不分片,为0表示分片。MF:为1表示“更多的���”,为0表示这是最后一片。13bit 片位移:本分片在原先数据报文中相对首位的偏移位。(需要再乘以8 ) 0x36 生存时间TTL。IP报文所允许通过的路由器的最大数量。每经过一个路由器,TTL减1,当为 0 时,路由器将该数据报丢弃。TTL 字段是由发送端初始设置一个 8 bit字段.推荐的初始值由分配数字 RFC 指定。发送 ICMP 回显应答时经常把 TTL 设为最大值 255。TTL可以防止数据报陷入路由循环。 此处为54. 0x06 协议类型。指出IP报文携带的数据使用的是哪种协议,以便目的主机的IP层能知道要将数据报上交到哪个进程。TCP 的协议号为6,UDP 的协议号为17。ICMP 的协议号为1,IGMP 的协议号为2。该 IP 报文携带的数据使用 TCP 协议,得到了验证。 0x14a5 16bitIP首部校验和。 0x0ab3 b561 32bit源ip地址。 0x0a60 5cd4 32bit目的ip地址。
剩余的数据部分即为TCP协议相关的。TCP也是20B固定长度+可变长度部分。
字节值 字节含义 0x989e 16bit源端口。1161616+81616+1416+11=39070 0x18eb 16bit目的端口6379 0xf65a ebff 32bit序列号。4133153791 0x0000 0000 32bit确认号。 0xa 4bit首部长度,以4byte为单位。共10*4=40字节。因此TCP报文的可选长度为40-20=20 0b000000 6bit保留位。目前置为0. 0b000010 6bitTCP标志位。从左到右依次是紧急 URG、确认 ACK、推送 PSH、复位 RST、同步 SYN 、终止 FIN。 0x7210 滑动窗口大小,滑动窗口即tcp接收缓冲区的大小,用于tcp拥塞控制。29200 0x872f 16bit校验和。 0x0000 紧急指针。仅在 URG = 1时才有意义,它指出本报文段中的紧急数据的字节数。当 URG = 1 时,发送方 TCP 就把紧急数据插入到本报文段数据的最前面,而在紧急数据后面的数据仍是普通数据。
可变长度部分,协议如下:
字节值 字节含义 0x0204 05b4 最大报文长度为,05b4=1460. 即可接收的最大包长度,通常为MTU减40字节,IP头和TCP头各20字节 0x0402 表示支持SACK 0x080a b062 e330 0000 0000 时间戳。Ts val=b062 e330=2959270704, ecr=0 0x01 无操作 0x03 0307 窗口扩大因子为7. 移位7, 乘以128
这样第一个包分析完了。dev2向dev发送SYN请求。也就是三次握手中的第一次了。 SYN seq(c)=4133153791
第二个包,dev响应连接,ack=4133153792. 表明dev下次准备接收这个序号的包,用于tcp字节注的顺序控制。dev(也就是server端)的初始序号为seq=4264776963, syn=1. SYN ack=seq(c)+1 seq(s)=4264776963
第三个包,client包确认,这里使用了相对值应答。seq=4133153792, 等于第二个包的ack. ack=4264776964. ack=seq(s)+1, seq=seq(c)+1 至此,三次握手完成。接下来就是发送ping和pong的数据了。
接着第四个包。
10:55:48.090073 IP dev2.39070 > dev.6379: Flags [P.], seq 1:15, ack 1, win 229, options [nop,nop,TS val 2959273132 ecr 3132256230], length 14
0x0000: 4500 0042 08d1 4000 3606 149d 0ab3 b561
0x0010: 0a60 5cd4 989e 18eb f65a ec00 fe33 5504
0x0020: 8018 00e5 4b5f 0000 0101 080a b062 ecac
0x0030: bab2 6fe6 2a31 0d0a 2434 0d0a 7069 6e67
0x0040: 0d0a
tcp首部长度为32B, 可选长度为12B. IP报文的总长度为66B, 首部长度为20B, 因此TCP数据部分长度为14B. seq=0xf65a ec00=4133153792 ACK, PSH. 数据部分为2a31 0d0a 2434 0d0a 7069 6e67 0d0a
0x2a31 -> *1
0x0d0a -> \r\n
0x2434 -> $4
0x0d0a -> \r\n
0x7069 0x6e67 -> ping
0x0d0a -> \r\n
dev2向dev发送了ping数据,第四个包完毕。
第五个包,dev2向dev发送ack响应。 序列号为0xfe33 5504=4264776964, ack确认号为0xf65a ec0e=4133153806=(4133153792+14).
第六个包,dev向dev2响应pong消息。序列号fe33 5504,确认号f65a ec0e, TCP头部可选长度为12B, IP数据报总长度为59B, 首部长度为20B, 因此TCP数据长度为7B. 数据部分2b50 4f4e 470d 0a, 翻译过来就是+PONG\r\n.
至此,Redis客户端和Server端的三次握手过程分析完毕。
总结
“三次握手,四次挥手”看似简单,但是深究进去,还是可以延伸出很多知识点的。比如半连接队列、全连接队列等等。以前关于TCP建立连接、关闭连接的过程很容易就会忘记,可能是因为只是死记硬背了几个过程,没有深入研究背后的原理。
所以,“三次握手,四次挥手”你真的懂了吗?
参考资料
【redis】http://bit.ly/2SHVyGo 【tcp option】http://bit.ly/2AEoKXL 【滑动窗口】http://bit.ly/2SJcLPD 【全连接队列】http://bit.ly/2rXdJdw 【client fooling】 http://bit.ly/2rXkzzB 【backlog RECV_Q】http://bit.ly/2AAujXo 【定时器】http://bit.ly/2SHWDhf 【队列图示】http://bit.ly/2AAesIg 【tcp flood攻击】http://bit.ly/2SLlDo6 【MSS MTU】http://bit.ly/2AzNWyM
via 文章 – 伯乐在线 http://bit.ly/2SLJX9e
0 notes
Text
Comprobar si está abierto un puerto TCP
while(1) { Get-NetTCPConnection | Select-Object LocalAddress,RemotePort,OwningProcess| Where-Object {$_.RemotePort -eq "443"} Start-Sleep -Seconds 5 clear }
View On WordPress
0 notes
Text
For some reason, I don’t like netstat. Never did. Fortunately PowerShell provides a similar command to netstat: Get-NetTCPConnection. Let’s discover the options of this command in form of this blog post.
Get-NetTCPConnection
Running without any parameter it gives you an overview of all TCP Connections. It will show you TCP Connections of all states (closed, waiting, listening, established …)
Get-NetTCPConnection

IPv4 only
To show only IPv4 Connections simply provide your Local IPv4 Address. It might be useful to sort on the Local Port:
Get-NetTCPConnection -LocalAddress 192.168.0.100 | Sort-Object LocalPort
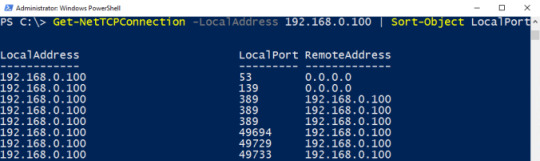
IPv6 only
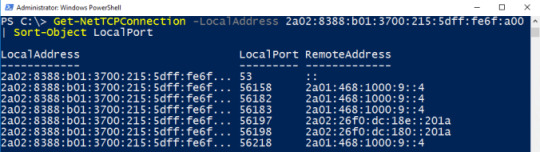
If you are lucky and your ISP provides you with IPv6 Adresses, then enter your IPv6 Global Unicast Address.
Get-NetTCPConnection -LocalAddress 2a02:8388:b01:3700:215:5dff:fe6f:a00 | Sort-Object LocalPort
Show established connections only
I guess the most important parameter is state. To show only established connections in a user-friendly view (Format-Table) run
Get-NetTCPConnection -State Established | Format-Table -AutoSize

Well, ok, we’ve seen in these first steps what Get-NetTCPConnection could do for us. Before we continue to the more advanced part of this post let’s compare the output to netstat.
As I’ve mentioned: The PowerShell cmdlet is my favourite.
Get-NetTCPConnection for Power Users
Resolving IP-Addresses
Do you know the IP of sid-500.com. Why not? 😉 If you don’t know the IP of my site how would you check if you are connected to it? Ok, sure there must be a connection because you’re reading my article. Well, if you know the hostname then run Resolve-DnsName to get the IP-Address!
Get-NetTCPConnection -RemoteAddress (Resolve-DnsName sid-500.com).IPAddress -ErrorAction SilentlyContinue | Format-List

For this it’s useful to use the Erroraction Parameter for avoiding ugly red error messages. Resolve-DNSName will give you 2 IPv4 Addresses of my site. But you are only connected to one of them. So you are not connected to the other one which causes the red lines.
Look at the following example. Microsoft has more than one Public IPv4 Address. I’m connected to only one of them. If you run this command with Erroraction silentlycontinue, you’ll see no red lines anymore.

Get TCP Connections on Remote Hosts
If you want to figure out the established TCP Connections on a remote host, simply use Invoke-Command. Note, that I’m logged on dc01. Server02 is the remote host. Both computers share the same domain.
Invoke-Command -ComputerName server02 {Get-NetTCPConnection -State Established}
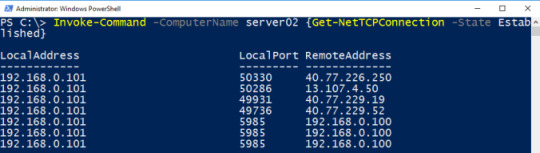
Get TCP Connections from all Servers
To retrieve all established connections from all servers of your domain (all OUs!) and to save them all to a file, run
(Get-ADComputer -Filter 'operatingsystem -like "*server*"').Name | Foreach-Object {Invoke-Command -ComputerName $_ {Get-NetTCPConnection -State Established -ErrorAction SilentlyContinue} | Sort-Object PSComputerName | Select-Object PSComputername, LocalPort, RemotePort, RemoteAddress} | Out-File C:\Temp\TCPConn.txt


That’s it for today. Hope you enjoyed it!
See also
For more about networking with PowerShell see also my articles
PowerShell: Testing the connectivity to the Default Gateway on localhost and Remote Hosts by reading the Routing Table
PowerShell: Use SSH to connect to remote hosts (Posh-SSH)
PowerShell: Check open/closed ports with Test-NetConnection
The new netstat: Playing with Get-NetTCPConnection For some reason, I don't like netstat. Never did. Fortunately PowerShell provides a similar command to netstat: Get-NetTCPConnection.
0 notes