#PostgreSQL Backups
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
Powerful Website Backup Solution
Perfect website backup services. As, the new generation more involve into creation of social media content. Mostly all adults are connected to the online digital world. The growing need of personal blog websites and business website leads to the creation of the solo content platforms. Current, hosting infrastructures are tailored to cater the needs only for the professionals. Due to the cheap…

View On WordPress
#backupsheep#database backup#ftp backup#ftps backup#Mariadb Backup#PostgreSQL Backups#sftp backup#website backup solution#wordpress backup
0 notes
Text
Postgresql database backup
Upback! The effortless database backup and recovery solution. We make it simple and secure to safeguard your data, focusing on essential database backup processes for MySQL, MariaDB, and PostgreSQL. Our easy-to-use management console allows you to perform scheduled database backups without the fuss and all the functionalities!
0 notes
Text
BDRSuite v7.0.0 GA Released New Features
BDRSuite v7.0.0 GA Released New Features #VembuBDRSuitev7.0.0GARelease #BackupandRecoverySoftware #KVMBackup #AzureBackup #AWSBackup #PostgreSQLBackup #FileShareBackup #TwoFactorAuthentication #ImportBackupData #PrePostBackupScripts #FileLevelRecovery
Vembu Technologies has recently unveiled the latest BDRSuite v7.0.0 GA, introducing many new features. This release has many new features and enhancements for comprehensive backup and recovery capabilities. Let’s look at BDRSuite v7.0.0 GA and the new features it contains. Table of contentsWhat is BDRSuite?Free version for home lab environmentsOverview of the new featuresKVM Backup and…

View On WordPress
#aws backup#azure backup#Backup and Recovery Software#File Level Recovery#File Share Backup#Import Backup Data#KVM Backup#PostgreSQL Backup#PrePost Backup Scripts#two-factor authentication#Vembu BDR Suite v7.0.0 GA Release
0 notes
Text
Exploring the Power of Amazon Web Services: Top AWS Services You Need to Know
In the ever-evolving realm of cloud computing, Amazon Web Services (AWS) has established itself as an undeniable force to be reckoned with. AWS's vast and diverse array of services has positioned it as a dominant player, catering to the evolving needs of businesses, startups, and individuals worldwide. Its popularity transcends boundaries, making it the preferred choice for a myriad of use cases, from startups launching their first web applications to established enterprises managing complex networks of services. This blog embarks on an exploratory journey into the boundless world of AWS, delving deep into some of its most sought-after and pivotal services.

As the digital landscape continues to expand, understanding these AWS services and their significance is pivotal, whether you're a seasoned cloud expert or someone taking the first steps in your cloud computing journey. Join us as we delve into the intricate web of AWS's top services and discover how they can shape the future of your cloud computing endeavors. From cloud novices to seasoned professionals, the AWS ecosystem holds the keys to innovation and transformation.
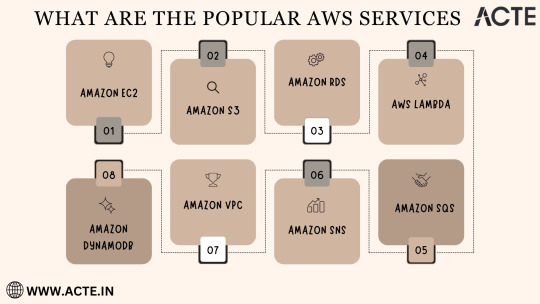
Amazon EC2 (Elastic Compute Cloud): The Foundation of Scalability At the core of AWS's capabilities is Amazon EC2, the Elastic Compute Cloud. EC2 provides resizable compute capacity in the cloud, allowing you to run virtual servers, commonly referred to as instances. These instances serve as the foundation for a multitude of AWS solutions, offering the scalability and flexibility required to meet diverse application and workload demands. Whether you're a startup launching your first web application or an enterprise managing a complex network of services, EC2 ensures that you have the computational resources you need, precisely when you need them.
Amazon S3 (Simple Storage Service): Secure, Scalable, and Cost-Effective Data Storage When it comes to storing and retrieving data, Amazon S3, the Simple Storage Service, stands as an indispensable tool in the AWS arsenal. S3 offers a scalable and highly durable object storage service that is designed for data security and cost-effectiveness. This service is the choice of businesses and individuals for storing a wide range of data, including media files, backups, and data archives. Its flexibility and reliability make it a prime choice for safeguarding your digital assets and ensuring they are readily accessible.
Amazon RDS (Relational Database Service): Streamlined Database Management Database management can be a complex task, but AWS simplifies it with Amazon RDS, the Relational Database Service. RDS automates many common database management tasks, including patching, backups, and scaling. It supports multiple database engines, including popular options like MySQL, PostgreSQL, and SQL Server. This service allows you to focus on your application while AWS handles the underlying database infrastructure. Whether you're building a content management system, an e-commerce platform, or a mobile app, RDS streamlines your database operations.
AWS Lambda: The Era of Serverless Computing Serverless computing has transformed the way applications are built and deployed, and AWS Lambda is at the forefront of this revolution. Lambda is a serverless compute service that enables you to run code without the need for server provisioning or management. It's the perfect solution for building serverless applications, microservices, and automating tasks. The unique pricing model ensures that you pay only for the compute time your code actually uses. This service empowers developers to focus on coding, knowing that AWS will handle the operational complexities behind the scenes.
Amazon DynamoDB: Low Latency, High Scalability NoSQL Database Amazon DynamoDB is a managed NoSQL database service that stands out for its low latency and exceptional scalability. It's a popular choice for applications with variable workloads, such as gaming platforms, IoT solutions, and real-time data processing systems. DynamoDB automatically scales to meet the demands of your applications, ensuring consistent, single-digit millisecond latency at any scale. Whether you're managing user profiles, session data, or real-time analytics, DynamoDB is designed to meet your performance needs.
Amazon VPC (Virtual Private Cloud): Tailored Networking for Security and Control Security and control over your cloud resources are paramount, and Amazon VPC (Virtual Private Cloud) empowers you to create isolated networks within the AWS cloud. This isolation enhances security and control, allowing you to define your network topology, configure routing, and manage access. VPC is the go-to solution for businesses and individuals who require a network environment that mirrors the security and control of traditional on-premises data centers.
Amazon SNS (Simple Notification Service): Seamless Communication Across Channels Effective communication is a cornerstone of modern applications, and Amazon SNS (Simple Notification Service) is designed to facilitate seamless communication across various channels. This fully managed messaging service enables you to send notifications to a distributed set of recipients, whether through email, SMS, or mobile devices. SNS is an essential component of applications that require real-time updates and notifications to keep users informed and engaged.
Amazon SQS (Simple Queue Service): Decoupling for Scalable Applications Decoupling components of a cloud application is crucial for scalability, and Amazon SQS (Simple Queue Service) is a fully managed message queuing service designed for this purpose. It ensures reliable and scalable communication between different parts of your application, helping you create systems that can handle varying workloads efficiently. SQS is a valuable tool for building robust, distributed applications that can adapt to changes in demand.
In the rapidly evolving landscape of cloud computing, Amazon Web Services (AWS) stands as a colossus, offering a diverse array of services that address the ever-evolving needs of businesses, startups, and individuals alike. AWS's popularity transcends industry boundaries, making it the go-to choice for a wide range of use cases, from startups launching their inaugural web applications to established enterprises managing intricate networks of services.
To unlock the full potential of these AWS services, gaining comprehensive knowledge and hands-on experience is key. ACTE Technologies, a renowned training provider, offers specialized AWS training programs designed to provide practical skills and in-depth understanding. These programs equip you with the tools needed to navigate and excel in the dynamic world of cloud computing.
With AWS services at your disposal, the possibilities are endless, and innovation knows no bounds. Join the ever-growing community of cloud professionals and enthusiasts, and empower yourself to shape the future of the digital landscape. ACTE Technologies is your trusted guide on this journey, providing the knowledge and support needed to thrive in the world of AWS and cloud computing.
8 notes
·
View notes
Text
5 useful tools for engineers! Introducing recommendations to improve work efficiency
Engineers have to do a huge amount of coding. It’s really tough having to handle other duties and schedule management at the same time. Having the right tools is key to being a successful engineer.
Here are some tools that will help you improve your work efficiency.
1.SourceTree
“SourceTree” is free Git client software provided by Atlassian. It is a tool for source code management and version control for developers and teams using the version control system called Git. When developers and teams use Git to manage projects, it supports efficient development work by providing a visualized interface and rich functionality.
2.Charles
“Charles” is an HTTP proxy tool for web development and debugging, and a debugging proxy tool for capturing HTTP and HTTPS traffic, visualizing and analyzing communication between networks. This allows web developers and system administrators to observe requests and responses for debugging, testing, performance optimization, and more.
3.iTerm2
“iTerm2” is a highly functional terminal emulator for macOS, and is an application that allows terminal operations to be performed more comfortably and efficiently. It offers more features than the standard Terminal application. It has rich features such as tab splitting, window splitting, session management, customizable appearance, and script execution.
4.Navicat
Navicat is an integrated tool for performing database management and development tasks and supports many major database systems (MySQL, PostgreSQL, SQLite, Oracle, SQL Server, etc.). Using Navicat, you can efficiently perform tasks such as database structure design, data editing and management, SQL query execution, data modeling, backup and restore.
5.CodeLF
CodeLF (Code Language Framework) is a tool designed to help find, navigate, and understand code within large source code bases. Key features include finding and querying symbols such as functions, variables, and classes in your codebase, viewing code snippets, and visualizing relationships between code. It can aid in efficient code navigation and understanding, increasing productivity in the development process.
2 notes
·
View notes
Text
Top Tips to Build a Secure Website Backup Plans

Why Website Backup Is Crucial
Website backup is a critical aspect of website management, offering protection against various threats and ensuring smooth operations. Here's an in-depth look at why website backup is essential:
1. Protection Against Data Loss: During website development, frequent changes are made, including code modifications and content updates. Without proper backup, accidental deletions or code errors can lead to irrecoverable data loss.
2. Safeguarding Against Cyber Attacks: Malicious cyber attacks, including ransomware, pose a significant threat to websites. Regular backups provide a safety net, allowing businesses to restore their websites to a pre-attack state quickly.
3. Mitigating Risks of Hardware and Software Failures: Hardware failures or software glitches can occur unexpectedly, potentially resulting in data corruption or loss. Website backup ensures that data can be restored swiftly in such scenarios.
4. Facilitating Smoother Updates and Overhauls: Website updates and overhauls are inevitable for staying current and meeting evolving requirements. Having backups in place streamlines these processes by providing a fallback option in case of unforeseen issues.
Understanding Website Backup
What is Website Backup? Website backup involves creating duplicate copies of website data, including media, code, themes, and other elements, and storing them securely to prevent loss or damage.
Components of Website Backup:
Website Files: Includes all website data such as code files, media, plugins, and themes.
Databases: Backup of databases like MySQL or PostgreSQL, if utilized.
Email Sending: Backup of email forwarders and filters associated with the website.
Tips for Secure Website Backup Planning
1. Choose the Right Backup Frequency: Frequency depends on website traffic, update frequency, and content sensitivity.
2. Opt for Third-Party Backup Solutions: Consider factors like storage capacity, automation, security features, and user-friendliness.
3. Utilize Backup Plugins for WordPress: Plugins like UpdraftPlus, VaultPress, and others offer secure and automated backup solutions.
4. Maintain Offsite Backups: Store backups in remote data centers or cloud services for added security.
5. Test Your Backups: Regular testing ensures backup integrity and readiness for restoration.
6. Supplement Hosting Backup Services: While hosting providers offer backups, explore additional backup solutions for enhanced security and control.
7. Consider Manual Backups: Manual backups provide flexibility and control, especially for specific needs or scenarios.
8. Encrypt Backup Data: Encrypting backup files adds an extra layer of security, preventing unauthorized access.
9. Monitor Backup Processes: Regular monitoring helps identify issues promptly and ensures backup availability.
10. Implement Disaster Recovery Plans: Prepare for unforeseen events with comprehensive disaster recovery strategies.
Secure Website Backup Service with Servepoet
For comprehensive website backup solutions, consider CodeGuard Backup service, offering automated daily backups, robust encryption, and user-friendly management features.
Conclusion
Building a secure website backup plan is vital for protecting against data loss, cyber threats, and operational disruptions. By following best practices and leveraging reliable backup solutions, businesses can safeguard their websites and ensure continuity of operations.
#buy domain and hosting#best domain hosting service#domain hosting services#marketing#cloud vps providers#web hosting and server#shared web hosting
2 notes
·
View notes
Text
Navigating the Cloud Landscape: Unleashing Amazon Web Services (AWS) Potential
In the ever-evolving tech landscape, businesses are in a constant quest for innovation, scalability, and operational optimization. Enter Amazon Web Services (AWS), a robust cloud computing juggernaut offering a versatile suite of services tailored to diverse business requirements. This blog explores the myriad applications of AWS across various sectors, providing a transformative journey through the cloud.

Harnessing Computational Agility with Amazon EC2
Central to the AWS ecosystem is Amazon EC2 (Elastic Compute Cloud), a pivotal player reshaping the cloud computing paradigm. Offering scalable virtual servers, EC2 empowers users to seamlessly run applications and manage computing resources. This adaptability enables businesses to dynamically adjust computational capacity, ensuring optimal performance and cost-effectiveness.
Redefining Storage Solutions
AWS addresses the critical need for scalable and secure storage through services such as Amazon S3 (Simple Storage Service) and Amazon EBS (Elastic Block Store). S3 acts as a dependable object storage solution for data backup, archiving, and content distribution. Meanwhile, EBS provides persistent block-level storage designed for EC2 instances, guaranteeing data integrity and accessibility.
Streamlined Database Management: Amazon RDS and DynamoDB
Database management undergoes a transformation with Amazon RDS, simplifying the setup, operation, and scaling of relational databases. Be it MySQL, PostgreSQL, or SQL Server, RDS provides a frictionless environment for managing diverse database workloads. For enthusiasts of NoSQL, Amazon DynamoDB steps in as a swift and flexible solution for document and key-value data storage.
Networking Mastery: Amazon VPC and Route 53
AWS empowers users to construct a virtual sanctuary for their resources through Amazon VPC (Virtual Private Cloud). This virtual network facilitates the launch of AWS resources within a user-defined space, enhancing security and control. Simultaneously, Amazon Route 53, a scalable DNS web service, ensures seamless routing of end-user requests to globally distributed endpoints.
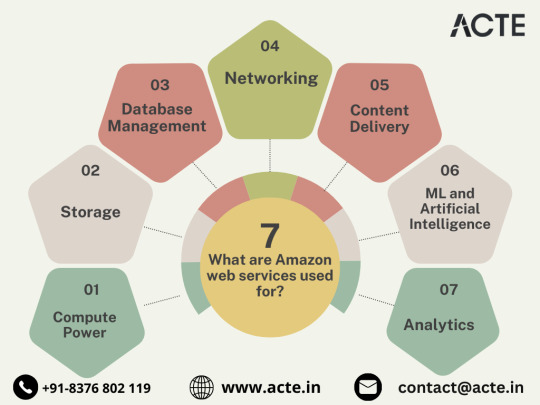
Global Content Delivery Excellence with Amazon CloudFront
Amazon CloudFront emerges as a dynamic content delivery network (CDN) service, securely delivering data, videos, applications, and APIs on a global scale. This ensures low latency and high transfer speeds, elevating user experiences across diverse geographical locations.
AI and ML Prowess Unleashed
AWS propels businesses into the future with advanced machine learning and artificial intelligence services. Amazon SageMaker, a fully managed service, enables developers to rapidly build, train, and deploy machine learning models. Additionally, Amazon Rekognition provides sophisticated image and video analysis, supporting applications in facial recognition, object detection, and content moderation.
Big Data Mastery: Amazon Redshift and Athena
For organizations grappling with massive datasets, AWS offers Amazon Redshift, a fully managed data warehouse service. It facilitates the execution of complex queries on large datasets, empowering informed decision-making. Simultaneously, Amazon Athena allows users to analyze data in Amazon S3 using standard SQL queries, unlocking invaluable insights.
In conclusion, Amazon Web Services (AWS) stands as an all-encompassing cloud computing platform, empowering businesses to innovate, scale, and optimize operations. From adaptable compute power and secure storage solutions to cutting-edge AI and ML capabilities, AWS serves as a robust foundation for organizations navigating the digital frontier. Embrace the limitless potential of cloud computing with AWS – where innovation knows no bounds.
3 notes
·
View notes
Text
Azure Data Engineering Tools For Data Engineers

Azure is a cloud computing platform provided by Microsoft, which presents an extensive array of data engineering tools. These tools serve to assist data engineers in constructing and upholding data systems that possess the qualities of scalability, reliability, and security. Moreover, Azure data engineering tools facilitate the creation and management of data systems that cater to the unique requirements of an organization.
In this article, we will explore nine key Azure data engineering tools that should be in every data engineer’s toolkit. Whether you’re a beginner in data engineering or aiming to enhance your skills, these Azure tools are crucial for your career development.
Microsoft Azure Databricks
Azure Databricks is a managed version of Databricks, a popular data analytics and machine learning platform. It offers one-click installation, faster workflows, and collaborative workspaces for data scientists and engineers. Azure Databricks seamlessly integrates with Azure’s computation and storage resources, making it an excellent choice for collaborative data projects.
Microsoft Azure Data Factory
Microsoft Azure Data Factory (ADF) is a fully-managed, serverless data integration tool designed to handle data at scale. It enables data engineers to acquire, analyze, and process large volumes of data efficiently. ADF supports various use cases, including data engineering, operational data integration, analytics, and data warehousing.
Microsoft Azure Stream Analytics
Azure Stream Analytics is a real-time, complex event-processing engine designed to analyze and process large volumes of fast-streaming data from various sources. It is a critical tool for data engineers dealing with real-time data analysis and processing.
Microsoft Azure Data Lake Storage
Azure Data Lake Storage provides a scalable and secure data lake solution for data scientists, developers, and analysts. It allows organizations to store data of any type and size while supporting low-latency workloads. Data engineers can take advantage of this infrastructure to build and maintain data pipelines. Azure Data Lake Storage also offers enterprise-grade security features for data collaboration.
Microsoft Azure Synapse Analytics
Azure Synapse Analytics is an integrated platform solution that combines data warehousing, data connectors, ETL pipelines, analytics tools, big data scalability, and visualization capabilities. Data engineers can efficiently process data for warehousing and analytics using Synapse Pipelines’ ETL and data integration capabilities.
Microsoft Azure Cosmos DB
Azure Cosmos DB is a fully managed and server-less distributed database service that supports multiple data models, including PostgreSQL, MongoDB, and Apache Cassandra. It offers automatic and immediate scalability, single-digit millisecond reads and writes, and high availability for NoSQL data. Azure Cosmos DB is a versatile tool for data engineers looking to develop high-performance applications.
Microsoft Azure SQL Database
Azure SQL Database is a fully managed and continually updated relational database service in the cloud. It offers native support for services like Azure Functions and Azure App Service, simplifying application development. Data engineers can use Azure SQL Database to handle real-time data ingestion tasks efficiently.
Microsoft Azure MariaDB
Azure Database for MariaDB provides seamless integration with Azure Web Apps and supports popular open-source frameworks and languages like WordPress and Drupal. It offers built-in monitoring, security, automatic backups, and patching at no additional cost.
Microsoft Azure PostgreSQL Database
Azure PostgreSQL Database is a fully managed open-source database service designed to emphasize application innovation rather than database management. It supports various open-source frameworks and languages and offers superior security, performance optimization through AI, and high uptime guarantees.
Whether you’re a novice data engineer or an experienced professional, mastering these Azure data engineering tools is essential for advancing your career in the data-driven world. As technology evolves and data continues to grow, data engineers with expertise in Azure tools are in high demand. Start your journey to becoming a proficient data engineer with these powerful Azure tools and resources.
Unlock the full potential of your data engineering career with Datavalley. As you start your journey to becoming a skilled data engineer, it’s essential to equip yourself with the right tools and knowledge. The Azure data engineering tools we’ve explored in this article are your gateway to effectively managing and using data for impactful insights and decision-making.
To take your data engineering skills to the next level and gain practical, hands-on experience with these tools, we invite you to join the courses at Datavalley. Our comprehensive data engineering courses are designed to provide you with the expertise you need to excel in the dynamic field of data engineering. Whether you’re just starting or looking to advance your career, Datavalley’s courses offer a structured learning path and real-world projects that will set you on the path to success.
Course format:
Subject: Data Engineering Classes: 200 hours of live classes Lectures: 199 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 70% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
Subject: DevOps Classes: 180+ hours of live classes Lectures: 300 lectures Projects: Collaborative projects and mini projects for each module Level: All levels Scholarship: Up to 67% scholarship on this course Interactive activities: labs, quizzes, scenario walk-throughs Placement Assistance: Resume preparation, soft skills training, interview preparation
For more details on the Data Engineering courses, visit Datavalley’s official website.
#datavalley#dataexperts#data engineering#data analytics#dataexcellence#data science#power bi#business intelligence#data analytics course#data science course#data engineering course#data engineering training
3 notes
·
View notes
Text
Database Management Systems: The Heart of Efficient Data Handling

A database management system (DBMS) is software that enables users to store, retrieve, and manage data efficiently. DBMS solutions ensure data integrity, security, and accessibility, making them a critical component for enterprises handling large datasets. There are various types of DBMS, including relational (SQL-based) and non-relational (NoSQL) databases, each serving different business needs. Relational databases, such as MySQL and PostgreSQL, are ideal for structured data, while NoSQL solutions like MongoDB and Cassandra are better suited for unstructured or semi-structured data. Modern DBMSs offer features like automated backups, indexing, and real-time query optimization. Organizations leverage DBMS to streamline operations, improve customer experiences, and enable seamless data sharing across departments. As businesses embrace cloud-based and AI-powered databases, the efficiency and scalability of DBMS solutions continue to evolve. Choosing the right DBMS is essential for ensuring reliable data management and supporting business growth. For more info: https://www.datastoryhub.ai/data-warehouse-and-database-management-systems/
0 notes
Text
Managed Server Enterprise Support: What You Need to Know
Enterprise IT environments demand reliable, secure, and high-performance server management to ensure business continuity. Managed server enterprise support provides proactive monitoring, maintenance, security, and troubleshooting for on-premises, cloud, or hybrid infrastructures.
1. Key Features of Managed Server Enterprise Support
🔹 24/7 Monitoring & Performance Optimization
✔ Real-time server health monitoring (CPU, memory, disk, network usage) ✔ Proactive issue detection to prevent downtime ✔ Load balancing & resource optimization
🔹 Security & Compliance Management
✔ Firewall & intrusion detection to block cyber threats ✔ Patch management & software updates to fix vulnerabilities ✔ Compliance audits (ISO 27001, HIPAA, GDPR)
🔹 Backup & Disaster Recovery
✔ Automated backups with offsite storage ✔ Disaster recovery solutions for business continuity ✔ RAID configuration & data redundancy
🔹 Server OS & Software Support
✔ Windows Server (2016, 2019, 2022) & Linux distributions (Ubuntu, CentOS, RHEL) ✔ Database management (MySQL, PostgreSQL, MS SQL) ✔ Virtualization & cloud integration (VMware, Hyper-V, AWS, Azure)
🔹 Helpdesk & Technical Support
✔ Dedicated IT support team with rapid response times ✔ Troubleshooting & issue resolution ✔ Custom SLAs for uptime guarantees
2. Types of Managed Server Enterprise Support
🔹 On-Premises Server Management
✔ Ideal for businesses with in-house data centers ✔ Supports hardware maintenance, OS updates, security patches ✔ Best for: Enterprises requiring full control over infrastructure
🔹 Cloud & Hybrid Server Management
✔ Managed services for AWS, Azure, Google Cloud ✔ Optimized for cloud security, scalability & cost-efficiency ✔ Best for: Enterprises adopting hybrid or multi-cloud strategies
🔹 Fully Managed vs. Co-Managed Support
✔ Fully Managed: Service provider handles everything (monitoring, security, backups, troubleshooting) ✔ Co-Managed: Internal IT team works alongside provider for collaborative management
3. Benefits of Enterprise Server Support
🔹 Minimized Downtime: 24/7 monitoring & quick response prevent disruptions 🔹 Stronger Security: Proactive firewall management, encryption & threat monitoring 🔹 Scalability: Adapt server resources as business grows 🔹 Cost Savings: Reduces IT staff workload & lowers infrastructure costs 🔹 Compliance Assurance: Meets industry security & legal requirements
4. How to Choose the Right Managed Server Provider
✔ Service Level Agreements (SLAs): Ensure 99.9%+ uptime guarantees ✔ Security Protocols: Must include firewalls, DDoS protection, and backups ✔ Support for Your Tech Stack: Compatible with Windows/Linux, databases, virtualization ✔ Customization & Scalability: Can adjust services based on business growth ✔ 24/7 Support & Response Time: Fast issue resolution & technical assistance
5. Cost of Managed Server Enterprise Support
💰 Pricing Models: ✔ Per Server: $100–$500/month (basic), $500–$2,500/month (enterprise) ✔ Per Resource Usage: Based on CPU, RAM, storage & bandwidth ✔ Custom Plans: Tailored pricing for hybrid & multi-cloud environments
6. Who Needs Managed Server Enterprise Support?
✔ Large Enterprises: Need mission-critical uptime & security ✔ eCommerce & SaaS Businesses: Require high-performance cloud hosting ✔ Financial & Healthcare Organizations: Must comply with data security regulations ✔ Growing Startups: Benefit from scalable, cost-effective infrastructure
Need a Custom Managed Server Plan?
Let me know your server type, workload, and business needs, and I can recommend the best managed enterprise support solution!

0 notes
Text
Using Linux for Database Administration: MySQL, PostgreSQL, MongoDB
Linux is the go-to operating system for database administration due to its stability, security, and flexibility. Whether you’re managing relational databases like MySQL and PostgreSQL or working with a NoSQL database like MongoDB, Linux provides the ideal environment for robust and efficient database operations.
In this post, we’ll explore how Linux enhances the administration of MySQL, PostgreSQL, and MongoDB, along with best practices for maintaining high performance and security.
Why Use Linux for Database Administration?
Stability and Performance: Linux efficiently handles high workloads, ensuring minimal downtime and fast processing speeds.
Security Features: Built-in security mechanisms, such as SELinux and iptables, provide robust protection against unauthorized access.
Open-Source and Cost-Effective: With no licensing fees, Linux offers complete flexibility and cost savings for startups and enterprises alike.
Community Support and Documentation: A vast community of developers and system administrators ensures continuous support and updates.
1. Managing MySQL on Linux
Overview of MySQL
MySQL is a popular open-source relational database management system known for its speed and reliability. It is widely used in web applications, including WordPress, e-commerce platforms, and enterprise solutions.
Key Administrative Tasks in MySQL
User Management: Create, modify, and delete database users with specific roles and permissions to enhance security.
Backup and Recovery: Regular backups are crucial for data integrity. Linux provides tools like cron to automate backup schedules.
Performance Tuning: Optimize query performance by configuring buffer sizes and enabling caching.
Security Configurations: Implement security measures such as data encryption, firewall configurations, and access control lists (ACLs).
Best Practices for MySQL on Linux
Regularly update MySQL and the Linux OS to protect against vulnerabilities.
Monitor system performance using tools like top, htop, and vmstat.
Secure remote access by restricting IP addresses and using SSH keys for authentication.
2. Managing PostgreSQL on Linux
Overview of PostgreSQL
PostgreSQL is an advanced open-source relational database known for its powerful features, including support for complex queries, custom data types, and full ACID compliance. It is commonly used in enterprise applications and data analytics.
Key Administrative Tasks in PostgreSQL
User and Role Management: Assign granular permissions and roles for enhanced security and access control.
Backup and Restoration: Use robust tools like pg_dump and pg_restore for consistent and reliable backups.
Performance Optimization: Tune query execution by optimizing indexes, adjusting shared buffers, and analyzing query plans.
Replication and High Availability: Implement streaming replication for high availability and disaster recovery.
Best Practices for PostgreSQL on Linux
Regularly maintain and vacuum databases to optimize storage and performance.
Enable logging and monitoring to detect slow queries and optimize performance.
Secure database connections using SSL and configure firewalls for restricted access.
3. Managing MongoDB on Linux
Overview of MongoDB
MongoDB is a popular NoSQL database that stores data in flexible, JSON-like documents. It is known for its scalability and ease of use, making it suitable for modern web applications and big data solutions.
Key Administrative Tasks in MongoDB
User Authentication and Authorization: Secure databases using role-based access control (RBAC) and authentication mechanisms.
Data Replication and Sharding: Ensure high availability and horizontal scalability with replication and sharding techniques.
Backup and Restore: Perform consistent backups using tools like mongodump and mongorestore.
Performance Monitoring: Monitor database performance using MongoDB’s built-in tools or third-party solutions like Prometheus and Grafana.
Best Practices for MongoDB on Linux
Use the WiredTiger storage engine for better concurrency and data compression.
Monitor and optimize memory usage for improved performance.
Secure communication with SSL/TLS encryption and IP whitelisting.
Performance Tuning Tips for Linux Databases
Optimize Memory Usage: Adjust buffer sizes and cache settings to enhance database performance.
Enable Query Caching: Speed up repeated queries by enabling caching mechanisms.
Monitor System Resources: Use monitoring tools like Nagios, Prometheus, and Grafana to track resource usage and database performance.
Automate Maintenance Tasks: Schedule routine tasks like backups, vacuuming, and indexing using Linux cron jobs.
Enhance Security: Secure databases with firewalls, SELinux, and role-based access controls.
Conclusion
Using Linux for database administration provides unmatched stability, performance, and security. Whether you are working with MySQL, PostgreSQL, or MongoDB, Linux offers a robust environment for managing complex database operations. By following best practices for installation, configuration, performance tuning, and security, you can ensure high availability and reliability of your database systems. For more details click www.hawkstack.com
0 notes
Text
Advanced Database Management in Full Stack Development
Introduction
A Full Stack Development project's foundation is effective database management. Data transactions and application performance are guaranteed by the capacity to build, optimize, and scale databases. Proficiency with SQL and NoSQL databases, indexing, query optimization, and high availability replication are essential for modern applications. To create scalable systems, developers also need to concentrate on cloud integration, backup plans, and database security. In order to guarantee maximum performance and dependability in full stack applications, this paper examines sophisticated database management strategies.
Choosing the Right Database: SQL vs. NoSQL
Choosing the right database is essential for the scalability of the program. Strong data consistency, defined schema, and ACID compliance are features of SQL databases (MySQL, PostgreSQL, and Microsoft SQL Server). Applications needing relational data storage, financial transactions, and sophisticated searches are best suited for them. NoSQL databases, such as MongoDB, Cassandra, and Firebase, offer distributed architecture, high scalability, and customizable schemas. Large-scale, unstructured data processing, such as real-time analytics and Internet of Things applications, is best handled by these. Database efficiency is increased by combining NoSQL for dynamic content and SQL for structured data.
Optimizing Query Performance and Scaling
Applications that have poorly optimized queries operate slowly. Data retrieval is accelerated by the use of indexing, query caching, and denormalization. In high-traffic applications, partitioning huge tables improves read/write performance. Performance is enhanced via read and write replicas, which disperse database loads. Sharding lowers latency by dividing big databases into smaller portions that are distributed across several servers. In full stack applications, database interaction is streamlined by using ORM (Object-Relational Mapping) technologies like SQLAlchemy, Hibernate, or Sequelize.
Database Security and Backup Strategies
In Full Stack Development, data availability and security must be guaranteed. Unauthorized access is avoided by putting role-based access control (RBAC) into practice. User information is protected by using hashing methods, SSL/TLS, and AES to encrypt important data. Data loss may be avoided by point-in-time recovery, disaster recovery plans, and routine database backups. AWS RDS, Google Cloud Firestore, and Azure Cosmos DB are examples of cloud-based databases that provide fault tolerance, replication, and automated backups to guarantee data dependability and integrity.
Conclusion
Building scalable, high-performance applications in Advanced Full Stack Development requires a solid understanding of database administration. System efficiency is increased by selecting between SQL and NoSQL databases, optimizing queries, and protecting data storage. A Full Stack Development Training curriculum gives developers hands-on experience while teaching them sophisticated database approaches. Database management internships provide professionals practical experience in handling data in the real world, preparing them for the workforce. A successful career in Full Stack Development is ensured by investing in database competence.
#advanced full stack development#advanced full stack development training#advanced full stack development internship#e3l#e3l.co
0 notes
Text
The Complete Guide to Migrating Your TYPO3 Website to TYPO3 v13
Introduction
Upgrading your TYPO3 website to TYPO3 v13 is a significant step that enhances performance, security, and user experience. This comprehensive guide provides a step-by-step roadmap to ensure a smooth and successful migration.
Understanding the Advantages of TYPO3 v13
Before migrating, it’s important to know what TYPO3 v13 brings:
Enhanced Performance: Faster page loads and a more responsive backend.
Improved Security: Latest security updates to protect your website.
New Features: Better content management tools and user-friendly enhancements.
Future-Proofing: Ensures long-term support and compatibility with new technologies.
Preparing for the Migration
A well-planned upgrade reduces risks. Here’s what you should do:
✔️ Backup Everything
Make a full backup of your website files and database.
Store it securely in case something goes wrong during migration.
✔️ Check System Requirements
TYPO3 v13 requires:
PHP 8.2+
Databases: MySQL 8.0+, MariaDB 10.3+, PostgreSQL 12+, SQLite 3.31.0+
Web Server: Apache, Nginx, or IIS (latest versions recommended)
✔️ Review Installed Extensions
Check if your extensions are compatible with TYPO3 v13.
Update them or find alternatives if they are no longer supported.
The Migration Process: Step-by-Step
Follow these steps to upgrade your website safely:
🔹 Update the TYPO3 Core
Download the latest TYPO3 v13 package.
Replace the old core files with the new ones.
🔹 Run the Upgrade Wizard
TYPO3 provides built-in Upgrade Wizards that update your database and configurations.
Follow the wizard's recommendations to ensure smooth migration.
🔹 Test Your Website Thoroughly
Check if all pages, extensions, and features work properly.
Fix broken links, missing images, or layout issues.
Conclusion
Upgrading to TYPO3 v13 enhances your website’s performance, security, and future readiness. By following these steps, you can ensure a smooth transition with minimal disruptions. Stay updated, monitor your website, and enjoy the latest features of TYPO3 v13!
#TYPO3#TYPO3UpgradeGuide#TYPO3v13#TYPO3WebsiteMigration#TYPO3Community#SEO#TYPO3CMSUpdate#TYPO3v13Migration
0 notes
Text
aws cloud,
aws cloud,
Amazon Web Services (AWS) is one of the leading cloud computing platforms, offering a wide range of services that enable businesses, developers, and organizations to build and scale applications efficiently. AWS provides cloud solutions that are flexible, scalable, and cost-effective, making it a popular choice for enterprises and startups alike.
Key Features of AWS Cloud
AWS offers an extensive range of features that cater to various computing needs. Some of the most notable features include:
Scalability and Flexibility – AWS allows businesses to scale their resources up or down based on demand, ensuring optimal performance without unnecessary costs.
Security and Compliance – With robust security measures, AWS ensures data protection through encryption, identity management, and compliance with industry standards.
Cost-Effectiveness – AWS follows a pay-as-you-go pricing model, reducing upfront capital expenses and providing cost transparency.
Global Infrastructure – AWS operates data centers worldwide, offering low-latency performance and high availability.
Wide Range of Services – AWS provides a variety of services, including computing, storage, databases, machine learning, and analytics.
Popular AWS Services
AWS offers numerous services across various categories. Some of the most widely used services include:
1. Compute Services
Amazon EC2 (Elastic Compute Cloud) – Virtual servers for running applications.
AWS Lambda – Serverless computing that runs code in response to events.
2. Storage Services
Amazon S3 (Simple Storage Service) – Object storage for data backup and archiving.
Amazon EBS (Elastic Block Store) – Persistent block storage for EC2 instances.
3. Database Services
Amazon RDS (Relational Database Service) – Managed relational databases like MySQL, PostgreSQL, and SQL Server.
Amazon DynamoDB – A fully managed NoSQL database for fast and flexible data access.
4. Networking & Content Delivery
Amazon VPC (Virtual Private Cloud) – Secure cloud networking.
Amazon CloudFront – Content delivery network for faster content distribution.
5. Machine Learning & AI
Amazon SageMaker – A fully managed service for building and deploying machine learning models.
AWS AI Services – Includes tools like Amazon Rekognition (image analysis) and Amazon Polly (text-to-speech).
Benefits of Using AWS Cloud
Organizations and developers prefer AWS for multiple reasons:
High Availability – AWS ensures minimal downtime with multiple data centers and redundant infrastructure.
Enhanced Security – AWS follows best security practices, including data encryption, DDoS protection, and identity management.
Speed and Agility – With AWS, businesses can deploy applications rapidly and scale effortlessly.
Cost Savings – The pay-as-you-go model reduces IT infrastructure costs and optimizes resource allocation.
Getting Started with AWS
If you are new to AWS, follow these steps to get started:
Create an AWS Account – Sign up on the AWS website.
Choose a Service – Identify the AWS services that suit your needs.
Learn AWS Basics – Use AWS tutorials, documentation, and training courses.
Deploy Applications – Start small with free-tier resources and gradually scale.
Conclusion
AWS Cloud is a powerful and reliable platform that empowers businesses with cutting-edge technology. Whether you need computing power, storage, networking, or machine learning, AWS provides a vast ecosystem of services to meet diverse requirements. With its scalability, security, and cost efficiency, AWS continues to be a top choice for cloud computing solutions.
0 notes
Text
Challenges and Solutions in Migrating from Firebird to PostgreSQL – Ask On Data
Migrating from one database management system (DBMS) to another can be a daunting task, especially when moving from a system like Firebird to PostgreSQL. While both are powerful, open-source relational databases, they have significant differences in architecture, functionality, and performance. The Firebird to PostgreSQL Migration process involves addressing several challenges that may arise, including data integrity, schema differences, and performance optimization. In this article, we will explore some common challenges in this migration and provide practical solutions to ensure a smooth transition.
1. Schema Differences and Compatibility Issues
One of the primary challenges when migrating from Firebird to PostgreSQL is the difference in schema structures and SQL syntax. Firebird uses a slightly different approach to handling data types, constraints, and indexes compared to PostgreSQL. For example, Firebird does not support some advanced PostgreSQL data types such as JSONB and ARRAY, which could complicate the migration process.
Solution: To overcome schema compatibility issues, start by thoroughly analysing the Firebird schema. Identify any Firebird-specific data types and operations, then map them to their PostgreSQL equivalents. You may need to rewrite certain parts of the schema, particularly for custom data types or stored procedures. There are also tools available that can help with this, such as pg_loader or DBConvert, which automate many of the mapping and conversion tasks.
2. Data Migration and Integrity
Migrating large volumes of data from Firebird to PostgreSQL can be another challenge. Ensuring data integrity and avoiding data loss during the migration process is crucial, especially if the database contains sensitive information or is in production use.
Solution: To preserve data integrity, a well-planned migration strategy is essential. Begin with a backup of the Firebird database before initiating any migration tasks. Then, consider using a phased migration approach, starting with less critical data to test the migration process before handling the main data sets. You can use ETL (Extract, Transform, Load) tools to facilitate data transfer while ensuring data types and constraints are properly mapped. Additionally, validating the migrated data through comprehensive testing is critical to confirm its accuracy and consistency.
3. Stored Procedures and Triggers
Firebird and PostgreSQL handle stored procedures and triggers differently. While Firebird uses its own dialect of SQL for creating stored procedures and triggers, PostgreSQL employs PL/pgSQL, which may require substantial changes in the logic and syntax of the existing procedures.
Solution: Manual conversion of stored procedures and triggers from Firebird to PostgreSQL is often necessary. Depending on the complexity, this could be a time-consuming process. It's advisable to map the logic of Firebird stored procedures to PostgreSQL's PL/pgSQL language, ensuring that any procedural or control flow statements are appropriately translated. If the application relies heavily on stored procedures, careful testing should be done to verify that the logic remains intact post-migration.
4. Performance Optimization
Performance optimization is a key concern when migrating databases. While PostgreSQL is known for its strong performance, tuning it to perform optimally for your workload after migration may require adjustments. Firebird and PostgreSQL have different query optimization engines, indexing methods, and transaction handling mechanisms, which can affect performance.
Solution: After migrating the schema and data, conduct a thorough performance analysis of the PostgreSQL instance. Use EXPLAIN ANALYZE and VACUUM to analyse query plans and identify any slow-performing queries. Indexing strategies in PostgreSQL may differ from Firebird, so ensure that indexes are appropriately created for optimal performance. Additionally, fine-tuning PostgreSQL’s configuration settings, such as memory allocation, query cache settings, and vacuum parameters, will help optimize the overall performance of the migrated database.
5. Application Compatibility
The final challenge to address during Firebird to PostgreSQL Migration is ensuring that the applications interacting with the database continue to function properly. The application layer may contain hardcoded SQL queries or assumptions based on Firebird’s behaviour, which might not work as expected with PostgreSQL.
Solution: After migrating the database, thoroughly test all application functionalities that interact with the database. Update any application queries or functions that rely on Firebird-specific features, and ensure they are compatible with PostgreSQL’s syntax and behaviour. Tools like pgAdmin and PostgreSQL JDBC drivers can help test and optimize the connection between the application and PostgreSQL.
Conclusion
Migrating from Firebird to PostgreSQL can be a complex yet rewarding process. By understanding the potential challenges with Ask On Data—such as schema differences, data integrity issues, and performance optimization—and implementing the appropriate solutions, you can ensure a successful migration. With careful planning, testing, and the use of migration tools, you can transition smoothly to PostgreSQL and take advantage of its powerful features and scalability.
0 notes
Text
Building Scalable Web Applications: Best Practices for Full Stack Developers
Scalability is one of the most crucial factors in web application development. In today’s dynamic digital landscape, applications need to be prepared to handle increased user demand, data growth, and evolving business requirements without compromising performance. For full stack developers, mastering scalability is not just an option—it’s a necessity. This guide explores the best practices for building scalable web applications, equipping developers with the tools and strategies needed to ensure their projects can grow seamlessly.
What Is Scalability in Web Development?
Scalability refers to a system’s ability to handle increased loads by adding resources, optimizing processes, or both. A scalable web application can:
Accommodate growing numbers of users and requests.
Handle larger datasets efficiently.
Adapt to changes without requiring complete redesigns.
There are two primary types of scalability:
Vertical Scaling: Adding more power (CPU, RAM, storage) to a single server.
Horizontal Scaling: Adding more servers to distribute the load.
Each type has its use cases, and a well-designed application often employs a mix of both.
Best Practices for Building Scalable Web Applications
1. Adopt a Microservices Architecture
What It Is: Break your application into smaller, independent services that can be developed, deployed, and scaled independently.
Why It Matters: Microservices prevent a single point of failure and allow different parts of the application to scale based on their unique needs.
Tools to Use: Kubernetes, Docker, AWS Lambda.
2. Optimize Database Performance
Use Indexing: Ensure your database queries are optimized with proper indexing.
Database Partitioning: Divide large databases into smaller, more manageable pieces using horizontal or vertical partitioning.
Choose the Right Database Type:
Use SQL databases like PostgreSQL for structured data.
Use NoSQL databases like MongoDB for unstructured or semi-structured data.
Implement Caching: Use caching mechanisms like Redis or Memcached to store frequently accessed data and reduce database load.
3. Leverage Content Delivery Networks (CDNs)
CDNs distribute static assets (images, videos, scripts) across multiple servers worldwide, reducing latency and improving load times for users globally.
Popular CDN Providers: Cloudflare, Akamai, Amazon CloudFront.
Benefits:
Faster content delivery.
Reduced server load.
Improved user experience.
4. Implement Load Balancing
Load balancers distribute incoming requests across multiple servers, ensuring no single server becomes overwhelmed.
Types of Load Balancing:
Hardware Load Balancers: Physical devices.
Software Load Balancers: Nginx, HAProxy.
Cloud Load Balancers: AWS Elastic Load Balancing, Google Cloud Load Balancing.
Best Practices:
Use sticky sessions if needed to maintain session consistency.
Monitor server health regularly.
5. Use Asynchronous Processing
Why It’s Important: Synchronous operations can cause bottlenecks in high-traffic scenarios.
How to Implement:
Use message queues like RabbitMQ, Apache Kafka, or AWS SQS to handle background tasks.
Implement asynchronous APIs with frameworks like Node.js or Django Channels.
6. Embrace Cloud-Native Development
Cloud platforms provide scalable infrastructure that can adapt to your application’s needs.
Key Features to Leverage:
Autoscaling for servers.
Managed database services.
Serverless computing.
Popular Cloud Providers: AWS, Google Cloud, Microsoft Azure.
7. Design for High Availability (HA)
Ensure that your application remains operational even in the event of hardware failures, network issues, or unexpected traffic spikes.
Strategies for High Availability:
Redundant servers.
Failover mechanisms.
Regular backups and disaster recovery plans.
8. Optimize Front-End Performance
Scalability is not just about the back end; the front end plays a significant role in delivering a seamless experience.
Best Practices:
Minify and compress CSS, JavaScript, and HTML files.
Use lazy loading for images and videos.
Implement browser caching.
Use tools like Lighthouse to identify performance bottlenecks.
9. Monitor and Analyze Performance
Continuous monitoring helps identify and address bottlenecks before they become critical issues.
Tools to Use:
Application Performance Monitoring (APM): New Relic, Datadog.
Logging and Error Tracking: ELK Stack, Sentry.
Server Monitoring: Nagios, Prometheus.
Key Metrics to Monitor:
Response times.
Server CPU and memory usage.
Database query performance.
Network latency.
10. Test for Scalability
Regular testing ensures your application can handle increasing loads.
Types of Tests:
Load Testing: Simulate normal usage levels.
Stress Testing: Push the application beyond its limits to identify breaking points.
Capacity Testing: Determine how many users the application can handle effectively.
Tools for Testing: Apache JMeter, Gatling, Locust.
Case Study: Scaling a Real-World Application
Scenario: A growing e-commerce platform faced frequent slowdowns during flash sales.
Solutions Implemented:
Adopted a microservices architecture to separate order processing, user management, and inventory systems.
Integrated Redis for caching frequently accessed product data.
Leveraged AWS Elastic Load Balancer to manage traffic spikes.
Optimized SQL queries and implemented database sharding for better performance.
Results:
Improved application response times by 40%.
Seamlessly handled a 300% increase in traffic during peak events.
Achieved 99.99% uptime.
Conclusion
Building scalable web applications is essential for long-term success in an increasingly digital world. By implementing best practices such as adopting microservices, optimizing databases, leveraging CDNs, and embracing cloud-native development, full stack developers can ensure their applications are prepared to handle growth without compromising performance.
Scalability isn’t just about handling more users; it’s about delivering a consistent, reliable experience as your application evolves. Start incorporating these practices today to future-proof your web applications and meet the demands of tomorrow’s users.
0 notes