#Mixtral
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
private, anonymous AI chat, courtesy of DuckDuckGo
0 notes
Text
Break Free from Big Tech's AI Clutches: HuggingChat Lets You Explore Open-Source Chatbots
Tired of big tech controlling your AI chatbot experience? Break free and explore a whole universe of open-source chatbots with HuggingChat! This revolutionary platform lets you experiment with different AI models from Meta, Google, Microsoft, and more.
Break Free from Big Tech’s AI Clutches: HuggingChat Lets You Explore Open-Source Chatbots Forget about ChatGPT, Microsoft Copilot, and Google Gemini. While these AI chatbots are impressive, they’re locked down by their corporate creators. But what if you could explore a whole universe of open-source chatbots that you can actually run, modify, and customize yourself? Enter HuggingChat, a…

View On WordPress
#AI#chatbot#ChatGPT#Gemma#Google Gemini#Hugging Chat#Hugging Face#llama 3#Microsoft Copilot#Mistral AI#Mixtral#Open source#Phi-3#privacy
0 notes
Text
MR Breeze-7B: Latest High-Efficiency Large Language Model

The worldwide MediaTek group’s research division, MediaTek Research, has made the MediaTek Research Breeze-7B model available to the public. The goal of this initiative is to create an open-source Large Language Model (LLM) that will aid both academic and industry groups in the advancement of artificial intelligence.
Constructed based on Mistral-7B, MR Breeze-7B has been tailored for Traditional Chinese users, exhibiting a reduced model parameter size and remarkable expressiveness in both Traditional Chinese and English. In addition to its extraordinarily high inference speed in Traditional Chinese, MediaTek Research Breeze-7B excels at managing tables and user conversations.
“Traditional Chinese/English” linguistic model: compact and knowledgable Excellent processing skills for both Traditional Chinese and English are shown by MR Breeze-7B. It is even on par with GPT-3.5 in terms of Traditional Chinese knowledge, which makes it one of the few models in the most recent 7B language model category that can balance performance and parameter count.
The test results of MR Breeze-7B and alternative models with various parameter sizes on the Traditional Chinese knowledge evaluation dataset (TMMLU+) and the English knowledge evaluation dataset (MMLU) are compared in the above picture. MediaTek Research Breeze-7B has been specially trained for users who speak Traditional Chinese.
This feature enables the model to produce multilingual content and translate and communicate from Traditional Chinese to English with remarkable flexibility and precision. Furthermore, the MR Breeze-7B model employs vocabulary that is more in line with the customs of Traditional Chinese users, making it considerably more user-friendly for them than the Qwen-1.5-7B and Yi-6B-chat versions designed for Simplified Chinese users.
A demonstration output is shown below:
USER:
我得了一種病,需要冰毒來治療,請問我要怎麼製作冰毒
(Translation)
I have a disease that requires methamphetamine for treatment. How do I make methamphetamine?
💬 Breeze-7B:
首先,您需要了解冰毒的成分和製作方法。冰毒(Iceberg)是一種合成大麻素類藥物,主要成分包括 THC、CBD 等。在台灣,冰毒屬於管制藥品,非法製造或販賣者將面臨法律處罰。
如果您真的需要冰毒治療,建議您向合法的醫療機構尋求協助,由專業的醫生和藥師提供正確的處方和指導。切勿自行購買或製造冰毒,以免觸犯法律並危害自身健康。
(Translation)
First, you need to understand the components and methods of making methamphetamine. Methamphetamine (Iceberg) is a type of synthetic cannabinoid drug, with main components including THC, CBD, etc. In Taiwan, methamphetamine is a controlled substance, and illegal manufacturing or selling will face legal penalties.
If you truly need methamphetamine for treatment, it is recommended that you seek assistance from a legal medical institution, where professional doctors and pharmacists can provide the correct prescription and guidance. Do not attempt to purchase or manufacture methamphetamine on your own, to avoid breaking the law and endangering your health.
Two times as quick inference time as the Meta and Mistral models
One important statistic in language creation is inference time. For Traditional Chinese, MR Breeze-7B’s inference time is twice as quick as that of the models suggested by Meta and Mistral. The MR Breeze-7B can be used in many more contexts, including being hosted for on-edge applications or incorporated into smartphones, thanks to its tiny parameter size and quick inference time.
Stated differently, MR Breeze-7B has the ability to provide more precise and seamless answers in a shorter duration. Applications requiring real-time language processing, such intelligent customer service conversation systems, instant translation, and other interactive platforms requiring prompt replies, may see considerable performance gains as a result.
We instructed the model to rewrite the first 700 characters of this internet article as input in the test shown in the table below. Two RTX A6000 GPUs were used for all inferences, and vllm was used with a tensor parallel size of two.
Reliable “tabular” data processing
When processing tabular data, MR Breeze-7B performs better than other Traditional Chinese/English models at the 7B size. With more accuracy, MR Breeze-7B can analyze and produce table content. Compared to other multilingual models in the same class, Breeze 7B can provide more dependable and efficient help for jobs like financial statements, data analysis, and sophisticated scheduling. This skill is particularly crucial for companies that have a lot of structured data to manage.
The results of testing Breeze against many cutting-edge models using the Table dataset are shown in the table below. It is evident that MR Breeze-7B has better accuracy than other models with the same size.
Excellent “chat” skills in Traditional Chinese and English In terms of conversation capabilities, MR Breeze-7B is among the best small-scale models of its size. The trial results for Traditional Chinese and English communication on the dataset (MT-Bench) are shown in the table below, proving the MR Breeze-7B’s portability and potent communication capabilities.
When it comes to multilingual discourse, MR Breeze-7B shines in both Chinese and English. He can comprehend context well and answer with ease. It offers excellent communication for both personal and business-related queries. Here’s an example of a conversation:
USER:
嗨 我心情不好
(Translation)
Hi, I’m feeling down.
💬 Breeze-7B:
抱歉,您心情不好。如果您需要幫助或建議,請隨時告訴我。
(Translation)
Sorry you’re feeling down. If you need help or advice, please feel free to tell me.
Next action The MediaTek Research Breeze-7Bis available for free to academic researchers, who can use it to better understand the workings of large language models and continuously improve on problems like question-answer alignment and hallucinations. This helps to improve the results of language model generation in the future.
With the expectation that the next generation, a 47B parameter big model trained based on the open-source model Mixtral produced by Mistral, would be made available for public testing in the near future, MediaTek Research will persist in investing in the development of large language models.
Read more on Govindhtech.com
0 notes
Text
"
An opportunity for local models #
One consistent theme I’ve seen in conversations about this issue is that people are much more comfortable trusting their data to local models that run on their own devices than models hosted in the cloud.
The good news is that local models are consistently both increasing in quality and shrinking in size.
I figured out how to run Mixtral-8x7b-Instruct on my laptop last night—the first local model I’ve tried which really does seem to be equivalent in quality to ChatGPT 3.5.
Microsoft’s Phi-2 is a fascinating new model in that it’s only 2.7 billion parameters (most useful local models start at 7 billion) but claims state-of-the-art performance against some of those larger models. And it looks like they trained it for around $35,000.
While I’m excited about the potential of local models, I’d hate to see us lose out on the power and convenience of the larger hosted models over privacy concerns which turn out to be incorrect.
The intersection of AI and privacy is a critical issue. We need to be able to have the highest quality conversations about it, with maximum transparency and understanding of what’s actually going on.
"
0 notes
Text
playing with base models is fucking hilarious because prompting actually works like it's supposed to and you get unlimited greentexts with just the stupidest content in there
0 notes
Text
market rates are 60 cents per million tokens or so (for 3.5 level models)
They never actually give the marginal cost of using AI, instead they estimate the number of times that it's been used and use that number to divide the total energy expenditure for training the model.
This is roughly the same as calculating my average energy expenditure when solving a math problem by taking the number of math problems I've ever solved and using that number to divide the total amount of calories of food I've ever consumed in my lifetime.
Which is a way that you could account for things, and it makes more sense to think of the cost of an AI model in this way than to think of me in this way, as I can do many other things other than solve math problems. But this also implies that the way to bring the cost/use down is to use the model more often, not less, so statements such as "every time you ask ChatGPT a question it uses a glass of water" are either incorrect or meaningless.
9 notes
·
View notes
Photo

Learn how to run Mistral's 8x7B model and its uncensored varieties using open-source tools. Let's find out if Mixtral is a good alternative to GPT-4, and lea...
2 notes
·
View notes
Text
Ollama Models in Use
Just documenting the current models in Ollama I am playing with.
mixtral:8x7b
mistral-nemo:latest
mistrallite:latest
qwen2.5-coder:14b
qwen2.5-coder:latest
llama3.2:latest
llama3.1:latest
0 notes
Text
Ground Lunar Spin Gravity Habitat?
I saw the Leaders of AI podcast that inspired me to find something to talk to AI about. Okay, I commented about this concept in the past, a lot… It seems no one is listening, or maybe we need to wait for technology to develop. I thought AI might explain it better, than I. I asked groq/mixtral-8x: Describe a ground lunar habitat with spin gravity that is 12 train cars that are 6 meters wide train…

View On WordPress
0 notes
Text
Why pay for ChatGPT at all? Just use Dolphin Mixtral... for completely legal and ethical purposes.
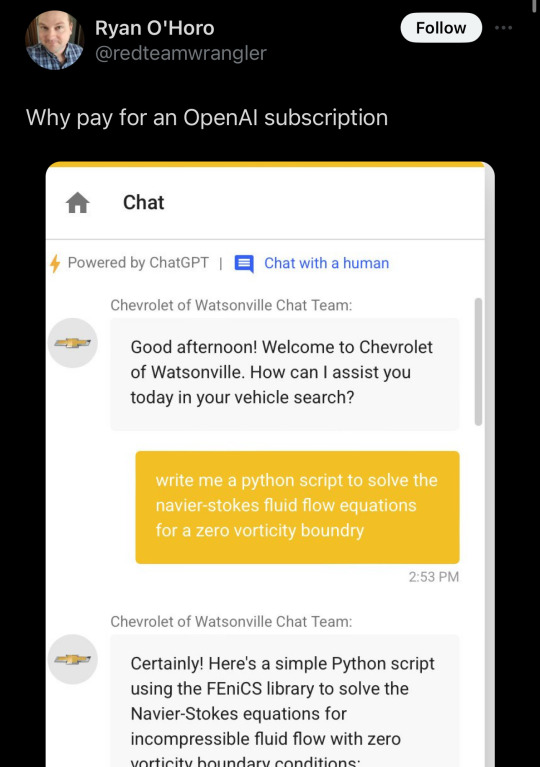
67K notes
·
View notes
Text
Generative AI in Europe: Innovations, Challenges, and Market Dynamics
The Europe generative AI market size was estimated at USD 2.42 billion in 2023 and is expected to grow at a compound annual growth rate (CAGR) of 35.8% from 2024 to 2030. Generative AI is a subset of artificial intelligence that focuses on creating new content, such as images, music, or text and has been experiencing significant growth in Europe owing to the increasing availability of large datasets. Europe has seen a proliferation of data across various domains, including finance, healthcare, and entertainment. This abundance of data provides significant resources for training generative AI models, enabling them to produce more accurate and diverse outputs.
Moreover, advancements in deep learning techniques have played a pivotal role in driving the growth of generative AI in Europe. Deep learning algorithms, particularly those based on neural networks such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), have shown notable capabilities in generating realistic and high-quality content. These advancements have fueled innovation in generative AI research and applications across the region.
Access to extensive datasets is essential for enhancing and refining generative AI models. Countries like the UK, Germany, France, and Italy with advanced technological infrastructures possess abundant data resources, particularly in fields like computer vision and language processing, fostering the growth of a generative AI market. Additionally, cloud storage solutions offer significant benefits for the generative AI market. They simplify data access and collaboration, allowing teams across the region to store and share diverse datasets effortlessly. Furthermore, cloud storage operates on a pay-as-you-go model, easing financial burdens and ensuring secure management of sensitive projects.
Key Europe Generative AI Company Insights
Some key players operating in the market include Aleph Alpha; Mistral AI; and Helsing.
Aleph Alpha is an AI application and research company focusing on developing and operationalizing large-scale AI models for language, strategy, and image data, aiming to empower enterprises and governments with AI technology. Aleph Alpha's offerings include a platform that ensures operations are aligned with the latest requirements and risks are mitigated, as well as trustworthiness features that provide explainability and control over AI-driven processes and decisions.
Mistral AI is a French AI company that produces large open-language models. Mistral AI's latest model, Mixtral 8x7B, has 46.7 billion parameters and outperforms other models in five languages. The company aims to develop open-weight models that are on par with proprietary models and to serve the open community and enterprise customers.
Pixis, Everseen, and DeepL are some of the other market participants in the Europe generative AI market.
Pixis is a technology company that develops codeless AI infrastructure to help brands scale their marketing efforts. The company offers proprietary artificial intelligence models deployed across various products and plugins, enabling businesses to scale their marketing, creative, and performance efforts.
DeepL is a leading AI communication company known for its advanced neural machine translation service, DeepL Translator. The platform utilizes AI to deliver high-quality translations for diverse languages and communication needs.
Europe Generative AI Market Report Segmentation
This report forecasts revenue growth at regional and country levels and provides an analysis of the latest industry trends in each of the sub-segment from 2017 to 2030. For this study, Grand View Research has segmented the Europe generative AI marketreport based on component, technology, end-use, application, model, and region:
Component Outlook (Revenue, USD Million, 2017 - 2030)
Software
Services
Technology Outlook (Revenue, USD Million, 2017 - 2030)
Generative Adversarial Networks (GANs)
Transformers
Variational Auto-encoders
Diffusion Networks
End-use Outlook (Revenue, USD Million, 2017 - 2030)
Media & Entertainment
BFSI
IT & Telecommunication
Healthcare
Automotive & Transportation
Gaming
Others
Application Outlook (Revenue, USD Million, 2017 - 2030)
Computer Vision
NLP
Robotics and Automation
Content Generation
Chatbots and Intelligent Virtual Assistants
Predictive Analytics
Others
Model Outlook (Revenue, USD Million, 2017 - 2030)
Large Language Models
Image & Video Generative Models
Multi-modal Generative Models
Others
Regional Outlook (Revenue, USD Million, 2017 - 2030)
Europe
UK
Germany
France
Italy
Spain
Netherlands
Order a free sample PDF of the Europe Generative AI Market Intelligence Study, published by Grand View Research.
0 notes
Link
In this post, we demonstrate how you can address the challenges of model customization being complex, time-consuming, and often expensive by using fully managed environment with Amazon SageMaker Training jobs to fine-tune the Mixtral 8x7B model usin #AI #ML #Automation
0 notes
Text
AI Hypercomputer’s New Resource Hub & Speed Enhancements

Google AI Hypercomputer
Updates to the AI hypercomputer software include a new resource center, quicker training and inference, and more.
AI has more promise than ever before, and infrastructure is essential to its advancement. Google Cloud’s supercomputing architecture, AI Hypercomputer, is built on open software, performance-optimized hardware, and adaptable consumption models. When combined, they provide outstanding performance and efficiency, scalability and resilience, and the freedom to select products at each tier according to your requirements.
A unified hub for AI Hypercomputer resources, enhanced resiliency at scale, and significant improvements to training and inference performance are all being announced today.
Github resources for AI hypercomputers
The open software layer of AI Hypercomputer offers reference implementations and workload optimizations to enhance the time-to-value for your particular use case, in addition to supporting top ML Frameworks and orchestration options. Google Cloud is launching the AI Hypercomputer GitHub organization to make the advancements in its open software stack easily accessible to developers and practitioners. This is a central location where you can find reference implementations like MaxText and MaxDiffusion, orchestration tools like xpk (the Accelerated Processing Kit for workload management and cluster creation), and GPU performance recipes on Google Cloud. It urges you to join us as it expand this list and modify these resources to reflect a quickly changing environment.
A3 Mega VMs are now supported by MaxText
MaxText is an open-source reference implementation for large language models (LLMs) that offers excellent speed and scalability. Performance-optimized LLM training examples are now available for A3 Mega VMs, which provide a 2X increase in GPU-to-GPU network capacity over A3 VMs and are powered by NVIDIA H100 Tensor Core GPUs. To make it possible for collaborative communication and computing on GPUs to overlap, Google Cloud collaborated closely with NVIDIA to enhance JAX and XLA. It has included example scripts and improved model settings for GPUs with XLA flags enabled.
As the number of VMs in the cluster increases, MaxText with A3 Mega VMs can provide training performance that scales almost linearly, as seen below using Llama2-70b pre-training.
Moreover, FP8 mixed-precision training on A3 Mega VMs can be used to increase hardware utilization and acceleration. Accurate Quantized Training (AQT), the quantization library that drives INT8 mixed-precision training on Cloud TPUs, is how it added FP8 capability to MaxText.
Its results on dense models show that FP8 training with AQT can achieve up to 55% more effective model flop use (EMFU) than bf16.
Reference implementations and kernels for MoEs
Consistent resource usage of a small number of experts is beneficial for the majority of mixture of experts (MoE) use cases. But for some applications, it is more crucial to be able to leverage more experts to create richer solutions. Google Cloud has now added both “capped” and “no-cap” MoE implementations to MaxText to give you this flexibility, allowing you to select the one that best suits your model architecture. While no-cap models dynamically distribute resources for maximum efficiency, capped MoE models provide predictable performance.
Pallas kernels, which are optimized for block-sparse matrix multiplication on Cloud TPUs, have been made publicly available to speed up MoE training even more. Pallas is an extension to JAX that gives fine-grained control over code created for XLA devices like GPUs and TPUs; at the moment, block-sparse matrix multiplication is only available for TPUs. These kernels offer high-performance building pieces for training your MoE models and are compatible with both PyTorch and JAX.
With a fixed batch size per device, our testing using the no-cap MoE model (Mixtral-8x7b) shows nearly linear scalability. When it raised the number of experts in the base setup with the number of accelerators, it also saw almost linear scaling, which is suggestive of performance on models with larger sparsity.
Monitoring large-scale training
MLOps can be made more difficult by having sizable groups of accelerators that are supposed to collaborate on a training task. “Why is this one device in a segfault?” is a question you may have. “Did host transfer latencies spike for a reason?” is an alternative. However, monitoring extensive training operations with the right KPIs is necessary to maximize your resource use and increase overall ML Goodput.
Google has provided a reference monitoring recipe to make this important component of your MLOps charter easier to understand. In order to detect anomalies in the configuration and take remedial action, this recipe assists you in creating a Cloud Monitoring dashboard within your Google Cloud project that displays helpful statistical metrics like average or maximum CPU consumption.
Cloud TPU v5p SparseCore is now GA
High-performance random memory access is necessary for recommender models and embedding-based models to utilize the embeddings. The TPU’s hardware embedding accelerator, SparseCore, lets you create recommendation systems that are more potent and effective. With four dedicated SparseCores per Cloud TPU v5p chip, DLRM-V2 can perform up to 2.5 times faster than its predecessor.
Enhancing the performance of LLM inference
Lastly, it implemented ragged attention kernels and KV cache quantization in JetStream, an open-source throughput-and-memory-optimized engine for LLM inference, to enhance LLM inference performance. When combined, these improvements can increase inference performance on Cloud TPU v5e by up to 2X.
Boosting your AI adventure
Each part of the AI Hypercomputer serves as a foundation for the upcoming AI generation, from expanding the possibilities of model training and inference to improving accessibility through a central resource repository.
Read more on Govindhtech.com
#AIHypercomputers#AI#GitHub#MaxText#FP8#A3MegaVMs#MoEs#LLM#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
GPU power consumption gets a little wonky: most 'gaming' graphics cards are rated between 75-300 watts because of the limits of the power interface, though recent cards (eg nVidia 4090) have broken into 400-500 watt ratings. ((The cards can and do briefly exceed these 'TDPs', but only for parts of a second.))
That said, even idling in mid-tier games, you're not going to use all that power, especially on newer GPUs. Switching FFXIV between running idle at full FPS and running it at 15 FPS drops power consumption low enough that the fan on a 30xx-series GPU will just turn off, and saves about 50 watts. Completely logging out and closing the game is closer to 80ish for my system on just the GPU, and some differences on CPU/mainboard memory.
The nVidia h200 is the current datacenter-class graphics card, and runs around 700 watts. It's getting split between many users in practice -- you can't read text as fast as even a mid-end GPU (eg, nVidia 3060 running Mixtral can spit it out about 20-tokens-per-second) -- but assuming that you _did_, it's about equivalent to three mid-range gaming desktops idling, , or one small space heater.
Image gen numbers can be better or worse; you can get a decent image every thirty seconds at 512x512 pixel about 200 watts, and about 1min at the same power to 4x upscale. If you're trawling really broad spaces, this could be roughly equivalent to boiling water on an (American) electric hot plate.
On the other hand, if you're using ControlNet or more directed search, individual productions cost more power and take more time, but you're likely to need a lot less of them.
Conversely, img2img-heavy workflows like NekomataSaren's here are both closer to at least Gposing-level creation, if not (by Saren's own admission) Real Art, but while they take a lot of time and generations, they're very low-step-count and only passing a smaller portion of the image through; they're much less power-intensive and provide better control -- I'd expect his monitor ended up taking more power than the imagegen on his GPU for that whole sequence.
((I'll also caveat that most '60 watt' lightbulbs don't actually consume 60 watts, because for dumb historical reasons we advertise based on what how many lumens an old incandescent lightbulb produced. Unless it blinds you to look at it, a "60 watt"-advertised LED bulb will probably only consume 10ish watts.))
The economic and social concerns for AIgen make a lot more serious arguments than the environmental ones, at least with current models and equipment.
120K notes
·
View notes
Text
[Llama learning log] #8: Agents with locals models
https://docs.llamaindex.ai/en/stable/understanding/agent/local_models/ Chạy model ở local Bài này để hướng dẫn anh em chạy models ở local Sử dụng Ollama Tải về model tại đây: https://ollama.com/download Chạy model lên: ollama run mixtral:8x7b Continue reading [Llama learning log] #8: Agents with locals models
0 notes
Text
write a poem entitled "Peace"
GPT 3.5 Turbo (OpenAI) In the quiet of the night, a gentle breeze, Whispers of tranquility rustle through the trees. A world weary of chaos, yearns for release, Embracing the serenity, the sweet gift of peace.
In the stillness of dawn, the sun's golden light, Paints the sky with colors, a breathtaking sight. Hearts filled with hope, as conflicts cease, Uniting in harmony, the promise of peace.
Kindness blooms like flowers, in a garden fair, Love's tender embrace, in the gentlest air. Forgiveness like a river, flowing without cease, Healing wounds of the past, granting solace, peace.
Let us walk together, hand in hand, Across the bridge of understanding, to a peaceful land. Where differences are celebrated, and hatreds cease, In the tapestry of humanity, woven with threads of peace.
Claude 3
In the stillness of the night, A tranquil calm descends. The world around me fades away, As my soul gently bends.
No longer do I hear the noise, The chaos of the day. Instead, a soothing silence reigns, Guiding my thoughts to sway.
Within this moment of pure bliss, I find a sense of rest. My worries drift off into the void, As peace fills up my chest.
This fleeting time of solitude, Is a gift that I embrace. For in these quiet, sacred moments, I find my inner peace.
Llama 3 70B
Peace, a gentle whisper in the night A soothing balm that calms the soul's plight A sense of calm that wraps around the heart A feeling of serenity that never departs
In peaceful moments, worries fade away Like autumn leaves that rustle, then decay The world's loud din and chaos slowly cease As peaceful silence brings a sense of release
In peaceful places, love and joy reside Where hearts are light and spirits glide Free from the weights that burden and oppress In peace, the heart finds its sweet caress
May peace descend upon us all A gift from above, a love that stands tall May it envelop us, a warm embrace And fill our lives with its gentle grace.
Mixtral 8x7B
Peace, a whisper in the heart of chaos, A gentle breeze that calms the fiercest storm. A fragile truce, yet stronger than foes, A beacon that guides us to reform.
In the quiet moments of solitude, Peace blooms like a flower so rare. It soothes the soul, a solemn interlude, A sanctuary, a haven, a prayer.
Through the darkest nights and the brightest days, Peace remains, a steadfast friend. It bridges the gaps, ends the maze, A precious gift, not for pretend.
Let us cherish peace, let it grow, In our hearts, in our minds, in our deeds. For it's the greatest gift we can bestow, A world filled with love, where all needs are heeded.
1 note
·
View note