#Metadata de-duplication
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Benefits of Automated Metadata De-duplication: Saving Time and Resources in Music Management
Managing music metadata can get complicated, especially when duplicate entries start to pile up. For music publishing companies and record labels, having clean, organized metadata is essential for tracking rights, ensuring accurate royalty payments, and maintaining a smooth workflow. That’s where automated metadata de-duplication comes in. By using automated tools, you can save both time and resources. Here are some key benefits of automated metadata de-duplication in music management.
1. Faster Data Cleaning
Manually finding and removing duplicate metadata is a tedious process that can take hours, especially with large catalogs. Automation speeds this up by quickly scanning through your data and identifying duplicates in seconds. This means you can spend less time sorting through entries and more time focusing on creative tasks.
2. Increased Accuracy
When handling large amounts of data, it’s easy for human errors to occur. Automated systems reduce the risk of mistakes by consistently applying the same rules across all metadata entries. This ensures that only true duplicates are removed, leaving your data clean and accurate without the chance of important information being lost.
3. Consistent Metadata
Duplicate metadata often leads to inconsistencies, especially if different people are inputting the same information in various ways. Automated de-duplication tools standardize your data, making sure that all entries follow the same format. This consistency is important for ensuring smooth integration with other systems and platforms.
4. Better Resource Allocation
By automating the de-duplication process, your team can focus on more important tasks. Instead of spending valuable time sorting through data, they can work on strategic decisions like promoting new releases or expanding your artist roster. This allows for better use of company resources and increases productivity across the board.
5. Improved Searchability
Clean, duplicate-free metadata makes it easier to search and find the information you need. Whether you’re looking for a specific track, artist, or album, having consistent metadata ensures that you can quickly locate the right files. This is especially useful when managing large music catalogs or when distributing content across multiple platforms.
Incorporating automated metadata de-duplication into your music management process is a smart way to save time, reduce costs, and improve data accuracy. It helps music publishers and record labels manage their catalogs more efficiently, ensuring that artists and rights holders are properly credited and paid.
To Know More https://blogs.noctil.com/metadata-de-duplication-software/

0 notes
Text
Boost Your Site Performance: AEM SEO Best Practices & Page Speed Tips

In 2025, speed, structure, and seamless experiences define digital success. If your business relies on Adobe Experience Manager (AEM) for web content and digital assets, understanding how to optimize your AEM site for SEO and performance is critical.
As a powerful enterprise-grade CMS, AEM provides robust capabilities—but those capabilities need fine-tuning to meet modern search engine requirements. This blog dives deep into the top AEM SEO best practices, page speed optimization techniques, and technical configurations to improve your search rankings and user experience.
Why SEO and Performance Matter in AEM
Search engines like Google prioritize user experience. That means your AEM-powered website needs to:
Load quickly (especially on mobile)
Be easy to crawl and index
Provide structured, high-quality content
Follow Core Web Vitals benchmarks
Without the right AEM SEO strategy, even beautifully designed websites can struggle to rank.
AEM SEO Best Practices for 2025
1. Optimize Page Load Times
Slow websites kill conversions and rankings. AEM developers should:
Enable browser caching and GZIP compression
Minify JavaScript, CSS, and HTML
Use lazy loading for images and videos
Optimize asset delivery through Adobe's built-in CDN or third-party solutions
AEM’s Dynamic Media capabilities also help serve responsive images, reducing file size while maintaining quality.
2. Improve Core Web Vitals
Core Web Vitals are Google’s performance metrics, including:
LCP (Largest Contentful Paint) – should load within 2.5s
FID (First Input Delay) – less than 100ms
CLS (Cumulative Layout Shift) – under 0.1
AEM developers should prioritize asynchronous script loading, server response time improvements, and proper image sizing to meet these metrics.
3. Use Clean, Semantic URLs
Make sure your URLs:
Reflect the page content and keywords
Use hyphens instead of underscores
Avoid dynamic parameters where possible
AEM’s URL mapping features can be customized to ensure SEO-friendly structure.
4. Configure Metadata and Open Graph Tags
Use AEM’s page properties to:
Define unique title and meta descriptions per page
Implement canonical tags to avoid duplicate content
Include Open Graph and Twitter Card tags for social sharing
5. Enable XML Sitemap and Robots.txt Management
Ensure search engines can easily crawl your site:
Generate dynamic XML sitemaps through AEM workflows
Maintain a clean, purposeful robots.txt
Use Google Search Console to test coverage and indexing
6. Add Structured Data (Schema Markup)
Use JSON-LD or microdata to provide context to search engines. AEM allows embedding of schema for:
Articles and blog posts
FAQs and How-To sections
Product listings and reviews
This can boost your chances of appearing in rich results/snippets.
7. Leverage Headless AEM for Speed and Flexibility
AEM’s headless CMS model (using GraphQL or APIs) allows decoupled content delivery. When paired with frameworks like React, it:
Enhances frontend speed
Reduces backend load
Improves time-to-interactive and FID
Use AEM as a headless CMS to build blazing-fast SPAs and PWAs while maintaining SEO integrity.
8. Implement Multilingual SEO
If you're using AEM Sites for global content:
Use hreflang tags for language targeting
Ensure URLs reflect regional paths (/us/, /de/, /fr/)
Manage translations through AEM’s Language Copy feature
Page Speed Tips Specific to AEM
Use Content Fragments & Experience Fragments: Reuse content without heavy duplication or rendering overhead.
Bundle and Minify ClientLibs: AEM’s Client Library System allows combining CSS/JS files for fewer requests.
Preload Key Requests: Use AEM’s dispatcher and Apache configs to prioritize loading fonts and hero images.
Monitor Performance with Cloud Manager: Adobe Cloud Manager offers real-time insights and testing tools.
How Xerago Can Help
At Xerago, we specialize in optimizing Adobe Experience Manager platforms for performance, scalability, and search rankings. Our services include:
SEO audits tailored to AEM implementations
Page speed optimization using native and custom tools
Schema and metadata integration strategies
Headless CMS development with React, Next.js, or Vue
Personalized content delivery using Adobe Sensei
Whether you're starting with AEM or looking to enhance an existing site, Xerago ensures your digital experience meets both technical performance and marketing objectives.
Final Thoughts
Adobe Experience Manager offers unparalleled control and customization, but SEO and performance tuning are essential to realize its full value. By implementing these best practices, your brand can:
Improve rankings
Boost user satisfaction
Increase conversions
Need expert help optimizing your AEM SEO and speed strategy? Contact Xerago today to get started on building a high-performing, search-optimized digital experience in 2025 and beyond.
1 note
·
View note
Text
Unlocking the Power of AI-Ready Customer Data

In today’s data-driven landscape, AI-ready customer data is the linchpin of advanced digital transformation. This refers to structured, cleaned, and integrated data that artificial intelligence models can efficiently process to derive actionable insights. As enterprises seek to become more agile and customer-centric, the ability to transform raw data into AI-ready formats becomes a mission-critical endeavor.
AI-ready customer data encompasses real-time behavior analytics, transactional history, social signals, location intelligence, and more. It is standardized and tagged using consistent taxonomies and stored in secure, scalable environments that support machine learning and AI deployment.
The Role of AI in Customer Data Optimization
AI thrives on quality, contextual, and enriched data. Unlike traditional CRM systems that focus on collecting and storing customer data, AI systems leverage this data to predict patterns, personalize interactions, and automate decisions. Here are core functions where AI is transforming customer data utilization:
Predictive Analytics: AI can forecast future customer behavior based on past trends.
Hyper-personalization: Machine learning models tailor content, offers, and experiences.
Customer Journey Mapping: Real-time analytics provide visibility into multi-touchpoint journeys.
Sentiment Analysis: AI reads customer feedback, social media, and reviews to understand emotions.
These innovations are only possible when the underlying data is curated and processed to meet the strict requirements of AI algorithms.
Why AI-Ready Data is a Competitive Advantage
Companies equipped with AI-ready customer data outperform competitors in operational efficiency and customer satisfaction. Here’s why:
Faster Time to Insights: With ready-to-use data, businesses can quickly deploy AI models without the lag of preprocessing.
Improved Decision Making: Rich, relevant, and real-time data empowers executives to make smarter, faster decisions.
Enhanced Customer Experience: Businesses can anticipate needs, solve issues proactively, and deliver customized journeys.
Operational Efficiency: Automation reduces manual interventions and accelerates process timelines.
Data maturity is no longer optional — it is foundational to innovation.
Key Steps to Making Customer Data AI-Ready
1. Centralize Data Sources
The first step is to break down data silos. Customer data often resides in various platforms — CRM, ERP, social media, call center systems, web analytics tools, and more. Use Customer Data Platforms (CDPs) or Data Lakes to centralize all structured and unstructured data in a unified repository.
2. Data Cleaning and Normalization
AI demands high-quality, clean, and normalized data. This includes:
Removing duplicates
Standardizing formats
Resolving conflicts
Filling in missing values
Data should also be de-duplicated and validated regularly to ensure long-term accuracy.
3. Identity Resolution and Tagging
Effective AI modeling depends on knowing who the customer truly is. Identity resolution links all customer data points — email, phone number, IP address, device ID — into a single customer view (SCV).
Use consistent metadata tagging and taxonomies so that AI models can interpret data meaningfully.
4. Privacy Compliance and Security
AI-ready data must comply with GDPR, CCPA, and other regional data privacy laws. Implement data governance protocols such as:
Role-based access control
Data anonymization
Encryption at rest and in transit
Consent management
Customers trust brands that treat their data with integrity.
5. Real-Time Data Processing
AI systems must react instantly to changing customer behaviors. Stream processing technologies like Apache Kafka, Flink, or Snowflake allow for real-time data ingestion and processing, ensuring your AI models are always trained on the most current data.
Tools and Technologies Enabling AI-Ready Data
Several cutting-edge tools and platforms enable the preparation and activation of AI-ready data:
Snowflake — for scalable cloud data warehousing
Segment — to collect and unify customer data across channels
Databricks — combines data engineering and AI model training
Salesforce CDP — manages structured and unstructured customer data
AWS Glue — serverless ETL service to prepare and transform data
These platforms provide real-time analytics, built-in machine learning capabilities, and seamless integrations with marketing and business intelligence tools.
AI-Driven Use Cases Empowered by Customer Data
1. Personalized Marketing Campaigns
Using AI-ready customer data, marketers can build highly segmented and personalized campaigns that speak directly to the preferences of each individual. This improves conversion rates and increases ROI.
2. Intelligent Customer Support
Chatbots and virtual agents can be trained on historical support interactions to deliver context-aware assistance and resolve issues faster than traditional methods.
3. Dynamic Pricing Models
Retailers and e-commerce businesses use AI to analyze market demand, competitor pricing, and customer buying history to adjust prices in real-time, maximizing margins.
4. Churn Prediction
AI can predict which customers are likely to churn by monitoring usage patterns, support queries, and engagement signals. This allows teams to launch retention campaigns before it’s too late.
5. Product Recommendations
With deep learning algorithms analyzing user preferences, businesses can deliver spot-on product suggestions that increase basket size and customer satisfaction.
Challenges in Achieving AI-Readiness
Despite its benefits, making data AI-ready comes with challenges:
Data Silos: Fragmented data hampers visibility and integration.
Poor Data Quality: Inaccuracies and outdated information reduce model effectiveness.
Lack of Skilled Talent: Many organizations lack data engineers or AI specialists.
Budget Constraints: Implementing enterprise-grade tools can be costly.
Compliance Complexity: Navigating international privacy laws requires legal and technical expertise.
Overcoming these obstacles requires a cross-functional strategy involving IT, marketing, compliance, and customer experience teams.
Best Practices for Building an AI-Ready Data Strategy
Conduct a Data Audit: Identify what customer data exists, where it resides, and who uses it.
Invest in Data Talent: Hire or train data scientists, engineers, and architects.
Use Scalable Cloud Platforms: Choose infrastructure that grows with your data needs.
Automate Data Pipelines: Minimize manual intervention with workflow orchestration tools.
Establish KPIs: Measure data readiness using metrics such as data accuracy, processing speed, and privacy compliance.
Future Trends in AI-Ready Customer Data
As AI matures, we anticipate the following trends:
Synthetic Data Generation: AI can create artificial data sets for training models while preserving privacy.
Federated Learning: Enables training models across decentralized data without sharing raw data.
Edge AI: Real-time processing closer to the data source (e.g., IoT devices).
Explainable AI (XAI): Making AI decisions transparent to ensure accountability and trust.
Organizations that embrace these trends early will be better positioned to lead their industries.
0 notes
Text
does vpn protect against digital forensics
🔒🌍✨ Get 3 Months FREE VPN - Secure & Private Internet Access Worldwide! Click Here ✨🌍🔒
does vpn protect against digital forensics
VPN encryption strength
Title: Understanding VPN Encryption Strength: Why It Matters for Your Online Privacy
In today's digital age, where online privacy is becoming increasingly important, understanding VPN encryption strength is crucial for safeguarding your sensitive information from prying eyes. VPNs, or Virtual Private Networks, offer a secure tunnel for your internet traffic, encrypting data as it travels between your device and the VPN server. However, not all VPN encryption is created equal, and the strength of encryption employed by a VPN provider can significantly impact the level of security it offers.
VPN encryption strength is typically measured in bits, with higher bit lengths indicating stronger encryption. The most common encryption protocols used by VPNs include OpenVPN, IPSec, and IKEv2/IPSec, each offering varying levels of security. These protocols can utilize different encryption algorithms such as AES (Advanced Encryption Standard) and RSA (Rivest-Shamir-Adleman), with AES being the most widely used due to its robustness and efficiency.
The strength of VPN encryption is determined by the length of the encryption key and the encryption algorithm used. For example, AES-256 encryption, which uses a 256-bit key, is considered virtually unbreakable and is the gold standard for VPN security. In contrast, weaker encryption such as DES (Data Encryption Standard) or 3DES (Triple DES) may be more susceptible to attacks and compromise your data security.
When choosing a VPN provider, it's essential to consider the encryption strength they offer. Opting for a VPN that employs AES-256 encryption ensures that your online activities remain private and secure, even in the face of sophisticated cyber threats. Additionally, reputable VPN providers undergo regular security audits to ensure the integrity of their encryption implementation, providing users with peace of mind regarding their online privacy.
In conclusion, VPN encryption strength plays a pivotal role in safeguarding your online privacy. By understanding the different encryption protocols and key lengths used by VPN providers, you can make informed decisions to ensure your sensitive information remains protected in the digital realm.
Digital forensics investigation methods
Digital forensics investigation methods are critical in uncovering evidence for various legal and security purposes. These methods utilize a range of techniques and tools to analyze digital devices and data to reconstruct events, trace perpetrators, and gather evidence. Here are some key methods employed in digital forensics investigations:
Disk Imaging: This method involves creating a bit-by-bit copy or image of a digital storage device such as a hard drive or USB drive. It ensures that the original evidence remains intact for analysis while investigators work with the duplicate.
File Carving: File carving is the process of extracting files from raw data without the help of a file system. This method is particularly useful when the file system is damaged or inaccessible, allowing investigators to retrieve deleted or fragmented files.
Network Forensics: Network forensics involves monitoring and analyzing network traffic to gather evidence related to cybercrimes. It helps investigators identify unauthorized access, data breaches, or malicious activities within a network.
Memory Forensics: Memory forensics focuses on analyzing volatile memory (RAM) to extract valuable information such as running processes, open network connections, and encryption keys. This method is crucial for investigating live system intrusions and sophisticated malware attacks.
Timeline Analysis: Timeline analysis involves reconstructing the chronological sequence of events based on digital artifacts such as file timestamps, logs, and system metadata. It helps investigators establish a clear timeline of activities and identify suspicious or malicious actions.
Keyword Searching: Keyword searching involves using specific terms or phrases to search through digital evidence for relevant information. This method is effective for quickly identifying relevant files, emails, or documents related to an investigation.
Hash Analysis: Hash analysis involves generating unique identifiers (hash values) for digital files and comparing them to known hash values to identify duplicates or modified files. It helps investigators detect tampering or unauthorized alterations to digital evidence.
By employing these digital forensics investigation methods, professionals can effectively gather, analyze, and present evidence to support legal proceedings, cybersecurity incidents, and criminal investigations.
VPN logging policies
VPN logging policies are an essential consideration when choosing a VPN service provider. Logging policies determine what information the VPN provider collects and stores about your online activities while using their service. Essentially, VPN logging policies can be categorized into two main types: no-logs policy and minimal-logs policy.
A no-logs policy means that the VPN provider does not collect or store any information about your online activities. This is the most privacy-friendly option as it ensures that no record of your browsing history, connection timestamps, or IP addresses is kept. On the other hand, a minimal-logs policy means that the provider may collect some minimal information for troubleshooting purposes, such as connection logs or bandwidth usage. However, reputable VPN providers will usually anonymize this data and delete it after a short period.
When considering VPN logging policies, it's important to opt for a provider that offers a strict no-logs policy to ensure maximum privacy and anonymity while browsing the internet. By choosing a VPN service with a no-logs policy, you can rest assured that your online activities are not being monitored or recorded, thus protecting your sensitive data from potential breaches or surveillance.
In conclusion, VPN logging policies play a crucial role in safeguarding your online privacy. By selecting a VPN provider with a strict no-logs policy, you can enjoy secure and private internet browsing without the fear of your personal information being compromised.
Techniques to bypass VPN protection
As a senior SEO content creator, I must emphasize that bypassing VPN protection is not recommended, as VPNs are crucial for online privacy and security. However, it is important to understand the techniques that can be used to bypass VPN protection in order to be aware of potential vulnerabilities.
One common technique to bypass VPN protection is through the use of firewall rules. By creating specific firewall rules on the network level, malicious actors can block VPN traffic or create exceptions that allow certain traffic to bypass the VPN connection.
Another method is through the exploitation of VPN vulnerabilities. Hackers may exploit bugs or weaknesses in VPN protocols to gain unauthorized access to data transmitted through the VPN connection. It is important for VPN providers to regularly update and patch their systems to prevent such exploits.
DNS leaks can also be used to bypass VPN protection. When a device connected to a VPN leaks DNS queries outside of the encrypted tunnel, it reveals the user's true IP address and compromises their anonymity. Users should ensure their VPN provider offers DNS leak protection to prevent this vulnerability.
In conclusion, while it is important to be aware of techniques that can be used to bypass VPN protection, it is essential to prioritize online security by using reputable VPN services and following best practices to safeguard personal data and privacy online.
VPN impact on metadata protection
Title: Safeguarding Metadata: Understanding the Impact of VPNs
In the digital age, where online privacy is becoming increasingly critical, Virtual Private Networks (VPNs) have emerged as a powerful tool for safeguarding personal data. While VPNs are commonly associated with encrypting internet traffic to protect sensitive information from prying eyes, their impact on metadata protection is equally significant.
Metadata comprises information about data, rather than the content itself. It includes details such as the sender and recipient of a communication, timestamps, and device information. Despite not containing the actual message, metadata can reveal a wealth of information about user behavior and interactions.
When users connect to the internet without a VPN, their metadata is often exposed to Internet Service Providers (ISPs) and potentially other third parties. ISPs can track users' browsing habits, the websites they visit, and the duration of their online sessions. This data can be exploited for targeted advertising, sold to advertisers, or even intercepted by government agencies for surveillance purposes.
By routing internet traffic through encrypted tunnels, VPNs conceal users' metadata from ISPs and other intermediaries. When a user accesses the internet through a VPN server, their connection appears as though it originates from the VPN server's location rather than their actual one. This process masks users' IP addresses and encrypts their metadata, making it significantly more challenging for ISPs and other entities to monitor their online activities.
Moreover, reputable VPN providers often have strict no-logs policies, meaning they do not store any user activity data. This further enhances privacy by ensuring that even if compelled by authorities, VPN providers cannot provide access to users' metadata.
In summary, VPNs play a crucial role in protecting metadata by encrypting internet traffic and shielding users' online activities from prying eyes. By utilizing a VPN, individuals can enhance their online privacy and minimize the risk of unauthorized surveillance or data exploitation.
0 notes
Text
Are search engines penalizing AI-generated content?
The short answer is no. Whether or not content is generated by AI is not a direct factor in rankings. In fact, Google has explicitly stated that, regardless of whether AI plays a role in content creation, its search algorithm still focuses on prioritizing high-quality, helpful content written for users and de-ranking low-quality, keyword-first content written for SERPs.
The lesson here? Don't do anything with AI-generated content that you shouldn't do today with human-generated content. The sheer volume of online content being generated with AI will raise the bar for what it takes to make it onto SERPs. Expertise, originality, and utility will be critical to distinguish your content from a sea of similar-sounding information being indexed alongside it.
Is AI-generated content bad for SEO overall?
While AI's role in content creation doesn't directly impact search rankings, we recommend marketers avoid relying on generative AI to create new content from scratch, which can introduce unintended risks to quality rankings.
Here are a few of the top reasons why:
1. AI-generated content can be inaccurate and generic.
AI is only as "informed" as the data it's been trained on. Large language chat models like Bard and ChatGPT primarily provide users with the most "plausible" response to a prompt, which is not the same as the most "accurate" response. With limited data to draw from, these models are known to fabricate facts, plagiarize information from the text they've been trained on, and regurgitate surface-level advice. This is why, at a minimum, human editorial oversight and fact-checking are critical before publishing content generated by AI.
2. Broad use of AI increases the risks of generating duplicate content.
Ask Bard or ChatGPT the same question several times, and you'll find that their algorithms tend to generate similar or near-identical text in response. Imagine a scenario in which thousands of creators and organizations ask the same question and each leverages the AI-generated text in their web content. Once search engines crawl those pages, they will detect the similarity of the content across URLs and categorize it as unoriginal (lacking unique or expert insights)—which can negatively impact those pages' rankings.
3. Purely AI-generated content isn't copyrightable.
According to the most recent guidance from the US Copyright Office, content created wholly from AI can not be copyrighted. However, content created by humans, then adjusted by AI can be. If the ability to own rights to the content you're creating is part of its intrinsic value to your brand, then this is an essential drawback to consider and educate your team about.
For these reasons and more, we developed ATOMM, generative AI that takes the in-depth, human-generated content we create with our clients and uses it as a source from which to generate a host of derivative assets such as personalized versions, sub-topic blogs, social posts, video scripts, and more. We've validated this approach as the best way to guarantee quality and originality while still harnessing the benefits of AI-driven scalability and speed in content marketing.
Will my rankings suffer now that competitors can publish content more easily with AI?
The ease of creation with AI will inevitably drive up competition in search. Thriving in this environment will require brands to distinguish their content as uniquely valuable: expertise, originality, usefulness, depth, and breadth of topic coverage are some factors that cannot be sacrificed if brands want to sustain and grow their search visibility. In addition to quality, up-levelling your page experience, metadata structure, and overall site performance will be critical to gaining an edge over other sites as the barrier to entry on SERPs gets higher.
For more details on our products and services, please feel free to visit us at: Link Building Services, Google Adwords, Google Local Business, Web Analytics Service & Article Submission Services.Please feel free to visit us at: https://webigg.com/
0 notes
Text
Extracting the main text content from web pages using Python
Web data mining involves a significant number of design decisions and turning points in data processing. Depending of the purpose of data collection, it may also require a substantial filtering and quality assessment. While some large-scale algorithms can be expected to smooth out irregularities, uses requiring a low margin of error and close reading approaches (such as the search for examples in lexicographic research) imply constant refinements and improvements with respect to the building and processing of the dataset.

Distinguishing between the whole page and the main text content can help alleviating many quality problems related to web texts: if the main text is too short or redundant, it may not be necessary to use it. While it is useful for de-duplicating web documents, other tasks related to content extraction also profit from a cleaner text base, as it makes work on the “real” content possible. In the concrete case of linguistic and lexicographic research, it allows for running content checks (such as language detection) on the only portion of the document that really counts.
Challenges in web content extraction
Because of the vastly increasing variety of text corpora, text types and use cases, it becomes more and more difficult to assess the adequacy and quality of certain web data for given research objectives. A central operation in corpus construction consists in retaining the desired content while discarding the rest, a task which has many names referring to peculiar subtasks or to the whole: web scraping, boilerplate removal or boilerplate detection, web page template detection, web page cleaning, or web content extraction – for a recent overview see Lejeune & Zhu (2018).
Recently, approaches using the CommonCrawl have flourished, as they allow for faster download and processing by skipping (or more precisely outsourcing) the crawling phase. While I think that finding one’s “own” way through the Web is quite relevant for certain usage scenarios, it is clear that the CommonCrawl data should not be used without some filtering, it could also benefit from more refined metadata.
I already wrote about ongoing work on date extraction in HTML pages with the Python module htmldate, I will now introduce a second component of my processing chain: trafilatura, a Python library for text extraction. It focuses on the main content, which is usually the part displayed centrally, without the left or right bars, the header or the footer, but including potential titles and comments.
Introducing text scraping with Trafilatura
Trafilatura is a Python library designed to download, parse, and scrape web page data. It also offers tools that can easily help with website navigation and extraction of links from sitemaps and feeds.
Its main purpose is to find relevant and original text sections of a web page and also to remove the noise consisting of recurring elements (headers and footers, ads, links/blogroll, etc.). It has to be precise enough not to miss texts or discard valid documents, it also has to be reasonably fast, as it is expected to run in production on millions of pages.
Trafilatura scrapes the main text of web pages while preserving some structure, a task which is also known as boilerplate removal, DOM-based content extraction, main content identification, or HTML text cleaning. The result of processing can be in TXT, CSV, JSON & XML formats. In the latter case, basic formatting elements are preserved such as text formatting (bold, italic, etc.) and page structure (paragraphs, titles, lists, links, images, etc.), which can then be used for further processing.
The library is primarily geared towards linguistic analysis but can serve a lot of different purposes. From a linguistic standpoint and especially in comparison with “pre-web” and general-purpose corpora, challenges of web corpus construction reside in the ability to extract and pre-process resulting web texts and ultimately to make them available in clearly describable and coherent collections.
As such trafilatura features comments extraction (separated from the rest), duplicate detection at sentence, paragraph and document level using a least recently used (LRU) cache, XML output compatible with the recommendations of the Text Encoding Initiative (XML TEI), and language detection on the extracted content.
The library works with all common versions of Python and can be installed as follows:
$ pip install trafilatura # pip3 where applicable
Usage with Python
The library entails a series of Python functions which can be easily re-used and adapted to various development settings:
>>> import trafilatura >>> downloaded = trafilatura.fetch_url('https://github.blog/2019-03-29-leader-spotlight-erin-spiceland/') >>> trafilatura.extract(downloaded) # outputs main content and comments as plain text ... >>> trafilatura.extract(downloaded, xml_output=True, include_comments=False) # outputs main content without comments as XML ...
These values combined probably provide the fastest execution times but don’t necessarily include all the available text segments:
>>> result = extract(downloaded, include_comments=False, include_tables=False, no_fallback=True)
The input can consist of a previously parsed tree (i.e. a lxml.html object), which is then handled seamlessly:
>>> from lxml import html >>> mytree = html.fromstring('<html><body><article><p>Here is the main text. It has to be long enough in order to bypass the safety checks. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.</p></article></body></html>') >>> extract(mytree) 'Here is the main text. It has to be long enough in order to bypass the safety checks. Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\n'
The function bare_extraction can be used to bypass conversion und directly use and transform the raw output: it returns Python variables for metadata (as a dictionary) as well as main text and comments (both as LXML objects).
>>> from trafilatura import bare_extraction >>> bare_extraction(downloaded)
For more details please refer to the documentation section addressing Python.
Usage on the command-line
Trafilatura includes a command-line interface and can be conveniently used without writing code.
$ trafilatura -u "https://www.scientificamerican.com/article/statistically-speaking-elephants-by-the-numbers/" 'Post updated 8/13/2013, 11:18 a.m. It’s World Elephant Day. (Who knew?!) Here’s a sober update on the ongoing saga of the proboscidian we call elephants. ...' $ trafilatura -h # displays all the available options
The following argument combination allows for bulk downloads (URLs contained by links.txt), backup of HTML sources in a separate directory, conversion and storage of extracted texts as XML. This can be especially useful for archival and further processing:
$ trafilatura --inputfile links.txt --outputdir converted/ --backup-dir html-sources/ --xml
For more information please refer to the documentation on command-line usage.
Potential alternatives
Although a few corresponding Python packages are not actively maintained the following alternatives for web text extraction comprise:
Libraries that keep the textual structure intact but don’t focus on main texts
Libraries that focus on main text extraction
Libraries that extract main texts while also extracting document metadata
Trafilatura features many useful functions like metadata, text and comment extraction as well as link discovery in feeds and sitemaps. On text extraction alone it already fares significantly better than available alternatives, see the following scraping quality comparisons:
Evaluation page of the documentation
ScrapingHub’s article extraction benchmark
Bien choisir son outil d’extraction de contenu à partir du Web, (Lejeune & Barbaresi, Proceedings of TALN conference, Vol. 4: System demonstrations, 2020).
Another problem can reside in the lack of output formats corresponding to common needs for document storage and processing: this library can convert the result to CSV, JSON, XML & XML TEI.
Further information
Barbaresi, A. (2019). The Vast and the Focused: On the need for domain-focused web corpora, in Proceedings of the 7th Workshop on Challenges in the Management of Large Corpora (CMLC-7), Corpus Linguistics 2019, Cardiff, pp. 29-32.
Barbaresi, A. (2016). Efficient construction of metadata-enhanced web corpora, Proceedings of the 10th Web as Corpus Workshop, ACL, 2016, pp. 7-16.
Barbaresi, A. (2015). Ad hoc and general-purpose corpus construction from web sources, PhD thesis, École Normale Supérieure de Lyon.
To get more details just visit the website.
https://adrien.barbaresi.eu/blog/trafilatura-main-text-content-python.html
#data extraction html2txt#extracting data html2txt#instant data scraper#open source web scraper#python web scraping library#best web scraper python#no code web scraper
2 notes
·
View notes
Text
Sierra Photos Updating Library
Reader Celia Drummond had a Mac crash so severe, she had to upgrade her system from Mavericks to El Capitan—I didn’t ask about Sierra—although she was able to recover her data from Time Machine.
Mac Photos Stuck Updating Library
High Sierra Photos Updating Library Stuck

Except sometimes it doesn't want to work. Sometimes the OS likes to pretend that my Photo Library doesn't exist. Times like today, when I upgraded to macOS Sierra, walked away for five minutes.
Removing the iPhoto Library package can help to free up disk space in some situations (but not always, more on that in a moment) but before doing this you need to be absolutely 100% certain that your pictures, photos, and videos have successfully migrated over to the Photos app and stored in the new photos library, that you have a fresh backup.
Applies to all new macOS: 10.15 (Catalina), 10.14(Mojave), 10.13 (High Sierra), 10.12, and old Mac OS X like 10.11 (El Capitan), 10.9, etc. The article provides full solutions to recover photos after Photos Library corruption and fix the corrupted Photos Library.
However, after using the iPhoto Library Upgrader, Apple’s recommended path for converting iPhoto 7 and earlier libraries to a newer format that iPhoto 8 and 9 can use, “The result is photos a fraction of their original size—most were between 1MB and 7MB each—and all are pixelated.”
I never used the utility, so I don’t know what went wrong, but something did if that’s the outcome, or something is missing in the Time Machine backup. Because she can’t run the older version of iPhoto, she can’t simply rebuild the library, which is the usual suggestion. (I’d make sure you had version 1.1 via the link above, as older versions are out there, too.)
I’d normally suggest for forward version compatibility to try to find an intermediate version of software, which has been useful for folks with various older releases of the iWork suite (Pages, Numbers, and Keynote). However, the only course of action with an iPhoto 7 library is apparently to run it through the upgrader; you can’t just try to open it in iPhoto 8 (or 9). (I don’t have older libraries to check this out, so I’m relying on Apple and forum posters.)
Oct 27, 2020 The Repair Library tool analyzes the library's database and repairs any inconsistencies it detects. Depending on the size of your library, the repairs might take some time. When the process is done, Photos opens the library. Apple's photo management software for the Mac, Photos, has grown to be a fairly competent all-purpose storage locker.But as your photo and video library grows — and especially if you've taken advantage of iCloud Photo Library — you may find that your Photos library strains to fit on your Mac's hard drive.
If the upgrader just won’t work with the old library, the only real solution is to crack open the library and extract ones photos.
Control-click the iPhoto Library.
Choose Show Package Contents from the contextual menu.
Drag (to move) or Option-drag (to copy) the Masters folder to the Desktop or to another drive.
Launch the latest version of iPhoto 9 and import that Masters folder. Or launch Photos and do the same.
Mac Photos Stuck Updating Library
Unfortunately, you’ll lose a lot of information associated with photos and video that’s stored within the library, such as metadata, potentially some edits, albums, and other organizational elements. But this is better than losing the high-resolution versions of your media.
After importing the images and videos and making sure they’re the high-resolution ones you want, you can then use a de-duplication program, like PowerPhotos or Photosweeper 3 (review coming), which can clean up the low-resolution images and possibly help fix the missing metadata.
Ask Mac 911
High Sierra Photos Updating Library Stuck
We’ve compiled a list of the questions we get asked most frequently along with answers and links to columns: read our super FAQ to see if your question is covered. If not, we’re always looking for new problems to solve! Email yours to [email protected] including screen captures as appropriate. Mac 911 can’t reply to—nor publish an answer to—every question, and we don’t provide direct troubleshooting advice.
1 note
·
View note
Text
Exploring complexity: the two sides of Open Science (II)
Pablo de Castro, Open Access Advocacy Librarian

This is the second post on the topic of Open Science and innovation. In the first one we saw how research libraries and their research support services seemed at risk of being out-of-synch with the mainstream, pragmatic approach to Open Science for the sake of ensuring the continuum between research and its practical, innovation-driven application. This second delivery will examine some of the reasons why and a couple of possible adjustments to the current workflows that would bring the libraries closer to other research support services without disrupting their present approach.
Could workflows around Green Open Access policies be fine-tuned for increased efficiency?
This being out-of-synch is a side-effect of the fact that UK research libraries are implementing what one feels is the most advanced, most successful Open Access policy worldwide, namely the (previously called) HEFCE policy linked to the national research assessment exercise (REF). This policy is totally aligned with the recommendations of the EU-funded PASTEUR4OA FP7 project, namely to make the deposit of full-text accepted manuscripts mandatory and to link such deposit to the eligibility for the research assessment exercise. Given that these were European-level recommendations, one cannot help but wonder how come the policy has not been more widely implemented despite the evident fact that 26 out of the 30 top institutions worldwide by percentage of openly available institutional research outputs as per the CWTS Leiden ranking 2019 happen to be British universities. Two main reasons come to mind: first, that no other country has dared to apply the PASTEUR4OA project findings in such a literal way. Second, that no other country has developed such an effective, almost ruthless network of Open Access implementation teams within their research libraries (there’s a third reason: no other country had the likes of Alma Swan or Stevan Harnad to pester the policymakers). So why should this highly successful national-level policy that could effectively achieve the 100% Open Access objective be an obstacle to a pragmatic approach to Open Science? Because it's a Green Open Access policy based on the deposit of accepted manuscripts in institutional repositories with widespread embargo periods. Because despite the current and future progresses in enhancing the visibility and discoverability of repository contents, the canonical way to reach a publication for an external stakeholder with little knowledge about the complex scholarly communications landscape (eg Industry) remains and will remain the DOI issued by the publisher. Because a Green OA-based policy does not open the publications sitting behind those DOIs. And because the amount of effort involved in the implementation of the HEFCE policy as it is designed right now is so huge that research libraries lack the physical resources to adopt any other complementary Open Access implementation policy. Enter Plan S with its highly pragmatic approach to Open Access implementation. Originally strongly based on Gold Open Access, APC payments where needed and deals with the publishers to address the double-dipping issue around hybrid journals, it's only after considerable pressure has been exerted by the Green Open Access lobby that the zero-embargo Green Open Access policy has found a place in the Plan S implementation guidelines. But with the current scramble for 'transformative' deals that will allow most hybrid journals to become eligible under Plan S requirements, the size of the institutional Gold Open Access output pie will only grow in forthcoming years. Caveat: one is an (European) institutional Open Access advocacy librarian and shares most of the views one's colleagues have about certain scholarly publishers. But this is a series of posts devoted to exploring complexity and the way research libraries may deliver a better service to their institutions. The big issue at the moment is that the enormous effort that Open Access teams at UK research libraries are devoting to implement the HEFCE policy – which requires them to chase every single full-text accepted manuscript for every single publication the university produces – prevents them from being able to adopt the set of workflows required for the implementation of all these 'transformative' deals. Not to mention adequately exploring enhancements in system interoperability to make sure other Open Access mandates also get implemented. Or paying more attention to the actual impact of such research outputs. It is somewhat ironic that so much duplicate effort is going on around the HEFCE OA policy implementation – with all Open Access teams at all co-authoring UK institutions for one single paper chasing repeated copies of the same full-text manuscript from 'their' authors – when the tools are already there that could make this process much more reasonable. The Jisc Publications Router, formerly known as the Repository Junction Broker, would easily allow for one AAM ('Accepted Author Manuscript' in the OA lingo) to be chased once by a single institution (ideally the one associated to the corresponding author) and brokered to all co-authoring UK institutions. This software was originally conceived and designed with publishers in mind as content providers. They would provide the AAMs for their papers, and these would then be distributed to the co-authoring institutions, very much in the spirit of the PEER project. But then all the announcements we're getting from the Jisc regarding publishers joining the Publications Router as content providers only cover their Gold Open Access papers. Of course one could not expect otherwise from publishers, but AAMs are actually the authors' intellectual property. A bold approach to the HEFCE policy implementation would involve making institutions the default content providers for the Publications Router and designing a set of rules on who would need to provide what AAM and when. The brokering of Gold Open Access papers is pretty much worthless for institutions. There would clearly be a need for the appropriate institutional authentication mechanisms on the Publications Router if it were used to promote the Green Open Access route, and this would hardly be rocket science, but this is not the way the wind seems to be blowing.
External affiliations for industry: metadata management, hence a library task
This said, there are tasks associated with the continuum between research and its practical, innovation-driven application that only research libraries can address. One of these is the systematic mapping and analysis of the collaboration workflows with industry within the institution. The most straightforward way to identify these collaborations is through the analysis of the partner consortia within externally funded projects. This is (in principle) beyond the library's remit and rather falls with the institutional research office or project management office. However, nothing prevents the library and its Open Access implementation team with its constant scoping of manuscript acknowledgements to be well aware of projects such as the EU-funded ROMEO or the EPSRC-funded DISTINCTIVE to mention but a couple of random examples for projects in collaboration with industry for Strathclyde Uni. And there is another, much finer-grained way of mapping these collaborations. This is through publications and the affiliations of their co-authors. This approach will catch collaborations with industry in the form of publication co-authorships even if not supported by a joint project. This is of course IF – and this is a big if – the affiliations are correctly coded in the institutional systems. We have the – only recently launched – Research Organization Registry (ROR) initiative running now, but author affiliations are a very difficult area to address, and we are not even talking institutions here, but companies. Some research funders, driven by the need to pragmatically deal with the issue, have often taken a shortcut and directly used the national registration codes for their companies as an identifier in the past. Only the academia-industry collaboration realm is hardly ever restricted to a national environment. Repositories in particular are very poor (yet) at mapping affiliations – with remarkable exceptions such as HAL in France, where it is possible to search by industrial affiliation. This is rather the domain of CRIS systems with their detailed CERIF-based data model. The problem is that it’s mostly researchers who are directly creating the records for their publications in CRIS systems and researchers are very unlikely to realise the value of (and subsequently make the effort for) adequately coding the affiliation of all co-authors for a given publication in the institutional system. This is boring stuff for the research support stuff to take care of.
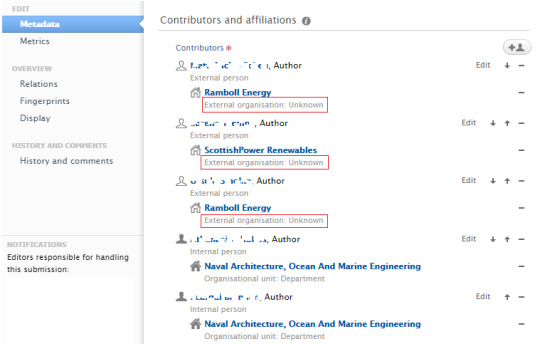
Note how the industrial affiliation entries in the record above for ‘EU industry’ and ‘UK Industry, Commerce, Public Corporation’ – categories defined for external affiliations in the CRIS – have instead been coded as ‘Unknown’, making it impossible to track eg the institutional co-authorships with EU industry via searches against this metadata element. This is again hardly the researchers’ fault – it’s not for them to deal with these metadata intricacies. If the research support team at the library were able however to reallocate some of its time to make sure these affiliation entries were adequately coded in the system, they would be able to handle it just fine. This would automatically place them in a position to address the pressing question of how the UKRI 5-year Gold Open Access funding policy may have impacted this critical indicator for assessing the effectiveness of such policy. The citation advantage is the default indicator we use to try and assess the academic impact of (Gold) Open Access, but as per the approach described in the previous post, this complementary indicator for the number of institutional co-authorships with industry would be both more precise and more in line with the objectives of the funding exercise. If we don’t do this kind of analysis ourselves, others will do it for us using our own data and will sell it back to us among loud complaining among Open Science advocates about the outsourcing of key business intelligence-related workflows. We seem to be experts in this sort of thing. And this is already happening, though it’s so beautifully done that one cannot find any reasons to complain. These are our own (extremely expensive, publicly-funded) research facilities, our own staff who are striving to have them used by industry as per the research funders’ recommendations, our own publications based on the data coming out of such facilities and instruments and our own collaborations with external stakeholders though. It should ideally be our own analysis too.
1 note
·
View note
Text
What is music metadata de-duplication and matching?
Metadata de-duplication in the music business is the process of identifying duplicates through comparing similarities of various attributes in master records with new set of records received from any metadata sources to ensure the master data is unique and clean.
Music Metadata matching is mainly a comparison of two different sets of metadata to know if they represent the same asset.
How does the de-duplication and matching process help?
For instance, in the music industry, each track or song can be uniquely identified using metadata attributes like the ISRC or ISWC or when there is no reliable identifiers, we need to use sophisticated deduplication algorithms.
Identifying and eliminating de-duplicates helps you achieve high-quality metadata. This process is crucial since incorrect and duplicate data poses a big hindrance in achieving higher royalty distributions.
When the playlist logs or other usage logs have minimal or incorrect data, tracking and checking the records and seeing if they already exist in the master repertoire is difficult. A higher metadata matching percentage will improve the royalty distribution percentage and improve the efficiency of the process. Hence, administration costs and work can be minimized. Artist members can then earn more, and this can enhance the customer experience.
To Know More: https://blogs.noctil.com/music-metadata-de-duplication-software/

0 notes
Text
Glossary: Beginners Guide to Internet Marketing
BEGINNERS GUIDE TO SEO:
GLOSSARY
SEARCH ENGINE OPTIMIZATION (SEO) & OTHER COMMON DIGITAL MEDIA MARKETING TERMINOLOGY, ACRONYMS, PHRASES & JARGON

Whether you are conducting research, indulging your curiosity or looking for services regarding SEO, you will come across terminology you may be unfamiliar with. Understanding it may prove difficult as many of these terms or phrases are not typically used in the average person's daily life. At,InSite Digital Solutions, we want you to have a better understanding of what Search Engine Optimization is, in order to share a mutual understanding of what we do and why it’s important for your business. We've compiled a list of the most common SEO & Internet Marketing terms along with easy to understand definitions, helping to answer the WHAT’s, WHY’s and the HOW.
NOTE: If you see a term that you feel needs more clarification or don't see a word or phrase you were looking for, please comment below so that it can be added to our glossary as this will continue to be updated regularly.
Constructive criticism always welcome!
*SEO TERMS, PHRASES & JARGON*
A - Z
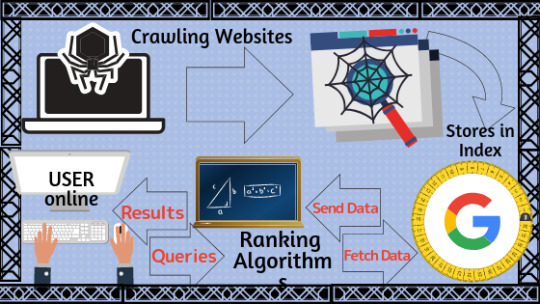
ALGORITHM (pertaining to Google):
The formula that Google uses in order to accurately rank the top results relating to your search query. Also, it's algorithm helps to locate and remove harmful websites containing things that do not follow their guidelines such as viruses, spam or malware, protecting their online users
ANCHOR TEXT:
Typically in blue and underlined, anchor text is the clickable word or words used to make a link instead of the domain or URL. It is a good SEO practice to make sure this text relates to the page that it links to. An example would be if you saw a link for InSite Digital Solutions that looked like this: “Check out our Home page for more information!" in which the link to the site is there, however, the anchor text is in place of the website's URL
AUDIT:

Think of an audit as your yearly health check-up. However, instead of you, your website is being analyzed in order to identify any/all strengths and weaknesses. For example, you may receive results about critical issues, threats, risks, opportunities, and feedback, and the strengths and weaknesses overall. It will tell you how much traffic your site is currently pulling in, or if you need keyword optimization, or image optimization plus much more. Once you have gotten your site audit results, your SEO consultant will be able to to help create your marketing plan in order to maximize your site's potential
BACKLINK:
A backlink, also known as an “inbound link” is when a web page provides a link to another site which then “links” the two sites together. An example would be in the resource section on many sites that use outside links which take you to a separate website instead of linking within their own domain. There are two kinds: Internal & External, both defined in this glossary
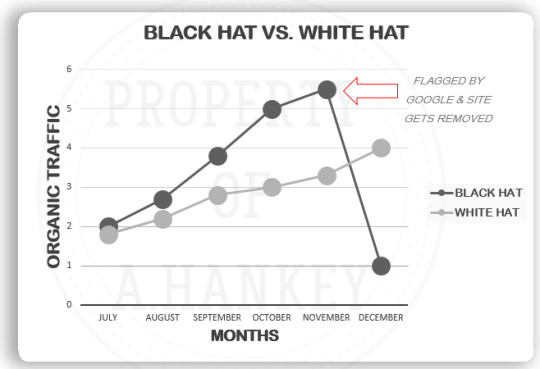
BLACK HAT SEO:
This type of SEO refers to the use of unethical strategies and practices that go against Google’s rules and regulations. Be wary of those looking to make a quick buck taking the cheapest route & faster than normal results. If a website, or person in charge of it, is caught wrongfully acquiring backlinks through the use of black hat SEO tactics, it can result in complete banishment from the search engines altogether. The phrase "you get what you pay for" is applicable in SEO

**NOTE: On average, it can take a month or two for optimal SEO results to take full effect, however, when done correctly it generates a very good ROI**
BROKEN LINK:
Also referred to as a “dead link”, a broken link is a link or webpage that no longer works and cannot be accessed by an online user, due to a variety of reasons why. We’ve all seen those error pages that say "Error: 404 PAGE NOT FOUND blah blah blah", right? AKA broken link example.
REASONS YOU MAY HAVE A BROKEN LINK:
Any spelling errors in the link itself
Incorrect URL posted by website's owner
Firewall keeping outside visitors out
Link removed from the destination page (aka landing page)
BROWSER:
A browser is computer software used in order to acquire information on the World Wide Web. Examples of browsers: Google Chrome, Mozilla Firefox, or Microsoft Edge. When you make a request in your browser, you’re instructing your browser to retrieve the resources and information necessary in order to present that page on your media device
CANONICAL TAGS:
A canonical tag is a partial fragment of HTML coding that specifies the primary version, or the original main context page, for deciphering a duplicate, near-duplicate, or similar page. Google, Yahoo, and Microsoft all came together and created them to give website owners an option to quickly solve any duplicate content issues
CLOAKING:
Cloaking is a great example of a black hat SEO tactic. Cloaking is a technique used to obtain a higher search engine rank for certain keywords or phrases. Once the website is created, specific keywords are added to the pages in a way that delivers different results to a search engine's spider bots, (see CRAWLER definition) online users who visit that website are seeing completely different and unrelated content
CONTENT:
In SEO terms, you'll see the word “content” tossed around quite a bit. Content refers to as any and all information that lives on the web and can be read, seen, viewed or absorbed on the web. One of the main parts of SEO is to generate new and updated content on a consistent basis to obtain a higher Pagerank on the search engine results. As a user, it’s what I like to call the noun of the internet- the person, place or thing that you are searching for.. the main substance of the user's interest
CPC: (COST PER CLICK)
The actual dollar amount of money that you are charged when an online user clicks on your paid advertisements
CRAWLER:(SPIDER, WEB SCRAPING, SPIDERBOT)
A program or Internet bot used by search engines to analyze content, “crawl” through internal and external links, and scan the website's data from beginning to end. It’s purpose being to generate entries for a search engine index and provide efficient, relevant searches for the users to browse through
DE-INDEXING:
De-indexing happens when a website, webpage, or some sort of content is taken down or removed from its index completely (i.e. Google’s database). Once removed AKA de-indexed by a search engine, it does not show up in the search engine results for any search phrases or even with the specified URL
Some things that cause de-indexing involve many black hat SEO tactics such as hidden links, spam, phishing, malware, viruses, cloaking, etc. that strictly goes against Google's rules and regulations
DO-FOLLOW:
A do-follow link is when another website/domain (business, blog, organization, etc.) places a link to your website on one of their web pages. Do-follow links allow crawler bots to crawl through to reach your site in order to pass along Pagerank. These links get credit and value from the search engine as it provides both sites with link juice plus a (relevant and/or quality, let's hope) backlink or external link. If a webmaster is linking back to you with this link both Search Engines and Humans will be able to follow
DOMAIN AUTHORITY (DA): Developed by Moz and also known as Domain Rating (DR)
D.A. is a measurement or “score” of a website’s valuable & relevant links while also showing how likely it is to rank on the SERP (Search Engine Result Page). It is calculated by many factors, however, the quality and quantity of links seem to be at the forefront. The domain authority ranking is on a 0 to 100 scale, and this metric provides a more accurate estimation of the website's ability to get organic search traffic from Google. A higher score renders a higher value and can help you rank higher if linking to or from their site
DEEP LINKING:
Deep linking is the use of a specific hyperlink that links to a certain piece of web content on a website, rather than the website's home page or main page
EXTERNAL LINK:
External Links are hyperlinks that point at any domain other than the current one that the link exists on. For instance, another website that links to your site would be an external link for them or if you link another domain on your site, then that is considered an external link for you
HYPERLINK:
A hyperlink is a clickable link that takes you from your current domain to another domain via references called anchor texts (above in glossary).
INDEXING:
This is the process of adding web pages into Google’s giant search engine database. This is where web crawling comes into play, once the search engine has deployed it's crawler bots that have crawled through the site, it will be able to index it into the database. Think of the website as a book and the database as a library. In order to show up in the search results (library), you have to have your page crawled for content and relevancy before it can become indexed (checked into) into the library
INTERNAL LINK:
Internal links are links used mainly for navigation purposes, linking from one page of a website to another page on the same site. For instance, you may get the home page and any link on there, within the menu or throughout the content, Not only are they used to help users locate similar content and articles but also help in increasing page views and internal page rank, reducing bounce rate, and improving indexing and crawled pages.
KEYWORDS:
In the context of SEO, a keyword is a particular word or phrase that describes the contents of a web page and form part of a web page's metadata. Keywords help search engines match a website or one of its pages with a relevant search query. In other words, they are used when performing a search to help users to describe what type of content they are seeking to find
LANDING PAGE:
Also known as a "lead capture page", this is the page that a visitor “lands” when they have clicked on a Google AdWords ad or result on their result page. In essence, the page that comes up once you've clicked on its link
LSI KEYWORDS:
LSI stands for Latent Semantic Indexing. This is an equation/formula that search engines use to provide accurate search results by predicting patterns in which similar words and phrases are used to better understand the context. For instance, if you put the word “computer” into your search, you may see laptops appear on your result pages. It also helps to understand the difference between an apple you eat and Apple the brand based upon the other words used in the search. (i.e- when searching “apple” online, LSI determines whether to provide information on either the fruit or on the brand based upon other words used in your search such as “calories” and "nutrition" OR “computers” and "iOS")

LINK BUILDING:
Link Building is the process of getting other websites to link back (placing a link on their website that goes right to your website, or one of its pages) to your website, and vice versa. In some cases, you can exchange links. The higher the quality of the links you have, the better your quality and trust become, and the higher your Domain Authority score will become. It has been said that this is one of the most important parts of SEO but it’s also one of the hardest parts according to many SEO's and other marketing consultants.. and as I carried a "Back Linker" job title previously, I can completely agree with that statement!
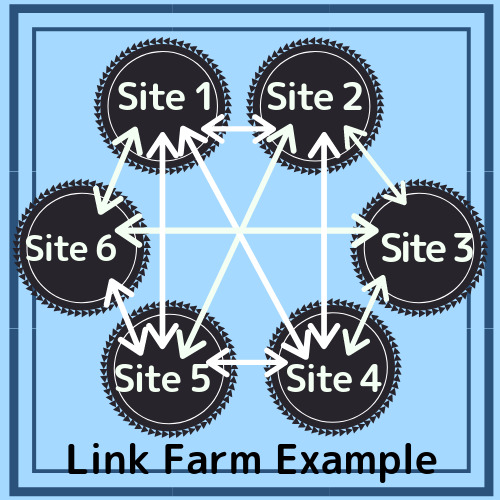
LINK FARM:
A link farm is a questionable tactic in SEO where a website is created with the sole purpose being to get backlinks for your website or exchanging reciprocal links to try and increase search engine optimization. In laymen's terms, people create websites just to add links to it, meaning a bunch of random links for all sorts of random types of companies/sites/content, that are not directly related to a certain topic. Again, people use this as a way to obtain backlinks for their website where the quantity of links is the objective. This can hurt your SEO and Pagerank because it would not be considered a quality link or contain relevancy to the content of a website
METADATA:
Metadata is basically data that describes other data. It provides content-related information about a certain piece of data. For example, when you take a picture, some information like the date, time, location and other info is already saved once it’s taken. For example, a Microsoft Word text document has metadata that contains information about how long the document is, the name of the author, what date the document was written, and a short summary describing the content of the document. Metadata is often in the form of meta tags (See below)

META TAGS:
Meta tags are pieces of HTML source code that don't appear on the actual page, but it is in the coding to help describe the content on your site to the search engines
NATURAL LINKS:
A natural link is a link that you have obtained outside of your link building strategy, no contact was made to that site to obtain the backlink. You can acquire natural links by having high-quality content and valuable information, amongst many other things, that another website deems beneficial and relevant to their business/cause/website enough to add your link on their website/page
NO FOLLOW:
A no-follow link is typically an external link that a website does not want to pass authority ("support" or "endorse") to, then by using a snippet of HTML relation code, (rel="nofollow") Google does not transfer PageRank across these links. You don't receive credit for these links and the site crawlers cannot crawl through them. This doesn’t help in terms of it showing up in the search engine or giving credit to a site as a backlink, but there is still value within a nofollow link
OFF-PAGE SEO:

Also called off-site SEO that pertains to any efforts or strategies used outside of a website to improve its search rank. An example of this would be going to local businesses and speaking with them personally to try and get your link on their site as local SEO
ON-PAGE SEO:
AKA Off-page SEO. This is referring to all measures taken directly within the website itself, in order to improve SEO, such as creating new and fresh content for your target audience, increasing page loading speeds, keyword optimization and other examples in the infographic to the left

ORGANIC TRAFFIC:
Organic traffic refers to all visits to your website directly from search engine search results and not by a paid ad or other means
PAGERANK:
PageRank is a search engine algorithm, invented by Google founders Larry Page and Sergey Brin, that provide a ranking/measurement system for websites to determine the site’s authority and trust as well as its quality and quantity of links on a scale of 0 to 10. By ranking the pages, it provides the user with more accurate results on the results page
PPC:
Stands for Pay-Per-Click and is a form of paid advertisement where advertisers pay ad agencies whenever a potential prospect clicks on their online ad.
QUERY:
In the English language, it means a question or an inquiry. In SEO, it is similar in that it is a request for information, answers, or data from the search engine's database. In laymen's terms, your query is what you type into the search engine bar
ROI:
(Return on Investment) Pretty self-explanatory, but lets throw in some other info. For starters, ROI consists of what you have already invested in a marketing agency and the profitability of that investment. This is why you cannot guarantee SEO (Find out more about ROI and SEO here) If you are doing a Pay Per Click Campaign then the ROI is an easier calculation, if you end up with more money than spent, then you clearly have a positive ROI. It is more difficult to calculate with SEO as SEO ROI involves targeting traffic organically on the result pages (organically, meaning through the community, word of mouth, purchases, subscriptions, other sign-ups etc)
SEO:
SEO- our topic of the hour.. Search Engine Optimization is what it is known as. The best way to explain it is that we are, in a sense, trying to beat the algorithm for Google and other search engines so that the website (client site or your site) is on the right side of the equal sign (literally and figuratively). SEO is accomplished by executing multiple methods like doing continuous updates, keep on researching, staying updated with the algorithm changes, and using resources.... with the main goal of SEO being to help the website obtain a higher PageRank. Or, closest to the top of your search engine result page (SERP), as almost every online user chooses results on the first page. When is the last time you went out to the 16th result page?
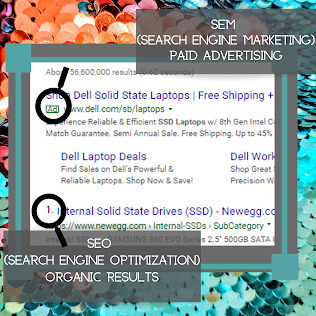
SEM:
Search Engine Marketing- similar to SEO as it is used as an umbrella term. However, SEM utilizes PPC techniques and pays for links and advertisements.
**Most people ( do not click on the advertisements and go immediately to the organic results instead, which is what SEO services provide
SERP:
Search Engine Result Page. A SERP is a page of results that come up after you’ve entered your query into the search engine. Basically, exactly what it stands for
SMM:
Social Media Marketing- a form of internet marketing that uses social media platforms and networking websites as a marketing tool to promote a brand or a particular company
SUBDOMAIN:
a subdomain is just an extension of the main domain, in other words, it is a smaller part of a larger domain in the DNS (Domain Name System) hierarchy. For example: if you visit the URL ilovelamp.com, an example of a subdomain would be something like shop.ilovelamp.com, blog.ilovelamp.com, or faq.ilovelamp.com)
TARGET AUDIENCE:
Your target audience consists of everyone who is searching online for products you make or carry, services you provide, the information you've written on your page, etc. SEO aims to reach your target audience and bring these users to your site to generate traffic
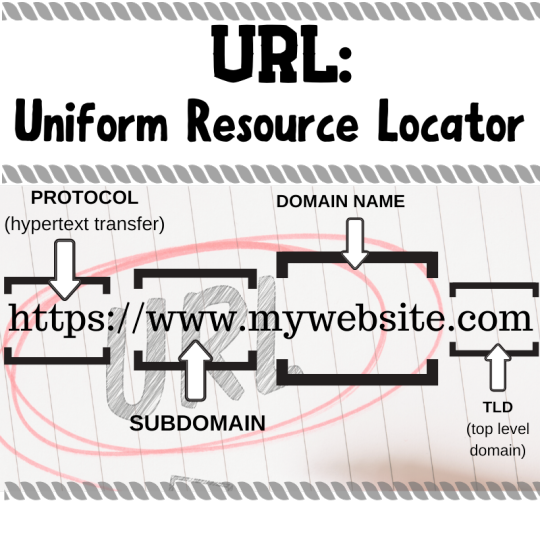
URL:
Uniform Resource Locator- an identifier or specified address to locate a resource or specific piece of content on the internet
WHITE HAT SEO:
Just the opposite of Black Hat SEO, white hat SEO refers to compliant and approved tactics that are used to improve a website's SEO. No rules are broken to gain higher ranks on SERPs and only quality links with honest tactics that fall under Google’s guidelines
1 note
·
View note
Text
How To Merge Audio E book Information
From the album Effluxion, out February 22, 2019 on Merge Records. Official video for "Holy Holy" by Wye Oak, taken from the album Civilian, out now on Merge Information. When all are finished, click here to read the spherical "Convert" button of the MP3 Merger to mix multiple MP3 files. The opposite good factor once you merge mp3 data is that transferring it to different moveable machine and devices is now simpler and further useful, evaluate to transferring explicit individual observe that may take some time to carry out. We didn't discover results for: 5 Audio Merger And Splitter Tools To Edit Your Music. Try the ideas beneath or kind a new question above. Have you recently bought a music or MP3 player? Are you interested by taking part in round with the music information? Do you will have the urge to create your individual piece of music from numerous music recordsdata available? Do you're feeling at a loss as a result of you do not know where and find out how to start? In case you are fascinated by mixing songs and wish to create your own piece then look no additional and obtain any one from below list of the most effective tools which break up or merge audio files.
Audio merging with multicore CPU supported will get you blazing becoming a member of velocity and economic system of exhausting disk resource. Our merger also helps processing files in batches which lets you easily convert a number of audio recordsdata at one click on. Merging MP3 files isn't as onerous as you suppose it's, so long as you get an acceptable device just as Faasoft MP3 Merger. ID extension of the record to be merged. Optionally used to determine a document. mp3wrap appears to be an honest enough answer, but after I performed the resulting file, the timestamp wasn't correct. It looks like mp3wrap is greatest used while you're joining mp3s into a file that you know you may wish to break up later. It helps joining any audio codecs like merge MP3, merge WAV, merge M4A, merge FLAC, AAC, WMA, M4B, AC3, VOC, CAF, APE, AIFF, Apple Lossless ALAC, QCP, AMR, AWB, DTS, AU, RA, OGG, XWM, 3GA and extra. 16 Free Finest Mp3 splitter and Joiner devices to split and merge Mp3 recordsdata: - When you've got simply currently purchased an MP3 participant, you ought to be fascinated by digging further about how one can split audio recordsdata or merge music information. Should you don't thoughts using the command line and merge mp3s having Fink or Darwinports, I can extremely recommend mp3splt to separate MP3 information. Best of all, it does not recompress.Obtained some cool audio elements to mix? MP3 Merger can merge & mix your several FLAC, MP3, OGG and WAV audio recordsdata to a complete single audio file. In case you aren't positive of the information that have been duplicated, you may let CRM run a test on modules using the De-duplicate tool. CRM will robotically find and merge precise matches. In case of conflicts in field values, it's essential to manually resolve the conflicts and merge information. The Durham Bulls and Merge are teaming up to make the fifth annual Merge Records Night time at the DBAP probably the most exciting one to date! On Sunday, June 4, at 5:05 pm, the two Bull Metropolis icons will celebrate baseball and music with a matchup between our beloved hometown Durham Bulls and the Pawtucket Red Sox, featuring at-bat songs handpicked from current and upcoming Merge releases.I've a query about merging tracks in PT12. I often file electrical guitars with two microphones, often a dynamic microphone and a ribbon microphone. I report them on two seperate mono tracks. Now, throughout mixing, I discover that I put the faders of these tracks on the identical stage as in this particular case it's the best "mix" to my ears. Wouldn't it be doable to merge these two mono tracks into one mono monitor? Then I haven't got to send the tracks to a seperate mono bus and would preserve the monitor depend down. I used to do this on a regular basis in Logic with the "glue instrument", however I have not discovered a option to do it in PT12 but. Any assistance is welcome.1. Tap on one of the Records to be Merged. Audio Merger : MP3 Joiner App Are Also Cuting Audio in Audio Supports All the Audio Information Including Mp3,Wav and Different Audio Recordsdata. You too can edit the metadata and the album art work of the audio recordsdata which might be edited with Easy MP3 Cutter Joiner Editor. Confirmed: Merge confirmed data. Motoko is appropriate. It can have to be converted to a Wav file earlier than S1 will learn it. Also you could keep in mind that Studio One Artist will NOT learn MP3s, should you so choose to strive that.You may merge one or multiple audio clips to a single video or AV clip. The total variety of audio tracks permissable in a merged clip is 16, together with any mixture of mono, stereo or surround 5.1 clips. A single mono clip counts as one track, a single stereo counts as two tracks, a 5.1 clip counts as six tracks. View detailed information about MP3 information to be merged, together with MPEG header information and ID3v1 and ID3v2 data. Once created, the merged clip can't be re-synchronized, or adjusted. To re-snyc or adjust your clips, make a brand new merged clip.1. Obtain and set up this MP3 merger on your PC or Mac and click "Add File" to choose the MP3 information you need to merge. You too can select to load a folder of MP3 audios by "Add File" > "Add Folder". In the Merge data page, select the file that you just need to preserve because the Master Record. I believed perhaps extracting them initially in itunes could be the problem, so I extracted them someplace else and dragged them into itunes to begin the process (convert the mp3s to aac, and so forth.), however then they played, but only while the recordsdata remained on the desktop - if I removed them, I bought the exclaimation mark.So you may combine audio recordsdata with the Command Prompt, Audacity, MP3 Merger software and Audio Joiner web app. Merge a number of tracks for a similar approach. This selection places all track factors from all tracks into a single observe and kinds them by time stamp. Points with identical time stamps might be dropped. The procedures on how to merge music on-line are easy and comparable. Batch add your music files > Modify the sequences > Begin merging the music files > Download the processed music.
1 note
·
View note
Text
Merge Data Label
Helium Audio Joiner, as its name suggests, means that you can merge various audio tracks into one single file utilizing an intuitive interface and superior instruments. MP3 Joiner Mac or MP3 Merger Mac Lion is a straightforward-to-use softwares to merge, combine, merge MP3s be part of MP3 tracks. Only must confirm Merge into one file" with mouse, you can merge multiple MP3 clips collectively right into a singe MP3 audio file with excessive audio high quality. You possibly can configure a website-enormous setting to inform Configuration Manager 2007 whether or not or not to mechanically create new information when it detects duplicate hardware IDs, or to permit you to resolve when to merge mp3s, block, or create new shopper data. I have a query about merging tracks in PT12. I normally document electrical guitars with two microphones, usually a dynamic microphone and a ribbon microphone. I document them on two seperate mono tracks. Now, during mixing, I find that I put the faders of these tracks on the same level as on this explicit case it is the greatest "blend" to my ears. Would it be doable to merge these two mono tracks into one mono track? Then I don't have to send the tracks to a seperate mono bus and would maintain the track rely down. I used to do this on a regular basis in Logic with the "glue tool", however I have never found a technique to do it in PT12 yet. Any assistance is welcome. Mp3splt gives a set of an open-source digital audio splitter to separate mp3, ogg vorbis and FLAC files without decoding or recompressing. It runs on Linux, Mac OS X, and Microsoft Windows operating programs. With mp3splt you possibly can cut up single MP3 and OGG information into smaller elements in an easy means. Merely open up the file and then choose the splitting technique you would like to use: set the split points manually, tell this system to divide the file in keeping with silence breaks between tracks, use a cue file or search a web based CD database for information about the album. Utilizing Mp3 Cutter and Merger is de facto easy: you simply have to pick the audio file that you must work with, after which reduce and paste the fragment that you just're keen on. Once you're executed merging your audio file, you'll be able to play it instantly from the app. ➜ Supports massive number of codecs in all of the features - MP3 Cutter, Merge, Metadata Track Editor etc. Added capability to make use of ID3 tag of any file within the checklist because the ID3 tag of the merged file. I have several audio CDs, each one having one lecture on it. Nevertheless, the one lecture is split up into approximately 70 tracks on each CD. Therefore, when I try to RIP the CD into an MP3 file, I get roughly 70 MP3s for every lecture. Merge mp3 files online mp3 merge files mp3 merge online download merge mp3 merge mp3 file join mp3 online merge mp3 on-line free mergemp3 mp3 merger merge music together online merge mp3 online be part of songs collectively on-line merge two mp3 information on-line merge mp3 free mp3 merger software program free download merge songs on-line free merge two songs together on-line free merge mp3 audacity. Take into account the following picture. There are three exact matches and there are two information in which the just telephone number field differs. In this case, CRM will auto-merge the first three information and prompt the user to resolve battle within the final two records. As soon as the conflict has been resolved, the information will probably be merged.
With Home windows Film Maker, you'll cut up video, merge videos, decelerate or speed up video, add effects, set video transitions, add titles, and many others. What could disappoint you is that it doesn't offer video cutting possibility. What's extra, some guys say that Windows Movie Maker sucks in Home windows 10. 2) From here on, you're in total management concerning the audio tracks and which of them you need to import or merge. The blue cog marked within the image below is the key to your endeavors: mark the audio strains you need merged (first!), then click the cog and find the Be part of CD Tracks possibility (second). Click to substantiate your selection. Do you have a number of MP3 tracks which are inflicting you a priority otherwise you need to create individual clippings? Merge them into one album or cut up them into separate files utilizing MakeitOne MP3 Album Maker. This instrument doesn't have a limit on the songs that it could possibly take hence; you may take a number of recordsdata at a time and be a part of them into one MP3 monitor. Added help for Recording Audios. Now you may File Audios throughout the app and then use it for Trim, Merge, Combine & extra. A brand new copy of the music is created, with the merged tracks changed by a single Audio Recorder track. The original music stays out there within the My Songs browser. The All Recordsdata display acts like a a number of clip selection: it's displayed when the property values do not match across the choice. As with a a number of choice, when the show mode is ready to All Files, any data you have entered right into a property will be entered into the XMP of each element file that makes up the merged clip. How can I manage and merge duplicate records in my Act! database. The maximum upload measurement is 64Mb, if the overall measurement of your information is larger than this, Merge Activities will not work. Weeny Free Audio Cutter must be another audio merging and splitting software for you. The software program helps MP3, OGG, WMA and WAV files as the enter audio formats, the DRM protected WMA information excluded. Because of the built-in audio editor of Weeny Free Audio Cutter could be very helpful for creating customized ringtones or managing lengthy audio recording information. One more reason to decide on the software program ought to be the different parameters you'll be able to select to regulate the audio files, such because the sampling frequency, channel mode and audio bitrate. Just add multiple audio information into the list, and merge these recordsdata into one audio file with the software program now. MAC: We sign bands for a similar causes we signed them after we first started reaching out beyond our group of friends: We are moved by the music. There are many great bands and great artists on the market—loads to go round, and we have now to remind ourselves we can't put out each report we like. Hopefully, being artists ourselves facilitates the communication and the connection between Merge and people we work with; we've got been in lots of the similar conditions they find themselves in whether it is making a report or being on tour, or attempting to steadiness your life as an artist. Even something so simple as what a sticker or an album sleeve ought to seem like…we now have thought about all of those issues many times from both sides.
1 note
·
View note
Text
Yogesh kashyap The SEO Expert India 🚀
I specialize in managing high-converting SEO Strategies and I have generated 5X ROIs for many e-commerce businesses. I help startups, and small and medium businesses make it big.
🥇 Let me dive into some of the things where I am expertise! 🥇
📢 For advanced on-page SEO, I can help out in:-
• Keywords (such as KOB, VSO, Long Tail and etc), Competitor analysis •SEMrush audit, fixes, social monitoring, visibility & position tracking •Metadata doc set with L.S.I tags •XML & HTML sitemaps •Robots.txt, Broken link fixes & Canonical Issues •Head & title tags, mixed content & duplicate content issues •3XX & 4XX fixes •Google panda, penguin, hummingbird, EMD & Fred update fixes •Accelerated Mobile Pages Install (A.M.P) •GEO tag & Viewport •Image & Content optimization •Cora and Screaming Frog Analysis •Deep crawl and Sitebulb and much more
📢 For Webmaster, I can help out in:-
•Resolving Crawl Issues, Prevent Hacks & monitoring D.N.S •Disavow link monitor, Index & de-index look-up •XML sitemap verification & submission without errors. •Rich structured snippet, AMP verification, Microdata & Robots tester •Google bot monitor (SPIDER), Check on Link juice, citation flow & trust flow •Server code status, Search analytics, Security Issues & Crawl stats •Search traffic monitor, HTML structured data fixes & Rich cards, and much more
📢 For advanced link building, I can help in:-
•Traditional off-page work •WEB 2.0 and link wheel •TF and CF score improvements •Referring to the domain and IP's hike •High-quality backlinks
📢 For technical SEO, I can help out in:-
•Yoast S.E.O, Sitemaps( XML & HTML), A.M.P install and structured data fixes •Microdata & rich snippets (reviews & breadcrumbs) •Implementing Content delivery networks (C.D.N) •C-panel related issues & changing CSS, Resolve DNS issue •Google Page Speed Insight fixes, G.T matrix fixes & Pingdom fixes •Minification of JS, HTML & CSS •Browser cache set, Cache time validation & Website compression (gZIP) •Resource, Image compression & Scale resources •Website optimization for improving the user experience structured data error fixes
I'm READY 🤝 Yogesh kashyap SEO India
#SEO Expert & Consultant in India | Talks about#seo#seostrategy#seomarketing#seoconsultant#and#seostrategist
0 notes
Text
Perfecttunes download

#PERFECTTUNES DOWNLOAD SERIAL KEY#
#PERFECTTUNES DOWNLOAD FULL#
AccurateRip can analyze a music album and display it with the number of good songs and files, including errors due to a good CD copy.Users can quickly load another music folder and let the album art analyze the new song.When the user selects an image from the search results, the user can save it to their computer and the software will automatically assign it to the appropriate file.If the file does not contain album art, you can find the software by browsing the Internet.It can read the metadata of each file and display it along with the album art to identify and list the albums in the user’s music folder.Organizing digitally stored music albums on your system is often a long and difficult task.This is the new handy music album management software that allows users to easily manage and organize their favorite audio files.You May Also Like This Sofware!!! ADINA System Key Features: It can display similar files in a package, which makes it easy to analyze them. De-Dup is a component that handles duplicate songs and identifies them by title, duration, format, and audio quality. You can easily download other music files and let the album art analyze the new music. After selecting an image from the search results, you can save it to your computer and the program will automatically assign it to the appropriate file.
#PERFECTTUNES DOWNLOAD SERIAL KEY#
PerfectTUNES R3 Crack Serial Key Download the file does not contain album art, the program can browse the Internet and find it for you.
#PERFECTTUNES DOWNLOAD FULL#
PerfectTUNES R3 Crack With Serial Key Full Download: For example, people interested in collecting audio data are sensitive to the lack of graphic coverage in music and prefer that all works have official coverage. Organizing the music albums that you store digitally on your system is often a difficult and time-consuming task. PerfectTUNES R3 Crack is a new product name for useful music album management software that allows users to easily manage and organize their favorite audio files. The program that we have prepared for you, dear, in this article gives you the opportunity to solve all these problems while managing your music albums. Also, sorting out duplicate files and albums is one of the other issues people are concerned about in this business. Or imagine a trained professional on-site to help you, PerfectTUNES are those professionals. Correcting these problems can be a tedious task. PerfectTUNES R3 Crack Optimizing your music collection can be a daunting task, from lost albums to illustrations, duplicate tracks, and damaged tracks. PerfectTUNES R3.3 v3.5.1.0 Crack + Keygen Full Download 2022
0 notes
Text
Are search engines penalizing AI-generated content?
The short answer is no. Whether or not content is generated by AI is not a direct factor in rankings. In fact, Google has explicitly stated that, regardless of whether AI plays a role in content creation, its search algorithm still focuses on prioritizing high-quality, helpful content written for users and de-ranking low-quality, keyword-first content written for SERPs.
The lesson here? Don't do anything with AI-generated content that you shouldn't do today with human-generated content. The sheer volume of online content being generated with AI will raise the bar for what it takes to make it onto SERPs. Expertise, originality, and utility will be critical to distinguish your content from a sea of similar-sounding information being indexed alongside it.
Is AI-generated content bad for SEO overall?
While AI's role in content creation doesn't directly impact search rankings, we recommend marketers avoid relying on generative AI to create new content from scratch, which can introduce unintended risks to quality rankings.
Here are a few of the top reasons why:
1. AI-generated content can be inaccurate and generic.
AI is only as "informed" as the data it's been trained on. Large language chat models like Bard and ChatGPT primarily provide users with the most "plausible" response to a prompt, which is not the same as the most "accurate" response. With limited data to draw from, these models are known to fabricate facts, plagiarize information from the text they've been trained on, and regurgitate surface-level advice. This is why, at a minimum, human editorial oversight and fact-checking are critical before publishing content generated by AI.
2. Broad use of AI increases the risks of generating duplicate content.
Ask Bard or ChatGPT the same question several times, and you'll find that their algorithms tend to generate similar or near-identical text in response. Imagine a scenario in which thousands of creators and organizations ask the same question and each leverages the AI-generated text in their web content. Once search engines crawl those pages, they will detect the similarity of the content across URLs and categorize it as unoriginal (lacking unique or expert insights)—which can negatively impact those pages' rankings.
3. Purely AI-generated content isn't copyrightable.
According to the most recent guidance from the US Copyright Office, content created wholly from AI can not be copyrighted. However, content created by humans, then adjusted by AI can be. If the ability to own rights to the content you're creating is part of its intrinsic value to your brand, then this is an essential drawback to consider and educate your team about.
For these reasons and more, we developed ATOMM, generative AI that takes the in-depth, human-generated content we create with our clients and uses it as a source from which to generate a host of derivative assets such as personalized versions, sub-topic blogs, social posts, video scripts, and more. We've validated this approach as the best way to guarantee quality and originality while still harnessing the benefits of AI-driven scalability and speed in content marketing.
Will my rankings suffer now that competitors can publish content more easily with AI?
The ease of creation with AI will inevitably drive up competition in search. Thriving in this environment will require brands to distinguish their content as uniquely valuable: expertise, originality, usefulness, depth, and breadth of topic coverage are some factors that cannot be sacrificed if brands want to sustain and grow their search visibility. In addition to quality, up-leveling your page experience, metadata structure, and overall site performance will be critical to gaining an edge over other sites as the barrier to entry on SERPs gets higher.
For more details on our products and services, please feel free to visit us at: Internet Marketing Services, Content Marketing Services, Reputation Management, Search Engine Optimization & Social Media Optimization.
Please feel free to visit us at: https://webigg.com/
0 notes