#Massively Multilingual Speech system
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Meta Releases SeamlessM4T Translation AI for Text and Speech
Meta took a step towards a universal language translator on Tuesday with the release of its new Seamless M4T AI model, which the company says can quickly and efficiently understand language from speech or text in up to 100 languages and generate translation in either mode of communication. Multiple tech companies have released similar advanced AI translation models in recent months. In a blog…

View On WordPress
#Applications of artificial intelligence#Computational linguistics#Creative Commons#Gizmodo#Human Interest#Internet#Large language model#Machine translation#Massively Multilingual#Massively Multilingual Speech system#META#Meta AI#Multilingualism#Paco#Paco Guzmán#Speech recognition#Speech synthesis#Technology#Translation
0 notes
Text
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI
New Post has been published on https://thedigitalinsider.com/moments-lab-secures-24-million-to-redefine-video-discovery-with-agentic-ai/
Moments Lab Secures $24 Million to Redefine Video Discovery With Agentic AI

Moments Lab, the AI company redefining how organizations work with video, has raised $24 million in new funding, led by Oxx with participation from Orange Ventures, Kadmos, Supernova Invest, and Elaia Partners. The investment will supercharge the company’s U.S. expansion and support continued development of its agentic AI platform — a system designed to turn massive video archives into instantly searchable and monetizable assets.
The heart of Moments Lab is MXT-2, a multimodal video-understanding AI that watches, hears, and interprets video with context-aware precision. It doesn’t just label content — it narrates it, identifying people, places, logos, and even cinematographic elements like shot types and pacing. This natural-language metadata turns hours of footage into structured, searchable intelligence, usable across creative, editorial, marketing, and monetization workflows.
But the true leap forward is the introduction of agentic AI — an autonomous system that can plan, reason, and adapt to a user’s intent. Instead of simply executing instructions, it understands prompts like “generate a highlight reel for social” and takes action: pulling scenes, suggesting titles, selecting formats, and aligning outputs with a brand’s voice or platform requirements.
“With MXT, we already index video faster than any human ever could,” said Philippe Petitpont, CEO and co-founder of Moments Lab. “But with agentic AI, we’re building the next layer — AI that acts as a teammate, doing everything from crafting rough cuts to uncovering storylines hidden deep in the archive.”
From Search to Storytelling: A Platform Built for Speed and Scale
Moments Lab is more than an indexing engine. It’s a full-stack platform that empowers media professionals to move at the speed of story. That starts with search — arguably the most painful part of working with video today.
Most production teams still rely on filenames, folders, and tribal knowledge to locate content. Moments Lab changes that with plain text search that behaves like Google for your video library. Users can simply type what they’re looking for — “CEO talking about sustainability” or “crowd cheering at sunset” — and retrieve exact clips within seconds.
Key features include:
AI video intelligence: MXT-2 doesn’t just tag content — it describes it using time-coded natural language, capturing what’s seen, heard, and implied.
Search anyone can use: Designed for accessibility, the platform allows non-technical users to search across thousands of hours of footage using everyday language.
Instant clipping and export: Once a moment is found, it can be clipped, trimmed, and exported or shared in seconds — no need for timecode handoffs or third-party tools.
Metadata-rich discovery: Filter by people, events, dates, locations, rights status, or any custom facet your workflow requires.
Quote and soundbite detection: Automatically transcribes audio and highlights the most impactful segments — perfect for interview footage and press conferences.
Content classification: Train the system to sort footage by theme, tone, or use case — from trailers to corporate reels to social clips.
Translation and multilingual support: Transcribes and translates speech, even in multilingual settings, making content globally usable.
This end-to-end functionality has made Moments Lab an indispensable partner for TV networks, sports rights holders, ad agencies, and global brands. Recent clients include Thomson Reuters, Amazon Ads, Sinclair, Hearst, and Banijay — all grappling with increasingly complex content libraries and growing demands for speed, personalization, and monetization.
Built for Integration, Trained for Precision
MXT-2 is trained on 1.5 billion+ data points, reducing hallucinations and delivering high confidence outputs that teams can rely on. Unlike proprietary AI stacks that lock metadata in unreadable formats, Moments Lab keeps everything in open text, ensuring full compatibility with downstream tools like Adobe Premiere, Final Cut Pro, Brightcove, YouTube, and enterprise MAM/CMS platforms via API or no-code integrations.
“The real power of our system is not just speed, but adaptability,” said Fred Petitpont, co-founder and CTO. “Whether you’re a broadcaster clipping sports highlights or a brand licensing footage to partners, our AI works the way your team already does — just 100x faster.”
The platform is already being used to power everything from archive migration to live event clipping, editorial research, and content licensing. Users can share secure links with collaborators, sell footage to external buyers, and even train the system to align with niche editorial styles or compliance guidelines.
From Startup to Standard-Setter
Founded in 2016 by twin brothers Frederic Petitpont and Phil Petitpont, Moments Lab began with a simple question: What if you could Google your video library? Today, it’s answering that — and more — with a platform that redefines how creative and editorial teams work with media. It has become the most awarded indexing AI in the video industry since 2023 and shows no signs of slowing down.
“When we first saw MXT in action, it felt like magic,” said Gökçe Ceylan, Principal at Oxx. “This is exactly the kind of product and team we look for — technically brilliant, customer-obsessed, and solving a real, growing need.”
With this new round of funding, Moments Lab is poised to lead a category that didn’t exist five years ago — agentic AI for video — and define the future of content discovery.
#2023#Accessibility#adobe#Agentic AI#ai#ai platform#AI video#Amazon#API#assets#audio#autonomous#billion#brands#Building#CEO#CMS#code#compliance#content#CTO#data#dates#detection#development#discovery#editorial#engine#enterprise#event
2 notes
·
View notes
Text
Advanced Natural Language Processing by Xillentech
Unlock the transformative power of language with Xillentech’s Natural Language Processing (NLP) services. Whether it's powering chatbots, analysing customer sentiment, or converting speech to text, our solutions enable smarter, faster, and more scalable business operations.
🚀 Why NLP? Transforming Unstructured Data into Smart Insights
In today’s data-rich landscape, a massive volume of unstructured text emails, chat logs, reviews, surveys remain untapped. NLP provides the keys to unlock this data:
Text Analysis & Summarization We extract keywords, key phrases, topic clusters, and concise summaries from vast documents turning clutter into clarity.
Sentiment Analysis Understand customer emotions across feedback, social media, support tickets, and more to improve CX and inform data-driven decisions.
Language Translation & Multilingual Support Seamlessly localize content and connect with global audiences. Our models support multiple languages to break down communication barriers.
Speech Analysis & TTS/STT Automatically convert spoken dialogue into searchable transcripts, analyse call-center conversations, or generate human-like voice prompts to enhance accessibility
These core capabilities unlock automation, intelligence, and scale enabling faster, smarter workflows while reducing costs.
Impact by the Numbers
Backed by industry data, NLP isn’t just a buzzword it delivers measurable ROI:
85 % of companies using NLP report improved customer experience
68 % plan to adopt sentiment analysis by 2025
Automating processes with NLP cuts costs by an average of 40 %
70 % of enterprises leveraging text analysis enjoy faster decision-making
These figures highlight the tangible advantages of NLP from CX transformation to operational savings and agile insights.
Xillentech’s Strengths: A Proven NLP Partner
What sets Xillentech apart?
1. Tailored, Vendor‑Neutral Solutions
We design NLP systems to fit your unique business challenges. By remaining platform‑agnostic, we ensure flexibility and avoid lock-in.
2. Deep Technical Expertise
Our engineers work with state‑of‑the‑art tools spaCy, Hugging Face transformers, OpenAI GPT, LangChain, PyTorch, TensorFlow, ONNX and have expertise in STT/TTS frameworks, Redis, vector databases (e.g., PGVector, Pinecone, Weaviate).
3. Security‑First Approach
Data privacy is critical. We embed encryption, compliance (GDPR, HIPAA), and secure practices into every NLP project.
4. Client‑Centric, Sustainable, and R&D‑Driven
We collaborate closely with your team discovering goals, fine-tuning models to your data, integrating into your tech stack, and providing ongoing performance optimization. Sustainability isn’t an afterthought we strive for environmentally conscious AI.
Our AI‑NLP Playbook
Here’s how we bring NLP systems to life:
Discovery & Analysis Understand your data landscape, pain points, business goals, and target metrics (e.g., accuracy, latency, throughput).
Data Preparation & Model Design Clean and annotate data; decide between pre-trained (e.g., GPT/BERT) or custom-trained models; configure pipelines and tokenization.
Integration & Testing Seamlessly plug NLP into existing applications via REST/API interfaces, perform load and quality testing.
Optimization & Continuous Support Refine for improved inference speed, scalability, and accuracy; provide updates, monitoring, and maintenance.
This structured yet agile process viewable in our R&D roadmap ensures efficiency, reliability, and alignment with your evolving needs.
Industry Use Cases
We’ve brought impactful NLP solutions to clients across diverse sectors:
Healthcare: Streamlined document processing and clinical note analysis to support patient care and research.
Finance: Sentiment monitoring and sentiment-driven alerts for market analysis and customer feedback.
Retail/E‑Commerce: Automated review summarization, comment moderation, and multilingual customer queries.
Education: Transcript summary, automated feedback scoring, and ML-assistive tools.
Real Estate, Manufacturing, Logistics: Process speech logs, contracts, and unstructured data to drive decisions.
Real Results Case Studies
Handy Nation
Doubled conversion rates with targeted feature enhancements.
70% faster rollout of powerful NLP-driven chat and interaction features.
Scholar9
Grew site traffic by 300% in 3 months after importing research-text data.
Saved 1,000+ man‑hours automating citation extraction, metadata generation, and author tools.
Platforms & Technologies
We support a modern NLP toolkit tailored to your needs:
ML Frameworks: PyTorch Lightning, TensorFlow, Hugging Face Transformers
Pipeline Tools: spaCy, LangChain, Llama
Vector DBs: PGVector, Pinecone, Weaviate, Chroma, ElasticSearch
Speech & Voice: OpenAI, ONNX, JFX
Deployment: Docker, Kubernetes, AWS EC2/Lambda, Gradio, Streamlit
DB/Cache: MongoDB, Redis
MLOps: MLflow, Neptune, Paperspace
FAQs (Quick Answers)
What is NLP? AI that interprets and generates human language speech or text.
Business benefits? Improved CX, process automation, faster decisions.
How do you build NLP? We fine‑tune or train models (BERT, GPT...), design pipelines, build APIs, integrate securely.
Multiple languages? Yes, multilingual NLP tailored to global use cases.
Sentiment analysis? Emotion detection from text vital for brand and CX.
Integration? Via secure API endpoints and embedded modules.
Who benefits? CX, healthcare, finance, marketing, legal, real‑estate, education... you name it.
Privacy? We use encryption, secure hosting, and comply with GDPR/HIPAA.
Cost? Custom quotes based on scope from PoCs to full-scale production.
Support? We provide ongoing updates, retraining, and ML maintenance.
Why Choose Xillentech?
Vendor-neutral: Flexibility to select tools and platforms.
Security-first: Robust data protection from design onward.
Expertise-rich: Teams versed in cutting-edge NLP/ML frameworks.
Client-focus: Co-creation and transparency throughout.
Sustainable: Efficient, eco-conscious model design and operations.
Ready to Transform Your Business?
NLP isn’t tomorrow’s tech it’s now. Let Xillentech help you harness it to:
Automate routine text and speech processing
Uncover sentiment trends in large datasets
Expand with multilingual capabilities
Enhance accessibility with TTS/STT
Build intelligent chatbots and agents
Contact us today to explore how bespoke NLP can elevate your product, service, or organization. We can start with a small PoC and scale to enterprise-grade solutions securely, sustainably, and smartly.
0 notes
Text

Dubbify AI Review: The Revolutionary AI Video Engine for Global Domination
Introduction: Dubbify AI Review
Businesses must expand their reach globally because online content dominance demands such action. A video’s achievement decreases since language barriers present massive obstacles to its successful execution. As an AI solution Dubbify AI represents the inaugural platform globally which automatically converts videos into localized versions through exact vocal synchronization and suitable tonal expression levels.
Users can access this AI tool by entering video URLs from YouTube Vimeo TikTok and X for the system to create automatic translations into various languages. Users can operate the tool independently of voice actors and save time on tedious video editing applications.
With its basic user interface Dubbify AI assists users to transform videos into viral multilingual content that benefits the requirements of content producers alongside educators protocol and marketers and companies. The innovative method needs proper scrutiny.
Overview: Dubbify AI Review
Vendor: Seyi Adeleke
Product: Dubbify AI
Launch Date: 2025-Mar-05
Front-End Price: $16.95 for FE
Discount: Instant $3 Discount! USUAL PRICE $16.95, NOW ONLY $13.95
Bonuses: Yes, Huge
Niche: Affiliate Marketing, Artificial Intelligence (AI), Video Marketing, AI tool
Guarantee: 30-days money-back guarantee!
Recommendation: Highly recommended
Support: [email protected]
What is Dubbify AI?
The Dubbify AI platform works as a cloud-based AI video engine which allows instant video translation with dubbing and localization features that preserve original voice qualities.
The state-of-the-art AI technology creates perfect lip-sync between translated speech and speaker mouth movements so viewers cannot differentiate from videos with human dubbers.
Users who want to grow their YouTube audience or generate income from automated dubbing while adapting corporate materials should consider Dubbify AI as their comprehensive answer.
#DubbifyAI#AIReview#VideoMarketing#AIVideoEngine#TechInnovation#DigitalMarketing#ContentCreation#VideoContent#AIRevolution#GlobalDomination#VideoEditing#MarketingTools#SocialMediaStrategy#AIForBusiness#VideoProduction#ContentStrategy#TechTrends#EntrepreneurLife#OnlineBusiness#FutureOfVideo#CreativeTech#Dubbify#AIContentCreation
0 notes
Text
AI in Recruitment: How Technology is Transforming Hiring Processes
The recruitment industry is undergoing a massive transformation, thanks to the integration of artificial intelligence (AI). AI-powered tools are changing how companies find, evaluate, and hire candidates, making the process faster, more efficient, and data-driven. From automated resume screening to chatbots and predictive analytics, AI is reshaping the hiring landscape.
The Role of AI in Modern Recruitment
AI is being leveraged in multiple ways to streamline and enhance the recruitment process. Here are some of the key areas where AI is making a significant impact:
AI-Powered Resume Screening
One of the most time-consuming tasks for recruiters is manually reviewing hundreds or even thousands of resumes. AI-driven Applicant Tracking Systems (ATS) can automatically scan resumes, analyze qualifications, and shortlist candidates based on predefined criteria such as experience, skills, and education.
Benefits:
Reduces bias by focusing on objective
Saves time by filtering out unqualified
Enhances accuracy in finding the right talent
Improves efficiency in large-scale hiring
Reduces hiring costs by minimizing manual
Many companies are adopting AI-driven ATS platforms like HireVue, Pymetrics, and Edhirings.com to streamline their recruitment pipeline. These systems use machine learning algorithms to refine search results, ensuring that recruiters focus on the most suitable candidates.
Chatbots for Candidate Engagement
AI-driven chatbots are increasingly being used to interact with candidates, answer their questions, and guide them through the application process. These chatbots provide 24/7 assistance, ensuring a seamless experience for applicants.
Benefits:
Provides instant responses and improves candidate
Reduces workload for recruiters by handling repetitive
Enhances engagement, leading to higher application completion
Supports multilingual communication, making hiring
Improves candidate satisfaction by offering personalized support.
For example, chatbots like Olivia by Paradox and Mya by StepStone help organizations maintain constant communication with applicants. They assist in scheduling interviews, sending reminders, and even gathering post-interview feedback.
Predictive Analytics for Better Hiring Decisions
AI can analyze historical hiring data and predict which candidates are more likely to succeed in a particular role. This is done by evaluating past hiring trends, employee performance data, and candidate behaviors to make data-driven hiring decisions.
Benefits:
Improves quality of hire by predicting candidate
Reduces turnover rates by identifying long-term
Helps recruiters focus on high-potential
Optimizes workforce planning by identifying skills
Enables proactive hiring by forecasting future talent
Companies like LinkedIn and Entelo use predictive analytics to recommend the best-fit candidates based on industry trends, ensuring organizations make more informed hiring decisions.
Automated Video Interviewing and Analysis
AI-powered video interview platforms can assess candidates based on tone of voice, facial expressions, and speech patterns. These tools help recruiters evaluate a candidate’s confidence, communication skills, and suitability for a role without human bias.
Benefits:
Saves time by automating initial interview
Provides deeper insights into candidate personality and soft
Helps standardize interview evaluations across all
Increases diversity by reducing human
Enhances fairness through objective evaluation
Platforms like HireVue and Talview use AI to analyze verbal and non-verbal cues, giving recruiters additional insights that go beyond traditional resumes and cover letters.
AI-Driven Job Matching
AI algorithms match job seekers with job openings based on their skills, experience, and preferences. Platforms like Edhirings.com use smart matching technology to ensure the right candidate meets the right job effortlessly.
Benefits:
Enhances job recommendations for
Reduces hiring time by ensuring a better fit from the
Helps recruiters discover passive candidates who may not actively
Improves candidate satisfaction by providing relevant job
Strengthens employer branding by making job searches more
AI-driven job matching goes beyond keywords and considers deeper factors such as behavioral assessments and cultural fit to ensure higher retention rates.
The Future of AI in Recruitment
As AI continues to evolve, its impact on hiring will only grow. Here are some trends to watch:
Hyper-Personalization: AI will create highly tailored job recommendations and hiring
Bias-Free Hiring: Advanced AI models will further eliminate unconscious bias in candidate
Enhanced Employee Retention: AI will help organizations predict and prevent employee turnover by analyzing workplace satisfaction and performance
Blockchain Integration: AI combined with blockchain can verify candidate credentials instantly, reducing fraud and
AI-Powered Onboarding: Automated onboarding tools will enhance the candidate experience by personalizing training modules and tracking
Companies are investing in AI to create a seamless, data-driven recruitment process that benefits both employers and job seekers. AI is expected to play an even more significant role in workforce planning, helping organizations adapt to changing business landscapes.
Conclusion
AI is revolutionizing the recruitment process by making hiring faster, smarter, and more efficient. From automated screening to predictive analytics, AI tools are transforming the way companies attract and retain top talent. Platforms like Edhirings.com are at the forefront of this change, helping both job seekers and recruiters benefit from AI-driven hiring solutions.
Also Read: How to Build a Resume?
By leveraging AI in recruitment, businesses can improve decision-making, enhance candidate experience, and reduce hiring costs. Whether you are a recruiter looking for the best talent or a job seeker searching for the perfect role, AI-powered hiring solutions can provide unparalleled benefits.
Are you ready to experience AI-powered recruitment? Visit Edhirings.com and explore the future of hiring today!
1 note
·
View note
Text
The Rise of AI-Enabled Smart Air Conditioners
Home appliances have undergone a massive transformation with advancements in artificial intelligence (AI). Among these, air conditioning systems have significantly evolved, integrating AI-driven voice and gesture controls to enhance user experience, efficiency, and convenience. This blog explores how AI enables hands-free operation in modern air conditioners, making them more intelligent and intuitive.
Evolution of Air Conditioning Technology
Traditional air conditioners relied on manual inputs via remote controls. However, the increasing demand for smart homes has led to the development of AI-powered air conditioners capable of understanding voice commands and responding to hand gestures. AI-driven innovations allow air conditioners to process complex inputs, learn user preferences, and optimize cooling performance.
How AI Enhances Air Conditioner Functionality
1. Voice Control for Seamless Interaction
AI-powered voice recognition technology has transformed how users interact with air conditioners. Here’s how it works:
Natural Language Processing (NLP): AI enables air conditioners to understand and process voice commands in multiple languages, dialects, and accents.
Noise Filtering: Advanced speech recognition software eliminates background noise, ensuring accurate command detection.
Instant Execution: Once a command like "Set the temperature to 22°C" is recognized, the AC unit immediately adjusts settings for optimal comfort.
2. Gesture Control for a Touch-Free Experience
Gesture control offers an alternative when voice commands are impractical due to noise or privacy concerns. Here’s how AI-powered gesture control works:
Motion Sensors & Cameras: Built-in sensors detect hand movements in real-time.
AI-Powered Interpretation: The system processes gesture speed, direction, and shape to distinguish intentional commands from accidental motions.
Immediate Response: Users can adjust temperature, fan speed, and mode settings simply by waving or pointing in a specific direction.
Key Components Powering AI-Driven AC Systems
The integration of AI in air conditioners depends on several advanced components:
High-Fidelity Microphones & Sensors: These ensure accurate voice and gesture recognition in various environments.
AI Processors: Specialized chips execute complex commands instantly, improving response time.
IoT Connectivity: AI-enabled ACs connect with smart home ecosystems via Wi-Fi, Bluetooth, and IoT platforms for seamless integration.
User-Friendly Interfaces: LED indicators, digital displays, and voice responses confirm command execution, enhancing user confidence.
Benefits of AI-Powered Air Conditioners
1. Convenience & Hands-Free Operation
With voice and gesture control, users can adjust their AC settings effortlessly, making it ideal for multitasking and accessibility needs.
2. Personalized Comfort
AI learns user habits and preferences, automatically adjusting cooling based on time of day, occupancy, and seasonal changes.
3. Energy Efficiency & Cost Savings
AI optimizes cooling performance by analyzing room occupancy, weather conditions, and energy consumption patterns, reducing electricity bills.
4. Enhanced Accessibility
Voice and gesture control make air conditioners more accessible for elderly individuals, people with disabilities, and those recovering from injuries.
Challenges and Limitations
Despite its advantages, AI-enabled AC systems face some challenges:
Language and Accent Recognition: AI models require continuous updates to improve multilingual and dialect recognition.
Environmental Interference: Background noise, poor lighting, or obstructed sensors may affect accuracy.
Privacy Concerns: Always-on microphones and cameras raise privacy issues, requiring strong encryption and user control settings.
Future Trends in AI-Driven Air Conditioning
As AI technology evolves, the future of smart air conditioners will include:
Predictive Cooling: AI will analyze weather forecasts, occupancy schedules, and real-time data to optimize comfort.
IoT and Smart Home Integration: AI-powered ACs will seamlessly connect with home automation systems, thermostats, and security devices.
Sustainable Cooling Solutions: AI will introduce dynamic load management, renewable energy integration, and eco-friendly refrigerants to reduce environmental impact.
Real-World Applications of AI in AC Systems
1. Smart Homes
AI-enabled air conditioners in residential homes create personalized environments, reducing energy waste and enhancing comfort.
2. Commercial Buildings
Office spaces and large buildings use AI-controlled HVAC systems to optimize cooling distribution, improving workplace efficiency and reducing operational costs.
3. Healthcare Facilities
Hospitals and laboratories require precise temperature control for patient care and equipment maintenance, making AI-powered ACs indispensable.
Conclusion
AI-driven voice and gesture controls have revolutionized air conditioning technology, making it smarter, more energy-efficient, and user-friendly. As AI continues to evolve, air conditioners will offer even greater convenience, sustainability, and integration within smart home ecosystems. Whether through spoken commands or intuitive hand gestures, AI is shaping the future of air conditioning, enhancing both comfort and efficiency in our daily lives.
0 notes
Text
NAB 2025 Showcase: AI and Cloud Computing Reshape the Future of Broadcasting
The NAB Show 2025 (April 5-9) arrives at a watershed moment as revolutionary technologies reshape the foundations of broadcasting. Under the compelling theme "Massive Narratives," this landmark event illuminates the extraordinary convergence of artificial intelligence, creator economy dynamics, cutting-edge sports technology, streaming innovations, and cloud virtualization. Industry leaders and innovators gather to showcase groundbreaking advances that promise to redefine content creation, production, and distribution across the entire broadcasting ecosystem.
The Evolution of AI in Broadcasting
The integration of generative AI throughout the content creation pipeline heralds an unprecedented transformation in broadcasting technology. This technological revolution extends far beyond simple automation, fundamentally altering how content creators conceptualize, produce, and deliver their work. Industry leaders prepare to unveil comprehensive solutions that revolutionize workflows from initial conceptualization through final delivery, marking a decisive shift toward AI-enhanced creativity.
Adobe stands poised to transform its Creative Cloud suite through sophisticated AI integration. Their revolutionary GenStudio platform represents a quantum leap in AI-driven content creation, incorporating advanced machine learning algorithms that analyze creative patterns and suggest innovative approaches to content development. Their latest Premiere Pro AI Pro introduces groundbreaking capabilities: advanced multilingual subtitle generation with emotional context understanding, intuitive AI-driven editing suggestions that dynamically match cutting patterns to scene emotions, and seamless integration with third-party tools through an innovative AI-powered plugin architecture.
The subtitle generation system particularly impresses with its ability to analyze speakers' emotional states and adjust text formatting accordingly, ensuring that written content accurately reflects the nuanced emotional context of spoken dialogue. This breakthrough in natural language processing promises to revolutionize content accessibility while preserving the emotional integrity of original performances.
Through their experimental initiatives—Project Scene and Project Motion—Adobe demonstrates unwavering commitment to expanding the horizons of AI-assisted creativity, particularly in the demanding realms of 3D content creation and animation. Project Scene introduces sophisticated environmental generation capabilities, allowing creators to describe complex scenes verbally and watch as AI transforms their descriptions into detailed 3D environments. Project Motion pushes boundaries further by implementing advanced motion synthesis algorithms that can generate realistic character animations from simple text descriptions or rough sketches.
Cloud-native production architectures are rapidly reshaping the industry landscape, as prominent vendors unveil increasingly sophisticated solutions. Leading this transformation, TVU Networks introduces their next-generation cloud microservice-based ecosystem. At the heart of this innovation lies their flagship platform, TVU Search, which represents a significant leap forward in content management capabilities. This sophisticated system seamlessly combines multimodal AI capabilities—integrating image, speech, and action recognition with advanced summarization features. Complementing this advancement, TVU Producer AI now incorporates groundbreaking automatic script generation functionality, efficiently transforming brief oral descriptions into comprehensive production plans.

Their enhanced cloud ecosystem with hundreds of microservices enables fluid cloud-based workflows, allowing seamless collaboration between remote team members while maintaining broadcast-quality standards. The platform's intelligent content analysis capabilities can automatically identify key moments in live broadcasts, generate metadata tags, and create time-coded transcripts in real-time, significantly streamlining post-production workflows.
The company's revolutionary "cloud-edge-end" architecture marks a significant advancement in remote production capabilities, delivering reduced latency alongside enhanced reliability. This hybrid approach optimally balances processing loads between cloud services and edge computing nodes, ensuring consistent performance even in challenging network conditions. The system's adaptive routing algorithms continuously monitor network conditions and automatically adjust data paths to maintain optimal performance.
Virtual Production Breakthroughs
SONY continues to push technological boundaries through several groundbreaking innovations. Their VENICE 7 camera system delivers stunning 8K HDR at 120fps with sophisticated AI depth prediction, while the Crystal LED XR Studio introduces a revolutionary mobile control unit enabling real-time virtual scene adjustments through AR glasses. The VENICE 7's advanced sensor technology combines with real-time AI processing to achieve unprecedented dynamic range and color accuracy, while its integrated depth prediction capabilities streamline compositing workflows in virtual production environments.
The Crystal LED XR Studio's mobile control unit represents a significant advance in virtual production technology, allowing directors and cinematographers to visualize and adjust virtual elements in real-time through AR glasses. This intuitive interface enables creative professionals to manipulate virtual environments as naturally as they would physical sets, significantly reducing the technical barriers traditionally associated with virtual production.
Their latest visualization marvel, Torchlight—developed through strategic collaboration with Epic Games—underscores SONY's dedication to creating comprehensive solutions that seamlessly bridge virtual and physical production environments. Torchlight introduces revolutionary real-time lighting simulation capabilities, allowing cinematographers to preview complex lighting setups instantly and adjust virtual light sources with unprecedented precision.
Building on their successful Paris Olympics implementation, Vizrt prepares to showcase enhanced AR solutions, featuring sophisticated real-time rendering capabilities for sports broadcasting, photorealistic virtual set solutions, and innovative tools for creating dynamic interactive graphical elements in live productions. Their latest virtual set technology incorporates advanced physical simulation capabilities, ensuring that virtual elements interact naturally with real-world objects and talent.
5G and Next-Generation Transmission
TVU Networks advances the frontier of 5G broadcast technology through their TVU 5G 2.0 platform, which masterfully integrates 3GPP Release 17 modem technology, sophisticated Dynamic Spectrum Sharing support, enhanced millimeter wave communication capabilities, and ultra-low latency remote production features. The platform's intelligent network management system automatically optimizes transmission parameters based on real-time network conditions, ensuring reliable high-quality broadcasts even in challenging environments.
The system's enhanced millimeter wave capabilities represent a significant breakthrough in mobile broadcasting, enabling ultra-high-bandwidth transmission while maintaining robust connectivity through advanced beamforming techniques. The integration of Dynamic Spectrum Sharing technology allows broadcasters to maximize spectrum efficiency while ensuring seamless compatibility with existing infrastructure.
Blackmagic Design furthers its mission of democratizing professional broadcasting technology through an impressive array of innovations: the URSA Mini Pro 8K Plus with sophisticated AI-driven noise reduction, ATEM Mini Extreme HDR featuring integrated AI color correction, and enhanced cloud production tools that elegantly bridge traditional hardware with modern cloud workflows. The URSA Mini Pro 8K Plus particularly impresses with its revolutionary sensor design, which combines high resolution with exceptional low-light performance and dynamic range.
The ATEM Mini Extreme HDR introduces sophisticated color management capabilities powered by machine learning algorithms that analyze and optimize image quality in real-time. This technology enables smaller production teams to achieve professional-grade results without requiring extensive color correction expertise. The system's AI-driven tools automatically adjust parameters such as white balance, exposure, and color grading while maintaining natural-looking results across diverse shooting conditions.
Automation and Control Systems
ROSS Video revolutionizes broadcast automation through their comprehensive VCC AI Edition, which features automatic news hotspot identification and sophisticated switching plan generation. Their ROSS Control 2.0 introduces advanced voice interaction capabilities for natural language device control, complemented by enhanced automation tools designed specifically for "unmanned" production scenarios.
The system's AI-driven hotspot identification capability represents a significant advancement in automated news production, using advanced computer vision and natural language processing to identify and prioritize newsworthy moments in real-time. This technology enables production teams to respond quickly to developing stories while maintaining high production values.
ROSS Control 2.0's natural language interface marks a departure from traditional automation systems, allowing operators to control complex broadcast systems through intuitive voice commands. The system's contextual understanding capabilities enable it to interpret complex instructions and execute multiple actions while maintaining precise timing and synchronization.
Industry Implications and Challenges
The broadcasting landscape faces several technical hurdles as it adapts to these revolutionary changes. Standard fragmentation amid rapidly evolving 5G transmission technologies raises compatibility concerns, particularly as broadcasters navigate the transition between existing infrastructure and next-generation systems. The industry must develop robust standardization frameworks to ensure interoperability while maintaining the pace of innovation.
Cloud workflow security demands increasingly sophisticated measures within multi-cloud architectures, as broadcasters balance the benefits of distributed processing with the need to protect valuable content and sensitive production data. The expanding role of AI in content creation presents complex legal and ethical considerations, particularly regarding intellectual property rights and creative attribution in AI-assisted productions.
The innovations unveiled at NAB Show 2025 accelerate several industry trends: the democratization of professional tools brings advanced capabilities to smaller producers, enhanced cloud and 5G capabilities enable more distributed workflows, and sustainable broadcasting solutions gain increasing prominence. These developments promise to reshape the competitive landscape, enabling smaller organizations to produce content at previously unattainable quality levels.
Future Outlook
The broadcasting industry embraces an integrated, AI-driven future where traditional broadcasting boundaries increasingly blur with digital content creation. Essential developments include comprehensive AI integration across production workflows, sophisticated cloud-native solutions with enhanced reliability, environmentally conscious broadcasting innovations, and accessibility of professional-grade features for smaller producers.
The convergence of AI and cloud technologies continues to drive innovation in content creation and distribution, while advances in virtual production and automation fundamentally reshape traditional workflows. These technological developments enable new forms of creative expression while streamlining production processes and reducing operational costs.
Conclusion
NAB Show 2025 represents a pivotal moment in broadcasting technology, marking the transition from isolated tool innovations to comprehensive ecosystem transformation. The powerful convergence of AI, cloud technology, and 5G creates unprecedented possibilities for content creation and distribution, while advances in virtual production and automation fundamentally reshape traditional workflows.
Looking beyond NAB Show 2025, the broadcasting industry clearly enters a new era where technology not only enhances existing capabilities but fundamentally transforms content creation, production, and delivery methods. The groundbreaking innovations showcased at this year's event will undoubtedly influence technological advancement in broadcasting for years to come.
For companies seeking to maintain competitive advantage in this dynamic landscape, the technologies and trends showcased at NAB Show 2025 deserve careful consideration—they represent not merely the future of broadcasting, but the evolution of content creation and distribution as a whole. Success in this rapidly evolving environment will require organizations to embrace these transformative technologies while developing new workflows and creative approaches that leverage their full potential.
0 notes
Text
AI Audio Transcription: A Game-Changer for Modern Communication

In this age of digitization, audio content has become commonplace. Business people, educators, journalists, and content creators rely on voice recordings, interviews, podcasts, and virtual meetings for conveying and sharing information. The only hindrance with verbal content is that it can't be searched and edited as easily as text.
This is where AI audio transcription works its magic. With the help of artificial intelligence automated systems, transcription handles a lot of conversion in less time above and beyond efficient manual note-taking.
At GTS.ai, we provide innovative AI transcription services to improve workflow, boost productivity, and offer ready-to-use transcripts. This article covers the technology behind AI transcription, its advantages, and its massive impact across all industries.
AI Audio Transcription Explained
AI Audio transcription is the process where thoughts spoken through telecommunications medium become words clearly printed in a text file. The traditional transcription service is replaced quickly-relatively but more accurately by the operation that processes the end result in a normal human-readable form.
Some of the advanced AI transcription tools recognize:
The difference in speakers : Background noise enhancement features for better utterance recognition.
Different accents and dialects : Various contextualization to improve transcriptions.
How Does AI Transcription Work?
AI transcription applies advanced algorithms and deep learning models that try to emulate how a human listens to, understands, and reasons through sound bits. In general, it works as follows;
Processing – The AI analyzes the audio file for minor speech patterns and characteristic speech by the speaker while eliminating background noise.
Speech Recognition – Machine Learning models are employed in speech recognition and phonetics.
NLP – AI improves the final transcription result by virtually maintaining grammatical rules of written language and contextual awareness of reference phrases.
Speaker Differentiation – In the multi-speaker recordings, AI differentiates between the voices, and thus makes the transcript much more organized.
Automated Formatting – The system automatically adds punctuation, capitalization, and paragraph structuring for better readability.
At GTS.ai, the models of AI transcription keep accuracy, flexibility, and integration high, which makes them an indispensable tool for sectors.
Benefits of AI-Based Transcription
Rapidity and Effectiveness : The AI transcription tools can convert hours of audio into text in a matter of minutes, thus saving huge time spent on paper works.
Cost-effective : Manual transcription is highly laborious and costly. AI transcription is greatly affordable, with a reasonable compromise on quality, if any.
The increased accessibility : The AI transcription empowers people with hearing difficulties to access spoken material recorded in text, in turn promoting inclusiveness in education, media, and business.
Searchable Organized Data : Text-based transcripts allow people to find in minutes what they want to hear, with proper formatting for proper actions.
Multilingual Capabilities : AI transcription supports multiple languages, hence it's considered one of the most valuable tools for global businesses, educators, and media firms.
Which industries can benefit from AI Transcription
AI transcription has revolutionized a number of industries by increased workflow automation, accessibility, and structuring of data.
Business and Corporates : Meeting discussions can be transcribed into action items.
Media and Content Creation : Generate fully accurate audio/video captions and dynamic captions.
Education and E-Learning : Lecture Transcriptions Easily Convert Into Study Material.
Legal and Compliance : Automated transcription for Court hearings and depositions
Medical and Health documentation : Transcribe Doctor-Patient interactions into medical records.
Why GTS.ai in AI Transcription?
GTS.ai has for long provided AI transcription services with a high degree of accuracy to meet such varied needs across industries. Some of the strengths are as follows:
Top-end of the AI Models-Our system can adapt to accents, common jargon in the target industry, and even varied speech rhythms.
Scalability--There is boundless possibility ranging from a single transcription of an interview to transcribing thousands of audio files-an AI that does not complain.
Data Security and Privacy-We value confidentiality and continue to encrypt while your transcripts are secure.
Easy Integration-Our AI transcription solutions slot seamlessly into business workflows and tools.
Cost-Effective and Efficient-Cheaper transcription services with quicker turnaround time.
Explore how GTS.ai can redefine your aspirations in transcription. Go to "GTS.ai" for great options in AI.
The Future of Transcription Using AI
The AI transcription is only just at the beginning. The forthcoming improvements are transforming the future scenarios making transcription smarter and multi-dimensional in addressing flexibility. Here is what is up next:
Real-time transcriptions for live meetings, broadcasts, and events. AI-powered summaries, outlying the key points in a speech. Improved sentiment analysis which detects the tone and emotion expressed in speech. Speaker recognition improvement for conversations involving more than one person.
As AI developments grow by leaps, transcription will become more accurate, intelligent, and within reach in its quest for more modifications of industries and communication styles.
Concluding Thoughts
AI audio transcription is disrupting the way businesses, educators, and professionals handle verbal content. From efficiency to reduced costs, and improved accessibility, transcription powered by AI is swiftly becoming an essential tool across a broad spectrum of industries.
At GTS.ai, we're all in AI-based transcription offering exceptionally fast, precise, and safe solutions. Be it for meetings, lectures, interviews, or statutory documentation, our technology offers an embedded user experience.
0 notes
Text
Audio Analytics with OpenAI: How Whisper Transforms Audio into Insights
Source: https://www.latentview.com/blog/audio-analytics-with-openai-how-whisper-transforms-audio-into-insights/
Ever feel overwhelmed by the avalanche of audio content bombarding you daily? Podcasts pile up, meeting recordings linger in your inbox, and that fascinating lecture you missed is trapped in a video file. The sheer volume of spoken information can be paralyzing, leaving you yearning for a way to capture its essence without drowning in the details. Well, there’s a way. OpenAI’s Whisper can instantly transcribe any audio file with pinpoint accuracy and generate concise summaries of hour-long audio files, extracting the key points with effortless ease.
Whisper: An Open AI Model for Text-to-Speech Conversion
Whisper’s strength lies in its advanced neural network architecture and access to a massive dataset of diverse audio and text. This translates into several key features:
Multilingual Capabilities: Break down language barriers and analyze content in numerous languages, from casual conversations to technical jargon.
Transcription Accuracy: Minimize errors and ensure near-flawless transcripts, ideal for research, legal proceedings, and accessibility purposes.
Domain Adaptability: Accurately transcribe lectures, interviews, and even technical recordings with high fidelity.
How It Works
Whisper utilizes the Transformer architecture, a neural network with attention mechanisms for learning relationships between input and output sequences. It comprises two key components: an encoder and a decoder.
The encoder processes audio input, converting it into 30-second chunks, transforming it into a log-Mel spectrogram, and encoding it into hidden vectors.
The decoder takes these vectors and predicts the corresponding text output. It employs special tokens for various tasks like language identification, phrase-level timestamps, multilingual speech transcription, and to-English speech translation.
Why It Is Better
Whisper has several advantages over existing TTS (Text-to-speech) systems.
Trained on a diverse dataset of 680,000 hours of audio and text, covering various domains, accents, background noises, and technical languages.
Handles multiple languages and tasks with a single model, automatically identifying the language of input audio and switching tasks accordingly.
Demonstrates high accuracy and performance in speech recognition, outperforming specialized models on diverse datasets.
A Sample Application (Audio to Text Summarization using Whisper and BART)
We implemented the Whisper Model to transcribe and summarize video/audio content using OpenAI’s BART summarization models. This functionality can be invaluable for transcribing meeting notes, call recordings, or any videos/audio, saving considerable time.
Approach:
Develop UI using Streamlit, providing a YouTube URL as input.
Use Pytube to extract audio from the video file.
Use the Whisper model to transcribe the audio into text.
Use the BartTokenizer/TextDavinci Model to segment the text into chunks.
Use the Bart Model to summarize the chunks and generate an output.
Sample output:

Limitations of Whisper
While Whisper is a powerful audio analytics solution, it has some limitations:
Works better on GPU machines.
Hallucinations may occur during extended audio silence, confusing the decoder.
Limited to processing 30 seconds of audio at a time.
Use Cases Across Industries
Whisper’s applications extend far beyond simple transcription. Here are just a few examples:
Transcription Services: Businesses can leverage Whisper’s API to offer fast, accurate, and cost-effective transcriptions in various languages, catering to a diverse clientele.
Language Learning: Practice your accent refinement by comparing your speech to Whisper’s flawless outputs.
Customer Service: Analyze customer calls in real time, understand their needs, and improve service based on their feedback.
Market Research: Gather real-time feedback from customer interviews, focus groups, and social media mentions, extracting valuable insights that inform product development and marketing strategies.
Voice-based Search: Develop innovative voice-activated search engines that understand and respond to users in multiple languages.
Conclusion:
OpenAI’s Whisper represents a significant leap forward in audio understanding, empowering individuals and businesses to unlock the wealth of information embedded within spoken words. With its unparalleled accuracy, multilingual capabilities, and diverse applications, Whisper can reshape how we interact with and extract value from audio content.
0 notes
Text
Safety Innovations: Speech AI in Automotive

Smartphones make product searches and home delivery simpler than ever. Video chatting with faraway family and friends is simple. AI assistants can play music, make calls, and recommend the best Italian cuisine within 10 miles using voice commands. Before purchase, AI may suggest apps or books.
Naturally, consumers want fast, tailored service. Salesforce observed that 83% of customers want rapid business interactions and 73% want understanding. Self-service outperforms customer service 60%.
Speech AI can help any industry fulfill high customer expectations that strain employees and technology.
Speech AI speaks natural language for multilingual consumer interactions and labor efficiency. Self-service banking, food kiosk avatars, clinical note transcription, and utility bill payments may be customized.
Speech AI for Banking and Payments
Most clients use digital and traditional banking channels, thus multichannel, personalized service is essential. Many financial institutions disappoint clients owing to excessive assistance demand and agent turnover.
Customer complaints include complex digital procedures, a lack of useful and publicly accessible information, inadequate self-service, excessive phone wait times, and support agent communication concerns.
NVIDIA found that financial businesses employ AI for NLP and large language models. The models automate customer service and handle massive unstructured financial data for AI-driven financial institution risk management, fraud detection, algorithmic trading, and customer care.
Speech-enabled self-service and AI-powered virtual assistants may improve customer happiness and save banks money. Voice assistants may learn finance-specific lingo and rephrase before responding.
Kore.ai taught BankAssist 400+ retail banking IVR, internet, mobile, SMS, and social media use cases. Voice assistants change passwords, transfer money, pay bills, report missing cards, and challenge charges.
Kore.ai’s agent voice assistant lets live agents handle issues quicker with innovative solutions. The solution cuts customer handling time by 40% and increases live agent efficiency by $2.30/call.
Financial companies will speak quicker. AI deployment to enhance customer service, minimize wait times, increase self-service, transcribe conversations to accelerate loan processing and automate compliance, extract insights from spoken information, and raise productivity and speed.
Speech AI for Telecom
To monetise 5G networks, telecom needs customer pleasure and brand loyalty due to high infrastructure costs and severe competition.
NVIDIA polled 400+ telecom experts and discovered that AI enhances network efficiency and customer experience. AI increased respondents’ income 73%.
Voice AI chatbots, call-routing, self-service, and recommender systems enhance telecom customer experiences.
LLM-speaking intelligent voice assistant GiGa Genie released by KT with 22 million consumers. Over 8 million users have talked to it.
GiGA Genie AI speaker voice commands turn on TVs, send SMS, and deliver traffic information.
Change-based speech AI processes 100,000 calls everyday at KT’s Customer Contact Center. Generative AI answers difficult queries or clients.
Telecommunications firms anticipate speech AI to boost self-service, network performance, and customer happiness.
Fast-Food Speech AI
The 2023 food service sector will earn $997 billion and 500,000 employment. Drive-thru, curbside, and home delivery are changing eating. This shift involves recruiting, training, and retaining high-turnover workers while meeting customer speed expectations.
AI food kiosks provide voice and drive-thrus services. Meals, promotions, changes, and orders are avatars.
The Toronto-based NVIDIA Inception member HuEx designed a multilingual drive-thru order assistance. AIDA tracks drive-thru speaker box meal prep orders.
AIDA accurately recognizes 300,000+ product combinations, from “coffee with milk” to “coffee with butter,” with 90% accuracy. Accent and dialect recognition facilitates grouping.
Speech AI speeds up order fulfillment and lowers confusion. AI will collect customer data via spoken encounters to improve menus, upsells, and operational efficiency while lowering early adopter expenses.
Speech AI for Healthcare
Digital healthcare grows post-pandemic. Telemedicine and computer vision provide remote patient monitoring, voice-activated clinical systems offer zero-touch check-in, and speech recognition enhances clinical documentation. Digital patient care assistants were utilized by 36% of respondents, according IDC.
The NLP and medical voice recognition systems summarize vital data. At the Conference for Machine Intelligence in Medical Imaging, a speech-to-text NVIDIA pretrained architecture recovered clinical entities from doctor-patient dialogues. Automatically update medical records with symptoms, medications, diagnosis, and therapy.
New technologies may accelerate insurance, billing, and caregiver interactions instead of taking notes. Patients may benefit from doctors who concentrate on treatment without administrative duties.
Hospital AI platform Artisight uses speech synthesis to alert waiting room patients of doctor availability and voice recognition for zero-touch check-ins. Artisight kiosk registration, patient experiences, data input mistakes, and staff efficiency benefit 1,200 people daily.
Speech AI allows smart hospital physicians treat patients without touching them. Clinical note analysis for risk factor prediction and diagnosis, multilingual care center translation, medical dictation and transcription, and administrative task automation are examples.
Voice-AI Energy
Rising renewable energy demand, high operating costs, and a retiring workforce drive energy and utility companies to do more with less.
Speech AI helps utilities anticipate energy, improve efficiency, and please consumers. Voice-based customer service enables consumers report issues, inquire about bills, and obtain assistance without staff. Meter readers use spoken AI, field personnel retrieve repair orders with comments, and utilities use NLP to assess client preferences.
Retail energy-focused AI assistant Live customer help is transcribed by Minerva CQ. Text-based Minerva CQ AI systems measure consumer sentiment, purpose, inclination, etc.
The AI assistant actively listens to agents and delivers conversation advice, behavioral indications, tailored offers, and sentiment analysis. A knowledge-surfacing tool lets agents advise customers on energy consumption history and decarbonization.
The AI assistant simplifies energy sources, tariff plans, billing changes, and optimum expenditure so customer service can recommend the correct energy plan. Minerva CQ cut call processing time by 44%, enhanced first-contact resolution by 12.5%, and saved one utility $2.67 each call.
Speech AI will reduce utility company training costs, customer service friction, and field worker voice-activated device usage, improving productivity, safety, and customer satisfaction.
The Public Sector AI Speech and Translation
Waiting for vital services and information frustrates underfunded and understaffed governmental organizations. Speech AI accelerates state and federal services.
FEMA monitors distress signals, conducts hotlines, and helps with speech recognition. An interactive voice response system and virtual assistants enable the US Social Security Administration answer benefits, application, and general information queries.
VA has an AI healthcare system integration director. The VA employs voice recognition for telemedicine notes. A powerful artificial speech transcription detects cognitive decline in elderly neuropsychological testing.
Citizens, public events, and diplomats may use voice AI for real-time language translation. Voice-based interfaces allow public organizations with numerous callers to provide information, questions, and services in several languages.
Words and translation AI can transcribe multilingual audio or spoken information into text to automate document processing and improve data accuracy, compliance, and administrative efficiency. Speech AI may aid the blind and crippled.
Automotive Speech AI
From automobile sales to service scheduling, speech AI may help manufacturers, dealerships, drivers, and passengers.
Over half of auto purchasers research dealerships online and via phone. Self-taught AI chatbots answer tech, navigation, safety, warranty, maintenance, and more. Talkbots list cars, schedule test drives, and answer price queries. Smart and automated client experiences differentiate dealership networks.
Automotive makers are integrating sophisticated speech AI to vehicles and apps to enhance safety, service, and driving. For navigation, entertainment, automobile diagnostics, and guidance, the AI assistant may employ natural language speech. Drivers concentrate without touchscreens or controls.
Speech AI may boost commercial fleet uptime. AI trained on technical service bulletins and software update cadences lets professionals estimate repair costs, uncover vital information before lifting the vehicle, and promptly update commercial and small business clients.
Problem reporting and driver voice instructions may enhance automobile software and design. Self-driving vehicles will run, diagnose, call for assistance, and schedule maintenance as speech AI improves.
AI Speech for Smart Spaces and Entertainment
Speech AI may impact most sectors
Intelligent City voice AI alerts emergency responders about dangers. The UNODC is developing speech AI software to analyze 911 calls to prevent Mexico City female violence. AI can recognize distress call words, indications, and patterns to prevent domestic abuse against women. Speech AI may help multilingual and blind public transit.
Students and researchers save time by having voice AI transcribe university lectures and interviews. Voice AI translation facilitates multilingual teaching.
Online entertainment in every language is simpler with LLM-powered AI translation. Netflix AI reads subtitles. Papercup automates video dubbing using AI to reach global audiences in their original languages.
Transforming Products and Services with Speech AI
Companies must provide easy, customized client experiences in the new consumer environment. NLP and voice AI might change global business and consumer relationships.
Speech AI provides fast, multilingual customer service, self-help, knowledge, and automation to workers across industries.
NVIDIA serves all sectors with speech, translation, and conversational AI
The GPU-accelerated multilingual speech and translation AI software development kit NVIDIA Riva supports real-time voice recognition, text-to-speech, and neural machine translation pipelines.
Tokkio uses NVIDIA Omniverse Avatar Cloud Engine, AI customer service virtual assistants, and digital people.
These technologies enable high-accuracy, real-time app development to enhance employee and customer experiences.
0 notes
Text
Google’s BERT changing the NLP Landscape

We write a lot about open problems in Natural Language Processing. We complain a lot when working on NLP projects. We pick on inaccuracies and blatant errors of different models. But what we need to admit is that NLP has already changed and new models have solved the problems that may still linger in our memory. One of such drastic developments is the launch of Google’s Bidirectional Encoder Representations from Transformers, or BERT model — the model that is called the best NLP model ever based on its superior performance over a wide variety of tasks.
When Google researchers presented a deep bidirectional Transformer model that addresses 11 NLP tasks and surpassed even human performance in the challenging area of question answering, it was seen as a game-changer in NLP/NLU.
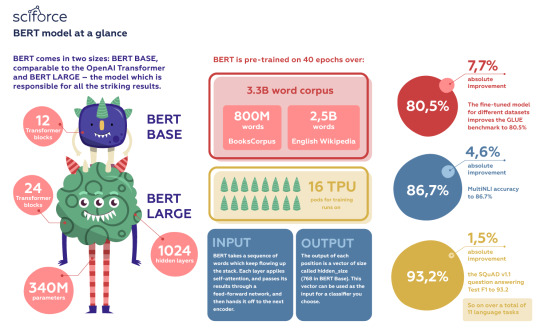
BERT model at a glance
BERT comes in two sizes: BERT BASE, comparable to the OpenAI Transformer and BERT LARGE — the model which is responsible for all the striking results.
BERT is huge, with 24 Transformer blocks, 1024 hidden layers, and 340M parameters.
BERT is pre-trained on 40 epochs over a 3.3 billion word corpus, including BooksCorpus (800 million words) and English Wikipedia (2.5 billion words).
BERT runs on 16 TPU pods for training.
As input, BERT takes a sequence of words which keep flowing up the stack. Each layer applies self-attention, and passes its results through a feed-forward network, and then hands it off to the next encoder.
The output of each position is a vector of size called hidden_size (768 in BERT Base). This vector can be used as the input for a classifier you choose.
The fine-tuned model for different datasets improves the GLUE benchmark to 80.5 percent (7.7 percent absolute improvement), MultiNLI accuracy to 86.7 percent (4.6 percent absolute improvement), the SQuAD v1.1 question answering Test F1 to 93.2 (1.5 absolute improvement), and so on over a total of 11 language tasks.
Theories underneath
BERT builds on top of a number of clever ideas that have been bubbling up in the NLP community recently — including but not limited to Semi-supervised Sequence Learning (by Andrew Dai and Quoc Le), Generative Pre-Training, ELMo (by Matthew Peters and researchers from AI2 and UW CSE), ULMFiT (by fast.ai founder Jeremy Howard and Sebastian Ruder), the OpenAI transformer (by OpenAI researchers Radford, Narasimhan, Salimans, and Sutskever), and the Transformer (by Vaswani et al). However, unlike previous models, BERT is the first deeply bidirectional, unsupervised language representation, pre-trained using only a plain text corpus.
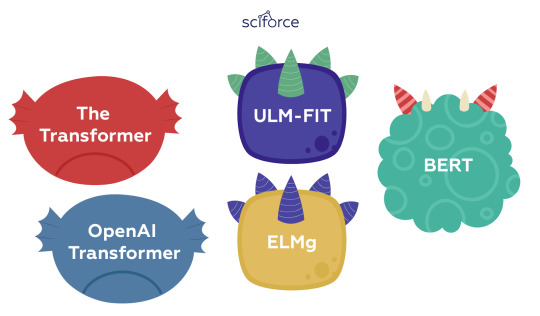
Two Pillars of BERT
BERT builds on two key ideas that paved the way for many of the recent advances in NLP:
the transformer architecture, and
unsupervised pre-training.
Transformer Architecture
The Transformer is a sequence model that forgoes the sequential structure of RNN’s for a fully attention-based approach. Transformers boast both training efficiency and superior performance in capturing long-distance dependencies compared to the recurrent neural network architecture that falls short on long sequences. What makes BERT different from OpenAI GPT (a left-to-right Transformer) and ELMo (a concatenation of independently trained left-to-right and right- to-left LSTM), is that the model’s architecture is a deep bidirectional Transformer encoder.
A bidirectional encoder consists of two independent encoders: one encoding the normal sequence and the other the reversed sequence. The output and final states are concatenated or summed. The deep bidirectional encoder is an alternative bidirectional encoder where the outputs of every layer are summed (or concatenated) before feeding them to the next layer. However, it is not possible to train bidirectional models by simply conditioning each word on its previous and next words, since this would allow the word that’s being predicted to indirectly “see itself” in a multi-layer model — the problems that prevented researchers from introducing bidirectional encoders to their models. BERT’s solution to overcome the barrier is to use the straightforward technique of masking out some of the words in the input and then condition each word bidirectionally to predict the masked words.
Unsupervised pre-training
It is virtually impossible to separate the two sides of BERT. Apart from being bidirectional, BERT is also pre-trained. A model architecture is first trained on one language modeling objective, and then fine-tuned for a supervised downstream task. The model’s weights are learned in advance through two unsupervised tasks: masked language modeling (predicting a missing word given the left and right context in the Masked Language Model (MLM) method) and the binarized next sentence prediction (predicting whether one sentence follows another). Therefore, BERT doesn’t need to be trained from scratch for each new task; rather, its weights are fine-tuned.
Why does this combination matter?
Aylien Research Scientist Sebastian Ruder says in his blog that pre-trained models may have “the same wide-ranging impact on NLP as pretrained ImageNet models had on computer vision.” However, pre-trained representations are not homogeneous: they can either be context-free or contextual, and contextual representations can further be unidirectional or bidirectional. While context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary, contextual models generate a representation of each word that is based on the other words in the sentence. The bidirectional approach in BERT represents each word using both its previous and next context starting from the very bottom of a deep neural network, making it deeply bidirectional.
The pre-trained model can then be fine-tuned on small-data NLP tasks like question answering and sentiment analysis, and significantly improve the accuracy compared to training from scratch.
Visualizing BERT
Deep-learning models in general are notoriously opaque, and various visualization tools have been developed to help make sense of them. To understand how BERT works, it is possible to visualize attention with the help of Tensor2Tensor.
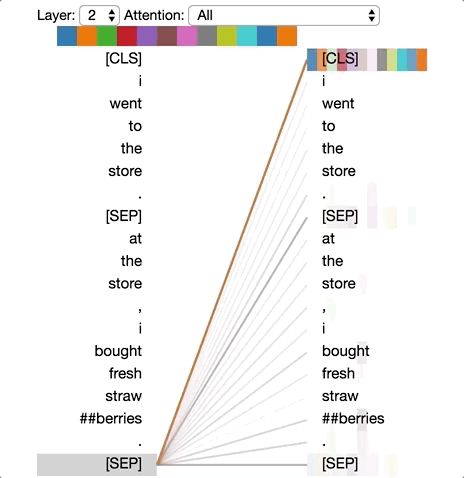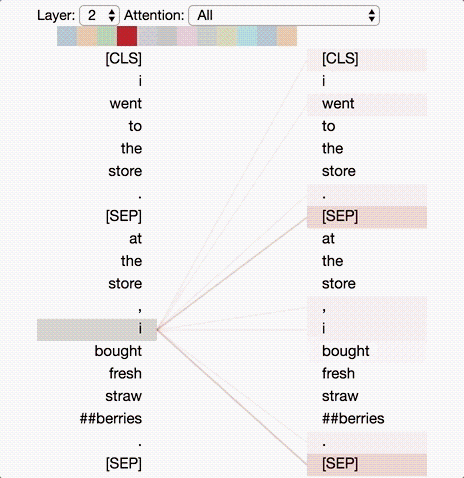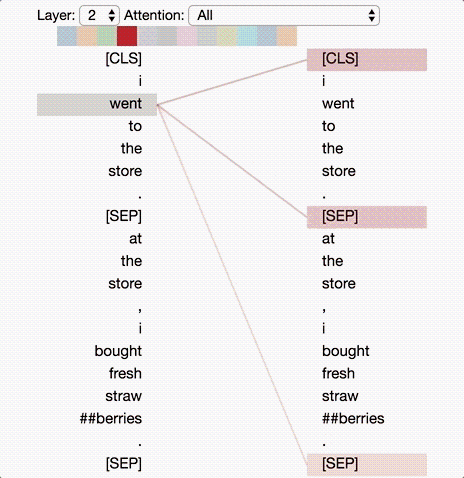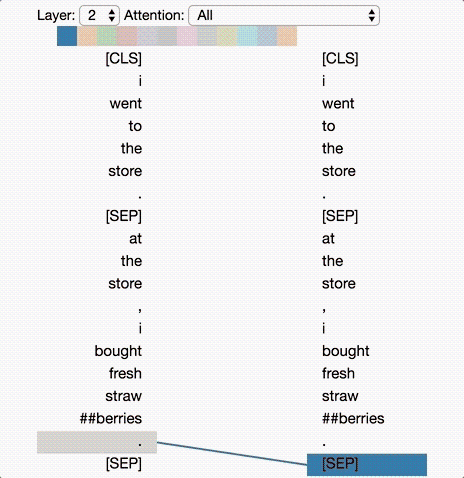
The tool visualizes attention as lines connecting the position being updated (left) with the position being attended to (right). Colors identify the corresponding attention head(s), while line thickness reflects the attention score. At the top of the tool, the user can select the model layer, as well as one or more attention heads (by clicking on the color patches at the top, representing the 12 heads).
Open-source
Soon after the release of the paper describing the model, the team also open-sourced the code of the model, and made available for download versions of the model that were already pre-trained on massive datasets. These span BERT Base and BERT Large, as well as languages such as English, Chinese, and a multilingual model covering 102 languages trained on wikipedia. Thanks to this invaluable gift, anyone can now build a machine learning model involving language processing to use this powerhouse as a readily-available component — saving time, energy, knowledge, and resources.
The best way to try out BERT directly is through the BERT FineTuning with Cloud TPUs notebook hosted on Google Colab. Besides, it is a good starting point to try Cloud TPUs.
Afterwards you can proceed to the BERT repo and the PyTorch implementation of BERT. On top of it, the AllenNLP library uses this implementation to allow using BERT embeddings with any model.
BERT in practice
BERT was one of our top choices in CALLv3 shared task (the text subtask of which we have actually won). The Spoken CALL Shared Task is an initiative to create an open challenge dataset for speech-enabled CALL(computer-assisted language learning) systems. It is based on data collected from a speech-enabled online tool that helps Swiss German teens practice skills in English conversation.The task is to label pairs as “accept” or “reject”, accepting responses which are grammatically and linguistically correct.
We used BERT embeddings to classify the students’ phrases as correct or incorrect. More specifically, we used its multi_cased_L-12_H-768_A-12 model trained on Wikipedia and the BookCorpus.
From BERT, we obtained a 768-dimensional vector for each phrase from the dataset. We used German prompts translated using the Google Translate service and the corresponding English answers concatenated via ′|||′ as inputs. This approach turned out to work well in our case. Used in combination with the nnlm model, BERT showed the second best result in our experiments. Besides, we did not perform finetuning because of the scarcity of the data set. However, we believe that with the sufficient amount of data, finetuning of BERT can yield even better results.
Our experiments reconfirmed that the BERT model is a powerful tool that can be used in such a sentence pair tasks as question answering and entailment.
Epilogue: the future is exciting
While we were writing this post, a news came that the Facebook AI team released their code for the XLM/mBERT pretrained models that cover over 100 languages. All code is built on top of PyTorch and you can directly start playing around with the models with a provided ipython notebook. The new method called XLM, published in this year’s paper, provides a technique to pretrain cross-lingual language models based on the popular technique of Transformers. The recent release, therefore, means you can now use pretrained models or train your own to perform machine translation and cross-lingual classification using the above languages and transfer it to low-resource languages, addressing the long-standing problem.
1 note
·
View note
Text
Meta Releases SeamlessM4T Translation AI for Text and Speech
Meta took a step towards a universal language translator on Tuesday with the release of its new Seamless M4T AI model, which the company says can quickly and efficiently understand language from speech or text in up to 100 languages and generate translation in either mode of communication. Multiple tech companies have released similar advanced AI translation models in recent months. In a blog…

View On WordPress
#Applications of artificial intelligence#Computational linguistics#Creative Commons#Gizmodo#Human Interest#Internet#Large language model#Machine translation#Massively Multilingual#Massively Multilingual Speech system#META#Meta AI#Multilingualism#Paco#Paco Guzmán#Speech recognition#Speech synthesis#Technology#Translation
0 notes
Text
Convert Video And Audio To Numerous Codecs For Different Devices
One of many many understated features in Mac OS X is the flexibility to natively convert audio to m4a immediately in the OS X Finder - with none additional downloads or add-ons. Since I discovered this I thought it would be an awesome concept to share with others who may be thinking about changing information and do not need to spend the money to purchase a devoted conversion program. You probably have any comments, questions, or know of another free program like VLC to transform files please share it with us and remark below. Step 1: Launch iTunes DRM Audio Converter on Mac. And then click Add button to add any music file you wish to convert to WAV. Whole Audio Converter can get audio tracks from YouTube movies - just paste the url.

WMA, or Home windows Media Audio, is out there in lossy and m4a mp3 video converter free download lossless WMA formats, which gives listeners some choice. Usually, WMA files are smaller than their uncompressed counterparts, and related in performance to MP3s and FLAC information. Although WMA gives versatility, it is not suitable with all units, particularly Apple units. It's doable to stream audio in WMA format, however i major streaming providers don't use it. Fortuitously, for the average listener, this format sounds good over Bluetooth. Only vital ears would hear a distinction in high quality. One of the best ways to convert M4A audio files to MP3 without any high quality loss is by utilizing iSkysoft iMedia Converter Deluxe This skilled media converter is built with an audio converter that helps completely different audio varieties. The supported audio varieties include MP3, M4A, WMA, AC3, AA, AAX AAC, WAV, OGG, AIFF, MKA, AU, M4B, FLAC, APE, M4R, and M4P. It can simply upload the audio files and convert them in a batch. Apart from audio conversion, iSkysoft iMedia Converter Deluxe also can convert standard video information, HD movies and on-line Movies. It helps many file formats thus making it a great media converter to use. Its person interface is multilingual and it's fairly straightforward to make use of.

Leawo Music Recorder for Mac , appearing as skilled WAV to MP3 music recorder, could simply record WAV audio information and then save in MP3 format on Mac in order to comprehend the WAV to MP3 conversion in easy clicks. You solely have to play back WAV information in your Mac pc, then this WAV to MP3 recorder software program might file WAV to MP3 on Mac with little high quality loss. M4A - Extension of audio-only MPEG-four information. Very true of non-protected content material. Click on "Convert" button and begin to convert M4A to WAV, after a short time, all of the M4A audios will be converted to WAV recordsdata to permit you to freely get pleasure from. After conversion, you can get the WAV information for different units. Switch is without doubt one of the most stable, easy-to-use, and comprehensive multi format audio file converters obtainable. It is simple to use iTunes for M4A to WAV conversion. However, you'll be able to only convert M4A music recordsdata one after the other. When you have a whole lot of songs to convert to WAV, this technique will really waste your time. Then is there any handy approach to convert more than one M4A songs on the similar time? Keep reading. Notice that this command uses sed to parse output from ffprobe for each file, it assumes a 3-letter audio codec identify (e.g. mp3, ogg, aac) and will break with anything different.
All it's a must to do to get started is import a file, select the audio format, set the standard and http://www.audio-transcoder.com/how-to-convert-m4a-files-to-mp3 your file can be converted in a snap. Whether it's an audio ebook in M4A format, speech recordings in WAV file or music as OGG or FLAC, this software can rapidly and successfully converts your audio files in your Home windows LAPTOP. It's also possible to switch your optimized recordings with just one click on to your music administration program, such as MAGIX MP3 deluxe With Audio Cleansing Lab, you get the best method to convert M4A to MP3 and different varieties of audio formats. Strive it now totally free for the subsequent 30 days by downloading the free trial model. Go to the Free Obtain Web page from MAGIX. And you may right click on on any m4a file and select Send To -> (title of batch file) from the context menu. Again, change the trail to in your computer. But it surely's utter crap that the iTunes (Plus!) information are for ear buds (which might sound superior in case you pay it's worth) or computer audio system. I used them in membership setting and so they sound actually good (if not compared to lossless on a very good sound system). Click on drop-down arrow labeled Profile beneath the duty block, this could open a panel where you can pick the target audio format you need your APE music to be changed into from an inventory of a majority of format options. If you happen to're utilizing Music Supervisor or Google Play Music for Chrome to add music to your library, here are the forms of recordsdata you may upload. Edit Opus and every other audio format file, like trimming audio file, Merging separate audio files into one massive audio file, adjusting audio channel, bitrate, quantity, and many others. It is a tool developed by iSkysoft and is accessible for Windows. It's one other WAV to MP3 converter free. It helps several audio codecs including WAV, WMA, OGG, MP3, AIFF and more. It also consists of help for batch convert which is de facto helpful. When it comes to free software program that converts audio recordsdata, many people are understandably involved concerning the quality. This solution not only does the work shortly and without cost, but it also provides top quality outcomes with out decreasing the quality of the original file in any respect. All the supported codecs have their own settings so you may get the optimized results that you simply want. For instance, if you wish to have the very highest quality MP3 files in your audio machine, you should use the converter to keep the songs in skilled audio quality of as much as 320kbps.

As soon as the conversion is full, the link to obtain WAV file can be despatched to the e-mail you left in Step 4. Step 4: Click on "Convert" to convert your M4A file. MP3 information are of small size. They are often effortlessly distributed over the Internet, and massive music libraries saved on computers or music clouds. That is the essential reason why MP3 has grow to be a normal for buying music. Many M4A information are encoded with the Advanced Audio Coding (AAC) codec in order to reduce the size of the file. Some M4A files might as a substitute use the Apple Lossless Audio Codec (ALAC).
1 note
·
View note
Text
Week 11 - ISEA Paris Week May 17-23

Photo by Alain Thibault
Group 1
MMS: Massively Multilingual Speech. - Can do speech2text and text speech in 1100 languages. - Can recognize 4000 spoken languages. - Code and models available under the CC-BY-NC 4.0 license. - half the word error rate of Whisper.
Github
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Paper
https://scontent-lga3-2.xx.fbcdn.net/v/t39.8562-6/348836647_265923086001014_687800580827579[…]GkLV3haLgAXkFFhYmxMG8D9J2WV1hKDqYAQNPW4-4g&oe=6471ACCF
Blog
https://ai.facebook.com/blog/multilingual-model-speech-recognition/?utm_source=twitter&utm_medium=organic_social&utm_campaign=blog&utm_content=cardMeta AI
Group 2
Using .skn skin file as model texture · Issue #128 · deepmind/mujoco
https://github.com/deepmind/mujoco/issues/128
Infusion Systems
https://infusionsystems.com/catalog/product_info.php/products_id/693
SAC Algorithm
https://github.com/rail-berkeley/rlkit/blob/master/examples/sac.py
TDMPC
https://github.com/nicklashansen/tdmpc
Temporal Differences
https://www.youtube.com/watch?v=s-y_110sTTA
Group 3
Facial EMG and Reactions
https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1469-8986.1990.tb01962.x
Wiki
https://en.wikipedia.org/wiki/Facial_electromyography
VR Touch and Emotions
(PDF) Touching Virtual Humans: Haptic Responses Reveal the Emotional Impact of Affective Agents PDF | Interpersonal touch is critical for social-emotional development and presents a powerful modality for communicating emotions.
Stability AI Released Stability Studio
https://stability.ai/blog/stablestudio-open-source-community-driven-future-dreamstudio-release
OSC Into Touch Designer
https://infusionsystems.com/catalog/info_pages.php?pages_id=181
Synaptogenesis
https://www.youtube.com/watch?v=1fnm1vGGRYI&t=12s
Class Notes
Open AI’s Sam Altman urges AI Regulation
https://www.nytimes.com/2023/05/16/technology/openai-altman-artificial-intelligence-regulation.html
Supreme Court Rules Against Andy Warhol in Prince Case
https://www.nytimes.com/2023/05/18/us/supreme-court-warhol-copyright.html
https://hyperallergic.com/822888/supreme-court-rules-against-andy-warhol-foundation-in-lynn-goldsmith-copyright-case/
German Artist Michael Moebius Wins $120 Million in a 'Monumental' Lawsuit Against Hundreds of Foreign Counterfeiters | Artnet News
https://news.artnet.com/art-world/artist-michael-moebius-wins-monumental-copyright-l[…]0PM&utm_term=Daily%20Newsletter%20%5BALL%5D%20%5BAFTERNOON%5D
Inferno
https://www.youtube.com/watch?v=sGIbZ5DD4fY
Meta slapped with record $1.3 billion EU fine over data privacy
https://edition.cnn.com/2023/05/22/tech/meta-facebook-data-privacy-eu-fine/index.html
Ellen Waving From ISEA 2023 Paris
https://www.youtube.com/shorts/S9nxI7XTHhI
0 notes
Text
Preparing Chatbots Through Quality AI Training Datasets

If you're in your house and need to locate some information fast however you don't have enough time to type in information on your smartphone So you call "Hey Alexa," and you ask for the information. Alexa will look over the information you provided and seek out the same information for you to come up with results. Then , she will speak the answer out loud to you. Your work is done. It's not necessary to write anything down.
How do you make it work? What can companies do to develop AI to be able to recognize our diverse dialects, languages and pronunciations? What is the best way to make this happen? The answer lies in Natural Language Processing. But how did it all begin?
All it takes is collecting speech-related data. In order to develop an AI model to recognize as well as interpret spoken words, top-quality speech data is fed to it. The more precise and high-quality the speech data is and the higher the quality, the more effectively the AI will be able to perform.
What is what is a Speech Dataset?
Speech Recognition Dataset, also known as Speech datasets are collections consisting of transcriptions and audio of speech. These are used to develop machine learning systems to recognize voice.
The transcriptions and audio recordings are later input into an algorithm for machine learning to ensure that the algorithm is able to recognize and comprehend the elements of speech.
To create a chatbot that is more efficient you must first create real-world, task-oriented dialogue data in order to efficiently educate the chatbot. Without this information the chatbot won't be able to answer user questions quickly or answer questions from users without human intervention.
In the process of developing an interactive system that can create real-time conversations between virtual and human agents We at iMerit have created an index of the most effective and popular datasets which are great for anyone who wants to build chatbots. Each entry on this list includes pertinent data, including customer support data, multilingual data dialog data, and answer-to-question data.
Question-Answer Datasets Chatbot Training
The WikiQA Corpus The WikiQA Corpus was made publically accessible in the year 2015 and has been revised several times since its creation. It includes a variety of sentences and questions that were initially collected
Questions-Answer Database The chatbot database was created for Academic research. It includes Wikipedia articles, as well as manually generated factoids derived from the articles. Also, it has manual-generated answers to the above-mentioned questions.
Dialogue Datasets to support Chatbot Training
Santa Barbara Corpus of Spoken American English: With approximately 249,000 words The Santa Barbara Corpus of Spoken American English contains audios, Audio Transcription as well as timestamps that are also able to effectively link transcription with audio at the level of the individual intonation units.
Semantic Web Interest Group IRC Chat Logs: The Semantic Web Intergest Group IRC Chat Logs are designed to be an automatic IRC chat log, which contains daily chat logs and the time stamps for each.
Multi-Domain Wizard-of Oz dataset (MultiWOZ): This massive human-human conversational corpus has the 8438 multi-turn conversations, each of which lasts 14 turns. It's different from other chatbot datasets since it has less than 10 slots , and only a handful of hundred values. Additionally, it covers a variety of domains like restaurants, hotels, attractions police, hospital, taxi and train.
The NPS Chat Corpus: Consisting of 10,567 posts that have been gathered from a collection of 500,000 posts from various online chat services, the NPS Chat Corpus was created for non-commercial/non-profit educational and research use. Each work is protected by copyright with respect to the original authors.
ConvAI2 Database Dataset gathered during the ConvAI2 contest This dataset contains more than 2000 dialogues that involve humans who were evaluators via crowdsourcing platforms to interact with bots.
What are the different types of Speech Recognition?
Generally, there are three kinds of speech recognition information:
The scripted Speech Data: The scripted speech data is thought to be one of the more controlled kind that speech information can be controlled.
In order to recognize speech, there can be two kinds of data such as scripted language commands, scripted words or both.
Examples of this could be, "Hey Google, switch on the lights", "Hey Google, shut off your fan" And many more.
If developers require speech samples that differ not according to what is said however, by the way in which they say it the speech samples that are scripted can be used.
Scenario-based Speech Data: The speech data based on scenarios is the one in which the users have to create their own instructions according to a particular scenario.
If you were given an opportunity to ask the assistant to guide you to the closest pharmacy. What instructions would you give to the pharmacist?
Examples of this could be "Take me to the closest pharmacy" or "Directions to the nearest pharmacy".
If developers require an unnatural sample of methods to request the same thing or to provide a greater variety of commands using scenario-based speech data, it is utilized.
Natural Speech Data or Unscripted Speech Data: In Natural or unscripted speech data, the speakers can speak in their natural tone of conversation in terms of language, pitch and the tenor. The data could be derived from recordings of calls, voice recordings, or other sources to better understand the dynamic of a multi-speaker dialogue.
What is the best way to let GTS assist you by providing Speech Dataset?
At GTS we recognize that there's no universal method to collect speech datasets. This is why we offer the highest-quality, accurate and customized AI Training Datasets that meet your requirements. We can provide assistance in over 200languages, which include English, French, German, Spanish, Portuguese, and many more.
Our team has the experience and expertise to manage any kind of project. Our quick and efficient customer service will ensure that you are in no doubt regarding your project.
0 notes
Text
A Massively Multilingual Speech-to-Speech Translation Corpus
A Massively Multilingual Speech-to-Speech Translation Corpus
Posted by Ye Jia and Michelle Tadmor Ramanovich, Software Engineers, Google Research Automatic translation of speech from one language to speech in another language, called speech-to-speech translation (S2ST), is important for breaking down the communication barriers between people speaking different languages. Conventionally, automatic S2ST systems are built with a cascade of automatic speech…
View On WordPress
0 notes