#LLMs for dummies
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown: 1. Explaining tokens 2. Large Language Models 3. LLM Interfaces 4. AO3 and Generative AI [here] 5. Fic and ChatGPT [here] 6. Some Closing Notes [here] [post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
85 notes
·
View notes
Text
Terrible isekai guides you might meet
Ok I keep thinking about that post about someone not believing the stupid rules of the fantasy land they're in I reblogged the other day and I'm now trying to think of just terrible options for meeting your guide to this new world when you get isekai'd.
The conspiracy theorist: You've got no background here, so sadly it's not your fault you don't clock that the faun you met after walking through that magic wardrobe is actually a nutjob.
You're quite a way into your quest to defeat the dark lord before you find out he's really a duly elected politician and probably does not, in fact, keep a dungeon full of tortured gnomes beneath his castle.
"Yeah, if you believe the establishment" says the faun, rolling his eyes. With hindsight, you recall the fact he lived alone in a shack in the woods and how perhaps you should have thought more about that.
The helpful AI: You awaken in a futuristic looking facility, your last memory is of sticking a fork in the toaster like your mother always told you not to. There's a console to your right, and the text is in your own language! "Hello, how may I help you today?" the speaker announces in a friendly tone. You tentatively say "where am I?", but are still surprised when the voice answers.
They've clearly improved things a lot since your day, but it's still embarrassing how long, and how many failed solutions to problems it presented, before you finally twig that it's still just an LLM. They've got the voice tone right, and the speech is far more natural, but it's still basically a hallucinating predictive text machine. You begin to doubt everything it's told you.
The confident idiot: Look, it's not their fault they never got a decent education. Just like it's not your fault you don't know enough about this place to know how wrong they are. Maybe the moon here really is a projection on the sky? It's not, and they've clearly misunderstood something they once heard about how the light of the moon is actually reflecting off it, but you weren't to know that. I mean, you just saw a fucking unicorn, all bets were off.
Sadly for you, the helpful young man who found you lying in the middle of the road and nursed you back to health, is kind of an idiot. Helpful, has the best of intentions at heart, but still an idiot. And worse yet, he's just intelligent enough to make logical leaps from all the information he's misunderstood over the years. Everything he taught you is like 40-70% right, or close to right, and you realise it's probably going to take twice as long to unpick which of the things you learnt were true and which bits weren't.
It's five years later, and you're still stuck in that strange world, you're used to it now, this is your home. In the tavern one evening you take a moment to lean over to a trusted companion and utter the stupidest sentence you've ever said: "So, uh, weird question but...do unicorns actually have venomous horns?"
The cultist: Yeah so uh, listen they seemed so nice when they met you! The friendly woman in the shining white armour, who couldn't do enough to help this lost stranger in her land.
Later you learn the visual shorthand here is a bit different to the one you grew up with and you've joined the great war between Good and Evil on the side of Evil. Whoops.
The skull-helmeted warrior-priests of the squid god are the good guys. Actually, it makes a sort of sense when you think about it, that the guys with the lion motif on their breastplates are the bad guys. Lions will eat humans; squid are mostly just delicious. And of course a cultist is friendly to a lost person seemingly with no connections, that's how cults work back in your world too, dummy. Shame they want to "end the world in blood" and all that.
#writing#isekai#portal fantasy#in case you were wondering no actually unicorns have a venomous *bite*#and the squid priests are from a culture of fisher-folk - the skull helmets are a reference to their role as protectors of those lost at se#I'm sure I've got more thoughts to come on this but I'll post this as is for now#I'm thinking also like someone who thinks they're being pranked or filmed#maybe a larper too
3 notes
·
View notes
Text
While we're at it…
Duolingo has never been a platform that paid translators fairly. In fact, right from the start, they have shown zero respect for the translation industry and for the skills required to be a good translator. Their initial business model involved a crowdsourced translation service where they'd let language learners translate texts and then sell those translations to their clients (e.g., see this 2015 TechCrunch article).
Furthermore, the growth of Duolingo as a language-learning platform was only possible due to lots of naive language nerds who worked for free and helped create all those exercises through the company's Volunteer Contribution Program. That was a classic techbro asshole move on Duolingo's part: appeal to the good intentions of people with a passion for the subject/product, keep them motivated with lots of shallow talk about how their work will contribute to a brighter future where people have free access to knowledge and education, blablabla – and while all those well-meaning dummies worked for free, the people behind Duolingo were cashing in the big checks, getting investors involved, and planning the further commercialization of their product.

And make no mistake: The grand gestures they're now making, such as honoring those volunteers with fancy awards and VIP access to special events, and even the promised belated financial compensation to be distributed among all volunteers are just tiny drops in the bucket that won't hurt the company at all. And they won't undo all the exploitation that has been going on there for years. The partial switch to AI is just another non-suprising move following a long tradition of similarly profit-driven moves.
But they're not the only jerks out there doing this. Two more examples: Facebook (of course, eyeroll) and TED Talks. The latter's subtitles are also created by volunteers. And not only that: Many of those volunteers are actual translators (often with proper training and all) at the beginning of their career who unfortunately think that's a great way to build their portfolio and get some of that awesome exposure. But it is not. It's just a shitty way of helping all those rich tech companies get richer and further devaluing the translation profession. (If you happen to be a newbie translator reading this and looking to build your portfolio, do pro bono translations for people and organizations who really need your help!)
Obviously, this scheme is found in other fields as well, with people in creative industries being particularly vulnerable and gullible. Whenever someone promises your work will serve a greater good or provide you with career-boosting exposure, take a deep breath and then a close look at what kind of business or product you're about to support with your free labor. 9 times out of 10 you should be asking for real compensation.

And if you're a user of such products, 9 times out of 10 you should stop using them (and you should definitely stop paying for them).
But of course, life is complicated. Even if you should stop doing something, it's not always possible. Or at least not right away. (For example, I still use Facebook because of some non-public groups only found there.) But there's something you certainly can and must do: Pay more attention. Find out where your money is going, or, in the case of free services: Who will get your data, and how can they profit from them? Who's getting paid, and who's not getting paid? What's the history of the company or product? And do you really need it?
At least in some cases you will realize that you don't need the service or product at all.
AI in the form of large language models (LLMs) and generative algorithms used for tools like ChatGPT, Midjourney etc. increases this dilemma because it makes it even more difficult to find and use products whose creation didn't involve a lot of people getting exploited. And this will be the case for at least a while until the techbro hype has died down and people will learn to appreciate the value (well-paid) humans bring to a product or service. Lots of companies are currently trying to cut costs and corners by integrating these new AI models into their workflows. For some, it has already backfired (just ask the law firm Levidow, Levidow & Oberman about their little ChatGPT whoopsie); others will still learn this lesson the hard way. And of course, things will get reaaally fun when there's so much AI-generated content that the models will start ingesting too much of it, thereby poisoning themselves. Grab your popcorn, folks!

On a more serious note though: AI itself isn't the problem. It's an umbrella term that comprises a multitude of different methods and strategies, some of which are extremely useful (for example, in early-stage cancer detection). And there are many people, companies, and organizations that try to integrate AI into their workflows in a careful, cautious manner. You're already using lots of things in your daily life that wouldn't be possible without AI. Even your use of Tumblr is likely enabled by AI because fast internet requires smart routing of all that data traffic.
So from now on, when you look behind the scenes of how a tool or service gets provided, the mere fact that some AI is involved shouldn't be a disqualifier. You need to dig deeper. What kind of AI? What purpose is it used for? Does it actually help humans work smarter or does it force them to work harder?
There are problematic people on both ends of the spectrum: techbro bootlickers praising our AI overlords on one end, and uninformed luddites waving "boycott AI" signs on the other end. But a solution and a way out of this mess can only be found somewhere in the middle.
(Much more could be said about the use of AI/MT in the translation industry, how it's currently evolving, and how often people (unknowingly) support the exploitation of translators... Maybe in a future post...)
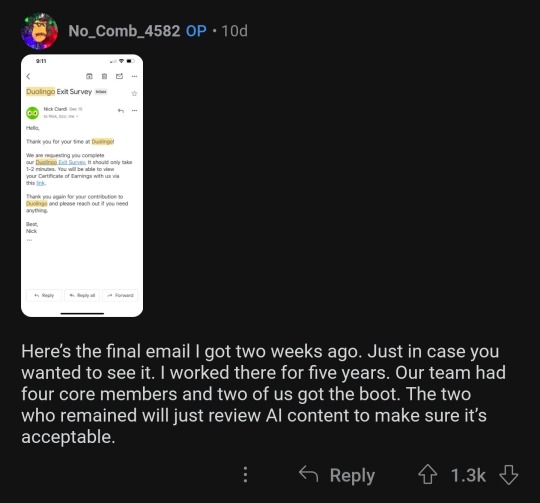
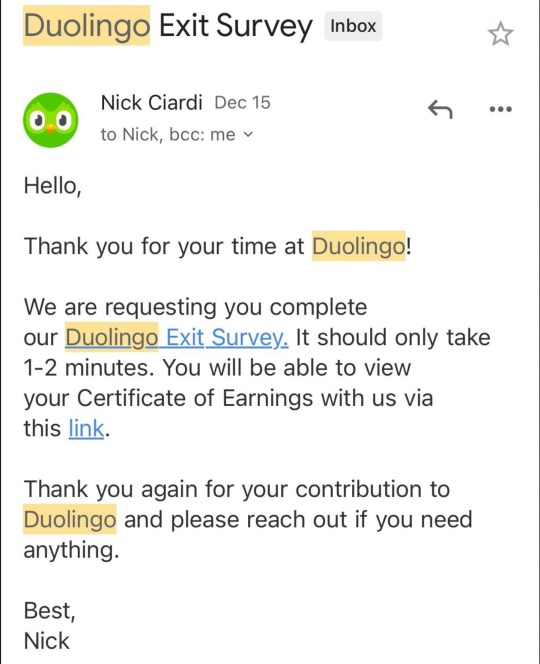
Heads up to not use Duolingo or to cease using it
In December 2023 they laid off a huge percentage of their translation teams, replacing them with ai and having the remaining members review the ai translations to make sure the translations are “acceptable” (Note how they use the world acceptable and not accurate)
Link to the tweet that informed me of this:
https://x.com/rahll/status/1744234385891594380?s=46&t=a5vK0RLlkgqk-CTqc0Gvvw
If you’re a current user prepare for an uptick in translations errors as I’ve already seen people in the comments say they’ve noticed
#Duolingo#AI#XL8#special shoutout to efka-m#an unfinished email to you has been sitting in my drafts for ages#I promise I'll finish it some day#(maybe I should ask ChatGPT to help me? :-D)
44K notes
·
View notes
Text
WHITE PAPER ABOUT HOW TO LEARNING AI TECHNOLOGY

White paper on learning AI technology step by step, including a proof of concept (POC) snippet in Python.
We'll cover the foundational concepts of AI, machine learning (ML), natural language processing (NLP), deep learning (DL), large language models (LLM), neural networks, and the main frameworks and libraries.
This guide will also explain how these components work together to build AI solutions.

Introduction to AI
Artificial Intelligence (AI) is a field that focuses on creating machines capable of performing tasks that typically require human intelligence. These tasks include learning, reasoning, problem-solving, perception, and language understanding. AI technologies are based on machine learning, which involves training machines to learn from data and improve their performance over time.
Machine Learning (ML)
Machine learning is a subset of AI that focuses on the development of algorithms that allow computers to learn from and make decisions or predictions based on data. There are two main types of machine learning:
- Supervised Learning: The model is trained on a labeled dataset.
- Unsupervised Learning: The model learns from an unlabeled dataset to identify patterns and structures.
Natural Language Processing (NLP)
NLP is a branch of AI that focuses on the interaction between computers and human language. It involves programming computers to process and analyze large amounts of natural language data. NLP is used in applications such as chatbots, virtual assistants, and language translation.
Deep Learning (DL)
Deep learning is a subset of machine learning that uses neural networks with many layers (hence "deep") to model and understand complex patterns in datasets. It's particularly effective for tasks such as image and speech recognition.
Large Language Models (LLM)
LLMs are a type of deep learning model that are trained on a vast amount of text data. They can generate human-like text and understand the context of the input data. Examples include GPT-3 and BERT.
Neural Networks
Neural networks are the foundation of deep learning. They consist of layers of interconnected nodes or "neurons" that mimic the neurons in a human brain. Neural networks learn from data by adjusting the weights of the connections between nodes.
Main Frameworks and Libraries
- TensorFlow: An open-source library developed by Google for building and training neural networks.
- PyTorch: Developed by Facebook, PyTorch is known for its flexibility and ease of use.
- Keras: A high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano.
- Scikit-learn: A library for machine learning in Python, built on NumPy, SciPy, and matplotlib.
- NLTK (Natural Language Toolkit): A leading platform for building Python programs to work with human language data.

POC Snippet in Python
Here's a simple Python code snippet to demonstrate the use of TensorFlow for building a neural network:
```python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Define the model
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model
model.fit(data, labels, epochs=10, batch_size=32)
```
This code creates a simple neural network with one hidden layer and trains it on random data. It's a basic example to illustrate how to use TensorFlow for building neural networks.

How These Components Work Together
- ML and NLP: Machine learning algorithms are used to analyze and interpret text data, enabling NLP applications.
- DL and Neural Networks: Deep learning uses neural networks to learn complex patterns in large datasets, making it possible to build advanced NLP models.
- LLM and NLP: Large language models like GPT-3 are trained on vast amounts of text data and can generate human-like text, enhancing NLP applications.
- Frameworks and Libraries: These tools provide the necessary functions and structures to implement AI technologies, making it easier to develop and train models.
By understanding and integrating these components, developers can build powerful AI solutions that can analyze and interpret data, understand human language, and make predictions or decisions based on that data.
0 notes
Text
What Does AI Stand For. Modern Explanation
Isaac Asimov launched the Three Laws of Robotics in plenty of books and stories, most notably the "Multivac" collection a couple of super-intelligent laptop of the identical name. Machines with intelligence have the potential to make use of their intelligence to make ethical selections. Logicis used for knowledge illustration and problem-solving, but it may be utilized to other issues as well. For instance, the satplan algorithm makes use of logic for planningand inductive logic programming is a technique for studying. AI gradually restored its status in the late 1990s and early 21st century by discovering specific options to specific issues https://www.willbhurd.com/an-artificial-intelligence-definition-for-dummies/.

The conventional targets of AI research embody reasoning, information representation, planning, studying, natural language processing, perception, and the ability to maneuver and manipulate objects. AI additionally attracts upon pc science, psychology, linguistics, philosophy, and a lot of other fields. Faster computers, algorithmic enhancements and entry to large quantities of knowledge enabled advances in machine learning and perception; data-hungry deep studying strategies began to dominate accuracy benchmarks around 2012. According to Bloomberg's Jack Clark, 2015 was a landmark year for artificial intelligence, with the number of software tasks that use AI inside Google increased from a "sporadic utilization" in 2012 to greater than 2,seven hundred initiatives.
In the coaching process, LLMs process billions of phrases and phrases to be taught patterns and relationships between them, making the models in a position to generate human-like answers to prompts. Overall, the most notable developments in AI are the event and launch of GPT 3.5 and GPT four. But there have been many other revolutionary achievements in synthetic intelligence -- too many, in reality, to include all of them right here.
Deep studying techniques enable this automated studying through the absorption of big amounts of unstructured knowledge such as textual content, images, or video. The method during which deep learning and machine learning differ is in how every algorithm learns. Deep learning automates a lot of the characteristic extraction piece of the method, eliminating some of the handbook human intervention required and enabling using larger knowledge sets. You can consider deep studying as "scalable machine studying" as Lex Fridman famous in identical MIT lecture from above. Classical, or "non-deep", machine learning is more depending on human intervention to study. Human specialists determine the hierarchy of features to know the differences between data inputs, usually requiring more structured knowledge to learn.
For more on the controversy over artificial intelligence, go to ProCon.org. No, artificial intelligence and machine learning usually are not the same, however they are what does ai stand for intently related. Machine studying is the method to train a computer to be taught from its inputs however with out explicit programming for every circumstance. Machine learning helps a pc to realize synthetic intelligence.
Much of present analysis includes statistical AI, which is overwhelmingly used to unravel specific problems, even extremely profitable techniques similar to deep learning. This concern has led to the subfield of artificial general intelligence (or "AGI"), which had a number of well-funded establishments by the 2010s. This capability is what many refer to as AI, however machine learning is actually a subset of synthetic intelligence.
That means constructing the proper governance constructions and making sure ethical rules are translated into the event of algorithms and software program. Because of the proliferation of information and the maturity of other innovations in cloud processing and computing power, AI adoption is growing quicker than ever. Companies now have access to an unprecedented amount of knowledge, including darkish knowledge they didn’t even understand they'd till now. Get up to speed on synthetic intelligence and study the means it might help you drive enterprise value with our curated collection of insights, stories and guides. Artificial intelligence is reworking the means in which the world runs, and can proceed to do so as time marches on. Now is a perfect time to become involved and get a level in IT that can help propel you to an exciting AI profession.
The subsequent few years would later be referred to as an "AI winter", a interval when acquiring funding for AI projects was difficult.
Artificial intelligence has turn out to be a hot-button topic in recent months due to its potential to revolutionize how we stay and work.
The industry-specific platform is the seller's seventh and contains data units and other pre-built capabilities to satisfy the wants ...
Theory of Mind AI can think about subjective components corresponding to person intent when making selections.
Its worth of practically one hundred billion U.S. dollars is expected to develop twentyfold by 2030, as much as practically two trillion U.S. dollars.
AI has had an extended and typically controversial history from the Turing test in 1950 to today's generative AI chatbots like ChatGPT. The European Union's General Data Protection Regulation is contemplating AI rules. GDPR's strict limits on how enterprises can use consumer information already limits the training and functionality of many consumer-facing AI applications. While AI tools current a variety of latest performance for businesses, using AI additionally raises ethical questions as a end result of, for higher or worse, an AI system will reinforce what it has already discovered. Artificial intelligence has made its method into a wide variety of markets. AI can personalize content material, messaging, adverts, recommendations and websites to particular person customers.
Google's father or mother company, Alphabet, has its arms in several completely different AI methods by way of a few of its corporations, together with DeepMind, Waymo, and the aforementioned Google. General customers and companies alike have a wealth of AI providers obtainable to expedite what does ai stand for tasks and add convenience to day-to-day life -- you in all probability have one thing in your house that uses AI in some capacity. Google sister companyDeepMindis an AI pioneer making strides towards the final word objective of synthetic basic intelligence . Though not there yet, the company initially made headlines in 2016 with AlphaGo, a system that beat a human professional Go participant. The achievements of Boston Dynamics stand out within the area of AI and robotics. Though we're nonetheless a good distance away from creating AI on the degree of expertise seen within the moive Terminator, watching Boston Dyanmics' robots use AI to navigate and reply to different terrains is spectacular.
ChatGPT is an instance of ANI, as it's programmed to perform a specific task, which is to generate text responses to the prompts it is given. The first “robot citizen,” a humanoid robotic named Sophia, is created by Hanson Robotics and is capable of facial recognition, verbal communication and facial expression. The phrase “artificial intelligence” is coined on the Dartmouth Summer Research Project on Artificial Intelligence. Led by John McCarthy, the convention is broadly thought of to be the birthplace of AI.
Theory Of Thoughts
Around the identical time, Waymo, Google’s subsidiary, expanded its self-driving taxi services exterior Arizona. Conceptually, studying implies the flexibility of pc algorithms to enhance the data of an AI program by way of observations and previous experiences. Technically, AI applications process a group of input-output pairs for an outlined operate and use the outcomes to foretell outcomes for new inputs.
What Are The Different Types Of Ai?
Data privacy and the unauthorized use of AI could be detrimental each reputationally and systemically. Companies should design confidentiality, transparency and safety into their AI packages on the outset and ensure information is collected, used, managed and stored safely and responsibly. Ethics theater, the place corporations amplify their accountable use of AI via PR whereas partaking in unpublicized gray-area activities, is an everyday concern. Responsible AI is an rising functionality aiming to build trust between organizations and both their employees and prospects. There are some ways to define synthetic intelligence, however the extra necessary conversation revolves around what AI lets you do. The expertise underpinning ChatGPT will transform work and reinvent enterprise.
It covers an ever-changing set of capabilities as new technologies are developed. Technologies that come underneath the umbrella of AI embrace machine studying and deep learning. General AI is extra like what you see in sci-fi movies, where sentient machines emulate human intelligence, pondering strategically, abstractly and creatively, with the flexibility to deal with a spread of advanced tasks.
The machine intelligence that we witness all around us right now is a type of narrow AI. Examples of slim AI embody Apple’s Siri and IBM’s Watson supercomputer. To begin with, an AI system accepts information enter within the form of speech, textual content, image, etc. The system then processes information by applying various guidelines and algorithms, decoding, predicting, and performing on the input information. Upon processing, the system provides an outcome, i.e., success or failure, on data input.
The system learns to analyze the sport and make strikes, after which learns solely from the rewards it receives, reaching the point of being ready to play by itself and earn a excessive rating without human intervention. Since then, DeepMind has created a protein-folding prediction system, which can predict the complicated 3D shapes of proteins, and it's developed applications that can diagnose eye diseases as effectively as the highest medical doctors all over the world. ChatGPT is an AI chatbot capable of natural language era, translation, and answering questions. Though it's arguably the most well-liked AI tool, due to its widespread accessibility, OpenAI made significant waves in the world of artificial intelligence with the creation of GPTs 1, 2, and three. An intelligent system that may be taught and constantly enhance itself continues to be a hypothetical idea. However, it is a system that, if utilized effectively and ethically, could result in extraordinary progress and achievements in medicine, technology, and more.
What Is Generative Ai?
AI, ChatGPT particularly, has passed a concept of thoughts check commensurate with 9-year-old ability, as of February 2023. AI has the flexibility to devour and process huge datasets and develop patterns to make predictions for the completion of future tasks. While the term "synthetic intelligence" has entered the frequent language and turn into trivial within the media, there is not any really shared definition.
Also, OpenAI, in August 2021, launched a greater model of its tool, Codex, which parses pure language and generates programming code in response. The company can be working on the following version of GPT-3 (i.e., GPT-4), and it's anticipated that GPT-4 shall be 500 occasions the size of GPT-3 when it comes to the parameters that it might use to parse a language. AI-driven planning determines a procedural course of action for a system to attain its targets and optimizes overall efficiency through predictive analytics, information analysis, forecasting, and optimization fashions. Limited memory machines can store and use past experiences or data for a brief time frame. For example, a self-driving automobile can store the speeds of autos in its vicinity, their respective distances, pace limits, and other relevant info for it to navigate through the visitors.
Human info processing is simple to elucidate, nevertheless, human subjective expertise is difficult to explain. For example, it's straightforward to think about a color-blind one who has learned to identify which objects of their field of view are purple, however it is not clear what could be required for the individual to know what pink seems like. AI can remedy many problems by intelligently looking by way of many attainable options. For instance, logical proof could be considered as looking for a path that leads from premises to conclusions, the place each step is the appliance of an inference rule. Planning algorithms search by way of trees of objectives and subgoals, searching for a path to a goal aim, a process called means-ends analysis. Robotics algorithms for shifting limbs and greedy objects use native searches in configuration area.
AI comes in completely different types which have turn out to be broadly out there in everyday life. The good speakers in your mantle with Alexa or Google voice assistant built-in are two nice examples of AI. Other good examples are well-liked AI chatbots, such asChatGPT, the new Bing Chat, and Google Bard.
The second imaginative and prescient, generally known as the connectionist approach, sought to attain intelligence by way of studying. Proponents of this method, most prominently Frank Rosenblatt, sought to attach Perceptron in methods inspired by connections of neurons. James Manyika and others have compared the two approaches to the thoughts and the brain .
0 notes
Photo

LLM-Vario ray (Dummy) PEQ box. The LLM-Vario ray (dummy) is a 3d printed replica of the original one. It has an open space inside its body where some small items can be stored. The mount on the bottom side fits on standart picatinny rails "21 mm" Color: Black, Tan, Dimesnions: Height -13,5cm x Width 6,5cm x Lenght 4,2 cm Price : Clean ( 55 eur) ( polished, sanded) Raw ( 40 eur) ( 3d printed) We are shipping worldwide., and the delivery time is 1-3 weeks. If you are interested in ordering a batch there is a discount included. Awesome profiles for you guys to check out ---- @e.r_maraudeurs @drache_ragnarok @callsign_bubba_ @devilnorseman @t41s_david @christophenoguera #airsoftengland #Llm #peqbox #dummy #milsimlife #milsimwest #airsoftnation #airsoftequipment #airsoftinternational #dummy #gun #airsoftcustom #milsim #milsimgear #customdesign #3d_crafts_ #airsofteu #airsoftworldwide #airsoftgermany #prop #replica #scalemodel #rheinmetall @ Belgrade, Serbia (at Belgrade, Serbia) https://www.instagram.com/p/B7Em8ymnXda/?igshid=k80ubbx4h8qz
#airsoftengland#llm#peqbox#dummy#milsimlife#milsimwest#airsoftnation#airsoftequipment#airsoftinternational#gun#airsoftcustom#milsim#milsimgear#customdesign#3d_crafts_#airsofteu#airsoftworldwide#airsoftgermany#prop#replica#scalemodel#rheinmetall
0 notes
Text
Week 2
UX is important even for LLMs HuggingFace's Inference Endpoint with GPT-Neo 125m was draining my wallet super fast! I was being charged by the hour without any usage! Shut it down and Created an Open AI account instead. Open AI's documentation and onboarding is much easier to navigate. I couldn't make heads or tails of HuggingFace's onboarding. It was clearly designed for AI devs and not for dummies. Meanwhile Open AI has step-by-step instructions and code examples. Not easy either, but at least they lowered a rope ladder for those of us on the lower rungs of IQ. I spent all of last week setting up my web hosting on AWS (Amazon Web Services). It was much more involved than I'm used to. So many different services have to be individually set up and daisy-chained in the exact right way or else none of it works. Just figuring out how to provide a secure connection for visitors via HTTPS took me 3 DAYS! Thank sweet Jesus for YouTube tutorials - all of which were made by Indian Developers. Shout out to Indian Devs! So far this week I've been setting up my backend infrastructure which will be Python built on Django. WTF is that you ask? Exactly! I didn't know either. I had to ask ChatGPT a bunch of questions and do follow up Google research to understand the different Python frameworks to decide which would be best for my concept. Lowering the cost of intelligence ChatGPT has been writing code for me, but about 20% of the time the code is wrong or has some bits missing. Even with these drawbacks, it is an absolute miracle for someone with even rudimentary code fluency. If there's an implementation error, I can share the exact error message with ChatGPT and it'll troubleshoot the issue with me until it works. It's like working with a senior engineer who has infinite patience for dumb questions. ChatGPT is democratizing abilities previously monopolized by the smartest, most focused humans. But will lowering the cost of intelligence inadvertently violate some kind of hidden ratio Mother Nature uses to mitigate risk? This might just be anecdotal, but it seems the most intellectually accomplished humans rarely if ever leave offspring who match or surpass them. And in the case of geniuses like Nikola Tesla and Alan Turing, no genetic lineage is produced at all (and like, does anyone give a shit about Einstein's kids?). What if this is some kind of natural intelligence rate-limiting function? In tech circles the question that often comes up is "Why can't we create more Elon Musks?". Maybe Gaia would respond with "I'll tell you why you fools! Because if you have that many geniuses, the odds of more Dr. Evils goes up and all it takes is just an extra pinch of those to ruin the whole casserole!". Everyone thinks if something is good, more of it must be better to infinity, but this isn't true. The difference between medicine and poison is... Dosage. Perhaps we should be weary of ODing on intelligence.
1 note
·
View note
Text
The Ugly Truth About Immigration Law Firms
Things about Best Immigration Lawyers In California
Table of ContentsSome Of ImmigrationLos Angeles Immigration Lawyers Things To Know Before You BuyBest Immigration Lawyers In California - The FactsThe Ultimate Guide To Los Angeles Immigration LawyersImmigration Lawyer Los Angeles Fundamentals ExplainedAll about Immigration Lawyer Los Angeles
youtube
The same can be said for acquiring experience in a social outreach company, company that depends on non-citizen staff members, or government office that handles migration. If a straight link with immigration is not offered, any kind of paid or volunteer task that includes public talking, creating, research, or various other skills valued in the legal occupation could be worth pursuing.
These may consist of courses and even concentrations or certifications in migration legislation or associated locations, which give a vital academic foundation for an occupation in this specialty - law firm. Along with academics, and as kept in mind above, you ought to likewise seek as several possibilities to gain hands-on experience in the legal field as you can, specifically in immigration lawrelated work.

Immigration Lawyers Fundamentals Explained
For the majority of people planning to practice law, including immigration legislation, the JD is the basic degree. Yet some regulation school graduates take place to pursue various other levels or credentials calling for extra study, such as the Master of Laws (LLM) or the Physician of Scientific Research of Law/Doctor of Juridical Scientific Research (JSD or SJD).
Immigration Lawyers for Dummies
It's clear that legal careers often tend to pay well, though individual lawyers' salaries can vary significantly, even within the same legal specialty, like migration law. The solutions you offer, clientele you offer, as well as area of the country you practice in can all impact earning potential. According to the U.S - Immigration help..

The Definitive Guide to Immigration Lawyers

8 Simple Techniques For Immigration Lawyer Los Angeles
Mean incomes top $140,000 for those used by the federal government, while pay for state as well as local government ranges from $85,000 to $93,000 each year (ILOLA). Legal representatives used by big, effective law office or huge firms tend to gain more than those that possess their own practices or work for nonprofit organizations.
An attorney who approves a placement with a tiny migration not-for-profit, for instance, may select that choice with the understanding that while the wage is lower than standard, the job offers the opportunity to offer people in life-altering circumstances who do not have the resources to acquire lawful help or else. Not to state the contentment prices are continually greater for public passion attorneys.
Some Known Incorrect Statements About Best Immigration Lawyers In California
There are certainly plenty of on-line resources to help you find out more about coming to be an immigration legal representative; nonetheless, you might locate it's practical to begin by getting in touch with individuals in the field. This might mean conducting an informative interview with a working immigration legal representative, perhaps via your undergraduate institution (ask the occupation or graduates workplaces at your institution).
You might likewise obtain a chance to chat regarding migration law at a law school fair. Another useful resource is the American Migration Lawyers Association, a national company of even more than 15,000 lawyers as well as instructors that exercise and also educate migration law. This nonpartisan nonprofit provides proceeding lawful education, info, as well as professional services.
As you check out migration law with these and various other sources, you might find it uses the ideal occupation possibility for you. citizenship.
The Ultimate Guide To Immigration Lawyer Los Angeles
A good migration attorney can make all the difference to your situation (california). Several are difficult working, sincere experts who really want to help. They could, besides, possibly be making a great deal even more cash in some various other area of law. They're also handling a tough, delay-prone administration; and also facing even more stress than ever because the COVID-19 pandemic led to numerous immigration office closures and also more hold-ups.
Whether you are looking for to file a petition for a visa or permit, attempting to stay clear of expulsion, or looking for some other immigration advantage, ensure you get the right sort of lawyer in your corner. Right here are some ideas to prevent the shadier types of experts (law firm). A few "high-volume, reduced value" migration lawyers prowl the corridors of migration offices trying to solicit organization.
Besides, any kind of great immigration lawyer is possibly going to be also busy exercising migration law and also benefiting their customers to spend their time rounding up new customers by doing this. Would certainly you ask a neighbor to change your heart shutoff, or your physician to complete your tax forms? Ideally not.
More About Best Immigration Lawyers In Los Angeles
Unfortunately, numerous non-lawyers; also some well-meaning ones, that don't acknowledge exactly how facility this area of regulation really is; claim to be qualified of assisting foreigners who need assist with the migration procedure. Oftentimes, they supply little worth apart from a keying service. In the most awful cases, they may literally take your cash and also run, or submit your types in incorrect as well as dangerous means without telling you the definition of what they're doing (ILOLA).
If the only evaluations you transform up show the lawyer obtaining jailed or disbarred, you can conserve yourself a personal conference. Take care of any type of https://www.google.com/maps?cid=10302068370223715763 migration lawyer who suggests that you do something shady: perhaps rest on an application or to a USCIS policeman, provide the attorney money with which to reward an immigration authority, or buy a fake permit from him or her - Linda Lee.
The depressing point is that if you are captured supporting such a system, you are likely to get right into far more trouble than the attorney. Claiming, "But he informed me that buying this environment-friendly card stamp was the fastest way to operate in the UNITED STATE!" is most likely to obtain you nowhere, and also will develop an irreversible tarnish on your immigration document, possibly making you disqualified for any type of future visas or permits (inadmissible).
Getting My Immigration Lawyer To Work

The Ultimate Guide To Best Immigration Lawyers In Los Angeles
Eventually, the outcome of your instance depends on a migration judge, the Department of Homeland Protection and/or USCIS. Any kind of attorney claiming she or he has a 100% success rate and guaranteeing you a specific outcome may need to be a lot more carefully examined. While the majority of good immigration attorneys will likely be rather busy, you ought to be able to speak with them and their workplace team to get a sense of their commitment to clients in addition to their total demeanor and perception of honesty.
0 notes
Text
I was among the first to sit the SQE pilot — here’s what I thought
‘The MCQ format was very patronising and far too easy. It was like a dummies guide to the law!’
I was one of a number of people who sat the Solicitors Qualifying Examination (SQE) stage one pilot last month. The candidates ranged from LLB graduates to Legal Practice Course (LPC) graduates but most of the candidates were working in practice. My background is not ‘conventional’ and I took the pilot because I was interested in knowing whether the SQE would cater for people like me. I do not have any GCSEs or A-levels because I left school at the age of 14 to care for my ill mother. I studied for my LLB over six years and then completed a combined LLM-LPC over two years.
The SQE1 pilot was a three-day assessment consisting of 360 multiple-choice questions on the foundations of legal knowledge, namely business law; property law; wills and trusts; criminal law; EU law; public and constitutional law; tort law; contract law; and professional conduct. There were also two research questions and four writing questions. No materials were provided, and the exams were closed-book. Prior to the exam I emailed the Solicitors Regulation Authority (SRA) for revision guidance and was referred to the pilot specification which told me that anything within the above topics would be examined.
Day one
The exam started with three rounds of 60 questions with 110 minutes for each on a mixture of the topics outlined above. The questions were scenario-based (one scenario per question) with five possible answers. Most of the questions were simple but after speaking with some recent LLB graduates it became clear that they did not know many of the answers — especially to the questions on the topics that are exclusively covered on the LPC.
The questions often dropped big hints towards the answers which could be guessed by the facts of the scenario. I gave answers which were my best guesses based on both the questions and also the five answer options. Some I could have argued more than one answer was correct. There was no mention of any specific law, the SRA Code of Conduct, the Civil Procedure Rules (CPR) or the Criminal Procedure Rules (CPR) in any of the questions.
I found the MCQ format very patronising and far too easy — it was like a dummies guide to the law! The questions did not test my legal knowledge to the standard that my law degree did. The time allocated for each question was far too long, and because the exam was closed-book and conducted in front of a computer, there was nothing I could do if I did not know the answer. I finished each round with around 40-50 minutes to spare. The whole day was timed so I was unable to leave until the clock ran down.
Day two
Day two consisted of two rounds of one research question and two writing questions. I was given an email from a partner of a firm telling me he was advising a client on their obligations to file accounts; he told me he was working on the technical areas of the advice and asked if I could research the simpler part of whether a small to medium enterprise (SME) had to file accounts. I was given eight pieces of material and had to sift through these to find the correct answer. I did not feel as if this was ‘legal research’ and I was not required to carry out any research myself using legal databases. I liken it to being passed a pile of car magazines and asked to find a red car in them. I was then required to type a memo to the partner.
The next section was writing. I was given another email from a partner telling me he had to advise a client and was handling the technical part, while I was required to write a paragraph to insert into the letter explaining section 36 of the Criminal Justice and Public Order Act 1994. The final writing section consisted of a memo to a partner explaining Part 24 of the CPR. Both of these sources were provided. The next round was the same as above.
This section of the assessment did not test my research or writing ability at all because I could cut and paste (and did) several parts from the material provided. The spell-check facility was disabled so at least that was something. The main issue I found was the noise: 15 people typing at the same time was deafening (even with ear plugs!) I was not required to apply the law or to advise but just explain the area of law in “everyday English”.
Day three
The final day followed the structure of the first day: three rounds of 60 multiple-choice questions which focused on the areas of law outlined above. When speaking with some of the other candidates post-exam it was obvious they had the same set of questions I had on day one and vice versa. The questions were, again, simple but this time they were poorly written and I had to take extra time today (than I did previously) due to the poor grammar and punctuation.
Final thoughts
I do not believe the MCQ format enables candidates to demonstrate knowledge of the law; it is all a matter of common sense. There was no application of the law nor was I given the chance to demonstrate wider knowledge or make an argument one way or the other. I do not feel the questions allowed any of the skills required in future practice to be demonstrated such as problem-solving or the ability to be analytical. What these questions allow for is someone to study the exam but not the law or the skills required to be a lawyer. Overall, I felt the questions were condescending and pandering in their nature. It remains to be seen what SQE2, which will be piloted later this year, holds.
Richard Robinson (pseudonym) is a paralegal.
The post I was among the first to sit the SQE pilot — here’s what I thought appeared first on Legal Cheek.
from All About Law https://www.legalcheek.com/2019/04/i-was-among-the-first-to-sit-the-sqe-pilot-heres-what-i-thought/
0 notes
Text
Actually, this is going to keep bugging me if I don’t add some sources, so: I’d originally come at that post with the mindset of “...you want to corrupt training datasets?????” which is why the numbers come in on point 3 for “here is the maximum impact you could achieve if all other factors were ignored.” But let me briefly flip around to the other side to explain why I feel so confident in saying AO3 wasn’t included in AI training at all.
Real fast, does anyone have sources for why people think AO3 was included in LLM training? The only one I’ve ever seen cited is this news article that’s based off a Reddit post that came to the conclusion that GPT-3 (the LLM behind the program Sudowrite that they were trying out specifically) must have been trained on AO3 data because Sudowrite recognized Omegaverse terms, a trope that they said was specific to fanfic and therefore it followed that AO3 must’ve been scraped deliberately for training data as it’s currently the largest fanfic repository available.
(And I just...no. Just…no. That is wild conjecture. Omegaverse is not exclusive to fandom content and hasn’t been for years. Not only is it present in published books and original stories, it’s also spread across multiple web sources, from fic sites to Reddit to social media to even mfucking Wikipedia. Furthermore, AO3 currently being the largest fanfic repository on the web still does not indicate that it is the source.
Anyways, if anyone has more information on why this is such a big thing please tell me, it’s been driving me nuts lol. Do not tell me ChatGPT tho, because that one’s an even bigger no from me. AO3 did make a statement on data scraping, but it just confirmed AO3 was included in previous Common Crawl scrapes which like…wasn’t news.)
I’m mainly going to reference the paper ‘Language Models are Few-Shot Learners’ (PDF) for this, which breaks down the methodology behind the training data for GPT-3 as it’s the primary LLM in question (OpenAI has not released any information on GPT-4’s training data). However, while these exact numbers and sources are specific to GPT-3, its methodology for data selection, curation, pre-processing, and utilization has been referenced by several other LLM developers.
Now, onto some specifics!
Within the documentation, OpenAI listed their training data sources as:
Common Crawl - 60% (0.44)
WebText2 - 22% (2.9)
Books1 - 8% (1.9)
Books2 - 8% (0.43)
Wikipedia - 3% (3.4)
Of these sources, the only one AO3 could be scooped up in is the Common Crawl. Trying to summarize the methodology in the paper but:
This Common Crawl based dataset was compiled from 41 data shards from 4 years (2016-2019) of the Common Crawl monthly archive data. 4 years of Common Crawl data is roughly a total of 45 TB, which was then filtered down to about 570 GB. As mentioned before, Common Crawl is not saving every page of every website, but rather samples of their scraped websites in their efforts to respect and not violate people’s copyright. They also maintain a statistics page for their monthly archives, including a data chart for the 500 most present domains within a monthly dataset (link). AO3 is not even a part of the top 500 registered domains (blogspot is the highest of these top 500, making up a total 0.6% of all the scraped pages; google.ch is the lowest of these, making up 0.004%). The data shards from these monthly data drops each totaled to just under ~14 GB. So one data shard would be ~0.005% of one of monthly data drop (based off a partial list on Wikipedia, average size of the Common Crawl monthly data archive was ~250ish TiB from 2016-2019).
Note: C4 (aka the Colossal Clean Crawled Corpus, PDF link) is not a part of GPT-3’s training data, but sometimes a portion of it is used in other LLM’s training data. I mistakenly called it a web crawler previously, but it’s actually derived from the April 2019 Common Crawl data drop and of this filtered data, AO3 ranks as the 516th domain and its data totals to ~8.2M tokens (aka ~0.005%) of the full C4 dataset. It’s going to have a lower presence in the full unfiltered Common Crawl, esp anything prior to 2019 if site size makes a difference (ref).
After the data shards were compiled, that data was then filtered by quality (and underwent fuzzy deduplication, but that filtering doesn’t apply to this as much as it was primarily used to remove Reddit pages). To filter this data by quality, they used a classifier to rank the Common Crawl data against their high quality data sources for similarity (highly similarity is desired). The lower quality data wasn’t removed per se, but this priority ranking matters because while the Common Crawl data makes up 60% of their training data, it’s only 0.44 times as likely to be seen during the training process (in comparison to Wikipedia data, which makes up only 3% of the training data but is 3.4 times as likely to be seen). Additionally, there is more training data than what they use to train the AI (ie, they have a total of ~500 billion tokens, but they only train the model on 300 billion of those tokens). Part of the already highly reduced Common Crawl training data still never sees the LLM.
So like. Yes. There is always the possibility that some fic got scooped up into LLMs’ pre-training data.
But it probably wasn’t.
pulling out a section from this post (a very basic breakdown of generative AI) for easier reading;
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
#no one cares but i keep twitching when i see a notif so#*tucks this away for the early hours*#LLMs for dummies#generative ai#*edits to correct a few mistakes. i should not have written this up at 4am on too little sleep 🤣
101 notes
·
View notes
Text
I was among the first to sit the SQE pilot — here’s what I thought
‘The MCQ format was very patronising and far too easy. It was like a dummies guide to the law!’
I was one of a number of people who sat the Solicitors Qualifying Examination (SQE) stage one pilot last month. The candidates ranged from LLB graduates to Legal Practice Course (LPC) graduates but most of the candidates were working in practice. My background is not ‘conventional’ and I took the pilot because I was interested in knowing whether the SQE would cater for people like me. I do not have any GCSEs or A-levels because I left school at the age of 14 to care for my ill mother. I studied for my LLB over six years and then completed a combined LLM-LPC over two years.
The SQE1 pilot was a three-day assessment consisting of 360 multiple-choice questions on the foundations of legal knowledge, namely business law; property law; wills and trusts; criminal law; EU law; public and constitutional law; tort law; contract law; and professional conduct. There were also two research questions and four writing questions. No materials were provided, and the exams were closed-book. Prior to the exam I emailed the Solicitors Regulation Authority (SRA) for revision guidance and was referred to the pilot specification which told me that anything within the above topics would be examined.
Day one
The exam started with three rounds of 60 questions with 110 minutes for each on a mixture of the topics outlined above. The questions were scenario-based (one scenario per question) with five possible answers. Most of the questions were simple but after speaking with some recent LLB graduates it became clear that they did not know many of the answers — especially to the questions on the topics that are exclusively covered on the LPC.
The questions often dropped big hints towards the answers which could be guessed by the facts of the scenario. I gave answers which were my best guesses based on both the questions and also the five answer options. Some I could have argued more than one answer was correct. There was no mention of any specific law, the SRA Code of Conduct, the Civil Procedure Rules (CPR) or the Criminal Procedure Rules (CPR) in any of the questions.
I found the MCQ format very patronising and far too easy — it was like a dummies guide to the law! The questions did not test my legal knowledge to the standard that my law degree did. The time allocated for each question was far too long, and because the exam was closed-book and conducted in front of a computer, there was nothing I could do if I did not know the answer. I finished each round with around 40-50 minutes to spare. The whole day was timed so I was unable to leave until the clock ran down.
Day two
Day two consisted of two rounds of one research question and two writing questions. I was given an email from a partner of a firm telling me he was advising a client on their obligations to file accounts; he told me he was working on the technical areas of the advice and asked if I could research the simpler part of whether a small to medium enterprise (SME) had to file accounts. I was given eight pieces of material and had to sift through these to find the correct answer. I did not feel as if this was ‘legal research’ and I was not required to carry out any research myself using legal databases. I liken it to being passed a pile of car magazines and asked to find a red car in them. I was then required to type a memo to the partner.
The next section was writing. I was given another email from a partner telling me he had to advise a client and was handling the technical part, while I was required to write a paragraph to insert into the letter explaining section 36 of the Criminal Justice and Public Order Act 1994. The final writing section consisted of a memo to a partner explaining Part 24 of the CPR. Both of these sources were provided. The next round was the same as above.
This section of the assessment did not test my research or writing ability at all because I could cut and paste (and did) several parts from the material provided. The spell-check facility was disabled so at least that was something. The main issue I found was the noise: 15 people typing at the same time was deafening (even with ear plugs!) I was not required to apply the law or to advise but just explain the area of law in “everyday English”.
Day three
The final day followed the structure of the first day: three rounds of 60 multiple-choice questions which focused on the areas of law outlined above. When speaking with some of the other candidates post-exam it was obvious they had the same set of questions I had on day one and vice versa. The questions were, again, simple but this time they were poorly written and I had to take extra time today (than I did previously) due to the poor grammar and punctuation.
Final thoughts
I do not believe the MCQ format enables candidates to demonstrate knowledge of the law; it is all a matter of common sense. There was no application of the law nor was I given the chance to demonstrate wider knowledge or make an argument one way or the other. I do not feel the questions allowed any of the skills required in future practice to be demonstrated such as problem-solving or the ability to be analytical. What these questions allow for is someone to study the exam but not the law or the skills required to be a lawyer. Overall, I felt the questions were condescending and pandering in their nature. It remains to be seen what SQE2, which will be piloted later this year, holds.
Richard Robinson (pseudonym) is a paralegal.
The post I was among the first to sit the SQE pilot — here’s what I thought appeared first on Legal Cheek.
from Legal News And Updates https://www.legalcheek.com/2019/04/i-was-among-the-first-to-sit-the-sqe-pilot-heres-what-i-thought/
0 notes
Text
I was among the first to sit the SQE pilot — here’s what I thought
‘The MCQ format was very patronising and far too easy. It was like a dummies guide to the law!’
I was one of a number of people who sat the Solicitors Qualifying Examination (SQE) stage one pilot last month. The candidates ranged from LLB graduates to Legal Practice Course (LPC) graduates but most of the candidates were working in practice. My background is not ‘conventional’ and I took the pilot because I was interested in knowing whether the SQE would cater for people like me. I do not have any GCSEs or A-levels because I left school at the age of 14 to care for my ill mother. I studied for my LLB over six years and then completed a combined LLM-LPC over two years.
The SQE1 pilot was a three-day assessment consisting of 360 multiple-choice questions on the foundations of legal knowledge, namely business law; property law; wills and trusts; criminal law; EU law; public and constitutional law; tort law; contract law; and professional conduct. There were also two research questions and four writing questions. No materials were provided, and the exams were closed-book. Prior to the exam I emailed the Solicitors Regulation Authority (SRA) for revision guidance and was referred to the pilot specification which told me that anything within the above topics would be examined.
Day one
The exam started with three rounds of 60 questions with 110 minutes for each on a mixture of the topics outlined above. The questions were scenario-based (one scenario per question) with five possible answers. Most of the questions were simple but after speaking with some recent LLB graduates it became clear that they did not know many of the answers — especially to the questions on the topics that are exclusively covered on the LPC.
The questions often dropped big hints towards the answers which could be guessed by the facts of the scenario. I gave answers which were my best guesses based on both the questions and also the five answer options. Some I could have argued more than one answer was correct. There was no mention of any specific law, the SRA Code of Conduct, the Civil Procedure Rules (CPR) or the Criminal Procedure Rules (CPR) in any of the questions.
I found the MCQ format very patronising and far too easy — it was like a dummies guide to the law! The questions did not test my legal knowledge to the standard that my law degree did. The time allocated for each question was far too long, and because the exam was closed-book and conducted in front of a computer, there was nothing I could do if I did not know the answer. I finished each round with around 40-50 minutes to spare. The whole day was timed so I was unable to leave until the clock ran down.
Day two
Day two consisted of two rounds of one research question and two writing questions. I was given an email from a partner of a firm telling me he was advising a client on their obligations to file accounts; he told me he was working on the technical areas of the advice and asked if I could research the simpler part of whether a small to medium enterprise (SME) had to file accounts. I was given eight pieces of material and had to sift through these to find the correct answer. I did not feel as if this was ‘legal research’ and I was not required to carry out any research myself using legal databases. I liken it to being passed a pile of car magazines and asked to find a red car in them. I was then required to type a memo to the partner.
The next section was writing. I was given another email from a partner telling me he had to advise a client and was handling the technical part, while I was required to write a paragraph to insert into the letter explaining section 36 of the Criminal Justice and Public Order Act 1994. The final writing section consisted of a memo to a partner explaining Part 24 of the CPR. Both of these sources were provided. The next round was the same as above.
This section of the assessment did not test my research or writing ability at all because I could cut and paste (and did) several parts from the material provided. The spell-check facility was disabled so at least that was something. The main issue I found was the noise: 15 people typing at the same time was deafening (even with ear plugs!) I was not required to apply the law or to advise but just explain the area of law in “everyday English”.
Day three
The final day followed the structure of the first day: three rounds of 60 multiple-choice questions which focused on the areas of law outlined above. When speaking with some of the other candidates post-exam it was obvious they had the same set of questions I had on day one and vice versa. The questions were, again, simple but this time they were poorly written and I had to take extra time today (than I did previously) due to the poor grammar and punctuation.
Final thoughts
I do not believe the MCQ format enables candidates to demonstrate knowledge of the law; it is all a matter of common sense. There was no application of the law nor was I given the chance to demonstrate wider knowledge or make an argument one way or the other. I do not feel the questions allowed any of the skills required in future practice to be demonstrated such as problem-solving or the ability to be analytical. What these questions allow for is someone to study the exam but not the law or the skills required to be a lawyer. Overall, I felt the questions were condescending and pandering in their nature. It remains to be seen what SQE2, which will be piloted later this year, holds.
Richard Robinson (pseudonym) is a paralegal.
The post I was among the first to sit the SQE pilot — here’s what I thought appeared first on Legal Cheek.
from Legal News https://www.legalcheek.com/2019/04/i-was-among-the-first-to-sit-the-sqe-pilot-heres-what-i-thought/
0 notes
Text
Why SEBI is Failing at Regulating Insider Trading in India
[Bhavya Bhandari is currently pursuing an LLM. in Corporation Law at NYU School of Law. She can be reached at [email protected].
The Indian securities market regulator has been criticized in the last two decades for its failure to investigate and prosecute perpetrators of insider trading. Even when the perpetrators are caught and punished, the penalty is often so low that the regulations have lost any deterrent effect they might possess. This post highlights some of the reasons behind the low rates of investigation and prosecution of insider trading offences in India]
The SEBI (Prohibition of Insider Trading) Regulations, 2015 (like the erstwhile 1992 versions of the regulations) intends to regulate the rights of insiders to trade in the stocks of their company, not to banish them completely from holding and selling any stocks in their companies. This seems logical – barring them would be too harsh, and will also promote devious practices at the expense of outside shareholders. Whether this approach has worked is questionable however; insider trading continues to be rampant in India, much to the chagrin of Indian and foreign investors.
The Securities and Exchange Board of India (SEBI)e has investigated a number of insider trading cases in the last two decades, but has achieved a low rate of successful convictions. The process of investigation is also often too slow. The table below sets out the number of insider trading investigations SEBI initiated and completed between 2010-15:
Year Investigations taken up Investigations completed 2010-11 28 15 2011-12 24 21 2012-13 11 14 2013-14 13 13 2014-15 10 15
Recently, a new scandal emerged to the limelight: Reuters reported that WhatsApp group chats had been used to circulate (surprisingly accurate) unpublished price sensitive information (UPSI) relating to the quarterly numbers of at least 12 companies, just a few days before the public announcements of the numbers. These leaks pertained to the financials of big companies – such as Dr. Reddy’s Laboratories Ltd., a pharma company with a large market cap. SEBI is now investigating the matter, but this has led to renewed criticism about the regulator’s laxity in investigating and prosecuting insider trading matters in the last two and a half decades. Reportedly, SEBI has used its search and seizure operations (which it seldom does) at around 34 locations in its efforts to investigate the WhatsApp leak.
So, what are the solutions? Should the law be amended to prohibit an insider from trading in the stocks of a company altogether? Or do the problems lie not with the regulations, but their implementation? Has SEBI been too soft in investigating and prosecuting insider trading offences, thus causing companies to take the regulations too lightly? Or does it lack the necessary powers and tools to catch the offenders?
SEBI’s low rates of successful investigation and conviction of insider trading cases could be due to a combination of these factors:
SEBI was only recently granted the power to call for phone records of suspects under investigation:
Insider trading is tough to detect and punish in any jurisdiction as it is, but the fact that SEBI has not been empowered with some basic investigative powers and tools is a major reason behind the low prosecution of insider trading cases even while it is widely acknowledged that insider trading is ‘deeply rooted’ in the Indian stock markets. SEBI even lacked the basic power to call for phone records until recently. A huge Ponzi scam (Saradha scam) in 2013 resulted in the Indian government urgently passing the Securities Laws (Amendment) Second Ordinance, 2013 permitting SEBI to call for the phone records of persons under investigation.[1] The Ordinance was formally adopted by the Parliament through the Securities Laws (Amendment) Act, 2014 (with retrospective effect from the date of the Ordinance) in 2014.
Up until the Ordinance in 2013, call records could not be obtained by SEBI under any circumstances. It is unfortunate that the Government waited until a huge scandal like Saradha, where around USD 6 billion was illegally mobilized from investors, to take this step. Without having had the ability to call for the phone records of suspects until recently, the regulator may have had its hands tied at the time of investigation in collection of evidence. The only way SEBI could go after suspected offenders then was by analyzing their trade patterns on the stock market, but many offenders found a way out of this by trading in the name of dummy companies. Many of them continue to trade in the accounts of their relatives and friends as well. The new power of SEBI to call for phone records was challenged (on the grounds of violation of right to privacy) before the Bombay High Court in 2014, but the Court ruled that SEBI has the power to call for phone records under the SEBI Act, so long as it is called as a part of a genuine investigation and not a ‘fishing’ enquiry. Hopefully, SEBI will now utilize this newly granted power to the fullest.
SEBI lacks the power to wiretap phone calls:
SEBI does not have the power to wiretap phone calls, a crucial tool used by other jurisdictions such as U.S. in obtaining evidence against insider trading suspects for the purposes of investigation and successful conviction. This power was denied to SEBI on the grounds of ‘misuse’. Currently, the Indian Telegraph Act, 1885, governs wiretapping. On the other hand, the U.S. Securities and Exchange Commission (SEC) unearthed crucial evidence by wiretapping the conversations between Raj Rajaratnam and Rajat Gupta, which ultimately led to their conviction.
SEBI has not utilized its existing powers and penal provisions to their fullest capacity:
In some ways SEBI has more powers than the SEC, but it has failed to utilize it to the fullest. While it is fair that SEBI has demanded additional powers from the Government to conduct searches and seizures, obtain call records, wiretap suspects, etc., a look at the existing cases reveal that SEBI has failed to utilize its existing powers to the fullest. Take for instance, SEBI’s powers to levy a penalty. As discussed, SEBI has the power under section 15G of the SEBI Act to impose a penalty of up to INR 25,00,00,000 (approximately USD 3,905,000) or three times the amount of profits made, whichever is higher. However, the maximum penalty SEBI has ever imposed is only INR 60,00,000 (approximately USD 94,000). There is no reasonable explanation for this. Also, SEBI has the power to petition before a criminal court and institute criminal proceedings against a person. If convicted, the person can be imprisoned for a period of up to 10 years. However, no one has ever been sent to prison for insider trading, even in the fairly big cases.
SEBI does not have the human resources to conduct a thorough investigation:
It has been a long-held belief that SEBI with its 780 odd employees has too much on its plate to handle. That is one employee for every six companies listed on the Indian exchange, while the SEC has fifteen times the number of employees (and one for every company listed on an American exchange). That, coupled with the fact that insider-trading cases are tougher to investigate, and its offenders harder to convict, especially without technologies such as wiretapping to aid, may have caused SEBI to prioritize other investigations over insider trading investigations. SEBI has recently stated that it will hire more staff to address these issues.
In conclusion, it appears that while SEBI does not have some powers (or only received them recently) that are vital to investigate insider-trading violations, SEBI has also failed to utilize all of its powers. In addition, the Government must consider granting wiretapping powers to SEBI. SEBI must also utilize the powers it has received recently, such as its power to review any phone records, and its widened search and seizure powers, etc. to improve its rate of investigation and successful conviction.
– Bhavya Bhandari
[1] SEBI Act, Sec. 11(2)(ia).
The post Why SEBI is Failing at Regulating Insider Trading in India appeared first on IndiaCorpLaw.
Why SEBI is Failing at Regulating Insider Trading in India published first on https://divorcelawyermumbai.tumblr.com/
0 notes
Text
I’m always tempted to post the AO3 & generative AI part of my LLMs for dummies post separate as it’s own thing every time I see someone say AO3 gets scraped for training data o(-(
#you people are very very VERY bad at research#‘x PROVES this was trained on fic!!!’ no. no it fucking doesn’t. you’re so off you don’t even have a corkboard and red string.#sighs
0 notes
Text
AO3 and Generative AI
There are unfortunately some massive misunderstandings in regards to AO3 being included in LLM training datasets. This post was semi-prompted by the ‘Knot in my name’ AO3 tag (for those of you who haven’t heard of it, it’s supposed to be a fandom anti-AI event where AO3 writers help “further pollute” AI with Omegaverse), so let’s take a moment to address AO3 in conjunction with AI. We’ll start with the biggest misconception:
1. AO3 wasn’t used to train generative AI.
Or at least not anymore than any other internet website. AO3 was not deliberately scraped to be used as LLM training data.
The AO3 moderators found traces of the Common Crawl web worm in their servers. The Common Crawl is an open data repository of raw web page data, metadata extracts and text extracts collected from 10+ years of web crawling. Its collective data is measured in petabytes. (As a note, it also only features samples of the available pages on a given domain in its datasets, because its data is freely released under fair use and this is part of how they navigate copyright.) LLM developers use it and similar web crawls like Google’s C4 to bulk up the overall amount of pre-training data.
AO3 is big to an individual user, but it’s actually a small website when it comes to the amount of data used to pre-train LLMs. It’s also just a bad candidate for training data. As a comparison example, Wikipedia is often used as high quality training data because it’s a knowledge corpus and its moderators put a lot of work into maintaining a consistent quality across its web pages. AO3 is just a repository for all fanfic -- it doesn’t have any of that quality maintenance nor any knowledge density. Just in terms of practicality, even if people could get around the copyright issues, the sheer amount of work that would go into curating and labeling AO3’s data (or even a part of it) to make it useful for the fine-tuning stages most likely outstrips any potential usage.
Speaking of copyright, AO3 is a terrible candidate for training data just based on that. Even if people (incorrectly) think fanfic doesn’t hold copyright, there are plenty of books and texts that are public domain that can be found in online libraries that make for much better training data (or rather, there is a higher consistency in quality for them that would make them more appealing than fic for people specifically targeting written story data). And for any scrapers who don’t care about legalities or copyright, they’re going to target published works instead. Meta is in fact currently getting sued for including published books from a shadow library in its training data (note, this case is not in regards to any copyrighted material that might’ve been caught in the Common Crawl data, its regarding a book repository of published books that was scraped specifically to bring in some higher quality data for the first training stage). In a similar case, there’s an anonymous group suing Microsoft, GitHub, and OpenAI for training their LLMs on open source code.
Getting back to my point, AO3 is just not desirable training data. It’s not big enough to be worth scraping for pre-training data, it’s not curated enough to be considered for high quality data, and its data comes with copyright issues to boot. If LLM creators are saying there was no active pursuit in using AO3 to train generative AI, then there was (99% likelihood) no active pursuit in using AO3 to train generative AI.
AO3 has some preventative measures against being included in future Common Crawl datasets, which may or may not work, but there’s no way to remove any previously scraped data from that data corpus. And as a note for anyone locking their AO3 fics: that might potentially help against future AO3 scrapes, but it is rather moot if you post the same fic in full to other platforms like ffn, twitter, tumblr, etc. that have zero preventative measures against data scraping.
2. A/B/O is not polluting generative AI
…I’m going to be real, I have no idea what people expected to prove by asking AI to write Omegaverse fic. At the very least, people know A/B/O fics are not exclusive to AO3, right? The genre isn’t even exclusive to fandom -- it started in fandom, sure, but it expanded to general erotica years ago. It’s all over social media. It has multiple Wikipedia pages.
More to the point though, omegaverse would only be “polluting” AI if LLMs were spewing omegaverse concepts unprompted or like…associated knots with dicks more than rope or something. But people asking AI to write omegaverse and AI then writing omegaverse for them is just AI giving people exactly what they asked for. And…I hate to point this out, but LLMs writing for a niche the LLM trainers didn’t deliberately train the LLMs on is generally considered to be a good thing to the people who develop LLMs. The capability to fill niches developers didn’t even know existed increases LLMs’ marketability. If I were a betting man, what fandom probably saw as a GOTCHA moment, AI people probably saw as a good sign of LLMs’ future potential.
3. Individuals cannot affect LLM training datasets.
So back to the fandom event, with the stated goal of sabotaging AI scrapers via omegaverse fic.
…It’s not going to do anything.
Let’s add some numbers to this to help put things into perspective:
LLaMA’s 65 billion parameter model was trained on 1.4 trillion tokens. Of that 1.4 trillion tokens, about 67% of the training data was from the Common Crawl (roughly ~3 terabytes of data).
3 terabytes is 3,000,000,000 kilobytes.
That’s 3 billion kilobytes.
According to a news article I saw, there has been ~450k words total published for this campaign (*this was while it was going on, that number has probably changed, but you’re about to see why that still doesn’t matter). So, roughly speaking, ~450k of text is ~1012 KB (I’m going off the document size of a plain text doc for a fic whose word count is ~440k).
So 1,012 out of 3,000,000,000.
Aka 0.000034%.
And that 0.000034% of 3 billion kilobytes is only 2/3s of the data for the first stage of training.
And not to beat a dead horse, but 0.000034% is still grossly overestimating the potential impact of posting A/B/O fic. Remember, only parts of AO3 would get scraped for Common Crawl datasets. Which are also huge! The October 2022 Common Crawl dataset is 380 tebibytes. The April 2021 dataset is 320 tebibytes. The 3 terabytes of Common Crawl data used to train LLaMA was randomly selected data that totaled to less than 1% of one full dataset. Not to mention, LLaMA’s training dataset is currently on the (much) larger size as compared to most LLM training datasets.
I also feel the need to point out again that AO3 is trying to prevent any Common Crawl scraping in the future, which would include protection for these new stories (several of which are also locked!).
Omegaverse just isn’t going to do anything to AI. Individual fics are going to do even less. Even if all of AO3 suddenly became omegaverse, it’s just not prominent enough to influence anything in regards to LLMs. You cannot affect training datasets in any meaningful way doing this. And while this might seem really disappointing, this is actually a good thing.
Remember that anything an individual can do to LLMs, the person you hate most can do the same. If it were possible for fandom to corrupt AI with omegaverse, fascists, bigots, and just straight up internet trolls could pollute it with hate speech and worse. AI already carries a lot of biases even while developers are actively trying to flatten that out, it’s good that organized groups can’t corrupt that deliberately.
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be informative and a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown: 1. Explaining tokens 2. Large Language Models 3. LLM Interfaces 4. AO3 and Generative AI [here] 5. Fic and ChatGPT [here] 6. Some Closing Notes [here] [post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
85 notes
·
View notes