#JobSize
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Link
#Aufgabenpriorisieren#BusinessValue#Controllinginstrument#CostofDelay#CustomerValue#Entwicklungskosten#ExcelDatei#ExcelVorlage#Excel-Tool#InternerAufwand#JobSize#KomplexitätderImplementierung#OpportunityEnablementValue#Projektpriorisierung#RiskReduction#UserValue#WeightedShortestJobFirst#WertDegression#WSJF
0 notes
Text
Norwex Kitchen Cloth - Sea Mist (Green)
Norwex Kitchen Cloth – Sea Mist (Green)
Price: (as of – Details) Norwex Kitchen Cloth – Sea Mist (Green) Made of extra-absorbent Norwex MicrofiberMade tough to handle any jobSize: 35cm x 26cm / 13.78″ x 10.24″

View On WordPress
0 notes
Text
How to get started with Neptune ML
Amazon Neptune ML is an easy, fast, and accurate approach for predictions on graphs. In this post, we show you how you can easily set up Neptune ML and infer properties of vertices within a graph. For our use case, we have a movie streaming application and we want to infer the the top genres for a movie using a process known as node classification. To illustrate this node classification use case with Neptune ML, we use the MovieLens 100K Dataset** as an example property graph. The MovieLens dataset contains users, movies, genres, and ratings as vertices, and user-to-rating, rating-to-movie, and movie-to-genre as edges. You can try out other capabilities of Neptune ML using samples provided with Neptune. The workflow contains six steps: Set up the test environment. Launch the node classification notebook sample. Load the sample data into the cluster. Export the graph. Perform ML training. Run Gremlin queries with Neptune ML. Setting up the test environment The easiest way to try out Neptune ML is to use the AWS CloudFormation template provided in this post. The CloudFormation template sets up a new Neptune cluster; sample Neptune ML notebooks illustrating link prediction, node classification, and node regression; and an export service for exporting data to Amazon SageMaker. Run the following command (provide the stack name and deployment Region): aws cloudformation create-stack --stack-name --template-url https://s3.amazonaws.com/aws-neptune-customer-samples/v4/cloudformation-templates/neptune-ml-nested-stack.json --parameters ParameterKey=EnableIAMAuthOnExportAPI,ParameterValue=false ParameterKey=Env,ParameterValue=test0941 --capabilities CAPABILITY_IAM --region --disable-rollback When the stack creation is complete, navigate to the Outputs tab for the NeptuneBaseStack stack on the AWS CloudFormation console. Record the following parameter values: DBClusterEndpoint – Your Neptune cluster endpoint NeptuneLoadFromS3IAMRoleArn – The ARN used for bulk loading data into Neptune Navigate to the Outputs tab for the NeptuneMLCoreStack stack Record the following values: NeptuneExportApiUri – The URL for the Neptune export service NeptuneMLIAMRoleArn – The ARN for running the model training APIs Create an Amazon Simple Storage Service (Amazon S3) bucket where you store the output and training models for the different use cases. When the AWS CloudFormation setup is complete, you can confirm that the neptune_lab_mode parameter for the cluster parameter group associated with your cluster contains NeptuneML=enabled. Launching the node classification sample On the Neptune console, launch the notebook associated with the cluster you created. Open the Neptune folder and you should see a folder for Machine Learning. From the list, launch the node classification notebook for Gremlin. You can try out other samples as you explore Neptune ML capabilities. Loading sample data into the cluster Using the node classification notebook, let’s load sample data into the cluster. We use the MovieLens dataset. The script in the notebook formats and stores the MovieLens data into an S3 bucket for use with the Neptune bulk loader. Run the %load magic command to load data into Neptune. For Source, enter the bucket name with our dataset. For Load ARN, enter the value for NeptuneLoadFromS3IAMRoleArn. The loading time takes less than 5 minutes to complete. When the data is loaded into Neptune, you see a success message. Running Gremlin queries to verify the data You can run Gremlin queries to understand the vertices and edges in the data. Run the two groupCount() steps on the vertices and edges. The following screenshots show that the data contains user, movie, genre and ratings as vertices, and wrote, rated, about, and included_in as edges. You can also visualize the relationships between a user and movies using the following query: %%gremlin -p v,oute,inv g.V('user_1').outE('rated').inV().path().limit(25) The following screenshot shows the graph: You can drop the genre property from few movie vertices so you can infer the genres for those movies. The steps in the notebook outline how you can drop the properties for a given movie. %%gremlin g.V().has('movie', 'title', within('Toy Story (1995)', 'Twelve Monkeys (1995)', 'Mr. Holland's Opus (1995)')). properties('genre').drop() In the following steps, we export the graph, train the ML model, and run inference queries from Neptune. Exporting the graph For node classification, use the following command to set the parameters for export URI, S3 bucket URL, and Neptune IAM Role details from earlier: import neptune_ml_utils as neptune_ml EXPORT_URL='' S3_URI="" NEPTUNE_ML_IAM_ROLE_ARN="" The export service lets you export the content of the graph into Amazon S3 quickly. We have provided a Python utility neptune_ml_utils to run ML commands from the Neptune notebook. This uses ML model APIs provided by Neptune, which take care of setting up SageMaker instances and creating data processing jobs. The export command accepts a JSON configuration to select graph data for export. EXPORT_PARAMS={ "command": "export-pg", "params": { "endpoint": neptune_ml.get_host(), "profile": "neptune_ml", "cloneCluster": False }, "outputS3Path": f'{S3_URI}/neptune-export', "additionalParams": { "neptune_ml": { "targets": [ { "node": "movie", "property": "genre" } ], "features": [ { "node": "movie", "property": "title", "type": "word2vec", "language": "en_core_web_lg" }, { "node": "user", "property": "age", "type": "bucket_numerical", "range" : [1, 100], "num_buckets": 10, "slide_window_size": 10 } ] } }, "jobSize": "medium"} export_file_location = neptune_ml.run_export(EXPORT_URL, EXPORT_PARAMS) print(f'Export File Location: {export_file_location}') Exporting the sample data takes about 5 minutes to complete. You can now verify that the files are available in the S3 bucket. Performing ML training ML training lets you build an ML model and create an inference endpoint for queries. The process includes three steps: Perform feature preprocessing on the graph data for GNNs. This step can normalize properties for numeric or text data. Build a model selection strategy and run a tuning job to select the best model for the data. Create an endpoint for querying predictions by deploying the ML model in SageMaker. You can choose to run each of these steps separately on the graph dataset using REST APIs. The easier option is to use the neptune_ml_utils utility in the notebook to run all three in a single command after setting the PROCESSING_PARAMS, TRAINING_PARAMS, and ENDPOINT_PARAMS. See the following code: neptune_ml.train_model(export_file_location, TRAINING_JOB_NAME, PROCESSING_PARAMS, TRAINING_PARAMS, ENDPOINT_PARAMS) The ML training duration depends on the data size. The sample can take about 30-45 minutes to complete. When the training job is complete, record the endpoint name for the next step. Running Gremlin queries with Neptune ML You can now run Neptune ML node classification tasks using Gremlin queries. We have added extensions to the Gremlin query syntax to query ML reference endpoints and passing parameters. Let’s see how we can query our graph to infer what genre is the top for the movie Toy Story . To use the inference endpoint within a Gremlin query, we need to specify the endpoint in the with step using Neptune#ml.endpoint. Next, to infer the value of a property, we use the Gremlin properties() step with a with() step like this with the properties(��genre”).with(“Neptune#ml.classification”) to infer the genre property. Additional options exist to allow you to limit the number of predicted results as well as set the threshold value for those results. For a description of all the available predicates, see documentation. The following query with the Neptune ML query extensions predicts the genre of a given movie: %%gremlin g.with("Neptune#ml.endpoint"," ") .with("Neptune#ml.iamRoleArn",""). V().has('title', 'Toy Story (1995)').properties("genre").with("Neptune#ml.classification").value() This query pattern can be used to find the predicted genre for any movie in the database. You can also run the query for other user nodes. The following screenshot shows the output for user_4. Cleaning Up Now that you have completed this walkthrough you have created an inference endpoint which is currently running and will incur the standard charges. If you are done trying out Neptune ML and would like to avoid these recurring costs, run the command to delete the inference endpoint neptune_ml.delete_endpoint(TRAINING_JOB_NAME, NEPTUNE_ML_IAM_ROLE_ARN) You can also delete the root CloudFormation stack you created earlier. This removes all resources used by this example. Summary In this post, we illustrated a simple node classification use case with NeptuneML. To learn more about this feature, see Neptune ML documentation. We encourage you to use these steps to try out the link prediction, node classification, or node property regression use cases. We have provided notebook samples for each. If you have questions or feedback, please connect with via comments to this post or the Amazon Neptune Discussion Forums. **F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872 About the Authors George Karypis is a Senior Principal Scientist, AWS Deep Learning. He leads a research group that is developing graph neural network-based models for learning on graphs tasks with applications to knowledge graphs, recommender systems, fraud & abuse, and life sciences. Karthik Bharathy is the product leader for Amazon Neptune with over a decade of product management, product strategy, execution and launch experience. Dave Bechberger is a Sr. Graph Architect with the Amazon Neptune team. He used his years of experience working with customers to build graph database-backed applications as inspiration to co-author “Graph Databases in Action” by Manning. https://aws.amazon.com/blogs/database/how-to-get-started-with-neptune-ml/
0 notes
Photo
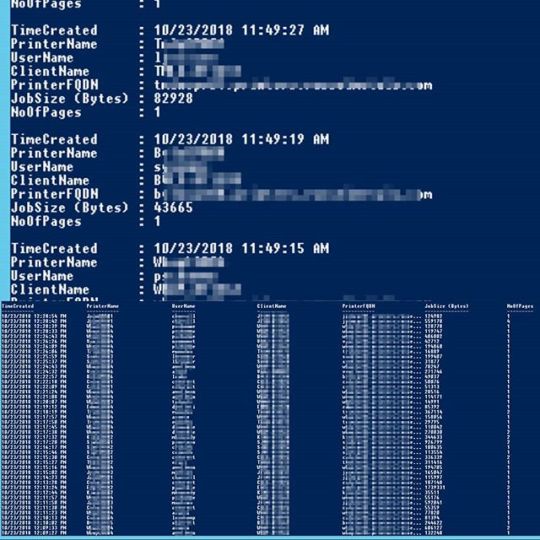
Get-PrinteJobsHistory⠀ Retrieves Print Jobs history from Windows Print Server using Powershell⠀ ⠀ This script will give you following details about print jobs:⠀ ---------------------------⠀ TimeCreate (Time of the print jobs)⠀ PrinterName (Name of the printer)⠀ UserName (User who sent the print job)⠀ ClientName (User's computer name)⠀ PrinterFQDN (Fully qualified domain name of the printer)⠀ JobSize (Bytes) (Size of the print job)⠀ NoOfPages (Number of pages printed)⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ #powershell #windows #microsoft #scripting #automation #windowsserver #server2016 #server2012 #Windows10 #windows7 #printserver #windowsprintserver #printing #printer #print https://ift.tt/2q8xpMn
0 notes
Photo
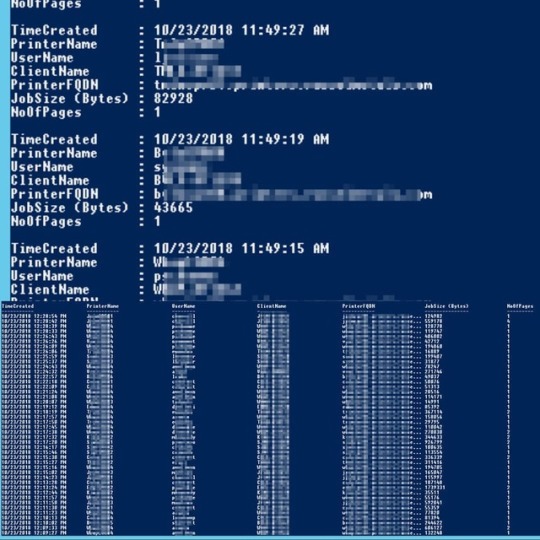
Get-PrinteJobsHistory⠀ Retrieves Print Jobs history from Windows Print Server using Powershell⠀ ⠀ This script will give you following details about print jobs:⠀ ---------------------------⠀ TimeCreate (Time of the print jobs)⠀ PrinterName (Name of the printer)⠀ UserName (User who sent the print job)⠀ ClientName (User's computer name)⠀ PrinterFQDN (Fully qualified domain name of the printer)⠀ JobSize (Bytes) (Size of the print job)⠀ NoOfPages (Number of pages printed)⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ .⠀ #powershell #windows #microsoft #scripting #automation #windowsserver #server2016 #server2012 #Windows10 #windows7 #printserver #windowsprintserver #printing #printer #print (at Mississauga, Ontario) https://www.instagram.com/p/BpSKpryBl5-/?utm_source=ig_tumblr_share&igshid=1f4wiy22hezi2
#powershell#windows#microsoft#scripting#automation#windowsserver#server2016#server2012#windows10#windows7#printserver#windowsprintserver#printing#printer#print
0 notes