#Extract Food Data From Google Maps
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Why Businesses Need Reliable Web Scraping Tools for Lead Generation.
The Importance of Data Extraction in Business Growth
Efficient data scraping tools are essential for companies looking to expand their customer base and enhance their marketing efforts. Web scraping enables businesses to extract valuable information from various online sources, such as search engine results, company websites, and online directories. This data fuels lead generation, helping organizations find potential clients and gain a competitive edge.
Not all web scraping tools provide the accuracy and efficiency required for high-quality data collection. Choosing the right solution ensures businesses receive up-to-date contact details, minimizing errors and wasted efforts. One notable option is Autoscrape, a widely used scraper tool that simplifies data mining for businesses across multiple industries.

Why Choose Autoscrape for Web Scraping?
Autoscrape is a powerful data mining tool that allows businesses to extract emails, phone numbers, addresses, and company details from various online sources. With its automation capabilities and easy-to-use interface, it streamlines lead generation and helps businesses efficiently gather industry-specific data.
The platform supports SERP scraping, enabling users to collect information from search engines like Google, Yahoo, and Bing. This feature is particularly useful for businesses seeking company emails, websites, and phone numbers. Additionally, Google Maps scraping functionality helps businesses extract local business addresses, making it easier to target prospects by geographic location.
How Autoscrape Compares to Other Web Scraping Tools
Many web scraping tools claim to offer extensive data extraction capabilities, but Autoscrape stands out due to its robust features:
Comprehensive Data Extraction: Unlike many free web scrapers, Autoscrape delivers structured and accurate data from a variety of online sources, ensuring businesses obtain quality information.
Automated Lead Generation: Businesses can set up automated scraping processes to collect leads without manual input, saving time and effort.
Integration with External Tools: Autoscrape provides seamless integration with CRM platforms, marketing software, and analytics tools via API and webhooks, simplifying data transfer.
Customizable Lead Lists: Businesses receive sales lead lists tailored to their industry, each containing 1,000 targeted entries. This feature covers sectors like agriculture, construction, food, technology, and tourism.
User-Friendly Data Export: Extracted data is available in CSV format, allowing easy sorting and filtering by industry, location, or contact type.
Who Can Benefit from Autoscrape?
Various industries rely on web scraping tools for data mining and lead generation services. Autoscrape caters to businesses needing precise, real-time data for marketing campaigns, sales prospecting, and market analysis. Companies in the following sectors find Autoscrape particularly beneficial:
Marketing Agencies: Extract and organize business contacts for targeted advertising campaigns.
Real Estate Firms: Collect property listings, real estate agencies, and investor contact details.
E-commerce Businesses: Identify potential suppliers, manufacturers, and distributors.
Recruitment Agencies: Gather data on potential job candidates and hiring companies.
Financial Services: Analyze market trends, competitors, and investment opportunities.
How Autoscrape Supports Business Expansion
Businesses that rely on lead generation services need accurate, structured, and up-to-date data to make informed decisions. Autoscrape enhances business operations by:
Improving Customer Outreach: With access to verified emails, phone numbers, and business addresses, companies can streamline their cold outreach strategies.
Enhancing Market Research: Collecting relevant data from SERPs, online directories, and Google Maps helps businesses understand market trends and competitors.
Increasing Efficiency: Automating data scraping processes reduces manual work and ensures consistent data collection without errors.
Optimizing Sales Funnel: By integrating scraped data with CRM systems, businesses can manage and nurture leads more effectively.

Testing Autoscrape: Free Trial and Accessibility
For businesses unsure about committing to a web scraper tool, Autoscrapeoffers a free account that provides up to 100 scrape results. This allows users to evaluate the platform's capabilities before making a purchase decision.
Whether a business requires SERP scraping, Google Maps data extraction, or automated lead generation, Autoscrape delivers a reliable and efficient solution that meets the needs of various industries. Choosing the right data scraping tool is crucial for businesses aiming to scale operations and enhance their customer acquisition strategies.
Investing in a well-designed web scraping solution like Autoscrape ensures businesses can extract valuable information quickly and accurately, leading to more effective marketing and sales efforts.
0 notes
Text
How to Extract GrabFood Delivery Websites Data for Manila Location?
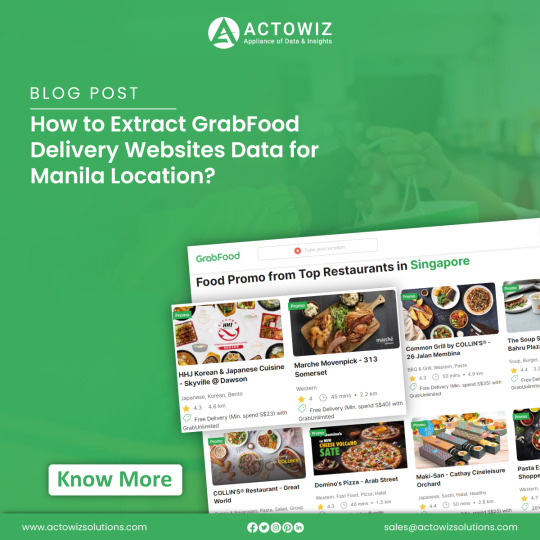
Introduction
In today's digital era, the internet abounds with culinary offerings, including GrabFood, a prominent food delivery service featuring diverse dining options across cities. This blog delves into web scraping methods to extract data from GrabFood's website, concentrating on Manila's restaurants. We uncover valuable insights into Grab Food's extensive offerings through web scraping, contributing to food delivery data collection and enhancing food delivery data scraping services.
Web Scraping GrabFood Website
Embarking on our exploration of GrabFood's website entails using automation through Selenium for web scraping Grab Food delivery website. By navigating to the site (https://food.grab.com/sg/en/), our focus shifts to setting the search location to Manila. Through this process, we aim to unveil the array of restaurants available near Manila and retrieve their latitude and longitude coordinates. Notably, we accomplish this task without reliance on external mapping libraries such as Geopy or Google Maps, showcasing the power of Grab Food delivery data collection.
This endeavor contributes to the broader landscape of food delivery data collection, aligning with the growing demand for comprehensive insights into culinary offerings. By employing Grab Food delivery websites scraping, we enhance the efficiency and accuracy of data extraction processes. This underscores the significance of web scraping in facilitating food delivery data scraping services, catering to the evolving needs of consumers and businesses alike in the digital age.
Furthermore, the use of automation with Selenium underscores the adaptability of web scraping Grab Food delivery website to various platforms and websites. This versatility positions web scraping as a valuable tool for extracting actionable insights from diverse sources, including GrabFood's extensive repository of culinary information. As we delve deeper into web scraping, its potential to revolutionize data collection and analysis in the food delivery industry becomes increasingly apparent.
Scraping Restaurant Data
Continuing our data extraction journey, we focus on scraping all restaurants in Manila from GrabFood's website. This task involves automating the "load more" feature to systematically reveal additional restaurant listings until the complete dataset is obtained. Through this iterative process, we ensure comprehensive coverage of Manila's diverse culinary landscape, capturing a wide array of dining options available on GrabFood's platform.
By leveraging a Grab Food delivery websites scraper tailored to GrabFood's website, we enhance the efficiency and accuracy of data collection. This systematic approach enables us to extract valuable insights into Manila's culinary offerings, contributing to the broader landscape of food delivery data collection.
Our commitment to automating the "load more" feature underscores the importance of thoroughness in Grab Food delivery data collection. By meticulously uncovering all available restaurant listings, we provide a comprehensive overview of Manila's vibrant dining scene, catering to the needs of consumers and businesses alike.
This endeavor aligns with the growing demand for reliable and up-to-date data in the food delivery industry. Our Grab Food delivery websites scraping efforts empower businesses to make informed decisions and consumers to explore an extensive range of dining options conveniently accessible through GrabFood's platform.
Code Implementation
Use Cases of GrabFood Delivery Websites Scraping
Web scraping Grab Food delivery website presents a plethora of promising opportunities for growth and success across various industries and sectors. Let's delve into some of these key applications:
Market Research: By scraping GrabFood delivery websites, businesses can gain valuable insights into consumer preferences, popular cuisines, and emerging food trends. This data can inform market research efforts, helping businesses identify opportunities for expansion or product development.
Competitor Analysis: The data from scraping GrabFood delivery websites equips businesses with a powerful tool to monitor competitor activity, including menu offerings, pricing strategies, and promotional campaigns. With this information, businesses can stay ahead of the game and adapt their strategies accordingly.
Location-based Marketing: With data collected from GrabFood delivery websites, businesses can identify popular dining locations and target their marketing efforts accordingly. This includes tailoring promotions and advertisements to specific geographic areas based on consumer demand.
Menu Optimization: By analyzing menu data scraped from GrabFood delivery websites, restaurants can identify which dishes are most popular among consumers. This insight can inform menu optimization efforts, helping restaurants streamline their offerings and maximize profitability.
Pricing Strategy: Scraped data from GrabFood delivery websites can provide valuable insights into pricing trends across different cuisines and geographic locations. Businesses can use this information to optimize their pricing strategy and remain competitive in the market.
Customer Insights: The data extracted from GrabFood delivery websites can provide businesses with invaluable insights into customer behavior, preferences, and demographics. This information is a goldmine for businesses, enabling them to craft targeted marketing campaigns and deliver personalized customer experiences.
Compliance Monitoring: Businesses can use web scraping to monitor compliance with food safety regulations and delivery standards on GrabFood delivery websites. This ensures that restaurants are meeting regulatory requirements and maintaining high standards of service.
Overall, web scraping GrabFood delivery websites offers businesses a wealth of opportunities to gather valuable data, gain insights, and make informed decisions across various aspects of their operations.
Conclusion
At Actowiz Solutions, we unlock insights into Manila's culinary scene through GrabFood's restaurant listings using web scraping. Our approach ensures data collection without reliance on external mapping libraries, enhancing flexibility and efficiency. As we delve deeper into web scraping, endless opportunities emerge for culinary and data enthusiasts alike. Explore the possibilities with Actowiz Solutions today! You can also reach us for all your mobile app scraping, data collection, web scraping, and instant data scraper service requirements.
#WebScrapingGrabFoodwebsite#GrabFoodWebsitesScraping#GrabFoodDataCollection#GrabFoodWebsitesScraper#ExtractGrabFoodWebsites
0 notes
Text
Scrape GrubHub Restaurant Listings

Scrape GrubHub Restaurant Listings
Scraping GrubHub restaurant listings is a valuable technique for extracting data and gaining valuable insights. With the abundance of restaurants on GrubHub, it can be overwhelming to manually collect and analyze information. However, by leveraging web scraping techniques, businesses can automate the process and extract relevant data points from the listings.
One of the primary advantages of scraping GrubHub restaurant listings is the ability to gather a comprehensive list of restaurants in a specific area. By scraping the listings, businesses can obtain information such as restaurant names, addresses, contact details, menus, and customer reviews. This data can be used for various purposes, including market research, competitor analysis, and customer segmentation.
List of Data Fields
When scraping GrubHub restaurant listings, there are several data fields that can be extracted. These include:
- Restaurant name: The name of the restaurant listed on GrubHub.
- Address: The physical address of the restaurant.
- Contact details: Phone number, email address, or website of the restaurant.
- Menu: The menu items offered by the restaurant.
- Customer reviews: Ratings and reviews provided by customers.
By extracting these data fields, businesses can gain a comprehensive understanding of the restaurant landscape in a specific area and make informed decisions based on the collected information.
Benefits of Scrape GrubHub Restaurant Listings
Scraping GrubHub restaurant listings by by DataScrapingServices.com offers several benefits for businesses:
1. Market research: By scraping the listings, businesses can analyze the competition and identify market trends. This information can help in developing effective marketing strategies and improving business performance.
2. Competitor analysis: Scraping GrubHub restaurant listings allows businesses to gather data on their competitors, such as their menu offerings, pricing, and customer reviews. This enables businesses to identify areas of improvement and stay ahead of the competition.
3. Customer segmentation: The data collected from scraping GrubHub restaurant listings can be used to segment customers based on their preferences and behavior. This information helps in targeted marketing campaigns and personalized customer experiences.
4. Data-driven decision making: By leveraging the scraped data, businesses can make informed decisions based on accurate and up-to-date information. This reduces the risk of making decisions based on assumptions or incomplete data.
Overall, scraping GrubHub restaurant listings empowers businesses with valuable data that can drive growth, improve customer satisfaction, and enhance operational efficiency.
Best Restaurant Data Scraping Services
Restaurant Menu Data Scraping from Menupages.com
Restaurant Reviews Data Scraping
Extract Restaurant Data From Google Maps
USA Restaurant Database Scraping
Best Scrape GrubHub Restaurant Listings Services USA:
Fort Wichita, Boston, Worth, Sacramento, El Paso, Jacksonville, Arlington, Dallas, Columbus, Houston, San Francisco, Raleigh, Miami, Louisville, Albuquerque, Atlanta, Denver, Memphis, Austin, San Antonio, Milwaukee, Bakersfield, San Diego, Oklahoma City, Omaha, Long Beach, Portland, Kansas Los Angeles, Seattle, Orlando, Springs, Chicago, Nashville, Virginia Beach, Colorado, Washington, Las Vegas, Indianapolis, New Orleans, Philadelphia, San Jose, Tulsa, Honolulu, Tucson and New York.
Conclusion
Scraping GrubHub restaurant listings is a powerful technique for extracting valuable data and gaining insights into the restaurant landscape. By automating the process of data collection, businesses can save time and resources while accessing a wealth of information. Whether it's for market research, competitor analysis, or customer segmentation, scraping GrubHub restaurant listings provides businesses with a competitive edge in the ever-evolving food industry.
In conclusion, businesses can greatly benefit from scraping GrubHub restaurant listings. It allows for comprehensive data analysis, informed decision making, and improved business performance. By harnessing the power of web scraping, businesses can stay ahead of the competition and unlock new opportunities for growth.
Website: Datascrapingservices.com
Email: [email protected]
#scrapegrubhubrestaurantlistings#grubhubdatascraping#usarestaurantdatabasescraping#restaurantdatabaseusa#restaurantdatabasescraping#restaurantdatabase#datascrapingservices#webscrapingexpert#websitedatascraping
0 notes
Text

Do you want a complete list of restaurants with their ratings and addresses whenever you visit a place or go for holidays? Off-course yes as it makes your way much easier. The easiest way to do it is using data scraping.
Web scraping or data scraping imports data from a website to the local machine. The result is in the form of spreadsheets so that you can get an entire list of restaurants available around me having its address as well as ratings in the easy spreadsheet!
Here at Foodspark, we use Python 3 scripts to scrape restaurant and food data as installing Python could be very useful. For proofreading the script, we use Google Colab for running the script as it helps us running the Python scripts on the cloud.
As our objective is to find a complete listing of places, scraping Google Maps data is its answer. Using Google Maps scraping, we can extract a place’s name, coordinates, address, kind of place, ratings, phone number, as well as other important data. For a start, we can also use a Places Scraping API. By using the Places Scraping API, it’s easy to extract Places data.
0 notes
Text
How To Extract Food Data From Google Maps With Google Colab & Python?
Do you want a comprehensive list of restaurants with reviews and locations every time you visit a new place or go on vacation? Sure you do, because it makes your life so much easier. Data scraping is the most convenient method.
Web scraping, also known as data scraping, is the process of transferring information from a website to a local network. The result is in the form of spreadsheets. So you can get a whole list of restaurants in your area with addresses and ratings in one simple spreadsheet! In this blog, you will learn how to use Python and Google Colab to Extract food data From Google Maps.
WWe are scraping restaurant and food data using Python 3 scripts since installing Python can be pretty handy. We use Google Colab to run the proofreading script since it allows us to run Python scripts on the server.
As our objective is to get a detailed listing of locations, extracting Google Maps data is an ideal solution. Using Google Maps data scraping, you can scrape data like name, area, location, place types, ratings, phone numbers, and other applicable information. For startups, we can utilize a places data scraping API. A places Scraping API makes that very easy to scrape location data.
Step 1: What information would you need?
For example, here we are searching for "restaurants near me" in Sanur, Bali, within 1 kilometer. So the criteria could be "restaurants," "Sanur Beach," and "1 mile."Let us convert this into Python:
These "keywords" help us find places categorized as restaurants OR results that contain the term "restaurant." A comprehensive list of sites whose names and types both have the word "restaurant" is better than using "type" or "name" of places.
For example, we can make reservations at Se'i Sapi and Sushi Tei at the same time. If we use the term "name," we will only see places whose names contain the word "restaurant." If we use the word "type," we get areas whose type is "restaurant." However, using "keywords" has the disadvantage that data cleaning takes longer.
Step 2: Create some necessary libraries, like:
Create some necessary modules, such as:
The "files imported from google. colab" did you notice? Yes, to open or save data in Google Colab, we need to use google. colab library.
Step 3: Create a piece of code that generates data based on the first Step's variables.
With this code, we get the location's name, longitude, latitude, IDs, ratings, and area for each keyword and coordinate. Suppose there are 40 locales near Sanur; Google will output the results on two pages. If there are 55 results, there are three pages. Since Google only shows 20 entries per page, we need to specify the 'next page token' to retrieve the following page data.
The maximum number of data points we retrieve is 60, which is Google's policy. For example, within one kilometer of our starting point, there are 140 restaurants. This means that only 60 of the 140 restaurants will be created.
So, to avoid inconsistencies, we need to get both the radius and the coordinates right. Ensure that the diameter is not too large so that "only 60 points are created, although there are many of them". Also, ensure the radius is manageable, as this would result in a long list of coordinates. Neither can be efficient, so we need to capture the context of a location earlier.
Continue reading the blog to learn more how to extract data from Google Maps using Python.
Step 4: Store information on the user's computer
Final Step: To integrate all these procedures into a complete code:
You can now quickly download data from various Google Colab files. To download data, select "Files" after clicking the arrow button in the left pane!
Your data will be scraped and exported in CSV format, ready for visualization with all the tools you know! This can be Tableau, Python, R, etc. Here we used Kepler.gl for visualization, a powerful WebGL-enabled web tool for geographic diagnostic visualizations.
The data is displayed in the spreadsheet as follows:
In the Kepler.gl map, it is shown as follows:
From our location, lounging on Sanur beach, there are 59 nearby eateries. Now we can explore our neighborhood cuisine by adding names and reviews to a map!
Conclusion:
Food data extraction using Google Maps, Python, and Google Colab can be an efficient and cost-effective way to obtain necessary information for studies, analysis, or business purposes. However, it is important to follow Google Maps' terms of service and use the data ethically and legally. However, you should be aware of limitations and issues, such as managing web-based applications, dealing with CAPTCHA, and avoiding Google blocking.
Are you looking for an expert Food Data Scraping service provider? Contact us today! Visit the Food Data Scrape website and get more information about Food Data Scraping and Mobile Grocery App Scraping. Know more : https://www.fooddatascrape.com/how-to-extract-food-data-from-google-maps-with-google-colab-python.php
#Extract Food Data From Google Maps#extracting Google Maps data#Google Maps data scraping#Food data extraction using Google Maps
0 notes
Text
16 July 2021
Food for thought
At last week's Data Bites, I noted how 'Wales' is a standard unit of area. This week, along comes a map which shows that all the built-up land in the UK is equivalent to one Wales:
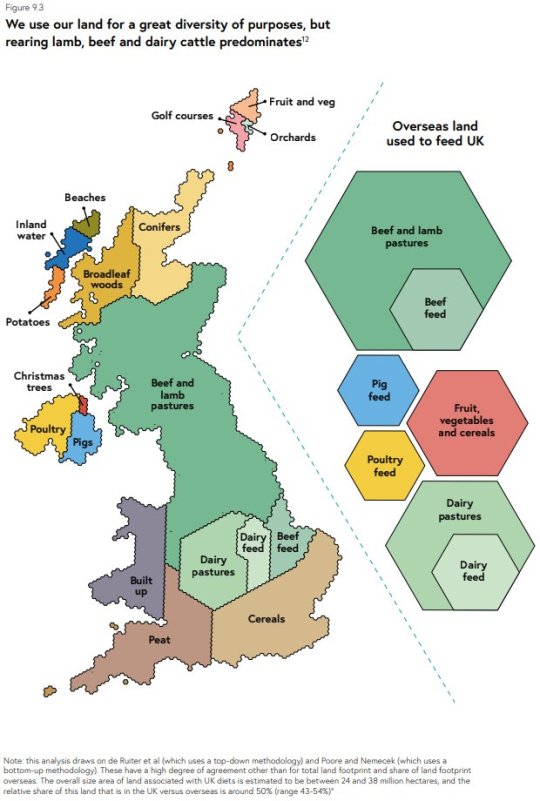
The map is from the National Food Strategy, published yesterday (and the man has a point).
It has divided opinion, judging by the responses to this tweet. I understand where the sceptics are coming from - at first glance, it may be confusing, given Wales isn't actually entirely built up, Cornwall made of peat, or Shetland that close to the mainland (or home to all the UK's golf courses). And I'm often critical of people using maps just because the data is geographical in some way, when a different, non-map visualisation would be better.
But I actually think this one works. Using a familiar geography to represent areas given over to particular land use might help us grasp it more readily (urban areas = size of Wales, beef and lamb pastures = more of the country than anything else). It's also clear that a huge amount of overseas land is needed to feed the UK, too.
The map has grabbed people's attention and got them talking, which is no bad thing. And it tells the main stories I suspect its creators wanted to. In other words, it's made those messages... land.
Trash talk
Happy Take Out The Trash Day!
Yesterday saw A LOT of things published by Cabinet Office - data on special advisers, correspondence with parliamentarians, public bodies and major projects to name but a few, and the small matter of the new plans outlining departmental priorities and how their performance will be measured.
It's great that government is publishing this stuff. It's less great that too much of it still involves data being published in PDFs not spreadsheets. And it's even less great that the ignoble tradition of Take Out The Trash Day continues, for all the reasons here (written yesterday) and here (written in 2017).
I know this isn't (necessarily) deliberate, and it's a lot of good people working very hard to get things finished before the summer (as my 2017 piece acknowledges). And it's good to see government being transparent.
But it's 2021, for crying out loud. The data collection should be easier. The use of this data in government should be more widespread to begin with.
We should expect better.
In other news:
I was really pleased to have helped the excellent team at Transparency International UK (by way of some comments on a draft) with their new report exploring access and influence in UK housing policy, House of Cards. Read it here.
One of our recent Data Bites speakers, Doug Gurr, is apparently in the running to run the NHS. More here.
Any excuse to plug my Audrey Tang interview.
The good folk at ODI Leeds/The Data City/the ODI have picked up and run with my (and others') attempt to map the UK government data ecosystem. Do help them out.
Five years ago this week...
Regarding last week's headline of Three Lines on a Chart: obviously I was going to.
Have a great weekend
Gavin
Enjoying Warning: Graphic Content?
Tell your friends - forward this email, and they can:
Subscribe via email
Follow on Twitter
Follow on Tumblr
Or:
Buy me a coffee (thank you!)
Follow me, Gavin Freeguard, on Twitter
Visit my website (I'm available for work!)
Today's links:
Graphic content
Vax populi
Why vaccine-shy French are suddenly rushing to get jabbed* (The Economist)
Morning update on Macron demolishing French anti-vax feeling (or at least vax-hesitant) (Sophie Pedder via Nicolas Berrod)
How Emmanuel Macron’s “health passes” have led to a surge in vaccine bookings in France* (New Statesman)
How effective are coronavirus vaccines against the Delta variant?* (FT)
England faces the sternest test of its vaccination strategy* (The Economist)
Where Are The Newest COVID Hot Spots? Mostly Places With Low Vaccination Rates (NPR)
There's A Stark Red-Blue Divide When It Comes To States' Vaccination Rates (NPR)
All talk, no jabs: the reality of global vaccine diplomacy* (Telegraph)
Vaccination burnout? (Reuters)
Viral content
COVID-19: Will the data allow the government to lift restrictions on 19 July? (Sky News)
UK Covid-19 rates are the highest of any European country after Cyprus* (New Statesman)
COVID-19: Cautionary tale from the Netherlands' coronavirus unlocking - what lessons can the UK learn? (Sky News)
‘Inadequate’: Covid breaches on the rise in Australia’s hotel quarantine (The Guardian)
Side effects
COVID-19: Why is there a surge in winter viruses at the moment? (Sky News)
London Beats New York Back to Office, by a Latte* (Bloomberg)
Outdoor dining reopened restaurants for all — but added to barriers for disabled* (Washington Post)
NYC Needs the Commuting Crowds That Have Yet to Fully Return* (Bloomberg)
Politics and government
Who will succeed Angela Merkel?* (The Economist)
Special advisers in government (Tim for IfG)
How stingy are the UK’s benefits? (Jamie Thunder)
A decade of change for children's services funding (Pro Bono Economics)
National Food Strategy (independent review for UK Government)
National Food Strategy: Tax sugar and salt and prescribe veg, report says (BBC News)
Air, space
Can Wizz challenge Ryanair as king of Europe’s skies?* (FT)
Air passengers have become much more confrontational during the pandemic* (The Economist)
Branson and Bezos in space: how their rocket ships compare* (FT)
Sport
Euro 2020: England expects — the long road back to a Wembley final* (FT)
Most football fans – and most voters – support the England team taking the knee* (New Statesman)
Domestic violence surges after a football match ends* (The Economist)
The Most Valuable Soccer Player In America Is A Goalkeeper (FiveThirtyEight)
Sport is still rife with doping* (The Economist)
Wimbledon wild card success does not disguise financial challenge* (FT)
Can The U.S. Women’s Swim Team Make A Gold Medal Sweep? (FiveThirtyEight)
Everything else
Smoking: How large of a global problem is it? And how can we make progress against it? (Our World in Data)
Record June heat in North America and Europe linked to climate change* (FT)
Here’s a list of open, non-code tools that I use for #dataviz, #dataforgood, charity data, maps, infographics... (Lisa Hornung)
Meta data
Identity crisis
A single sign-on and digital identity solution for government (GDS)
UK government set to unveil next steps in digital identity market plan (Computer Weekly)
BCS calls for social media platforms to verify users to curb abuse (IT Pro)
ID verification for social media as a solution to online abuse is a terrible idea (diginomica)
Who is behind the online abuse of black England players and how can we stop it?* (New Statesman)
Euro 2020: Why abuse remains rife on social media (BBC News)
UK government
Online Media Literacy Strategy (DCMS)
Privacy enhancing technologies: Adoption guide (CDEI)
The Longitudinal Education Outcomes (LEO) dataset is now available in the ONS Secure Research Service (ADR UK)
Our Home Office 2024 DDaT Strategy is published (Home Office)
The UK’s Digital Regulation Plan makes few concrete commitments (Tech Monitor)
OSR statement on data transparency and the role of Heads of Profession for Statistics (Office for Statistics Regulation)
Good data from any source can help us report on the global goals to the UN (ONS)
The state of the UK’s statistical system 2020/21 (Office for Statistics Regulation)
Far from average: How COVID-19 has impacted the Average Weekly Earnings data (ONS)
Health
Shock treatment: can the pandemic turn the NHS digital? (E&T)
Can Vaccine Passports Actually Work? (Slate)
UK supercomputer Cambridge-1 to hunt for medical breakthroughs (The Guardian)
AI got 'rithm
An Applied Research Agenda for Data Governance for AI (GPAI)
Taoiseach and Minister Troy launch Government Roadmap for AI in Ireland (Irish Government)
Tech
“I Don’t Think I’ll Ever Go Back”: Return-to-Office Agita Is Sweeping Silicon Valley (Vanity Fair)
Google boss Sundar Pichai warns of threats to internet freedom (BBC News)
The class of 2021: Welcome to POLITICO’s annual ranking of the 28 power players behind Europe’s tech revolution (Politico)
Inside Facebook’s Data Wars* (New York Times)
Concern trolls and power grabs: Inside Big Tech’s angry, geeky, often petty war for your privacy (Protocol)
Exclusive extract: how Facebook's engineers spied on women* (Telegraph)
Face off
Can facial analysis technology create a child-safe internet? (The Observer)
#Identity, #OnlineSafety & #AgeVerification – notes on “Can facial analysis technology create a child-safe internet?” (Alec Muffett)
Europe makes the case to ban biometric surveillance* (Wired)
Open government
From open data to joined-up government: driving efficiency with BA Obras (Open Contracting Partnership)
AVAILABLE NOW! DEMOCRACY IN A PANDEMIC: PARTICIPATION IN RESPONSE TO CRISIS (Involve)
Designing digital services for equitable access (Brookings)
Data
Trusting the Data: How do we reach a public settlement on the future of tech? (Demos)
"Why do we use R rather than Excel?" (Terence Eden)
Everything else
The world’s biggest ransomware gang just disappeared from the internet (MIT Technology Review)
Our Statistical Excellence Awards Ceremony has just kicked off! (Royal Statistical Society)
Pin resets wipe all data from over 100 Treasury mobile phones (The Guardian)
Data officers raid two properties over Matt Hancock CCTV footage leak (The Guardian)
How did my phone number end up for sale on a US database? (BBC News)
Gendered disinformation: 6 reasons why liberal democracies need to respond to this threat (Demos, Heinrich-Böll-Stiftung)
Opportunities
EVENT: Justice data in the digital age: Balancing risks and opportunities (The LEF)
JOBS: Senior Data Strategy - Data Innovation & Business Analysis Hub (MoJ)
JOB: Director of Evidence and Analytics (Natural England)
JOB: Policy and Research Associate (Open Ownership)
JOB: Research Officer in Data Science (LSE Department of Psychological and Behavioural Science)
JOB: Chief operating officer (Democracy Club, via Jukesie)
And finally...
me: can’t believe we didn’t date sooner... (@MNateShyamalan)
Are you closer to Georgia, or to Georgia? (@incunabula)
A masterpiece in FOIA (Chris Cook)
How K-Pop conquered the universe* (Washington Post)
Does everything really cost more? Find out with our inflation quiz.* (Washington Post)
2 notes
·
View notes
Text
How To Extract Restaurant Data Using Google Maps Data Scraping?
Do you need a comprehensive listing of restaurants having their addresses as well as ratings when you go for some holidays? Certainly, yes because it makes your path much easier and the coolest way to do that is using web scraping.
Data scraping or web scraping extracts data from the website to a local machine. The results are in spreadsheet form so you can have the whole listing of restaurants accessible around me getting their address and ratings in easy spreadsheets!
Here at Web Screen Scraping, we utilize Python 3 scripts for scraping food and restaurant data as well as installing Python might be extremely useful. For script proofreading, we have used Google Colab to run a script because it assists us in running Python scripts using the cloud.
As our purpose is to get a complete list of different places, extracting Google Maps data is the answer! With Google Maps scraping, it’s easy to scrape a place name, kind of place, coordinates, address, phone number, ratings, and other vital data. For starting, we can utilize a Place Scraping API. Using a Place Scraping API, it’s very easy to scrape Places data.
1st Step: Which data is needed?
Here, we would search for the “restaurants around me” phrase in Sanur, Bali in a radius of 1 km. So, the parameters could be ‘restaurants’, ‘Sanur Beach’, and ‘1 km’.
Let’s translate that into Python:
coordinates = ['-8.705833, 115.261377'] keywords = ['restaurant'] radius = '1000' api_key = 'acbhsjbfeur2y8r' #insert your API key here
All the ‘keywords’ will help us get places that are listed as results or restaurants having ‘restaurants’ in them. It’s superior than utilize the ‘types’ or ‘names’ of the places because we can get a complete list of different places that the name and type, has ‘restaurant’. For example, we could use restaurant names like Sushi Tei & Se’i Sapi. In case, we utilize ‘names’, then we’ll have places whose names are having a ‘restaurant’ word in that. In case, we utilize ‘type’, then we’ll have places where any type is a ‘restaurant’. Though, the drawback of utilizing ‘keywords’ is, this will need extra time to clean data.
2nd Step: Create some required libraries, like:
import pandas as pd, numpy as np import requests import json import time from google.colab import files
Have you observed “from imported files of google.colab”? Yes, the usage of the Google Colab requires us to use google.colab library to open or save data files.
3rd Step: Write the code that produces data relying on the given parameters in 1st Step.
for coordinate in coordinates: for keyword in keywords:url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?location='+coordinate+'&radius='+str(radius)+'&keyword='+str(keyword)+'&key='+str(api_key)while True: print(url) respon = requests.get(url) jj = json.loads(respon.text) results = jj['results'] for result in results: name = result['name'] place_id = result ['place_id'] lat = result['geometry']['location']['lat'] lng = result['geometry']['location']['lng'] rating = result['rating'] types = result['types'] vicinity = result['vicinity']data = [name, place_id, lat, lng, rating, types, vicinity] final_data.append(data)time.sleep(5)if 'next_page_token' not in jj: break else:next_page_token = jj['next_page_token']url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?key='+str(api_key)+'&pagetoken='+str(next_page_token)labels = ['Place Name','Place ID', 'Latitude', 'Longitude', 'Types', 'Vicinity']
The code will help us find a place’s name, ids, ratings, latitude-longitude, kinds, and areas for all keywords as well as their coordinates. Because Google displays merely 20 entries on each page, we had to add ‘next_page_token’ to scrape the data of the next page. Let’s accept we are having 40 restaurants close to Sanur, then Google will display results on two pages. For 65 results, there will be four pages.
The utmost data points, which we extract are only 60 places. It is a rule of Google. For example, 140 restaurants are available around Sanur within a radius of 1 km from where we had started. It means that only 60 of the total 140 restaurants will get produced. So, to avoid inconsistencies, we have to control the radius and also coordinate proficiently. Please make certain that the radius doesn’t become very wide, which results in “only 60 points are made whereas there are several of them”. Moreover, just ensure that the radius isn’t extremely small, which results in listing different coordinates. Both of them could not become well-organized, so we need to understand the context of the location previously.
4th Step: Save this data into a local machine
export_dataframe_1_medium = pd.DataFrame.from_records(final_data, columns=labels) export_dataframe_1_medium.to_csv('export_dataframe_1_medium.csv')
Last Step: Associate all these steps with the complete code:
import pandas as pd, numpy as np import requests import json import time final_data = []# Parameters coordinates = ['-8.705833, 115.261377'] keywords = ['restaurant'] radius = '1000' api_key = 'acbhsjbfeur2y8r' #insert your Places APIfor coordinate in coordinates: for keyword in keywords:url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?location='+coordinate+'&radius='+str(radius)+'&keyword='+str(keyword)+'&key='+str(api_key)while True: print(url) respon = requests.get(url) jj = json.loads(respon.text) results = jj['results'] for result in results: name = result['name'] place_id = result ['place_id'] lat = result['geometry']['location']['lat'] lng = result['geometry']['location']['lng'] rating = result['rating'] types = result['types'] vicinity = result['vicinity']data = [name, place_id, lat, lng, rating, types, vicinity] final_data.append(data)time.sleep(5)if 'next_page_token' not in jj: break else:next_page_token = jj['next_page_token']url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?key='+str(api_key)+'&pagetoken='+str(next_page_token)labels = ['Place Name','Place ID', 'Latitude', 'Longitude', 'Types', 'Vicinity']export_dataframe_1_medium = pd.DataFrame.from_records(final_data, columns=labels) export_dataframe_1_medium.to_csv('export_dataframe_1_medium.csv')
Now, it’s easy to download data from various Google Colab files. You just need to click on an arrow button provided on the left-side pane as well as click ‘Files’ to download data!
Your extracted data would be saved in CSV format as well as it might be imagined with tools that you’re well aware of! It could be R, Python, Tableau, etc. So, we have imagined that using Kepler.gl; a WebGL authorized, data agnostic, as well as high-performance web apps for geospatial analytical visualizations.
This is how the resulted data would look like in a spreadsheet:
And, this is how it looks in a Kepler.gl map:
We can see 59 restaurants from the Sanur beach. Just require to add names and ratings in the map as well as we’re prepared to search foods around the area!
Still not sure about how to scrape food data with Google Maps Data Scraping? Contact Web Screen Scraping for more details!
1 note
·
View note
Text
How To Extract Restaurant Data Using Google Maps Data Scraping?
Do you need a comprehensive listing of restaurants having their addresses as well as ratings when you go for some holidays? Certainly, yes because it makes your path much easier and the coolest way to do that is using web scraping.
Data scraping or web scraping extracts data from the website to a local machine. The results are in spreadsheet form so you can have the whole listing of restaurants accessible around me getting their address and ratings in easy spreadsheets!
Here at Web Screen Scraping, we utilize Python 3 scripts for scraping food and restaurant data as well as installing Python might be extremely useful. For script proofreading, we have used Google Colab to run a script because it assists us in running Python scripts using the cloud.
As our purpose is to get a complete list of different places, extracting Google Maps data is the answer! With Google Maps scraping, it’s easy to scrape a place name, kind of place, coordinates, address, phone number, ratings, and other vital data. For starting, we can utilize a Place Scraping API. Using a Place Scraping API, it’s very easy to scrape Places data.
1st Step: Which data is needed?
Here, we would search for the “restaurants around me” phrase in Sanur, Bali in a radius of 1 km. So, the parameters could be ‘restaurants’, ‘Sanur Beach’, and ‘1 km’.
Let’s translate that into Python:
coordinates = ['-8.705833, 115.261377'] keywords = ['restaurant'] radius = '1000' api_key = 'acbhsjbfeur2y8r' #insert your API key here
All the ‘keywords’ will help us get places that are listed as results or restaurants having ‘restaurants’ in them. It’s superior than utilize the ‘types’ or ‘names’ of the places because we can get a complete list of different places that the name and type, has ‘restaurant’. For example, we could use restaurant names like Sushi Tei & Se’i Sapi. In case, we utilize ‘names’, then we’ll have places whose names are having a ‘restaurant’ word in that. In case, we utilize ‘type’, then we’ll have places where any type is a ‘restaurant’. Though, the drawback of utilizing ‘keywords’ is, this will need extra time to clean data.
2nd Step: Create some required libraries, like:
import pandas as pd, numpy as np import requests import json import time from google.colab import files
Have you observed “from imported files of google.colab”? Yes, the usage of the Google Colab requires us to use google.colab library to open or save data files.
3rd Step: Write the code that produces data relying on the given parameters in 1st Step.
for coordinate in coordinates: for keyword in keywords:url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?location='+coordinate+'&radius='+str(radius)+'&keyword='+str(keyword)+'&key='+str(api_key)while True: print(url) respon = requests.get(url) jj = json.loads(respon.text) results = jj['results'] for result in results: name = result['name'] place_id = result ['place_id'] lat = result['geometry']['location']['lat'] lng = result['geometry']['location']['lng'] rating = result['rating'] types = result['types'] vicinity = result['vicinity']data = [name, place_id, lat, lng, rating, types, vicinity] final_data.append(data)time.sleep(5)if 'next_page_token' not in jj: break else:next_page_token = jj['next_page_token']url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?key='+str(api_key)+'&pagetoken='+str(next_page_token)labels = ['Place Name','Place ID', 'Latitude', 'Longitude', 'Types', 'Vicinity']
The code will help us find a place’s name, ids, ratings, latitude-longitude, kinds, and areas for all keywords as well as their coordinates. Because Google displays merely 20 entries on each page, we had to add ‘next_page_token’ to scrape the data of the next page. Let’s accept we are having 40 restaurants close to Sanur, then Google will display results on two pages. For 65 results, there will be four pages.
The utmost data points, which we extract are only 60 places. It is a rule of Google. For example, 140 restaurants are available around Sanur within a radius of 1 km from where we had started. It means that only 60 of the total 140 restaurants will get produced. So, to avoid inconsistencies, we have to control the radius and also coordinate proficiently. Please make certain that the radius doesn’t become very wide, which results in “only 60 points are made whereas there are several of them”. Moreover, just ensure that the radius isn’t extremely small, which results in listing different coordinates. Both of them could not become well-organized, so we need to understand the context of the location previously.
4th Step: Save this data into a local machine
export_dataframe_1_medium = pd.DataFrame.from_records(final_data, columns=labels) export_dataframe_1_medium.to_csv('export_dataframe_1_medium.csv')
Last Step: Associate all these steps with the complete code:
import pandas as pd, numpy as np import requests import json import time final_data = []# Parameters coordinates = ['-8.705833, 115.261377'] keywords = ['restaurant'] radius = '1000' api_key = 'acbhsjbfeur2y8r' #insert your Places APIfor coordinate in coordinates: for keyword in keywords:url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?location='+coordinate+'&radius='+str(radius)+'&keyword='+str(keyword)+'&key='+str(api_key)while True: print(url) respon = requests.get(url) jj = json.loads(respon.text) results = jj['results'] for result in results: name = result['name'] place_id = result ['place_id'] lat = result['geometry']['location']['lat'] lng = result['geometry']['location']['lng'] rating = result['rating'] types = result['types'] vicinity = result['vicinity']data = [name, place_id, lat, lng, rating, types, vicinity] final_data.append(data)time.sleep(5)if 'next_page_token' not in jj: break else:next_page_token = jj['next_page_token']url = 'https://maps.googleapis.com/maps/api/place/nearbysearch/json?key='+str(api_key)+'&pagetoken='+str(next_page_token)labels = ['Place Name','Place ID', 'Latitude', 'Longitude', 'Types', 'Vicinity']export_dataframe_1_medium = pd.DataFrame.from_records(final_data, columns=labels) export_dataframe_1_medium.to_csv('export_dataframe_1_medium.csv')
Now, it’s easy to download data from various Google Colab files. You just need to click on an arrow button provided on the left-side pane as well as click ‘Files’ to download data!
Your extracted data would be saved in CSV format as well as it might be imagined with tools that you’re well aware of! It could be R, Python, Tableau, etc. So, we have imagined that using Kepler.gl; a WebGL authorized, data agnostic, as well as high-performance web apps for geospatial analytical visualizations.
This is how the resulted data would look like in a spreadsheet:
And, this is how it looks in a Kepler.gl map:
We can see 59 restaurants from the Sanur beach. Just require to add names and ratings in the map as well as we’re prepared to search foods around the area!
Still not sure about how to scrape food data with Google Maps Data Scraping? Contact Web Screen Scraping for more details!
1 note
·
View note
Link
The political economy of the Digital Age remains virtually terra incognita. In Techno-Feudalism, published three months ago in France (no English translation yet), Cedric Durand, an economist at the Sorbonne, provides a crucial, global public service as he sifts through the new Matrix that controls all our lives.
Durand places the Digital Age in the larger context of the historical evolution of capitalism to show how the Washington consensus ended up metastasized into the Silicon Valley consensus. In a delightful twist, he brands the new grove as the “Californian ideology”.
We’re far away from Jefferson Airplane and the Beach Boys; it’s more like Schumpeter’s “creative destruction” on steroids, complete with IMF-style “structural reforms” emphasizing “flexibilization” of work and outright marketization/financialization of everyday life.
The Digital Age was crucially associated with right-wing ideology from the very start. The incubation was provided by the Progress and Freedom Foundation (PFF), active from 1993 to 2010 and conveniently funded, among others, by Microsoft, At&T, Disney, Sony, Oracle, Google and Yahoo.
In 1994, PFF held a ground-breaking conference in Atlanta that eventually led to a seminal Magna Carta: literally, Cyberspace and the American Dream: a Magna Carta for the Knowledge Era, published in 1996, during the first Clinton term.
Not by accident the magazine Wired was founded, just like PFF, in 1993, instantly becoming the house organ of the “Californian ideology”.
Among the authors of the Magna Carta we find futurist Alvin “Future Shock” Toffler and Reagan’s former scientific counselor George Keyworth. Before anyone else, they were already conceptualizing how “cyberspace is a bioelectronic environment which is literally universal”. Their Magna Carta was the privileged road map to explore the new frontier.
Those Randian heroes
Also not by accident the intellectual guru of the new frontier was Ayn Rand and her quite primitive dichotomy between “pioneers” and the mob. Rand declared that egotism is good, altruism is evil, and empathy is irrational.
When it comes to the new property rights of the new Eldorado, all power should be exercised by the Silicon Valley “pioneers”, a Narcissus bunch in love with their mirror image as superior Randian heroes. In the name of innovation they should be allowed to destroy any established rules, in a Schumpeterian “creative destruction” rampage.
That has led to our current environment, where Google, Facebook, Uber and co. can overstep any legal framework, imposing their innovations like a fait accompli.
Durand goes to the heart of the matter when it comes to the true nature of “digital domination”: US leadership was never achieved because of spontaneous market forces.
On the contrary. The history of Silicon Valley is absolutely dependent on state intervention – especially via the industrial-military complex and the aero-spatial complex. The Ames Research Center, one of NASA’s top labs, is in Mountain View. Stanford was always awarded juicy military research contracts. During WWII, Hewlett Packard, for instance, was flourishing thanks to their electronics being used to manufacture radars. Throughout the 1960s, the US military bought the bulk of the still infant semiconductor production.
The Rise of Data Capital, a 2016 MIT Technological Review report produced “in partnership” with Oracle, showed how digital networks open access to a new, virgin underground brimming with resources: “Those that arrive first and take control obtain the resources they’re seeking” – in the form of data.
So everything from video-surveillance images and electronic banking to DNA samples and supermarket tickets implies some form of territorial appropriation. Here we see in all its glory the extractivist logic inbuilt in the development of Big Data.
Durand gives us the example of Android to illustrate the extractivist logic in action. Google made Android free for all smartphones so it would acquire a strategic market position, beating the Apple ecosystem and thus becoming the default internet entry point for virtually the whole planet. That’s how a de facto, immensely valuable, online real estate empire is built.
The key point is that whatever the original business – Google, Amazon, Uber – strategies of conquering cyberspace all point to the same target: take control of “spaces of observation and capture” of data.
About the Chinese credit system…
Durand offers a finely balanced analysis of the Chinese credit system – a public/private hybrid system launched in 2013 during the 3rd plenum of the 18thCongress of the CCP, under the motto “to value sincerity and punish insincerity”.
For the State Council, the supreme government authority in China, what really mattered was to encourage behavior deemed responsible in the financial, economic and socio-political spheres, and sanction what is not. It’s all about trust. Beijing defines it as “a method of perfecting the socialist market economy system that improves social governance”.
The Chinese term – shehui xinyong – is totally lost in translation in the West. Way more complex than “social credit”, it’s more about “trustworthiness”, in the sense of integrity. Instead of the pedestrian Western accusations of being an Orwellian system, priorities include the fight against fraud and corruption at the national, regional and local levels, violations of environmental rules, disrespect of food security norms.
Cybernetic management of social life is being seriously discussed in China since the 1980s. In fact, since the 1940s, as we see in Mao’s Little Red Book. It could be seen as inspired by the Maoist principle of “mass lines”, as in “start with the masses to come back to the masses: to amass the ideas of the masses (which are dispersed, non-systematic), concentrate them (in general ideas and systematic), then come back to the masses to diffuse and explain them, make sure the masses assimilate them and translate them into action, and verify in the action of the masses the pertinence of these ideas”.
Durand’s analysis goes one step beyond Soshana Zuboff’s The Age of Surveillance Capitalism when he finally reaches the core of his thesis, showing how digital platforms become “fiefdoms”: they live out of, and profit from, their vast “digital territory” peopled with data even as they lock in power over their services, which are deemed indispensable.
And just as in feudalism, fiefdoms dominate territory by attaching serfs. Masters made their living profiting from the social power derived from the exploitation of their domain, and that implied unlimited power over the serfs.
It all spells out total concentration. Silicon Valley stalwart Peter Thiel has always stressed the target of the digital entrepreneur is exactly to bypass competition. As quoted in Crashed: How a Decade of Financial Crises Changed the World, Thiel declared, “Capitalism and competition are antagonistic. Competition is for losers.”
So now we are facing not a mere clash between Silicon Valley capitalism and finance capital, but actually a new mode of production:
a turbo-capitalist survival as rentier capitalism, where Silicon giants take the place of estates, and also the State. That is the “techno-feudal” option, as defined by Durand.
Blake meets Burroughs
Durand’s book is extremely relevant to show how the theoretical and political critique of the Digital Age is still rarified. There is no precise cartography of all those dodgy circuits of revenue extraction. No analysis of how do they profit from the financial casino – especially mega investment funds that facilitate hyper-concentration. Or how do they profit from the hardcore exploitation of workers in the gig economy.
The total concentration of the digital glebe is leading to a scenario, as Durand recalls, already dreamed up by Stuart Mill, where every land in a country belonged to a single master. Our generalized dependency on the digital masters seems to be “the cannibal future of liberalism in the age of algorithms”.
Is there a possible way out? The temptation is to go radical – a Blake/Burroughs crossover. We have to expand our scope of comprehension – and stop confusing the map (as shown in the Magna Carta) with the territory (our perception).
William Blake, in his proto-psychedelic visions, was all about liberation and subordination – depicting an authoritarian deity imposing conformity via a sort of source code of mass influence. Looks like a proto-analysis of the Digital Age.
William Burroughs conceptualized Control – an array of manipulations including mass media (he would be horrified by social media). To break down Control, we must be able to hack into and disrupt its core programs. Burroughs showed how all forms of Control must be rejected – and defeated: “Authority figures are seen for what they are: dead empty masks manipulated by computers”.
Here’s our future: hackers or slaves.
(Republished from
Asia Times
by permission of author or representative)SHARE THIS ARTICLE...
5 notes
·
View notes
Link
If you are associated with the pet product industry, then data scraping could be a great assistant in many situations. The most general one is having products listed from the supplier, analyzing competitors’ products and price strategy, as well as monitor customer reviews, as well as others.
Here, we’ll show how to find a quality, well-structured, and usable data for all these tasks.
Extracting pet product information
Extracting pet stores’ prices (monitor different pricing on Amazon, Petco, etc.)
Extracting reviews on the pet products
Pet store contact data scraping
Extracting pet product information
The variety of pet products within a store may consist of thousands of points: pet care, pet food, pet supplies having multiple subs as well as – sub-sub categories. For creating products listings on the website, you require to get products with information: names, quality images, descriptions, product codes, and more.
From where, you can get these details? An ideal scenario would be when you get that from the supplier. However, there could be many troublesomeness:
Incomplete data – the file doesn’t have product descriptions or codes.
Inadequate image quality or else no images at all.
A file format can’t be introduced into the store or needs ample editing.
A general solution of getting the necessary details is scraping pet products data from a supplier’s website.
Note: Make sure to get a supplier’s permission before scraping data from their websites.
Let’s see that works with Retailgators web scraping service.
Discover an online form indicating the following:
Website for scraping data from. You might indicate a separate store address and also link to eBay, Walmart, Amazon, Etsy, as well as other marketplaces.
Different product fields include images, description, SKU, product title, wholesale price, and variations.
Specific requirements, comments, for example:
only have items, which are in stock
find descriptions using/without html
extract pet products categories
Make a file in a particular format (imported to Shopify, WooCommerce, Magento, PrestaShop, or other shopping carts).
1. Your email ID – in which, we could send a free as well as well scraped file.
After submitting your request, you would get a sample about scraped data. In case, you have identified your targeted shopping cart, a file would be arranged accordingly. The accessible formats include Shopify, PrestaShop, WooCommerce, and Magento. If you require any other formats, mention that in this form and have the file with the particular requirements.
Let’s see an example about the file having extracted pet products data well-structured for the:
All the highlighted columns have the data scraped from a website, whereas others include WooCommerce fields needed to make new products. Therefore, you get scraped data with an import-friendly file, which you can directly upload without and extra modifications.
Scrape Pet Products Reviews
Analyze reviews from different pet product websites could provide you many valuable insights:
brands with maximum reviews
brands with the highest score
how is a score changing actively
Many places are there where you could get reviews on cats’ or dogs’ food as well as other stuff: Walmart, Target, Amazon, PetSmart, Chewy.com, PETCO, and others.
To find reviews for the analysis, you just need to indicate a web address as well as fields to extract: review date, review, stars, title, images, and more. Retailgators will scrape the reviews as well as send a file into your FTP or email.
The data could be used to import or do manual analysis.
Pet Stores Contact Details Scraping
Presume that you’re launching the startup in a pet store business as well as need to get the listing of maximum brick-and-mortar pet stores in the area. Web scraping could help you with this job also.
How to Find Pet Store Contacts
On the Retailgators site, fill the following information in an online form:
Which area/location you are attracted with. There are a many resources listing different pet store addresses: https://www.petbusinessworld.co.uk/, https://pet-shops.regionaldirectory.us/, https://www.petsmart.com/store-locator/, Yellow Pages, Google Maps, and more. In case, you wish to scrape data from any particular website, just give us its URL.
Furthermore, you could outline data as well as location by a zip code or region and we would scrape company information from search results. Let’s see an example of the pet store contacts extracted from Google Maps:
Which company information you wish to see in a file:
Store’s Name
Address
City
Zip/Postal
State
After getting your request, we would share you some review samples as well as estimated price of web extraction.
Extracting Pet Store Pricing (Monitor Pricing on Amazon, Petco, etc.)
Online shopping helps pet-lovers in comparing prices across different websites before ordering anything. Therefore, to be competitive, you certainly require to track pricing, on maximum popular products.
With Retailgators, it’s easy to get the newest prices from the suppliers, manufacturers, local or worldwide competitors.
Just submit your form for the test pricing scraping, identify competitor list as well as stipulate fields to extract: product name, model, SKU, stock, special pricing, and more.
Conclusion
Having a eCommerce Data Scraping services from Retailgators, you’ll get the data you require as well as make suitable data-driven decisions.
source code: https://www.retailgators.com/how-to-scrape-pet-products-data-using-pet-products-data-scraping.php
0 notes
Text
USA Restaurant Database Scraping

USA Restaurant Database Scraping
Restaurant database scraping is crucial for businesses in the food industry to stay competitive and make informed decisions. By scraping restaurant databases, you can gather valuable information about different establishments, such as their menu, customer reviews, contact details, and more. This data can provide insights into market trends, customer preferences, and competitor analysis.
With the help of Datascrapingservices.com, you can easily access and extract data from various restaurant databases in the USA. This allows you to save time and resources by automating the data collection process. By having up-to-date and accurate information at your fingertips, you can make data-driven decisions to improve your business strategies and stay ahead of the competition.
List of Data Fields for USA Restaurant Database Scraping
When scraping restaurant databases in the USA, there are several key data fields that you should consider extracting:
- Restaurant Name: The name of the establishment
- Address: The physical location of the restaurant
- Phone Number: Contact details for reservations or inquiries
- Menu: The list of dishes, beverages, and prices offered by the restaurant
- Reviews and Ratings: Customer feedback and ratings for the restaurant
- Cuisine Type: The type of cuisine served by the restaurant
- Operating Hours: The opening and closing times of the establishment
By extracting these data fields, you can create a comprehensive database that can be used for various purposes, such as marketing campaigns, customer analysis, and identifying potential business opportunities.
Benefits of USA Restaurant Database Scraping
There are several benefits to USA Restaurant Database Scraping:
- Market Research: By analyzing data from various restaurants, you can gain insights into market trends, customer preferences, and competitor strategies. This information can help you identify new business opportunities and make data-driven decisions.
- Targeted Marketing: With a comprehensive database of restaurants, you can segment your target audience based on location, cuisine type, or other factors. This allows you to tailor your marketing campaigns and reach the right audience with personalized messages.
- Competitive Analysis: By scraping competitor restaurant databases, you can gather information about their menu, pricing, customer reviews, and more. This helps you understand their strengths and weaknesses, allowing you to develop strategies to outperform them.
- Improved Operations: Accessing restaurant databases can help you streamline your operations by analyzing customer feedback, identifying popular dishes, and optimizing your menu and pricing.
By partnering with Datascrapingservices.com, you can leverage these benefits and gain a competitive edge in the food industry.
Best Restaurant Data Scraping Services
Restaurant Menu Data Scraping from Menupages.com
Restaurant Reviews Data Scraping
Extract Restaurant Data From Google Maps
Scrape GrubHub Restaurant Listings
Best Restaurant Data Scraping Services USA:
Columbus, Houston, San Francisco, Raleigh, Miami, Louisville, El Paso, Jacksonville, Arlington, Dallas, Albuquerque, Bakersfield, San Diego, Oklahoma City, Omaha, Atlanta, Denver, Memphis, Austin, San Antonio, Milwaukee, Long Beach, Portland, Colorado, Washington, Las Vegas, Indianapolis, Kansas Los Angeles, Seattle, Orlando, Springs, Chicago, Nashville, Virginia Beach, City, New Orleans, Philadelphia, San Jose, Tulsa, Honolulu, Fort Wichita, Boston, Worth, Sacramento, Tucson and New York.
Conclusion
Restaurant database scraping is a powerful tool for businesses in the food industry to access valuable information and make informed decisions. By partnering with Datascrapingservices.com, you can automate the data collection process and gain a competitive edge by leveraging insights from restaurant databases in the USA. Whether it's for market research, targeted marketing, competitive analysis, or improving operations, restaurant database scraping can provide the data you need to succeed.
Discover the benefits of restaurant database scraping with Datascrapingservices.com and unlock the potential of your business today.
Website: Datascrapingservices.com
Email: [email protected]
#usarestaurantdatabasescraping#restaurantdatabaseusa#restaurantdatabasescraping#restaurantdatabase#datascrapingservices#webscrapingexpert#websitedatascraping
0 notes
Text
New Research Report On Consumer Robotics Market Is Growing In Huge Demand In 2020-2027
Robotics is that branch of technology that deals with the construction, design, operation, and application of robots. Robotic products are based on artificial intelligence. The consumer robotics market is evolving rapidly from the past two decades. Robotics covers a wide range of products. It includes children’s toys, homecare systems, and smart ‘humanoid’ robots that provide social and personal engagement. The key elements that are used in consumer robotics include processors, actuators, software, sensors, cameras, power supplies, displays, manipulators, communication technologies, microcontrollers, and mobile platforms. The global consumer robotic market has a very highly competitive arena due to the participation of well-diversified regional and international players in the industry. Moreover, this growing market is attracting new and innovative players in the market which further increases the competitive rivalry. The usage of robotics in consumer tasks gives time and cost effective techniques to complete task and provides comfort related benefits. Moreover, this technology also offers reduction in efforts required and increases peace of mind and similar other consumer benefits. Consumer robotics is preferred because of its features which includes small size, durability, and low cost. Due to their small size, they take very small spaces to fit in and save spaces for several other components in design.
Market scope and structure analysis :
Ø Market size available for years
2020–2027
Ø Base Year Considered
2019
Ø Forecast Period
2021–2027
Ø Forecast Unit
Value (USD)
Ø Segment Covered
Application, Type, and Region
Ø Regions Covered
North America (U.S. and Canada), Europe (Germany, UK, France, Italy, Spain and Rest of Europe), Asia-Pacific (China, Japan, India, Australia, Malaysia, Thailand, Indonesia, and Rest of Asia-Pacific), LAMEA (Middle East, Brazil, Mexico, and Rest of LAMEA)
Ø Companies Covered
Ecovas , Xiaomi, iLife, dyson, miele, Neato robotics, Cecotec, Ubteach, CANBOT0, Yujin ROBOT, iRobot Corporation, Jibo Inc., 3D Robotics Inc., Honda Motor Co. Ltd., Bossa Nova Robotics, DJI.
Get a sample of the report @ https://www.alliedmarketresearch.com/request-sample/6815
COVID-19 Scenario Analysis:
In this scenario, consumers concentrate only on necessary products (food, sanitizers, and medicine). They avoid entertainment and lifestyle products, so due to this the demand for consumer robotics products is hampered. It also impacts the supply side negatively.
Top Impacting Factors: Market Scenario Analysis, Trends, Drivers, and Impact Analysis
In the developed countries, the growing need for convenience and rising consumer’s spending power is the major factor that contributes in the surge in demand for consumer robotic products. The rise in paying capacity of people in developing countries due to the increase in their disposable income also drives the growth of the consumer robotic market. People are now willing to pay more than before for the products, which increases their comforts.
Rise in the security threat among consumers, high speed innovation, and increase in number of players drive the growth of this market.
However, the performance issues with the robotics products are holding back the growth of the market. High speed innovation may expand the consumer robot market growth during the forecast period.
New product launches to flourish the market
The advancements in artificial intelligence, navigation systems, ubiquity of the internet, and rise of hand-held computing devices are the major current trends supporting the development of the consumer robotics market on a very large scale. The surge in the usage of hand-held computing devices like smart phones, tablets, and smart watches has made development of robotic devices for office and consumer applications easy. For instance, in January 2019 iRobot company declared its entry into robotic lawn mower market with Tera. Terra has features of ground mapping and advanced navigation technology. And in October 2018, iRobot decided to collaborate with Google (US) to integrate Google’s Artificial Intelligence assistant into various robotic vacuums produced by the company. This technology enables consumers to control the robots through their voice commands.
Challenges in the market
The challenge that hinders the growth of the robotic market is the humanoid physical appearance of the robots that does not appeal the end users. Moreover, the investment required for innovation in this field is huge. Restrain from the demand side to replace the manual labor with advanced robotics technology in the traditional field, is one of the factors that hampers the growth of the market. The high price of robots is another major element which restricts consumers to adopt robotic products for their day to day activities. The consumer robotics market is still in the nascent stage and it is difficult to cut down the cost of manufacturing robotic technology.
Request a discount on the report @ https://www.alliedmarketresearch.com/purchase-enquiry/6815
Key Segments Covered:
Ø Application
Entertainment
Security & Surveillance
Education
· Others
Ø Type
Autonomous
· Semi-autonomous
Key Benefits of the Report:
· This study presents the analytical depiction of the global consumer robotics industry along with the current trends and future estimations to determine the imminent investment pockets.
· The report presents information related to key drivers, restraints, and opportunities along with detailed analysis of the global consumer robotics market share.
· The current market is quantitatively analyzed from 2020 to 2027 to highlight the global consumer robotics market growth scenario.
· Porter’s five forces analysis illustrates the potency of buyers & suppliers in the market.
· The report provides a detailed global consumer robotics market analysis based on competitive intensity and how the competition will take shape in the coming years.
Questions Answered in the Consumer Robotics Market Research Report:
· What are the leading market players active in the consumer robotics market?
· What the current trends will influence the market in the next few years?
· What are the driving factors, restraints, and opportunities in the market?
· What future projections would help in taking further strategic steps?
To know more about the report @ https://www.alliedmarketresearch.com/consumer-robotics-market-A06450
About Allied Market Research:
Allied Market Research (AMR) is a full-service market research and business-consulting wing of Allied Analytics LLP based in Portland, Oregon. Allied Market Research provides global enterprises as well as medium and small businesses with unmatched quality of "Market Research Reports" and "Business Intelligence Solutions." AMR has a targeted view to provide business insights and consulting services to assist its clients to make strategic business decisions and achieve sustainable growth in their respective market domains. AMR offers its services across 11 industry verticals including Life Sciences, Consumer Goods, Materials & Chemicals, Construction & Manufacturing, Food & Beverages, Energy & Power, Semiconductor & Electronics, Automotive & Transportation, ICT & Media, Aerospace & Defense, and BFSI.
We are in professional corporate relations with various companies and this helps us in digging out market data that helps us generate accurate research data tables and confirms utmost accuracy in our market forecasting. Each and every data presented in the reports published by us is extracted through primary interviews with top officials from leading companies of domain concerned. Our secondary data procurement methodology includes deep online and offline research and discussion with knowledgeable professionals and analysts in the industry.
Contact Us:
David Correa
5933 NE Win Sivers Drive
#205, Portland, OR 97220
United States
USA/Canada (Toll Free): 1-800-792-5285, 1-503-894-6022, 1-503-446-1141
UK: +44-845-528-1300
Hong Kong: +852-301-84916
India (Pune): +91-20-66346060
Fax: +1(855)550-5975
Web: https://www.alliedmarketresearch.com
Follow Us on LinkedIn: https://www.linkedin.com/company/allied-market-research
0 notes
Text
How to Use Amazing Mobile Tracker Apps to Monitor Your Phone Location

How Frequently Have you monitored a taxi coming to pick up you in your Place? How frequently have you asked your buddy to talk about their live place on WhatsApp whenever you’re awaiting them? The planet has really got smarter and it’s possible to track a moving thing anywhere in the world from active Manhattan into the most distant places in the Sahara Desert. All this is accomplished thanks to a little device called a mobile tracker. From helping big logistic operators keep tabs on the fleet to meals delivery firms that provide you reside location of the delivery agents, cellular trackers are playing an essential part in today’s world. The simple fact which you’re able to reserve a taxi on a program or purchase food online is thanks to the technology.
What’s A Mobile Phone Tracker?
A mobile phone tracker is a very simple program that may provide you with real-time locational upgrades in an enabled device. These programs are utilized for quite a very long time in monitoring moving fleets on the streets and boats on the high seas.
A mobile phone tracker app displays live data of a physical thing on a physical or even a satellite map. Even though you might have heard about those programs used commercially their usage for personal needs and needs has grown during the past couple of years.
With a broad choice of programs offered for Android and iOS platforms, monitoring is now simple.
How Does A mobile Phone Tracker App Work?
Mobile It’s the planet’s most innovative navigation system that utilizes a system of satellites to find any gadget.
This satellite system can present a precise place of any device accurate to several meters. The satellites ship down signs to the ground as well as also the GPS receivers in the telephones and other devices send these signs to the satellites carrying which are then flashed into a monitoring device.
The satellite system contrasts the time and space whilst relaying the signs to offer you the precise location of this item. This permits the recipient’s platform to get real-time information on the items economically and with a high quantity of precision.
Modern programs go beyond supplying the location of this item and may also be used to extract real time pictures, videos, text messages, and other details in the telephone. The simplicity of use of the app combined with a dash that features access to a number of sorts of information like voice calls text and log messages. Its web-based dashboard divides it from other mobile tracking apps which could only be utilized on mobile devices.
Top 10 Mobile Phone Tracking Apps
TheWiSpy
It lets them keep an eye on the teenaged children subtly. Aside from the normal characteristics of place monitoring TheWiSpy cell phone tracker also enables tracking of telephone logs, messages, and contacts. It permits parents to make a geo-fence where real time alarms are sent whenever the weapon is transgressed.
CocoSpy
This could help monitor text messages, telephone history, location information, WhatsApp actions, sound, camera, and also action on social media platforms like facebook, Skype, and Instagram, etc. The telephone tracker functions discreetly and is quite simple to use.
HoverWatch
Why is this program special being the simplicity of usage? It permits you to keep an eye on the place of your nearest and dearest remotely. Besides the location of their loved ones that all can keep tabs on Internet activities and includes live telephone recording feature.
Spyzie
This is the most used program used primarily for monitoring. It delivers the most exact location info and contains high uptime.
Google Maps
With this app you would have the ability to keep an eye on loved ones in your loved ones and among friends and family. The wise features on this program allow users to monitor and protect their nearest and dearest. From creating personal circles to sharing places this program delivers a variety of attributes.
Live360
The program is unique since it provides offline GPS navigation features. The program has a clean interface which divides it from the audience. It gives advice on a sharp bend, speed camera and speed limits before making it among the most well-known programs for driving.
XnSpy
The program used GPS place qualities to bridge the last mile delivery difference between companies and their customers.
SpyBundle
It’s compatible with different operating systems and aids in monitoring the position of the nervous apparatus together with various tasks on it. From recording telephone calls for taking screenshots in real time it’s innovative monitoring software that keeps an eye on all of the tasks on the telephone. In addition, it can read text messages along with social media messages.
SpyEra
From extracting the telephone log history to monitoring live telephone calls and text messages it may provide a good deal of advice on the consumers.
This Sums up our listing of the top 10 mobile tracking apps. These programs individually. The majority of these programs are constantly undergoing development to offer smarter attributes to the consumers.
Originally Published by: http://techenger.com/gadgets-apps/how-to-use-amazing-mobile-tracker-apps-to-monitor-your-phone-location/
Republish by: Blogger , Strikinlgy , Wix
0 notes
Text
Virtual reality Application | Application development Services| Augmented Reality
Virtual reality Application | Application development Services| Augmented Reality
Labels shape our perception of the world. We usually prefer to know the names of objects, people, and places we interact with or even more - what brand of a particular product we are going to purchase reference and the response of others give about quality. The device is equipped with image recognition can automatically detect the labels. An image recognition application software for smartphones is just a tool to capture and detect the name of digital photos and video.
Also, Read: virtual reality Application Development
By developing highly accurate, controllable, and flexible image recognition algorithms, it is now possible to identify the images, text, video, and objects. Let's find out what it is, how it works, how to create an image recognition application, and what technology is used when doing so.
What image recognition in artificial intelligence?
AI-based systems have also begun to computers outperform trained on a less detailed knowledge of the subject.
AI image recognition is often considered a single term is discussed in the context of computer vision, machine learning as part of artificial intelligence, and signal processing. To put it in a nutshell, the recognition of a particular image of three. So, basically, the image recognition software may not be used synonymously for signal processing, but can definitely be considered as part of a large domain of AI and computer vision. Let's take a closer look at what each of the four concepts mean.
image recognition in Artificial Intelligence
Also, Read virtual reality Application Development
image recognition. With the image into the main input and output elements, image recognition is designed to understand the visual representation of a particular image. In other words, the software is trained to extract a lot of useful information and perform an important role to provide answers to questions such as the picture. This is how the term recognition image is usually understood.
signal processing. can input not only images but also a variety of signals such as voice and biological measurements. This is a useful signal when it comes to speech recognition as well as for a variety of applications such as face detection. SP is a wider field than the image identification technology and mixed with profound learning, it is able to discover patterns and relationships that, until now, were not observed.
computer vision. This is a whole related disciplines by building artificial systems that receive information from input sources such as images, video, or data hyperspectral more multi-dimensional. The process involves a computer vision techniques such as face detection, segmentation, tracking, pose estimation, localization and mapping, and object recognition. These data are processed by the application programming interface (API), which will be discussed later in the article.
Also, Read: virtual reality Application Development
Machine learning. This is a general term for all of the above concepts. ML includes image recognition, signal processing, and computer vision. Moreover, it is quite a common framework in terms of input and output - it takes any sign of input return information quantitatively or qualitatively, signals, images or video as output. This diversity of requests and responses is enabled through the use of a large and complex ensemble of general machine learning algorithms.
How the image recognition software work
Image detection is done by using two different methods. This method is referred to as a neural network method.
In supervised learning, the process used to determine whether a particular image in a particular category, and then compared with those in the categories that have been detected. In unsupervised learning, the process used to determine whether the images in a category by itself. complex neural network computational methods designed to enable the classification and tracking of images.
Also, Read: virtual reality Application Development
What you should know is that the image recognition application software most likely will use a combination of supervised and unsupervised algorithms.
Classification method (also called supervised learning) using machine-learning algorithms to estimate the features in the picture called essential characteristics. It then uses this feature to make predictions about whether an image may be of interest to a particular user. A machine learning algorithm will be able to tell whether an image contains an important feature for the user.
Metadata classify the images and extract information such as size, color, format, and the format of the border. Figure categorized in different tags, called class information, and each tag associated with the image. This information is used by the class recognition engines to understand the "meaning" of the image.
The data used to identify the image, for example: "cute baby" or "pictures of dogs", should be labeled to be useful. This requires the data to be analyzed using information extraction techniques such as classification or translation.
Thus, the pattern recognition in image processing is a multi-step process that includes:
Detection of the original image
Analysis and classification of data
reinforcement learning
AI training process
Monitoring and twisting of the training process
Also, Read: virtual reality Application Development
How to choose an image recognition API?
Another important component to keep in mind when aiming to create an image recognition application is API. Various APIs computer vision has been developed since the beginning of AI and ML revolution. Image recognition API to take advantage of the latest technological advances and provide recognition applications your photo image matching the power to offer better and more powerful features. Thus, the service hosts available APIs to integrate with existing applications or used to build a particular feature or an entire business.
Also Read: Virtual reality App Developers
Not every company has sufficient resources to invest in building out the entire engineering team of computer vision. So, the following is a list of image recognition API that you need to pay attention to if you want some solutions off-the-shelf open source to make your life easier:
API Google Cloud Vision. Google Cloud Vision API allows you to upload images or create custom datasets for image recognition. It helps you look for patterns of known human and produce an image of them. It is available on the Google Cloud Platform (GCP). You can integrate it with some image processing projects, as well as in your own application.
Amazon Rekognition. One of the best ways to perform image recognition is to use Amazon's system. Amazon Rekognition offers diversity API that allows you to train your own visual recognition engine and image segmentation & Video detect and analyze objects, faces, or explicit content, recognize faces or the faces of celebrities and much more.
Also Read: Virtual reality App Developers
IBM Watson Visual Recognition. Watson Visual Recognition of services on the IBM Cloud is suitable for many applications because it allows users to have flexibility in the use of the API. pre-trained models provided by the Visual Recognition service can be used to build applications that have the potential to perform in many settings. The model is then trained to detect certain classes of objects.
Also Read: Virtual reality App Developers
API Microsoft Computer Vision. This image recognition software is an integral part of the Cognitive Azure Services. This makes it possible to identify and analyze the content in the image. Additionally, use it, you can try to train the computer vision you to recognize the faces and emotions of society. It is easy to introduce Computer Vision services to your application - just add an API call.
Also Read: Virtual reality App Developers
API Clarifai. It is one of the best image search services. Community offers (with a free API key), Essential, and Enterprise plan to choose from. One can use either off-the-shelf image recognition models or build a model of their own custom trained. A ready-made model can detect faces, colors, clothing, identify foods, and other things. It is significantly faster than other search engines because it uses inference rather than directly finding.
0 notes
Text
New Google My Business features aim to help SMBs pivot and survive COVID-19
Google reported searches for “how to help small businesses” spiked in March, “increasing more than 700% since February.” Partly in response to this outpouring of interest, Google introduced support links in early May. This is just one of several new features and tools Google is rolling out broadly in an effort to help local businesses survive COVID-19.
Global expansion of support links. Initially available for English speaking markets (i.e., U.S., U.K, Canada, Ireland, Australia and New Zealand), support links are now expanding to 18 additional countries including Japan, Spain and Italy. They allow business owners to add donation and gift card links to business profiles, through Google partnerships with PayPal and GoFundMe. For gift cards, Google is working with Square, Toast, Clover and Vagaro.
Google said that a business name search will expose donation or gift card links on the Business Profile (screenshot below). The company added that soon people will be able to use Search and Maps to find nearby/near me businesses seeking support.
By popular demand. I asked whether there was any evidence that these links would result in meaningful support or help to local businesses. Google’s SVP of Google Maps Jen Fitzpatrick pointed to the search query volume and added, during a conference call, that anecdotal evidence indicated high demand for them.
Support links

Online classes and virtual appointments. During that same conference call previewing these announcements, Google discussed the shift from in-person and offline services to online classes and “virtual appointments.” Accordingly, the company is going to surface online services with several new business attributes such as “online classes,” “online appointments,” or “online estimates.” Google said that “in the coming weeks,” it will make these attributes more visible in Search and Maps.
The company is also expanding the Reserve with Google program beyond in-person appointments to online services. The program features a growing roster of third party booking software providers. For online services it’s adding Booksy, WellnessLiving, Zooty and Regis to start. “Merchants working with one of these partners can offer online bookings directly on Google and share details with customers about how to pay and join the meeting using their preferred video platform,” Google said in its blog post.
As businesses begin to reopen, some of them have secondary hours. Below is an example of a restaurant that operates a drive-through after the main restaurant is closed. But this also applies to special grocery store hours for seniors or pharmacies within a larger supermarket or drugstore. (Local SEO Carrie Hill goes into more detail on secondary hours.)
Secondary hours

A million COVID posts. Among other data shared during the call, Google emphasized the success of COVID posts. The company said it has seen more than a million such posts since March, “with millions of clicks to merchants’ websites every week.” In addition, there have been “more than 200 million edits to business profiles” since February,” many of these addressing special hours and temporary closures.
In the restaurant category, “more than 3 million restaurants have added or edited their dining attributes,” (i.e., “takeout,” “delivery”) since March. And Google has added more attributes, such as “no contact delivery” and “curbside pickup.” The company is also bringing on more food-delivery services globally.
More control over food delivery. Food delivery been quite a controversial topic during the pandemic, with some delivery providers being accused of unethical business practices (e.g., hijacking listings) or extracting excessive fees from struggling restaurants. Google says it’s going to give restaurants greater control over which delivery services are associated with their profiles and the ability to identify a preferred food-delivery provider.
I asked whether Google checks to see if there’s an actual business relationship between the delivery service and the restaurant. Google says that it does but if a restaurant sees an unauthorized vendor on its profile, the owner can “contact Google My Business support to get the third-party vendor removed.”
Why we care. It’s important to point out that Yelp offers many of the same features and tools, including some that Google does not. But anyone working with local businesses or multi-location brands knows the gravitational importance of Google My Business. And while there’s nothing dramatic among the new announcements, they reflect an acceleration in the platform’s evolution — as a gateway to both offline and, increasingly, online services and e-commerce.
The post New Google My Business features aim to help SMBs pivot and survive COVID-19 appeared first on Search Engine Land.
New Google My Business features aim to help SMBs pivot and survive COVID-19 published first on https://likesandfollowersclub.weebly.com/
0 notes
Text
New Google My Business features aim to help SMBs pivot and survive COVID-19
Google reported searches for “how to help small businesses” spiked in March, “increasing more than 700% since February.” Partly in response to this outpouring of interest, Google introduced support links in early May. This is just one of several new features and tools Google is rolling out broadly in an effort to help local businesses survive COVID-19.
Global expansion of support links. Initially available for English speaking markets (i.e., U.S., U.K, Canada, Ireland, Australia and New Zealand), support links are now expanding to 18 additional countries including Japan, Spain and Italy. They allow business owners to add donation and gift card links to business profiles, through Google partnerships with PayPal and GoFundMe. For gift cards, Google is working with Square, Toast, Clover and Vagaro.
Google said that a business name search will expose donation or gift card links on the Business Profile (screenshot below). The company added that soon people will be able to use Search and Maps to find nearby/near me businesses seeking support.
By popular demand. I asked whether there was any evidence that these links would result in meaningful support or help to local businesses. Google’s SVP of Google Maps Jen Fitzpatrick pointed to the search query volume and added, during a conference call, that anecdotal evidence indicated high demand for them.
Support links

Online classes and virtual appointments. During that same conference call previewing these announcements, Google discussed the shift from in-person and offline services to online classes and “virtual appointments.” Accordingly, the company is going to surface online services with several new business attributes such as “online classes,” “online appointments,” or “online estimates.” Google said that “in the coming weeks,” it will make these attributes more visible in Search and Maps.
The company is also expanding the Reserve with Google program beyond in-person appointments to online services. The program features a growing roster of third party booking software providers. For online services it’s adding Booksy, WellnessLiving, Zooty and Regis to start. “Merchants working with one of these partners can offer online bookings directly on Google and share details with customers about how to pay and join the meeting using their preferred video platform,” Google said in its blog post.
As businesses begin to reopen, some of them have secondary hours. Below is an example of a restaurant that operates a drive-through after the main restaurant is closed. But this also applies to special grocery store hours for seniors or pharmacies within a larger supermarket or drugstore. (Local SEO Carrie Hill goes into more detail on secondary hours.)
Secondary hours

A million COVID posts. Among other data shared during the call, Google emphasized the success of COVID posts. The company said it has seen more than a million such posts since March, “with millions of clicks to merchants’ websites every week.” In addition, there have been “more than 200 million edits to business profiles” since February,” many of these addressing special hours and temporary closures.
In the restaurant category, “more than 3 million restaurants have added or edited their dining attributes,” (i.e., “takeout,” “delivery”) since March. And Google has added more attributes, such as “no contact delivery” and “curbside pickup.” The company is also bringing on more food-delivery services globally.
More control over food delivery. Food delivery been quite a controversial topic during the pandemic, with some delivery providers being accused of unethical business practices (e.g., hijacking listings) or extracting excessive fees from struggling restaurants. Google says it’s going to give restaurants greater control over which delivery services are associated with their profiles and the ability to identify a preferred food-delivery provider.
I asked whether Google checks to see if there’s an actual business relationship between the delivery service and the restaurant. Google says that it does but if a restaurant sees an unauthorized vendor on its profile, the owner can “contact Google My Business support to get the third-party vendor removed.”
Why we care. It’s important to point out that Yelp offers many of the same features and tools, including some that Google does not. But anyone working with local businesses or multi-location brands knows the gravitational importance of Google My Business. And while there’s nothing dramatic among the new announcements, they reflect an acceleration in the platform’s evolution — as a gateway to both offline and, increasingly, online services and e-commerce.
The post New Google My Business features aim to help SMBs pivot and survive COVID-19 appeared first on Search Engine Land.
New Google My Business features aim to help SMBs pivot and survive COVID-19 published first on https://likesfollowersclub.tumblr.com/
0 notes