#Amazonproductscraping
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Distinguish the Best Selling Amazon Products Using Amazon Product Scraping
Enter your text Distinguish the Best Selling Amazon Products Using Amazon Product Scraping
A large-size e-commerce company is required to identify the best-sellers for the platform using Amazon data analysis. Distinguish the Best Selling Amazon Products Using Amazon Product Scraping
Get Started Now
Client
A large-size e-commerce Indian player
IWeb Data Scraping Offerings
Amazon Product Data Scraping with our web data crawling solutions.
Client’s Challenge
The client wanted to extract Amazon products data to recognize the best-selling Amazon products as well as in response come with all future best-sellers for the e-commerce platform.
The customer also needed the best-selling products from an entire catalog as well as categories, grouped individually. The required data points included the product’s name, brand, model, description, ratings, specifications, bestseller’s ranks, and review counts.
Our Solution: Amazon Products Data Scraping
Client’s Requests: The client had provided us with the list of specific data points for getting extracted from Amazon. The newest data sets were mandatory from Amazon every week.
Scraping Setup: IWeb Data Scraping has set the data crawlers with programming to fetch the required data fields as well as those particular cases are available under our web crawling offerings because Amazon product data scraper is precisely well-programmed for scraping data from all particular source websites.
Data Delivery: With years of expertise in Amazon product data scraping, we have begun offering clean data to the client straight away after this setup has been completed. A data format delivery has selected by this customer was XML and the data was uploaded openly in the client’s S3 location.
Web Scraping Advantages
All the technically complicated characteristics of web crawling and data scraping were handled well by our professional team.
Monitoring got established for a resource website to find changes, which need modifications of crawlers.
The customer had Amazon’s best-selling products, category-wise as well as ready to get fed in the apps. Our greater-tech stack had dealt millions of records every week.
The setup had been completed within a few days and data was provided within record timings.here...
Know More: https://www.iwebdatascraping.com/distinguish-the-best-selling-amazon-products-using-amazon-product-scraping.php
#BestSellingAmazonProducts#AmazonProductScraping#ScrapeBestSellingAmazonProducts#Amazonproductdatascraper#ExtractBestSellingAmazonProducts
0 notes
Text
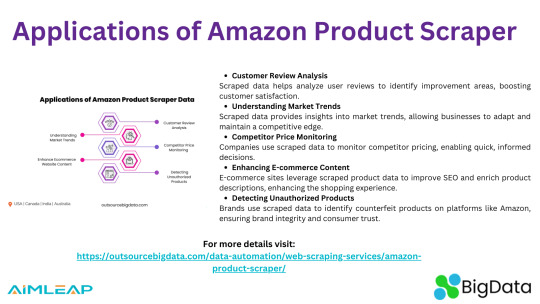
Amazon product scrapers provide businesses with valuable insights by extracting data such as customer reviews, competitor prices, and market trends. This data helps companies enhance their product listings, optimize pricing strategies, improve SEO, and detect unauthorized or counterfeit products, ultimately boosting sales and customer satisfaction.
0 notes
Text
Amazon Product Scraper | Web Scraping Amazon Product Data

Amazon Product Scraper - Web Scraping Amazon Product Data
RealdataAPI / amazon-product-scraper
You can use the Amazon Product Data Scraper to obtain Amazon product information such as prices, reviews, and ASINs without using Amazon API. This service is available in various countries, including Australia, Canada, Germany, France, Singapore, USA, UK, UAE, India, and others. It is considered the best Amazon Product data scraping service provider.
Customize me! Report an issue E-commerce
Readme
API
Input
Related actors
What is Amazon Data Scraper, and what is its working process?
Amazon Data Extractor Is A Data Scraping Actor That Allows You To Scrape Amazon Product Data From Product URLs Or Subcategory URLs.https://www.amazon.com/s?i=specialty-aps&bbn=16225007011&rh=n%3A16225007011%2Cn%3A1292115011
Generally, Amazon Subcategory Permalink Includes /S After The Amazon Domain. Therefore Ensure To Maintain Your URL Looks Like The Above Example.
Therefore, Add Any Links In The Input And Choose As Many Products As You Want To Collect. Then Export The Output Schema. You Can Also Get This Information Directly From The API Without Logging In To The Real Data API Platform.
Why extract products from Amazon?
Extracting Products From Amazon Can Help You
Track the performance of Amazon subcategories and categories to put them into context.
Improve your messaging and advertising campaigns.
Uncover emerging and growing brands to benchmark your product performance inside its category depending on reviews, traffic, and conversions.
Utilize Amazon data to stay ahead in competitive intelligence.
For More Motivation, Explore How Data Extraction Is Helping ECommerce Analytics To Transform.
Is it legal to extract Amazon product data?
You Can Scrape Publicly Available Amazon Data Like Product Prices, Descriptions, Or Ratings. To Know More, You Can Check Out Our Blog.
How can I extract Product data from Amazon?
You Can Follow This Step-By-Step Tutorial For The Amazon Product Data Scraping Process.
Do you want more Amazon scraping alternatives?
Check Out The Below Amazon Scrapers.
Amazon ASINs Scraper
Amazon Reviews Scraper
Amazon Best Sellers Scraper
Input options
While Running This Scraper, You Must Configure What You Wish To Extract With The Process. You Can Feed An Input As A JSON File Or In The Real Data API Editor. Most Input Points Have Default Values.
Go To The Dedicated Input Option For Detailed Examples And Descriptions Of Each Input Field.
Note The Below Points While Using This Actor To Scrape Amazon Products.
You May Not Get Price Information If No Sellers Are In A Particular Delivery Country. Setting Up A Specific Real Data API Proxy Country In The Proxy Setting Must Help You. You'll Still Find The Difference In Product Prices Based On The United States. Amazon Also Displays Several Offers For Your Proxy Geolocation.
Sample result of Amazon Data Scraper
{ "Title": "SanDisk 1TB Extreme MicroSDXC UHS-I Memory Card With Adapter - Up To 190MB/S, C10, U3, V30, 4K, 5K, A2, Micro SD Card- SDSQXAV-1T00-GN6MA", "Url": "Https://Www.Amazon.Com/Dp/B09X7MPX8L", "Asin": "B09X7MPX8L", "InStock": True, "InStockText": "Only 8 Left In Stock - Order Soon. Only 8 Left In Stock - Order Soon.", "Brand": "SanDisk", "Price": { "Value": 145.5, "Currency": "$" }, "ListPrice": { "Value": 299.99, "Currency": "$" }, "ShippingPrice": Null, "Stars": 4.8, "StarsBreakdown": { "5star": 0.86, "4star": 0.09, "3star": 0.02, "2star": 0.01, "1star": 0.01 }, "ReviewsCount": 36704, "AnsweredQuestions": 151, "BreadCrumbs": "Electronics › Computers & Accessories › Computer Accessories & Peripherals › Memory Cards › Micro SD Cards", "ThumbnailImage": "Https://M.Media-Amazon.Com/Images/I/716kSUlHouL.__AC_SX300_SY300_QL70_FMwebp_.Jpg", "Description": Null, "Features": [ "Save Time With Card Offload Speeds Of Up To 190MB/S Powered By SanDisk QuickFlow Technology (Up To 190MB/S Read Speeds, Engineered With Proprietary Technology To Reach Speeds Beyond UHS-I 104MB/S, Requires Compatible Devices Capable Of Reaching Such Speeds. Based On Internal Testing; Performance May Be Lower Depending Upon Host Device Interface, Usage Conditions And Other Factors. 1MB=1,000,000 Bytes. SanDisk QuickFlow Technology Is Only Available For 64GB, 128GB, 256GB, 400GB, 512GB, And 1TB Capacities. 1GB=1,000,000,000 Bytes And 1TB=1,000,000,000,000 Bytes. Actual User Storage Less.)", "Pair With The SanDisk Professional PRO-READER SD And MicroSD To Achieve Maximum Speeds (Sold Separately)", "Up To 130MB/S Write Speeds For Fast Shooting (Based On Internal Testing; Performance May Be Lower Depending Upon Host Device Interface, Usage Conditions And Other Factors. 1MB=1,000,000 Bytes.)", "4K And 5K UHD-Ready With UHS Speed Class 3 (U3) And Video Speed Class 30 (V30) (Compatible Device Required. Full HD (1920x1080), 4K UHD (3840 X 2160), And 5K UHD (5120 X 2880) Support May Vary Based Upon Host Device, File Attributes And Other Factors. See HD Page On SanDisk Site. UHS Speed Class 3 (U3) Designates A Performance Option Designed To Support Real-Time Video Recording With UHS-Enabled Host Devices. Video Speed Class 30 (V30), Sustained Video Capture Rate Of 30MB/S, Designates A Performance Option Designed To Support Real-Time Video Recording With UHS-Enabled Host Devices. See The SD Association’s Official Website.)", "Rated A2 For Faster Loading And In-App Performance (A2 Performance Is 4000 Read IOPS, 2000 Write IOPS. Results May Vary Based On Host Device, App Type And Other Factors)" ], "VariantAsins": [], "ReviewsLink": "/SanDisk-Extreme-MicroSDXC-Memory-Adapter/Product-Reviews/B09X7MPX8L?ReviewerType=All_reviews", "Delivery": "Thursday, January 26", "FastestDelivery": "Sunday, January 22", "ReturnPolicy": "Eligible For Return, Refund Or Replacement Within 30 Days Of Receipt Eligible For Return, Refund Or Replacement Within 30 Days Of Receipt", "Support": "Free Amazon Tech Support Included", "VariantAttributes": [], "PriceVariants": Null, "Seller": { "Name": "Direct Suppliers US", "Id": "A210SJF12S88M5", "Url": "/Gp/Help/Seller/At-A-Glance.Html/Ref=Dp_merchant_link?Ie=UTF8&Seller=A210SJF12S88M5&Asin=B09X7MPX8L&Ref_=Dp_merchant_link&IsAmazonFulfilled=1", "ReviewsCount": Null, "AverageRating": Null }, "BestsellerRanks": Null, "LocationText": "Select Your Address" }
Integrations with Amazon Data Scraper
You Can Connect This API With Almost All Web Applications Or Cloud Services Using Real Data API Integrations. You Can Connect With Slack, GitHub, Zapier, Make, Google Drive, And Sheets. You Can Also Use Webhooks To Conduct Event Actions, Like Getting An Alert When Amazon API Completes The Execution.
Executing Amazon Data Scraping Actor with Real Data API
The Real Data API Actor Offers You Programmatic Access To The Real Data API Platform. The Actor Is Organized About RESTful HTTP Points To Allow You To Schedule, Manage, And Execute Real Data API Actors. The Actor Also Gives You Access To All Datasets, Fetch Outputs, Track API Performance, Develop And Update Versions, Etc.
To Use The Actor Using Node.Js, Try The Real Data API Client NPM Package, And To Use It Using Python, Try The Real Data API PyPL Package.
Visit The Real Data API Actor Reference Document For Details, Or Open The API Tab To Explore Program Examples.
Know More: https://www.realdataapi.com/amazon-product-data-scraper.php
#AmazonProductScraper#WebScrapingAmazonProductData#ExtractAmazonProductData#AmazonProductDataCollection#ScrapeAmazonProductData#EcommerceDataScraping
0 notes
Text
Amazon Data Scraping Services
One of the largest online retailers, Amazon is the largest online marketplace in the world, consistently selling more than $200 billion in products each year. With WebScrapingExpert, you can access millions of public records on Amazon that most people will never be able to find on their own.
What is an Amazon Data Scraping Service?
By using a web scraping service, you can easily get access to data that is hidden or difficult to find elsewhere. There are many different types of web scraping services, so it is important to choose the right one for your needs. Amazon web scraping services offers a wide range of Amazon Web Scraping services such as data ingestion, data extraction, and data analysis. With experience in project management, we offer complete solutions for scraping Amazon content. Our software can extract any data you need, from names, product features, and images to category information and reviews.
When your business needs market research or preparation for a directory of products, contact us.
Web-Scraping-Service-Data-Extraction-Data-Scraping-Service
Amazon of Data List
– By Brand – By Category – By Product URLs – By Search Keywords – By SKUs/UPC/ASIN – By Store Name
Amazon Listing of Data Fields
We can scrape following data fields:
– Product Name/Title – Product Description – Product Variants – Brand, Manufacturer – Buy Box Price – List Price – Discounted Price – Offered Price – Buy Box Seller Details – Multiple Seller Details & Prices – ASIN, ISBN, UPC – Bullet Points (Description) – Product Specification – Features – Model Number – Product Type: New & Used – Product Weight & Shipping Weight – Product Images – Merchant Description – Product Reviews & Ratings – Sales Ranking – Shipping Information – Best Seller Ranking (BSR) Under Different Categories
Any type of data can be extracted from a website using WebScrapingExpert - from basic information like titles and URLs to complex content such as product descriptions and customer reviews. Additionally, we can scrape social media sites like Facebook and Twitter to gather valuable market insights.
Amazon ASIN Product Data Scraping
Every Amazon product has an ASIN number, which is a ten-digit numeric code. That is the first identifier assigned when a new product is added to Amazon’s inventory. You must have this number in your account before you can sell on Amazon. The only place you can find it is in the Adding a product page of your Amazon Sellers’ Central account by utilizing the search box on the Amazon page. Find what you’re looking for using the product name, UPC code, or EAN, and make sure it is not already available on Amazon.
Amazon Best Seller Ranks Data Scraping
Best Seller Rank is a measure of total sales on Amazon and shows you where your item sold best in its category.
With WebScrapingExpert, you can easily search lists of tens of thousands of best-selling products in Amazon categories from scraped seller data from Amazon, the United States, and the United Arab Emirates. Furthermore, you can choose which top sellers and which group of sellers you wish to question. You may also specify by category which products you wish to group together.
Amazon Buy Box Price Scraping
Amazon Buy Box is the primary way to purchase items on Amazon. A company that sells products on Amazon for an affordable price will be chosen as an eligible Buy Box vendor. WebScrapingExpert offers professional services related to Amazon's Buy Box system at a reasonable cost. This percentage varies based on each individual writer, and a vendor is chosen from all competing companies.
Amazon Sponsored Listings Scraping
Boost your market presence and increase conversions by using Amazon Sponsored Product Ads.
Amazon Inventory Scraping
We offer a service that tracks Amazon's inventory levels in real time. We'll help you understand what your inventory is, set it up, maintain it, and let you know when your stocks are low. Our Amazon Web Scraping services can help you save time by doing the legwork for you.
Amazon Category Rank Data Scraping
While some sellers may be skeptical of Amazon's category rank, there are a lot of nuances to consider when improving your product or service. A product will rank highly on Amazon at first because its usage will rise. Once sales drop to a new low, its ranking may continue to rise again once the number of sales again rises again. In order to keep your Amazon rankings high, WebScrapingExpert is there to scrape your data from Amazon so you can easily and effectively use it in your ongoing campaigns. Amazon's Category Rank allows you to compare products in the same category with one another. Ranking numbers are not necessarily indicative of sales volume, as is often misunderstood. To attain a higher ranking, a product must sell significantly more than its competitors during a given period of time.
Amazon Seller Data Scraping
Amazon Seller Data allows you to match your products better in your market and beat your competitors by scraping Amazon Seller Data. Using the WebScrapingExpert, you can find Amazon categories, lists, and recent trends, and ask for items that generate the best revenue for your site based on Amazon categories, lists, and trends. From a category, a user can get 100,000 Amazon sellers, or they can select the specific ones they want to mention.
>>Get Your Data in Any File Format
Ecommerce websites scraped data can be sent in following file formats:
XML
JSON
CSV
XLS
Excel
Why choose us?
WebScrapingExpert manages this effortlessly and without any infrastructure to maintain. Sites with limited connectivity or scrapers would have difficulty mining huge amounts of data quickly with a high degree of accuracy. The vast customization options of WebScrapingExpert allow you to complete any data analysis with accuracy and precision. WebScrapingExpert always ensures your query is resolved as soon as possible.
Our team of experts has years of experience extracting data from websites. If you would like to know more about our services or get a quote, feel free to contact us. We will be happy to discuss your project requirements and provide you with a custom solution.
If you are looking for the Amazon Data Scraping services, then email us at: [email protected].
0 notes
Text
What is Amazon Distribution Data Scraping Services?
Our Amazon Distribution Data services scrape all the product data from the Amazon Distribution. All this data gets applied by the users for tracing and framing the product’s shopping inclination.
About Amazon Distribution
Amazon Distribution is the members-only website and app which has been specially designed to fulfill the requirements of Department Stores, Kiranas, Pharmacies, as well as other resellers. They provide an extensive range of products at reasonable prices as well as the suitability of next-day delivery at door-step. Being a member, you could buy thousands of products for resale any time at economical prices as well as in bulk, pay through different payment options accessible, have bills for your order, as well as reliable and convenient door-step deliveries on the next day.
Amazon Distribution has created particular features precisely meant for easing the purchase procedure for the business customers including ‘Add to Cart’ functionality on search pages. Their wide assortment consists of products in different categories including Beauty, Baby Care, Laundry, Health & Personal Care, Stationery, and Food & Beverages. On AmazonDistribution.in, they provide 100% genuine products having year-round advertising offers, discounts, as well as the finest schemes.
iWeb Scraping provides the Best Amazon Distribution Data Scraping services to extract or Scrape Amazon Distribution Data. Get affordable Web Scraping Services from iWeb Scraping.
List Of Data Fields
At iWeb Scraping, we scrape the following data fields from Amazon Distribution:
Product Name
ASIN
Brand
MRP
Listing Price
Incl. GST
Margin
Product Weight

Where the databases get used as the data resource for saving data, the data distribution means those sources that store aged data. The databases store current data whereas data warehouses store respected data.
In case, you wish to launch new products, you can find the product development fitting to a similar niche on a marketplace like Amazon. You may utilize Amazon Distribution Data Scraping Services for scraping data from the Amazon Distribution website. The extracted data would get used for comparison and route product tactics.
If you wish to launch an online store, you need more detailed and aged data like which kind of products are very popular currently, are they user’s option, what changes marketers have done in products, etc. Therefore, you need a scraper to harvest data from marketplaces like Amazon Distribution. It’s easy to use tools like Amazon Distribution Data scraper to fulfill your requirements.
Our Amazon Distribution Data services scrape all the product data from the Amazon Distribution website. All these data get implemented through the users for tracing and framing the product’s shopping favorite. It also arranges product data in CSV format. This is appropriate when you extract massive data as it eases users getting ‘one-click scraping, they don’t require to search for every product individually.
#AmazonDistributionDataScraping#ScrapeAmazonDistributionData#Amazonscraper#AmazonProductScraper#AmazonDataExtractor
1 note
·
View note
Link
iWeb Scraping provides the Best Amazon Distribution Data Scraping services to extract or Scrape Amazon Distribution Data. Get affordable Amazon Distribution Scraping services from iWeb Scraping.

#AmazonDistributionDataScraping#ScrapeAmazonDistributionData#AmazonScraper#AmazonProductScraper#AmazonDataExtractor
1 note
·
View note
Photo

We provide the ideal amazon Scraping Tool that perfectly meets your business requirements. Get information such as Product Name, Category, Search URL, Company Name, Pricing, Stock, offers, bestsellers list, Ratings, Reviews, and much more by Amazon data scraper.
For more information, visit our official page https://www.linkedin.com/company/hir-infotech/ or contact us at +91 99099 90610
#amazonscraper#amazonproductscraper#amazonproductscrapertool#webscraper#WebScrapingTools#webdatamining#datascraping#hirinfotech
1 note
·
View note
Text
Web Scraping for Price Drops - Track Amazon, Flipkart, Myntra Deals
Web Scraping for Price Drops helps you track deals on Amazon, Flipkart, and Myntra, ensuring you never miss discounts.
Know more>> https://www.actowizsolutions.com/web-scraping-price-drops-track-amazon-flipkart-myntra-deals.php
#AmazonProductScraping#WebScrapingAmazon#EcommerceDataScraping#AmazonDataExtraction#ScrapeAmazonData#AmazonPriceTracking#AmazonDataScraper#FlipkartProductScraping#WebScrapingFlipkart#FlipkartDataExtraction#ScrapeFlipkartData#FlipkartPriceTracking#FlipkartDataScraper#FlipkartScrapingTools#MyntraProductScraping#WebScrapingMyntra#MyntraDataExtraction#MyntraDealsScraping#ScrapeMyntraData#MyntraPriceTracking#MyntraDataScraper
0 notes
Text
Distinguish the Best Selling Amazon Products Using Amazon Product Scraping
Identify top-selling Amazon products effortlessly through Amazon product scraping, extracting valuable data to pinpoint bestsellers and inform strategic decisions effectively.
Know More: https://www.iwebdatascraping.com/distinguish-the-best-selling-amazon-products-using-amazon-product-scraping.php
#BestSellingAmazonProducts#AmazonProductScraping#ScrapeBestSellingAmazonProducts#Amazonproductdatascraper#ExtractBestSellingAmazonProducts#Ecommercedatascrapingservices#ScrapeDatafromEcommerceWebsite
0 notes
Text

Scrape Amazon Product Listings To Elevate Your E-Commerce Strategy
Scrape Amazon product listings for competitive analysis, pricing insights, and market research. Uncover valuable data to optimize your e-commerce strategies and stay ahead of the competition.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-listings-to-e-commerce-strategy.php
#ScrapeAmazonProductListings#scrapeAmazondata#Amazonproductscraping#Amazondatascrapingservices#AmazonProductListingsdatascraper#extractfromAmazonproductpages#AmazonProductScraper#Amazonscrapingtool
0 notes
Text
Scrape Amazon Product Listings To Elevate Your E-Commerce Strategy
Scrape Amazon Product Listings To Elevate Your E-Commerce Strategy

Amazon's e-commerce platform offers many services, yet easy access to their product data needs to be present. E-commerce professionals often find the need to scrape Amazon product listings, whether for competitive analysis, price monitoring, or API integration for app development. Address this challenge effectively through e-commerce data scraping.
It's worth noting that the necessity to scrape Amazon data is broader than just small businesses. Even retail giants like Walmart have engaged in Amazon product scraping to monitor pricing trends and adapt their strategies and policies accordingly.
Reasons to Scrape E-Commerce Product Data

Scraping e-commerce data offers several valuable benefits:
Competitive Analysis: E-commerce data scraping helps businesses analyze and monitor competitors' product offerings, pricing strategies, and market positioning, enabling them to make informed decisions and stay competitive.
Price Monitoring: Real-time price monitoring through web scraping allows businesses to adjust their pricing strategies to remain competitive and maximize profits. E-commerce data scraping services also help consumers find the best deals.
Market Research: Scraping e-commerce data provides insights into market trends, consumer preferences, and emerging product categories. This information is crucial for making data-driven decisions and identifying growth opportunities.
Product Development: E-commerce data scraping can help businesses identify gaps in the market, consumer demands, and product features. This information is valuable for developing new products and improving existing ones.
Inventory Management: Retailers can use e-commerce data scraper to track stock levels, ensuring they have the right products in the right quantities. It prevents overstocking or understocking, reducing costs and optimizing supply chain management.
Customer Insights: Analyzing user reviews, ratings, and feedback from e-commerce platforms can help businesses gain valuable customer insights. This feedback helps improve customer service, identify pain points, and enhance the shopping experience.
Why Scrape Amazon Product Data?

Amazon holds a wealth of critical data: products, ratings, reviews, special offers, and more. E-commerce data scraping benefits both sellers and vendors. Navigating the vast internet data landscape, particularly in e-commerce, is challenging, but Amazon data scraping can simplify it.
Enhance Product Design: Products undergo iterative development phases. After initial design, putting a product on the market is just the beginning. Client feedback and evolving needs demand redesign and improvement. Hence, scraping Amazon data, like size, material, and colors, aids in identifying opportunities to enhance product design.
Incorporate Customer Input: After scraping fundamental design features and identifying areas for improvement, it's essential to consider customer input. While user reviews differ from raw product data, they often provide insights into design and the purchase process. Scrape Amazon data, specifically reviews, to highlight familiar sources of customer confusion. E-commerce data scraping simplifies reviewing and comparing feedback, facilitating trend detection and issue resolution.
Find the Optimal Pricing: Material and style matter, but the cost is a top priority for many customers. Price is the primary factor distinguishing similar products, especially in Amazon search results. Scraping price data for your and your competitor's products unveils a range of pricing options. This data helps determine where your company stands within that range, factoring in manufacturing and shipping costs.
Access Amazon Product Data Unavailable via the Product Advertising API: While Amazon offers a Product Advertising API like other APIs, it doesn't provide all the information displayed on a product page. Amazon data scraping services can fill this gap, enabling the extraction of comprehensive product page data.
List of Data Scraped from Amazon

Glean the data from scraping Amazon product listings offers numerous advantages. Manual data collection is more challenging than it seems. Amazon product scraping tools expedite the process, including:
Product Name: Extract essential insights for naming and creating a unique product identity through e-commerce data scraping.
Price: Crucial for pricing decisions, scraping Amazon product listings reveals market trends and preferred pricing.
Amazon Bestsellers: Identify main competitors and successful product types with Amazon bestseller scraping.
Image URLs: Opt for the best-suited images and gather inspiration for your product designs from scraped image URLs.
Ratings and Reviews: Utilize customer input stored in sales, reviews, and ratings to understand customer preferences through Amazon data scraping.
Product Features: Understand product technicalities and use them to define your Unique Selling Proposition (USP).
Product Type: Automate the process of categorizing products, as manually scraping hundreds of product types is impractical.
Product Description: Create compelling and elaborate product descriptions to attract customers.
Company Description: Scrape Amazon product listings to gain insights into competitors' activities and offerings.
Product Rank: Gain a competitive edge by understanding product rankings and the positions of your direct competitors through Amazon product data scraping.
Challenges Adhered While Scraping Amazon Product Data and How to Overcome Them

Challenges when scraping Amazon product data at scale pose significant hurdles, particularly on e-commerce platforms. Key issues your scraper tool may encounter include:
Detection by Amazon: Amazon can identify and block bot activity, especially with high request volumes. Solutions include solving captchas or rotating IPs and increasing time gaps for scraping.
Varying Page Structures: Regular technical changes on websites can disrupt scrapers, as they lie with specific web page customizations. Adapting code to search for specific product details sequentially can help.
Inefficiency: Scrapers typically have defined algorithms and speeds, which may not be suitable for scraping Amazon product listings with diverse page structures. Designing your scraper to adjust the number of requests based on the structure can be a solution.
Cloud Platform and Computational Resources: Scraping Amazon and other e-commerce websites requires substantial memory resources. Cloud-based platforms and efficient network resources are necessary. Transfer the data to permanent storage to expedite the process.
Data Management: Storing vast amounts of data is essential. Using a database to record the scraped data is advised to prevent data loss.
To overcome Amazon's anti-scraping mechanisms:
Use Proxies and Rotate Them: Frequent IP changes or proxy rotation mimic human behavior, reducing the likelihood of being labeled a bot.
Reduce ASINs Scraped per Minute: Avoid overwhelming the system by spacing out requests and controlling the number of active requests during data scraping.
Specify User Agents: Employ various User Agent Strings, similar to proxies, and rotate them for each Amazon request. It prevents getting blocked from e-commerce sites and enhances your scraping effectiveness.
Steps Involved in Scraping Amazon Product Data

To scrape Amazon product data using Python, follow these steps:
1. Install Prerequisites: Begin by ensuring you have Python, Pip, and the lxml package installed. Then, use Pip to install a web scraping framework for large-scale data extraction.
2. Create a Dedicated Project Directory: Create a separate directory for your scraping project, where you'll organize all the necessary files and scripts. This directory will serve as the workspace for your Amazon data scraping efforts.
3. Specify Fields to Scrape in items.py: In your project directory, you'll typically have an 'items.py' file. Here, you define the specific data fields you intend to extract from Amazon product pages. This step helps structure the data you'll collect.
4. Develop a New Spider: A Spider defines the scraping rules and logic. Create a new Spider tailored to your Amazon data scraping needs. In this Spider, you'll define:
start_urls: These are the initial URLs from which you'll start the scraping process, usually Amazon product pages.
allowed_domains: Define the domains within the scope of your scraping, e.g., amazon.com.
parse() Function: This is where you specify the logic for data extraction. You'll instruct function on how to navigate the pages, locate the data you want (such as product names, prices, and reviews), and extract it. This function is the heart of your scraping process.
5. Customize Data Processing in pipelines.py: In some cases, you should apply additional data processing to the scraped information. The 'pipelines.py' file is the place to define functions for data processing. For example, you could clean or format the data before saving it to your chosen storage destination.
Following these steps, you can set up your project to effectively scrape the desired Amazon product data. Adapt your Spider's logic to target the specific information you want to extract from Amazon's product pages.
Conclusion: Scraping Amazon product listings offers businesses valuable insights for competitive analysis, pricing strategies, and market research. It empowers companies to stay ahead of the competition, optimize pricing, and identify growth opportunities. Moreover, it aids in product development and inventory management, ensuring efficient supply chain operations. Analyzing customer feedback from scraped data helps enhance customer service and the overall shopping experience. Amazon data scraping is a powerful tool for informed decision-making and maintaining a solid presence in the e-commerce landscape.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-listings-to-e-commerce-strategy.php
#ScrapeAmazonProductListings#scrapeAmazondata#Amazonproductscraping#Amazondatascrapingservices#AmazonProductListingsdatascraper#extractfromAmazonproductpages#AmazonProductScraper#Amazonscrapingtool
0 notes
Text
Scrape Amazon Product Listings To Elevate Your E-Commerce Strategy
Scrape Amazon product listings for competitive analysis, pricing insights, and market research. Uncover valuable data to optimize your e-commerce strategies and stay ahead of the competition.
Know More: https://www.iwebdatascraping.com/scrape-amazon-product-listings-to-e-commerce-strategy.php
#ScrapeAmazonProductListings#scrapeAmazondata#Amazonproductscraping#Amazondatascrapingservices#AmazonProductListingsdatascraper#extractfromAmazonproductpages#AmazonProductScraper#Amazonscrapingtool
0 notes
Text
Amazon Product Scraper | Web Scraping Amazon Product Data
Effortlessly scrape Amazon product data with our powerful web scraper. Gain insights, monitor trends, and boost your business efficiency with Amazon Product Scraper.
Know More: https://www.realdataapi.com/amazon-product-data-scraper.php
#AmazonProductScraper#WebScrapingAmazonProductData#ExtractAmazonProductData#AmazonProductDataCollection#ScrapeAmazonProductData#EcommerceDataScraping
0 notes
Text

This blog is a comprehensive, step-by-step guide to constructing your web scraper for Amazon product data!
Know More: https://www.realdataapi.com/develop-amazon-product-scraper-using-nodejs.php
#AmazonProductScraper#ScrapingAmazonProductData#ScrapeAmazonProductData#AmazonWebScraper#AmazonProductDataCollection#ECommerceScraper#ScrapeEcommerce
0 notes
Text
How to Develop an Amazon Product Scraper Using Node.js?
Unlocking Amazon's Treasure Trove of Data: A Guide to Building a Data Extraction Bot with Node.js
Have you ever found yourself needing a deep understanding of a product market? Whether you're launching software and need pricing insights, seeking a competitive edge for your existing product, or simply looking for the best deals, one thing is sure: accurate data is your key to making informed decisions. And there's another common thread in these scenarios - they can all benefit from the power of web scraping.
Web scraping is the art of automating data extraction from websites using software. It's essentially a way to replace the tedious "copy" and "paste" routine, making the process less monotonous and significantly faster, too – something a bot can achieve in seconds.
But here's the big question: Why would you want to scrape Amazon's pages? You're about to discover the answer. However, before we dive in, it's essential to clarify one thing: While scraping publicly available data is legal, Amazon does have measures to protect its pages. Therefore, it's crucial always to scrape responsibly, avoid any harm to the website, and adhere to ethical guidelines.
Why You Should Harvest Amazon Product Data
As the world's largest online retailer, Amazon is a one-stop shop for virtually anything you want to purchase, making it a goldmine of data waiting to be tapped.
Let's start with the first scenario. Unless you've invented a groundbreaking new product, Amazon offers something similar. Scraping these product pages can yield invaluable insights, including:
Competitors' Pricing Strategies: Gain insights into how your competitors price their products, enabling you to adjust your prices for competitiveness and understand their promotional tactics.
Customer Opinions: Explore customer reviews to understand your potential client base's priorities and find ways to enhance their experience.
Most Common Features: Analyze the features offered by competitors to identify critical functionalities and those that can be prioritized for future development.
Essentially, Amazon provides all the essential data for in-depth market and product analysis, equipping you to effectively design, launch, and expand your product offerings.
The second scenario applies to both businesses and individuals alike. The concept is similar to what was mentioned earlier. By scraping price, feature, and review data for various products, you can make an informed decision and choose the option that provides the most benefits at the lowest cost. After all, who doesn't love a good deal?
Not every product warrants this level of scrutiny, but the benefits are evident for significant purchases. Unfortunately, scraping Amazon comes with its fair share of challenges.
Navigating the Hurdles of Scraping Amazon Product Data
Not all websites are created equal, and as a general rule, the more intricate and widespread a website, the more challenging it becomes to scrape. As we previously highlighted, Amazon stands as the juggernaut of e-commerce, underscoring its immense popularity and its considerable complexity.
To begin with, Amazon is well aware of how scraping bots operate, and they have implemented countermeasures. Suppose a scraper follows a predictable pattern, sending requests at fixed intervals or with nearly identical parameters at a speed beyond human capacity. In that case, Amazon detects this behavior and promptly blocks the IP address. While proxies can circumvent this issue, they may not be necessary for our example since we will only scrap a few pages.
Moreover, Amazon intentionally employs diverse page structures for its products. In other words, if you inspect the pages of different products, you will likely encounter significant variations in their layout and attributes. This deliberate tactic forces you to adapt your scraper's code for each specific product system. Attempting to apply the same script to a new page type necessitates rewriting portions, making you work harder for the desired data.
Lastly, Amazon's vastness poses another challenge. If you aim to collect copious amounts of data, running your scraping software on a personal computer may prove excessively time-consuming for your requirements. This predicament is exacerbated by the fact that scraping too quickly will block your scraper. Therefore, if you seek substantial data swiftly, you'll need a robust scraping solution.
Enough dwelling on the obstacles—let's focus on solutions!
How to Create an Amazon Web Scraper
Let's keep things straightforward as we walk through the code. Feel free to follow along with the guide.
IDENTIFYING THE TARGET DATA
Imagine this scenario: you're planning to move to a new location in a few months and need to find new shelves to accommodate your books and magazines. You aim to explore all available options and secure the best possible deal. To kick things off, head to Amazon's marketplace, search for "shelves," and see what we can find.
Let's take a moment to assess our current setup. A glance at the page reveals that we can readily gather information about:
The appearance of the shelves
The contents of the package
Customer ratings
Pricing
Product links
Suggestions for more affordable alternatives for some items
This is undoubtedly a wealth of data to work with!
PREPARING THE NECESSARY TOOLS
Before proceeding to the next step, let's ensure we have the following tools installed and configured:
1. Chrome: You can download it [here](insert Chrome download link here).
2. VSCode: Follow the installation instructions for your specific device found [here](insert VSCode installation link here).
3. Node.js: Before diving into the world of Axios and Cheerio, we must first install Node.js and the Node Package Manager (NPM). The simplest way to do this is by obtaining and running one of the installers from the official Node.js source.
Now, let's kickstart a new NPM project. Create a fresh folder for your project and execute the following command:npm init -y
To set up the web scraper, we'll need to install some dependencies in our project, starting with Cheerio.
Cheerio
Cheerio is an open-source library that simplifies extracting valuable information by parsing HTML markup and offering an API for data manipulation. With Cheerio, we can select HTML elements using selectors like $("div"), which selects all < div > elements on a page. To install Cheerio, execute the following command within your project's directory:npm install cheerio
Axios
A JavaScript library employed for performing HTTP requests within Node.js.npm install axios
EXAMINE THE PAGE SOURCE
In the upcoming steps, we will delve deeper into how the page's information is structured. Our objective is to understand what can be extracted from the source comprehensively.
Developer tools are invaluable for interactively navigating the website's Document Object Model (DOM). While we will be using Chrome's developer tools, feel free to utilize any web browser you're accustomed to.
As illustrated in the screenshot above, the containers housing all the data possess the following class names:sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20
In the subsequent step, we will employ Cheerio to target all the elements containing the data we require.
RETRIEVING THE DATA
As observed, we import the required dependencies in the first two lines. Subsequently, we establish a fetchShelves() function, which utilizes Cheerio to extract all elements containing information about our products from the page. It iterates through each of them, appending them to an empty array to achieve a more structured outcome.
Please substitute shelves.push(title) using shelves.push(element) to encompass all the pertinent information.
We are now successfully selecting all the essential data and appending it to a new object named element. Each element is subsequently added to the shelves array, resulting in a collection of objects that exclusively contain the desired data.
FORMATTING THE DATA
Having successfully retrieved the desired data, saving it as a .CSV file is prudent to enhance its readability. Once we've collected all the data, we'll employ the Node.js-provided fs module to create a new file named "saved-shelves.csv" within the project's folder.
Indeed, as depicted in the initial three lines, we format the data we collected earlier by concatenating all the values within a shelf object, separated by commas. Utilizing the fs module, we generate a file named "saved-shelves.csv," insert a new row comprising the column headers, incorporate the freshly formatted data, and implement a callback function to manage potential errors.
Bonus Tips: Scraping Single Page Applications
As websites increasingly adopt dynamic content as the standard, our task of scraping data becomes more challenging due to the complexity of modern web pages. Developers often employ various mechanisms to load dynamic content, complicating the scraping process. If you need to become more familiar with this concept, think of it as trying to navigate a browser without a graphical user interface.
However, there's a solution: ✨Puppeteer✨, the magical Node library that provides a high-level API for controlling a Chrome instance via the DevTools Protocol. Despite lacking a traditional browser interface, Puppeteer offers the same functionality and can be programmatically controlled with just a few lines of code. Let's explore how it works.
In the example provided, we kickstart a Chrome instance and establish a fresh browser page, directing it to a specific URL. Following this, we command the headless browser to wait for the appearance of an element with the class rpBJOHq2PR60pnwJlUyP0 on the page. Additionally, we specify a timeout duration of 2000 milliseconds, determining how long the browser should patiently await the complete page load.
By utilizing the evaluate method on the page variable, we instruct Puppeteer to execute JavaScript code within the context of the page right after identifying the specified element. This strategic move grants us access to the HTML content of the page, allowing us to extract the page's body as the resulting output. Finally, we gracefully conclude our task by closing the Chrome instance through the close method called on the browser variable.
This meticulous process yields a result encompassing all dynamically generated HTML code, showcasing the prowess of Puppeteer in handling dynamic HTML content loading.
For those who might find Puppeteer challenging to work with, it's worth noting that alternative tools are available, including NightwatchJS, NightmareJS, or CasperJS. While they may possess minor differences, the overarching procedure remains relatively consistent.
SETTING USER-AGENT HEADERS
The "user-agent" is a crucial request header that provides the website you're visiting with information about your browser and operating system. It essentially informs the website about your client configuration. While this information is used to optimize content for your specific setup, websites also rely on it to identify potentially suspicious behavior, especially when they detect a high volume of requests, even if the IP address changes.
Setting an appropriate "user-agent" header in your HTTP requests can be essential when web scraping, as it helps you mimic a legitimate browser and reduce the chances of being identified as a bot. This, in turn, helps you avoid IP bans and access restrictions on websites you're scraping.
ROTATING USER-AGENT HEADERS
To minimize the risk of detection and blocking, it's advisable to regularly change your "user-agent" header. It's essential to avoid sending an empty or outdated header because this behavior would be atypical for an ordinary user and could raise suspicion.
RATE LIMITING
While web scrapers are capable of swiftly gathering content, it's crucial to exercise restraint and not operate at maximum speed for two important reasons:
Excessive requests in a short timeframe can overload a website's server, potentially causing it to slow down or even crash. This can disrupt the website's service for both the owner and other legitimate visitors, essentially resembling a Denial of Service (DoS) attack.
In the absence of rotating proxies, sending a high volume of requests per second is a clear indication of automated bot activity, as humans wouldn't typically generate hundreds or thousands of requests in such rapid succession.
The solution to these issues is to implement a delay between your requests, a practice referred to as "rate limiting." Fortunately, rate limiting is relatively straightforward to implement.
In the Puppeteer example provided earlier, right before creating the body variable, you can use Puppeteer's waitForTimeout method to introduce a pause of a few seconds before initiating another request:
This simple delay mechanism helps you avoid overloading the website's server and prevents your scraping activity from standing out as automated and potentially disruptive.await page.waitForTimeout(3000);
In this code snippet, the delay function returns a promise that resolves after the specified number of milliseconds. You can then await this promise in your Axios-based web scraping logic to introduce the desired delay between requests, similar to what we did with Puppeteer's waitForTimeout method.
By employing these rate-limiting techniques, you can prevent excessive strain on the target server and emulate a more human-like approach to web scraping.
Closing Thoughts
So, there you have it—a comprehensive, step-by-step guide to constructing your web scraper for Amazon product data! However, it's crucial to acknowledge that this was tailored to a specific scenario. You must adjust your approach to obtain meaningful results if you intend to scrape a different website. Each website may present unique challenges and intricacies, so adaptability and problem-solving are essential to successful web scraping endeavors. For more details about building an Amazon product scraper, contact Real Data API now!
Know More: https://www.realdataapi.com/develop-amazon-product-scraper-using-nodejs.php
#AmazonProductScraper#ScrapingAmazonProductData#ScrapeAmazonProductData#AmazonWebScraper#AmazonProductDataCollection#ECommerceScraper#ScrapeEcommerce
0 notes
Text
How to Develop an Amazon Product Scraper Using Node.js?
This blog is a comprehensive, step-by-step guide to constructing your web scraper for Amazon product data!
Konw More: https://www.realdataapi.com/develop-amazon-product-scraper-using-nodejs.php
#AmazonProductScraper#ScrapingAmazonProductData#ScrapeAmazonProductData#AmazonWebScraper#AmazonProductDataCollection#ECommerceScraper#ScrapeEcommerce
0 notes