
Statistics
We looked inside some of the posts by searchvoidstar and here's what we found interesting.
Average Info
Notes Per Post
8
Likes Per Post
6
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
3 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
Decrease your idle CPU usage when developing typescript apps with this one environment variable
TL;DR:
add this to your bashrc
export TSC_WATCHFILE=UseFsEventsWithFallbackDynamicPolling
This particular watcher variable is not the default setting for typescript, but it changes the default from polling for file changes to a watcher. There is discussion here
https://github.com/microsoft/TypeScript/issues/31048
The issue thread shows that it can go from roughly ~7% idle CPU usage to 0.2%. This corresponds roughly what I see too. Detailed docs for typescript discuss some of the reasoning behing not making this the default
https://github.com/microsoft/TypeScript-Handbook/blob/master/pages/Configuring%20Watch.md#background
It claims that some OS specific behaviors of file watching could be harmful to making it the default. For example, that (maybe?) on linux, it may use a large number of file watchers which can exceed notify handles (this is a setting I commonly have to increase in linux, guide here https://dev.to/rubiin/ubuntu-increase-inotify-watcher-file-watch-limit-kf4)
PS: you could also edit your package.json of your `create-react-app --template typescript` for example like this...then users of your app will get a similar benefit.
-"start": "react-scripts start" +"start":"cross-env TSC_WATCHFILE=UseFsEventsWithFallbackDynamicPolling react-scripts start"
disclaimer: there may be reasons that typescript does not have this enabled by default so be aware
0 notes
Text
An amazing error message if you put more than 2^24 items in a JS Map object
One of the fun things about working with big data is that you can often hit weird limits with a system.
I was personally trying to load every "common" single nucleotide polymorphism for the human genome into memory (dbSNP), of which there are over 37 million entries (there are many more uncommon ones)
Turns out, you may run into some hard limits. Note that these are all V8-isms and may not apply to all browsers or engines (I was using node.js for this)
const myObject = new Map(); for (let i = 0; i <= 50_000_000; i++) { myObject.set(i,i); if(i%100000==0) { console.log(i) } }
This will crash after adding approx 16.7M elements and say
0 100000 200000 ... 16400000 16500000 16600000 16700000 Uncaught RangeError: Value undefined out of range for undefined options property undefined
That is a very weird error message. It says "undefined" three times! Much better than your usual "TypeError: Can't find property 'lol' of undefined". See https://bugs.chromium.org/p/v8/issues/detail?id=11852 for a bug filed to help improve the error message perhaps. Now, also interestingly enough, if you use an Object instead of a Map
const myObject = {}; for (let i = 0; i <= 50_000_000; i++) { myObject['myobj_'+i]=i; if(i%100000==0) { console.log(i) } }
Then it will print....
0 100000 200000 ... 8000000 8100000 8200000 8300000
And it will actually just hang there...frozen...no error message though! And it is failing at ~8.3M elements. Weird right? This is roughly half the amount of elements as the 16.7M case
Turns out there is a precise hard limit for the Map case
For the Map: 2^24=16,777,216
For the Object it is around 2^23=8,388,608 HOWEVER, I can actually add more than this, e.g. I can add 8,388,609 or 8,388,610 or even more, but the operations start taking forever to run, e.g. 8,388,999 was taking many minutes
Very weird stuff! If you expected me to dig into this and explain it in deep technical detail, well, you'd be wrong. I am lazy. However, this helpful post on stackoverflow by a V8 js engine developer clarifies the Map case!! https://stackoverflow.com/questions/54452896/maximum-number-of-entries-in-node-js-map
V8 developer here. I can confirm that 2^24 is the maximum number of entries in a Map. That's not a bug, it's just the implementation-defined limit.
The limit is determined by:
The FixedArray backing store of the Map has a maximum size of 1GB (independent of the overall heap size limit)
On a 64-bit system that means 1GB / 8B = 2^30 / 2^3 = 2^27 ~= 134M maximum elements per FixedArray
A Map needs 3 elements per entry (key, value, next bucket link), and has a maximum load factor of 50% (to avoid the slowdown caused by many bucket collisions), and its capacity must be a power of 2. 2^27 / (3 * 2) rounded down to the next power of 2 is 2^24, which is the limit you observe.
FWIW, there are limits to everything: besides the maximum heap size, there's a maximum String length, a maximum Array length, a maximum ArrayBuffer length, a maximum BigInt size, a maximum stack size, etc. Any one of those limits is potentially debatable, and sometimes it makes sense to raise them, but the limits as such will remain. Off the top of my head I don't know what it would take to bump this particular limit by, say, a factor of two -- and I also don't know whether a factor of two would be enough to satisfy your expectations.
Great details there. It would also be good to know what the behavior is for the Object, which has those 100% CPU stalls after ~8.3M, but not the same error message....
Another fun note: if I modify the Object code to use only "integer IDs" the code actually works fine, does not hit any errors, and is "blazingly fast" as the kids call it
const myObject = {}; for (let i = 0; i <= 50_000_000; i++) { myObject[i]=i; if(i%100000==0) { console.log(i) } }
I presume that this code works because it detects that I'm using it like an array and it decides to transform how it is working internally and not use a hash-map-style data structure, so does not hit a limit. There is a slightly higher limit though, e.g. 1 billion elements gives "Uncaught RangeError: Invalid array length"
const myObject = {}; for (let i = 0; i <= 1_000_000_000; i++) { myObject[i]=i; if(i%100000==0) { console.log(i) } }
This has been another episode...of the twilight zone (other episodes catalogued here) https://github.com/cmdcolin/technical_oddities/
7 notes
·
View notes
Text
Do you understand your NPM dependencies?
You are writing a library...or your writing an app and you want to publish some of the components of it as a library....
Here are some questions in the form of...comments...
- Did you realize that your yarn.lock will be ignored for anyone who installs your libraries?
- Did you realize this means that your perfectly running test suite with your yarn.lock could be a failing case for consumers of your app unless you don't use semver strings like ^1.0.0 and just hardcode it to 1.0.0?
- Did you realize the default of ^1.0.0 automatically gets minor version bumps which are often fairly substantial changes, e.g. even breaking possibly?
- Did you know that larger libraries like @material-ui/core don't like to bump their major version all the time for example so large changes are often made to the minor version?
Just something to be aware of! You can always ride the dragon and accept these minor breakages from semver bumps, but it can introduce some issues for your consumers
1 note
·
View note
Text
Fighting a proxy war with your team lead through the junior programmers
NOTE: This post contains vivid descriptions of bad teamwork patterns. I am learning from my own (mis)behavior and trying to identify ways I can improve. One of the clearest ways you can clearly improve is: don't do the juniors work for them! If you see your own behavior in this post, then try to think about how to improve. Let me know in the comments if you have any recommendations
At work, we all have to put pen to paper eventually and tasks get farmed out to various people. Some of the larger tasks are often given a "basic spec" so that "anyone can pick them up and do them..." . That way, presumably, just everyone is on board with the plan more, juniors can pick up tasks more easily, etc. However, the overengineering or poor assessment of system requirements may happen if the issue is spec'd out prematurely. And sometimes, I bristle at it, and think a simpler system could be made.
So, I essentially disagreed with the initial plans, and encouraged the person assigned to the issue to gain experience by implementing a more basic version outside of our main codebase. I guess the plan would be that they would then use those lessons, but still go with the pre-spec'd out system that was written about in the issue. But I encouraged them to implement just the basic version inside our main codebase.
Now here's where it gets ugly. During a call, I tried forcefully claiming that this more basic system wwas actually sufficient, and we don't need the overengineered version. My team lead later talks with me and is pretty upset how I behaved on the call. I probably sound like a fucking brat for sure. The junior goes off and works on this issue for another like 2 weeks. He comes back and has scoped out a complex set of new requirements to make the overengineered thing possible. I claim that this shows the overengineered thing fundamentally misunderstands the problem scope, and that we need to redesign the spec now.
At this point, I have essentially been using the junior as a proxy in a war with my team lead. It is not pleasant. I wish my team lead would let the ground floor developers lead rather than push down crazy overengineered plans. I think that the juniors just get bogged down by the architectural hairballs they receive. And, all the while, I am just fighting a war for "simplicity" that just never wins. And then we end up with a hairball down the line, and things break, and the juniors don't really take full ownership of the things they created, so it seems like I have to go in and fix them (I know, I'm a fucking brat programmer, but I just can't let these things stay broken so I go in and fix and try not to let an issue sit on the board for weeks at a time)
0 notes
Text
thoughts on kanban board and dogfooding
In general, I feel like kanban isn't a great experience. I don't know if I have a better solution, and some of the opinions discussed here may be sort of bratty as such. There may also be wildly varying experiences with kanban depending on team culture but this is my current experience with it.
Now, our kanban board...
Currently we have 4 columns
- "Incoming" this column is when a new issue comes in and someone manually tags using Github issue labels to go on the board. This has to be done manually by the person creating or reviewing an issue. I rarely do this for issues I create, so issues I create don't often get visibility on kanban by default unless I remember to go and do this manually.
- "Prioritized" where there is just a big backlog of things. It is a total mix of issue size and complexity and importance. I get the sense many things should be removed or deprioritized from our list, but I don't really feel "empowered" to do this, even though I probably should.
- "In progress" contains many stalled or long running issues that devs are working on for months, and you get very little visibility into it. Also, the team is currently mired in side projects that are not even on our github board, and have not created any github issues, so we have no visibility into what these team members are doing on the side projects via our main board. I'm not a project manager but I like to see what the team is working on and provide insights if I can.
- "Done" column has the completed issues but no sprint timeframes are used so it's not really meaningful to look at except to say "yay" and clear it out periodically
Maybe minor concerns first: the "In progress" column doesn't really capture things at a granular enough level. I think it would be worth making "stalled", "needs review" columns also. Those could just be labels, however, I think there becomes so many of them that they need to get out of the "in progress" zone to provide clarity. But just doing that might not really change the world here...
The "Done" column is useless, so not really worth discussing.
With the "Prioritized" column, I get the sense that we are not critically assessing our trajectory, or strategizing, or giving time to dogfood the product ourselves so we can head off potential issues (instead waiting for the customer/user of our open source code to bring them to our attention!!!). The devils advocate would say, well, if you are an engineer then use your own critical thinking skills, make the issue, and put it on the board yourself in the proper place, and shape the kanban board to how you like it. Maybe true, but my feeling is that a) it's not a good use of my time and b) the psychology of the board discourages all members from doing this leading to c) endless slog of developing new "features" and patching over our sloppy code occasionally addressed with "bug fix" cards without considering real improvement. Again, the engineer in me says, in some sense, features that get implemented need to be "done" and we can't be constantly going back and revisiting them (right?) but only to a certain extent...you get the right platform down, and then you iterate successfully on it.
I liked this picture from the "Software engineering at google" book (free pdf https://abseil.io/resources/swe_at_google.2.pdf)
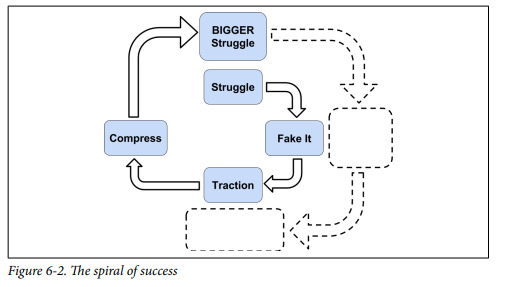
The spiral of success, to me, reads like: you once you solve one of your engineering problems, you gotta do it right, so that you can move on because the bigger struggles will never stop coming.
0 notes
Text
remembering
This is year marks the five six years since my sisters suicide (I can't even count). Every year, I feel like the month of May is unreasonably bad and emotional for me. I never really know how to deal with it, it's not something I talk about a lot about. I'm always just having such a shit show with my everyday life that I have a hard time talking to therapists who I just ramble on about day to day things to. And sometimes it seems like I just "make it about me" or something...just filter everything through my own lens
It hurts a lot. I remember her sometimes in such weird fragments of memory, and they are not necessarily the deepest or seemingly special. She also had a really hard life and it is hard to think about that sometimes too. I remember when she was growing up I'd try to teach her to do stuff like wash dishes and she really didn't want to wash the knives and I remember feeling bad because I pushed her too hard trying to learn do that once. I remember when she was home schooled (because there was a limbo time when our family considered moving overseas) and I helped her a little bit with the online classes, and playing a game kind of like bomberman with her online, her on her computer and me on mine. I remember taking her and our cousin, who was one of her best friends, to lakeside theme park. I remember I had made a silly mixtape for that lakeside trip that was pretty silly with indie pop songs and stuff. I remember driving her to school one mildly snowy morning when she had returned from the wilderness school, when I was living at home in college. Then this is not even my sister but I think of bad memories like me playing music too loud and my mom storming down to tell me to shut it off. I imagine that I just must have caused her pain from living at home during that time or something. I remember when she was going through really tough times I'd just try to relate to her and say she was doing really well. I remember one night she went to denver by herself and I remembered doing crazy stuff like that when I was in high school too. There was maybe more of an undercurrent of difficulty there though. I remember I was visiting Berkeley and her and my dad came and met up with me and we went down to the san francisco bridge, with it's rusty chains down by the water. I remember she came to visit me in Columbia Missouri, I picked her and my dad up in St Louis, and we drove them to a car dealership when my sister got her first car. They came back and we swam in a hotel pool in Columbia. My dad is such a strong person I feel like and really gave us all the best for us kids.
Lara loved music. I remember stumbling into her room one time and really loving some of the songs she had. One was by a band called Braves. She loved friends. She was forced to break out of her shell a little bit and I think she really started to grow. You look through some photos and you can see she her doing group projects outdoors, covered in dirt. There are pictures of her resting her head on her friends shoulders. Pictures of her visiting paris and amsterdam with our cousin. I remember her for being shy, but loving...the youngest sibling...i can't even now fathom the pain and I just am trying to remember memories here but I miss her so much now...miss you Lara
np https://www.youtube.com/watch?v=G5NHwu-e0CQ

0 notes
Text
http song
(to the tune of baby beluga...half drempt up song)
http is for you and me
its the language of the computer world
you can send me a message
on facebook messenger
or my website at this url
it goes http is for you and me
its the language of the computer world
you can see my site
we got gifs and bytes
and the message box to send email s
and when u send that message
and you hit the send button
itll go into the interweb
with the satellites
itll go to space
and also through the deep blue sea
itll fly on past
past the sharks and fish
that will wave as it flows along
the intercontinental
super special kelper
underwater internet cable
and when i wake on up
in the italian village
i will open up my email then
ill have a little cup
of a tiny espresso
and ill have 1 new unread message
0 notes
Text
Making a HTTPS accessible S3 powered static site with CloudFront+route 53
This is not a very authoritative post because I stumbled though this but I think I got it working now on my website :)
Setup your S3 bucket
First setup your S3 bucket, your bucket must be named yourdomain.com e.g. named after your domain
Then if you have a create-react-app setup I add a script in package.json that runs
“predeploy”: “npm run build”, “deploy”: “aws sync --delete build s3://yourdomain.com”
Then we can run “yarn deploy” and it will automatically upload our create-react-app website to our S3 static site bucket.
Then make sure your bucket has public permissions enabled https://docs.aws.amazon.com/AmazonS3/latest/dev/example-bucket-policies.html#example-bucket-policies-use-case-2Then make sure your bucket has “static site hosting” enabled too
Setup route 53, and make your NS entries in domains.google.com
I bought a domain with domains.google.com
Google then emailed me to validate my ownership
Then I went to aws.amazon.com route 53 and I created a hosted zone
This generated 4 name server entries and I added those to the domains.google.com site
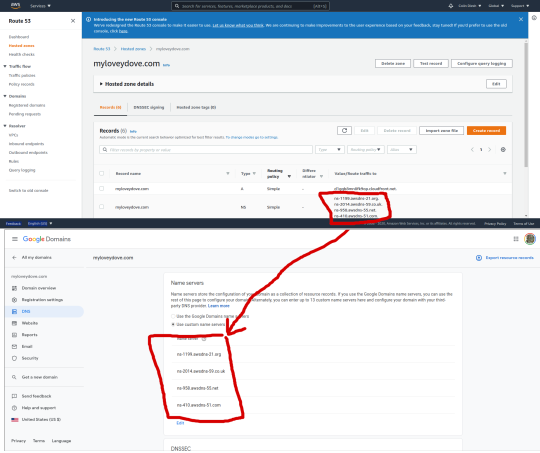
Screenshot shows copying the NS values from route 53 to the name servers area of domains.google.com
Setup your Amazon certificate for making SSL work on CloudFront
To properly setup However, this does not work so you need to go to Amazon Certificates->Provision certificates
We request the certificate for www.yourdomain.com yourdomain.com Then it generates some codes for a CNAME value for each of those two entries, and has a button to autoimport those CNAME values to route53
Then it will say “Pending validation”...I waited like an hour and then it changed to “Success”.
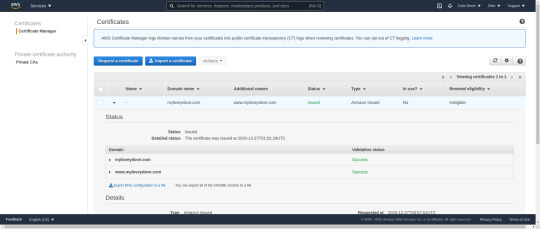
Screenshot shows the now successful Amazon Certificate. After you get this, you can proceed to finishing your cloudfront
Create a CloudFront distribution and add “Alternative CNAME” entries for your domain
Then we can update our CloudFront distribution and add these to the “Alternative CNAME” input box
yourdomain.com www.yourdomain.com
Note also that I first generated my certificate in us-east-2 but the “Import certificate form” in cloudfront said I had to create it in us-east-1
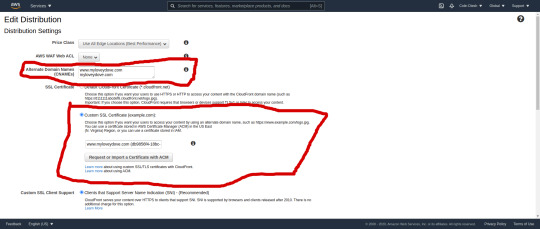
Add a default object index.html to the CloudFront setting
Make your CloudFront “default object” is index.html
You have to manually type this in :)
Add the CloudFront distribution to your Route 53
Add a Route 53 “A” record that points to the CloudFront domain name e.g. d897d897d87d98dd.cloudfront.net
Summary of steps needed
The general hindsight 20/20 procedure is
Upload your static content to an S3 bucket called yoursite.com (must be your domain name)
Make your S3 bucket have the “static website” setting on in the properties menu and add a permissions policy that supports getObject e.g. https://docs.aws.amazon.com/AmazonS3/latest/dev/example-bucket-policies.html#example-bucket-policies-use-case-2
Create a CloudFront distribution for your website
Make the CloudFront default object index.html
Create your domain with domains.google.com or similar
Point the google domain’s name server to Route 53 NS list from AWS
Add Route 53 A records that point to the CloudFront domain name e.g. d897d897d87d98dd.cloudfront.net
Create Amazon issued certificate for yourdomain.com, which can auto-import a validation CNAME to your Route 53
Make your CloudFront domain support your Alternative CNAME’s e.g. yourdomain.com which requires importing (e.g. selecting from a list that they auto-populate) your Amazon-issued-certificate
Troubleshooting and notes
Problem: Your website gives 403 CloudFlare error Solution: You have to get the Alternateive CNAME configuration setup (pre-step involves the certificate request and validation) Problem: Your website gives an object not found error Solution: Set the CloudFront “default object” to index.html
Random comment
This is one of those processes (creating the cloudfront/route 53) that probably could have done with the aws-sam CLI and it would have possibly been easier, it is quite fiddly doing all these steps in the web interface
0 notes
Text
Making a serverless website for photo and video upload pt. 2
This post follows on https://searchvoidstar.tumblr.com/post/638408397901987840/making-a-serverless-website-for-photo-upload-pt-1
It is possible I zoomed ahead too fast to make this a continuous tutorial, but overall I just wanted to post an update
In pt. 1 I learned how to use the `aws-sam` CLI tool. This was a great insight for me about automating deployments. I can now simply run `sam deploy` and it will create new dynamodb tables, lambda functions, etc.
After writing pt 1. I converted the existing vue-js app that was in the aws tutorial and converted it to react. Then I extended the app to allow
- Posting comments on photos - Uploading multiple files - Uploading videos etc.
It will be hard to summarize all the changes since now the app has taken off a little bit but it looks like this:
Repo structure
./frontend # created using npx create-react-app frontend --template typescript ./frontend/src/App.tsx # main frontend app code in react ./lambdas/ ./lambdas/postFile # post a file to the lambda, this uploads a row to dynamodb and returns a pre-signed URL for uploading (note that if the client failed it’s upload, that row in the lambda DB might be in a bad state...) ./lambdas/getFiles # get all files that were ever posted ./lambdas/postComment # post a comment on a picture with POST request ./lambdas/getComments?file=filename.jpg # get comments on a picture/video with GET request
Here is a detailed code for uploading the file. We upload one file at a time, but the client code post to the lambda endpoint individually for each file
This generates a pre-signed URL to allow the client-side JS (not the lambda itself) to directly upload to S3, and also posts a row in the S3 to the filename that will. It is very similar code in to https://searchvoidstar.tumblr.com/post/638408397901987840/making-a-serverless-website-for-photo-upload-pt-1
./lambdas/postFile/app.js
"use strict";
const AWS = require("aws-sdk"); const multipart = require("./multipart"); AWS.config.update({ region: process.env.AWS_REGION }); const s3 = new AWS.S3();
// Change this value to adjust the signed URL's expiration const URL_EXPIRATION_SECONDS = 300;
// Main Lambda entry point exports.handler = async (event) => { return await getUploadURL(event); };
const { AWS_REGION: region } = process.env;
const dynamodb = new AWS.DynamoDB({ apiVersion: "2012-08-10", region });
async function uploadPic({ timestamp, filename, message, user, date, contentType, }) { const params = { Item: { timestamp: { N: `${timestamp}`, }, filename: { S: filename, }, message: { S: message, }, user: { S: user, }, date: { S: date, }, contentType: { S: contentType, }, }, TableName: "files", }; return dynamodb.putItem(params).promise(); }
const getUploadURL = async function (event) { try { const data = multipart.parse(event); const { filename, contentType, user, message, date } = data; const timestamp = +Date.now(); const Key = `${timestamp}-${filename}`;
// Get signed URL from S3 const s3Params = { Bucket: process.env.UploadBucket, Key, Expires: URL_EXPIRATION_SECONDS, ContentType: contentType,
// This ACL makes the uploaded object publicly readable. You must also uncomment // the extra permission for the Lambda function in the SAM template.
ACL: "public-read", };
const uploadURL = await s3.getSignedUrlPromise("putObject", s3Params);
await uploadPic({ timestamp, filename: Key, message, user, date, contentType, });
return JSON.stringify({ uploadURL, Key, }); } catch (e) { const response = { statusCode: 500, body: JSON.stringify({ message: `${e}` }), }; return response; } };
./lambdas/getFiles/app.js
// eslint-disable-next-line import/no-unresolved const AWS = require("aws-sdk");
const { AWS_REGION: region } = process.env;
const docClient = new AWS.DynamoDB.DocumentClient();
const getItems = function () { const params = { TableName: "files", };
return docClient.scan(params).promise(); };
exports.handler = async (event) => { try { const result = await getItems(); return { statusCode: 200, body: JSON.stringify(result), }; } catch (e) { return { statusCode: 400, body: JSON.stringify({ message: `${e}` }), }; } };
./frontend/src/App.tsx (excerpt)
async function myfetch(params: string, opts?: any) { const response = await fetch(params, opts); if (!response.ok) { throw new Error(`HTTP ${response.status} ${response.statusText}`); } return response.json(); }
function UploadDialog({ open, onClose, }: { open: boolean; onClose: () => void; }) { const [images, setImages] = useState<FileList>(); const [error, setError] = useState<Error>(); const [loading, setLoading] = useState(false); const [total, setTotal] = useState(0); const [completed, setCompleted] = useState(0); const [user, setUser] = useState(""); const [message, setMessage] = useState(""); const classes = useStyles();
const handleClose = () => { setError(undefined); setLoading(false); setImages(undefined); setCompleted(0); setTotal(0); setMessage(""); onClose(); };
return ( <Dialog onClose={handleClose} open={open}> <DialogTitle>upload a file (supports picture or video)</DialogTitle>
<DialogContent> <label htmlFor="user">name (optional) </label> <input type="text" value={user} onChange={(event) => setUser(event.target.value)} id="user" /> <br /> <label htmlFor="user">message (optional) </label> <input type="text" value={message} onChange={(event) => setMessage(event.target.value)} id="message" /> <br /> <input multiple type="file" onChange={(e) => { let files = e.target.files; if (files && files.length) { setImages(files); } }} />
{error ? ( <div className={classes.error}>{`${error}`}</div> ) : loading ? ( `Uploading...${completed}/${total}` ) : completed ? ( <h2>Uploaded </h2> ) : null}
<DialogActions> <Button style={{ textTransform: "none" }} onClick={async () => { try { if (images) { setLoading(true); setError(undefined); setCompleted(0); setTotal(images.length); await Promise.all( Array.from(images).map(async (image) => { const data = new FormData(); data.append("message", message); data.append("user", user); data.append("date", new Date().toLocaleString()); data.append("filename", image.name); data.append("contentType", image.type); const res = await myfetch(API_ENDPOINT + "/postFile", { method: "POST", body: data, });
await myfetch(res.uploadURL, { method: "PUT", body: image, });
setCompleted((completed) => completed + 1); }) ); setTimeout(() => { handleClose(); }, 500); } } catch (e) { setError(e); } }} color="primary" > upload </Button> <Button onClick={handleClose} color="primary" style={{ textTransform: "none" }} > cancel </Button> </DialogActions> </DialogContent> </Dialog> ); }
template.yaml for AWS
AWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: S3 Uploader
Resources: filesDynamoDBTable: Type: AWS::DynamoDB::Table Properties: AttributeDefinitions: - AttributeName: "timestamp" AttributeType: "N" KeySchema: - AttributeName: "timestamp" KeyType: "HASH" ProvisionedThroughput: ReadCapacityUnits: "5" WriteCapacityUnits: "5" TableName: "files"
# HTTP API MyApi: Type: AWS::Serverless::HttpApi Properties: # CORS configuration - this is open for development only and should be restricted in prod. # See https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-property-httpapi-httpapicorsconfiguration.html CorsConfiguration: AllowMethods: - GET - POST - DELETE - OPTIONS AllowHeaders: - "*" AllowOrigins: - "*"
UploadRequestFunction: Type: AWS::Serverless::Function Properties: CodeUri: lambdas/postFile/ Handler: app.handler Runtime: nodejs12.x Timeout: 3 MemorySize: 128 Environment: Variables: UploadBucket: !Ref S3UploadBucket Policies: - AmazonDynamoDBFullAccess - S3WritePolicy: BucketName: !Ref S3UploadBucket - Statement: - Effect: Allow Resource: !Sub "arn:aws:s3:::${S3UploadBucket}/" Action: - s3:putObjectAcl Events: UploadAssetAPI: Type: HttpApi Properties: Path: /postFile Method: post ApiId: !Ref MyApi
FileReadFunction: Type: AWS::Serverless::Function Properties: CodeUri: lambdas/getFiles/ Handler: app.handler Runtime: nodejs12.x Timeout: 3 MemorySize: 128 Policies: - AmazonDynamoDBFullAccess Events: UploadAssetAPI: Type: HttpApi Properties: Path: /getFiles Method: get ApiId: !Ref MyApi
## S3 bucket S3UploadBucket: Type: AWS::S3::Bucket Properties: CorsConfiguration: CorsRules: - AllowedHeaders: - "*" AllowedMethods: - GET - PUT - HEAD AllowedOrigins: - "*"
## Take a note of the outputs for deploying the workflow templates in this sample application Outputs: APIendpoint: Description: "HTTP API endpoint URL" Value: !Sub "https://${MyApi}.execute-api.${AWS::Region}.amazonaws.com" S3UploadBucketName: Description: "S3 bucket for application uploads" Value: !Ref "S3UploadBucket"
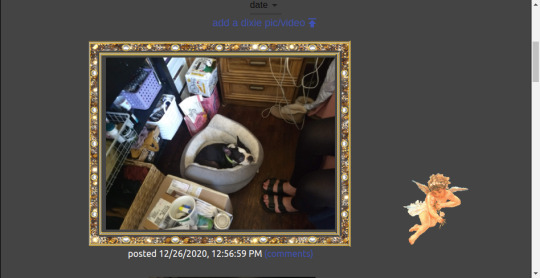
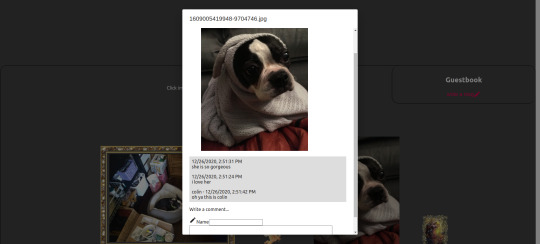
To display all the pictures I use a switch from video or img tag based on contentType.startsWith(’video’). I also use the “figcaption” HTML tag to have a little caption on the pics/videos
./frontend/src/App.tsx
function Media({ file, style, onClick, children, }: { file: File; onClick?: Function; style?: React.CSSProperties; children?: React.ReactNode; }) { const { filename, contentType } = file; const src = `${BUCKET}/${filename}`; return ( <figure style={{ display: "inline-block" }}> <picture> {contentType.startsWith("video") ? ( <video style={style} src={src} controls onClick={onClick as any} /> ) : ( <img style={style} src={src} onClick={onClick as any} /> )} </picture> <figcaption>{children}</figcaption> </figure> ); }
Now the really fun part: if you get an image of a picture frame like https://www.amazon.com/Paintings-Frames-Antique-Shatterproof-Osafs2-Gld-A3/dp/B06XNQ8W9T You can make it a border for any image or video using border-image CSS
style = { border: "30px solid", borderImage: `url(borders/${border}) 30 round` }
Summary
The template.yaml automatically deploys the lambdas for postFile/getFile and the files table in dynamoDB
The React app uses postFile for each file in an <input type=“file”/>, the code uses React hooks and functional components but is hopefully not too complex
I also added commenting on photos. The code is not shown here but you can look in the source code for details
Overall this has been a good experience learning to develop this app and learning to automate the cloud deployment is really good for ensuring reliability and fast iteration.
Also quick note on serverless CLI vs aws-sam. I had tried a serverless CLI tutorial from another user but it didn’t click with me, while the aws-sam tutorial from https://searchvoidstar.tumblr.com/post/638408397901987840/making-a-serverless-website-for-photo-upload-pt-1 was a great kick start for me. I am sure the serverless CLI is great too and it ensures a bit less vendor lock in, but then is also a little bit removed from the native aws config schemas. Probably fine though
Source code https://github.com/cmdcolin/aws_photo_gallery/
0 notes
Text
Making a serverless website for photo upload pt. 1
I set out to make a serverless website for photo uploads. Our dearly departed dixie dog needed a place to have photo uploads.
I didn’t want to get charged dollars per month for a running ec2 instance, so I wanted something that was lightweight e.g. serverless, and easy
I decided to follow this tutorial
https://aws.amazon.com/blogs/compute/uploading-to-amazon-s3-directly-from-a-web-or-mobile-application/
I really liked the command line deployment (aws-sam) because fiddling around with the AWS web based control panel is ridiculously complicated
For example I also tried following this tutorial which uses the web based UI (https://www.youtube.com/watch?v=mw_-0iCVpUc) and it just did not work for me....I couldn’t stay focused (blame ADHD or just my CLI obsession?) and certain things like “Execution role” that they say to modify are not there in the web UI anymore, so I just gave up (I did try though!)
To install aws-sam I used homebrew
brew tap aws/tap brew install aws-sam-cli brew install aws-sam-cli # I had to run the install command twice ref https://github.com/aws/aws-sam-cli/issues/2320#issuecomment-721414971
git clone https://github.com/aws-samples/amazon-s3-presigned-urls-aws-sam cd amazon-s3-presigned-urls-aws-sam sam deploy --guided # proceeeds with a guided installation, I used all defaults except I made “UploadRequestFunction may not have authorization defined, Is this okay? [y/N]: y”
They then in the tutorial describe trying to use postman to test
I test with `curl` instead
❯❯❯ curl 'https://fjgbqj5436.execute-api.us-east-2.amazonaws.com/uploads'
{"uploadURL":"https://sam-app-s3uploadbucket-1653634.s3.us-east-2.amazonaws.com/112162.jpg?Content-Type=image%2Fjpeg&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIAU6CQBER6YBNCDDMJ%2F20201224%2Fus-east-2%2Fs3%2Faws4_request&X-Amz-Date=20201224T174804Z&X-Amz-Expires=300&X-Amz-Security-Token=IQoJb3JpZ2luX2VjEDIaCXVzLWVhc3QtMiJGMEQCIH65IvgJsofUpIX46lTaG3Pi5WC85ti1lukM3iICh%2BB%2BAiAJEyynPNPhZN8%2Bg1ylO7wthqud9cBcNIChIp2H%2F%2BR7mCryAQjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDMzOTQ3MDI2MzQyMSIMLqPo1IYyH7udCGZuKsYBSEF3c50YXkmPeSWcLsEzq%2BFBTpeOIrwZTyCUjbJ7fgJUakhM1YRX40jExstN8eJcMXqw00Xd5lYHvZDbU9ajwWPLRAxcEN5BQ0utqn0NGTLyJhibzJUj8cjgm5RguIEKe9GUtMVWa9mi7C5%2FlFpS0i9jK5BSVf74JyPSLETV5mzMMzy5kHBQMGjw1dR66E3MG8PjIqfgKjhVtZmlaicf5OmeqNI2%2F8T5ye%2FICRsH4d7KNEmj4FELa8buW8U%2Fn97ThfH3P7XmMNOok%2F8FOuEBDj1EHluCT4DfZ1jIXjvrJsVv1WtV4POQDn2Dah%2BWosBn%2BFNTtQtw841ACDarYR1ZVbuwcpTjfBPlGuSOncPsbzOhzDy7wYyumsPKsXoPdxTncMWbx4BQkbU5SeF9hjpfIKRMSOqkJBN7%2BtgHXwuW1rfYMDN2OAlQZpTj7uWMPWojUMbvMzyHvI2pfgcRAlrBdGGYDigyjWl9QXP%2Bdi6WiR7XCSXbWcIAJDZh%2Beb%2BIH1asmMJtpAK6nMP8gWczaYh7PMeYyVOIs2B20xQBy%2Bz7oe%2BYQ2GfdEr2hgqPH3jd%2B7c&X-Amz-Signature=11b8cd524c25ef51193e3b3fc4816760ebcde8bfc74bd52f3f91d8bf409620f5&X-Amz-SignedHeaders=host","Key":"112162.jpg"}%
The premise of this is you make a request, and then the response from the API is a pre-signed URL that then allows you to upload directly to S3. You can use `curl <url> --upload-file yourfile.jpg`. This automatically does a PUT request to the s3 bucket (yes, this is talking directly to s3 now, not the lambda! the lambda is just for generating the “pre-signed URL” to let you upload). Careful to copy it exactly as is
curl "https://sam-app-s3uploadbucket-1653634.s3.us-east-2.amazonaws.com/112162.jpg?Content-Type=image%2Fjpeg&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=ASIAU6CQBER6YBNCDDMJ%2F20201224%2Fus-east-2%2Fs3%2Faws4_request&X-Amz-Date=20201224T174804Z&X-Amz-Expires=300&X-Amz-Security-Token=IQoJb3JpZ2luX2VjEDIaCXVzLWVhc3QtMiJGMEQCIH65IvgJsofUpIX46lTaG3Pi5WC85ti1lukM3iICh%2BB%2BAiAJEyynPNPhZN8%2Bg1ylO7wthqud9cBcNIChIp2H%2F%2BR7mCryAQjb%2F%2F%2F%2F%2F%2F%2F%2F%2F%2F8BEAAaDDMzOTQ3MDI2MzQyMSIMLqPo1IYyH7udCGZuKsYBSEF3c50YXkmPeSWcLsEzq%2BFBTpeOIrwZTyCUjbJ7fgJUakhM1YRX40jExstN8eJcMXqw00Xd5lYHvZDbU9ajwWPLRAxcEN5BQ0utqn0NGTLyJhibzJUj8cjgm5RguIEKe9GUtMVWa9mi7C5%2FlFpS0i9jK5BSVf74JyPSLETV5mzMMzy5kHBQMGjw1dR66E3MG8PjIqfgKjhVtZmlaicf5OmeqNI2%2F8T5ye%2FICRsH4d7KNEmj4FELa8buW8U%2Fn97ThfH3P7XmMNOok%2F8FOuEBDj1EHluCT4DfZ1jIXjvrJsVv1WtV4POQDn2Dah%2BWosBn%2BFNTtQtw841ACDarYR1ZVbuwcpTjfBPlGuSOncPsbzOhzDy7wYyumsPKsXoPdxTncMWbx4BQkbU5SeF9hjpfIKRMSOqkJBN7%2BtgHXwuW1rfYMDN2OAlQZpTj7uWMPWojUMbvMzyHvI2pfgcRAlrBdGGYDigyjWl9QXP%2Bdi6WiR7XCSXbWcIAJDZh%2Beb%2BIH1asmMJtpAK6nMP8gWczaYh7PMeYyVOIs2B20xQBy%2Bz7oe%2BYQ2GfdEr2hgqPH3jd%2B7c&X-Amz-Signature=11b8cd524c25ef51193e3b3fc4816760ebcde8bfc74bd52f3f91d8bf409620f5&X-Amz-SignedHeaders=host" --upload-file test.jpg
There is no response, but I can then check the s3 console and see the file upload is successful (all files are renamed)
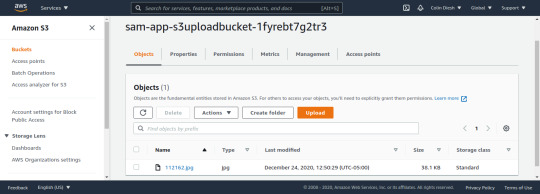
Figure shows that the file upload is successful :)
Then we can edit the file frontend/index.html from the repo we cloned to contain the lambda with the /uploads/ suffix
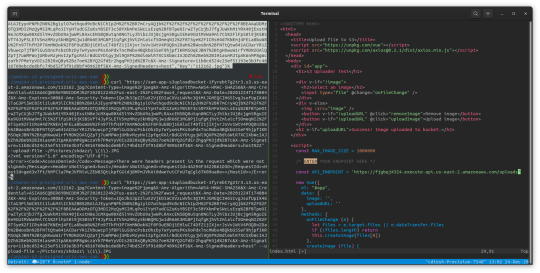
Figure shows editing the index.html with the lambda endpoint
Then we manually upload this file to another s3 bucket or test it locally
aws s3 cp index.html s3://mybucket/
...visit that in the browser
At this point the files are getting uploaded but not publically accessible. To make them publically accessible we uncomment the ACL: ‘public-read’ in the getSignedURL/app.js folder in the github repo

Figure showing the public-read uncommented
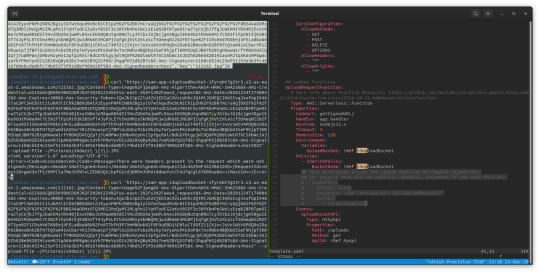
Figure showing the lines that need uncommenting in template.yaml in the root of the github repo that allows putObject in s3 with the public-read ACL
Re-run `sam deploy --guided`, same thing as at the start
Now the objects are publicly accessible!
0 notes
Text
Peanut allergy
had a pretty bad experience with peanut allergy on thursday.
order chinese food around 4pm
drive across town to pick it up
there’s a car crash en route and the horn is stuck blaring making the scene pretty chaotic
get the food, drive back home
eat crab rangoon, eat the rice, eat the lo mein, and finally take a bite of an eggroll
dont really realize instantly but know it tastes weird about halfway through it
i take 2 benedryl and then start watching youtube for awhile
the pain in my stomach starts making it hard to focus but throwing up is also miserable so i just wait
11pm i instinctively need to vomit
retching, terrible experience.
my nose closes up which is sign of airways closing, this often happens *after* throwing up
then i take 2 more benedryl and drink water
then 10 minutes later i have to throw up again, this time pure water and benedryll powder coats my whole system which doesn’t feel as bad but is still pretty miserable
take more benedryl, fall asleep in a daze
i wake up friday still feeling pretty miserable, i did not vomit out everything probably so it is still messing up my body
i sleep until like noon and realize i have a work call. i tell ppl i got a peanut allergy and that i’m zonked so i skip call.
i am definitely zonked indeed, its hard to describe my state but it is like i had a fever and my brain is melted
i dont understand why an eggroll had peanut in it....google it....apparently some people add peanut butter to it? weird
my girlfriend makes me a really nice salad for dinner
i google about peanut allergy genomics but dont get too far
i take a shower and sit around in a bathrobe
on saturday, which is today, i am still headachy and fragile but hopefully recovering
random note: i am also allergic to fenugreek, which is closely related to peanut (https://en.wikipedia.org/wiki/Fenugreek#Risks_and_side_effects) and i only found this out recently. it explains a lot about mild reactions that i’ve gotten to indian foods over the years. I also have sensitivity to soy protein, lentil, and sometimes chickpea especially like gram flour
0 notes
Text
Challenges I have faced learning React
Learning React was a big challenge for me. I started learning React in earnest in 2019. It was a difficult experience overall, but I wanted to go over my learning experience, and maybe find some lessons in the mix. This goes mostly into personal details and doesn’t really get too technical, however, I review the commit logs and try and backtrace my feelings that I remember at the time.
If I were to take away anything from this, it’s probably that pair programming was really useful especially as a remote worker, I had nothing before that except weekly standups where I felt really depressed. Also stay patient, stay thankful, and try to focus while you learn
Introduction to me
I am maybe what you’d call a front-end engineer. I have done web development for about 7 years now. My first job (2013-2016) was an academic staff support programming job. I helped with tasks in a lab with other grad students. This gave me a lot of perspective on weird hacky dinosaur backends like RoR, PHP, Perl CGI, Java servlets, etc all collide on the frontend and it is pretty much insane. I got perspective on dev-ops, full-stack, front-end dev, and data analysis
Early dabbles with React circa 2016
I had a random form I wanted to code and wanted to try using React. I imported React via a CDN and gave it a shot, and it seemed simple enough, but I kept getting really confused about what the “state” the form was in. I didn’t realize it then, but I was getting very confused by state management concepts that I didn’t know existed. Now I know that I was really missing some intro material, for example CONTROLLED COMPONENTS. Instead, I kept googling weird things like “two way data binding react” and variants of this. I had never used angular but I heard of two way data binding, and I just felt like it was what I needed. I even posted about my frustrations about this on the react subreddit and was downvoted. Felt bad. I was just really confused. I abandoned the project in react and just used our normal jqueryish thing.
New job in 2018, while taking grad school courses
In 2018, I was taking some grad school classes working on a CS masters. The algorithms class was hard but mentally stimulating. Most of the other classes did not interest me, and I did not get very involved in the school outside of a couple classes. I get a call for this new job in May 2018, and I am hired on as a remote developer in June 2018. The team understands I’m working while in school.
I was really happy to be involved. I had worked on the old codebase as an open source contributor. Now, they decide they are going to do “the big rewrite” and are going to use React. We do some work trying to liftover some of the old code into npm modules that can be re-used to start with, and this was a learning experience, I had never published my code as NPM modules. I learned jest testing and stuff as well. My first module was a indexedfasta parser (@gmod/indexedfasta).
Starting in October 2018, my coworker started building the new react app prototype. My coworker keeps asking me “what state management library should we use”. I just had no idea about React still, I had not ever looked into state management, and basically just was like “I dunno!”. I had no way to form an opinion. I was also still taking some classes and remained pretty out of the loop with prototype development. We would have weekly meetings but I just wouldn’t really understand the goings ons. This didn’t feel great
I am floundering...not understanding what’s going on with the rewrite, so I decide to quit grad school to focus on the new project
It’s December 2018, I go home for Christmas and I have an honest talk with my parents and tell them “I don’t get what is happening in the new codebase, I’m honestly unhappy, and it just does all this ‘react’ stuff” but I can’t explain react to them I just say the code is automatically reacting to other things.
So I talk to my parents about how I’m struggling and they say “well if you are unhappy you might have to leave your job” and they are not like, cheering for me to leave but they say that. At this point, it really hit me that I do like this job and I decided to try to focus on work. I decide to quit grad school
I try and make an honest attempt to get involved in the project, start pair programming
On January 10th 2019 I make my first commit to the project by doing some monkey-see monkey-do type coding. I copy a bunch of files and just put them in the right place, tweak some lines, and start to figure out how to make things run. By the end of January 2019 I get my first code change merged.
In February 2019, I start modifying some more things in the codebase, just little one-liner bugfixes, which I like more than the large monkey-see moneky-do file copying and modifying.
In January, I also suggested that we start doing pair-programming sessions. This made a huge difference for me in learning how to code. The pair programming often went way over my head and it felt like my coworkers were giving me like abstract “koans”. Nevertheless, these were extremely helpful for me to help get caught up.
I start to reading “Learning React”
In March 2019, I got the book “Learning React” (O’Reilly2017 https://www.oreilly.com/library/view/learning-react/9781491954614/) for my kindle. Reading this book was a big help I felt, and provided a needed “brain reset” for me. The book worked well for me, I read it each night on my kindle, and the functional component concepts were super enlightening. To me it was so much better reading a book than say and internet tutorial because I could focus, not have distractions, etc. My eyes would just glaze over every time I clicked on React blog posts and stuff before this.
So anyways, March 2019 goes on, and I’m learning, but our codebase still feels pretty complicated and alien. We use mobx-state-tree and the glue for mobx-state-tree to react e.g. the mobx-react doesn’t really make sense to me. I remember asking my coworkers why my component was not updating and they eventually find out it’s because I keep not using the observe() wrapper around my components.
I start to experiment with Typescript
In April 2019 I start to experiment with typescript and release a typescript version of some data parsing code. I start by explicity specifying a lot of types but I eventually start getting into the zen of “type inference” and I turn off the @typescript-eslint/explicit-function-return-type so I get implied return types.
I start using React hooks
In May 2019 I try out my first React hook, I try a useState instead. It worked well. I couldn’t really figure out why I would use it instead of the mobx state management we used elsewhere, but the example was that it was a click and drag and it made sense to keep that click and drag state local to the component rather than the “app”
I start using react-testing-library
In June 2019, I create “integration test” level tests for our app. I had used react-testing-library for some components before this, but this was using react-testing-library to render the entire “app level” component. I was happy to pioneer this and was happy to try this out instead of doing true browser tests, and I think this has worked out well.
Some caveats: I got very caught up with trying to do canvas tests initially. I really wanted to use jest-mock-canvas but we were using offscreencanvas via a pretty complicated string of things, so I don’t make progress here, and I also got confused about the relationship between node-canvas and jest-mock-canvas (they are basically totally different approaches). Later on, I find using jest-image-snapshot of the canvas contents works nice (ref https://stackoverflow.com/questions/33269093/how-to-add-canvas-support-to-my-tests-in-jest)
Other random note: when building out the integration tests, we got a lot of “act warnings” which were confusing. These were fixed in React 16.9 (released August 2019), but we had to ignore them and they basically just confused me a lot and made it feel like I was battling a very complex system rather than a nice simple one.
Conclusions
Overall, I just wanted to write up my whole experience. It felt really difficult for me to make these changes. I also went through a breakup during this time, had a bad living situation, etc. so things were a struggle. If anyone else has had struggles learning react, tell your story, and let me know. I’d like to also thank everyone who helped me along the way. I feel like a much better coder now, yet, I should always keep growing. The feeling of uncomfortableness could be a growing experience.
0 notes
Text
Misconceptions your team might have during The Big Rewrite
Disclaimer: I enjoy the project I am working on and this is still a work in progress. I just had to rant about the stuff I go through in my job here, but it does not reflect the opinions of my emplorer, and my personal opinion is despite these troubles we are coming along nicely
I joined a team that was doing the big rewrite in 2018. I was involved in the project before then and knew it’s ins and outs, and frankly think it’s still a great system. In order to break it’s “limitations” a grand v2 gets started. I think my team has been good. My tech lead is really good at architecture. Where I really resist kind of “writing new architecture that is not already there”, he can pull up entirely new concepts and abstractions that are all pretty good. Myself, I don’t much enjoy writing “new architecture” if there is something already there that I can use, and I’ll try to refer to the existence of an existing thing instead of creating new exotic stuff.
Now, what happened during the big rewrite so far. 4 people on the team, 2 years in
Persistent confusion about sources of slowness in our app
- it's only slow because devtools is open (maybe it is! but this is definitely a red herring. the code should work with devtools open. reason that’s been stated: devtools adds a “bunch of instrumentation to the promises that slows it down”...stated without any evidence during a 3 hour long planning call...) - it's only slow because we're using a development build of react, try a production build (the production build makes some stuff faster, but it is NOT going to save your butt if you are constantly rerending all your components unnecessarily every millisecond during user scroll, which is something we suffered from, and it creeps back in if you are not careful because you can’t write tests against this so often one day I’ll be looking at my devtools and suddenly things are rendering twice per frame (signature of calling an unnecessary setState), tons of unnecessary components rendering in every frame (signature of componentShouldUpdate/bad functional react memoizing, etc)) - it's slow because we are hogging the main thread all the time, our killer new feature in v2 is an intense webworker framework. now main thread contention is a concern, but really our app needs to just be performant all around, webworkers just offloads that cpu spinning to another core. what we have done in v2 is we went whole hog and made our code rely on OffscreenCanvas which 0 browsers support. also, our webworker bundles (worker-loader webpack build) are huge webpack things that pretty much contain all the code that is on the main thread so it’s just massive. that makes it slow at loading time, and makes it harder to think about our worker threads in a lighter-weight way, and the worker concept is now very deeply entrenched in a lot of the code (all code has to think of things in terms of rpc calls) - it's slow because there are processes that haven't been aborted spinning in the background, so we must build out an intensive AbortController thing that touches the entirety of all our code including sending abort signals across the RPC boundary in hopes that a locked up webworker will respond to this (note: our first version of the software had zero aborting, did not from my perspective suffer. arguments with the team have gotten accusatory where I just claim that there is no evidence that the aborting is helping us, pointing to the fact that our old code works fine, and that if our new code suffers without aborting, that means something else is wrong. I have not really been given a proper response for this, and so the curse of passing AbortSignals onto every function via an extra function parameter drags on - it's slow because we are not multithreading..., so we put two views of the same data into different webworkers (but now each webworker separately downloads the same data, which leads to more resource spent, more network IO, more slowness)
confusion about what our old users needs are
- tracks not having per-track scroll (problem: leads to many scrolls within-scrolls, still unresolved problem) - the name indexing was always a big problem (yes it is slow but is it really THE critical problem we face? likely not: bioinformatics people run a data pipeline, it takes a couple days, so what). use elasticsearch if it sucks so bad - our users are "stupid" so they need to have every single thing GUI editable (interesting endeavor, but our design for this has been difficult, and has not yet delivered on simplifying the system for users) - our users "do not like modal popups" so we design everything into a tiny sidedrawer that barely can contain the relevant data that they want to see - having interest in catering to obscure or not very clear “user stories” like displaying the same exact region twice on the screen at once saying “someone will want to do this”, but causing a ton of extra logical weirdness from this - not catering to emerging areas of user needs such as breaking our large app into components that can be re-used, and instead just going full hog on a large monolith project and treating our monolith as a giant hammer that will solve everyones problems, when in reality, our users are also programmers that could benefit from using smaller componentized versions of our code - confusion about “what our competitors have”. sometimes my team one day was like “alright we just do that and then we have everything product X has?” and I just had to be clear and be like, no! the competitor has a reall pretty intricate complex system that we could never hope to replicate. but does that matter? probably not, but even still, we likely don’t have even 20% of the full set of functions of a competitor. luckily we have our own strengths that make us compelling besides that 20% - making it so our product requires a server side component to run, where our first version was much more amenable to running as a static site
more to be added
but what does all this imply?
there are persistent confusion about what the challenges we face are, what the architectural needs are, what our user stores are, what our new v2 design goals are, and more. It’s really crazy
0 notes
Text
Quitting smoking: one year cold turkey, but I have worse allergies now
Approximately a year ago, I began thinking it would be time to quit smoking. I smoked since about 16 years of age. Started with camel turkish royal, then marlboro, then lucky strike, which was continued, then a lot of pall mall...I quit from age 23-25...I relapsed the day I got news of my sister’s passing. So from 25 to 29, I smoked! I suppose they say quitting before you are 30 is a good idea. So it was a bit after the new years so kind of like a new years resolution. My roommates and I all agreed to do it at the same time. We had an acupuncturist friend stick our ears with needles and looked like little freaks with needles in our ears around the table.
At this time I had a kind of bad sleeping setup and I had a blanket my friend gave to me, and it was very cold in our house at nights so I’d sleep with my head fully underneath it. Before quitting, this was basically fine, but almost everyday post smoking I would wake up feeling really stuffy like I had a cold, and I just kept telling everyone that I was sick! I didn’t really want to think that it was related to allergies because it felt so much like a cold to me.
Eventually, I sort of discovered that it was the blanket was the cause and I got a little bit better after that. Later in the year, a person in our house had the flu, and I got it and got really sick and bed ridden for over a week and then I felt like I never got back to 100%. Again, I started getting the stuffiness when I woke up. It seems like it may have kicked my immune system back into allergy sensitive mode. I think perhaps at this time it may have been a sensitivity to pet dander on pillow cases and in the house, and it is a subtle thing but it is so obvious when you wake up with stuffy nose and itchy throat that goes away pretty fast after you walk around the house for a little while.
In any case, I am very happy I quit smoking. I never think about smoking anymore. I don’t get cravings. I feel great aside from these allergic reactions. I wish I could find more information on the web about quitting smoking being related to some allergies, but I haven’t found too much.
One article about smoking being related to some lower allergies
“Our results suggest that smoking may be causally related to a higher risk of asthma and a slightly lower risk of hay fever.”
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5440386/
0 notes
Text
Behind the release: the story of the bugs and features in a standard maintenance release of jbrowse
Every once in awhile, you might see that your favorite program, JBrowse, has a new release. There are a ton of little snippets in the release notes, you might as well just go ahead and upgrade, but what went into all those little fixes? Going to the blog post has links to the github issues, http://jbrowse.org/blog/2018/12/13/jbrowse-1-16-0.html but I felt like maybe I’d add a little more context for some of them:
PS This is sort of motivated by @zcbenz blog on Electron (https://twitter.com/zcbenz http://cheng.guru/) which tells the software in terms of actual commit messages and such.
- The webpack build doing a production build by default. This seems pretty straightforward, but was also difficult because I use WSL and the UglifyJs plugin had trouble on WSL using the parallel: 4 option to use multiple processors. This was really annoying and resulted in the webpack build just hanging for no reason and only careful google-fu really uncovered other people having this issue. I removed the parallelism as the speed gain wasn’t even really justifiable https://github.com/gmod/jbrowse/pull/1223
- The incorporation of the @gmod/bam module. This was an almost 2 months process after my first module, @gmod/indexedfasta. It required really getting down to the binary level for BAM and was pretty tough. The module has already itself had 12 releases https://github.com/GMOD/bam-js/blob/master/CHANGELOG.md
- Added support for indexing arbitrary fields from GFF3Tabix files. This was fairly straightforward but required making design decisions about this. Previously flatfile-to-json.pl files would have a command line flag to index arbitrary fields. Since gff3tabix files are specified via config, I allowed specifying arbitrary fields via config.
- Added ability to render non-coding transcript types to the default Gene glyph. This one was a nice feature and enables you to see non-coding types, but required some weird design decisions because I could not override the “box->style->color” from a higher level type simply using the _defaultConfig function, so I needed to override the getStyle callback that was passed down to the lower levels, so that it was able to use the default lower level style and also our non-coding transcript style. See this part of the code for details https://github.com/GMOD/jbrowse/commit/ec638ea1cc62c8727#diff-a14e88322d8f4e8e940f995417277878R22
- Added hideImproperPairs filter. This was fairly straightforward but it is one of these bugs that went unnoticed for years...the hideMissingMatepairs flag would hide things didn’t have the sam 0x02 flag for “read mapped in proper pair”, but reads with this flag could still be paired. Doing the 1.16 release that focused on paired reads helped focus on this issue and now hideMissingMatepairs filters on “mate unmapped” and hideImproperPairs is the “read mapped in proper pair”
- Added useTS flag. This one is fairly straightforward, it is similar to useXS which colors reads based on their alignment in canonical splice site orientations. I figured I could just copy the useXS to the useTS since I figured they are the same, but I went ahead and manually generated RNA-seq alignments with minimap2 and found that the useTS is actually flipped the opposite of useXS, so it was valuable to get actual test data here.
- Fixed issue where some generate-names setups would fail to index features. This was a bad bug that was brought to light by a user. I was kind of mind boggled when I saw it. In JBrowse 1.13-JBrowse 1.15 a change was introduced to name indexing with a memory leak. In JBrowse 1.15 that was removed. But, there was another change where refseqs could return empty name records, because they were handled separately. But if the initial fill up of the name buffer of 50000 was exceeded by the reference sequence, then there would be empty name records after this point and cause the name indexing to stop. Therefore this bug would only happen when the reference sequence indexing buffer exceeded 50000 items which could happen even when there are less than 50000 refseqs due to autocompletions
- Fixed issue with getting feature density from BAM files via the index stats estimation. This involved parsing the “dummy bin” from index files, and I found it was failing on certain 1000 genomes files. I actually don’t really know what the story behind this was, but our tabix code was better at parsing the dummy bins than my bam code, and it was the same concept, so I took a note from their codebase to use it in bam-js code. Commit here https://github.com/GMOD/bam-js/commit/d5796dfc8750378ac8b875615ae0a7e81371af76
- Fixed issue with some GFF3Tabix tracks having some inconsistent layout of features. This is a persistently annoying fact in tabix files where we cannot really get a unique ID of a feature based on it’s file offset. Therefore this takes the full crc32 of a line as it’s unique ID.
- Fixed CRAM store not renaming reference sequences in the same way as other stores. This one was interesting because rbuels made a fix but it caused features from one chromosome to show up on the wrong ones, so chr1 reads where showing up on chrMT. This happened because it was falling back to the refseq index if it chrMT wasn’t in the embedded “sam header” in the CRAM file, but it should only fallback to refseq index if there is not any embedded “sam header” in the CRAM file.
- Fixed bug where older browsers e.g. IE11 were not being properly supported via babel. This was a absolutely terrible bug that I found over thanksgiving break. It was a regression from 1.15 branch of JBrowse. Previous versions from 1.13 when webpack was up until 1.15 used @babel/env. It was changed to babel-preset-2015 but it was not being run correctly. Then I found that even if I did get it running correctly, it was unable to properly babel-ify the lru-cache module because it used something called Object.defineProperty(’length’, ...) to change how the length property was intepreted which was illegal in IE11. The ‘util.promisify’ NPM module also did this in some contexts. I found that I could use the quick-lru module and the es6-promisify module instead of lru-cache and util.promisify as a workaround. Then I had to update all @gmod/tabix, @gmod/vcf, @gmod/bgzf-filehandle, @gmod/indexedfasta, @gmod/tribble-index, @gmod/bam, and JBrowse proper to use these modules instead, and make the bable chain, which typically does not parse node_modules, to build these modules specifically (I didn’t want to setup babel toolchains for every single one of these modules, just one in the jbrowse main codebase...). This was really a lot of work to support IE11 but now that works so *shrug*
- Fixed bug where some files were not being fetched properly when changing refseqs. This was actually fixed when I changed out lru-cache for quick-lru and fixed a bug where the cache size was set to 0 due to a erroneous comment that said “50*1024 // 50MB”...of course it should have said “50*1024*1024 // 50MB” https://github.com/GMOD/jbrowse/commit/2025dc0aa0091b70
- Fixed issue where JBrowse would load the wrong area of the refseq on startup resulting in bad layouts and excessive data fetches. This was actually a heinous bug where jbrowse upon loading would just navigateTo the start of the reference sequence automatically and then to wherever was specified by the user. This resulted in track data to start downloading immediately from the start of the chromosome and resulted in for example 350 kilobases of reference sequence from all tracks to start downloading, which when I was implementing view as pairs, was causing me to download over 100MB routinely. This was terrible, and after fixing I only download about 10MB over even large regions for most BAM files. Additionally, this bug was causing the track heights to be calculated incorrectly because the track heights would actually be calculated based on distorted canvas bitmaps. https://github.com/gmod/jbrowse/issues/1187
- JBrowse Desktop was not fetching remote files. This was a weird issue where remote file requests were considered a CORS requests to any external remote. This was solved by changing the usage of the fetch API in JBrowse for node-fetch which does not obey CORS. Note that electron-fetch was also considered, which uses Chromiums network stack instead of node’s, but that had specific assumptions about the context in which it was called.
- Fixed issue where some parts of a CRAM file would not be displayed in JBrowse due to a CRAM index parsing issue. This was based on a sort of binary search that was implemented in JBrowse where the elements of the lists were non-overlapping regions, and the query was a region, and the output should be a list of the non-overlapping regions that overlap the query. Most algorithms for binary search don’t really tell you how to do searches on ranges so needed to roll up my sleeves and write a little custom code. An interval tree could have been used but this is too heavy-weight for non-overlapping regions from the index https://github.com/GMOD/cram-js/pull/10
- Fixed an issue where BAM features were not lazily evaluating their tags. When a function feature.get(’blahblahblah’) is called on a BAM feature, it checks to see if it’s part of a default list of things that are parsed like feature start, end, id, but if not, it has to parse all the BAM tags to see if it is a tag. Since they are called “lazy features” the tag processing is deferred until it is absolutely needed. As it turned out, the incorporation of CRAM in 1.15 was calling a function to try to get the CRAM’s version of CIGAR/MD on the BAM features unnecessarily invoking the tag parsing on every feature up front and therefore making the feature not really lazy anymore. This restored the “lazyness” aspect of BAM.
- Fixed issue where CRAM layout and mouseover would be glitchy due to ID collisions on features. In the 1.15 releases, CRAM was introduced, and we thought that the concept of taking CRC32 of the entire feature data days were over because there is the concept of a “unique ID” on the features. However, this ID was only unique within the slices, so around the slice boundaries there were a lot of bad feature layouts and mouseovers would fail because they would map to multiple features, etc. I found a way to unique-ify this by giving it the sliceHeader file offset. https://github.com/GMOD/cram-js/pull/10
- We also had behind the scenes work by igv.js team member jrobinso who helped on the CRAM codebase to incorporate a feature where for lossy read names, so that a read and it’s mate pair would consistently be assigned the same read name based on the unique ID mentioned above. There was also a rare issue where sometimes the mate pair’s orientation was incorrectly reported based on the CRAM flags, but the embedded BAM flags correctly reported it.
- Finally the paired reads feature. This was a feature that I really wanted to get right. It started when garrett and rbuels were going to san diego for the CIVIC hackathon, and we talked about doing something that matched a “variant review system” that they had done for the IGV codebase, which involved detailed inspection of reads. I thought it would probably be feasible for jbrowse to do this, but I thought essentially at some point that enhancing jbrowse’s read visualizations with paired reads would be a big win. I had thought about this at the JBrowse hackathon also and my discussions then were that this was very hard. Overall, I invented a compromise that I thought was reasonable which was that there can be a “maxInsertSize” for the pileup view beyond which the pairing wouldn’t be resolved. This allowed (a) a significant reduction in data fetches because I implemented a “read redispatcher” that would actually literally resolve the read pairs in the separate chunks and (b) a cleaner view because the layout wouldn’t be polluted by very long read inserts all the time and also, for example, if you scrolled to the right, and suddenly a read was paired to the left side of your view, it would result in a bad layout (but with max insert size, the window of all reads within maxinsertsize are always resolved so this does not happen) and finally ( c) the paired arc view was incorporated which does not use read redispatching and which can do very long reads. All of these things took time to think through and resolve, but it is now I think a pretty solid system and I look forward to user feedback!
0 notes
Text
Response to “You fired your top talent”
This post is not necessarily against the post “you fired your top talent” or “we fired our top talent”. Just maybe an inquiry to why things happen as they do with high performing and low performing workers
In my experience, it seems like workers can be completely unproductive even when they are "coming into work every day". I can't really explain why, but I have been in unproductive roles where I was totally on dead ends, and I don't think it's necessarily because I was unskilled. For example, I have also been on projects where I just fully absorbed the code and became a core contributor (maybe even became a "Rick"). Then it was kind of insane because as a core contributor, when I looked around, I just saw other people doing unproductive and even counterproductive things.
Now, as the article says, where was "management"? Would they have helped, for example to manage Rick better or spread work out, as the article seems to suggest? IMO, I think not. Maybe the article is a plea for better management (the article itself is a response to another one where management simply fired their “Rick”) but I think it is just so frequent that management is pretty incompetent in technical ways that I have a hard idea of knowing whether my experience is bad or not (note that I do believe, in many cases, that their diplomacy efforts and people skills are pretty impressive so I don’t believe in “no management”). But can they manage the technical work? I am not sure. For example, management I have worked under always seem to have a bunch of "pet project" features that they harped on about. We could have a meeting every week, and this same thing would occur every other week, and you have to repeatedly explain why it is a problem in the current codebase. In some sense, as a core dev, you might even start to believe the management is psychotic for even wanting some of these features that they harp on about because there are so many more important real things you need, and implementing their pet project or fixing their pet peeve would actually damage the codebase.
The real work on the project isn’t the pet projects that management has, it is plugging away at issues, enabling better code through good abstractions (functional, architectural, object oriented, or configuration abstractions). Good code often can just be a proliferation of existing good code patterns in a monkey-see monkey-do thing, and eventually you don’t always need to go to stackoverflow for an answer eventually because the entire mental map you obtain enables you to pick and choose solutions from your own project. Abstractions can then enable certain more productive things to happen down the line, make things flexible. Then many parts of code work in fixing issues should make things more stable and accurate (hopefully you are not just working yourself into a hacky soup when you are “fixing” your issues). In the worst case, something you created actually just multiplies issues for you because suddenly everything is dependent on a hack. Sometimes I feel like some devs just really fail to see this and start to just hack things to the fucking bone trying to make it work. If you are a productive contributor working on the project, you might be able to recognize a lot of these things, and hopefully realize that productive is not just “create hacks” or “we need to change frameworks” (how many conference calls have we had where management disparages library x as being unhip? or calling the old devs “dumb” for not having implemented their pet project before they quit? management can be dumb as a rock imo, and as I no longer work there, I’m really happy to rip into their bad habits)
What about the idea that things need "documenting" to enable other devs to work on the project? I think this is a red herring. In fact, “Rick” probably is documenting things if he’s a good developer. He probably has important notes that you would understand if you were actually even using the product as it is meant to be used (and not, simply using the product to test whether your pet prioject was finally implemented, or working on a crazy side project that is tangential to what most users use the product for, these tangential misguided uses of your core product often comes from UNPRODUCTIVE DEVS and MANAGEMENT not from RICK! Rick probably has the best knowledge about not only the code, but also the future potential of the project and the current needs of users (if he does mail list support for example, he’s might be in correspondence with users already). There might be a very deep configuration option that Rick made that few people know about, but when you realize that config variable exists, you will be so appreciative. In fact, you are overjoyed because now you just flip that config switch instead of editing the codebase and recompiling to enable something. The entry probably exists in documentation, but you don’t care until you need it. Also, the original article seems to claim that these config switches add “complexity” and claim their trimmed down version that they made “without Rick” is more “bug free” but many times, config switches can be completely painless (e.g. read a global json object. that’s absolutely painless in javascript. don’t complain about globals to me for a read only config) and don’t add significant complexity, they actually just add flexibility!
Now, I've had devs explain "architecture" to me, and afterwards it completely means nothing to me. They give me some crazy idea that essentially boils down to “oh this is MVC, and there are some crazy modules at each layer, but yea, enjoy” and I really am not enlightened at all. To even get what’s going on, I have to begin deeply working with the code. Now because of that, there might be a sort of explanation of why a dev is unproductive, namely that for whatever reason or another, they are not taking a dive into the code, and therefore, they just don’t engage. Learning to use “grep” and everything to find what part of code does whatever thing is really important as far as this goes, but eventually, you need to just get a big mental map of everything.
The idea of a developer having a “responsibility” for their code is something that I truly think could be important too. You can really only build the mental map if you are doing things with the code, so for example, a successful project would have a good system of getting developers on tasks that are appropriate and reasonable. In a project I succeeded in, the original developers left the project and I was basically in a position where I could take up a lot of slack and responsibility for the project, so I did so with eagerness. In another example, I've been given projects that I don't feel like is part of the core product or even the core codebase (being assigned smaller code projects that may or may not find use in a core product)
If I was to make an analogy, sometimes you need to really take some personal responsibility to make a project happen. When I am working on home repairs, of which I have a LOT of as I am basically fixing up houses in my spare time now, I find that I can simply be of assistance my friend who is also helping fix the house, or I can spearhead a project on my own. Or, my friend (who is better at repairs than me) can kindly suggest a project that I can do. In one sense, he can be a manager but only because he really knows what is also going on in the codebase. But I can also, take the responsibility to make things happen myself. If I have a good enough mental map of what to do, I can then perform all the google queries, the store trips, know what tools to use, and execute all on my own.
With my house-fixing-up project, if I was to have my parents be "management" (they love getting pictures of progress and making suggestions) then literally what they keep telling me to do is put in a washer and dryer in, even though we are not even finished with demo (demolition) work and the place is a mess. Surely they know some other stuff, and might even be able to suggest things to do or people to call if they were more deeply involved, but basically, the management can't help very deeply. Similarly, documentation of all my work isn't going to help, because really it is the process of being involved in the coding and fixing of existing issues that makes you know what needs work. The documentation, per se, is all online on google for example "how to put in light switch" but your mental map of what needs to go where in the house is what pushes the project forward.
0 notes
Text
GFF3Sort - A gff3 tabix companion tool
Almost a year ago today, I helped implement GFF3Tabix parsing in JBrowse. This is an alternative to the flatfile-to-json.pl pipeline, and as it happens it is much faster! One important thing to do is to perform coordinate sorting of the data.
Now I am delighted to see a new tool on biorxiv that discusses creating a GFF3Sort tool that perfectly fits tabix GFF processes, and properly sorts GFF files for tabix processing. Their tool is posted here http://biorxiv.org/content/early/2017/06/04/145938
0 notes