
Statistics
We looked inside some of the posts by getcybercare and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
5 months ago
Number of Posts By Type
Text
11
Last Seen Tumblr Blogs





Fun Fact
The most popular pages on Tumblr are about Minecraft, GIFs, and David J. Peterson.
Text
Handling Hawk’s Deluge of Data with AWS
When a user loads a web page, all the associated code runs on their computer. Unless communicated explicitly to a server, what they do with the code is unknown. Choices they make, errors and UX bugs are all locked away on their computer. And then they vanish forever when the user closes the browser window.
This is a problem for developers, who need to know those things.
At Cyber Care, we became dissatisfied with the available solutions to that problem. Most locked you into a funnel paradigm, or required you to interpret complex heatmaps. Some only handled error reporting. We wanted a solution that would do what we needed, without constraining us in ways we weren't committed to.
So we started developing Hawk: our answer to the problem.
One major technical difficulty with Hawk, from the beginning, was data volume. We didn't have the budget to spin up huge, inefficient servers. But as Hawk ran day by day during development, the pile of data mounted higher and higher.
We went through several server paradigms to handle it.
Starting Simple
In our first iteration, our “reporter” script (the JavaScript file that Hawk users included on their websites to facilitate reporting data to Hawk) sent data to REST endpoints on a NodeJS server, which then stored the data in MongoDB. This approach was simple and familiar, and allowed us to easily develop Hawk locally and deploy it in production.
For our production server, we picked AWS Lightsail for its low price, but one of the downsides is that (for the server size we selected), you’re expected to use an average of no more than 10% CPU. When you exceed the limit, the server slows to a crawl. On top of that, disk usage is throttled too.
Hawk’s most important feature was providing a visual recording of what the user actually saw on their screen. Our initial implementation was to send the full HTML serialization of the DOM to the server each time something changed in the DOM. We were also:
capturing details about JS errors and failed XHR and fetch requests,
using WebSockets to send the HTML to site owners logged in on usehawk.com, so they could watch sessions live
using Puppeteer to render the HTML to PNG images to include in email notifications
so it was easy to overwhelm our server.
A Little Lambda
The first optimization we made was moving the storage of HTML snapshots to S3 and the rendering of PNG images into a Lambda function. We still had the data coming into our server, but rather than writing it to disk in our Mongo database, we sent the HTML to S3 and kicked off a Lambda function. The Lambda function loaded the HTML from S3 in Puppeteer, took a screenshot, and saved the PNG into S3.
Lambda was a much better choice for running Puppeteer and rendering HTML to PNGs than our resource-constrained Lightsail server. With Lambda, you’re only charged for the time when your function is running and Amazon handles scaling for you. If 100 requests come in at the same time, you can run 100 instances of your Lambda function concurrently. And if there’s no traffic between midnight and 6:00am, you don’t pay anything during that period. Lambda also allows your function to remain loaded in memory for a period of time after it completes. They don’t charge for this time, but in our case, this meant we didn’t have to wait for Chrome to launch each time our function ran.
This was a good first step, but we still had a lot of data flowing through our humble Lightsail server.
API Gateway, Lambda and S3
We knew that our Lightsail server was the center of our performance problems. We could have upgraded to a larger server (in EC2, for example), but while this might “fix” things in the short-term, it wouldn’t scale well as Hawk grew. After our positive experience with Lambda, we knew that we wanted to move as much as possible off of our server.
We used AWS API Gateway as the new entry point for receiving data from our reporter script. We created an API for each category we needed to handle (snapshot [HTML] data, events, site-specific configuration, etc.). Each API had from one to a handful of REST endpoints that invoked a Lambda function. We unified the APIs under a single domain name using API Gateway Custom Domain feature.
Data Storage
For data storage, we knew that we didn’t want to use our MongoDB server. We considered using AWS’s schemaless database, DynamoDB. However, querying in DynamoDB seemed very limited (dependent on indices, with additional charges for each index). We decided that S3 (although not designed to be a database) would work just as well for our purposes. S3 makes it easy to list files in ascending order, with an optional prefix. So for events (including page navigations and errors), we organized them in S3 by account, then by site, and then using an “inverted timestamp”, for example:
5cd31ad21d581b0071b53abc/5cd31ad21d581b0071b53def/7980-94-90T78:68:…
The timestamp is generated by taking an ISO-8601 formatted date and subtracting each digit from 9; this results in the newest events being sorted at the top, which is the order Hawk wanted to display them in the UI.
Live View
To support live viewing of sessions, we needed a way to get the data from the visitor to the site owner. This involved a couple of Lambda functions and some SQS queues: On the visitor side of things:
Our html-to-s3 Lambda function accepts screenshot data (HTML, window dimensions, etc.) from a site visitor and stores it in S3.
It then checks for the existence of an SQS queue named live-viewers-requests-{siteId}-{sessionId}
If such a queue exists, it reads messages off of that queue. Each message contains the name of a queue that should be notified of new screenshot data for the session.
It sends the name of the screenshot data in S3 to each queue found in step 3.
And then on the viewer side:
Our live-viewer Lambda function takes site and session ids as parameters, and the name of the last screenshot the viewer received.
It queries S3 to see if a newer screenshot is available. If so, it returns that screenshot.
Otherwise, it creates a randomly-named SQS queue, and sends a message containing that random queue name to live-viewers-requests-{siteId}-{sessionId}.
It then waits for a message on the randomly-named queue. If it receives one within 23 seconds, it returns the screenshot contained in the message.
Otherwise, it returns a specific error code to Hawk's front-end to indicate that no new data was available. The front-end can then retry the request.
Keeping Lambda functions small and fast
API Gateway APIs time out after 29 seconds. In order to avoid having our requests time out, and to ensure we didn't slow down our customer's sites by having concurrent, long-running requests, we split some of our endpoints into multiple Lambda functions. For example, the html-to-s3 function we mentioned above is actually split into a couple of pieces. The first accepts the HTML from the client, stores it in S3, asynchronously kicks of the next Lambda function in the process, and returns as quickly as possible. The next Lambda function in the chain deals with SQS, and if necessary, kicks off a final Lambda function to render the HTML to a PNG image.
Authentication
When a Hawk user wanted to retrieve data, our web app used the /signin endpoint on our Lightsail server, which returned a JWT. Subsequent requests were then sent to API Gateway, with the JWT included in a request header. Our Lambda functions could then validate the signature on the JWT and extract the necessary data (eg. the account id) without needing to contact our server.
We're happy with where Hawk ended up. If your team is dealing with a project that produces an overwhelming amount of data, maybe something we did might work for you.
0 notes
Text
Libraries We Love
Everybody already loves React. It’s a beautiful framework that revolutionized rapid application development, and we use it and adore it. jQuery, Angular, NPM, Bootstrap – everybody’s talking about them and everybody’s using them. They’re great.
But we thought it was time to shine the light on a few smaller javascript libraries – maybe not the stars of the show, but doing yeoman’s service in our daily coding, and deserving more attention than they get. To that end, allow me to present 3 javascript libraries we love:
moment.js
Moment is used in a whopping 70 files in the codebase of our flagship product, NowRenting. If you need to do anything involving dates or times, it’s the one-stop, slices-and-dices Swiss Army Knife to make your problems seem small and insignificant.
It utilizes chaining and descriptive function names to make it obvious at a glance what it’s doing. Do you need to display the time exactly three days and thirty minutes after midnight on June 2, 1989? No problem:
moment('June 2, 1989, 12:00am', 'MMMM D, YYYY, h:mma') .add(3, 'days') .add(30, 'minutes') .format('MMMM D, YYYY, h:mma')
Amazing!
MJML
It used to be impossible to send graphically rich, responsive emails. Coders assigned the task pulled their hair out: it took endless amounts of time and just as endless numbers of nested html tables. Imagine CSS selectors sixty or a hundred elements deep, and you begin to get an idea what it was like before MJML came on the scene.
MJML is a markup language that compiles to styled HTML that will show up nicely in any email client. It looks like this:
<mjml> <mj-body> <mj-section> <mj-column> <mj-text>Wow!</mj-text> </mj-column> </mj-section> </mj-body> </mjml>
And it’s as easy as it looks. MJML does exactly what a library should do: abstract away the toil so you can focus on what’s important.
classnames
Classnames is a different kind of animal from moment or MJML. Instead of hiding the difficult or tedious parts of a task under an easy function or markup syntax, classnames enables you to make your React code more React-ish.
At its simplest, you pass in strings and it sticks them together; at its best, it allows you to control the logic of popping classes on and off of elements without having to deal directly with string concatenation. Instead, you pass in an object with classes as names and booleans as values. This leaves your code more functional and maintainable.
You can rewrite this (from their docs):
var btnClass = 'btn'; if (this.state.isPressed) btnClass += ' btn-pressed'; else if (this.state.isHovered) btnClass += ' btn-over';
as
var btnClass = classNames({ btn: true, 'btn-pressed': this.state.isPressed, 'btn-over': !this.state.isPressed && this.state.isHovered });
Since objects are easier to manipulate than branching blocks of if statements, this gives you a much more direct line between the program’s state and its output.
0 notes
Text
Reactive Programming
Reactive programming has become a popular paradigm for many in recent years. ReactiveX (http://reactivex.io) is one implementation available in several languages (Java, JavaScript, .NET Scala, Swift and others). Today I am going to look at Observables, with a focus on their implementation in Java.
Reactive programming uses the observer pattern (https://en.wikipedia.org/wiki/Observer_pattern). What Reactive programming boils down to is that it basically is a way of programming for asynchronous streams and event-based programs. It's basic building block is the Observable, and that is used to emit objects (including event objects). After the Observables are created, the objects they emit can be filtered and mapped.
The Observable and the Emitting Lifecycle
One way to think of Observable is as a cousin of the Iterable. Like an Iterable, it deals with a series of objects. Also, like Iterable, it has methods which handle the getting of the next object and handling when there are no more objects to stream. But unlike Iterables, you don't have to be concerned with threads and how work might be split among multiple threads. To the user, this doesn't matter. However, what the user does have to be concerned with is how to create and use Observables, which can be kind of confusing.
The Observable class has many helper methods, several which can be used for the creation of the Observable. The easiest to use is the just() method. An Observable can can be created using that method, and then other methods can be chained to it. Showing an example would be the best way to show object creation and use other methods:
Observable .just("Joe", "Bill", "Steve", "Bob") .subscribe(new Subscriber<String>() { @Override public void onCompleted() { System.out.println("Observable is compete."); } @Override public void onError(Throwable throwable) { System.out.println("Error: " + throwable.getMessage()); } @Override public void onNext(String name) { System.out.println("Name:" + name); } }); // Output: // Name: Joe // Name: Bill // Name: Steve // Name: Bob // Observable is complete.
Notice that the subscribe method is called right after the just method. The subscribe method is called so that a mechanism can be provided for receiving push-based notifications from the Observable. Another way to think of a Subscriber is that it is an Observer. In fact, the Subscriber class is an abstract implementation of the Observer interface, which contains the onCompleted onNext and onError methods. When you think of it using the words 'observer' and 'observable', it is easy to understand how they are related.
As each name is emitted, the onNext method is called, and once no more objects are left to emit, onCompleted is called, unless there is an error for onError to handle. These 3 methods are called by default during the cycle of emitting objects from an Observable. There is default behavior with each of these methods, and as you can see above, those behaviors can be overridden by explicitly using @Override on those methods.
Operators
Another way the default behaviors are overridden is by using one of the many operators available. In the ReactiveX library, there are dozens of such methods. They are called during the onNext phase of the emitting cycle. Once we have the observable emitting items, we can use the operators to make more complicated behavior. Since there are dozens of operators that can perform work on the emitted items, it makes sense to look at one of the most powerful (and most useful) operators that ReactiveX has to offer. That is the filter operator. If we wanted to use this operator on the example above, we would implement it like this:
Observable .just("Joe", "Bill", "Steve", "Bob") .filter(name -> name.length() != 3) .subscribe(new Subscriber<String>() { @Override public void onCompleted() { System.out.println("Observable is compete."); } @Override public void onError(Throwable throwable) { System.out.println("Error: " + throwable.getMessage()); } @Override public void onNext(String name) { System.out.println("Name:" + name); } }); // Output: // Name: Bill // Name: Steve // Observable is complete.
The additional filter method call above uses Java 8 lambda notation, which makes the logic even more simple and consice.
Reference and Tutorials
Now that you have a taste of what ReactiveX is about, a great place to check out is the documentation on operators (http://reactivex.io/documentation/operators.html). There you will find not just an alphabetical list (which can be overwhelming), but the operators grouped by function, and a useful decision tree for selecting what operator will fit your needs.
Here's some more links for further learning: (Some of these focus on other languages, like .NET, but give a good explanation of the underlying principles of the ReactiveX framework) https://channel9.msdn.com/Blogs/Charles/Erik-Meijer-Rx-in-15-Minutes https://channel9.msdn.com/Series/Rx-Workshop/Rx-Workshop-Introduction http://www.introtorx.com/ http://reactivex.io/tutorials.html
0 notes
Text
Tales of a Cybercare Engineer: How We Dealt With 10 Billion DOM Nodes in IE9
Recently, our engineering team received a request to prototype a new feature. By prototype I mean we create a Node server that exposes a stubbed API, documented by our backend team. We do this so that we can demo frontend features to stakeholders as early as possible to get feedback. We then communicate this feedback with the backend team to make our APIs more robust when they get around to implementing the real deal. All our stories have an integration phase where we hook them up to the real APIs. But, I digress.
In this post I will describe our problem and walk you through the process we took to come up with a solution. You will learn techniques to efficiently handle nodes in the DOM, attach event listeners, tradeoff analysis, general problem solving, and more. Note that this post focuses on the DOM. We faced other problems, such as how to load huge volumes of data across a network, which omitted from this post for the sake of simplicity.
The Job
To keep our client’s projects anonymous, I’ll outline the problem we were faced with using a made up scenario, but realistic volume and expectations. Say you work for a vending machine company that has machines in 1500 buildings across the US. Each of those buildings could house 300 machines; now that’s a lot of machines! Each of those machines may have 10 different rows of snacks. Finally, each row of snacks could contain 100 individual snack packs.
The prototype we were asked to build, then, would be to show an inventory for all snack packs. The UI would consist of nest-able accordion-style rows. The first level of rows would be for buildings. Once clicked, they would expand to show rows for each machine. Finally, clicking on a row of machines would open a list of tables where each table represents a snack row and each row in the table would represent a snack pack. Here’s an amazing picture to illustrate:
The Analysis
As of writing this post we still do not have full knowledge of data volume. All we know is the largest vending machine company has 1429 buildings in their inventory. We made an educated guess about the other figures after discussing with Product. As an agile team at Cybercare, we frequently come across similar scenarios where estimation is key to success.
First, we made a mock-prototype, if you will, of what the UI would look like. This gave us an idea of how many DOM nodes would be required to render each snack pack. We came up with a minimum of around 25 DOM nodes per pack.
So, 25 nodes per 100 snack packs per 10 snack rows per 300 machines per 1429 buildings. That’s only…10.7 billion nodes. We needed to brainstorm.
Next, we had a meeting to discuss our thoughts. Several different approaches spawned from these discussions and we were unable to come to a consensus. So, I was tasked with the job of coding mock-prototypes of our two best suggestions:
Use traditional infinite scrolling
Only attach DOM nodes when a row is clicked
Infinite scrolling didn’t do much for performance. The reason being that the number of DOM nodes increases linearly as you add new vending machine buildings, but exponentially as you add snack packs. Infinite scrolling can reduce the number of buildings in view at any given time, but it can’t reduce the number of nodes in each building since it’s an accordion.
Option two was clearly more performant, so our team agreed to move forward with that approach, but we were not out of the woods yet. A couple issues remained:
Every time the user clicks a row, a large number of nodes had to be appended to the DOM. This blocks the main thread and cannot be made asynchronous.
Memory leakage was a concern. If any event listeners, or the like, referenced our DOM nodes after deleting, the garbage collector would not clean them up. We had to be mindful of the memory footprint.
Solving #1
Our team uses AngularJS—a powerful framework, but not the most performant. We discovered that, even on a fast machine, appending DOM nodes when opening a bottom-level accordion row blocked the main thread for around 2.5 seconds on IE9. This was detrimental to user experience. This included appending all elements to a DocumentFragment before appending to the DocumentFragment to the real DOM.
We ditched AngularJS in favor of native JavaScript APIs. Two-way data binding was just too expensive and not necessary for this use case. There was also discussion of making another mock-prototype to test performance with one-way data binding, but we decided that we could eek maximum performance out of vanilla JavaScript.
We made several other optimizations along the way:
Used string concatenation where possible to take advantage of the HTML parser. It is much faster than appending DOM nodes on account of running in the browser’s native language C/C++.
Instead of attaching event listeners to each row, we attached a single listener to the root element and let events bubble up. More of a memory optimization.
Convinced Design that we should only allow one accordion row at each level to be open at a time. Meaning only one building and one of its’ vending machine rows can be open at a time.
We were able to reduce the amount of time the main thread was hogged down to less than 0.3 seconds in IE9, which was acceptable considering we were testing for the worst-case scenario in terms of data volume. All other browsers were effectively instant from a user perspective.
Solving #2
Luckily, jqLite has a solid remove() algorithm for deleting DOM nodes, which cleans up event listeners to prevent memory leakage. All there was left to do was test memory usage.
By using Chrome developer tools, to profile memory usage, and following this procedure:
Start profiling
Open a bunch of accordion rows
Close all rows
Run garbage collector
Stop profiling
We produced:
What do all these squiggly lines tell us? First of all, this graph is normalized. Meaning that, for example, although the green line (number of nodes) starts at the bottom, it doesn’t mean we don’t have any nodes on the page. It just means none have been added relative to when we started. There are a couple takeaways:
The both the green line and yellow line are at the baseline at the end of the profile, once we have closed all rows. This means the DOM elements and event listeners were cleaned up properly.
After closing all rows and running the garbage collector the heap usage end height, the blue line, is the same as before we started opening any rows. This is a strong indication that the garbage collector marked and swept all memory allocated by expanding the rows and appending DOM elements.
This gave us confidence that our algorithms were not leaking memory.
Other Optimizations
Now confident about our memory usage integrity, we essentially indexed the data structure. By maintaining a one-to-one mapping between DOM nodes and data, we were able to easily edit the data structure as needed in O(1) time.
Conclusion
This problem may not win a Nobel Prize, but it was fun to solve nonetheless. As with many problems we face at Cybercare, most solutions require cross-team collaboration and analysis. We dealt with differences in opinions on how to approach the problem, came to a consensus with an efficient plan, and gained a more robust understanding of the tradeoffs and limitations of our technology stack.
0 notes
Text
What’s new in Windows 10
The majority of people in the business world use Windows to run their infrastructure and desktop clients. For the desktop, the go to choice is still Windows 7. While Windows 8 has been out for some time, businesses have largely decided to skip it because of the issue with the interface and lack of a start menu. That all changes with Windows 10. You may be asking yourself what is Windows 10, and why should I care?
Windows 10 is the newest flagship operating system from Microsoft. Windows 10 was released on July 29th 2015 replacing Windows 8.1. Users of Windows 7 and 8.1 were eligible to get a free upgrade from Microsoft. Windows 10 sees the return of the start menu, though a much more enhanced version. The new interface is a very modern and sophisticated look especially when compared with its predecessor, Windows 8.1.
Versions
There are 7 versions of Windows 10. Each one is designed either for a different function or a different type of device. They include:
Windows 10 Home – Home edition for PCs and Tablets.
Windows 10 Pro – Windows 10 Home + Business features like the ability to join a domain.
Windows 10 Enterprise – Adds Enterprise features such as branch caching and has special licensing.
Windows 10 Education – Designed for use in education. Has special licensing.* Windows 10 Mobile – For smartphones and small tablets.
Windows 10 Mobile Enterprise – Adds enterprise features
Windows 10 IoT – For use in small devices that are part of the Internet of Things.
Updated Features
Command Prompt
While not one of the biggest updates, the updated command prompt is much easier to use than earlier iterations. A nice new feature is the ability to resize the command prompt, allowing you to see more than ever before. The updated command prompt also supports various keyboard shortcuts such as ctrl + v to paste.
File Explorer
The file explorer in Windows 10 has been updated with new features that help you browse faster. When you open the file explorer there are two new default sections, frequent folders and recent files. Frequent folders shows all the folders that you frequently use grouped together for easy access. Below that, you will see the recent files section which shows the most recent files that you have opened and edited.

Start Menu
The start menu makes a triumphant return in Windows 10. The biggest complaint about Windows 8 was the lack of the start menu. The start menu in Windows 10 is part Windows 7 start menu, part Windows 8 live tiles. The live tiles on the start menu really work because they can give you updates about constantly changing things like weather or stocks.

Taskbar
The taskbar has been redesigned and has a much more modern and elegant look to it. There is now a search box by default on the taskbar. Instead of becoming a raised icon when opened, apps now will have lines underneath to denote they are open. You can see different lengths to have a visual idea how many windows are open.

New Features
Action Center
The action center is a new feature in Windows 10 which aggregates several features together. The Action Center is opened by clicking the icon to the right of the system tray that looks like a document. Inside you will find any notifications that you have received. At the bottom you will see several tiles for toggling systems on and off such as airplane mode and Tablet Mode.

Cortana
Cortana is a new personal assistant that is shipped with Windows 10. Cortana allows you to search by typing or by speech right from the task bar. Cortana has also been integrated into the Microsoft Edge browser. You can ask Cortana questions and you can have her set things up for you. You can create and modify Calendar events and set reminders. You can even ask questions and Cortana will go out to the web and try to find the best answer.
MS Edge
Microsoft Edge is the new browser by Microsoft replacing Internet Explorer as the default browser. More than an upgrade, Microsoft Edge has been built from the scratch. Edge also makes it easier than ever to share. There is a dedicated share button on Edge that allows you to share to any applicable apps you have installed, making it just a few clicks. You can even decide whether you want to share the whole site or just a section of it using their clip tool. Another neat feature is web notes. Web notes allow you to highlight and draw right on the site. You can save to OneNote or share your notes right on Edge.

Print to PDF
A great new feature is the ability to print directly to PDF, no extra software required. Previous Windows versions shipped with an XPS printer which was Microsoft’s version of a PDF. If you wanted to add PDF support you would need to install a 3rd party tool to do so. With PDFs being the standard document type, this is a long overdue update.
Task View
Task view is a way to see all the apps you have opened on each screen. To activate task view, hit the Windows key + tab. You can also hit a button on the taskbar. It is the one to the right of the search bar that looks like 3 standing rectangles. This will display all open applications as tiles. If you have a multi-monitor setup, the effect will be more profound. Activating task view will show all open applications on that monitor as tiles. This allows you to see not only what you have open where, but to switch between apps very easily when you have a lot open.

Universal Apps
With Universal Apps, Microsoft hopes to get rid of dedicated platform apps. Instead Universal apps can run across any of the Windows 10 Devices. This allows developers to speed up development time by not having to develop for different platforms. Microsoft has also made an effort to make it easier than ever to port apps from Android and iPhone to Universal apps.
Video Recording
Using the XBOX for Window’s Game DVR you can natively record video of your desktop. While perhaps not intended to be used with anything but gaming, this application lets you record most applications. To open the Game DVR hit Windows key + G. It will ask you if the application you have selected is a game. Even if it isn’t, it is ok to hit yes. This will bring up the main menu of the Game DVR. Hit the record button to begin recording your interaction with the application. You can also use the keyboard shortcut Windows key + Alt + R to begin recording.

Virtual Desktops
Windows has finally implemented a favorite feature of many Linux users. Virtual desktops allow you to have several different GUI environments you can switch between. By opening up the task view by pressing the Windows key + tab, you can create new desktops by clicking the icon in the lower right hand corner with the plus symbol on it. This will create a second ‘desktop’. You can have different things open on each one. This allows you to do things like separate personal and work related open applications to a certain desktop.

0 notes
Text
Utilizing Apache Cassandra a Small Introduction
What is Apache Cassandra?
Apache Cassandra is an open source NoSQL database solution. Currently Cassandra is one of the leaders in providing scalable NoSQL databases to handle critical applications. Some notable companies that implement Cassandra solutions are Netflix, Hulu, and Comcast.
Pros and Cons of Cassandra vs other NoSQL solutions
Pros:
Easy to manage in large scale implementations
Quick to setup nodes and clusters
Lightning fast database writes
CQL (Cassandra Query Language) similar to SQL interface
Cons:
Indexes can be tricky to setup
Lack of joining functionality
Data replication is configured on a by node basis
Note: the remaining topics assume that Apache Cassandra is installed locally on your machine. It will contain a brief tutorial covering booting up Cassandra,connecting to Cassandra instances,and building out sample keyspaces and tables.
Starting up Cassandra on a local machine
Begin by changing directories to the bin file of the apache-cassandra folder. Then run the command “sudo sh cassandra -f”. If everything starts up correctly expect Cassandra to return the listening for thrift clients messag.


Building and connecting to a sample keyspace
In our example below we will be building a basic keyspace named “zoo”. After the keycap has been created we will connect to the keycap with the command “use zoo;”.

Building a sample table
For our sample we will have a table “animal” with the following fields making up an animal species (PRIMARY_KEY), name, color, and id_tag.

Populating and Querying the sample table
The below insert statements represent a way to populate Cassandra with data in our case we are adding to animals to the zoo a rhinoceros and a lion. The select command represents a simple way to query all of the animals in the zoo.

Closing Statements
Overall Apache Cassandra is a powerful tool that can be in many different situations. The above only serves as a brief introduction on how to get Cassandra up and running and there is a lot more information to learn.
Links:
http://cassandra.apache.org/download/ https://cassandra.apache.org/doc/cql/CQL.html
0 notes
Text
Tips for Creating Scalable and Modular Application Styles Using CSS Preprocessors
When creating styles for any type of application, it’s always important to consider the potential for future growth and scalability. In an ideal world, an assessment should be done from the project’s infancy to understand needs and deliverables. Scalability and modularity are something we talk about very frequently, and these two concepts play an integral role in preparing and making sure your app is really ready for the growth and prosperity you are hoping for.
When it comes to front-end application design, styles in particular, some simple ground-work can be done to help you get well on your way to creating a scalable and modular app before any code is even written. The below is just a recommendation, and even if you don’t actually make this a deliverable for your own application, be sure to at the very least mull over these ideas prior to getting started.
Seek inspiration and influence - Check out websites like dribbble, designspiration and behance to inspire yourself and help get those creative juices flowing for the application.
Create a strategy for your brand identity - e.g. logos, color palettes, font families, typography, iconography etc.
Identify which technologies will be used - e.g. Bootstrap, LESS/SASS, AngularJS, jQuery.
Create your styles based on highly regarded principles/guidelines - e.g. Idiomatic CSS, OOCSS, SMACSS
Identify which responsive breakpoints you will cater the app to - e.g. mobile, phablet, tablet, desktop and large devices.
Create a list of initial components the application will require styles for - e.g. navigation, headings, buttons, modals etc..
Let’s talk about LESS, Baby
Either LESS or SASS will do the trick as a CSS Preprocessor and set us up for success in keeping our styles scalable. For the purpose of this article I will be focusing solely on LESS. All of the concepts I will be discussing here are interchangeable with either LESS or SASS, excluding the obvious differences to syntax.
CSS Preprocessors extend CSS by allowing the use of variables, mixins, functions and other techniques giving developers the ability to create semantic, scalable, maintainable, themable and extendable styles for an application. In addition, when used properly, they makes it easier for developers to use "DRY" (don’t repeat yourself) practices in creating styles.
To maintain a modular approach, create LESS Directories with module specific LESS Files, within each module folder of your application. To be more specific, the module folder should include any module specific javascript, view templates and styles (in our case LESS). This approach allows us to do two important things for modularity--separate each module into its own specific directory and list all module files together using a birds of a feather technique. Birds of a feather assumes that the files and directories within the module folder are directly related and required by this module only. Some examples of modules could be login, search or navigation and the directory structure can be seen below:
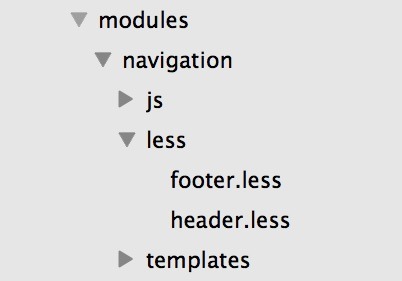
In addition to module specific styles, we still need some global styles, right? Global styles should live in a separate LESS Directory entirely, and should not be specific to any one module. Some examples of global styles would be individual LESS Files for your main styles, variables, mixins and typography to name a few. Whether module based or global, all LESS Files should be transcompiled into production ready CSS at build time regardless of their file location.
Write Styles, In Style
An important aspect of style creation is the formatting/code organization developers follow throughout the lifecycle of your project. The guidelines I follow are a fusion of two highly respected sets of principles -- Nicholas Gallagher’s Idiomatic CSS and SMACSS (Scalable and Modular Architecture for CSS). The below excerpts are nearly taken word for word from the Idiomatic CSS Guidelines. Some updates/ideas have been added/removed to better suit the overall architecture I find most helpful in my projects.
Don't try to prematurely optimize your code; keep it readable and understandable. All code in any code-base should look like a single person typed it, even when many people are contributing to it.
Never mix spaces and tabs for indentation. All of my project use spaces only, utilizing 2 characters for spacing for indentation levels. Be sure to remove any trailing whitespace prior to committing code. Failure to do so will cause unnecessary headaches for other developers during code reviews of diffs/blames and can introduce errors in corresponding pull requests.
Most popular IDE's and Text Editors have plug- ins or settings available to hide trailing whitespace.
Place comments on a new line above their subject. Make liberal use of comments to break CSS code into discrete sections.
Use one discrete selector per line in multi-selector rulesets.
Include a single space before the opening brace of a ruleset.
Include a single space after the colon of a given rule.
color: #000;
Include one declaration per line in a declaration block.
Use one level of indentation for each declaration.
Use lowercase and shorthand hex values.
color: #aaa;
Quote attribute values in selectors.
input[type="checkbox"]
Include a space after each comma in comma-separated property or function values.
Include a semi-colon at the end of the last declaration in a declaration block.
Place the closing brace of a ruleset in the same column as the first character of the ruleset.
Separate each ruleset by a blank line.
Where possible, developers should consider the use of rem rather than em or px to define font-sizes relative to the root element (in most cases the html element). This will ensure typography will adapt to a responsive design approach. If elements are defined using rem, a simple update to the root element's font-size will cause the rest of the app's font-sizes to change and in turn be relative to this font-size. Developers can define multiple root element font-sizes using media queries and the corresponding rem font-sizes will scale appropriately. Browser support should be investigated prior to using rem.
Declaration order within a specific ruleset is extremely important to the organization and structure of styles and should be in the following order: positioning, display, box-model, background and font.
.selector { position: absolute; z-index: 10; top: 0; right: 0; bottom: 0; left: 0; display: inline-block; overflow: hidden; box-sizing: border-box; width: 100px; height: 100px; padding: 10px; border: 10px solid #333; margin: 10px; background: #000; color: #fff; font-family: sans-serif; font-size: 16px; text-align: right; }
Large blocks of single declarations can use a slightly different, single-line format. In this case, a space should be included after the opening brace and before the closing brace.
.selector-1 { width: 10%; } .selector-2 { width: 20%; } .selector-3 { width: 30%; }
Long, comma-separated property values - such as collections of gradients or shadows - should be arranged across multiple lines in an effort to improve readability and produce more useful diffs.
.selector { background-image: linear-gradient(#fff, #ccc), linear-gradient(#f3c, #4ec); box-shadow: 1px 1px 1px #000, 2px 2px 1px 1px #ccc inset; }
With the utilization of CSS Preprocessors, please avoid large numbers of nested rules. For the purpose of this project, please do not use any rulesets nested more than 3 levels deep. Break rules up when readability starts to be affected to allow for a more digestible code base.
When creating CSS Preprocessor mixins always place .mixin(arg) statements on the first lines of a declaration block.
The creation of classes should entail a structure that defines base, modifiers and states where appropriate. Consider the following example:
// Base Styles .button {}; // Modifier Styles .button-primary {}; .button-secondary {}; // State Styles .button.is-collapsed {}; .button.is-expanded {};
When creating class names, be sure to be as semantic and as descriptive--evenly overly descriptive where possible. Developers should be able to have at least a general gist of the background around a ruleset by it's name. Developers should also use selector intent when creating rules. Avoid the use of type/ID selectors where possible, and utilize classes that target the element accurately and explicitly. An example of this would be applying a class called .main‐nav to target an unordered list whose purpose is a site's main navigation rather than something to the tune of header ul.
If a class involves a particular state change such as expanded or collapsed, use the word is as the naming prefix of choice, e.g. is‐collapsed, is‐expanded or is‐hidden.
Va Va Va Va Variables
Va Va Va Variables The creation of preprocessor variables should be semantic rather than raw, and should dictate the variable's specific purpose. Raw would represent the value in a literal sense, where semantic would represent the value by giving it an actual meaning. For example, if we were to create a variable for the color of a login widget's text, for the purpose of reusability in other applications, an appropriate variable name would be @color‐text rather than @black. Using a semantic name like @color‐text ensures that any updating of the color of the text in the future is a 1:1 update--assuming the variables were used as intended. To update the color, a developer would simply update the definition of @color‐text to its new value, e.g. @color‐text: #333;. If a raw variable such as @black was used, this would not be considered a 1:1 change as it could be used in a variety of other situations such as borders, backgrounds, buttons etc.. A semantic naming pattern assumes developers will utilize variables for their intended purpose. The below example showcases the difference between Raw and Semantic Variables.

When building styles for an application, I find it most practical to first list out my Raw Variables, and then assign these variables as an alias definition to my Semantic Variables. Again we can see that semantic naming allows us to only have to update the variable definition in one place, and it will then be represented in any instances where that semantic variable name is referenced throughout the application. This is perhaps one of the the most important aspects of setting our styles for scalability, as it makes global style changes a snap. Giving your variables meaning early and often will save you a great deal of time and aggravation in the long run. When dealing with clients, several things can change at the drop of a hat. Preparing a great foundation of semantic variables will make the process of updating styles seamless--making for happy developers and happy clients.
I owe a special thanks to my fellow colleagues Chad and Shawn, who are the very reason I have learned to write CSS the right way as I do today. Cheers!
0 notes
Text
Harnessing the Power of the Cloud
What is cloud computing?
In the beginning, the internet relied on client/server systems where the server is a physical computer or series of networked computers that have a permanent IP address from where it "serves" the client pages and data. The term cloud computing refers to an infrastructure where servers are contained in large groups, but consumers only have to pay for the limited amount of computing power that they need. The computing power they need can shrink or grow, just like a cloud. The main logical difference between traditional computing and cloud computing is that the client, which used to call a server that always has the same IP address, now has to call a server (usually using virtualization techniques) who's IP address is constantly changing. Because the servers "shrink and grow", they come into and out of instance constantly, so there is never 1 constant set of IP address for the client to talk to. Cloud technology requires mechanisms that allow for the discovery of the IP address a client needs to communicate with.
Why Amazon Web Services?
The major player in providing cloud infrastructure to consumers is Amazon Web Services (AWS). As of the beginning of 2015, AWS' market share is 28%, making it the leader.
Amazon can provide database support, storage and content delivery, mobile service, analytics, and many more services for an enterprise (no matter how big or small) to manage their web presence. These services are fully scalable for any size business or web app because as an AWS consumer, you only pay for the services (and how much) you use.
What is NetflixOSS?
AWS has its own web console and deployment services. But, to make it easier to deal with the deployment side of maintining an app in the clouds, Netflix has made a series of Java libraries available as open source. This means that these tools and their code are available to use free of change. Because they come from open source projects, any developer can improve on the code base. Open source software has a history of being highly supported (because a whole international developer community works on improving the code constantly) and of the highest quality (because the code is constantly peer reviewed by developers who are motivated by making great code even better).
Netflix Asgard is just one of dozens of NetflixOSS (Netflix Open Source Software) tools available. It is named after the celestial region of the gods in Norse mythology, where the thunder god Thor resides. For the sake of web developers, it is where we go to control and manage what is going on in "the cloud".
Asgard allows the user to bypass interaction of AWS via command line through its own graphical user interface. It streamlines the process of deploying and managing applications running on AWS. Asgard is a grails project, therefore it is a code base that can be customized to serve the users' needs. Once deployed it is available at a designated URL.
With AWS, web apps are first made into Amazon Machine Instances (AMIs) by creating an EC2 (Elastic Computee Cloud) instance, which is basically a resizable server for a web app. Being resizable is really the key to what makes AWS so successful: You only pay for what you use. The process of making a WAR (Java web archive, an archive that is a Java web app ready to be deployed into a servlet container such as Tomcat) into an AMI can be done using any of the tools out there. Basically, Apache Tomcat needs to be installed on the EC2 instance, and then the .WAR file is saved to Tomcat's /webapps folder. However the web app is converted to an AMI, the AMI needs to be deployed and managed. Web applications have many groups of different moving parts, and deploying them can involve some tricky interaction with the command line, or requires the development of complicated scripts. With Asgard, the easily fallible process of deploying a web app via the command line is completed by using a few simple forms and some clicks of the mouse. For instance, increasing the number of instances in order to react to increasing traffic to your site is easily done with Asgard.
The GUI integrates with deployment and maintenance tasks/tools that every app needs, like security groups, automated deployment tasks, database instances, and maintenance script scheduling. As you can see above, increasing or deleting instances is integrated with the GUI
An example of another NetflixOSS library is Eureka. As I mentioned above, cloud computing requires that IP addresses change constantly. Eureka solves this problem while it also allows load balancing to work even though the IPs are constantly changing.
All of the NetflixOSS libraries integrate well with each other, and new tools are constantly being added at at their code repository.
Links:
http://netflix.github.io/#repo http://aws.amazon.com/
#cloudcomputing#amazonwebservices#cloud deployment#ec2#cloud computing#netflixoss#open source#java web development
0 notes
Text
Agile in Practice
Enterprise level web apps can be massive. As with any project, planning and organizing are essential to a successful outcome. Like many teams, my team is Agile. We use this methodology to carry out the frontend portion of our web app. It is safe to assume that most teams create workflows that cater to their needs - that of actual development and of their product features. Though many of these specified workflows vary across all dev teams, the Agile style and its baseline principles offer a means to see projects through to the end with quality code, relevant products and a happy client. Here is an overview of how I, a frontend dev, and my team works in Agile.
Quickly, what is Agile?
In case you are not familiar Agile describes a set of alternatives to managing projects. It functions particularly well for software development. It is different from traditional Waterfall methods in that Agile focuses on an iterative process. Where higher value is placed on customer collaboration and responding to change.
Agile is an umbrella term that encompases several variations of the methodology. A few of these variations include: Scrum, Kanban, Test Driven Development and Extreme Programming. My team is a Scrum team.
What is unique to Scrum?
Structured timeframes, client input, and iterative evaluations of products and features. Product expectations can change quickly. New business requirements can be thrown into a feature at any moment. Scrum allows a team to be adaptive to these changes in an organized way. Though the expectation is to be reactive to change, high value is also placed planning and prioritizing within a reasonable scope. From a business perspective Scrum can provide reduced Time to Market. For developers, we can expect clear deadlines, continuous communication, and specific feature requirements.
Who is Scrum?
Our Scrum Team
Scrum Master
Product Owner
Developers/Architects/DevQA
Designers
Since we are a frontend team we also collaborate with the Design team who create our mockups. They also provide input towards feature expectations.
Scrum Master
Scrum Master is a facilitator between business requirements and technical input. This person assigns tasks and enforces adherence to agreed upon timeframes. You can expect the Scrum Master to lead team meetings and escalate blockers. As a developer your scrum master would be your go to person for any unknown questions. For example, if a bug ticket is created with a confusing description, you would ask your Scrum Master to clear it up for you.
Product Owner
The Product Owner is responsible for maintaining product vision. They are the person who will keep in mind stakeholder interests. They manage expectations and prioritization of the deliverable Product. They are in charge of maximizing the Return on Investment and therefore have final say in product requirements.
Developers/Architects/DevQA
Devs, architects and DevQA are expected to manage the implementation of features themselves. We are typically supported by a project management software system. We use the Atlassian Suite. Our DevQA is responsible for testing issues before they get sent to QA, QA.
Designers
The design team, for us, creates visual prototypes of how the UI should look.
Sprint schedule
We work in three week sprints. This allows us to ensure we are testing: unit, regression and E2E. Below is an example of how a typical sprint looks for us.
Issue Priority:
User Stories - large feature requirements, ex. Home page
QA Bugs - bugs filed by QA team
Dev Bugs - bugs logged by our dev team, should be fixed and merged before moving to QA
As the dev team, we are expected to complete tasks in this order. Stories are typically going to introduce new features and will likely take a large part of the sprint to complete. They are also likely to be high on the list of time sensitive deliverables. Therefore, should be completed first so that we can ensure they are fully functioning. QA bugs come back from the QA team. Dev bugs are those that we find as developers or are logged by our devQA team.
Each week
Each week we have a code freeze on that Thursday where whatever tasks we have completed can be merged and included in our friday release. We release every Friday. From that Thursday through Friday, devs will be going through the app looking for regressions and hot fixing if time permits.
Week 1:
Bug scrub
Thursday Code freeze
Regression test & hot fix
Friday release
Bug scrubs are working sessions where the Scrum Master, Designers and Devs walk through the app in search of bugs that will be logged as dev bugs. This is a time when design can see what is existing in the UI and make recommendations if needed.
Week 2:
Backlog Grooming
Thursday Code freeze
Regression test & hot fix
Friday release
Backlog grooming is another working session where stories or tasks that need refining are addressed. Dev bugs and QA bugs that were found in previous sprints will live here until they are analyzed. User stories that are too big or out of scope will also live here. This is a time where Product and devs can collaborate on expectations. We discuss how business logic can affect the development of the features. These tasks are evaluated based on whether they can fit within the scope of the next sprint and are added based on priority.
Week 3:
Sprint Planning
Thursday Code Freeze
Unit Testing
Sprint Retrospective
Friday release
Rather than having a sprint planning meeting at the beginning of a sprint, we have it during the last week of the current sprint. That way we can start the new sprint with tasks already assigned and time estimated. Sprint planning is intended to assign tasks to developers and provides a time to address any unclear requirements that were not specified in the backlog grooming. Usually by this third week devs take the time to write unit tests if they don’t already exist, or go in and refactor ugly code. A sprint retrospective is a time for the team to reflect. It is a time to discuss what can be done to improve future sprints and better ways to overcome obstacles.
Time to start the next sprint!
All in all the scrum keeps up organized and conscious of the end goal. As a team, it is up to us to get the job done together!
0 notes
Text
Frontend Debugging Tools & Tricks
There are plenty of excellent blog posts out there that discuss dev tool features. This post assumes you know your way around at least one browser’s dev tools. My current project is a webkit-only web application, so I’ll be using Chrome.
There’s an elephant in the room and its name is breakpoint
A breakpoint is a “mark” you can place in your code. When your program runs and comes across the line you marked with a breakpoint, it will stop execution.
So what makes them so useful?
Don’t think of breakpoints as halts in execution. Think of them as windows that let you peek at the context (variables, methods, objects, scopes, etc.) at a given point in the program.
But wait, there’s more!
You can also see how you got to the marked point in your program. We’ll see how to leverage breakpoints to become a better debugger later on.
Types of breakpoints
Chrome offers many types of breakpoints. Every one is worth learning and will make you a better debugger. I use all of them almost on a daily basis. We’ve got:
Line Breakpoints
Caught Exception Breakpoints
Uncaught Exception Breakpoints
DOM Breakpoints
XHR Breakpoints
Event Listener Breakpoints
Fret not, they all do the same thing; the only difference is how and when they make your program stop.
Leveraging Breakpoints
Line, caught exception, and uncaught exception breakpoints are common to almost all programming languages.
Line breakpoints let you specify a line to stop on. Because execution halting is controlled entirely by the programmer, using these effectively can require some whit.
Normally, line breakpoints always evaluate to true, but you can change how they evaluate, in Chrome, by right clicking the mark and selecting “Edit Breakpoint…”. This saves you the trouble of hard-coding a conditional and setting a breakpoint inside.
Caught and uncaught exception breakpoints are more straightforward. Instead of straining over those big ugly stack trace dumps in the console, just pause on exception. Then you can toy with the context just before the error occurred.
Ok, now for the cool web-specific ones: DOM, XHR, and event listener breakpoints.
DOM breakpoints are probably my favorite. There are 3 subtypes: break on subtree modification, break on attributes modification, and break on node removal. Pretty self-explanatory. I don’t use these a ton, but when the moment is right they can save hours of work.
For example, our framework uses Zepto (a lightweight jQuery framework). Zepto has a method called css, which applies inline styles to html elements. We use it for things like moving UI components and hiding cached pages in our SPA. Tracking down where these inline styles get applied can normally be a tricky process, but in Chrome I can set a break on attribute modification breakpoint and follow the call stack backwards to find the source.
XHR breakpoints are particularly nice if you are working with application endpoints. Chrome allows you to specify a piece of the url which, if present, will trigger an execution halt. Event listener breakpoints pause on scroll, focus, submit, keydown, load, etc. I think you get it.
The Good Parts
Some of the most useful tools in any developer’s metaphorical toolbox are ones that allow tracking of variables and objects. These are particularly important in reactive programming languages, where program execution often cannot be tracked in a synchronous manner.
We need ways to tell when an object is changed at an arbitrary time. Event messages may enter the message queue in a different order every time the program is run. This can cause issues called race conditions. Tracking object properties are quite helpful for diagnosing these conditions—more on that in a bit.
Object.observe & Array.observe
These methods are used for asynchronously observing changes to Arrays and Objects. Part of the ECMA7 proposal, these methods are inspired by the concept of native two-way data binding. Both are experimental for the time being, but that doesn’t mean we can’t use them for debugging!
Warning: Don’t use these methods in production.
Object.observe and Array.observe work the same way, but Array.observe provides additional information in the changes object provided to the callback.
var obj = { x: 0, y: 1 }; Object.observe(obj, function(changes) { console.log(changes); }); obj.z = 2; // [{name: 'z', object: {x: 0, y: 1, z: 2}, type: 'add'}] obj.x = ‘test’; // [{name: 'x', object: {x: ‘test’, y: 1, z: 2}, oldValue: 0, type: 'update'}] delete obj.z; // [{name: 'z', object: {x: ‘test’, y: 1}, oldValue: 2, type: 'delete'}]
Since Object.observe’s callback is asynchronous, setting a breakpoint inside will not reveal what changed the object. In other words, there’s no call stack. In most debugging cases, we need to know the culprit responsible for the change.
Getters & Setters
Enter getters and setters. These bad boys reveal the call stack when a property is get or set.
function FunctionOne(val){ this.value = val; } FunctionOne.prototype = { get value(){ return this._value; //breakpoint }, set value(val){ this._value = val; //breakpoint - shows all 3 functions in call stack } }; function FunctionTwo() { new FunctionOne(1); } function FunctionThree() { FunctionTwo(); } FunctionThree();
Congratulations, you now have debugging superpowers. While this is a synchronous example, for simplicity, getters and setters work with asynchronous code as well. There is another less aesthetic, pre-ECMA5, way of defining getters and setters with __defineGetter__ and __defineSetter__ methods. Of course, the syntax above is preferred.
Additional Tools
Show some love for console.dir
In Chrome, console.log usually prints out a tree. Unfortunately, it stringifies certain classes of objects. If you find console.log just not cutting it, give console.dir a whorl. Sometimes a little extra information is what it takes to squash that bug.
Another cool point to note is console.dir doesn’t give special treatment to DOM objects.
Don’t forget there is an entire Console API.
Node Inspector
Being the avid Chrome dev tool user that I am, I sorely missed them when debugging JavaScript on the server. Node Inspector to the rescue!
StrongLoop is continuing to develop this tool and have added a lot of cool features. If using Blink Developer Tools on the server doesn’t make you feel warm and fuzzy inside, I don’t know what will.
Conclusion
There are many tools to help debugging and this post has only scratched the surface. Learning how to leverage breakpoints is crucial for debugging and will save you time, money, and most importantly hair. Sometimes in reactive programming languages it can be difficult to get the call stack in code that responds to events. Tools like Object.observe, getter, and setter methods can help.
0 notes
Text
Why We Are
When it comes to establishing a company identity, people often ask the question--Who are we? We asked ourselves this question in 2008, when the business was founded, and came up with a pretty simple answer: We’re a software company that specializes in web and mobile apps. It seemed right--it made sense, it properly identified what we did, and there was consensus among us--and yet it wasn’t helpful to us in establishing our identity. There are hundreds of software companies making web apps, so how does one go about distinguishing themselves from the others? We found that to do this, there was a much more important question to answer -- Why we are. Unlike the former, though, this isn’t always an easy topic to tackle. After some deliberation, we felt we were on the right track. We agreed that Cyber Care, at it’s core, exists as a creative outlet for a bunch of tech geeks.
There are two types of creative “camps” so to speak. The first are those who create for the sake of expression, or identity. These are your artists, musicians, architects etc. You might say that this group is exploring the question of “why we are” on a much broader scale. Then there is the second camp -- the practical creators. This group, first and foremost, looks for their creative efforts to be applicable to the world right now. These are your inventors, engineers, and might I say software developers? At the heart of it, though, both the artist and the engineer are united by their will to create--It’s no wonder we saw so many artist/inventor types during the renaissance when western society began to explore and create on a grand scale.
As a company, Cyber Care falls more into the second camp, but we certainly still have an interest in the first. While we strive to create great software products that are functionally intuitive and broadly applicable, we do feel that an inventive and pleasing aesthetic are an important part of the experience. So the question we ultimately found ourselves looking to answer, then, was how can we make software development a valuable creative venture, and how does that benefit the community in a practical and applicable way? Well, we already had some experience doing this, as it turns out.
In 2011, Cyber Care was approached by a business owner who felt that his scheduling software was out of date and becoming a bit archaic, and he sought to improve upon it. But how do you fix something that isn’t broken? Conventional wisdom says we don’t, right? Creative development isn’t about fixing things that work, though, it’s about iteration, improvement, and innovation. “OK”, we said, we already know that job scheduling software exists and functions properly, but how can we contribute to improving it? What if we can create an online repository for all jobs that would allow us to see scheduling changes in real time and on location? What if we can clean out all of the unnecessary clutter that comes along with the current scheduling platforms for service companies and only provide the features we want? That’s about how it started, and what we ended up with was ServiceTask. The best part of this work was that it helped us to understand our place in the software development world as web technology experts. In the case of ServiceTask, it was the collaboration between ourselves and the client that bred innovation and allowed us to introduce the benefits of web applications to someone in a field that may not otherwise experience them. The spirit of the web is to connect people across time, space and informational gaps, so lets capture that spirit and apply it broadly. This is why we are.
0 notes