
Statistics
We looked inside some of the posts by databoutique and here's what we found interesting.
Average Info
Notes Per Post
14
Likes Per Post
12
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
3 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Kde vzal Igor Matovič hlasy?
Vítězství, byť ne tak drtivé, strany Igora Matoviče naznačovaly všechny únorové výzkumy veřejného mínění na Slovensku, a to jak publikované, tak i ty nepublikované. Přesto je na jeho volebním zisku zarážející, kde dokázal od podzimu tak razantně nabrat hlasy. V komentářích se často objevují úvahy, že je odebral Koltebovcům, či že je získal na úkor stran demokratické opozice (PS/Spolu, Za ludí či SaS). Jsou ale tyto úvahy správné? Zkusme se na volební výsledky podívat z datového pohledu.
Slovenský statistický úřad pravidelně publikuje výsledky voleb v dobře strojově zpracovatelném formátu. Pokud za východisko naší analýzy vezmeme data z těch obcí, kde přišlo hlasovat alespoň 5 000 voličů, můžeme spočítat, jak silně spolu výsledky stran v těchto obcích korelují. Tedy zda dobrý výsledek jedné strany je svázaný s dobrým výsledkem strany jiné. Do naší analýzy jsme zařadili výsledky následujících stran:
Naopak jsem vynechali maďarské strany, které jsou silně regionálně vázány.
Výsledek je následující:
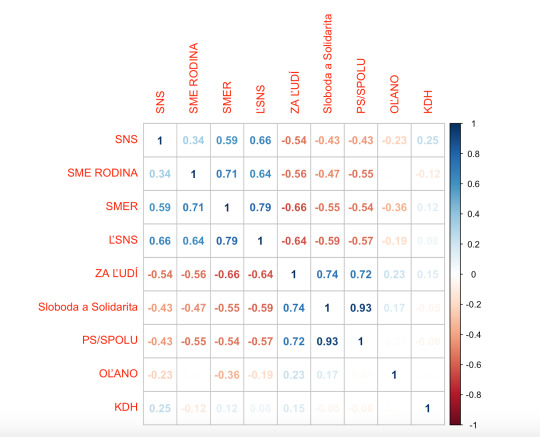
Na první pohled je vidět, že tu máme dvě seskupení, jejichž výsledky jsou spolu silně spojeny. První je nacionálně konzervativní blok Smeru, LSNS, Sme rodina a SNS. Tam kde uspěla dobře jedna strana z nich, často uspěli i tři a naopak. Druhým blokem jsou opoziční strany Za ludí, Sloboda a Solidarita a PS/Spolu. Také výsledky těchto stran spolu silně souvisí. Oba bloky jsou celkem jasně čitelné a dá se předpokládat, že právě strany z těchto bloků si mezi sebou přelévaly nejvíc voliče. To by nás nemělo přiliš překvapovat, když se podíváme na stejnou tabulku z voleb před čtyřmi lety, uvidíme v případě nacionálně konzervativního bloku podobný obrázek:

Voliči SMERu, LSNS a SNS měli k sobě již v té době blízko. (viz Smer, SNS a Kotleba - jak se to rýmuje?)
Vraťme se ale zpět k letošním volbám a ke stranám KDH a OLANO, které nepatří do silných bloků a jejichž výsledky nekorelují s nikým. KDH nakonec zůstalo před branami parlamentu, naopak OLANO velmi uspělo. To že jeho výsledky dopadly tak dobře a zároveň s nikým silně nekorelují, lze číst tak, že byl schopen brát všem, nikoli někomu přednostně. Matovič pravděpodobně odebíral hlasy všem politickým soupeřům zleva i zprava. Tomu odpovídá procento hlasů, které dostal napříč jednotlivými okrsky a které můžeme vidět na další grafu:
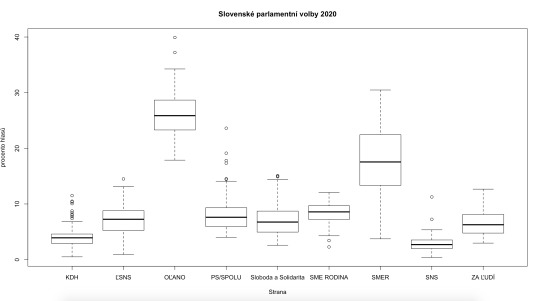
Rozdíl mezi 1 a 3 kvartilem výsledků Matovičova OLANO je přibližně 6 procent, u Smeru je to 9 procent. Má tedy výrazně stabilnější výsledek napříč regiony a opět se tak ukazuje, že jeho výsledek není žádným způsobem výrazně regionálně specifický.
Když se podíváme na místa, kde Matovič velmi uspěl, zjistím, že jsou to zároveň místa, kde došlo k velkému nárustu voličů oproti minulým volbám, což je poslední faktor, který musíme vzít do úvahy. Kupříkladu Košice - Sever, Poprad, Trnava nebo Snina vykazovali nárůst voličů o 17 až 23 procent oproti minulým volbám. Existuje zde nějaká souvislost?
Slovenské volby 2020 přivedly k voličským urnám mnohem více voličů než ty předchozí. Zatímco v roce 2016 bylo odevzdáno 2 607 750 hlasů, v roce 2020 to bylo 2 881 511. Doplňme tedy do naší tabulku ještě procentuální nárůst počtu voličů v jednotlivých oblastech a podívejme se na ní znovu:

Co vidíme je korelace mezi procentem o které vzrostl počet voličů v daném okrsku a ziskem OLANO. Jinými slovy, v obcích nad 5000 voličů rostly zisky Igora Matoviče v souladu s nárůstem počtu voličů. Tady je druhý zdroj Matovičova úspěchu, úspěšně zabodoval u voličů, kteří minule nebyli volit, využil aktivizační potenciál.
Tolik data, kdybychom opustili jejich půdu, tak můžeme ještě trochu spekulovat.
Za prvé: Igor Matovič svou kampaní pravděpodobně neoslabil jen Kotlebovce nebo jen demokraickou opozici apod. Dokázal oslovit slabé voliče všech stran a nabídnout jim alternativu vůči nacionálním a sociálním konzervativcům a zároveň vůči liberálně-konzervativní pravici. Vytvořil takové uskupení, které jste mohli volit, pokud vám nebyli přijemní ani jedni ani druzí a chtěli jste volit, kandidátka OLANO byla velmi pestrá a když se podíváte na využití “kroužkování” u jednotlivých stran, tak voliči OLANO ji využili docela dost. Navíc právě ke kroužkování sám Matovič vyzval, když sám kandidoval z posledního místa kandidátky.

Za druhé: Igor Matovič stáhl k sobě zřejmě velkou část voličů, která minule nevolila, ale chtěla letos volit. Nabídl jim možnost si vybrat z nepřeberného množství názorových proudů uvnitř kandidátky.
Tajemství úspěchu OLANO možná leží v tom, že nemá žádnou jasnou ideologii, ale umí dobře pracovat s pocit, že to není zapotřebí, že je třeba pojmenovat nepřítele a dát průchod vůli lidu.
Josef Šlerka
0 notes
Text
Josef Šlerka and Vít Šisler, Charles: Who is Shaping Your Agenda? Social network analysis of anti-Islam and anti-immigration movement audiences on Czech Facebook
This study was originaly published in: Expressions of Radicalization: Global Politics, Processes and Practices, edited by Kristian Steiner and Andreas Onnerfors, Palgrave Macmillan, 2018, pp. 61-85.
Introduction
The internet has become a crucial tool for people with similar interests to reach out to each other for information and support, to share ideas, and to create personal networks (Rainie and Wellman, 2012:107). Several researchers have suggested that online interactions and materials should be considered key elements in radicalization (Bouchard and Levey, 2015:2). Indeed, radical movements increasingly use the internet to advance their goals (Bouchard and Nash, 2015:53). Beyond easy access, little or no regulation and censorship, the anonymity of communication, and the fast flow of information, the internet offers the ability to shape coverage in traditional mass media (Weimann, 2006:30).
The democratization of mobile internet access around the world and the emergence of Web 2.0 have led to a more user-centric online environment. Radical movements can now rely on a crowd of anonymous sympathizers who are collectively engaged in the virtual dissemination of narratives and media content supporting their cause (Ducol, 2015: 84). Social media extend the traditional frontiers of radical online milieus by blending into platforms such as YouTube, Twitter, and Facebook (see Weimann, 2010). Today, any understanding of radicalization must take into consideration the impact (or lack thereof) of social media on social settings, media consumption, and the production of knowledge.
As Steiner and Önnerfors (2017) write in the introduction to this volume, radicalization is a multi-faceted, dynamic, processual, and multidimensional phenomenon that defies easy definition. By the same token, Schmid (2013:7) notes that “radical” is a relative concept whose meaning has changed over time. As Neumann (2013:876) argues, radicalization has no obvious essential or inherent characteristics; rather, it is a process of positioning relative to chosen points of reference. As such, it can only be understood in terms of its distance from these points of reference, be they “status quo or mainstream positions on the political spectrum of a given society” (Schmid, 2013:56).
In this chapter, we study radicalization as a social process and communicative practice, where “radical ideas are transmitted by social networks” (Dalgaard-Nielsen, 2010:803) and contribute to the polarization of public political discourse. Such radicalization processes include, yet are not limited to, advocating sweeping political change and system-transforming solutions for government and society that depart from “the democratic rule of law and international human rights standards” (Schmid, 2013:8). This chapter focuses on the radicalization of public discourse in light of the contemporary migration crisis and on the role of anti-Islamic and anti-immigration movements in shaping the agendas of mainstream media through social network sites.
User-generated data connected to the proliferation of social media are growing exponentially. Analysis of these “big social data” opens up new perspectives for research in social sciences and the humanities (boyd and Crawford, 2012; Halavais, 2015; Manovich, 2011). Meanwhile, advances in information and computer technologies present new research methods and new approaches. Being able to quantitatively process large datasets through automation opens a path to new research questions and new ways to answer them (Šlerka and Šisler, 2017).
Manovich (2011) argues that the rise of social media and advances in computing tools to process massive amounts of data make possible a fundamentally new approach to the study of human beings and society. We no longer must choose between data size and data depth. We can study exact trajectories formed by billions of cultural expressions, experiences, texts, and links. The detailed knowledge and insights that before could only be gathered about a few can now be gathered about many. In Manovich’s (2011) terms, we are no longer forced to choose between surface data about the many or deep data about a few.
In light of current debate about the migration crisis and the simultaneous proliferation of radical movements in the public sphere, we are in crucial need of critical investigation of the structural and dynamic aspects of audience formation and agenda shaping on social network sites. With Bouchard and Levey (2015:4), we believe that integrating network concepts and network methods into the study of radicalization is fundamentally important (from theoretical, empirical, and policy perspectives) to bringing the field forward. The network methods approach allows the structural aspects of various groups to be accurately depicted without potentially false assumptions about the ways these groups function. It lets patterns and unexpected findings to emerge from the data (Bouchard and Nash, 2015:50).
Digital media can “support the formation of a public sphere, where a diversity of opinion and information can interact, or, conversely, to function as an echo chamber that reinforces established perspectives and opinions” (Colleoni, Rozza and Arvidsson, 2014:317). Given that both these scenarios are well established and simultaneously contested in the research on political communication on the internet (see e.g. Brundidge, 2010; Stroud, 2010), exploratory research analysing big social data through network methods is particularly viable for enhancing our understanding of online radicalization. It is also very important to ensure that our research methods are transparent to allow other researchers to engage with, replicate, and possibly falsify our research and findings.
This chapter presents exploratory research on the social network sites of Czech anti-immigration and anti-Islamic movements. It analyses the audiences of these movements’ sites on Facebook and explores their similarities, differences, and affinities through social distance computed based on their fans’ likes. The chapter uses the new, formally defined, quantitative method Normalized Social Distance (NSD) developed by Šlerka (2013) and detailed by Šlerka and Šisler (2017). NSD calculates the distance between various social groups based on members’ intentional stances as expressed on social networking sites. NSD provides an opportunity for distant reading of social network sites, enabling us to formally represent and analyse the structural aspects of big social data.
The primary aim of this chapter is to investigate how near to, or far from, each other Facebook audiences of Czech anti-immigration and anti-Islam movements are in terms of NSD. We also analyse their distance from major Czech news media, established political parties, and politicians active in public debate about the migration crisis. The secondary aim of this chapter is to examine the structural interplays between Czech anti-immigration and anti-Islamic movements’ active audiences and the news media’s shaping of agendas on Facebook. Through quantitative analysis of the most popular posts, we explore how diverse audiences elevate particular stories on Czech news media through the distribution of likes on Facebook.
More generally, this chapter aims to present a new methodological framework for the analysis of big social data, especially data from Facebook. The case study itself serves as an example of the method using a concrete dataset, which explains or clarifies possible further interpretative approaches. The methods proposed in this chapter constitute a coherent set of tools, which could be adopted relatively easily by a variety of actors to support their research or decisions with empirical evidence.
Social Network Sites and Self-Representative Performance
The term “social media” conveys several meanings. Most authors in the field agree that social media constitute a virtual space in which the possibility of social interaction between users plays a crucial role and these interactions have a specific impact on the creation of user identities, communication situations, and communities (boyd and Ellison, 2007; Obar and Wildman, 2015). Nevertheless, the term blurs the distinction between different platforms and communication channels (Obar and Wildman, 2015:746).
Given the analytical ambiguity of “social media” we have opted to use the term “social networking sites” instead. In accordance with boyd and Ellison (2007), we define social networking sites as web-based services that allow individuals to (1) construct a public or semi-public profile within a defined system, (2) articulate a list of other users with whom they share a connection, and (3) view and go through their list of connections and those made by others within the system.
We have argued elsewhere that these connections shared with other users on social networking sites are the result of social actions and possess an intentionality of their own (Šlerka and Šisler, 2017). The user’s behaviour in social networks is not only a social action taken towards others, but also a representation of an intentionality that presupposes other subjects and anticipates their interpretations of such behaviour. The analysis of actions on social networking sites is thus an analysis of data representing not only certain behaviours, but also “intentional stances” (Dennett, 1996).
If we understand user behaviour on social networking sites within Goffman’s (1959) framework of dramaturgical sociology, the user’s profile and social action conducted through that profile could be considered part of a “personal facade” or as actions happening on the “front stage.” From this perspective, all the elements that form a personal profile on a social network site are elements of the facade that users select to represent their personal identity. The choice of name, profile photo, description, privacy settings, etc. could all be perceived as expressions of the user’s identity and front stage performance.
Social actions conducted on social networking sites (e.g., status posts, comments, “likes” of other users’ pages or posts) are forms of self-representative performance (Wallace, Buil and de Chernatony, 2012). Social networking sites can thus be seen both as spaces for daily self-presentation and stages for performance and interaction. Actions on social networking sites have intentionality and can be analysed both quantitatively and qualitatively. From the perspectives of digital humanities and automated computational processing, it is quite possible to process all these social actions in an exploratory manner and search for structural patterns in the resulting data (Šlerka and Šisler, 2017).
Existing Research
Existing research on social networking sites relevant for our study can be divided roughly into three research clusters: (1) users’ online behaviour, (2) media consumption and agenda shaping, and (3) online radicalization.
Kosinski, Stillwell, and Graepel (2013) demonstrate how publicly accessible information about users’ Facebook likes can be used to predict automatically and accurately a range of highly sensitive personal attributes including sexual orientation, ethnicity, religious and political views, personality traits, intelligence, happiness, use of addictive substances, parental separation, age, and gender. Taking a different tack, Pelletier and Horky (2013) present exploratory qualitative research to look at the motivations and consequences associated with liking commercial brands’ pages on Facebook. Wallace et al. (2014) similarly explore a typology of fans (i.e., individuals who like different brands’ pages on Facebook). Recent exploratory qualitative studies have investigated individual users’ motivations to like their friends’ posts on Facebook (Basalingappa, Subhas and Tapariya, 2015).
Social networking sites may play a significant role in how people gather political information (Bode, 2016). Social ties play a major role how the public learns about politics, offline social networks play a role in the dissemination of information (Ellison and Fudenberg, 1995), and information from trusted people is deemed more credible and is more likely to be taken seriously (Huckfeldt, Beck, Dalton, and Levine, 1995:1027). Today, exposure to political information within social networking sites is much like that from the sources that came before them, such as news websites and more traditional media (Bode, 2012). However, research suggests that the potential for users to gather political information from social media is not always realized within the general population (Bode, 2016). News publishers take social networking sites seriously and include them in their media strategy. A recent report published by Parse.ly (2015), an analytics firm that collects data for digital publishers, suggests that Facebook already drives more traffic to news media websites than Google. Consequently, larger news and media sites have become much more reliant on Facebook and shape their editorial policies accordingly (Ingram, 2015).
Content on Facebook’s News Feed is selected by algorithms based on a user’s previous behaviours (Pariser, 2011) and individuals are increasingly exposed to information from like-minded individuals (Flaxman, Goel and Rao, 2016), leading to renewed speculation about “echo chambers” and “filter bubbles” devoid of attitude-challenging content (Bakshy, Messing and Adamic, 2015:1130). Increasing reliance on Facebook as a gateway to news media could lead to reaffirmation of people’s existing political orientations. In their seminal study, Bakshy et al. (2015) examined how 10.1 million US Facebook users interacted with socially shared news. They measured ideological homophily in friend networks and the extent to which heterogeneous friends could expose others to cross-cutting content. Their findings suggest that (1) with Facebook’s automatic ranking of posts, people on average have slightly less cross-cutting content in their News Feed, and (2) exposure to ideologically different content is further limited by individual choices (Bakshy et al., 2015:1131). Nevertheless, “despite these tendencies, there is substantial room for individuals to consume more media from the other side; on average, viewers clicked on 7% of hard content available in their feeds” (Bakshy et al., 2015:1131). In other words, rather than people browsing only ideologically aligned news sources or opting out of hard news altogether, Bakshy et al.’s research shows that social network sites “expose individuals to at least some ideologically cross-cutting viewpoints” (2015:1132).
A limited, albeit growing, body of research on social network sites addresses online radicalization. Social ties and social influence have been found to be central to the radicalization process (Hegghammer, 2006; Sageman, 2004, 2008). Social network sites are used by various radical movements to spread beliefs and ideologies, recruit members, and create online virtual communities with a common agenda (Agarwal, 2015). As Ducol (2015:86) argues, interactive features of modern web-based technologies, including social networking sites, have facilitated a broader dissemination of autonomous, user-generated content outside official websites and digital platforms. Meanwhile, they have also eased the emergence of undefined online communities, radical digital milieus (Conway, 2012), that encompass a broad cross-section of producers and consumers who all contribute to the everyday re-making and dissemination of radical narratives through cyberspace.
Agarwal’s (2015) comprehensive review of research on online radicalization includes characterization, classification, and an in-depth meta-analysis of about 100 conference and journal papers published over the past 10 years, revealing that most such studies target events specific to a country or region (mainly USA and Latin America) and mine English language texts. Most studies use a variety of information retrieval methods, automated text processing, and methods of analysis based on machine learning.
As far as we know, no other study has used NSD to analyse social networking sites’ audiences to examine online radicalization and none has discussed anti-Islamic and anti-immigration movements on Facebook in the Czech Republic.
Normalized Social Distance
The concept of NSD was introduced by Šlerka (2013) and detailed by Šlerka and Šisler (2017). For the sake of brevity, we describe only key features of NSD here and refer readers to the above-mentioned studies for details.
NSD is a formally defined method that calculates distance between social groups based on intentional stances expressed in group members’ activities on social networking sites – in our case, on Facebook pages. The resulting number expresses how far or close various sites’ audiences are in relation to each another. Importantly, NSD relies on post likes (i.e., likes given to specific posts published by the page in question) rather than page likes (i.e., likes given to a page in general). This methodological distinction assumes that while a page like could represent a variety of intentional stances ranging from interest in the page’s activity to support of the ideas expressed, a post like probably expresses affirmation of the ideas in a particular post (see Wallace et al., 2014).
Theoretically, NSD stems from McPherson, Smith-Lovin, and Cook’s (2001) concept of homophily in social networks, from Lin’s (1998) information-theoretic definition of similarity, and particularly from Cilibrasi and Vitányi’s (2010) concept of normalized web distance.
Homophily is the principle that contact is more frequent between similar people than dissimilar people (McPherson et al., 2001); it assumes that similarity breeds connection. The homophily principle structures network ties of every type including marriage, friendship, work, advice, support, information transfer, co-membership, etc. The result is that people’s personal networks tend to be homogeneous in many sociodemographic, behavioural, and intrapersonal characteristics. Homophily limits people’s social worlds in a way that has powerful implications for the information they receive, the attitudes they form, and the interactions they experience. Homophily also implies that distance in social characteristics translates into network distance, the number of relationships through which a piece of information must travel to connect two individuals (McPherson et al., 2001).
Introduced by Cilibrasi and Vitányi (2010), normalized web distance (NWD) is a semantic measure of similarity derived from the number of hits returned by an internet search engine for a given set of keywords. Words or phrases with the same or similar meanings (in a natural language sense) tend to be close in units of web distance, while words with dissimilar meanings tend to be further apart. We can perceive NWD as an expression of semantic distance. Using internet search engines, particularly Google, NWD often relies on contexts expressing a large body of common-sense knowledge. In a series of experiments, the accuracy of NWD was evaluated against expert opinion with positive results (Cilibrasi and Vitányi, 2010).
NWD comes with the idea of a semantic layer of information, but we propose that there is another, more pragmatic, layer above it that depends on the degree of similarity expressed by the online behaviour of two different social groups. We can also formally define the method of calculating the distance between these two social groups (Šlerka and Šisler, 2017).
Formally, we define NSD as follows, where f(x) is the number of members in the group x; f(y) is the number of members in the group y; f(x, y) is the number of elements that are simultaneously members of both groups; and N is the number of all elements in the given corpus:
With distance thus formally defined, we should be able to measure the distance between any two social subgroups that fall under the umbrella of another one. NSD is a universal metric that can be adjusted for data from any social network sites. In the following case study, we applied the formula to Facebook pages; calculating the proximity of these pages based on post likes from these pages’ active users. The resulting matrix is a bimodal network with a relatively low density that can be examined using traditional exploratory techniques such as hierarchical cluster analysis, multidimensional scaling, or principal component analysis (Šlerka and Šisler, 2017).
Clustering of Anti-Immigration and Anti-Islam Movements on Czech Facebook
The first aim of this study was to conduct exploratory research on anti-Islamic and anti-immigration movements on Czech Facebook. Primarily, we analyse how close or far audiences of these movements are in relation to each other in terms of NSD. Secondarily, we analyse the proximity of these movements’ audiences to key Czech news media, established political parties, and politicians active in the public debate on the migration crisis.
Dataset
We identified 56 Facebook pages for Czech anti-immigration and anti-Islamic movements, news media, political parties and movements, think tanks, campaigns, and individual politicians who are active in the public debate on the migration crisis. A list of these pages is provided in the Appendix.
For clarity, we have translated these pages’ names into English wherever possible (e.g. Green Party) or labelled these pages according to the following key:
(n) = news media (m) = political movement or party (p) = individual politician
In specific cases, we provide a full description of the page in parentheses (e.g., Miloš Zeman [President]).
Method
We adopted the following procedure to compute the NSD of the selected pages to each another:
We downloaded all public posts by all the pages’ administrators between 1 September 2015 and 28 December 2015 for a total of 19,321 posts.
We downloaded a complete list of 540,775 unique online identifications (IDs) for those liking at least one of these posts. These users distributed 3,351,034 likes among the 19,321 posts.
Based on information from Facebook Audience Insights (2016), we estimated the Czech Facebook region to include 3,500,000 unique users.
Based on these data, we computed the NSD between all the selected Facebook pages.
Results
The results of NSD can be visualized in several ways. For this study, we combined graphic visualization and clustering analysis.
Figure 1 depicts only significant pages (i.e., those with significantly overlapping audiences in terms of NSD). The nodes in the graph denote individual pages; the links denote significant proximity in terms of NSD (i.e., NSD(x,y) ≤0.5).
Figure 1. Anti-immigration and anti-Islamic movements’ proximity to media, politicians, and political parties on Czech Facebook based on the NSD metric.
Figure 2 illustrates our clustering (k-means) clustering analysis. This method aims to partition our observations into clusters in which each observation belongs to the cluster with the nearest mean, which serves as a prototype for the cluster. This results from partitioning the data space into Voronoi cells. (The results of NSD analysis are multidimensional, and their visualization in a two-dimensional space should be understood as a mathematical approximation.)
Figure 2. k-means clustering of anti-Islamic and anti-immigration movements, news media, politicians, and political parties on Czech Facebook based on the NSD metric.
Discussion
NSD analysis provides us with an opportunity for the distant reading of social network sites and their audiences. This distant reading clarifies structural aspects not necessarily visible on the level of “lose reading, (i.e., content analysis or interviews).
In our case study, the results of NSD analysis (in both the graph visualization and the clustering analysis) show several key findings about the anti-Islamic and anti-immigration movements and the proximity of these pages’ audiences to one another; as well as to Czech news media sites and the sites of Czech political parties.
The findings show several tightly connected clusters of pages on Czech Facebook whose audiences are significantly close to one another and share similar intentional stances. The users in these clusters like and share similar content and rarely reach out to different clusters.
Among these clusters, we can identify one, which could be labelled as anti-Islamic, anti-immigrant, nationalist, and/or anti-European Union (EU). This cluster consists of audiences active on the pages of the anti-Islamic political movements, Block against Islam and Stop Islam in the Czech Republic; the anti-EU and nationalist party, Freedom and Direct Democracy; and the libertarian/conservative Free Citizens’ Party. All these parties use strong anti-immigration rhetoric. Importantly, this cluster includes Miloš Zeman, President of the Czech Republic, who is known for his strong anti-Islamic and anti-immigration discourse. The news site Parlamentní listy, which also plays a prominent role in this cluster, publishes the un-redacted opinions of politicians and authors from across the political spectrum, yet still commonly linked to conservative and nationalist media. These pages’ audiences are very close to each other in NSD terms and show a significant overlap. They tend to rely on similar or close news sources and to like significantly similar content.
Another cluster consists of the active audiences of the liberal/left Green Party, the liberal Pirate Party, and an anti-discrimination campaign, Hate Free Culture. These pages’ audiences are close to the liberal weekly Respekt and the liberal daily newspaper Hospodářské noviny. As in the previous cluster, these audiences tend to rely on similar or close news sources and to like significantly similar content on Facebook.
At first glance, the public debate on the migration crisis seems highly polarized in the Czech Republic. News media tend to portray Czech society as fundamentally divided into two camps, corresponding roughly to the two audience clusters mentioned above on Czech Facebook (Šlerka, 2016). Similarly, many politicians perceive the migration crisis to be a divisive topic that can score them significant political points and they use it as such.
The NSD analysis reveals that, although these two audience clusters are significant and very active on other pages on Facebook, there are at least two other similarly significant clusters that seem to be primarily unrelated to the migration crisis debate and are rarely mentioned in the news media. These two clusters include, first, the audience of the ANO (“YES”) political movement and its leader, Andrej Babiš (also the Czech finance minister). ANO is a relatively new political entity that has often been portrayed as anti-establishment or populist; positioning itself as an alternative to the older “corrupt” parties. It has a vaguely defined programme and primarily promotes the “proper” technocratic management of public affairs (Šlerka, 2016). The other significant group unrelated to the migration debate is the audience of the Czech Social Democratic Party and Prime Minister Bohuslav Sobotka. Importantly, these two parties currently make up the government and lead the polls. These clusters have no significant proximity to any particular media outlets and have no significant overlap with the two active clusters identified earlier.
In summary, the NSD analysis reveals that, although public debate on the immigration crisis seems highly polarized into two adversarial clusters, it is more significantly fragmented in at least four different clusters, whose audiences rarely share the same content and whose intentional stances, as manifested by Facebook likes, rarely overlap. This structural fragmentation negatively influences public debate, while, in Habermasian (1989) terms, the possibility of communicative actions and mutual reasoning is seriously limited.
Limitations
NSD is a quantitative method best suited to exploratory research. Unlike semantic methods in the digital humanities, NSD is featureless and is in principle unrelated to the content of the data analysed. It focuses on the actions of social network sites’ audiences (typically Facebook likes) and computes the distance between the audiences of different sites based on these actions. The assumption of the NSD method is that user behaviours on social networks are not only social actions, but representations of intentionality that presuppose other subjects and anticipate their interpretation of such behaviours. The analysis of actions on social network sites is thus the analysis of data representing not only certain behaviours, but also the intentional stances they represent. The NSD method allows falsification of results through qualitative analysis of the content users share and like. The falsifications the authors of this chapter have conducted so far suggest a possibly significant correlation between NSD and qualitative analysis, but further research is needed to confirm or refute this.
Post Overlaps Related to the Migration Crisis Debate on Czech Facebook
The second aim of the study was to analyse the structural interplays between the active audiences of anti-Islamic and anti-immigration movements and the agenda-shaping of Czech news media on Facebook. Through quantitative analysis of the most popular posts, this part of the study explored how diverse audiences elevate particular news on Czech news media Facebook pages through likes.
Dataset
We used the same dataset of Facebook pages as in the previous section (i.e., the 56 Facebook pages of Czech anti-immigration and anti-Islamic movements, news media, political parties and movements, think tanks, campaigns, and individual politicians active in the public debate on the migration crisis listed in the Appendix).
Method
In the second part of the study, we used but a more straightforward, quantitative analysis of post overlaps than the NSD:
We downloaded all the posts by the pages’ administrators from September and October 2015 and all unique user IDs for those who liked at least one of these posts.
We filtered these posts based on two additional criteria: popularity and overlaps. For the final data sets we selected only posts that (a) gained at least 50 likes in each selected month and (b) had at least a 15% overlap in likes with at least one other page on the list.
We treated the data from the two months as separate datasets to compare their structural patterns. The final dataset from September 2015 consists of 6,554 posts that attracted 1,072,425 likes from 261,833 unique users. The final dataset from October 2015 consists of 6,918 posts that attracted 930,570 likes from 220,575 unique users.
We computed the percentage of likes for individual posts from users who simultaneously liked another post on a different page in the dataset during the given period. From this basic matrix, we computed percentage overlaps among all the pages in the dataset. The algorithm for the computation is detailed in Šlerka (2016).
Results
The results of the post overlap analysis are twofold: First, we can visualize the complete data as a correlation matrix, using the Pearson product-moment correlation. The Pearson correlation is a measure of the linear correlation between two variables x and y, giving a value between +1 and −1 inclusive, where +1 is a total positive correlation, 0 is no correlation, and −1 is a total negative correlation. The Pearson correlation is a measure of the degree of linear dependence between two variables. We have visualized the significant post overlaps among the pages in the dataset from September 2015 (Figure 3) and October 2015 (Figure 4).
Figure 3. Post/page overlap in September 2015.
Figure 4. Post/page overlap in October 2015.
Second, we can visualize the results as a table, listing all the posts with significant. For brevity, we include only one detailed example here. The complete results can be found in Šlerka (2016).
In the following example, we analysed Facebook posts from ČT24, a Czech national TV station operating as a public broadcasting service, and their overlaps with other audiences active in the migration crisis debate. In October 2015, ČT24 posted 1,301 posts on its Facebook page and an average post gained 169.5 likes (median = 64.0). From these posts, only 116 posts gained at least 300 likes and had at least 20% overlap with the audiences of other pages. These could be labelled as “trending” posts that were highly visible on Czech Facebook. Most (93) of these post overlaps were between ČT24 and other news media, and we therefore excluded them from our analysis. From the remaining 23 posts, 14 were related to the migration crisis debate and had significant overlaps with other active audiences (Table 1).
Table 1. Post/page overlaps on ČT24
Posting page Page with overlap Name of the post Total likes Likes overlap (%) ČT24 (n) Stop Islam in the Czech Republic (m) Eurosceptic party, Alternative for Germany (AFD), wants to file a criminal complaint against Chancellor Angela Merkel. 387 37.47 ČT24 (n) Stop Islam in the Czech Republic (m) Due to the open policy towards refugees, the German Public Prosecutor received hundreds of criminal complaints against Merkel. 395 36.96 ČT24 (n) Stop Islam in the Czech Republic (m) The Bulgarian border police shot dead a refugee, who illegally crossed the border, on the border with Turkey. 360 33,06 ČT24 (n) Stop Islam in the Czech Republic (m) Three-fifths of Czechs aren’t satisfied with EU membership. 330 32.73 ČT24 (n) Stop Islam in the Czech Republic (m) Harsh criticism for Merkel during a CDU regional conference. 314 31.53 ČT24 (n) Stop Islam in the Czech Republic (m) The Czech Republic will send two dozen soldiers and special military equipment to help the Hungarian army. 447 26.17 ČT24 (n) Stop Islam in the Czech Republic (m) Czech Army sends 650 soldiers to the Austrian border. 340 25.00 ČT24 (n) TOP 09 (m) President Zeman scares the public with his statements about refugees. 574 24.39 ČT24 (n) Hate Free Culture Eastern Europe should show more solidarity with refugees. 453 24.28 ČT24 (n) TOP 09 (m) Pope Francis denounces vicious campaigns waged against refugees in Europe. 508 21.65 ČT24 (n) Tomio Okamura (p) Three-fifths of Czechs aren’t satisfied with EU membership. 330 21.52 ČT24 (n) Tomio Okamura (p) Due to the open policy towards refugees, the German Public Prosecutor received hundreds of criminal complaints against Merkel. 395 21.27 ČT24 (n) Hate Free Culture Pope Francis denounces vicious campaigns waged against refugees in Europe. 508 20.67 ČT24 (n) TOP 09 (m) Eastern Europe should show more solidarity with refugees. 453 20.09
Discussion
The findings in the second part of the study are twofold: First, the Pearson linear correlation of the page/posts overlap can be perceived as a falsification method for the NSD analysis conducted in the previous case study. Although it uses a different dataset (the posts that active audiences of individual pages liked on different, third-party pages), we can see that the correlation matrix creates clusters of pages with significant overlaps that significantly correspond to the clusters resulting from the NSD analysis. Like the first part of the study, we can identify two adversarial clusters and two smaller, unrelated clusters.
Second, the ČT24 example provides empirical evidence on how the active audiences of individual sites elevate particular news stories on Czech news media sites through likes. The findings indicate that specific content, particularly material related to the migration crisis, gains significant prominence on social networks through the actions of relatively small, yet coherent and active, audiences for anti-Islamic and anti-immigration movement pages on Facebook.
This elevation then influences the way news media and politicians prepare and promote their content on social network sites; shaping public debate on the crisis. Facebook closely monitors what content is trending for each page and automatically offers page editors the option to “boost” already-successful posts via paid display (promoted content). At the same time, Facebook encourages page editors to learn what kind of content their audience cares about most and repeat that style or use similar content when preparing future posts (Facebook, 2013).
Through concrete examples, we can identify which posts that alert readers to the negative consequences of immigration regularly gain significant, above average, numbers of likes on Facebook. In most cases, more than a third of these likes come from a relatively small audience: the active audience of the radical Stop Islam in the Czech Republic movement. By the same token, news aimed to bring soberer analytical information to readers is disproportionately liked by the active audience of the anti-discrimination Hate Free Culture campaign.
Given that each additional like further spreads a post to the Facebook profiles of all the “friends” of the user who liked that post, what emerges is a further solidification of “small worlds,” where similar media content circulates and similar world-views permeate.
Concluding Remarks
As Bouchard and Levey (2015:2) note, the internet “may act as a facilitator and conduit for radical views online, but rarely as an all-encompassing creator of radical offline behaviour.” So far, very little is known about how individuals experience and react to the consumption of radical materials found online or about what influence it has on them (Ducol, 2015:87). Although the internet is often singled out as the key means through which individuals are radicalized, “research thus far has fallen short of unearthing the actual mechanisms through which this radicalization takes place” (Edwards and Gribbon, 2013:40). In the words of Ducol (2015:97), the internet “represents only one piece of the radicalization puzzle. Future research should pay closer attention to diachronic dynamics that may exist between online environments and ‘real world’ social settings”.
Importantly, social network sites involve real people who cannot be considered outside the socializing settings that constrain their beliefs and inform their guiding rules and daily actions in the real world (Ducol, 2015:90). Primary empirical research appears to be essential to gaining a more detailed picture of how social network sites might influence the processes of media consumption and knowledge production.
In this chapter we have presented an exploratory study on the social network sites of Czech anti-immigration and anti-Islam movements. We analysed audiences of these movements’ sites on Facebook and explored their similarities, differences, and affinities through social distance based on their fans’ likes. We used the new, formally defined, quantitative method of NSD that calculates distances between various social groups based on the intentional stances expressed by these groups’ members’ activities on Facebook. The results of NSD can be visualized in graphs or dendrograms and methods of network analysis can be applied to them. As such, NSD provides an opportunity for the distant reading of social network sites, enabling us to formally represent and analyse the structural aspects of big social data.
The methods proposed in this chapter constitute a coherent set of tools and interpretive approaches, which enable the formal representation, replication, and validation of the structural analysis of big social data and could be relatively easily adopted by other researchers in different contexts. The case study presented in this chapter could serve as an illustrative example, clarifying further possible interpretative approaches.
The main findings of this study show that, although public debate on the immigration crisis on Czech Facebook is partially highly polarized into two adversarial clusters, it is more significantly fragmented into at least four different clusters, whose audiences rarely share the same content and whose intentional stances, as manifested by Facebook likes, rarely overlap. The main findings tend to support the argument that social network sites could indeed create echo chambers and filter bubbles, thus strengthening confirmation bias (Stroud, 2010; Pariser, 2011; Flaxman et al., 2016). Nevertheless, the results are highly dependent on a specific context, i.e. the Czech migration crisis debate, and can by no means be generalized to all political communication on Facebook. Further research is needed to pinpoint specific conditions under which similar – or different – clustering occurs.
The secondary findings of this study reveal how the active audiences of individual sites elevate particular stories on Czech news media sites through likes. Specific content related to the migration crisis gains significant prominence on Czech Facebook through the actions of relatively small, yet coherent and active, audiences for anti-Islamic and anti-immigration movements. The structural aspects of the interplays between social network sites’ audiences and news media are largely neglected by both academia and policy-makers, despite their possibly significant influence on public attitudes. Beyond a theoretical framework, this chapter offers concrete methods and tools for enabling a complex structural analysis of social media sites’ audiences. Because the datasets our methods work with are publicly available, the methods and tools we propose could be used by a variety of actors (researchers, media analysts, media outlets, think tanks, governmental agencies, etc.) to support their research and decision-making processes with empirical evidence.
Acknowledgements
This chapter was partially supported by the Charles University grant project Progres 5: Životní dráhy, životní styly a kvalita života z pohledu individuální adaptace a vztahu aktérů a institucí.
References
Agarwal, S. (2015) “Applying Social Media Intelligence for Predicting and Identifying On-line Radicalization and Civil Unrest Oriented Threats”, Arxiv.org, Available online: (accessed 4 May 2016).
Bakshy, E., Messing, S. and Adamic, L. A. (2015) “Exposure to ideologically diverse news and opinion on Facebook”, Science 348 (6239): 1130-1132.
Basalingappa, A., Subhas, M. S. and Tapariya, R. (2015) “Understanding Likes on Facebook: An Exploratory Study”, in IV. International Conference on Communication, Media, Technology and Design Proceedings, Famagusta, North Cyprus: Eastern Mediterranean University Press.
Bode, L. (2012) Political Information 2.0: A study in political learning via social media. Unpublished dissertation, University of Wisconsin.
Bode, L. (2016) Political News in the News Feed: Learning Politics from Social Media. Mass Communication and Society, 19 (1): 24-48.
Bouchard, M. and Levey, P. (2015) “Radical and connected: An introduction” in M. Bouchard (ed.) Social Networks, Terrorism and Counter-terrorism, New York: Routledge.
Bouchard, M. and Nash, R. (2015) “Researching terrorism and counter-terrorism through a network lens” in M. Bouchard (ed.) Social Networks, Terrorism and Counter-terrorism, New York: Routledge.
boyd, d. m. and Crawford, K. (2012) “Critical Questions for Big Data”, Information, Communication & Society, 15 (5): 662-679.
boyd, d. m. and Ellison, N. B. (2007) “Social Network Sites: Definition, History, and Scholarship”, Journal of Computer-Mediated Communication, 13 (1): 210–230.
Brundidge, J. (2010) “Encountering ‘Difference’ in the Contemporary Public Sphere: The Contribution of the Internet to the Heterogeneity of Political Discussion Networks”, Journal of Communication, 60 (4): 680-700.
Cilibrasi, R. L. and Vitányi, P. M. B. (2010) “Normalized Web Distance and Word Similarity”, in N. Indurkhya and F. J. Damerau (eds.) Handbook of Natural Language Processing, Boca Raton, FL: CRC Press.
Colleoni, E., Rozza, A. and Arvidsson, A. (2014) “Echo Chamber or Public Sphere? Predicting Political Orientation and Measuring Political Homophily in Twitter Using Big Data”, Journal of Communication, 64 (2): 317-332.
Conway, M. (2012) From al-Zarqawi to al-Awlaki: The emergence and development of an online radical milieu. Counter Terrorism Exchange, 2 (4): 12–22.
Dalgaard-Nielsen, A. (2010) “Violent Radicalization in Europe: What We Know and What We Do Not Know”, Studies in Conflict & Terrorism, 33 (9): 797-814.
Dennett, D. C. (1996) The Intentional Stance, Cambridge, MA: The MIT Press.
Ducol, B. (2015) “A radical sociability: In defense of an online/offline multidimensional approach to radicalization” in M. Bouchard (ed.) Social Networks, Terrorism and Counter-terrorism, New York: Routledge.
Edwards, C. and Gribbon, L. (2013) Pathways to violent extremism in the digital era. The RUSI Journal, 158 (5): 40–47.
Ellison, G. and Fudenberg, D. (1995) Word-of-mouth communication and social learning. The Quarterly Journal of Economics, 110: 93–125.
Facebook (2013) “12 Best Practices for Media Companies Using Facebook Pages”, Facebook.com, Available online: (accessed 23 September 2016).
Facebook Audience Insights (2016) Available online: (accessed 4 May 2016).
Flaxman, S., Goel, S. and Rao, J. M. (2016) “Filter Bubbles, Echo Chambers, and Online News Consumption”, Public Opinion Quarterly, 80 (S1): 298-320.
Goffman, E. (1959) The Presentation of Self in Everyday Life, New York: Anchor Books.
Habermas, J. (1989) The Structural Transformation of the Public Sphere: An Inquiry into a Category of Bourgeois Society. Cambridge, MA: MIT Press.
Halavais, A. (2015) “Bigger Sociological Imaginations: Framing Big Social Data Theory and Methods”, Information, Communication & Society, 18 (5): 583-594.
Hegghammer, T. (2006) Terrorist recruitment and radicalization in Saudi Arabia. Middle East Policy, 13 (4): 39–60.
Huckfeldt, R., Beck, P. A., Dalton, R. J. and Levine, J. (1995) Political environments, cohesive social groups, and the communication of public opinion. American Journal of Political Science, 39: 1025–1054.
Ingram, M. (2015) “Facebook has taken over from Google as a traffic source for news”, Fortune.com, Available online: (accessed 23 September 2016).
Kosinski, M., Stillwell, D. and Graepel, T. (2013) “Private Traits and Attributes are Predictable from Digital Records of Human Behavior”, PNAS, 110 (15): 5802–5805.
Lin, D. (1998) “An Information-Theoretic Definition of Similarity”, in ICML “98 Proceedings of the Fifteenth International Conference on Machine Learning, San Francisco, CA: Morgan Kaufmann Publishers.
Manovich, L. (2011) “The Promises and the Challenges of Big Social Data”, Software Studies Initiative. Available online: (accessed 4 May 2016).
McPherson, M., Smith-Lovin, L. and Cook, J. M. (2001) “Birds of a Feather: Homophily in Social Networks”, Annual Review of Sociology, 27: 415-444.
Neumann, P. (2013) “The Trouble with Radicalization”, International Affairs, 89 (4): 873-893.
Obar, J. A. and Wildman, S. (2015) “Social Media Definition and the Governance Challenge: An Introduction to the Special Issue”, Telecommunications Policy, 39 (9): 745–750.
Pariser, E. (2011) The Filter Bubble: What the Internet Is Hiding from You, London: Penguin Press.
Parse.ly (2015) “Authority Report: The State of Tags in Digital Media”, Parsely.com, Available online: (accessed 23 September 2016).
Pelletier, M. and Horky, A. (2013) “The Anatomy of a Facebook Like: An Exploratory Study of Antecedents and Outcomes”, Annals of the Society for Marketing Advances, 25: 207-208.
Rainie, L. and Wellman, B. (2012) Networked: The New Social Operating System. Cambridge, MA: MIT Press.
Sageman, M. (ed.) (2004) Understanding Terror Networks. Philadelphia: University of Pennsylvania Press.
Sageman, M. (ed.) (2008) Leaderless Jihad: Terror Networks in the Twenty-First Century. Philadelphia: University of Pennsylvania Press.
Schmid, A. (2013) Radicalisation, De-Radicalisation, Counter-Radicalisation: A Conceptual Discussion and Literature Review. ICCT Research Paper, Hague: ICCT. Available online: (accessed 9 January 2017).
Steiner, K. and Önnerfors, A. (2017) “Introduction” in A. Önnerfors and K. Steiner (eds.) Expressions of Radicalization: Global Politics, Processes and Practices, New York: Palgrave Macmillan.
Stroud, N. J. (2010) “Polarization and Partisan Selective Exposure”, Journal of Communication, 60 (3): 556-576.
Šlerka, J. (2013) “Jak se fanoušci politických stran liší - politické strany na Facebooku (2.)”, Data Boutique, Available online: (accessed 4 May 2016).
Šlerka, J. (2016) “Polarizovaná společnost? Nikoli, je to složitější”, ReporterMagazin.cz, Available online: (accessed 23 September 2016).
Šlerka, J. and Šisler, V. (2017) “Normalized Social Distance: Quantitative Analysis of Religion-centered Gaming Pages on Social Networks” in V. Šisler, K. Radde-Antweiler and X. Zeiler (eds.) Methods for Studying Video Games and Religion, New York: Routledge (in print).
Wallace, E., Buil, I. and de Chernatony, L. (2012) “Facebook ‘Friendship’ and Brand Advocacy”, Journal of Brand Management, 20: 128–146.
Wallace, E., Buil, I., de Chernatony, L., and Hogan, M. (2014) “Who ‘Likes’ You... and Why? A Typology of Facebook Fans from ‘Fan’–atics and Self Expressives to Utilitarians and Authentics”, Journal of Advertising Research, 54 (1): 92-109.
Weimann, G. (2006) Terror on the Internet: The New Arena, The New Challenges. Washington DC: United States Institute of Peace.
Weimann, G. (2010) Terror on Facebook, Twitter and YouTube. Brown Journal of World Affairs, 16 (2): 45–54.
Appendix: Complete dataset
Daniel Herman (Minister of Culture), Martin Stropnický (Minister of Defence), Jan Veleba (p), Svobodné fórum (n), Alexandra Udženija (p), Andrej Babiš (Minister of Finance), ANO (m), Pavel Bělobrádek (Minister of Science), Blesk (n), Block Against Islam (m), Pirate Party, Milan Chovanec (Minister of the Interior), Social Democratic Party, ČT24 (n), Echo24 (n), Jiří Dienstbier (Minister for Human rights), Referendum (n), European Commission CR, European Values, Generation Identity, Hate Free Culture, Freedom and Direct Democracy, iDNES (n), Hospodářské noviny (n), Miroslav Lidinský (p), Stop Islam in Czech Republic (m), Jana Černochová (p), Marian Jurečka (p), Miroslav Kalousek (p), Christian and Democratic Union (m), Martin Konvička (p), Communist Party, Lidové noviny (n), Lubomír Zaorálek (Minister of Foreign Affairs), Michaela Marksová-Tominová (Minister of Social Affairs), NO to Brussels - National Democracy (m), Svatopluk Němeček (Minister of Health), Novinky (n), Civic Democratic Party, Parlamentní Listy (n), Petr Fiala (p), Pravý břeh (n), Miloš Zeman (President), Czech Radio - Radiožurnál (n), Reflex (n), Karla Šlechtová (Minister of Regional Development), Bohuslav Sobotka (Prime Minister), Green Party, Pavel Svoboda (p), Free Citizens' Party, Tomio Okamura (p), Tomáš Zdechovský (p), TOP 09 (m), TV Noe (n), Respekt (n), Kateřina Valachová (Minister of Education)
Note: For clarity, we have translated the Facebook pages’ names into English wherever possible (e.g. Green Party) or labelled these pages according to the following key: (n) = news media, (m) = political movement or party, (p) = individual politician. In specific cases, we provide a full description of the page in parentheses.
0 notes
Text
Josef Šlerka and Vít Šisler: Normalized social distance: Quantitative analysis of religion-centered gaming pages on social networks
This study was originaly published in V. Šisler, K. Radde-Antweiler, and X. Zeiler (Eds.), Methods for studying video games and religion. New York, NY: Routledge.
Today, we are witnessing exponential growth in user-generated data, as well as a proliferation of social media that connect vast numbers of users and facilitate the maintenance of social relationships based on various grounds. Analysis of this “big social data” opens up new perspectives for research in social sciences and humanities (Manovich 2011, boyd and Crawford 2012, Halavais 2015). Meanwhile, the advances of information and computational technology bring new research methods and approaches, stemming in particular from computer and information sciences, to the “traditional” humanities. The ability to process large datasets in a quantitative and automated fashion opens a path to new research questions and new methods for answering them.
As Manovich (2011) argues, this rise of social media along with the progress in computational tools that can process massive amounts of data makes possible a fundamentally new approach for the study of human beings and society. In particular, we no longer have to choose between data size and data depth. We can study exact trajectories formed by billions of cultural expressions, experiences, texts and links. The detailed knowledge and insights that before can only be reached about a few can now be reached about many. In Manovich’s (2011) terms, we are no longer forced to choose between “surface data” about many or “deep data” about a few.
Although some authors have voiced an important criticism questioning the assumptions, values and biases of this new wave of research (boyd and Crawford 2012), the possibility to analyze vast, user-generated content in an automated fashion provides us with an opportunity for a “distant reading” (Moretti 2005) of social network sites and their audiences. This distant reading highlights structural aspects, which are not necessarily visible on the level of a “close reading,” such as content analysis or interviews, and thus paves the way for further research.
The primary aim of this chapter is to present a new methodological and interpretative framework for the analysis of big social data: in particular, user-generated data obtained from Facebook. The chapter introduces a new, formally-defined, quantitative method called Normalized Social Distance (NSD), developed by the main author of this chapter (Šlerka 2013). NSD calculates the distances between various social groups, based on the intentional stances expressed by members of these groups in their activities on social networks. NSD results can be visualized in graphs, clusters or dendrograms, and standard methods of network analysis can be applied to them. As such, NSD provides an opportunity for a distant reading of social network sites, enabling us to formally represent and analyze the structural aspects of big social data.
The case study presented in this chapter serves as an example that highlights the use of NSD on a concrete dataset and explains possible further interpretative approaches. Thematically, the case study focuses on religion-centered gaming pages on social networks. These are Facebook pages providing news, reviews and other gaming-related content and that describe themselves in religious terms and/or state religiously-motivated aims in their descriptions (e.g. Christian Gamers Alliance, Gamers 4 Christ, Muslim Gamers, Atheist Gamer, etc.). The case study explores 15 religion-centered gaming pages on Facebook and analyzes publicly available data about 10275 of their users. It aims to explore these pages’ audiences and their similarities, differences and affinities through NSD computed from their fans’ likes. In particular, the research questions for our case study are as follows: How “close” or “far” from each other, in terms of NSD, are religion-centered gaming pages on Facebook? How are these pages clustered? Does the self-declared religious affiliation of these pages play a role in the way they are clustered?
The results of the case study indicate that there exist several tightly-connected clusters of religion-centered gaming pages on Facebook, whose audiences are significantly “close” to each other and share similar intentional opinions. These clusters are divided primarily along the lines of self-declared religion, with different Christian gaming pages’ clusters being significantly “closer” to each other than to other religious clusters. There also tends to be a local bridge existing between Atheist and Christian gaming pages’ clusters.
The method proposed in this chapter could be relatively easily adopted by other researchers in different contexts to support their research with empirical evidence. It has to be emphasized that the use of NSD is not limited to any specific research field or knowledge domain. The method is particularly viable when dealing with research questions concerning large datasets of user-generated content, self-presentation and manifestation of intentional opinions. It is along these lines that research on religion and gaming can benefit from NSD the most.
Theoretical background
This chapter utilizes the concept of gamevironments (Radde-Antweiler, Waltemathe and Zeiler 2014) as a theoretical and analytical frame. It is based on an actor-centered approach, which integrates the analysis of video games as digital artifacts with broader cultural and social context. Within the framework of gamevironments, we focus on the gamer-generated content on social network sites and the social and religious context of gaming.
Mäyrä (2008: 25) suggests that video games and gaming cultures play a role in the way identity is negotiated and defined within late modern societies. In this sense, specific game cultures can be interpreted as subcultures, i.e. groups of people who have some practices, values and interests in common and who form, through their interaction, a distinct group within a larger culture. Importantly, members of specific game cultures often subscribe to websites, discussion boards or social network sites that are produced and maintained by active gamers in their free time. These stand as a virtual, but identifiable, shared space. Contemporary gaming communities have social elements beyond physical interaction and have come to a point where online and offline spaces can be seen as “merged” rather than separate (Flew 2005). Today, social media (such as Facebook, Twitter, Instagram or YouTube) are emblematic examples of such virtual shared spaces.
Despite different opinions on how to define social media, most authors agree that social media constitute a virtual space, in which the possibility of social interaction between users plays a crucial role (boyd and Ellison 2007, Obar and Wildman 2015). These interactions have a specific impact on the creation of user identities, communication situations and communities. The term “social media” is used to convey a wide variety of meanings in a way that blurs the distinction between different platforms and communication channels (Obar and Wildman 2015: 746).
For the sake of this study, we decided not to use the term social media given its analytical ambiguity. Rather, we have opted to use the term “social network sites.” In accordance with boyd and Ellison (2007), we define social network sites as web-based services that allow individuals to (1) construct a public or semipublic profile within a bounded system, (2) articulate a list of other users with whom they share a connection, and (3) view and traverse their list of connections and those made by others within the system. Typical examples of social network sites are Facebook and Twitter.
Importantly, we contend that the “connections shared with other users” on social network sites are the result of social actions and possess an intentionality of their own (Weber 1978). The actions on social networks could take all the forms as envisioned by Weber, i.e. affectional, rational, traditional or instrumental. However, their manifestations may vary (e.g. status message, comment, like, befriending someone, etc.). As such, the user’s behavior in social networks is not only a social action taken towards others, but also a representation of an intentionality that presupposes other subjects and anticipates their interpretation of such behavior. The analysis of actions on social network sites is thus an analysis of data representing not only a certain behavior, but also “intentional stances” (Dennett 1996).
From this perspective, social network sites constitute a new media environment for mass social interaction. Among many of the plausible theoretical frameworks enabling interpretative approaches to these social interactions, we propose the use of Goffman’s dramaturgical sociology. In his seminal work, Goffman (1959) advances a conceptual framework of theatrical performance that can be applied to the study of personal interaction. He proposes that when individuals enter the presence of others, they will try to guide and control the impression that others might get of them by changing or fixing their setting, appearance and manner. Following this theatrical analogy, Goffman spoke of a “front stage,” where the individuals are on a stage in front of the audiences and try to present an idealized picture of themselves. There is also a “back stage” that can be considered as a hidden or private place where individuals can be themselves and set aside their role or identity in society. Importantly, Goffman argued that when actors take on established roles, they oftentimes find particular fronts already established for such performances. The result is that fronts tend to be selected, not created (Ritzer 2010: 377).
If we understand user behavior on social network sites within Goffman’s framework, the user’s specific profile and social action conducted based on the profile could be considered part of a “personal facade” or as actions happening on the “front stage.” All the elements that form a personal profile on a social network site are the elements of the facade that users select with regard to their personal identity. The choice of name, profile photo, description, privacy settings, etc. could all be perceived as expressions of the user’s identity and front stage performance.
In other words, social actions conducted within the environment of social network sites (like status posts, comments, likes of particular pages or posts of other users, etc.) are means of self-representative performance (Wallace, Buil and de Chernatony 2012). Social network sites can be seen both as spaces of our daily self-presentation and as stages of our performance and interaction. Actions on social network sites have intentionality of their own and can be subjected to any traditional type of research: be it quantitative or qualitative. From the perspective of the digital humanities and automated computational processing, it is possible, to a large extent, to process all these social actions in an exploratory manner and search for structural patterns within the resulting data.
Existing research on big social data obtained from social network sites focuses mainly on the possible links between online social behavior and personal traits (Kosinski, Stillwell and Graepel 2013, Bachrach, Kosinski, Graepel, Kohli and Stillwell 2012) and the motivations of users to like particular pages (Pelletier and Horky 2013, Wallace, Buil, de Chernatony and Hogan 2014, Basalingappa, Subhas and Tapariya 2015).
Kosinski et al. (2013) demonstrate that easily accessible digital records on behavior (namely Facebook likes) can be used to predict automatically and accurately a range of highly-sensitive personal attributes including: sexual orientation, ethnicity, religious and political views, personality traits, use of addictive substances, parental separation, age and gender. By the same token, Bachrach et al. (2012) examine correlations between users’ personalities and the properties of their Facebook profiles such as the size and density of their friendship network, number of uploaded photos, and number of events attended.
Taking a different tack, Pelletier and Horky (2013) present exploratory, qualitative-based research in order to look at the motivations and consequences associated with liking particular brands’ pages on Facebook. Similarly, Wallace et al. (2014) explore a typology of fans, i.e. individuals who like different brands’ pages on Facebook. Recently, exploratory qualitative studies investigating the motivations of individual users to like their friends’ posts on Facebook have also appeared (Basalingappa et al. 2015).
There exists only limited, albeit growing, research on religious gamers and their online behavior (Bernauer 2012, Luft 2014). Bernauer (2012) examines the way Christian groups have appropriated mainstream video games and converted them into entertainment that they consider doctrinally and morally acceptable. She explores websites that have been created to review mainstream games in light of their potential appropriateness for Christian consumers. She also examines groups of Christians that play online games and the sets of rules they impose upon themselves and their guilds while engaging in this activity.
In his research on Christian gamers, Luft (2014) explores how evangelicals share their faith in different online chat rooms related to gaming. He argues that religion is a determining factor in how these evangelical gamers experience the video game medium with regard to their self-identification, the choices and behaviors they exhibit during the course of gameplay and the way they interpret the content of their games (Luft, 2014: 155). Luft’s research offers important insight into how religion shapes evangelical play. In particular, his study encourages the field to be mindful of the social and communal aspect of gaming. Christian gaming websites proliferated as evangelicals went online to seek out a like-minded community that shared their values. These websites have both reflected and reinforced particular standards of conduct valued by the community (Luft 2014: 166).
Studying religious gamers and their online behavior can provide useful insights into gaming as a social practice. As far as we know, there is neither a study discussing religion-centered gaming pages on social networks (in general), nor Facebook pages (in particular). Furthermore, there is no study utilizing a concept similar to NSD for analyzing social network sites’ audiences in the field of religion and gaming.
Method
In a nutshell, NSD is a formally-defined method that calculates the distance between social groups, based on the intentional stances expressed through the activities of group members on social network sites: in our case on Facebook pages. The resulting number expresses how “far” or “close” the audiences of various sites are to one another. Importantly, and contrary to all the above-mentioned studies, NSD relies on “post likes” (i.e. likes that an individual gave to concrete posts published by the page in question) rather than “page likes” (i.e. likes that an individual gave to a page as a whole). This methodological distinction is based on the assumption that, while a page like could represent a broad variety of intentional stances (ranging from support of the ideas expressed on the page to the intention just to be informed about the page’s activity), a post like is more likely an expression of affirmation for a concrete post (for the motivations of pages’ fans see Wallace et al. 2014). NSD could, in theory, be modified to include other behavior on social network sites (like shares and comments), yet the motivations behind these social actions could vary significantly and inclusion of these actions would require additional coding.
Before we detail the formula of NSD, we have to define three concepts that were fundamental for its development: homophily, similarity and distance. Furthermore, we have to introduce briefly the concept of normalized web distance, which we adopted in order to develop the NSD formula.
Homophily
For the sake of this study, we have adopted McPherson, Smith-Lovin and Cook’s (2001) concept of homophily in social networks. Homophily is the principle that a contact between similar people occurs at a higher rate than among dissimilar people. In other words, it assumes that similarity breeds connection. The homophily principle structures network ties of every type: including marriage, friendship, work, advice, support, information transfer, co-membership, etc. The result is that people’s personal networks tend to be homogeneous with regard to many sociodemographic, behavioral and intrapersonal characteristics. Homophily limits people’s social worlds in a way that has powerful implications for the information they receive, the attitudes they form and the interactions they experience. Furthermore, homophily implies that distance in terms of social characteristics translates into network distance: the number of relationships through which a piece of information must travel to connect two individuals (McPherson et al. 2001).
Similarity
The concept of similarity, which is the driving force behind organizing, plays a central role in the homophily principle. Similarity and network distance can be formalized and represented numerically. We have adopted Lin’s (1998) information-theoretic definition of similarity that can be used to measure similarity in a number of different domains. The similarity measure is not defined directly by a formula. Rather, it is derived from a set of assumptions (Lin 1998: 2):
Similarity between A and B is related to their commonality. The more commonality they share, the more similar they are.
Similarity between A and B is related to the differences between them. The more differences they have, the less similar they are.
Maximum similarity between A and B is reached when A and B are identical; no matter how much commonality they share.
If these assumptions are deemed reasonable, the similarity measure necessarily follows.
Distance
We define distance for the sake of this study as an expression of the mutual similarity or dissimilarity of any two instances. The more similar to each other the two instances are, the lower the number expressing their distance. The more different the two instances are, the greater the number expressing their distance. The distance metric is a specific expression of similarities between instances that meet the following three conditions, where d represents the distance between the instances x, y and z:
Minimality: d(x, y) => 0; d(x, y) = 0 if x = y;
Symmetry: d(x, y) = d(y, x);
The Triangle Inequality: d(x, y) + d(y, z) ≥ d(x, z).
Normalized web distance
The concept of Normalized Web Distance (NWD) was introduced by Cilibrasi and Vitányi (2010) and stems from the Kolgomorov complexity (Li and Vitányi 1997). NWD is a semantic measure of similarity derived from the number of hits returned by the internet search engine for a given set of keywords. Words or phrases with the same or similar meanings in a natural language sense tend to be “close” in units of web distance, while words with dissimilar meanings tend to be “farther” apart.
Cilibrasi and Vitányi (2010) formalize NWD as follows, where f(x) is a number of websites that contain x; f(y) is a number of websites that contain y; f(x,y) is a number of websites that contain both x and y; and N is a number of all websites indexed by the search engine used:
We could perceive NWD as the expression of distance between two instances on a semantic layer. Utilizing internet search engines, particularly Google, NWD could rely on contexts expressing a large body of common-sense knowledge. Series of experiments evaluating the accuracy of NWD against expert opinion brought satisfying results (Cilibrasi and Vitányi 2007, 2010). The subjects of the experiments were names of works by Dutch painters from the 17th century, names of English novels, numbers and colors, Chinese names and names of works by Shakespeare. A further experiment tried to reconstruct semantic links as expressed by expert opinion in WordNet using NWD. On average, the NWD method ended up agreeing well with the WordNet semantic concordance made by human experts, while the mean of the accuracies of agreements was 0.8725 (Cilibrasi and Vitányi 2010: 311).
If NWD comes with the idea of a semantic layer of information, we propose that there is another, more pragmatic, layer above it that counts on the degree of similarity expressed by the online behavior of two different social groups. We can also formally define the method of calculating the distance between these two social groups.
Normalized social distance: formal definition
Formally, we define NSD as follows, where f(x) is the number of members of the group x; f(y) is the number of members of the group y; f(x, y) is the number of elements that are simultaneously members of both groups; and N is the number of all elements in the given corpus:
With the distance formally defined in this way, we should be able to measure the distance between any two social subgroups that are under the umbrella of another one. NSD is a universal metric that can be adjusted for data from any social network sites. In the following case study, we applied the formula to Facebook pages; calculating the proximity of these pages based on the post likes distributed by these pages’ active users.
In practice, the whole process proceeds as follows:
Basic dataset:
We create a list of Facebook pages whose mutual distance we want to measure.
We download all the posts posted by the admins of these pages via the Facebook API, based on our selection criteria (e.g. last 300 posts or all posts posted in the last 6 months).
We further download, via the Facebook API, the complete list of IDs for users who liked these posts. We download only posts that have been posted by the page admins and that have been liked on the respective page. We don’t download comments and shares. Similarly, we don’t download likes of posts shared by users on their own Facebook pages and profiles.
Transformation:
We create a list of active users, i.e. a list of unique IDs that belong to users who liked at least one post on the page. In other words, we don’t create the list of a page’s “fans” (i.e. users who liked the whole page) but a list of active users related to that page.
In a similar way, we create lists of unique IDs for all the pages we plan to analyze.
Calculation:
We determine the approximate number of all users in the Facebook region for which we count the normalized distance (e.g. Czech Facebook, English Facebook, Polish Facebook, etc.). This number represents the number of Facebook users, who might possibly like the posts on the pages in question. In most cases, we can use the Facebook Audience Insights service, which provides the number of active users per region and language. The term “normalized” thus refers to the fact that the transformation description size must be seen in relation to the size of the participating objects (see Vitányi, Balbach, Cilibrasi and Li 2009: 40).
Subsequently, we calculate the distance matrix between all the pages in accordance with the NSD formula. If there is no intersection between the two pages, we assign an infinity value to their distance. Thus, we maintain the triangulation principle.
The resulting matrix is a bimodal network with a relatively low density that can be examined using traditional exploratory techniques: such as Hierarchical Cluster Analysis (HCA), Multidimensional Scaling (MDS) or Principal Component Analysis (PCA).
Case study
The case study deals with religion-centered gaming pages on Facebook. By religion-centered gaming pages we mean Facebook pages that provide news on video games, video game reviews and other gaming-related content and that simultaneously describe themselves in religious terms and/or state religiously-motivated aims in their description.
Religion-centered gaming pages on Facebook may serve a variety of purposes. Some of them strive to provide a “safe space” for religious gamers who want to share their passion with other gamers of similar faith: without prejudice and ostracization. For example, the description of the Muslim Gamers (2015) page states:
I have seen many other Muslim gamers get abused and banned from other sites and forums just because they announce that they are a Muslim and are looking for other Muslims with whom they can play together. There really isn’t a place where they can discuss Islam, games and technology without the fear of being abused, or even worse, banned from the site and getting a feeling of rejection, just because they are Muslim. As a result, we have been working on this site and I am trying to let other Muslims know about it.
Taking a different tack, other religion-centered gaming pages focus on community building and sharing religiously-oriented gaming news and reviews. One such example is the Christian Gamer (2015) page:
We are gamers; we are Christians. We have taken a passion that we have for gaming and intertwined it with the passion we have for God. We are here to provide everyone with the accountability and ability to fellowship together in the gaming world without losing their witness. Come join us here and get to know other passionate gamers.
Some pages have evangelical and proselytizing aims, such as the GameChurch (2015) page that targets gamers, parents and pastors:
GameChurch exists to bridge the gap between the gospel and the gamer. Video games are the world’s largest and fastest-growing media outlet. We are a non-profit dedicated to bringing the message of Jesus’ love, hope and acceptance into the culture of video games.
Finally, some of the religion-centered gaming sites have an anti-religion agenda; i.e. the Atheist Gamer (2015) page:
We come together from all walks of life to share our love of video games and other fictional works of geek culture, while having a mutual desire for a secular world. We enjoy games, but we know it’s harmful to take fiction and treat it as reality. Atrocities have been committed due to people taking fictional works and treating them as law. The most harmful pieces of fictional material that exist go by the name of “religion.” With all of our power we will not stop fighting until logic and reason become the only “religion.” We are Atheist Gamers and we DO NOT believe in God-Mode.
Important for our research (despite the significantly heterogeneous motivations), all the religion-centered gaming pages express strong intentional stances related to religious identity and gaming.
Dataset
While searching for religion-centered gaming pages, we used the Facebook search form, searching for all the possible combinations of the words (Christian, Muslim, Jewish, Atheist, Hindu, Buddhist, Christianity, Islam, Judaism, Atheism, Hinduism, Buddhism, Christ, Buddha, Islamic, Pagan, Halal, Kosher) and (games, gamer, gamers, gaming) in page names or descriptions. We limited our search to English language pages only. We have conducted an identical search via the Google search form and analyzed all the relevant results within the first 10 pages of results. We have found many websites that provide gaming-related content, while describing themselves in religious terms. In cases where these websites also had a presence on Facebook, we added their Facebook page to our dataset.
Overall, we found 25 religion-centered gaming pages on Facebook (note that we searched only for public Facebook pages, not for closed groups). We excluded pages that have less than 150 page likes. The final dataset thus comprises the following 15 pages:
3 Day Respawn, Christ Centered Gamer, Christian Games Now, Christian Gamers Alliance, Christian Gamers Guild, Gamers 4 Christ, Gamers4Jesus, Geeks Under Grace, GameChurch, Hardcore Christian Gamer, Muslim Gamers, Islamic Quizzes & Games, Atheist Gamers and Geeks, Atheist Gamer, The Atheist Gaming Network.
Aim
The primary aim of this case study is to conduct exploratory research on religion-centered gaming pages on Facebook. Within this exploratory research, we aim to investigate the following research questions: How “close” or “far” are religion-centered gaming pages on Facebook from each other in terms of NSD? How are these pages clustered and how are the clusters connected?
The secondary aim is to investigate whether the religious affiliation of the religion-centered gaming pages on Facebook plays a role in the way these sites are clustered in terms of NSD. Based on the concept of homophily in social networks (McPherson et al. 2001), we have formulated the following main hypothesis:
H: Gaming pages of the same religious tradition will be closer to other gaming pages of this religious tradition than to gaming pages of different religious traditions in terms of NSD.
In relation to our dataset, the operationalized hypotheses are as follows:
H1: Christian gaming pages will be closer to other Christian gaming pages than to Muslim and Atheist gaming pages in terms of NSD.
H2: Muslim gaming pages will be closer to other Muslim gaming pages than to Christian and Atheist gaming pages in terms of NSD.
H3: Atheist gaming pages will be closer to other Atheist gaming pages than to Christian and Muslim gaming pages in terms of NSD.
Procedure
We have adopted the procedure described above in order to compute the NSD of these pages to each other:
We have downloaded the last 600 posts posted by admins of all the pages. If a page had less than 600 posts, we downloaded all the posts posted on that page within the last 2 years. The oldest post dates from 2 September 2013, while the newest one was from 1 September 2015. We downloaded 5054 posts altogether.
We have downloaded the complete list of IDs for users who liked at least one of these posts. We downloaded the IDs of 10275 unique users, who distributed 49714 likes among 5054 posts.
We have determined the size of the Facebook region (i.e. English Facebook) as 600000000 users. This size is based on information from Facebook Audience Insights (Facebook 2016).
Based on this data, we have computed the NSD of all these pages to one another. have adopted the procedure described above in order to compute the NSD of these pages to each other:
Results
The results of NSD can be visualized in several ways. For the sake of this study, we have adopted graph visualization and dendrograms.
First, the graph visualization (Figure 10.1) depicts religion-centered gaming pages on Facebook and their clustering. The nodes in the graph denote individual pages, while the links denote significant proximity in terms of NSD (i.e. NSD(x,y) <= 0.5).
Second, a cluster dendrogram (Figure 10.2) depicts the religion-centered gaming pages on Facebook in a tree diagram illustrating the arrangement of the clusters produced by hierarchical clustering. (Note that the Muslim Gamers and Islamic Quizzes & Games pages are not included in the dendrogram, since they are not connected to the one large component with all the other pages in terms of NSD.)
Analysis
The NSD method provides us with an opportunity for a “distant reading” of social network sites and their audiences. It highlights structural aspects. In our case study, the results of the NSD method (both graph visualization and cluster analysis) show several key findings about the religion-centered gaming sites on Facebook.
First, the findings indicate that there exist several tightly-connected clusters of religion-centered gaming pages on English Facebook, whose audiences are significantly “close” to each other and share similar intentional stances. The users located in these clusters enjoy similar content and rarely reach out to different clusters. Among these clusters we can identify a large one that can be characterized as “Christian pages” and one smaller cluster that can be characterized as “Atheist pages.” Although the cluster for Christian pages can be further broken down into two significantly different clusters, the pages in both of these two clusters are closer to each other than to the pages in the Atheist page cluster (or to the two isolated pages that can be identified as “Muslim pages”).
Second, the results indicate that the clusters of religion-centered gaming pages on Facebook are organized primarily along the lines of self-declared religious affiliation. As such, the empirical evidence confirms the two hypotheses presented in the secondary goal of this study, i.e. H1 and H3. However, the hypothesis H2 has to be rejected, since the NSD method didn’t find any significant audience overlaps between the only two Muslim pages in the study. (Note that these two pages don’t have any audience overlaps with other pages included in the study either).
Third, the data exhibits many of the broad structural features of large social networks, including a “giant component” (Easley and Kleinberg 2010: 57) – a single connected component containing most (in this case 87%) of the individual nodes in the network. We can identify a “local bridge” (Easley and Kleinberg 2010: 51) between the “Christian page” and “Atheist page” clusters. It consists of a single significant audience overlap between the pages, Christ Centered Gamer and Atheist Gamers and Geeks.
To sum it up, the NSD analysis reveals that the religion-centered gaming pages on English Facebook are polarized to three significantly different clusters, whose audiences rarely like the same content and whose intentional stances (as manifested through Facebook post likes) rarely overlap. These clusters are organized primarily along the lines of self-declared religious affiliations. Finally, the data exhibits many of the structural features of large social networks, including a giant component and local bridges.
Discussion
This chapter has presented an exploratory study on religion-centered gaming pages on social networks. In particular, it analyzed the audiences of religion-centered gaming pages on Facebook and explored their similarities, differences and affinities through social distance computed based on their fans’ likes. The chapter has introduced a new formally-defined method called Normalized Social Distance (NSD) that calculates the distances between various social groups, based on the intentional stances expressed through the activities of these groups’ members on Facebook. NSD provides an opportunity for a distant reading of social network sites, enabling us to represent and analyze formally the structural aspects of big social data.
NSD is a quantitative method that serves primarily for exploratory research. Unlike semantic methods in the digital humanities, NSD is featureless and is in principle unrelated to the content of the data analyzed. It focuses on social network sites’ audiences’ actions (typically Facebook likes) and computes how “far” or “close” to each other the audiences of different sites are based on these actions. The intuition behind the NSD method is that the users’ behavior in social networks is not only a social action taken toward others, but it is also a representation of an intentionality that presupposes other subjects and anticipates their interpretation of such behavior. The analysis of actions on social network sites is thus an analysis of data representing not only certain behavior, but also intentional stances. As such, the NSD method could possibly be falsified by a qualitative analysis of the content the users share and like. The falsifications we have conducted so far suggest a significant correlation between NSD and qualitative analysis, yet further research is needed.
The advantages and limitations of the NSD method have always be evaluated in the light of the respective research question. On a general level, these advantages and limitations can be summarized as follows:
Advantages
NSD calculates distance between social groups based on intentional stances expressed by these groups’ members. It works with the pragmatic layer of information obtained from social network sites, i.e. with information generated by the user’s online behavior.
NSD is a quantitative method for exploratory research. It structures and visualizes data according to existing patterns, enabling researchers to make sense of vast datasets of empirical evidence.
There is no sampling and no human coding within the NSD method. NSD works with complete datasets.
The NSD method enables further use of standard methods of network analysis (hierarchical clustering, multidimensional scaling and principal component analysis).
NSD enables falsification of its results through qualitative research.
Limitations
The research field of NSD is limited to social network sites. Although in principle it is possible to calculate NSD on offline datasets, the possibilities to gather complete datasets beyond the realm of social network sites are seriously limited. The results of NSD could not be generalized beyond the segment of the population that is active on social networks.
The NSD method works with public profiles only. Data from closed groups and closed profiles can’t be obtained in an automated and legal manner.
NSD needs a minimal number of active page fans on analyzed pages in order to be statistically valid. We assume that pages with less than 150 page likes should be excluded from NSD analysis.
NSD is designed primarily as a method for exploratory research, with all the limitations that come with this type of research endeavor.
Given there is no human coding, the NSD method is featureless. In other words, without further qualitative research, we don’t know which intentional stances create what connections and audience overlaps.
The NSD method proposed in this chapter constitutes a coherent methodological frame, which enables formal representation, replication and validation of the structural analysis of big social data and could be relatively easily adopted by other researchers in different contexts. Given its focus on intentional stances and manifestation of identity, NSD could become a viable tool in the field of religion and gaming; particularly, in the analysis of online social networks, audience studies and research on community and identity.
Acknowledgements
This study was partially supported by the Charles University programs Progres Q15 and Primus/Hum/03.
References
Atheist Gamer (2015) Page Info [Facebook]. Available at https://www.facebook.com/AtheistGamer/info/?tab=page_info, accessed 4 May 2016.
Bachrach, Y., Kosinski, M., Graepel, T., Kohli, P. and Stillwell, D. (2012) ‘Personality and Patterns of Facebook Usage’, in WebSci ‘12 Proceedings of the 4th Annual ACM Web Science Conference, New York: ACM.
Basalingappa, A., Subhas, M. S. and Tapariya, R. (2015) ‘Understanding Likes on Facebook: An Exploratory Study’, in IV. International Conference on Communication, Media, Technology and Design Proceedings, Famagusta: Eastern Mediterranean University Press.
Bernauer, L. (2012) ‘Playing for Christ: Christians and Computer Games’, in A. Possamai (ed.) Handbook of Hyper-real Religions, Leiden: Brill.
boyd, d. m. and Crawford, K. (2012) ‘Critical Questions for Big Data’, Information, Communication & Society, 15(5): 662-679.
boyd, d. m. and Ellison, N. B. (2007) ‘Social Network Sites: Definition, History, and Scholarship’, Journal of Computer-Mediated Communication, 13(1): 210-230.
Christian Gamer (2015) Page Info [Facebook]. Available at https://www.facebook.com/HardcoreChristianGamer/info/?tab=page_info, accessed 4 May 2016.
Cilibrasi, R. L. and Vitányi, P. M. B. (2007) ‘The Google Similarity Distance’, IEEE Transactions on Knowledge and Data Engineering, 19(3): 370-383.
Cilibrasi, R. L. and Vitányi, P. M. B. (2010) ‘Normalized Web Distance and Word Similarity’, in N. Indurkhya and F. J. Damerau (eds.) Handbook of Natural Language Processing, Boca Raton: CRC Press.
Dennett, D. C. (1996) The Intentional Stance, Cambridge: MIT Press.
Easley, D. and Kleinberg, J. (2010) Networks, Crowds, and Markets: Reasoning about a Highly Connected World, New York: Cambridge University Press.
Facebook (2016) Facebook Audience Insights [Facebook]. Available at https://www.facebook.com, accessed 4 May 2016.
Flew, T. (2005) New Media: An Introduction, New York: Oxford University Press.
GameChurch (2015) Ministry. Available at http://gamechurch.com/ministry, accessed 4 May 2016.
Goffman, E. (1959) The Presentation of Self in Everyday Life, New York: Anchor Books.
Halavais, A. (2015) ‘Bigger Sociological Imaginations: Framing Big Social Data Theory and Methods’, Information, Communication & Society, 18(5): 583-594.
Kosinski, M., Stillwell, D. and Graepel, T. (2013) ‘Private Traits and Attributes are Predictable from Digital Records of Human Behavior’, PNAS, 110(15): 5802-5805.
Li, M. and Vitányi, P. (1997) An Introduction to Kolmogorov Complexity and Its Applications, New York: Springer.
Lin, D. (1998) ‘An Information-Theoretic Definition of Similarity’, in ICML ‘98 Proceedings of the Fifteenth International Conference on Machine Learning, San Francisco: Morgan Kaufmann Publishers.
Luft, S. (2014) ‘Hardcore Christian Gamers: How Religion Shapes Evangelical Play’, in H. Campbell and G. Grieve (eds.) Playing with Religion in Digital Games, Bloomington: Indiana University Press.
Manovich, L. (2011) The Promises and the Challenges of Big Social Data, New York: Software Studies Initiative. Available at http://lab.softwarestudies.com/2011/03/promises-and-challenges-of-big-social.html, accessed 4 May 2016.
Mäyrä, F. (2008) An Introduction to Game Studies: Games and Culture, London: Sage.
McPherson, M., Smith-Lovin, L. and Cook, J. M. (2001) ‘Birds of a Feather: Homophily in Social Networks’, Annual Review of Sociology, 27: 415-444.
Moretti, F. (2005) Graphs, Maps, Trees: Abstract Models for a Literary History, New York: Verso.
Muslim Gamers (2015) Page Info [Facebook]. Available at https://www.facebook.com/MuslimGamers/info/?tab=page_info, accessed 4 May 2016.
Obar, J. A. and Wildman, S. (2015) ‘Social Media Definition and the Governance Challenge: An Introduction to the Special Issue’, Telecommunications Policy, 39(9): 745-750.
Pelletier, M. and Horky, A. (2013) ‘The Anatomy of a Facebook Like: An Exploratory Study of Antecedents and Outcomes’, Annals of the Society for Marketing Advances, 25: 207-208.
Radde-Antweiler, K., Waltemathe, M. and Zeiler, X. (2014) ‘Video Gaming, Let’s Plays, and Religion: The Relevance of Researching Gamevironments’, gamevironments, 1: 1-36.
Ritzer, G. (2010) Sociological Theory, New York: McGraw-Hill.
Šlerka, J. (2013) Jak se fanoušci politických stran liší – politické strany na Facebooku (2.), Praha: Data Boutique. Available at http://databoutique.cz/post/62064377499, accessed 4 May 2016.
Vitányi, P., Balbach, F., Cilibrasi R. and Li, M. (2009) ‘Normalized Information Distance’, in F. Emmert-Streib and M. Dehmer (eds.) Information Theory and Statistical Learning, Berlin: Springer.
Wallace, E., Buil, I. and de Chernatony, L. (2012) ‘Facebook ‘Friendship’ and Brand Advocacy’, Journal of Brand Management, 20: 128-146.
Wallace, E., Buil, I., de Chernatony, L., and Hogan, M. (2014) ‘Who “likes” You... and Why? A Typology of Facebook Fans from “Fan”–atics and Self Expressives to Utilitarians and Authentics’, Journal of Advertising Research, 54(1): 92-109.
Weber, M. (1978) ‘The Nature of Social Action’, in W. G. Runciman (ed.) Weber: Selections in Translation, New York: Cambridge University Press.
1 note
·
View note
Text
Slušní lidé na Facebooku
Před několika týdny mne na Facebooku veřejně oslovil Pavel Doležal s prosbou, zda bych se nemohl podívat na profil fanoušků stránky Slušní lidé (https://www.facebook.com/hnutislusnilide/). Zajímala ho analýza oblíbených stránek aktivních fanoušků této stránky. Tedy analýza, kterou u nás původně rozšířil Jan Schmid, a která se stala výchozí iniciací pro značnou část mojí dizertace. S výsledky podobných analýz měli čtenáři Databoutique možnost se seznámit už víckrát, například v textu Facebook podle Klubu českého pohraničí aneb rudý květ v modré dálce. Rozhodl jsem se Pavlovi udělat radost, ale protože obvykle tato analýza vyvolává otázky ohledně toho, jaké jsou vlastně motivace uživatelů Facebooku stát se fanouškem nějaké stránky či olajkovat nějaký post, přidal jsem k analýze i teoretickou přílohu: “Proč se lidé stávají fanoušky a lajkují posty”.
Výchozí dataset
Pro naše účely jsem stáhl 154 postů publikovaných mezi 15. 1. 2017 až 15. 5. 2017. Ke každému postu jsem stáhl všechny ID uživatelů Facebooku, kteří měli s danými posty nějaký typ reakce (Like, Angry…). Celkem šlo o 22 874 reakcí od 8 344 uživatelů. Složení typu zapojení bylo následující:
Z datasetu jsem vybral pouze lajky, a zaměřil jsem se na uživatele, kteří lajkovali nejčastěji. Důvodem, proč jsem pro další analýzu zvolil jen lidi, kteří dali lajk a nikoli ostatní typy reakcí, je relativní novost ostatních reakcí a absence relevantních studií o rozdílech, které přináší.
Z datasetu jsem vybral 475 uživatelů, kteří dali 7 a více lajků pod posty v daném období. Celkem tvoří 41,5 % veškerých lajků na stránce.
Facebook neposkytuje přes API přístup k seznamu oblíbených stránek, a to ani u otevřených profilů. Použil jsem skript pro jednoduché stahování přímo z facebookových profilů. V našem případě se tak podařilo získat údaje k 311 profilům. Z těch se podařilo stáhnout celkem 32 194 stránek.
Affinitní stránky vůči stránce Slušní lidé
Základní možností, kterou lze pro analýzu našeho datasetu využít, je spočítat míru affinity stránek oblíbených fanouškovským jádrem stránky. V zásadě se jedná o využití tzv. affinity indexu, který vyvinuli lidé v týmu Cahners Publications a Simmons Market Research Bureau pro potřeby vyhodnocování intenzity vztahu mezi médiem a cílovou skupinou reklamy. Jednoduchost výpočtu indexu přispívá k tomu, že je dnes běžným standardem v tzv. media planningu a svoje uplatnění nachází i jinde.
Server MediaGuru jej ve svém slovníčku definuje přehledně takto:
"Afinita (TAI, Target Affinity Index, vhodnost) je index, který popisuje vhodnost konkrétního reklamního nosiče (magazínu, TV pořadu) pro cílovou skupinu, kampaň. Charakterizuje, jak konkrétní cílová skupina sleduje dané médium ve srovnání s obecnou populací (obvykle dospělí 15+ nebo dospělí 12+). Počítá se jako sledovanost média v konkrétní cílové skupině děleno sledovaností v populaci. (...) Čím vyšší afinita, tím je médium vhodnější pro oslovení konkrétní cílové skupiny. Obvykle afinita vyšší než jedna znamená, že médium je vhodné pro použití v kampani (cílová skupina ho sleduje relativně více než populace).
Příklad: Deník Sport čte v populaci 3,4 % lidí (mužů i žen) ve věku 12 a více let. Mezi muži ve věku 12 a více let najdeme 6,5 % mužů, kteří četli poslední vydání Sportu. Afinita deníku Sport v cílové skupině muži 12+ je rovna 6,5 % / 3,4 % = 1,9. Muži čtou deník Sport relativně více než populace." (zdroj)
U nás prvně aplikoval tuto metodu na facebookové stránky Jan Schmid, se kterým jsme ostatně společně publikovali několik postů k dané otázce na tomto blogu. Jeho východisko je následující:
Víme, kolik procent fanoušků z našeho zkoumaného datasetu je zároveň fanouškem nějaké jiné stránky.
Víme, kolik má tato stránka na Facebooku fanoušků.
Můžeme spočítat kolik procent fanoušků domácí populace je fanouškem stránky, protože víme, kolik je přibližně aktivních uživatelů domácího Facebooku (pro nás to bude 4.000.000).
Následně tak můžeme spočítat kolikrát častěji, se vyskytují fanoušci dané stránky uvnitř zkoumaného datasetu, než kdyby se jednalo o náhodně vybranou skupinu uživatelů Facebooku o stejné velikosti.
Ukažme si to na jednoduchém příkladu: V našem datasetu například víme, že 64 uživatelů je fanouškem stránky Hlasuji pro czexit. To je 20 % z celého datasetu. Přitom ale stránka Hlasuji pro czexit má na Facebooku 44 731 fanoušků, což znamená, že jejich fanouškem je 0,011% uživatelů českého Facebooku. V praxi je tak v našem datasetu 18,5x více fanoušků a stránka Hlasuji pro czexit je tak silně affinitní vůči stránce Slušní lidé. Oproti tomu stránka "nametests.com český" má v naší analyzované skupině uživatelů 16 % příznivců, v celém českého Facebooku ji pak má lajknutou 15 % všech uživatelů. Affinita se tu blíží 1, a tím pádem stránka není affinitní.
Kromě samotné affinity ale hraje roli i celkové procentuální zastoupení v datasetu. Na obrázku můžete vidět stránky, které jsou nejvíce zastoupeny v našem zkoumaném datasetu, a zároveň mají affinitu větší než 10.
obrázek ve větším rozlišení
To, že samotná stránka Slušní lidé nemá 100%, není nutně špatně, protože záleží na formě, kterou se posty dostávají k uživatelům. Podíváme-li se na seznam stránek, je vidět, že mezi nimi dominují stránky iniciativ a politiků spojených především s antiimigrační rétorikou. Což není nijak překvapivé vzhledem k rétorice stránky samotné.
Hierarchické shlukování
Nevýhodou affinitního modelu je však to, že jeho výsledky jsou de facto jednorozměrné a neumožňují shluknout stránky podle svých fanoušků. Tedy dát k sobě stránky, které jsou si více podobné než jiné, na základě podobné struktury oblíbených stránek mezi jejich fanoušky v našem datasetu.
Na vstupu byla matice, v níž řádky tvořily facebookové stránky, které v našem datasetu měly alespoň 10% společného průniku a affinitu rovnou nebo větší než 10. Sloupce byly ID fanoušků z našeho datasetu. Jejich průnik byla buď jedna, pokud byl fanouškem, nebo nula, pokud nebyl.
Předmětem tohoto blogpostu však není úvod do shlukovacích postupů a případné zájemce raději odkážu na internetové zdroje. Já jsem pro naše účely zvolil metodu hierarchického shlukování, která se snaží spočítat míru podobnosti jednotlivých znaků (v našem případě facebookových stránek) a vizualizovat je pomoci tzv. dendrogramu. Výsledek naší jednoduché analýzy vidíte na výsledném obrázku:
obrázek ve větším rozlišení
Základní čtení dendrogramů je relativně jednoduché, v našem případě vidíme na ose y vynesený koeficient podobnosti a na ose x, pak jednotlivé objekty. Výška vertikální úsečky tak reprezentuje míru nepodobnosti. Čím větší, tím jsou si facebookové stránky méně podobné. Stále měřeno z pohledu preferencí jejich fanoušků v našem datasetu. Naopak pořadí objektů na ose x nenese žádný speciální význam, než vyjádření jejich blízkosti. Mohla by tak být i zrcadlově převrácena.
Vidíme, že se stránky poměrně rychle rozdělují do dvou, respektive tří větví. První větev, kterou jsem označil jako A, reprezentuje víceméně stránky patřící ke stránkám politických stran, médií a hnutí, které se vyznačují vysokou mírou nespokojenosti se stavem společnosti. Vidíme také, jak se tato větev štěpí na další větve. Větev A1 reprezentuje především hnutí spojené s osobou Tomia Okamury a Miloše Zemana. Ve větvi A2 naopak vidíme spíše pravicové subjekty ve spojení se silně protiimigračními médii a okruh stránek spojených s tzv. konvičkovci. Zde také najdeme politiky jako jsou Petr Robejšek či Václav Klaus mladší. Ve větvi A3 už nacházíme hlavně stránky z názorového okraje spektra, většinově nacionalistické.
Větev B je silně spojená s části brněnské scény. Je tu jak parodický KKRD Boys server, tak stránky spojené s Gaunym (o tom, kdo je Gauny, se rozsáhle rozepisuje tento článek. A to jak s institucí GaunySecurity, tak s Gaunyho primitivními komiksy, ale také se stránkami MMA bojovníků Tomáše "Rattlesnaka" Hrona a Jiřího "Denise" Procházky.
Poslední větev C by šlo rozdělit na dvě separované skupiny. ODS a její politiky (minulé či přítomné) a stránky vyjadřující silnou příslušnost k Brnu. Což asi u skupiny působící v Brně nepřekvapí.
Závěry
Pokud jste dočetli až sem, tak mám radost. Závěr si udělejte sami, pro mne jsou Slušní lidé další z nepřeberného množství subjektů, které se pohybují v poli extrémní pravice, zhruba tak, jak toto pole vymezuje Ministerstvo vnitra.
Osobně mne překvapuje silná vazba části fanoušků k ODS, ale vysvětlení pro ni přináší možná již zmíněná zpráva JKG 2017: Brněnská ODS si podává ruku s neonacisty a fotbalovými chuligány na serveru Antifa. Případně poněkud vyhrocená rétorika některých představitelů ODS. Na druhou stranu není v jádru fanoušků na Facebooku vidět zas tak silný příklon k panslavismu, jak ho vidí bulvární Expres.
Tak, a já jen doufám, že je Pavel spokojenej.
A tady je slíbená příloha:
Appendix: Proč se lidé stávají fanoušky a lajkují posty
Dnes je k dispozici již celá řada výzkumů o motivaci uživatelů Facebooku stát se fanouškem nějaké stránky. Hlavním důvodem je (nepřekvapivě) zůstat v kontaktu s obsahem stránky (Pelletier and Horky, 2013). Přičemž již existují uspokojivé typologie fanoušků stránek podle vztahu k samotné značce (Wallace et al., 2014, Bunker et al., 2013). Další studie se pak věnují motivaci podloženou očekáváním užitku z obsahu stránky, třeba v podobě slev u obchodních značek (Murthy et. al., 2013). Důležitou, byť ne absolutní roli, hraje při stávání se fanouškem nějaké stránky potřeba sebevyjádření. Uživatel, který je fanouškem stránky, nejenže vyjadřuje svůj kladný postoj k obsahu postů stránky, ale také tímto krokem dává svůj postoj veřejně najevo (Wallace et al., 2014). Lajkování stránek (ale i postů, jak ještě uvidíme) je tak svého druhu divadelním aktem (ve smyslu Goffmanovi dramaturgické sociologie). Výzkumy samozřejmě zohledňují i jiné motivace jako kupříkladu fakt, že v postu stránky se objevuje oblíbená herečka uživatele (Lipsman et. al, 2012).
Všechny uvedené studie se věnují především facebookovým stránkám obchodních značek a typologie uživatelů je tak primárně zkoumaná nad specifickým typem obsahu. Tomu je přizpůsobené i pojmenování jednotlivých skupin uživatelů. Kupříkladu Elaine Wallace hovoří o čtyřech typech: Fan-atics, Self-expressives, Utilitarians, Authentics. Distinktivní rysy v motivaci jednotlivých typů jsou dány především mírou loajality vůči brandu, mírou identifikace s brandem a potřebou být informován o dění kolem brandu.
Zjednodušeně řečeno dominantní motivací pro to stát se fanouškem nějaké stránky je pozitivní vztah buď k samotné značce či obsahu postu. Existuje však skupina fanoušků, kteří jsou ve svých motivacích vedeni utilitární potřebou „zůstat v obraze" či být prostě informován.
Pokud jde o výzkumy motivace udělení lajků pod samotné posty na Facebooku, tak ty nejsou zdaleka tak frekventované. Avšak výsledky studie Facebook users' motivation for clicking the "Like" button (Chin, C., Lu, H., & Wu, C. (2015)) naznačují značnou míru kompatibility s typologiemi uživatelů podle vztahu k značce. Chin a Lu pracují s následujícími typy motivace pro lajk: hedonická, utilitární, udržovací, konformní a spřízněná.
Výzkum taiwanského týmu ukazuje, že všechny tyto motivace jsou přítomny v chování a podílejí se na chování uživatelů (svou roli hrají ještě subjektivní normy, ale ty nás v tuto chvíli nezajímají). Ze závěru studie pak vyplývá, že hedonická, utilitární a spřízněná úzce souvisí s obsahem postu. Zatímco udržovací především s tím, kdo postuje, a vztahem lajkujícího k němu. Poslední konformní je pak motivována celkovým vztahem k sociální skupině.
Homofilie aneb svůj k svému
Ovšem nutnou podmínkou pro zisk samotného lajku pod postem je jeho zobrazení uživateli. Nejčastějším místem, kde se s posty setká, aniž by je musel sám aktivně vyhledávat, je tzv. news feed. Ten je Facebookem definován jako:
"the constantly updating list of stories in the middle of your home page. News Feed includes status updates, photos, videos, links, app activity and likes from people, Pages and groups that you follow on Facebook." (zdroj).
Samotný news feed ovšem neobsahuje všechny posty od přátel, stránek apod., nýbrž jejich výběr. Facebook o něm mluví takto:
"The stories that show in your News Feed are influenced by your connections and activity on Facebook. This helps you to see more stories that interest you from friends you interact with the most. The number of comments and likes a post receives and what kind of story it is (ex: photo, video, status update) can also make it more likely to appear in your News Feed." (zdroj)
Postup, který Facebook užívá pro začlenění Stories (jak říká v tomto kontextu postům) není obecně znám, je předmětem obchodního tajemství Facebooku, a navíc se neustále vyvíjí. Obsah, který tak Facebook svým uživatelům nabízí je sestaven co nejvíce na míru a přizpůsoben zájmům každého uživatele.
Facebookem zmiňovaný důraz na propojení mezi uživateli, které ovlivňuje jaký obsah se nám v news feedu bude zobrazovat, zásadně souvisí s principem nazývaným jako homofilie. Ten lze jednoduše popsat jako fakt, že za přátele máme především lidi s nimiž sdílíme určité vlastnosti a hodnoty. Tento princip dominuje jak sítím ve skutečném životě (McPherson M, Smith-Lovin L, Cook JM (2001), tak v sociálních sítích, jak ostatně potvrzuje řada výzkumů. Ať již jde o homofilii v oblasti věku či národnosti (Ugander 2011), homofilii rasovou (Wimmer, A., Lewis K. (2010) či další (Bakshy et al . 2015).
To, že je obsah formován sítí přátel daného uživatele potvrzuje i studie zaměstnanců Facebooku ve spolupráci s Michiganskou univerzitou publikovaná v časopise Science pod názvem Exposure to ideologically diverse news and opinion on Facebook. Ve studii se věnovali dopadu algoritmu tvořícího news feed na uživatele Facebooku. Výzkum potvrdil, že platí předpoklad názorové homofilie. Tedy, že uživatelé, kteří se sami viděli jako liberálové, měli mezi svými přáteli signifikantně více liberálů a naopak konzervativci více konzervativců. Výzkum také potvrdil, že liberálové byli více vystaveni liberálnímu obsahu a konzervativci konzervativnímu. Dále pak ukázal, že míra prokliku u postů, které přinášely opačný pohled na daný problém byl nižší. Jinými slovy, hlavní roli podle výzkumníků nehrál algoritmus, ale skutečné sociální sítě lidí. Ti nejsou ochotni kliknout na obsah přinášející opačný pohled na problém.
Zdá se tedy, že interakce pod posty jsou výrazem zájmu uživatele, který vede k tomu, že se mu Facebook snaží nabízet obsah, u něhož lze předpokládat uživatelovo zapojení. Lajky pod posty i lajky stránek samotných vyjadřují určitý postoj a zároveň jsou něčím motivované.
Josef Šlerka
Literatura
Bakshy, E.,Messing S., Adamic. L. (2015) Exposure to ideologically diverse news and opinion on Facebook. Science 05 Jun 2015: Vol. 348, Issue 6239, pp. 1130-1132
Bunker, M., Rajendran, K.N., and Corbin, S. (2013).The antecedents of satisfaction for facebook “likes” and their effect on word of mouth. Marketing Management Journal, 23(2), 21-34.
Chin, C., Lu, H., & Wu, C. (2015). Facebook users' motivation for clicking the "Like" button. Social Behavior and Personality: An international journal, 43, 579-592.
Lipsman, A. , Mudd, G., Rich, M. and Bruich , S. (2012).The power of “Like” how brands reach (and influence ) fans through social media marketing, Journal of Advertising Research, 52(1),40-52h
McPherson M, Smith-Lovin L, Cook JM (2001) Birds of a feather: homophily in social networks. Annual Review of Sociology 27: 415-444.
Meloun, M., Militký, J.: Přednosti analýzy shluku ve vícerozměrné statistické analýze https://meloun.upce.cz/docs/publication/152.pdf
Pelletier, M. and Horky, A. ()2013). The Anatomy of a Facebook Like: An Exploratory Study of Antecedents and Outcomes. A nnals of the Society for Marketing Advances 25: 207208. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.453.6863&rep=rep1&type=pdf
Ugander, J., Karrer. B., Backstrom, L., Marlow, C. (2011). The Anatomy of the Facebook Social Graph. arXiv:1111.4503
Wallace, E., Buil, I., de Chernatony, L., and Hogan, M. (2014). Who “ likes" You... and why? A Typology of Facebook Fans from “Fan” –atics and Self Expressives to Utilitarians and Authentics”, Journal of Advertising Research, 54(1), Jun 2014, 92- 109
Wimmer, A., Lewis K. (2010). Beyond and Below Racial Homophily: ERG Models of a Friendship Network Documented on Facebook.American Journal of Sociology Vol. 116, No. 2 (September 2010), pp. 583-642
1 note
·
View note
Text
Kolik falešných uživatelů sleduje Andreje Babiše na Twitteru? #sorryjako
V minulých dnech se objevila řada spekulací o pravosti či nepravosti followerů (omluva za anglicismus, ale české ekvivalenty mi nejdou přes prsty) českého ministra financí Andreje Babiše. Argumentem je podivná skladba účtů, které Andreje Babiše sledují. Prý vypadají podezřele. Málo nebo žádní followerové, žádné utweetnutí, poměrně nedávná registrace účtu a podobně. Dokladem má být i výstup ze služby Twitter Audit (UPDATE 2: 17.5. 2017 cca 9:30 - služba Twitter Audit nemá nic společného s firmou Twitter, jen parazituje na jejím názvu, pracuje tedy jen s veřejně dostupnými daty. Tolik pro upřesnění.), který přisoudil Babišovi plných 56% falešných účtů. Služba Twitter Audit sama píše, že využívá pro svoje výpočty údaje o počtu tweetů, datumu posledního tweetu a poměru followers a friends. Nakolik se v datech z Twitteru pohybuju, považuji všechny tyhle údaje za více než pochybné, pokusím se vysvětlit proč a vysvětlení podepřít i nějakými čísly.
Základní úvaha
Při práci s daty z Twitteru nastává celá řada problémů, z nichž je relativně malý počet dotazů do API Twitteru tím nejmenším. Zásadní problém je totiž způsob, jak vytvořit něco jako relevantní vzorek uživatelů Twitteru, na kterém by bylo možné něco zkoumat, protože neexistuje nic jako seznam všech Twitter uživatelů. Můžete začít nějakým velkým účtem, rozbalovat postupně jeho graf a podívat se na to, koho sledují lidé, kteří sledují daný účet. Nicméně, tím předpokládáte, že Twitter je spojitý graf, což je předpoklad více než troufalý. Další problém je aktivita uživatelů, či distribuce počtu followerů, která je značně nerovnoměrná. Podle některých starších výzkumů se zdá, že 44 procent registrovaných účtů nebylo nikdy použito a přibližně 40 procent účtů nemá žádné followery. (MCGLAUN, Shane. Metrics suggest 44% of Twitter uses never tweet. In: Slash Gear [online]. 2014 [cit. 2017-05-15]. Dostupné z: https://www.slashgear.com/metrics-suggest-44-of-twitter-uses-never-tweet-14325098/)
Jinými slovy, na Twitteru je jistě řada hodně aktivních uživatelů, ale pak je tu také spousta těch, co si někdy vytvořili účet ze zvědavosti, pro přístup k nějaké službě atp. To je také důvod, proč Twitter reportuje jaký je počet měsíčně aktivních uživatelů, nikoli počet zřízených účtů. Pak jsou ovšem tzv. bots, tedy účty zřízené stroji a stroji manipulované. Výzkumníci z University of Southern California a Indiana University odhadují že jich je 9% až 15% (Dostupné z: https://arxiv.org/pdf/1703.03107.pdf), nicméně, jejich strojová detekce není zdaleka tak jednoduchá. Jak třeba naložit s účty, které automaticky posílají na Twitter vaše nově publikovaná videa na YouTube? Twitter se snaží s boty dlouhodobě bojovat a zabíjet je, takže životnost některých účtu je velmi malá.
Navíc je tu ještě jeden problém. Na Twitteru spolehlivě funguje tzv. Matoušův efekt. Čím větší je účet na Twitteru, tím větší má šanci, že dostane víc nových followerů a to jak od botů, které se snaží prostě přemísťovat po grafu podle spojnic a ty vedou k větším účtům častěji než k menším, tak protože jsou větší účty častěji nabízeny k následování. Zde nastává další problém. Twitter vrací seznamy followerů od nejnovějších po nejstarší. V praxi tak máte mnohem větší šanci mezi účty, které vidíte na seznamu followerů ve webovém rozhraní, vidět směsku divných účtů, než na jeho konci. To je důvod, proč nemá smysl zkoumat posledních X followerů účtu, ale vždy účet celý.
Pár čísel z domácího Twitteru
Vraťme se k nyní k twitterovému účtu Andreje Babiše. Protože jsem se problémem toho, kolik má český Twittter uživatelů a jak se chovají, zabýval už v minulosti, vyhrabal jsem jeden starší dataset ze zaří 2015, který obsahuje seznam a detaily k followerům těchto účtů: AlexandrMitrofa, AndrejBabis, cermak, CT24zive, cuketka, etabery, iDNEScz, jindrichsidlo, jirkakral, josefslerka, MaresLeos, O2_CZ, O2GuruCZ, RESPEKT_CZ, robertzaruba, Roman_Vanek, Terihodanova, tmobile_cze, veselovskyma, Vodafone_CZ, Vodafone_pece
Zmíněný dataset jsem stáhl přes public Twitter API pomocí knihovny twitteR a data jsou k dispozici pro další analýzy zde. Občas se v něm objeví nějaké nečistoty (například -1 friends u některých účtů), ale ty jsem pro další analýzu vyčistil.
Před pár dny jsem si stáhl aktuální seznam followerů Andreje Babiše. Tentokrát jsem ale použil knihovnu rtweet. Výsledný seznam je ke stažení zde. V knihovně rtweet se nejdříve stahují ID uživatelů a pak k nim detaily. Twitter mi odmítl vrátit detaily k 22.776 účtům z celkového počtu 314.093 Babišových followerů, automaticky jsem s nimi tedy pracoval jako podezřelými (víc dále).
Pokud se podívám na dataset ze září 2015, najdeme v něm údaje o celkem 391.379 unikátních twitterových účtech. Median počtu followerů lidí, kteří followují naše účty jsou 2 followeři a průměr 377.
To potvrzuje, že počty followerů na Twitteru jsou velmi nerovnoměrně distribuované. Přesněji, v našem vzorku má 75% účtu 8 nebo méně followerů. A 99% účtů z našeho datasetu má 724 nebo méně followerů.
Byť nemáme v našem datasetu všechny české účty a nemůžeme ho považovat za skutečně reprezentativní vzorek. Věříme-li ale zákonu velkých čísel, víme, že platí, čím více má účet followerů, tím více se počet jejich followerů bude blížit průměru v datasetu. Podívejme se tedy na jednotlivé účty:
Stejně to dopadne i když se podíváme na to, jak je to s počty friends v celém datasetu září 2015 a u jednotlivých účtů.
No a výsledky pro jednotlivé účty opět odpovídají.
V sloupci s mediany vidíme, že se s velikosti účtu začínají chovat stejně. Oproti tomu průměr, který je extrémně závislý na okrajových hodnotách, tu lítá jako hadr na holi, zvláště u menších účtů.
Čím více má účet followers, tím více bude pravděpodobně jejich struktura podobná průměrné populaci českého Twitteru (byť přísně vzato nejde o náhodný vzorek), naopak čím méně má followerů, tím větší je šance, že se od ní bude (třeba i radikálně) lišit.
Pojďme s teď podívat na počty účtů, které jsou odlišné od běžného očekávání, nemají třeba žádného followera, nikdy nepublikovaly žádný status, nemají popisku a podobně. Tedy vhodné adepty na klasifikaci jako podezřelý účet. V našem datasetu ze zaří 2015 vypadají následovně:
Vzájemně jsou spolu velmi silně korelovány (s vyjímkou počtu followerů, kteří následují jen jednoho uživatele, a i ty jsou korelovány docela slušně, navíc dosahuji jen velmi malého počtu). V praxi je tak prakticky jedno, jakou hodnotu či kombinaci hodnot si pro další počty zvolíme.
UPDATE 1 [15.5. 2017 cca 17:10] Michal Illich na Twitteru a nezávisle na něm Aleš Antonín Kuběna na Facebooku mne upozornili (viz ostatně i diskuse pod blogem), že bych neměl korelovat absolutní čísla. Přídávám proto korelaci poměrů mezi parametrem a počtem followerů. Z ní je vidět, že parameter OneFriend je zcela nezávislý a oslabila se síla korelace ZeroListed.
KONEC UPDATE
Já jsem se zaměřil jen na jednu hodnotu a to počet účtů s nulovým počtem followerů v poměru k celkovému počtu followerů. Pokud si je vyneseme na graf uvidíme tohle:
Protože vím, že je rozdíl mezi jednotlivými účty v řádech, budeme obě osy logaritmovat a provedeme regresi.
Výsledek je nepřekvapivý a poměrně funkční:
Co nás ale zajímá teď je otázka, jak dopadne v tomto modelu účet Andreje Babiše v roce 2017. Přidejme tedy účet @andrejbabis z roku 2017 k našemu datasetu a nevrácených 22.776 přičtěme k těm účtům, které jsou brány jako účty s nula followery. Výsledek je následující:
Zdá se, že účet Andreje Babiše je svými followers přesně tam, kde má být.
Kolik má Babiš falešných následovníku?
Je možné, že jich má plno nicméně to nejde zjistit tak jednoduše, jak to vypadalo na první pohled. Z pohledu prezentovaných kritérií nevypadá účet @andrejbabis jako nějak zvlášt jiný, než ostatní zkoumané účty. K tomu, abychom mohli říct, že má účet Andreje Babiš nápadně moc falešných followerů, bychom museli provést mnohem hlubší analýzu, včetně analýzy sítě followerů, to je však výrazně naročnější.
Josef Šlerka
P.S. Děkuji všem, kteří mi dávali zpětnou vazbu na předchozí verze textu. Zejména pak Petr Koubskému, který mne donutil to celé přepsat.
1 note
·
View note
Text
Střípek: České politické strany na Facebooku
Myslím si, že jednoduše odhadovat jak dopadnou volby podle toho, jak se daří politickým stranám na Facebooku je poměrně odvážené a pro volby do krajů do platí dvojnásob. Důvodů je celá řada: volební systém, rozložení populace českého Facebooku ale také například druh voličů, který chodí k těmto volbám. Podle Facebook Audience Insights je z Prahy skoro 30 procent uživatelů Facebooku, což nekopíruje geografické rozložení v zemi ani náhodou. Ještě horší je to s věkem, kdy aktivních uživatelů po padesátce je minimum oproti jejich podílu ve společnosti apod. Viz kupříkladu výzkumy týmu Jakuba Macka (https://www.researchgate.net/publication/280154937_Stara_a_nova_media_participace_a_ceska_spolecnost_vyzkumna_zprava) z nichž je i tento obrázek:

Všechno tohle je třeba zohlednit při práci s daty... Na druhou stranu jsou krajské volby vynikající záminkou se podívat, jak se daří politickým stranám na Facebooku. Já jsem si vybral facebookové stránky těch stran, které mají dle výzkumů největší šanci se do PSP znovu dostat tedy: ČSSD, ANO, KSČM, TOP09, ODS a KDU-ČSL. Stáhl jsem z jejich stránek všechny veřejné posty a seznam ID uživatelů, kteří na stránkách něco olajkovali (bez ohledu, jestli se tomu říká like, sad či jinak.) Výsledek můžete posoudit sami, opět v interaktivní aplikaci:
https://slerka.shinyapps.io/kumulativniProhlizec/
Co mne zaujalo?
TOP 09 si v našem datasetu vede zdaleka nejlépe. Svůj vrchol měla v časech Čapího hnízda a návštěvy čínského prezidenta. Nicméně měsíc před krajskými volbami začala znovu velmi silně posilovat a myslím, že má slušnou šanci využít dobře svůj volební potenciál zejména ve větších městech.

Hnutí ANO na Facebooku začalo ztrácet po týdnu s Čapím hnízdem unikátně zapojené. Neztrácí ale nic na volebních preferencích. Což by mohlo naznačovat, že se jí proměňuje volební elektorát směrem k elektorátu, který je méně zastoupen na Facebooku. Případně to může znamenat menší angažovanost jeho voličů a fanoušků.
ODS se zlepšuje postupně a dlouhodobě. Co mne překvapilo, je využití banálního marketingového triku a la "Souhlasíš, dej lajk," který ji vynesl zdaleka nejvíc lajků u postu s předvolebním výzkumem SANEPu.
ČSSD není na Facebooku úplně silná v kramflecích, avšak od začátku srpna se začala víc snažit, byť k první trojce má pořád hodně daleko. Určitou perličkou ovšem je, že její nejúspěšnější post byl spíš naladěn proti-muslimsky. Za výrok: "My tady nemáme žádnou silnou muslimskou komunitu. Popravdě řečeno si ani nepřejeme, aby se tady nějaká silná muslimská komunita vytvořila," si Bohuslav Sobotka odnesl přes tisíc lajků.
KSČM není na Facebooku nijak silná, nicméně i ona zabodovala svým antiněmeckým vystoupením ve věci migrace a také posty o Kateřině Konečné. V poměru k ostatním jsou však i její výsledky žalostné.
A jak že tedy dopadnou nadcházející volby? Nevím, ale v každém případě běžte volit.
Josef Šlerka
1 note
·
View note
Text
Upadá zájem o české zpravodajské servery?
Před několika týdny jsem u sebe na Facebooku umístil screenshoty měsíční návštěvnosti zpravodajských sekcí českých serverů podle měření Netmonitoru. Obzvlášť výsledky Parlamentních listů, které se umístily v první desítce, vyvolaly řadu otázek na téma, jak je to návštěvností zpravodajství v čase.
První výsledkem je jednoduchá aplikace v Rku:
https://slerka.shinyapps.io/netmonitor/
v které si můžete prohlédnout pageviews a RU dle platforem, jak jsou měřeny v NetMonitoru za posledních 15 měsíců v sekci Zpravodajství.
V přehledu jsou pouze ty stránky, které byly měřeny po celou dobu 15 měsíců a nejsou u nich dlouhodobé výpadky způsobené např. výpadkem měřením. Zvolil jsem jako základní metriku pageviews (tedy počty navštívených stránek v kategorii), protože v sobě zahrnuje celkové zobrazení bez ohledu na zařízení. Krom toho naznačuje celkový zájem. Počet pageviews není snadno převeditelný na reálné uživatele. Na druhou stranu ale není možné spárovat v měření reálné uživatele (RU) z různých zařízení, proto jsem do aplikace přidal i možnost zobrazit data data za RU přes jednotlivé platformy.
Protože denní statistiky vypadají spíš jako chaotická pila než něco ke čtení, je k dispozici primárně graf se sedmidenním pohyblivým průměrem.

Co mne při první prohlížení data zaujalo:
celkový počet měřených shlédnutých stránek od začátku roku klesá
u top pěti hráčů je nejméně postiženým server iDnes, ostatním výrazně počet pageviwes poklesl
zdá se, že mediálně nejvděčnějšími byly v daném období teroristické útoky v Paříži a Bruselu
pro mne osobně je velmi zajímavý rychlý a výrazný pád Britských listů a postavení Parlamentní listů, kterým se sice výrazně lépe než před rokem, ale víceméně od jara jejich pageviews spíše stagnují až klesají
pokud se podíváme na propad z pohledu RU PC, kteří tvoří největší skupinu, tak vidíme, že se jedná především o zásadní pokles na jaře roku 2016
Jaké jsou možné příčiny těchto propadů? Může jich být několik a to například:
vliv nativních aplikací pro mobilní zařízení, které mohou, ale nemusí být měřeny v Netmonitoru. Proti tomu ovšem mluví
fakt, že je pokles viditelný i u stránek, které žádnou aplikaci nemají
stoupající podíl agregátorů zpráv, které de facto parazitují na stávající zpravodajských serverech
špatně nasazené měřící kódy či špatné zařazení kategorie
pokles zájmu čtenářů o zpravodajství jako takové
přesuny čtenářů k serverům, které nejsou v Netmonitoru měřeny
Můj osobní favorit je mix těchto příčin s velkým podílem poklesu celkového zájmu o zpravodajské servery. Tipnul bych si, že lidé více rozprostřeli svůj zájem mezi vícero serverů a že také budou více se zprávami přicházet do styku třeba na Facebooku, aniž by prokliknuli na samotné linky. Zkusíme se nato podívat v některém z dalších blogpostů.
Josef Šlerka
UPDATE: V diskusi u mne na Facebooku se objevil ještě požadavek číselného srovnání dvou období. Pokud počítáme součet pageviews za červen až srpen 2015 oproti stejnému obodobí 2016, tak dostaneme tato čísla:
471 184 736červen 2015 455 390 934červen 2016 484 284 753červenec 2015 456 893 785červenec 2016 466 951 440srpen 2015 443 369 834srpen 2016
Meziroční pokles kolem 5%. Navíc v roce 2016 jsou navíc započítány zpravodajské části serverů: zet.cz, svobodneforum.cz, tiscali.cz ,ac24.cz, globe24.cz.
0 notes
Text
Facebook podle Klubu českého pohraničí aneb rudý květ v modré dálce
Pokud jde o Facebook, stále častěji se mi vybavuje Švejk a jeho návštěva blázince kde se dozvídáme, že uvnitř světa existuje ještě jeden, mnohem větší. Nějak podobně to na Facebooku funguje. Jelikož je každý z nás do určité míry uzavřen ve své sociální bublině, býváme možná občas překvapeni, jaké stránky a skupiny lze potkat, když se vydáme na výpravu “k těm druhým.” Já jsem jednu takovou výpravu podnikl na podnět mluvčího českého prezidenta. Jiří Ovčáček v jednom svém tweetu zmínil Klub českého pohraničí: (kontext je podle mne jazykově trochu zmatený, podotýkám jen, že se jednalo o jeho komentář k návštěvě ministra kultury na jedné sudetské akci.)
3/3 Pokud jde o neškodný krajanský spolek, není nutné, aby byl navštíven českým ministrem. Partnerem je Klub českého pohraničí.
— Jiří Ovčáček (@PREZIDENTmluvci) May 18, 2016
Protože jsem o tomhle spolku již dlouho neslyšel, podíval jsem se na to, zda má na Facebooku stránky. A skutečně má. Najdete ho zde: https://www.facebook.com/klub.ceskeho.pohranici
Jako cover foto má skupinu lidí vzdávající čest u nějakého pomníku. Fotka je zřejmě z roku 2012 a na internetu je k nalezení mj. u článku Jana Jandourka “Za smrt komunistických pohraničníků mohou především sami šéfové KSČ”. Samotná stránka má lehce přes 800 fanoušků, což není nijak závratné, ale ani nijak špatné.

Oblíbené stránky stránky
Podívejme se nyní, jaké stránky má samotná stránka ráda a jaké stránky mají rády tyto stránky (mimochodem sami si můžete udělat podobnou anlýzu přes https://apps.facebook.com/netvizz/ a data vizualizovat v Gephi). Výsledek je zde:

Barvy v naší síti jsou určeny strojem a ukazují které body mají k sobě blíže než k jiným. Velikost bodů reprezentuje počet vazeb, které směřují ke stránce. Malá síť s dominatním Komunistickým svazem mládeže a Komunistickou stránou Čech a Moravy ukazuje docela pěkný shluk kolem současných komunistů. Jak mne upozornil Tomáš Koloc na Facebooku, některé instituce spolu sídlí (či sídlily) na stejné adrese. Namátkou KSČM, Klub českého pohraničí a Slovanský výbor České republiky.
Oblíbené facebookové stránek uživatelů
Pojďme se podívat dál. Jakých stránek jsou fanoušky lidé, kteří lajkují na stránce Klub českého pohraniční? Obligátní dotaz na Graph Search Facebooku nedal úplně uspokojivé výsledky viz screenshot:

Nezbylo tak, než projít profily těch, co aktivně lajkují na stránce Klub českého pohraničí. Na stránce jsem za odbobí leden 2015 až konec dubna 2016 našel 192 uživatelů Facebooku, kteří zde něco olajkovali. Z nich jsem prozkoumal profily 136 uživatelů, kteří mají veřejně dostupný seznam olajkovaných stránek. Celkem měli v oblíbnených 19176 stránek, což je v průměru 141 stránek na jednoho. Z těchto stránek jsem vybral jen ty, které se v datasetu objevily 19x a více (víme jistě, že alespoň 10% aktivních fanoušků je má jako oblíbené).
Zbylo 97 stránek, které jsem seřadil podle míry afinity k zkoumané stránce (princip afinity najdete popsaný v tomto blogpostu). Jejich předhled je nadmíru zajímavý, byť v zásadě jen rozšřuje očekávané pole.
11.brigáda Pohraniční Stráže, zväzok SNP - Všem kteří nezapoměli že sloužili na státní hranici .Velitelům , spolubojovníkům ,přátelům . Tiše a pevně stojí Děvín nad soutokem Moravy ... (affinita 566x) 12.BRIGÁDA POHRANIČNÍ STRÁŽE - Všem, kteří hrdě stálí hranici. Velitelům, spolubojovníkům, přátelům. V tom kraji Přimda hlavu hrdě zvedá a Dyleň mraky rozráží. V tom kraj... (affinita 592x) 15. brigáda PS České Budějovice - Vše o 15. brigádě PS České Budějovice... (affinita 660x) 9.brigáda Pohraničnej Stráže Domažlice - STRÁNKA JE URČENÁ VŠETKÝM ĽUĎOM,KTORÍ MAJU ZAUJEM O PROBLEMATIKE OCHRANY ŠTÁTNEJ HRANICE,SLUŽILI NA 9.BRIGÁDE PS DOMAŽLICE... (affinita 650x) Antimajdan - Antimajdan Česká republika! Ukrajinské manýry tady nechceme!!! ... (affinita 89x) Bratři Mašínové jsou Vrazi - V dokumentu Svědomí hrdinů autor ukazuje odvrácenou tvář odbojové činnosti bratří Mašínů a jejich společníků, která dodnes názorově polarizu... (affinita 149x) BUDU Volit KSČM - Tato stránka je pro všechny stejně smýšlející lidi.... (affinita 205x) Červená karta pro Českou televizi - Jsme hrubě nespokojeni s Českou televizí, a proto ji dáváme červenou kartu.... (affinita 107x) Československá Socialistická Republika- ČSSR 1960-1990. - JEDNÁ SE O NOSTALGII PO NAŠEM SPOLEČNÉM STÁTĚ FEDERATIVNÍM ČECHŮ A SLOVÁKŮ.... (affinita 114x) Chceme aby ČR vystoupila z EU a připojila se k Ruské federaci - EU je kapitalistické společenství zotročující obyčejné lidi. Jedině Ruská federace je zárukou míru, prosperity a stability.... (affinita 119x) Chci poděkovat Miloši Zemanovi, že nazval věci pravými jmény - Největší nepřítel státu již nejsou komunisté nebo nacisté, ale pražská kavárna plná zakřiknutých levicových neomarxistů, co nosí kostěné brý... (affinita 47x) Sputnik Česká Republika - Sledujte nás na Twitteru https://twitter.com/sputnik_cz... (affinita 27x) We Are Here At Home .com - JESTLI MILUJEŠ SVOU ZEM ,, KLIKNI A PODPOŘ SEBE A SVŮJ NÁROD,, ČESKÁ REPUBLIKA ZŮSTANE NAŠE A PO NAŠEM. A TO HEZKY ČESKY!... (affinita 8x) Karel Gott - OFICIÁLNÍ FACEBOOK KARLA GOTTA... (affinita 2x) halonoviny.cz - Zpravodajský portál Halonoviny.cz přináší aktuální domácí zprávy i ze světa. Je internetovou verzí tištěného deníku Haló noviny.... (affinita 910x) Hej, občané z.s., za silnou a suverénní ČR - Už neváhej a přidej se, dá se toho spousta změnit. Každý sám za sebe, za společným cílem Přihlaš se na: https://www.facebook.com/groups/he... (affinita 68x) Svoboda a přímá demokracie Tomio Okamura - SPD - Oficiální Facebook hnutí Svoboda a přímá demokracie. Jsme opoziční sněmovní politickou sílou vedenou Tomiem Okamurou. ... (affinita 17x) Jiřina Švorcová - Herečka Jiřina Švorcová... (affinita 418x) JUDr PhDr Zdeněk Ondráček, Ph.D. - Poslanec KSČM... (affinita 381x) Kašleme na Vás, Miloš Zeman je nejlepší prezident - V reakci na události 17. 11. 2014 a červené kartičky vznikla tato skupina. Proto kašleme na odpůrce. Díky nim se národ postavil na svou st... (affinita 61x) Klub vojenské historie Brigáda Pohraniční Stráže HRANIČÁŘ - Jsme klubem vojenské historie Pohraniční stráže.Ve své činnosti se zabýváme historií, výcvikem Pohraniční stráže a OSH.... (affinita 499x) Klub českého pohraničí - KČP - Jen zůstane-li naše pohraničí české, zůstane českou i celá naše vlast!... (affinita 1771x) Ing. Jaromír Kohlíček, CSc. - VÍTEJTE NA MÝCH FACEBOOKOVÁCH STRÁNKÁCH! Budu rád za vaše připomínky,náměty,rád se s vámi setkám na akcích a besedách.Stačí mne zde kontakto... (affinita 807x) KSČM - Komunistická strana Čech a Moravy - Oficiální Facebook stránka KSČM. Naším cílem je socialismus, demokratická společnost svobodných, rovnoprávných občanů.... (affinita 173x) Konec Kalouska v Česku - Nemám rád Kalouska,Vondru,kmotry ODSouzených a Stop 09 a další pány,kteří si myslí,že mohou beztrestně krást peníze,které mají spravovat!!!A... (affinita 45x) Kateřina Konečná - Jsem europoslankyně za KSČM - díky Vám, pro Vás a s Vámi.... (affinita 182x) Pavel Kováčik - Oficiální stránka poslance Parlamentu ČR za Kraj Vysočina a předsedy poslaneckého klubu KSČM... (affinita 314x) Komunistická strana Československa (KSČ) - Komunistická strana Československa (KSČ)... (affinita 542x) KSČM - Komunistická strana Čech a Moravy Aktuální politické, ekonomické a další informace z tisku a internetu... (affinita 744x) KSČM Bruntál - Pro levicově smýšlející lidi... (affinita 887x) KSČM Klášterec nad Ohří - Oficiální profil místní organizace KSČM... (affinita 943x) KSČM Krušné hory - Stránka o činnosti základních organizací KSČM Kovářská, Vejprty a Výsluní... (affinita 744x) KSČM Radonicko - Stránka Základní Organizace KSČM Radonice, okres Chomutov.... (affinita 857x) KSČM - S lidmi pro lidi v Kroměříži - KSČM Kroměříž je tu pro Vás, obyčejné občany, aby hájila Vaše zájmy dle svého hesla S lidmi pro lidi!... (affinita 663x) KSČM - Slezská Ostrava - Vítejte na oficiálním profilu KSČM Slezska Ostrava http://www.kscmslezskaostrava.cz/... (affinita 902x) Komunistická strana Čech a Moravy (KSČM) - Programovým cílem KSČM je socialismus, demokratická společnost svobodných, rovnoprávných občanů, společnost politicky a hospodářsky pluralit... (affinita 223x) ZO KSČM Horní Suchá - Předseda: Jan Charvát Kontakt: [email protected] Místopředsedové: Januš Adamus Josef Konopka... (affinita 735x) Ksčm Plzeňského Kraje - KSČM Plzeňského kraje... (affinita 884x) OV KSČM Rokycany - Stránky Okresního výboru Komunistické strany Čech a Moravy v Rokycanech... (affinita 994x) KSČM Vyškov - Oficiální stránky OV KSČM Vyškov.... (affinita 1111x) KSČM BRNO - Stránky pro příznivce brněnské KSČM - jediné protisystémové parlamentní strany.... (affinita 1072x) KSČM Frenštát p/R. - Vítejte na stránkach KSČM Frenštát pod Radhoštěm.... (affinita 1142x) Jihomoravská KSČM - S lidmi pro lidi! I na jižní Moravě!... (affinita 414x) KSČM Ostrava-Jih - Stránka Obvodní koordinační rady KSČM Ostrava 3 , Ostrava - Jih Mapy.cz: https://mapy.cz/s/EYvW... (affinita 1087x) KSČM Praha - Krajský výbor Komunistické strany Čech a Moravy Praha... (affinita 738x) KSČM Praha 3 - Obvodní výbor KSČM Praha 3 http://www.praha3.kscm.cz... (affinita 801x) KSČM - Praha 8 - OV KSČM Praha 8 se podílí na předvolební kampani s. Jiřího Dolejše, který za Prahu 8, Čakovice a Letňany kandiduje do Senátu Parlametu ČR ... (affinita 622x) Komunistický svaz mládeže (KSM) - Mladí komunisté: Za důstojný život místo živoření - za socialismus! http://www.ksm.cz... (affinita 235x) Společnost česko-kubánského přátelství - Cílem Společnosti česko-kubánského přátelství je rozvíjet přátelství a solidaritu s kubánským lidem.... (affinita 689x) Ludvík Svoboda-přátelé - www.ludviksvoboda.cz... (affinita 171x) Marta Semelová - Facebooková stránka voličů a podporovatelů Marty Semelové... (affinita 1014x) Mašínové jsou loupežní vrazi. - ... (affinita 177x) MěV KSČM Brno - Stránka MěV KSČM Brno... (affinita 995x) Miloš Zeman - můj prezident - Neoficiální soukromá stránka fanoušků. oficiální stránky jsou zde: www.zemanmilos.cz www.facebook.com/prezidentcr www.hrad.cz... (affinita 33x) Milujeme Rusko - Milujeme Rusko (2) Stránka byla založena 30.3.2015 z důvodu útoku Hackera na naši původní Milujeme Rusko... (affinita 13x) Mladí komunisté Středočeský kraj - Krajská organizace Mladých komunistů ve Středočeském kraji je součástí celostátní organizace Komise mládeže ÚV KSČM. Naším cílem je mladým l... (affinita 733x) Moje země Moje pravidla - Informativní, diskusní stránka, upozorňující na probíhající islamizaci Evropy. Tvá je Evropa! I ty nes hrdě odkaz svých předků! ... (affinita 12x) Muzeum Pohraniční stráže - Muzeum POHRANIČNÍ STRÁŽE umožní po svém otevření poznat život jejich příslušníků na základě osobních zkušeností. Umožní pomocí projektu ŽIVÁ... (affinita 596x) nametests.com český - ... (affinita 2x) Národní domobrana - Národní domobrana je nezávislou, veřejně apolitickou a nadstranickou iniciativou občanů, kteří hodlají bránit svoji domovinu.... (affinita 43x) Návrh na zákaz krajněpravicové TOP 09 a zločinecké ODS - Motto: starej Kalous s novým potěrem aneb starej hampejz s novým nátěrem ... (affinita 105x) Ne majetek církvím! - Je nerozum dávat církvím majetek, když nejsou schopny spravovat ani ten, který teď mají. Jsou stovky polorozpadlých far, o které se nikdo ne... (affinita 51x) Nebudeme volit TOP 09 a ODS - Nebudeme volit TOP 09 a ODS... (affinita 63x) Nechceme u nas cizi vojska. - ... (affinita 251x) Nechceme Schwarzenberga - Schwarzenberga považujeme za škůdce našim národním zájmům a odmítáme jakékoli jeho veřejné působení v ČR.... (affinita 46x) Nechci, aby Miroslav Kalousek vládl České republice. - ... (affinita 69x) Nestydím se za svého prezidenta - Nestydíš se za svého prezidenta? Tak dej like :) Miloš Zeman... (affinita 50x) Nestydím se za svého prezidenta - Miloš Zeman byl zvolen prezidentem ČR ve svobodných demokratických volbách a my věříme, že bude jednat v zájmu všech občanů, jak na domácí p... (affinita 86x) NEVOLÍM stranu TOP 09 !!! - Skupina pro všechny, kteří odmítají volit stranu TOP 09 s Kalouskem a Karlem Schwarzenbergem!... (affinita 73x) Jsme pro spojení České republiky a Slovenska - Pokud někdo může chtít, aby se Slovensko připojilo k Maďarsku, je to úplný blázen. My ale myslíme racionálně a chceme dát opět dohromady dva... (affinita 130x) Obecné pravdy - Stránka se vám líbí? I když toho moc neumíte, můžete s námi spolupracovat! Ozvěte se! ... (affinita 4x) Ostravští veteráni Pohraniční stráže. - Setkání Ostravských veteránů Pohraniční stráže... (affinita 989x) ParlamentníListy.cz - www.ParlamentniListy.cz - aktuality nejen z české politiky. Registrovaní uživatelé mohou o politicích nejen číst, ale přímo s nimi komunikov... (affinita 13x) PhDr. Miloslav Ransdorf, CSc. - 3. místopředseda Výboru pro průmysl, výzkum a energetiku - ITRE.... (affinita 66x) Pohraniční Stráž ČSSR - Tato stránka je pro všechny, kteří byli u PS a pro jejich příznivce...... (affinita 210x) Pomník dvou mladých sovětských letců u Velké Polomi - Pomník sovětských letců - pilot podporučík Ivan Pavlovič Kiotov a střelec Nikolaj Alexandrovič Komlov ... (affinita 944x) Miloš Zeman - prezident České republiky - Oficiální stránka Miloše Zemana - prezidenta České republiky www.zemanmilos.cz, @MZemanOficialni... (affinita 10x) Vladimír Remek - Facebooková stránka podporovatelů Vladimíra Remka... (affinita 356x) Skála Josef - Stránka fans PhDr. Josefa Skály, CSc. , historika, publicisty a úplně normálního člověka. S bohatými životními zkušenostmi a lidskostí... (affinita 1339x) Miroslav Sládek - Oficiální stránka PhDr. Miroslava Sládka... (affinita 30x) Svaz mladých komunistů Československa - Oficiální stránka Svazu mladých komunistů Československa na webu www.facebook.com... (affinita 478x) Společnost Julia Fučíka - Společnost Julia Fučíka... (affinita 1245x) Stanislav Grospič - Facebooková stránka voličů a podporovatelů Stanislava Grospiče... (affinita 1399x) Stojíme za Milošem Zemanem - Podporujeme prezidenta Miloše Zemana a stojíme za ním. Žvásty pravdoláskařů a útoky médií jsou sprosté. Ať se konečně smíří, že kníže volby ... (affinita 70x) Imigranty v ČR nechceme - Účelem této stránky je sjednotit všechny slušné lidi a vlastence, kteří si uvědomují katastrofické následky probíhající arabsko-africké inva... (affinita 7x) Росси́я - Российская Федерация - Russia - It's for people who love and respect Russia,Russian people,nature culture , history. Thank you for your big support.... (affinita 0x) Tomio Okamura - SPD - Oficiální stránka Tomia Okamury a jeho příznivců www.tomio.cz https://twitter.com/tomio_cz https://www.facebook.com/hnutispd ... (affinita 3x) Vojska USA v Česku nechceme - ... (affinita 143x) Vojtěch Filip - Facebooková stránka voličů a podporovatelů Vojtěcha Filipa... (affinita 327x) Miloslava Vostrá - Oficiální stránka místopředsedkyně ÚV KSČM a poslankyně Parlamentu ČR za Středočeský kraj... (affinita 203x) Vraťte nám stát - Ukradli jste nám stát, vraťte ho zpátky!... (affinita 36x) Zachování Benešových dekretů - Zachování Benešových dekretů ... (affinita 187x) ZÁLOŽÁCI ČSLA za krásnější budoucnost - Sdružovat nejen vojáky bývalé ČSLA, ale všechny, kteří budou mít zájem ... (affinita 381x) Miloš Zeman - Neoficiální stránka českého prezidenta Miloše Zemana. Unofficial site of Czech president. http://milos.chytrak.cz... (affinita 26x) Miloš Zeman prezident ČR. - Dne 26.1.2013 se stal Miloš Zeman prezidentem České republiky! Jsem hrdý na svého prezidenta! Lajkujte,Sdílejte přátelům tuto stránku! Děk... (affinita 97x) OV KSČM Znojmo - KSČM je politická strana, která se hlásí k hodnotám a tradicím pokrokového levicového hnutí.... (affinita 1963x) ZO-mladých KSČM Prostějov - Základní organizace mladých komunistů při OV KSČM Prostějov. Předseda Zdeněk Gottwald... (affinita 929x)
Shluky stránek
Protože víme, jací uživatelé mají olajkované jaké stránky, můžeme najít i skupiny stránek, které jsou si podobnější podle lidí, kteří je mají jako oblíbené (viz postup z této studie. V našem případě byl jako threshold zvolena hodnota 0.7).

celkový pohled

nacionalistický blok

pohraničníci

základní organizace KSČM a satelity
komunistické jádro

"zemanovci"
Facebookové skupiny
Když už jsem se věnovali tomu, jaké stránky mají oblíbné aktivní fanoušci Klubu českého pohraničí, podíval jsem se také na to, v jakých skupinách na Facebooku tito lidé jsou. Vybral jsem opět ty, kde je alespoň 10% aktivních lajkujícícíh. Výsledek ukazuje následující výpis:
Chceme socialismus ! - Skupina lidí a občanů nespokojených se současnou politickou, ekonomickou a společenskou situací v ČR, občanů, kterým se lhalo v listopadu 19... Chceme pryč z NATO a EU - Rusko je náš opravdový přítel !!! - V současnosti stojíme na rozcestí. Máme na výběr, zda hájit společně s Ruskem morální a rodinné hodnoty našich otců a dědů, nebo se jako záp... Zeman musí v roce 2018 znovu kandidovat. - Žádáme členy skupiny, aby při vkládání svých příspěvků,- také i průvodních textů při vkládání článků se zdrželi vulgárních vyjádření, také v... Občané proti církevním restitucím - Tato skupina slouží jako necenzurované diskusní fórum pro všechny Čechy v republice ale i pro všechny Čechy, kteří jsou v zahraničí.Je pro ... Lidé společně proti kapitalismu - Jsme lidé co nesouhlasí se současným protilidovým systémem a jednoznačně chceme lepší spravedlivější systém.... Chceme jiné Česko... - Krize Západu, řízená migrace miliónu uprchlíků, arogance moci Bruselu a Berlína nás musí vést k obnově myšlenky po samostatném národním stát... Bratři Mašínové jsou vrazi, ne hrdinové - Bratři Ctirad Mašín a Josef Mašín byli, jsou a budou vrazi ne hrdinové.Tohle není levicová skupina, ale vyjadření odporu proti povyšování zl... S Kalouskem se nemluví... - Miroslav Kalousek je nejopudivějším politikem od roku 1989. Nese osobní odpovědnost za ekonomický a sociální propad minulých let. Je oním čl... CÍRKEVNÍ RESTITUCE A PRÁVO V NAŠÍ ZEMI - Nehážeme všechny herce do jednoho pytle. Tato skupina je zaměřena na protest těch umělců, kteří sepisují petici za schválení církevních rest... Lidé společně proti kapitalismu a za socialismus - Skupina má za cíl přiblížit skutečnost, že jediným účinným nástrojem proti kapitalismu je autentická levice, opírající se o vědecký světový ... OPRAVDOVÍ KOMUNISTÉ - V této skupině je vítán každý přiznivce marxismu - leninismu. Každý, kdo usiluje o opravdový socialismus a národní hospodářství. Každý, kdo ... Přátelé Ruska v České Republice :) - Dnes je hlavně zásadně důležité aby nebyla válka, proto je nutné pomoci geopolitickým mantinelům se prolnout, propojit a pochopit, nejprve a... VOLÍME KSČM - Facebook základna voličů Komunistické strany Čech a Moravy - Z PROGRAMU PRO BUDOUCNOST: Prosazování zákona o majetkových přiznáních pro všechny občany nad určitou výši hodnoty majetku. Prodloužení pro... Stop předsudkům proti komunistům - Tato skupina chce prostřednictvím diskusního fóra mezi členy strany, jejími příznivci, odpůrci ale i nepřáteli odstranit předsudky proti kom... Souhlasime s vyroky pana prezidenta Milose Zemana. - http://www.petice24.com/podporujeme_prezidenta_zemana ... Českoslovenští vojáci v záloze proti válce plánované velením NATO - 1951 Já, občan lidově demokratické republiky Československé, slavnostně přísahám, že budu čestným, statečným, ukázněným a bdělým vojákem, ... Marxistická Vlastenecká Levice - Vlastenectví neznamená ani izolacionismus, ani nacionalismus...vlastenectví znamená lásku k vlasti a tradicím a historii národa...Být komuni... Miluji Českou Republiku - Skupina je určena pro vkládání vašich nekomerčních příspěvků z České republiky. Samozřejmě můžete také přidat slušné fotky ze zahraničí, Ret... LIDI, POJDME DO NICH!!! - !!! POZOR !!!!! Nové pravidlo pro diskutující: 1.Kdo bude urážet v diskuzi druhé dostane ban na 24.hod nasbírá dotyčný 6.banu za měsíc b... Přátelé Ruska v České republice - Jsme neformální otevřená skupina, která čelí zfanatizovanému jednostrannému pohledu západních i českých politiků a médií proti vynucenému... Občané proti fašismu na Ukrajině, v ČR, na celém světě. - Občané proti fašizmu!... Zanechme předsudků vůči komunistům - Víte vůbec co dnešní komunisté chtějí? Mluvte s nimi. Možná budete mile překvapeni Členství v této skupině ani samotný její provoz nesmí bý...
Závěrem
Pokud jste dočetli až sem, gratuluji vám. Právě jste došli na konec exkurze tak trochu jiným Facebookem, než je ten běžně představovaný. Pokud teď čekáte pointu, asi se jí nedočkáte, chtěl jsem jen jednou ukázat jak také vypadá český Facebook.
A pokud jde o Jiřího Ovčáčka a jeho původní tweet? Zavřete oči, představte si sraz Klubu českého pohraničí. K pultu přistupuje Daniel Herman, pronáší první větu svého projevu a pohraničníci mu ve stoje tleskají. Jakou větu by asi musel říct? Co si o tom myslíte? Napište mi to do komentářů....
Josef Šlerka
2 notes
·
View notes
Text
Slovo "inkluze" a vůbec slovník politických stran a politiků na Facebooku - díl první
Před časem jsem zjistil, že můj oblíbený nástroj pro "distant reading" textů Voyant Tools prošel velkými změnami a lze si ho i stáhnout k sobě do počítače. Nástroj nabízí řadu vizualizací a mezi jinými i možnost tzv. bubble lines, které ukazují, na jakých místech se v textech vyskytují hledaná klíčová slova. Napadlo mne, že by se takhle šlo hezky podívat i na posty na Facebooku a vztáhnout je k datu publikace.
Stáhl jsem tedy posty politických stran a vybraných politiků (přiznám se, že na základě tématu inkluze jsem přidal hlavně ministryni Valachovou) za období leden až začátek května 2016 a vyrobil jednoduchou aplikaci (Rko a Elasticsearch) pro generování podobného grafu. Barevné body označují, že ten den byl stránce alespoň jeden post obsahující dané klíčové slovo.
Jako první jsem zkusil slovo inkluze. "Prý se snažím získat na inkluzi jakési politické body. A prosím vás u koho," napsal Petr Fiala v únoru. A jak tedy vypadaly stránky na Facebooku? I když v roce 2016 okrajově zmínily téma inkluze lidovci i další stránky, suverénně nejvíce prostoru ji věnovala ODS a ministryně Valachová. Co je však nejzajímavější? Není mezi nimi ani jeden post ČSSD. Jinými slovy, ani jeden post ČSSD neobsahuje přímo slovo inkluze. Ostatně stejně jako v případě ANO.

Avšak je slovo inkluze příznakové pro posty právě ODS? Voyant Tools pro podobné analýzy nabízí identifikaci tzv. different words, tedy slov, která odlišují jednotlivé korpusy. Podobnou funkci má i přímo Elasticsearch pod názvem significant terms a i na našem malém korpusu přináší docela zajímavé výsledky. Všechny strany se samozřejmě od sebe odlišují jmény svých politiků, ale občas také specifickými slovy.
Výsledky jsou celkem nepřekvapivé, ale ilustrativní. Zelení mají mezi svými příznakovými slovy: klimatický a fosilní. Piráti se výrazně liší slovy jako cenzurní, loterijní, ttip a autorský.

Lidovci mají výrazné slovo zemědělství.

Babišovo ANO se odlišuje například slovy hazard a korupce.

Oproti tomu ODS má papírování, bezpečnost apod.

Nejvíce mne ovšem pobavil Tomio Okamura se svými sdílejte a prosím.

Z mého pohledu představují bubble lines i significant terms docela pěkný nástroj pro rychlejší orientaci ve větším počtu statusů. Uvidíme, jak dopadne jejich aplikace na větší korpusy. Omezení jsou zatím celkem jasná: hledáme pouze ve statusech stránek, nikoi v obrázkách nebo textech odkázů a pracuji pouze s klíčovými slovem. Ovšem zdá se, že to lze do budoucna napravit.
Pokud jde o větu: "Prý se snažím získat na inkluzi jakési politické body. A prosím vás u koho,” prozatím můžeme říct, že ODS se tématu rozhodně věnuje intenzivně. Jak úspěšně a u koho, na to se podíváme příště.
Josef Šlerka P.S. Byly použity tyto stránky: Bohuslav Sobotka, Česká pirátská strana, ČSSD, Miroslav Kalousek, Kateřina Valachová, Komunistická strana Čech a Moravy (KSČM), Tomio Okamura - SPD, ANO, Andrej Babiš, NE Bruselu - Národní demokracie, KDU-ČSL, Občanská demokratická strana, Strana zelených,Miloš Zeman - prezident České republiky, Karel Schwarzenberg, Strana svobodných občanů, Petr Fiala, Markéta Adamová a TOP 09
2 notes
·
View notes
Text
Smer, SNS a Kotleba - jak se to rýmuje?
Nedávno jsem se, ve spojení se slovenskými parlamentmími volbami, věnoval blízkosti (podobnosti) slovenský politických stran na základě jejich fanoušků Facebooku. Nedalo mi to a podíval jsem se na slovenské volby ještě jednou, tentokrát ale na jejich výsledky. Zejména z pohledu toho, jak moc jsou v souladu nebo nesouladu s výsledky mého předchozího šetření. Tento text je takovým shrnutím některých momentů, které mne zaujaly.
Prvním z nich byla blízkost Smeru a SNS, respektive Kotlebova Našeho Slovenska a SNS. Druhým outlierství uskupení Sme rodina. Konečně pak třetím chuchvalec stran SAS, OLANO a Sieť, které spolu tvořili vzájemně propojený trojúhelník (viz původní blogpost Slovenské volby a Facebook).
Korelace volebních výsledků stran a její geografické rozmístění
Když se podíváme na rozpětí výsledků voleb ve volebních obvodech, kde bylo více než 5.000 voličů u volební urny (jedná se o 80 míst), na první pohled je vidět, že existují strany, které zaznamenaly extrémní rozdíly v úspěšnosti v jednotlivých obvodech, jako např. Smer, SaS a Most-Híd. Naopak jsou tu strany, jejichž úspěch vypadá rozložený poněkud rovnoměrněji jako např. Naše Slovensko a Sme rodina. (Blížší popis violin plotu, který jsem použíl místo boxplotu je zde.)

Jinými slovy, jsou tu strany, které tak nějak dostaly ve všech větších městech stejně hlasů a strany, které v počtu hlasů zaznamenaly veliké rozdíly v různých volebních obvodech. Jak tyto strany ale roztřídit dál? Vodítkem může být kupříkladu korelace vzájemných percentuálních výsledků v našem datasetu. Ta vypadá takto:

V matici je vidět silná korelace Smeru a SNS a o něco slabší korelace trojce Smer, SNS a Naše Slovensko. Na druhé staně sice slabší korelace mezi trojúhelníkem Siet, Olano a SaS. Stranou, která koreluje negtivně se stranami Smer, SNS a Naše Slovensko je “maďarský” HíD-Most. (K debatě o korelaci strany viz také tenhle starší blogpost). Zdá se, že výsledky voleb mou předchozí analýzu blízkosti politických stran úplně nezpochybňují, zároveň ale ukazují na poměrně zásadně odlišné postavení Mostu-Hídu. Vraťme se proto zpět k datasetu 80 obcí v nichž přišlo volit více než 5.000 voličů. Obce si můžeme seskupit do shluků podle podobnosti percentuálních výsledků voleb (já jsem zvolil k-means clustering a 4 shluky).
Výsledek vypadá takto:
větší rozlišení
Jak chápat jednotlivé shluky? Podívejme se, jak v nich dopadly volby.
Shluk číslo 1 reprezentuje oblasti, kde drtivě vyhrál Smer.

Shluk číslo 2 oblasti, kde byl souboj vládnoucího Smeru a ostaních stran vyrovnanější a výsledky SNS a LSNS horší.

V klastru 3 pak najdeme místa, kde uspěly opoziční SaS a OLANO a dobře dopadl také Most-Híd (to neznamená, že nutně všude vyhrály.)

A konečně pak klastr 4 ukazuje místa, kde silně bodoval Most-Híd (opět to neznamená, že vždy nutně vyhrál.)

Klastr 1 tedy představuje bašty Fica, Klastr 3 a 4 místa, kde je opozice úspěšná a klastr 2 města, o která se bude v budoucnu nejvíce hrát. Zároveň ale toto rozvrstveni dobře ukazuje důvody postavení Mostu-Hídu v našich tabulkách. Jeho silná místa jsou spojená především se specifickými oblastmi Slovenska a jinde prakticky nebodoval. Data ze sociálních sítí ale s geografickým rozložením nepočítají.

Interaktivní mapa je zde.
Smer, SNS a Kotleba - jak se to rýmuje?
Na závěr ještě jednu poznámku. Blízkost voličů Smeru, SNS a Kolebova Našeho Slovenska naznačuje celá řada faktorů, včetně přepočtů přesunů mezi stranami, tak, jak je počítal Michal Škop pomocí ekologické inference, nebo přímo výsledky dotazníkového šetření voličů, které provedla agentura Median.
Zmiňovaná agentura se také ptala voličů na to, jak důležité pro ně jsou témata jako vztah strany k Riešenie nezamestnanosti, Imigrácia a otázka prijímanie utečencov nebo Štátny rozpočet, dane a zadlžovanie. Pro voliče byly samozřejmě všechna tamata důležitá, ale přeci jen se mezi nimi našly rozdíly (podrobnosti zde).
Pokusil jsem se shluknout strany pomoci hierarchického klastrovaní. To, stručně řečeno, ukazuje, jak rychle se objevují rozdíly mezi jednotlivými prvky od hypotetického prvního bodu, kde jsou stejné. Výsledky poměrně dobře korespondují s ostatními daty:

Opět vidíme, že LSNS, Smer a SNS k sobě mají z pohledu voličů blízko, na rozdíl od opozičního bloku vpravo. Zde se může vynořit otázka, proč Fico za této konfigurace ztratil hlasy právě ve prospěch SNS a LSNS. Odpověď může být banální, část voličů mu jednoduše přestala věřit. Ostatně, podívejte se na slide č.15 prezentace Medianu a uvidíte sami. Jak mi potvrdil i Daniel Prokop z Medianu: "V otázce zdravotnictví Smer úplně vyhořel a i v nezaměstanosti ho zařadilo mezi TOP nejkompetenější strany snad jen 23 % voličů, kterým na tomto tématu záleží."
Josef Šlerka Speciální díky patří Michalu Škopovi za data k analýze. Další díky patří Danielu Prokopovi a Jurajovi Smatanovi za cennou diskusi.
2 notes
·
View notes
Text
Slovenské volby a Facebook
Do slovenských parlamentních voleb zbývá už jen pár dní a protože připravuji pro TV Markiza nějaká data o působení slovenských politických stran na Facebooku, naskytla se mi příležitost zpracovat některé metody analýzy nad jinou politickou scénou, než tou naší domácí. Připravil jsem celkem tři různé analýzy/nástroje, které různě osvětlují situaci u našich sousedů.
Blízkost stran pomocí normalized distance
Prvním je mapa vztahu vybraných politických stran, které na Slovensku kandidují do parlamentu. Na vstupu byla matice s údaji o blízkosti (podobnosti) fanoušků facebookových stránek spočítaná pomocí Normalized Facebook Distance. Data se týkají posledních čtyř měsíců a počítám s uživateli, kteří alespoň jednou olajkovali nějaký post stránky (detailnější popis metody naleznete třeba v tomhle seriálu nebo v této prezentaci od slajdu 85 dál).
Výsledkem je síť vztahů podobností mezi stránkami, kdy spojení je determinováno vzdáleností menší než 0.55. V grafu je vidět relativní izolovanost dvou subjektů a to Kotlebova uskupení Naše Slovensko (které má blízko jen k nacionalistům ze SNS), nové hvězdy slovenské politiky hnutí Sme rodina a ryze maďarské strany SMK. Dále je pěkně vidět i nejblížší konkurence Ficova Smeru, kterým je Slovenská národná strana a svízelné postavení hnutí Sieť, jehož fanoušci mají blízko k řadě dalších stran a jsou pravděpodobně poměrně váhající.

Obsahový překryv
Druhou aplikací je přehled toho, co na zpravodajských serverech (i jinde) lajkují fanoušci politických stran za poslední cca měsíc. Metodologicky jsem přitom vycházel z této analýzy.
V našem případě korelační matice podobnosti zájmů fanoušků o stejný obsah ukazuje existenci dvou velkých bloků:
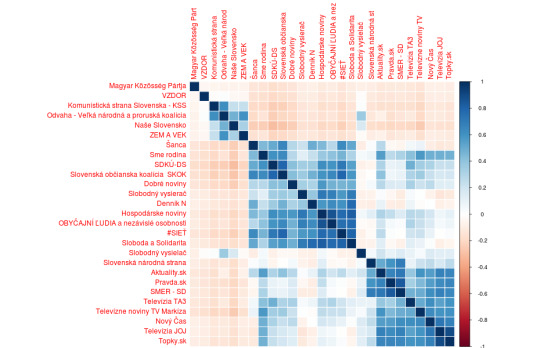
V jednom nalezneme hlavně fanoušky Slovenské národní strany a Ficova Smeru. jejich stěžejní zpravodajský vkus zaplňují hlavně televizní zprávy a částečně bulvár. Druhým jsou pak opoziční subjekty, které mají svou oporu hlavně v tisku.
Interaktivní aplikace (najdete ji zde: https://slerka.shinyapps.io/slovensko-postanalyzer/) pak ukazuje, které posty hlavně vyvolávaly zájem fanoušku politických stran. Pozastavil bych se u dvou zajímavosti: zdá se, že téma migrace nějak signifikantně nezaujalo fanoušky Ficova Smeru posty stránky Sme rodina rezonovali především s fanoušky TV Joj a netýkaly se nijak zvlášť nějakého politického tématu, mohlo by to tak naznačovat slabší motivaci potenciálních voličů dostavit se nakonec k volbám
Dynamika vyvoje počtu lajkujících
Poslední aplikace ukazuje dynamiku unikátních lajkujících na stránkách jednotlivých politických stran za poslední rok a můžete si v něm porovnat výkonnosti a dynamiku jejich kampaní (pro české prostředí jsem podobnou aplikaci publikoval na podzim).
Při jejím zkoumání věnujte pozornost hlavně projektu Sme rodina s brutálním růstem počtu fanoušků, kterým překovává zaběhnuté strany. Jak ale víme z mnoha předchozích výzkumů, nemusí velký počet fanoušků na Facebooku znamenat účast v parlamentu.
Aplikaci naleznete zde: https://slerka.shinyapps.io/slovensko-kumulativni-grafy/
Závěr
Nejsem expert na slovenskou politiku, nicméně se zdá, že některá dílčí zjištění potvrzují analýzy tradičních výzkumných agentur (problém SNS vs Smer, nestabilní postavení některých menších subjektů apod.) Pravdu ale ukáží až vikednové volby a následné analýzy. Josef Šlerka
0 notes
Text
Zrušení FB stránky “Islám v České republice nechceme” iniciativu nepoškodilo
Tento týden uplyne měsíc od okamžiku, kdy Facebook smazal oficiální stránku uskupení Islám v České republice nechceme (měla ID: 120236192937 a username ivcrn). Okamžitě po jejím zrušení se aktivita skupiny převedla na záložní stránku s ID: 513697425424894 a username ivcrn.news a pokračovala dál. (Technická: ne, nebyla to nová stránka, ale záložní stránka, kterou mělo IVČRN dlouhou dobu.)
Na Facebooku i v klasických médiích se rozpoutala debata o tom, zda je to správně a také, zda to nakonec uskupení spíše nepomůže k větší oblibě. Jak to dopadlo? Po měsíci velmi zajímavě a v podstatě pro české antiislamisty dobře. Pojďme se podívat na data.
Východiskem pro naše zkoumaní bude počet unikátních fanoušků, kteří olajkovali nějaký post stránky za 7 dní. Na následujícím grafu je vidět průběh na původní stránce Islám v České republice nechceme od 6. 6. 2015 do 25. 12. 2015. Červená tečkovaná čára pak vyznačuje klouzavý sedmidenní průměr těchto hodnot.

Na grafu je patrné určité nasycení poptávky. (Psal jsem o něm pro Reportér v článku Polarizovaná společnost? Nikoli, je to složitější, kde také najdete data za celý rok a letmou interpretaci.) Největšímu zájmu se stránka těšila na konci srpna a během září. Od té doby se zájem o ní stabilizoval a v prosinci se víceméně držel pod 15.000 unikátně lajkujících na stránce.
Začátkem ledna přišlo její smazání a vynucený přesun aktivity na stránku záložní. Jak již bylo řečeno výše, záložní stránka existovala už delší dobu a můžeme se podívat na průběh počtu unikátních fanoušků, kteří olajkovali alespoň jeden post za 7 dní v čase od 6. 2. 2015 do 6. 2. 2016.

Jak je vidět, přepnutí hlavní komunikace ze smazané stránky do záložní v podstatě během pár dnů přivedlo čísla zpět na původní úroveň a i momentálně rostou. To je vidět i na dalším grafu, který ukazuje propojení zmíněné metriky obou stránek v čase. Bohužel nemám k dispozici data ke stránce v období mezi 25. 12. a 11. 1., ale i tak je to zajímavý pohled. Data před výpadkem patří původní stránce, data po výpadku stránce záložní.

Takže jak to je? Poškodilo? Nepoškodilo? Podle mého názoru smazání stránky „Islám v České republice nechceme“ samotné iniciativě neuškodilo, spíše drobně pomohlo (pokud tedy nepředpokládáme nějká prudký nárůst na Nový rok). Spadl ji sice počet fanoušlů na třetinu, jenže faktické zapojení zůstalo stejné. Dokonce se dá předpoládat, že tímto pročištěním stoupl faktický reach stránky. Náhradní stránka v podstatě během pár dnů nabrala dech a dnes počty unikátních lajkujících na ní vykazují lepší výsledky, než měla původní stránka na konci minulého roku. Jak to bude dál, uvidíme.
Josef Šlerka
1 note
·
View note
Text
Little data goodbye to David Bowie
Inspired by a blogpost Genre-based Music Recommendations Using Open Data (and the problem with recommender systems) I decided to create a small data homage to David Bowie. To be completely honest, I wasn’t his avid listener. Bowie has always fascinated me more as a self-creation project of its own kind. Maybe that’s why I decided to learn more about him through data.
I created a visualization of network of those artists that are similar to Bowie and those that are similar to them. In other words, I started with a list of artists and groups similar to Bowie and then I made one more step and included artists similar to all those already in the list. My starting point was the Last FM API that offers lists of similar artist. After downloading these data I used R to calculate clusters of similar artists and then I visualized this network using Gephi. (You’ll find more methodological remarks at the end of this blogpost.) And so was the following graph created:

plná velikost obrázku
The colors indicate machine-chosen clusters of artists and groups that are closer to each other than to the rest of the data set. The size of the label reflects the so called betweenness centrality, which means that the bigger the label of a point, the greater its importance in facilitating paths between others in the network. Indeed, these points are sometimes called “bridges”. For those of you who would like to examine this network in more detail, I have prepared an interactive version.
After I had published the first version of this graph on my facebook page, a friend of mine asked me privately how would I name these coloured clusters. And to tell the truth, I had no idea. After a moment’s thought I turned again to the Last FM data for help. There are four large clumps in the graph and for each of these I downloaded all user tags for all artists and groups contained within it. The resulting wordclouds look quite good.
Rock cluster of the sixties

Rock cluster of the sixties - wordcloud

Rock cluster of the seventies and eighties

Rock cluster of the seventies and eighties - wordcloud

New wave and new alternative cluster

New wave and new alternative cluster - wordcloud

Punk, postpunk, alternative cluster

Punk, postpunk, alternative cluster - wordcloud

Not bad, right? RIP David Bowie.
Methodological notes
For those interested here is just a few notes on how I put everything together.
In the beginning I took the data provided by the Last FM service. It offers not only a list of similar artists but also a score of similarity on the scale from 0 to 1. Since Last FM is eager to please, it often returns a list of 100 items with very low scores. Therefore I’d decided to set a minimum score of 0.3 and my reason for this particular number was nothing more than a gut feeling from looking at lists of similar artists that I actually knew.
I filtered tags that had more than one occurrence.
It would be better to use some algorithm for detection of significant terms instead of wordclouds. Maybe some other time.
ZIt seems that Last FM works with asymmetric similarity, so when A is similar to B, B doesn’t have to be similar to A. This may cause some headaches to technical minded students, but it’s not an uncommon phenomenon and e.g. Amos Tversky has a few articles about this. (Hint: On the scale 0 – 10, is Canada similar to the USA? And the other way around, on the scale 0 – 10, are the USA similar to Canada? Check out for example the proceedings Amos Tversky: Preference, Belief, and Similarity).
Josef Šlerka (special thnx to Leni Krsová a Daniel Prokop) Translated by Vít Tuček
3 notes
·
View notes
Text
Malé datové sbohem Davidu Bowiemu
Inspirován blogpostem Genre-based Music Recommendations Using Open Data (and the problem with recommender systems) jsem se rozhodl udělat malou datovou poctu Davidu Bowiemu. Abych byl zcela upřímný: Bowie mne vždy fascinoval spíš jako svého druhu projekt sebetvoření, než že bych byl jeho nadšeným posluchačem. Možná proto jsem se rozhodl se s ním seznámit víc prostřednictvím dat.
Vytvořil jsem tedy viuzalizaci sítě umělců složenou z těch, co jsou podobní Bowiemu a z těch, kdo jsou podobní jim. Jinými slovy: začal jsem seznamem umělců a kapel podobných Bowiemu a pak jsem udělal ještě jeden krok: našel jsem umělce a kapely podobné jim. Východiskem mi bylo API Last FM, které nabízí seznamy podobných umělců. Z něj jsem data postahoval, v Rku spočítal klastry podobných umělců a vše pak vizualizoval pomocí programu Gephi (metodologické detaily najdete na konci blogpostu). A tak vznikl následující graf:

plná velikost obrázku
Barvy označují strojem určené shluky umělců a kapel, které mají k sobě blížeji než k jiným. Velkost popisku pak reprezentuje tzv. betweenness centrality, tedy přibližně čím je popisek větší, tím důležitější jsou body v sítí pro zprostředkování cesty mezi jinými body. Ostatně proto se jim také někdy říká mosty. Pro ty z vás, co by si graf rádi více proklikali, jsem připravil interaktivní verzi.
Když jsem dal jednu z prvních verzí grafu k sobě na Facebook, ozval se mi kamarád po Messengeru s otázkou, jak bych ty barevné grafy pojmenoval. A já musel s pravdou ven, že nevím a musel bych se zamyslet. Nakonec jsem se rozhodl povolat na pomoc opět data z Last FM. V síti jsou zřetelné čtyři velké shluky a tak jsem ke skupinám a umělcům v nich postahoval, jak jsou otagovaní uživatelskými tagy, a následně vytvořil wordcloudy. Výsledky vypadají docela slušně.
Rockový klastr šedesátek

Rockový klastr šedesátek - wordcloud

Rockový klastr sedmdesátek a osmdesátek

Rockový klastr sedmdesátek a osmdesátek - wordcloud

Klastr nové vlny a nové alternativy

Klastr nové vlny a nové alternativy - wordcloud

Klastr punku, postpunku a alternativy

Klastr punku, postpunku a alternativy

Za mne docela dobrý, ne? RIP David Bowie.
Metodologické poznámky
Pro zájemce jen několik poznámek k tomu, jak jsem dával dohromady data.
Na začátku jsem vzal data poskytovaná službou Last FM. Ta nabízí totiž i seznam podobných umělců k hledanému umělci, včetně skóre podobnosti na škále 0 až 1. Protože se Last FM pokouší vždy vyhovět, často vrací seznam o 100 položkách s velmi nízkými hodnotami podobnosti. Já jsem se proto rozhodl nastavit minimální míru na větší než 0.3 a důvodem mi nebylo nic víc, než pocit při prohlížení seznamu podobných umělců, které jsem znal.
U tagů jsem použil pouze ty, které měly více než jeden výskyt. Lepší než wordcloudy by bylo použít třeba některý z algoritmů používaných pro detekci tzv. significant terms, ale to snad někdy jindy.
Zdá se, že Last FM pracuje s asymetrickou podobností, takže když je A podobné B, nemusí být B podobné A. Některým studentům technických škol to může vadit, ale on to není tak neobvyklý jev, a třeba Amos Tversky o tom má pár článků (hint: na škále 0 - 10 je Kanada podobná USA? A obráceně: na škále 0 - 10 jsou USA podobné Kanadě? Podívejte se třeba do jeho sborníku Amos Tversky: Preference, Belief, and Similarity).
Josef Šlerka (special thnx to Leni Krsová, Daniel Prokop a Vít Tuček)
0 notes
Text
Digital humanities - stručné vymezení
Pokusil jsem se o stručné vymezení toho, co jsou vlastně Digital Humanities z mého pohledu. Hlavní důvodem je moje neustálá debata o tomto pojmu na akademické půdě. Berte, prosím, tenhle text jako podklad k debatě o Digital Humanities, která se bude dále vést.
Digital humanities přichází jako reakce humanitních a sociálních věd na rozvoj výpočetní techniky a nových (digitálních) médií od poloviny minulého století. S nástupem počítačů se postupně objevují projekty využívající jejich výpočetní sílu a možnosti zpracovávat množství informací, kterou jsou jinak prakticky neuchopitelné jednotlivcem.
Za jednoho z prvních průkopníků v této oblasti se považuje jezuita Roberto Busa, který přišel již v roce 1949 s projektem kompletního zpracování index verborum díla Tomáše Akvinského. Projekt samotný byl nakonec realizován v letech 1974 – 1980 v tištěné verzi 56 svazků za podpory společnosti IBM. Při projektu bylo kompletně dílo Tomáše Akvinského přepsáno do děrných štítků, z nich byla poté vytvořena počítačem úplná konkordance. Dnes je celý Index Thomisticus přístupný na webu.[1] Díky tomu je možné během zlomků sekund vyhledat všechny výskyty daného slova v objemném díle.
Tento průkopnický projekt dobře ukazuje základy přístupu v digital humanities. Byl umožněn výpočetní sílou a novými médii, mění samotný přístup k výzkumu a konečně zaměňuje i celkový přístup k informacím, z nichž výzkum vychází. Tyto změny jsou právě tím, co vymezuje prostor digital humanities.
Komputační obrat
Postupný nástup počítačů v druhé polovině 20. století a zejména jejich neustále klesající cena přinášejí zásadní změnu mj. i ve vědecké práci. Při původním využívání výpočetní síly ve vědě se výzkumník potýkal s relativně drahým sběrem dat ve větším množství a s jejich poměrně drahým zpracováním. Proto byl velký důraz kladen především na formulaci hypotézy a její potvrzování (případně falzifikaci). Od 80. let se však situace mění, díky výkonnému softwaru se postupně dostává do popředí tzv. explorační analýza dat, při níž může výzkumník procházet velké množství dat za účelem nalezení většího počtu hypotéz, které stojí za to dále testovat. K technikám explorační datové analýzy tak patří kupříkladu multidimensional scaling, PCA, ale také běžné vizualizace jako je box-plot či scatter-plot.
Původně čistě statistický přístup je pak doplněn o metody tzv. data miningu, tedy přístupu, který se snaží o získávání netriviálních informací z analýzy dat a který vychází především z tradic počítačové vědy. Mezi základní data-miningové techniky tak patří kupříkladu rozhodovací stromy, asociační pravidla, neuronové sítě, regresní analýza či shluková analýza. Náleží sem ovšem i nejrůznější formy sumarizace včetně vizualizací.[2]
Nová média
Komputační obrat přichází plynule s nástupem nových médií, jak je vymezuje Lev Manovich. Ve své knize The Language of New Media z roku 2001 charakterizuje novomediální svět pomocí pěti základních atributů.[3]
1. Číselná reprezentace Každé „Novomediální dílo může být vymezeno formálně, matematicky. Například obraz nebo tvar lze popsat matematickou funkcí,“ z čehož vyplývá, že „Novomediální dílo je předmětem algoritmické manipulace. Uplatněním vhodného algoritmu můžeme například automaticky odstranit zrnitost z fotografie, vylepšit její kontrast, rozpoznat tvary nebo změnit proporce. Řečeno ve zkratce, média se stávají programovatelnými.“ Jaký je přímý dopad? Kupříkladu ten, že mobilní aplikace, které nabízejí různé úpravy fotografií pomoci filtrů, jako jsou Hipstamatic nebo Instagram, de facto transformují estetiku starých fotoaparátů do matematických vzorců.
2. Modularita Manovich popisuje modularitu takto: „Jednotlivé prvky médií, obrazy, zvuky, tvary i jednání jsou reprezentovány jako soubory diskrétních vzorků, ať již jde o pixely, mnohoúhelníky, voxely, znaky, skripty. Na vyšší úrovni jsou tyto jednotky skládány do objektů, ale ponechávají si svojí oddělenou identitu.“ Právě tato modularita, daná předchozí možností číselné reprezentace umožňuje kupříkladu existenci webových stránek, které se skládají z oddělených vrstev. Stejně tak je modularita základem pro další vlastnosti novomediálního díla.
3. Automatizace Automatizace jako další z atributů novomediálního díla vychází z číselného kódování a modulární struktury, které „[…] umožňují automatizovat řadu operací při vytváření, manipulaci a přístupu k novým médiím. Lidská intencionalita proto může být z tvůrčího procesu alespoň částečně odstraněna.“ Nejvíce viditelným je pro běžného účastníka mediálního světa efekt prohledávatelnosti obsahu, který nejlépe reprezentuje vyhledávač Google.
4. Variabilita Variabilita novomediálních artefaktů vychází z předchozích bodů. Novomediální dílo lze totiž verzovat a modifikovat či dokonce přizpůsobovat individualitě konzumenta. „Stará média zahrnovala lidského tvůrce, který osobně sestavoval prvky textů, obrazů nebo zvuků do určité kompozice, nebo sekvence. Tím, že byly uloženy do materiálu, je jejich souslednost pevně daná. Může být vytvořeno mnoho kopií původního originálu, které budou v souladu s logikou industriální společnosti zcela identické. Nová média jsou naopak charakteristická svou variabilitou. (Jiná označení tohoto principu nových médií jsou proměnlivost, nebo tekutost.) Namísto identických kopií novomediální objekt dává vzniknout mnoha různým verzím. Spíše než, že by je vytvářel lidský autor, jsou automaticky sestavovány počítačem.“
5. Překódování Překódování je přirozeným důsledkem interakce kultury a digitálního světa. Platí zde totiž, že „Logika počítačů se vepisuje hluboko do kulturní úrovně médií již z toho důvodu, že nová média jsou vytvářena, rozšiřována, ukládána i archivována díky počítači. Způsoby, kterými počítače formují náš svět, reprezentují a zpřístupňují data, klíčové operace ovládají počítačové programy (vyhledávání, třídění, filtrování), rozhraní člověk-počítač (HCI), zkrátka vše, co můžeme označit za ontologii, epistemologii a pragmatiku počítače, to vše ovlivňuje kulturní úroveň nových médií, jejich organizaci, nové žánry, ale také obsah.“
Digital humanities
Zatímco počítače představují motor nového, digitálního světa, tak digitalizovaná data jsou jeho pohon. V procesu postupné digitalizace lidského světa a jeho historie se otevírají zcela nové možnosti pro výzkum jak v oblasti humanitních, tak sociálních věd.
Můžeme sledovat kupříkladu ambiciózní projekt využívající poměrně komplikovaných postupů (jakým jsou kupříkladu aplikace algoritmu Latent Dirichlet Allocation) na modelování témat v rámci korpusu anglicky psané literatury 19. století jako ve studii Significant themes in 19th-century literature od Matthew L. Jockerse a Davida Mimno..[4] Autoři používají techniku modelování témat pro analýzu více než 3400 děl americké, anglické a irské literatury.
Jiné projekty se snaží využít možností, které nabízí vizualizace velkých obrazových korpusů podle definovaných vlastností. Můžeme tak třeba sledovat dynamiku vývoje světlosti obrazů moderny či zkoumat obrazy Mondriana s ohledem na jejich barevnost, jak to ukazují práce Lva Manoviche v softwaru ImagePlot.[5]

Vidíme tedy, že existují způsoby výzkumu, jejichž využití v řadě oblastí humanitních a sociálních věd bylo umožněno až novými médii, respektive fenomény s nimi spojenými – zejména nástupem počítačů. Pro tyto nové způsoby výzkumu, které jsou ovšem často spojeny i se zcela novými druhy výsledků bádání, se vžilo označení digital humanities. Byť, podobně jako v případě definování nových i sociálních médií, se vedou časté spory o přesnou definici.
Ve sborníku Debates in the Digital Humanities[6] můžeme najít 21 odpovědí na otázku, co jsou digital humanities? Velká část těchto definic se týká především průniku mezi komputačními postupy a humanitními vědami jako v případě Johna Unswortha z University of Illinois, který definuje digital humanities jako: „Využití komputačních nástrojů při práci humanitních věd.“ [7] Najdeme tu ovšem i vymezení, která přidávají i fakt, že se jedná o komunitu výzkumníků, kteří se pohybují v oblastech zprostředkovaných digitálními médii. Tyto definice totiž zjevně odkazují na skutečnost, že jedním z motorů výzkumu digital humanities je využívání nových médií jako prostředí pro samotné vytváření vědecké komunity.
Autoři učebnice The Digital Humanities: A primer for Students and Scholars[8] vybírají dvě zásadně odlišné definice digital humanities, které podle nich dobře ilustrují napětí, jež sebou koncept digital humanities přináší.
První definici, kterou autoři zmiňují, je definice z Wikipedie: „Digital humanities is an area of research and teaching at the intersection of computing and the disciplines of the humanities. Developing from the fields of humanities computing, humanistic computing and digital humanities praxis digital humanities embraces a variety of topics, from curating online collections to data mining large cultural data sets. Digital humanities (often abbreviated DH) currently incorporates both digitized and born-digital materials and combines the methodologies from traditional humanities disciplines (such as history, philosophy, linguistics, literature, art, archaeology, music, and cultural studies) and social sciences with tools provided by computing (such as data visualization, information retrieval, data mining, statistics, text mining, digital mapping), and digital publishing.“[9]
Tato definice je podle autorů učebnice v rozporu s inkluzivním vymezením Anne Burdick v publikaci MIT Digital humanities.[10] „[Digital Humanities] asks what it means to be a human being in the networked information age and to participate in fluid communities of practice, asking and answering research questions that cannot be reduced to a single genre, medium, discipline, or institution.“ [11]
Zatímco první z nich se orientuje hlavně na otázku metodologickou a vychází především z dialogu mezi počítačovými vědci a vědci z humanitních oblastí, v druhém případě se jedná o mnohem širší oblast, která de facto padá do oblasti nazývané Manovichem transcoding, tedy vlivu digitální proměny lidské společnosti na člověka samotného. Autoři učebnice sami říkají, že by bylo dokonce lepší pojmenovat takto vymezené oblasti dvěma rozdílnými termíny. Metodologickou část pojmenovat jako digital humanities a část širší pojmout jako humanities computing. Sami se kloní k původnímu vymezení oblasti digital humanities jako primárně metodologické změně v samotné práci v humanitních vědách, která má svůj historický kořen především v nástupu počítačů. Navíc starší práce používají termín humanities computing jako označení samotného pole výzkumu, kde se protínají jednotlivé vědní oblasti a metodologie, jak to ilustruje obrázek z knihy Willarda McCartyho Humanities Computing.[12]

Nicméně obecná shoda v této oblasti nepanuje a snad ani není zcela nutná. Důležité je, že jsme vždy nejen na novém poli výzkumu, ale také přicházíme do styku s novým způsobem práce samotné výzkumnické komunity, která využívá nové technologie k efektivnější komunikaci, zrychlení cyklu průzkumu dat, zkoumání hypotéz a konečně i k zpřístupňování velkých datových korpusů kolegům i širší veřejnosti.
Kritika
Ačkoli je digital humanities relativně mladá disciplína (byť s celou řadou úctyhodných předchůdců), je podrobovaná řadě kritických pohledů a to nejen z pohledu kulturní kritiky, ale ze samotného pohledu metodologického. Tuto kritiku shrnují Bernhard Rieder a Theo Rohle v eseji Digital Methods: Five Challenges do pěti výzev, před kterými dle nich digital humanities dnes stojí.[13] Jsou jimi: zdání objektivity (The lure of objectivity), síla obrazu (The power of visual evidence), neznalost metody (Black-boxing), Institutional perturbations a problém universalismu (The quest for universalism).
V doslovu k českému vydání Morretiho knihy Graphs, maps, trees: Abstract models for a literary history jsem se ji pokusil shrnout: pokud věci počítáte, mohou se zdát objektivnější. Vizualizace dat sebou nenese často jen snadnější nahlédnutí pravdy, ale také rétorickou sílu, která může klamat. Moderní technologie přinášejí snadnou dostupnost matematických analýz pro všechny, aniž by bylo nutné rozumět jejich fungování. Často tak můžeme aplikovat datovou analýzu nevhodným způsobem a i přesto dostat odpovědi, které dávají na první pohled smysl. Komputační metody sebou nutně ponesou větší zapojení vědců vzdělaných v jiných oblastech, a budou tak oslabovat původní kontexty, které humanitní vědy vymezují. Zapojení, více méně matematických modelů, ovšem také oživuje představu universální gramatiky světa, která svůj výraz nachází především v matematicky založených vědách.
Digital humanities a DIKW
Kritiku nastíněnou v předchozím odstavci je nutno brát vážně. Nicméně je zároveň třeba vidět postavení digital humanities v širším kontextu procesu znalostí a poznání. Tady nám může posloužit zjednodušený koncept poznání formalizovaný v informační vědě do tzv. pyramidy poznání neboli konceptu DIKW.

Zkratka DIKW je utvořena z pojmů Data – Information – Knowledge – Wisdom. Procesu, při kterém z dat získáváme smysluplné informace, které je třeba interpretovat s přihlédnutím k doménové znalosti, jenž se data týkají. Teprve od tohoto pohybu myšlení se lze dostat k samotnému smysluplnému poznání.
V tomto kontextu přinášejí nová média možnost zásadního rozšíření dat, s nimiž můžeme pracovat. V procesu digitalizace (ať již rukopisů či třeba jen geolokovaných záznamů o archeologických nálezech) roste datová základna natolik, že její rozsah již prakticky vylučuje možnosti zpracování bez použití počítačů. Komputační obrat, který přinášejí počítače a jimi zprostředkované zpracování dat, pak rozšiřuje možnost vytěžení informací z těchto dat. Ovšem jejich interpretace z pohledu vědy stále zůstává především v lidském porozumění zkoumané oblasti. Doménová znalost interpretů a vědecká práce zůstává v tomto ohledu stejná, pouze získává zcela nové vstupy pro pochopení světa.
Josef Šlerka
[1] http://www.corpusthomisticum.org/it/index.age [2] https://en.wikipedia.org/wiki/Data_mining [3] Český překlad se připravuje k vydání na přelom roku 2015/2016. Citace pocházejí právě z pracovní verze českého překladu. [4] Poetics 41 (2013) 750–769 online: http://digitalcommons.unl.edu/cgi/viewcontent.cgi?article=1105&context=englishfacpubs [5] http://lab.softwarestudies.com/p/imageplot.html [6] Matthew K. Gold, Editor: Debates in the Digital Humanities, University of Minnesota Press, 2012. [7] Gold, s. 70. [8] Eileen Gardiner, Ronald G. Musto: The Digital Humanities: A primer for Students and Scholars, Cambridge University Press, 2015. [9] https://en.wikipedia.org/wiki/Digital_humanities [10] Anne Burdick, Johanna Drucker, Peter Lunenfeld, Todd Presner, Jeffrey Schnapp: Digital_Humanities. MIT Press, 2012, s. vii. [11] Willard McCarty: Humanities Computing. Palgrave Macmillan, 2005. [12] David M. Berry (ed.): Understanding Digital Humanities. Palgrave Macmillan, 2012.
0 notes
Text
Jak lajkovali na Facebooku antiislamisté, sluníčkáři a další v říjnu?
Podobně jako v minulý měsíc jsem i pro říjen připravil webovou aplikaci
https://slerka.shinyapps.io/postanalyzer
ve které si můžete prohlédnout jaké posty získaly významný podíl lajků od uživatelů Facebooku aktivních na jiných stránkách. Dataset jsem ponechal stejný jako minule a přidal možnost přepínat mezi měsíci - aplikace zpřístupňuje pohled na posty vybraných facebookových stránek za září a říjen 2015. Dataset nahraný v aplikaci obsahuje pouze ty posty stránek, které měly alespoň 50 lajků, a našla se alespoň jedna stránka s níž měl post překryv minimálně 15 procent. Za období 1.9. - 30.9. 2015 se jednalo o 1.072.425 lajků od 261.833 unikátních uživatelů pod 6.554 posty. Za období 1.10. - 31.10. 2015 se jednalo o 930.570 lajků od 220.575 unikátních uživatelů pod 6.918 posty.
Výsledky jsou opět celkem nepřekvapivé, dobře je ilustruje korelační matice postů.

Stejně jako minule je na vstupu tabulka, v níž jsou řádky tvořeny stránkami, které mají zvolený překryv vůči konkrétním postům (v případě naší matice se jedná o překryv alespoň 30% pod posty s více než 50 lajků) Tato tabulka je převedena na matici, v níž jsou řádky i sloupce tvořeny seznamem stránek, a hodnoty vyjadřují kolik konkrétních postů oslovilo fanoušky obou stránek. Nad touto maticí je pak spočítáno, jak spolu korelují jednotlivé stránky podle lajkování jejich fanoušků na jiných stránkách. Čím tmavší modrá, tím větší pozitivní korelace. Čím tmavší červená, tím větší negativní korelace. (Barvy jsou bezpříznakové, vychází z běžné grafické reprezentace v Rku.)
Josef Šlerka
0 notes
Text
Jaké posty lajkují antiislamisté, sluníčkáři a další?
Komunikace stránek na Facebooku má v podstatě tři základní druhy zpětné vazby. Komentář, lajk a sdílení. Za úspěšné považujeme hlavně ty posty, které získají velké množství lajků. Řada administrátorů stránek se pak snaží podle tohoto kritéria řídit svoje aktivity.
Až do tohoto bodu je vše srozumitelné. Problém ale nastává ve chvíli, kdy si uvědomíte, že lajk je informace jednorozměrná. Víme, od koho je, ale nevíme kupříkladu, kde ještě onen lajkující také lajkuje. Nevíme zkrátka nic o preferencích lajkujících, a tak se může stát, že jako stránka veřejnoprávní získáváte obrovské množství lajků pod postem informujícím o silném názoru prezidenta na islám, a nemáte příliš šancí poznat, zda tyto lajky pocházejí od různých skupin uživatelů, nebo zda značnou část lajkujících tvoří kupříkladu fanoušci Tomio Okamury.
Rozhodl jsem se proto udělat malý experiment. Vzal jsem 56 facebookových stránek věnujících se politickým tématům z českého Facebooku a stáhl všechny jejich posty za měsíc září. Potom jsem ke každému postu stáhl seznam lajkujících a z výsledku připravil malou aplikaci v Rku, v níž je možné se na tato data dívat z pohledu různých průniků. Celkem se jednalo o 1,072,425 lajků od 261,833 unikátních uživateleů pod 6,554 posty. Výsledky jsou zajímavé.
Například následující zářijové posty stránky Echo24 na Facebooku získaly svoje lajky z velké části (30 a 43 %) od lidí, kteří také během září olajkovali nějaký post na stránce Islám v České republice nechceme.

Následující post stránky Echo24 získal pro změnu 30 % lajků od lidí, kteří v září také něco olajkovali na stránce TOP09.

V obou případech se zprávy týkají situace kolem uprchlíků v Evropě, přitom ale oslovují zcela jiné publikum. Když se na zářijové posty Echa24 podíváme ještě blíže, zjistíme ještě o trochu větší diverzitu. Vidět je to v následující tabulce. Ukazuje kolik postů Echa24 získalo v září víc než 200 lajků a zároveň je alespoň ze 30 procent olajkovali lidé, kteří ve stejné době lajkovali post některé jiné ze zkoumaných stránek.
Vidíme tu stránky patřící intuitivně do více skupin. Minimálně tu máme silně anti-islamistické stránky Tomio Okamury a Islámu v ČR nechceme, dále pak skupinu dalších médií, a konečně pak stránky dvou politických stran, Svobodných a TOP09.
Jak jsou ale tyhle stránky spolu spojené z pohledu postů na stránce Echo24, jež jejich fanoušci lajkovali? Podívejme se na následující graf:

Vidíme tu, že lajkující ze stránky Blesku se ve své zálibě s nikým neprotnuli v žádném postu, zatímco fanoušci Svobodných mají v oblibě právě jeden post společně s fanoušky Tomia Okamury a Islámu v ČR. (Dokonce se může jednat o ty samé fanoušky, to by ale již bylo na další analýzu a někde je třeba se zastavit.)
Mimochodem, post, který se líbil 30 % lajkerům ze stránky Blesku byl tento:

Samozřejmě se můžeme podívat na celek našeho datasetu z většího odstupu a spočítat korelační matici chování fanoušků stránek. Na vstupu je tabulka, v níž jsou řádky tvořeny stránkami, které mají zvolený překryv vůči konkrétním postům (v našem případě se jedná o překryv alespoň 30% pod posty s více než 50 likes) Následně je tato tabulka převedena na matici, v níž jsou řádky i sloupce tvořeny seznamem stránek, a hodnoty vyjadřují kolik konkrétních postů oslovilo fanoušky obou stránek. Nad touto maticí je pak spočítané, jak spolu korelují jednotlivé stránky podle lajkování jejich fanoušků na jiných stránkách.
Výsledek je možná nepřekvapivý, ale přehledný:

Čím tmavší modrá, tím větší pozitivní korelace. Čím tmavší červená, tím větší negativní korelace. Výsledek se počítal pro posty, které mají alespoň 50 lajků a mají překryv s nějakými jinými fanoušky alespoň 30 %. Vidíme, že aktivní lajkeři příspěvkl stránek Blesku, Martina Konvičky, Svobody a Přímé demokracie, IVČR, Tomio Okamury, Blok proti Islámu, Svobodných, Miloše Zemana a Parlamentních listů mají velké zalíbení v podobných stránkách.
Vedle tohoto “národoveckého” bloku tu krystalizují blok tvořený ODS, TOP 09 a stránkami Miroslava Kalouska, Petra Fialy, Echo24, Reflexu a Svobodného fóra, který lze pojmenovat “konzervativně-liberální pravice”.
Minibloky tvoří i stránky ČSSD a jí blízkých politiků a Strana Zelených, HateFree Culture, částečně KDÚ-ČSL a jeji politici, plus tituly z nakladatelství Economia.
Na začátku jsem zmínil, že jsem si pro tuto analýzu vytvořil malou aplikaci. Jestli si ji chcete sami vyzkoušet, můžete zde: https://slerka.shinyapps.io/postanalyzer. Můžete si zkusit měnit i parametry pro korelační matici a sledovat, jak se mění podle parametrů. Podle mne zůstává poměrně stabilní snad jen s výjimkou postavení ODS a Petra Fialy.
Myslím, že dává zajímavé vhledy do toho, jaký obsah láká, a hlavně koho láká.
Josef Šlerka
0 notes