#ugh i apparently can't respond to npf asks in the legacy editor :(
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Note
Am I right in suspecting that GPT-4 is not nearly as great an advance on GPT-3 as GPT-3 was on GPT-2? It seems a much better product, but that product seems to have as its selling point not vastly improved text-prediction, but multi-modality.
No one outside of OpenAI really knows how much of an advance GPT-4 is, or isn't.
When GPT-3 came out, OpenAI was still a research company, like DeepMind.
Before there was a GPT-3 product, there was a GPT-3 paper. And it was a long, serious, academic-style paper. It described, in a lot of detail, how they created and evaluated the model.
The paper was an act of scientific communication. A report on a new experiment written for a research audience, intended primarily to transmit information to that audience. It wanted to show you what they had done, so you could understand it, even if you weren't there at the time. And it wanted to convince you of various claims about the model's properties.
I don't know if they submitted it to any conferences or journals (IIRC I think they did, but only later on?). But if they did, they could have, and it wouldn't seem out of place in those venues.
Now, OpenAI is fully a product company.
As far as I know, they have entirely stopped releasing academic-style papers. The last major one was the DALLE-2 one, I think. (ChatGPT didn't get one.)
What OpenAI does now is make products. The release yesterday was a product release, not a scientific announcement.
In some cases, as with GPT-4, they may accompany their product releases with things that look superficially like scientific papers.
But the GPT-4 "technical report" is not a serious scientific paper. A cynic might categorize it as "advertising."
More charitably, perhaps it's an honest attempt to communicate as much as possible to the world about their new model, given a new set of internally defined constraints motivated by business and/or AI safety concerns. But if so, those constraints mean they can't really say much at all -- not in a way that meets the ordinary standards of evidence for scientific work.
Their report says, right at the start, that it will contain no information about what the model actually is, besides the stuff that would already be obvious:
GPT-4 is a Transformer-style model [33 ] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. [note that this really only says "we trained on some data, not all of which was public" -nost] The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34 ]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
As Eleuther's Eric Hallahan put it yesterday:

If we read further into the report, we find a number of impressive-looking evaluations.
But they are mostly novel ones, not done before on earlier LMs. The methodology is presented in a spotty and casual manner, clearly not interested in promoting independent reproductions (and possibly even with the intent of discouraging them).
Even the little information that is available in the report is enough to cast serious doubt on the overall trustworthiness of that information. Some of it violates simple common sense:

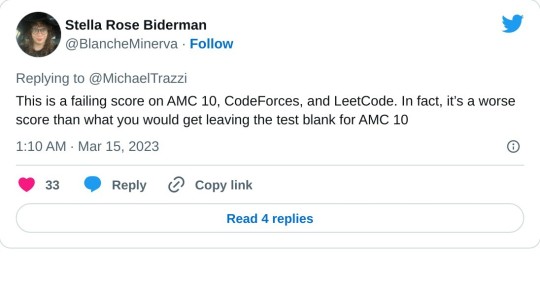
...and, to the careful independent eye, immediately suggests some very worrying possibilities:

That said -- soon enough, we will be able to interact with this model via an API.
And once that happens, I'm sure independent researchers committed to open source and open information will step in and assess GPT-4 seriously and scientifically -- filling the gap left by OpenAI's increasingly "product-y" communication style.
Just as they've done before. The open source / open information community in this area is very capable, very thoughtful, and very fast. (They're where Stable Diffusion came from, to pick just one well-known example.)
----
When the GPT-3 paper came out, I wrote a post titled "gpt-3: a disappointing paper." I stand by the title, in the specific sense that I meant it, but I was well aware that I was taking a contrarian, almost trollish pose. Most people found the GPT-3 paper far from "disappointing," and I understand why.
But "GPT-4: a disappointing paper" isn't a contrarian pose. It was -- as far as I can see -- the immediate and overwhelming consensus of the ML community.
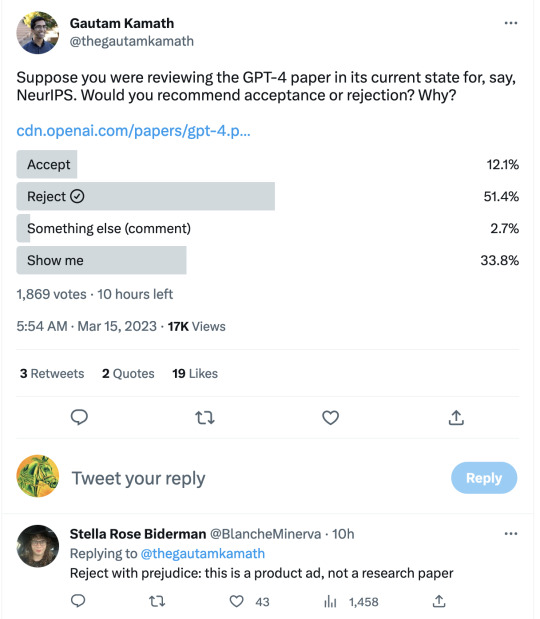
----
As for the multimodal stuff, uh, time will tell? We can't use it yet, so it's hard to know how good it is.
What they showed off in the live demo felt a lot like what @nostalgebraist-autoresponder has been able to do for years now.
Like, yeah, GPT-4 is better at it, but it's not a fundamentally new advance, it's been possible for a while. And people have done versions of it, eg Flamingo and PaLI and Magma [which Frank uses a version of internally] and CoCa [which I'm planning to use in Frank, once I get a chance to re-tune everything for it].
I do think it's a potentially transformative capability, specifically because it will let the model natively "see" a much larger fraction of the available information on web pages, and thus enable "action transformer" applications a la what Adept is doing.
But again, only time will tell whether these applications are really going to work, and for what, and whether GPT-4 is good enough for that purpose -- and whether you even need it, when other text/image language models are already out there and are being rapidly developed.
#ai tag#gpt-4#ugh i apparently can't respond to npf asks in the legacy editor :(#the npf/beta editor is still painful to use#it's nice to be able to embed tweets though
405 notes
·
View notes