#part of this assignment is to demonstrate how python can be better for processing data than excel
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Data Science Course Coaching With ML
Your Project group will be assigned a project mentor and shall be given chance to work on the project With steerage and Assistance. We have promotions and early chook offer every so often. Please verify on web site or discuss to our sales team to know extra about relevant discount. We present each choices i.e Classroom training and instructor led reside coaching choice. Based in your requirement and wish ,you possibly can selected coaching mode. We consider the requirement and need for freshers and Working professionals are completely different. So, We have separate course for freshers and dealing professionals.
You will study each detail of a typical Machine Learning project and understand how to solve real-world problems by making use of AI-associated solutions that make a enterprise influence. The Complete Machine Learning Course is a comprehensive coaching program designed for individuals who need to perceive the ins and outs of Machine Learning. The course will train you every thing you have to know to start constructing a career in Data Science.
As part of this module you be taught additional totally different regression methods used for predicting discrete data. These regression techniques are used to investigate the numeric data known as depend information. Based on the discrete chance distributions specifically Poisson, unfavorable binomial distribution the regression models try to fit the data to those distributions.
You will also be taught concerning the google page ranking algorithm as a part of this module. Extension to logistic regression We have a multinomial regression method used to predict a a number of categorical consequence. Understand the concept of multi logit equations, baseline and making classifications using chance outcomes.
This is helping to create myriad knowledge science/analytics job alternatives in this house. The void between the demand and provide for the Data Scientists is huge and hence the salaries pertaining to Data Science are sky high and considered to be the most effective in the industry. Data Scientist profession path is long and profitable because the era of online data is perpetual and growing sooner or later. Kickstart your studying of Python for data science, in addition to programming normally, with this newbie-pleasant introduction to Python. Python is likely one of the world’s most popular programming languages, and there has never been higher demand for professionals with the power to apply Python fundamentals to drive enterprise options across industries. To perceive the data, they use a variety of tool libraries, corresponding to Machine Learning, statistics and probability, linear and logistic regression, time collection analysis, and more.
This information science demonstrates your proficiency in complicated drawback solving with the most sophistical technology available in the market. The Data Science certificates is your passport to an accelerated career path. 360digitmgResearch Lab is likely one of the best information science training institute in Hyderabad. This team advised me to go along with an information science course, for the first two days I heard the demo and simply received impressed by their instructing and with no second thought choose data science course.
Other than that, lots of the actual advantages, like accessing graded homework and tests, are only accessible should you improve. If you have to keep motivated to finish the complete course, committing to a certificate also puts money on the line so you’ll be much less more likely to give up. I assume there’s definitely private value in certificates, but, unfortunately, not many employers value them that much. One massive difference between Udemy and other platforms, like edX, Coursera, and Metis, is that the latter supply certificates upon completion and are usually taught by instructors from universities. It turned out to be extremely powerful working on one thing I was keen about. It was easy to work exhausting and be taught nonstop as a result of predicting the market was something I actually needed to accomplish.
With the instruments hosted within the cloud on Skills Network Labs, you will be able to check each tool and follow directions to run simple code in Python, R or Scala. To end the course, you'll create a ultimate project with a Jupyter Notebook on IBM Watson Studio and reveal your proficiency preparing a notebook, writing Markdown, and sharing your work with your friends. This certificate could be very nicely recognized in 360digitmg-affiliated organizations, including over 80 prime MNCs from all over the world and a number of the Fortune 500companies. You will work on highly exciting initiatives within the domains of excessive know-how, ecommerce, advertising, sales, networking, banking, insurance coverage, etc.

360digitmg doesn't currently have a approach to offer certificates, so I usually discover Udemy programs to be good for extra utilized studying materials, whereas Coursera and edX are normally better for concept and foundational materials. Python is used on this course, and there’s many lectures going through the intricacies of the various information science libraries to work via actual-world, interesting issues. This is likely one of the solely data science programs around that really touches on every a part of the data science process. Lastly, when you’re extra thinking about studying information science with R, then definitely check out 360digitmg new Data Analyst in R path.
youtube
In this tutorial you will study joint probability and its functions. Learn how to predict whether or not an incoming email is a spam or a ham e-mail. Learn about Bayesian likelihood and the applications in solving advanced business issues. The Boosting algorithms AdaBoost and Extreme Gradient Boosting are mentioned as a part of this continuation module You may also learn about stacking methods. Learn about these algorithms which are offering unprecedented accuracy and serving to many aspiring data scientists win the primary place in numerous competitions corresponding to Kaggle, and so on. As part of this module, you'll proceed to be taught Regression techniques applied to foretell attribute Data.
Explore more on - data science course in hyderabad with placements
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address:-2-56/2/19, 3rd floor, Vijaya towers, near Meridian school, Ayyappa Society Rd, Madhapur, Hyderabad, Telangana 500081
Contact us ( 099899 94319 )
https://360digitmg.com/data-science-course-training-in-hyderabad
Hours: Sunday - Saturday 7 AM - 11 PM
#data science course in hyderabad with placements#data science institutes in hyderabad#Best Data Science courses in Hyderabad
0 notes
Text
My Programming Journey: Machine Learning using Python
After learning how to code in SAIT I decided I wanted to take things to the next level with my programming skills and try Machine Learning by myself, given that Artificial Intelligence has always been a really intriguing topic for me and I like a good old challenge to improve, grow and, most importantly, learn new things.
A lot is said about Machine Learning, but we can define it as algorithms that gather/analyze data and learn automatically through experience without being programmed to do so. The learning is done by identifying patterns and making decisions or predictions based on the data.
ML is not a new technology but recently has been growing rapidly and being used in everyday life. Examples that we are all familiar with are:
-Predictions in Search Engines
-Content recommendations from stream services or social media platforms
-Spam detection in emails
-Self-driving cars
-Virtual assistants
The Importance of Machine Learning
The vast amount of data available and processing power in modern technology makes it the perfect environment to train machine-learning models and by building precise models an organization can make better decisions. Most industries that deal with big data recognize the value of ML technology. In the health care industry, this technology has made it easier to diagnose patients, provide treatment plans and even perform precision surgeries. Government agencies and financial services also benefit from machine-learning since they deal with large amounts of data. This data is often used for insights and security, like preventing identity theft and fraud.
Other things like speech and language recognition, facial recognition for surveillance, transcription and translation of speech and computer vision are all thanks to machine learning, and the list goes on.
Types of Machine Learning
Usually, machine learning is divided into three categories: supervised learning, unsupervised learning and reinforcement learning.
Supervised learning
For this approach, machines are exposed to labelled data and learn by example. The algorithm receives a set of inputs with the correct outputs and learns by comparing its output with the correct output and modify the model as needed. The most common supervised learning algorithms are classification, regression and artificial neural networks.
Unsupervised learning
Unlike the previous approach, the unsupervised learning method takes unlabelled data so that the algorithm can identify patterns in data. Popular algorithms include nearest-neighbor mapping and k-means clustering.
Reinforcement learning
This approach consists of the algorithm interacting with the environment to find the actions that give the biggest rewards as feedback.
Iris Flower Classification Project
The iris flower problem is the “Hello World” of machine learning.

Iris flowers in Vancouver Park by Kevin Castel in Unsplash - https://unsplash.com/photos/y4xISRK8TUg
I felt tempted to try a machine learning project that I knew was too advanced for me and flex a little or fail miserably, but I decided to start with this iconic project instead. The project consists of classifying iris flowers among three species from measurements of sepals and petals’ length and width. The iris dataset contains 3 classes of 50 instances each, with classes referring to a type of iris flower.
Before Starting the Project
For this project, and for the rest of my machine learning journey, I decided to install Anaconda (Python 3.8 distribution), a package management service that comes with the best python libraries for data science and with many editors, including Visual Studio Code, the editor I will be using for this demonstration.
You can get Anaconda here: https://repo.anaconda.com/archive/Anaconda3-2021.05-Windows-x86_64.exe
I find that Anaconda makes it easy to access Python environments and it contains a lot of other programs to code and practice, as well as nice tutorials to get acquainted with the software.
In the following videos, I will be going step by step on the development of this project:
youtube
youtube
If videos aren't your thing, the readable step-by-step instructions are here in the post:
Prior to this project, I already had Visual Studio Code installed on my computer since I had used it for previous semesters. From VSCode I installed Python and then I selected a Python interpreter. The Python interpreter I will use is Anaconda, because it has all the dependencies I need for coding.
Getting Started
I configured Visual Studio Code to be able to develop in Python, then I created a python file named ml-iris.py and imported the libraries, which are the following:
The main libraries I will be using are numpyand sklearn.
· Numpy supports large, multidimensional arrays and a vast collection of mathematical operations to apply on these arrays.
· Sklearn includes various algorithms like classification, regression and clustering, the dataset used is embedded in sklearn.
From the previously mentioned libraries, I am using the following methods:
· load_iris is the data source of the Iris Flowers dataset
· train_test_split is the method to split the dataset
· KNeighborsClassifier is the method to classify the dataset.
I will be applying a supervised learning type of ML to this project: I already know the measurements of the three kinds of iris species; setosa, versicolor or virginica. From these measurements, I know which species each flower belongs to. So, what I want is to build a model that learns from the features of these already known irises and then predicts one of the species of iris when given new data, this means new irises flowers.
Now I start building the model:

The first step (line 6), I define the dataset by loading the load_iris() dataset from Sklearn.
Next step (line 7), I retrieve the target names information from the dataset, then format it and print it.
I repeat this step for retrieval of feature names, type and shape of data, type and shape of target, as well as target information (lines 8 to 13).
Target names should be Setosa, Versicolor and Virginica.
Feature names should be sepal length, sepal width, petal length and petal width.
Type of data should be a numpy array.
Shape of data is the shape of the array, which is 150 samples with 4 features each.
Type of target is a numpy array.
Shape of target is 150 samples.
The target is the list of all the samples, identified as numbers from 0 to 2.
· Setosa (0)
· Versicolor(1)
· Virginica(2)
Now I need to test the performance of my model, so I will show it new data, already labelled.
For this, I need to split the labelled data into two parts. One part will be used to train the model and the rest of the data will be used to test how the model works.
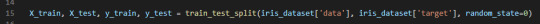
This is done by using the train_test_split function. The training set is x_train and y_train. The testing set is x_test and y_test. These sets are defined by calling the previously mentioned function (line 15). The arguments for the function are samples (data), features (target) and a random seed. This should return 4 datasets.
The function extracts ¾ of the labelled data as the training set and the remainder ¼ of the labelled data will be used as the test set.
Then I will print the shape of the training sets:

And the shape of the testing sets:

Now that the training and testing sets are defined, I can start building the model.
For this, I will use the K nearest neighbors classifier, from the Sklearn library.

This algorithm classifies a data point by its neighbors (line 23), with the data point being allocated to the class most common among its K nearest neighbors. The model can make a prediction by using the majority class among the neighbors. The k is a user-defined constant (I used 1), and a new data point is classified by assigning the label which is most frequent among the k training samples nearest to that data point.

By using the fit method of the knn object (K Nearest Neighbor Classifier), I am building the model on the training set (line 25). This allows me to make predictions on any new data that comes unlabelled.

Here I create new data (line 27), sepal length(5), sepal width(2.9), petal length(1) and petal witdth(0.2) and put it into an array, calculate its shape and print it (line 28), which should be 1,4. The 1 being the number of samples and 4 being the number of features.
Then I call the predict method of the knn object on the new data:
The model predicts in which class this new data belongs, prints the prediction and the predicted target name (line 32, 32).
Now I have to measure the model to make sure that it works and I can trust its results. Using the testing set, my model can make a prediction for each iris it contains and I can compare it against its label. To do this I need the accuracy.

I use the predict method of the knn object on the testing dataset (line 36) and then I print the predictions of the test set (line 37). By implementing the “mean” method of the Numpy library, I can compare the predictions to the testing set (line 38), getting the score or accuracy of the test set. In line 39 I’m also getting the test set accuracy using the “score” method of the knn object.
Now that I have my code ready, I should execute it and see what it comes up with.
To run this file, I opened the Command Line embedded in Anaconda Navigator.
I could start the command line regularly but by starting it from Anaconda, my Python environment is already activated. Once in the Command Line I type in this command:
C:/path/to/Anaconda3/python.exe "c:/path/to/file/ml-iris.py"
And this is my result:
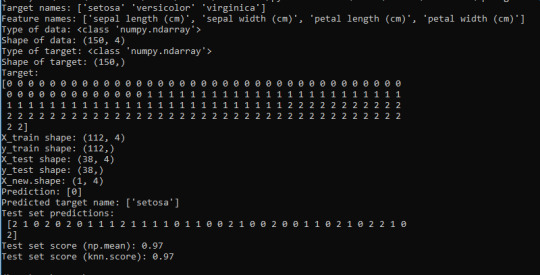
The new data I added was put into the class 0 (Setosa). And the Test set scores have a 97% accuracy score, meaning that it will be correct 97% of the time when predicting new iris flowers from new data.
My model works and it classified all of these flowers.
References
· https://docs.python.org/3/tutorial/interpreter.html
· https://unsplash.com/photos/y4xISRK8TUg
· https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
· https://www.sas.com/en_ca/insights/analytics/machine-learning.html
· https://en.wikipedia.org/wiki/Machine_learning
· https://medium.com/gft-engineering/start-to-learn-machine-learning-with-the-iris-flower-classification-challenge-4859a920e5e3
0 notes
Text
Space Case (crossover with Star Trek: DS9)
Julian Bashir carefully stepped over an upturned root that appeared in his way. He and a small contingent of officers had been asked to survey a small planet just an hour past the Gamma side of the wormhole. After completing an orbital inspection, they’d docked the runabout and began a more in-depth sweep of one of the moderately-populated areas. The planet’s inhabitants were easily capable of space flight; they simply chose to keep to themselves.
Julian had found multiple plant samples that would make for fascinating medical study when they got back to the station, but he’d somehow managed to wander far enough from the rest of the group in the process that, even with his abilities, he’d be hard-pressed to make his way back before nightfall. He sighed and started looking for a decent tree to climb. Most of the branches were just out of his reach, but if he could get up there, he’d be able to get his bearings and get back to the others.
A sharp rustling brought him up short. He looked around with trepidation; the last thing he needed was to be mauled by some alien predator. He reached for his phaser, not taking his eyes off where he’d heard the sound. But, just to be sure…
“Hello?” He called out.
The rustling returned, but now it was clearly coming from the understory. He watched as the leaves parted and his observer emerged.
“Hello, yourself!”
It was a man, or at the very least, a male humanoid. He appeared early- to middle-aged, bare-chested, with long auburn hair and a square jaw. He smiled brightly at Julian, but it faltered when he saw what he was reaching for.
“Hey now, l-let’s not be hasty. I’m not gonna hurt you!”
Slowly, Julian lowered his hand from his phaser. He might end up regretting it, but he was going to give the man the benefit of the doubt.
“Can’t be too careful these days.” Julian quipped, folding his arms across his chest. “So, what brings you this far out into the jungle?”
“Oh, I live here. Can’t you tell?” The man laughed, perching his head on his closed fist. “My, but you’re an interesting fellow, aren’t you? My name’s Kenny. What’s yours?”
“Julian.” He replied.
“Pleasure to make your acquaintan— whoops!” He’d reached to shake Julian’s hand, but he’d overbalanced and had nearly fallen out of the tree. As he hoisted himself back up, Julian saw what had been earlier obscured by foliage: a long serpentine tail that made up the lower half of Kenny’s body. Julian couldn’t help but stare; he’d never seen anything like Kenny outside of Terran folklore.
“My goodness!” He breathed.
Kenny gave an embarrassed chuckle. “Sorry if I startled you.”
“Started me?!” Julian was beaming with excitement. “You’re incredible! A miracle of evolution! Oh, would you mind terribly if I took some scans of you?”
Kenny shrugged and spread his arms wide. Taking this as consent, Julian pulled out his tricorder and started taking scans. As the information came in regarding Kenny’s skeletal and muscular systems, he looked on in wonder.
“Truly remarkable!”
“Ooh, can I see?” Kenny asked, hanging from the branch by his massive tail.
Julian mulled it over for a moment. It might be viewed as a violation of the Prime Directive, but he considered any damage negligible. Besides, how would Kenny use the information anyway? With a light shrug, he tilted the screen up so that Kenny could see.
“Neat! So that’s what I look like on the inside?”
He nodded. “Now if I could get some synaptic readings…”
_______________
This continued for a good half an hour, until Julian’s scientific curiosity was mostly satisfied. With a new species, one could never be completely satisfied, knowledge-wise. Julian had never been happier on an assignment, and Kenny seemed to be enjoying it as well.
“Ya know,” Kenny said with a mischievous smile, “I can do something else too.”
“Really?” Julian asked, looking up from his data.
“Yeah! Want a demonstration?”
“All right.” He wondered if he should be concerned.
“Just look right here.” Kenny pointed at his eyes with the tip of his tail.
Julian shrugged and did as he was bid. As he watched, Kenny’s eyes started changing colors, rippling out from his pupils. They went faster and faster, and soon he was struggling to keep up. He felt dizzy, then slightly euphoric.
“Pretty neat, huh?” Kenny asked with a smile.
“Y-yeah…” He blinked hard, trying to clear his head. His own eyes were glazing over, reflecting the colors back to Kenny. He felt Kenny’s tail winding around his waist in a firm squeeze.
“Why don’t we have a little alone time up in the canopy, hm? Doesn’t that sound nice?”
It really did, honestly. Just as he was about to nod his head in agreement, a memory flickered in the back of his mind: an old children’s program about a boy who lived in a jungle, and a python with very similar powers. Red-alert klaxons started shrieking in his brain.
“You’re n-not gonna eat me, are you?” He asked, dazed by the continued display.
The colors suddenly melded back into Kenny’s dark eyes as he pouted. “Why does everyone always ask me that? I don’t eat people!” He smiled and pinched Julian’s cheek. “And even if I did, I wouldn’t eat you. You’re too cute!”
A small giggle escaped Julian’s lips. That was always nice to hear, no matter the context. He’d started to relax, just a little, when his mind began to clear. He really shouldn’t be just sitting here, should he? He should be trying to find a way back to the runabout with the others. He really should be leaving, instead of staying there wishing he could go back to staring into Kenny’s eyes again, letting the dizzying array of colors flood his mind until he forgot everything else. Oh, it was so tempting…
“Dax to Bashir.”
Julian blinked out of his reverie and chuckled. “I, ah, I gotta take this.” He took a deep breath to steady himself, then turned and activated his commbadge. For some reason, it felt easier to focus if he kept his eyes closed. “Bashir here.”
“Julian, there’s some kind of problem with the runabout’s engines. O’Brien is working on them, but it’ll be a few hours before they’ll be up and running. How soon can you get back here?”
“Well,” he trailed off, feeing embarrassed, “I’m actually a bit lost. Any chance you could beam me back?”
“No can do, Julian. Whatever’s wrong with the engines is affecting the transporters too. Just stay where you are and we’ll come get you. Alright?”
“Understood. Thanks for letting me know. Bashir out.”
Julian sighed and rubbed at his forehead. Of all the times for a runabout to break down, it had to be on the planet where he was stuck with a serpentine humanoid with questionable motives. At least he was beginning to feel more alert, if only a little.
“Sounds like you’re gonna be here a while longer.” Kenny purred from behind him.
“Yes, it certainly does.”
“Well, I happen to know an excellent way of passing the time!”
“And what might that be?” He asked, turning back to face Kenny.
The second the words left his mouth, he knew what was about to happen, but he couldn’t shut his eyes fast enough to avoid his temptation of fate. Instantly, his vision was swamped by a myriad of colored rings. Still a bit woozy from the last time, Julian was unable to resist becoming transfixed, eyes glassy and reflecting the colors back. He wobbled on his feet, only to be caught by Kenny’s tail.
“Woah, easy there! I’ve got you!”
Julian leaned back into the coils, unconcerned that he’d almost fallen. He wasn’t really worried about anything right now; he just felt so good. Not even when he’d been on painkillers for a sports injury had he felt so blissed out. He trailed his fingertips lightly against Kenny’s scales, laughing softly at the texture. It was as if someone had flipped a switch, and all Julian needed to do anymore was feel.
Kenny smiled mischievously and wrapped his coils around Julian, then gently pulled the two of them up into the trees. Julian didn’t squirm or seem distressed in any way; his entrancement kept him completely relaxed, trusting Kenny entirely with his safety. They settled against a junction of thick branches, and Kenny made a pseudo-nest out of his coils for Julian to recline in.
“Feel better?” Kenny asked, toying with Julian’s hair.
Julian hummed in agreement, leaning into the touch. It felt so nice to just be held like this, drifting in this fog of euphoria. He absolutely never wanted to come out of it, ever.
“Good, good.” He purred. The coils tightened around Julian in a hug. “I thought we could just stay up here for a while. You could take a nice afternoon nap while you wait for your friends, and I’ll cuddle you until you wake up.” He lightly scratched behind Julian’s ear. “Would you like that, darling? Just have a little rest?”
“Mmm… yes, please.” Julian murmured. A nap sounded absolutely wonderful. He felt so comfy and relaxed, he could easily doze off.
“Aww, so polite!” Kenny cooed. He shifted his coils to form a makeshift blanket. “You just settle down and look in my eyes for as long as you can, just until you fall asleep. Can you do that?”
“Mm-hm…” Julian replied, nestling under the coils.
“Good…” Kenny’s eyes started to almost glow as the colors spun, hypnotizing Julian more the longer he stared. He didn’t mind, though; it felt so good to just keep staring as long as he could. As he continued to stare, Kenny started rhythmically stroking Julian’s hair and began to sing.
“Hush, my little moonbeam, Let your dreams take wing. To soothe your mind and bring you peace, This little song I’ll sing.”
Ohh, a lullaby! That would be so nice. He hadn’t been sung to sleep since he was a child. A big dreamy smile formed on Julian’s face. Kenny had such a pretty singing voice, so very pretty…
“Pillow your head on my lap, my dear, And snuggle close to me. All your thoughts drift far away. There’s no place you’d rather be.”
He did snuggle close to Kenny, yawning all the while. He was just so deliciously warm and cozy, and the coils that covered him felt like the weighted blanket he kept in his quarters, soothing him immensely. Kenny’s song made his own mother’s lullabies seem so trite in comparison. His eyelids fluttered and drooped. He wanted to keep staring into Kenny’s eyes, but he felt so sleepy.
“You’re safe and warm in my embrace, That promise I will keep. There’s starlight in your heavy eyes, Now it’s time to go to sleep.”
With another yawn, Julian’s eyes sank closed and he drifted into a deep, peaceful sleep. Kenny smiled, gave him a light squeeze with his tail, and placed a goodnight kiss on top of his head. He gently leaned back against the tree trunk and let his own eyes close, just for a minute.
____________________________
A soft beeping tugged him back into consciousness. Kenny yawned and stretched, rubbing his eyes. That had been a very nice nap, hadn’t it? He glanced over at his new friend, still sleeping soundly in his coils, and gave him a cuddly squeeze with his tail. Julian smiled in his sleep and hummed softly in contentment. He was just so darn cute!
The beeping that had woken him became louder and more insistent. Julian grumbled softly and tried to shift one of the coils over his head to muffle the sound, but it was a touch too heavy for him to lift. Giving up, Julian’s eyes slowly fluttered open and he sat up and stretched. At first, his mind was blissfully empty, but after a moment or two his memories trickled back.
“Morning…” he yawned.
Kenny chuckled. “Good morning, sleepyhead. How are you feeling?”
“Mmm… good, thanks.” Julian rubbed at his eyes, wishing he could have slept a little longer. He’d been having such a lovely dream. The setting sun in his eyes suddenly brought him up short. “Wait… it’s not morning, is it?”
“Nope!” Kenny laughed. “Almost dinner time!”
He finally started paying attention to the noise in the background, then glanced down at his commbadge. “They’re looking for me. I’d best get down from here.”
“Allow me.” Kenny offered, then gently lowered Julian to the forest floor. Now aware enough to appreciate it, Julian looked around in wonder at the environment. His feet softly connected with the ground and the tail wrapped around him slid away. He sighed softly in disappointment as the warmth retreated.
A thought suddenly occurred to him. “Oh, how am I going to explain you? I could get in trouble for what I showed you! And there’ll be a whole exobiology team wanting to study you and not all of them are nice, and—“
“Shh…” Kenny pressed a finger against Julian’s lips. “It’s okay. I’ll just make myself scarce before anyone else gets here.”
Julian mentally calculated the away team’s distance from the beeping of his commbadge, which was slowly but steadily increasing. “It’ll be a good twenty or thirty minutes before they get here. What should we do?”
“Well,” Kenny mulled it over, “you could tell them I got away while you were taking readings, and you couldn’t catch me.” A mischievous grin grew on his face. “You were a little foggy when you woke up, right? A little hazy in the head?”
“Well, yes, but—” Julian frowned at him in suspicion. “Kenny, what exactly are you planning?”
He chuckled and lifted Julian’s chin with his finger. “Oh, nothing.”
“Kenny, you can’t put me under again. I’m far too wired to sleep!”
“Don’t you worry; I’ve got a quick fix for that!” Kenny’s eyes rippled and glowed, and Julian was entranced almost instantly. His entire body felt unbearably heavy, and his knees buckled. Once again, Kenny caught him before he could hit the ground. “What was that about being too wired?”
“K-Kenny, you… um…” Julian struggled to form a coherent sentence, but all his thoughts were swept away by the colors rippling in Kenny’s eyes, which were soon reflected in his own. A dazed, sleepy smile formed on his face. “S-so pretty…”
“Yeah, really pretty.” Kenny purred, stroking Julian’s hair. He pulled Julian into a little cuddle and gently eased him to the ground. “You’re still so tired, huh? Need to have a little catnap?”
“Yes…” He slurred, already beginning to drift.
Kenny gently arranged Julian so that his head was pillowed on his arms. “There we are, nice and comfy!”
“Mmm, comfy…” Julian agreed, snuggling down with a yawn. “So sleepy…”
“Yessss,” Kenny replied with a sibilant coo. “So very sleepy, aren’t you? Can’t even keep your eyes open? They’re just too heavy?”
Julian’s eyes were almost completely closed. “H-heavy…” He yawned. “C-can’t…”
Kenny hushed him. “Don’t worry about that, darling. Just close your dreamy little eyes for a while. Have a nice long sleep.”
“ ‘Kay…” he murmured, eyes drifting shut. “Nuh-night…”
“Sweet dreams, Julian.” He purred in his ear. “Sweet, sweet dreamssssss…”
After that, Julian heard nothing more.
___________________________
Lieutenant Jadzia Dax held the tricorder out in front of her as she stepped over an exposed tree root. The signal was increasing in strength, so Julian had to be somewhere nearby. She was still kicking herself for letting him wander off.
“Remind me why we brought Doctor Nitwit on this mission?” Eddington groused.
“Because I find him infinitely less irritating than I find you!” O’Brien replied with a snap. The bloody Starfleet yes-man rubbed him the wrong way far too many times. If it had been up to him, they’d have brought Nog; the boy might be a cadet, but at least he wasn’t a pain in the arse.
“I thought favoritism wasn’t permitted in mission assignments!”
“Girls, girls, you’re both lovely.” Jadzia muttered. A sharp signal increase caused her to turn to the left, lift a branch, and stop dead in her tracks.
“Now what?” Eddington looked over her shoulder and groaned in disbelief. “Really? This is where he’s been all day?!”
A few yards in front of them, on a bed of moss, Julian was curled up fast asleep. He had his head resting on his arms and a soft smile on his face. He looked so adorable, Jadzia was hard-pressed to wake him.
Eddington did not share her feelings.
“We’ve been working our asses off for half a day, and he’s out here getting his beauty sleep? That lazy son of a—”
“Now, hang on! What do ya mean, ‘we’? I distinctly remember hearing you snoring away in the back of the runabout!”
Eddington flushed red. “I was not!”
“Oh, then it must’ve been somebody with a bloody chainsaw!”
While the other two continued to argue, Jadzia rolled her eyes and quietly walked over to Julian and shook his shoulder. “Julian? Time to get up.”
Julian stirred, then slowly woke. “J-Jadzia?” He yawned. “Must’ve dozed off.”
He unsteadily got to his feet, leaning on Jadzia for support. Seeing that he was up, O’Brien and Eddington has moved their argument towards the runabout instead. Jadzia gave Julian’s shoulder a squeeze and walked him the same direction, promising him that he could rest on the flight back to the station.
There was a soft rustle from the leaves behind them. Julian glanced behind and, when Jadzia wasn’t paying attention, waved goodbye. Part of a large, tawny snake tale slid out and waved back.
#ask-nagakenny#submission#story#anonymous#ds9#julian bashir#hypnosis#aaaAAAA this is so cute i'm dying <3
27 notes
·
View notes
Text
011 // Distractions I: Random Map Generator (Part 0)

A Python Implementation of Amit Patel's Polygonal Map Generator
Early last year, I took some time away from my game to work on a random map generator, and not for a first attempt. One of the earliest things I had wanted to create in Python was a map generator, but, lacking any idea of how to do it and anything more than a modest talent for mathematics, it never came to much. And then, last March, I give it a third try, this time based on RedBlob Games' very good tutorial-demonstration essay, constructed in ActionScript. (ActionScript, which I know bits and scraps of but have been away from for years..)
I took about half a year out and worked on creating a Python implementation of that code (borrowing from some other sources as well and leaning on the mathematics knowledge of my brilliant girlfriend), and although I doubt that this code will lend itself to my current game so far, it did prove to be a very constructive learning experience. (If you have arrived here looking for the code itself, I imagine I will post it once I get it to some presentable state, whenever that happens. Please look forward to it!)
Here is a point-form description of how the maps are generated (although the previously-linked essay describes it much better).
The map generation process takes place in three main phases:

- 0. Random point selection and Voronoi diagram generation.
i - Random points selected using Python's random.sample() method.
ii - Diagram setup.
iii - Voronoi diagram and Delaunay triangulation generation by Fortunes algorithm (the steepest part of the learning curve goes here).
iv - Diagram resolution.
v - Lloyd relaxation and diagram regeneration (repeat from (ii) for n steps, using Voronoi cell centroids from current diagram relaxation).
vi - Generate 'noisy' borders.
vii - Resolve cell perimeter points.

- 1. Water body propagation and elevation profile generation
i - Determine land-water cell ratio; diagram border/ocean configuration.
ii - Distribute water to starting ocean and lake cells.
iii - Initial water cells pass surplus water volume to their neighbours (recursive).
iv - Assign basic elevation values to cell vertices (elevation equal to minimum 'hops' to nearest coastal vertex, less distance over lakes).
v - Scale elevations relative to a maximum elevation (preserves relative altitudes; excludes water).
vi - Apply elevation data to cells (based on the elevations of their vertices).
- 2. Meteorology, rivercourses, and biome assignment
i - Determine runoff corners for cells (rainwater accumulates at their lowest perimeter vertex).
ii.a- Determine rivercourses (non-coastal vertices transmit accumulated water to their lowest-elevation adjacent vertex).
ii.b- I did not have to do it but rivers terminate at lakes, and lakes generate output rivers, and it is all far more complex than I can put into a single sentence. Sorry; I will try to explain it properly some other time. :s
iii - Apply rainfall to cells (base per-pixel rainfall multiplied by cell size) (I want to work out some kind of rainshadow thing here but I have not gotten around to it yet).
iv - Assign 'moisture' values to cells based on the volume of water flowing (and standing) around them.
v.a - Assign biome types to cells based on their elevation and moisture parameters.
v.b - Some biomes overlap, and when they do, choose one at random.
v.c - I added some special biomes which also respond to average incline among vertices, volume of adjacent water or sand, salt, and a few others.
v.d - Some biomes can 'spread' to adjacent biomes if conditions are correct. (This took a bit of fine-tuning)
vi - Assign cells to custom groups based on common properties (biome, elevation, relative location on the diagram, et cetera..).
- 3. I also made a thing that renders the map in 3d, since all the data is there already!

There are a few different ideas that the Patel essay includes, which I have not implemented here yet-- Perlin noise looks pretty but I do not know how to make it work in Python (yet). I have not added roads yet either, although it does not seem over-hard compared with the complexity of rivers. I am still experimenting with different map generation geometries, with various degrees of success. The Voronoi diagram generator still has some strange and infrequent flaws I do not know how to resolve (or, in fact, even how to trigger or reproduce), and the noisy-borders math implementation I have set up creates some aesthetic issues here and there (most noticeably on the borders of dart-shaped, rather than kite-shaped, Voronoi cells).
I also have had some ideas about how to illustrate the maps beyond blocks of colour (it might be nice if forests had some depth, or at least did not end abruptly at cell borders) and how to group cells up into geometric or 'political' regions, but the time I have dedicated to it has decreased since I returned to the project I have posted here so far. For what it's worth, I have no plans to abandon it, but I also cannot work on both at once so well..
Anyhow, this is the first post in a potential series to do with this map generator. As I add to it or find additional uses, I will do my best to post them here! See you next week! :y
#longpost#tech#distractions#mappos#random map generation#voronoi#off-topic#in-line images#discount 3d rendering#worldbuilding
10 notes
·
View notes
Text
Lessons from a software project
I am adding to my usual weekly rotation of posts to write about a software project that I recently (almost) finished. I want to get my thoughts down now while it is fresh in my mind.
Project Overview
The project is a bug tracker. It is online here. The GitHub repo is here. It is a simple, classic bug tracker. The app allows teams to define several projects and maintain a list of outstanding issues for each project, assigned by user. Project managers and issue owners can mark issues as complete. An individual could use it as a personal to-do list as well. The mail element of the technology stack are as follows.
- React frontend, generated with create-react-app. It is a single page app with all the app’s functionality. It is implemented on GitHub pages.
- Auth0 for authentication.
- A Node backend. It handles api calls to the database. It is deployed on an Amazon Web Services EC2 t2.micro instance running Amazon Linux 2.
- PostgresQL database. It stores user data and data about teams, projects, and issues. It is implemented with an Amazon RDS t3.micro instance.
- SB Admin 2, a Bootstrap theme, for styling.
The purpose of this project is to serve as a portfolio piece indicating that I am capable of full stack development. As such I think it is a good step and the best full stack project I have done so far, but I think I can do better next time. Some of the ways I can do better are detailed below.
Functionality
The functionality of the app is fairly limited relative to what I wanted. It allows creation and deletion of teams, projects, and issues, as well as completion of issues by their owners. I would have liked to add timestamps for issue creation and due date; some sorting functionality; and mechanisms for modifying teams, projects, and issues without deleting and recreating them, but I ran out of time that I was willing to devote to the project.
I’ve tested the project extensively locally, but there are so many variables in the deployment that I don’t know how it is going to survive in the wild. We will see.
There are a couple things that I don’t think are quite right but do not seem to be major problems and that I gave up worrying about. For one thing, the front end seems to be firing off more API calls than I think it should be. I’m pretty sure it has something to do with React’s useEffect being triggered more often than I want, but I did not figure out the precise reason in the course of investigating. There were a couple of icons that are part of the SB Admin 2 theme that for whatever reason I couldn’t get to appear properly, and I gave up on those.
Development
The main challenge in development was locally wiring up the various pieces. The actual programming of the app wasn’t too hard. This was my first project with PostgresQL, and I found the system to be straightforward enough. It was also my first attempt to use Auth0. I found the system to be challenging to use, though it provides much more functionality and ease of use for user than any authentication that I would be able to develop myself.
I have used Node many times before. I like it and find it straightforward. The app in this case is fairly simple and primarily serves the function of interfacing between the front end and the database. In theory I think I could have made database calls directly from the front end, but that doesn’t seem like a good design decision.
I’ve done a few React apps, all with create-react-app. I think that was a mistake. I’ve been using create-react-app as a crutch. The system brings about some serious bloatware. The next time I do something with React, I should find an alternative way to develop and deploy the app. Beyond that, my system of passing parameters through the app is also a bit of a mess. I believe Redux would help streamline that process, and Redux is on my todo list, but it is not something I am familiar with yet. I used a few class components, but I think I should have just kicked that habit and done everything with function components; I see no reason why I couldn’t have.
SB Admin 2 was a pleasure to use. Design isn’t my strongest suit, nor is it primarily what I wanted to illustrate with this project. Going off the project template, I found it easy to make an app that looks presentable. I’m a little dissatisfied with the color scheme, which has something of that “corporate kindergarten” aesthetic to it, but that is acceptable.
Deployment
Actually putting this thing online so others could use it was a major time sink and source of frustration learning experience. I noted in last week’s blog post that this endeavor falls under the job description of a DevOps person, which is not what I am aspiring to be. DevOps is its own form of problem solving, which for the right person could be a lot fun. It also commands a market premium for people who have those skills. I now see very clearly why.
I made a very big mistake that I will not be repeating on future projects. I tried to develop everything locally and get full app functionality locally before taking on deployment. Worse, I tried to treat the entire project as a single package. I was not, for instance, planning on using AWS RDS for the database. I had set up PostgresQL on my local machine and tried to do the same on the EC2 instance. I was also planning on building and running the React frontend out of the same instance.
Almost none of this worked. I installed PostgresQL on the EC2 instance, and it seemed to work for a while, but after a while I couldn’t connect at all. Repeatedly uninstalling and reinstalling the database just caused the DevOps gods to laugh. It was only then that I decided to separate the database to RDS. Even then, somehow the pq module (the Node modules that connects to a PostgresQL database) got borked and I had to uninstall and reinstall it to get that working.
I also tried to run the Node and React apps out of a single concurrently instance. Again, it worked fine locally but failed on deployment. I still don’t fully understand why it didn’t work. Part of the problem was security. For whatever reason React wanted to build to an HTTP instead of an HTTPS deploy, which Chrome flagged as a security hazard. I struggled to figure out how to add an SSL certificate and that only seemed to partially solve the problem. Then I got a CORS (cross-origin resource sharing) error. I tried modifying the Node app to an HTTPS instead of an HTTP server, but that didn’t seem to solve the problem. Even now I’m still not sure it is working right. My browser loads the front end all right but still gives me a security flag.
There was also an issue of the proxy in packages.json not working. Again, it worked fine in dev but just flat out refused to work on the deploy. I gave up trying to figure out why and just started doing full URLs in the fetch requests.
It is obvious in retrospect, and for future projects, that I should have done one or both of two things:
1) Go for a modular design from the beginning. Now all the major pieces are in different places (except I deployed SB Admin 2 with the front end), and that leaves fewer opportunities for conflict. There was no reason not to plan it out that way from the beginning.
2) Figure out the deploy process at the outset. This is the “walking skeleton” methodology. I would add only the minimal “hello world” substance to each piece, then fully ship the project to demonstrate a working architecture. Then I go about building out the pieces. Had I done this at the start, it would have saved me a great deal of stress later on.
Some General Thoughts
The difficulty of a project grows superlinearly in the number of mutually interrelated components. This is probably the same basic mechanism that causes complex infrastructure projects to almost always go over schedule and budget. Modularity needs to be a watchword. I’ve learned my lesson on that.
In general I was pretty happy with AWS. The performance seems to be quite good. It wasn’t too hard to use. The AWS console is huge and can be difficult to navigate. Their system of traffic access rules is a bit confusing but was manageable.
People often complain about JavaScript development. I think the problem is not with JavaScript itself, but with the NPM zoo. Despite the allegedly modular design of NPM packages, the inscrutable chain of dependencies are such that they are inherently non-modular in practice. Reproducibility is a serious problem. Security is a problem. There are vulnerabilities such as shown in the left-pad incident. The system leads to bloatware. It fosters a bad habit of programmers pulling in packages for simple functions they could easily write themselves. The multiplicity of potential clashes between packages of different versions is a factor driving the development of virtual machines and containerization, tools which introduce their own inefficiencies through abstraction. There has got to be a better way. I wonder if there exists anything that be for JavaScript what Acaconda is for Python. There certainly should be.
Security and networking are two things that are important and I just don’t understand very well yet. I think this process would have been easier if I knew what was going on when those bugs came up.
What’s Ahead
For now I am taking a breather to celebrate the completion of this project. While there are some deficiencies in this latest project, I think the place to correct them is on the next project, rather than try to push this one any further. Eventually I want to plan out and execute another full stack project. I don’t know what it will look like yet, but it should be something more interesting than a bug tracker.
In the meantime, I am working through a JavaScript bootcamp and have fallen behind on the projects there. For my next portfolio piece, I want to do something more algorithms-oriented, where the challenge will be in the actual coding rather than in the DevOps.
0 notes
Text
Emerging Big Data Trends
Huge information market will be worth us$46.34 billion by end of 2018. this plainly demonstrates enormous information is in a steady period of development and advancement. idc gauges that the worldwide income from huge information will reach us$203 billion by 2020 and there will be near 440,000 major information related occupation jobs in the only us with just 300,000 talented experts to fill them. saying farewell to 2017 and just in the third month of 2018, we take a gander at the stamped contrasts in the enormous information space what energizing might be seemingly within easy reach for huge information in 2018. following huge information patterns is only like observing the customary moves in the breeze the minute you sense its bearing, it changes. however, the accompanying enormous information patterns are probably going to get down to business in 2018, Learn Big Data training in Chennai at Greens Technologys.

1) Major information and open source
Forester conjecture write about huge information tech advertise uncovers that hadoop use is expanding 32.9% year on year. open source huge information systems like hadoop, start and others are overwhelming the enormous information space, and that incline is probably going to proceed in 2018. as indicated by the tdwi best practices report, hadoop for the venture by philip russom, 60% of the organizations intend to have hadoop bunches running underway by end of 2018. specialists say that in 2018, numerous associations will grow the utilization of huge information structures like hadoop, start and nosql innovations to quicken enormous information handling. organizations will enlist talented information specialists versed in instruments like hadoop and start with the goal that experts can access and react to information continuously through profitable business experiences.
2) Major information examination will incorporate perception models
A review of 2800 experienced bi experts in 2017 anticipated information disclosure and information perception would turn into a noteworthy pattern. information revelation currently isn't just about understanding the investigation and connections yet in addition speaks to methods for introducing the examination to uncover further business bits of knowledge. people have more noteworthy capacity to process visual examples adequately. convincing and charming perception models will turn into the decision for preparing huge informational collections making it a standout amongst the most huge enormous information drifts in 2018.
3) 2018 will be the time of gushing achievement
2018 will be the year when the objective of each association receiving huge information technique is accomplish genuine spilling investigation: the capacity to process and break down an informational collection while still it is currently creation. this implies gathering bits of knowledge which are actually up-to-the-second without repeating datasets. starting at now, this implies making a trade off with the measure of the dataset or enduring a deferral however by end of 2018 associations will be near evacuating these breaking points.
4) Meeting the "dull information" challenge in 2018
Notwithstanding all the promotion about the expanding information volume that we produce each day, it can't be denied that databases over the globe stay in simple shape, un-digitized, and consequently unexploited for any sort of business investigation. 2018 will see expanded digitization of the dull (information that isn't yet given something to do) put away as paper documents, authentic records, or some other non-computerized information recording positions. this new rush of dull information will enter the cloud. associations will grow enormous information arrangements that will enable them to move information effectively into hadoop from conditions which are generally exceptionally dull, for example, centralized servers.
5) AI and machine figuring out how to be quicker, more brilliant and more proficient in 2018
AI and machine learning innovation are developing at a lightning pace helping organizations change through different utilize cases, for example, ongoing advertisements, extortion location, design acknowledgment, voice acknowledgment, and so forth machine learning was among the best 10 key innovation slants in 2017 yet 2018 will observer it past guideline based convention calculations. machine learning calculations will turn out to be quicker and more precise helping endeavors make more suitable expectations.
These are only a portion of the best huge information slants that industry specialists anticipate, the constantly advancing nature of this area implies that we are probably going to expect a few amazements. enormous information is driving the innovative space towards a more splendid and upgraded future. with expanding number of associations bouncing on the enormous information fleeting trend, 2018 will be a significant year. here's to another incredible year of information driven creations, developments, and disclosures.
Most ideal approach to learn enormous information and hadoop
In spite of the fact that books and online instructional exercises are imperative channels to confer essential information of enormous information and hadoop, it is helpful to take up teacher drove huge information investigation courses to pick up a thorough comprehension of the innovation.
In a period of extreme rivalries and developing advances, the most ideal approach to sparkle over others is to have a strong base of the expertise in which you wish to manufacture your profession. teacher drove huge information hadoop web based preparing gives hands-on understanding to the members to have a superior hold on the innovation.
There are a few preparing and improvement foundations that give on the web, live, virtual and classroom preparing for experts. you can likewise decide on huge information accreditation, which will enable you to separate yourself among the crowd.
Many preparing associations orchestrate small scale session preparing modules that are structured particularly to suit the preparation needs of the members.
Our specialists propose picking educator drove web based preparing for enormous information investigation courses to get the essentials cleared up and afterward you can pick among different online instructional exercises and books to fortify your base and upgrade your insight into huge information and hadoop. different ivy group instructive foundations like harvard and stanford have likewise made their seminars on enormous information and information sciences accessible for nothing, on the web.
who ought to learn huge information?
There are no pre-characterized parameters to assign who can learn enormous information examination and who can't. in any case, you should realize that employments identified with huge information are a blend of arithmetic (measurements) and software engineering. in this way, a man with quantitative fitness and an essential comprehension of PC programming would be appropriately reasonable to learn huge information.
To choose whether you should prepare yourself in huge information and hadoop or not, you should comprehend what comprises a major information work.
To be exact, there is no significant set of working responsibilities for this. it is fundamentally a different exhibit of positions here and there and over an association that needs information wise experts who can oversee, process and draw significant bits of knowledge from the flood of information being amassed in the association.
Numerous huge information and hadoop courses expect students to have involvement in java or essential learning of c++, python, and linux. be that as it may, it's anything but a standard set in stone.
Try not to have any thought of java or linux? no stresses, you can even now burrow your hands on enormous information and hadoop.
As a rule, huge information examination courses are intended for framework engineers, programming designers, modelers, information stockpiling directors, venture chiefs, bi experts and testing experts.
Requirements for learning hadoop
Hadoop is composed in java and it keeps running on linux. thusly, it is very basic that a man who needs to learn hadoop must have the information of java and ought to be comfortable with the directions in linux.
Having said that, given me a chance to stick to what I have said before; there are no strict essentials to learn hadoop. hadoop is only one of the structures utilized in huge information. what's more, obviously, it is being utilized a ton. also, indeed, it very well may be securely named as one of the fundamental parts of enormous information. yet, there are a few unique instruments and innovations other than hadoop that are utilized to oversee and investigate enormous information.
Devices, for example, hive and pig that are based over Hadoop, don't require nature with java and offer their own abnormal state dialects for working with information which are then naturally changed over into map reduce programs in java.
Be that as it may, it is constantly favourable to know the fundamental ideas of java and Linux as it helps in acing the aptitudes better. information ofsql is useful for learning Hadoop in light of the fact that hive, pig, hbase, these rely upon question dialect which is propelled by sql.
Distinctive preparing suppliers state diverse requirements relying upon the course module, its extension, and the structure.
To spell it in strict terms, the requirements to learn enormous information and Hadoop are:
Numerical inclination
All-encompassing comprehension of PC design, systems, document framework, circulated PC association, information incorporation procedures
Capacity to measurably break down data
Comprehension of the field and the market for which the enormous information and hadoop benefit is required
It will be out of line to announce who can and who can't work with enormous information and hadoop, or all things considered with any huge information innovation. it is an occurrence field which is rising each day and the greater part of us can lay our hands and contribute towards its development and improvement.
Big Data @ Greens Technologys
If you are seeking to get a good Big Data training in Chennai, then Greens Technologys should be the first and the foremost option.
We are named as the best training institute in Chennai for providing the IT related training. Greens Technologys is already having an eminent name in Chennai for providing the best software courses training.
We have more than 115 courses for you. We offer both online and physical training along with the flexible timings so as to ease the things for you.
0 notes
Text
Hack.lu 2017 Wrap-Up Day 2
As said yesterday, the second day started very (too?) early… The winner of the first slot was Aaron Zauner who talked about pseudo-random numbers generators. The complete title of the talk was “Because ‘User Random’ isn’t everything: a deep dive into CSPRGNs in Operating Systems & Programming Languages”. He started with an overview of random numbers generators and why we need them. They are used almost everywhere even in the Bash shell where you can use ${RANDOM}. CSPRNG is also known as RNG or “Random Number Generator”. It is implemented at operating system level via /dev/urandom on Linux on RtlGenRandom() on Windows but also in programming languages. And sometimes, with security issues like CVE-2017-11671 (GCC fails to generate incorrect code for RDRAND/RDSEED. /dev/random & /dev/urandom devices are using really old code! (fro mid-90’s). According to Aaron, it was a pure luck if no major incident arises in the last years. And today? Aaron explained what changed with the kernel 4.2. Then he switched to the different language and how they are implementing random numbers generators. He covered Ruby, Node.js and Erlang. All of them did not implement proper random number generators but he also explained what changed to improve this feature. I was a little bit afraid of the talk at 8AM but it was nice and easy to understand for a crypto talk.
The next talk was “Keynterceptor: Press any key to continue” by Niels van Dijkhuizen. Attacks via HID USB devices are not new. Niels reviewed a timeline with all the well-known attacks from 2005 with the KeyHost USB logger until 207 with the BashBunny. The main problems with those attacks: they need an unlocked computer, some social engineer skills and an Internet connection (most of the time). They are products to protect against these attacks. Basically, they act as a USB firewall: USBProxy, USBGuest, GoodDog, DuckHunt, etc. Those products are Windows tools, for Linux, have a look at GRSecurity. Then Niels explains how own solution which gets rid of all the previous constraints: his implants is inline between the keyboard and the host. It must also have notions of real)time. The rogue device clones itself as a classic HID device (“HP Elite USB Keyboard”) and also adds random delays to fake a real human typing on a keyboard. This allows bypassing the DuckHunt tool. Niels makes a demonstration of his tool. It comes with another device called the “Companion” which has a 3G/4G module that connects to the Keynterceptor via a 433Mhz connection. A nice demo was broadcasted and his devices were available during the coffee break. This is a very nice tool for red teams…
Then, Clement Rouault, Thomas Imbert presented a view into ALPC-RPC.The idea of the talk: how to abuse the UAC feature in Microsoft Windows.They were curious about this feature. How to trigger the UAC manually? Via RPC! A very nice tool to investigate RPC interface is RpcView. Then, they switched to ALPC: what is it and how does ir work. It is a client/server solution. Clients connect to a port and exchange messages that have two parts: the PORT_MESSAGE header and APLC_MESSAGE_ATTRIBUTES. They explained in details how they reverse-engineering the messages and, of course, they discovered vulnerabilities. They were able to build a full RPC client in Python and, with the help of fuzzing techniques, they found bugs: NULL dereference, out-of-bounds access, logic bugs, etc. Based on their research, one CVE was created: CVE-2017-11783.
After the coffee break, a very special talk was scheduled: “The untold stories of Hackers in Detention”. Two hackers came on stage to tell how they were arrested and put in jail. It was a very interesting talk. They explained their personal stories how they were arrested, how it happened (interviews, etc). Also gave some advice: How to behave in jail, what to do and not do, the administrative tasks, etc. This was not recorded and, to respect them, no further details will be provided.
The second keynote was assigned to Ange Albertini: “Infosec and failure”. Ange’s presentation are always a good surprise. You never know how he will design his slides.As he said, his talk is not about “funny” failures. Infosec is typically about winning. The keynote was a suite of facts that prove us that we usually fail to provide good infosec services and pieces of advice, also in the way we communicate to other people. Ange likes retro-gaming and made several comparisons between the gaming and infosec industries. According to him, we should have some retropwning events to play and learn from old exploits. According to Ange, an Infosec crash is coming like the video game industry in 1983 and a new cycle is coming. If was a great keynote with plenty of real facts that we should take care of! Lean, improve, share, don’t be shy, be proactive.
After the lunch, I skipped the second session of lightning talks and got back for “Sigma – Generic Signatures for Log Events” by Thomas Patzke. Let’s talk with logs… When the talk started, my first feeling was “What? Another talk about logs?” but, in fact, it was interesting. The idea behind Sigma is that everybody is looking for a nice way to detect threats but all solutions have different features and syntax. Some example of threats are:
Authentication and accounts (large amount of failed logins, lateral movement, etc.)
Process execution (exec from an unusual location, unknown process relationship, evil hashes, etc…
Windows events
The problem we are facing: there is a lack of standardised format. Here comes Sigma. The goal of this tool is to write use case in YAML files that contain all the details to detect a security issue. Thomas gave some examples like detecting Mimikatz or webshells.
Sigma comes with a generator tool that can generate queries for multiple tools: Splunk, Elasticsearch or Logpoint. This is more complex than expected because field names are different, there are inconsistent file names, etc. In my opinion, Sigma could be useful to write use cases in total independence of any SIEM solution. It is still an ongoing project and, good news, recent versions of ISP can integrate Sigma. A field has been added and a tool exists to generate Sigma rules from MISP data.
The next talk was “SMT Solvers in the IT Security – deobfuscating binary code with logic” by Thaís Moreira Hamasaki. She started with an introduction to CLP or “Constraint Logic Programming”. Applications in infosec can be useful like malware de-obfuscation. Thais explained how to perform malware analysis using CLP. I did not follow more about this talk that was too theoretical for me.
Then, we came back to more practical stuff with Omar Eissa who presented “Network Automation is not your Safe Haven: Protocol Analysis and Vulnerabilities of Autonomic Network”. Omar is working for ERNW and they always provide good content. This time they tested the protocol used by Cisco to provision new routers. The goal is to make a router ready for use in a few minutes without any configuration: the Cisco Autonomic network. It’s a proprietary protocol developed by Cisco. Omar explained how this protocol is working and then how to abuse it. They found several vulnerabilities
CVE-2017-6664: There is no way to protect against malicious nodes within the network
CVE-2017-6665 : Possible to reset of the secure channel
CVE-2017-3849: registrar crash
CVE-2017-3850: DeathKiss – crash with 1 IPv6 packet
The talk had many demos that demonstrated the vulnerabilities above. A very nice talk.
The next speaker was Frank Denis who presented “API design for cryptography”. The idea of the talk started with a simple Google query: “How to encrypt stuff in C”. Frank found plenty of awful replies with many examples that you should never use. Crypto is hard to design but also hard to use. He reviewed several issues in the current crypto libraries then presented libhydrogen which is a library developed to solve all the issues introduced by the other libraries. Crypto is not easy to use and developer don’t read the documentation, they just expect some pieces of code that they can copy/paste. The library presented by Frank is called libhyrogen. You can find the source code here.
Then, Okhin came on stage to give an overview of the encryption VS the law in France. The title of his talk was “WTFRance”. He explained the status of the French law against encryption and tools. Basically, many political people would like to get rid of encryption to better fight crime. It was interesting to learn that France leads the fight against crypto and then push ideas at EU level. Note that he also mentioned several politician names that are “against” encryption.
The next talk was my preferred for this second day: “In Soviet Russia, Vulnerability Finds You” presented by Inbar Raz. Inbar is a regular speaker at hack.lu and proposes always entertaining presentations! This time he came with several examples of interesting he found “by mistake”. Indeed, sometimes, you find interesting stuff by accident. Inbar game several examples like an issue on a taxi reservation website, the security of an airport in Poland or fighting against bots via the Tinder application. For each example, a status was given. It’s sad to see that some of them were unresolved for a while! An excellent talk, I like it!
The last slot was assigned to Jelena Milosevic. Jelena is a nurse but she has also a passion for infosec. Based on her job, she learns interesting stuff from healthcare environments. Her talk was a compilation of mistakes, facts and advice for hospitals and health-related services. We all know that those environments are usually very badly protected. It was, once again, proven by Jelena.
The day ended with the social event and the classic Powerpoint karaoke. Tomorrow, it will start again at 08AM with a very interesting talk…
[The post Hack.lu 2017 Wrap-Up Day 2 has been first published on /dev/random]
from Xavier
0 notes
Text
75% off #Projects in Hadoop and Big Data – Learn by Building Apps – $10
A Practical Course to Learn Big Data Technologies While Developing Professional Projects
Intermediate Level, – 10 hours, 43 lectures
Average rating 3.7/5 (3.7 (97 ratings) Instead of using a simple lifetime average, Udemy calculates a course’s star rating by considering a number of different factors such as the number of ratings, the age of ratings, and the likelihood of fraudulent ratings.)
Course requirements:
Working knowledge of Hadoop is expected before starting this course Basic programming knowledge of Java and Python will be great
Course description:
The most awaited Big Data course on the planet is here. The course covers all the major big data technologies within the Hadoop ecosystem and weave them together in real life projects. So while doing the course you not only learn the nuances of the hadoop and its associated technologies but see how they solve real world problems and how they are being used by companies worldwide.
This course will help you take a quantum jump and will help you build Hadoop solutions that will solve real world problems. However we must warn you that this course is not for the faint hearted and will test your abilities and knowledge while help you build a cutting edge knowhow in the most happening technology space. The course focuses on the following topics
Add Value to Existing Data – Learn how technologies such as Mapreduce applies to Clustering problems. The project focus on removing duplicate or equivalent values from a very large data set with Mapreduce.
Hadoop Analytics and NoSQL – Parse a twitter stream with Python, extract keyword with apache pig and map to hdfs, pull from hdfs and push to mongodb with pig, visualise data with node js . Learn all this in this cool project.
Kafka Streaming with Yarn and Zookeeper – Set up a twitter stream with Python, set up a Kafka stream with java code for producers and consumers, package and deploy java code with apache samza.
Real-Time Stream Processing with Apache Kafka and Apache Storm – This project focus on twitter streaming but uses Kafka and apache storm and you will learn to use each of them effectively.
Big Data Applications for the Healthcare Industry with Apache Sqoop and Apache Solr – Set up the relational schema for a Health Care Data dictionary used by the US Dept of Veterans Affairs, demonstrate underlying technology and conceptual framework. Demonstrate issues with certain join queries that fail on MySQL, map technology to a Hadoop/Hive stack with Scoop and HCatalog, show how this stack can perform the query successfully.
Log collection and analytics with the Hadoop Distributed File System using Apache Flume and Apache HCatalog – Use Apache Flume and Apache HCatalog to map real time log stream to hdfs and tail this file as Flume event stream. , Map data from hdfs to Python with Pig, use Python modules for analytic queries
Data Science with Hadoop Predictive Analytics – Create structured data with Mapreduce, Map data from hdfs to Python with Pig, run Python Machine Learning logistic regression, use Python modules for regression matrices and supervise training
Visual Analytics with Apache Spark on Yarn – Create structured data with Mapreduce, Map data from hdfs to Python with Spark, convert Spark dataframes and RDD’s to Python datastructures, Perform Python visualisations
Customer 360 degree view, Big Data Analytics for e-commerce – Demonstrate use of EComerce tool ‘Datameer’ to perform many fof the analytic queries from part 6,7 and 8. Perform queries in the context of Senitment analysis and Twiteer stream.
Putting it all together Big Data with Amazon Elastic Map Reduce – Rub clustering code on AWS Mapreduce cluster. Using AWS Java sdk spin up a Dedicated task cluster with the same attributes.
So after this course you can confidently built almost any system within the Hadoop family of technologies. This course comes with complete source code and fully operational Virtual machines which will help you build the projects quickly without wasting too much time on system setup. The course also comes with English captions. So buckle up and join us on our journey into the Big Data.
Full details Understand the Hadoop Ecosystem and Associated Technologies Learn Concepts to Solve Real World Problems Learn the Updated Changes in Hadoop Use Code Examples Present Here to Create Your own Big Data Services Get fully functional VMs fine tuned and created specifically for this course.
Full details Students who want to use Hadoop and Big Data in their Workplac
Reviews:
“This course is very polished, straightforward, and fun!” (Rozar)
“Don’t feel very engaged with the course, hopefully this will change after I start doing assignments and projects” (Mohamed El-Kholy)
“Would have been better if the instructor showed us how to set up all these projects instead of just reading through the code.” (Sampson Adu-Poku)
About Instructor:
Eduonix Learning Soultions Eduonix-Tech . Eduonix Support
Eduonix creates and distributes high quality technology training content. Our team of industry professionals have been training manpower for more than a decade. We aim to teach technology the way it is used in industry and professional world. We have professional team of trainers for technologies ranging from Mobility, Web to Enterprise and Database and Server Administration.
Instructor Other Courses:
Linux For Absolute Beginners Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (22) $10 $30 Projects In ReactJS – The Complete React Learning Course Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (16) $10 $40 Implementing and Managing Hyper-V in Windows Server 2016 Eduonix Learning Soultions, 1+ Million Students Worldwide | 200+ Courses (1) $10 $20 Become An AWS Certified Solutions Architect – Associate Learn to build an Auth0 App using Angular 2 Youtube: Beginners Guide To A Successful Channel The Developers Guide to Python 3 Programming Learn To Build A Google Map App Using Angular 2 Learn Web Development Using VueJS …………………………………………………………… Eduonix Learning Soultions Eduonix-Tech . Eduonix Support coupons Development course coupon Udemy Development course coupon Software Engineering course coupon Udemy Software Engineering course coupon Projects in Hadoop and Big Data – Learn by Building Apps Projects in Hadoop and Big Data – Learn by Building Apps course coupon Projects in Hadoop and Big Data – Learn by Building Apps coupon coupons
The post 75% off #Projects in Hadoop and Big Data – Learn by Building Apps – $10 appeared first on Udemy Cupón/ Udemy Coupon/.
from Udemy Cupón/ Udemy Coupon/ http://coursetag.com/udemy/coupon/75-off-projects-in-hadoop-and-big-data-learn-by-building-apps-10/ from Course Tag https://coursetagcom.tumblr.com/post/155983197388
0 notes
Text
SSTIC 2017 Wrap-Up Day #3
Here is my wrap-up for the last day. Hopefully, after the yesterday’s social event, the organisers had the good idea to start later… The first set of talks was dedicated to presentation tools.
The first slot was assigned to Florian Maury, Sébastien Mainand: “Réutilisez vos scripts d’audit avec PacketWeaver”. When you are performed audit, the same tasks are already performed. And, as we are lazy people, Florian & Sébastien’s idea was to automate such tasks. They can be to get a PCAP, to use another tool like arpspoof, to modify packets using Scapy, etc… The chain can quickly become complex. By automating, it’s also more easy to deploy a proof-of-concept or a demonstration. The tool used a Metasploit-alike interface. You select your modules, you execute them but you can also chain them: the output of script1 is used as input of script2. The available modules are classified par ISO layer:
app_l7
datalink_l2
network_l3
phy_l1
transport_l4
The tool is available here.
The second slot was about “cpu_rec.py”. This tool has been developed to help in the reconnaissance of architectures in binary files. A binary file contains instructions to be executed by a CPU (like ELF or PE files). But not only files. It is also interesting to recognise firmware’s or memory dumps. At the moment, cpu_rec.py recognise 72 types of architectures. The tool is available here.
And we continue with another tool using machine learning. “Le Machine Learning confronté aux contraintes opérationnelles des systèmes de détection” presented by Anaël Bonneton and Antoine Husson. The purpose is to detect intrusions based on machine learning. The classic approach is to work with systems based on signatures (like IDS). Those rules are developed by experts but can quickly become obsolete to detect newer attacks. Can machine learning help? Anaël and Antoine explained the tool that that developed (“SecuML”) but also the process associated with it. Indeed, the tool must be used in a first phase to learning from samples. The principle is to use a “classifier” that takes files in input (PDF, PE, …) and return the conclusions in output (malicious or not malicious). The tool is based on the scikit-learn Python library and is also available here.
Then, Eric Leblond came on stage to talk about… Suricata of course! His talk title was “À la recherche du méchant perdu”. Suricata is a well-known IDS solution that don’t have to be presented. This time, Eric explained a new feature that has been introduced in Suricata 4.0. A new “target” keyword is available in the JSON output. The idea arise while a blue team / read team exercise. The challenge of the blue team was to detect attackers and is was discovered that it’s not so easy. With classic rules, the source of the attack is usually the source of the flow but it’s not always the case. A good example of a web server returned an error 4xx or 5xx. In this case, the attacker is the destination. The goal of the new keyword is to be used to produce better graphs to visualise attacks. This patch must still be approved and merge in the code. It will also required to update the rules.
The next talk was the only one in English: “Deploying TLS 1.3: the great, the good and the bad: Improving the encrypted web, one round-trip at a time” by Filippo Valsorda & Nick Sullivan. After a brief review of the TLS 1.2 protocol, the new version was reviewed. You must know that, if TLS 1.0, 1.1 and 1.2 were very close to each others, TLS 1.3 is a big jump!. Many changes in the implementation were reviewed. If you’re interested here is a link to the specifications of the new protocol.
After a talk about crypto, we switched immediately to another domain which also uses a lot of abbreviations: telecommunications. The presentation was performed by Olivier Le Moal, Patrick Ventuzelo, Thomas Coudray and was called “Subscribers remote geolocation and tracking using 4G VoLTE enabled Android phone”. VoLTE means “Voice over LTE” and is based on VoIP protocols like SIP. This protocols is already implemented by many operators around the world and, if your mobile phone is compatible, allows you to perform better calls. But the speakers found also some nasty stuff. They explained how VoLTE is working but also how it can leak the position (geolocalization) of your contact just by sending a SIP “INVITE” request.
To complete the first half-day, a funny presentation was made about drones. For many companies, drones are seen as evil stuff and must be prohibited to fly over some places. The goal of the presented tool is just to prevent drones to fly over a specific place and (maybe) spy. There are already solutions for this: DroneWatch, eagles, DroneDefender or SkyJack. What’s new with DroneJack? It focuses on drones communicating via Wi-Fi (like the Parrot models). Basically, a drone is a flying access point. It is possible to detected them based on their SSID’s and MAC addresses using a simple airodump-ng. Based on the signal is it also possible to estimate how far the drone is flying. As the technologies are based on Wi-Fi there is nothing brand new. If you are interested, the research is available here.
When you had a lunch, what do you do usually? You brush your teeth. Normally, it’s not dangerous but if your toothbrush is connected, it can be worse! Axelle Apvrille presented her research about a connected toothbrush provided by an health insurance company in the USA. The device is connected to a smart phone using a BTLE connection and exchange a lot of data. Of course, without any authentication or any other security control. The toothbrush even continues to expose his MAC address via bluetooth all the tile (you have to remove the battery to turn it off). Axelle did not attached the device itself with reverse the mobile application and the protocol used to communicate between the phone and the brush. She wrote a small tool to communicate with the brush. But she also write an application to simulate a rogue device and communicate with the mobile phone. The next step was of course to analyse the communication between the mobile app and the cloud provided by the health insurance. She found many vulnerabilities to lead to the download of private data (up to picture of kids!). When she reported the vulnerability, her account was just closed by the company! Big fail! If you pay your insurance less by washing your teeth correctly, it’s possible to send fake data to get a nice discount. Excellent presentation from Axelle…
To close the event, the ANSSI came on stage to present a post-incident review of the major security breach that affected the French TV channel TV5 in 2015. Just to remember you, the channel was completely compromised up to affecting the broadcast of programs for several days. The presentation was excellent for everybody interested in forensic investigation and incident handling. In a first part, the timeline of all events that lead to the full-compromise were reviewed. To resume, the overall security level of TV5 was very poor and nothing fancy was used to attack them: contractor’s credentials used, lack of segmentation, default credentials used, expose RDP server on the Internet etc. An interesting fact was the deletion of firmwares on switches and routers that prevented them to reboot properly causing a major DoS. They also deleted VM’s. The second part of the presentation was used to explain all the weaknesses and how to improve / fix them. It was an awesome presentation!
My first edition of SSTIC is now over but I hope not the last one!
[The post SSTIC 2017 Wrap-Up Day #3 has been first published on /dev/random]
from Xavier
0 notes