#data collection and annotation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
#artificial intelligence#data collection#technology#video annotation#machine learning#image and video annotation
1 note
·
View note
Text

Join our global work-from-home opportunities: varied projects, from short surveys to long-term endeavors. Utilize your social media interest, mobile device proficiency, linguistics degree, online research skills, or passion for multimedia. Find the perfect fit among our diverse options.
#image collection jobs#Data Annotation Jobs#Freelance jobs#Text Data Collection job#Speech Data Collection Jobs#Translation jobs online#Data annotation specialist#online data annotation jobs#image annotation online jobs
0 notes
Text
The Importance of Speech Datasets in the Advancement of Voice AI:

Introduction:
Voice AI is Speech Datasets revolutionizing human interaction with technology, encompassing virtual assistants like Siri and Alexa, automated transcription services, and real-time language translation. Central to these innovations is a vital component: high-quality speech datasets. This article examines the significance of speech datasets in the progression of voice AI and their necessity for developing precise, efficient, and intelligent speech recognition systems.
The Significance of Speech Datasets in AI Development
Speech datasets consist of collections of recorded human speech that serve as foundational training resources for AI models. These datasets are crucial for the creation and enhancement of voice-driven applications, including:
Speech Recognition: Facilitating the conversion of spoken language into written text by machines.
Text-to-Speech: Enabling AI to produce speech that sounds natural.
Speaker Identification: Differentiating between various voices for purposes of security and personalization.
Speech Translation: Providing real-time translation of spoken language to enhance global communication.
Essential Characteristics of High-Quality Speech Datasets
To create effective voice AI applications, high-quality speech datasets must encompass:
Diverse Accents and Dialects: Ensuring that AI models can comprehend speakers from various linguistic backgrounds.
Varied Noise Conditions: Training AI to function effectively in real-world settings, such as environments with background noise or multiple speakers.
Multiple Languages: Facilitating multilingual capabilities in speech recognition and translation.
Comprehensive Metadata: Offering contextual details, including speaker demographics, environmental factors, and language specifics.
Prominent Speech Datasets for AI Research
Numerous recognized speech datasets play a crucial role in the development of voice AI, including:
Speech: A comprehensive collection of English speech sourced from audiobooks.
Common Voice: An open-source dataset created by Mozilla, compiled from contributions by speakers worldwide.
VoxCeleb: A dataset focused on speaker identification, containing authentic recordings from various contexts.
Speech Commands: A dataset specifically designed for recognizing keywords and commands.
How Speech Datasets Enhance AI Performance
Speech datasets empower AI models to:
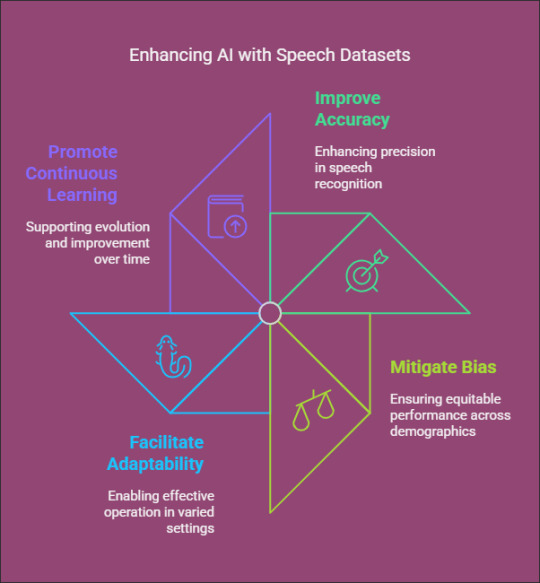
Improve Accuracy: Training on a variety of datasets enhances the precision of speech recognition.
Mitigate Bias: Incorporating voices from diverse demographics helps to eliminate AI bias and promotes equitable performance.
Facilitate Adaptability: AI models trained on a wide range of datasets can operate effectively across different settings and applications.
Promote Continuous Learning: Regular updates to datasets enable AI systems to evolve and improve over time.
Challenges in Collecting Speech Data
Despite their significance, the collection of speech datasets presents several challenges, including:
Data Privacy and Ethics: Adhering to regulations and ensuring user anonymity is essential.
High Annotation Costs: The process of labeling and transcribing speech data demands considerable resources.
Noise and Variability: Obtaining high-quality data in various environments can be challenging.
Conclusion
Speech datasets play Globose Technology Solutions a critical role in the advancement of voice AI, providing the foundation for speech recognition, synthesis, and translation technologies. By leveraging diverse and well-annotated datasets, AI researchers and developers can create more accurate, inclusive, and human-like voice AI systems.
0 notes
Text
Annotated Text-to-Speech Datasets for Deep Learning Applications

Introduction:
Text To Speech Dataset technology has undergone significant advancements due to developments in deep learning, allowing machines to produce speech that closely resembles human voice with impressive precision. The success of any TTS system is fundamentally dependent on high-quality, annotated datasets that train models to comprehend and replicate natural-sounding speech. This article delves into the significance of annotated TTS datasets, their various applications, and how organizations can utilize them to create innovative AI solutions.
The Importance of Annotated Datasets in TTS
Annotated TTS datasets are composed of text transcripts aligned with corresponding audio recordings, along with supplementary metadata such as phonetic transcriptions, speaker identities, and prosodic information. These datasets form the essential framework for deep learning models by supplying structured, labeled data that enhances the training process. The quality and variety of these annotations play a crucial role in the model’s capability to produce realistic speech.
Essential Elements of an Annotated TTS Dataset
Text Transcriptions – Precise, time-synchronized text that corresponds to the speech audio.
Phonetic Labels – Annotations at the phoneme level to enhance pronunciation accuracy.
Speaker Information – Identifiers for datasets with multiple speakers to improve voice variety.
Prosody Features – Indicators of pitch, intonation, and stress to enhance expressiveness.
Background Noise Labels – Annotations for both clean and noisy audio samples to ensure robust model training.
Uses of Annotated TTS Datasets
The influence of annotated TTS datasets spans multiple sectors:
Virtual Assistants: AI-powered voice assistants such as Siri, Google Assistant, and Alexa depend on high-quality TTS datasets for seamless interactions.
Audiobooks & Content Narration: Automated voice synthesis is utilized in e-learning platforms and digital storytelling.
Accessibility Solutions: Screen readers designed for visually impaired users benefit from well-annotated datasets.
Customer Support Automation: AI-driven chatbots and IVR systems employ TTS to improve user experience.
Localization and Multilingual Speech Synthesis: Annotated datasets in various languages facilitate the development of global text-to-speech (TTS) applications.
Challenges in TTS Dataset Annotation
Although annotated datasets are essential, the creation of high-quality TTS datasets presents several challenges:
Data Quality and Consistency: Maintaining high standards for recordings and ensuring accurate annotations throughout extensive datasets.
Speaker Diversity: Incorporating a broad spectrum of voices, accents, and speaking styles.
Alignment and Synchronization: Accurately aligning text transcriptions with corresponding speech audio.
Scalability: Effectively annotating large datasets to support deep learning initiatives.
How GTS Can Assist with High-Quality Text Data Collection
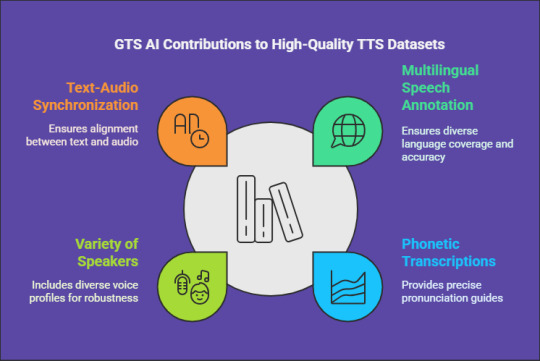
For organizations and researchers in need of dependable TTS datasets, GTS AI provides extensive text data collection services. With a focus on multilingual speech annotation, GTS delivers high-quality, well-organized datasets specifically designed for deep learning applications. Their offerings guarantee precise phonetic transcriptions, a variety of speakers, and flawless synchronization between text and audio.
Conclusion
Annotated text-to-speech datasets are vital for the advancement of high-performance speech synthesis models. As deep learning Globose Technology Solutions progresses, the availability of high-quality, diverse, and meticulously annotated datasets will propel the next wave of AI-driven voice applications. Organizations and developers can utilize professional annotation services, such as those provided by GTS, to expedite their AI initiatives and enhance their TTS solutions.
0 notes
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note

Text
The Backbone of Machine Learning: Image Datasets Explained

Introduction
In the realm of artificial intelligence (AI) and image datasets for machine learning (ML) are the unsung heroes that power intelligent systems. These datasets, comprising labeled images, are foundational to training ML models to understand, interpret, and generate insights from visual data. Let's discuss the critical role image datasets play and why they are indispensable for AI success.
What Are Image Datasets?
Image datasets are the collections of images curated for the training, testing, and validation of machine learning models. Many of these datasets come with associated annotations or metadata that provide the context, for example, in the form of object labels, bounding boxes, or segmentation masks. This contextual information is used in supervised learning in which the ultimate goal is teaching a model how to make predictions using labeled examples.
Why Are Image Datasets Important for Machine Learning?
Training Models to Identify PatternsMachine learning models, especially deep learning models such as convolutional neural networks (CNNs), rely on large volumes of data to identify patterns and features in images. A diverse and well-annotated dataset ensures that the model can generalize effectively to new, unseen data.
Fueling Computer Vision Applications From autonomous vehicles to facial recognition systems, computer vision applications rely on large, robust image datasets. Such datasets empower machines to do tasks like object detection, image classification, and semantic segmentation.
Improving Accuracy and Reducing BiasHigh-quality datasets with diverse samples help reduce bias in machine learning models. For example, an inclusive dataset representing various demographics can improve the fairness and accuracy of facial recognition systems.
Types of Image Datasets
General Image Datasets : These are datasets of images spread across various classes. An example is ImageNet, the most significant object classification and detection benchmark.
Domain-specific datasets : These datasets are specifically designed for particular applications. Examples include: medical imagery, like ChestX-ray8, or satellite imagery, like SpaceNet.
Synthetic Datasets : Dynamically generated through either simulations or computer graphics, synthetic datasets can complement or even sometimes replace real data. This is particularly useful in niche applications where data is scarce.
Challenges in Creating Image Datasets
Data Collection : Obtaining sufficient quantities of good-quality images can be time-consuming and resource-intensive.
Annotation Complexity : Annotating images with detailed labels, bounding boxes, or masks is time-consuming and typically requires human expertise or advanced annotation tools.
Achieving Diversity : Diversity in scenarios, environments, and conditions should be achieved to ensure model robustness, but this is a challenging task.
Best Practices for Building Image Datasets
Define Clear Objectives : Understand the specific use case and requirements of your ML model to guide dataset creation.
Prioritize Quality Over Quantity : While large datasets are important, the quality and relevance of the data should take precedence.
Leverage Annotation Tools : Tools like GTS.ai’s Image and Video Annotation Services streamline the annotation process, ensuring precision and efficiency.
Regularly Update the Dataset : Continuously add new samples and annotations to improve model performance over time.
Conclusion
Image datasets have been the very backbone of machine learning, training models to perceive and learn complex visual tasks. As such, the increase in demand for intelligent systems implies that high-quality, annotated datasets are of importance. Businesses and researchers can take advantage of these tools and services, such as those offered by GTS.ai, to construct robust datasets which power next-generation AI solutions. To learn more about how GTS.ai can help with image and video annotation, visit our services page.
0 notes
Text
Why Your AI Project Needs Quality Video Data Collection Services

Introduction
Artificial intelligence (AI) has undergone significant advancements in recent years, facilitating innovations in various sectors including healthcare, retail, and transportation. A key factor contributing to this development is the accessibility of high-quality data, especially video data. This type of data is essential for training AI models, particularly in the fields of computer vision, robotics, and autonomous systems. Nevertheless, obtaining precise and dependable outcomes hinges on the quality of the video data utilized. It is important to examine the necessity of superior Video Data Collection Services for your AI project and the impact they can have.
The Importance of Video Data in AI Development
Video data serves as a comprehensive and dynamic reservoir of information, offering essential context, motion patterns, and visual specifics that are vital for artificial intelligence systems. This data is particularly important in several fields, including:
Computer Vision: Technologies such as facial recognition, object detection, and activity monitoring depend on a variety of video datasets.
Autonomous Systems: Self-driving vehicles and drones necessitate high-quality video data to accurately interpret and navigate their surroundings.
Healthcare: Video-based diagnostic instruments and surgical robots rely on precise visual information.
Retail: Analyzing customer behavior, ensuring in-store security, and facilitating automated checkout processes utilize video data to enhance operational efficiency.
The effectiveness and continuous improvement of these AI systems hinge on a robust foundation of video data.
Why Quality Matters in Video Data Collection
Inadequate or biased video data can result in erroneous model predictions, diminished performance, and potential ethical dilemmas. The significance of high-quality video data collection services cannot be overstated for the following reasons:
Precision and Dependability
High-caliber video datasets enable AI models to generate precise predictions and informed decisions. Quality services prioritize the collection of well-annotated and varied data, thereby minimizing the likelihood of errors and biases during the training phase.
Variety and Inclusiveness
AI systems that are trained on varied datasets exhibit superior performance in practical applications. Professional video data collection services obtain data from a range of demographics, environments, and conditions, enhancing the robustness and inclusivity of your AI system.
Adherence to Ethical Standards
Data privacy and ethical considerations are paramount in the development of AI. Trustworthy services guarantee that video data is collected with proper consent and complies with international regulations such as GDPR or CCPA, thereby safeguarding your organization against legal liabilities.
Time and Cost Efficiency
Establishing an in-house video data collection pipeline demands significant resources. By delegating this responsibility to specialists, you can conserve both time and financial resources, enabling your team to concentrate on the development and implementation of models.
Scalability
As your AI initiative expands, the demand for more extensive datasets increases correspondingly. Professional video data collection services are well-prepared to manage this growth, delivering consistent and dependable data as your needs change.
How GTS.AI Can Help

At Globose Technology Solutions.AI, we are dedicated to delivering superior video data collection services that are specifically designed to address the distinct requirements of your AI initiatives. The following aspects distinguish our offerings:
Proficiency in Data Collection: Our team possesses significant expertise in acquiring a wide range of high-quality video datasets across multiple sectors.
Tailored Solutions: We develop data collection methodologies that align with your particular use case, guaranteeing the best outcomes for your AI models.
Sophisticated Annotation: Through meticulous and comprehensive annotations, we improve the functionality of video datasets for machine learning applications.
Commitment to Ethical Standards: We emphasize adherence to data privacy laws and ensure that all data collection activities are conducted in an ethical and transparent manner.
Conclusion
The effectiveness of your AI initiative is fundamentally linked to the quality of the data utilized in its development. By investing in professional video data collection services, you can ensure precision, scalability, and ethical standards, thereby providing your AI models with a robust foundation for success. Collaborate with GTS.AI to harness the full potential of your AI project through meticulously curated video datasets.
Are you prepared to advance your project? Explore GTS.AI to discover more about our offerings and how we can assist you on your AI journey.
0 notes
Text
High-Quality Image Annotation: The Foundation of AI Excellence

Introduction:
In the realm of artificial intelligence and machine learning, data holds paramount importance. Specifically, high-quality labeled image data is crucial for developing robust and dependable AI models. Whether it involves facilitating autonomous vehicles, enabling facial recognition, or enhancing medical imaging applications, accurate image annotation guarantees that AI systems function with precision and efficiency. At GTS.AI, we are dedicated to providing exceptional image annotation services customized to meet the specific requirements of your project.
The Significance of High-Quality Image Annotation
Image Annotation, or labeling, involves identifying and tagging components within an image to generate structured data. This annotated data serves as the cornerstone for training AI algorithms. But why is quality so critical?
Precision in Model Outcomes: Inaccurately labeled data results in unreliable AI models, leading to erroneous predictions and subpar performance.
Accelerated Training Processes: High-quality annotations facilitate quicker and more effective training, conserving both time and resources.
Enhanced Generalization: Well-annotated datasets enable models to generalize effectively, performing admirably even with unfamiliar data.
Primary Applications of Image Annotation
Image annotation has become essential across various sectors:
Autonomous Vehicles: Training vehicles to identify objects, traffic signs, and lane markings.
Healthcare: Assisting diagnostic tools with annotated medical images for disease identification.
Retail: Improving inventory management and personalized shopping experiences through object detection.
Security: Supporting facial and object recognition systems for surveillance and access control.
What Distinguishes GTS.AI?
At GTS.AI, we recognize that each project has distinct needs. Here’s how we guarantee superior image annotation services:
Cutting-Edge Annotation Techniques
We utilize a range of labeling methods, including:
Bounding Boxes: Optimal for object detection tasks.
Semantic Segmentation: Providing pixel-level accuracy
Scalability and Efficiency
Our international team, equipped with state-of-the-art tools, enables us to manage projects of any magnitude, providing timely results without sacrificing quality.
Comprehensive Quality Control
Each labeled dataset is subjected to several verification stages to ensure both accuracy and consistency.
Tailored Solutions
We customize our services to meet your unique requirements, whether related to annotation formats, workflow integration, or types of datasets.
Data Compliance and Security
The security of your data is our utmost concern. We comply with stringent data privacy regulations to ensure the confidentiality of your datasets.
Real-World Success Examples
Our image labeling services have enabled clients to achieve outstanding outcomes:
Healthcare Innovator: Supplied annotated X-ray images for training an AI model aimed at early disease detection.
Retail Leader: Labeled product images for a visual search application, enhancing customer engagement.
Autonomous Driving Pioneer: Provided high-quality annotations of road scenes, expediting AI training schedules.
Collaborate with GTS.AI for Exceptional Image Labeling
High-quality image labeling transcends mere service; it represents a strategic investment in the success of your AI projects. At Globose Technology Solutions, we merge expertise, technology, and precision to deliver unmatched results.
Are you prepared to advance your AI initiatives? Visit our image and video annotation services page to discover more and initiate your project today!
0 notes
Text

How Video Transcription Services Improve AI Training Through Annotated Datasets
Video transcription services play a crucial role in AI training by converting raw video data into structured, annotated datasets, enhancing the accuracy and performance of machine learning models.
#video transcription services#aitraining#Annotated Datasets#machine learning#ultimate sex machine#Data Collection for AI#AI Data Solutions#Video Data Annotation#Improving AI Accuracy
0 notes
Text
#off-the-shelf datasets#dataset provider#ai training data#data collection#data annotation#dataset for AI
0 notes
Text
#off-the-shelf datasets#dataset provider#ai training data#data collection#data annotation#dataset for AI
0 notes
Text
Capture, Upload, Earn: The Simplicity of Image Data Collection Jobs

Introduction:
If you’re seeking a flexible, remote opportunity that allows you to contribute to the advancement of artificial intelligence, consider exploring image data collection jobs. These positions involve capturing and curating images to train AI and machine learning models, playing a crucial role in the development of technologies like facial recognition, autonomous vehicles, and smart assistants.
📸 What Is Image Data Collection?
Image data collection entails gathering photographs that serve as training material for AI systems. These images can range from everyday objects and environments to specific themes or scenarios, depending on the project’s requirements. The collected data helps AI models learn to recognize patterns, objects, and contexts, enhancing their accuracy and functionality. dash.gts.ai
💼 Why Consider Image Data Collection Jobs?
Remote Flexibility: Work from the comfort of your home or any location of your choice.
No Specialized Equipment Needed: A basic camera or smartphone is sufficient for most projects.
Diverse Projects: Engage in various assignments, from capturing urban landscapes to documenting specific objects.
Contribute to AI Development: Your work directly impacts the improvement of AI technologies used globally.
🛠️ Getting Started
To begin your journey in image data collection:
Sign Up: Register on platforms that offer image data collection projects.
Select Projects: Choose assignments that align with your interests and schedule.
Capture Images: Follow the project’s guidelines to collect the required images.
Submit Work: Upload your images through the platform’s submission system.
Receive Compensation: Payments are typically processed upon project completion, with details provided upfront. dash.gts.ai
🔗 Explore Opportunities
For more information on available projects and to sign up, visit: https://dash.gts.ai/image-data-collection
Embark on a rewarding path that combines creativity with technology, all while enjoying the convenience of remote work.
0 notes
Text
The Significance of Image Datasets in Machine Learning

Introduction:
The fields of machine learning and Image Datasets For Machine Learning artificial intelligence have transformed various sectors, including healthcare. autonomous vehicles, facial recognition, and e-commerce. Central to these advancements is a vital component: image datasets. High-quality image datasets form the backbone of training ML models, allowing them to identify patterns, categorize objects, and generate precise predictions. This article delves into the importance of image datasets in machine learning and their influence on the development of AI-driven technologies.
What Constitutes Image Datasets?
An image dataset refers to an organized collection of either labeled or unlabeled images utilized for the training and evaluation of machine learning models. These datasets enable models to learn visual characteristics, recognize objects, and enhance their decision-making processes.
Image datasets can be classified into two main categories:
Labeled Image Datasets: Each image is accompanied by annotations that provide relevant information, such as object classifications, bounding boxes, or segmentation masks. Examples include ImageNet
Unlabeled Image Datasets: These datasets consist of images without any accompanying labels, typically employed in unsupervised learning or self-supervised AI models.
The Significance of Image Datasets in Machine Learning
Training AI Models for Precision
Machine learning models necessitate extensive data to achieve effective generalization and performance. A meticulously assembled image dataset offers a variety of examples, allowing models to identify differences in lighting, angles, backgrounds, and object characteristics.
Supporting Computer Vision Applications
Image datasets serve as the foundation for computer vision applications, including facial recognition, medical imaging analysis, autonomous vehicles, and automated quality assurance in manufacturing. The absence of comprehensive datasets would hinder these applications from attaining high levels of accuracy.
Mitigating Bias and Improving Model Generalization
A varied dataset is crucial in preventing machine learning models from developing biases towards particular demographics, environments, or image qualities. Well-balanced datasets contribute to minimizing unfair biases in AI systems, thereby enhancing their reliability and ethical standards.
Enhancing Object Detection and Classification
For object detection tasks, models require thoroughly annotated datasets to identify multiple objects within various scenes. High-quality datasets significantly improve the models' capacity to classify objects accurately, thereby reducing the occurrence of false positives and false negatives.
Progressing AI in Specialized Domains
Image datasets are essential in sectors such as healthcare, where artificial intelligence is employed to identify diseases through medical imaging. High-resolution datasets of medical images facilitate the AI's ability to recognize patterns in resulting in enhanced diagnostic accuracy and better patient outcomes.
Challenges in the Collection of Image Datasets

The compilation of image datasets, while crucial, presents several challenges:
Data Privacy and Security: The management of sensitive images, such as those related to medical information, introduces significant ethical dilemmas.
Quality Assurance: It is imperative to maintain high standards for image accuracy, resolution, and appropriate annotation.
Diversity and Representation: It is essential to mitigate biases by incorporating a wide range of demographics and scenarios.
Conclusion
Image datasets serve as a fundamental component in the progression of machine learning, enhancing AI's capacity to analyze and comprehend visual information. As AI technology advances, the necessity for high-quality, diverse, and meticulously Globose Technology Solutions annotated image datasets will persist. Organizations and researchers must emphasize the importance of dataset quality, ethical practices, and equity to create effective AI models that serve the greater good.
0 notes
Text
How to Develop a Video Text-to-Speech Dataset for Deep Learning

Introduction:
In the swiftly advancing domain of deep learning, video-based Text-to-Speech (TTS) technology is pivotal in improving speech synthesis and facilitating human-computer interaction. A well-organized dataset serves as the cornerstone of an effective TTS model, guaranteeing precision, naturalness, and flexibility. This article will outline the systematic approach to creating a high-quality video TTS dataset for deep learning purposes.
Recognizing the Significance of a Video TTS Dataset
A video Text To Speech Dataset comprises video recordings that are matched with transcribed text and corresponding audio of speech. Such datasets are vital for training models that produce natural and contextually relevant synthetic speech. These models find applications in various areas, including voice assistants, automated dubbing, and real-time language translation.
Establishing Dataset Specifications
Prior to initiating data collection, it is essential to delineate the dataset’s scope and specifications. Important considerations include:
Language Coverage: Choose one or more languages relevant to your application.
Speaker Diversity: Incorporate a range of speakers varying in age, gender, and accents.
Audio Quality: Ensure recordings are of high fidelity with minimal background interference.
Sentence Variability: Gather a wide array of text samples, encompassing formal, informal, and conversational speech.
Data Collection Methodology
a. Choosing Video Sources
To create a comprehensive dataset, videos can be sourced from:
Licensed datasets and public domain archives
Crowdsourced recordings featuring diverse speakers
Custom recordings conducted in a controlled setting
It is imperative to secure the necessary rights and permissions for utilizing any third-party content.
b. Audio Extraction and Preprocessing
After collecting the videos, extract the speech audio using tools such as MPEG. The preprocessing steps include:
Noise Reduction: Eliminate background noise to enhance speech clarity.
Volume Normalization: Maintain consistent audio levels.
Segmentation: Divide lengthy recordings into smaller, sentence-level segments.
Text Alignment and Transcription
For deep learning models to function optimally, it is essential that transcriptions are both precise and synchronized with the corresponding speech. The following methods can be employed:
Automatic Speech Recognition (ASR): Implement ASR systems to produce preliminary transcriptions.
Manual Verification: Enhance accuracy through a thorough review of the transcriptions by human experts.
Timestamp Alignment: Confirm that each word is accurately associated with its respective spoken timestamp.
Data Annotation and Labeling
Incorporating metadata significantly improves the dataset's functionality. Important annotations include:
Speaker Identity: Identify each speaker to support speaker-adaptive TTS models.
Emotion Tags: Specify tone and sentiment to facilitate expressive speech synthesis.
Noise Labels: Identify background noise to assist in developing noise-robust models.
Dataset Formatting and Storage
To ensure efficient model training, it is crucial to organize the dataset in a systematic manner:
Audio Files: Save speech recordings in WAV or FLAC formats.
Transcriptions: Keep aligned text files in JSON or CSV formats.
Metadata Files: Provide speaker information and timestamps for reference.
Quality Assurance and Data Augmentation
Prior to finalizing the dataset, it is important to perform comprehensive quality assessments:
Verify Alignment: Ensure that text and speech are properly synchronized.
Assess Audio Clarity: Confirm that recordings adhere to established quality standards.
Augmentation: Implement techniques such as pitch shifting, speed variation, and noise addition to enhance model robustness.
Training and Testing Your Dataset
Ultimately, utilize the dataset to train deep learning models such as Taco Tron, Fast Speech, or VITS. Designate a segment of the dataset for validation and testing to assess model performance and identify areas for improvement.
Conclusion
Creating a video TTS dataset is a detailed yet fulfilling endeavor that establishes a foundation for sophisticated speech synthesis applications. By Globose Technology Solutions prioritizing high-quality data collection, accurate transcription, and comprehensive annotation, one can develop a dataset that significantly boosts the efficacy of deep learning models in TTS technology.
0 notes
Text

0 notes