#best manufacturing ai blog writer
Note
Don't let them get you down. I hate AI "art" with a passion, but yours was just a way to make a bland post more colorful. Like a sticker on a note. You didn't try to "trick" anyone and please never stop doing what you love. Please continue your great blog, i love it so much. Try not to let them get to you.
You are kind. You also must suspect that I love it when people complain. Tumblr is awesome for manufactured drama like that. And it's always fun to poke the new Puritans. ;)
And, yeah, AI is already, and is only going to be a bigger, scourge on artists and writers. But box-checking outrage in safe and consequence-less ways does precisely nothing. If you're really against AI, cancel Netflix (I have), cancel Spotify (I have), cancel your subscriptions to any apps you use for content that push AI tools (Adobe, Blender, etc.) or steal/use pirated versions if you must, donate to the Authors Guild (https://authorsguild.org/) or, more usefully, EU activists like these folk because the EU is much more likely to ever pass legislation that will have an effect (the US is pretty much a lost cause).
[The EU's online privacy laws are more powerful than US ones and currently have de facto international binding status because companies want to do business in the EU -- so when it comes to copyright protections or AI prevention, the best approach is probably modeled on that. The most likely way we'll get any kind of actual copyright protection is through the EU's laws like the GDPR that in effect governs US companies' behavior. But I digress...]
Social media is meaningless when it comes to anything long term. Use your money to "vote" because it's the only way to really change anything. (Will it work? Probably not. But at least you're not playing morality police to make yourself feel self-righteous and thinking practically about how you can make a difference.)
#Anonymous#NOW I'M PREACHING!!#See I can write meaningless social media posts that won't make a dick of difference too instead of doing something real
35 notes
·
View notes
Text
Are Content Writers Still Relevant ?
By Rohit C
We live in the day and age where almost all fields of work are dominated by AI, be it problem solving, development, manufacturing and most commonly and most frequently in the field of content writing. Will AI tools like ChatGPT prove to be the ‘Writers’ Apocalypse’? Follow along if you are a content writer yourself or you’re curious enough to see where the future of content writing will go from its current juncture.
We’ll go through the following points in this blog:
Who is a content writer?
How has AI made content writing easier?
Will content writers lose their prominence to AI?
Can writers and AI coexist?
Who is a Content Writer?
Writers can be categorized into various types based on the field and scope of their works. This includes authors, social media writers, UX writers, technical writers, documentation specialists, report writers, etc. Any piece of work a writer produces can be termed as ‘content’.
Out of the above mentioned writers, the one category that doesn’t cater much to the audience perspective are authors. This is because their works are bound mostly by their personal creative liberty which also means that they don’t follow any particular template that can be perfectly generated artificially making them immune to changing trends. It’s either a hit or a miss.
All the other categories of writers mentioned above exist as a means of message conveyance to either the general public or to any particular group of people, and when people can be grouped into distinct sections, a general way of work or a ‘template’ is thus formed. This template when artificially reproduced generates content almost similar to what the referred writer would write on his/her own.
How has AI made Content Writing easier?
Writing is a talent that not everyone can acquire in equal proportions. A content writer is composed mainly of two factors- creativity and language. Being creative alone is useless unless you find the means to put it to use. In the case of writing, a person with an idea may not know the proper language to express it. In such cases, he/she consults a content writer and having received inputs from the client, also blending his own creative skills, the writer puts forward that idea in front of the target audience in a presentable manner. Here, the content writer acts as the ideator’s voice.
With the advent of generative AI tools like ChatGPT, an ideator cuts the time and cost of consulting a content writer just by giving a detailed explanation of his/her idea and letting AI do the rest. But for a computer to write content like humans, it has to first think like humans. Right? This is where the ‘template’ mentioned earlier comes into the picture.
AI can be trained to follow the general pattern in which content writers of various fields produce their respective contents. Over prolonged periods of testing and perfecting, the current generation of artificial intelligence has now acquired the ability to produce content that can even compete with the best contents known to mankind in terms of language and idea conveyance.
Will Content Writers lose their prominence to AI?
To put it straightly, AI is indeed one of the best content writers we have nowadays and there is no running away from this truth. Many have also started implementing it for official uses. So the question arises- Are content writers still relevant? Why pay a writer when you can get the job done for free? Why write this blog when I can make ChatGPT do it for me?
Yes, I can generate this blog using ChatGPT just by some simple prompts. But would it be the same as the one I would write as an individual? It is true that AI can think like a human. But can it think like every human? If no two humans can think exactly alike then is it possible for AI to replicate creativity in the exact scale? So the answer is YES, content writers are still relevant, but with a clause that they meet the a certain bar of excellence set by the industry.
Nobody wants substandard content these days. Content for content’s sake can be generated by AI much better in comparison to a below average to average content writer. Thus, even though their prominence is guaranteed, only the best writers out there will survive the post ChatGPT era. Survival of the fittest is what is and will be followed as AI becomes more and more human.
Can Writers and AI coexist?
Even though AI generates appropriate contents, it lacks a ‘heart’. The ability of a writer to think beyond the box is not something that can be easily reciprocated. Afterall, what AI receives is just a prompt while writers undergo a whole thinking cycle before planning their content. The same idea can be expressed in a million different ways and the most innovative way is what the industry expects from a content writer.
The world is changing at a fast pace. In comes changing trends, changing preferences, changing outlooks and it’s much easier for a human to keep up with the flow. Also it’s easier for an ideator to share the idea with a human than a bot as one thing he/she receives in return apart from the content is opinions which AI does not generally provide. But a writer is a human after all and unlike AI he/she can be affected by moods, emotions and circumstances of life which reflects in the quality of work output. In such cases it is absolutely fine to rely on AI generated content just to fill in the spaces.
AI is a tool in the hands of an able content writer. Humans need not know everything there is to know regarding content. There may be words that can be cut short, synonyms that can be used, grammar that could have gone unnoticed. To err is human after all. In such scenarios, AI can be the quickest and most reliable helper to content writers be it for checking errors or to improve the existing content as a whole without losing the essence provided by the writer or the ideator’s intent. Thus, a content writer willing to embrace AI becomes the go-to man for the job.
Conclusion
Creativity is talent, writing is skill and AI is a tool. So is the reality of content writing today. No matter how human an AI is, it’s still less human than an actual human. The depth, emotions and innovations a writer can bring about in his work cannot be replicated by a piece of code. But as a tool in the hands of the right person, AI can make the best writer even better.Yes, I can write this blog on my own and its absolutely ok if I use Grammarly to check for errors and ChatGPT to shorten it. In conclusion, if the role of a content give writer exists, it’s because not everyone writes content and that relevance is not going to tarnish anytime soon.
Thank You.
0 notes
Text
Safe Sarms Muscle
Muscle Building And Sporting Activities Supplements.
Content
Skin Problem.
Medications As Well As Supplements.
Api Services & Chemical Growth
Why Are Individuals Using Collagen Peptide Powder Everyday In The Uk?

The testosterone-induced muscle hypertrophy is mostly due to a boost in satellite cell as well as myonuclear number, as well as enhancing the quantity of healthy protein synthesis and also hindering healthy protein destruction. Shop AOD Online is a young entrepreneur, electronic marketing expert and also blog writer. He's creator of TheWebReach.com and offers Digital Advertising and marketing services like Search Engine Optimization, Guest Post, Inbound Marketing as well as much more. He enjoys to aid people to grow their business worldwide via his digital advertising and marketing knowledge. He's enthusiastic about creating blog sites and also writes innovative material for the viewers. If you do not have power in your body, after that you can never ever end up being a bodybuilder, so in truth sense, it is essential to have power.
Shop Epithalon Online ='border: black solid 1px;padding: 12px;'>
Copper Peptides: Benefits for Skin and Hair Care, and How to Use Them - Healthline
Copper Peptides: Benefits for Skin and Hair Care, and How to Use Them.
Posted: Mon, 26 Oct 2020 07:00:00 GMT [source]
Nonetheless, provided the possibility for high estrogen negative effects while making use of ligandrol UK, it is suggested that you purchase anti estrogen supplement. Where Ostarine is among the most effective SARMs to include in a cutting cycle, LGD has actually verified itself as an excellent bulking agent. LGD has a half-life varying in between 24 as well as 36 hrs so daily dosing is optimal. Using cardarine for women, and which for sarms are the best to underpin and all-natural gym regimen. Establish superb tone, strength, and also cut fat utilizing a straightforward women sarms cycle, as well as uncover what dose and also cycle length you need to be making use of. For some background info, i have been raising continually for 3-4 years, gone from pounds at 15% bodyfat. I am doubting whether i need to run a cycle of mk-677 due to the fact that research study seems to verify recovery results on injuries as a result of the boosted growth hormone.
Skin Concern.
This will certainly help increase cardiovascular endurance in order to improve outcomes. Check out our sarms pills for sale to purchase them prior to the stock finishes. S1 has displayed a real capacity to help recover those with debilitating injuries and also to quicken injury recuperation. The helpful results on recuperation make clinical usage highly appealing. Ostarine can and also will certainly reduce your natural testosterone manufacturing in longer, greater dosed cycles, so a serm pct is needed. Ostarine can additionally trigger gyno in some customers, so it is recommended that you have an ai, like exemestane, handy. The addition of ghrp or peptides in the cycle will minimize the threat of injury.
DNP is a commercial chemical that isn't suitable for human consumption. It's highly harmful as well as creates substantial adverse effects, as well as has caused at least 3 reported deaths. Among products that were taken off the market was a steroid product called Celtic Dragon. This item left 2 males hospitalised with serious jaundice and liver damage. " Structure strength takes years, not weeks or months. It's an act of technique as well as must be made with dedication to hard training and a great diet regimen." They're legally readily available to purchase over the counter along with online. Prohibited supplements, consisting of some claiming to be "fat loss" or "slimming", have been connected to a handful of fatalities.
Medications As Well As Supplements.
These advantages, in conjunction with the extremely small opportunity of adverse effects show MK677 to be a breakthrough medicine. Keep in mind that some comparable speculative medications (such as Cardarine/GW, Ibutamoren/ MK-677, and also YK11) are occasionally marketed as SARMS - they aren't yet are still occasionally incorporated right into SARM stacks. A few of these sites supply unlawful products along with lawful weight-loss medicines, making it very tough to tell the difference. Using DNP over a long period of time can cause cataracts as well as peeling skin, and also may trigger damage to the heart and also nervous system. DNP is thought to be especially prominent amongst bodybuilders, that are attracted to its pledges of quick-fix quick weight-loss.
youtube
When one takes anabolic steroids, the cells get swamped with androgens, and all receptors become saturated. As a result, a message is sent to all the body cells that cause their growth. This may be an advantage to any person looking to getting muscle mass, however it is a downside at the exact same time. In SARMs, a steroidal agent with anabolic activity imitates testosterone. It boosts lean muscular tissue mass, yet without troubling sex drive and also expanding the prostate. Also, you won't experience loss of hair and also opposite side impacts that anabolic drugs trigger.
This is much easier than having to area out and bear in mind when to take your dosage on a daily basis. It was at first created to treat as well as prevent muscle mass waste among cancer cells as well as weakening of bones patients. It has actually been considered and wanted to be utilized for avoiding muscular tissue degeneration, cachexia and also sarcopnia, as well as has actually additionally been discussed for usage during TRT/HRT. Studies conducted had a dose of between 5-25 mg per day, with 25 mg being one of the most typical as well as efficient dose. MK677 has a 1 day fifty percent life and also showed to be best tolerated by rats when fed to them each early morning on a vacant belly. MK677 has severe benefits in relation to aiding with a much deeper sleep. Nevertheless, it can hinder sleep patterns if taken too late at night or too near bedtime.
Api Solutions & Chemical Development
Dylan - what is the best sarm for recouping from an injury, specifically a lower leg tension fracture? The most effective way to improve fat loss and also muscle mass is to cycle mk-2866 with an additional sarm like gw throughout the cutting phase.

The body doesn't know the distinction in between what it develops naturally or gets from SARMs. All it understands is there is a rise is that production degree and also it is mosting likely to benefit from it. On the flip side, the use of anabolic steroids is going to create the body to quit making testosterone. Therefore, the customer needs to stack with various other items to try to get it launched again. When they are no more taking the steroids, it is still going to take time for the natural production of testosterone to happen once more. Generally, your body regulates the manufacturing of androgens to avoid their imbalance.
Why Are Individuals Using Collagen Peptide Powder Everyday In The Uk?
Stenabolic + growth hormone or andarine s4 + ghrp-6 + cjc-1295 dac to stop injuries as well as accelerate the recovery. You don't have to resemble an average body builder, physical fitness model or athlete; all you got to do is use a SARM. If you have actually not become aware of them or require some even more details, this article will give you with all the details concerning this medicine. They are careful androgen receptor modulators that show the same kind of result as that of androgenic drugs, however the only distinction is that they are more careful in their action. SARMs are chemically comparable to steroids as well as are likewise as effective in enhancing fat loss as well as muscle growth. As long as SARMs advantages are identical to those of anabolic steroids, their discerning activity makes the SARMs negative effects less. It means that as soon as you decide to make use of SARMs, you get to bid bye-bye to hormonal imbalance issues, acne, virilization in females and also prostate problems that can be produced by the use some steroids.
Neuropeptides are the most varied class of signifying molecules in the mind, and also are involved in a broad series of brain features, consisting of analgesia, recreation, discovering and memory, incentive, food consumption and even more.
Pharmaceutical items which imitate the effects of endogenous peptide ligands are call peptidomimetics.
This on a regular basis up-dated website offers a run-through of the synthetic processes associated with manufacturing of stomach peptides, as well as regulation of these procedures.
They differ from peptide hormones because they are produced from nerve cells as well as act locally on adjoining nerve cells, whereas peptide hormonal agents are secreted in to the blood by neuroendocrine cells and act at distant websites.
Neuropeptides are tiny proteinaceous cell-cell signaling particles generated and also launched by neurons.
In addition, SARMs are tougher to identify during medicine examinations, which, integrated with less negative effects, make them a much better option for athletes. In order to benefit from the extremely significant bulking impacts of LGD4033, a dosage of 5-10mg need to be taken daily for 8 weeks. To obtain the most effective LGD-4033 results for reducing, a dose of 3-5mg everyday is recommendedn, normally for an 8 week cycle. LGD has the ability to bind to the AR with an extremely high fondness. LGD is typically identified as an ARligand that is cells selective. It was initially created to treat muscle mass squandering in cancer people, age-related muscle loss, along with severe and also persistent health problem. Ostarine has a 24-hour half life, so it's unneeded to break up your daily dose.
There are places that are recommended if you're looking to purchase SERMS. Considering that RAD140 is a relatively brand-new supplement, there isn't a great deal of info on the side results. Clinical research studies have shown that there are no reported side effects of the supplement. Reggie Johal is the creator of Predator Nourishment, a UK based health and supplement shop. Reggie owes a lot of his substantial stamina as well as physical fitness knowledge to his previous profession as a Fantastic Britain American Footballer. The ordinary cycle size is 6 to 10 weeks at a dose variety of 10mg to 25mg.

You can find out even more concerning the damaging actions of these steroids on this site. As their name states, discerning androgen receptor modulators act upon bone and muscle cells. By triggering receptors on them, these substances promote the growth of brand-new cells. They do not bind to androgen receptors on other organs in the body This quality of selectivity is what differentiates SARMs from anabolic steroids.
However it's impossible to say whether SARMs can have these adverse effects on everybody, or maybe they need to be excluded in only specific cases. Nonetheless, the notion has hardly been talked about outside the U.S.A., which might make some individuals think. There are those that speak up noisally against making use of SARMs, however many scientists as well as authorities are only seeing carefully.
Can you take peptides orally?
Summary: Peptides represent a billion-dollar market in the pharmaceutical industry, but they can generally only be taken as injections to avoid degradation by stomach enzymes. Scientists have now developed a method to generate peptides that resist enzymatic degradation and can be taken orally.
This makes your body capable of combating many vital diseases that you can not visualize. With this help, you have the ability to obtain even more weight and can do a health club properly. Nowadays, everyone suches as to head to the gym as a result of their conscience towards their health and wellness. If your desire is to do body building, after that in the meanwhile, you require a lot of diet plans since nourishment is a vital part of making the body. There are several items out there with the assistance of which you can quickly do body building and get to a great level.
There are some homes inside this medicine that help in increasing your power degree. After consuming it, the blood circulation of your body boosts to ensure that you really feel energised. As blood flow increases, the variety of white blood cells inside your body rises, which develops anti-oxidants.
Does caffeine increase hair growth?
But according to research, the caffeine in coffee can help stimulate hair growth and stop hair loss. One 2007 laboratory study found that caffeine helped block the effects of DHT in male hair follicles. https://pharmalabglobal.com/product-category/tb500/ stimulated hair shaft elongation, resulting in longer, wider hair roots.
There is a growing industry in sports nutrition supplements offered on the high road and online. They may also seek means to manage their cravings when they're trying to reduce weight as part of a muscle building diet regimen.
MK677 can be made use of continuously for 1-2 years without issue of a specific ending up being desensitised to it. However, it is constantly important to recognize the opportunities that could accompany usage. It is evident by the checklist of benefits that MK677 is extremely desirable.
#Shop AOD Online#Shop BPC157 Online#Shop CJC-1295 DAC Online#Shop CJC-1295 NO DAC Online#Shop Epithalon Online#Shop HCG Online#Shop Hgh Fragment Online#Shop Ipamorelin Online#Shop Melanotan 2 Online#Shop Oxytocin Online#Shop Pt141 Online#Shop Sermorelin Online#Shop Tb500 Online#Purchase AOD#Purchase BPC157#Purchase CJC-1295 DAC#Purchase CJC-1295 NO DAC#Purchase Epithalon#Purchase HCG#Purchase Hgh Fragment#Purchase Ipamorelin#Purchase Melanotan 2#Purchase Oxytocin#Purchase Pt141#Purchase Sermorelin#Purchase Tb500#99% Purity AOD#99% Purity BPC157#99% Purity CJC-1295 DAC#99% Purity CJC-1295 NO DAC
1 note
·
View note
Text
Simoun, a review
(Disclaimer: The following is a non-profit unprofessional blog post written by an unprofessional blog poster. All purported facts and statement are little more than the subjective, biased opinion of said blog poster. In other words, don’t take anything I say too seriously.)
Just the facts 'Cause you're in a Hurry!
Manufacturer’s Suggested Retail Price for Season (MSRP): 25.00 USD
How much I paid: 23 Dollars USD.
Number of Episodes: 26 Episodes
Price per episode: 1 Dollar per episode
Length per Episode: 25 Minutes on average. 21 Without Intro and Ending song.
Number of Discs: 5 DVD Discs in total.
Episodes per Disc: 5 or 6.
Licensed and Localized by: Media Blasters
Animation Studio: Deen
Audio: Japanese Audio with Subtitles available
Bonus Features: Staff and Voice Actor Commentary.
My Personal Biases: I actually saw Simoun a while back but never reviewed it. I like other shows in the Shoujo Ai genre such as Mai Hime, Mai Otome, Maria Watches over Us, Strawberry Panic and yes, even Kannazuki no Miko/Destiny of the Shrine Maiden.
My Verdict: Simoun is probably one of the best shows and anime series I’ve seen even if it wasn’t part of the shoujo ai genre. It stands up to one of the best in the business with its beautiful animation, amazing soundtrack, incredible world building and interesting characters. But its tone and message is joyless, sullen and grim. Even when the series has a handful of hopeful (not happy mind you) scenes, there’s still the sense of loss. If you can stomach some truly heart wrenching scenes, check this show out when you can.
A/N: Okay, so Media Blasters is the official licenser of the show and translated most of the subs. A lot of the names were also translated but a lot of fans noticed a change in names. Mainly, a lot of characters whose names end with a “u” end up having the “u” dropped. So Caimu is Kaim, Anubitufu is Anubituf and Aeru is Aer. Also, Rodoreamon is apparently Rotreamon now. I’m going to use the names Media Blasters chose for the characters for the sake of simplicity.
Simoun, a review

youtube
I consider myself a fan of shoujo-ai or Yuri anime. I own a couple of boxsets of Yuri anime. I watch Yuri anime. Even the stuff that bores me (Strawberry Panic) or annoys me (Kannazuki no Miko/Destiny of the Shrine Maiden) at least makes me rewatch it again and again. Like all things, I tend to have agreements of which shows I like and which shows I detest like the fucking plague.
But, then comes a series that not only makes me rethink preconceptions I had about religion, war, politics, children, innocence and romances, but also makes me rethink myself and how I rate things on a good or bad rating.
Simoun is a particularly hard series for me to review. It’s a study of contrasts.
While I can honestly say the efforts put forth by the director, the animators, the voice actors and the writers is nothing less than something I find in a movie studio and the passion put into this project is nothing less than soul bearing, it remains one of the most polarizing and controversial shows I’ve ever reviewed.
So, let me say this upfront so you can understand where I’m coming from:
Simoun is a fantastic anime that covers the concepts of children at war, religion rivaling technology, gender roles, maturity, war in the name of religion, and the loss of innocence… that also happens to have lesbian romances.
It’s probably one of the few shows that’s legitimately good and can recommend to people who aren’t shoujo ai fans.
The scope magnificent, the animation, even the stilled shots, are gorgeous to look at, the music is haunting and the characters and voice actors do their absolute best to make the characters come alive. Even the use of CGI ships against a 2D backdrop manage to still look compelling (if a bit dated).
A war breaks out between three nations Simulacrum, Argentum, and Plumbum over Simulacrum helical motor technology that powers the airships known as Simouns. Two fleets of the Simoun, Chor Caput and Chor Tempest, stumble upon a huge Argentum airship fleet attempting steal a Simoun. Suffering massive losses in the battle, the pair Neviril and Amuria of Chor Tempest attempt an extremely powerful but extremely dangerous maneuver out of desperation named the Emerald Ri Mājon. Neviril hesitates after making eye contact with the enemy, and the pair fail resulting in an explosion that takes Amuria with it. The fight leaves the sibyllae or members of Chor Tempest extremely demoralized and Neviril in despair.
This is not Strawberry Panic, an all-girls school romance; this is Ender’s Game and Top Gun for the Shoujo Ai Genre. I would even hesitate to use the word Romance to describe this show because of how dark and at times bleak it can get. But, if you can stomach through the hardships and the gut wrenching scenes, you will find a light at the end of the tunnel and will find hope for the world and its characters.
The people of Daikūriku are all born female. In Simulacrum, the girls grow up until age of seventeen, when they make a pilgrimage to a holy place known as "the Spring" to select their permanent sex. Four new sibyllae join Chor Tempest, one of them an excellent pilot with an unshakeable morale named Aer. Aer immediately decides to partner with Neviril, however despite her persistent attempts, Neviril remains too mired in her grief over Amuria's death to accept her.
How committed are the producers to this premise of everyone being born female? So committed that they literally hired only female voice performers to voice all the characters, even the older men with facial hair. It’s that fact that haunts the world around them. Certain countries do not have access to the well so they have to perform sex reassignment surgery operations for half of the population to keep them afloat. And the use of such technology is polluting their world to the point of seeing nothing but red and black.
This show came out in 2006 before the idea of there being more than 2 genders, debates on whether gender and general roles are a social or biological constructs and gender fluidity became popularized on internet sites like Tumblr.
(I will point out to my internet skeptic friends that the show’s setting depicts EVERYONE as being born biologically female and, according to this world, that certain members MUST transition to the male gender to keep society functioning.)
But be warned; the show can get bleak and downright depressing at times. If you thought it was hard to sit through some of the darker parts of Kannazuki no Miko or My-Hime, you haven’t seen anything yet!
For example, as early as Episode 4 (one of the ‘filler’ episodes), Aer and Rimone take an unauthorized flight and get ambushed on the ground by an enemy soldier. The Soldier dies only to have his body stiffen up with his hands on the controls of the Simoun. Rimone points out that prying his hands off will break the controls, stranding them there in enemy territory while the enemy comes closer.
So Aer has to take her tiny pocket knife and SAW OFF THE SOLDIER’S HANDS FROM THE REST OF HIS BODY.
It’s not even the amount of blood or gore that’s disturbing; it’s seeing a child having to endure and do such a thing that’s so messed up.
See, one of the interesting things I love is seeing how characters interact or react to the world around them. In Simoun, the Sybillae are so used to the idea of war that hearing about people dying is nothing new for them but the idea of having to deal with a mouse is frightening. It’s the type of world where a kiss on the lips between women is so commonplace but Rotreamon cutting off her braids is more dramatic.
If there’s a consequence to the proceedings it’s the characters.
Don’t get me wrong; the characters aren’t ‘bad’ per say and a lot are very interesting and have interesting dynamics, such as the incestuous undertone of Kaim and Alti, the mechanic Waporif dealing with the idea of faith and technology, the class struggle between Roderamon and Mamina. Even Floe, the cute girl and comedic relief, doesn’t escape the world unscathed.
It’s just that the world and the situations and the conflict are so interesting, that you start to notice that the characters are a bit on the stock type. (Then again, I think you need familiar stock types so you can digest some of the bigger concepts.)
But our main pair, Neviril and Aer, are the center of the proceedings and it’s their relationship that nails it. You get the sense that Neviril and Aer are both locked in a sense of immaturity, albeit from different perspectives. Neviril is locked in the idea of being pure and being a priestess forever, even going so far as to not fly again once Amuria dies. Aer, meanwhile, is an impulsive hothead who wants to do nothing but fly, even at the cost of being an adolescence.
But as the war rages on and the casualties of people they know and love start piling up, the two eventually find comfort in each other’s arms. It first seems like Aer is the stronger of the two only for her to completely break down when one death becomes one death too many.
If Junji Nishimura’s direction and co-writing are what brings the characters alive, Toshihiko Sahashi’s music is what makes them transcendent. Every so often, he would incorporate pieces of church music, classical music and tango to make the dichotomy and juxtaposition of certain scenes blow you away.
Yes, Tango.
youtube
Towards the latter half of the series, I noticed that the animation liked to use still shots with characters still talking.
At first, I thought this was intentional by the showrunners. But, as I rewatched the series, it dawned on me that the animation budget was probably blown on the CGI battles and the rest of the team had to resort to cost saving techniques for the show.
CAVEAT: Shows like Simoun do not get made every day. Directors and writers willing this bold of a risk to tell this dense of a tale should be rewarded. And yet for the same time, it’s not for the faint of heart. It’s not for the casual viewer. In some ways, it’s not even for anime fans. This is the anime version of 12 years a Slave as it provides a brutal, harsh and unflinching look at the world.
Do you hate this show?
No, because if I hated it, I’d simply write it off and say it’s a piece of crap just to be done with it.
It’s not. If anything, Simoun is an ambitious anime made by well-intentioned people that for a lot of people is not going to resonate with them. And I’m not even throwing shade on religious viewers who have trouble digesting the heavier concepts. Even more progressive minded viewers are not going to sign on to a lot of the negative and just melancholy tones throughout the work. The work isn’t so much dark as say parts of Kannazuki or Mai Hime are as it is bleak. There’s a sense of melancholy in the air that just persists and there’s no getting rid of it with glimmers of hope scattered here and there.
Why is recommending the anime so hard for you if you thought it was good?
Because for a lot of people, a lot of the world building, concept provoking and issue debates are not what they wanted. Aside from the heavy themes and messages, a lot of the technical flaws do stick out. Neviril and other character designs were a bit off putting to me the first time I saw it, resembling more like dolls than usual anime characters. The CGI Simouns are interesting in concept (and I like the idea of rendering them in CG to show off how alien/foreign they are) but do show a dated look. And for some people, the slow (intentionally deliberate or not) pacing will drive them nuts.
I came upon Simoun as I was exploring Yuri anime and wanted to see, yes, anime girls kissing. What I got instead were thought provoking concepts that only changed my view but changed the views of people around me.
Buying this show just to watch girls kissing each other is like, as Jeff Foxworthy said, buying a 747 just to eat the peanuts.
Erica Friedman, writer of the blog Okazu Yuri, once said this show is not for the Lowest Common Denominator. And upon rewatching Simoun, I had the startling realization that not only was Friedman right but also that I was part of the Lowest Common Denominator.
Simoun is more of a show that I admire and respect the hell of, than I actually like and the fault lies more because of me than what the show did. And for 23 USD with the amount of content AND the numerous special features including Director Commentary and cast interviews, this is truly a must buy!
That ending shot gets me every time.
Verdict: Buy it!
#simoun#neviril#aer#aeru#caimu#kaim#alti#alty#dominura#rimone#limone#mamina#mamiina#roderamon#rotreamon#junji#nishimura#junji nishimura#toshihiko#sasashi#toshikiko sahashi#yuri#shoujo ai#lesbian#lgbt#fumi#akira#aoi hana#aoi#hana
9 notes
·
View notes
Text
Outriders: A New Blast-Off Story Trailer Gets Released
LG claims that their OLED TV is one of the best selling products across the world. The blog has an overall review of the LG OLED 48CX product as per the official specifications launched by the company. The LG OLED 48CX, the new product by LG, has something for everyone.

Let’s Start With The Availability Of The Product
LG is going to launch two models at the same time. If you are living in the UK, then you can buy either OLED48CX5LB or OLED48CX6LA. The only difference in both models is the finish of the product. But both the models are identical in terms of specs and features.
If you are in the US, then you will get this product with the model name as OLED48CXPUB. Bad news for the people living in Australia, as they can’t buy this product during the launch. But after some time, they can.
Design Of LG OLED 48CX
Disappointingly, the new LG’s OLED TV looks identical to the last year released C9, which might affect its sale. There is no doubt that C9 is a good-looking product, and the CX will have a similar design, but there must be some changes. As people always look for a unique product, and the company has many ways to improve the design.
Undoubtedly, the new OLED panel is extremely thin, which is a good thing about this product. The company needs to work to adjust the speakers, connections, and processing pieces.
Features
According to the new norms released by LG, all the products launched by them (except B series) in this year have the same panel and processing units. You might see the difference in the sound system and the styling. You will get 4K flagship experience on 48-inches TV.
The significant feature in this TV is Artificial Intelligence (AI). There are several features like AI Picture Pro, and AI Sound Pro that enhance the user experience.
Additionally, it supports HLG, HDR10, and Dolby Vision, making it better than its competitors like Panasonic and Philips. But you might go into a state of confusion as it doesn’t have the Dolby Vision IQ setting in the menu of the TV. Don’t worry! The product by LG enables this feature automatically when required.
Did you know? LG was the first TV manufacturer who offered certified HDMI 2.1 sockets to their users. These kinds of sockets don’t guarantee the support of the next-generation HDMI feature, but there might be some new involvement with this feature.
Picture Quality
The company claims to offer flagship OLED performance through the OLED48CX. In testing, it was proved that their product delivers exactly what they are claiming.
You might find that the color of the TV is vibrant and lush, and it produces an effortlessly natural picture. The color on the TV is entirely realistic.
If you see the overall picture quality, it is crisp, natural, and users might feel absolute joy. There are plenty of specs and features that are sufficient to produce an amazing contrast when watching anything on HDR mode.
Sound Quality
Before analyzing it, you have to learn about its AI features that are part of all the CX models. This smart TV has a Smart AI feature that analyzes and adjusts the TV’s sound according to your room. In testing, it is revealed that the AI feature always tries to deliver smooth audio, which is audible to all the people available in that room.
The overall performance of the sound with this feature is quite good. Sometimes the speakers might struggle while playing some soundtracks.
If you have decided to buy the LG 48CX OLED TV, it will be a great option to purchase a soundbar. If you want a better soundbar option, then you can go for the Sonos Arc.
Final Verdict
It is a perfect product for those who want to buy a perfect TV, but don’t want to get a big one. It is one of the best small size TVs with excellent sound and picture quality.
But if you are in the UK and want to use some apps like BBC iPlayer, then don’t buy this product.
Jackson Henry. I’m a writer living in USA. I am a fan of technology, arts, and reading. I’m also interested in writing and education. You can read my blog with a click on the button above.
Source-New Blast-Off Story Trailer Gets Released
0 notes
Text
Newsletter: How Fast Will the Economy Grow?
DOW JONES, A NEWS CORP BUSINESS
News Corp is a network of leading business worldwides of varied media, news, education, and details services.
DOW JONES
Barron’s
BigCharts
DJX
Dow Jones Newswires
Factiva
Financial News
Mansion Global
MarketWatch
NewsPlus
Private Markets
Risk & Compliance
WSJ Conference
WSJ Pro
WSJ.com
NEWS CORP
Big Decisions
Company Viewer
Checkout51
Harper Collins
Real Estate
Makaan
New York City Post
News America Marketing
PropTiger
REA
realtor.com
Storyful
The Australian
The Sun
The Times
Unruly
DJIA
▲
2927528
-0.01%
S&P 500
▲
336046
0.25%
Nasdaq
▲
964648
0.19%
U.S. 10 Year
▲
-1/32 yield
1.589%
Petroleum
▲
4994
0.75%
Euro
▲
1.0923
0.12%
Subscribe Now
Sign In
The Wall Street Journal
Areas
My Journal.
House
World
U.S.
Politics
Economy
Service
Tech
Markets
Opinion
Life & Arts
Property
WSJ. Magazine
Today’s Paper
SHOW ALL SECTIONS
HIDE ALL AREAS
World Home
Africa
Asia
Canada
China
Europe
Latin America
Middle East
Economy
World Video
U.S. Home
Economy
Law
New York
Politics
Real Time Economics
Washington Wire
Journal Report
U.S. Video
What’s News Podcast
Politics Home
Election 2020
Project Wire
WSJ/NBC News Poll
Politics Video
Economy Home
Real Time Economics
Bankruptcy
Central Banking
Personal Equity
Strategic Intelligence
Equity Capital
Economic Forecasting Study
Economy Video
Company House
Management
Tech/WSJ. D
The Future of Whatever
Aerospace & Defense
Autos & Transportation
Business Real Estate
Consumer Products
Energy
Entrepreneurship
Financial Solutions
Food & Services
Health Care
Hospitality
Law
Manufacturing
Media & Marketing
Natural Resources
Retail
CFO Journal
CIO Journal
CMO Today
Logistics Report
Danger & Compliance
Heard on the Street
Artificial Intelligence
Bankruptcy
Central Banking
Personal Equity
Cybersecurity
Strategic Intelligence
Venture Capital
Company Video
Journal Report
Business Podcast
Tech Home
CIO Journal
The Future of Whatever
Christopher Mims
Joanna Stern
Julie Jargon
Billion Dollar Startup Club
Tech Video
Tech Podcast
Start-up Stock Tracker
Markets House
Bonds
Business Realty
Commodities & Futures
Stocks
Your Money
Heard on the Street
MoneyBeat
Wealth Adviser
Market Data House
U.S. Stocks
Currencies
Products
Bonds & Rates
Shared Funds & ETFs
CFO Journal
Journal Report
Markets Video
Your Cash Informing Podcast
Secrets of Wealthy Women Podcast
Viewpoint Home
Sadanand Dhume
James Freeman
William A. Galston
Daniel Henninger
Holman W. Jenkins
Andy Kessler
William McGurn
Walter Russell Mead
Peggy Noonan
Mary Anastasia O’Grady
Jason Riley
Joseph Sternberg
Kimberley A. Strassel
Books
Film
Television
Theater
Art
Work Of Art Series
Music
Dance
Opera
Exhibition
Cultural Commentary
Editorials
Commentary
Letters to the Editor
The Weekend Interview
Potomac Watch Podcast
Foreign Edition Podcast
Viewpoint Video
Notable & Quotable
Best of the Web Newsletter
Early Morning Editorial Report Newsletter
Life & Arts House
Arts
Books
Cars And Trucks
Food & Beverage
Health
Ideas
Property
Science
Sports
Style & Style
Travel
WSJ. Magazine
WSJ Puzzles
The Future of Everything
Far & Away
Life Video
Arts Video
Property Home
Business Real Estate
Home of the Day
Real Estate Video
WSJ. Magazine House
Fashion
Art & Style
Travel
Food
Culture
CONCEAL ALL AREAS
Objective greater, reach even more.
Get the Wall Street Journal $12 for 12 weeks.
Subscribe Now
Sign In
House
World
Areas
Africa
Asia
Canada
China
Europe
Latin America
Middle East
Sections
Economy
More
World Video
U.S.
Sections
Economy
Law
New York City
Politics
Columns & Blogs
Real Time Economics
Washington Wire
More
Journal Report
U.S. Video
What’s News Podcast
Politics
Areas
Election 2020
Campaign Wire
More
WSJ/NBC News Poll
Politics Video
Economy
Blog Sites
Actual Time Economics
WSJ Pro
Bankruptcy
Central Banking
Private Equity
Strategic Intelligence
Venture Capital
More
Financial Forecasting Survey
Economy Video
Business
Sections
Management
Tech/WSJ. D
The Future of Everything
Industries
Aerospace & Defense
Autos & Transportation
Business Real Estate
Customer Products
Energy
Entrepreneurship
Financial Services
Food & Solutions
Healthcare
Hospitality
Law
Manufacturing
Media & Marketing
Natural Resources
Retail
C-Suite
CFO Journal
CIO Journal
CMO Today
Logistics Report
Threat & Compliance
Columns
Heard on the Street
WSJ Pro
Expert System
Bankruptcy
Central Banking
Private Equity
Cybersecurity
Strategic Intelligence
Equity Capital
More
Company Video
Journal Report
Business Podcast
Tech
Areas
CIO Journal
The Future of Whatever
Columns & Blogs
Christopher Mims
Joanna Stern
Julie Jargon
More
Billion Dollar Startup Club
Tech Video
Tech Podcast
Startup Stock Tracker
Markets
Areas
Bonds
Industrial Real Estate
Commodities & Futures
Stocks
Your Money
Columns & Blogs
Heard on the Street
MoneyBeat
Wealth Consultant
Market Data
Market Data House
U.S. Stocks
Currencies
Products
Bonds & Rates
Shared Funds & ETFs
More
CFO Journal
Journal Report
Markets Video
Your Money Informing Podcast
Secrets of Wealthy Women Podcast
Opinion
Writers
Sadanand Dhume
James Freeman
William A. Galston
Daniel Henninger
Holman W. Jenkins
Andy Kessler
William McGurn
Walter Russell Mead
Peggy Noonan
Mary Anastasia O’Grady
Jason Riley
Joseph Sternberg
Kimberley A. Strassel
Reviews
Books
Movie
Television
Theater
Art
Masterpiece Series
Music
Dance
Opera
Exhibition
Cultural Commentary
More
Editorials
Commentary
Letters to the Editor
The Weekend Interview
Potomac Watch Podcast
Foreign Edition Podcast
Viewpoint Video
Notable & Quotable
Best of the Web Newsletter
Morning Editorial Report Newsletter
Life & Arts
Sections
Arts
Books
Automobiles
Food & Drink
Health
Concepts
Property
Science
Sports
Style & Fashion
Travel
More
WSJ. Publication
WSJ Puzzles
The Future of Everything
Far & Away
Life Video
Arts Video
Realty
Areas
Commercial Real Estate
Home of the Day
More
Real Estate Video
WSJ. Magazine
Areas
Style
Art & Style
Travel
Food
Culture
Browse
Subscribe
Check In
Fed Seeing Dangers of Wider Coronavirus Disruptions.
Work Stoppages Reach Highest Level in Almost 20 Years.
Credit-Card Debt in U.S. Rises to Tape $930 Billion.
Trump Deficit Forecast Is Constructed on Shaky Assumptions, Professionals State.
Fed’s Bullard: 2019 Rate Cuts Increase Possibility of Soft Landing.
Fed’s Daly States Low Jobless Rate Not Automatic Indication of Tight Labor Market.
Trump Wants to Double Costs on AI, Quantum Computing.
Coronavirus Toll on Shipping Reaches $350 Million a Week.
Coronavirus Drives China’s Inflation to Highest Level in Over 8 Years.
Fed Chairman Heads to Capitol Hill Facing New Questions Over Development Threats.
Trump Proposes $4.8 Trillion Budget Plan, With Cuts to Security Nets.
Fed’s Bowman: Existing Fed Policy Will Support Expansion.
U.S.-China Trade War Reshaped Global Commerce.
Economy Week Ahead: Fed Chair Affirms, U.S. CPI and EU Trade Data.
Smallest U.S. Firms Battle to Discover Workers.
Next Story >
Actual Time Economics
Newsletter.
By
Jeffrey Sparshott
.
Jeffrey Sparshott
The Wall Street Journal
Bio
@jeffsparshott
.
Why New Hampshire Matters for the Top 5 Democratic Contenders
Viewpoint: Buttigieg’s War and’ The Quickest Way Home’
Viewpoint: The Cow Dung Treatment for Coronavirus
Why New Hampshire Matters for

the Leading 5 Democratic Competitors
China Slowly Heads Back to Work After Coronavirus Shutdown
The U.S. Is Susceptible to an Iranian Cyberattack. Here’s How.
.
.
Viewpoint: The White Home Budget Proposal Does Not Curb Entitlements
‘ Parasite’ Controls the Oscars With Four Wins
A Lot Of Popular Articles

Opinion: Buttigieg’s War and’ The Fastest Way House’
.
How a
Reality-TV Producer Became Rainmaker to$300 Billion Saudi Fund

Viewpoint: The Cow Dung Cure for Coronavirus
. 98.6 Degrees Fahrenheit Isn’t the Typical Anymore
.
.
.
.
.
%%.
from Job Search Tips https://jobsearchtips.net/newsletter-how-fast-will-the-economy-grow/
0 notes
Text
5 prime benefits of AI for start-ups and small businesses

AI or Artificial Intelligence combines the dual power of computing capabilities as well as human-like adaptability. It offers AI a distinct position...much better than traditional computing. In many instances, the AI can be as reliable as a human employee. Thus investing in AI can prove to be a great decision for the enterprises, especially for the start-ups and small enterprises with limited resources to spend on hiring human talent. Here are a few ways in which AI can help start-ups and small businesses to manage their business affairs confidently. Here are a few ways in which AI is helping small businesses across the world:
Getting more insights out of the available data
Data is rightly called the new gold for digital businesses due to the vital role it plays in recognizing the latest trends and planning better business strategies based on key insights. A growing number of progressive small businesses are actively collecting and utilizing data for improving their business potential. The problem, however, is that it is a time consuming and tedious activity and the present technologies only present the half-solution as they still require consistent human intervention for categorizing the data, presenting it incomprehensible format and most importantly analyzing it from different aspects. Expensive costs and management hassles associated with hiring data scientists or outsourcing analytical tasks like Statistical Regression Skills prevents the small businesses from harnessing the actual benefits of their data collection exercises that may defeat the very objective of such tasks. AI can offer the precise solution here due to its evolving model, better automating skills and strong analytical capabilities.
By employing the advanced analytical techniques like statistical regression analysis the AI tools can deliver deeper and diverse business insights to the small businesses. It helps them in managing various aspects of their business like retaining the present customers, acquiring new clients, recognizing the actual strengths and weakness of their business model and exploring new avenues with higher possibilities. By identifying and wisely linking the diverse elements of the available data the AI can tell that how the different factors are affecting the business that allows them to take a wise decision and modify the changes for better benefits.
Strengthening Human Resources
Small companies lack the brand value and high packages and perks required for attracting bright talent. Due to budget and time constraints, they don’t have the privilege to dedicated an expert HR panel and implement elaborate hiring processes for deeper analysis of the candidate’s viability. They end up hiring a mediocre candidate and it results in lukewarm, static work culture. It places them in a disadvantageous position, especially when compared to their bigger counterparts.
Instead of humanly wading through a high volume of resumes and selecting the best candidate the companies can delegate this entire exercise to the AI tools. It not only saves them from unnecessary stress and efforts but also promises a more rationalized ad elaborate approach while deciding the most relevant candidate for the job. l
With its quick automation and well defined analytical capabilities, the AI can capably find the best candidate irrespective of the volume and diversity of the resumes.
Based on its algorithm backed deep learning capabilities the AI can sift through the past hiring techniques and deeply analyzes the outcomes to pick the most fruitful HR practices. Depending upon the same it can suggest the best hiring process for selecting the right candidates that are perfectly fit for the job. It helps the HR department to concentrate efforts in the right direction and base their decision on solid analysis supported by stats and facts instead of following intuition based approach with uncertain results. Going a mile further the AI can also help the HR with other details like best places to find the ideal candidate, align their communication with the candidates’ persona to get desired outcome and accessing insights of their past work history to know about major factors like stability, professional commitment, performance, job-specific skills and overall potential of the candidate in the long term. It helps the HR team to hire the top talent that is the best fit for the job role.
Independently managing petty daily tasks
The employees of small businesses are generally overburdened with multitasking due to the lack of sufficient manpower strength. Their time and efforts are divided between the front end and backend operations that severely affect their performance and reduce their productivity. With its deep learning capabilities and self-evolving model, the AI can efficiently reduce the workload of the employees by independently managing miscellaneous mundane and tedious backend tasks like scheduling, basic accounting, and other petty daily activities. It allows the staff to concentrate on their key responsibilities that eventually boost their performance.
Taking ownership of R&D activities
Marketing research plays an essential role for small businesses and helps them to gain better traction the market. Thanks to AI the businesses no longer need to divert their manpower resources to conduct market research. AI can actively help the businesses in entire research exercises right from collecting and filtering the data to conducting deep and wholesome analysis.
Conclusion
AI has several distinct advantages over traditional technology. It can not only save time and efforts but more importantly, it can actively learn and evolve with the time. While the big businesses across the globe have already started employing AI technologies, it is equally beneficial for the start-ups and the small businesses. By wisely implementing AI technologies the start-ups and small businesses can gain a competitive edge without inflating their overheads. In this article, we have presented some of the major ways in which the AI can help starts and small businesses to enjoy better benefits and increase their profitability.

Articles By
Jitendra Bhojwani
[email protected]
Expertise:
Jitendra Bhojwani (Jatin) is a versatile writer who considers and respects writing as a meditative technique to get rid of negative thoughts and stress. His favorite niches include history, travel, lifestyle and technology.

And Naveen Sharma
Expertise:
Naveen Sharma is a visionary entrepreneur with over 2 decades of experience in Information Technology (infrastructure as well as Software & Automation) who extensively writes on latest technologies
Key Words
Business Insights, Business, Insights, Altek Media Group, Altek, Media, Video, video production, online, online magazine, digital marketing strategy, digital, marketing, strategy, Blogging, social media, Marketing Funnel, Brand, Content Management System, logistics, Lean manufacturing, manufacturing, CEO, infograhics, instagram, facebook, linked in, google, Key Performance Indicator, Automation, Optimization, exit planning, Public relations, video, Advanced Manufacturing, Agile, lean, oem, smart, supply chain, Net Neutrality, Big Data, Data Mining, Actionable Analytics, Artificial Intelligence, Machine Learning, Personalization, Voice Recognition, Chatbots, Augmented Reality, Virtual Reality, Smart Factory, Industry 4.0, Quantum Computing, BlockChain, Technological Unemployment, Digital, benchmarking, flexable, Kaizen, prototyping, robotics, six sigma, Business Insights, Business, Insights, Altek Media Group, Altek, Media, Video, video production, online, online magazine, digital marketing strategy, digital, marketing, strategy, Blogging, social media, Marketing Funnel, Brand, Content Management System, logistics, Lean manufacturing, manufacturing, CEO, infograhics, instagram, facebook, linked in, google, Key Performance Indicator, Automation, Optimization, exit planning, Public relations, video, Advanced Manufacturing, Agile, lean, oem, smart, supply chain, Net Neutrality, Big Data, Data Mining, Actionable Analytics, Artificial Intelligence, Machine Learning, Personalization, Voice Recognition, Chatbots, Augmented Reality, Virtual Reality, Smart Factory, Industry 4.0, Quantum Computing, BlockChain, Technological Unemployment, Digital, benchmarking, flexable, Kaizen, prototyping, robotics, six sigma
Read the full article
#ActionableAnalytics#AdvancedManufacturing#Agile#Altek#AltekMediaGroup#ArtificialIntelligence#AugmentedReality#Automation#benchmarking#BigData#BlockChain#Blogging#Brand#Business#BusinessInsights#CEO#Chatbots#ContentManagementSystem#DataMining#digital#digitalmarketingstrategy#exitplanning#facebook#flexable#google#Industry4.0#infograhics#Insights#instagram#Kaizen
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:
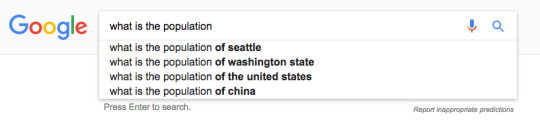
This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Text
Review: Everything to Know About LG OLED 48CX
LG claims that their OLED TV is one of the best selling products across the world. The blog has an overall review of the LG OLED 48CX product as per the official specifications launched by the company. The LG OLED 48CX, the new product by LG, has something for everyone.

Let’s Start With The Availability Of The Product
LG is going to launch two models at the same time. If you are living in the UK, then you can buy either OLED48CX5LB or OLED48CX6LA. The only difference in both models is the finish of the product. But both the models are identical in terms of specs and features.
If you are in the US, then you will get this product with the model name as OLED48CXPUB. Bad news for the people living in Australia, as they can’t buy this product during the launch. But after some time, they can.
Design Of LG OLED 48CX
Disappointingly, the new LG’s OLED TV looks identical to the last year released C9, which might affect its sale. There is no doubt that C9 is a good-looking product, and the CX will have a similar design, but there must be some changes. As people always look for a unique product, and the company has many ways to improve the design.
Undoubtedly, the new OLED panel is extremely thin, which is a good thing about this product. The company needs to work to adjust the speakers, connections, and processing pieces.
Features
According to the new norms released by LG, all the products launched by them (except B series) in this year have the same panel and processing units. You might see the difference in the sound system and the styling. You will get 4K flagship experience on 48-inches TV.
The significant feature in this TV is Artificial Intelligence (AI). There are several features like AI Picture Pro, and AI Sound Pro that enhance the user experience.
Additionally, it supports HLG, HDR10, and Dolby Vision, making it better than its competitors like Panasonic and Philips. But you might go into a state of confusion as it doesn’t have the Dolby Vision IQ setting in the menu of the TV. Don’t worry! The product by LG enables this feature automatically when required.
Did you know? LG was the first TV manufacturer who offered certified HDMI 2.1 sockets to their users. These kinds of sockets don’t guarantee the support of the next-generation HDMI feature, but there might be some new involvement with this feature.
Picture Quality
The company claims to offer flagship OLED performance through the OLED48CX. In testing, it was proved that their product delivers exactly what they are claiming.
You might find that the color of the TV is vibrant and lush, and it produces an effortlessly natural picture. The color on the TV is entirely realistic.
If you see the overall picture quality, it is crisp, natural, and users might feel absolute joy. There are plenty of specs and features that are sufficient to produce an amazing contrast when watching anything on HDR mode.
Sound Quality
Before analyzing it, you have to learn about its AI features that are part of all the CX models. This smart TV has a Smart AI feature that analyzes and adjusts the TV’s sound according to your room. In testing, it is revealed that the AI feature always tries to deliver smooth audio, which is audible to all the people available in that room.
The overall performance of the sound with this feature is quite good. Sometimes the speakers might struggle while playing some soundtracks.
If you have decided to buy the LG 48CX OLED TV, it will be a great option to purchase a soundbar. If you want a better soundbar option, then you can go for the Sonos Arc.
Final Verdict
It is a perfect product for those who want to buy a perfect TV, but don’t want to get a big one. It is one of the best small size TVs with excellent sound and picture quality.
But if you are in the UK and want to use some apps like BBC iPlayer, then don’t buy this product.
Jackson Henry. I’m a writer living in USA. I am a fan of technology, arts, and reading. I’m also interested in writing and education. You can read my blog with a click on the button above.
Source-Everything to Know About LG OLED 48CX
0 notes
Text
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
What Does Natural Language Processing Mean for Writers, Content, and Digital Marketing? An Essay.
Terrible Movie Pitch:
The battle for the voice of the internet has begun. In one corner, we have computer programs fortified by algorithms, Artificial Intelligence, Natural Language Processing, and other sexy STEM buzzwords. In the other corner, we have millions of copywriters armed with the only marketable skill a liberal arts education can provide: communication. Who will lol the last lol?
Spoiler:
Writers, your jobs are probably safe for a long time. And content teams stand to gain more than they stand to lose.
I remember the day someone told me a computer had written a best-selling novel in Russia. My first thought? “I need to get the hell out of content marketing.”
The book was called True Love—an ambitious topic for an algorithm. It was published in 2008 and “authored” by Alexander Prokopovich, chief editor of the Russian publishing house Astrel-SPb. It combines the story of Leo Tolstoy’s Anna Karenina and the style of Japanese author Haruki Murakami, and draws influence from 17 other major works.
Frankly, that sounds like it’d make for a pretty good book. It also sounds a lot like how brands create their digital marketing strategies.
Today, every brand is a publisher. Whether you’re a multi-billion-dollar technology company or a family-run hot sauce manufacturer, content rules your digital presence. Maybe this means web guides, blog posts, or help centers. Maybe it means a robust social media presence or personalized chatbot dialogue. Maybe you feel the need to “publish or perish,” and provide value and engagement in a scalable way.
Brands require a constant influx of written language to engage with customers and maintain search authority. And in a way, all the content they require is based on 26 letters and a few rules of syntax. Why couldn’t a machine do it?
In the time since I first heard about True Love, I’ve moved from content writing to content strategy and UX, trying to stay one step ahead of the algorithms. But AI in general and Natural Language Processing in particular are only gaining momentum, and I find myself wondering more and more often what they’ll mean for digital marketing.
This essay will endeavor to answer that question through conversations with experts and my own composite research.
Portent’s Matthew Henry Talks Common Sense
“The Analytical Engine has no pretensions to originate anything. It can do whatever we know how to order it to perform.”
-Lady Ada Lovelace, 1842, as quoted by Alan Turing (her italics)
Lady Lovelace might have been the first person to contend that computers will only ever know as much as they’re told. But today’s white-hot field of machine learning and Artificial Intelligence (AI) hinges on computers making inferences and synthesizing data in combinations they were never “ordered to perform.”
One application of this Machine Learning and AI technology is Natural Language Processing (NLP), which involves the machine parsing of spoken or written human language. A division of NLP is Natural Language Generation (NLG), which involves producing human language. NLP is kind of like teaching computers to read; NLG is like teaching them to write.
I asked Portent’s Development Architect Matthew Henry what he thinks about the possibilities for NLP and content marketing. Matthew has spent over a decade developing Portent’s library of proprietary software and tools, including a crawler that mimics Google’s own. Google is one of the leading research laboratories for NLP and AI, so it makes sense that our resident search engine genius might know what the industry’s in for.
I half expected to hear that he’s already cooking up an NLP tool for us. Instead, I learned he’s pretty dubious that NLP will be replacing content writers any time soon.
“No computer can truly understand natural language like a human being can,” says Matthew. “Even a ten year old child can do better than a computer.”
“A computer can add a million numbers in a few seconds,” he continues, “which is a really hard job for a human being. But if a cash register computer sees that a packet of gum costs $13,000, it won’t even blink. A human being will instantly say Oh, that’s obviously wrong. And that’s the part that’s really hard to program.”
“Knowing that something is obviously wrong is something we do all the time without thinking about it, but it’s an extremely hard thing for a computer to do. Not impossible—to extend my analogy, you could program a computer to recognize when prices are implausible, but it would be a giant project, whereas for a human being, it’s trivial.”
It’s not news that there are things computers are really good at that humans are bad at, and some things humans are really good at that computers can’t seem to manage. That’s why Amazon’s Mechanical Turk exists. As they say,
“Amazon Mechanical Turk is based on the idea that there are still many things that human beings can do much more effectively than computers, such as identifying objects in a photo or video, performing data de-duplication, transcribing audio recordings, or researching data details.”
Amazon calls the work humans do through Mechanical Turk “Human Intelligence Tasks,” or HITs. Companies pay humans small sums of money to perform these HITs. (A made-up example might be identifying pictures where someone looks “sad” for 10 cents a pop.)
Matthew might instead call these HITs, “Common Sense Tasks,” like knowing a pack of gum shouldn’t cost $13,000.
“People underestimate the power of common sense,” Matthew says. “No one has ever made a computer program that truly has common sense, and I don’t think we’re even close to that.”
And here’s the real quantum leap for not only NLP but Artificial Intelligence: right now, computers only know what they’ve been told. Common sense is knowing something without being told.
It sounds cheesy to say that our imaginations are what separate us from the machines, but imagination isn’t just about being creative. Today, computers can write poetry and paint like Rembrandt. Google made a splash in 2015 when the neural networks they’d trained on millions of images were able to generate pictures from images of random noise, something they called neural net “dreams.” And in 2016, they announced Project Magenta, which uses Google Brain to “create compelling art and music.”
So it’s not “imagination” in any artistic terms. It’s imagination in the simplest, truest form: knowing something you haven’t been told. Whether it’s Shakespeare inventing 1,700 words for the English language, or realizing that kimchi would be really good in your quesadilla, that’s the basis of invention. That’s also the basis of common sense and of original thought, and it’s how we achieve understanding.
To explain what computers can’t do, let’s dig a little deeper into one of the original Common Sense Tasks: understanding language.
Defining “Understanding” for Natural Language
NLP wasn’t always called NLP. The field was originally known as ”Natural Language Understanding” (NLU) during the 1960s and ‘70s. Folks moved away from that term when they realized that what they were really trying to do was get a computer to process language, not understand it, which is more than just turning input into output.
Semblances of NLU do exist today, perhaps most notably in Google search and the Hummingbird algorithm that enables semantic inferences. Google understands that when you ask, “How’s the weather?” you probably mean, “How is the weather in my current location today?” It can also correct your syntax intuitively:

And it can also anticipate searches based on previous searches. If you search “Seattle” and follow it with a search for, “what is the population,” the suggested search results are relevant to your last search:

This is semantic indexing, and it’s one of the closest things out there to true Natural Language Understanding because it knows things without being told. But you still need to tell it a lot.
“[Google’s algorithm] Hummingbird can find some patterns that can give it important clues as to what a text is about,” says Matthew, “but it can’t understand it the way a human can understand it. It can’t do that, because no one’s done that, because that would be huge news. That would basically be Skynet.”

In case you don’t know what Skynet is and you’re also too embarrassed to ask Matthew, too, here’s the Knowledge Graph.
Expert Opinion: NLP Scholar Dr. Yannis Constas on Why Language is So Freaking Hard to Synthesize
To find out what makes natural language so difficult to synthesize, I spoke with NLP expert Dr. Yannis Constas, a postdoctoral research fellow at the University of Washington, about the possibilities and limitations for the field. [1]
There are a lot. Of both. But especially limitations.
[Note: If you don’t want a deep dive into the difficulties of an NLP researcher, you might want to skip this section.]
“There are errors at every level,” says Yannis.
“It can be ungrammatical, you can have syntactic mistakes, you can get the semantics wrong, you can have referent problems, and you might even miss the pragmatics. What’s the discourse? How does one sentence entail from the previous sentence? How does one paragraph entail from the previous paragraph?”
One of the first difficulties Yannis tells me about is how much data it takes to train an effective NLP model. This “training” involves taking strings of natural language that have been labeled (by a human) according to their parts of speech and feeding those sentences into an algorithm, which learns to identify those parts of speech and their patterns.
Unfortunately, it takes an almost inconceivable amount of data to “train” a good algorithm, and sometimes there just isn’t enough input material in the world to make an accurate model.
“When we’re talking about a generic language model to train on, we’re talking about hundreds of millions of sentences,” he says. “That’s how many you might need to make a system speak good English with a wide vocabulary. However, you cannot go and get hundreds of millions of branded content sentences because they don’t exist out there.”
Yannis says he once tried to make an NLP model that could write technical troubleshooting guides, which might be a popular application for something like corporate support chatbots. He only had 120 documents to train it on. It didn’t work very well.
Right now, his research team is trying to figure out a way to combine corpuses of language to overcome the twin pitfalls of meager input:
Output that doesn’t make much linguistic sense
Output that all sounds pretty much the same
“We tried to take existing math book problems targeted at 4th graders and make them sound more interesting by using language from a comic book or Star Wars movie,” says Yannis. “That was specific to that domain, but you can imagine taking this to a marketing company and saying, ‘Look, we can generate your product descriptions using language from your own domain.’”
That’s the grail of NLP: language that is accurate to the domain yet diverse and engaging. Well, one of the grails. Another would be moving past the level of the sentence.
“80 to 90 percent of the focus of NLP has been on sentence processing,” says Yannis. “The state-of-the-art systems for doing semantic processes or syntactic processing are on a sentence level. If you go to the document level—for example, summarizing a document—there are just experimental little systems that haven’t been used very widely yet…The biggest challenge is figuring out how to put these phrases next to one another.”
It’s not that hard for an algorithm to compose a sentence that passes the Turing Test, or even hundreds of them. But language is greater than the sum of its parts, and that’s where NLP fails.
“When you break out of the sentence level, there is so much ambiguity,” says Yannis. “The models we have implemented now are still very rule-based, so they only cover a very small domain of what we think constitute referring expressions.”
“Referring expressions,” Yannis tells me, are those words that stand in for or reference another noun, like he, she, it, or these. He uses the example, “Cate is holding a book. She is holding it and it is black.” An NLP model would probably be at a loss for realizing that “she” is “Cate,” and “it” is “the book.”
“It’s something that sounds very simple to us,” says Yannis, “because we know how these things work because we’ve been exposed to these kinds of phenomena all our lives. But for a computer system in 2017, it’s still a significant problem.”
Models are also inherently biased by their input sources, Yannis tells me. For example, we’re discussing an AI researcher friend of his who combines neural networks and NLP to generate image descriptions. This seems like it would be an amazing way to generate alt tags for images, which is good for SEO but a very manual pain in the ass.
Yannis says that even this seemingly-generic image captioning model betrays bias. “Most images that show people cooking are of women,” he says. “People that use a saw to cut down a tree are mostly men. These kinds of biases occur even in the data sets that we think are unbiased. There’s 100,000 images—it should be unbiased. But somebody has taken these photos, so you’re actually annotating and collecting the biases.
“Similarly, if you were to generate something based on prior experience, the prior experience comes from text. Where do we get this text from? The text comes from things that humans have written…If you wanted to write an unbiased summary of the previous election cycle, if you were to use only one particular news domain, it would definitely be biased.”
(Oh yeah, and using neural networks for creating image captions isn’t just biased, it’s not always accurate. Here are a few examples from Stanford’s “Deep Visual-Semantic Alignments for Generating Image Descriptions:

Sometimes it’s right. Sometimes hilariously wrong.
Finally, perhaps one of the biggest hurdles for NLP is particular to machine learning. Interestingly, it sounds a lot like something Matthew said.
“One common source of error is lack of common sense knowledge,” says Yannis. “For example, ‘The earth rotates around the sun.’ Or even facts like, ‘a mug is a container for liquid.’ You’ve never seen that written anywhere, so if a model were to generate that it wouldn’t know how to do it. If it had knowledge of that kind of thing, it could make the inference that coffee is a liquid and so this mug could be a container of coffee. We are not there. Machines cannot do that unless you give them that specification.”
[1] Note: This interview was conducted in May of 2017. Quotes from Yannis only reflect his work, experience, and understanding at the point of this interview.
NLP is Hard. So is Programming. English is Harder.

Source
It’s kind of funny that we need common sense to navigate our language, because so much of it makes so little sense. Perhaps especially English.
There are synonyms, homonyms, homophones, homographs, exceptions to every rule, and loan words from just about every other language. There are phrases like, ”If time flies like an arrow then fruit flies like a banana.” If you need this point really driven home, read the poem “The Chaos,” by Gerard Nolst Trenité, which contains over 800 irregularities of English pronunciation. Irregularities are systemic—they’re in pronunciation, spelling, syntax, grammar, and meaning.
Code is actually simpler and less challenging than natural language, if you think about this deeply. People have this impression it’s a heavy, mathematical thing to do, and it’s a job skill, so maybe it’s harder. But I can spend six months at Javascript and I’m fairly good at Javascript; if I’ve spent six months with Spanish, I’m barely a beginner.
-Internet linguist Gretchen McCulloch to Vox
Code is the “language” of computers because it’s perfectly regular, and computers aren’t good at synthesizing information or filling in the blanks on their own. That requires imagination and common sense. A computer can only “read” a programming language that’s perfectly written—ask any programmer who’s spent hours pouring over her broken code looking for that one semicolon that’s out of place. If our minds processed language the way a computer does, you couldn’t understand this sentence:

Sure, computers can autocorrect those four misspelled words, and there’s a red line under them on my word processor. But that’s because there are rules for that, like how you can train a computer to recognize that a candy bar shouldn’t cost $13,000 because that’s 10,000 times the going rate.
Humans, however, are great at making inferences from spotty data. Our bodies do it all the time. Our eyes and brain are constantly inventing stuff to fill in the blind spot in our field of vision, and we can raed setcennes no mtaetr waht oredr the ltteers in a wrod are in, as lnog as the frist and lsat ltteer are in the rghit pclae.
Inference is something we were built (or rather, evolved) to do, and we’re great at it. In fact, humans actually learn languages better when they try less hard. Language takes root best in our “procedural memory,” which is the unconscious memory bank of culturally learned behaviors, rather than in our “declarative memory,” which is where you keep the things you’ve deliberately worked to “memorize.” Children can pick up other languages more easily than adults because they’re tapping into their procedural memory.
Computers, however, were designed to excel where humans are deficient, not to just duplicate our greatest strengths.
Trying to teach a computer to process and generate natural language is kind of like trying to build a car that can dance.
It’s fallacious to assume that because a car is much better than a human at going in one direction really fast, they would also make much better dancers if we could only get the formulas right. Instead, it seems, we should focus on the ways machines’ strengths help us compensate for our deficiencies.
The Future of AI and NLP means Helping Us, Not Replacing Us
The power of the unaided mind is highly overrated. Without external aids,..
https://ift.tt/2qL1iCo
0 notes
Last Seen Blogs




