#In-house API Q1 course
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Apple killed the IDFA: A comprehensive guide to the future of mobile marketing

Tremors from Apple’s bombshell revelation at WWDC last week that the IDFA will effectively be killed continue to reverberate. iOS 14 will be released in September, and if past iOS releases are any indication, more than half of all iOS devices will run iOS 14 by October. WWDC 2020 featured Apple’s Thanos moment: with a snap of its fingers, Apple obliterated a large proportion of the mobile ad tech ecosystem.
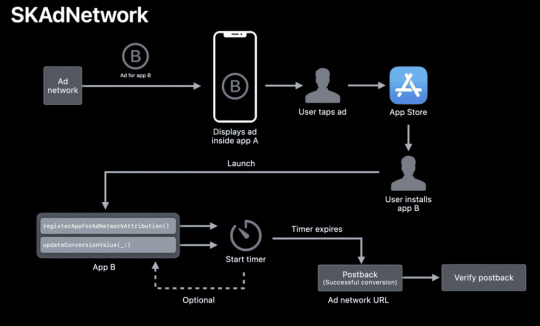
A brief overview of the IDFA-related changes that will be introduced in iOS 14:
Device IDFAs will be made available to specific apps on the basis of user opt-in via a pop-up at app open. LAT as a setting will continue to exist at the device level, meaning no apps will have access to the device IDFA if LAT is turned on;
Apple will use the SKAdNetwork API to receive meta data from ad clicks and to send postbacks from the app client to advertising networks that drive app installs. As of iOS 14, new parameters will be added to SKAdNetwork that provide information around the source publisher, and a conversion event;
The postbacks to ad networks can include ad campaign IDs, but only 100 values (labels 1-100) per ad network are available to be mapped;
The postbacks to ad networks can also include conversion event IDs, but only 64 of those (labels 0-63) are available to be mapped;
The postbacks to ad networks will also include a “Redownloaded” flag that indicates whether the app is being downloaded by a user for the first time or not;
Postbacks will be sent based on a sequence of timers (the logic is somewhat complicated — more information on this below) and will include just one conversion event per attributed install. This means that advertisers won’t get absolute counts of events but rather counts of highest value events that users complete within the conversion measurement period;
IDFV, or ID For Vendors, will continue to be made available for publishers per device for all of their apps. What this means is that a publisher will have a unique device identifier available to it across its apps on any given single device. That is, if a user has installed three of my apps on her iPhone, I will have access to a unique IDFV for that user that is the same as accessed from all three of my apps.
In Apocalypse Soon, which I published in February, I outlined a hypothetical chain of events that began with Apple deprecating the IDFA at WWDC 2020. The IDFA has been living on borrowed time since the introduction of Limit Ad Tracking; its elimination was wholly foreseeable. I posted my thoughts on how the death of the IDFA will impact the mobile advertising ecosystem in this Twitter thread, which still represents my latest understanding. Below is more detail on the topics covered in the thread, as well as a few additional topics.
Lots of FUD being dispensed regarding IDFA deprecation. Here's what I think changes in the post-IDFA world: (1/X) pic.twitter.com/q2EXpJj7w5
— Eric Seufert (@eric_seufert) June 25, 2020
Opt-in rates for IDFA access
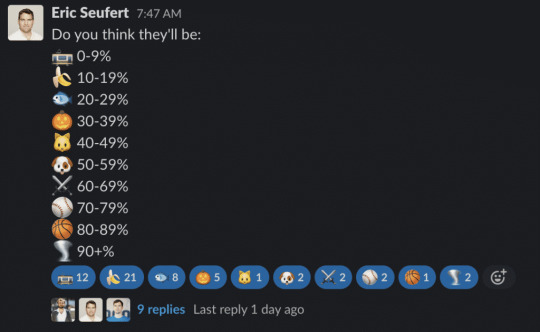
My belief is that user opt in rates for IDFA access will fall between 10-20%. Opt in rates will dictate the impact of these privacy changes on all aspects of the mobile advertising ecosystem, but with opt-in rates at the 10-20% level, the IDFA is effectively dead.
In an informal poll conducted in the Mobile Dev Memo Slack team, the majority of respondents indicated that they believe opt in rates for ad tracking will fall between 0-20% (see below). The language presented within the opt-in popup is intimidating: App X would like permission to track you across apps and websites owned by other companies (note that a second string of text underneath this one can be customized by the developer). This verbiage seems specifically designed by Apple to deter users from accepting tracking.
Attribution
I believe that deterministic, user-level app attribution will cease to exist once SKAdNetwork adoption reaches critical mass — likely by the end of the year or throughout Q1 2021.
I’ve heard the argument that some advertisers might continue to use MMPs to attribute the small (10-20%) subset of users that opt into ad tracking, because that sample of users could be used to extrapolate composition ratios to the broader set of acquired installs. For instance, if 30% of the opt-in users were acquired via Facebook ads, then that ratio might be applied to the cohorts of opt-out users whose provenance is unknowable — this knowledge could help advertisers budget ad spend, and would justify MMP tracking for the opt-in users.
But there is sampling bias inherent in this: the group of users that opt into tracking are unlikely to behave like those that don’t. We see this now with LAT users: LAT users for many advertisers tend to monetize better than non-LAT users, with the hypothesis being that they are more technically savvy (because they managed to find the LAT setting).
And even if the opt-in subset of users was useful for the purpose of extrapolating ratios, this small volume of attributions would not support the MMP industry at the scale that it currently exists: either dramatic consolidation would take place or a few of the major firms would simply fail as MMP budgets evaporate to 10-20% of their current level.
Another factor that will determine the fate of user-level ad attribution is Google’s adoption of opt-in tracking for Android. If Google doesn’t create an opt-in tracking mechanism for Android, then install attribution could continue to exist to serve the Android market. But this seems unlikely: Google and Apple operate more or less in lockstep with respect to privacy. Google introduced its LAT equivalent (Ads personalization) one year after Apple introduced LAT. Furthermore, Google has had attribution services in its crosshairs since at least 2017, when it introduced install attribution to Firebase.
It seems possible that MMPs adapt to this change by serving as auditors: receiving install receipts from ad networks, aggregating them, and reconciling campaign and event identifiers against naming conventions and revenue values, and using cost data to present per-campaign ROAS reporting.
This functionality would be useful and is almost certainly something that few advertisers want to build themselves, but it’s also mostly administrative: an accounting service of sorts that doesn’t unlock much value. Put another way: this isn’t a service that advertisers would be willing to pay tens of thousands of dollars per month for, and it wouldn’t support the current size and scope of the mobile ad attribution market. MMPs will need to pivot into lines of business that provide commercial insight if they want to continue to charge MMP prices.
Re-targeting and Custom Audiences / Lookalike Audiences
Re-targeting on mobile is currently done via advertising identifiers: an advertiser provides Facebook or a re-targeting DSP with a list of advertising identifiers that it wants to target, and those channels serve ads to those devices when a matching impression or bid request surfaces.
Without an advertising identifier to use in serving a specific device, it seems unlikely that re-targeting DSPs will be able to function as they currently do: they simply won’t be able to accurately identify a given device. Facebook will be able to facilitate re-targeting, since it can use any number of user-specific (versus device-specific) identifiers to target individuals: email addresses, phone numbers, etc. Back in 2014, I posited that Facebook acquired WhatsApp specifically to amass a large bank of phone numbers, which are perfect identifiers because they rarely change and are tied exclusively to a device (versus an email address, which is tied to an account that can be accessed from any number of devices).
This reality is likely to impact product design: developers will seek to either incentivize or simply require users to register accounts using their email addresses or phone numbers so that those identifiers can be stored and used for re-targeting and lookalike list construction. The ad platforms that don’t already offer lookalike and custom audience construction directly from lists (notably, Google UAC) will also likely roll these products out to compete with Facebook.
Of course, all of this assumes that Apple and Google are amenable to email being used as a proxy for the advertising identifier when users have explicitly opted out of ad tracking. A user might be horrified to know that they restricted an app’s access to their advertising identifier — which can be reset — only to have their email address, which is attached to many other aspects of their life, used for the same purpose. Note that Apple introduced its privacy-centric Sign in with Apple authentication service at last year’s WWDC; it could potentially enforce use of it as an alternative for user registration in apps to prevent exactly this scenario.
Managed DSPs
In discussing mobile DSPs in the new, IDFA-less environment, a distinction must be drawn between in-housed or self-serve DSPs, which facilitate advertiser-led programmatic media buying, and managed DSP services, which are utilized by advertisers essentially as ad networks.
As discussed in the recent MDM Podcast, How a bid becomes a DAU, the core value proposition of managed DSPs are their device graphs, or their lists of device advertising identifiers paired with knowledge around which of those devices have monetized, and in what apps. Once these device graphs become irrelevant, managed DSPs will lose competitive advantage over other programmatic solutions, even in-house DSPs. My former colleague Nebojsa Radovic summarized this dynamic in a Twitter thread:
One of the frequent questions I got regarding IDFA removal is whether DSPs will be able to survive?
— Nebojsa Radovic (@eniac) June 26, 2020
It’s unclear what path forward exists for managed DSPs without advertising identifiers. Managed DSPs can of course optimize advertising campaigns at the publisher and placement level, but that level of granularity tends to not be efficient for advertising optimization: programmatic supply suffers from an adverse selection bias as most programmatic inventory is backfill. And if advertisers can in-house programmatic spend and be on equal footing with managed DSPs, why would they pay hefty fees to managed services?
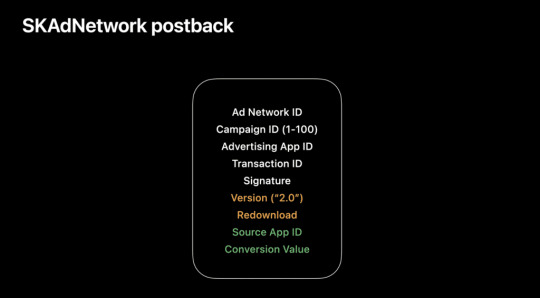
updateConversionValue(_:)
The Conversion flag in an SKAdNetwork postback will allow the advertising network to receive notification that some conversion event has taken place from within traffic acquired by a campaign. This flag will allow ad networks to count events at the level of the campaign cohort, eg. Campaign X generated 15 counts of Event Y. But this is worth clarifying further.
Advertisers will be able to map up to 64 in-app events to identifiers (integers in the range 0-63) that will be sent to SKAdNetwork via the updateConversionValue method when executed. Whenever an install is attributed by SKAdNetwork, a rolling 24-hour postback timer begins counting down to 0, and each time a mapped event is fired, the timer resets. Once the timer reaches 0, the postback is fired to the ad network that supplied the install.
A mapped event identifier will only be recorded for the postback if either no conversion event has yet to be recorded for the attributed user or if the identifier is larger than that which is previously recorded for the attributed user. According to the SKAdNetwork documentation, it seems that the postback timer can be reset up to 64 times, so long as increasing event identifiers are being recorded. Once the initial timer completes, Apple begins another timer on a random length of time between 0 and 24 hours to obfuscate the source of the event, and the postback is fired when that second timer completes.

This postback logic will dramatically alter app monetization design: advertisers will aspire to strike a meaningful balance between minimum elapsed time between install and postback receipt and maximum monetization and / or engagement signal contained within the postback (ie. higher values of the conversion event carrying important information about the value of the user).
Developers will strive to instrument their apps such that the most valuable users fire as many of the 64 events as possible within the first few sessions of app use to facilitate the postback being received in a timely manner. This new dynamic will accelerate the existing trend of integration between app monetization and user acquisition: the user acquisition team of the very near future will play a central role in designing the content path that users take before a conversion event is fired via SKAdNetwork.
Event-optimized campaigns
Since networks receive conversions, they can optimize campaigns against them, albeit not at the granularity level of individual user identifiers, and not with exact event counts: if a network receives a conversion identifier, if will only know that the event mapped to that identifier executed at least once, but it won’t know whether that event executed more than once or if any other events with lower identifier values were executed.
Facebook, for instance, could use these conversion receipts to optimize targeting with broad demographic features as well as to build correlations between targets and app types. This won’t be as efficient as its current method, which uses the features of individual users — especially monetization history — to hone targeting for the App Event Optimization (AEO) campaign strategy, but it will still allow for event-optimized targeting.
The Value Optimized (VO) campaign strategy is harder to execute without advertising identifiers because it relies on the magnitude of monetization expected from an individual user — if the advertiser is unable to post all revenue events back to Facebook with user identifiers attached, and Facebook can only receive the one event signal per user per campaign (absent any revenue data), then Facebook has no way of gauging magnitude of monetization or engagement. All of this similarly applies to tCPA / tROAS campaigns on Google’s UAC.
I believe that the shift to SKAdNetwork-tracked conversions might actually benefit ad networks that compete with the Self Attributing Networks (SANs). Currently, many advertisers withhold conversion events from non-SAN ad networks in an attempt to hide the identities of their most valuable users from them: if an ad network knows that User X monetized in App A, the network might specifically target User X for App B‘s campaigns in order to improve their conversion efficiency. Given that revenue context is excluded from the SKAdNetwork postbacks, there’s no reason for any advertiser to withhold that information from ad networks, and they are put on equal footing with Facebook and Google.
In-app ad monetization
In-app monetization is governed by the same forces that change the economics of DSP advertising. Header bidding especially will be fundamentally impacted by a lack of advertising identifiers: header bidding provides for a programmatic unified auction that allows advertisers to bid on inventory at the ad level (versus ad waterfalls, which bid on CPM values that are set intermittently based on historical averages).
It seems likely that the eradication of advertising identifiers depresses CPMs across the board because performance will only be measurable at the campaign level. It is very difficult to make the economics of programmatic buying work if individual users can’t be targeted based on proprietary information. If bid logic reverts back to historical campaign performance (via the conversions logged with SKAdNetwork postbacks), then header bidding — which, again, provides the ability to bid at the level of an individual impression — won’t really confer any advantage over CPM-based waterfall ad mediation.
Cross promotion
One interesting tidbit found in the updated SKAdNetwork documentation is the fact that the Identifier For Vendors (IDFV) will remain accessible regardless of whether a user has opted into ad tracking. The IDFV is a unique device identifier available to app developers across its own apps on a given user’s device. For example, a User X might have three of Developer A‘s apps installed on her phone: App 1, App 2, and App 3. In this case, Developer X would have access to a unique IDFV for User X within its own apps on User X‘s phone: it could use this to store engagement and monetization data for User X across all three of its apps.
The IDFV cannot be used for acquisition attribution, but it can be used to great effect for cross promotion, which might provide a competitive advantage to developers that oversee portfolios of apps that feature large MAU. And the IDFV might become an important vector of M&A: a developer might not be able to transparently acquire high-value users, but it can acquire developers with large but declining user bases and cross promote those users across its existing portfolio on the basis of monetization history. I discussed the power of an intelligent cross promotion mechanism for developers with large portfolios in my 2016 GDC presentation about my efforts in building an internal ad network at Rovio.
What’s the net impact?
More important than how the privacy changes to iOS announced at WWDC 2020 impact the mobile ad tech ecosystem is how they impact consumers. My personal opinion here is that an app-level tracking opt in mechanism provides users with an even more granular level of control over their personal data, and in that respect, this is a welcome and positive change to the ecosystem.
I think the net impact of these privacy changes to advertisers is neutral to slightly negative. Advertisers won’t have attribution transparency at the user level, but as I argued in the beginning of this piece and in Media mix models are the future of mobile advertising, that transparency in the current paradigm is, to a large degree, a facade: last-click attribution provides advertisers with the veneer of control and measurability, but the reality is that the pool of users swirling throughout the overlapping fields of vision of the major ad networks has rendered value attribution impossible. And Google and Facebook had an unfair advantage in poaching the last click for most ad interactions, anyway.
Many sophisticated advertisers have been moving towards top-down, macro-level incrementality models over the past 12-24 months. The loss of device-level identifiers will hasten that transition out of necessity, but that doesn’t also mean it’s not the most prudent approach to advertising. Fast forwarding two or three years, I don’t think the mobile advertising ecosystem — from an advertiser’s perspective — looks meaningfully different now than it would have if Apple had announced business as usual for the IDFA at WWDC 2020. This trajectory had already been established.
Obviously the impact of tracking opt-in on much of the mobile ad tech terrain will be more severe, and the outlook for companies residing in those outposts is not as rosy.
Caveat lector
Apple’s privacy announcement from WWDC 2020 is only one week old, and the documentation they have released about the updates coming to SKAdNetwork are, in many places, incomplete or vague. The above represents my best guess at what will happen to the mobile advertising ecosystem, which is complex and multi-faceted, over the next 6-24 months. My opinion has been informed by exhaustive study of Apple’s documentation and through talking to a large number of people across the ecosystem, but my perspective is limited by the amount of information available. I believe that I approach this topic objectively and without any inherent bias, but readers should judge that for themselves.
Thank you
I have gained very valuable perspective around the changes coming to iOS 14 by speaking with people over the past few months whose opinions and insight I value greatly. Thank you to: Gadi Eliashiv, Nebojsa Radovic, David Barnard, David Philippson, Dick Filippini, Maor Sadra, and John Koetsier.
Apple killed the IDFA: A comprehensive guide to the future of mobile marketing published first on https://leolarsonblog.tumblr.com/
0 notes
Text
Annotated edition for the May 24, 2020, Week in Ethereum News
Several people this week have told me they want a “drama” section in the newsletter and have asked me to annotate the Aragon and Autark Ado this week.
Perhaps that’s why the Aragon drama leads the most clicked list:
So why is Aragon suing its grantee? Aragon held a vote where the community approved these grants. Aragon now does not want to pay, claiming breach of contract - presumably that they did not believe Autark was not delivering fast enough or that products that were up to snuff. It’s a bit hard to follow the play-by-play but at some point Aragon decided that after spending 600k of the 1.6m awarded grant, they did not want to pay any longer, so Autark threatened to sue. Aragon offered to settle for $250k of the remaining million in grant payments, but it appears Autark rejected because Aragon would cut off the ANT incentive payments. So Aragon sued Autark, to make sure that the case happens on its home turf in Switzerland which benefits their deep pockets versus Autark’s (now unfunded) startup budget.
For what it’s worth, I believe I voted against Autark’s first request and while I thought I voted against the second one, it turns out I didn’t vote. There were a lot of votes in that round, and it was obviously going to pass (it passed “unanimously” with only 1 ANT voting against), so i must have decided not to spend the gas.

This all seems pretty boring, it’s just back and forth arguing over a contract, why are other people commenting on it?
1. Aragon has a reputation for not paying people.
It has long been an open secret in the industry that Aragon routinely doesn’t pay people in full or on time.
Grants are hard! I can empathize with both Aragon (presumably feeling like it wasn’t getting enough ROI) and Autark (presumably thinking that a community approved grant couldn’t be secretly overturned by Jorge and Luis).
2. Aragon sold a token for tens of millions of dollars, but after 3 years the only use for the token was a tokenholder vote. Now, the results of those votes are unilaterally and privately discarded.
It’s been over 3 years since Aragon raised a crazy amount of money selling a token. In that time frame, the only use for the token has been these votes.
If Jorge and Luis could decide by themselves to countermand the results of any of those votes without even telling the tokenholders anything, then what was the point of these votes? Why did I waste my ETH paying gas to vote in these things?
[Digression: They also recently released an ANJ token that you can exchange ANT for, but I don’t count being able to exchange a token for another token as utility. After more than 3 years, I cannot think of any other possible utility for ANT. Note: i’m very bearish on “dispute resolution by tokenholder vote”]
3. Aragon marketing hasn’t matched Aragon actions
The Aragon Manifesto was a clarion call. In black and white terms it paints the picture of transparency and technology as a solution for society’s problems of centralization, censorship and oppression.
Yet the rhetoric hasn’t matched the reality. They’ve declared that Aragon is the world’s court, yet go running to Swiss courts to claim jurisdiction rather than even attempt to use Aragon Court in parallel (since they can’t possibly lose in either venue).
They’re the rich ones with deep pockets, yet they’ve repeatedly chosen not to pay grantees who have very little leverage in negotiation (with the exception of Prysmatic after they complained).
None of it has been transparent (though of course there are often good reasons).
----
The Aragon team so far has responded to all these concerns by saying things like “you’re questioning our good intentions” or “the courts will decide”.
It is obvious that Aragon will win in the courts. They have the deep pockets; Autark doesn’t. They drafted the contract, and any decent lawyer will have drafted it so Aragon can’t possibly lose. Even if the contract somehow wasn’t one-sided, Aragon chose to run to the home field courts. It would be shocking if they lost.
Aragon’s intentions aren’t bad; that’s not really in question. I’m 100% sure that Jorge and Luis’s intentions are good and that any individual decision is defensible.
What is in question is their decision making overall. When you stake your brand on “transparency” and anti-oppression, then people will feel disappointed when your brand promises do not match your actions.
------------------------------------------------------
Enough with the drama. As with last week, a few things I think I’d read if i were an Eth holder interested in high level things.
Carl Beekhuizen’s Eth2 keys explainer
5 things crypto can learn from Visa’s struggle for adoption in the 1970s
Brave’s anti-fingerprinting v2, available in the beta releases but coming soon in the main releases
Working in reverse order, it’s always surprising to me how little people understand how much info your browser is leaking. Fingerprinting basically lets people figure out who you are even if you switch IP addresses, clear your browsing history, etc. I used to work in anti-fraud, and I was surprised how often you could figure stuff out from the fingerprints. Good for anti-fraud, but bad for privacy. Brave is changing the game on fighting fingerprinting!
I’m old enough to remember when Visa and especially Amex were not the ubiquitous things that they are today in America. There were some interesting parallels around their ads “think of it as money.” The more things change, the more things stay the same.
A good Eth2 keys explainer, definitely worth reading if you’re interesting in staking.
On to the annotations. The stuff that I think might deserve extra comment, not necessarily the stuff I think is most important.
Eth1
Péter Szilágyi’s snap sync, and some benchmarking of snap vs fast sync
Discovery peer advertisement efficiency analysis, also applicable to eth2
Sync improvements are a big deal, as the initial sync time is one of the things that most people find daunting around running a full node.
Depending on who you are, this may not be considered sexy, but it’s an important thing for eth1 usability.
Eth2
phase 0 spec v0.12 – added latest IETF standard. This is THE spec for the eth2 launch, barring any updates for bugs
Lighthouse client update – BLS key implementation, under Trail of Bits audit, 300mb RAM to run 2000 validators
Lodestar client update – syncing to both Schlesi and Topaz testnets
Prysmatic client update – Schlesi fork post-mortem, slashing client and protection
Fizzy v0.1 – WASM interpreter written in C++
Carl Beekhuizen’s Eth2 keys explainer
There’s been plenty of talk around “this is the spec” before, so I sorta can’t blame someone who says “but you’ve already said that before!”
Basically, they were all true, but with specific exceptions. And that’s still true - there will likely be some kind of bug or clarification found so that that this isn’t THE spec that launches the eth2 chain in a few months. But unless something crazy happens, this spec for the eth2 chain isn’t going to change except to fix bugs.
Layer2
Fuel does a demo of Reddit’s community points in an optimistic rollup that reduces transaction fees by 60x
Loopring to pass 1 million trades on its zk rollup in just 3 months of being live
Gazelle (formerly Plasma Chamber) alpha release with an API for deposit, transfer and exit
Fuel’s demo is pretty cool. It’s obviously just a demo - they don’t have a way to withdraw back to the testnet where Reddit’s community points are house.
Dexes continue to improve! Using their zk rollup, Loopring has a trading experience that is just as good as a centralized exchange, but with much cheaper fees and no risk of centralized exchanges getting hacked and losing your crypto.
This newsletter is made possible by 0x!

0x is excited to sponsor Week in Ethereum News and invite readers to try out our new DEX!
Sign up here to get early access to Matcha, your new home for fast, secure token trading.
Stuff for developers
web3js v1.2.8 with Ethers v5 ABI coder integration, ENS’s contenthash, and EIP-1193’s AbstractProvider
Mocking Solidity code with Waffle
A writeup of Solhint v3’s features
How to get randomness onchain using Chainlink’s VRF
Offchain voting for personal tokens, tutorial from Austin Griffith
Gas and circuit constraint benchmarks of binary and quinary incremental Merkle trees using Poseidon
Loopring’s new approach to generating frontend keys to sign offchain requests
Hegic had to shut down again because of an exploit that Sam Sun reported weeks beforehand
tBTC found a bug during their rollout; launch delayed
Matic’s mainnet is in the process of going live
I’ve seen some games migrate over to Matic.
Matic is “in the process” of going live. I note the “in the process” because I see a bunch of new blockchain projects saying that they are live, but....they aren’t really by any definition I would use.
But as I said previously in an annotated edition, it’s a process. It’s not exactly some binary “we’re live now.” Even Ethereum went live in July 2015 with less than full features.
Ecosystem
Tornado.cash non-custodial mixer is now trustless, with the admin function burned and the frontend available at https://tornadocash.eth.link
Ethereum Foundation q1 update, including how EF thinks about funding
Intro to dwebsites. dweb = ENS + IPFS (and equivalents)
Network usage is at an all time high. With similar use of the Eth2 chain, Ethereum will have negative issuance of ETH because part of every transaction fee is burned
I was surprised that gas usage is so high that we’d be in negative issuance if Eth2 was live.
I’ve said before that I’m not sure how I feel about negative issuance. On the one hand, the worry is that negative issuance means that no one has any incentive to use their ETH. On the other hand, that’s already the reality today - hardly anyone wants to pay for anything in ETH at $200, because basically every ETH holder I know has obscenely high expectations for what the price is likely to do in the near to medium term.
Some interesting thoughts in the EF update about how EF thinks about funding.
Meanwhile it’s great to see Tornado continue to improve the trustlessness of their product. Incredible work from the Roman S team. (if you missed the joke, it’s because both of them are named Roman and have last names that begin with S)
Enterprise
Using Eth mainnet, Baseline Protocol privately and securely synchronizes data and business logic across SAP and Microsoft Dynamics
Hyperledger Fabric founder John Wolpert’s common sense statement on using blockchain and Ethereum mainnet
The Baseline Protocol as lean strategy
Depository Trust & Clearing Corporation’s Project Whitney using Ethereum mainnet to “support private market securities, from issuance through secondary markets”
I’m surprised by how quickly the use mainnet approach has taken hold. If you rewind back to the last hype cycle, relatively few even considered the idea, even as enterprises were buying private chains that didn’t make much sense. (hat tip to GridPlus CEO Mark D’Agostino’s seminal No Country for Private Blockchains article)
DAOs and Standards
Aragon sues to avoid paying grantee a community-voted grant
Exploring DAOs as a new kind of institution
MetaCartel is becoming a DAO incubator
ERC2665: ERC721 transfer fee extension
EIP2666: Repricing of precompiles and Keccak256 function
Application layer
Uniswap v2 launched, with more features – direct token pairs, price oracles, flash swaps, etc
UMA launches the ETHBTC synthetic token, so you can bet on The Flippening
idle v3 – stablecoin yield rebalancer adds dydx, USDT, and a risk-adjusted strategy
Maker changes USDC stability fee to .75% and WBTC to 1%. Also, how Dai became a favorite in Latin America
Argent launches v1 of smart contract wallet with one touch access to TokenSets, PoolTogether, Aave, Uniswap V2, Compound, Maker and Kyber.
5/5 DeFi in the app layer section. Of course what I put in the app layer section vs what I put elsewhere is certainly arbitrary.
And hey, why isn’t Tornado Cash on DeFiPulse? It’s got a decent amount of value locked up.
Tokens/Business/Regulation
5 things crypto can learn from Visa’s struggle for adoption in the 1970s
WBTC mints another 1500 BTC on May 21. There’s now 5200 BTC on Ethereum compared to less than 3000 BTC on Lightning and Liquid combined
Blockchain code as antitrust, Schrepel and Buterin paper
ETH to soon surpass BTC on Bitcoiners’ preferred stock-to-flow metric
Staking will turn Ethereum into a functional store of value
What’s interesting about that 3000 BTC is that Liquid is just a trusted sidechain, and it has 2200 of the 3000 BTC. Now to be fair, WBTC definitely has some trust assumptions as well.
Still isn’t it interesting to see BTC migrate to Ethereum, where it can be used relatively trustlessly, rather than go to Blockstream’s products?
General
KYC puts lives at risk: BlockFi hack leaks client name, address, and crypto addresses. Similarly, a hacker claims to have exploited Shopify for Trezor and Ledger databases, though Ledger says the databases don’t match
Using zero knowledge proofs for vulnerability disclosure
World Economic Forum’s principles for a decentralized future (transparency, self-sovereign data, privacy and accountability)
JK Rowling jokes about trolling BTC because of her significant ETH holdings
The Winklevosses say they own a similar amount of ETH and BTC
Brave’s anti-fingerprinting v2, available in the beta releases but coming soon in the main releases
Using zero knowledge proofs for vulnerability disclosures is very cool. It’s a pretty classic problem if you’re a whitehat hacker - how do you disclose the vulnerability and then trust that you get anywhere near the value back that you deserve from someone’s bug bounty program? There are examples - even in the Ethereum space, where people should understand the value - of responsible disclosure not getting paid anything commensurate to what they deserved.
I’ll be interested to see if BlockFi suffers as a result of the hack. They’ve certainly put at risk any whales which used their service and didn’t give a PO Box/false address/whatever. Yet the history of database hacks even in our space is that most people just eventually return as if no hack ever happened.
Soon this annotated edition will be going paid, more details coming soon.
That’s all for this week!
Housekeeping
Follow me on Twitter @evan_van_ness to get the annotated edition of this newsletter, usually forthcoming in a day or so, as well as a real-time source of Eth news.
Did you get forwarded this newsletter? Sign up to receive it weekly
Permalink: https://weekinethereumnews.com/week-in-ethereum-news-may-24-2020/
Dates of Note
Upcoming dates of note (new/changes in bold):
May 26 – last day to apply for Ethereum India fellowship
May 28 – EIP1559 implementation call
May 29 – core devs call
May 29-June 16 – SOSHackathon
June 16 – deadline to apply for Gitcoin’s Kernel incubator
[Post updated at night for accuracy.]
0 notes
Text
New Post has been published on Forex Blog | Free Forex Tips | Forex News
!!! CLICK HERE TO READ MORE !!! http://www.forextutor.net/crude-oil-nosedive-to-5-month-lows-discouraging-for-opec/
Crude Oil Nosedive to 5-Month Lows Discouraging for OPEC
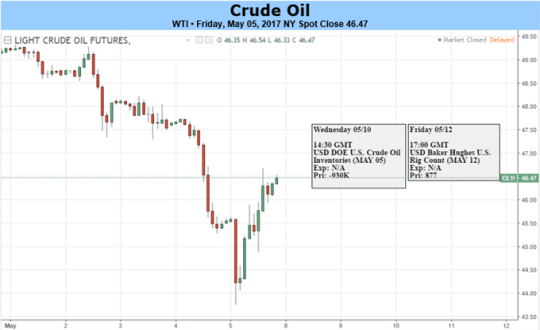
Fundamental Forecast for USOIL : Bearish
Crude Oil falls to lowest levels since November as price support ($47.11) is taken out
OPEC stuck in an increasingly difficult scenario
Options insight shows many seeing the drop as an opportunity
Per Baker Hughes, US Oil Rig count rose 6 to 703 total showing further pressure on OPEC
Will Crude Oil be able to recover in 2Q? See our forecast to find out what is driving market trends!
Crude Oil was a big theme of the reflation trade that favored proof of pending economic growth as commodity prices pushed higher in Q4/Q1. The rise in commodities from November to December was backed by what looked to be a perfect storm. In the month of November, a new administration had taken over the White House that was pro-growth in terms of infrastructure and lower taxes. Also in November, the Organization of Petroleum Exporting Countries (OPEC) agreed to cut production to balance the Oil market’s oversupply issue that had caused a sharp crash. Everything seemed to be going great for Oil.
Fast forward to the first week of May and little appears to be going right for the energy commodity. As of Friday morning, Crude Oil has traded 21.3% lower in 2017 from the opening range high of 2017. Some would call this a bear market as evidenced by a 20% drop. However, when you look at the industry alone, there doesn’t seem to be the panic that the price would indicate. We continue to see bullish call spreads being purchased in the options market in anticipation of eventual price recovery despite short-term downside still favored. Also, CEO of Marathon Oil, Lee Tillman recently noted that from a supply and demand point of view, little has changed as the price has plunged.
Still, the price plunge in Oil puts OPEC in an increasingly difficult scenario. They have all-but agreed to extend the production curb until the end of 2017 which in the immediate scenario, reduces their income. Of course, this was done in hopes of balancing the Oil market leading to higher prices, which would allow them to earn more money from a net present value perspective when production resumed to normal levels. However, one ‘stick in the mud’ to OPEC’s plan has been the hedging that took place from US producers when Oil was at $50, which is allowing the to produce freely as the price drops and has helped them lock in ~20% gains given a ~$35 production price per barrel. Adding insult to injury, on Friday afternoon Baker Hughes International showed that active rigs increased in the US (i.e., more production) for the 16th straight week in the US.
The chart below shows Friday’s rebound after the early morning sell-off. However, if you’ve heard the term, ‘dead count bounce’, it’s being put to the test in Crude. In other words, we’ll see what Crude Bulls are made of when we get to the Fibonacci zone (38.2-61.8% retracement) of the April-May range that occupy’s 47.50-50.00 zone. If the price is unable to close above here on a weekly basis, we could be setting up for more declines.
Crude Oil reached extended downside target, now retracement in focus
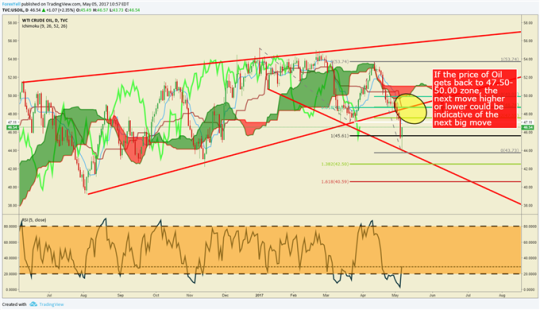
Chart Created by Tyler Yell, CMT
Next Week’s Data Points That May Affect Energy Markets:
The fundamental focal points for the energy market next week:
Tuesday4:30 PM ET: API weekly U.S. oil inventory report
Wednesday 10:30 AM ET: EIA Petroleum Supply Report
Fridays 1:00 PM ET: Baker-Hughes Rig Count at
Friday 3:30 PM ET: Release of the CFTC weekly commitments of traders report on U.S. futures, options contracts
Crude Oil Nosedive to 5-Month Lows Discouraging for OPEC Crude Oil Nosedive to 5-Month Lows Discouraging for OPEC https://rss.dailyfx.com/feeds/forex_market_news $inline_image
0 notes